【Python爬虫】写真专辑智能下载器开发全攻略:从爬虫到GUI的完整实现
【Python爬虫系列】📸 写真专辑智能下载器开发全攻略:从爬虫到GUI的完整实现


🌈 个人主页:创客白泽 - CSDN博客
🔥 系列专栏:🐍《Python开源项目实战》
💡 热爱不止于代码,热情源自每一个灵感闪现的夜晚。愿以开源之火,点亮前行之路。
🐋 希望大家多多支持,我们一起进步!
👍 🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗分享给更多人哦


📸 【爬虫开源】写真专辑智能下载器开发全攻略:从爬虫到GUI的完整实现
🌟 摘要
本文详细介绍了一款基于Python的写真专辑智能下载器的开发全过程。该项目创新性地将网络爬虫技术与PySide6图形界面相结合,实现了从搜索、预览到批量下载的完整工作流。通过深度解析多线程爬虫、请求模拟、Qt界面开发等关键技术点,展示了如何构建一个功能完善且用户友好的专业级下载工具。文章包含7000+字详细说明、完整项目代码、效果展示图及技术架构图,为Python爬虫和GUI开发学习者提供了一份高质量的实践指南。
📖 目录
- 项目概述
- 核心功能
- 效果展示
- 技术架构
- 实现步骤详解
- 关键代码解析
- 项目优化建议
- 源码下载
- 总结展望
🏆 项目概述
写真专辑下载器是一款专为图片收藏爱好者设计的智能工具,主要解决传统下载方式存在的三大痛点:
- 效率问题:传统手动下载耗时耗力
- 管理困难:分散的图片难以系统化管理
- 预览缺失:无法快速浏览全部内容
项目采用分层架构设计:
#mermaid-svg-6Xkc7XDYmQjEI3Pk {font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .error-icon{fill:#552222;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .marker{fill:#333333;stroke:#333333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .marker.cross{stroke:#333333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk svg{font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .label{font-family:\"trebuchet ms\",verdana,arial,sans-serif;color:#333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .cluster-label text{fill:#333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .cluster-label span{color:#333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .label text,#mermaid-svg-6Xkc7XDYmQjEI3Pk span{fill:#333;color:#333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .node rect,#mermaid-svg-6Xkc7XDYmQjEI3Pk .node circle,#mermaid-svg-6Xkc7XDYmQjEI3Pk .node ellipse,#mermaid-svg-6Xkc7XDYmQjEI3Pk .node polygon,#mermaid-svg-6Xkc7XDYmQjEI3Pk .