llama-factory+cot数据集,使用lora微调qwen2.5-0.5b_llamafactory cot数据集训练
1. 环境准备
python3.11版本
进入:https://github.com/hiyouga/LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e \".[torch,metrics]\"数据集下载:https://modelscope.cn/datasets/YorickHe/CoT_zh/files
需要将csv数据集转换为json存储,如:
import csvimport jsonimport osdef convert_csv_to_json(csv_path, json_path): \"\"\" Convert CSV file to JSON format. Args: csv_path (str): Path to the CSV file json_path (str): Path to save the JSON file \"\"\" data = [] # Read CSV file with open(csv_path, \'r\', encoding=\'utf-8\') as csv_file: csv_reader = csv.DictReader(csv_file) for row in csv_reader: data.append(row) # # Write JSON file # with open(json_path, \'w\', encoding=\'utf-8\') as json_file: # json.dump(data, json_file, ensure_ascii=False, indent=4) # Split data into train and test sets train_data = data[:1000] test_data = data[1000:1100] # Define paths for train and test JSON files train_json_path = os.path.join(os.path.dirname(json_path), \"CoT_Chinese_train.json\") test_json_path = os.path.join(os.path.dirname(json_path), \"CoT_Chinese_test.json\") # Write train JSON file with open(train_json_path, \'w\', encoding=\'utf-8\') as train_json_file: json.dump(train_data, train_json_file, ensure_ascii=False, indent=4) # Write test JSON file with open(test_json_path, \'w\', encoding=\'utf-8\') as test_json_file: json.dump(test_data, test_json_file, ensure_ascii=False, indent=4) # print(f\"Split data into {len(train_data)} training samples and {len(test_data)} test samples\") # print(f\"Train JSON file saved at: {train_json_path}\") # print(f\"Test JSON file saved at: {test_json_path}\") print(f\"Converted {len(data)} rows from CSV to JSON\") print(f\"JSON file saved at: {json_path}\")if __name__ == \"__main__\": # Get the directory of the current script current_dir = os.path.dirname(os.path.abspath(__file__)) # Define paths csv_path = os.path.join(current_dir, \"CoT_Chinese_data.csv\") json_path = os.path.join(current_dir, \"CoT_Chinese_data.json\") # Convert CSV to JSON convert_csv_to_json(csv_path, json_path)大模型准备:下载地址(魔搭社区)
下载脚本如:需要安装modelscope
from modelscope import snapshot_downloadmodel_dir = snapshot_download(\'Qwen/Qwen2.5-14B-Instruct-GPTQ-Int4\', cache_dir=\'/Users/***/Documents/code/llm\')2. 开始微调
数据集存放位置:
微调yaml:
### modelmodel_name_or_path: /workspace/models/Qwen/Qwen2___5-0___5B-Instructtrust_remote_code: true### methodstage: sftdo_train: truefinetuning_type: loralora_rank: 8lora_target: all## deepspeed: /workspace/LLaMA-Factory/examples/deepspeed/ds_z3_offload_config.json # choices: [ds_z0_config.json, ds_z2_config.json, ds_z3_config.json]### datasetdataset: cot_traintemplate: qwencutoff_len: 2048max_samples: 1000overwrite_cache: truepreprocessing_num_workers: 16dataloader_num_workers: 4### outputoutput_dir: saves/Qwen-0.5b/lora/sft-cotlogging_steps: 10save_steps: 500plot_loss: trueoverwrite_output_dir: truesave_only_model: falsereport_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]### trainper_device_train_batch_size: 1gradient_accumulation_steps: 