大数据技术之Hadoop全家桶学习指南:HDFS+MapReduce+Yarn
大数据技术之Hadoop全家桶学习指南:HDFS+MapReduce+Yarn
文章目录
- 大数据技术之Hadoop全家桶学习指南:HDFS+MapReduce+Yarn
- 背景
- 一、Hadoop是什么?由哪些组件构成?
- 二、Hadoop组件介绍
-
- 1.HDFS架构概述
- 2.MapReduce架构概述
- 3.Yarn架构概述
- 4.HDFS、MapReduce、Yarn三者关系
- 总结
背景
随着互联网的发展,海量数据怎么存,怎么算成了一个问题,在这种背景下Hadoop应运而生,为大数据的存储和计算提供了一种方法,话不多说,进入正文。
一、Hadoop是什么?由哪些组件构成?
Hadoop的核心思想是分布式存储,主要由三个组件构成HDFS、MapReduce、Yarn 正如下图:
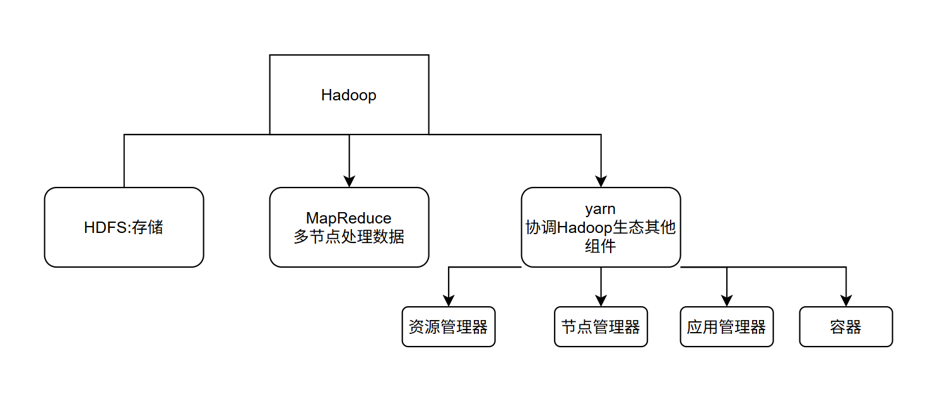
HDFS :通过将大数据切分成多个数据块并分布式存储在不同服务器上,提高了存储效率与容错性
MapReduce:将计算任务划分为若干子任务,在多个节点上并行处理后再进行结果汇总,提升了计算能力和处理速度
Yarn:作为资源管理和调度平台,负责协调集群中的计算资源,确保各任务高效运行
二、Hadoop组件介绍
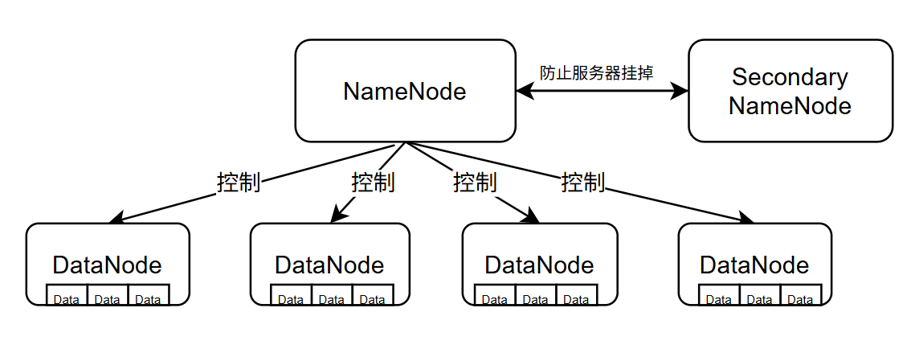
1.HDFS架构概述
