程序员学习笔记(十六)
分布式理论
分布式(Distributed) 是指将一个系统或任务拆分成多个部分,分散在不同的物理或逻辑节点(如服务器、计算机、设备等)上协同工作,最终共同完成目标。其核心思想是通过分工协作和资源共享,提高系统的可靠性、扩展性和性能。
介绍一下cap理论
CAP 原则又称 CAP 定理, 指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性), 三者不可得兼。
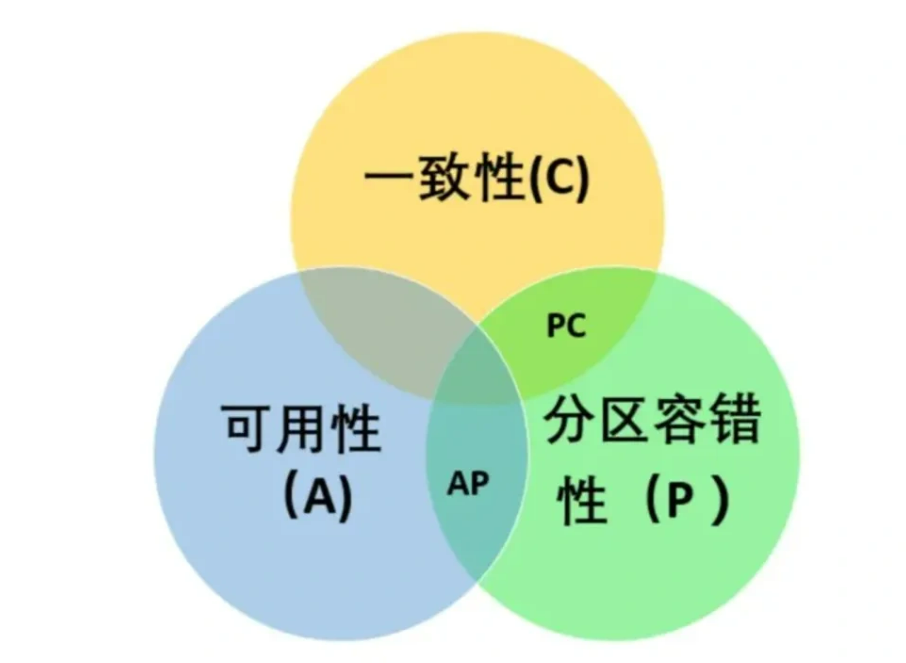
- 一致性(C) : 在分布式系统中的所有数据备份, 在同一时刻是否同样的值(等同于所有节点访问同一份最新的数据副本)
- 可用性(A): 在集群中一部分节点故障后, 集群整体是否还能响应客户端的读写请求(对数据更新具备高可用性)
- 分区容忍性(P): 以实际效果而言, 分区相当于对通信的时限要求. 系统如果不能在时限内达成数据一致性, 就意味着发生了分区的情况, 必须就当前操作在 C 和 A 之间做出选择
分布式锁
用redis怎么实现分布式
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。
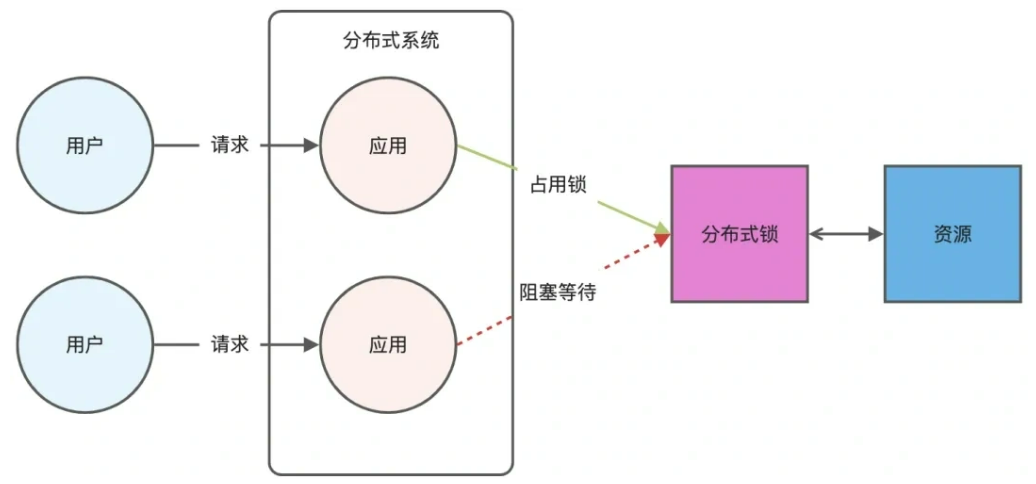
Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁,而且 Redis 的读写性能高,可以应对高并发的锁操作场景。Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
//lock_key 就是 key 键;//unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;//NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;//PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。SET lock_key unique_value NX PX 10000解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放if redis.call(\"get\",KEYS[1]) == ARGV[1] then return redis.call(\"del\",KEYS[1])else return 0end其他方法实现分布式锁
基于zookeeper来实现分布式
zookeeper是一个为分布式应用提供一致性服务的软件,它内部是一个分层的文件系统目录树结构,规定统一个目录下只能有一个唯一文件名。
