python爬虫入门级讲解
一、驱动浏览器
1.selenium库驱动浏览器
作用:用代码远程操控浏览器,让它像真人一样自动完成网页点击、输入、滚动、截图等所有可见操作
核心概述:
-
组成:浏览器原生 WebDriver(驱动) + 客户端代码(Python/Java 等)。
-
流程:脚本 → WebDriver → HTTP 命令 → 浏览器 → 执行动作 → 结果返回。
-
功能:元素定位、点击/输入、JS 执行、Cookie/LocalStorage、滚动、截图、下载、无头模式。
-
浏览器支持:Chrome、Edge、Firefox、Safari、IE(已弃)。
安装WebDriver
以edge为例
搜索edgedriver下载
点开官网下拉 下方有不同版本
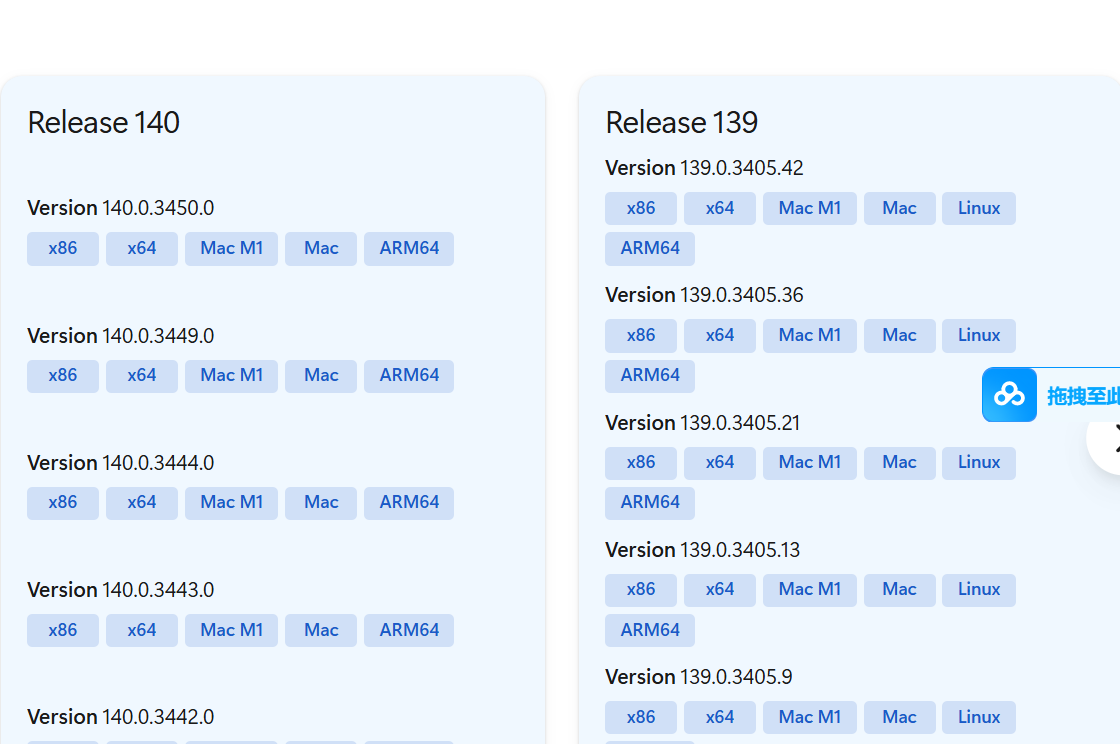
挑选版本
点击右上角三个点:...
点击帮助与反馈中的红框框住部分
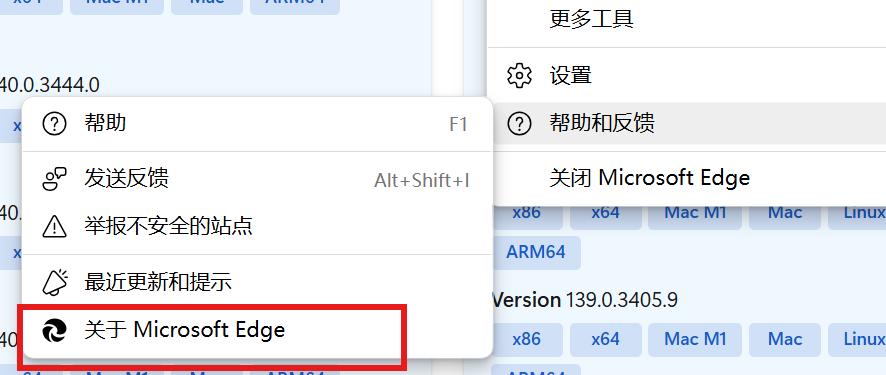
选择对应版本

下载完成后:
解压完点开复制该应用程序
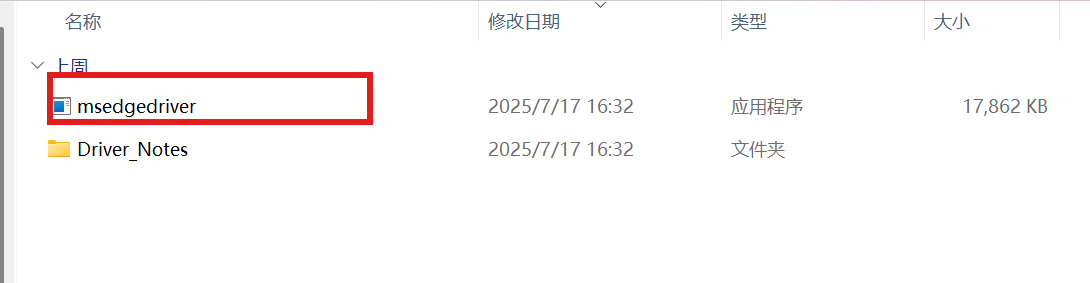
在cmd中找到python位置
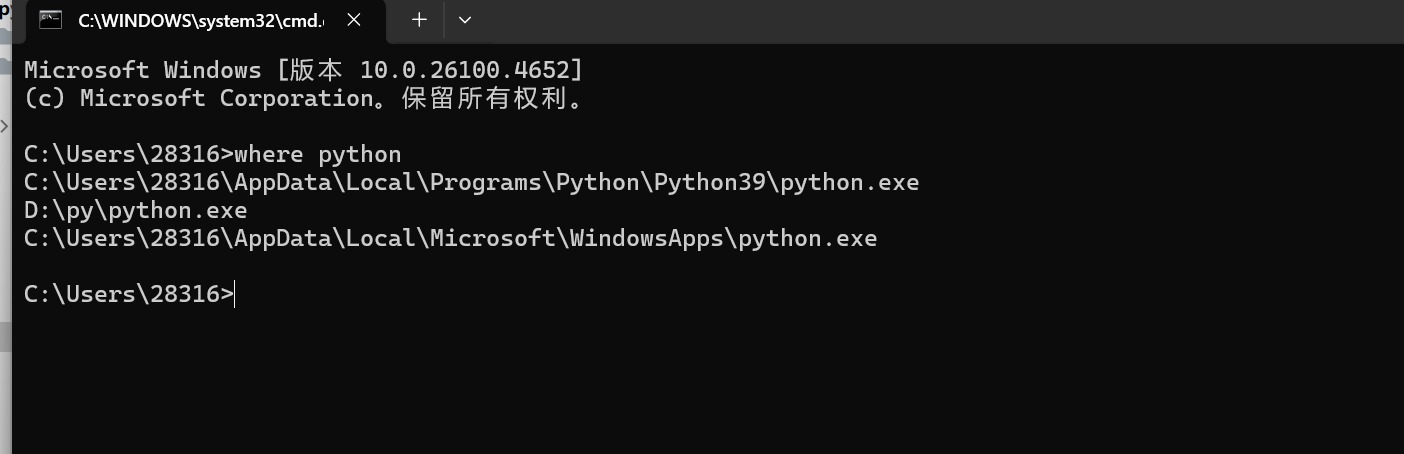
在路径中找到Scripts文件点开
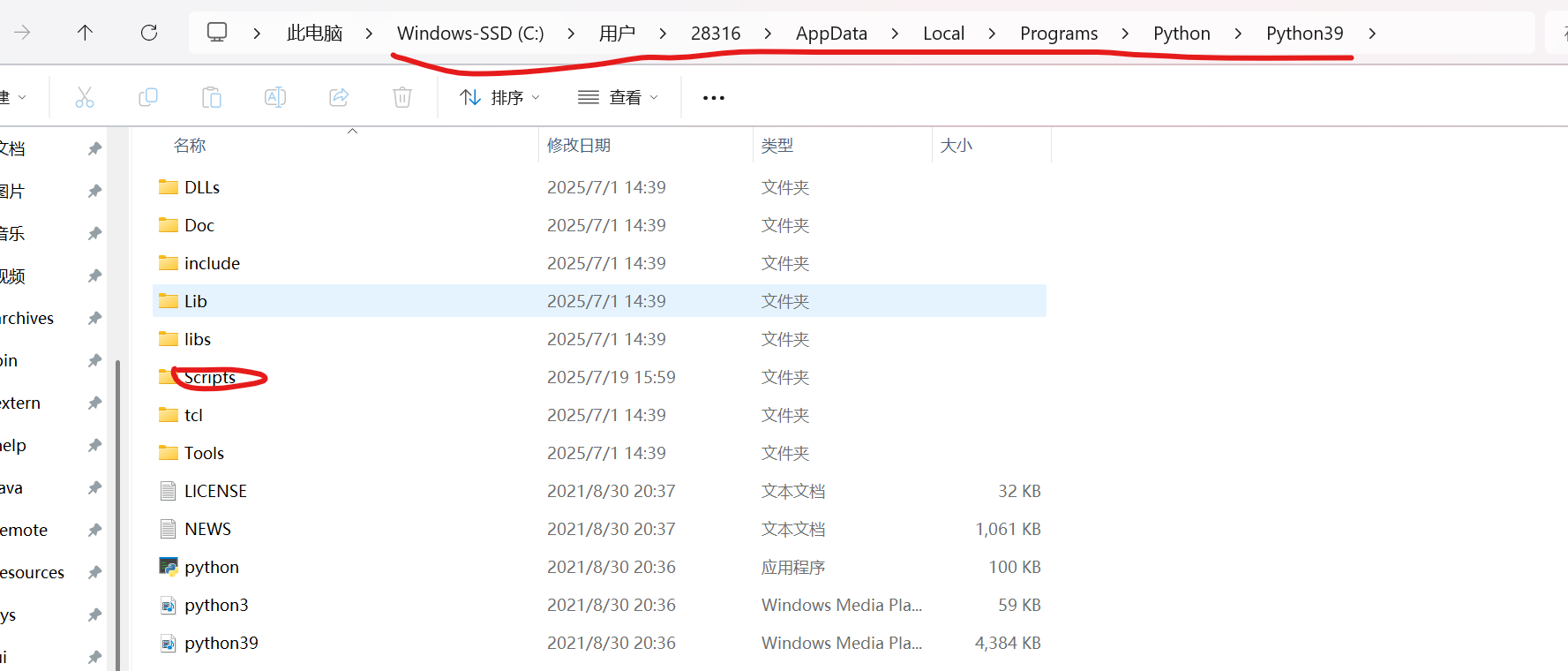
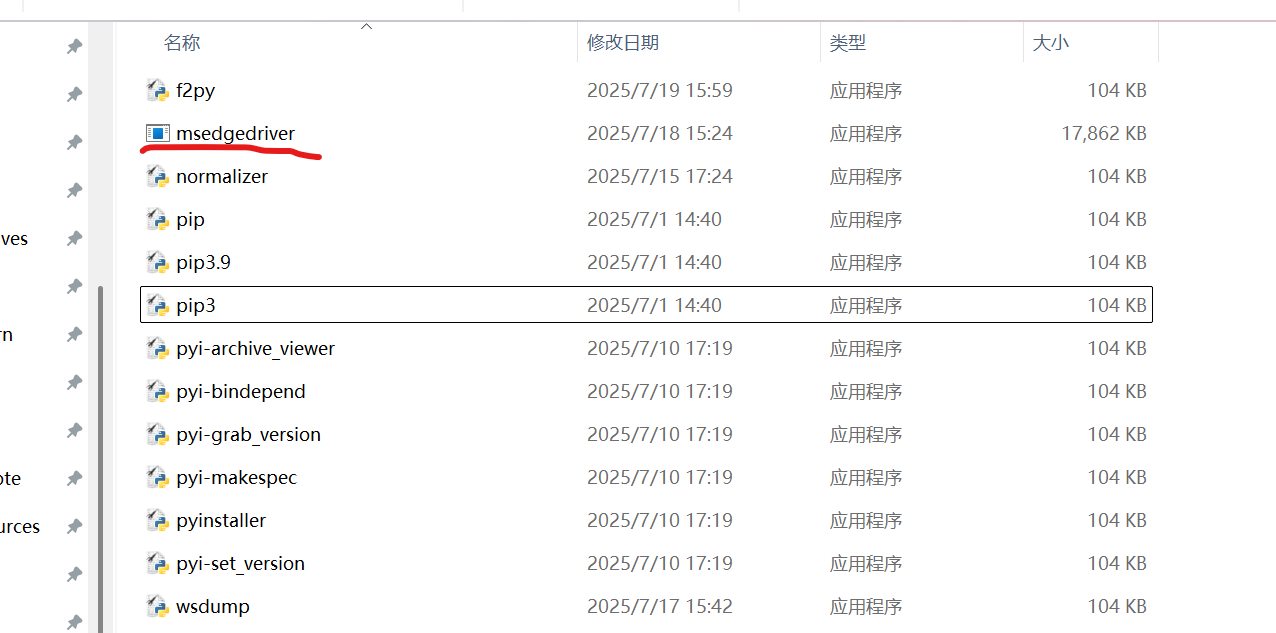
将驱动复制到文件内(完成WebDriver安装)
二、驱动浏览器
使用selenium之前要先下载selenium库,因为是第三方库,可以使用pip下载
1.WebDriver使用形式如下:
webdriver.浏览器类型名()
webdriver.Edge(executable_path=\"edgedriver\",port = 0,options = None)
executable_path:表示浏览器驱动路径
port :表示希望服务运行的端口,如果保留为0,驱动程序将会找到一个空闲端口
options:表示由类Options创建的对象,用于实现浏览器的绑定。
示例代码:
驱动阿b
from selenium import webdriver #导入 Selenium 的“总入口”模块 webdriver,后续用 webdriver.Edge() 创建浏览器实例。from selenium.webdriver.edge.options import Options #从 Selenium 的子模块中导入 Options 类,用来给 Edge 浏览器传递启动参数(例如指定可执行文件路径、无头模式等)。# from selenium.webdriver.common.keys import Keys# from selenium.webdriver.common.by import Byedge_options = Options() #创建一个 Options 对象,用来存放 Edge 浏览器的启动配置edge_options.binary_location = r\"C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe\"driver = webdriver.Edge(options=edge_options) #启动 Edge 浏览器,并把刚才的 edge_options 作为参数传入,从而让浏览器按指定路径启动。driver.get(\'https://www.bilibili.com/\')# driver.find_element(By.TAG_NAME,\"input\").send_keys(\"天地缓缓\",Keys.RETURN)input(\"\")2. 对网页操作
WebDriver内方法很多,查找元素记住这几种基本够用
def find_element(self, by=\'id\', value=None): # 查一个
def find_elements(self, by=\'id\', value=None):#查多个
def find_element(self, by=\'name\', value=None): # 查一个
def find_elements(self, by=\'name\', value=None):#查多个
def find_element(self, by=\'tag\', value=None): # 查一个 查标签名
def find_elements(self, by=\'tag\', value=None):#查多个
def find_element(self, by=\'class\', value=None): # 查一个
def find_elements(self, by=\'class\', value=None):#查多个
使用时导入两个库
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
加载浏览器网页方法:
get()方法:
功能:用于打开指定网页,在当前浏览器会话中加载url指向的网页
get(url)
打开阿b:
from selenium import webdriver #导入 Selenium 的“总入口”模块 webdriver,后续用 webdriver.Edge() 创建浏览器实例。from selenium.webdriver.edge.options import Options #从 Selenium 的子模块中导入 Options 类,用来给 Edge 浏览器传递启动参数(例如指定可执行文件路径、无头模式等)。edge_options = Options() #创建一个 Options 对象,用来存放 Edge 浏览器的启动配置edge_options.binary_location = r\"C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe\"driver = webdriver.Edge(options=edge_options) #启动 Edge 浏览器,并把刚才的 edge_options 作为参数传入,从而让浏览器按指定路径启动。driver.get(\'https://www.bilibili.com/\')示例代码:
3.获取 渲染后的网页代码
通过get()方法获取浏览器中的网页资源后,浏览器将自动渲染源代码内容,并生成渲染后的内容,这时使用page_source()方法即可获取渲染后的网页代码。
示例代码:
from selenium import webdriverfrom selenium.webdriver.edge.options import Optionsfrom selenium.webdriver.common.by import Byedge_options = Options()edge_options.binary_location =r\"C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe\"driver= webdriver.Edge(options=edge_options)driver.get(\'https://www.ptpress.com.cn/\')print(driver.page_source)获取和操作网页元素
除了正则表达式外,WebDriver提供了大量用于获取网页指定元素的方法。
在获取了网页的某个元素后,可以使用以下方法对此元素进行相应操作。
tag_name()方法:获取元素的名称
text()方法:获取元素的文本内容
click()方法:单击此元素
submit()方法:提交表单
send_keys()方法:模拟输入信息
size()方法:获取元素的尺寸
在元素中输入信息:
打开阿b并输入’天地缓缓‘
from selenium import webdriver #导入 Selenium 的“总入口”模块 webdriver,后续用 webdriver.Edge() 创建浏览器实例。from selenium.webdriver.edge.options import Options #从 Selenium 的子模块中导入 Options 类,用来给 Edge 浏览器传递启动参数(例如指定可执行文件路径、无头模式等)。from selenium.webdriver.common.keys import Keysfrom selenium.webdriver.common.by import Byedge_options = Options() #创建一个 Options 对象,用来存放 Edge 浏览器的启动配置edge_options.binary_location = r\"C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe\"driver = webdriver.Edge(options=edge_options) #启动 Edge 浏览器,并把刚才的 edge_options 作为参数传入,从而让浏览器按指定路径启动。driver.get(\'https://www.bilibili.com/\')driver.find_element(By.TAG_NAME,\"input\").send_keys(\"天地缓缓\",Keys.RETURN)input(\"\") 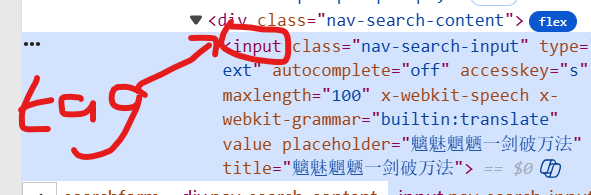
项目案例:
获取图书数据
获取该网页人民邮电出版社,Excel图书商品的书名,价格,作者等信息。
示例代码:
步骤1:
使用selenium库实现在官网进行Excel图书的搜索
步骤2:
由于存在多个页面,因此需要点击更多,点击后获取更多该图书的内容
步骤3:
使用上述的方法获取元素内容
步骤4:
该页面的图书全部获取后需要点击下一页
from selenium import webdriverfrom selenium.webdriver.edge.options import Optionsfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.common.by import Byimport timedef get_info(driver): time.sleep(5) eles_p = driver.find_elements(By.CLASS_NAME, \'book_item\') for ele_p in eles_p: ele_p.click() #获取该图书的更多内容 handles = driver.window_handles driver.switch_to.window(handles[-1]) time.sleep(5) name = driver.find_element(by=By.CLASS_NAME,value=\'book-name\').text price = driver.find_element(by=By.CLASS_NAME, value=\'price\').text author = driver.find_element(by=By.CLASS_NAME, value=\'book-author\').text with open(\'book.txt\',\'a\',encoding=\'utf-8\') as file: file.write(\'图书名:{}\\t价格:{}\\t作者名:{}\\n\'.format(name,price,author)) driver.close() handles = driver.window_handles driver.switch_to.window(handles[-1])edge_options = Options()edge_options.binary_location = r\"C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe\"driver = webdriver.Edge(options=edge_options) #启动Edge浏览器driver.get(\'https://www.ptpress.com.cn/\') #用driver控制浏览器elements = driver.find_elements(By.TAG_NAME, value=\"input\")[0].send_keys(\'excel\'+Keys.RETURN) #在搜索狂框输入Exceltime.sleep(3)handles = driver.window_handlesdriver.switch_to.window(handles[-1])driver.find_elements(by=By.ID,value=\'booksMore\')[0].click()handles = driver.window_handlesdriver.switch_to.window(handles[-1])get_info(driver)while True: driver.find_element(by=By.CLASS_NAME,value=\'ivu-page-next\').click() #点击下一页 get_info(driver)file.close()

