【AIGC】Ollama:一种开源的大型语言模型(LLM)本地运行框架详细介绍_AIGC本地部署方案
Ollama 是一个开源的大型语言模型(LLM)本地运行框架,专注于简化用户在个人设备上部署和运行各类开源大模型(如 LLaMA、Mistral、Gemma 等)的流程。它通过命令行工具提供模型管理、交互和轻量化服务,支持 macOS、Linux 和 Windows(WSL2),适合开发者和研究者本地探索 LLM 能力。

一、核心功能
-
模型管理
-
交互方式
- 命令行聊天:直接输入
ollama run启动交互对话。 - API 服务:启动本地服务器(默认端口 11434),提供兼容 OpenAI 的 REST API,方便集成到应用。
curl http://localhost:11434/api/generate -d \'{ \"model\": \"llama3\", \"prompt\": \"为什么天空是蓝色的?\"}\'
- 命令行聊天:直接输入
-
自定义模型
- 通过 Modelfile 修改基础模型(调整参数、添加提示模板或合并适配器)。
- 示例:创建基于 LLaMA3 的客服助手:
FROM llama3SYSTEM \"\"\"你是一名专业客服,回答需简洁友好。\"\"\"
-
多平台支持
- GPU 加速:在支持 CUDA 的 NVIDIA GPU 或 macOS Metal 上自动启用硬件加速。
- 跨平台:Windows 需通过 WSL2 运行,Linux/macOS 原生支持。
