【Python 采集沃尔玛公开数据】沃尔玛的人机验证,然后无脑过验证,轻松拿数据,手把手教会你_沃尔玛人机验证
文章日期:2024.12.19
使用工具:Python
本章知识:分析沃尔玛人机验证,过人机验证,成功测试拿取公开数据
文章难度:低等(没难度)
文章全程已做去敏处理!!! 【需要做的可联系我】
AES解密处理(直接解密即可)(crypto-js.js 标准算法):在线AES加解密工具
仅供学习!仅供学习!仅供学习!
首先要注意,本文仅作为分析学习测试,无其他意图,觉得文章不错就随便表示一下吧,我将会持续更新更好的内容供大家学习参考
告知:requests 模块即可搞定。不需要自动化模拟。
不知道大家有没有发现,在测试沃尔玛的时候,刚开始还能请求,当正式开始干的时候,程序他就不行了,因为出现了验证页面
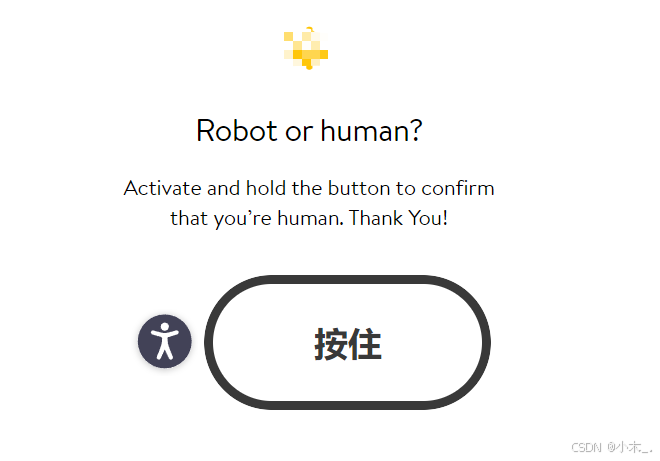
然后你觉得是ip被干掉了,就去买了ip池,用上以后就会发现,还是不行。
这个时候,懂的都会先去看看是不是 cookie 缺少认证信息,或 headers 缺少认证信息,在或者就是检查伪装头,然后检查网络,最后程序还是不行。
在这个检查处理的过程中,程序可能会又跑起来,但过一会就又挂了。今天就给大家看一下我是怎么搞定的
首先,要注意下
数据量大的朋友,还是需要依赖ip池的,经过我的测试,海外池是最佳选择,国内池备选(会卡一点,甚至可能跑不起来,慎选)
数据量小,不需要多线程高并发的,就可以不用考虑池子,一条一条数据慢慢跑就行,不影响,只是会慢
1、打开某某网站(使用文章开头的AES在线工具解密):
WKeDxkxE9eZH5iHrE5KQBFkJHXzvXD1BLa3G7XkjiBY=
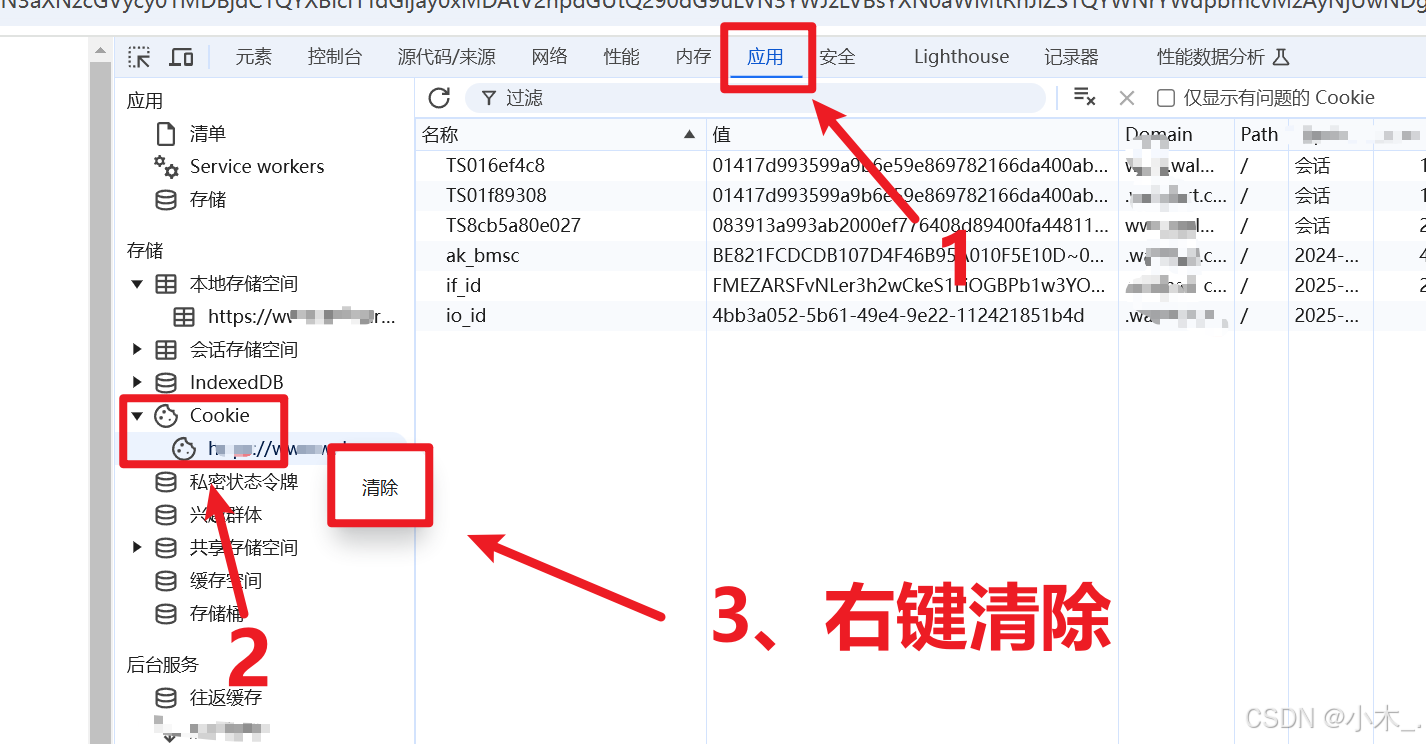
2、我们随便打开一个商品,打开商品后如果他自动跳转到其他人机验证页面了,就需要你们提前先复制一个商品链接,然后按照我的步骤来走,如果没有人机验证,就直接按照我的步骤来,先打开F12 控制台,点击应用,然后找到cookie,全部清除,无论cookie里有什么,一并全部清除干净
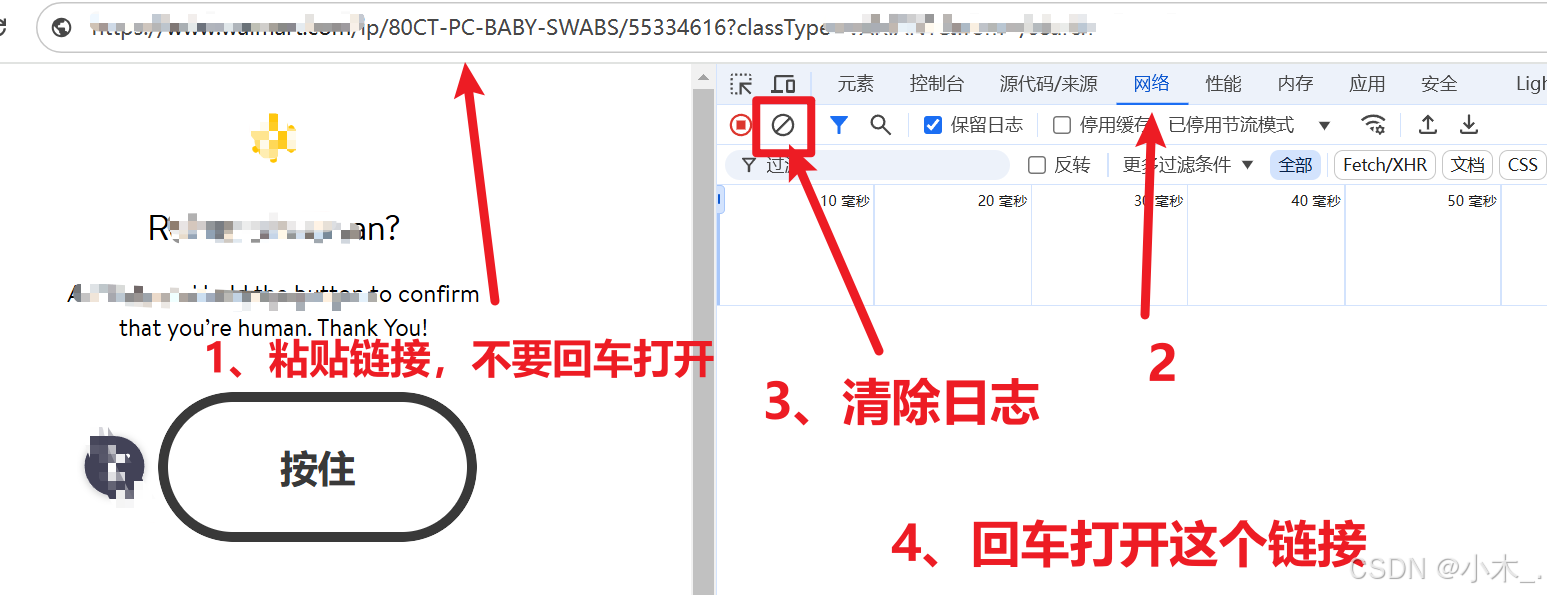
