Java 大厂面试题 -- JVM 面试题全解析:横扫大厂面试_jvm面试题
最近佳作推荐:
Java 大厂面试题 – 从菜鸟到大神:JVM 实战技巧让你收获满满(New)
Java 大厂面试题 – JVM 与云原生的完美融合:引领技术潮流(New)
Java 大厂面试题 – 揭秘 JVM 底层原理:那些令人疯狂的技术真相(New)
Java 大厂面试题 – JVM 性能优化终极指南:从入门到精通的技术盛宴(New)
Java 大厂面试题 – JVM 深度剖析:解锁大厂 Offe 的核心密钥(New)
个人信息:
微信公众号:开源架构师
微信号:OSArch
我管理的社区:【青云交技术福利商务圈】和【架构师社区】
2025 CSDN 博客之星 创作交流营(New):点击快速加入
推荐青云交技术圈福利社群:点击快速加入
JVM 面试题全解析:横扫大厂面试
- 引言:
- 正文:
- 结束语:
- 🎯欢迎您投票
引言:
嘿,亲爱的技术爱好者们!大家好呀!在如今竞争激烈的 Java 技术圈,JVM(Java 虚拟机)就像是一座巍峨的高山,矗立在每个 Java 开发者的职业攀登路上,更是各大厂面试时的关键关卡。不管你是刚踏入编程世界的新手小白,还是在代码江湖中摸爬滚打多年、渴望更上一层楼的资深大侠,把 JVM 相关知识掌握得炉火纯青,无疑是拿到理想 Offer 的重要法宝。今天,作为在 Java 领域深耕多年,参与过多个大型项目 JVM 调优、踩过无数坑又成功趟出一条路的老司机,我迫不及待地想把自己的经验和对 JVM 面试题的深度剖析分享给大家,帮你一路披荆斩棘,顺利拿下大厂 Offer!
正文:
一、JVM 基础知识
1.1 类加载机制
JVM 的类加载过程堪称一场精心编排的 “代码盛宴”,主要由加载、验证、准备、解析和初始化这五个关键环节构成,这些知识在《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第 3 版)》中有详细且权威的阐述。为了更直观地展示这个过程,请看如下流程图:
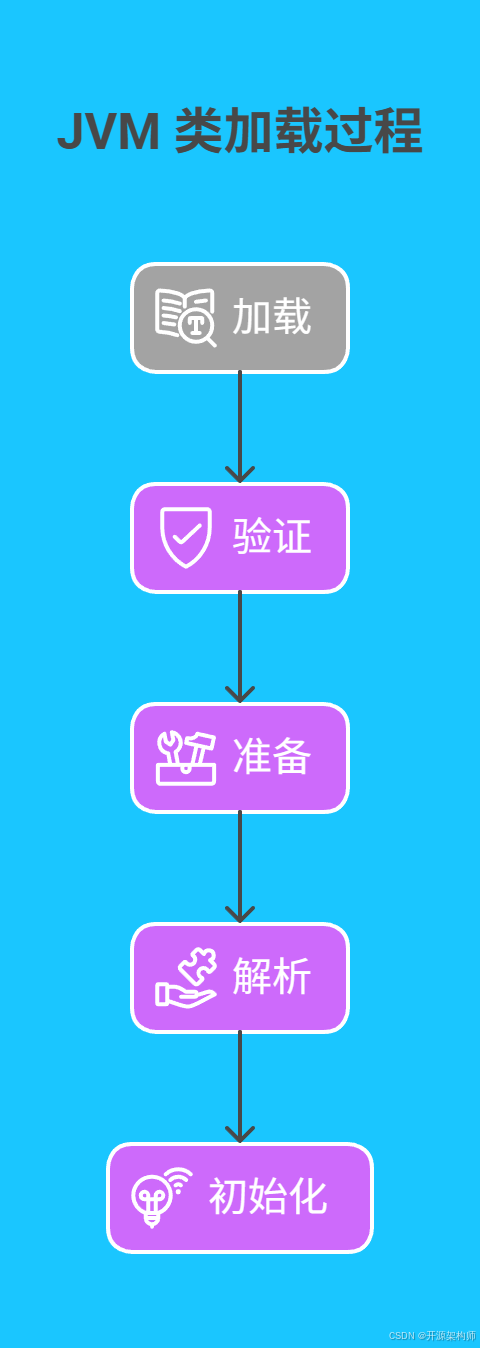
- 加载:这是类加载的开场秀,JVM 会从各种 “货源”,比如本地文件系统、网络等,获取.class 文件的二进制字节流。想象一下,当我们启动一个简单的 Hello World 程序:
public class HelloWorld { // main方法是程序执行的入口 public static void main(String[] args) { System.out.println(\"Hello, World!\"); }}JVM 就像一个勤劳的快递员,先找到HelloWorld.class文件,然后把它的字节流 “搬运” 到内存中,为后续的操作做好准备。在这个过程中,JVM 会通过类加载器(ClassLoader)完成加载任务,常见的类加载器有启动类加载器(Bootstrap ClassLoader)、扩展类加载器(Extension ClassLoader)和应用程序类加载器(Application ClassLoader),它们各司其职,共同完成类的加载工作。
- 验证:如同严格的安检员,验证环节会对加载进来的字节流进行全方位检查,确保它符合 JVM 规范。比如检查字节流中的魔数(它是.class 文件格式的独特 “身份证”,固定值为
0xCAFEBABE)是否正确,文件结构是否规整,字节码指令是否合法等,防止心怀不轨的恶意代码或者格式错乱的字节流混入其中,扰乱 JVM 的正常运行。 - 准备:这个阶段,JVM 开始为类变量(被
static修饰的变量)分配内存并赋予初始值。不过要注意哦,实例变量得等到对象实例化的时候才会有自己的 “专属空间”。举个例子:
public class VariableTest { // 类变量,在准备阶段分配内存并初始化为0 static int staticVariable = 10; // 实例变量,在对象实例化时才分配内存 int instanceVariable; }在准备阶段,staticVariable会先被设置为 0(这里虽然代码中赋值为 10,但准备阶段先赋默认值 0,真正赋值 10 是在初始化阶段),而instanceVariable此时不会分配内存。
- 解析:这一步是将常量池内的符号引用转换为直接引用。符号引用就像是一个模糊的地址描述,而直接引用则是直接指向目标的指针、相对偏移量等。例如,在代码中引用一个类的方法,在解析之前是以符号形式存在,解析后就变成了可以直接调用的实际地址,让 JVM 在运行时能更高效地访问相关数据。
