使用Spark-TTS-0.5B模型,文本合成语音
文章目录
-
- 背景
- 模型介绍
- 拉取开源代码
- conda下载与使用
- 项目环境配置
- 修改部分代码文件
- 进阶玩法
- 小结
背景
~~~~ 由于本博主遇到了需要文本转语音的相关需求,经过多方面的调研和研究,市面上的实现这个需求的方法有很多,可以直接通过调取api的方式实现,文本转语音。也可以使用AI模型的方式实现。本片文章主要使用AI模型的方式实现,主要就是为了记录一下当时遇到的各种坑。
模型介绍
~~~~ 功能说明:可以将自己录制的语音进行克隆,然后输入文本,语音将按照你克隆的声音读出,直接通过模型的方式合成语音。
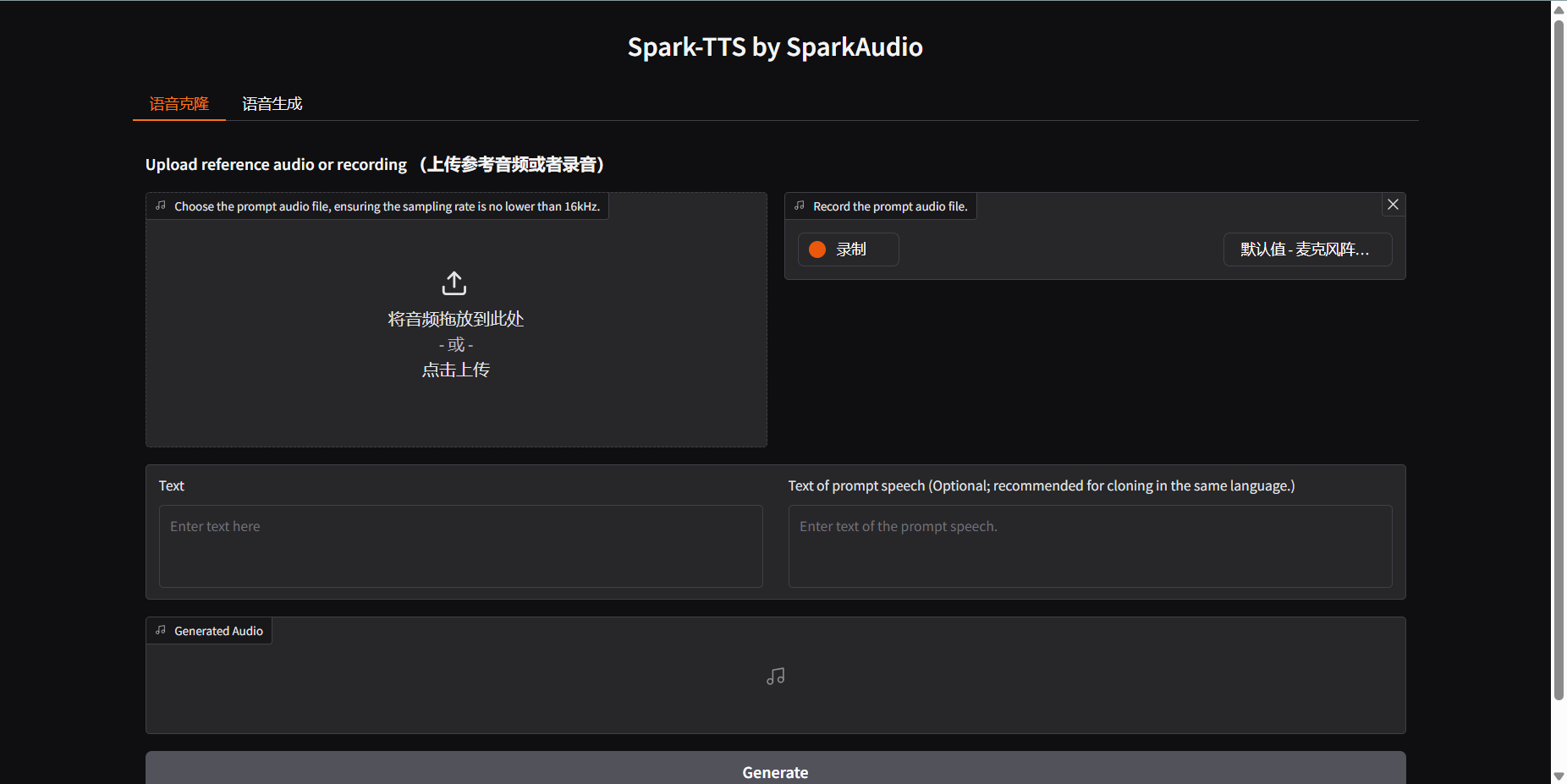
