MatterPort3D 数据集 | 简介 | 多途径下载_mp3d数据集
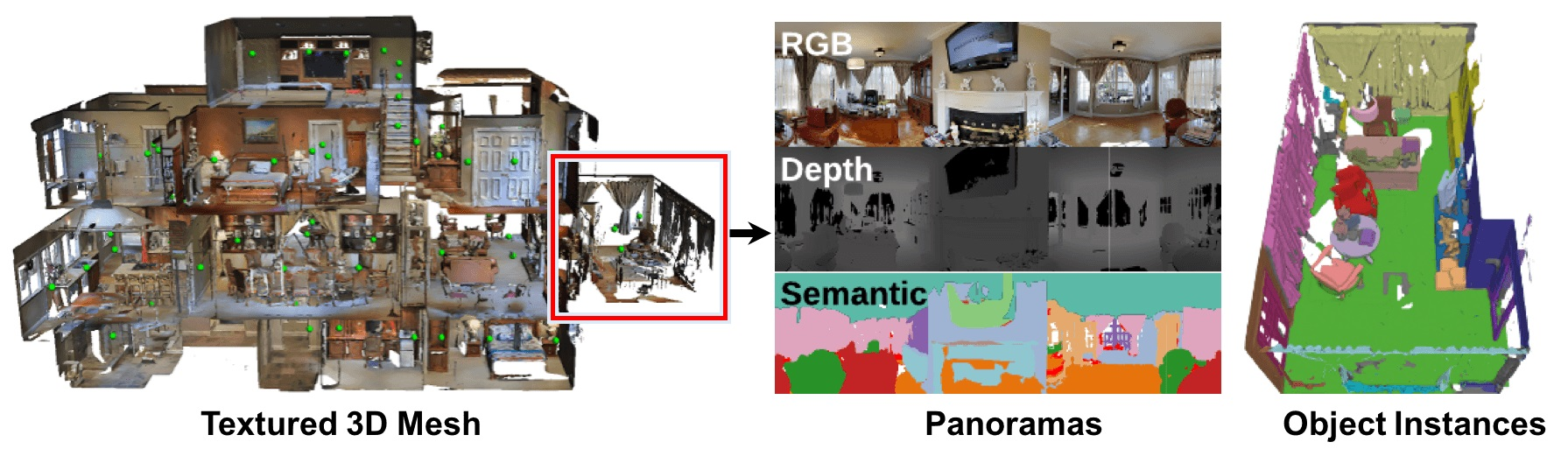
Matterport3D,简称MP3D,是室内场景的一个大规模 RGB-D 数据集。可用于机器人具身导航算法开发。
包含 90 个建筑规模场景的 194,400 张RGB-D图像,以及10,800个全景视图。
数据集提供了表面重建、相机姿态以及二维和三维语义分割的注释。
支持各种监督和自监督计算机视觉任务,包括关键点匹配、视图重叠预测、基于颜色的法线预测、语义分割和场景分类。
项目地址:https://niessner.github.io/Matterport/
代码地址:https://github.com/niessner/Matterport
论文地址:Matterport3D: Learning from RGB-D Data in Indoor Environments
1、数据集下载(官方)
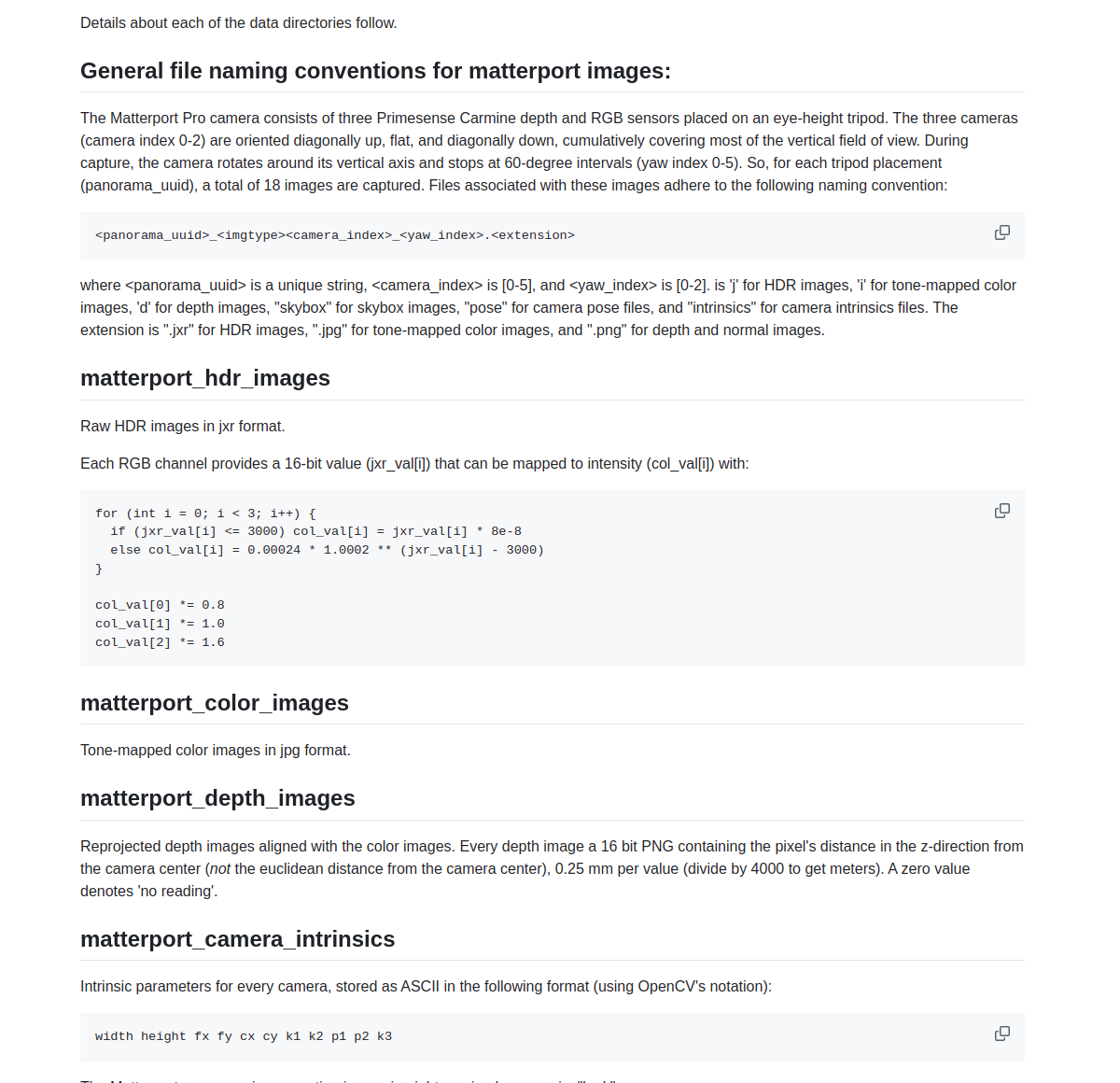
该数据集包含多种类型的标注:彩色和深度图像、相机姿态、带纹理的 3D 网格、建筑平面图和区域标注、对象实例语义标注。
数据集的格式参考:https://github.com/niessner/Matterport/blob/master/data_organization.md
需要填写并签署使用条款协议表格,然后将其发送至matterport3d@googlegroups.com以请求访问数据集。
2、Habitat-Lab 提供示例下载
Scenes datasets 如下表格所示:
data/scene_datasets/habitat-test-scenes/{scene}.glbdata/scene_datasets/replica_cad/configs/scenes/{scene}.scene_instance.jsondata/scene_datasets/hm3d/{split}/00\\d\\d\\d-{scene}/{scene}.basis.glbdata/scene_datasets/gibson/{scene}.glbdata/scene_datasets/mp3d/{scene}/{scene}.glbdata/scene_datasets/hssd-hab/scenes/{scene}.scene_instance.jsondata/scene_datasets/ai2thor-hab/ai2thor-hab/configs/scenes/{DATASET}/{scene}.scene_instance.json点击“Matterport3D”后,能看到下载命令:
python -m habitat_sim.utils.datasets_download --uids mp3d_example_scene --data-path data/但是这只是一个示例场景,用于在 Habitat-sim 中执行单元测试,无法下载完整的“Matterport3D”数据。
Task datasets 如下表格所示:
data/datasets/rearrange_pick/replica_cad/v0/data/datasets/pointnav/gibson/v1/data/datasets/pointnav/gibson/v1/data/datasets/pointnav/gibson/v2/data/datasets/pointnav/mp3d/v1/data/datasets/pointnav/hm3d/v1/data/datasets/objectnav/mp3d/v1/data/datasets/objectnav/hm3d/v1/data/datasets/objectnav/hm3d/v2/data/datasets/objectnav/hssd-habdata/datasets/objectnav/procthor-habdata/datasets/eqa/mp3d/v1/data/datasets/vln/mp3d/r2r/v1data/datasets/instance_imagenav/hm3d/v1/data/datasets/instance_imagenav/hm3d/v2/data/datasets/instance_imagenav/hm3d/v3/data/datasets/pointnav/gibson/v1/data/datasets/pointnav/mp3d/v1/3、批量下载
首先创建一个Conda环境,名字为mp3d,python版本为3.9
进入mp3d环境
conda create -n mp3d python=3.9conda activate mp3d然后安装requests依赖库
pip install requests编写批量下载的代码:
#!/usr/bin/env python# -*- coding: utf-8 -*-import argparseimport collectionsimport osimport tempfileimport urllibfrom urllib import requestimport requestsfrom time import sleepfrom requests.exceptions import ConnectionError, ChunkedEncodingError, RequestExceptionimport sysBASE_URL = \'http://kaldir.vc.in.tum.de/matterport/\'RELEASE = \'v1/scans\'RELEASE_TASKS = \'v1/tasks/\'RELEASE_SIZE = \'1.3TB\'TOS_URL = BASE_URL + \'MP_TOS.pdf\'FILETYPES = [ \'cameras\', \'matterport_camera_intrinsics\', \'matterport_camera_poses\', \'matterport_color_images\', \'matterport_depth_images\', \'matterport_hdr_images\', \'matterport_mesh\', \'matterport_skybox_images\', \'undistorted_camera_parameters\', \'undistorted_color_images\', \'undistorted_depth_images\', \'undistorted_normal_images\', \'house_segmentations\', \'region_segmentations\', \'image_overlap_data\', \'poisson_meshes\', \'sens\']TASK_FILES = { \'keypoint_matching_data\': [\'keypoint_matching/data.zip\'], \'keypoint_matching_models\': [\'keypoint_matching/models.zip\'], \'surface_normal_data\': [\'surface_normal/data_list.zip\'], \'surface_normal_models\': [\'surface_normal/models.zip\'], \'region_classification_data\': [\'region_classification/data.zip\'], \'region_classification_models\': [\'region_classification/models.zip\'], \'semantic_voxel_label_data\': [\'semantic_voxel_label/data.zip\'], \'semantic_voxel_label_models\': [\'semantic_voxel_label/models.zip\'], \'minos\': [\'mp3d_minos.zip\'], \'gibson\': [\'mp3d_for_gibson.tar.gz\'], \'habitat\': [\'mp3d_habitat.zip\'], \'pixelsynth\': [\'mp3d_pixelsynth.zip\'], \'igibson\': [\'mp3d_for_igibson.zip\'], \'mp360\': [\'mp3d_360/data_00.zip\', \'mp3d_360/data_01.zip\', \'mp3d_360/data_02.zip\', \'mp3d_360/data_03.zip\', \'mp3d_360/data_04.zip\', \'mp3d_360/data_05.zip\', \'mp3d_360/data_06.zip\']}def get_release_scans(release_file): # scan_lines = urllib.urlopen(release_file) scan_lines = request.urlopen(release_file) scans = [] for scan_line in scan_lines: scan_line = str(scan_line, \'utf-8\') scan_id = scan_line.rstrip(\'\\n\') scans.append(scan_id) return scansdef download_release(release_scans, out_dir, file_types): print(\'Downloading MP release to \' + out_dir + \'...\') for scan_id in release_scans: scan_out_dir = os.path.join(out_dir, scan_id) download_scan(scan_id, scan_out_dir, file_types) print(\'Downloaded MP release.