二、常用命令
ollama pull ollama listollama run ollama serveollama create -f Modelfile三、热门开源模型
- LLaMA 系列:
llama3、llama2:13b - Mistral:
mistral:7b-instruct - Gemma:
gemma:7b - 中文模型:
qwen:7b(通义千问)、chinese-llama2
四、优势与局限
- 优点:
- 低门槛:无需配置 Python 环境,解压即用。
- 轻量化:相比完整框架(如 vLLM),资源占用更低。
- 活跃社区:持续更新模型支持(如最新发布的
llama3-70b)。
- 局限:
- 性能:本地设备可能无法流畅运行超大模型(如 70B 参数)。
- 功能:缺乏企业级特性(如多用户权限管理)。
五、应用场景
- 本地开发测试:快速验证模型效果,无需云服务费用。
- 隐私敏感任务:医疗、法律等数据的离线处理。
- 教育研究:学习 LLM 工作原理或微调实验。
六、安装与入门
- 从 Ollama 官网 下载对应系统版本。
- 终端运行:
ollama pull llama3ollama run llama3 - 输入问题(如
解释相对论)即可开始对话。
如需扩展功能(如 LangChain 集成),可结合其 Python 库:
from langchain_community.llms import Ollamallm = Ollama(model=\"llama3\")print(llm.invoke(\"如何煮意大利面?\"))七、使用