3、由于我界面跳转了,我就直接粘贴一个商品链接,粘贴后不要打开,先把控制台的日志清除了,然后再打开链接
4、可以看到控制台已经抓到包了,我们把找到这个文件,打开去看看服务器返回了什么 cookie 信息,细心的人总能发现不一样的东西,有没有人发现我的人机验证自动消失了,由此可以看出他并不是针对你的ip进行的风控,很大概率是cookie里的令牌
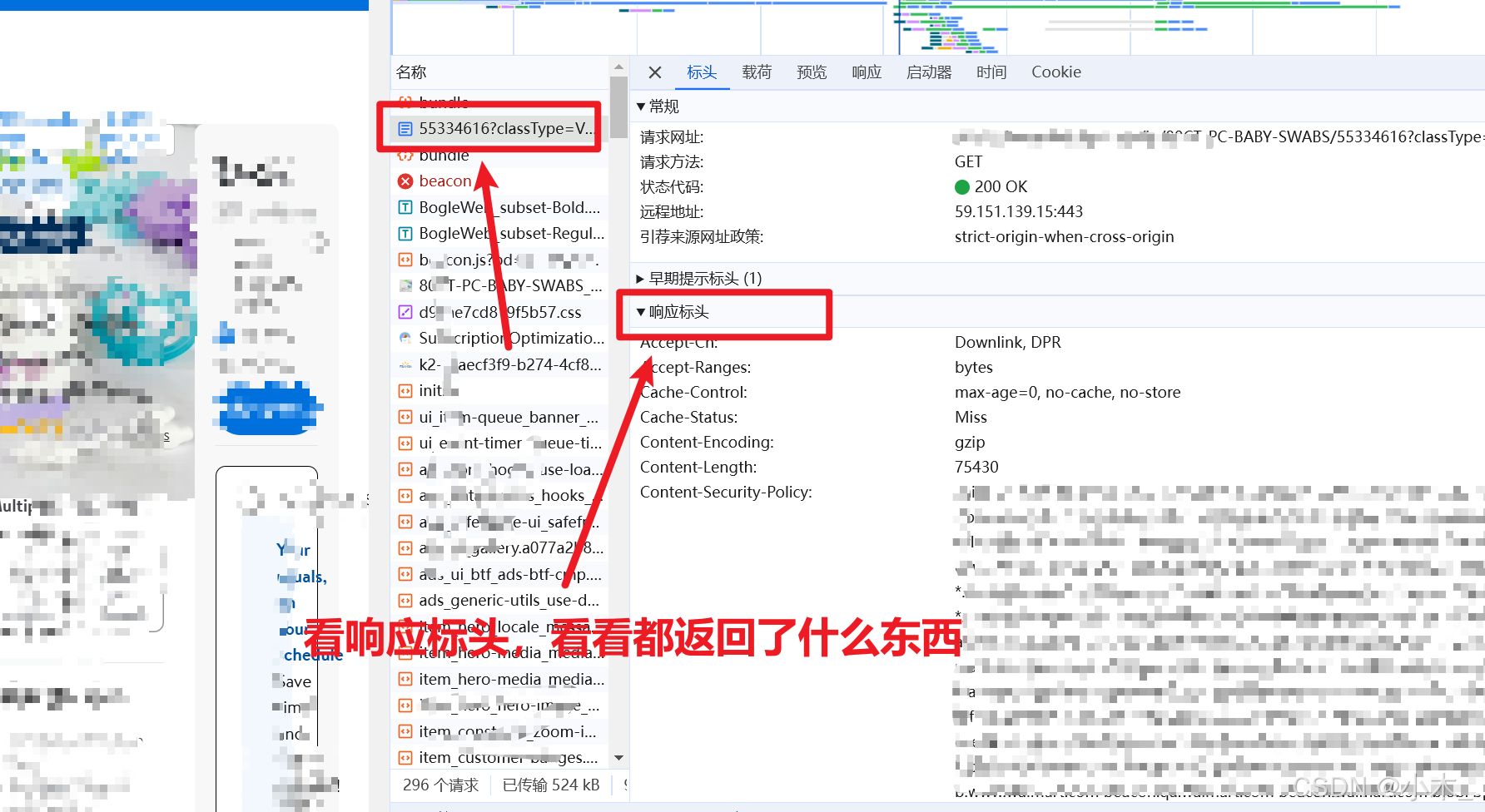
5、我对他服务器返回的内容加上他自己的cookies进行了测试,最终发现【_pxvid】是临时令牌,意思就是这给令牌是由服务器进行返回,可以临时访问数据,如果没有令牌就不能访问数据,如果访问过多令牌就会被封锁,需要等待人机验证才可以解开封锁,最重要的是,此令牌从服务器返回过来并不能直接使用,需要等待10秒,10后才可以使用此令牌.
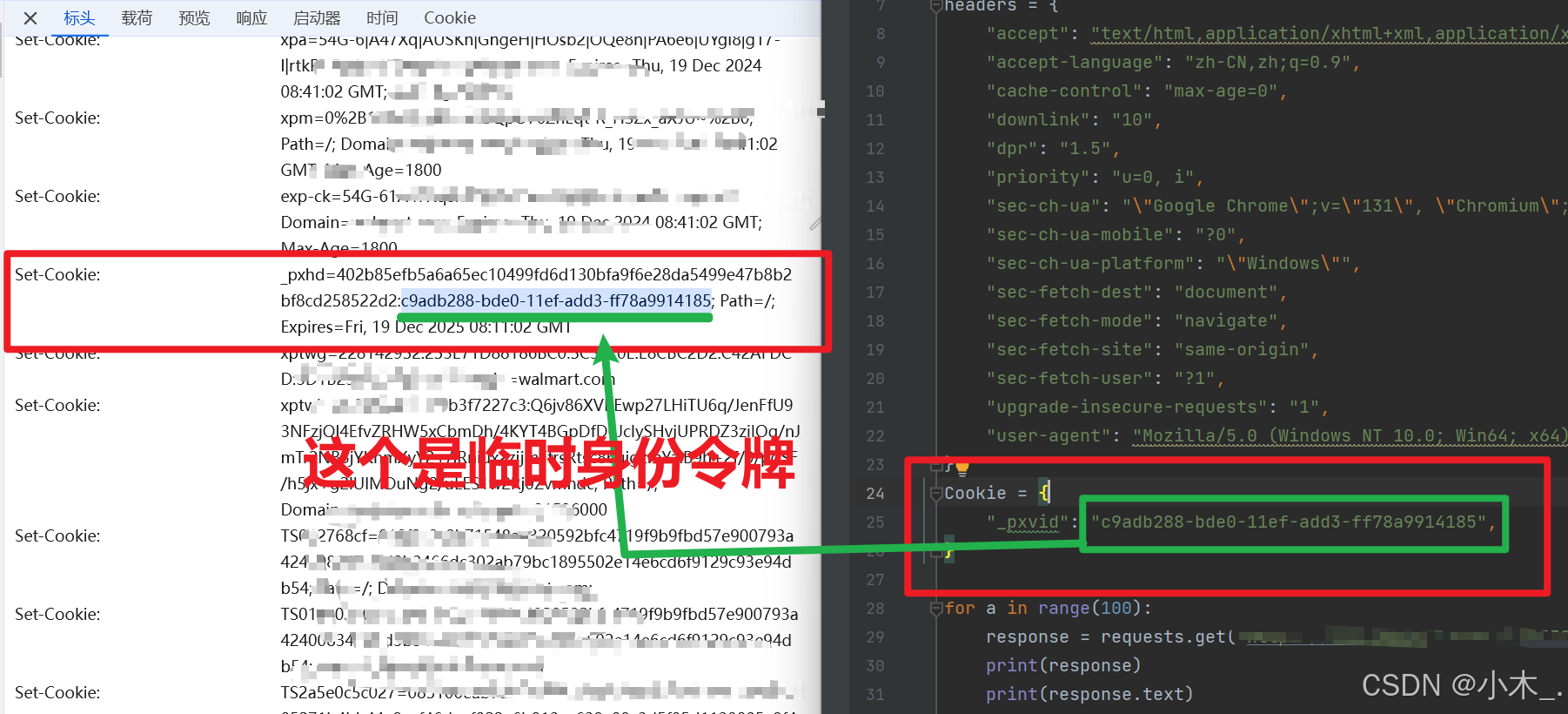
6、【原理讲解步骤】为了测试,你们可以打开浏览器,先把自己搞风控,然后在清除所有的cookie信息,然后地址栏里输入商品的链接进行打开,如果没有出现人机验证,那你就重新再来一次直到出现人机验证为之,如果打开商品链接后有人机验证,那你可以在去清除一下cookie,但注意,这次不要清除全部的cookie,要保留两个参数,【_pxhd】【_pxvid】这两个参数不要清除,然后默默等待10秒,然后再次输入商品链接回车,你会发现人机验证没有了。
原理就很简单,就是让服务器返回一个令牌,但由于令牌是刚返回的,这个时候令牌还没用生效,选哟等待10秒,如果没用生效前你直接用令牌请求,那就会报错,然后网站就会给你人机验证,验证成功后就会给你一个生效的令牌。如果按照我的方法,只需要获取令牌后,等待10秒令牌生效,就可以直接获取资源了,就不用担心人机验证的问题

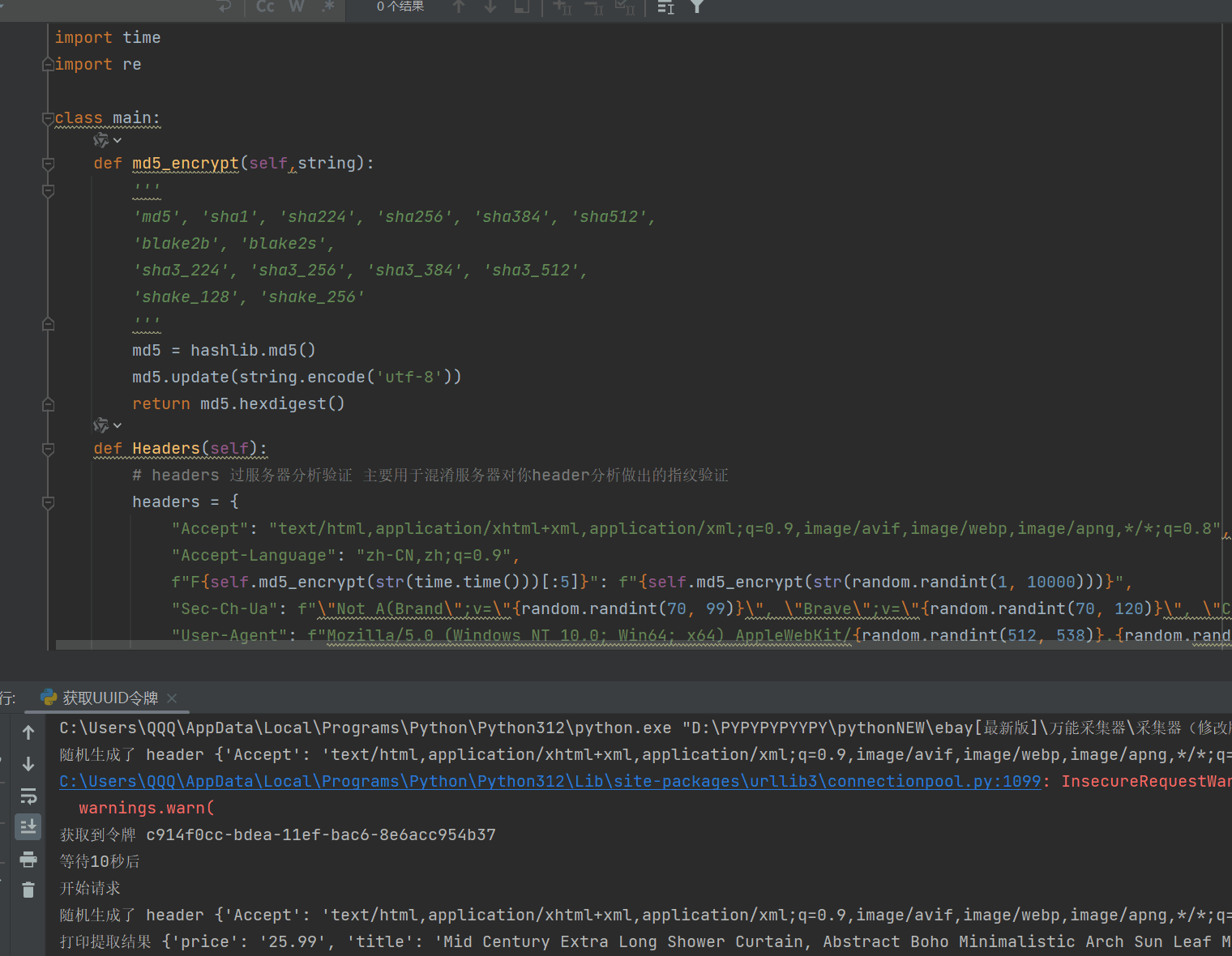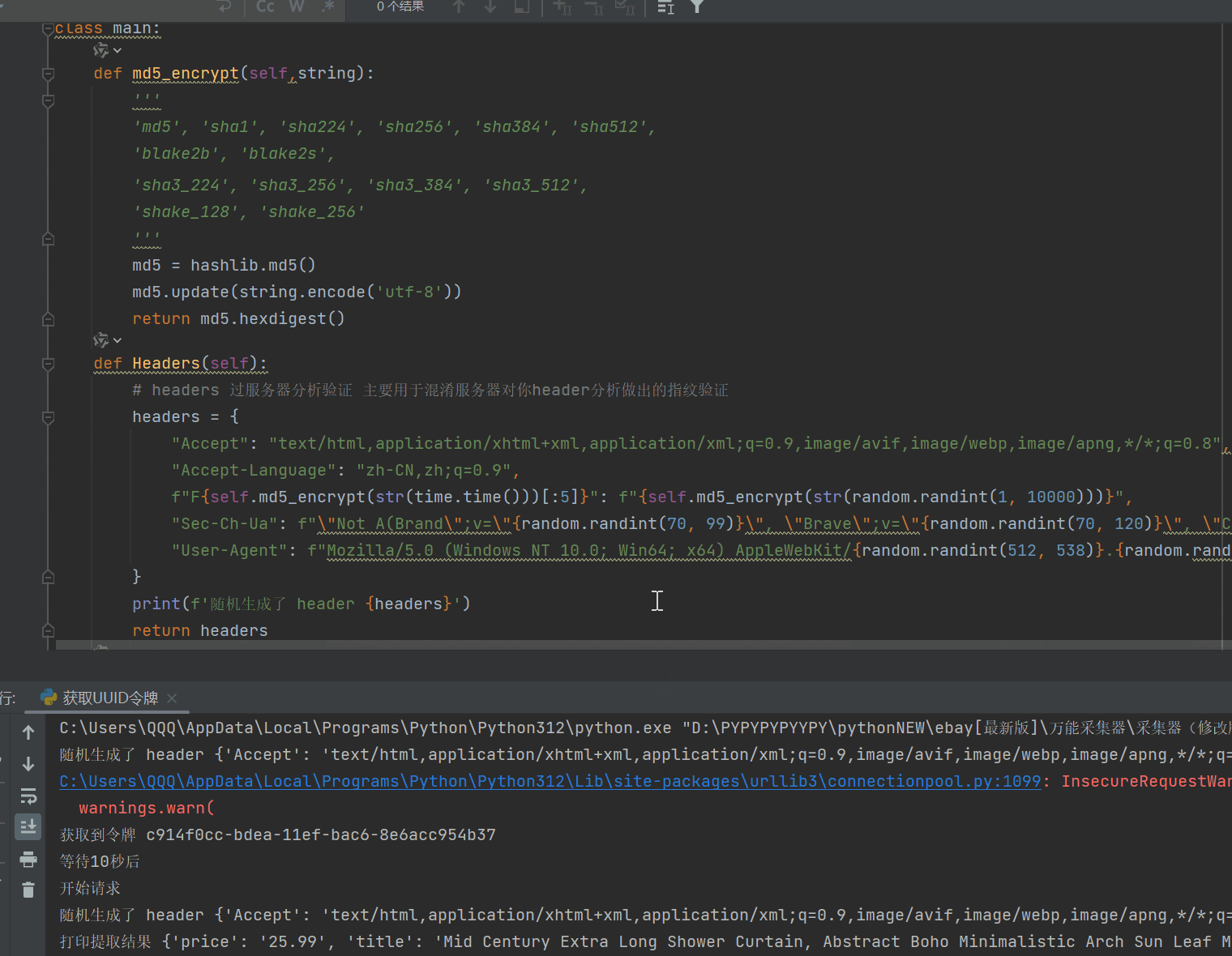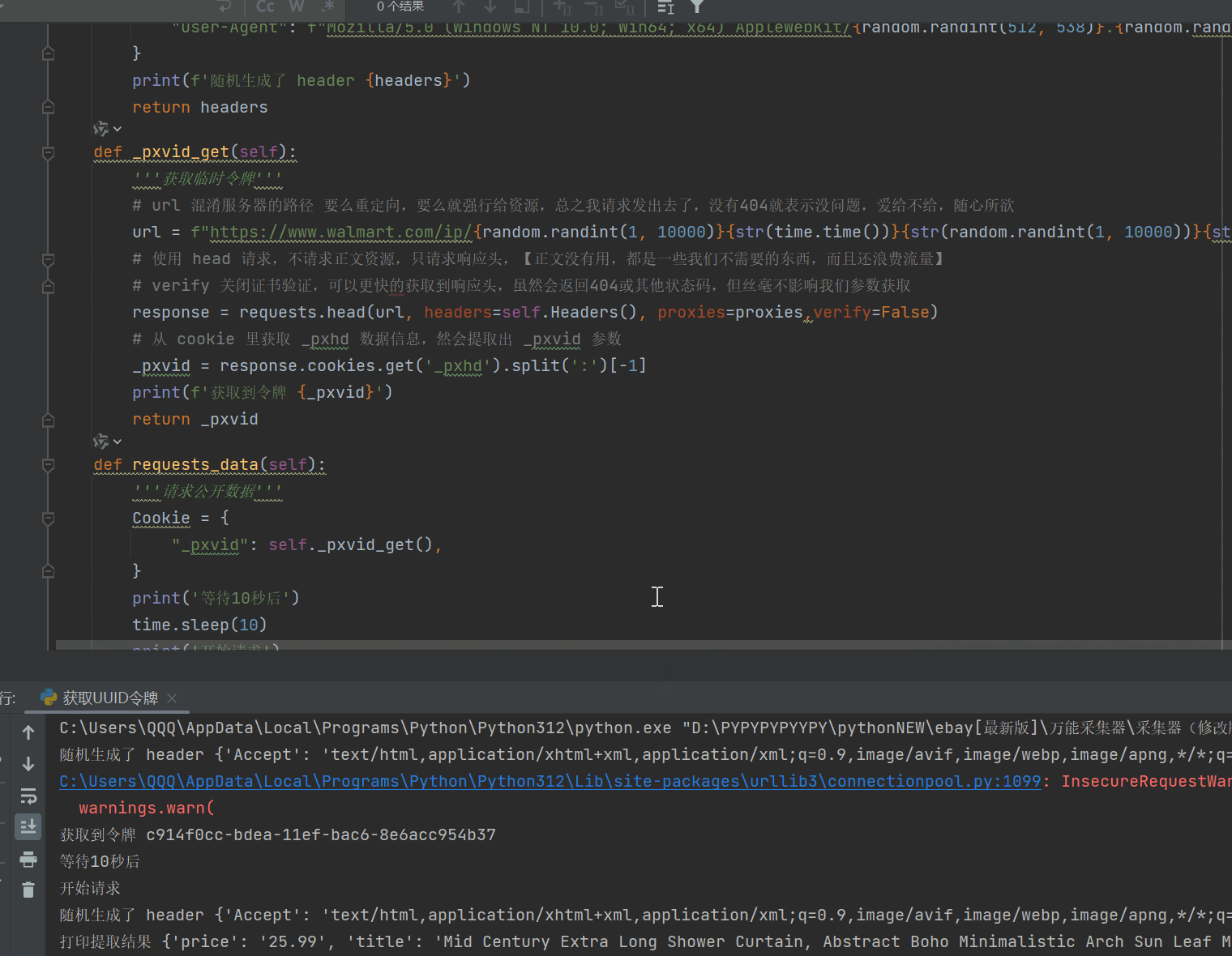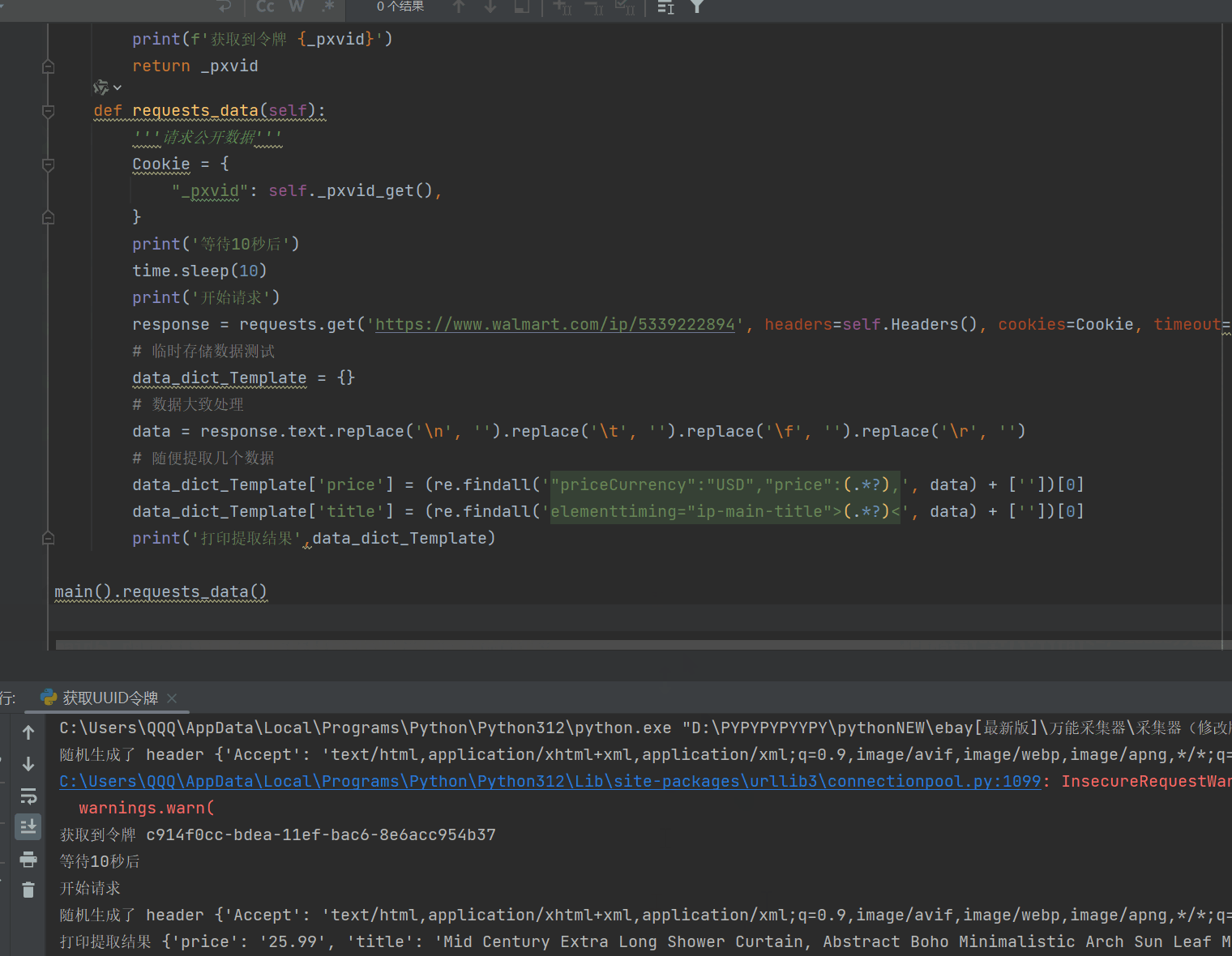
