【MyBatis-Plus】核心开发指南:高效CRUD与进阶实践_mybatisplus 接口开发教材

目录
1.前言
插播一条消息~
2.正文
2.1介绍
2.2基础操作
2.2.1准备工作
2.2.2编码
2.2.3CRUD测试
2.3复杂操作
2.3.1常见注解
2.3.1.1@TableName
2.3.1.2@TableField
2.3.1.3@TableId
2.3.2打印日志
2.3.3条件构造器
2.3.3.1QueryWrapper
2.3.3.2UpdateWrapper
2.3.3.3LambdaQueryWrapper
2.3.3.4LambdaUpdateWrapper
2.3.4自定义SQL
2.3.4.1注解方式
2.3.4.2XML映射
核心技巧:Wrapper条件集成
2.3.4.3常见故障
3.小结
1.前言
在传统MyBatis开发中,我们常陷入重复劳动:
- 每张表需手动编写基础CRUD的Mapper接口与XML
- 复杂查询需拼接SQL字符串,易引发语法错误与SQL注入风险
- 分页、乐观锁等通用功能需重复造轮子
MyBatis-Plus(MP)的诞生直击上述痛点。作为MyBatis的增强工具包,它在保留MyBatis所有灵活性的基础上,通过两大核心设计大幅提升开发效率:
- 内置通用Mapper/Service:自动化单表CRUD操作,减少70%重复代码
- 链式条件构造器:用类型安全的Java API替代SQL字符串拼接
- 插件化架构:分页、性能分析、乐观锁等企业级功能开箱即用
本文将系统解析MP的核心工作机制,涵盖以下重点:
- 基础CRUD的零SQL实现
- 注解驱动的表字段映射策略
- 基于Lambda的条件构造器安全写法
- 自定义SQL与MP特性的无缝融合
插播一条消息~
🔍十年经验淬炼 · 系统化AI学习平台推荐
系统化学习AI平台![]() https://www.captainbed.cn/scy/
https://www.captainbed.cn/scy/
📚 完整知识体系:从数学基础 → 工业级项目(人脸识别/自动驾驶/GANs),内容由浅入深
💻 实战为王:每小节配套可运行代码案例(提供完整源码)
🎯 零基础友好:用生活案例讲解算法,无需担心数学/编程基础
🚀 特别适合
- 想系统补强AI知识的开发者
- 转型人工智能领域的从业者
- 需要项目经验的学生
2.正文
2.1介绍
什么是MyBatis Plus呢?
简介 | MyBatis-Plus![]() https://baomidou.com/introduce/
https://baomidou.com/introduce/
一句话:在MyBatis基础上只做增强不做改变,简化开发的“效率神器”。
它保留了MyBatis的全部特性,同时内置了CRUD接口、分页插件、代码生成器等实用功能,让你告别重复写SQL的痛苦。
2.2基础操作
2.2.1准备工作
核心依赖配置:
com.baomidou mybatis-plus-boot-starter 3.5.3.1 mysql mysql-connector-java 8.0.33配置文件(application.yml):
spring: datasource: url: jdbc:mysql://localhost:3306/mp_demo?useSSL=false&serverTimezone=UTC username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Drivermybatis-plus: configuration: # 关键:开启SQL日志 log-impl: org.apache.ibatis.logging.stdout.StdOutImpl global-config: db-config: # 全局表前缀 table-prefix: t_实体类定义:
@Data@TableName(\"user\") // 指定对应数据库表public class User { @TableId(type = IdType.AUTO) // 主键自增策略 private Long id; private String name; private Integer age; @TableField(\"user_email\") // 映射字段名 private String email;}Mapper接口定义:
@Mapperpublic interface UserMapper extends BaseMapper { // 无需任何方法声明 // 已自动继承17个基础CRUD方法}2.2.2编码
核心CRUD方法:
@Servicepublic class UserService { @Autowired private UserMapper userMapper; // 插入 public int createUser(User user) { return userMapper.insert(user); // 注意:自增ID会自动回填到user对象 } // 按ID查询 public User getUserById(Long id) { return userMapper.selectById(id); } // 更新 public int updateUser(User user) { return userMapper.updateById(user); } // 删除 public int deleteUser(Long id) { return userMapper.deleteById(id); } // 查询所有 public List getAllUsers() { return userMapper.selectList(null); // null表示无条件 }}2.2.3CRUD测试
测试场景设计:
@SpringBootTestclass UserCrudTests { @Autowired private UserService userService; @Test void testFullCrudFlow() { // 1. 创建测试数据 User newUser = new User(); newUser.setName(\"TestUser\"); newUser.setAge(30); newUser.setEmail(\"test@mp.com\"); // 2. 插入测试(验证日志输出) int createResult = userService.createUser(newUser); assertEquals(1, createResult); // 影响行数=1 assertNotNull(newUser.getId()); // 自增ID回填验证 // 3. 查询验证 User dbUser = userService.getUserById(newUser.getId()); assertEquals(\"TestUser\", dbUser.getName()); // 4. 更新测试 dbUser.setEmail(\"updated@mp.com\"); int updateResult = userService.updateUser(dbUser); assertEquals(1, updateResult); // 5. 二次查询验证更新 User updatedUser = userService.getUserById(dbUser.getId()); assertEquals(\"updated@mp.com\", updatedUser.getEmail()); // 6. 删除测试 int deleteResult = userService.deleteUser(updatedUser.getId()); assertEquals(1, deleteResult); // 7. 验证删除结果 User deletedUser = userService.getUserById(updatedUser.getId()); assertNull(deletedUser); }}关键日志分析(控制台输出):
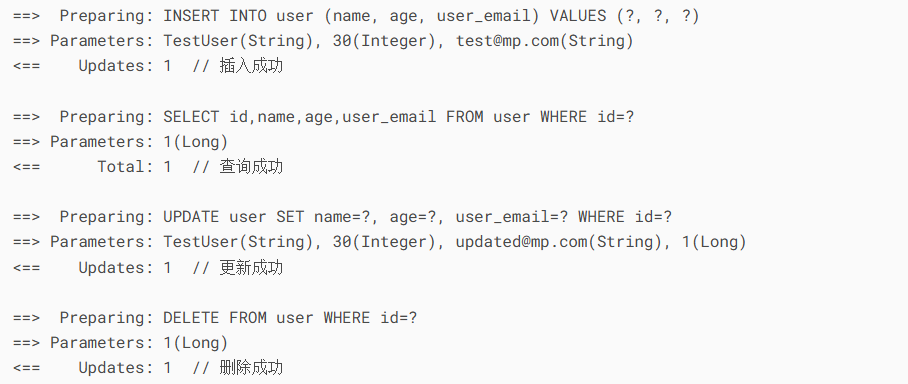
技术要点总结:
零SQL实现:所有基础CRUD操作无需编写SQL语句
自动映射:
表名映射:
@TableName或全局配置字段映射:自动驼峰转下划线(
userEmail → user_email)主键策略:通过
@TableId指定(自增/雪花算法等)方法继承:
// BaseMapper提供的基础方法int insert(T entity);int deleteById(Serializable id);int updateById(T entity);T selectById(Serializable id);List selectList(@Param(\"ew\") Wrapper queryWrapper);事务支持:默认继承Spring事务管理
自动填充:插入/更新时自动填充
create_time等字段(需配合@TableField)
2.3复杂操作
2.3.1常见注解
2.3.1.1@TableName
作用:建立实体类与数据库表的映射关系
使用场景:
表名与类名不一致时(如类名
User对应表名sys_user)需要动态表名(如分表场景)
需要指定数据库schema
核心参数:
@TableName( value = \"sys_user\", // 实际表名 schema = \"enterprise_db\", // 数据库schema keepGlobalPrefix = true // 是否使用全局表前缀)public class User { // ...}配置示例:
# application.ymlmybatis-plus: global-config: db-config: table-prefix: \"tbl_\" # 全局表前缀 table-underline: true # 开启下划线命名转换使用规则:
优先使用注解中的
value值未配置
value时,自动转换类名(User → user)开启
keepGlobalPrefix时,表名 = 全局前缀 + value值
2.3.1.2@TableField
作用:建立属性与表字段的映射关系
核心参数:
public class User { @TableField( value = \"full_name\", // 数据库字段名 exist = true, // 是否为表字段(false表示虚拟字段) insertStrategy = FieldStrategy.NOT_NULL, // 插入策略 updateStrategy = FieldStrategy.IGNORED, // 更新策略 fill = FieldFill.INSERT_UPDATE // 自动填充策略 ) private String name;}字段策略(FieldStrategy):
自动填充(FieldFill):
// 自动填充处理器@Componentpublic class AutoFillHandler implements MetaObjectHandler { @Override public void insertFill(MetaObject metaObject) { this.strictInsertFill(metaObject, \"createTime\", LocalDateTime.class, LocalDateTime.now()); } @Override public void updateFill(MetaObject metaObject) { this.strictUpdateFill(metaObject, \"updateTime\", LocalDateTime.class, LocalDateTime.now()); }}// 实体类配置public class User { @TableField(fill = FieldFill.INSERT) private LocalDateTime createTime; @TableField(fill = FieldFill.INSERT_UPDATE) private LocalDateTime updateTime;}2.3.1.3@TableId
作用:标识主键字段并指定主键策略
核心参数:
public class User { @TableId( value = \"user_id\", // 主键字段名 type = IdType.ASSIGN_ID // 主键生成策略 ) private Long id;}主键策略(IdType):
雪花算法配置:
mybatis-plus: global-config: db-config: id-type: assign_id worker-id: 1 # 工作机器ID(0-31) datacenter-id: 1 # 数据中心ID(0-31)注解应用综合示例
