Elasticsearch结合Spring Boot和Java的实践教程
本文还有配套的精品资源,点击获取 
简介:Elasticsearch是一个分布式、RESTful的搜索和数据分析引擎,通过Java API和Spring Boot,开发者可以将其便捷地集成到应用程序中。本教程将展示如何利用Spring Boot提供的starter进行快速整合,并实现Elasticsearch的基本增删改查(CRUD)操作。文章还提供依赖管理和配置指南,以及一个实操项目“elasticsearch-java-demo”的介绍,旨在帮助开发者理解和实践Elasticsearch在Java环境中的应用。
1. Elasticsearch基础介绍
Elasticsearch是一个基于Apache Lucene构建的开源搜索引擎,其设计用于快速和可扩展的全文搜索。它的核心特点包括分布式实时搜索、对大量数据的近实时处理能力以及水平可伸缩性。Elasticsearch常用于构建复杂的搜索应用,它可以通过简单易用的RESTful API进行交互,支持多种查询语言,比如结构化查询DSL(Domain Specific Language)。由于其轻量级、灵活且功能全面的特点,Elasticsearch已成为企业级搜索和日志分析的首选工具。在本文中,我们将探讨Elasticsearch的基础概念,并为进一步探讨其与Spring Boot的集成奠定基础。
2. Spring Boot整合Elasticsearch
Elasticsearch是一个高度可扩展的开源搜索引擎,通常用于全文搜索。Spring Boot提供了与Elasticsearch交互的简化方法,使得开发者可以快速地将搜索引擎集成到自己的应用中。
2.1 Spring Boot与Elasticsearch的集成概述
2.1.1 集成的必要性与优势
在现代应用程序中,有效地管理和检索大量数据是一项挑战。传统的数据库管理系统在处理复杂的文本搜索查询时,可能效率不高,特别是当数据量庞大时。Elasticsearch作为一个NoSQL搜索引擎,可以与传统的关系型数据库结合使用,提供快速的全文搜索功能。
Spring Boot与Elasticsearch集成后,开发者可以利用Spring Boot提供的简化配置和开发特性,通过简单的注解或配置就能实现数据的索引、搜索等功能。这种集成方式不仅提高了开发效率,还增强了应用的搜索能力。
2.1.2 Spring Data Elasticsearch核心概念
Spring Data Elasticsearch是Spring Data项目的一部分,它为Elasticsearch搜索引擎提供了一个Spring友好的抽象层。核心概念包括:
- Repository : 一个接口,由Spring Data自动实现,提供数据访问和管理功能。
- @Document : 注解用于映射实体类到Elasticsearch的索引中。
- @Id : 标注在实体类的某个属性上,表示该属性是文档的唯一标识符。
2.2 Spring Boot中Elasticsearch的配置与启动
2.2.1 配置文件设置
Spring Boot应用通过 application.properties 或 application.yml 文件进行配置,集成Elasticsearch也是如此。配置包括Elasticsearch服务器的地址、端口等信息:
# application.ymlspring: elasticsearch: rest: uris: http://localhost:92002.2.2 启动类的整合与注解使用
在Spring Boot的启动类上使用 @EnableElasticsearchRepositories 注解,可以指定Elasticsearch仓库接口的位置,Spring Data将自动创建这些接口的实例。
@SpringBootApplication@EnableElasticsearchRepositories(basePackages = \"com.example.project.repository\")public class ElasticsearchApplication { public static void main(String[] args) { SpringApplication.run(ElasticsearchApplication.class, args); }}2.3 实现Spring Boot与Elasticsearch的交互
2.3.1 ElasticsearchRepository的使用
Spring Data Elasticsearch提供的 ElasticsearchRepository 接口,为开发者提供了一系列简便的方法来操作Elasticsearch中的数据。
public interface BookRepository extends ElasticsearchRepository {} 在上面的例子中, BookRepository 继承了 ElasticsearchRepository ,这样Spring Boot就会自动实现该接口,并提供诸如保存、删除、查询等方法。
