mz0965-基于Python的图书管理系统的设计与实现-
🌟 毕业设计指导交流 🌟
同学们好!作为一名计算机专业的技术爱好者,我在毕业设计领域积累了一些经验,希望能和大家分享交流。从选题到答辩,欢迎一起探讨技术问题。
💡 技术方向:
熟悉Java全栈(SSM/Spring Boot)、Python数据分析、微信小程序/安卓开发等技术栈,可以互相学习项目开发经验。
📂 学习资源:
整理了一些开源项目案例(含代码和文档),需要参考的同学可以留言讨论,也欢迎分享你的项目经验。
🛠 交流内容:
- 选题思路探讨
- 技术方案可行性分析
- 论文写作经验分享
- 代码调试问题互助
✨ 欢迎在评论区留言讨论,一起进步!记得遵守社区规范,保持学术诚信哦~
目 录
前 言
第一章 绪论
1.1 研究背景
1.2 研究目的和意义
1.3 国内外研究现状
1.3.1 国内研究现状
1.3.2 国外研究现状
1.4 论文组织结构
第二章 技术分析
2.1 MySQL数据库
2.2 Python语言
2.3 Vue框架
第三章 系统分析
3.1 可行性分析
3.1.1 经济可行性
3.1.2 技术可行性
3.1.3 操作可行性
3.2 功能需求分析
3.2.1 管理员功能需求分析
3.2.2 用户功能需求分析
3.2.3 审计员功能需求分析
3.3 性能需求分析
第四章 系统设计
4.1 系统功能模块设计
4.2 数据库设计
4.2.1 实体关系设计
4.2.2 数据库表
第五章 系统的设计与实现
5.1 管理员功能的设计与实现
5.1.1 管理员登录页面
5.1.2 用户管理页面
5.1.3 图书管理页面
5.1.4 出版社管理页面
5.2 用户功能的设计与实现
5.2.1 用户登录页面
5.2.2 图书查询页面
5.2.3 借阅管理页面
5.2.4 我的收藏页面
5.3 审计员功能的设计与实现
5.3.1 审计员登录页面
5.3.2 审计管理页面
第六章 系统测试
6.1 测试目的
6.2 测试方法
6.3 测试用例
6.4 测试结果分析
结 论
参考文献
致 谢
前 言
信息技术的迅猛发展和数字化转型的深入推进,为传统图书馆管理模式施加重重压力,过去依靠人工记录与纸质文档存档的管理方式效率低下且容易出现差错。馆藏资源扩展以及借阅需求上升,使管理人员的工作压力迅速增加,图书类别日益丰富,读者需求愈加多元化,传统的手工管理模式难以应对现代图书馆高效运行的迫切要求,智能化与高效的图书管理新方案探索显得尤为迫切。
近年来计算机技术的迅速推进为图书管理领域提供了创新性解决方案,Python语法简洁且性能优异,在数据处理、Web开发及自动化操作等方面优势显著,尤其在各类管理信息系统的构建中显示其特性。Vue借助模块化设计与响应式功能,可实现直观高效的前端交互,MySQL以卓越的数据存储能力与高可靠性保障系统运行中的信息安全与稳定性能,关键技术的融合不仅为图书管理系统的构建奠定了技术基础,也展现出信息技术推动传统行业转型升级的重要意义。
该系统设计采用前后端分离架构,提升了图书管理自动化与服务效率,系统为管理员、普通用户及审计员提供功能支持,功能模块包含图书信息处理、借阅归还操作、数据统计分析以及权限管理等核心内容。管理员借助系统实现库存的精细化管理;普通用户通过自助终端完成借阅;审计员可实时监测系统状态并确保数据安全,这些功能降低了人工操作的工作量,优化了系统运行效率,同时基于数据分析为图书馆决策提供依据。
疫情防控常态化与社会信息化的推进,使无接触服务和数字化管理模式逐步转变为现代图书馆发展的核心方向,本系统通过设计在线预约、自助借阅等功能模块应对趋势,减少人员直接接触风险。用户行为数据的深度分析和挖掘技术能够构建个性化资源推荐机制,优化读者体验,图书馆借助该系统的实施逐步向智慧化与数字化运营方式转变,提升服务效能与管理水平,本课题的研究成果不仅具有实践推广价值,同时可为其他机构开展数字化转型的技术路径与参考方案。
第一章 绪论
1.1 研究背景