\')def download_file(url, out_file, max_retries=5, chunk_size=1024*1024): \"\"\" 下载单个文件,支持断点续传和自动重试,并打印实时下载进度。 兼容 Python2/3。 \"\"\" out_dir = os.path.dirname(out_file) if not os.path.isdir(out_dir): try: os.makedirs(out_dir) except OSError: pass # 获取文件总大小 head = requests.head(url, allow_redirects=True) if head.status_code != 200: raise IOError(\"无法获取文件大小: {0},状态码 {1}\".format(url, head.status_code)) total_size = int(head.headers.get(\'Content-Length\', 0)) # 计算已下载起点 resume = 0 if os.path.exists(out_file): resume = os.path.getsize(out_file) if resume >= total_size: print(\"跳过已存在文件 %s\" % out_file) return print(\"开始下载 %s (%0.2f MB)\" % (out_file, total_size / 1024.0**2)) retries = 0 last_print = 0 while resume < total_size and retries = 5 or resume == total_size: sys.stdout.write(\"\\r下载进度: %3d%% (%0.2f/%0.2f MB)\" % ( percent, resume / 1024.0**2, total_size / 1024.0**2 )) sys.stdout.flush() last_print = percent # 将本次下载数据追加到目标文件 with open(tmp_path, \"rb\") as tmpf, open(out_file, \"ab\") as outf: outf.write(tmpf.read()) os.remove(tmp_path) r.close() break # except (requests.ConnectionError, requests.ChunkedEncodingError, IOError) as e: except (ConnectionError, ChunkedEncodingError, IOError) as e: retries += 1 wait = 2 ** retries print(\"\\n[重试 %d/%d] 已下载 %0.2f MB,等待 %d 秒后重试...\" % ( retries, max_retries, resume / 1024.0**2, wait )) sleep(wait) if resume < total_size: raise IOError(\"下载失败:只获取到 %d / %d 字节\" % (resume, total_size)) # 下载完成后换行 sys.stdout.write(\"\\n下载完成:%s\\n\" % out_file)def download_scan(scan_id, out_dir, file_types): print(\'Downloading MP scan \' + scan_id + \' ...\') if not os.path.isdir(out_dir): os.makedirs(out_dir) for ft in file_types: url = BASE_URL + RELEASE + \'/\' + scan_id + \'/\' + ft + \'.zip\' out_file = out_dir + \'/\' + ft + \'.zip\' download_file(url, out_file) print(\'Downloaded scan \' + scan_id)def download_task_data(task_data, out_dir): print(\'Downloading MP task data for \' + str(task_data) + \' ...