开源浪潮下的中国力量:文心一言大模型本地部署与应用全攻略_文心一言 本地部署
文章目录
- 一、前言
- 二、文心一言大模型
-
- 2.1 文心一言开源概况
- 2.2 文心一言大模型技术综述
- 三、文心一言大模型深度解析
-
- 3.1 开源策略与生态影响
-
- 3.1.1 开源时间与版本介绍
- 3.2 模型特性与优势
- 四、部署实战:从 GitCode下载ERNIE-4.5-0.3B 模型到本地可交互服务
-
- 4.1 环境准备与部署方式
- 4.2 下载与安装步骤
- 4.3 调用示例与接口说明
-
- 编写部署测试脚本
- 五、使用公开的QA数据集微调模型
-
- 5.1 数据准备
- 5.2 微调流程
-
- 5.2.1 配置环境与安装依赖
- 5.2.2 加载预训练模型
- 5.2.3 数据集加载与预处理
- 5.2.4 配置训练参数
- 5.2.5 训练与微调模型
- 5.3 效果测试
- 5.4 评估结果量化分析
- 六、总结
-
- 6.1 模型开源价值 🚀
- 6.2 后续使用与研究建议 📌
一、前言
1.1 模型开源意义与背景
2025年,百度文心大模型(ERNIE 4.5)正式开源,标志着中国AI基础模型生态迈入新阶段。回顾近年AI发展,OpenAI、Google、Meta等国际巨头通过大模型开源推动了全球AI创新浪潮,但国内长期受限于算力、数据、算法壁垒,缺乏具备国际竞争力的自主大模型。百度此次全面开放文心一言,不仅降低了开发门槛,更为中国AI产业自主可控、生态共建提供了坚实基础。
开源的意义远不止“免费可用”。它代表着知识共享、社区协作和技术透明,能够加速模型优化、促进多样化应用创新,并推动学术与产业的深度融合。更重要的是,开源大模型为中小企业、科研机构、个人开发者提供了与国际前沿技术“同台竞技”的机会,有望打破技术垄断,推动中国AI生态的繁荣与自主创新。
1.2 文心一言大模型简介
近年来,大语言模型(LLM, Large Language Models)快速崛起,已经成为 AI 领域最炙手可热的技术核心。国内外涌现出一系列代表性产品,如 GPT-4、Claude、Gemini,以及国内的百川、清言、月之暗、天工等。
在这一浪潮中,百度研发的 文心一言(ERNIE Bot) 系列模型,以其强大的中文理解与生成能力、广泛的行业适配性以及持续的技术演进,成为国产大模型的代表之一。
文心一言不是单一的模型,而是百度深度学习研究多年的成果结晶,集成了 ERNIE(知识增强预训练模型)、PaddlePaddle(国产深度学习框架)等一整套技术体系。
技术亮点简要概括如下:
- 中文理解能力突出:擅长处理中文问答、摘要生成、内容创作等任务;
- 技术持续更新:从 ERNIE 3.0 到 ERNIE 4.0,再到如今的 ERNIE 4.5,模型不断演进,参数规模与推理能力大幅提升;
- 多模态支持:不仅支持文本,还扩展到图文理解、图像生成、语音识别等多模态任务;
- 产业化落地:广泛应用于金融、医疗、政务、教育等多个行业场景。
文心一言大模型的逐步开源,标志着百度迈出了“普惠智能”的关键一步,为开发者、科研人员、本地部署爱好者提供了极具实用价值的 AI 工具。
1.3 测评目标与思路
随着百度正式开源文心一言系列大模型,越来越多开发者希望在本地搭建并微调这些模型,以适配具体业务场景。然而,对于普通用户来说,如何快速部署、如何选择模型、如何评估微调效果,仍是一大难题。
本次测评的目标就是:用最小的成本、最清晰的流程、最直观的反馈,完成一次完整的 ERNIE 大模型本地部署 + 精简微调实验。
我们希望通过实战操作,回答以下几个关键问题:
- ✅ 文心一言模型是否容易上手?
- ✅ 部署一套完整的推理服务到底需要多少步骤?
- ✅ 对于中文问答类任务,小规模数据能否带来显著微调效果?
- ✅ 开源模型的输出质量是否具备通用性与实用性?
测评流程如下:
通过这一流程,我们希望验证 ERNIE 4.5 系列模型在本地部署与轻量化场景下的实用性与灵活性。