图书馆藏书量的扩展与读者需求的多样化,令传统手工管理模式暴露出诸多缺陷,借阅记录手工登记不仅效率低下且出错风险高,图书库存与读者信息管理耗费大量人力,纸质档案查询维护也极为不便[1]。疫情防控常态化的背景下,对无接触借阅和数字化管理的需求更加迫切,Python开发效率高、可扩展性强,在管理系统开发中优势独特,Vue交互式前端结合MySQL的稳定存储能力,为构建智能图书管理系统提供了可靠方案,数据可视化和智能推荐等功能的数字化管理系统,不仅能解决传统弊端,还能满足图书馆现代化的服务需求。
1.2 研究目的和意义
本研究设计并实现一个基于Python+Vue+MySQL的图书管理系统,以应对传统图书馆管理模式下流程繁琐、效率低下以及数据管理困难等现象,系统借助Python开发效率、Vue前端交互以及MySQL数据存储稳定性,构建一个包含图书信息管理、借阅归还处理、用户权限管理与数据统计分析等功能的一体化平台,通过系统开发,旨在提升图书馆自动化水平,优化管理模式,减少人力资源浪费,同时为用户提供便捷的自助借阅服务,满足信息化时代图书馆发展的需求[2]。
现实意义在于,数字化管理替代手工操作,提升图书管理的准确性和效率,降低人为错误,自助借阅功能提高读者体验,减少图书馆运营成本。数据分析模块为采购决策、读者服务优化提供数据支撑,助力科学化管理,学术角度来看,本研究探索现代信息技术在图书管理领域的应用模式,为开发同类系统的后续研究提供可行方案,为传统行业数字化转型提供实践参考。
1.3 国内外研究现状
1.3.1 国内研究现状
国内图书管理研究的重头集中在高校与公共图书馆信息化升级,普遍基于BS架构技术栈以强化管理效率与使用体感,例如南京汇文《Libsys》与北京金盘《GDLIS》这些商业系统主要采用JavaEE,提供编目、借阅、读者服务等主要性能,近年来高校与研究机构开始探索新一代管理系统,采用轻量级框架优化性能,如SpringBoot+MyBatis+MySQL的方案降低复杂度并减少维护成本[3]。 研究者引入Vue等前端框架,交互体验方面也逐步强化,结合RESTfulAPI后,前后端分离能力更具优势,RFID技术的使用使图书自动盘点与自助借还逐步应用,数据分析模块的融入在系统决策上更具辅助性。现有研究中,权限精细化控制、多终端适配、AI推荐等智能化应用仍存在不足,本研究采用Python+Vue+MySQL全栈架构,在数据高效管理方面施下重点,系统响应速度提升与用户使用体验增强都逐步显化,扩展性、易用性和智能化程度都更具应用特征。
1.3.2 国外研究现状
国外图书管理系统的发展趋势倾向于智能化、云化与多租户架构,美国ExLibris的《Alma》、InnovativeInterfaces的《Sierra》和OCLC的《WorldShare》这些系统,普遍使用微服务和容器化架构,并结合Elasticsearch实现高效检索,AmazonAWS或MicrosoftAzure提供云服务,助力图书馆联盟间的资源共享,在技术上,广泛采用Java/SpringCloud或Node.js构建后端,数据库为PostgreSQL或MongoDB,前端则多使用React或Angular框架,配合GraphQL优化API性能[4]。 国外研究偏重数据分析与人工智能的使用,例如采用机器学习和自然语言处理优化图书推荐,预测借阅需求,并且实现编目自动化,近年来,Koha与Evergreen这些开源方案在中小型图书馆中广泛应用,其低成本和高可定制性特征相当注重。本研究借鉴了如前后端分离、RESTfulAPI、MySQL优化检索等成熟技术,同时结合国内需求,利用Vue+Django技术栈完成轻量化部署,未来计划增加数据分析模块,以提升智能化水平,基础管理功能可以满足,同时可扩展性与维护便捷性也一并兼顾[5]。
1.4 论文组织结构
本课题主要从基于Python的图书管理系统相关研究背景以及技术分析、系统分析、系统设计、系统的设计与实现、系统测试六个方面进行分别论述。
第一章绪论,主要介绍了基于Python的图书管理系统的研究背景、目的和意义、国内外发展现状以及论文的组织结构。
第二章技术分析,主要介绍了基于Python的图书管理系统在本课题所用到的关键技术。