\') for task_data_id in task_data: if task_data_id in TASK_FILES: file = TASK_FILES[task_data_id] for filepart in file: url = BASE_URL + RELEASE_TASKS + \'/\' + filepart localpath = os.path.join(out_dir, filepart) localdir = os.path.dirname(localpath) if not os.path.isdir(localdir): os.makedirs(localdir) download_file(url, localpath) print(\'Downloaded task data \' + task_data_id)def main(): parser = argparse.ArgumentParser(description= \'\'\' Downloads MP public data release. Example invocation: python download_mp.py -o base_dir --id ALL --type object_segmentations --task_data semantic_voxel_label_data semantic_voxel_label_models The -o argument is required and specifies the base_dir local directory. After download base_dir/v1/scans is populated with scan data, and base_dir/v1/tasks is populated with task data. Unzip scan files from base_dir/v1/scans and task files from base_dir/v1/tasks/task_name. The --type argument is optional (all data types are downloaded if unspecified). The --id ALL argument will download all house data. Use --id house_id to download specific house data. The --task_data argument is optional and will download task data and model files. \'\'\', formatter_class=argparse.RawTextHelpFormatter) parser.add_argument(\'-o\', \'--out_dir\', required=True, help=\'directory in which to download\') parser.add_argument(\'--task_data\', default=[], nargs=\'+\', help=\'task data files to download. Any of: \' + \',\'.join(TASK_FILES.keys())) parser.add_argument(\'--id\', default=\'ALL\', help=\'specific scan id to download or ALL to download entire dataset\') parser.add_argument(\'--type\', nargs=\'+\', help=\'specific file types to download. Any of: \' + \',\'.join(FILETYPES)) args = parser.parse_args() release_file = BASE_URL + RELEASE + \'.txt\' release_scans = get_release_scans(release_file) file_types = FILETYPES # download task data if args.task_data: if set(args.task_data) & set(TASK_FILES.keys()): # download task data out_dir = os.path.join(args.out_dir, RELEASE_TASKS) download_task_data(args.task_data, out_dir) else: print(\'ERROR: Unrecognized task data id: \' + args.task_data) print(\'Done downloading task_data for \' + str(args.task_data)) # key = raw_input(\'Press any key to continue on to main dataset download, or CTRL-C to exit.\') key = input(\'Press any key to continue on to main dataset download, or CTRL-C to exit.