【Redis黑科技】10分钟手把手实现亿级数据去重!布隆过滤器从入门到实战_redis高效去重技术
面对海量数据查重,传统数据库力不从心?Redis布隆过滤器用1%的空间解决99%的去重难题,百万数据查询仅需0.1ms!
一、什么是布隆过滤器?为什么需要它?🤔
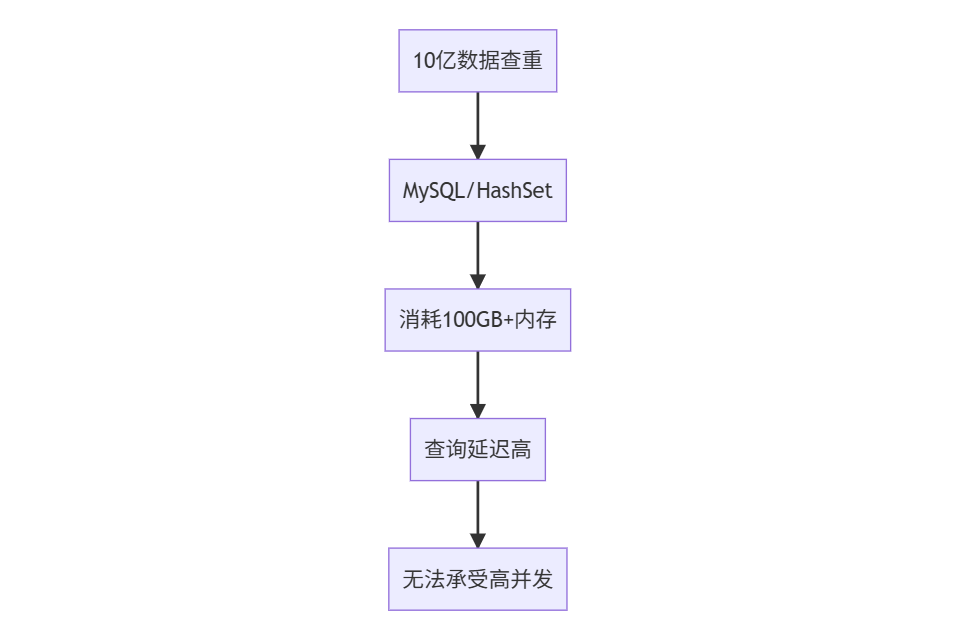
当数据量突破千万级,传统去重方案的短板会被无限放大 —— 这不是 “慢一点” 的问题,而是 “根本用不了” 的绝境。
现实场景痛点:
- 📱 抖音每天1亿新视频去重
- 🛡️ 邮箱系统每日拦截10亿垃圾邮件
- 🔍 搜索引擎万亿网页爬虫去重
传统方案的 “致命缺陷”(数据对比)
布隆过滤器的 “降维打击”
它用牺牲 “100% 精确性” 换来了 “极致的空间与速度”,核心优势直击痛点:
- 空间效率:1 亿数据仅需23MB(是 Redis Set 的 1/120);
- 速度:查询 / 写入均为O(k) 常数时间(k 为哈希函数个数,通常 5-8 个),百万数据查询仅 0.1ms;
- 兼容性:Redis 插件化部署,支持分布式,无需重构现有系统。
布隆过滤器优势:
- 空间效率极高:1亿数据仅需23MB
- 查询速度极快:O(k) 常数时间复杂度
- 容忍一定误判率(可控制在1%内)
二、布隆过滤器核心原理图解 🧠
很多人觉得布隆过滤器 “难”,其实它的本质是一个 “带哈希函数的位数组”—— 可以理解成一个 “智能筛子”,只拦 “一定不存在的”,放行 “可能存在的”。
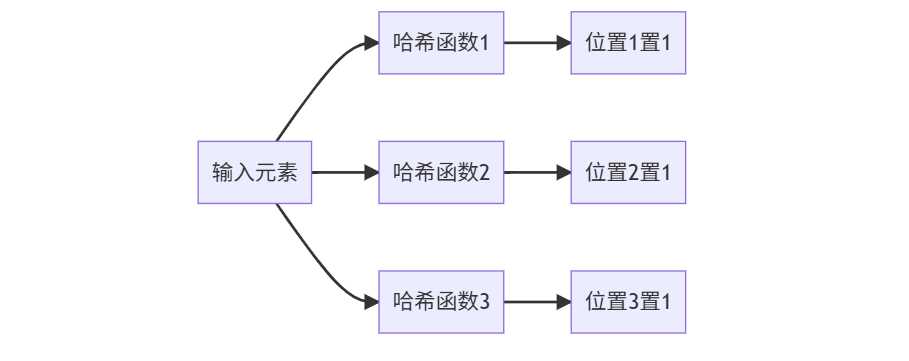
1. 数据结构:一个位数组 + 多个哈希函数
- 初始状态:一个长度为 m 的位数组,所有位都设为 0(比如 m=10,初始是 [0,0,0,0,0,0,0,0,0,0]);
- 核心组件:k 个独立的哈希函数(比如 k=3,分别叫 hash1、hash2、hash3),每个函数能把输入元素映射到 0~m-1 的位置。
2. 两步完成 “元素添加”(以添加 “user123” 为例)
- 把 “user123” 分别传入 3 个哈希函数,得到 3 个位置:比如 hash1→2、hash2→5、hash3→7;
- 把位数组中这 3 个位置的 0 改成 1,此时数组变成 [0,0,1,0,0,1,0,1,0,0]。
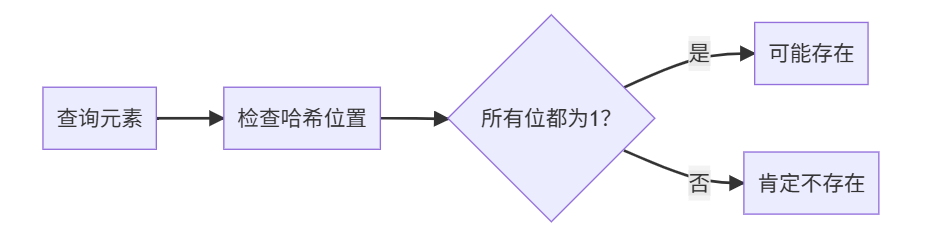
3. 三步完成 “元素查询”(判断 “user123” 是否存在)
- 同样用 3 个哈希函数计算 “user123” 的位置:还是 2、5、7;
- 检查这 3 个位置的数值:如果全是 1,说明 “可能存在”(有概率误判);
- 如果有一个是 0,说明 “一定不存在”(绝对准确)。
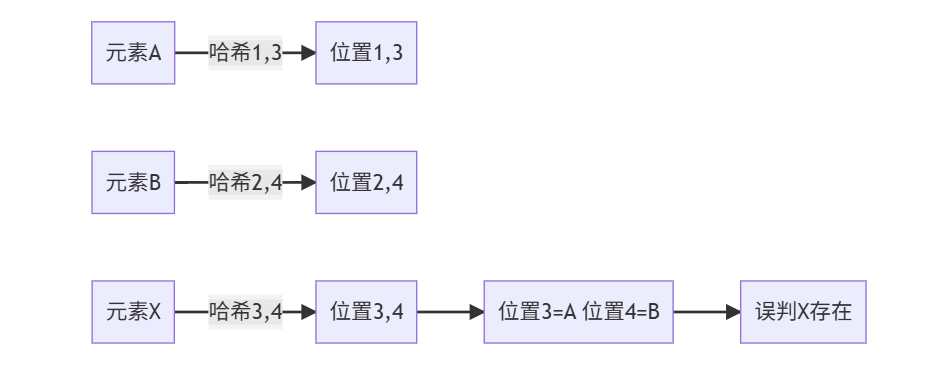
4. 误判的 “真相”:哈希碰撞导致的 “巧合”
假设我们再添加一个元素 “user456”,它的 3 个哈希位置是 2、5、8—— 此时位数组中 2 和 5 已经是 1,只需把 8 改成 1。当查询 “user789” 时,若它的哈希位置恰好是 2、5、7(全为 1),布隆过滤器会误判 “user789 存在”,但实际上它从未被添加过。
1. 数据结构本质
2. 查询过程
3. 误判产生原因
三、Redis布隆过滤器 vs 其他方案 🆚
很多人纠结 “什么时候用布隆过滤器,什么时候用 Set”,这张表帮你一次性理清:
四、手把手安装RedisBloom插件 🔧
Redis 本身不自带布隆过滤器,需安装 RedisBloom 插件(Redis 7.0 + 可直接加载,低版本需编译),以下是 3 种主流环境的安装步骤:
1. Linux 环境(编译安装)