- 初始化:终于到了 “真刀真枪” 执行 Java 代码的时候啦!静态变量赋值、静态代码块执行等操作都在这个环节完成。接着上面的例子,在初始化阶段,
staticVariable就会被真正赋值为 10 。如果类中存在静态代码块,也会按照顺序依次执行,例如:
public class InitializationExample { static int staticVariable; static { staticVariable = 20; System.out.println(\"静态代码块执行,staticVariable赋值为20\"); } public static void main(String[] args) { System.out.println(\"main方法执行,staticVariable的值为:\" + staticVariable); }}在这个程序中,首先会执行静态代码块,给staticVariable赋值为 20 并输出信息,然后在main方法中输出staticVariable的值。
1.2 内存区域划分
JVM 的内存就像一个精心规划的 “代码城市”,主要划分成以下五个区域,每个区域都有自己独特的 “职责”,这些内容在 Oracle 官方 Java 文档中都能找到可靠依据。为了更清晰地展示它们之间的关系,我们用表格来呈现:
new关键字创建的对象,如new String(\"hello\");static final常量等native修饰的方法)服务- 堆:这里是 Java 对象实例的 “诞生地”,几乎所有通过
new关键字创造出来的对象都在堆上安营扎寨。堆是线程共享的热闹区域,也是垃圾回收大军重点 “巡逻” 的地方。例如:
public class HeapExample { public static void main(String[] args) { // 创建一个Person对象,在堆上分配内存 Person person = new Person(\"Alice\", 25); }}class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; }}person对象就会在堆内存中找到属于自己的小天地。堆还可以进一步细分为新生代和老年代,新生代又包括 Eden 区和两个 Survivor 区,不同区域采用不同的垃圾回收策略。
- 方法区:作为存储已加载类信息、常量、静态变量等数据的 “信息仓库”,在 JDK 8 及以后,方法区的实现变成了元空间(Metaspace)。它不再像以前那样受限于永久代的大小,而是可以灵活使用本地内存,极大地提高了内存管理的灵活性。像类的全限定名、方法字节码等重要信息都在这里 “安居乐业”。例如,当定义一个包含常量和静态变量的类:
public class MethodAreaExample { public static final String CONSTANT_STR = \"常量字符串\"; public static int staticVariable; public static void main(String[] args) { System.out.println(CONSTANT_STR); }}其中的CONSTANT_STR常量和staticVariable静态变量的相关信息就存储在方法区(元空间)中。
- 虚拟机栈:这是线程私有的 “秘密基地”,它描绘了 Java 方法执行时的内存模型。每个方法被调用时,就像搭建一个临时的 “小舞台”—— 栈帧,用来存放局部变量表、操作数栈、动态链接、方法出口等 “演出道具”。当一个方法调用另一个方法时,新的栈帧就像新的演员上台一样入栈,方法执行完后栈帧再有序出栈。比如:
public class StackExample { public static void main(String[] args) { method1(); } public static void method1() { int num1 = 10; int num2 = 20; int result = method2(num1, num2); System.out.println(\"结果:\" + result); } public static int method2(int a, int b) { return a + b; }}main方法先搭建自己的栈帧 “舞台”,调用method1时method1的栈帧上台,method1再调用method2时method2的栈帧登场,执行完后依次谢幕出栈。在这个过程中,局部变量num1、num2、result、a、b等都存储在对应的栈帧的局部变量表中。