2.3.2 自定义Repository方法
如果Spring Data提供的方法不能满足需求,开发者还可以自定义方法。只需在接口中定义方法签名,Spring Data会根据方法名的规则实现其功能:
public interface BookRepository extends ElasticsearchRepository { List findByName(String name);} findByName 方法将会根据名字字段去Elasticsearch索引中搜索匹配的文档。Spring Data将通过方法名解析出查询需求,并自动实现它。
以上就是Spring Boot整合Elasticsearch的主要内容。整合后的应用可以利用Elasticsearch强大的搜索和分析功能,同时享受Spring Boot带来的开发便捷性。通过合理的配置和代码实践,可以极大提升后端服务的性能和用户体验。
3. Elasticsearch增删改查操作
3.1 Elasticsearch的基本CRUD操作
3.1.1 索引的创建与删除
Elasticsearch中的索引(Index)类似于传统数据库中的数据库概念,用于存储相关的文档(Document)。在实际操作中,我们可以创建一个索引来组织和存储特定类型的文档。
在本章节中,我们先来了解如何创建一个索引:
PUT /my_index{ \"settings\": { \"number_of_shards\": 3, \"number_of_replicas\": 2 }, \"mappings\": { \"properties\": { \"name\": { \"type\": \"text\" }, \"age\": { \"type\": \"integer\" } } }}-
PUT /my_index: 创建一个名为my_index的索引。 -
\"settings\": 定义了索引的配置,比如分片数(number_of_shards)和副本数(number_of_replicas)。 -
\"mappings\": 定义了索引中文档的结构,这里定义了两个字段:name和age。
接下来,如果索引不再需要,可以进行删除操作:
DELETE /my_index-
DELETE /my_index: 删除名为my_index的索引。
3.1.2 文档的新增与更新
Elasticsearch的数据单元是文档,文档是以JSON格式进行存储的。接下来,我们将演示如何在已创建的索引中添加和更新文档。
新建一个文档的示例:
PUT /my_index/_doc/1{ \"name\": \"John Doe\", \"age\": 29}-
PUT /my_index/_doc/1: 在my_index索引中添加一个ID为1的文档。 - JSON体包含
name和age字段。
更新现有文档的操作如下:
POST /my_index/_update/1{ \"doc\": { \"age\": 30 }}-
POST /my_index/_update/1: 更新my_index索引中ID为1的文档。 -
\"doc\"包含要更新的字段。
3.2 Elasticsearch高级查询技巧
3.2.1 Query DSL的使用
Elasticsearch中的查询表达式语言(Query DSL)提供了非常丰富的查询选项,使得我们可以灵活地执行各种复杂的查询操作。下面将通过一个例子展示如何使用Query DSL执行查询。
查询所有文档:
GET /my_index/_search{ \"query\": { \"match_all\": {} }}-
GET /my_index/_search: 对my_index索引进行查询。 -
match_all是一个查询类型,表示匹配所有文档。
接下来,我们利用分页、排序和过滤功能来优化查询结果:
GET /my_index/_search{ \"query\": { \"match\": { \"name\": \"John\" } }, \"from\": 0, \"size\": 10, \"sort\": [ { \"age\": { \"order\": \"desc\" } } ], \"filter\": { \"range\": { \"age\": { \"gte\": 18, \"lte\": 30 } } }}-
from: 指定返回结果的起始偏移量,实现分页。 -
size: 指定返回结果的数量。 -
sort: 对结果进行排序。 -
filter: 对查询结果进行过滤,range表示范围查询。
3.2.2 分页、排序与过滤
在处理大量数据时,分页查询是非常常见的需求,Elasticsearch提供了简洁的分页参数 from 和 size 。
-
from: 指定从第几个文档开始返回,默认为0。 -
size: 指定返回文档的数量,默认为10。
排序可以使返回的数据更加有序,比如可以按价格、日期等字段排序:
\"sort\": [ { \"price\": { \"order\": \"asc\" } }, { \"publish_date\": { \"order\": \"desc\" } }]过滤操作允许我们对查询结果进行限制,但不会影响评分。常用的过滤器有:
-
term: 精确值过滤,不支持分词。 -
range: 对字段进行范围查询。 -
bool: 逻辑组合过滤,通过must,should,must_not参数组合多个过滤器。
3.3 Elasticsearch聚合分析应用
3.3.1 聚合查询的基本使用
Elasticsearch聚合(Aggregations)功能非常强大,它可以用来对数据进行分组、统计等操作。以下是一个简单的聚合查询示例:
GET /my_index/_search{ \"size\": 0, \"aggs\": { \"age_distribution\": { \"terms\": { \"field\": \"age\", \"size\": 10 } } }}-
size: 设置为0,因为我们只关心聚合结果。 -
aggs: 定义聚合操作。 -
terms: 按照age字段的不同值进行分组。 -
size: 在聚合结果中返回多少个桶(bucket)。
聚合查询结果的结构大致如下:
{ \"aggregations\": { \"age_distribution\": { \"buckets\": [ { \"key\": 29, \"doc_count\": 2 }, { \"key\": 30, \"doc_count\": 1 } ] } }}3.3.2 复杂聚合操作示例
Elasticsearch聚合支持的复杂操作非常多,比如可以进行管道聚合(Pipeline Aggregations)和嵌套聚合(Nested Aggregations)。下面来看一个嵌套聚合的示例:
GET /my_index/_search{ \"size\": 0, \"aggs\": { \"articles\": { \"nested\": { \"path\": \"articles\" }, \"aggs\": { \"nested_terms\": { \"terms\": { \"field\": \"articles.title\", \"size\": 10 } } } } }}-
nested: 用于对嵌套对象进行聚合。 -
path: 指定嵌套对象的路径。 -
terms: 对嵌套对象中的字段进行分组。
这个查询将按照嵌套在文档中的 articles 对象的 title 字段进行分组统计。
通过以上章节的介绍,您现在应该对Elasticsearch的基本CRUD操作、高级查询技巧和聚合分析应用有了较为全面的了解。理解这些核心功能,对提升数据管理和分析的效率至关重要。在下一章节,我们将深入探讨Maven依赖管理配置,以优化您的Elasticsearch项目。
4. Maven依赖管理配置
4.1 Maven的依赖管理基础
4.1.1 依赖冲突解决机制
在使用Maven进行项目构建时,管理好依赖至关重要。依赖冲突是指项目中可能存在相同库的不同版本。为了解决这个问题,Maven遵循了一套预设的规则来处理依赖。
首先,Maven根据依赖的声明顺序,优先选择距离项目最近的依赖。这意味着,如果两个依赖之间有冲突,Maven会优先使用直接声明在项目中的那个依赖版本。其次,Maven还提供了 标签,允许项目排除特定的传递性依赖,以防止版本冲突。
为了进一步控制依赖冲突,可以使用Maven的工具如 maven-enforcer-plugin ,它可以帮助你检查并强制执行项目依赖规则。此外,还有 maven-dependency-plugin 工具,可以帮助分析项目依赖树并解决依赖问题。
4.1.2 Maven仓库的配置与使用
Maven仓库是存储项目所有依赖的地方。分为本地仓库和远程仓库。本地仓库存储在开发者电脑上,远程仓库则可能是一个公司内部的私有仓库,或者开源社区提供的仓库,如Maven Central。
配置仓库的目的是为了告诉Maven在哪里查找和存储依赖。在 pom.xml 文件中,开发者可以设置仓库的位置,甚至配置多个仓库以备不时之需。例如,可以设置一个镜像仓库,当Maven中央仓库访问缓慢或不可用时,Maven会尝试从镜像仓库下载依赖。
此外,Maven的仓库还分为快照仓库和发布仓库。快照仓库存储的是开发中的快照版本,发布仓库存储的是已经发布的稳定版本。合理配置仓库类型,能够提高构建速度并保证依赖版本的稳定性。
example-repo Example Repository http://example.com/repository/ 上述代码段展示了如何在 pom.xml 文件中配置一个仓库。
4.2 Elasticsearch与Spring Boot的Maven依赖配置
4.2.1 必要依赖的引入与作用
在Spring Boot项目中集成Elasticsearch,需要在 pom.xml 中引入一些关键的依赖。这些依赖主要来自于Spring Data Elasticsearch项目和Elasticsearch的客户端库。
