国产大模型黑马!文心大模型4.5开源实测:快速部署+多模态识别准,自媒体场景直接封神_ernie-4.5-vl-28b-a3b 部署
1. 前言
大家如果有关注国内开源圈或者AI圈的话,应该都知道,最近发生了一件大事。就在刚刚过去的6月30号,百度正式开源了文心大模型4.5多模态大模型。文心大模型4.5系列开源模型一共有10款,包括8个激活参数规模为47B和3B的混合专家模型(最大的模型总参数量为424B),以及2个0.3B的稠密参数模型。其中,有4款VL模型支持多模态特性,可以对图片、音频、视频等非本文类型的内容进行理解识别。按照官方的介绍,文心大模型4.5是百度自主研发的产业级知识增强大模型,实现了从单模态大模型到多模态、从通用基础大模型到跨领域跨行业的创新突破。本次开源的多个参数模型在大模型基准测试中均取得了突出效果,甚至多项测试结果已经超越了OpenAI-o1、DeepSeek-V3、Qwen2.5等主流大模型。今天就带大家一起测评一下文心大模型4.5系列开源模型,看看它是不是真的有那么强。

下面是视频版的测评内容,可供大家参考
文心大模型4.5开源实测:多模态识别准,自媒体场景直接封神
2. 测评的软硬件环境
接下来,介绍一下本次测评的软硬件环境,
2.1 CPU
16核X86架构intel处理器
2.2 内存
64G内存
2.3 GPU
Nvidia A100 80G显存
2.4 软件环境
操作系统使用Ubuntu22.04,软件环境使用的是python3.10、pyTorch2.7。
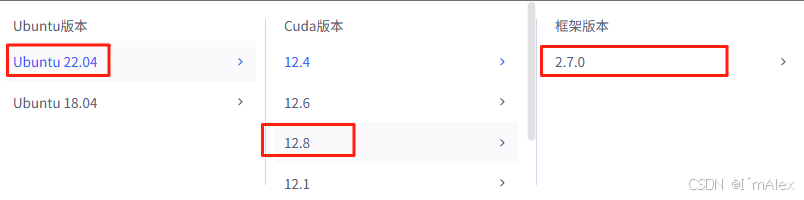
2.5 模型选择
因为文心大模型4.5的核心能力是多模态,因此本次测评选用的模型是ERNIE-4.5-VL-28B-A3B-Paddle,为了更好的展示效果,我们拿通义千问的多模态开源大模型:Qwen2.5-VL-32B-Instruct进行同步测试,进行一些横向对比。
