基于Spark的儿童影视数据分析及可视化系统(源码+定制+开发)
博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!

目录:
一、详细操作演示视频 在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流! 承诺所有开发的项目,全程售后陪伴!!!
2 相关工具及介绍
2.1 Python 语言
2.2 Hive 简介
2.3 Hadoop 技术
2.4 数据采集
2.5 Spark
2.6 环境部署
2.7(可选)系统架构与数据流
2.8(可选)面向儿童内容的合规与安全
2.9(可选)可视化与交互设计要点
编辑系统实现界面展示:
核心代码介绍:
2.7 测试概述
2.8软件测试原则
2.9测试用例
编辑编辑编辑编辑论文部分参考:编辑
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!
承诺所有开发的项目,全程售后陪伴!!!

2 相关工具及介绍
2.1 Python 语言
Python 由 Guido van Rossum 在 20 世纪 90 年代设计,语法简洁、动态类型、跨平台且生态完善。其“胶水语言”特性使其能高效衔接爬虫、数据清洗、Hive/Spark、Web 服务与可视化等模块。
在本课题中,Python 主要用于:
-
数据采集:Requests/Scrapy/Playwright(应对反爬与动态加载)抓取儿童影视条目、分级/标签、家长评价与弹幕等;
-
数据清洗:Pandas/pyarrow 进行去重、缺失值处理、分级标准(如年龄段)归一化;
-
任务编排:Airflow/Cron 进行批处理调度;
-
后端服务:Flask/Django 提供可视化与推荐 API。
贴合儿童场景的注意点:对年龄分级、内容标签(教育性/暴力风险/时长)进行统一编码;过滤成人向或不适龄的条目。
2.2 Hive 简介
Hive 是构建在 Hadoop 之上的数据仓库工具,将 HDFS 中的结构化/半结构化数据映射为表,并提供类 SQL 的 HiveQL。底层可选择 MapReduce、Tez、Spark 等引擎。
在本课题中,Hive 作为 离线数仓,用于统一管理与分析“儿童影视原始数据—清洗数据—主题宽表”,原因如下:
-
类 SQL 语法降低开发门槛,建模与统计高效;
-
面向海量分析优于传统 OLTP 数据库;
-
支持 UDF/UDAF,可扩展内容分级与标签解析;
-
基于 HDFS,具备高扩展与高可靠;
-
计算引擎可切换。本项目将默认 MapReduce 切换为 Tez 或 Spark,以提升迭代查询与复杂聚合的性能。
2.3 Hadoop 技术