- 本地方法栈:和虚拟机栈功能类似,不过它服务的对象是本地方法(用
native修饰的方法),是 Java 与非 Java 代码(通常是 C 或 C++ 代码)沟通的桥梁 “引桥” 部分。例如,当 Java 程序需要调用操作系统的某些功能时,就可能会使用本地方法,此时本地方法栈就会发挥作用。 - 程序计数器:它是线程私有的 “小记事本”,负责记录当前线程执行字节码的行号。因为 JVM 的多线程是通过线程轮流切换实现的,所以每个线程都得有自己的 “小本本”,随时记录自己的执行进度。当一个线程被暂停,然后再次恢复执行时,就可以根据程序计数器记录的位置继续执行。
二、JVM 性能优化
2.1 垃圾回收机制
垃圾回收在 JVM 性能优化的大舞台上可是绝对的 “主角” 之一,常见的垃圾回收算法各具特色,其原理和特性在《垃圾回收的算法与实现》一书中有非常深入的讲解。为了便于对比,我们用表格梳理这些算法的特点:
- 标记 - 清除算法:这套算法的流程就像一场 “大扫除”,先给需要清理的对象贴上 “可回收” 的标签,然后统一清理这些对象占用的内存空间。它的优点是简单直接,但缺点也很明显,就像打扫完房间后留下一堆杂物,会产生内存碎片,影响后续内存分配的效率。例如,在一个内存区域中,有多个对象被标记为可回收,回收后会在内存中留下不连续的空闲空间,当需要分配较大内存对象时,可能会因为碎片问题导致分配失败。
- 复制算法:它把内存比作两个房间,每次只用其中一个。当这个房间快满了,就把还 “活着” 的对象搬到另一个房间,然后把原来的房间彻底清空。这样虽然解决了内存碎片问题,但相当于浪费了一半的空间,内存利用率不高。在新生代的垃圾回收中,经常采用类似的策略,把新生代划分成 Eden 区和两个 Survivor 区,每次使用 Eden 区和其中一个 Survivor 区。当 Eden 区满了,就将存活的对象复制到另一个 Survivor 区,然后清理 Eden 区和当前使用的 Survivor 区。
- 标记 - 整理算法:这是在标记 - 清除算法基础上的 “升级版大扫除”,不仅标记可回收对象,还会把存活的对象往一端 “归拢”,然后清理掉边界外的内存。既解决了碎片问题,又提高了内存利用率,在老年代的垃圾回收中有时会派上用场。因为老年代对象存活率高,复制算法会造成大量复制操作,而标记 - 整理算法更适合这种场景。
- 分代收集算法:它就像一个聪明的管理者,根据对象存活周期的不同,把堆内存划分成新生代、老年代等区域,然后对不同区域采用最合适的回收算法。新生代对象 “寿命短”,存活率低,就用复制算法;老年代对象 “长寿”,存活率高,就用标记 - 整理或标记 - 清除算法,这也是目前 JVM 广泛采用的垃圾回收策略。

2.2 JVM 参数调优
合理调整 JVM 参数就像是给汽车精心调校发动机,能让应用性能大幅提升。下面是一些常见又关键的 JVM 参数,其作用和调优策略在各大 JVM 官方文档以及大量的实践经验中都能找到支撑。
在实际项目中,JVM 参数的调整需要根据应用的类型、规模、硬件资源等多方面因素综合考虑。例如,对于一个基于 Spring Boot 开发的中型电商应用,部署在 4 核 8GB 内存的服务器上,经过压测和监控分析,我们可以尝试如下参数配置:
# 设置堆内存初始大小和最大值均为4GB,避免堆内存动态扩展带来的性能开销-Xms4g -Xmx4g # 开启G1垃圾回收器,适合大内存、多核心服务器环境,降低垃圾回收停顿时间-XX:+UseG1GC # 设置元空间初始大小为256MB-XX:MetaspaceSize=256m # 设置元空间最大大小为512MB-XX:MaxMetaspaceSize=512m # 设置G1垃圾回收器期望的停顿时间为200毫秒-XX:MaxGCPauseMillis=200 # 设置G1垃圾回收器年轻代占堆内存的比例为30%-XX:G1NewSizePercent=30 -Xmx和-Xms:-Xmx用来设定 JVM 堆内存的 “最大容量”,-Xms则是设置初始堆内存大小。对于一个运行稳定的 Web 应用,比如基于 Spring Boot 搭建的小型电商网站,为了避免堆内存频繁动态扩展带来的性能损耗,我们可以把-Xmx和-Xms设置成相同的值。