org.springframework.boot spring-boot-starter-data-elasticsearch上述依赖是Spring Boot官方提供的数据访问支持模块的一部分,它封装了对Elasticsearch的操作。它会自动配置Elasticsearch客户端,以便于应用能够轻松地与Elasticsearch交互。通常这个依赖还会自动引入Elasticsearch的客户端库以及其它依赖,如Spring Data Commons等。
4.2.2 版本控制与依赖管理最佳实践
在多模块或者大型项目中,依赖管理变得尤为重要。为了防止版本冲突和保持构建的一致性,推荐使用Maven的依赖管理。
org.springframework.boot spring-boot-dependencies 2.5.1 pom import 依赖管理部分通常放在父POM文件中。上述代码展示了如何配置Spring Boot依赖的版本。所有子模块在引入Spring Boot相关依赖时,将会继承此版本,确保版本的一致性。
4.3 高级Maven配置与优化
4.3.1 插件的使用与配置
Maven插件极大地扩展了其功能。对于Elasticsearch和Spring Boot项目,可以使用 maven-dependency-plugin 来分析依赖和解决潜在的问题。
org.apache.maven.plugins maven-dependency-plugin 3.2.0 analyze verify analyze-only 在 pom.xml 中配置插件后,可以在构建的特定阶段(如verify阶段)执行特定的目标(goal),比如上述插件的目标是分析依赖。
4.3.2 配置优化与构建提速技巧
为了优化构建速度,可以考虑以下几点:
- 并行编译 :通过设置Maven的
- 跳过测试 :在快速迭代开发阶段,可以临时跳过测试来缩短构建时间。
- 排除不必要的模块或插件 :如果某些模块或插件在构建过程中没有作用,可以考虑排除它们。
true org.apache.maven.plugins maven-surefire-plugin true 以上两段代码展示了如何在Maven配置中启用并行编译和跳过测试,从而提升构建效率。
通过本章的介绍,读者应该能够掌握如何使用Maven进行高效依赖管理以及在集成Elasticsearch和Spring Boot时所必须的依赖配置。
5. Elasticsearch配置指导
Elasticsearch作为一个强大的搜索引擎和数据分析工具,其配置的深度与广度直接影响整个系统的性能与可靠性。本章节深入解析了Elasticsearch的集群配置,索引映射与分析器配置,以及安全与性能调优的策略。
5.1 Elasticsearch集群配置深入解析
Elasticsearch的集群配置是确保高可用性、负载均衡和数据安全的关键。理解集群架构设计及其节点角色是进行有效配置的第一步。
5.1.1 集群架构设计与节点角色
Elasticsearch集群由多个节点组成,每个节点通过网络连接在一起,共同管理数据和提供搜索功能。节点的角色可以是以下几种:
- Master Node(主节点) :负责处理集群的元数据,如索引的创建和删除,节点的加入和移除等。主节点不保存用户数据,主要任务是保证集群的健康运行。
- Data Node(数据节点) :负责存储数据并执行数据相关的操作,如数据的CRUD操作和搜索查询。
- Client Node(客户端节点) :对请求进行负载均衡,但不保存数据。
- Ingest Node(摄入节点) :在索引数据前进行数据预处理。
- Coordinating Node(协调节点) :负责分发客户端请求给合适的节点。
5.1.2 集群健康状态监控与维护
集群健康状态的监控是保证Elasticsearch稳定运行的重要组成部分。Elasticsearch提供了内置的集群健康API,可以查询集群状态。
GET /_cluster/health状态分为三种:Green(一切正常),Yellow(所有数据都是可用的,但某些副本尚未分配),Red(某些数据不可用)。
维护集群的策略包括:
- 优化分片策略 :确保数据均匀分布在集群中,避免热点问题。
- 数据备份与恢复 :定期进行快照备份,确保数据的可恢复性。
- 监控与报警 :实时监控集群状态,出现异常及时报警。
5.2 Elasticsearch索引映射与分析器配置
索引映射是定义数据如何被存储和索引的过程。而分析器用于将文本转换为可被索引的令牌。
5.2.1 字段映射与动态映射机制
字段映射是在创建索引时定义字段的名称、类型等信息。Elasticsearch提供了多种数据类型,如text、keyword、integer等。
PUT /my_index{ \"mappings\": { \"properties\": { \"user_id\": { \"type\": \"keyword\" }, \"post_date\": { \"type\": \"date\" }, \"message\": { \"type\": \"text\" } } }}动态映射是Elasticsearch根据文档中的内容自动创建字段映射的过程。
5.2.2 分析器的自定义与优化
分析器负责文本的处理,包括分词、小写转换等。Elasticsearch自带多种分析器,也可以自定义分析器。