第三章系统分析,主要从可行性分析、功能需求分析、性能需求分析三个方面对基于Python的图书管理系统进行介绍。
第四章系统设计,主要对基于Python的图书管理系统的系统功能模块设计和数据库设计来进行展示。
第五章系统的设计与实现,主要对基于Python的图书管理系统的各个功能介绍,并通过截图对系统功能进行展示。
第六章系统测试,主要从基于Python的图书管理系统的测试目的、测试方法、测试用例和测试结果分析进行介绍。
第二章 技术分析
2.1 MySQL数据库
MySQL作为开源的轻量级关系型数据库管理系统,其高性能、高可靠性、跨平台兼容性与低成本等特性,尤其适用于中小型系统中数据存储与管理任务,在本系统的设计中,核心数据库角色由MySQL承担,图书信息、用户数据和借阅记录等关键数据的存储与查询任务都离不开它[6]。事务处理支持特性在借书还书操作中确保了数据一致性与安全性,多索引优化与高效SQL查询也由MySQL支持,用户检索请求能够快速响应,这提升了系统的并发访问能力[7]。 Python后端借助ORM框架实现无缝集成,数据操作逻辑的简化通过此类框架完成,与Vue前端的交互则通过API实现,灵活性和扩展性在系统中也得以保证,MySQL的稳定性和社区的成熟支持为系统长期运维提供了保障。
2.2 Python语言
Python编程语言同时实现了高性能和高可读性,后端开发时它被广泛视为优选工具,其显著特征的第三方库生态系统和跨平台兼容性,为软件开发生命周期中的编码效率提升了层次。动态类型系统与简洁的语言设计在构建图书管理系统等数据密集型或业务逻辑复杂的系统中显示了其高效性,通过整合Django框架与Python语言,确保了后端服务的快速开发,利用ORM工具简化了对MySQL数据库的处理,这一技术组合在图书信息管理及借阅记录维护等任务中有效保持了数据库数据的一致性与事务完整性,使常见的CRUD操作流程被显著简化[8]。 NumPy、Pandas等Python的第三方库为借阅模式预测和用户行为分析这类数据处理模块提供了坚实的技术保障,其JSON解析功能内置,可助力Vue前端借助RESTfulAPI达成高效的交互[9]。使用asyncio等Python的多线程机制与异步I/O框架,在高并发情境下系统运行效能可大幅提升,在确保系统稳定时也强化了横向扩展能力。
2.3 Vue框架
Vue作为JavaScript渐进式框架,其轻量级特性、响应式数据处理以及组件化开发等特征在前后端分离的系统中广泛应用,双向数据绑定与虚拟DOM优化渲染效率等核心优势,结合丰富的生态系统如Vuex进行状态管理、VueRouter控制路由行为,显著提高了前端交互质量与开发效率,在本图书管理系统中,Vue通过RESTfulAPI实现动态数据交互,和Django后端框架结合,减少前后端耦合性[10]。 组件化开发模式令用户界面模块化,便于管理与复用,图书检索、借阅记录和个人中心等模块均可拆为独立组件,代码可维护性增强,Vue的特性能够实时更新借阅状态和查询结果等关键数据,与ElementUI等组件库结合快速搭建符合国内用户习惯的友好界面,系统的可用性与开发效率整体优化,为后续智能化功能扩展如个性化推荐提供灵活的技术支持。
第三章 系统分析
3.1 可行性分析
3.1.1 经济可行性
系统开发采用Python、Vue与MySQL,这些工具均为开源且无需授权费用,从而在软件成本控制中节省了资源,PyCharm社区版和Navicat免费版等工具同样无需额外成本,整体经济性保持在低水平[11]。Django框架的ORM特性为后端开发降低了数据库管理代码的比重,从而提升了开发周期的使用性,MySQL作为成熟的关系型数据库,对图书、用户、借阅记录等结构化数据处理显示其技术性,同时它支持集群部署扩展,从而避免了额外的费用风险,基于Python与Vue,开发者能高效获取相关技术文档与开源组件,如ElementUI,不仅减少自主开发组件的经济与周期成本,也强化了系统整体可行性。
3.1.2 技术可行性