Hadoop 以 HDFS(分布式文件系统)与 MapReduce 为核心,为大数据提供低成本、高容错的存储与计算基础。
-
高容错:多副本策略保障节点故障下的数据安全;
-
高扩展:可水平扩展至数千节点;
-
高吞吐:适配超大数据集的批处理场景;
-
组件协作:与 Hive、YARN、Spark、Oozie/Airflow 等无缝对接。
在本课题中,Hadoop 主要承担 分布式存储(HDFS) 与 资源调度(YARN) 的角色;MapReduce 并非主力计算引擎,批分析与模型训练更多由 Spark 完成。
2.4 数据采集
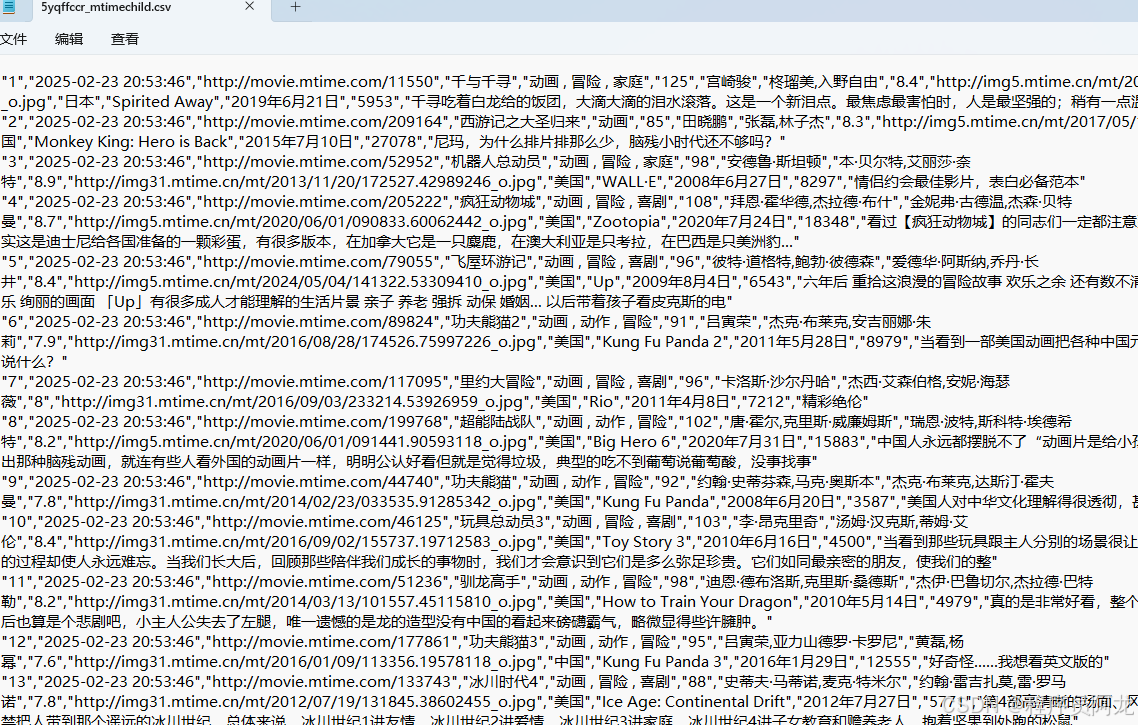
为便于后续处理与装载,爬取的儿童影视数据优先 落地为 CSV/Parquet:
-
来源与字段示例:片名、地区、年份、时长、适龄段(如 0–3/4–6/7–12 岁)、分级标签(教育性/暴力/恐怖/商业广告暴露)、主演/导演、简介、家长/儿童评价、评分、播放平台与上架状态等;
-
CSV 优势:轻量、易写入与传输、与 Hive 兼容好;同时推荐在清洗后写入 Parquet/ORC(列式、压缩、高效扫描);
-
反爬与合法性:遵守 Robots 协议与使用条款;必要时通过公开数据集或平台提供的合规接口获取数据;
-
增量采集:以“上次采集时间”为游标,降低全量扫描成本;
-
敏感信息:避免采集个人可识别信息(PII),对用户文本进行脱敏与去标识化。
2.5 Spark
Spark 是基于内存的统一分析引擎,采用 DAG 调度 与 RDD/DataFrame/Dataset 模型,适合迭代计算与交互分析,速度可达传统 MapReduce 的 10–100 倍。
-
内存计算与缓存:常用维表/特征表可缓存以提升多轮训练迭代性能;
-
优化的 Shuffle:减少中间落盘,提高大规模 Join/聚合吞吐;
-
丰富生态:Spark SQL、MLlib、Structured Streaming,适配离线与准实时;
-
运行模式:Local/Standalone/YARN;生产建议 Spark on YARN。
在本课题中,Spark 主要用于:
-
离线批处理:清洗、宽表构建、画像聚合;
-
特征工程:内容侧(时长、题材、色彩/画风标签等)与行为侧(观看时长占比、完播率、家长评分);
-
推荐/排序:协同过滤(ALS)或内容召回 + 学习排序(如 GBDT/LR);
-
指标统计:适龄分布、热门题材、时段偏好、家长满意度等。
2.6 环境部署
软件/版本(示例,可根据资源调整)
-
操作系统:Linux(CentOS 7+/Rocky Linux/Ubuntu LTS)
-
JDK:1.8.0_241+(或 11 LTS)
-
Hadoop:3.3.5
-
Hive:3.1.3(Metastore 使用 MySQL 5.7/8.0)