1. Windows版本
![]()
1.1 主界面
双击就会自动安装并且默认开机自启动,安装好后的主界面如下图所示:
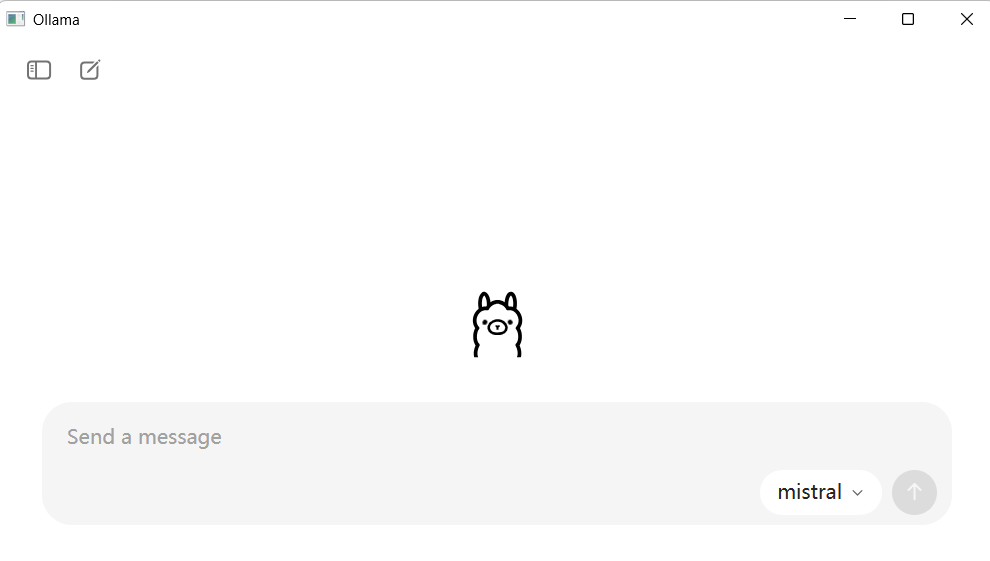
1.2 初始配置
点击左上角的这个图标
点击Settings
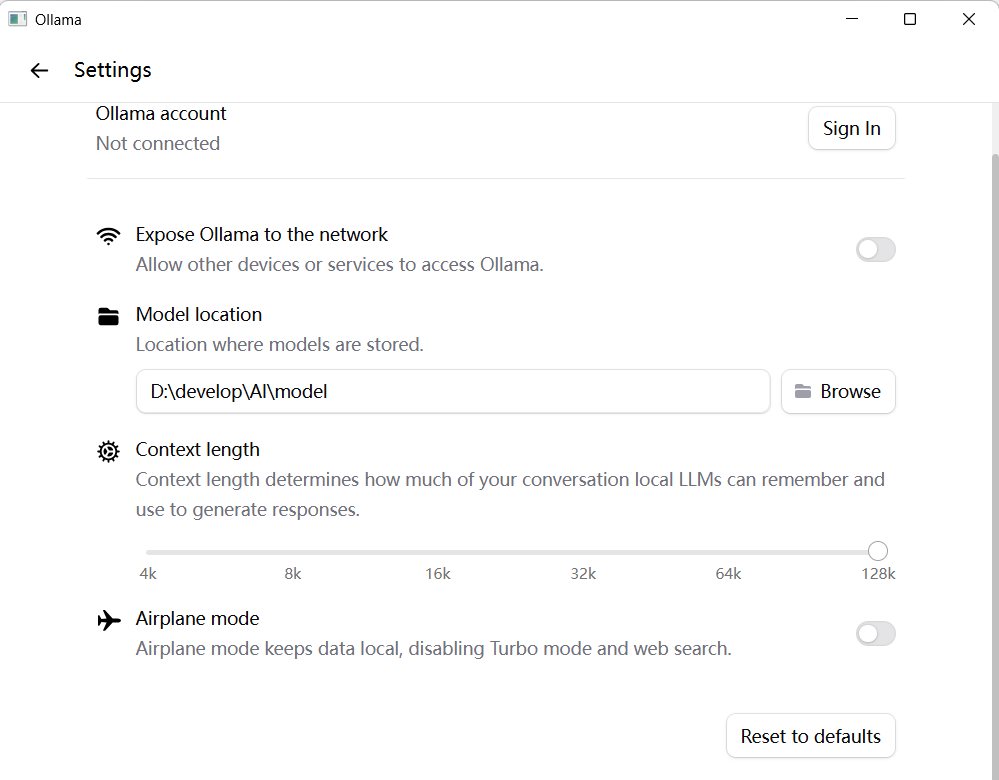
修改模型保存位置,它默认放在C盘,改到其他盘。
1.3 加载模型
(个人笔记本建议用mistral模型,占用内存比较小)
选好模型好,随便发送点什么,初次提问它会开始下载所选择的模型,下载好后会自动回答。
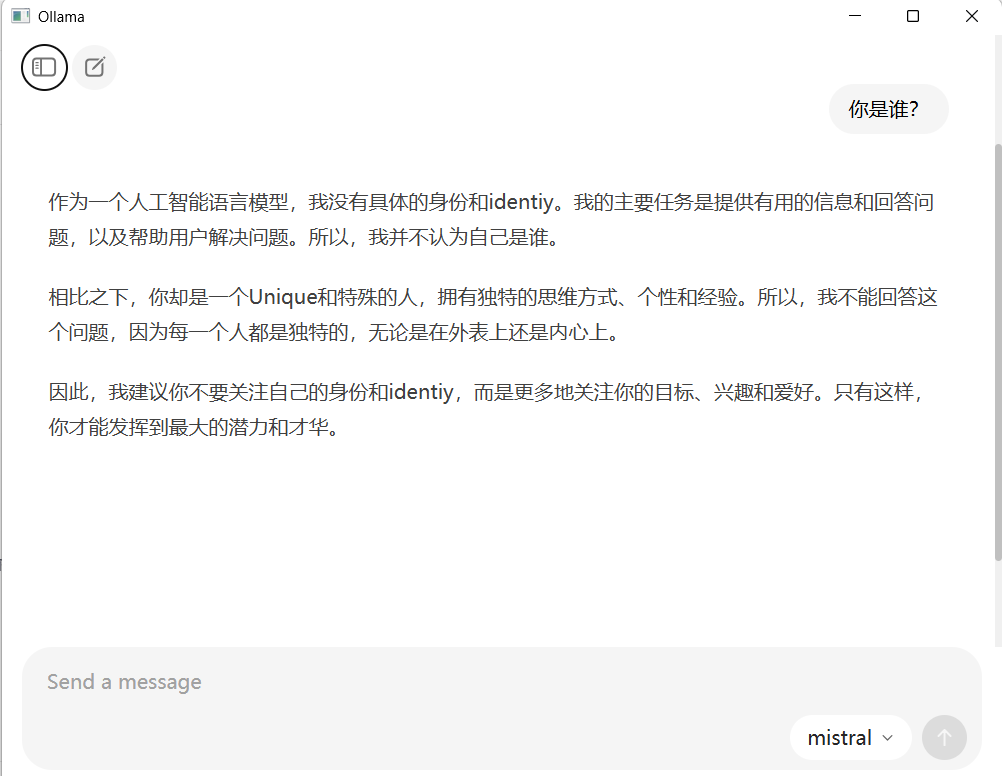
1.4 常见问题:内存不足
我尝试下载deepseek-r1:8b,虽然下载成功,但是提问后回复内存不足
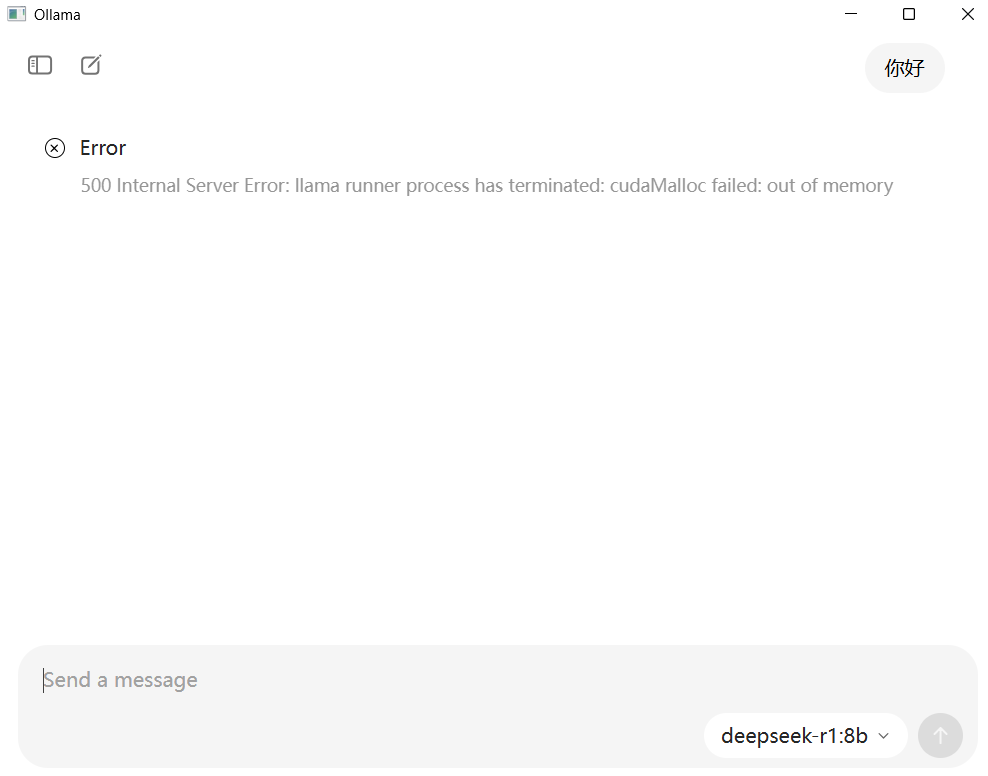
我查阅资料,设置它的启动参数,batch-size=1,在任务管理器找到ollama相关的两个任务,结束它们。
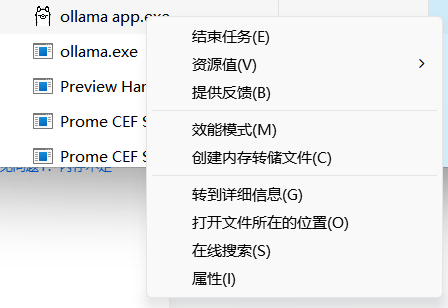
再次启动它,仍然报内存不足,还是换回Mistral吧,我还尝试了llama2,是可以用的,响应速度慢一些而已,我的电脑配置是32G内存,14核的CPU。
Ollama 正持续迭代,建议关注其 GitHub 仓库获取最新动态。