Hadoop Distribured File System,简称HDFS,是一个分布式文件系统
(1)NameDode:负责管理HDFS的元数据,如文件和目录结构,以及文件块的位置。它是HDFS的核心,控制整个文件系统的操作。
(2)DataNode:存储实际的数据块(block),负责数据的读写操作,并定期向NameNode报告其状态。
(3)SecondaryNode:定期备份 NameNode 的元数据,以防止 NameNode 崩溃导致的数据丢失。
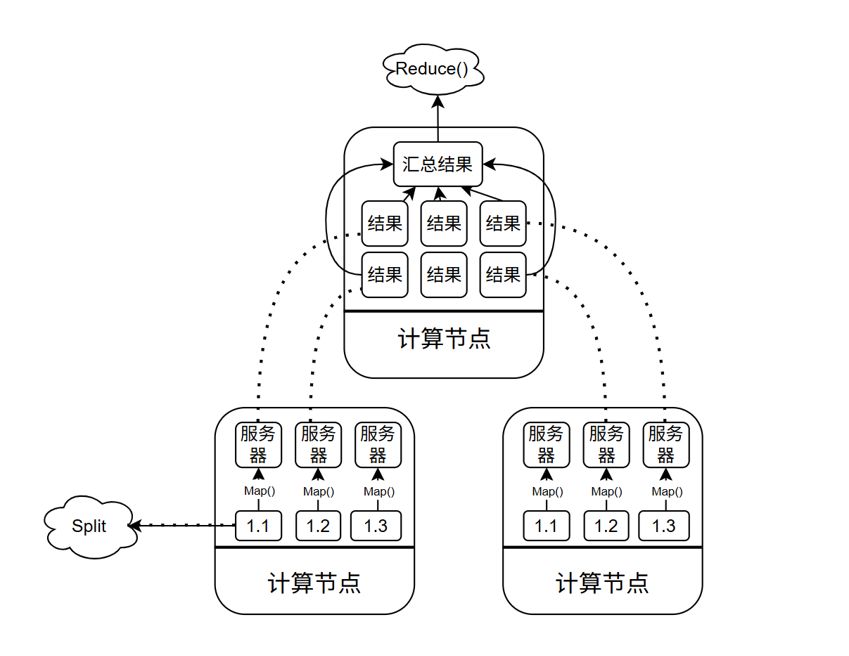
2.MapReduce架构概述
MapReduce将计算任务分成两个步骤:Map和Reduce
(1)Map:将要计算的数据拆分成一个分片(split)放进服务器中进行并行处理,生成中间结果
(2)Reduce:对中间结果进行汇总,输出最终结果
3.Yarn架构概述
Yet Another Resource Negotiator,简称Yarn 是 Hadoop 生态系统中的资源管理层,主要负责集群资源的管理和调度。
(1)ResourceManager:整个集群资源的管理者,负责管理所有计算资源的分配
(2)NodeManager:单个节点服务器资源的管理者。
(3)ApplicationMaster:单个任务运行的管理者。
(4)Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。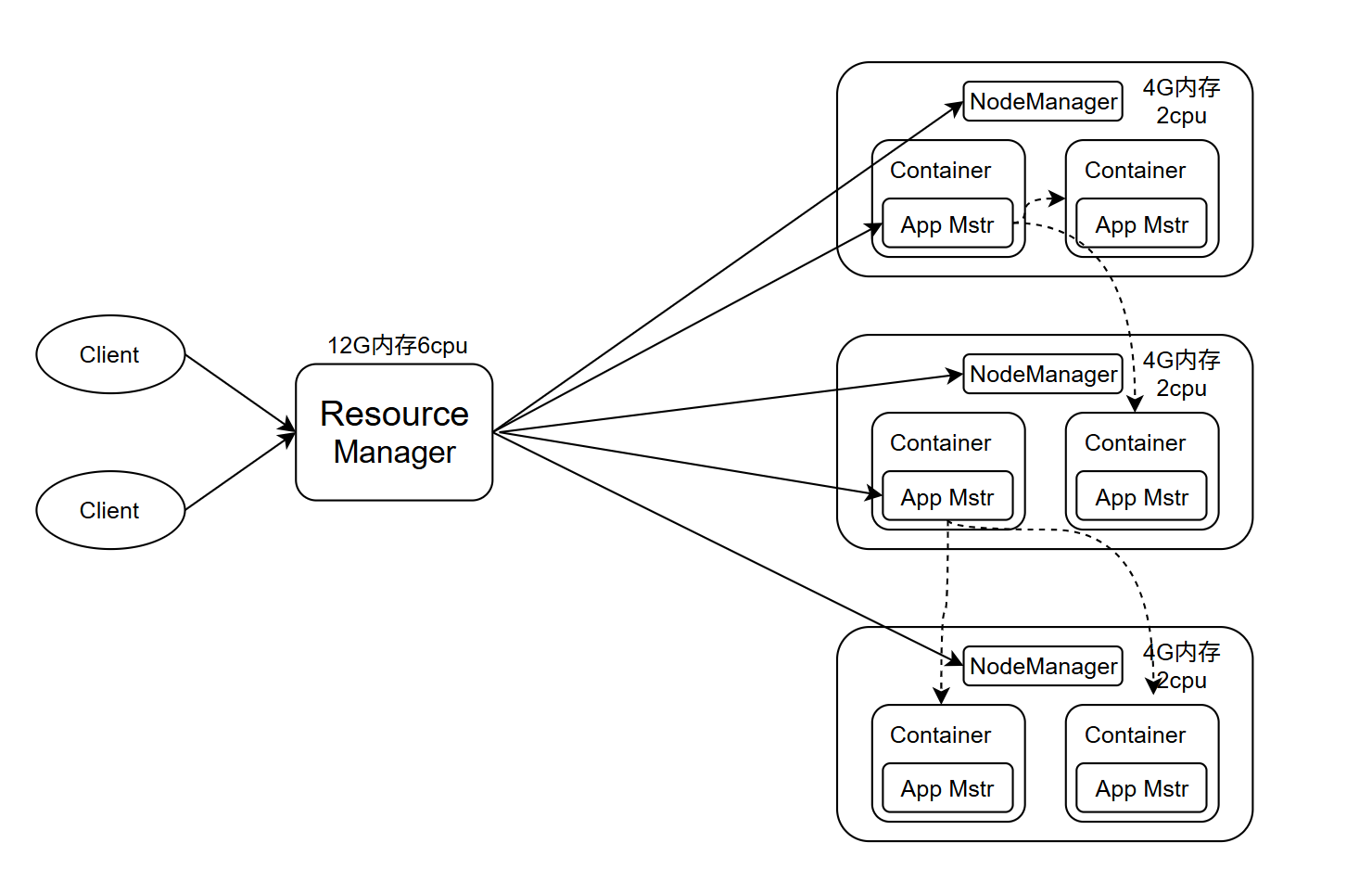