-
Spark:3.4.x(与 Hadoop/Hive 版本匹配)
-
Python:3.8/3.10,依赖管理(pip/Poetry)
-
Web 框架:Flask(或 Django)
-
可视化:ECharts
-
虚拟化:VMware 16.0 / KVM / Docker(可选)
-
调度:crontab / Airflow(推荐)
部署步骤(摘要)
-
准备 3 台虚拟机:配置固定 IP(如 192.168.144.131/132/133),设置主机名与
/etc/hosts,开启 SSH 免密; -
安装 JDK 与 Hadoop:配置
hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml; -
初始化 HDFS:
hadoop namenode -format→start-all.sh启动,浏览器访问http://192.168.144.131:9870验证; -
安装 Hive:初始化元数据库(MySQL),配置
hive-site.xml与 Metastore,设置执行引擎为 Tez 或 Spark; -
部署 Spark:与 YARN 集成;分发 Spark 二进制与依赖(如 MySQL JDBC);
-
部署 Web 服务:通过 Flask/Django 暴露查询与可视化接口;
-
调度与监控:Airflow 编排批任务;启用 YARN/HDFS/Spark UI 与日志收集;
-
存储格式建议:原始层(Raw)CSV → 清洗层(DWD)Parquet/ORC(Snappy 压缩)→ 应用层(APP)宽表。
2.7(可选)系统架构与数据流
-
数据层:爬虫 → HDFS(Raw)→ Hive(ODS/DWD/DWS/APP)。
-
计算层:Spark SQL 做清洗聚合;Spark MLlib 做召回/排序与画像生成。
-
服务层:Flask/Django 读取 Hive(或离线同步到 MySQL/ClickHouse)为前端提供 API。
-
可视化层:ECharts 构建仪表盘(热门题材、适龄分布、家长评分趋势、地区偏好、完播率排行)。
-
调度层:Airflow 统一编排,支持每日离线更新与临时重算。
2.8(可选)面向儿童内容的合规与安全
-
分级合规:统一年龄段与敏感标签(暴力、恐怖、广告),在清洗阶段强制校验;
-
隐私保护:不保存可识别个人信息;行为日志做去标识化与聚合统计;
-
家长控制:在推荐环节加入“适龄校验 + 家长评分加权 + 敏感内容降权/过滤”。
2.9(可选)可视化与交互设计要点
-
默认展示安全结果:首页仅展示通过适龄校验与高家长评分的内容;
-
周/月度趋势:以日期为维度展示观看量、完播率与家长评分;
-