从技术层面进行考察,Django的MVT架构为图书管理系统的快速开发提供了助力,用户认证、数据分页、ORM操作等功能,借助内置模块就可实现,这避免了重复开发,前端采用Vue与ElementUI能实现交互体验的流畅性,图书检索、分页展示、借阅记录管理等功能通过组件化开发可以高效地完成[12]。 数据库层面MySQL对事务管理与索引优化存在支持,这为图书库存管理、借阅统计和用户数据分析等场景的高效处理进行实现,Python的pandas库完成图书借阅趋势分析存在支持,Celery可使异步任务,另外Nginx+Gunicorn部署方案使系统稳定运行存在确保,技术成熟度高且落地性强相关特征也存在。
3.1.3 操作可行性
本系统面向图书管理员与普通用户,界面基于Vue+ElementUI进行设计,操作直观,管理员能轻松完成入库、借还管理、权限设置等任务,普通用户则可便捷检索图书、申请借阅、查看信息。系统使用B/S架构,无需额外安装软件,通过浏览器即可访问,审计日志记录管理员所有操作,确保使用可追溯[13]。数据库借助Navicat可视化维护,管理员无须掌握复杂SQL命令,可直观查看修改数据,整体来看,系统交互友好,管理便捷,满足不同角色需求,操作可行性相当可观。
3.2 功能需求分析
3.2.1 管理员功能需求分析
管理员主要功能模块有:管理员:数据大屏、出版社管理、作者管理、分类管理、图书管理、图书借阅(图书查询、借阅管理、我的收藏)、角色管理、用户管理、审计管理、公告管理、系统监控。管理员用例图如图3-1所示。
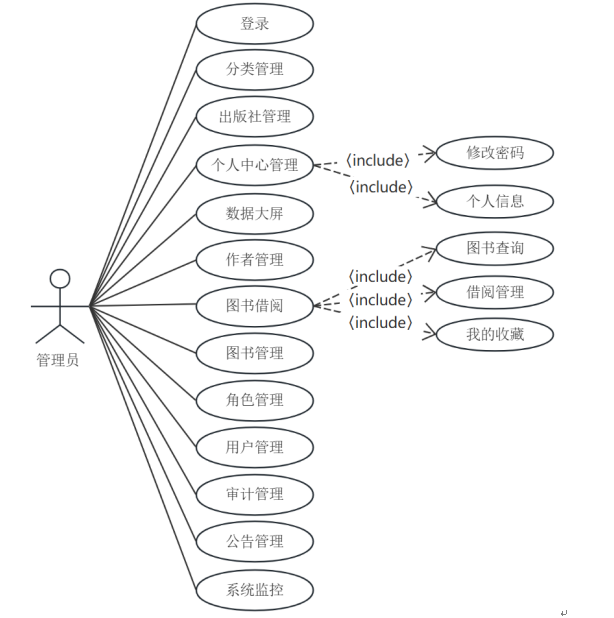
图3-1 管理员用例图
3.2.2 用户功能需求分析
用户主要功能模块有:图书借阅(图书查询、借阅管理、我的收藏)。用户用例图如图3-2所示。
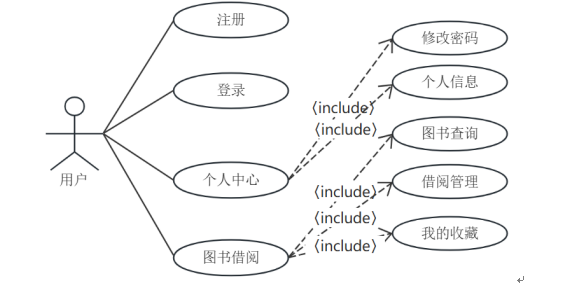
图3-2 用户用例图
3.2.3 审计员功能需求分析
审计员主要功能模块有:审计管理。商家用例图如图3-3所示。
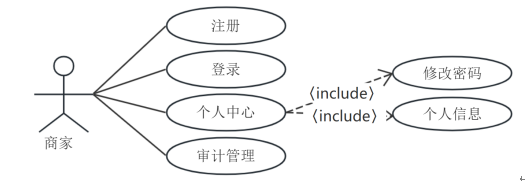
图3-3 审计员用例图
3.3 性能需求分析
界面需求:该系统以Vue与ElementUI组件库为构建依据,采用模块化设计及优化策略,交互界面直观且操作流畅,核心功能模块包含图书查询、借阅记录管理、分类维护等,这些都通过独立组件实现,页面渲染复杂度降低,运行效率提升[14]。管理员后台嵌入数据可视化模块,ECharts技术生成动态统计图表,界面卡顿问题有效解决,多维度数据分析的可靠支持也有效提供,响应式布局设计确保兼容PC端和移动端访问需求,跨终端操作的一致性与便捷性也有效保障。 用户行为反馈机制全程融入系统,表单提交后关联列表信息实时更新,手动刷新的冗余操作减少,大数据量场景如book表格展示时,分页加载方式规避了因一次性加载过多数据而导致的性能瓶颈,前端优化手段包含图片懒加载和静态资源CDN加速,这些手段显著缩短页面加载时间,系统运行效率与用户体验质量从而全面提升。
响应时间: 数据库设计中,高频查询需求的满足,如book表和user表相关功能的操作,MySQL构建isbn_number、name字段等特定索引,使数据检索、资源借阅等核心业务达到毫秒级响应,后端架构下DjangoORM深度优化SQL查询,防止N+1查询问题,避免book表与author表、publisher表联合查询时性能瓶颈的产生,API服务层采用JWT认证机制,传统Session管理的服务器端会话状态存储消耗极大减少,用户登录验证与权限控制的整体效率明显提高[15]。 高频访问场景下,例如首页图书推荐模块,数据库查询压力通过Redis机制缓解,Nginx与Gunicorn在服务端架构中协同运行,多进程模式提升了系统并发处理能力,确保了高并发情境下服务的稳定,负载测试时,JMeter模拟了百个并发用户场景,关键接口平均响应时间被控制在300毫秒以内,这与日常业务需求和用户体验要求完全契合。