7、【获取临时令牌_pxvid】接下来就是怎么去获取这个令牌,其实很简单,就是直接去请求然后获取标头即可,我想有人肯定也尝试过,但还是会出现问题,这我就要给你看看原理图了,仔细看注释!!
获取 【_pxvid】的方法和技巧,方法如下,主要看图!!
【header】要随机一些内容,尽可能的混淆服务器对header的分析,服务器会分析header并生成指纹进行限制或风控,所以我设置了随机
【请求方法head】采用head请求,专门获取响应头信息,不获取正文信息,可以有效节省大量流量支出
【关闭证书验证】关闭可以有效提高请求速度,服务器返回的任何错误状态码都和我们要做的事情无关,所以可以关闭,以达到速度的提升
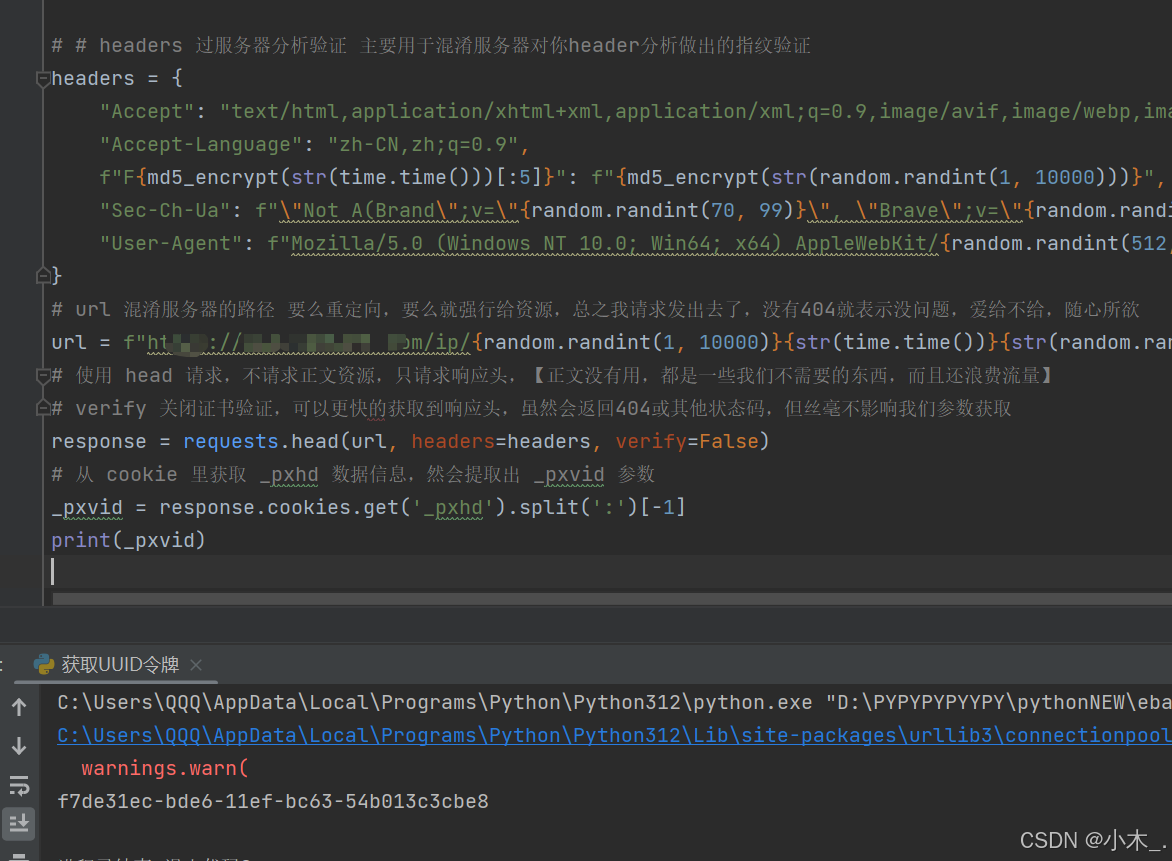
8、有了临时令牌,接下来我们要去测试获取公开数据了,如果数据量大的朋友,请自行添加ip池。
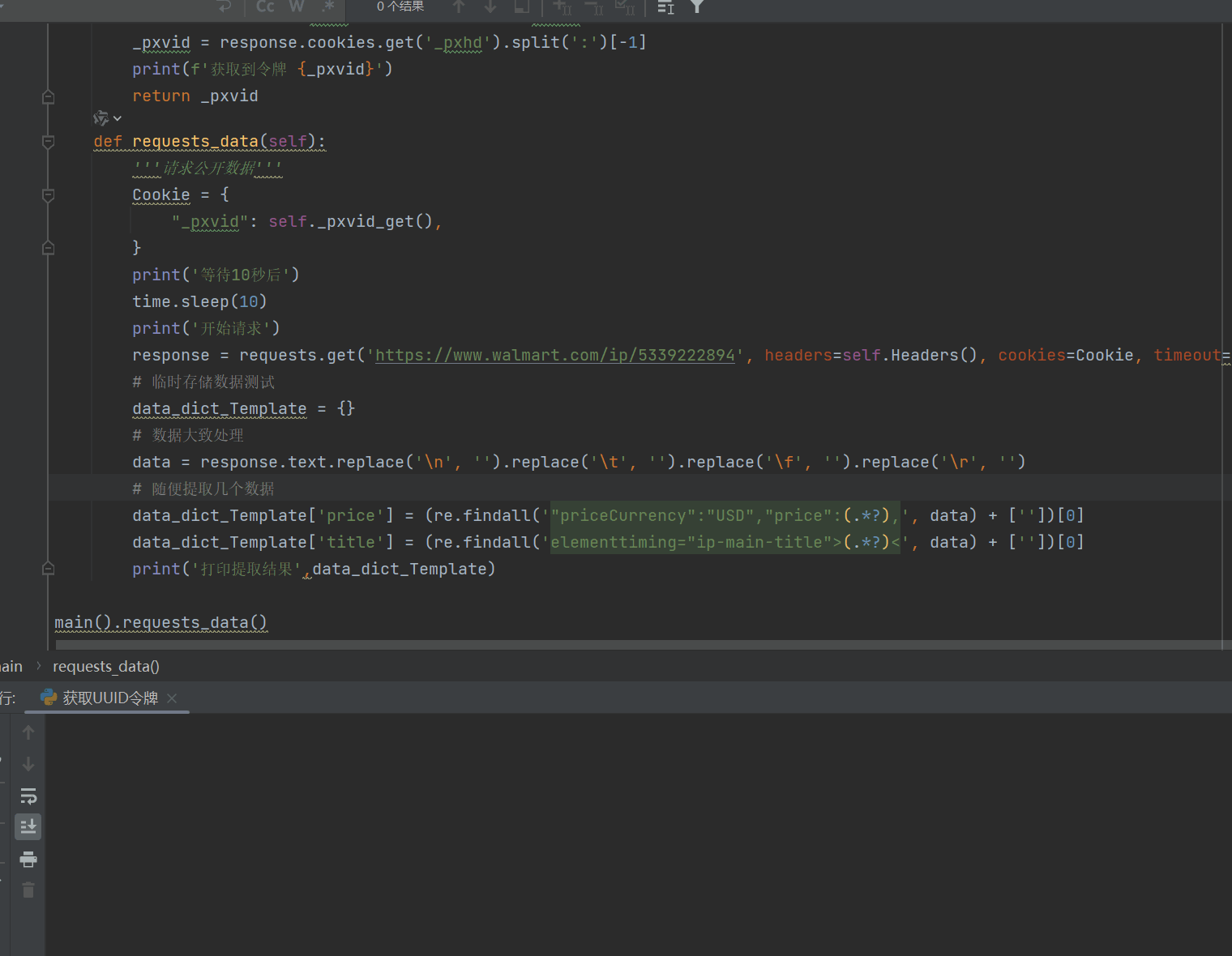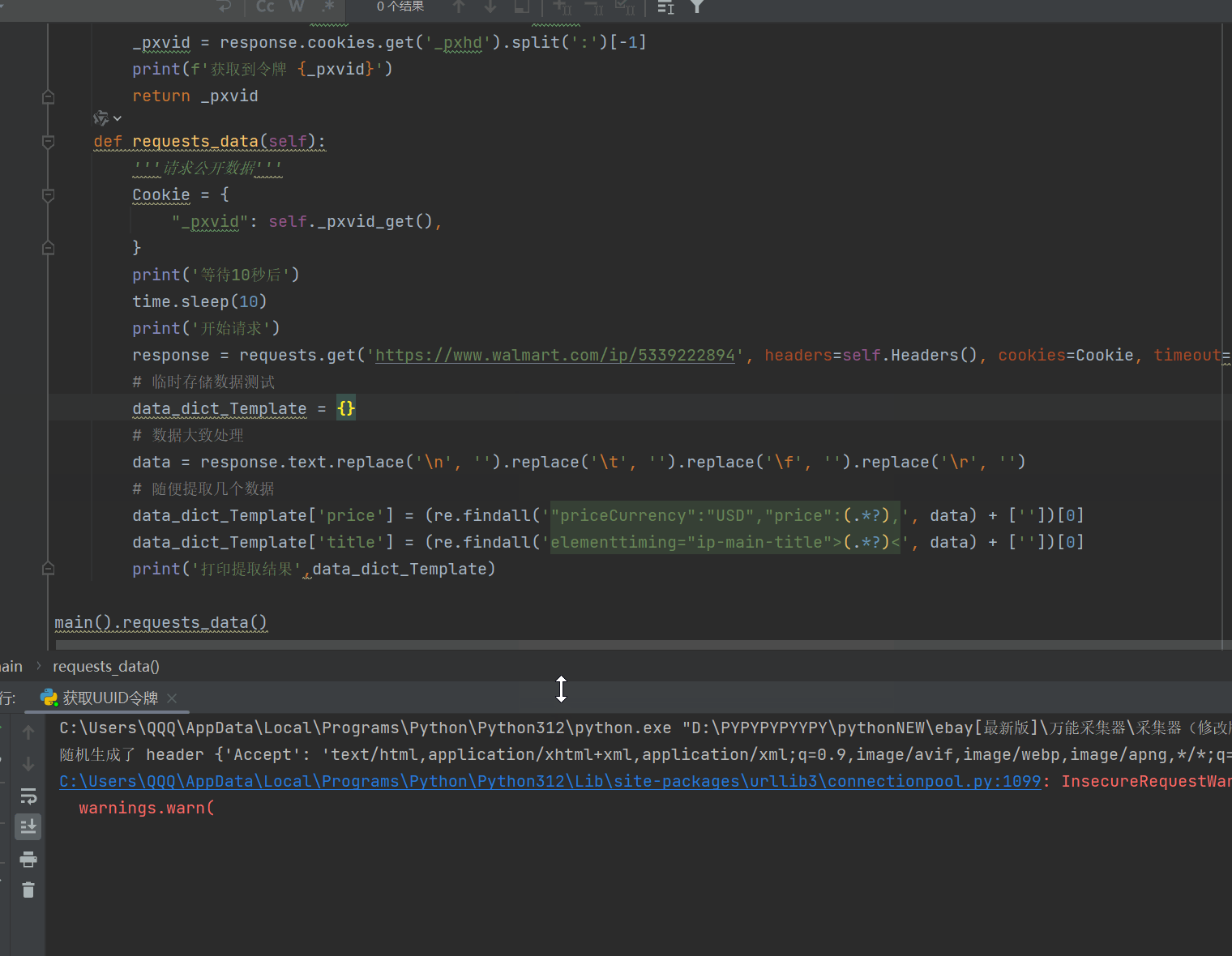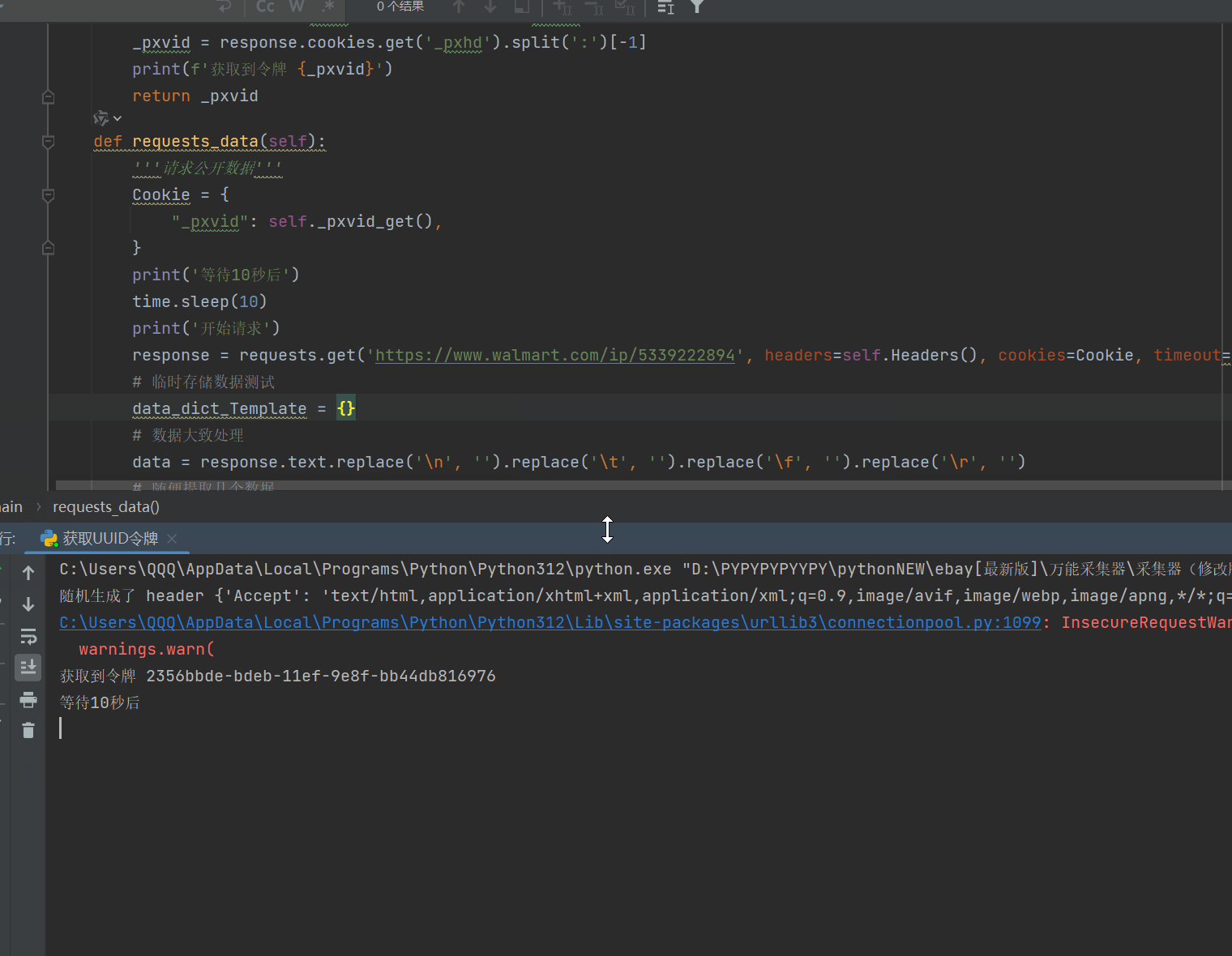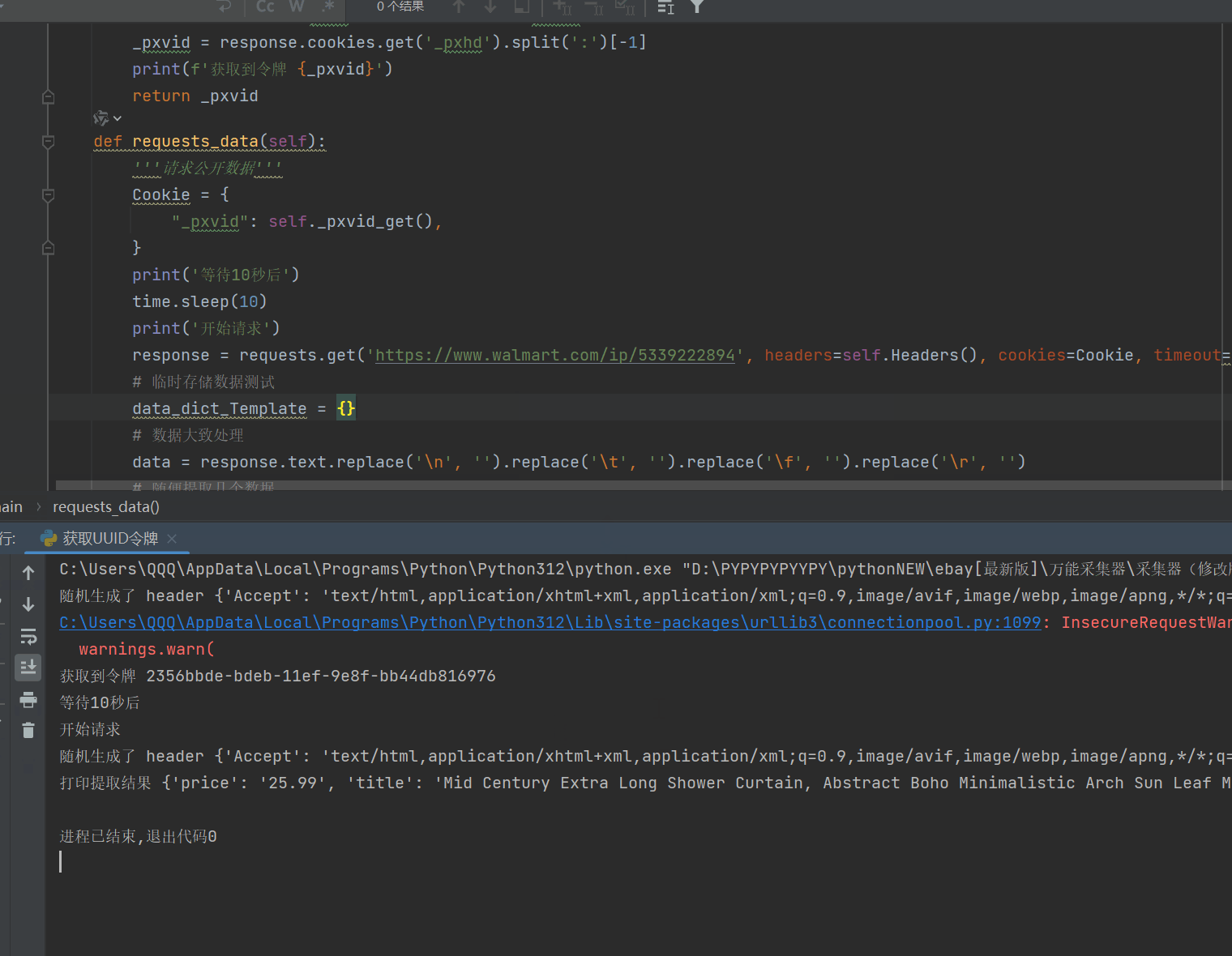
9、如果你觉得还是很麻烦,跑的很慢,我可以给你讲一下思路,如果你是多线程,比如有100个线程,你可以在程序刚启动的时候,先启动线程生成100个临时令牌,然会用列表存储着100个临时令牌,这是程序开始计时10秒,然会继续获取100个令牌存储为副本令牌,当这次的令牌都请求完成后,差不多也都10秒了,这时就可以用第一次的令牌分配给100个线程,去采集,预估每个令牌可以采集2-4次,然后使用副本令牌,在使用副本令牌的时候,就离开在请求100个令牌作为备用,以此来做到程序不停,速度很快。
给大家看看一下我的成功,由于动图太大,只能给大家看图片
这是刚开始启动的时候,程序会先更具线程数量生成令牌,我开了100个线程,使用了海外池子
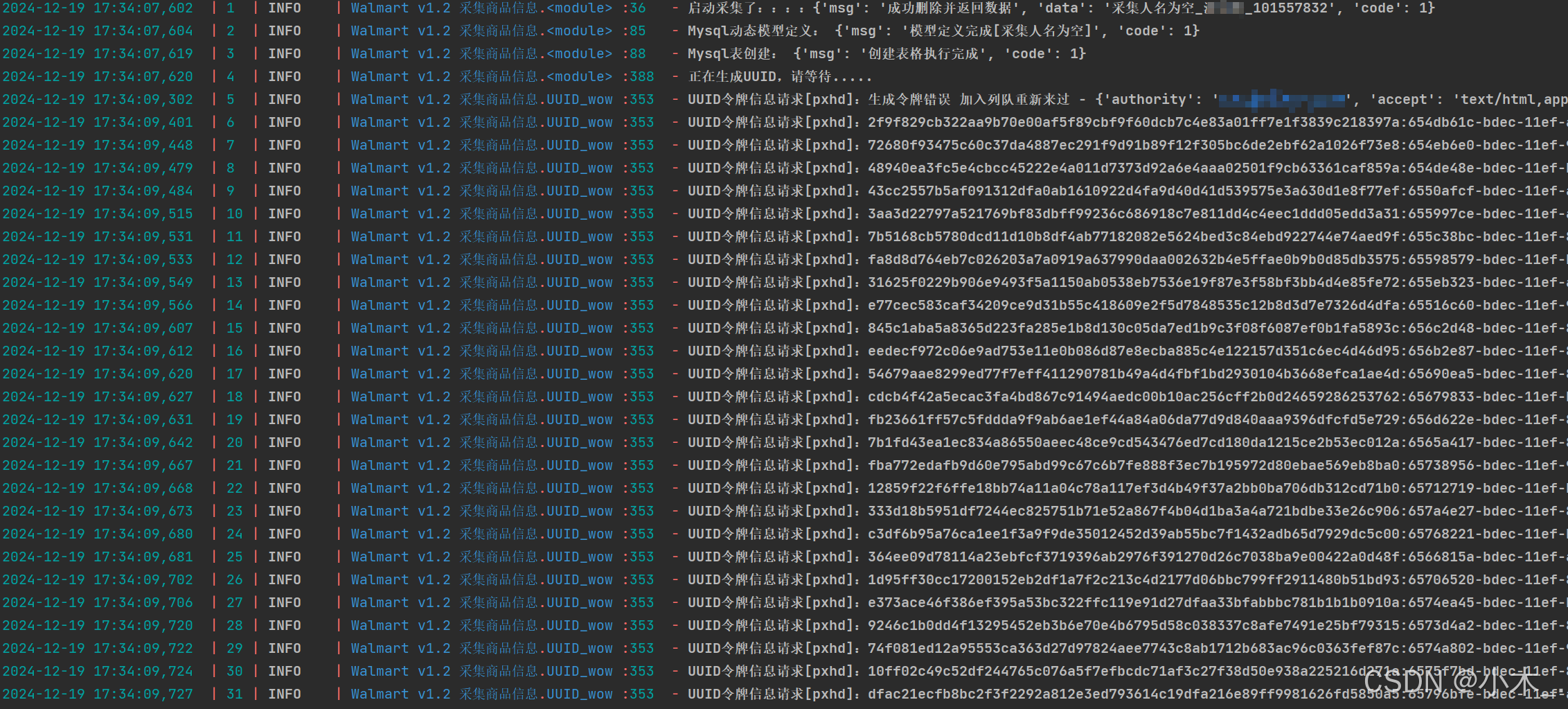
我设置了11秒,是为了防止报错,然后副令牌这时还没有生成,因为我设置了时间,50秒后生成新的令牌暂存到副令牌列表,然后再过40秒后,将副令牌替换到主令牌使用,然后再过50秒才会生成新的令牌,都是为了防止令牌提前过期或其他问题