筛选器:年龄段、题材(动画/益智/自然/历史)、时长档、语言、地区;
-
质量提示:对低评分或投诉多的内容加“风险标识”与可解释原因(如“广告过多”)。
 系统实现界面展示:
系统实现界面展示:
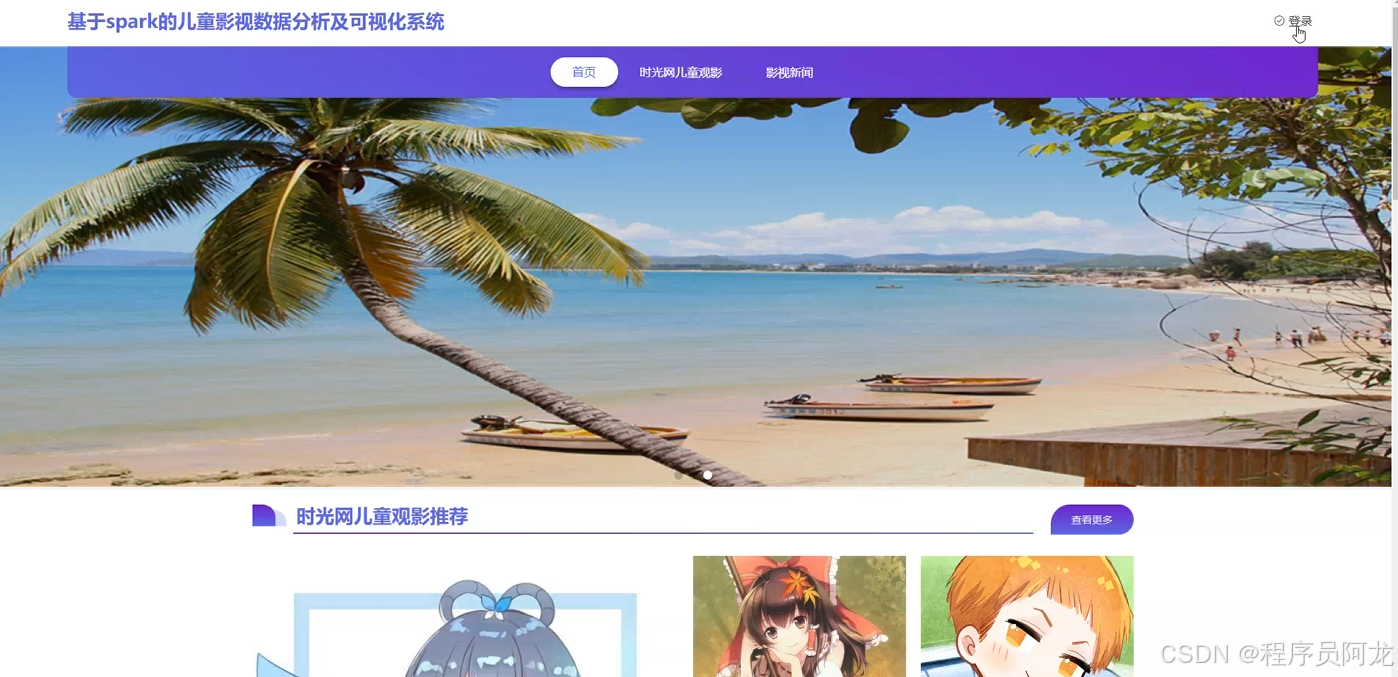
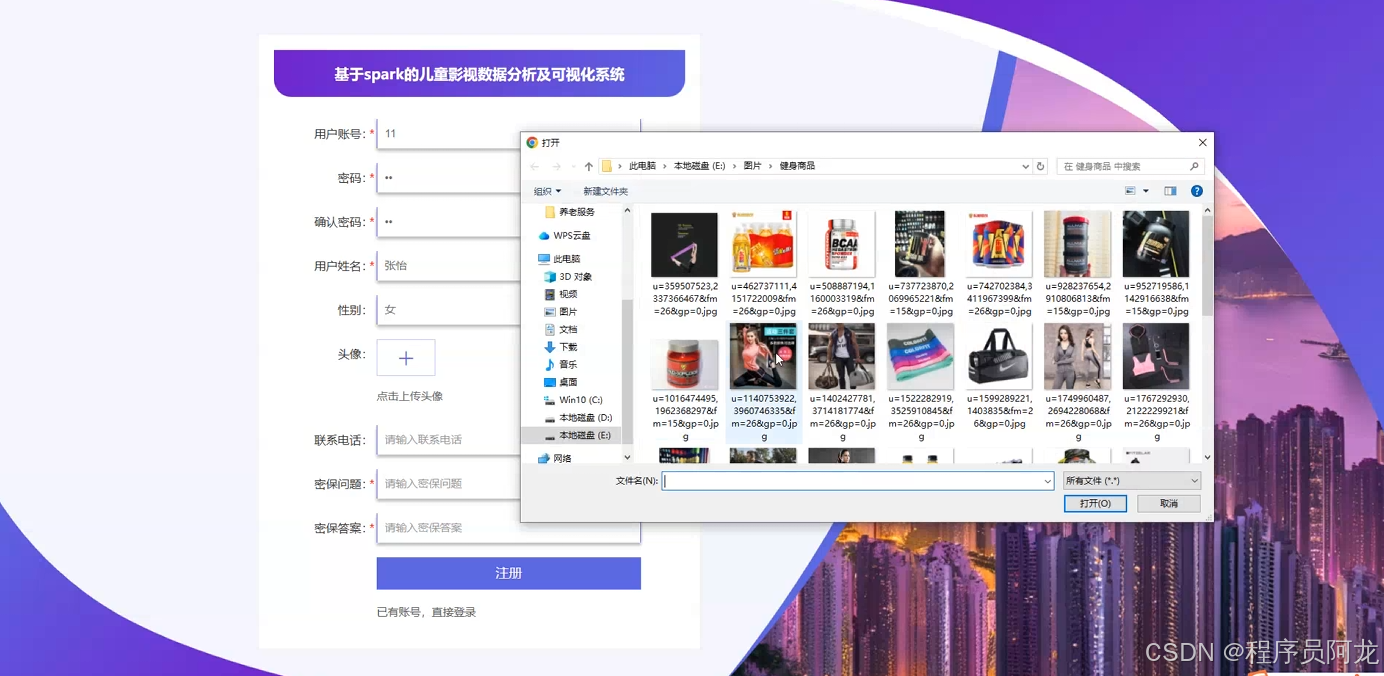
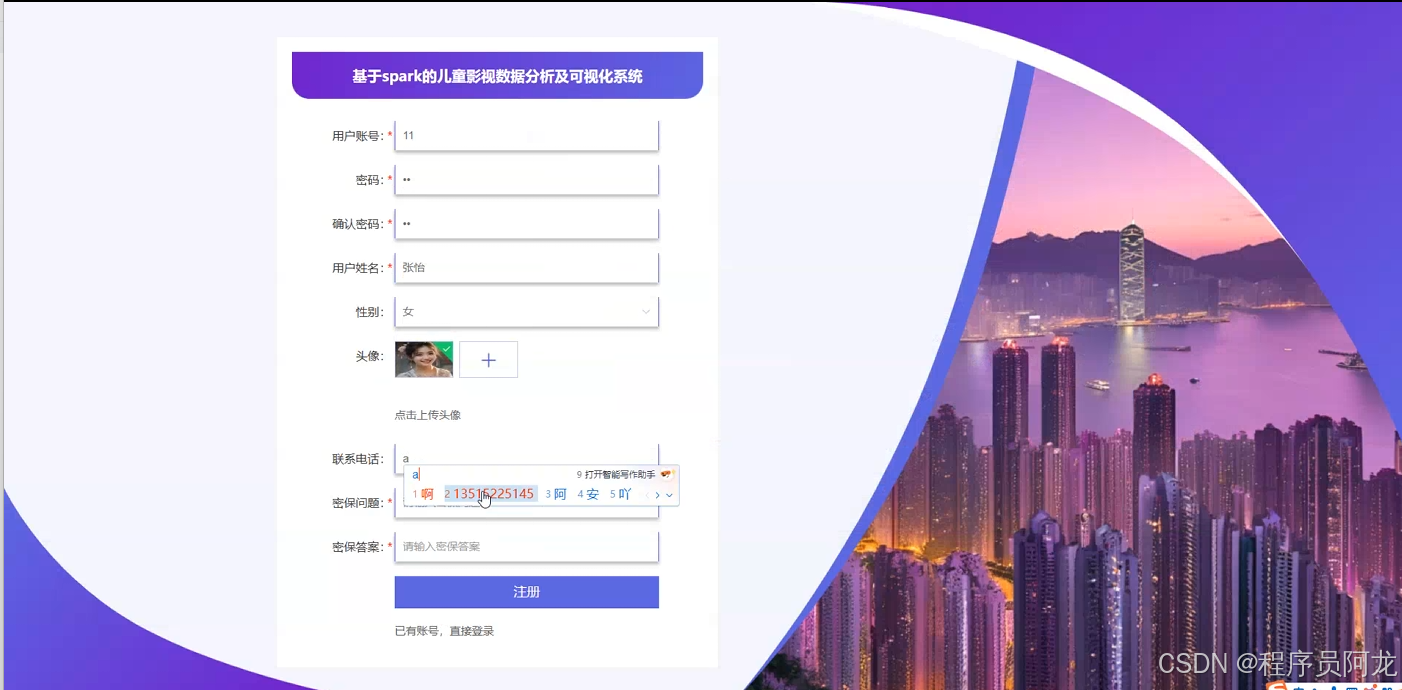
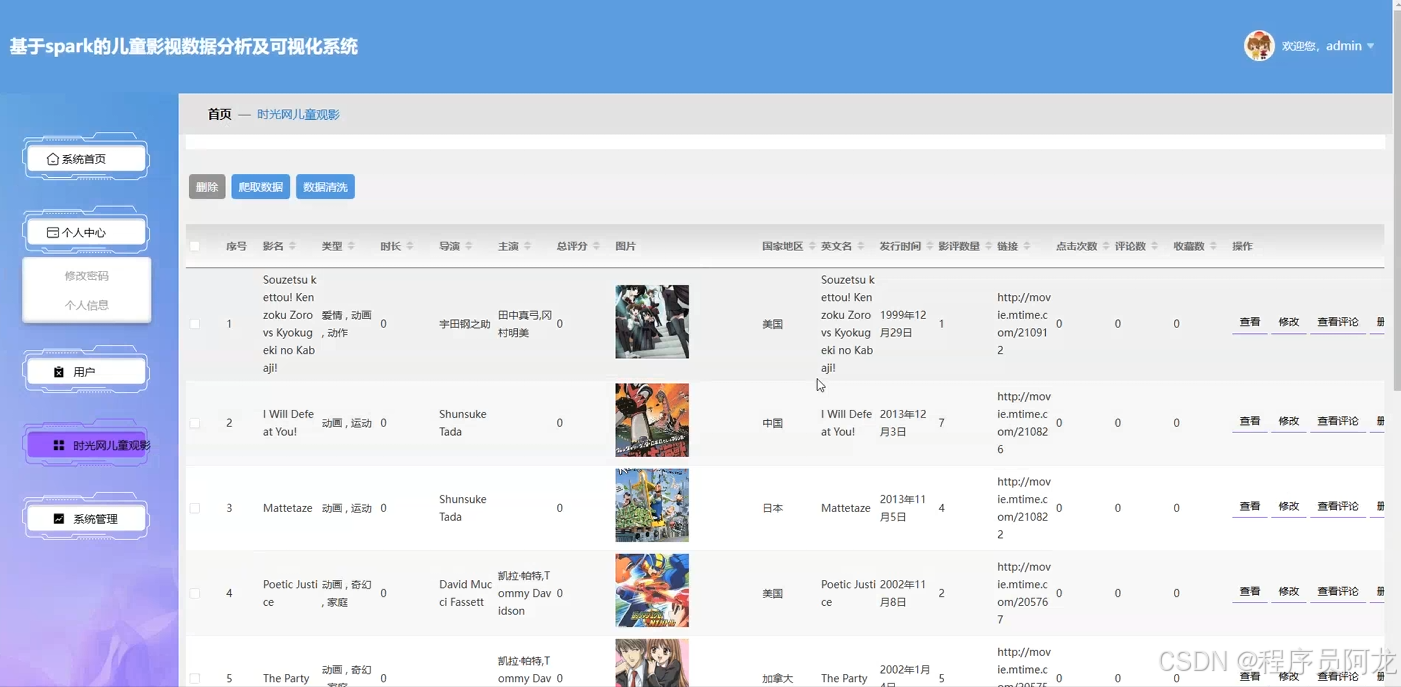
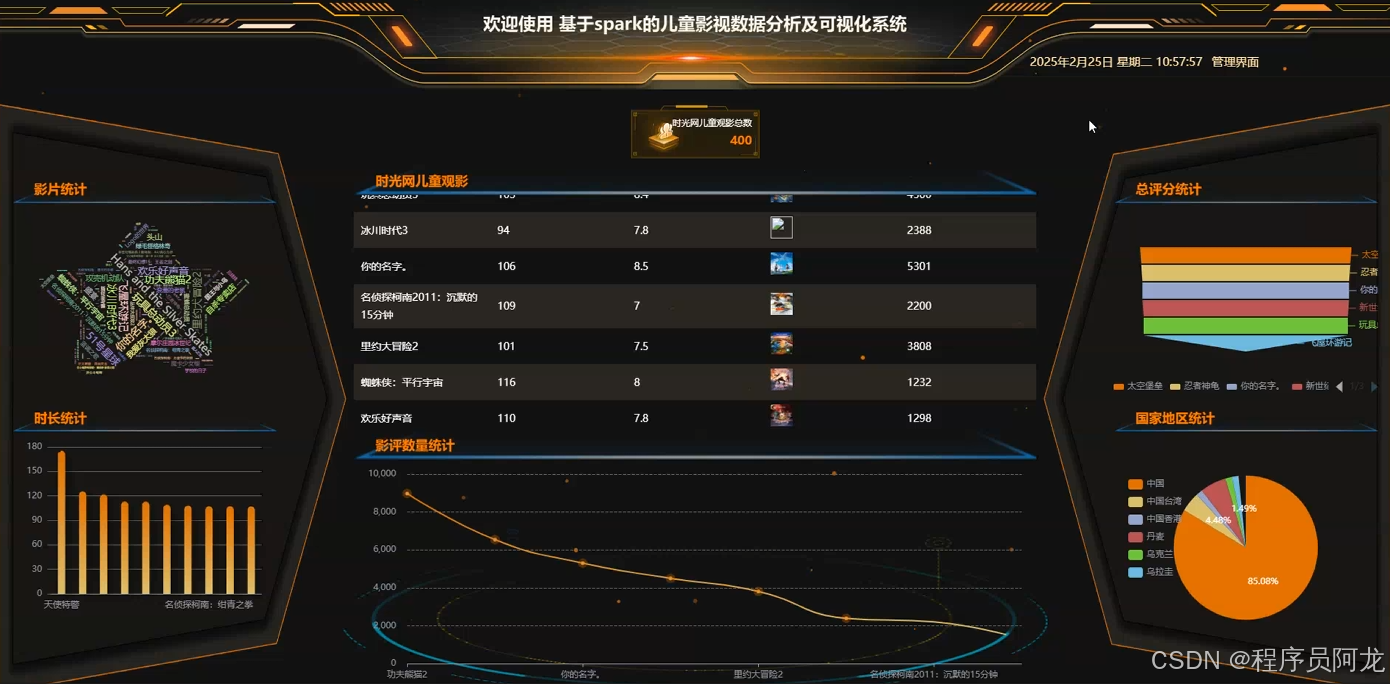

核心代码介绍:
CREATE DATABASE IF NOT EXISTS kids_dw;USE kids_dw;SET hive.execution.engine=tez; -- 或 sparkSET hive.exec.dynamic.partition=true;SET hive.exec.dynamic.partition.mode=nonstrict;-- 原始层(ODS/RDW):外部表映射 CSVCREATE EXTERNAL TABLE IF NOT EXISTS ods_videos ( video_id BIGINT, title STRING, year INT, region STRING, duration_min INT, age_min INT, age_max INT, genres STRING, -- 多值 | 分隔:animation|education|nature tags STRING, -- 多值 | 分隔:no_violence|no_horror|... provider STRING, -- 平台 lang STRING)ROW FORMAT SERDE \'org.apache.hadoop.hive.serde2.OpenCSVSerde\'WITH SERDEPROPERTIES (\"separatorChar\"=\",\",\"quoteChar\"=\"\\\"\")STORED AS TEXTFILELOCATION \'/data/kids/raw/\';CREATE EXTERNAL TABLE IF NOT EXISTS ods_users ( user_id BIGINT, age INT, -- 儿童年龄(或区间代表值) region STRING)ROW FORMAT SERDE \'org.apache.hadoop.hive.serde2.OpenCSVSerde\'STORED AS TEXTFILELOCATION \'/data/kids/raw/\';-- interaction_type:view/finish/rate-- rate 