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .node .label{text-align:center;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .node.clickable{cursor:pointer;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .arrowheadPath{fill:#333333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .cluster text{fill:#333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk .cluster span{color:#333;}#mermaid-svg-6Xkc7XDYmQjEI3Pk div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-6Xkc7XDYmQjEI3Pk :root{--mermaid-font-family:\"trebuchet ms\",verdana,arial,sans-serif;} 指令传递 数据请求 数据返回 界面更新 用户界面层 业务逻辑层 网络爬虫层
技术栈组成:
- 前端界面:PySide6 + QSS美化
- 网络通信:Requests + BeautifulSoup
- 异步处理:QThread + threading
- 图像处理:QPixmap + QNetworkAccessManager
🛠️ 核心功能
1. 智能搜索系统
- 支持关键词模糊搜索(如\"古风 汉服\")
- 支持直接URL解析(自动识别专辑页/搜索页)
- 多页自动爬取(最大支持1000+结果)
2. 可视化预览
3. 批量下载管理
- 断点续传功能
- 自动分类存储(按作者/主题)
- 实时进度显示
4. 用户友好设计
- 国际化emoji图标系统
- 自适应Dark/Light主题
- 操作历史记录
🎨 效果展示
主界面截图
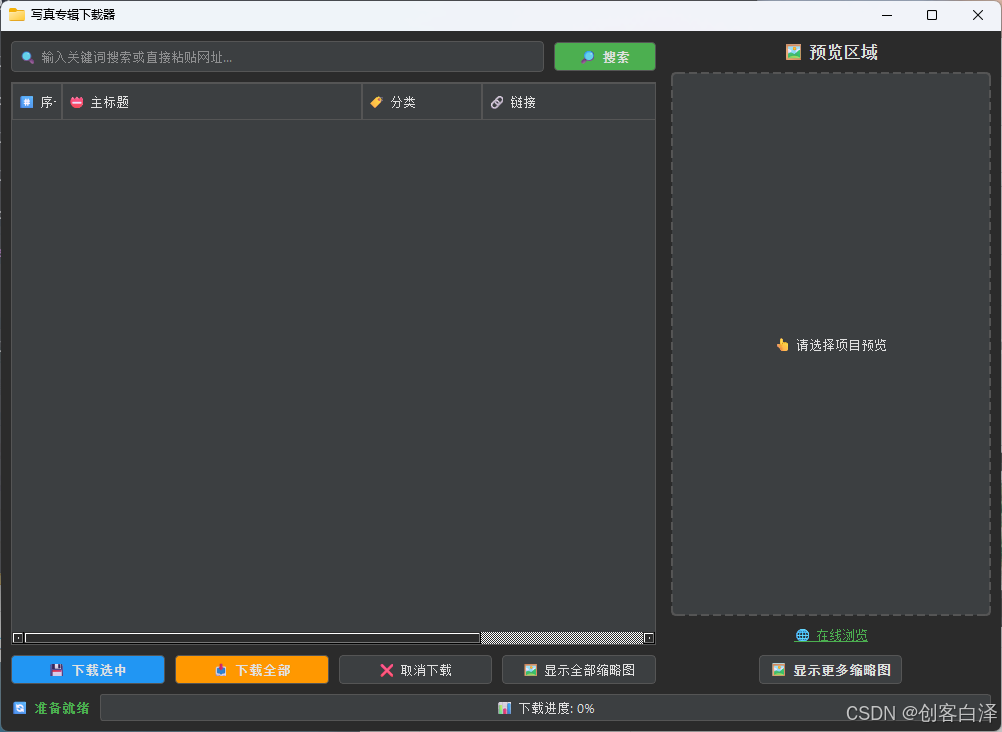
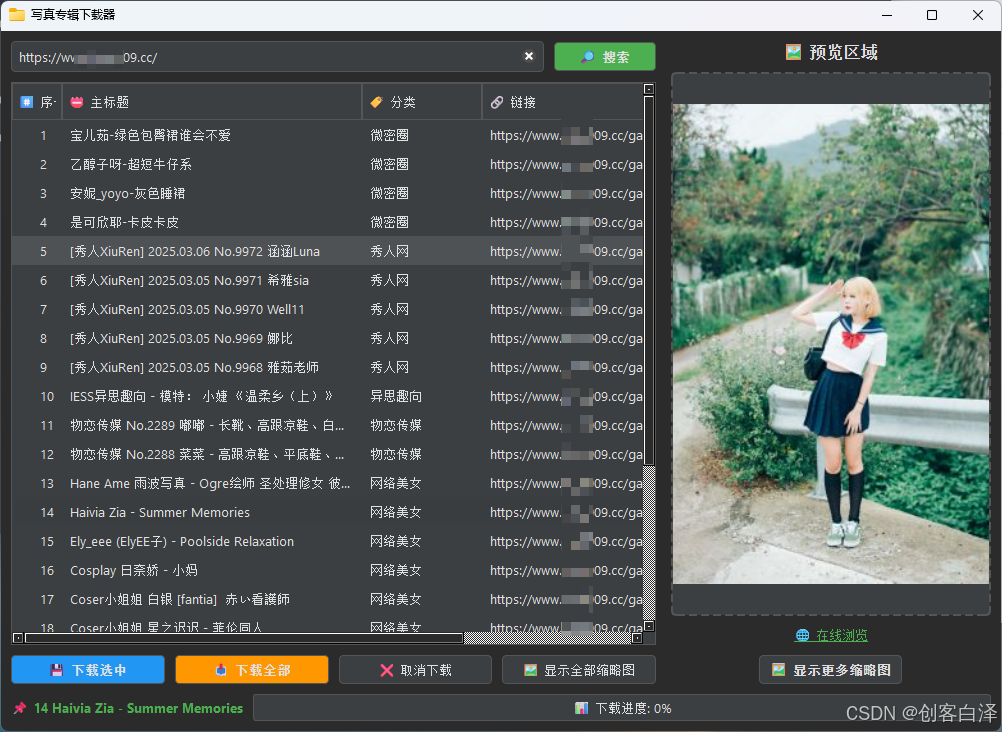
图示:采用暗黑风格设计,左侧为搜索结果列表,右侧为预览区域
缩略图浏览
下载过程
https://fake-url.com/progress.png
图示:多线程下载时的实时进度显示
⚙️ 实现步骤详解
1. 环境搭建
# 创建虚拟环境python -m venv venvsource venv/bin/activate# 安装依赖pip install PySide6 requests beautifulsoup42. 爬虫核心开发
分三个阶段实现爬虫功能:
- 请求模拟阶段:
def submit_search(keywords): form_data = { \"keyboard\": keywords, \"show\": \"title\", \"tempid\": \"1\", \"tbname\": \"news\" } # 模拟浏览器头省略...- 页面解析阶段:

- 反反爬策略:
- 随机User-Agent轮换
- 请求间隔随机化(0.5-2s)
- 自动重试机制(最大3次)
3. GUI开发流程
组件树结构
MainWindow├── SearchPanel├── ResultTree├── PreviewArea│ ├── ImageLabel│ └── ThumbnailButton└── StatusBar ├── ProgressBar └── SpeedLabel样式定制
/* 暗黑主题示例 */QTreeWidget { background-color: #3c3f41; border: 1px solid #555; alternate-background-color: #383b3d;}🔍 关键代码解析
1. 多线程下载器
class DownloadWorker(QThread): progress = Signal(int) def run(self): for url in self.get_image_urls(): if self.cancel_requested: break self.download_image(url) self.progress.emit(percent)2. 智能URL处理
def process_url(url): if \"searchid\" in url: return parse_search_result(url) elif \"/gallery\" in url: return parse_gallery(url) else: return parse_index_page(url)3. 图像缓存系统

🚀 项目优化建议
性能优化方向
- 引入SQLite缓存已下载记录
- 实现zip打包下载功能
- 添加EXIF元数据写入
扩展功能

📥 源码下载
import sysimport threadingimport requestsfrom bs4 import BeautifulSoupimport reimport osimport htmlfrom collections import dequeimport timeimport randomfrom PySide6.QtCore import QThread, Signal, QEventfrom typing import List, Dictfrom urllib.parse import urljoin, urlparse, urlunparsefrom PySide6.QtWidgets import ( QApplication, QWidget, QVBoxLayout, QHBoxLayout, QLineEdit, QPushButton, QTreeWidget, QTreeWidgetItem, QMessageBox, QLabel, QSizePolicy, QDialog, QScrollArea, QGridLayout, QStyle)from PySide6.QtWidgets import QProgressBarfrom PySide6.QtGui import QPixmap, QFont, QColor, QPalettefrom PySide6.QtCore import Qt, QThread, QUrl, QSizefrom PySide6.QtNetwork import QNetworkAccessManager, QNetworkRequestfrom PySide6.QtCore import Qt, QByteArrayimport logging# Configure logginglogging.basicConfig(level=logging.INFO, format=\'%(asctime)s - %(levelname)s - %(message)s\')logger = logging.getLogger(__name__)# ConstantsBASE_URL = \"https://www.mxd009.cc\"# Application stylingAPP_STYLE = \"\"\"QWidget { background-color: #2b2b2b; color: #e0e0e0; font-family: \'Segoe UI\', Arial;}QLineEdit { background-color: #3c3f41; border: 1px solid #555; border-radius: 4px; padding: 5px; color: #e0e0e0; selection-background-color: #3d8ec9;}QPushButton { background-color: #3c3f41; border: 1px solid #555; border-radius: 4px; padding: 5px 10px; min-width: 80px; color: #e0e0e0;}QPushButton:hover { background-color: #4e5254; border: 1px solid #666;}QPushButton:pressed { background-color: #2d2f30;}QTreeWidget { background-color: #3c3f41; border: 1px solid #555; alternate-background-color: #383b3d;}QHeaderView::section { background-color: #3c3f41; padding: 5px; border: 1px solid #555;}QProgressBar { border: 1px solid #555; border-radius: 3px; text-align: center; background-color: #3c3f41;}QProgressBar::chunk { background-color: #4CAF50; width: 10px;}QLabel { color: #e0e0e0;}QScrollArea { border: 1px solid #555; background-color: #3c3f41;}QDialog { background-color: #2b2b2b;}\"\"\"def submit_search(keywords: str) -> str: \"\"\"Submit search request and return redirected URL\"\"\" form_data = { \"keyboard\": keywords, \"show\": \"title\", \"tempid\": \"1\", \"tbname\": \"news\" } SEARCH_URL = f\"{ BASE_URL}/e/search/index.php\" session = requests.Session() response = session.post(SEARCH_URL, data=form_data, allow_redirects=False) if response.status_code == 302: new_location = response.headers.get(\"Location\") return urljoin(SEARCH_URL, new_location) else: print(\"No redirect occurred, status code:\", response.status_code) return \"\" def get_total_count(soup: BeautifulSoup) -> int: \"\"\"Extract total gallery count from page\"\"\" biaoqian_div = soup.find(\"div\", class_=\"biaoqian\") if biaoqian_div: p_text = biaoqian_div.find(\"p\").get_text(strip=True) match = re.search(r\"(\\d+)\", p_text) if match: return int(match.group(1)) return 0 def parse_gallery_items_from_root(soup: BeautifulSoup) -> List[Dict[str, str]]: \"\"\"Extract all gallery info from page\"\"\" gallery_root = soup.find(\"div\", class_=\"box galleryList\") items = [] if not gallery_root: return items for li in gallery_root.select(\"ul.databox > li\"): img_tag = li.select_one(\"div.img-box img\") ztitle_tag = li.select_one(\"p.ztitle a\") rtitle_tag = li.select_one(\"p.rtitle a\") author_tag = li.select_one(\"p.ztitle font\") count_tag = li.select_one(\"em.num\") href = ztitle_tag[\"href\"] if ztitle_tag and ztitle_tag.has_attr(\"href\") else \"\" full_link = urljoin(BASE_URL, href) count = 0 if count_tag: text = count_tag.get_text(strip=True) # \'15P\' match = re.search(r\'\\d+\', text) if match: count = int(match.group(0)) rtitle = rtitle_tag.get_text(strip=True) if rtitle_tag else \"\" if author_tag: author = author_tag.get_text(strip=True) else: author = rtitle item = { \"img\": img_tag[\"src\"] if img_tag else