拓展性: 分层架构设计在该系统中实现,前端、后端与数据库各模块间耦合性低,特定组件的独立升级或替换便利性增加,比如前端框架引入Vue3,数据库设计时,核心表预留扩展字段,“book”表新增“description”字段,“user”表增加“book_collect_list”字段应对未来业务扩展属性扩展的需求。系统支持分布式部署,MySQL主从复制技术分担负写压力,Redis集群方案优化缓存性能且实现动态扩展,功能扩展基于插件化设计理念,第三方服务模块如支付宝、微信支付接口可灵活集成,核心代码运行稳定性保持不受影响。 高并发情境中,Elasticsearch的引入对图书检索性能优化显著,Docker与Kubernetes技术的助力下弹性伸缩动态实现,流量峰值波动从而有效应对,接口设计对RESTful规范全面遵循,这为未来移动端和第三方平台的适配奠定基础,业务需求逐步扩展时,功能模块的细化拆分推荐采用微服务架构,系统的可维护性与持续迭代能力提升。
第四章 系统设计
4.1 系统功能模块设计
系统功能结构设计中包含基于角色的权限控制机制,对不同用户角色配置了存在差异的功能模块,管理员角色具备最高权限,可进行出版社、作者及分类等基础数据管理,也负责图书借阅管理,同时承担用户权限配置、系统运行监控和公告发布等核心管理任务。用户仅开放图书借阅相关功能,满足借阅服务自助化操作需求,审计员作为特殊角色,专注于审计管理的操作日志,保障系统操作具备可追溯性并满足安全合规要求。严格的权限划分实现了功能隔离,既确保系统管理的全面与安全,也使用户体验达到简洁高效,多层次管理体系在不同角色功能划分下生成,图书管理系统的各项业务需求都可满足。系统功能结构图如图4-1所示。
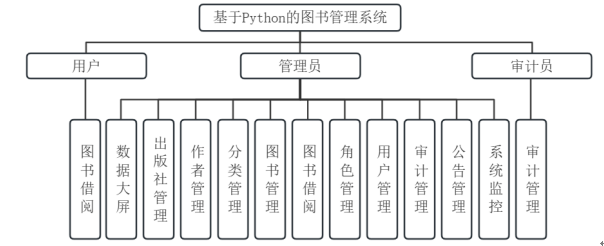
图4-1 系统功能结构图
4.2 数据库设计
4.2.1 实体关系设计
数据库概念设计围绕图书管理系统的核心业务流程构建关键实体及其交互关系。管理员实体支撑系统配置和权限管理,是维护系统正常运行的中枢;用户实体记录读者信息和借阅行为,作为借阅服务的基础数据支撑;图书实体完整描述馆藏资源状态,包括库存、流通等核心业务属性;审计员实体独立记录操作日志和异常事件,形成安全审计追踪机制;图书管理实体则作为业务枢纽,关联图书入库、编目、流通等全生命周期操作。这些实体之间通过权限控制、借阅登记、操作审计等关系相互关联,构建出一个既能满足读者自助借阅需求,又能保障图书馆后台管理规范运作的完整数据体系,在确保业务效率的同时兼顾了数据安全性和可追溯性。
管理员实体属性图如图4-2所示。
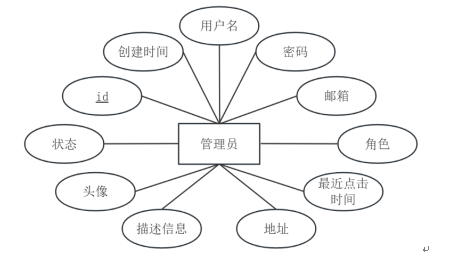
图4-2 管理员实体属性图
角色实体属性图如图4-3所示。
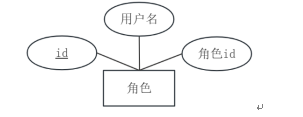
图4-3 角色实体属性图
图书实体属性图如图4-4所示。

图4-4 图书实体属性图
公告实体属性图如图4-5所示。
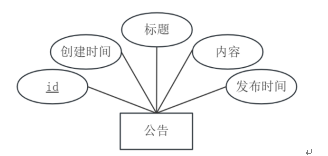
图4-5 公告实体属性图
审计实体属性图如图4-6所示。
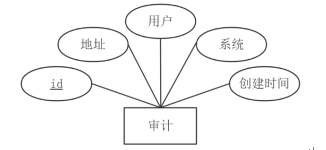
图4-6审计实体属性图
系统总体E-R图如图4-7所示。
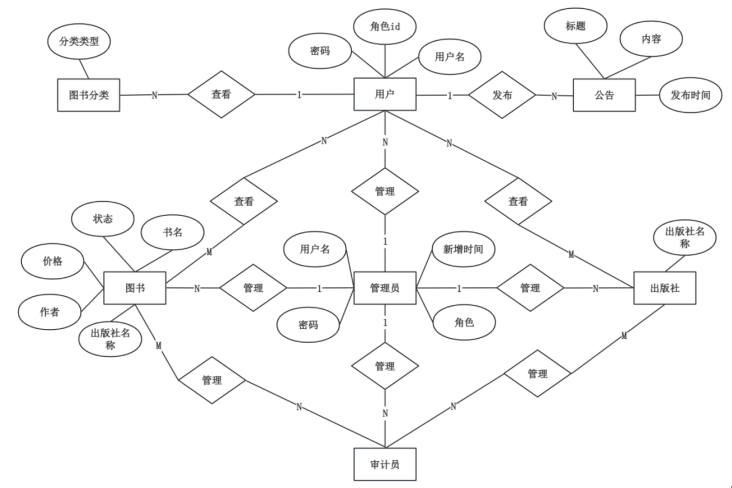
图4-7 系统总体E-R图
4.2.2 数据库表
此系统需要后台数据库,下面介绍数据库中的各个表的详细信息。
版本表主要用于储存版本信息,主要字段描述如表4-1所示。
表4-1 alembic_version 版本表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
version_num
varchar
(32)
√
版本号
审计表主要用于储存审计信息,主要字段描述如表4-2所示。
表4-2 audit 审计表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
op_time
datetime
√
NULL
创建时间
3
op_ip
varchar
(15)
地址
4
op_user
varchar
(32)
用户
5
op_module
varchar
(32)
系统
6
op_event
varchar