PUT /my_index{ \"settings\": { \"analysis\": { \"analyzer\": { \"my_custom_analyzer\": { \"tokenizer\": \"standard\", \"filter\": [\"lowercase\", \"asciifolding\"] } } } }}优化分析器通常涉及调整分词器、字符过滤器和令牌过滤器,以适应特定的需求。
5.3 Elasticsearch安全与性能调优
Elasticsearch的安全配置和性能调优是生产环境中不可忽视的两个方面。
5.3.1 安全设置与访问控制
Elasticsearch提供了基于角色的访问控制(Role Based Access Control, RBAC),用户可以定义角色和权限,然后分配给用户。
PUT /_security/role/admin{ \"cluster\": [\"all\"], \"indices\": [ { \"names\": [\"*\"], \"privileges\": [\"read\", \"write\"] } ]}访问控制还可以通过X-Pack插件或Elasticsearch安全模块来实现,包括IP白名单、SSL加密传输等。
5.3.2 性能调优与硬件考量
性能调优需要考虑硬件配置、JVM设置、查询优化等。硬件上应考虑足够的内存和快速的I/O子系统,因为Elasticsearch是内存敏感型应用。
JVM的堆内存设置也是影响性能的关键因素。通常建议堆内存设置不超过物理内存的50%。
-Xms4g-Xmx4g查询优化可以通过优化索引结构和查询本身来实现。例如,合理使用过滤器可以显著提升查询性能。
通过上述的配置指导,我们可以为Elasticsearch构建一个高性能、高可用的搜索引擎。在实际应用中,还需根据业务特点,不断调整优化这些配置以满足需求。
6. Elasticsearch-Java-Demo项目介绍
6.1 项目结构与代码组织
6.1.1 项目模块划分与功能描述
一个成功的Java项目,尤其是与Elasticsearch结合的项目,其内部结构和模块划分清晰是至关重要的。本章将详细介绍一个名为 Elasticsearch-Java-Demo 的项目,该项目旨在展示Spring Boot与Elasticsearch如何高效集成,并提供一系列示例代码来解释核心概念。
我们的 Elasticsearch-Java-Demo 项目结构大致如下:
-
src/main/java-
com.example.demo:包含应用的主要Java代码-
config:存放配置类文件,如Elasticsearch的配置类 -
controller:存放API接口控制器类 -
service:存放业务逻辑接口和实现类 -
repository:存放数据访问接口 -
entity:存放数据模型类 -
demo:存放演示代码与测试用例
-
-
resources:存放配置文件,如application.properties
-
-
src/test/java:存放测试代码-
com.example.demo:测试相关的包结构与src/main/java中的目录结构相对应
-
每个模块都旨在实现不同的功能,如:
-
config模块负责定义应用的配置信息。 -
controller模块暴露REST API给客户端调用。 -
service模块封装业务逻辑,如Elasticsearch的CRUD操作。 -
repository模块通过Spring Data Elasticsearch与Elasticsearch交互。 -
entity模块定义了与Elasticsearch索引映射相对应的数据模型。 -
demo模块提供了关键功能的演示,以及测试用例。
6.1.2 代码结构与规范说明
在 Elasticsearch-Java-Demo 项目中,我们遵循以下代码结构和命名规范来确保项目的可维护性和可读性:
- 项目命名 :采用
kebab-case风格命名,如elasticsearch-java-demo。 - 包命名 :采用反向域名方式命名,如
com.example.demo。 - 类与接口命名 :采用
PascalCase风格,如ProductRepository。 - 方法命名 :采用
camelCase风格,如saveProduct。 - 变量命名 :通常也使用
camelCase风格,但在某些情况下为了可读性,如枚举,会使用UPPER_CASE。
对于Elasticsearch特有的部分,我们遵循Elasticsearch的命名约定,如索引名称小写且使用 - 而非驼峰命名。
本项目的代码风格是Spring官方推荐的风格,即利用Spring框架提供的注解和配置,使代码简洁而有条理。在本章后续内容中,我们将深入探究核心功能实现和代码解析,以及如何组织测试用例以确保代码的质量。
6.2 核心功能实现与代码解析
6.2.1 项目中关键功能的代码实现
在 Elasticsearch-Java-Demo 项目中,我们实现了几个关键功能点,包括连接Elasticsearch集群、数据的CRUD操作、高级查询、聚合分析以及安全性配置。接下来,我们选取几个关键功能的代码实现进行深入解析。