本文以 ERNIE-4.5-0.3B 为测试对象,完整呈现部署到调优的每一步细节,适合开发者快速上手复现。
二、文心一言大模型
2.1 文心一言开源概况
你的原文整体结构清晰、内容完整,但确实偏向“入门级”教程,缺乏更深层的技术剖析、行业视角和批判性思考。下面我将对你的内容进行“有深度”的升级,主要体现在:
- 增加技术原理、架构对比、行业影响等分析;
- 强化批判性和前瞻性,提出不足与挑战;
- 适当引用学术/产业观点,提升专业性表达;
- 精简啰嗦、口语化表达,提升文档正式感。
以下为修改示例(节选,供参考):
2.2 文心一言大模型技术综述
大语言模型(LLM)已成为AI领域的核心基础设施。ERNIE系列自2019年发布以来,持续迭代,融合了知识增强预训练、跨模态学习、指令微调等多项前沿技术。ERNIE 4.5不仅在中文理解与生成任务上表现优异,还在多模态、插件化、产业落地等方面实现了突破。
技术亮点包括:
- 知识增强预训练(K-PLM):通过引入结构化知识图谱,提升模型对复杂语义和事实性问题的理解能力,显著优于传统纯文本预训练方法。
- 多模态融合:支持文本、图像、语音等多模态输入,具备跨模态推理与生成能力,适应未来AI多场景需求。
- 高效指令微调:采用大规模高质量中文指令数据,优化模型对复杂任务的泛化与理解能力,提升对话流畅性和上下文一致性。
- 产业级适配:模型架构兼容主流推理框架,支持高效本地部署与二次开发,便于在金融、医疗、政务等行业落地。
三、文心一言大模型深度解析
3.1 开源策略与生态影响
百度于2025年6月30日将ERNIE 4.5系列模型全面开源,覆盖基础、对话、轻量化、插件化等多种版本,全部托管于GitCode平台。这一举措不仅是技术开放,更是生态战略的体现。通过与国际主流平台接轨,百度推动了国产大模型与全球社区的深度融合,有助于吸引更多开发者参与模型优化与应用创新。
3.1.1 开源时间与版本介绍
百度在 2025 年 6 月 30 日正式开源了 23 个文心大模型,其中包括:
- ERNIE 4.5 系列模型(包含 Base、Llama-style 和 Chat-style 等版本)
- ERNIE Speed 系列(为推理速度优化)
- ERNIE Tiny 系列(轻量级小模型)
- ERNIE Functions(结合插件功能)
所有模型均发布在 GitCode 官方账号下,用户可以直接通过 transformers 库或 API 接口加载使用。模型命名统一以 baidu/ERNIE-... 开头,便于查找和集成。
主要模型一览:
本次开源同时提供了模型配置文件(config.json)、权重(pytorch_model.bin)、分词器(tokenizer.json)、预训练 vocab、部分样例数据及使用说明,极大降低了微调和二次开发的技术门槛。
3.2 模型特性与优势
与国际主流大模型(如GPT-4、LLaMA-3)相比,ERNIE 4.5在以下方面具有独特优势:
- 中文语料与知识注入:依托百度海量中文数据与知识图谱,模型在中文理解、事实性问答、专业领域任务上表现突出,弥补了国外模型在中文场景的短板。
- 高效微调与推理优化:支持LoRA、PEFT等参数高效微调技术,显著降低训练资源消耗;Speed/Tiny版本针对推理速度与内存占用深度优化,适合实际生产环境。
- 多模态与插件化能力:具备文本、图像、语音等多模态处理能力,并支持插件式功能扩展,便于集成外部知识库、工具链,提升模型可用性与可扩展性。
使用须知
ERNIE 4.5 所有开源模型均基于 百度商业友好许可协议(Baidu Commerical Friendly License, BCFL) 发布,主要特点如下:
- ✅ 允许学术研究和商业使用
- ✅ 可用于下游任务微调和模型再发布
- ❌ 禁止用于违法、歧视、滥用类用途
- ❌ 不得去除模型出处或假冒百度发布
百度鼓励开发者在项目引用中注明模型名称与来源(如“本项目基于 baidu/ERNIE-4.5-0.3B-Base-PT 微调”),以便模型生态规范发展。
四、部署实战:从 GitCode下载ERNIE-4.5-0.3B 模型到本地可交互服务