(64)
描述
作者表主要用于储存作者信息,主要字段描述如表4-3所示。
表4-3 author 作者表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
name
varchar
(64)
作者名
图书表主要用于储存图书信息,主要字段描述如表4-4所示。
表4-4 book 图书表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
name
varchar
(64)
书名
3
isbn_number
varchar
(17)
条形码
4
publishing
int
出版社名称
5
author
int
作者
6
book_price
float
价格
7
book_status
int
状态
8
publish_time
datetime
√
NULL
出版时间
9
inbound_time
datetime
√
NULL
入库时间
10
outbound_time
datetime
√
NULL
借出时间
11
photo
varchar
(48)
√
NULL
图片
12
borrowers
varchar
(32)
√
NULL
借阅人员
13
description
varchar
(1024)
√
NULL
描述
14
expire_time
datetime
√
NULL
归还时间
15
book_type
int
图书类型
16
score
float
√
NULL
评分
17
borrow_times
int
√
0
借阅次数
图书分类表主要用于储存分类信息,主要字段描述如表4-5所示。
表4-5 classification 图书分类表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
type_name
varchar
(64)
分类类型
公告表主要用于储存公告信息,主要字段描述如表4-6所示。
表4-6 notice 公告表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
title
varchar
(128)
√
NULL
标题
3
content
varchar
(1024)
内容
4
release_time
datetime
√
NULL
发布时间
出版社表主要用于储存出版社信息,主要字段描述如表4-7所示。
表4-7 publisher 出版社表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
name
varchar
(64)
出版社名称
角色表主要用于储存角色信息,主要字段描述如表4-8所示。
表4-8 role 角色表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
name
varchar
(16)
√
NULL
用户名
3
permission_ids
varchar
(256)
角色id
管理员表主要用于储存管理员信息,主要字段描述如表4-9所示。
表4-9 user 管理员表
序号
列名
数据类型
长度
主键
自增
允许空
默认值
列说明
1
id
int
√
√
主键
2
name
varchar
(80)
√
NULL
用户名
3
password
varchar
(120)
√
NULL
密码
4
varchar
(120)
√
NULL
邮箱
5
role_id
int
√
NULL
角色
6
register_time
datetime
√
NULL
创建时间
7
last_login_time
datetime
√
NULL
最近点击时间
8
ip
varchar
(15)
√
NULL
地址
9
description
varchar
(256)
√
NULL
描述信息
10
book_collect_list
varchar
(1024)
√
NULL
图书列表收藏
11
status
tinyint
√
NULL
状态
12
avatar