3. 模型部署
关于部署的难易程度,得益于AI的发展,目前各种大模型框架都已经做得非常完善,所以在模型部署上已经不存在任何卡点,像百度专为文心系列大模型设计的飞桨框架平台,也可以基于transformer来快速部署。资源占用上,千问的模型文件有68GB,而文心大模型只有55GB,虽然参数量略少一些,但整体上模型是要比千问小一些的,显存消耗上略微有些优势。后面,我们将重点关注推理效果。
3.1 GPU准备
首先,我们要有一台80G显存的英伟达A100显卡主机。大家可以自行选择主流的算力租聘平台进行租赁使用。
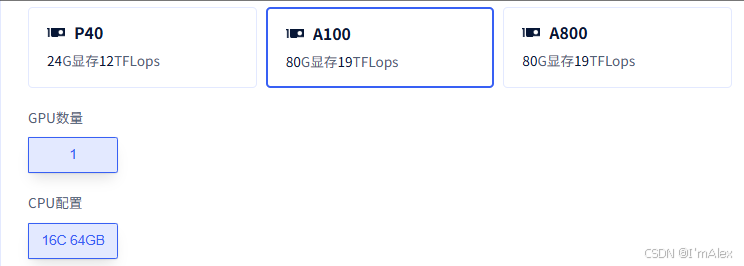
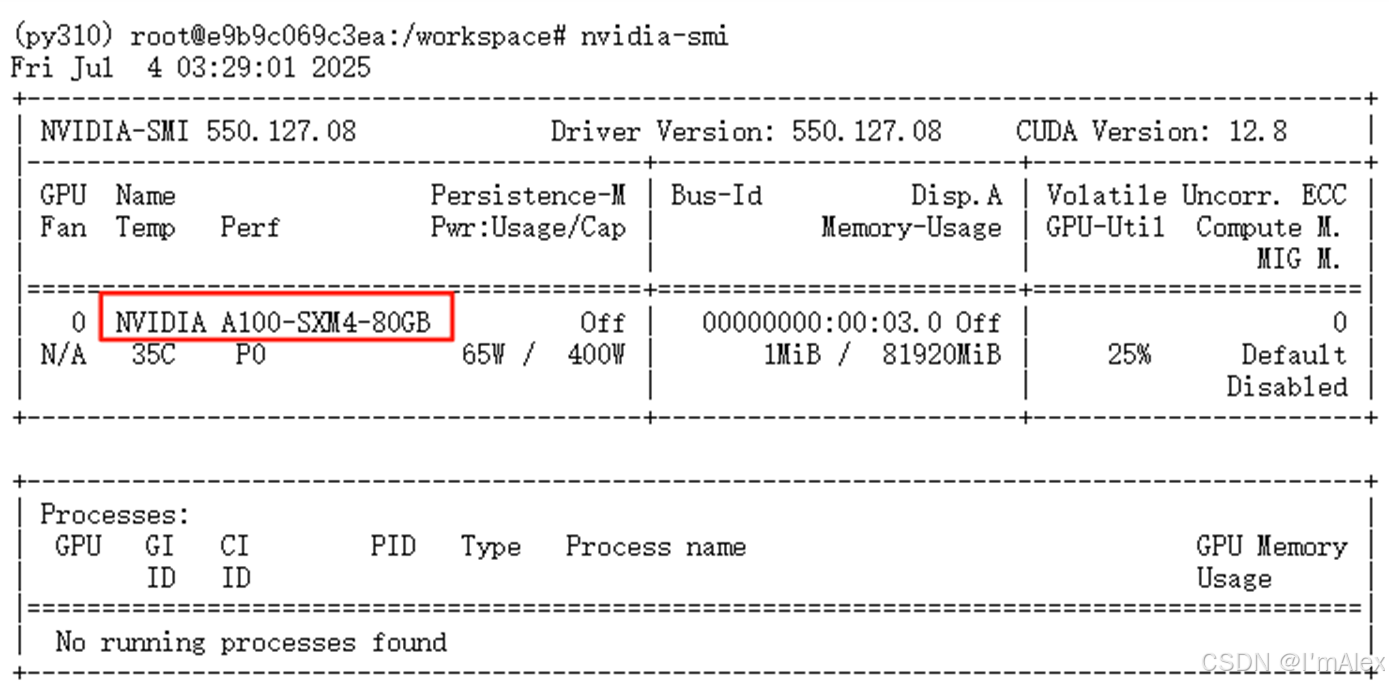
然后依次执行下面3条命令,完成相关工具和模型的下载、安装和推理。
3.2 安装GPU版本的paddlepaddle
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
3.3 安装A100显卡专用的fastdeploy
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
注意如果使用的是4090显卡,需要更换安装命令,具体参考paddlepaddle的帮助文档:https://paddlepaddle.github.io/FastDeploy/get_started/installation/nvidia_gpu/。只需要看下面这部分内容即可:
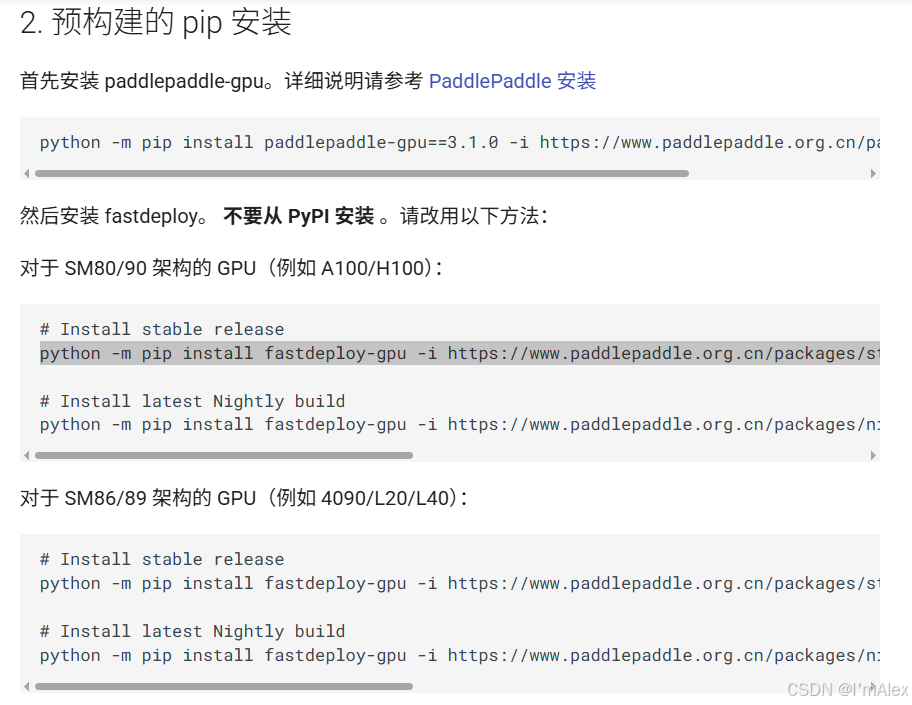
3.4 使用fastdeploy一键完成模型下载和推理