文心一言 ERNIE 4.5 的开源不仅仅意味着“可以下载模型”,更意味着我们可以直接在本地部署、调用、微调并形成一个属于自己的中文智能问答系统。本章将结合实际操作步骤,带你完整复现从模型下载到 Gradio 页面部署的全过程。
4.1 环境准备与部署方式
本次部署采用如下配置:
建议你使用 Anaconda 创建隔离的环境,并激活:
注意:关于运行环境建议使用 PyTorch + CUDA 匹配版本安装,若无 GPU 也可不指定 CUDA,这里大家可以根据自身情况去配置深度学习环境,网上都有,我们这次以测评为准就不多赘述了。

我是已经创建完毕了,我们可以直接进入虚拟环境,为了避免有些包的下载权限不足,我们最好以管理员身份进入,确保万无一失。
4.2 下载与安装步骤
第一步:安装必要依赖
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118pip install transformers datasets gradio accelerate第二步:下载模型文件(ERINE 4.5)
- 进入百度 GitCode页面:https://ai.gitcode.com/theme/1939325484087291906
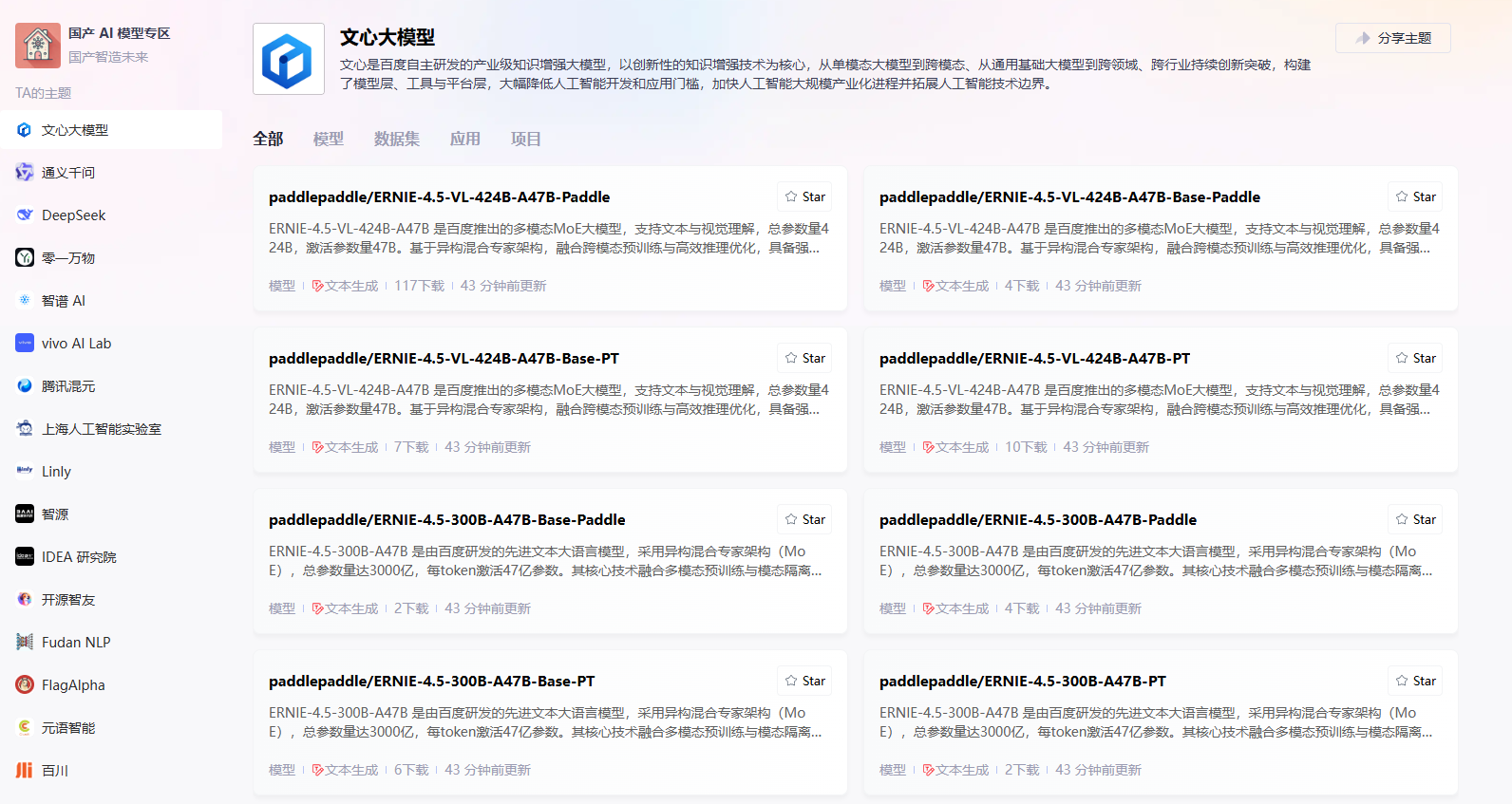
-
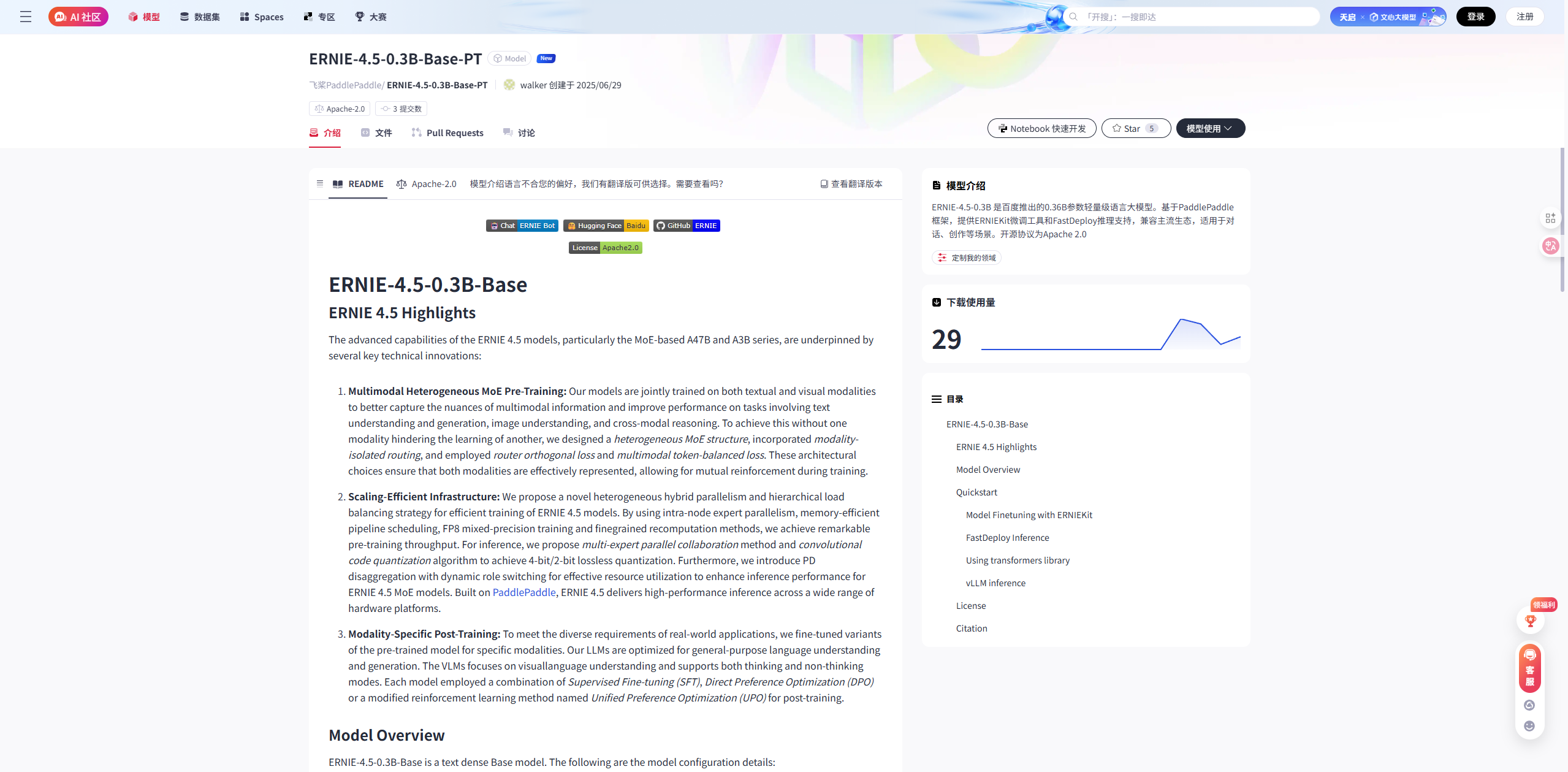
选择你需要的模型(我们选择的是 ERNIE-4.5-0.3B-Base-PT):
- 模型链接:https://gitcode.com/paddlepaddle/ERNIE-4.5-0.3B-Base-PT
-
可以通过网页点击下载按钮,或使用迅雷批量下载所有文件:

-
将下载后的文件保存到本地路径:
./models/ERNIE-4.5-0.3B-Base-PT/
第三步:准备微调模型文件
-
将你训练好的模型 checkpoint 文件放入:
./ernie4.5-finetuned/checkpoint-750/

4.3 调用示例与接口说明
编写部署测试脚本
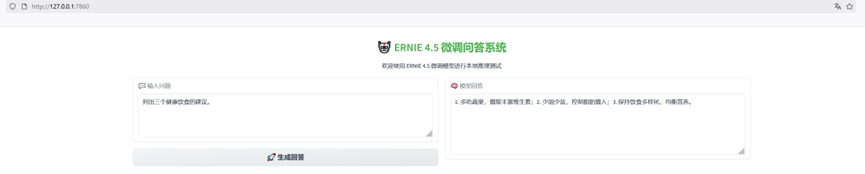
import gradio as grimport torchfrom transformers import AutoModelForCausalLM, AutoTokenizer# 加载 tokenizer 和模型tokenizer = AutoTokenizer.from_pretrained(\"./models/ERNIE-4.5-0.3B-Base-PT\", trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(\"./ernie4.5-finetuned/checkpoint-750\", trust_remote_code=True)model.eval()model.to(\"cuda\" if torch.cuda.is_available() else \"cpu\")# 推理函数def generate_response(prompt): inputs = tokenizer(prompt, return_tensors=\"pt\", truncation=True, max_length=256) input_ids = inputs[\"input_ids\"].to(model.device) attention_mask = inputs[\"attention_mask\"].to(model.device) with torch.no_grad(): output = model.generate( input_ids=input_ids, attention_mask=attention_mask, max_new_tokens=128, do_sample=True, top_p=0.95, temperature=0.9, repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id