4.HDFS、MapReduce、Yarn三者关系
当海量数据到来时,数据会被切分并存储在 HDFS 中。当需要进行计算时,数据从 HDFS 中提取并进一步切分为多个计算分片。YARN 负责管理和调度服务器资源,将每个分片分配到相应的服务器,并通过 Map() 函数并行处理,最后使用 Reduce() 函数对结果进行汇总。这就是 Hadoop 中三个关键组件的协同工作过程。
三者关系正如下图:
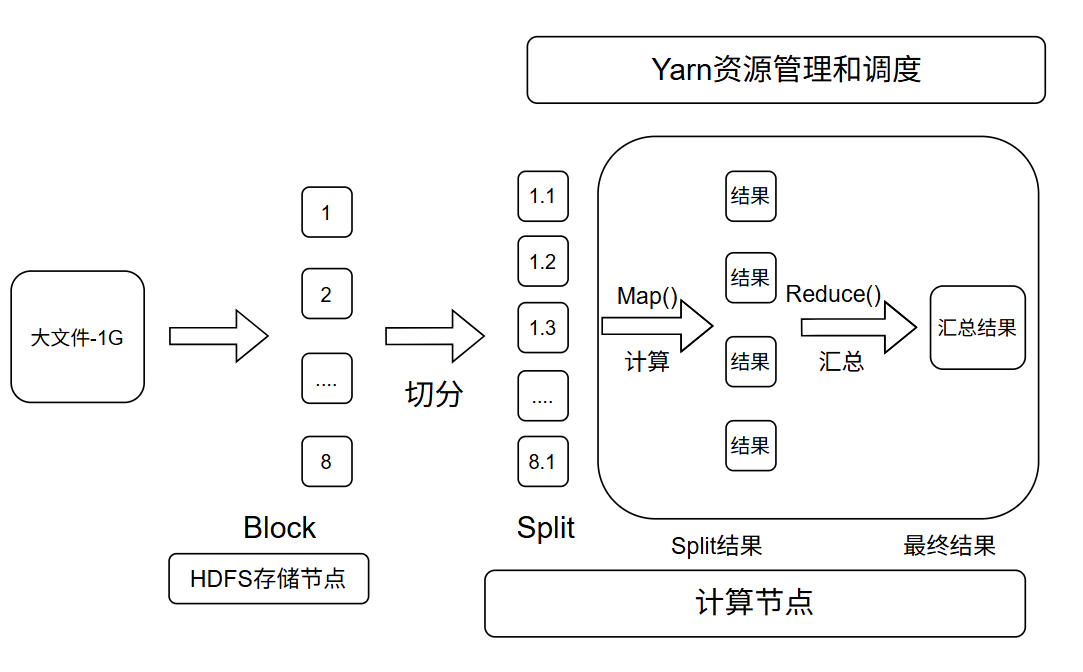
总结
Hadoop 是一个强大的大数据处理框架,它通过 HDFS、MapReduce 和 YARN 三大核心组件,实现了高效的分布式存储与计算。HDFS 通过将数据分块存储在多台服务器上,确保了数据的高可用性与容错性;MapReduce 则将计算任务切分并并行处理,极大地提高了计算效率;而Yarn负责资源的动态调度和管理,保证了集群资源的高效利用。这三者紧密协作,使得 Hadoop 能够处理海量数据并为大数据应用提供可靠的基础架构。
Hadoop 的分布式架构为数据密集型行业提供了解决方案,尤其在处理大规模数据分析时,展现了其强大的处理能力和可扩展性。随着大数据的快速发展,Hadoop 仍然是许多企业处理复杂数据任务的首选平台。
创作不易,大家点个小心心呗,记得关注博主哦~下期我们讲Hive、Spark、Flink和Hadoop之间的关系,谢谢大家的支持啦!


