爬虫实战指南:从定位数据到解析请求的全流程解析
爬虫的本质是什么?
爬虫的本质就是用代码模拟人类在浏览器里的操作,像点击网页、填写表单、提交数据等行为,自动化地进行网页数据的获取和处理。比如:
- 发送 GET 请求 来请求网页内容,相当于你在浏览器地址栏输入网址按回车。
- 发送 POST 请求 来提交表单数据,比如登录、搜索等操作。
所以爬虫其实就是用程序来“模仿”人的浏览器操作,通过网络请求与服务器交互,自动抓取和处理网页信息。
在学习爬虫之前尽量要学习一些HTML基础知识,html是构建Web内容的一种语言描述方式
如何确定和提取网页数据?
在爬虫开发过程中,了解如何定位数据以及如何从网页中提取所需信息是至关重要的。本篇文章将逐步介绍如何在网页中找到数据源并通过编写爬虫进行数据抓取。
一、确定需要的数据在哪里
1.1 查找网页源代码
在开始抓取数据之前,第一步是查看网页的源代码。通常我们可以右键点击页面并选择“查看页面源代码”,或者直接按 Ctrl+U (Windows) / Cmd+Option+U (Mac) 打开源代码查看窗口。
如何分析源代码:
-
查找关键字:使用浏览器的搜索功能 (
Ctrl+F) 查找与数据相关的关键字,例如搜索Example Domain
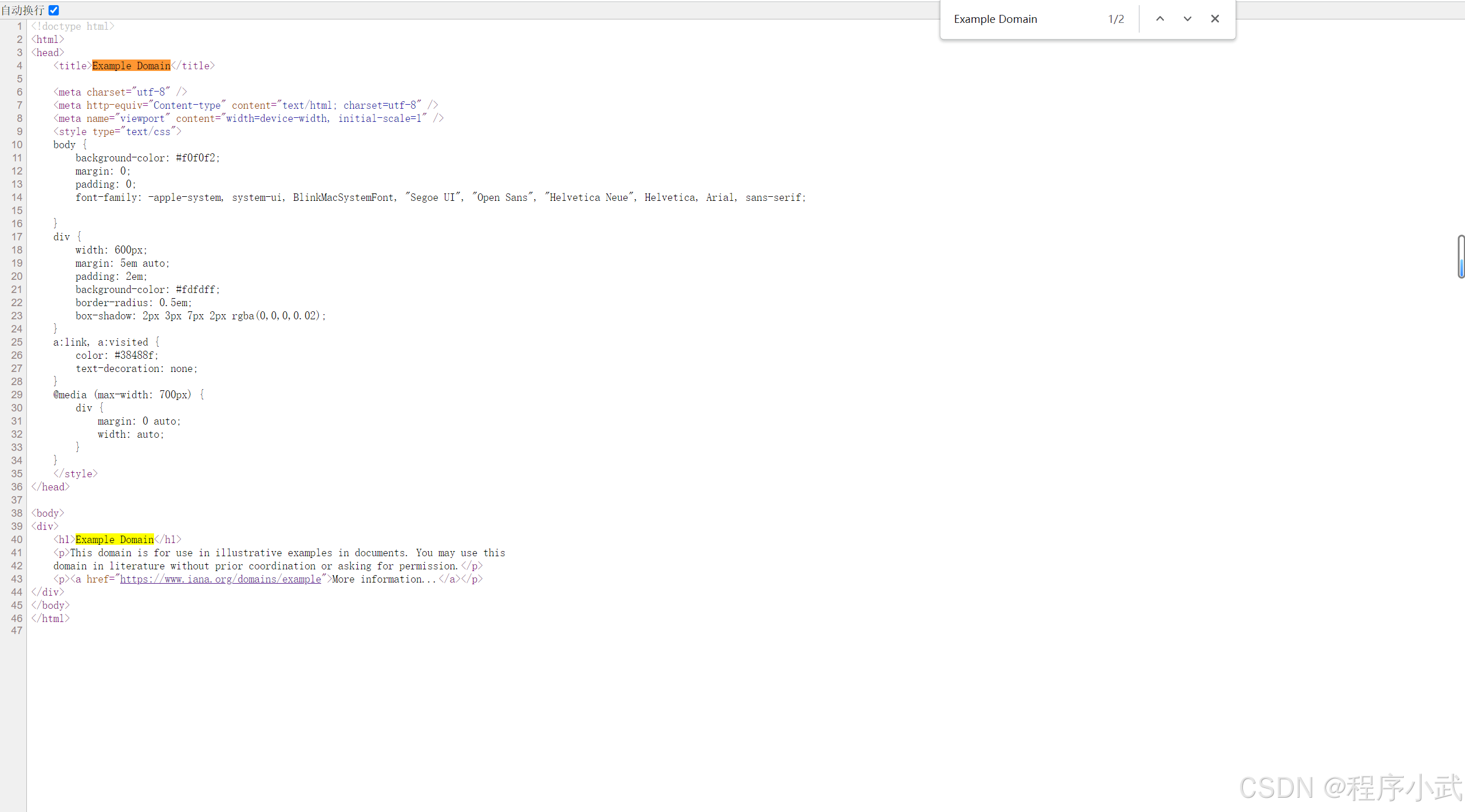
-
检查 HTML 标签:通常网页的数据是以
,,等 HTML 标签嵌套在页面中的。通过查找特定的 CSS 类名或者 id 属性,我们可以直接定位到这些数据。
上述图片,可以看到搜索的结果在源代码里面
- 假如存在在源代码,示例代码:
import requestsfrom bs4 import BeautifulSoupurl = \'https://example.com/data-page\'#发送请求response = requests.get(url)#使用bs4初始解析对象soup = BeautifulSoup(response.text, \'html.parser\')#查找h1标签的数据data_items = soup.find_all(\'h1\')for item in data_items: #输出标签文本 print(item.text)解释:
-
requests:这是一个常用的 Python 库,用于发送 HTTP 请求并获取响应。这里我们用它来发送 GET 请求,获取网页内容 -
BeautifulSoup:这是一个 HTML 解析库,用于从网页的源代码中提取数据。在这里它用来解析获取到的 HTML 内容;;也可以使用其他库,比如re正则,xpath等
1.2 判断数据是否在源代码中
如果数据不直接出现在源代码中(也就是通过
ctrl +f搜索不到的情况),可能是通过 JavaScript 动态加载的。这时,我们需要进一步分析 HTTP 请求。
二、查看XHR请求和分析数据(源代码没有需要的数据)
为什么有些数据它没在页面源代码中?