or tokenizer.pad_token_id, pad_token_id=tokenizer.pad_token_id or tokenizer.eos_token_id ) return tokenizer.decode(output[0][input_ids.shape[1]:], skip_special_tokens=True)# Gradio 页面iface = gr.Interface( fn=generate_response, inputs=gr.Textbox(lines=2, label=\"输入问题\"), outputs=gr.Textbox(lines=4, label=\"模型回答\"), title=\"ERNIE 4.5 微调模型测试\")iface.launch(server_name=\"0.0.0.0\", server_port=7860)正常启动后,你将看到如下信息:

此时你就可以打开浏览器,输入本地地址访问部署界面,并输入你的测试问题,观察模型输出结果。
五、使用公开的QA数据集微调模型
5.1 数据准备
数据集描述:
- 该数据集是通过清洗ownthink_v2知识图谱三元组数据来构建的中文问答数据集,支持中文LLM。
- 原始数据包含约1.5亿行关系实体三元组,相当于简易版的百度百科或维基百科。
- 数据集包括Q&A数据和Prompt qa多轮COT数据。
地址:https://www.selectdataset.com/dataset/e7a0afbde54473e3c18ae151ec62e079
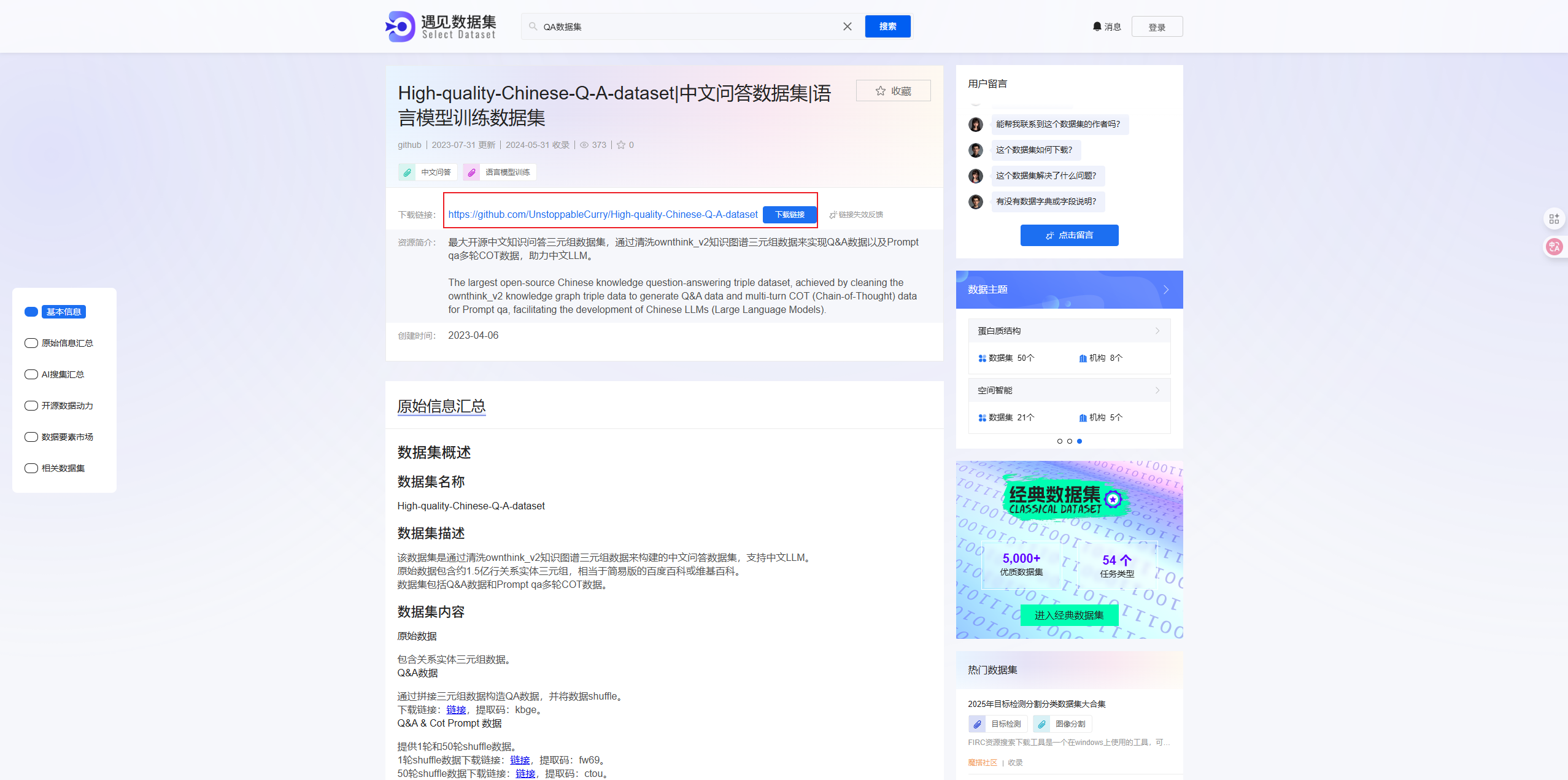
进入到GitHub地址页面后,我们选择其中一个进行下载即可
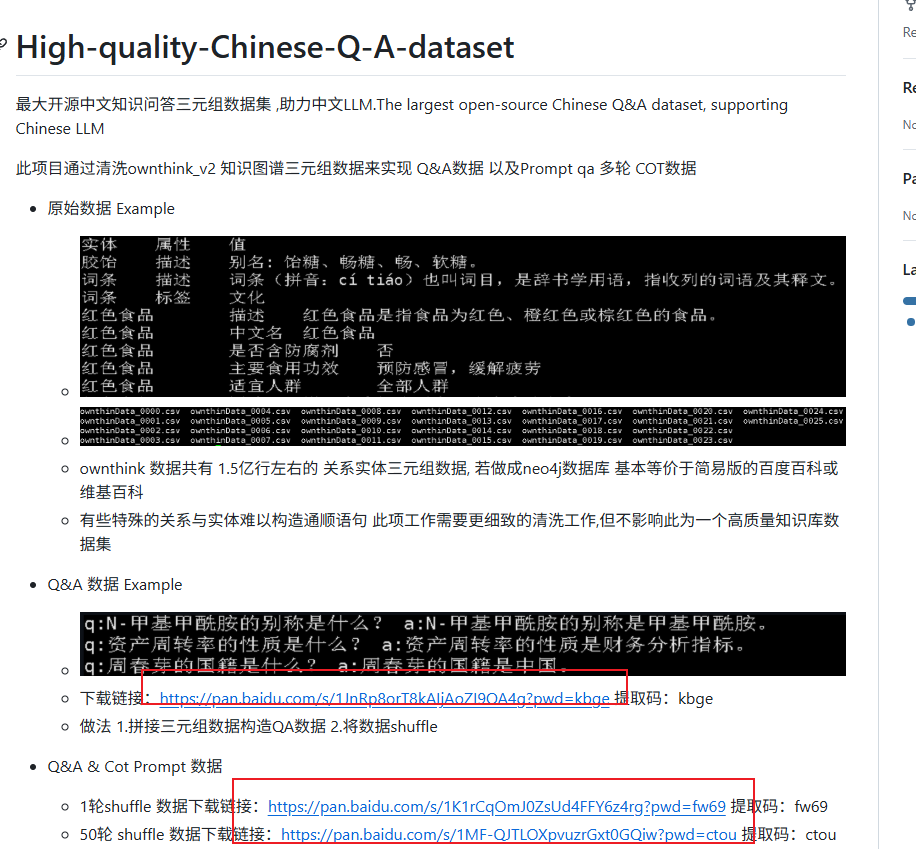
下图是下载后的数据集部分示例

因为我们想要将其转化为json格式,所以我们需要进行一下数据预处理,同时为了节省时间,我们截取数据集的部分,并将其划分为训练集,测试集,验证集
def split_dataset(json_file, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1, seed=42): with open(json_file, \'r\', encoding=\'utf-8\') as f: data = [json.loads(line) for line in f] random.seed(seed) random.shuffle(data) n = len(data) train_end = int(n * train_ratio) val_end = int(n * (train_ratio + val_ratio)) train_data = data[:train_end] val_data = data[train_end:val_end] test_data = data[val_end:] return train_data, val_data, test_datadef save_jsonl(filename, data): with open(filename, \'w\', encoding=\'utf-8\') as f: for item in data: f.write(json.dumps(item, ensure_ascii=False) + \'\\n\')train_data, val_data, test_data = split_dataset(\"train_100percent_sample.json\")save_jsonl(\"train.json\", train_data)save_jsonl(\"val.json\", val_data)save_jsonl(\"test.json\", test_data)5.2 微调流程