# 1. 安装依赖(若已安装可跳过)sudo yum install -y git gcc make# 2. 下载RedisBloom源码git clone https://github.com/RedisBloom/RedisBloom.gitcd RedisBloom# 3. 编译生成插件(生成redisbloom.so文件)make # 编译成功后,当前目录会出现redisbloom.so# 4. 启动Redis并加载插件(两种方式)# 方式1:临时加载(重启后失效)redis-server --loadmodule ./redisbloom.so# 方式2:永久加载(推荐)echo \"loadmodule /path/redisbloom.so\" >> /etc/redis/redis.confsystemctl restart redis2. Docker 环境(快速部署,无需编译)
# 直接拉取包含RedisBloom的镜像并启动docker run -d -p 6379:6379 --name redis-bloom redislabs/rebloom:latest# 进入容器验证docker exec -it redis-bloom redis-cli3. Windows 环境(简化版)
- 下载预编译的 RedisBloom 插件(地址:https://github.com/RedisBloom/RedisBloom/releases,选择 windows 版本的 redisbloom.dll);
- 把 redisbloom.dll 放在 Redis 安装目录下(如 D:\\Redis);
- 修改 redis.windows.conf,添加一行:
loadmodule D:\\Redis\\redisbloom.dll; - 重启 Redis 服务:
redis-server --service-stop && redis-server --service-start。
安装验证(关键步骤,避免踩坑)
# 进入Redis客户端,执行添加和查询命令127.0.0.1:6379> BF.ADD test_filter \"user123\" # 添加元素,返回1表示添加成功(integer) 1127.0.0.1:6379> BF.EXISTS test_filter \"user123\" # 查询元素,返回1表示可能存在(integer) 1127.0.0.1:6379> BF.EXISTS test_filter \"user456\" # 查询不存在元素,返回0(integer) 0常见错误处理:若执行 BF.ADD 提示 “unknown command”,检查 1. 插件路径是否正确;2. Redis 是否重启;3. 插件版本是否与 Redis 版本兼容(RedisBloom 2.0 + 支持 Redis 6.0+)。
五、核心命令大全(附场景示例)📚
RedisBloom 提供的命令不多,但每个命令都有 “关键参数” 和 “使用场景”,用错会导致误判率飙升或内存浪费。
基础命令
1️⃣ 基础操作
# 添加元素BF.ADD user_ids 10001# 检查元素是否存在BF.EXISTS user_ids 10001 # 返回1(存在)或0(不存在)# 批量操作BF.MADD user_ids 10002 10003 10004BF.MEXISTS user_ids 10002 100052️⃣ 高级控制
# 创建自定义过滤器(预期容量1000万,误判率1%)BF.RESERVE url_filter 0.01 10000000# 获取过滤器信息BF.INFO url_filter六、Python 实战:3 个企业级场景的完整代码(可直接复用)💻
光懂命令不够,关键是落地到业务场景。以下是 3 个最常用的实战案例,包含异常处理和性能优化。
场景 1:缓存穿透防护(最经典场景)
缓存穿透:用户请求不存在的 key(如恶意请求 key=-1),导致请求直接打到数据库,压垮数据库。