@TableName(value = \"sys_users\", schema = \"hr_db\")public class User { @TableId(type = IdType.ASSIGN_ID) private Long id; @TableField(value = \"full_name\", updateStrategy = FieldStrategy.NOT_EMPTY) private String name; @TableField(exist = false) // 非数据库字段 private String tempToken; @TableField(fill = FieldFill.INSERT) private LocalDateTime createTime; @TableField( value = \"is_deleted\", insertStrategy = FieldStrategy.NEVER, // 插入时不包含 updateStrategy = FieldStrategy.NEVER // 更新时不包含 ) private Boolean deleted;}关键提示:
使用
@TableField(exist=false)标记DTO扩展字段敏感字段设置
updateStrategy=FieldStrategy.NEVER防止意外更新主键策略必须与实际数据库结构匹配(自增字段需配置
AUTO)开启SQL日志验证注解是否生效
2.3.2打印日志
核心价值:
- SQL审计 → 验证自动生成的SQL是否符合预期
- 性能优化 → 识别慢查询和N+1问题
- 故障排查 → 定位参数绑定错误和语法异常
配置方式
基础配置(application.yml):
mybatis-plus: configuration: # 标准输出(控制台) log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # SLF4J+Logback(生产推荐) # log-impl: org.apache.ibatis.logging.slf4j.Slf4jImpl日志级别控制:
# Logback配置(src/main/resources/logback.xml) # 查看参数细节日志格式解析
典型日志输出:

字段说明:
Preparing:Parameters:Total:Updates:Time: 23ms日志级别策略:
2.3.3条件构造器
核心架构
// 条件构造器类继承体系AbstractWrapper ├── QueryWrapper // 查询条件构造 ├── UpdateWrapper // 更新条件构造 ├── LambdaQueryWrapper // Lambda安全查询 └── LambdaUpdateWrapper // Lambda安全更新2.3.3.1QueryWrapper
核心功能:构建SELECT查询条件
适用场景:复杂条件查询、排序、分组
基础用法:
QueryWrapper query = new QueryWrapper();query.select(\"id\", \"name\", \"age\") // 指定查询列 .like(\"name\", \"张\") // 模糊查询 .gt(\"age\", 20) // 大于 .between(\"create_time\", startDate, endDate) // 范围查询 .orderByDesc(\"id\") // 排序 .last(\"LIMIT 10\"); // 自定义SQL片段List users = userMapper.selectList(query);链式条件方法:
eq(\"column\", val)column = valne(\"column\", val)column valgt(\"column\", val)column > valge(\"column\", val)column >= vallt(\"column\", val)column < valle(\"column\", val)column <= valbetween(c, v1, v2)c BETWEEN v1 AND v2like(\"c\", \"val%\")c LIKE \'val%\'in(\"c\", list)c IN (v1,v2)isNull(\"c\")c IS NULLgroupBy(\"c1,c2\")GROUP BY c1,c2having(\"sum(a)>0\")HAVING sum(a)>02.3.3.2UpdateWrapper
核心功能:构建UPDATE操作条件
适用场景:条件更新、字段增量操作
基础用法:
UpdateWrapper update = new UpdateWrapper();update.set(\"email\", \"new@email.com\") // 设置更新值 .setSql(\"balance = balance + 100\") // 原生SQL更新 .eq(\"status\", 1) // 更新条件 .gt(\"last_login\", LocalDate.now().minusMonths(3)); // 三个月内有登录int rows = userMapper.update(null, update); // entity传null特殊操作符:
// 数学运算update.setSql(\"view_count = view_count + 1\");// JSON字段更新 (MySQL 5.7+)update.setSql(\"profile = JSON_SET(profile, \'$.level\', 2)\");// CASE WHEN更新update.setSql(\"vip_level = CASE WHEN score>1000 THEN 2 ELSE 1 END\");2.3.3.3LambdaQueryWrapper
核心价值:消除字段名字符串硬编码
编译时检查:字段引用通过方法引用实现
基础用法:
LambdaQueryWrapper lambdaQuery = new LambdaQueryWrapper();lambdaQuery.select(User::getId, User::getName) .like(User::getName, \"王\") .between(User::getAge, 20, 30) .orderByDesc(User::getCreateTime);List users = userMapper.selectList(lambdaQuery);复杂嵌套查询:
lambdaQuery.and(wrapper -> wrapper.gt(User::getScore, 90) .or() .eq(User::getVipLevel, 2) ) .nested(wrapper -> wrapper.lt(User::getAge, 18) .or() .gt(User::getAge, 60) );等价SQL:
SELECT id, name FROM user WHERE (score > 90 OR vip_level = 2) AND (age 60)2.3.3.4LambdaUpdateWrapper
核心价值:类型安全的更新操作
基础用法:
LambdaUpdateWrapper lambdaUpdate = new LambdaUpdateWrapper();lambdaUpdate.set(User::getEmail, \"updated@email.com\") .set(User::getUpdateTime, LocalDateTime.now()) .eq(User::getDepartmentId, 101) .in(User::getRole, Arrays.asList(\"admin\", \"editor\"));int rows = userMapper.update(null, lambdaUpdate);条件更新技巧:
// 按条件设置不同值lambdaUpdate.setSql(\"score = CASE \" + \"WHEN age 50 THEN score + 5 \" + \"ELSE score + 8 END\") .le(User::getScore, 100);四类构造器对比矩阵
2.3.4自定义SQL
解决MP的局限性场景:
- 多表关联查询(JOIN操作)
- 复杂聚合函数(SUM/COUNT嵌套)
- 数据库特性函数(如Oracle的CONNECT BY)
- 存储过程/函数调用
- 特殊分页需求(优化count查询)
实现方式对比
2.3.4.1注解方式
基础语法:
@Select(\"SELECT * FROM user WHERE age > #{minAge}\")List findAdultUsers(@Param(\"minAge\") int minAge);动态条件注解:
@Select(\"\" + \"SELECT * FROM user \" + \"WHERE 1=1 \" + \" AND name LIKE #{name} \" + \" AND age >= #{minAge} \" + \"\")List findUsersDynamic( @Param(\"name\") String name, @Param(\"minAge\") Integer minAge);多表关联示例:
@Select(\"SELECT u.*, d.dept_name \" + \"FROM user u \" + \"LEFT JOIN department d ON u.dept_id = d.id \" + \"WHERE u.status = 1\")List<Map> findUsersWithDept();限制:
不支持
${ew.customSqlSegment}注入复杂SQL可维护性差
2.3.4.2XML映射
基础配置:
mybatis-plus: mapper-locations: classpath*:mapper/**/*.xml核心技巧:Wrapper条件集成
Mapper接口定义:
public interface UserMapper extends BaseMapper { // 使用@Param(\"ew\")固定命名 List selectComplexUsers(@Param(\"ew\") Wrapper wrapper);}XML映射实现:
SELECT u.id, u.name, d.dept_name AS deptName, COUNT(o.id) AS orderCount FROM user u LEFT JOIN department d ON u.dept_id = d.id LEFT JOIN orders o ON o.user_id = u.id ${ew.customSqlSegment} GROUP BY u.idJava调用示例:
LambdaQueryWrapper wrapper = new LambdaQueryWrapper();wrapper.like(User::getName, \"张\") .gt(User::getAge, 25) .orderByDesc(User::getCreateTime);List users = userMapper.selectComplexUsers(wrapper);生成SQL:
SELECT u.id, u.name, d.dept_name, COUNT(o.id)FROM user uLEFT JOIN department d ON u.dept_id = d.idLEFT JOIN orders o ON o.user_id = u.idWHERE name LIKE \'%张%\' AND age > 25 -- 自动生成的条件GROUP BY u.idORDER BY create_time DESC -- 自动排序2.3.4.3常见故障
ew.customSqlSegment无效@Param(\"ew\")selectPageCount方法@ResultMap配置resultMapstatementTypestatementType=\"CALLABLE\"通过合理选择自定义SQL方案,可在保持MP高效开发的同时,应对各类复杂数据库操作场景。
3.小结
通过本文的系统讲解,我们完整梳理了MyBatis Plus的核心功能体系。从环境搭建到复杂查询,从自动映射机制到条件构造器的深度应用,每个技术点都提供了可落地的解决方案。
- 开发效率提升:通用Mapper消灭单表CRUD代码
- 维护成本降低:Lambda Wrapper杜绝SQL拼接错误
- 架构统一性:注解体系提供标准化映射方案
BaseMapper@TableId)@TableFieldexist=false${ew.customSqlSegment}开发建议:MP适用于80%的单表操作场景,剩余20%复杂查询通过
自定义SQL+Wrapper解决。掌握此平衡点,可最大化开发效能。
建议开发者在实际项目中逐步引入MyBatis Plus的特性,从基础CRUD开始,逐步过渡到复杂查询和分页处理。通过本文提供的代码示例模板,可以快速构建标准的数据库访问层,最终实现\"代码精简、开发效率提升\"的优化目标。