\') # download specific file types? if args.type: if not set(args.type) & set(FILETYPES): # print(\'ERROR: Invalid file type: \' + file_type) print(\'ERROR: Invalid file type: \' + file_types) return file_types = args.type if args.id and args.id != \'ALL\': # download single scan scan_id = args.id if scan_id not in release_scans: print(\'ERROR: Invalid scan id: \' + scan_id) else: out_dir = os.path.join(args.out_dir, RELEASE, scan_id) download_scan(scan_id, out_dir, file_types) elif \'minos\' not in args.task_data and args.id == \'ALL\' or args.id == \'all\': # download entire release if len(file_types) == len(FILETYPES): print(\'WARNING: You are downloading the entire MP release which requires \' + RELEASE_SIZE + \' of space.\') else: print(\'WARNING: You are downloading all MP scans of type \' + file_types[0]) print(\'Note that existing scan directories will be skipped. Delete partially downloaded directories to re-download.\') print(\'***\') print(\'Press any key to continue, or CTRL-C to exit.\') # key = raw_input(\'\') key = input(\'\') out_dir = os.path.join(args.out_dir, RELEASE) download_release(release_scans, out_dir, file_types)if __name__ == \"__main__\": main()创建一个文件夹,用于存放数据集,比如data
下载所以MP3D的数据,1.3T左右,执行命令:
python download_mp.py --task habitat -o ./data打印信息:
Downloading MP task data for [\'habitat\'] ...
Done downloading task_data for [\'habitat\']
Press any key to continue on to main dataset download, or CTRL-C to exit.
WARNING: You are downloading the entire MP release which requires 1.3TB of space.
Note that existing scan directories will be skipped. Delete partially downloaded directories to re-download.
***
Press any key to continue, or CTRL-C to exit.Downloading MP release to ./data/v1/scans...
Downloading MP scan 1pXnuDYAj8r ...
下载完成:./data/v1/scans/1pXnuDYAj8r/cameras.zip
开始下载 ./data/v1/scans/1pXnuDYAj8r/matterport_camera_intrinsics.zip (0.10 MB)
下载进度: 100% (0.10/0.10 MB)
下载完成:./data/v1/scans/1pXnuDYAj8r/matterport_camera_intrinsics.zip
开始下载 ./data/v1/scans/1pXnuDYAj8r/matterport_camera_poses.zip (0.61 MB)
下载进度: 100% (0.61/0.61 MB)
下载完成:./data/v1/scans/1pXnuDYAj8r/matterport_camera_poses.zip
开始下载 ./data/v1/scans/1pXnuDYAj8r/matterport_color_images.zip (537.00 MB)
下载进度: 100% (537.00/537.00 MB)
............