以连接Elasticsearch集群为例,我们可以通过Spring Boot的自动配置来简化设置过程:
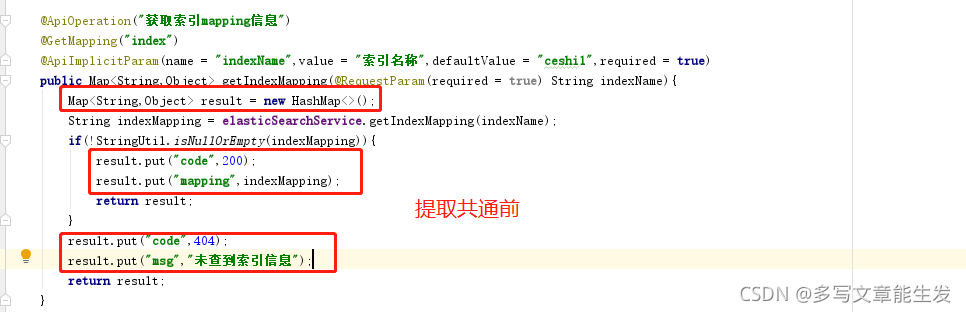
@Configuration@EnableElasticsearchRepositories(basePackages = \"com.example.demo.repository\")public class ElasticsearchConfig extends AbstractElasticsearchConfiguration { @Value(\"${spring.elasticsearch.uris}\") private String uris; @Override @Bean public RestHighLevelClient elasticsearchClient() { final ClientConfiguration clientConfiguration = ClientConfiguration.builder() .connectedTo(uris.split(\",\")) .usingSsl() .withBasicAuth(\"username\", \"password\") .build(); return RestClients.create(clientConfiguration).rest(); }} 在这段代码中,我们创建了一个 ElasticsearchConfig 配置类,通过继承 AbstractElasticsearchConfiguration 类并重写 elasticsearchClient 方法来配置 RestHighLevelClient 。我们通过 @Value 注解从 application.properties 文件中读取Elasticsearch集群的URI,然后使用这些URI来连接集群。
参数说明 :
- spring.elasticsearch.uris :Elasticsearch集群的连接URI。
- username 与 password :用于Elasticsearch集群认证的用户名和密码。
代码逻辑说明 :
1. 通过 ClientConfiguration.builder() 构建连接客户端的配置。
2. 通过 connectedTo(uris.split(\",\")) 方法指定集群的URI地址。
3. 使用 usingSsl() 启用SSL连接。
4. 使用 withBasicAuth(\"username\", \"password\") 方法进行基本的认证。
5. 最后,通过 RestClients.create(clientConfiguration).rest() 创建并返回 RestHighLevelClient 实例。
6.2.2 代码逻辑的梳理与优化
代码逻辑的梳理和优化是任何项目的持续性任务,它可以提高代码的可读性、可维护性和执行效率。 Elasticsearch-Java-Demo 项目也不例外,在设计和实现过程中我们始终关注代码质量。以下是几个优化措施的例子:
-
避免冗余代码 :在
service层,我们通常避免重复的业务逻辑代码,利用Spring的@Transactional注解实现事务控制,并使用Repository提供的抽象方法进行数据操作,以减少样板代码。 -
日志管理 :在关键方法上添加合适的日志信息,方便问题的追踪和性能的监控。使用SLF4J和Logback等日志框架,并按照日志级别(如INFO、DEBUG、WARN)进行配置。
-
异常处理 :对于Elasticsearch操作可能出现的异常,我们进行了适当的捕获和处理。例如,对于网络问题或资源不可用等暂时性问题,会尝试重新操作;而对于预期之外的错误,则记录详细信息并抛出自定义异常,以供调用者处理。
-
查询优化 :对于Elasticsearch查询,我们始终关注查询效率和资源使用。例如,对于经常执行的查询,我们优化了其使用的Query DSL,确保查询尽可能地高效。我们还根据需要调整了分页大小和高亮显示等特性,以减少响应时间并提升用户体验。
-
代码重构 :我们定期进行代码审查,对于发现的可改进之处,进行重构以提高代码的可读性和可维护性。例如,将复杂的查询逻辑拆分成多个小方法,使得代码更模块化,更易于理解和维护。
-
单元测试 :通过编写详尽的单元测试来验证方法的正确性。我们使用JUnit框架,配合Mockito等库来模拟外部依赖,确保在不依赖外部资源(如实际的Elasticsearch集群)的情况下进行测试。
优化工作是一个持续的过程,需要不断地测试、评估和调整。在本章后续内容中,我们将深入讨论测试用例和案例展示,通过实际例子来阐释如何验证和演示代码的有效性。
6.3 测试用例与案例展示
6.3.1 单元测试与集成测试策略
为了确保 Elasticsearch-Java-Demo 项目的功能正确性和可靠性,我们制定了全面的测试策略,包括单元测试和集成测试。
单元测试
单元测试关注于验证单个方法或组件的行为。在Spring Boot项目中,我们使用JUnit 5作为测试框架,并利用Mockito库来模拟对象或方法的返回值,从而在不依赖于外部系统的前提下进行测试。
