SQL 技术深度剖析:从执行原理到性能优化
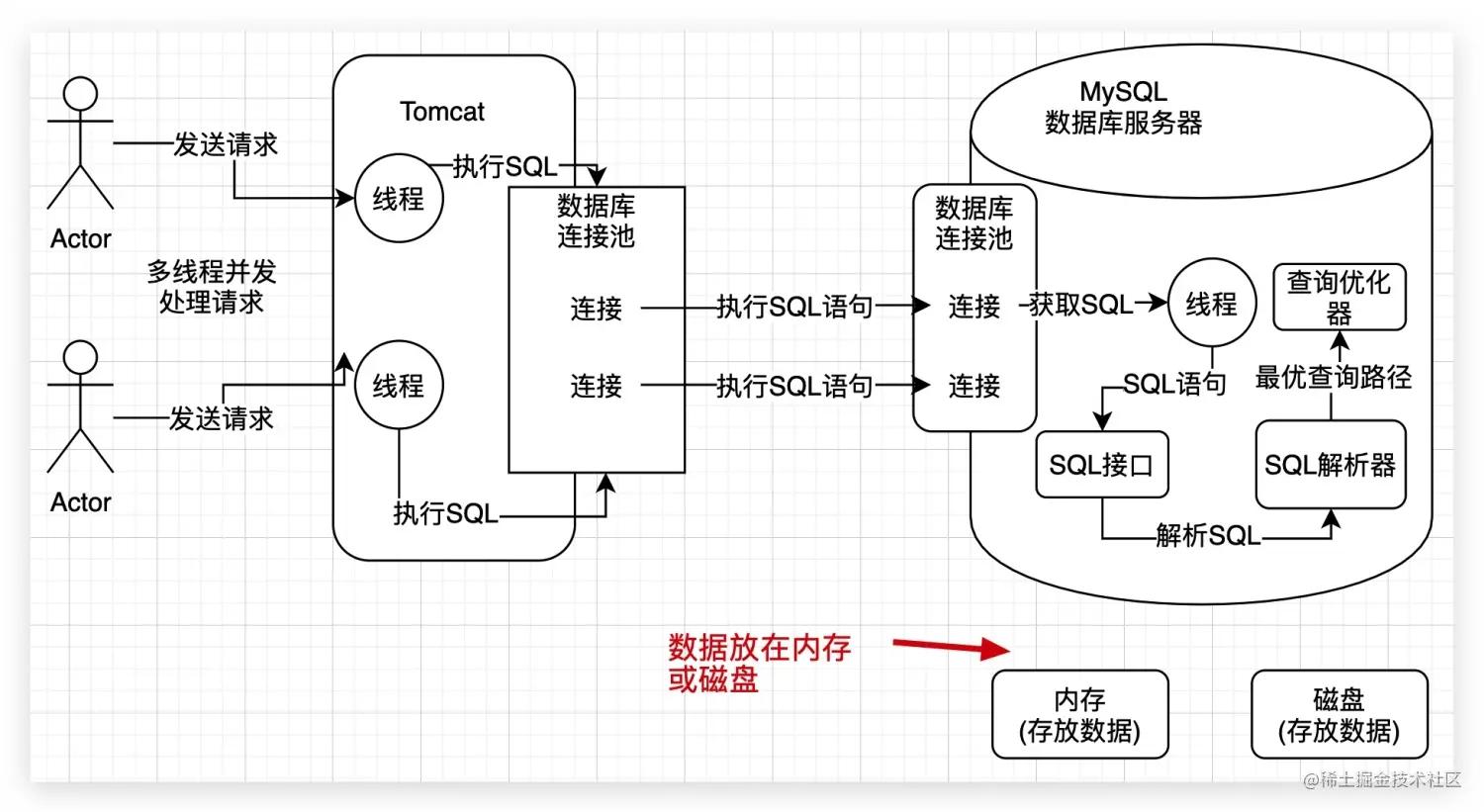
在数据库应用的世界里,SQL 语句的性能如同系统的 “心脏跳动”,直接决定着应用程序的响应速度和整体运行效率。当面对日益增长的数据量和复杂的业务查询需求时,深入理解 SQL 的底层执行原理,并掌握科学的性能优化方法,成为每一位开发者和数据库管理员的必备技能。
一、SQL 执行原理:揭开查询的神秘面纱
SQL 作为一种声明式语言,用户只需描述 “想要什么”,而无需关心 “如何实现”。但在数据库内部,一条 SQL 语句的执行要经历一系列复杂的过程。
首先是词法和语法分析阶段。数据库系统会对输入的 SQL 语句进行扫描,将其分解为一个个 token(如关键字、表名、列名等),然后根据 SQL 语法规则检查语句的合法性。
接下来是语义分析。这一阶段会验证语句中涉及的数据库对象(如表、列、函数等)是否存在,以及用户是否具有操作这些对象的权限。同时,还会进行一些类型转换等工作,确保语句的语义正确。
然后进入查询优化器阶段,这是 SQL 执行过程中最关键的环节之一。查询优化器的主要任务是根据数据库的统计信息(如表的行数、列的基数、索引的分布等),为 SQL 语句生成最优的执行计划。执行计划是一系列操作的集合,包括表的连接方式(如嵌套循环、哈希连接、合并连接)、访问路径(如全表扫描、索引扫描)等。
最后,数据库引擎按照生成的执行计划执行 SQL 语句,并将结果返回给用户。
二、查询优化器:SQL 性能的 “智慧大脑”
查询优化器的性能直接影响着 SQL 语句的执行效率,其核心目标是在众多可能的执行计划中选择成本最低的一个。这里的成本主要包括 I/O 成本、CPU 成本和内存成本等。
(一)优化策略
查询优化器通常采用两种优化策略:基于规则的优化(RBO)和基于成本的优化(CBO)。
基于规则的优化是根据预设的规则来选择执行计划。例如,对于带有索引的列进行查询时,优先选择索引扫描而不是全表扫描。这种方法简单直观,但缺乏灵活性,无法根据实际的数据分布情况进行调整。
基于成本的优化则是根据数据库的统计信息计算每个可能执行计划的成本,然后选择成本最低的执行计划。它能够更好地适应不同的数据场景,因此现代数据库大多采用这种优化策略。
(二)成本估算模型
成本估算模型是基于成本的优化器的核心。它会根据表的大小、索引的类型和分布、数据的选择性等因素,估算出每个操作的成本。例如,全表扫描的成本通常与表的行数成正比,而索引扫描的成本则与索引的高度、索引页的数量以及查询的选择性有关。
为了提高成本估算的准确性,数据库需要定期收集和更新统计信息。如果统计信息过时,查询优化器可能会生成不理想的执行计划,导致 SQL 性能下降。
三、索引:SQL 优化的 “加速器”
索引是提高 SQL 查询性能的重要手段,它就像书籍的目录,能够帮助数据库快速定位到所需的数据。
(一)索引的类型
常见的索引类型包括 B 树索引、哈希索引、 bitmap 索引等。