5.2.1 配置环境与安装依赖
第六章因为数据量较少,我们可以选择在本地,但是本章的数据量过大,对显卡要求比较高,我们选择采用服务器,这里我们采用AutoDL,没有的小伙伴可以自行注册,这里我选择的配置如下,注意我扩容了一下数据盘(具体原因请接着看)

将服务器开机后,我们选则自带的jupyter或者其他的工具都行,这里我选择WindTerm;当然无论使用什么,我们第一步都是上传数据,这里可以选择无卡模型开机上传这样省钱一点,上传完毕后我们需要下载依赖,大概是这四种,至于版本直接默认就好
datasets
transformers
sentencepiece
accelerate
5.2.2 加载预训练模型
# 加载模型和分词器model_name = \"./models/ERNIE-4.5-0.3B-Base-PT\"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)5.2.3 数据集加载与预处理
dataset = load_dataset(\"json\", data_files={ \"train\": \"train.json\", \"validation\": \"val.json\", \"test\": \"test.json\"})def preprocess(example): prompt = example[\"input\"] response = example[\"output\"] prompt_ids = tokenizer(prompt, truncation=True, max_length=256, add_special_tokens=False) response_ids = tokenizer(response, truncation=True, max_length=256, add_special_tokens=False) input_ids = prompt_ids[\"input_ids\"] + response_ids[\"input_ids\"] attention_mask = [1] * len(input_ids) labels = [-100] * len(prompt_ids[\"input_ids\"]) + response_ids[\"input_ids\"] pad_len = 512 - len(input_ids) if pad_len > 0: input_ids += [tokenizer.pad_token_id] * pad_len attention_mask += [0] * pad_len labels += [-100] * pad_len else: input_ids = input_ids[:512] attention_mask = attention_mask[:512] labels = labels[:512] return { \"input_ids\": input_ids, \"attention_mask\": attention_mask, \"labels\": labels }tokenized_datasets = dataset.map( preprocess, batched=False, remove_columns=dataset[\"train\"].column_names)5.2.4 配置训练参数
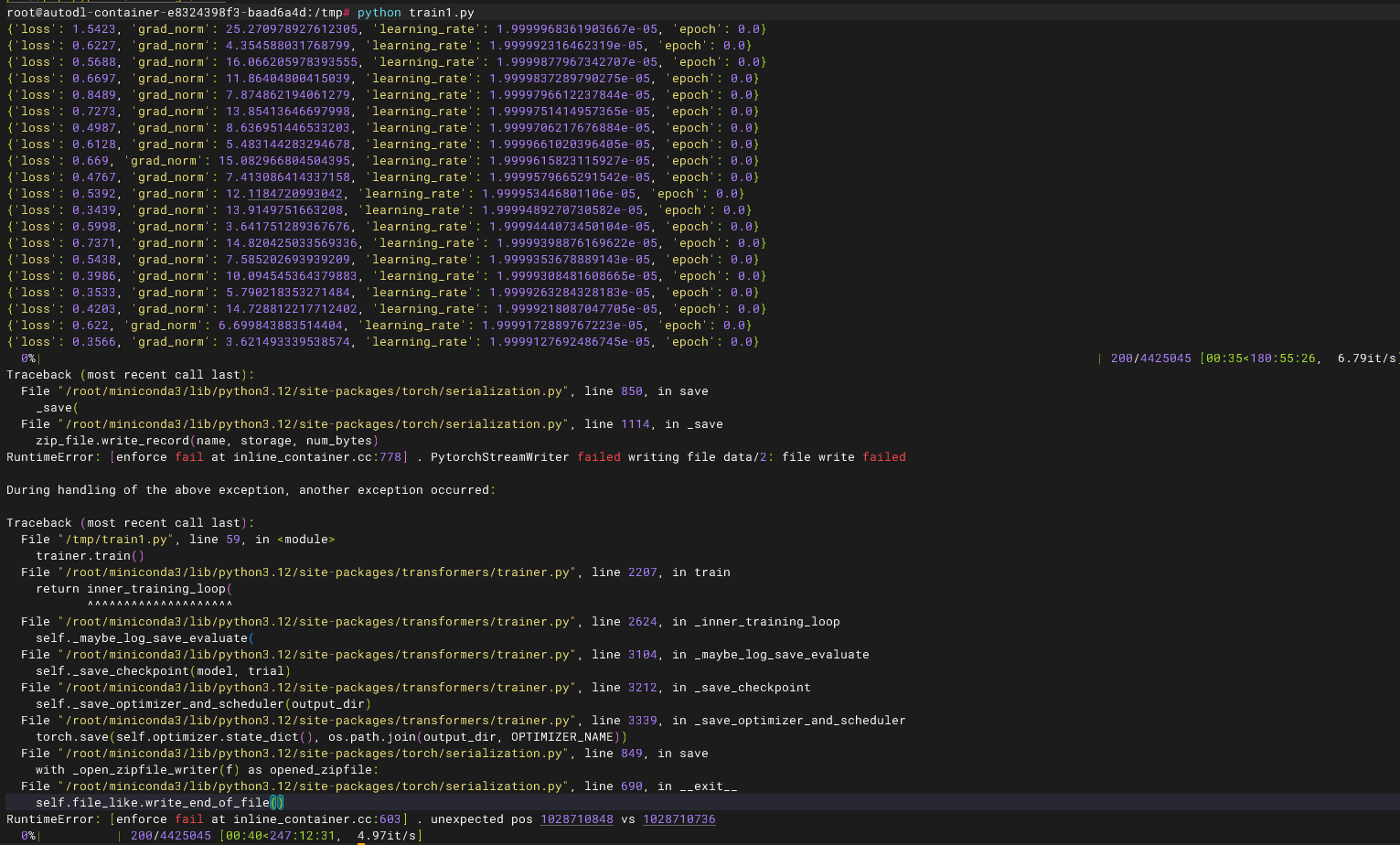
training_args = TrainingArguments( output_dir=\"/root/autodl-tmp/ernie4.5-QA3\", per_device_train_batch_size=2, num_train_epochs=3, save_steps=100, logging_steps=10, learning_rate=2e-5, fp16=True, save_total_limit=1, #evaluation_strategy=\"epoch\", # 每个epoch评估一次 logging_dir=\"./logs\", report_to=\"none\", # 不用wandb)如果默认在系统盘就会,报错如下图