假设服务器配备了 8GB 内存,经过实际压测发现应用稳定运行时大概需要 4GB 内存,那就可以设置-Xmx4g -Xms4g。-XX:+UseG1GC:这是开启 G1(Garbage - First)垃圾回收器的 “钥匙”。G1 垃圾回收器特别适合大内存、多核心的服务器环境,它采用分区的内存管理方式,能将内存划分为多个大小相等的 Region,通过优先回收垃圾多的 Region,实现更短的垃圾回收停顿时间。它就像一个高效的 “垃圾清理团队”,能大大缩短垃圾回收时的停顿时间,让应用响应更快。比如在大型分布式数据库应用中,数据量庞大且对响应时间要求苛刻,使用 G1 垃圾回收器就能显著减少垃圾回收造成的停顿,提升整个系统的性能。-XX:MetaspaceSize和-XX:MaxMetaspaceSize:在 JDK 8 及以后,它们负责管理元空间的大小。-XX:MetaspaceSize确定元空间的初始尺寸,-XX:MaxMetaspaceSize则限定了元空间的最大容量。当应用中频繁使用反射、动态代理等技术,会动态生成大量类时,合理调整这两个参数能有效防止元空间溢出问题,保证应用稳定运行。例如,在一个使用了大量框架和动态生成类的微服务项目中,如果发现元空间占用过高,就可以适当增大这两个参数的值。-XX:MaxGCPauseMillis:用于设置 G1 垃圾回收器期望的停顿时间目标,单位是毫秒。JVM 会尽量调整垃圾回收的行为,以满足这个停顿时间要求,但这并不意味着每次垃圾回收都能精确达到该时间。-XX:G1NewSizePercent:设置 G1 垃圾回收器中年轻代占堆内存的初始比例。通过调整这个参数,可以控制年轻代的大小,从而影响垃圾回收的频率和性能。
三、JVM 多线程并发
3.1 线程安全问题
在多线程的 “热闹集市” 中,JVM 很容易遇到线程安全的 “小麻烦”,其中最典型的就是多个线程同时读写共享变量时可能出现的数据 “混乱” 情况。就拿银行转账来说吧,假设有两个账户 A 和 B,A 要给 B 转 100 元,代码如下:
public class Account { private double balance; public Account(double balance) { this.balance = balance; } public double getBalance() { return balance; } // 转账方法,存在线程安全问题 public void transfer(Account target, double amount) { this.balance -= amount; target.balance += amount; }}public class ThreadSafetyExample { public static void main(String[] args) { Account accountA = new Account(1000); Account accountB = new Account(500); Thread thread1 = new Thread(() -> { for (int i = 0; i < 100; i++) { accountA.transfer(accountB, 10); } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 100; i++) { accountA.transfer(accountB, 10); } }); thread1.start(); thread2.start(); try { thread1.join(); thread2.join(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(\"账户A余额:\" + accountA.getBalance()); System.out.println(\"账户B余额:\" + accountB.getBalance()); }}在上述代码中,由于transfer方法不是原子操作,当两个线程同时执行该方法时,就可能出现数据不一致的情况。比如线程 1 和线程 2 同时读取accountA的余额进行减法操作,随后分别写入结果,这就会导致其中一个线程的操作被覆盖,最终账户余额计算错误。
解决这类问题通常有以下两种方法:
- 使用
synchronized关键字:它就像一把 “独家锁”,能保证同一时刻只有一个线程能进入被同步的代码块。修改后的代码如下:
public class Account { private double balance; public Account(double balance) { this.balance = balance; } public double getBalance() { return balance; } // 使用synchronized保证转账操作的原子性 public synchronized void transfer(Account target, double amount) { this.balance -= amount; target.balance += amount; }}public class ThreadSafetyFixedExample { public static void main(String[] args) { Account accountA = new Account(1000); Account accountB = new Account(500); Thread thread1 = new Thread(() -> { for (int i = 0; i < 100; i++) { accountA.transfer(accountB, 10); } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 100; i++) { accountA.transfer(accountB, 10); } }); thread1.start(); thread2.start(); try { thread1.join(); thread2.join(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(\"账户A余额:\" + accountA.getBalance()); System.out.println(\"账户B余额:\" + accountB.getBalance()); }}加上synchronized后,当一个线程进入transfer方法时,其他线程就需要等待,直到该线程执行完方法释放锁,从而保证了转账操作的原子性,避免数据不一致的问题。
- 使用
java.util.concurrent包下的原子类:以AtomicInteger为例,它内部的方法基于 CAS(Compare - And - Swap)操作,就像一个精准的 “数据卫士”,能保证原子性。比如在统计网站访问量时,多个线程同时对访问量进行自增操作,使用AtomicInteger就能确保数据准确无误:
import java.util.concurrent.atomic.AtomicInteger;public class AtomicExample { private static AtomicInteger visitCount = new AtomicInteger(0); public static void main(String[] args) { Thread thread1 = new Thread(() -> { for (int i = 0; i < 1000; i++) { visitCount.incrementAndGet(); } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 1000; i++) { visitCount.incrementAndGet(); } }); thread1.start(); thread2.start(); try { thread1.join(); thread2.join(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(\"总访问量:\" + visitCount.get()); }}AtomicInteger的incrementAndGet方法是原子操作,它会先比较当前值与预期值是否相同,如果相同则更新为新值并返回,否则继续尝试,从而保证了多线程环境下数据的一致性。
3.2 线程池原理
JVM 中的线程池就像是一个高效的 “任务处理工厂”,以ThreadPoolExecutor为例,它的核心参数及原理如下,这些知识在 Java 官方并发包文档里都有详细且权威的说明。为了更清晰地展示线程池的工作流程,请看如下流程图:

- 核心线程数(corePoolSize):这是线程池启动时就创建好的 “常驻部队” 数量,这些线程即使暂时没活干,也会一直 “坚守岗位”。比如一个处理用户订单的线程池,根据平时订单处理的平均工作量,我们可以设置核心线程数为 5,这 5 个线程随时准备 “接单” 处理任务。当有新任务提交时,如果核心线程尚未满,就会立即创建核心线程来执行任务。
- 最大线程数(maximumPoolSize):它规定了线程池能容纳的最多线程数量。当任务队列满了,而且当前正在工作的线程数还没达到最大线程数时,线程池就会紧急 “扩招”,创建新的线程来处理任务。继续上面订单处理的例子,在电商大促期间,订单量暴增,我们可以把最大线程数设置为 20,以便应对高并发的情况。不过要注意,如果线程数达到最大线程数且任务队列已满,新提交的任务就会触发拒绝策略。
- 空闲线程存活时间(keepAliveTime):当线程池里的线程数量超过了核心线程数,那些多出来的空闲线程如果在指定时间(比如 60 秒)内都没新任务,就会被 “裁员” 销毁,这样可以及时释放资源,避免浪费。例如,当大促结束后,订单量减少,多余的线程在空闲 60 秒后就会被自动回收。
- 任务队列(workQueue):它是存放等待执行任务的 “临时仓库”,常见的有
ArrayBlockingQueue(有界队列)、LinkedBlockingQueue(无界队列)等。有界队列能限制任务堆积的数量,当队列满了就按照设定的拒绝策略处理新任务;无界队列虽然能容纳大量任务,但如果任务源源不断涌进来,处理速度又跟不上,就可能导致内存被撑爆。比如在一个高并发的秒杀活动中,如果使用ArrayBlockingQueue作为任务队列,设置队列容量为 1000,当同时涌入的订单任务超过 1000 且线程池线程已满时,就需要根据拒绝策略来处理后续任务。 - 拒绝策略:当线程池无法处理新提交的任务时(线程数达到最大线程数且任务队列已满),就会执行拒绝策略。常见的拒绝策略有:
AbortPolicy:默认策略,直接抛出RejectedExecutionException异常,阻止系统正常运行,适用于需要立即反馈错误的场景。CallerRunsPolicy:将任务回退到调用者线程中执行,如果调用者线程是主线程,可能会影响主线程的性能,不过可以降低新任务的提交速度。DiscardPolicy:直接丢弃无法处理的任务,不给出任何提示,适用于对任务不敏感的场景,比如日志记录任务。DiscardOldestPolicy:丢弃任务队列中最老的任务,然后尝试提交新任务,适用于任务时效性较强的场景。
以下是一个创建线程池并使用的示例代码:
import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class ThreadPoolExample { public static void main(String[] args) { // 创建一个线程池,核心线程数为3,最大线程数为5,空闲线程存活时间为60秒,任务队列容量为10 ThreadPoolExecutor executor = new ThreadPoolExecutor( 3, 5, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10), new ThreadPoolExecutor.CallerRunsPolicy() ); for (int i = 0; i < 20; i++) { int taskId = i; executor.submit(() -> { System.out.println(\"任务\" + taskId + \"开始执行\"); try { // 模拟任务执行时间 Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(\"任务\" + taskId + \"执行完毕\"); }); } // 关闭线程池 executor.shutdown(); }}在这个示例中,我们创建了一个线程池,并提交了 20 个任务。线程池会根据核心线程数、任务队列和最大线程数等参数来合理分配任务,当任务超出处理能力时,会按照设置的CallerRunsPolicy拒绝策略处理。最后调用shutdown方法关闭线程池,等待所有任务执行完毕后,线程池会释放资源。
四、JVM 实战案例解析
4.1 线上 OOM 问题排查与解决
在实际项目中,OOM(Out of Memory)是常见且棘手的问题。下面分享一个我处理过的线上 OOM 案例,帮助大家理解如何排查和解决这类问题。