~~~~ 这里主要通过国内的魔塔社区,找到了相关文本生成语音的模型。Spark-TTS-0.5B
还可以使用国外的hugging face模型平台需要自己所需要的模型。(这个需要科学上网)具体如何使用这里就不在介绍。
~~~~ 我所使用的就是这里的模型,如下图所示。
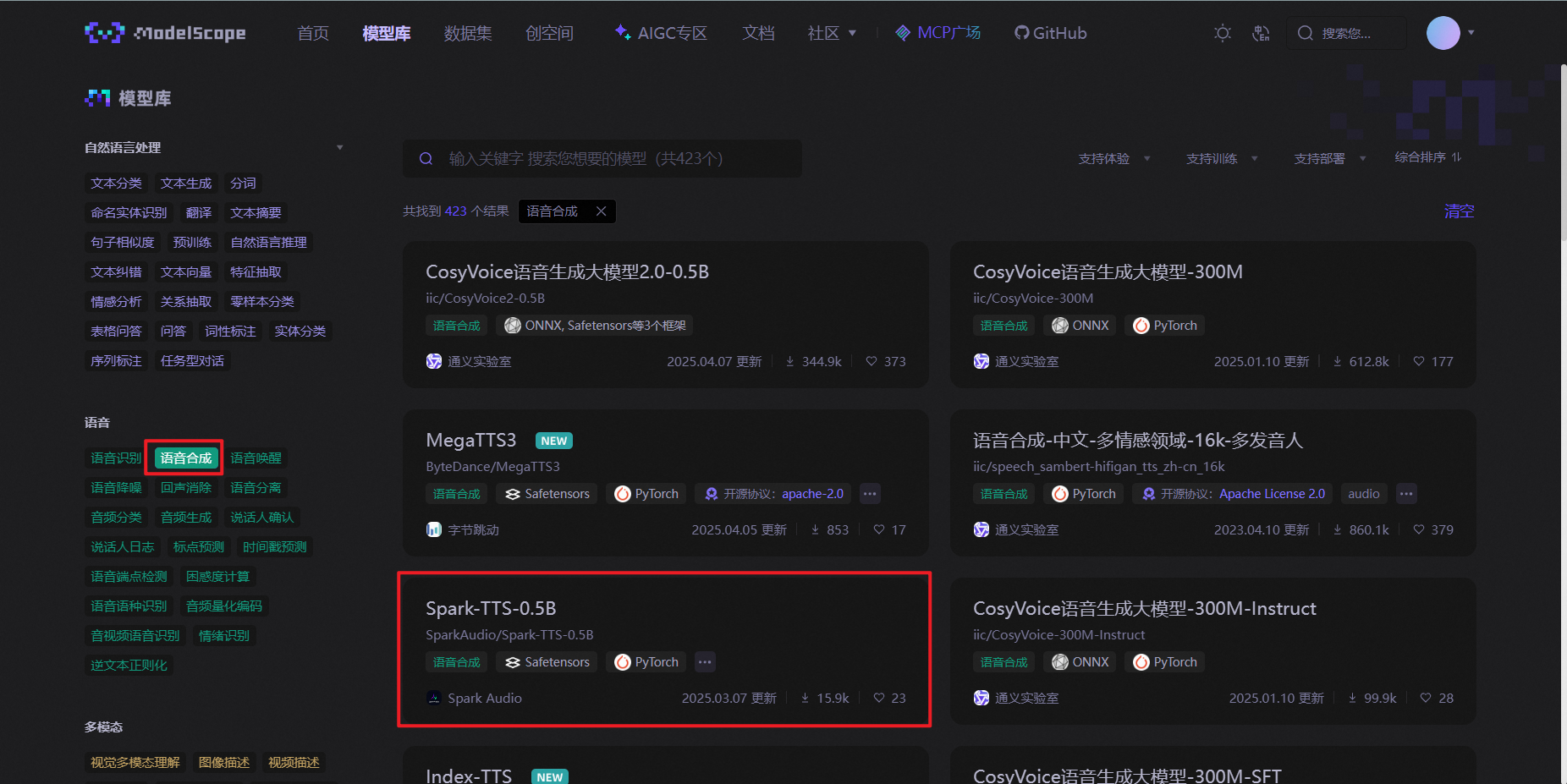
拉取开源代码
~~~~ 到自己的开发环境中拉取相关代码,这里使用的是pycharm和cursor,由于我所使用的pycharm版本加载不了conda环境(找了很多方法,还是不行不清楚是版本问题还是bug),所以这使用pycharm拉取相关代码进行开发,然后在cursor中配置相关的环境,以及运行。
Spark-TTS-0.5B 代码文件