数据模型:
- 永久节点:节点创建后,不会因为会话失效而消失
- 临时节点:与永久节点相反,如果客户端连接失效,则立即删除节点
- 顺序节点:与上述两个节点特性类似,如果指定创建这类节点时,zk会自动在节点名后加一个数字后缀,并且是有序的。
监视器(watcher):当创建一个节点时,可以注册一个该节点的监视器,当节点状态发生改变时,watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次。
利用Zookeeper的临时顺序节点和监听机制两大特性,可以帮助我们实现分布式锁
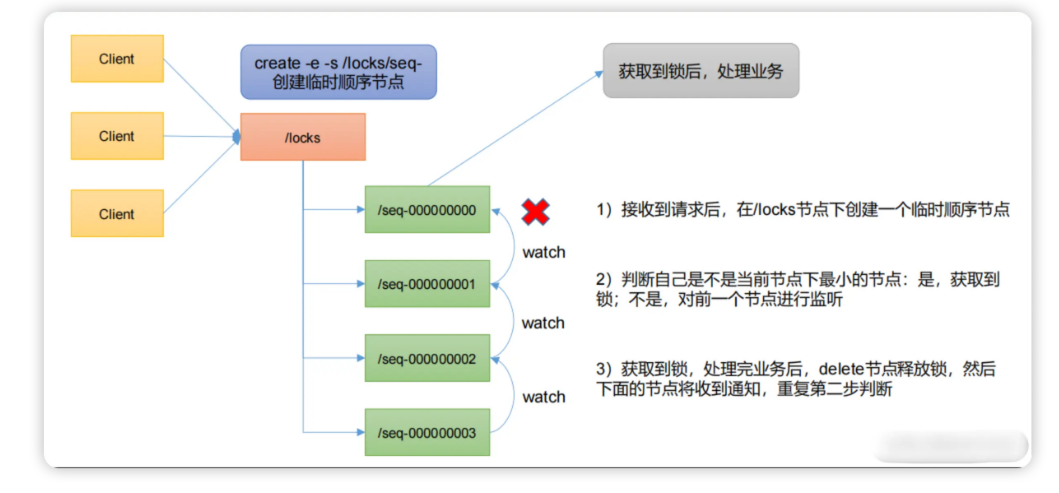
- 首先得有一个持久节点/locks, 路径服务于某个使用场景,如果有多个使用场景建议路径不同。
- 请求进来时首先在/locks创建临时有序节点,所有会看到在/locks下面有seq-000000000, seq-00000001 等等节点。
- 然后判断当前创建得节点是不是/locks路径下面最小的节点,如果是,获取锁,不是,阻塞线程,同时设置监听器,监听前一个节点。
- 获取到锁以后,开始处理业务逻辑,最后delete当前节点,表示释放锁。 后一个节点就会收到通知,唤起线程,重复上面的判断。
zookerper 实现的分布式锁是强一致性的,**因为它底层的 ZAB协议(原子广播协议), 天然满足 CP,**但是这也意味着性能的下降, 所以不站在具体数据下看 Redis 和 Zookeeper, 代表着性能和一致性的取舍。
如果项目没有强依赖 ZK, 使用 Redis 就好了, 因为现在 Redis 用途很广, 大部分项目中都引用了 Redis,没必要对此再引入一个新的组件, 如果业务场景对于 Redis 异步方式的同步数据造成锁丢失无法忍受, 在业务层处理就好了。
分布式事务
分布式事务的解决方案你知道哪些
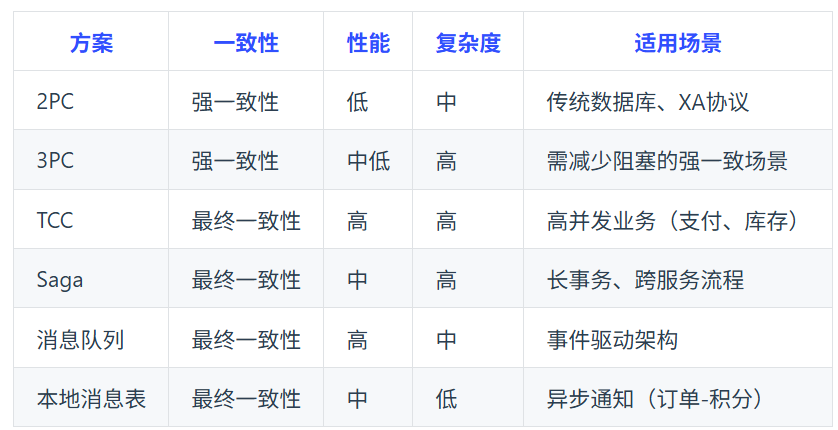
- 两阶段提交协议(2PC):为准备阶段和提交阶段。准备阶段,协调者向参与者发送准备请求,参与者执行事务操作并反馈结果。若所有参与者准备就绪,协调者在提交阶段发送提交请求,参与者执行提交;否则发送回滚请求。实现简单,能保证事务强一致性。存在单点故障,协调者故障会影响事务流程;性能低,多次消息交互增加延迟;资源锁导致资源长时间占用,降低并发性能。适用于对数据一致性要求高、并发度低的场景,如金融系统转账业务。