案例背景
某电商平台在促销活动期间,频繁出现 OOM 异常,导致系统崩溃。系统配置为 8 核 16GB 内存,运行着基于 Spring Boot 的微服务应用。
排查过程
- 获取 Heap Dump:通过 JVM 参数
-XX:+HeapDumpOnOutOfMemoryError在 OOM 发生时自动生成堆转储文件。
java -Xmx8g -Xms8g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof -jar application.jar- 分析 Heap Dump:使用 MAT(Memory Analyzer Tool)分析堆转储文件,发现大量的
java.util.ArrayList对象占用了约 70% 的堆内存。进一步分析发现这些 ArrayList 存储的是订单数据,且存在内存泄漏。 - 代码审查:检查相关代码,发现订单数据处理逻辑中存在问题。在批量处理订单时,将所有订单数据加载到内存中的 ArrayList,但处理完成后没有及时释放。
// 问题代码public List<Order> processOrders() { // 从数据库加载大量订单数据 List<Order> allOrders = orderRepository.findAll(); // 处理订单 List<Order> processedOrders = new ArrayList<>(); for (Order order : allOrders) { if (processOrder(order)) { processedOrders.add(order); } } // 返回处理后的订单列表,但allOrders占用的内存未释放 return processedOrders;}- 定位内存泄漏:继续深入分析,发现订单处理服务是一个单例,且持有一个静态的 HashMap 用于缓存处理结果,但没有设置缓存清理机制,导致缓存不断增长,最终引发 OOM。
解决方案
- 优化数据处理方式:改为分批处理订单数据,避免一次性加载大量数据到内存。
// 优化后代码public List<Order> processOrders() { List<Order> processedOrders = new ArrayList<>(); int pageSize = 1000; int page = 0; List<Order> pageOrders; do { // 分批从数据库加载订单数据 pageOrders = orderRepository.findByPage(page++, pageSize); // 处理当前批次的订单 for (Order order : pageOrders) { if (processOrder(order)) { processedOrders.add(order); } } // 释放当前批次的内存 pageOrders.clear(); } while (pageOrders.size() == pageSize); return processedOrders;}- 修复缓存问题:为缓存添加清理机制,设置最大容量和过期时间。
// 使用Guava Cache替代静态HashMapprivate static final LoadingCache<Long, OrderResult> orderResultCache = CacheBuilder.newBuilder() .maximumSize(10000) .expireAfterWrite(1, TimeUnit.HOURS) .build( new CacheLoader<Long, OrderResult>() { public OrderResult load(Long orderId) { return calculateOrderResult(orderId); } });- 调整 JVM 参数:根据应用特点,优化 JVM 参数配置。
java -Xmx10g -Xms10g -XX:+UseG1GC -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m -XX:MaxGCPauseMillis=200 -jar application.jar优化效果
通过以上优化,系统在促销活动期间稳定运行,未再出现 OOM 异常,响应时间也从原来的平均 500ms 降低到 300ms,吞吐量提升了 30%。