有些网页数据通过 AJAX 请求动态加载。这类数据通常不在初始的页面源代码中,而是由 JavaScript 在后台发送 XHR(XMLHttpRequest)请求来获取。
2.1 如何分析需要的数据
步骤1(搜索):
- 打开开发者工具:按
F12打开浏览器的开发者工具,切换到 \"网络(Network)。 - 清除网络日志:点击清除按钮,确保开发者模式未打开时遗漏了请求。
- 刷新页面:使用ctrl+r快捷键刷新页面,在 “Network” 标签下,刷新页面并观察加载的网络请求。关注那些类型为
XHR或 的请求。 - 搜索需要的数据:一般可以搜索到网址、请求或响应头,以及响应内容,例如
搜索互动科技:
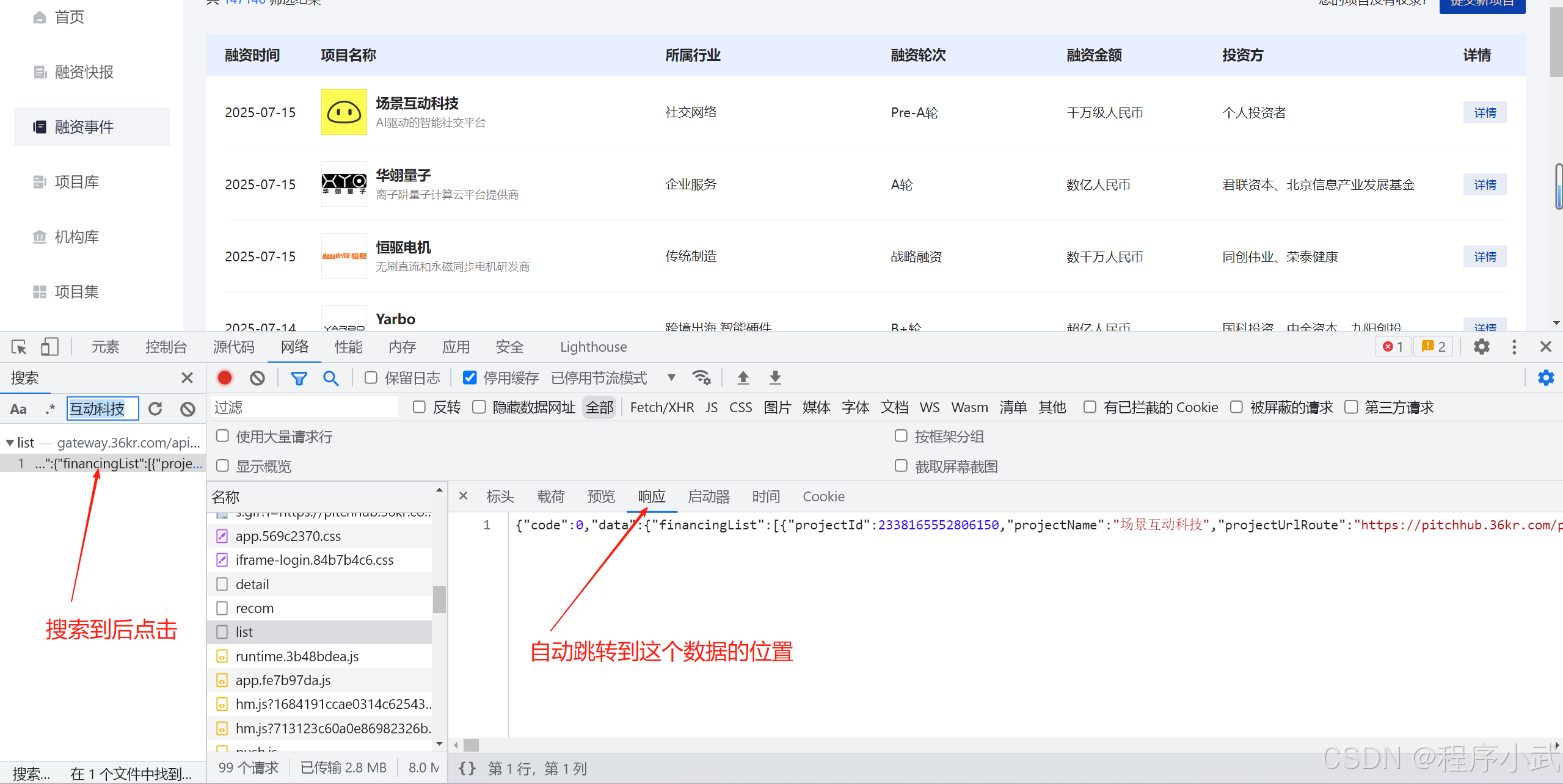
- 一般搜索的结果有很多,这个时候只能一个一个查看响应结果
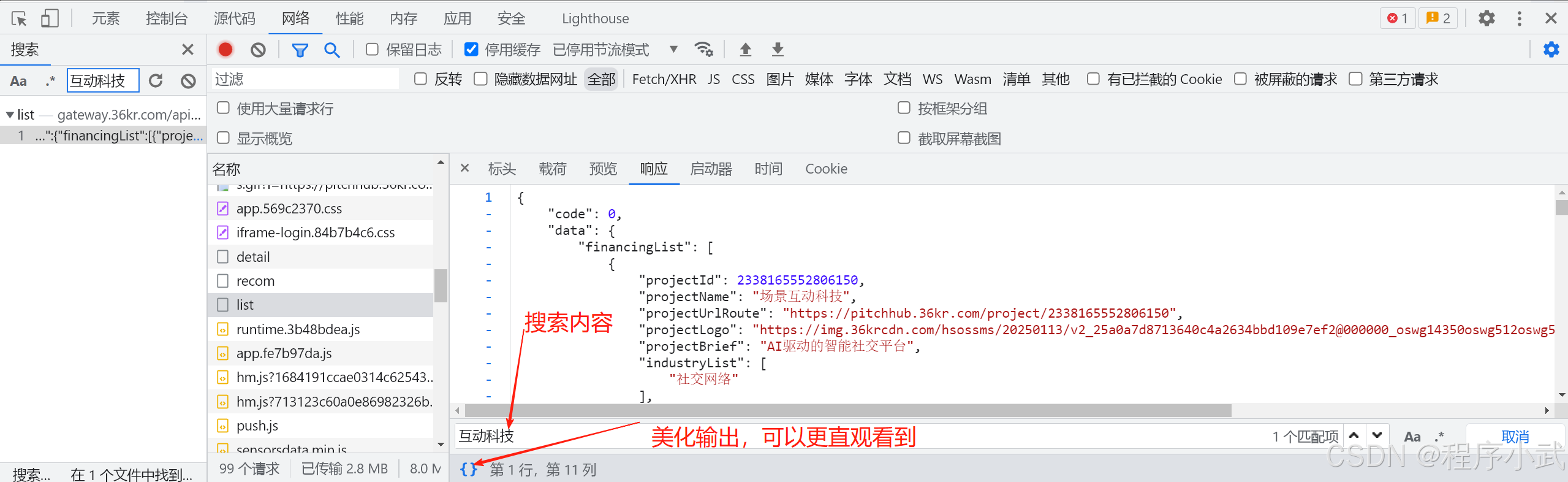
- 也可以在响应的结果里面使用ctrl+f进一步确认需要的数据,和搜索框一样
步骤2(发生请求):
- 清除网络日志:点击清除按钮,为了更好的捕获请求。