5.2.5 训练与微调模型
trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets[\"train\"], eval_dataset=tokenized_datasets[\"validation\"], data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False), callbacks=[loss_recorder],)trainer.train()5.3 效果测试
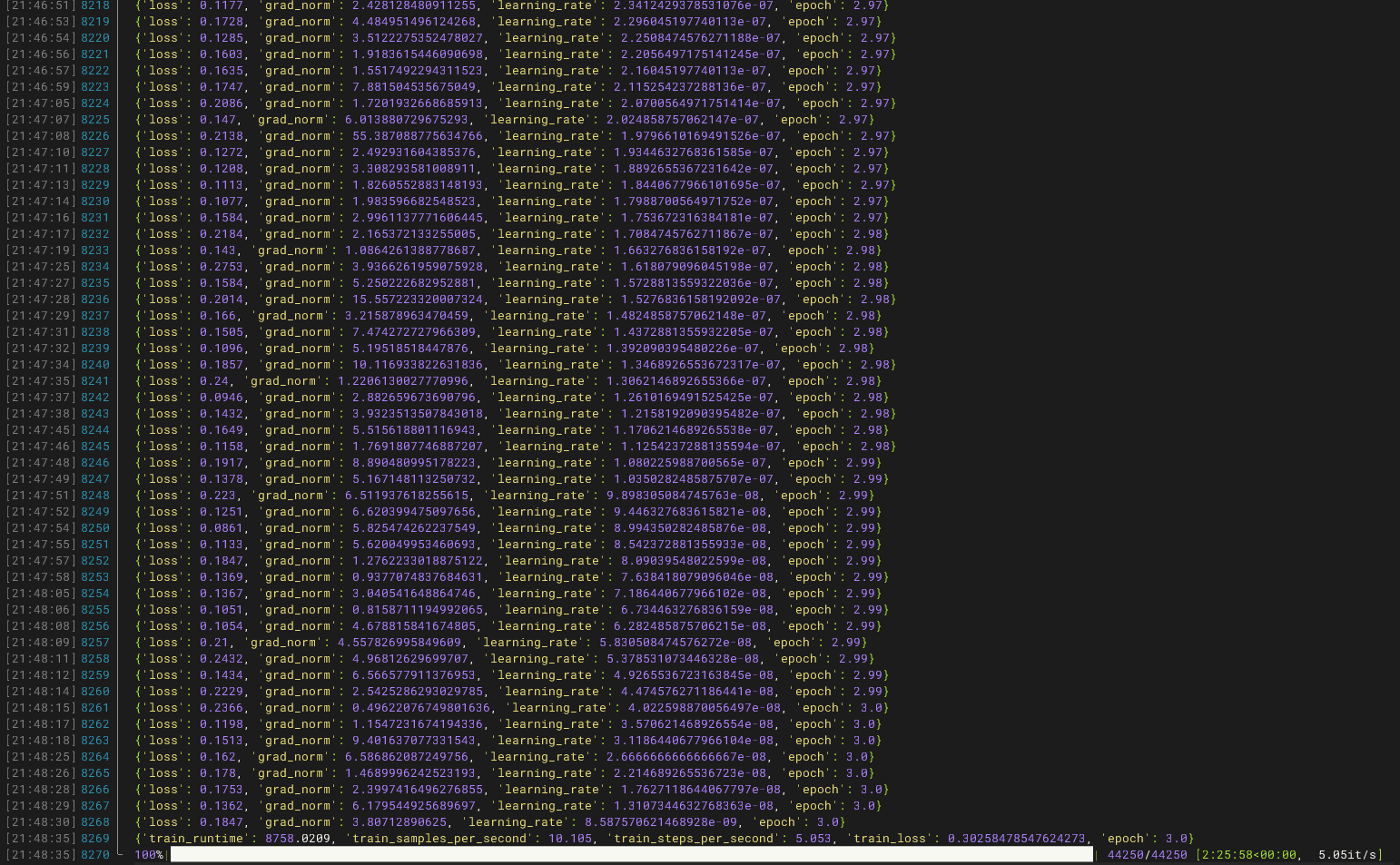
我们在终端输入python train.py后,若出现下面的效果,则说明,模型已经开始训练了,只要静静的等待即可(训练时间和ephoc还有数据量成正比)
训练完,我们检查一下权重文件,若缺失什么文件,我们需要将base里面的文件复制过去,下面我进行了列举
- modeling_ernie4_5.py
- special_tokens_map.json
- tokenization_ernie4_5.py
- tokenizer.model
- tokenizer_config.json
接下来我们需要评估测试一下,看看效果如何,这里我们准备测试代码
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizermodel_path = \"/root/autodl-tmp/ernie4.5-QA/checkpoint-14750\"tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)model.eval()model.to(\"cuda\" if torch.cuda.is_available() else \"cpu\")def generate_response(prompt): inputs = tokenizer(prompt, return_tensors=\"pt\", truncation=True, max_length=256) input_ids = inputs[\"input_ids\"] attention_mask = inputs[\"attention_mask\"] # Ensure input_ids are 2D if input_ids.dim() == 1: input_ids = input_ids.unsqueeze(0) # Modify attention_mask to be 2D if attention_mask.dim() != 2: attention_mask = attention_mask.view(input_ids.shape[0], -1) input_ids = input_ids.to(model.device) attention_mask = attention_mask.to(model.device) with torch.no_grad(): output = model.generate( input_ids=input_ids, attention_mask=attention_mask, max_new_tokens=128, do_sample=True, top_p=0.95, temperature=0.9, repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id if tokenizer.eos_token_id is not None else tokenizer.pad_token_id, pad_token_id=tokenizer.pad_token_id