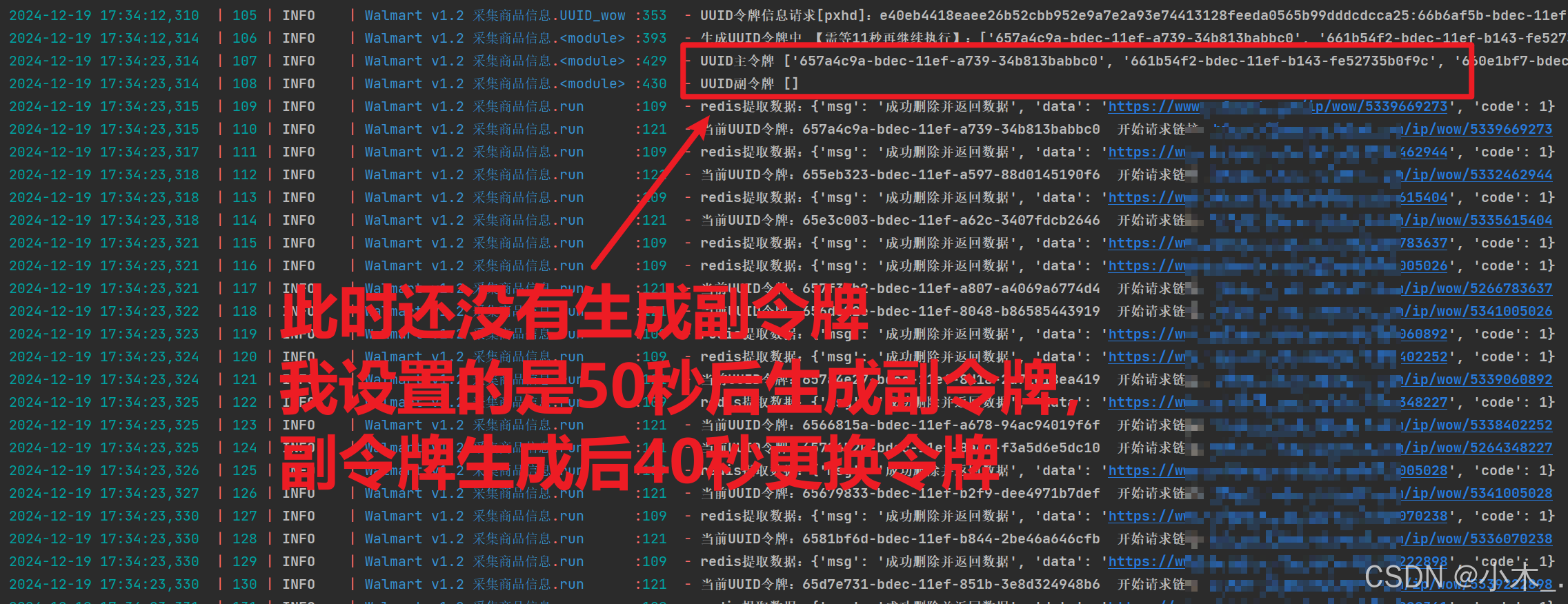
这是请求完成后的数据会被暂时存储到列队里,等待统一保存至数据库
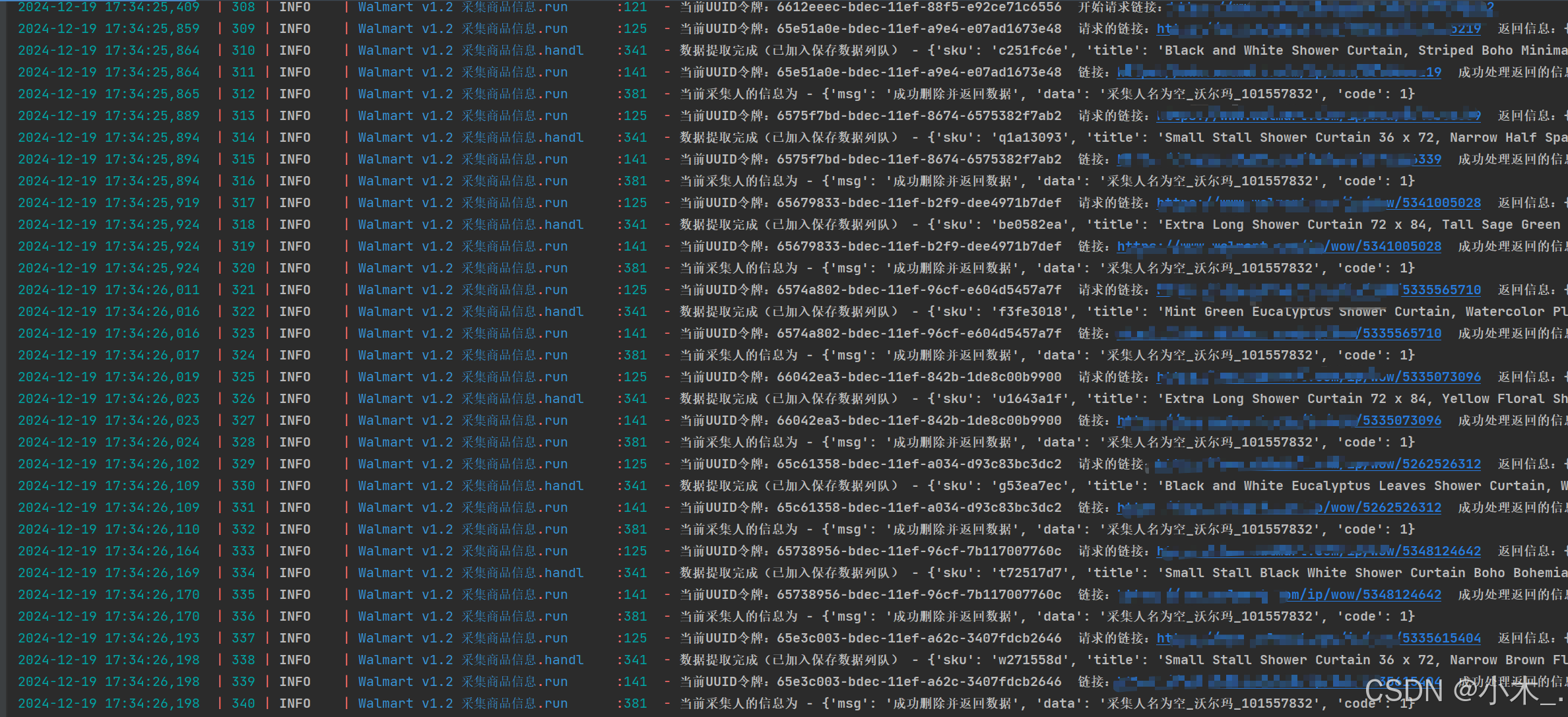
这就已经保存到数据库里了
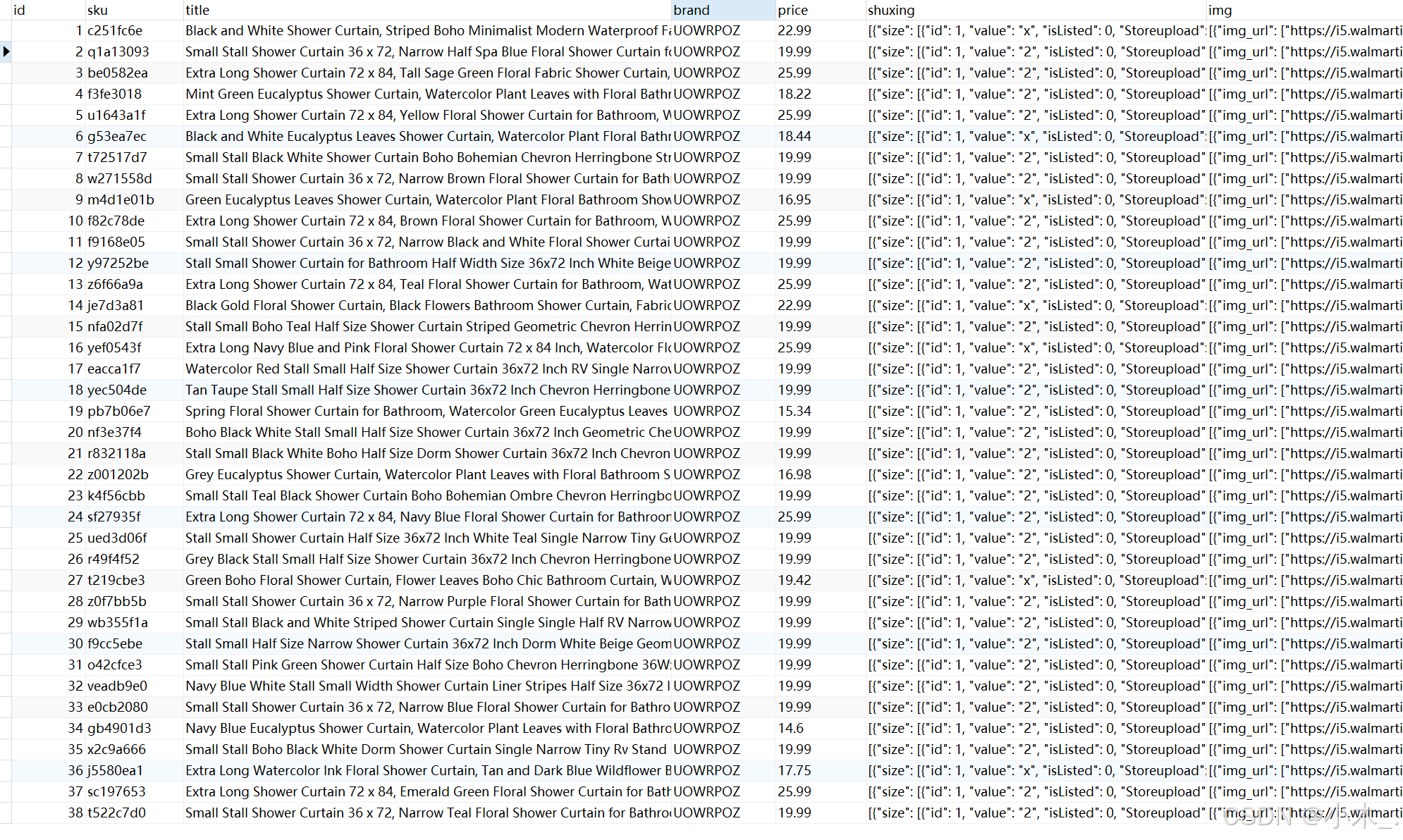
看成品吧
今天就到这里,动一下你的小手,你对我的认可是我最大的动力。
【获取_pxvid令牌.py】
\"\"\"File Name: 获取_pxvid令牌Author: 小木_.Date Created: 2023-07-14Last Modified: 2024-12-19Version: 1.0\"\"\"import randomimport requestsimport hashlibimport time# base64 解密def base64_decode(str): return base64.b64decode(str).decode(\'utf-8\')# 这个是链接被base64加密了,此步骤只用于去敏,无其他作用hosturl = base64_decode(\'aHR0cHM6Ly93d3cud2FsbWFydC5jb20v\')def md5_encrypt(string): \'\'\' \'md5\', \'sha1\', \'sha224\', \'sha256\', \'sha384\', \'sha512\', \'blake2b\', \'blake2s\', \'sha3_224\', \'sha3_256\', \'sha3_384\', \'sha3_512\', \'shake_128\', \'shake_256\' \'\'\' md5 = hashlib.md5() md5.update(string.encode(\'utf-8\')) return md5.hexdigest()# headers 过服务器分析验证 主要用于混淆服务器对你header分析做出的指纹验证headers = { \"Accept\": \"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8\", \"Accept-Language\": \"zh-CN,zh;q=0.9\", f\"F{md5_encrypt(str(time.time()))[:5]}\": f\"{md5_encrypt(str(random.randint(1, 10000)))}\", \"Sec-Ch-Ua\": f\"\\\"Not A(Brand\\\";v=\\\"{random.randint(70, 99)}\\\", \\\"Brave\\\";v=\\\"{random.randint(70, 120)}\\\", \\\"Chromium\\\";v=\\\"{random.randint(70, 120)}\\\"\", \"User-Agent\": f\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/{random.randint(512, 538)}.{random.randint(9, 37)} (KHTML, like Gecko) Chrome/{random.randint(100, 121)}.0.0.0 Safari/{random.randint(512, 538)}.{random.randint(9, 37)}\"}# url 混淆服务器的路径 要么重定向,要么就强行给资源,总之我请求发出去了,没有404就表示没问题,爱给不给,随心所欲url = f\"{hosturl}ip/{random.randint(1, 10000)}{str(time.time())}{str(random.randint(1, 10000))}{str(time.time())}{str(random.randint(1, 10000))}\"# 使用 head 请求,不请求正文资源,只请求响应头,【正文没有用,都是一些我们不需要的东西,而且还浪费流量】# verify 关闭证书验证,可以更快的获取到响应头,虽然会返回404或其他状态码,但丝毫不影响我们参数获取response = requests.head(url, headers=headers, verify=False)# 