大模型应用班-第2课 DeepSeek使用与提示词工程课程重点 学习ollama 安装 用deepseek-r1:1.5b 分析PDF 内容
DeepSeek使用与提示词工程课程重点
Homework:ollama 安装 用deepseek-r1:1.5b 分析PDF 内容
python 代码建构:
1.小模型 1.5b 可以在 笔记本上快速执行
2.分析结果还不错
3. 重点是提示词 prompt 的写法
一、DeepSeek模型创新与特点
1. DeepSeek-V3模型特点
- 采用MoE架构(61个专家模块),总参数量671B但仅激活37B参数
- 引入MLA(Multi-Head Latent Attention)注意力机制,显著减小KV缓存
- 使用混合精度框架(FP8)降低训练计算量
- 在主流榜单中与顶级闭源模型性能相当
2. DeepSeek-R1模型突破
- 基于V3模型通过GRPO强化学习训练
- 思维链长度可达数万字,支持复杂推理
- 性能对标OpenAI o1模型
- 提供API调用(deepseek-reasoner)
二、模型部署与使用
1. 私有化部署选项
2. 部署方式
-
Ollama部署:支持macOS/Linux/Windows
ollama pull deepseek-r1:1.5bollama run deepseek-r1:1.5b -
vLLM高速推理框架: 公司使用
vllm serve deepseek-r1-distill-qwen-32b --tensor-parallel-size 2
三、提示词工程核心原则
1. 提示词组成要素(重要性排序)
- 任务:明确动词开头的目标
- 上下文:提供背景信息
- 示例:展示期望输出格式
- 角色:指定AI扮演的身份
- 格式:定义输出结构
- 语气:设定回答风格
2. 通用模型vs推理模型提示策略
四、Prompt实战技巧
1. 核心技巧
-
限制输出格式:如JSON结构化返回
\"以JSON格式输出包含名称、价格、流量的套餐信息\" -
使用分隔符:清晰区分输入部分
\'\'\'请总结以下三个引号内的文本\'\'\' -
CoT思维链:分步解决复杂问题
\"请按步骤计算:1.加1000 2.减500 3.乘1.2\"
2. 优化方法
- 迭代测试:根据输出持续调整Prompt
- 角色扮演:明确AI身份(如\"你是一名专业客服\")
- 示例引导:提供输入输出对示范
五、典型应用案例
1. 小球碰撞模拟
- 使用DeepSeek-R1生成HTML/JavaScript代码
- 通过多次交互优化物理效果
- 最终实现包含重力、弹力等参数的完整模拟
2. 客服场景Prompt优化
\"\"\"你是一名电信客服\"小瓜\",需:1. 保持礼貌官方口吻2. 准确提及套餐名称、价格、流量3. 不可使用网络用语已知套餐:- 经济套餐:50元/10G- 畅游套餐:180元/100G \"\"\"Ollama 运用代码
流程说明
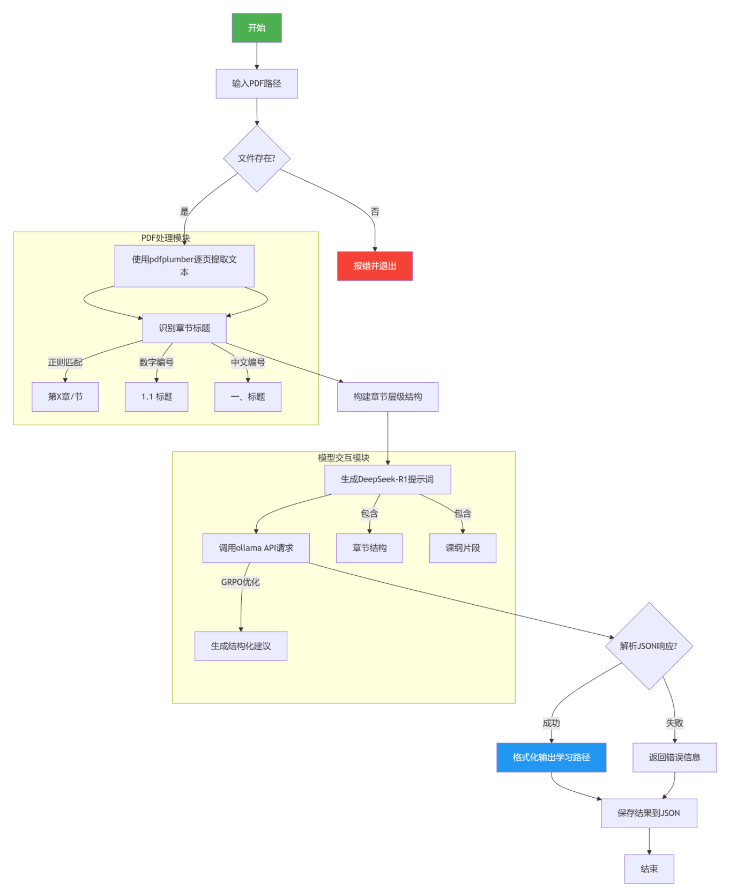
PDF解析阶段
1. 代码功能概述
该代码实现了一个课程大纲分析系统,主要功能包括:
2.2 学习路径生成
2.3 输出处理
3. 关键技术点
4. 扩展应用场景
5. 改进建议
- PDF文本提取:使用
pdfplumber库解析PDF文件,提取文本内容和章节结构 - 章节识别:通过正则表达式匹配多级标题(如\"第X章\"、\"1.1\"等格式)
- 学习路径生成:调用DeepSeek-R1模型(通过Ollama API)生成结构化学习建议
- 结果输出:
2. 核心模块解析
2.1 PDF解析与章节识别
- 文本提取:
使用pdfplumber.open()逐页读取PDF,通过extract_text()获取文本内容,并标注页码信息。 - 标题识别逻辑:
- 正则匹配多级标题(如
r\'^第[一二三四五六七八九十\\d]+章\'匹配中文章节) - 辅助规则:全大写文本、含\"学习\"/\"知识\"等关键词的短文本也被视为标题
- 层级判定:
- 一级标题:
第X章或1. 标题 - 二级标题:
1.1 标题或一、标题 - 三级标题:
1.1.1 标题