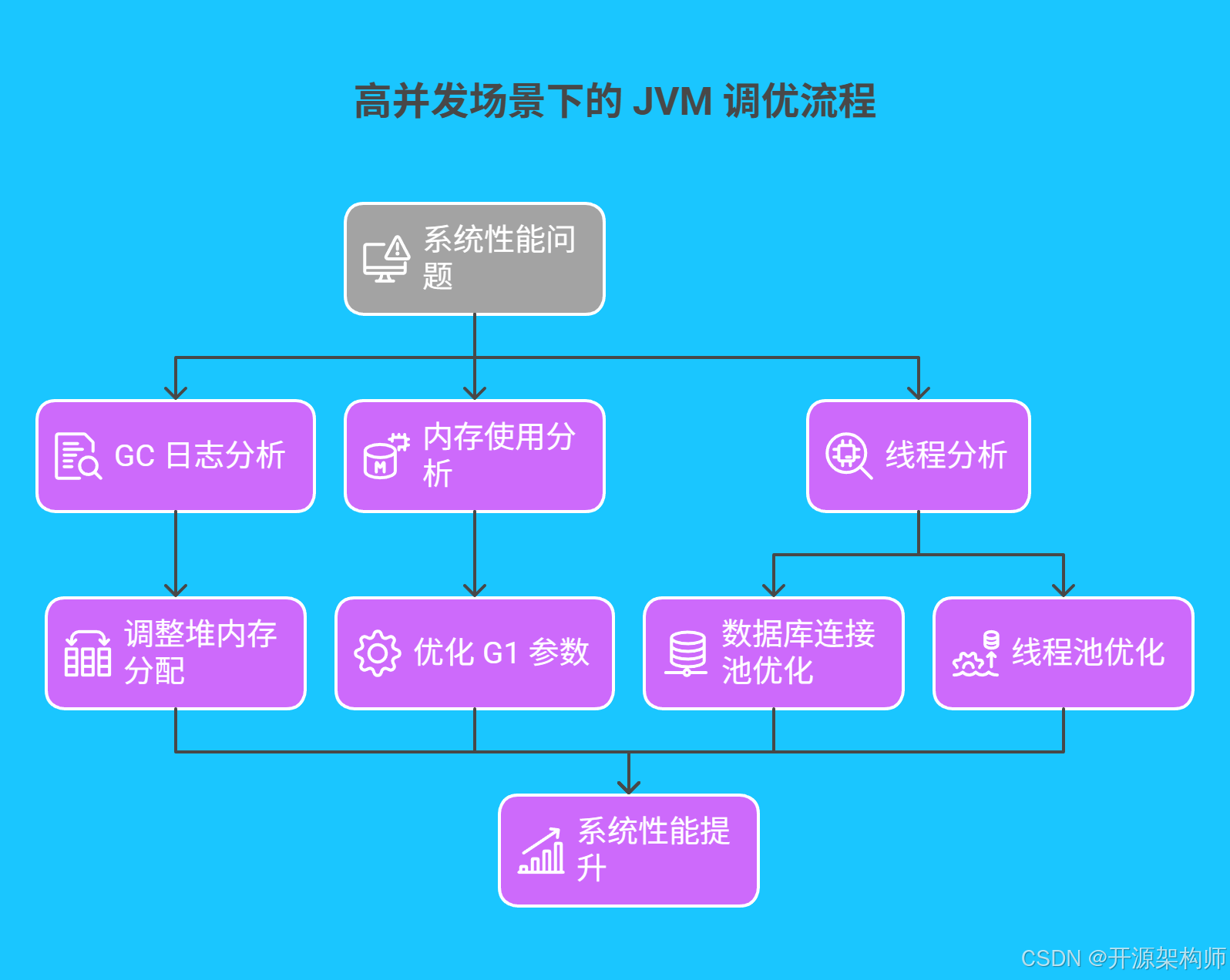
4.2 高并发场景下的 JVM 调优实践
案例背景
某社交平台在用户高峰期,系统响应缓慢,GC 频繁,用户体验差。系统配置为 16 核 32GB 内存,运行着基于 Spring Boot 和 Netty 的实时消息服务。
性能分析
- GC 日志分析:通过分析 GC 日志,发现 Minor GC 频繁(每分钟约 10 次),每次耗时约 100ms,且存在频繁的 Full GC(每小时约 2-3 次),每次耗时约 500ms-1s。
- 内存使用分析:使用 Jstat 监控发现,Eden 区和 Survivor 区使用不平衡,老年代增长较快。
- 线程分析:使用 Jstack 分析线程状态,发现大量线程处于 WAITING 状态,主要是等待数据库连接和锁资源。
调优方案
- 调整堆内存分配:
java -Xmx24g -Xms24g -Xmn12g -XX:SurvivorRatio=8 -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -jar application.jar- 优化 G1 参数:
-XX:G1HeapRegionSize=16m -XX:InitiatingHeapOccupancyPercent=45 -XX:G1ReservePercent=10- 数据库连接池优化:
spring: datasource: hikari: maximum-pool-size: 50 minimum-idle: 10 idle-timeout: 30000 max-lifetime: 1800000- 线程池优化:
@Beanpublic ThreadPoolTaskExecutor taskExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(20); executor.setMaxPoolSize(50); executor.setQueueCapacity(1000); executor.setKeepAliveSeconds(60); executor.setThreadNamePrefix(\"message-handler-\"); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); return executor;}优化效果
经过调优,系统性能显著提升:
- Minor GC 频率降低到每分钟 2-3 次,耗时减少到 30-50ms
- Full GC 基本不再出现
- 系统响应时间从平均 800ms 降低到 150ms
- 吞吐量提升了 50%,能够轻松应对高峰期的用户访问
结束语:
亲爱的开源构架技术伙伴们!通过对 JVM 面试题从基础知识、性能优化、多线程并发到实战案例等多个维度的深度剖析,相信大家对 JVM 相关知识已经有了更为全面和深入的理解。但技术的海洋浩瀚无垠,JVM 领域也在不断推陈出新,新的特性、优化策略如雨后春笋般不断涌现。希望大家在今后的学习和工作中,持续保持对 JVM 技术的热情和好奇心,不断探索实践,将这些知识运用到实际项目中,实现自身技术能力的螺旋式上升。
在你备战 JVM 面试的历程中,有没有因为某个知识点的巧妙理解,成功 “征服” 面试官!欢迎在评论区或架构师交流讨论区留言。让我们一起交流探讨,共同揭开 JVM 更多的神秘面纱!
亲爱的开源构架技术伙伴们!最后到了投票环节:你在 JVM 面试中,遇到最 “烧脑” 的问题属于哪个方向?快来投票吧!
---推荐文章---
- Java 大厂面试题 – 从菜鸟到大神:JVM 实战技巧让你收获满满(New)
- Java 大厂面试题 – JVM 与云原生的完美融合:引领技术潮流(New)
- Java 大厂面试题 – 揭秘 JVM 底层原理:那些令人疯狂的技术真相(New)
- Java 大厂面试题 – JVM 性能优化终极指南:从入门到精通的技术盛宴(New)
- Java 大厂面试题 – JVM 深度剖析:解锁大厂 Offe 的核心密钥(New)
- Java大厂面试高频考点|分布式系统JVM优化实战全解析(附真题)(New)
- Java大厂面试题 – JVM 优化进阶之路:从原理到实战的深度剖析(2)(New)
- Java大厂面试题 – 深度揭秘 JVM 优化:六道面试题与行业巨头实战解析(New)
🎯欢迎您投票
返回文章