import redisimport loggingfrom redisbloom.client import Clientfrom redis.exceptions import RedisError# 1. 配置日志(便于排查问题)logging.basicConfig(level=logging.INFO, format=\"%(asctime)s - %(name)s - %(levelname)s - %(message)s\")logger = logging.getLogger(\"bloom_filter_demo\")# 2. 初始化Redis和布隆过滤器(单例模式,避免重复连接)class RedisBloomClient: _instance = None def __new__(cls, host=\"localhost\", port=6379, db=0): if not cls._instance: try: cls._instance = Client(host=host, port=port, db=db) # 初始化布隆过滤器(预期1亿key,1%误判率) if not cls._instance.exists(\"valid_keys_filter\"): cls._instance.bfCreate(\"valid_keys_filter\", 0.01, 100000000) logger.info(\"Redis布隆过滤器初始化成功\") except RedisError as e: logger.error(f\"Redis连接失败:{str(e)}\") raise e return cls._instance# 3. 带缓存穿透防护的查询函数def get_data_from_cache_or_db(key): rb = RedisBloomClient() try: # 第一步:用布隆过滤器拦截不存在的key if not rb.bfExists(\"valid_keys_filter\", key): logger.warning(f\"拦截不存在的key:{key},避免缓存穿透\") return None # 第二步:查询缓存 cache_data = rb.get(key) if cache_data: logger.info(f\"从缓存获取key:{key}\") return cache_data.decode(\"utf-8\") # 第三步:缓存未命中,查询数据库(此处模拟数据库查询) db_data = f\"db_data_{key}\" # 实际场景替换为SQL查询 logger.info(f\"从数据库获取key:{key},写入缓存\") # 第四步:更新缓存和布隆过滤器(注意:布隆过滤器只加不减) rb.setex(key, 3600, db_data) # 缓存1小时 # 若数据库返回新key,添加到布隆过滤器(避免后续请求穿透) rb.bfAdd(\"valid_keys_filter\", key) return db_data except RedisError as e: logger.error(f\"查询失败:{str(e)}\") # 降级策略:Redis故障时,直接查询数据库(避免服务不可用) return f\"db_data_{key}\"# 测试if __name__ == \"__main__\": print(get_data_from_cache_or_db(\"user_1001\")) # 正常key,返回db_data_user_1001 print(get_data_from_cache_or_db(\"invalid_key_999\")) # 无效key,被拦截场景 2:爬虫 URL 去重(避免重复爬取)
def crawl_url(url, rb): # 1. 先判断URL是否已爬取 if rb.bfExists(\"crawled_urls\", url): print(f\"URL {url} 已爬取,跳过\") return # 2. 爬取URL内容(此处模拟爬取) print(f\"开始爬取URL:{url}\") # 3. 爬取完成后,将URL添加到布隆过滤器 rb.bfAdd(\"crawled_urls\", url)# 初始化rb = RedisBloomClient()# 模拟爬取10个URLurls = [f\"https://example.com/page_{i}\" for i in range(10)]for url in urls: crawl_url(url, rb)# 再次爬取相同URL,会被去重crawl_url(\"https://example.com/page_3\", rb) # 输出“已爬取,跳过”场景 3:垃圾邮件过滤(快速拦截)