可为空;ts 为 Unix 秒CREATE EXTERNAL TABLE IF NOT EXISTS ods_interactions ( user_id BIGINT, video_id BIGINT, interaction_type STRING, rate DOUBLE, watch_seconds INT, ts BIGINT)ROW FORMAT SERDE \'org.apache.hadoop.hive.serde2.OpenCSVSerde\'STORED AS TEXTFILELOCATION \'/data/kids/raw/\';-- 清洗层(DWD)DROP TABLE IF EXISTS dwd_interactions;CREATE TABLE dwd_interactions STORED AS PARQUET ASSELECT user_id, video_id, interaction_type, rate, watch_seconds, from_unixtime(ts) AS action_time, to_date(from_unixtime(ts)) AS action_date, hour(from_unixtime(ts)) AS action_hourFROM ods_interactionsWHERE user_id IS NOT NULL AND video_id IS NOT NULL AND (rate IS NULL OR (rate BETWEEN 0.5 AND 5));-- 维度拆分:流派与标签展开DROP TABLE IF EXISTS dim_video_genre;CREATE TABLE dim_video_genre STORED AS PARQUET ASSELECT v.video_id, v.title, v.year, v.region, v.duration_min, v.age_min, v.age_max, v.provider, v.lang, g AS genreFROM ods_videos vLATERAL VIEW explode(split(nvl(v.genres,\'\'), \'\\\\|\')) t AS g;DROP TABLE IF EXISTS dim_video_tag;CREATE TABLE dim_video_tag STORED AS PARQUET ASSELECT v.video_id, t AS tagFROM ods_videos vLATERAL VIEW explode(split(nvl(v.tags,\'\'), \'\\\\|\')) tt AS t;-- 宽表(DWS)DROP TABLE