- 点击事件按钮:点击某个按钮(例如
文化娱乐按钮)后,页面会动态加载数据并发送网络请求。此时,通过开发者工具捕获这些请求,可以更精准地获取数据,节省时间和精力。
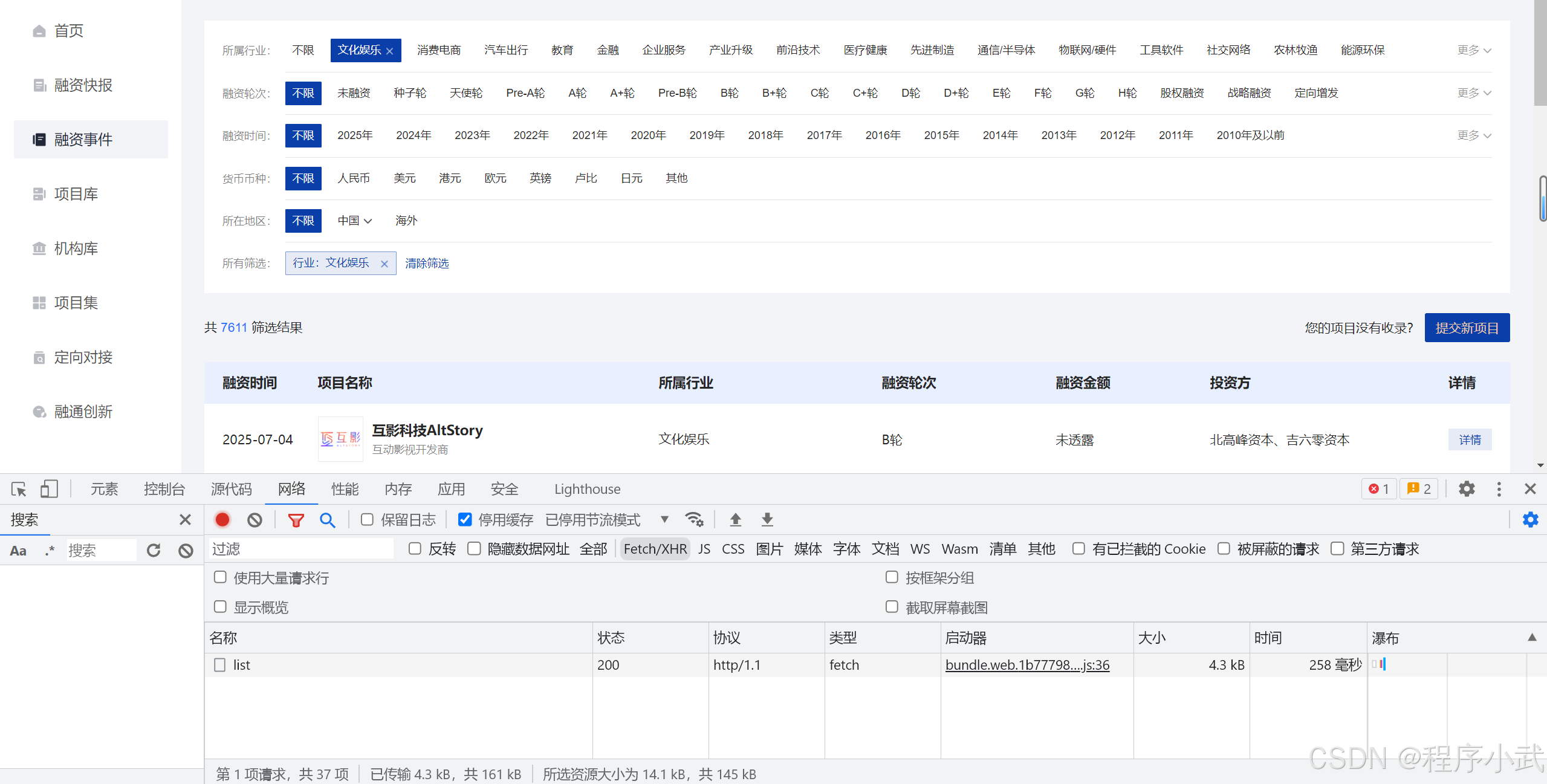
通过这种方法,可以过滤很多请求,而不需要大海捞针
- 查找数据源:这个时候在延续步骤1的方法进行搜索筛选,更容易找到
步骤3(看请求名字或大小):
1.查看请求名称:根据请求名称,判断是否是我们需要的接口请求。通常,API 请求会有易于识别的名称,如 data, list, items 等。
2.查看请求大小:有时请求的大小可以帮助我们判断其是否包含了我们需要的数据。较大的请求通常包含更多的信息,而小请求可能只是加载页面的一部分。
举例: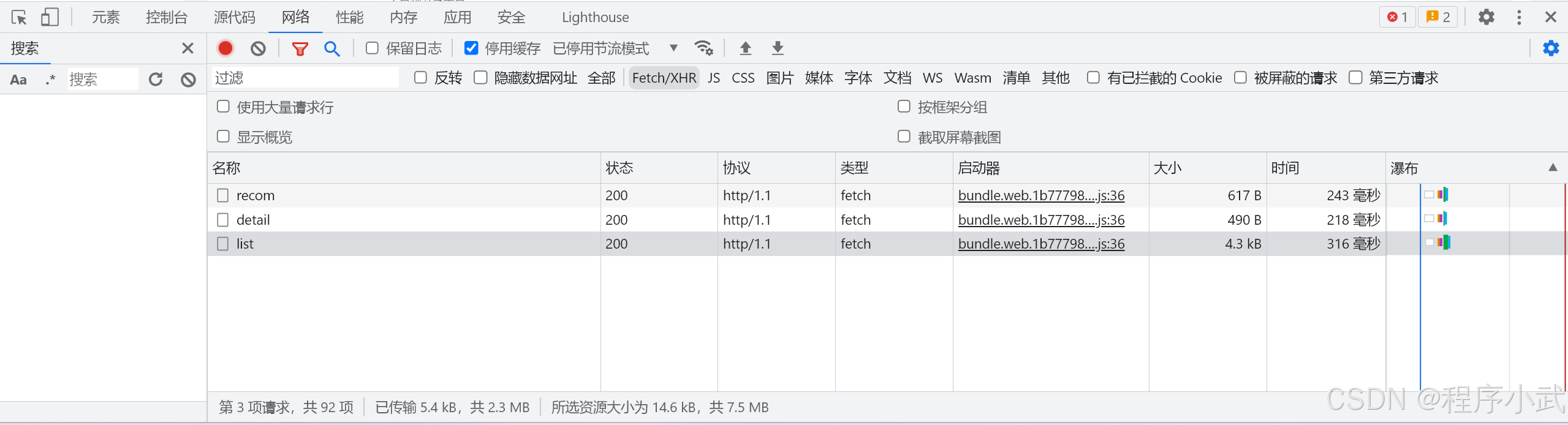
list、recom、detail、而list名字和大小(4.3kb)都非常符合,
通过分析这些请求名称或大小,可以更有效地找到包含所需数据的请求注意事项
如果你使用开发者工具无法找到需要的数据接口,可能有以下几个原因:
-
数据加密或混淆(概率大):某些网站可能会对API请求进行加密或混淆,以防止被抓取。你可能需要使用更复杂的技术,如逆向工程,或者在请求头和请求体中注入特定的参数。
-
请求是通过WebSocket进行的:有些实时应用程序(例如聊天、股票数据等)使用WebSocket进行双向通信,这种数据流通常不会通过普通的HTTP请求展示。你可以使用开发者工具中的“网络”标签页监控WebSocket连接。
-
数据嵌入在WebSocket或WebWorker中:某些网站的数据请求可能不是通过标准HTTP,而是通过WebWorker或WebSocket进行的。这些数据可能需要额外的技巧才能捕捉到。
-
反爬虫机制:一些网站为了防止自动化抓取,可能会使用验证码、cookie验证、请求头检查等手段。你需要分析这些机制并想办法绕过它们。
-
加载延迟或分页加载:有些网站的数据可能是通过分页加载的,或是延迟加载的(比如懒加载)。你可以尝试模拟滚动页面,或者使用“时间”标签查看是否有时间延迟请求。
三 如何确定请求方法?