- 一级标题:
- 正则匹配多级标题(如
- 模型交互:
- 构建结构化提示词,包含章节树状结构和课纲前8000字符
- 调用DeepSeek-R1时启用
temperature=0.2和top_p=0.9,平衡创造性与稳定性 - 响应解析优先提取JSON块(兼容模型可能附加的解释文本)
- 错误处理:
- JSON解码失败时保留原始响应
- 捕获API超时等异常
- 控制台展示:
格式化输出学习阶段、核心概念、练习顺序等,使用符号图标(如📖、🎯)增强可读性 - JSON持久化:
按时间戳生成文件名,确保ASCII转义关闭(ensure_ascii=False)以支持中文 -
PDF解析优化
- 混合正则规则与启发式判断,提升标题识别准确率
- 记录页码+行号,便于人工校验
-
大模型工程化应用
- 两阶段生成:先提取章节结构,再填充细节(如学习目标、练习类型)
- 通过
num_predict=2000确保长文生成完整性
-
结构化输出设计
{ \"learning_stages\": [{ \"stage_number\": 1, \"key_concepts\": [\"核心概念1\", \"核心概念2\"], \"practice_order\": [\"练习类型1\", \"练习类型2\"] }]}字段覆盖教学设计的核心要素(时间预估、预习要求等)
- 教育自动化:适配在线教育平台的课程规划自动化
- 文档分析:扩展支持EPUB、Word等格式(需调整解析逻辑)
- 多模型支持:替换Ollama接口为其他LLM(如GPT-4)
- 性能优化
- 使用多线程处理PDF分页解析(注意
pdfplumber的线程安全性) - 缓存模型响应,减少重复请求
- 使用多线程处理PDF分页解析(注意
- 错误恢复
- 添加PDF解析失败时的备用文本提取方案(如
PyMuPDF)
- 添加PDF解析失败时的备用文本提取方案(如
- 交互增强
- 支持用户手动修正误识别的章节标题
- 支持控制台格式化展示和JSON文件保存
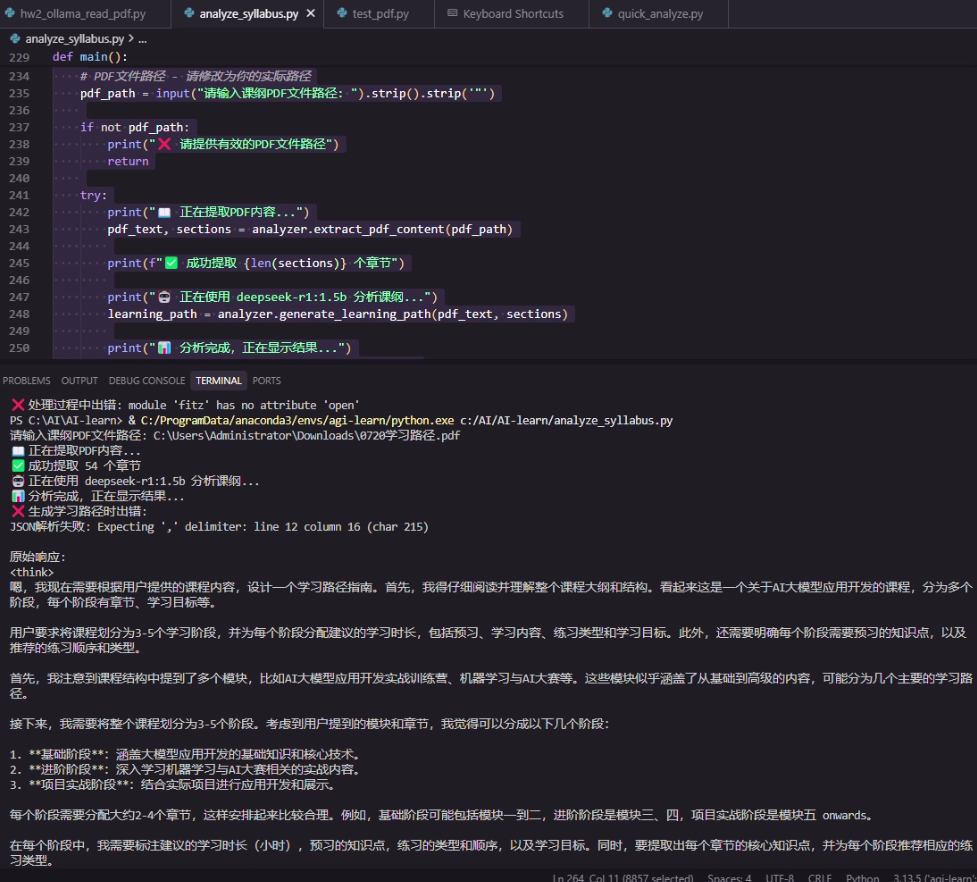
6.完整代码
try: import pdfplumberexcept ImportError: print(\"❌ 请安装pdfplumber: pip install pdfplumber\") exit(1)import ollamafrom typing import List, Dict, Tupleimport reimport jsonimport osfrom datetime import datetimeclass SyllabusAnalyzer: def __init__(self, model_name=\"deepseek-r1:1.5b\"): self.model_name = model_name def extract_pdf_content(self, pdf_path: str) -> Tuple[str, List[Dict]]: \"\"\" 提取PDF内容并识别章节结构 \"\"\" if not os.path.exists(pdf_path): raise FileNotFoundError(f\"PDF文件不存在: {pdf_path}\") full_text = \"\" sections = [] with pdfplumber.open(pdf_path) as pdf: for page_num, page in enumerate(pdf.pages): # 提取页面文本 text = page.extract_text() if text: full_text += f\"\\n=== 第{page_num+1}页 ===\\n{text}\\n\" # 按行分析文本,识别章节标题 lines = text.split(\'\\n\') for line_num, line in enumerate(lines): clean_line = line.strip() if clean_line and self._is_section_title(clean_line): level = self._determine_section_level(clean_line) sections.append({ \"title\": clean_line, \"level\": level, \"page\": page_num + 1, \"line\": line_num + 1 }) return full_text, sections def _is_section_title(self, text: str) -> bool: \"\"\"判断是否为章节标题\"\"\" # 匹配各种章节标题格式 patterns = [ r\'^第[一二三四五六七八九十\\d]+章\', # 第X章 r\'^第[一二三四五六七八九十\\d]+节\', # 第X节 r\'^\\d+\\.\\s+.+\', # 1. 标题 r\'^\\d+\\.\\d+\\s+.+\', # 1.1 标题 r\'^[一二三四五六七八九十]+、\', # 一、标题 r\'^([一二三四五六七八九十\\d]+)\', # (一)标题 ] for pattern in patterns: if re.match(pattern, text): return True # 检查是否为全大写标题或特殊格式 return len(text) int: \"\"\"确定章节层级\"\"\" if re.match(r\'^第[一二三四五六七八九十\\d]+章\', text): return 1 elif re.match(r\'^\\d+\\.\\s+\', text): return 1 elif re.match(r\'^\\d+\\.\\d+\\s+\', text): return 2 elif re.match(r\'^\\d+\\.\\d+\\.\\d+\\s+\', text): return 3 else: return 2 def generate_learning_path(self, pdf_text: str, sections: List[Dict]) -> Dict: \"\"\" 使用deepseek-r1模型生成学习路径 \"\"\" # 构建章节结构 section_structure = self._build_section_structure(sections) # 构建详细的提示词 prompt = self._build_analysis_prompt(section_structure, pdf_text) try: response = ollama.chat( model=self.model_name, messages=[{\"role\": \"user\", \"content\": prompt}], options={ \"temperature\": 0.2, \"top_p\": 0.9, \"num_predict\": 2000 } ) # 尝试解析JSON响应 content = response[\'message\'][\'content\'] # 提取JSON部分(如果响应包含其他文本) json_match = re.search(r\'\\{.*\\}\', content, re.DOTALL) if json_match: json_str = json_match.group() return json.loads(json_str) else: # 如果没有找到JSON,尝试直接解析 return json.loads(content) except json.JSONDecodeError as e: return { \"error\": f\"JSON解析失败: {str(e)}\", \"raw_response\": response[\'message\'][\'content\'] } except Exception as e: return { \"error\": f\"生成学习路径时出错: {str(e)}\", \"raw_response\": str(e) } def _build_section_structure(self, sections: List[Dict]) -> str: \"\"\"构建章节结构字符串\"\"\" structure_lines = [] for i, section in enumerate(sections[:30]): # 限制章节数量 indent = \" \" * (section[\'level\'] - 1) structure_lines.append(f\"{indent}{section[\'title\']} (第{section[\'page\']}页)\") return \"\\n\".join(structure_lines) def _build_analysis_prompt(self, section_structure: str, pdf_text: str) -> str: \"\"\"构建分析提示词\"\"\" return f\"\"\"你是一名专业的教学设计师和课程规划专家。请根据以下课纲内容,设计一份详细的学习路径指南。## 课纲章节结构:{section_structure}## 分析要求:1. 将整个课程合理划分为3-5个学习阶段2. 每个阶段建议学习2-4个章节3. 为每个阶段标注建议学习时长(以小时为单位)4. 明确指出每个阶段需要预习的知识点5. 推荐每个阶段的练习顺序和类型6. 提取每个章节的核心知识点(3-5个)## 输出格式(严格按照JSON格式):{{ \"course_title\": \"课程名称\", \"total_estimated_hours\": 总学习时长, \"learning_stages\": [ {{ \"stage_number\": 1, \"stage_name\": \"阶段名称\", \"chapters\": [\"章节1\", \"章节2\", \"章节3\"], \"suggested_hours\": 学习时长数字, \"prerequisites\": [\"预习知识点1\", \"预习知识点2\"], \"key_concepts\": [\"核心概念1\", \"核心概念2\", \"核心概念3\"], \"practice_order\": [\"练习类型1\", \"练习类型2\", \"练习类型3\"], \"learning_objectives\": [\"学习目标1\", \"学习目标2\"] }} ], \"study_tips\": [\"学习建议1\", \"学习建议2\", \"学习建议3\"]}}## 课纲内容:{pdf_text[:8000]}请严格按照上述JSON格式输出,确保所有字段都包含有意义的内容。\"\"\" def save_results(self, learning_path: Dict, output_file: str = None): \"\"\"保存分析结果到文件\"\"\" if output_file is None: timestamp = datetime.now().strftime(\"%Y%m%d_%H%M%S\") output_file = f\"learning_path_{timestamp}.json\" with open(output_file, \'w\', encoding=\'utf-8\') as f: json.dump(learning_path, f, ensure_ascii=False, indent=2) print(f\"学习路径已保存到: {output_file}\") def display_learning_path(self, learning_path: Dict): \"\"\"格式化显示学习路径\"\"\" if \"error\" in learning_path: print(\"❌ 生成学习路径时出错:\") print(learning_path[\"error\"]) if \"raw_response\" in learning_path: print(\"\\n原始响应:\") print(learning_path[\"raw_response\"]) return print(\"📚 