- 两阶段提交协议(2PC):为准备阶段和提交阶段。准备阶段,协调者向参与者发送准备请求,参与者执行事务操作并反馈结果。若所有参与者准备就绪,协调者在提交阶段发送提交请求,参与者执行提交;否则发送回滚请求。实现简单,能保证事务强一致性。存在单点故障,协调者故障会影响事务流程;性能低,多次消息交互增加延迟;资源锁导致资源长时间占用,降低并发性能。适用于对数据一致性要求高、并发度低的场景,如金融系统转账业务。
- TCC:将业务操作拆分为 Try、Confirm、Cancel 三个阶段。Try 阶段预留业务资源,Confirm 阶段确认资源完成业务操作,Cancel 阶段在失败时释放资源回滚操作。可根据业务场景定制开发,性能较高,减少资源占用时间。开发成本高,需实现三个方法,要处理异常和补偿逻辑,实现复杂度大。适用于对性能要求高、业务逻辑复杂的场景,如电商系统订单处理、库存管理。
- Saga:将长事务拆分为多个短事务,每个短事务有对应的补偿事务。某个短事务失败,按相反顺序执行补偿事务回滚系统状态。性能较高,短事务可并行执行减少时间,对业务侵入性小,只需实现补偿事务。只能保证最终一致性,部分补偿事务失败可能导致系统状态不一致。适用于业务流程长、对数据一致性要求为最终一致性的场景,如旅游系统订单、航班、酒店预订。
- 可靠消息最终一致性方案:基于消息队列,业务系统执行本地事务时将业务操作封装成消息发至消息队列,下游系统消费消息并执行操作,失败则消息队列重试。实现简单,对业务代码修改小,系统耦合度低,能保证数据最终一致性。消息队列可靠性和性能影响大,可能出现消息丢失或延迟,需处理消息幂等性。适用于对数据一致性要求为最终一致性、系统耦合度低的场景,如电商订单支付、库存扣减。
- 本地消息表:业务与消息存储在同一个数据库,利用本地事务保证一致性,后台任务轮询消息表,通过MQ通知下游服务,下游服务消费成功后确认消息,失败则重试。简单可靠,无外部依赖。消息可能重复消费,需幂等设计。适用场景是异步最终一致性(如订单创建后通知积分服务)。
阿里的seata框架
Seata 是开源分布式事务解决方案,支持多种模式
- AT模式:是 Seata 默认的模式,基于支持本地 ACID 事务的关系型数据库。在 AT 模式下,Seata 会自动生成回滚日志,在业务 SQL 执行前后分别记录数据的快照。当全局事务需要回滚时,根据回滚日志将数据恢复到事务开始前的状态。
- TCC模式:需要开发者手动编写 Try、Confirm 和 Cancel 三个方法。Try 方法用于对业务资源进行预留,Confirm 方法用于确认资源并完成业务操作,Cancel 方法用于在业务执行失败时释放预留的资源。
- SAGA 模式:将一个长事务拆分为多个短事务,每个短事务都有一个对应的补偿事务。当某个短事务执行失败时,会按照相反的顺序执行之前所有短事务的补偿事务,将系统状态回滚到初始状态。