下载完成:./data/v1/scans/1pXnuDYAj8r/undistorted_color_images.zip
开始下载 ./data/v1/scans/1pXnuDYAj8r/undistorted_depth_images.zip (1282.63 MB)
下载进度: 100% (1282.63/1282.63 MB)
下载完成:./data/v1/scans/1pXnuDYAj8r/undistorted_depth_images.zip
开始下载 ./data/v1/scans/1pXnuDYAj8r/undistorted_normal_images.zip (2808.76 MB)
下载进度: 90% (2528.00/2808.76 MB)
下载过程中,场景数据的文件:
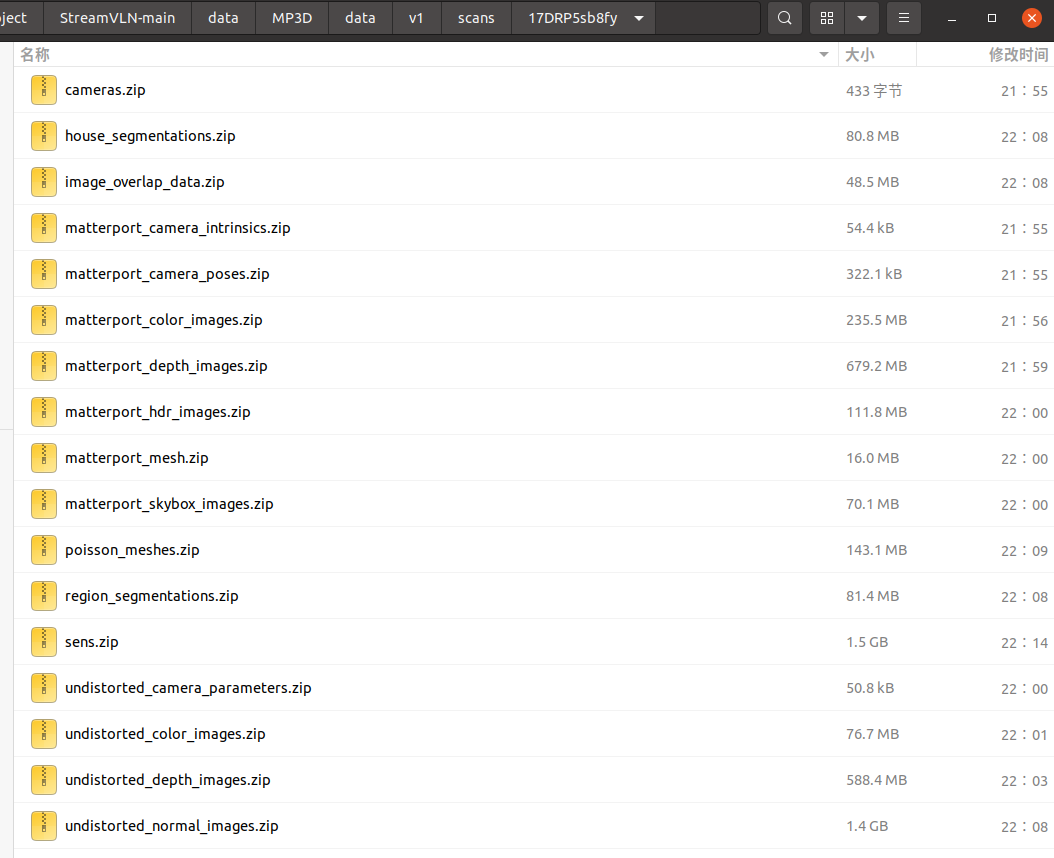
17DRP5sb8fy任务包含的内容:
...............
任务数据文件:

指定某个场景ID,进行下载,执行命令:
python download_mp.py --task habitat -o ./data --id 17DRP5sb8fy打印信息:
Downloading MP scan 17DRP5sb8fy ...
开始下载 ./data/v1/scans/17DRP5sb8fy/cameras.zip (0.00 MB)
下载进度: 100% (0.00/0.00 MB)
下载完成:./data/v1/scans/17DRP5sb8fy/cameras.zip
开始下载 ./data/v1/scans/17DRP5sb8fy/matterport_camera_intrinsics.zip (0.05 MB)
下载进度: 100% (0.05/0.05 MB)
........
下载完成:./data/v1/scans/17DRP5sb8fy/image_overlap_data.zip
开始下载 ./data/v1/scans/17DRP5sb8fy/poisson_meshes.zip (136.50 MB)
下载进度: 100% (136.50/136.50 MB)
下载完成:./data/v1/scans/17DRP5sb8fy/poisson_meshes.zip
开始下载 ./data/v1/scans/17DRP5sb8fy/sens.zip (1402.69 MB)
下载进度: 100% (1402.69/1402.69 MB)
下载完成:./data/v1/scans/17DRP5sb8fy/sens.zip
Downloaded scan 17DRP5sb8fy
4、便捷下载(简要文件)
下载地址:https://cloud.tsinghua.edu.cn/f/03e0ca1430a344efa72b/?dl=1
每个文件夹中,包含一个.glb文件:

分享完成~