本人的pycharm配置conda时一直出现如下错误,至今没有解决,如有大佬希望可以赐教。
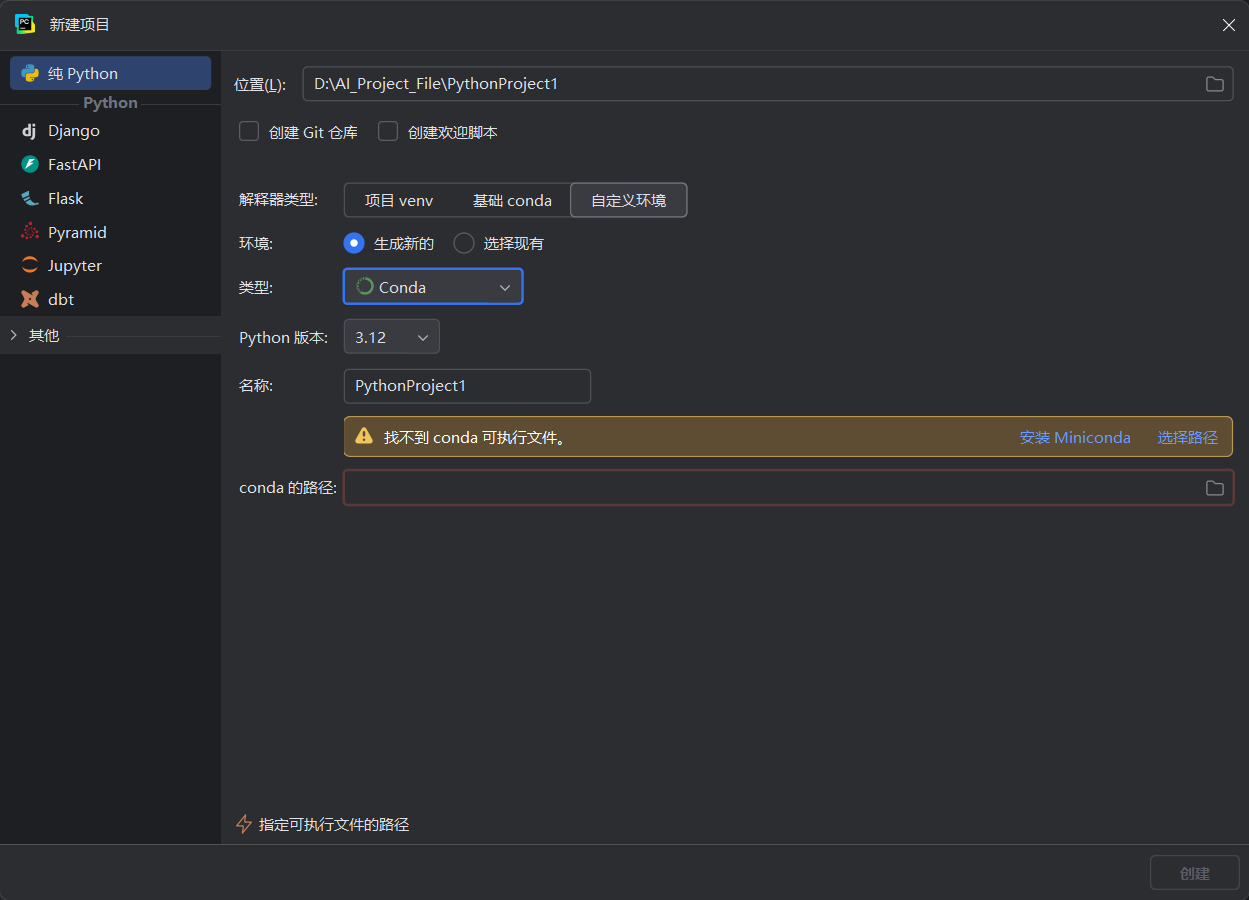
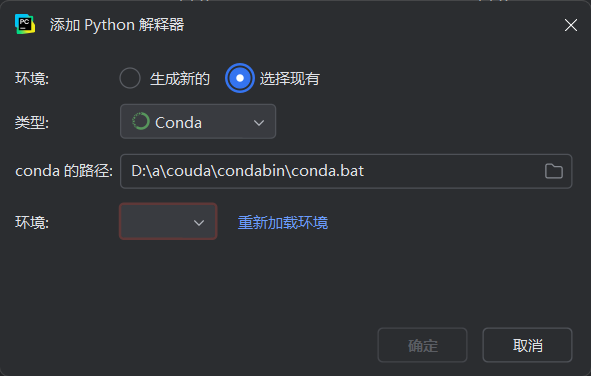
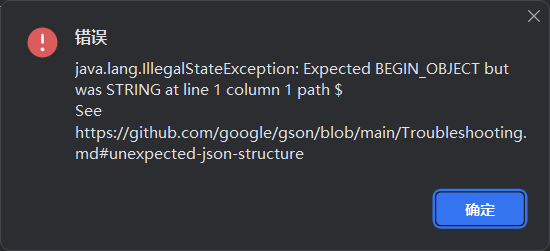
conda下载与使用
官网
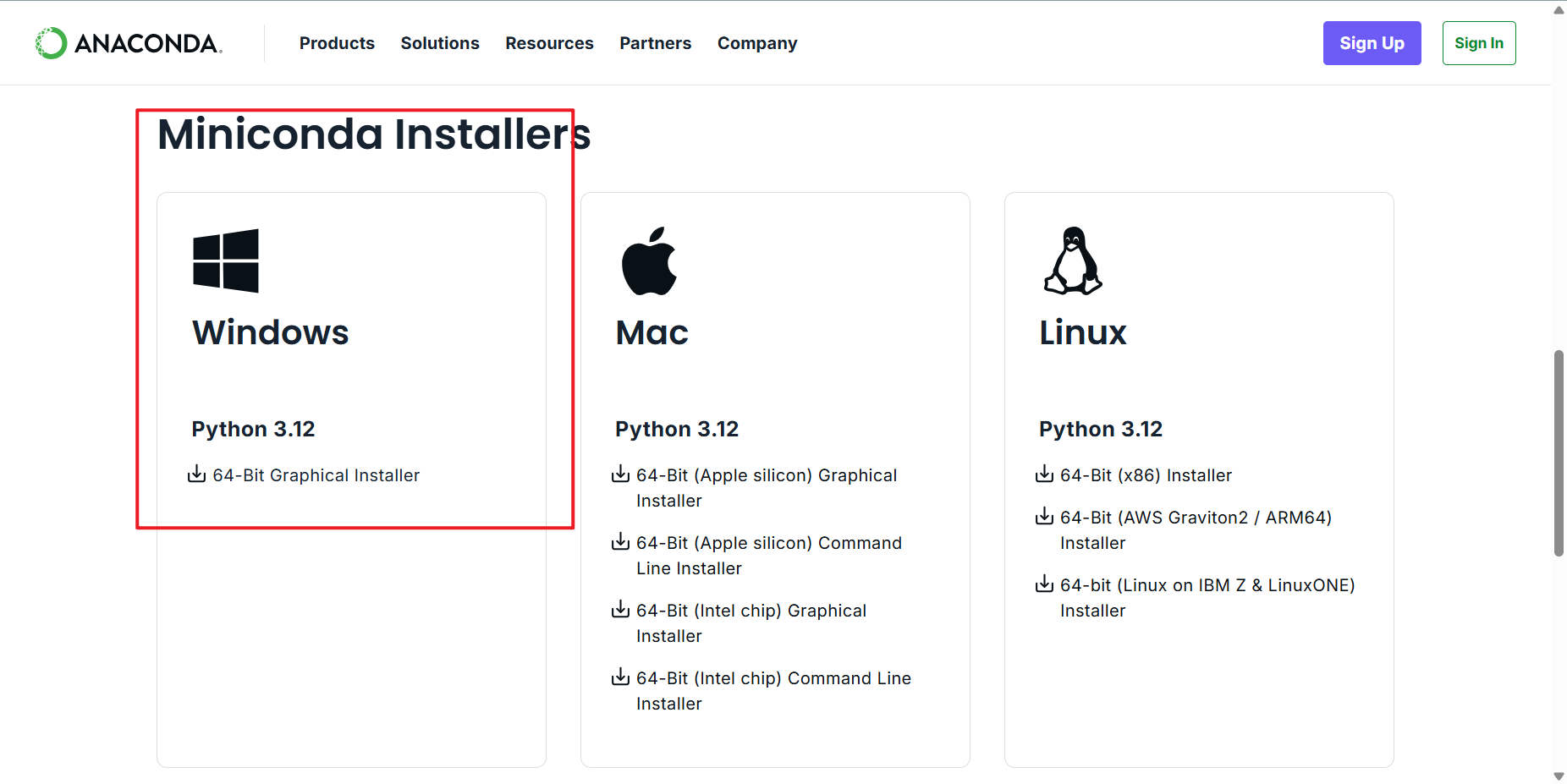
下载小版本即可,不需要完全版。
具体的按照步骤可以参照这个博主的安装教程。Conda安装以及相关配置
1.什么是 Conda 环境Conda 环境是一个独立的软件环境,它可以包含特定版本的 Python 解释器、各种 Python 包以及其他依赖项。