B 树索引是最常用的索引类型,它适用于范围查询和排序操作。B 树的结构使得查询时能够快速定位到数据的位置,并且支持高效的插入、删除和更新操作。
哈希索引适用于等值查询,它通过哈希函数将关键字映射到一个哈希桶中,查询时能够直接定位到数据。但哈希索引不支持范围查询和排序,因此适用场景相对有限。
bitmap 索引则适用于低基数列(即列的不同值较少),它通过位图来表示列值与行的对应关系,能够高效地进行列值的筛选和聚合操作。
(二)索引的设计原则
虽然索引能够提高查询性能,但并不是越多越好。过多的索引会增加数据插入、删除和更新的成本,因为每次操作都需要维护索引。因此,在设计索引时需要遵循以下原则:
- 为经常用于查询条件、连接条件和排序的列创建索引。
- 避免为经常更新的列创建过多索引,以免影响更新性能。
- 对于基数较低的列,谨慎创建 B 树索引,可以考虑使用 bitmap 索引。
- 合理设置索引的包含列,将查询中需要的非索引列包含到索引中,以避免回表查询,提高查询效率。
四、SQL 性能优化实战案例
(一)案例背景
某电商平台的订单表(orders)包含 millions 级别的数据,其中包含订单 ID(order_id)、用户 ID(user_id)、订单金额(amount)、订单时间(order_time)等字段。现在需要查询 “2023 年 1 月 1 日至 2023 年 1 月 31 日期间,用户 ID 为 10086 的用户的订单总金额”。
(二)初始 SQL 语句
SELECT SUM(amount)
FROM orders
WHERE user_id = 10086 AND order_time BETWEEN \'2023-01-01\' AND \'2023-01-31\';
(三)性能分析
执行上述 SQL 语句后,发现查询速度较慢。通过查看执行计划,发现数据库采用了全表扫描的方式,因为 orders 表上只在 order_id 列上创建了索引,而查询条件中涉及的 user_id 和 order_time 列没有索引。
(四)优化方案
为 user_id 和 order_time 列创建联合索引:
CREATE INDEX idx_user_order_time ON orders (user_id, order_time);
(五)优化效果
创建联合索引后,再次执行查询语句,数据库通过索引扫描快速定位到符合条件的数据,查询速度得到了显著提升。
五、总结与展望
SQL 技术作为数据库领域的核心,其执行原理和性能优化一直是开发者关注的焦点。通过深入理解查询优化器的工作机制、合理设计和使用索引,以及结合实际场景进行 SQL 语句的优化,可以显著提高数据库的性能,为应用程序提供更好的支撑。
随着大数据、云计算等技术的发展,SQL 技术也在不断演进,例如分布式 SQL 数据库的出现,为处理海量数据和高并发查询提供了新的解决方案。未来,我们还需要不断学习和探索新的 SQL 技术和优化方法,以适应不断变化的业务需求。