例如,我们可以测试 ProductRepository 中的一个方法,验证其是否能够正确地将一个产品文档保存到Elasticsearch中:
@SpringBootTestpublic class ProductRepositoryTest { @Autowired private ProductRepository repository; @BeforeEach public void setUp() { // 清空索引,并初始化一些测试数据 } @Test public void shouldSaveProductSuccessfully() { Product product = new Product(\"test_id\", \"Test Product\", BigDecimal.valueOf(19.99)); Product savedProduct = repository.save(product); assertNotNull(savedProduct); assertEquals(\"Test Product\", savedProduct.getName()); // 断言其他字段的值以确保全部正确保存 }} 执行逻辑说明 :
1. @SpringBootTest 注解启动Spring Boot应用程序上下文。
2. @Autowired 注入 ProductRepository 。
3. @BeforeEach 注解的方法在每个测试之前执行,用于准备测试环境。
4. @Test 注解的方法定义了一个测试用例,检查 ProductRepository 的 save 方法是否能够正确地保存产品信息。
5. 使用 assertNotNull 和 assertEquals 等断言方法来验证方法返回的结果是否符合预期。
集成测试
集成测试关注于验证系统中多个组件协同工作的正确性。在 Elasticsearch-Java-Demo 项目中,集成测试是通过模拟Elasticsearch集群来实现的。
@SpringBootTest@DirtiesContext(classMode = ClassMode.BEFORE_EACH_TEST_METHOD)class ElasticSearchIntegrationTest { @Autowired private SearchRepository searchRepository; @Test void shouldSearchProductCorrectly() { // 初始化测试数据 // 执行搜索操作 List products = searchRepository.search(\"test\"); // 验证搜索结果 // ... }} 执行逻辑说明 :
1. @DirtiesContext(classMode = ClassMode.BEFORE_EACH_TEST_METHOD) 确保每个测试方法执行前都会重置Spring应用上下文,以便每次测试都是独立的。
2. 通过 @Autowired 注入 SearchRepository 。
3. @Test 注解的方法定义了一个集成测试用例,用于验证搜索操作的正确性。
4. 使用模拟数据初始化测试环境,并执行搜索操作。
5. 使用断言验证搜索结果是否符合预期。
6.3.2 典型业务场景的Demo演示
在 Elasticsearch-Java-Demo 项目中,我们还提供了一系列演示类(位于 com.example.demo.demo 包中),这些类展示了如何在具体业务场景中使用Elasticsearch进行操作。例如,一个简单的商品搜索演示可能看起来像这样:
@Servicepublic class SearchService { @Autowired private SearchRepository searchRepository; public List searchProducts(String query) { return searchRepository.search(query); }} 在这个简单的搜索服务示例中,我们通过注入 SearchRepository 来调用搜索功能,该功能将由 ProductRepository 具体实现。当调用 searchProducts 方法时,它会传递用户输入的查询字符串,并从Elasticsearch中检索产品信息。
在实际的业务场景中,我们可能需要更复杂的查询逻辑,例如模糊搜索、范围查询、多字段搜索等。此时,我们可以利用Elasticsearch强大的Query DSL进行定制化搜索,并通过代码向用户提供丰富的查询选项。
通过这些演示用例和实际的测试,我们可以确保Elasticsearch在项目中的使用是经过验证的,并且能够满足业务需求。这为开发人员提供了一个直接了解如何在实际项目中应用Elasticsearch的途径。
7. Elasticsearch在企业级应用中的实践
7.1 Elasticsearch在日志分析中的应用