IF EXISTS dws_user_video;CREATE TABLE dws_user_video STORED AS PARQUET ASSELECT i.user_id, i.video_id, max(CASE WHEN interaction_type=\'rate\' THEN rate END) AS last_rate, sum(CASE WHEN interaction_type=\'view\' THEN 1 END) AS view_cnt, sum(CASE WHEN interaction_type=\'finish\' THEN 1 END) AS finish_cnt, avg(CASE WHEN interaction_type IN (\'view\',\'finish\') THEN watch_seconds END) AS avg_watch_sec, max(action_date) AS last_action_dateFROM dwd_interactions iGROUP BY i.user_id, i.video_id;-- 应用层(APP):指标/可视化表(空表,后续 Spark 写入)CREATE TABLE IF NOT EXISTS app_rating_hist (bin DOUBLE, cnt BIGINT) STORED AS PARQUET;CREATE TABLE IF NOT EXISTS app_hot_genre_30d (genre STRING, cnt BIGINT) STORED AS PARQUET;CREATE TABLE IF NOT EXISTS app_age_bucket (bucket STRING, uv BIGINT) STORED AS PARQUET;-- 推荐结果CREATE TABLE IF NOT EXISTS app_user_topn_recs ( user_id BIGINT, video_id BIGINT, score DOUBLE) STORED AS PARQUET;from pyspark.sql import SparkSession, functions as Fspark = (SparkSession.builder .appName(\"kids-etl-clean\") .enableHiveSupport() .getOrCreate())spark.sql(\"USE kids_dw\")# 例:对 duration/age 做基础合理性清洗,输出校验报告(可选)videos = spark.table(\"ods_videos\")bad_duration = videos.where((F.col(\"duration_min\") 