varchar
(256)
√
NULL
头像
第五章 系统的设计与实现
5.1 管理员功能的设计与实现
5.1.1 管理员登录页面
管理员可以通过系统提供的登录界面进入平台,输入用户名和密码完成身份验证。登录界面设计简洁直观,管理员可以轻松找到相应的登录入口,支持用户名安全验证通过顺畅的登录流程,管理员能够快速进入系统,享受高效便捷的服务。管理员登录页面如图5-1所示。
图5-1 管理员登录页面
5.1.2 用户管理页面
管理员可以通过输入用户名对用户列表进行精确查询,查看用户的详细信息,包括用户名、邮箱地址、状态、角色、注册时间、最后登录时间、描述等。此外,管理员还可以对用户进行管理操作,如新增用户、删除用户或修改用户信息。用户管理页面如图5-2所示。
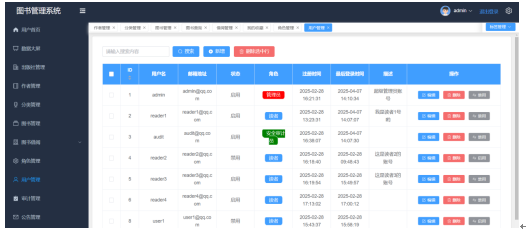
图5-2 用户管理页面
5.1.3 图书管理页面
管理员可以通过输入书名对图书列表进行精确查询,查看图书的详细信息,包括图片、书名、推荐分、ISBN条形码、出版社、作者、类别、价格、状态等。此外,管理员还可以对其进行管理操作,如新增、删除或修改信息。图书管理页面如图5-3所示。
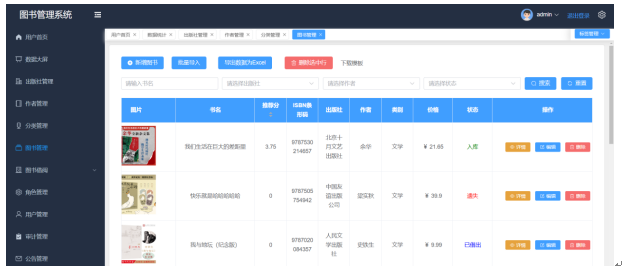
图5-3 图书管理页面
5.1.4 出版社管理页面
管理员可以通过输入出版社名称对出版社管理列表进行精确查询,查看出版社的详细信息,包括ID、出版社名称等。此外,管理员还可以对其进行管理操作,如新增、删除或修改信息。出版社管理页面如图5-4所示。
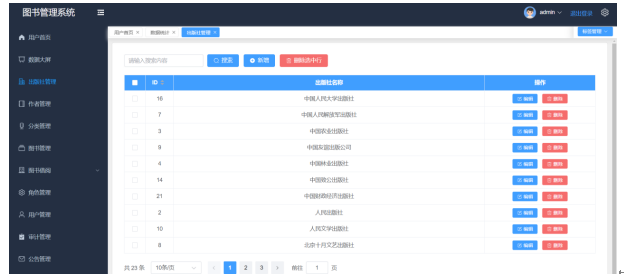
图5-4 出版社管理页面
5.2 用户功能的设计与实现
5.2.1 用户登录页面
用户可以通过系统提供的登录界面进入平台,输入用户名和密码完成身份验证。登录界面设计简洁直观,用户可以轻松找到相应的登录入口,支持用户名安全验证通过顺畅的登录流程,用户能够快速进入系统,享受高效便捷的服务。用户登录页面如图5-5所示。
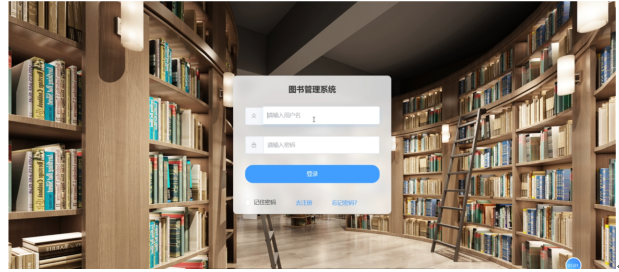
图5-5 用户登录页面
5.2.2 图书查询页面
用户可以通过输入商家名称对商家列表进行精确查询,查看商家的详细信息,包括图片、书名、ISBN条形码、出版社、作者、价格、出版时间等。此外,用户还可以对其进行查看详情操作。图书查询页面如图5-6所示。
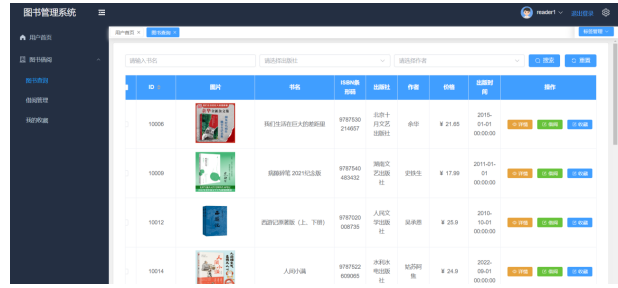
图5-6 图书查询页面
5.2.3 借阅管理页面
用户在购物车界面可以清晰查看所选商品的详细信息,包括商品名称、商品图片、单价、数量以及总价等。每个商品项都能直观显示,便于用户了解购物车中的所有内容。用户还可以对购物车内的商品进行查看、删除等操作。购物车页面如图5-7所示。
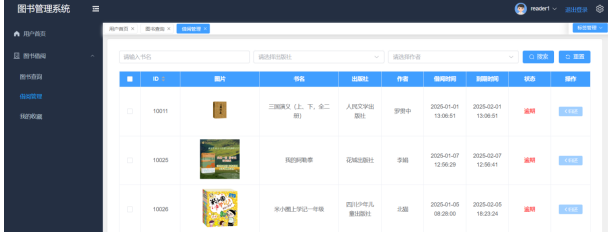
图5-7 借阅管理页面
5.2.4 我的收藏页面
用户可以通过输入书名对我的收藏列表进行精确查询,查看我的收藏的详细信息,包括图片、书名、出版社、作者、简介等。此外,用户还可以对其进行查看详情操作。我的收藏页面如图5-8所示。
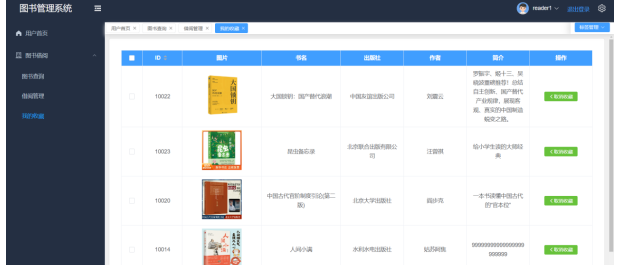
图5-8 我的收藏页面
5.3 审计员功能的设计与实现
5.3.1 审计员登录页面
审计员可以通过系统提供的登录界面进入平台,输入用户名和密码完成身份验证。登录界面设计简洁直观,审计员可以轻松找到相应的登录入口,支持用户名安全验证通过顺畅的登录流程,审计员能够快速进入系统,享受高效便捷的服务。审计员登录页面如图5-9所示。

图5-9 审计员登录页面
5.3.2 审计管理页面
商家可以通过输入关键词对审计管理列表进行精确查询,查看审计管理的详细信息,包括ID、事件类型、操作时间、操作人、用户IP、事件信息等。审计管理页面如图5-10所示。
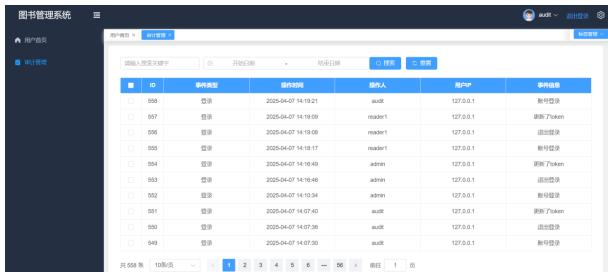
图5-10 审计管理页面
第六章 系统测试
6.1 测试目的