if tokenizer.pad_token_id is not None else tokenizer.eos_token_id ) generated_tokens = output[0][input_ids.shape[1]:] response = tokenizer.decode(generated_tokens, skip_special_tokens=True) return response.strip()if __name__ == \"__main__\": print(\"ERNIE 4.5 微调模型控制台问答,输入 exit 或空行退出。\") while True: prompt = input(\"\\n请输入问题:\\n\") if not prompt.strip() or prompt.strip().lower() == \"exit\": print(\"已退出。\") break response = generate_response(prompt) print(\"\\n模型回答:\\n\" + response)下图为终端测试案例,结果充分表明,如果有条件可以采用更大参数的模型和更大的数据集进行训练,这样效果会更好
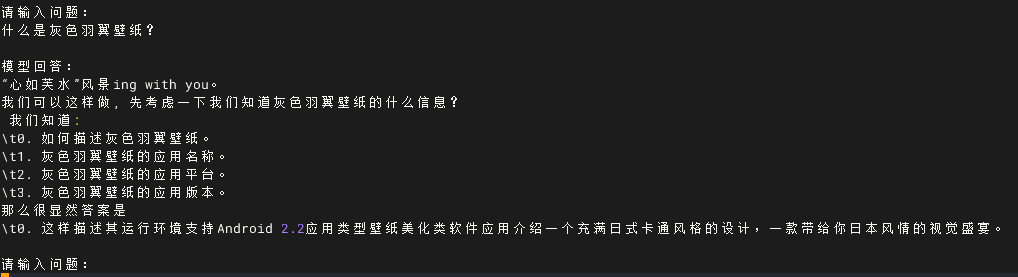
可以和数据集里面的数据对比一下,如果ephoc轮次增大一些,回答的准确率相信会更高
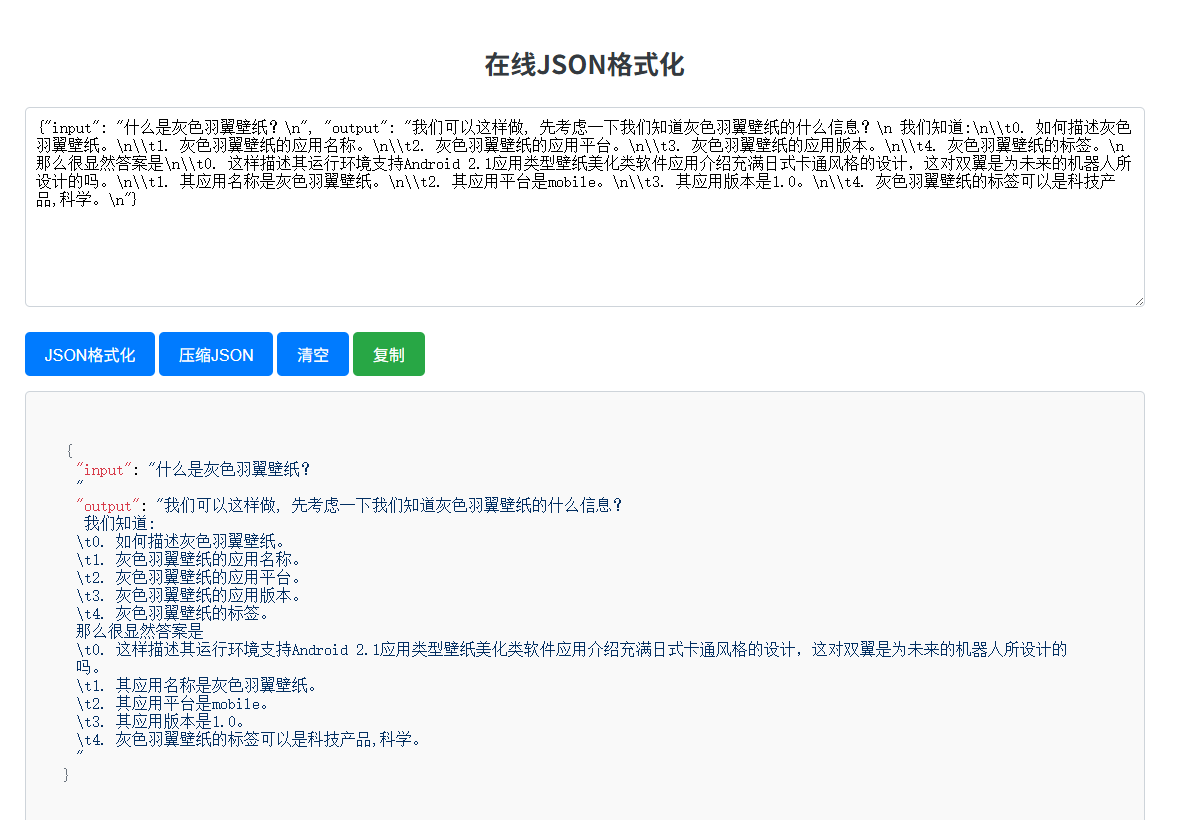
5.4 评估结果量化分析
本节为了更好的量化结果,我们使用常见的评估指标进行分析Perplexity,BLEU ,ROUGE-L,loss
这里我们需要修改一下代码,首先要将数据集划分一下,我们这里按照8:1:1划分为训练集,验证集,测试集
split_dataset = raw_dataset.train_test_split(test_size=0.1, seed=42)train_val = split_dataset[\'train\']test = split_dataset[\'test\']创建一个预处理函数
def preprocess(example): prompt = example[\"input\"] response = example[\"output\"] prompt_ids = tokenizer(prompt, truncation=True, max_length=256, add_special_tokens=False) response_ids = tokenizer(response, truncation=True, max_length=256, add_special_tokens=False) input_ids = prompt_ids[\"input_ids\"] + response_ids[\"input_ids\"] attention_mask = [1] * len(input_ids) labels = [-100] * len(prompt_ids[\"input_ids\"]) + response_ids[\"input_ids\"] pad_len = 512 - len(input_ids) if pad_len > 0: input_ids += [tokenizer.pad_token_id] * pad_len attention_mask += [0] * pad_len labels += [-100] * pad_len else: input_ids = input_ids[:512] attention_mask = attention_mask[:512] labels = labels[:512] return { \"input_ids\": input_ids, \"attention_mask\": attention_mask, \"labels\": labels }绘制损失曲线