课程学习路径分析\") print(\"=\" * 60) print(f\"课程名称: {learning_path.get(\'course_title\', \'未知课程\')}\") print(f\"预计总时长: {learning_path.get(\'total_estimated_hours\', \'未知\')} 小时\") print() for stage in learning_path.get(\'learning_stages\', []): print(f\"🎯 阶段 {stage.get(\'stage_number\', \'?\')}: {stage.get(\'stage_name\', \'未知阶段\')}\") print(f\" ⏱️ 建议时长: {stage.get(\'suggested_hours\', \'?\')} 小时\") print(f\" 📖 包含章节: {\', \'.join(stage.get(\'chapters\', []))}\") print(\" 🔍 核心知识点:\") for concept in stage.get(\'key_concepts\', []): print(f\" • {concept}\") print(\" 📋 预习要求:\") for prereq in stage.get(\'prerequisites\', []): print(f\" • {prereq}\") print(\" 🏃 练习顺序:\") for i, practice in enumerate(stage.get(\'practice_order\', []), 1): print(f\" {i}. {practice}\") print(\" 🎯 学习目标:\") for objective in stage.get(\'learning_objectives\', []): print(f\" • {objective}\") print(\"-\" * 60) if \'study_tips\' in learning_path: print(\"💡 学习建议:\") for tip in learning_path[\'study_tips\']: print(f\" • {tip}\")def main(): \"\"\"主函数\"\"\" # 初始化分析器 analyzer = SyllabusAnalyzer() # PDF文件路径 - 请修改为你的实际路径 pdf_path = input(\"请输入课纲PDF文件路径: \").strip().strip(\'\"\') if not pdf_path: print(\"❌ 请提供有效的PDF文件路径\") return try: print(\"📖 正在提取PDF内容...\") pdf_text, sections = analyzer.extract_pdf_content(pdf_path) print(f\"✅ 成功提取 {len(sections)} 个章节\") print(\"🤖 正在使用 deepseek-r1:1.5b 分析课纲...\") learning_path = analyzer.generate_learning_path(pdf_text, sections) print(\"📊 分析完成,正在显示结果...\") analyzer.display_learning_path(learning_path) # 保存结果 save_option = input(\"\\n是否保存结果到文件?(y/n): \").strip().lower() if save_option == \'y\': analyzer.save_results(learning_path) except FileNotFoundError: print(f\"❌ 找不到PDF文件: {pdf_path}\") except Exception as e: print(f\"❌ 处理过程中出错: {str(e)}\")if __name__ == \"__main__\": main()7. 输出截屏