系统功能测试核心验证系统是否依据需求规格正确完成各项任务,业务流程需如预期执行,例如图书借阅、归还、检索等,测试检查交互逻辑的合理,避免数据错误或异常行为出现,比如表单提交或库存计算失败。测试覆盖所有角色的功能权限,管理员和普通用户都包含在测试中,防止越权与缺失问题,边界条件的正确处理重点被测试,借书超期或库存为零时借书这些现象都需覆盖,系统健壮性增强。 功能测试要求对数据一致性进行验证,借阅记录与库存数据的实时同步等都包含在内,逻辑漏洞的避免可减少数据错乱的出现,修改或新增功能不影响原有模块正常运行,这通过回归测试确保,系统维护风险也因它降低,缺陷借助测试报告记录且进行修复跟踪,上线后的系统稳定与可靠性也通过它保障。
6.2 测试方法
该系统采用黑盒测试方法,验证功能需求为重,内容包括边界值分析、等价类划分和场景测试,不涉及代码内部逻辑,其意义在于检查系统行为是否与用户预期匹配,比如在测试图书借阅流程时,用正常值、异常值或边界值数据验证系统对输入的处理。这些测试能确保系统在复杂业务逻辑和容错性中不偏移预期功能,特别适合应对验收或用户界面的验证需求,搜索功能未按书名精确匹配的缺陷,它能发现,但对代码覆盖率不包含。针对业务规则复杂但实现逻辑封闭的模块,例如借还书与权限管理,此类方法可高效验证,通过重复执行流程化用例,它在需求变更后保持系统功能稳定。
白盒测试的聚焦点在于代码逻辑与结构,语句覆盖、分支覆盖这些方法都可采用,借由其检查程序内部运行与预期是否符合,核心意义在于发现隐藏的逻辑错误或性能瓶颈,例如测试借阅接口时,对高并发请求进行模拟分析数据库SQL执行效率,检查DjangoORM查询是否产生N+1问题等。开发者需要参与白盒测试,单元测试和集成测试结合后能精准定位代码缺陷,提高系统的健壮性与可维护性,此类方法在核心模块中尤其适合使用,补充了黑盒测试的盲区。它依赖代码可见性,由技术团队在开发阶段实施为适合,两者结合构建完整的测试体系之后可确保功能正确性与代码质量。
6.3 测试用例
管理员管理用户信息测试用例,如表6-1所示。
表6-1 管理用户信息测试用例表
测试内容
录入的数据
预期结果
实际结果
测试状态
添加用户信息
1.用户名:张三
2.性别:女
3.邮箱地址:123456
系统显示用户信息添加成功的提示
新的用户信息出现在用户信息列表中
系统显示用户信息添加成功的提示
新的用户信息出现在用户信息列表中
成功
删除用户信息
选择要删除的用户信息,点击删除按钮
提示“删除成功”,并在用户信息列表中删除该用户信息
提示“删除成功”,并在用户信息列表中删除该用户信息
成功
管理员管理图书信息测试用例,如表6-2所示。
表6-2 管理图书信息测试用例表
测试内容
录入的数据
预期结果
实际结果
测试状态
添加图书信息
1.书名:名称1
2.出版社:名称1
系统显示图书信息添加成功的提示
新的图书信息出现在图书信息列表中
系统显示图书信息添加成功的提示
新的图书信息出现在图书信息列表中
成功
删除图书信息
选择要删除的图书信息,点击删除按钮
提示“删除成功”,并在图书信息列表中删除该图书信息
提示“删除成功”,并在图书信息列表中删除该图书信息
成功
用户登录测试用例,如表6-3所示。
表6-3 用户登录系统测试用例表
测试内容
录入的数据
预期结果
实际结果
测试状态
用户登录
用户名:456
密码:123456
提示请填写用户名
提示请填写用户名
成功
用户登录
用户名:111
密码:123456
登录成功,进入系统首页
登录成功,进入系统首页
成功
6.4 测试结果分析
测试结果验证了系统核心功能基本符合需求,其中用户登录功能在黑盒测试中成功完成正常登录、密码错误登录和权限验证,未发现逻辑漏洞;管理员管理用户信息和图书信息的功能测试覆盖了新增、删除操作的正异常场景,数据一致性测试确保操作后数据库准确更新,并通过白盒测试确认后端接口参数校验和事务回滚机制有效。黑盒测试发现的2个边界问题已修复,白盒测试中通过代码覆盖率达到90%以上验证了核心逻辑完整性。最终测试报告显示系统满足基础业务需求,但涉及高并发场景的性能测试需在后续迭代中专项优化。