从 cookie 里获取 _pxhd 数据信息,然会提取出 _pxvid 参数_pxvid = response.cookies.get(\'_pxhd\').split(\':\')[-1]print(f\'获取到令牌 {_pxvid}\')【完整代码.py】
\"\"\"File Name: 获取_pxvid令牌 并请求公开数据Author: 小木_.Date Created: 2023-07-14Last Modified: 2024-12-19Version: 1.0\"\"\"import randomimport requestsimport hashlibimport timeimport reimport base64\'\'\'如果出现请求错误,请更换请求的商品链接即可如果更换后依然报错,有可能是网站进行了更新。\'\'\'# base64 解密def base64_decode(str): return base64.b64decode(str).decode(\'utf-8\')# 这个是链接被base64加密了,此步骤只用于去敏,无其他作用hosturl = base64_decode(\'aHR0cHM6Ly93d3cud2FsbWFydC5jb20v\')class main: def md5_encrypt(self,string): \'\'\' \'md5\', \'sha1\', \'sha224\', \'sha256\', \'sha384\', \'sha512\', \'blake2b\', \'blake2s\', \'sha3_224\', \'sha3_256\', \'sha3_384\', \'sha3_512\', \'shake_128\', \'shake_256\' \'\'\' md5 = hashlib.md5() md5.update(string.encode(\'utf-8\')) return md5.hexdigest() def Headers(self): # headers 过服务器分析验证 主要用于混淆服务器对你header分析做出的指纹验证 headers = { \"Accept\": \"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8\", \"Accept-Language\": \"zh-CN,zh;q=0.9\", f\"F{self.md5_encrypt(str(time.time()))[:5]}\": f\"{self.md5_encrypt(str(random.randint(1, 10000)))}\", \"Sec-Ch-Ua\": f\"\\\"Not A(Brand\\\";v=\\\"{random.randint(70, 99)}\\\", \\\"Brave\\\";v=\\\"{random.randint(70, 120)}\\\", \\\"Chromium\\\";v=\\\"{random.randint(70, 120)}\\\"\", \"User-Agent\": f\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/{random.randint(512, 538)}.{random.randint(9, 37)} (KHTML, like Gecko) Chrome/{random.randint(100, 121)}.0.0.0 Safari/{random.randint(512, 538)}.{random.randint(9, 37)}\" } print(f\'随机生成了 header {headers}\') return headers def _pxvid_get(self): \'\'\'获取临时令牌\'\'\' # url 混淆服务器的路径 要么重定向,要么就强行给资源,总之我请求发出去了,没有404就表示没问题,爱给不给,随心所欲 url = f\"{hosturl}ip/{random.randint(1, 10000)}{str(time.time())}{str(random.randint(1, 10000))}{str(time.time())}{str(random.randint(1, 10000))}\" # 使用 head 