400))bad_age = videos.where((F.col(\"age_min\") 18) | (F.col(\"age_min\") > F.col(\"age_max\")))bad_duration_count = bad_duration.count()bad_age_count = bad_age.count()print(f\"[CHECK] bad_duration={bad_duration_count}, bad_age={bad_age_count}\")# 若有异常,可在此处修正或过滤,再覆盖写回一张“干净”维表clean_videos = (videos .where((F.col(\"duration_min\") > 0) & (F.col(\"duration_min\") <= 400)) .withColumn(\"age_min\", F.when(F.col(\"age_min\") 18, 18).otherwise(F.col(\"age_max\"))) .where(F.col(\"age_min\") <= F.col(\"age_max\")))spark.sql(\"DROP TABLE IF EXISTS dim_videos_clean\")(clean_videos .write.mode(\"overwrite\") .saveAsTable(\"dim_videos_clean\"))print(\"[OK] dim_videos_clean written\")spark.stop()
2.7 测试概述
系统测试就是对项目是否存在错误而运行程序的一种检测方式。系统测试对于一个软件来说极为重要,并且在开发过程中占有很大的比重。每一次功能的实现都伴随着很多次的测试。它是软件是否能用的检测环节,对于软件质量的评估有着重要影响。系统能否被验收成功是测试中最后一个至关重要的环节。
2.8软件测试原则
当进行软件测试时,有一些原则需要遵循,以确保测试的有效性和效率。
第一:测试应该尽早开始。在需求分析和系统设计阶段就应该进行测试准备,以便尽早发现系统的不足之处。这样可以降低修复成本,提高开发效率。测试人员应该在分析需求时就参与进来,确保需求具备可测试性和正确性。
第二:测试应该是全面的。测试应该覆盖软件的各个功能模块和不同的使用场景,以确保软件在各种情况下都能正常运行。测试还应该关注软件的性能、安全性和可用性等方面,以全面评估软件的质量。