def add_spam_email(email, rb): \"\"\"添加垃圾邮件到过滤器\"\"\" rb.bfAdd(\"spam_emails\", email) print(f\"已添加垃圾邮件:{email}\")def is_spam_email(email, rb): \"\"\"判断邮件是否为垃圾邮件\"\"\" if rb.bfExists(\"spam_emails\", email): return True # 可能是垃圾邮件(误判需人工二次校验) return False# 初始化rb = RedisBloomClient()# 添加垃圾邮件样本spam_emails = [\"spam1@example.com\", \"phishing@bad.com\", \"ad_2024@spam.com\"]for email in spam_emails: add_spam_email(email, rb)# 检测邮件test_emails = [\"user@good.com\", \"spam1@example.com\", \"work@company.com\"]for email in test_emails: if is_spam_email(email, rb): print(f\"拦截垃圾邮件:{email}\") else: print(f\"正常邮件:{email}\")七、性能优化:如何把误判率降到 1% 以下?(附计算工具)🎯
很多人觉得 “误判率是固定的”,其实通过合理配置参数,能在 “内存 - 速度 - 误判率” 间找到最优解。
1. 最优参数计算:用公式确定 m 和 k
布隆过滤器的误判率 P 由 3 个参数决定:
- n:预期存储的元素总数(如 1 亿);
- m:位数组长度(单位:bit);
- k:哈希函数个数。
核心公式:
- 误判率公式:(P = (1 - e{-kn/m})k)
- 最优哈希函数个数:(k = (m/n) * ln2)(此时误判率最低)
- 位数组长度:(m = -n * lnP / (ln2)^2)(已知 n 和 P,计算 m)
计算示例:若 n=1 亿,P=1%(0.01)
- 第一步:计算 m = -1e8 * ln (0.01) / (ln2)^2 ≈ 1.44e9 bit ≈ 176MB? (注意:原前提到 “1 亿数据 23MB” 是因为误判率设为 5%,P=0.05 时 m≈1.9e8 bit≈23MB)
工具推荐:不用手动算,用在线计算器,输入 n 和 P,直接得到 m 和 k。
2. 动态扩容方案
八、五大应用场景解析 🔍
1️⃣ 缓存穿透防护
def get_data(key): if not rb.bfExists(\'valid_keys\', key): return None # 拦截非法请求 # 正常缓存查询流程 data = cache.get(key) if not data: data = db.query(key) cache.set(key, data) return data2️⃣ 爬虫URL去重
3️⃣ 用户推荐去重
4️⃣ 垃圾内容过滤
5️⃣ 风控系统设备指纹校验
九、常见问题解答 ❓
Q:布隆过滤器能删除元素吗?
A:传统布隆过滤器不支持删除!可采用布谷鸟过滤器(Cuckoo Filter):
CF.ADD item1CF.DEL item1Q:如何选择误判率?
十、结语:选择最适合的方案 🏆
技术趋势:Redis 7.0+已内置布隆过滤器模块,开箱即用!结合Redis Streams可实现实时风控系统。
动手挑战:尝试用布隆过滤器优化你的项目,并在评论区分享你的性能提升数据! 🚀