每个 Conda 环境都相互隔离,这意味着在一个环境中安装和配置的软件包不会影响其他环境。这样可以方便地在同一台计算机上同时管理多个不同项目,每个项目可以有自己独立的运行环境,避免不同项目之间的依赖冲突。2.Conda 环境的作用解决依赖冲突:不同的项目可能依赖于不同版本的软件包,使用 Conda 环境可以为每个项目创建独立的环境,指定所需的软件包版本,从而避免因依赖冲突导致的问题。方便项目迁移:可以将项目及其依赖的 Conda 环境一起打包,方便在不同的计算机或服务器上进行迁移和部署,确保项目在新的环境中能够稳定运行。支持多语言和多版本:Conda 不仅可以管理 Python 环境,还支持其他编程语言,如 R 等。同时,它可以轻松切换不同版本的编程语言,满足不同项目对语言版本的要求。3.创建和管理 Conda 环境创建环境:使用命令conda create -n env_name python=3.8可以创建一个名为env_name的新环境,并指定使用 Python 3.8 版本。激活环境:在 Windows 系统中,使用activate env_name命令激活环境;在 Linux 和 macOS 系统中,使用source activate env_name命令。激活后,后续的包安装和命令执行都将在该环境中进行。安装包:在激活的环境中,使用conda install package_name命令安装所需的软件包。例如,conda install numpy可以安装 NumPy 包。列出环境:使用conda env list命令可以查看当前系统中所有的 Conda 环境。删除环境:使用conda env remove -n env_name命令可以删除指定的环境。项目环境配置
前提:创建好对应的conda环境后,在到cursor中配置解释器以及环境。
例如:我创建后如下:
到cursor中配置相关conda环境
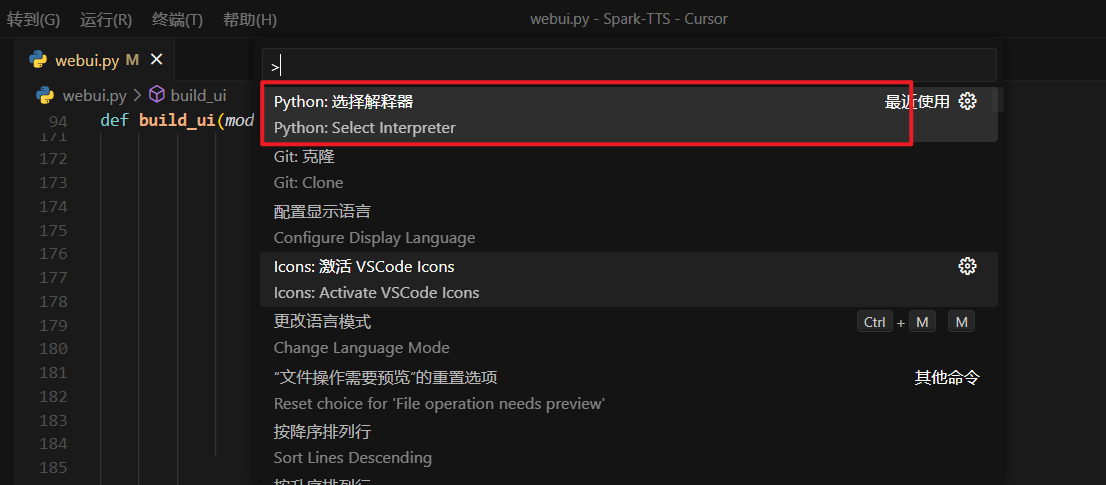
打开一个终端,执行如下命令,用于下载项目所需要的包以及各种依赖。
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com下载相关模型(时间较长):
from modelscope import snapshot_download# 在魔塔社区中的模型名词,以及将模型下载到什么位置。一级目录可能需要提前创建snapshot_download(\"SparkAudio/Spark-TTS-0.5B\", local_dir=\"SparkAudio/Spark-TTS-0.5B\")如下就是下载后的模型文件
修改部分代码文件
可能出现的错误:
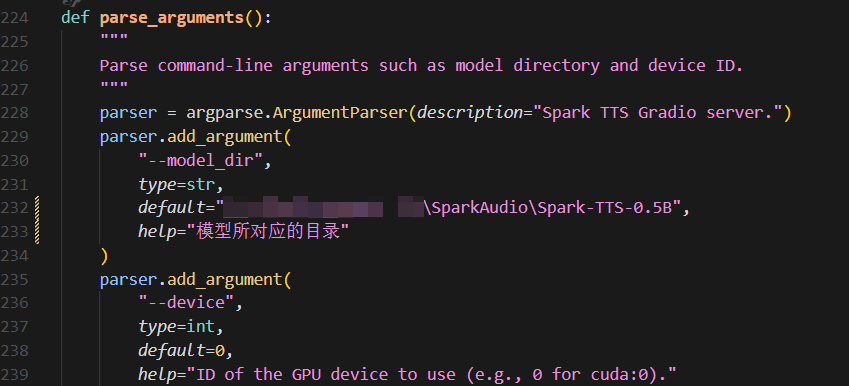
1.包环境没有下载完整。2.如果在cursor终端启动程序没有反应,可能是加载模型没有成功,这里可能需要修改为绝对路径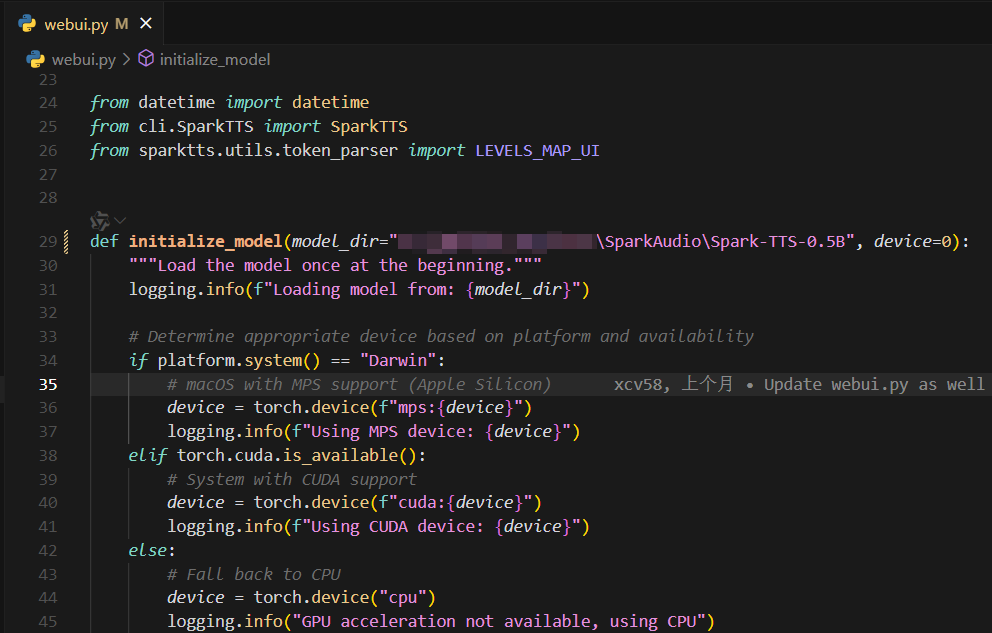
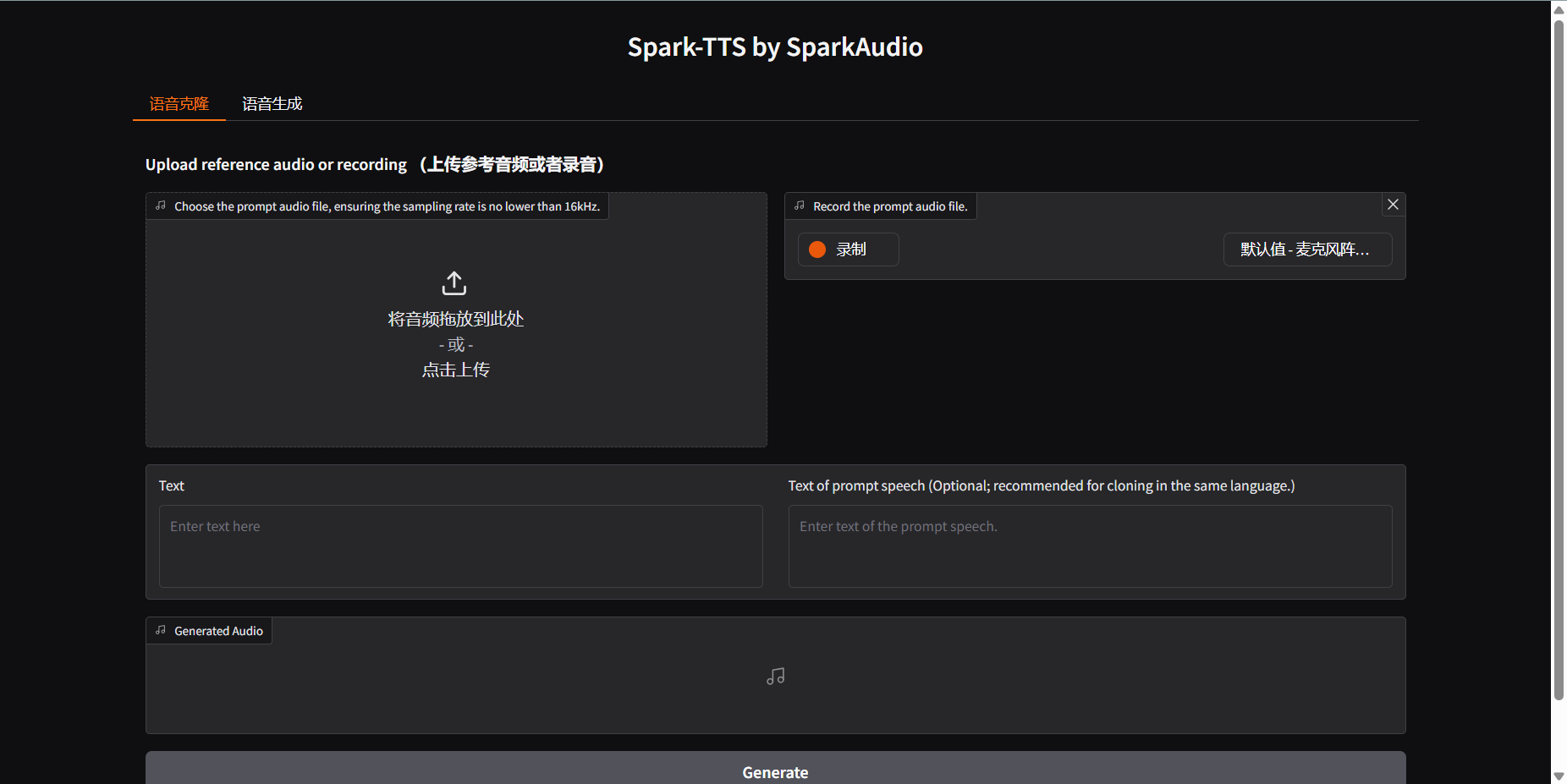