随着软件开发的复杂性增加,手动测试已经无法满足需求。自动化测试可以提高测试的效率和准确性,减少人为错误。通过编写自动化测试脚本,可以快速执行大量的测试用例,并及时发现问题。软件的开发是一个迭代的过程,每个迭代都会引入新功能和修复旧问题。因此,测试也应该是一个持续的过程,与开发同步进行。持续集成和持续交付等技术可以帮助实现持续测试,确保软件在每个迭代中都能达到预期的质量标准。通过测试不仅仅是为了发现问题,更重要的是提供有价值的反馈给开发人员。测试人员应该及时向开发人员报告问题,并提供详细的复现步骤和环境信息,以便开发人员能够快速定位和解决问题。
2.9测试用例
(1)用户登陆测试用例
表 6-1 用户登录用例表
项目/软件
编制时间
20xx/xx/xx
功能模块名
用户登陆模块
用例编号
xxxx
功能特性
用户身份验证
测试目的
验证是否输入合法的信息,允许合法登陆,阻止非法登陆
测试数据
用户名=1密码=a1身份= 非认证用户
操作步骤
操作描述
数 据
期望结果
实际结果
状态
1
输入用户名和密码
用户名= 1密码=1
显示进入后的页面。
同期望结果。
正常
2
输入用户名和密码
用户名= 1密码=aaa
显示警告信息“不存在该用户名或密码错误!”
同期望结果。
正常
3
输入用户名和密码
用户名= aaa密码=1
显示警告信息“不存在该用户名或密码错误”
同期望结果。
正常
4
输入用户名和密码
用户名=“” 密码=“”
显示警告信息“用户名密码不能为空!”
同期望结果。
正常
(2)用户注册测试用例
表 6-2 用户注册用例表
项目/软件
编制时间
20xx/xx/xx
功能模块名
用户注册模块
用例编号
xxxx
功能特性
用户注册
测试目的
验证私注册是否成功,注册数据是否合法
测试数据
用户名=aaa 密码=aaa电子邮件=dwa@qq.com
操作步骤
操作描述
数 据
期望结果
实际结果
测试状态
1
输入注册数据
用户名= aaa密码=aaa 电子邮件=dwa@qq.com
提示:注册成功!转入用户主页
同期望结果。
正常
2
输入注册数据
用户名= aaa密码=aaa 电子邮件=dwa@qq.com
提示:用户名已注册
同期望结果。
正常
3
输入注册数据
用户名= aaa密码=”” 电子邮件=dwa@qq.com
提示:密码不能为空
同期望结果。
正常
4
输入注册数据
密码=aaa 电子邮件=dwa@qq.com
提示:用户名为空
同期望结果。
正常



 论文部分参考:
论文部分参考:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
我是程序员阿龙,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是CSDN特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。
已经为上百名同学获得优秀毕业生!
源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏


