Python----目标检测(Ultralytics安装和YOLO-V8快速上手)_from ultralytics import yolo
一、Ultralytics安装
网址:主页 -Ultralytics YOLO 文档
Ultralytics提供了各种安装方法,包括pip、conda和Docker。通过 ultralytics pip包安装最新稳定版本的YOLOv8,或克隆Ultralytics GitHub 存储库以获取最新版本。可以使用Docker在隔离的容器中执行包,避免本 地安装。
pip install ultralytics==8.2.28 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install git+https://github.com/ultralytics/ultralytics.git@main注意:ultralytics需要PyTorch支持。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
二、使用YOLOV8
2.1、使用Ultralytics实现YOLOV8
Python接口使用户能够快速实现对象检测、分割和分类等功能。
from ultralytics import YOLO# 加载模型model = YOLO(\"yolov8n.pt\") # 使用YOLOV8n模型# 对图片列表进行批量推理results = model([\'./bus.jpg\'])#处理结果列表for result in results: boxes = result.boxes # Boxes对象,用于存储边界框输出 masks=result.masks #Masks对象,用于存储分割掩模输出 keypoints = result.keypoints # Keypoints对象,用于存储姿态关键点输出 probs=result.probs #Probs对象,用于存储分类概率输出 result.show() #显示结果到屏幕上 result.save(filename=\'result.jpg\') #保存结果2.2、使用Ultralytics实现YOLOV8流式预测
import cv2from ultralytics import YOLO#加载YOLOV8模型model=YOLO(\"yolov8n.pt\")# 打开视频文件video_path = \'WH038.mp4\'# cap = cv2.VideoCapture(0)#调用摄像头cap = cv2.VideoCapture(video_path)# 遍历视频帧while cap.isOpened(): # 从视频中读取一帧 success, frame= cap.read() if success: # 在帧上运行YOLOV8推理 results = model(frame) # 在帧上可视化推理结果 annotated_frame = results[0].plot() # 显示标注后的帧 cv2.imshow(\"YOLOV8推理结果\", annotated_frame) # 如果按下\'q\'键则退出循环 if cv2.waitKey(1) & 0xFF == ord(\"q\"): break else: # 如果视频播放完毕,则退出循环 break# 释放视频捕获对象并关闭显示窗口cap.release()cv2.destroyWindow()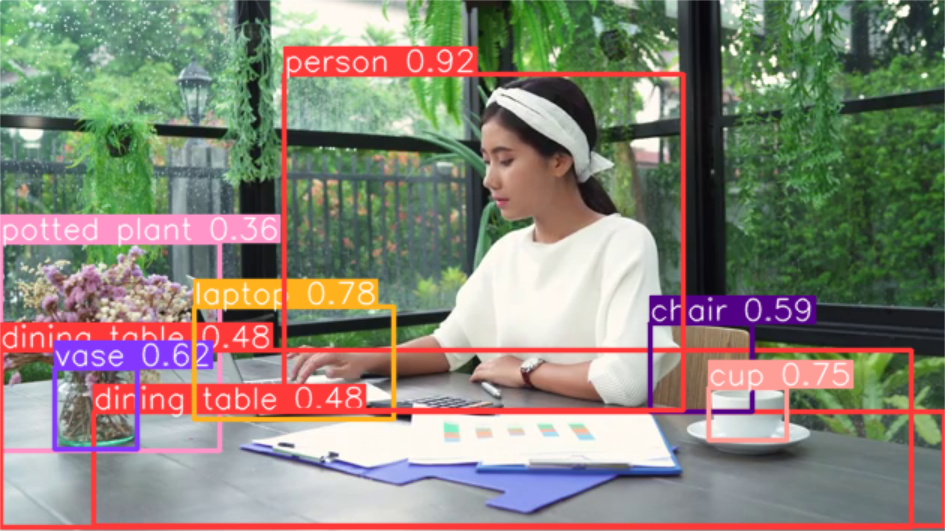
三、了解YOLOV8
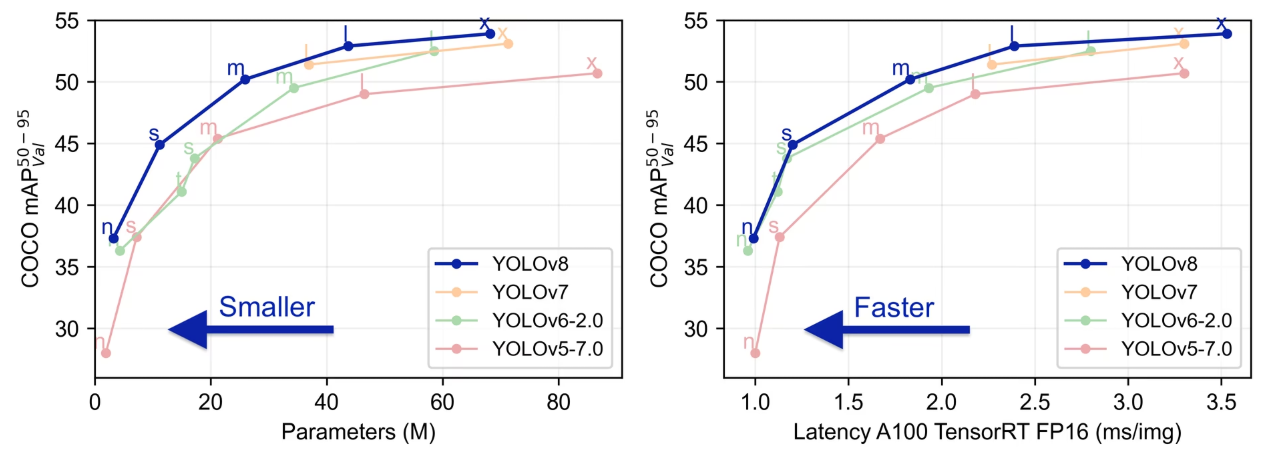
3.1、检测 (COCO)
有关在 COCO 上训练的这些模型的使用示例,请参阅检测文档,其中包括 80 个预训练类。
(像素)
50-95
CPU ONNX
(毫秒)
A100 TensorRT
(毫秒)
(M)
(B)
注意:
FLOPs (B) 表示 \"Floating Point Operations per second in Billion\",即每秒十亿次浮点运算。这个指标通常用于衡量一个模型在进行 推断或训练时的计算性能。浮点运算是指包括加法、减法、乘法、除法等 在内的基本数学运算,它们在深度学习模型中是非常常见的操作。
YOLOV8n 模型的 FLOPs (B) 值为 8.7,意味着在进行推断或训练时,该模 型每秒大约执行 8.7 亿次浮点数运算。
3.2、分割(COCO)
(像素)
50-95
50-95
CPU ONNX
(毫秒)
A100 TensorRT
(毫秒)
(M)
(B)
3.3、姿势 (COCO)
(像素)
50
CPU ONNX
(毫秒)
A100 TensorRT
(毫秒)
(M)
(B)
3.4、OBB (DOTAv1)
(像素)
50
CPU ONNX
(毫秒)
A100 TensorRT
(毫秒)
(M)
(B)
3.5、分类 (ImageNet)
(像素)
top1
top5
CPU ONNX
(毫秒)
A100 TensorRT
(毫秒)
(M)
(B) at 224
四、推理源
YOLOv8 可以处理不同类型的输入源进行推理,如下表所示。输入源包括 静态图像、视频流和各种数据格式。表中还标明了每种输入源是否可以在 流模式下使用参数 stream=True ✅.流模式有利于处理视频或实时流,因 为它会创建一个结果生成器,而不是将所有帧加载到内存中。
使用 stream=True 用于处理长视频或大型数据集,以有效管理内存。当 stream=False在这种情况下,所有帧或数据点的结果都会存储在内存中, 这可能会迅速累加,并导致大量输入出现内存不足错误。与此形成鲜明对 比的是 stream=True 利用生成器,它只将当前帧或数据点的结果保存在内 存中,从而大大减少了内存消耗并防止出现内存不足的问题
4.1、在图像文件上运行推理
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型model = YOLO(\"yolov8n.pt\") # 使用 \"yolov8n.pt\" 文件初始化 YOLO 模型。 # 这将加载预先训练好的权重。# 定义图像文件的路径source = \"bus.jpg\" # 指定要进行推理的图像文件名为 \"bus.jpg\"。# 在指定的图像源上运行推理results = model(source) # 将图像传递给模型进行推理。 # model(source) 返回一个 Results 对象列表, # 其中包含了模型对图像中目标的预测结果。4.2、通过 URL 对远程托管的图像或视频进行推理
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型model = YOLO(\"yolov8n.pt\") # 使用 \"yolov8n.pt\" 文件初始化 YOLO 模型。 # 这将加载预先训练好的权重。# 定义图像文件的路径source = \"https://ultralytics.com/images/bus.jpg\" # 在输入网址图片。# 在指定的图像源上运行推理results = model(source) # 将图像传递给模型进行推理。 # model(source) 返回一个 Results 对象列表, # 其中包含了模型对图像中目标的预测结果。4.3、在使用Python Imaging Library (PIL) 打开 的图像上运行推理
from PIL import Imagefrom ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型model = YOLO(\"yolov8n.pt\") # 使用 \"yolov8n.pt\" 文件初始化 YOLO 模型。 # 这将加载预先训练好的权重。# 定义图像文件的路径source = Image.open(\"bus.jpg\")# 在指定的图像源上运行推理results = model(source) # 将图像传递给模型进行推理。 # model(source) 返回一个 Results 对象列表, # 其中包含了模型对图像中目标的预测结果。4.4、在使用 OpenCV 读取的图像上运行推理
import cv2from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型model = YOLO(\"yolov8n.pt\") # 使用 \"yolov8n.pt\" 文件初始化 YOLO 模型。 # 这将加载预先训练好的权重。# 定义图像文件的路径source = cv2.imread(\'bus.jpg\')# 在指定的图像源上运行推理results = model(source) # 将图像传递给模型进行推理。 # model(source) 返回一个 Results 对象列表, # 其中包含了模型对图像中目标的预测结果。4.5、使用 RTSP、RTMP、TCP 和 IP 地址协议对远程流媒体源进行推理
如果在一个 *.streams 文本文件,则将运行批处理推理,即 8 个数据流将 以 8 的批处理大小运行,否则单个数据流将以 1 的批处理大小运行。
from ultralytics import YOLO # 从 ultralytics 库中导入 YOLO 类# 加载一个预训练的 YOLOv8n 模型model = YOLO(\"yolov8n.pt\") # 使用 \"yolov8n.pt\" 文件初始化 YOLO 模型。 # 这将加载预先训练好的权重。# 定义图像文件的路径source = \"rtsp://example.com/media.mp4\"source = \"path/to/list.streams\" # 在指定的图像源上运行推理results = model(source) # 将图像传递给模型进行推理。 # model(source) 返回一个 Results 对象列表, # 其中包含了模型对图像中目标的预测结果。五、推理论据
model.predict() 接受多个参数,这些参数可以在推理时传递,以覆盖默 认值:
可视化参数:
[class] [x_center] [y_center] [width] [height] [confidence]。有助于与其他分析工具集成。六、图像和视频格式
6.1、图像
yolo predict source=image.bmpyolo predict source=image.dngyolo predict source=image.jpegyolo predict source=image.jpgyolo predict source=image.mpoyolo predict source=image.pngyolo predict source=image.tifyolo predict source=image.tiffyolo predict source=image.webpyolo predict source=image.pfm6.2、视频格式
yolo predict source=video.asfyolo predict source=video.aviyolo predict source=video.gifyolo predict source=video.m4vyolo predict source=video.mkvyolo predict source=video.movyolo predict source=video.mp4yolo predict source=video.mpegyolo predict source=video.mpgyolo predict source=video.tsyolo predict source=video.wmvyolo predict source=video.webm七、返回值
predict() 调用将返回一个 Results 。
from ultralytics import YOLO# 加载一个预训练的 YOLOv8n 模型model = YOLO(\"yolov8n.pt\")# 对单张图片 \"bus.jpg\" 进行推理results = model(\"bus.jpg\") # 返回一个 Results 对象的列表,因为只处理了一张图片,所以列表中只有一个元素# 对图片列表 [\"bus.jpg\", \"zidane.jpg\"] 进行批量推理results = model([\"bus.jpg\", \"zidane.jpg\"]) # 返回一个 Results 对象的列表,列表中包含每个图片的推理结果boxes: ultralytics.engine.results.Boxes objectkeypoints: Nonemasks: Nonenames: {0: \'person\', 1: \'bicycle\', 2: \'car\', 3: \'motorcycle\', 4: \'airplane\', 5: \'bus\', 6: \'train\', 7: \'truck\', 8: \'boat\', 9: \'traffic light\', 10: \'fire hydrant\', 11: \'stop sign\', 12: \'parking meter\', 13: \'bench\', 14: \'bird\', 15: \'cat\', 16: \'dog\', 17: \'horse\', 18: \'sheep\', 19: \'cow\', 20: \'elephant\', 21: \'bear\', 22: \'zebra\', 23: \'giraffe\', 24: \'backpack\', 25: \'umbrella\', 26: \'handbag\', 27: \'tie\', 28: \'suitcase\', 29: \'frisbee\', 30: \'skis\', 31: \'snowboard\', 32: \'sports ball\', 33: \'kite\', 34: \'baseball bat\', 35: \'baseball glove\', 36: \'skateboard\', 37: \'surfboard\', 38: \'tennis racket\', 39: \'bottle\', 40: \'wine glass\', 41: \'cup\', 42: \'fork\', 43: \'knife\', 44: \'spoon\', 45: \'bowl\', 46: \'banana\', 47: \'apple\', 48: \'sandwich\', 49: \'orange\', 50: \'broccoli\', 51: \'carrot\', 52: \'hot dog\', 53: \'pizza\', 54: \'donut\', 55: \'cake\', 56: \'chair\', 57: \'couch\', 58: \'potted plant\', 59: \'bed\', 60: \'dining table\', 61: \'toilet\', 62: \'tv\', 63: \'laptop\', 64: \'mouse\', 65: \'remote\', 66: \'keyboard\', 67: \'cell phone\', 68: \'microwave\', 69: \'oven\', 70: \'toaster\', 71: \'sink\', 72: \'refrigerator\', 73: \'book\', 74: \'clock\', 75: \'vase\', 76: \'scissors\', 77: \'teddy bear\', 78: \'hair drier\', 79: \'toothbrush\'}obb: Noneorig_img: array([[[122, 148, 172], [120, 146, 170], [125, 153, 177], ..., [157, 170, 184], [158, 171, 185], [158, 171, 185]], [[127, 153, 177], [124, 150, 174], [127, 155, 179], ..., [158, 171, 185], [159, 172, 186], [159, 172, 186]], [[128, 154, 178], [126, 152, 176], [126, 154, 178], ..., [158, 171, 185], [158, 171, 185], [158, 171, 185]], ..., [[185, 185, 191], [182, 182, 188], [179, 179, 185], ..., [114, 107, 112], [115, 105, 111], [116, 106, 112]], [[157, 157, 163], [180, 180, 186], [185, 186, 190], ..., [107, 97, 103], [102, 92, 98], [108, 98, 104]], [[112, 112, 118], [160, 160, 166], [169, 170, 174], ..., [ 99, 89, 95], [ 96, 86, 92], [102, 92, 98]]], dtype=uint8)orig_shape: (1080, 810)path: \'D:\\\\目标检测\\\\bus.jpg\'probs: Nonesave_dir: \'runs\\\\detect\\\\predict3\'speed: {\'preprocess\': 6.001710891723633, \'inference\': 35.00771522521973, \'postprocess\': 5.001306533813477}]
Results对象具有以下属性:
orig_imgnumpy.ndarrayorig_shapetupleboxesBoxes, optionalmasksMasks, optionalprobsProbs, optionalProbs 对象,包含分类任务中每个类别的概率。keypointsKeypoints, optionalobbOBB, optionalspeeddictnamesdictpathstr
Results对象的方法:
update()Nonecpu()Resultsnumpy()Resultscuda()Resultsto()Resultsnew()Resultsplot()numpy.ndarrayshow()Nonesave()Noneverbose()strsave_txt()Nonesave_crop()Nonesave_dir/cls/file_name.jpg。tojson()str7.1、Boxes
Boxes 对象可用于索引、操作和将边界框转换为不同格式。
from ultralytics import YOLOmodel = YOLO(\"yolov8n.pt\")results = model(\"bus.jpg\")for i in results: print(i.boxes)cls: tensor([ 5., 0., 0., 0., 11., 0.], device=\'cuda:0\')conf: tensor([0.8705, 0.8690, 0.8536, 0.8193, 0.3461, 0.3013], device=\'cuda:0\')data: tensor([[1.7286e+01, 2.3059e+02, 8.0152e+02, 7.6841e+02, 8.7054e-01, 5.0000e+00], [4.8739e+01, 3.9926e+02, 2.4450e+02, 9.0250e+02, 8.6898e-01, 0.0000e+00], [6.7027e+02, 3.8028e+02, 8.0986e+02, 8.7569e+02, 8.5360e-01, 0.0000e+00], [2.2139e+02, 4.0579e+02, 3.4472e+02, 8.5739e+02, 8.1931e-01, 0.0000e+00], [6.4347e-02, 2.5464e+02, 3.2288e+01, 3.2504e+02, 3.4607e-01, 1.1000e+01], [0.0000e+00, 5.5101e+02, 6.7105e+01, 8.7394e+02, 3.0129e-01, 0.0000e+00]], device=\'cuda:0\')id: Noneis_track: Falseorig_shape: (1080, 810)shape: torch.Size([6, 6])xywh: tensor([[409.4020, 499.4991, 784.2324, 537.8136], [146.6206, 650.8826, 195.7623, 503.2372], [740.0637, 627.9874, 139.5888, 495.4068], [283.0555, 631.5919, 123.3235, 451.6003], [ 16.1764, 289.8419, 32.2241, 70.3949], [ 33.5525, 712.4718, 67.1049, 322.9278]], device=\'cuda:0\')xywhn: tensor([[0.5054, 0.4625, 0.9682, 0.4980], [0.1810, 0.6027, 0.2417, 0.4660], [0.9137, 0.5815, 0.1723, 0.4587], [0.3495, 0.5848, 0.1523, 0.4181], [0.0200, 0.2684, 0.0398, 0.0652], [0.0414, 0.6597, 0.0828, 0.2990]], device=\'cuda:0\')xyxy: tensor([[1.7286e+01, 2.3059e+02, 8.0152e+02, 7.6841e+02], [4.8739e+01, 3.9926e+02, 2.4450e+02, 9.0250e+02], [6.7027e+02, 3.8028e+02, 8.0986e+02, 8.7569e+02], [2.2139e+02, 4.0579e+02, 3.4472e+02, 8.5739e+02], [6.4347e-02, 2.5464e+02, 3.2288e+01, 3.2504e+02], [0.0000e+00, 5.5101e+02, 6.7105e+01, 8.7394e+02]], device=\'cuda:0\')xyxyn: tensor([[2.1340e-02, 2.1351e-01, 9.8953e-01, 7.1149e-01], [6.0172e-02, 3.6969e-01, 3.0185e-01, 8.3565e-01], [8.2749e-01, 3.5211e-01, 9.9982e-01, 8.1082e-01], [2.7333e-01, 3.7573e-01, 4.2558e-01, 7.9388e-01], [7.9441e-05, 2.3578e-01, 3.9862e-02, 3.0096e-01], [0.0000e+00, 5.1019e-01, 8.2846e-02, 8.0920e-01]], device=\'cuda:0\')cpu()numpy()cuda()to()xyxyconfclsidxywhxyxynxywhnxyxyconfclsidxywhxyxynxywhnxyxy (torch.Tensor | numpy.ndarray):格式为 [x1, y1, x2, y2] 的方 框。
conf (torch.Tensor | numpy.ndarray):每个方框的置信度得分。
cls (torch.Tensor | numpy.ndarray):每个方框的类标签:每个方框 的类标签。
id (torch.Tensor | numpy.ndarray,可选):每个方框的跟踪 ID(如 果有)。
xywh (torch.Tensor | numpy.ndarray):按要求计算的 [x, y, width, height] 格式的方框。
xyxyn (torch.Tensor | numpy.ndarray):归一化 [x1, y1, x2, y2] 方 框,相对于 orig_shape .
xywhn (torch.Tensor | numpy.ndarray):归一化的 [x、y、宽、高] 方框,相对于 orig_shape .
7.2、Masks
Masks 对象可用于索引、操作和将掩码转换为线段。
from ultralytics import YOLOmodel = YOLO(\"yolov8n.pt\")results = model(\"bus.jpg\")for i in results: print(i.masks)cpu()numpy()cuda()to()xynxy7.3、Keypoints
Keypoints 对象可用于索引、处理和归一化坐标。
from ultralytics import YOLOmodel = YOLO(\"yolov8n.pt\")results = model(\"bus.jpg\")for i in results: print(i.keypoints)cpu()numpy()cuda()to()xynxyconf7.4、Probs
Probs 对象可用于索引、获取 top1 和 top5 分类指数和分数。
from ultralytics import YOLOmodel = YOLO(\"yolov8n.pt\")results = model(\"bus.jpg\")for i in results: print(i.probs)cpu()numpy()cuda()to()top1top5top1conftop5conf7.5、OBB
OBB 指的是 \"Oriented Bounding Box\",即定向边界框。它是一种包围物 体的矩形框,与传统的边界框不同,OBB 可以沿着物体的方向进行旋转, 以更好地适应物体的实际形状和方向。 OBB 对象可用于索引、操作和将定向边界框转换为不同格式。
from ultralytics import YOLOmodel = YOLO(\"yolov8n.pt\")results = model(\"bus.jpg\")for i in results: print(i.obb)cpu()numpy()cuda()to()confclsidxyxyxywhrxyxyxyxyxyxyxyxyn八、绘制结果
plot() 方法中的 Results 对象,将检测到的对象(如边界框、遮罩、关 键点和概率)叠加到原始图像上,从而实现预测的可视化。该方法以 NumPy 数组形式返回注释图像,便于显示或保存。
from ultralytics import YOLO# 加载模型model = YOLO(\"yolov8n.pt\") # 使用YOLOv8n模型# 对图片列表进行批量推理results = model([\'./bus.jpg\']) # 返回结果对象的列表# 处理结果列表for result in results: result.show() # 显示结果到屏幕上 result.save(filename=\'result.jpg\') # 保存结果plot() 方法支持各种参数来定制输出
confboolTrueline_widthfloatNone。Nonefont_sizefloatNone。NonefontstrpilboolFalseimgnumpy.ndarrayNone,则使用原始图像。Noneim_gputorch.TensorNonekpt_radiusintkpt_lineboolTruelabelsboolTrueboxesboolTruemasksboolTrueprobsboolTrueshowboolFalsesaveboolfilename 指定的文件。Falsefilenamestrsave 是 True 时使用。None