启动成功:访问------>http:localhost:7860

可能有不一样的地方,语音克隆和语音生成的菜单,我修改了代码的注释,原可能时英文。
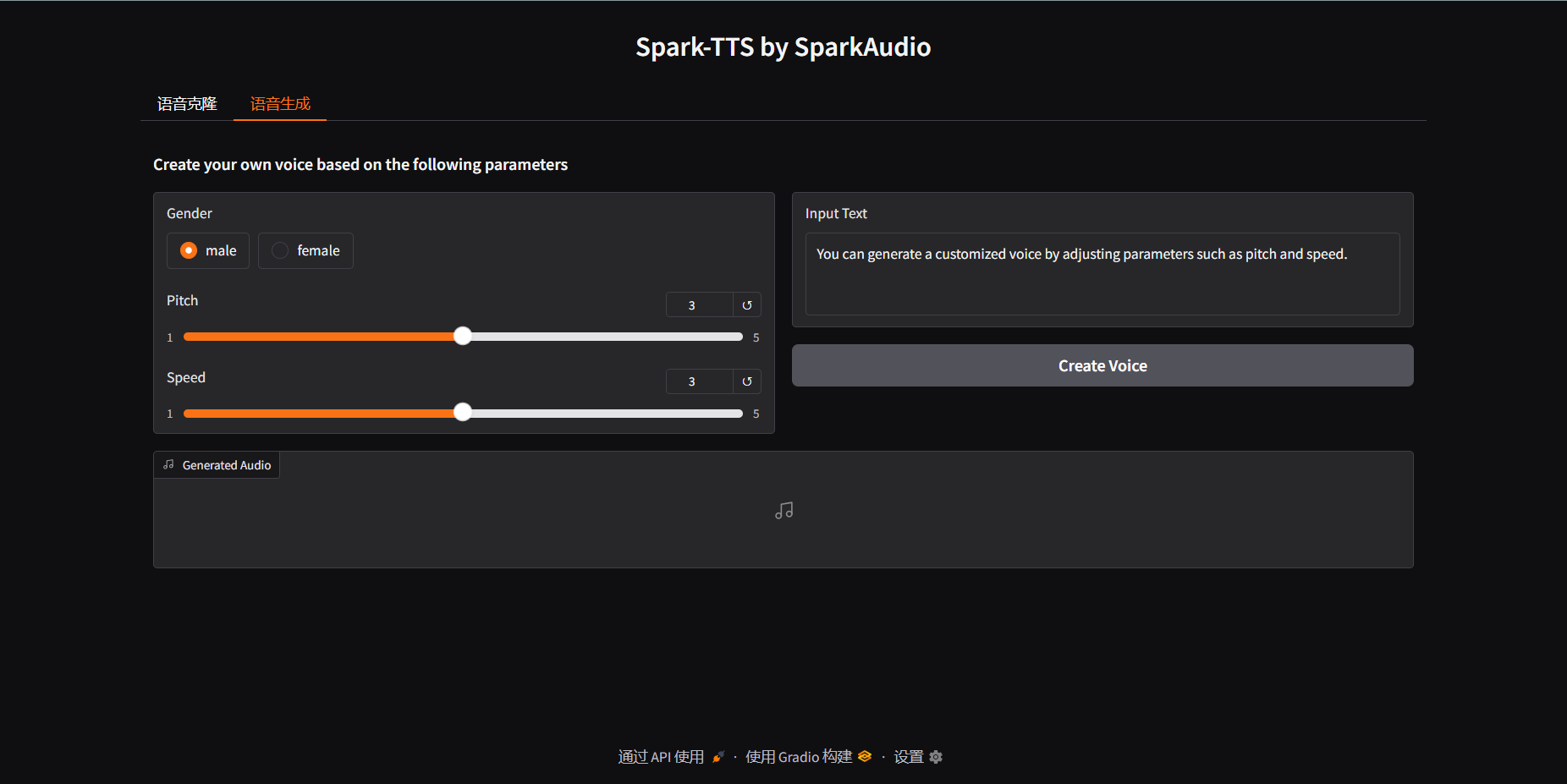
进阶玩法
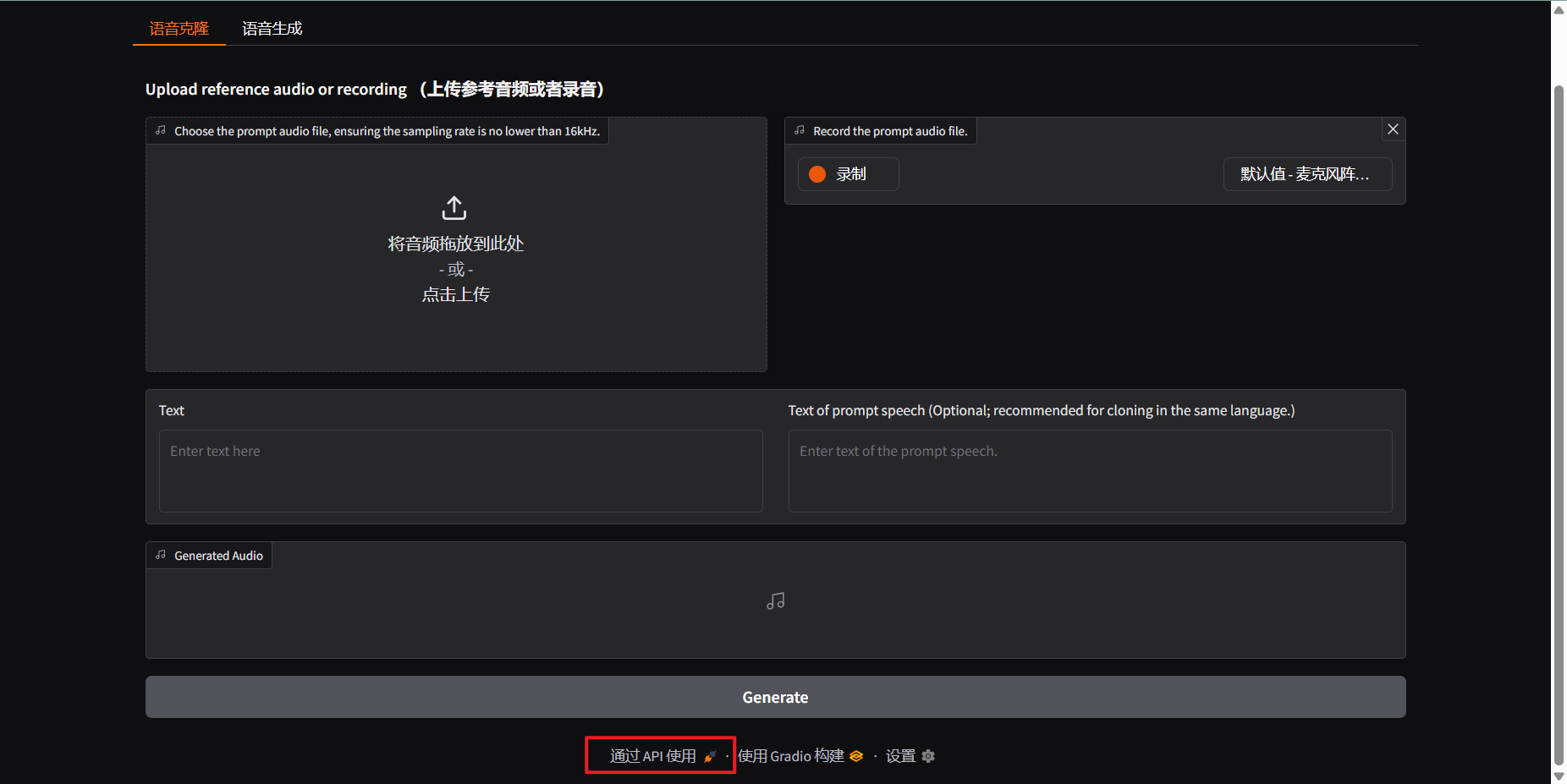
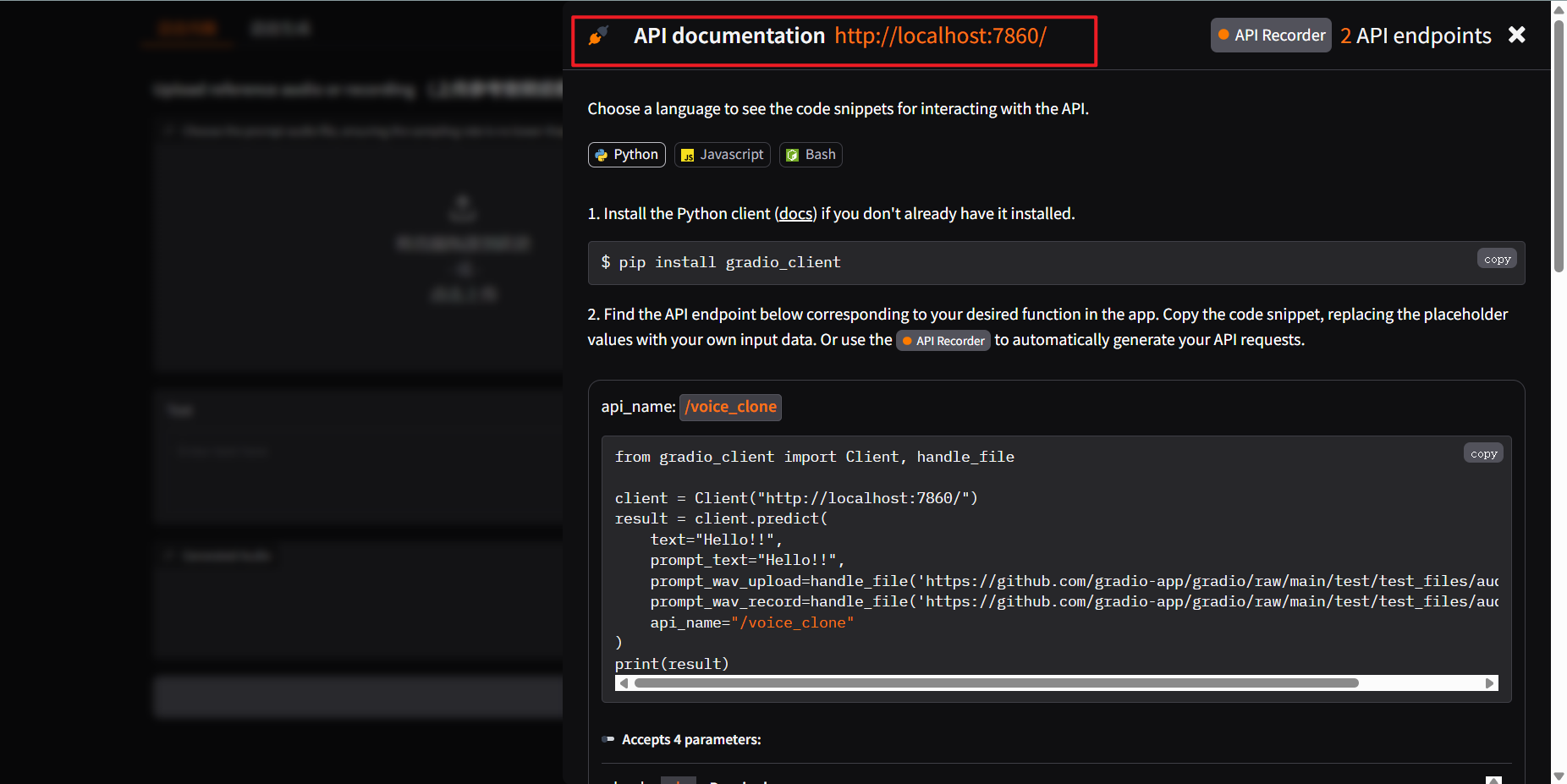
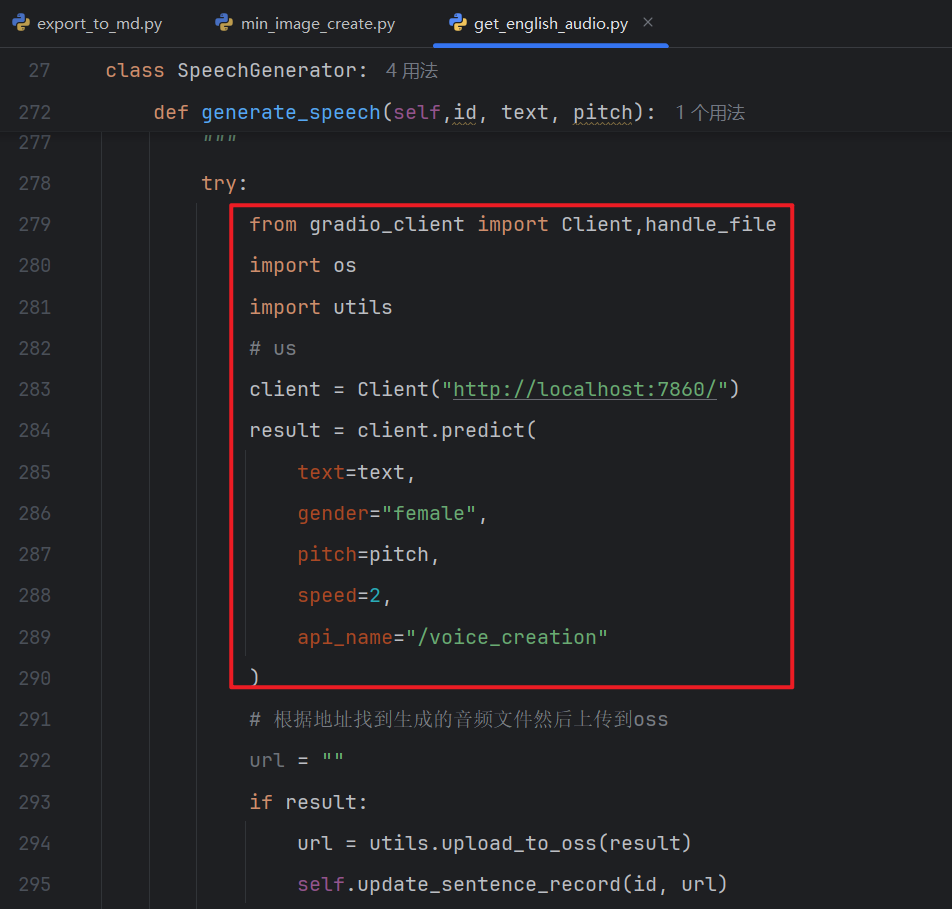
这个还提供了API接口,如果需要大批量的生成语音,可以使用脚本调取相关的接口批量生成语音。
小结
当时使用这个模型的时候遇到了很多问题,所以在此记录一下,也回顾一下。如有错误,望指正感谢。