1. 点击标头按钮:
-
选择一个请求后,点击标头后,即可看到请求方法、网址等
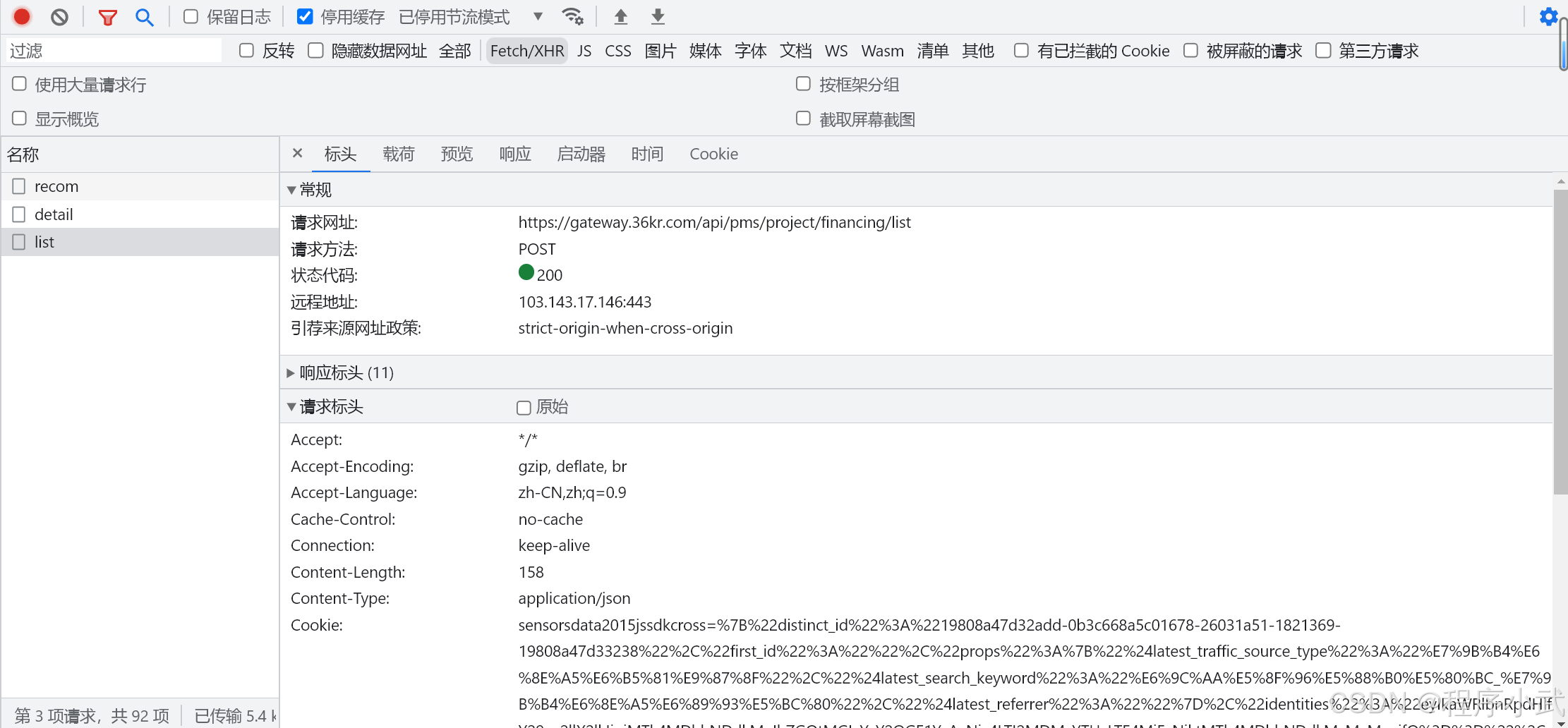
-
这里显示的请求方法为POST请求
XHR 请求的响应通常是 JSON 格式的数据,解析这个数据可以帮助我们提取需要的信息。常见的请求方法有
GET和POST。小结
GET 请求: 通常情况下,URL 中
包含 ?及其后面的查询参数(如 https://example.com/api/data?category=tech&page=2)表明这是一个 GET 请求。在 GET 请求中,数据通过 URL 的查询字符串传递,适用于从服务器获取资源或数据。POST 请求: 如果 URL 中
没有 ?,例如 https://example.com/api/data,通常表示这是一个 POST 请求。POST 请求常用于提交数据给服务器,数据通过请求体(body)传递,适用于数据创建、更新或提交表单信息等操作。
四、如何确定请求参数?
1.点击载荷按钮:
- 选择一个请求后,点击载荷后,即可看到请求参数

假如他显示表单数据,可以这么写代码:
显示表单数据示例代码(字典格式):
import requestsurl=\'https://example.com/api/data\'data = { \"column\": \"sse_main_latest\", \"pageNum\": \"1\", \"pageSize\": \"30\", \"sortName\": \"\", \"sortType\": \"\", \"clusterFlag\": \"false\"}response = requests.post(url,data=data)
显示请求载荷示例代码(json格式):
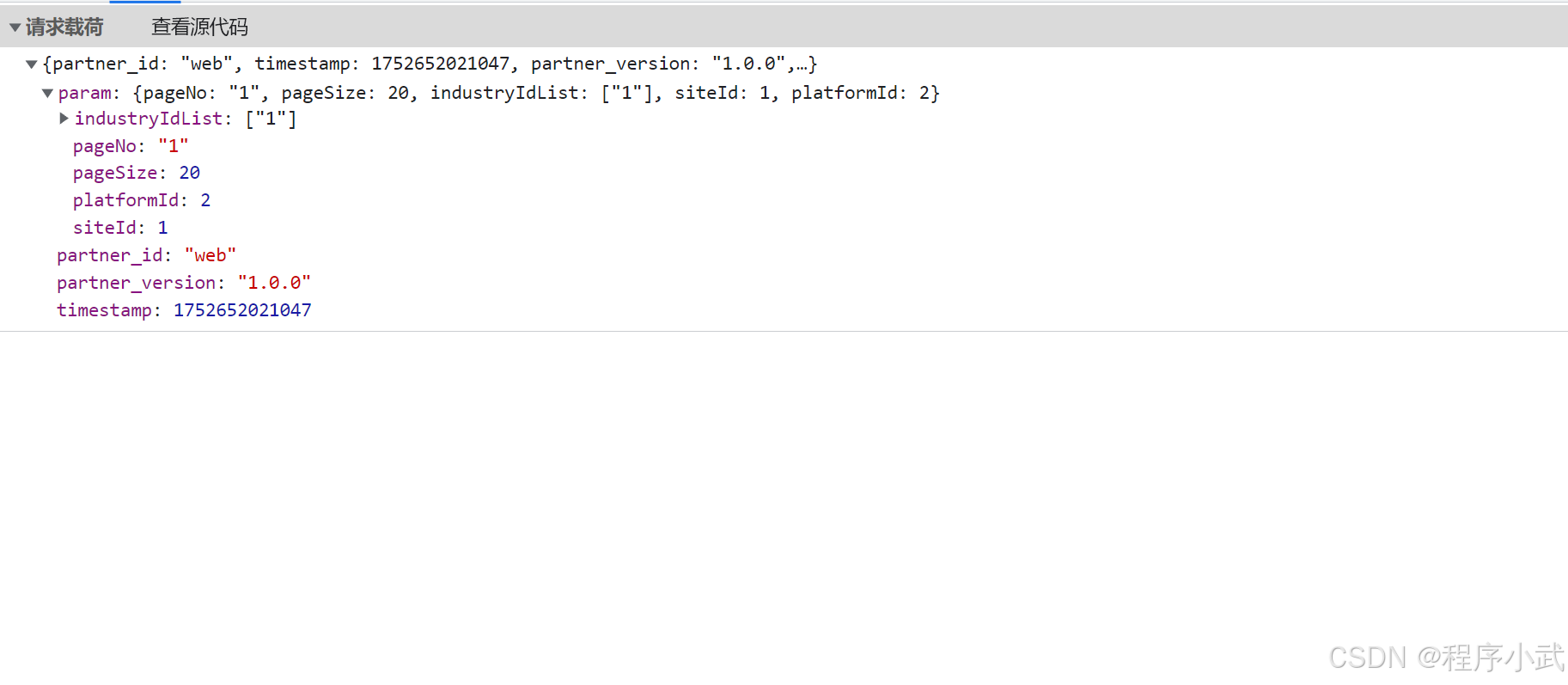
import requestsurl=\'https://example.com/api/data\'data={ \"partner_id\": \"web\", \"timestamp\": 1752652021047, \"partner_version\": \"1.0.0\", \"param\": { \"pageNo\": \"1\", \"pageSize\": 20, \"industryIdList\": [ \"1\" ], \"siteId\": 1, \"platformId\": 2 }}response = requests.post(url,json=data)- 点击
查看源代码后,鼠标选中后右键复制,粘贴到变量名即可
显示请求参数示例代码:
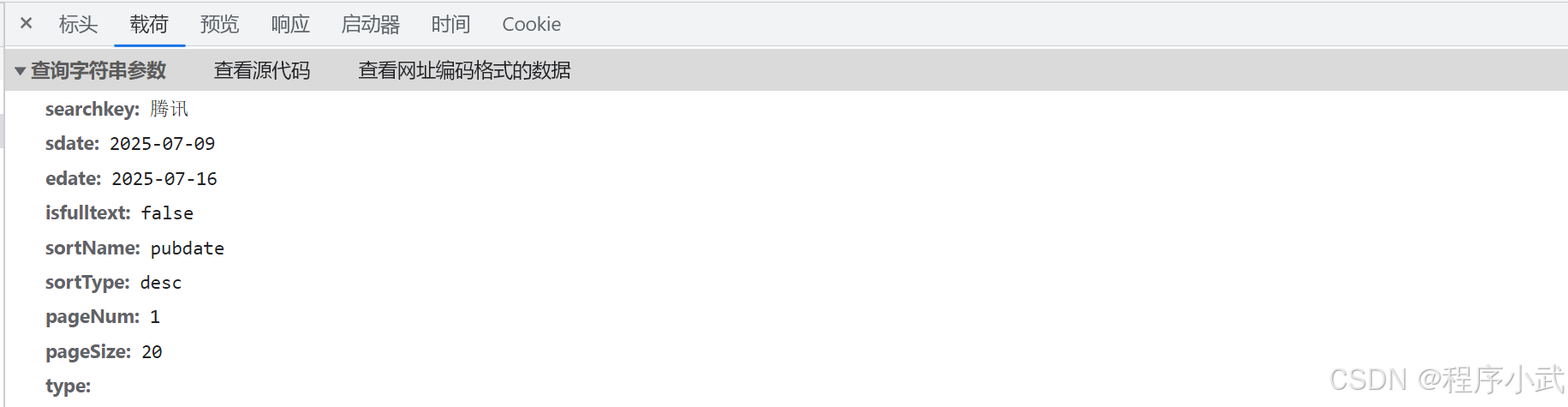
import requestsurl = \"http://www.example.com.cn/new/fulltextSearch/full\"params = { \"searchkey\": \"腾讯\", \"sdate\": \"2025-07-09\", \"edate\": \"2025-07-16\", \"isfulltext\": \"false\", \"sortName\": \"pubdate\", \"sortType\": \"desc\", \"pageNum\": \"1\", \"pageSize\": \"20\", \"type\": \"\"}response = requests.get(url, headers=headers, params=params)- 写法二:
import requestsurl = \"http://www.example.com.cn/new/fulltextSearch/full?searchkey=腾讯&sdate=2025-07-09&edate=2025-07-16&isfulltext=false&sortName=pubdate&sortType=desc&pageNum=1&pageSize=20&type=\"response = requests.get(url)- 写法一的话容易修改内容,但是写的比较麻烦
- 写法二的话不容易修改内容,但是不麻烦
- 根据需要选择
小结
假如params是表示请求的数据:
data=params:适用于 POST 请求,也可用于 GET 请求(显示请求表单使用)json=params:用于将数据以 JSON 格式发送,适用于 API 请求(显示请求载荷使用)根据网页实际情况选择,没有请求参数的话则不需要携带
五、如何确定该携带什么请求头?
1. 点击标头按钮 》点击请求标头,例如:
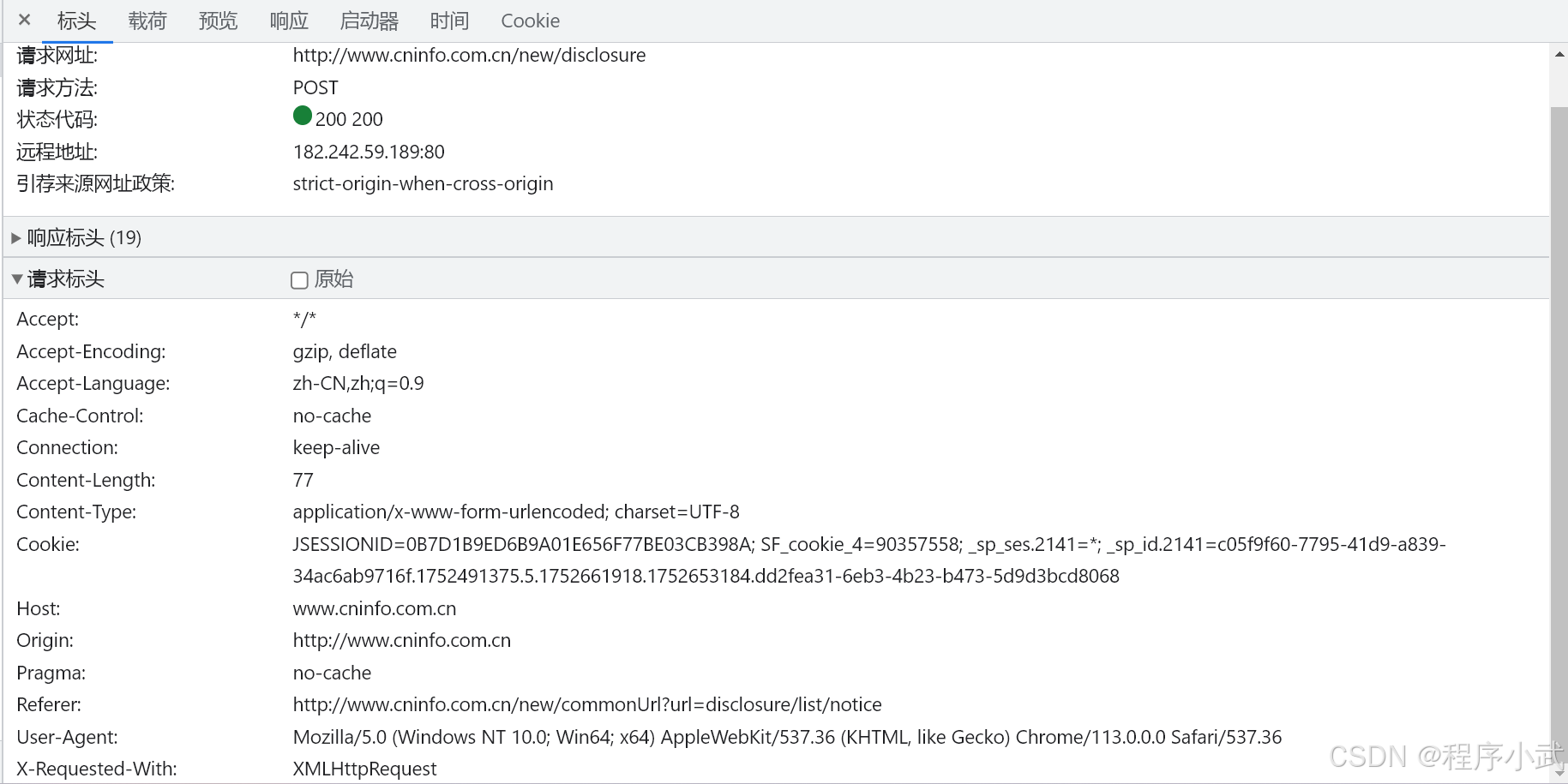
请求标头一般是键值对的形式
为什么要携带请求头?
- 携带请求头的目的是尽量模拟真实浏览器请求,
- 避免被目标网站识别为爬虫导致拒绝服务。
伪装的像正常用户访问访问,你也不希望爬虫程序对你的网址进行爬取
爬虫请求头推荐携带参数说明
请求头 是否必需 作用说明 Accept建议携带 告诉服务器客户端希望接受的数据类型, */*即可Accept-Encoding建议携带 支持的压缩格式,如 gzip, deflate,提升传输效率Accept-Language可选 语言偏好,通常带上更真实,如 zh-CN,zh;q=0.9Cache-Control可选 通常写 no-cache,避免缓存数据,确保数据实时Connection建议携带 keep-alive保持连接,减少建立连接的开销Content-Length不用手动设置 由请求库自动生成,避免错误 Content-Type必需(视请求类型) POST 请求时说明提交数据格式,如 application/x-www-form-urlencoded; charset=UTF-8Cookie视情况 需要登录或身份验证时携带,模拟用户会话 Host一般自动 请求库一般自动设置,可以不用手动写 Origin视情况 跨域请求时有用,模拟真实请求来源 Pragma可选 通常和 Cache-Control类似,避免缓存Referer建议携带 模拟来源页面,有些网站检查来源防止爬虫 User-Agent必需 标识请求客户端,模拟浏览器必不可少 X-Requested-With可选 AJAX 请求标识,模拟前端请求
小结
- 必须携带:
User-Agent、Content-Type(POST 请求)、Accept、Referer(大部分防爬网站会校验) - 视情况携带:
Cookie(需登录时)、Origin、X-Requested-With - 自动生成:
Content-Length、Host一般不用手动写 - 其它请求头可根据需要添加或省略,主要目的是模拟浏览器请求环境,避免被识别为爬虫。
如果你能抓包分析目标网站浏览器的真实请求,尽量复刻关键请求头参数,能大幅提升爬虫成功率。
注意事项
如果你已经找到了数据接口,但无法请求到数据,可能是由于以下几个原因:
-
缺少必要的请求头(Headers):许多接口请求需要特定的请求头(如
User-Agent、Authorization、Referer等)。确保你复制了正确的请求头,并在你的请求中加入这些信息 -
请求头过于复杂触发反爬虫机制:
如果你携带了过多的请求头,特别是包含了很多通常由浏览器自动生成的标头(如 Accept-Language、Accept-Encoding、Connection 等),有可能会触发网站的反爬虫机制。一些网站会检查请求头,如果它们检测到不符合正常浏览器行为(例如,某些头信息显得过于“完美”或不自然),就可能会拒绝请求。
解决方案:
- 简化请求头:尽量只保留最必要的请求头,如 User-Agent 和 Referer。有时候过多的请求头反而显得不真实。
- 模拟正常的请求头:根据你实际观察到的浏览器行为,模仿正常请求头而非通过“完美化”生成头。
-
Cookie问题:一些网站在请求数据时需要使用特定的 Cookie,或者要求请求中携带会话信息。如果你没有正确处理 Cookie 或者会话信息,就可能无法成功请求数据。你可以在开发者工具的“存储”或“Cookies”标签页中查看需要的 Cookie,并在你的爬虫请求中模拟这些信息。
-
接口参数过期或无效:有些接口的请求参数(例如时间戳、签名、token等)可能会过期或需要更新。如果你的请求中包含过期的参数,服务器可能会拒绝返回数据。你需要确保请求的参数是最新的。
-
CORS(跨域资源共享)限制:一些API接口可能启用了CORS限制,只允许来自特定域名的请求。如果你的请求是从不同的域名发出的,可能会被拒绝。你可以尝试使用浏览器插件或代理服务器绕过CORS限制,或者将请求发送到一个与目标API同域的服务器上。
六、如何确定数据解析方式?
在Python爬虫中,不同的数据格式通常需要使用不同的解析方法。以下是如何解析常见数据格式的一些方法:
1. 解析HTML(数据在源代码)
HTML页面可以使用
BeautifulSoup或lxml来解析和提取数据。下面是使用BeautifulSoup的基本示例:假如响应数据为(html源代码):
Example Domain
This domain is for use in illustrative examples in documents. You mayuse this domain in literature without prior coordination or asking forpermission.
示例代码:
import requestsfrom bs4 import BeautifulSoupresponse = requests.get(\'https://example.com\')soup = BeautifulSoup(response.text, \'html.parser\')# 提取页面中的所有标题(h1标签)titles = soup.find_all(\'h1\')for title in titles: print(title.get_text())2. 解析JSON响应
当爬取的响应数据是JSON格式时,通常使用
requests库进行请求并且可以通过
.json()方法直接解析JSON数据。假如响应数据为:
{ \"origin2\": \"306.60.94.138\", \"origin3\": \"103.30.91.135\", \"origin4\": \"102.65.93.137\", \"origin5\": \"108.60.96.138\", \"origin6\": \"406.63.95.131\",}示例代码:
import requestsresponse = requests.get(\'https://example.com/api/data\')data = response.json() # 自动解析为Python字典#考验字典的基础操作print(data[\'orrigin2\'])3. 解析JavaScript(JS)
如果响应是包含JavaScript的HTML页面,或返回的JS数据(例如:JSON数据嵌入JS中),可以使用
BeautifulSoup和re(正则表达式)结合来提取。假设页面中的JavaScript包含了JSON数据,像这样:
const fpsList = [{\"valid_minute\": 3, \"ip\": \"114.231.255.145\", \"last_check_time\": \"2025-07-18 15:45:05\", \"is_valid\": true, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 162, \"port\": \"22821\"}, {\"valid_minute\": 3, \"ip\": \"121.226.101.177\", \"last_check_time\": \"2025-07-18 15:30:03\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 280, \"port\": \"16677\"}, {\"valid_minute\": 3, \"ip\": \"114.232.2.182\", \"last_check_time\": \"2025-07-18 15:15:13\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 100, \"port\": \"16789\"}, {\"valid_minute\": 3, \"ip\": \"218.91.189.205\", \"last_check_time\": \"2025-07-18 15:00:03\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 124, \"port\": \"21092\"}, {\"valid_minute\": 3, \"ip\": \"180.120.133.231\", \"last_check_time\": \"2025-07-18 14:45:02\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 162, \"port\": \"18074\"}, {\"valid_minute\": 3, \"ip\": \"114.231.255.164\", \"last_check_time\": \"2025-07-18 14:30:02\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 223, \"port\": \"18174\"}, {\"valid_minute\": 3, \"ip\": \"114.232.4.175\", \"last_check_time\": \"2025-07-18 14:15:03\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 240, \"port\": \"21985\"}, {\"valid_minute\": 3, \"ip\": \"117.86.174.31\", \"last_check_time\": \"2025-07-18 14:00:02\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 286, \"port\": \"15829\"}, {\"valid_minute\": 3, \"ip\": \"114.232.125.73\", \"last_check_time\": \"2025-07-18 13:45:02\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 253, \"port\": \"20893\"}, {\"valid_minute\": 3, \"ip\": \"117.86.174.9\", \"last_check_time\": \"2025-07-18 13:30:03\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 226, \"port\": \"22858\"}, {\"valid_minute\": 3, \"ip\": \"49.79.138.177\", \"last_check_time\": \"2025-07-18 13:15:08\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 124, \"port\": \"18541\"}, {\"valid_minute\": 3, \"ip\": \"114.231.255.156\", \"last_check_time\": \"2025-07-18 13:00:05\", \"is_valid\": false, \"location\": \"\\u5357\\u901a\\u5e02\", \"speed\": 117, \"port\": \"17814\"}]你可以使用如下代码解析:
import requestsimport reimport jsonresponse = requests.get(\'https://example.com\')html = response.text# 正则提取 JS 代码中的 JSON 数据match = re.search(r\'var data = ({.*?});\', html)if match: json_data = json.loads(match.group(1)) print(json_data)七、总结
文章总结:
本文系统讲解了爬虫开发的核心流程与实战技巧,涵盖以下关键内容:
-
爬虫本质解析:明确爬虫是通过代码模拟浏览器操作,自动化获取网页数据的技术,强调学习HTML基础的重要性。
-
数据定位方法:
- 静态页面数据:通过查看网页源代码,利用关键字搜索、标签定位(如、
)提取信息。- 动态加载数据:分析XHR请求,通过开发者工具监控网络请求,筛选API接口并验证响应内容。
请求分析与模拟:
- 请求方法:区分GET与POST请求的特征(如URL参数、请求体),根据场景选择合适方法。
- 参数与请求头:解析表单数据、JSON载荷,强调携带关键请求头(如User-Agent、Referer)模拟真实浏览器,避免反爬机制。
数据解析技巧:
- HTML解析:使用BeautifulSoup或lxml提取标签内容。
- JSON与JS处理:通过
.json()方法解析API响应,结合正则表达式提取嵌入在JS中的数据。
实战注意事项:应对反爬虫(如验证码、Cookie验证)、分页加载、CORS限制等问题的解决方案。
希望这篇文章能帮助你更好地理解如何进行网页数据抓取。
- 静态页面数据:通过查看网页源代码,利用关键字搜索、标签定位(如