请求,不请求正文资源,只请求响应头,【正文没有用,都是一些我们不需要的东西,而且还浪费流量】 # verify 关闭证书验证,可以更快的获取到响应头,虽然会返回404或其他状态码,但丝毫不影响我们参数获取 response = requests.head(url, headers=self.Headers(), verify=False) # 从 cookie 里获取 _pxhd 数据信息,然会提取出 _pxvid 参数 _pxvid = response.cookies.get(\'_pxhd\').split(\':\')[-1] print(f\'获取到令牌 {_pxvid}\') return _pxvid def requests_data(self): \'\'\'请求公开数据\'\'\' Cookie = { \"_pxvid\": self._pxvid_get(), } print(\'等待10秒后\') time.sleep(10) print(\'开始请求\') response = requests.get(f\'{hosturl}ip/5339222894\', headers=self.Headers(), cookies=Cookie) # 临时存储数据测试 data_dict_Template = {} # 数据大致处理 data = response.text.replace(\'\\n\', \'\').replace(\'\\t\', \'\').replace(\'\\f\', \'\').replace(\'\\r\', \'\') # 随便提取几个数据 data_dict_Template[\'price\'] = (re.findall(\'\"priceCurrency\":\"USD\",\"price\":(.*?),\', data) + [\'\'])[0] data_dict_Template[\'title\'] = (re.findall(\'elementtiming=\"ip-main-title\">(.*?)<\', data) + [\'\'])[0] print(\'打印提取结果\',data_dict_Template)main().requests_data()