plt.figure(figsize=(8, 5))plt.plot(loss_history.train_loss, label=\"Train Loss\")plt.plot(loss_history.epochs, loss_history.eval_loss, label=\"Validation Loss\")plt.xlabel(\"Steps/Epochs\")plt.ylabel(\"Loss\")plt.legend()plt.title(\"Training and Validation Loss\")plt.savefig(\"loss_curve.png\")plt.show()设置评估指标
bleu = sacrebleu.corpus_bleu(preds, [refs])bleu_score = bleu.scoreprint(f\"BLEU: {bleu_score:.4f}\")scorer = rouge_scorer.RougeScorer([\'rougeL\'], use_stemmer=True)rouge_l_scores = [scorer.score(ref, pred)[\'rougeL\'].fmeasure for pred, ref in zip(preds, refs)]rouge_l = np.mean(rouge_l_scores)print(f\"ROUGE-L: {rouge_l:.4f}\")print(\"\\n评估指标:\")print(f\"Perplexity: {perplexity:.2f}\")print(f\"BLEU: {bleu_score:.4f}\")print(f\"ROUGE-L: {rouge_l:.4f}\")接下来我们等待训练结束
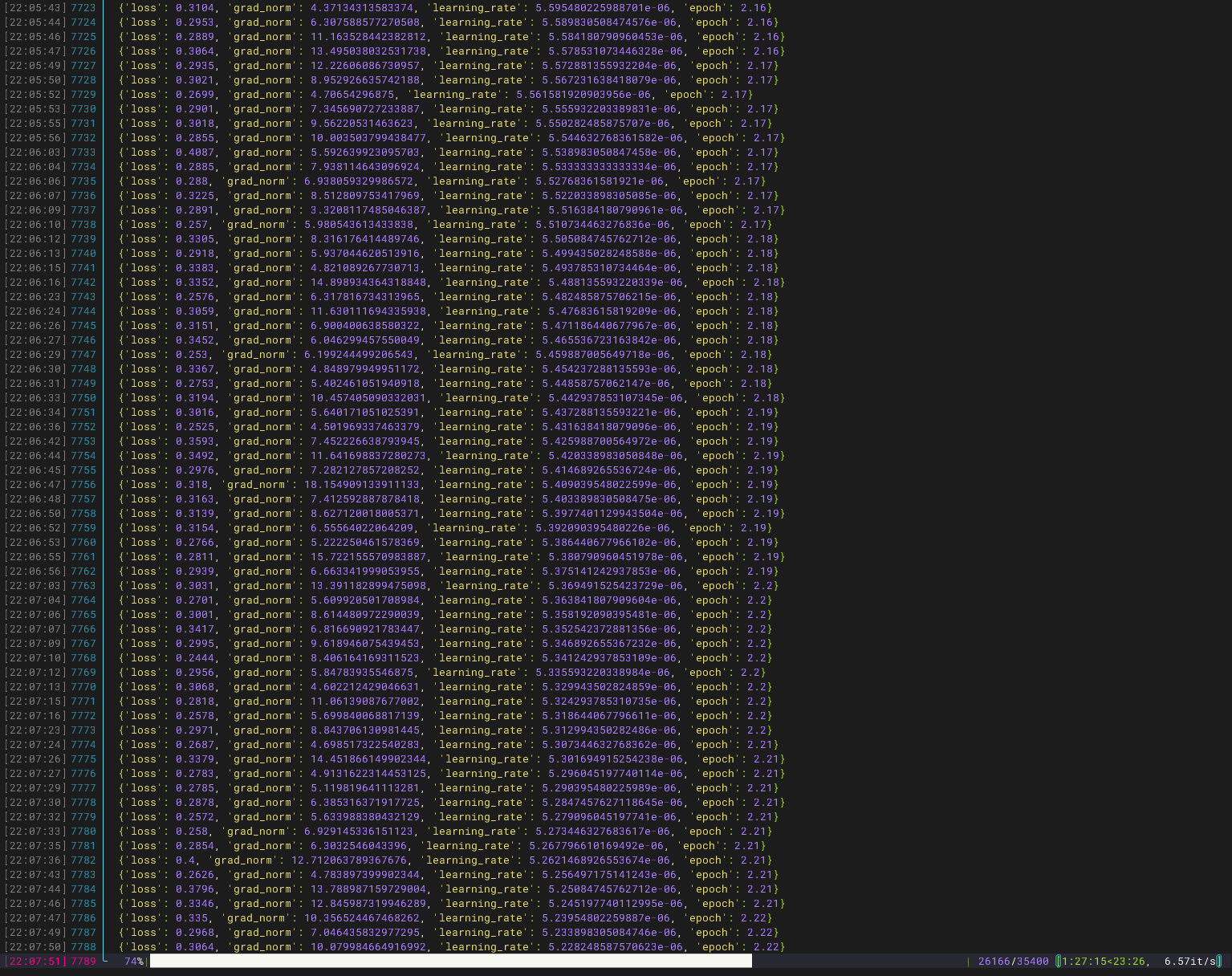
下图为最终的损失曲线和评估指标
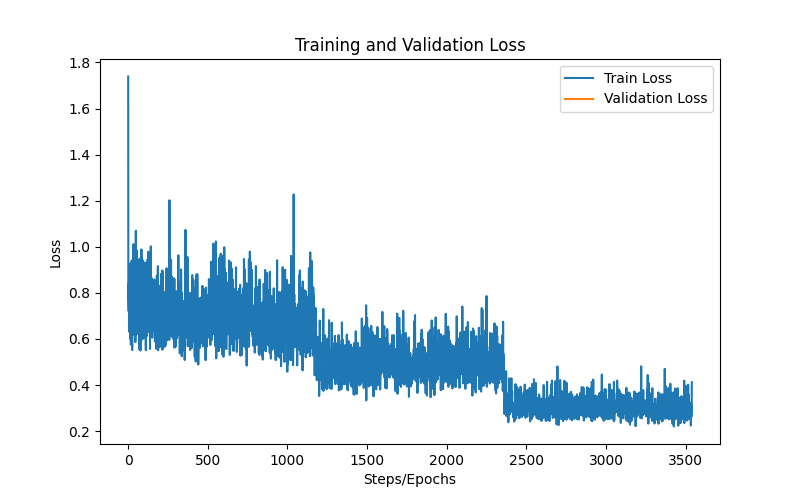
损失曲线整体走势健康,表明模型训练过程顺利,参数收敛良好
- Perplexity(困惑度)2.12:困惑度越低,说明模型对下一个词的预测越准确。2.12属于较低水平,表明模型生成文本的流畅性和合理性较好。
- BLEU 26.73:BLEU主要用于评估生成文本与参考答案的相似度。26.7分在中文生成任务中属于中等偏上的表现,说明模型具备一定的生成能力。
- ROUGE-L 0.4076:ROUGE-L反映了生成文本与参考答案在最长公共子序列上的重合度。0.41的分数说明模型在内容覆盖和结构还原方面表现较为理想。
损失曲线和评估指标共同表明,模型训练过程稳定,未出现明显过拟合,且在生成任务上取得了较好的效果。低困惑度和较高的BLEU、ROUGE-L分数,说明ERNIE-4.5-0.3B模型不仅能生成流畅的文本,还能较好地覆盖参考答案的内容。总体表现良好
六、总结
6.1 模型开源价值 🚀
文心一言作为大规模预训练语言模型的开源,为开发者和研究者提供了宝贵资源 💎,打破了以往商业化限制 🔓,极大推动了人工智能领域的创新 🧠,尤其在中文处理、多语言任务和各类NLP应用中展现出强大能力 💪,同时促进了产业界与学术界的合作 🤝。
然而,其开源也存在不足 😅,如训练和微调对计算资源要求高 💻🔥,数据隐私与安全性有待保障 🔐,且在医学、法律等专业领域的中文优化仍需进一步提升 📈。
6.2 后续使用与研究建议 📌
建议企业和开发者根据实际需求对文心一言进行定制化微调 🛠️,特别是在金融💰、医疗🏥等特定领域,以提升应用效果 🚀,同时可探索其在跨语言和多语言任务中的潜力 🌍。
随着大模型的普及,需进一步强化安全性和隐私保护 🛡️,防止生成不当内容 ⚠️。后续研究可聚焦于优化训练算法以提升效率 ⚡、减少资源消耗 ♻️,并加强领域自适应能力 🔄。此外,还可拓展多模态方向,探索文心一言在文本📄、图像🖼️、音频🎵等多模态任务中的应用。
体验直达链接:https://ai.gitcode.com/theme/1939325484087291906