2learning_rate: 1.0e-4num_train_epochs: 3.0lr_scheduler_type: cosinewarmup_ratio: 0.1bf16: trueddp_timeout: 180000000resume_from_checkpoint: null## eval# eval_dataset: alpaca_en_demo# val_size: 0.1# per_device_eval_batch_size: 1# eval_strategy: steps# eval_steps: 500验证原始模型脚本:
do_predict: truetrust_remote_code: truemodel_name_or_path: /workspace/models/Qwen/Qwen2___5-0___5B-Instructeval_dataset: cot_testdataset_dir: /workspace/ghz/datatemplate: qwenfinetuning_type: loraoutput_dir: ./saves/Qwen-0.5b/lora/predict_base_cotoverwrite_cache: trueoverwrite_output_dir: truecutoff_len: 1024preprocessing_num_workers: 16per_device_eval_batch_size: 1max_samples: 20predict_with_generate: true验证微调后的模型脚本:
do_predict: truetrust_remote_code: truemodel_name_or_path: /workspace/models/Qwen/Qwen2___5-0___5B-Instructadapter_name_or_path: /workspace/ghz/saves/Qwen-0.5b/lora/sft-cot/checkpoint-1500eval_dataset: cot_testdataset_dir: /workspace/ghz/datatemplate: qwenfinetuning_type: loraoutput_dir: ./saves/Qwen-0.5b/lora/predict_cotoverwrite_cache: trueoverwrite_output_dir: truecutoff_len: 1024preprocessing_num_workers: 16per_device_eval_batch_size: 1max_samples: 20predict_with_generate: true3. 结果分析
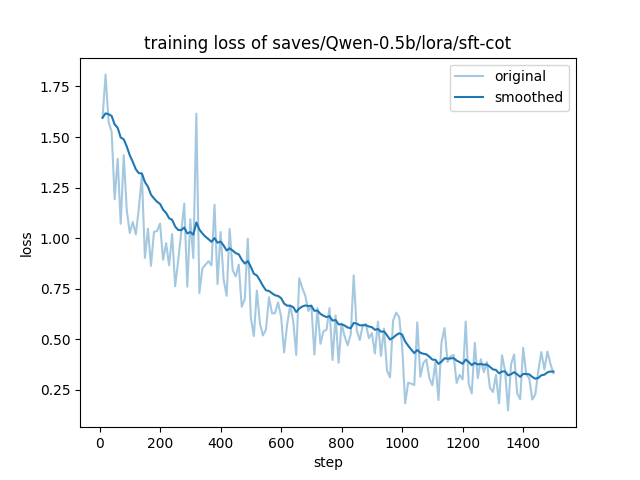
基线指标:
{ \"predict_bleu-4\": 4.060445, \"predict_model_preparation_time\": 0.0036, \"predict_rouge-1\": 28.444929999999992, \"predict_rouge-2\": 4.643019999999999, \"predict_rouge-l\": 11.495560000000001, \"predict_runtime\": 244.9049, \"predict_samples_per_second\": 0.082, \"predict_steps_per_second\": 0.082}微调后结果:
{ \"predict_bleu-4\": 38.08386, \"predict_model_preparation_time\": 0.0036, \"predict_rouge-1\": 61.52824499999999, \"predict_rouge-2\": 40.14397999999999, \"predict_rouge-l\": 52.85084500000001, \"predict_runtime\": 72.9308, \"predict_samples_per_second\": 0.274, \"predict_steps_per_second\": 0.274}选项结果:
基线:
B DB AD BC AC NoneA BD AA EB DC DE CE DC DC EB AA AE NoneC EE NoneA A对了2个微调后:
B BB BD BC BC DA CD EA AB BC BE EE NoneC EC BB DA BE BC CE DA A对了7个4. 指标含义解释
### 1. **BLEU-4(4.060445)**
• **定义**:基于4-gram的匹配度评估生成文本与参考文本的相似性,综合几何平均和简短惩罚因子计算。
• **解读**:该值较低(通常BLEU分数在0-1或0-100范围内),可能是由于生成的4-gram短语与参考文本匹配较少,或存在长度差异较大的问题。例如,若生成文本过短,简短惩罚因子会显著降低分数。
### 2. **ROUGE-1(28.4449)**
• **定义**:基于1-gram的召回率,衡量生成文本中单词在参考文本中的覆盖率。
• **解读**:28.44%的召回率表明生成文本覆盖了参考文本中约28%的单词,但仍有较多信息缺失。
### 3. **ROUGE-2(4.6430)**
• **定义**:基于2-gram的召回率,评估连续两个单词的匹配程度,反映生成文本的短语连贯性。
• **解读**:4.64%的得分较低,说明生成文本中符合参考文本的连续短语较少,可能存在语法或语义偏差。
### 4. **ROUGE-L(11.4956)**
• **定义**:基于最长公共子序列(LCS)的F1分数,综合生成文本与参考文本的语序和结构相似性。
• **解读**:11.5%的分数表明生成文本在整体句法结构和关键信息排列上与参考文本的匹配度较低。
### 5. **Runtime(244.9049秒)**
• **定义**:模型完成所有预测任务的总耗时。
• **解读**:约4分钟的推理时间可能受模型复杂度或硬件性能影响,需结合具体应用场景评估效率。
### 6. **Samples per Second(0.082)**
• **定义**:每秒处理的样本数量,反映模型推理速度。
• **解读**:每秒处理不足0.1个样本,表明模型计算效率较低,可能需优化模型架构或硬件资源。
### 7. **Steps per Second(0.082)**
• **定义**:每秒完成的推理步骤数,通常与“Samples per Second”一致。
• **解读**:与上述效率指标一致,进一步验证模型在实时性要求高的场景中可能存在瓶颈。
### 8. **Model Preparation Time(0.0036秒)**
• **定义**:模型加载、初始化或预处理的耗时。
• **解读**:极短的准备时间表明模型启动开销较小,适合快速部署。