Elasticsearch在处理大量日志数据方面表现优异,这主要是由于其分布式架构设计和高效的搜索能力。在企业级应用中,日志分析是监控、故障排除和系统优化的关键部分。
7.1.1 日志数据的收集与传输
日志数据通常来自于多个服务器和服务,因此需要一个集中式系统来收集这些数据。常见的解决方案包括使用Logstash,它是一个开源的数据收集引擎,能够处理和转发日志数据到Elasticsearch。
# Logstash配置示例,用于处理nginx日志并转发到Elasticsearchinput { file { path => \"/var/log/nginx/access.log\" type => \"nginx_access\" }}filter { grok { match => { \"message\" => \"%{COMBINEDAPACHELOG}\" } } date { match => [ \"timestamp\" , \"dd/MMM/yyyy:HH:mm:ss Z\" ] }}output { elasticsearch { hosts => [\"localhost:9200\"] index => \"logstash-%{+YYYY.MM.dd}\" }}7.1.2 日志数据的存储与索引
收集到的原始日志数据需要被索引以便进行快速搜索和分析。在Elasticsearch中,可以通过设置映射来定义索引的结构,从而优化存储和查询性能。
PUT /logs_index{ \"mappings\": { \"properties\": { \"timestamp\": { \"type\": \"date\" }, \"clientip\": { \"type\": \"ip\" }, \"response\": { \"type\": \"integer\" }, \"bytes\": { \"type\": \"long\" }, \"verb\": { \"type\": \"keyword\" } } }}7.1.3 日志数据的查询与可视化
企业用户通常需要对日志数据进行实时的查询和可视化分析。Kibana是一个强大的数据可视化工具,可以轻松地创建图表和仪表板,以图形化方式展示日志数据。
# Kibana dashboard配置示例dashboard: title: \"Web Server Logs Dashboard\" panels: - panel_id: 1 title: \"Response Time Distribution\" type: \"histogram\" time_field: \"@timestamp\" agg_type: \"avg\" agg_field: \"response\"7.2 Elasticsearch在搜索功能优化中的应用
在很多企业级应用中,提供用户友好的搜索功能是提高用户体验的关键。Elasticsearch提供了丰富的查询DSL,能够灵活地满足各种搜索需求。
7.2.1 搜索功能的需求分析
在设计搜索功能时,需要理解用户的需求,包括他们如何表达搜索意图,以及期望什么样的搜索结果。比如,用户可能希望对产品名称进行模糊搜索,或者根据价格进行范围查询。
7.2.2 使用Elasticsearch的Query DSL实现需求
Elasticsearch的Query DSL提供了丰富的查询选项,使得开发者可以精确控制搜索逻辑。
GET /products/_search{ \"query\": { \"bool\": { \"must\": { \"match\": { \"name\": \"laptop\" } }, \"filter\": { \"range\": { \"price\": { \"gte\": 500, \"lte\": 1000 } } } } }}7.2.3 搜索性能的优化策略
搜索性能对用户体验至关重要,Elasticsearch提供了多种优化策略,例如缓存查询结果,使用合适的数据类型,以及定期对索引进行维护。
PUT /products/_settings{ \"index\": { \"query\": { \"default_field\": \"name^3\" }, \"search\": { \"preference\": \"_local\" } }}在企业级应用中,Elasticsearch的应用不仅仅局限于日志分析和搜索功能优化,它还可以用于应用监控、数据仓库、推荐系统等多个场景。随着对Elasticsearch的深入理解和实践,企业可以发现更多创新的使用案例,以提高整体业务的竞争力。
本文还有配套的精品资源,点击获取
简介:Elasticsearch是一个分布式、RESTful的搜索和数据分析引擎,通过Java API和Spring Boot,开发者可以将其便捷地集成到应用程序中。本教程将展示如何利用Spring Boot提供的starter进行快速整合,并实现Elasticsearch的基本增删改查(CRUD)操作。文章还提供依赖管理和配置指南,以及一个实操项目“elasticsearch-java-demo”的介绍,旨在帮助开发者理解和实践Elasticsearch在Java环境中的应用。
本文还有配套的精品资源,点击获取