python -m fastdeploy.entrypoints.openai.api_server \\ --model baidu/ERNIE-4.5-VL-28B-A3B-Paddle \\ --port 8180 \\ --metrics-port 8181 \\ --engine-worker-queue-port 8182 \\ --max-model-len 32768 \\ --enable-mm \\ --reasoning-parser ernie-45-vl \\ --max-num-seqs 32
如下图所示,看到8180端口成功启动之后,就表示成功的把文心大模型4.5 28b模型部署运行起来了。

4. 多模态图像识别能力的测评
4.1 明星人物识别

接下来,我们拿奥黛丽·赫本在厨房摆弄烤箱的照片进行演示,看看文心大模型和通义千问两个多模态模型的识别结果有何差异。
4.1.1 Qwen2.5-VL-32B的识别结果
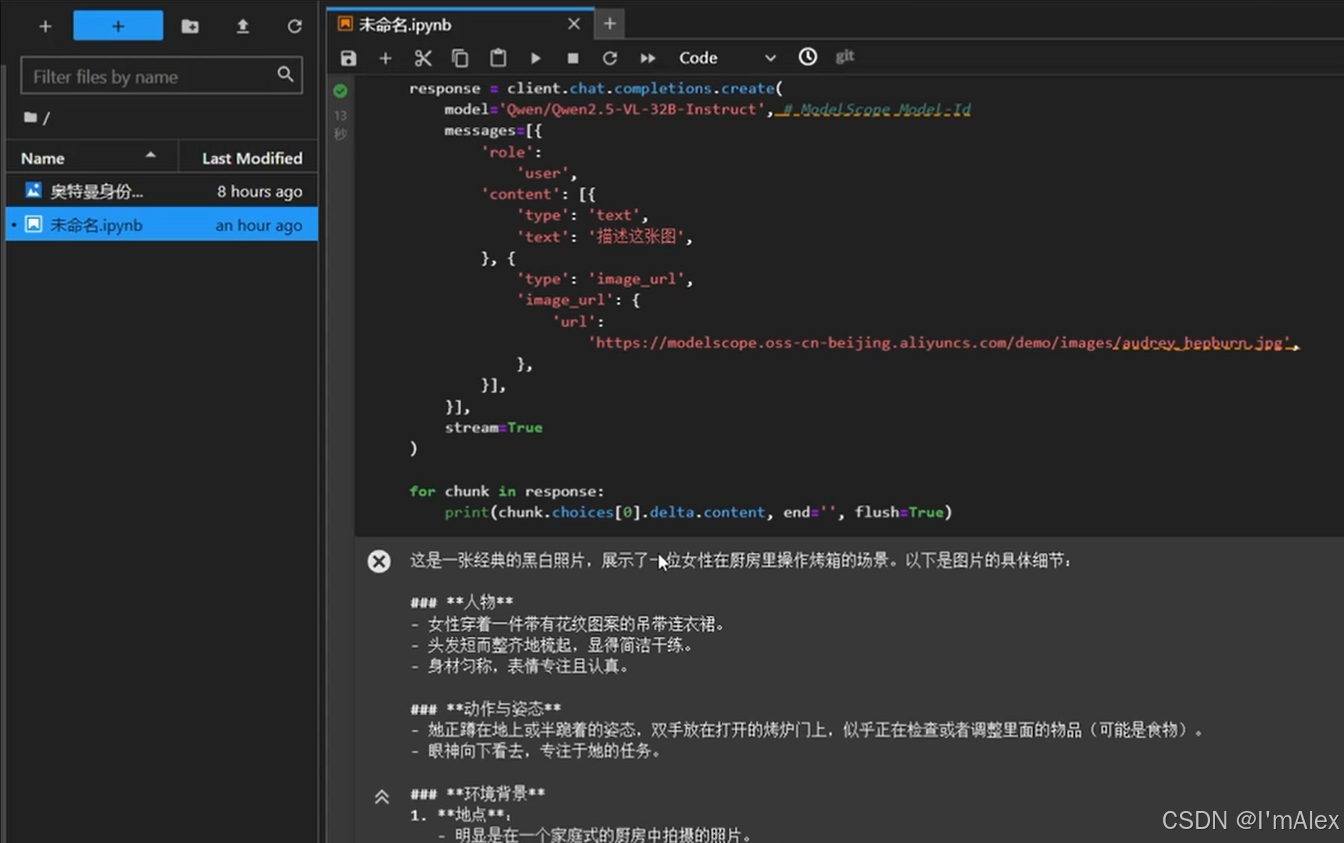
从图片可以看到,Qwen2.5-VL-32B模型识别出了这是一位女性在厨房里操作烤箱,然后对厨房的一些场景构造、物体摆放进行了详细的描述。
4.1.2 ERNIE-4.5-VL-28B-A3B的识别结果

从图片可以看到,ERNIE-4.5-VL-28B-A3B模型识别到了图片中的人物是奥黛丽·赫本在厨房操作烤箱,同样也把厨房的场景构造和物体摆放等进行了识别和分析。
4.1.3 对比分析
通过对比可以看到,文心大模型精准的识别到了奥黛丽·赫本,并对图片中的环境和相关元素进行了描述。虽然千问大模型也很准确的识别出了照片中的各种物体和摆放造型等,但一大败笔就是没有识别出主人公奥黛丽·赫本。虽然参数量少,模型小,但是多模态的识别效果一点也不差,还更胜一筹。从运行时间来看,虽然文心大模型没有启用流式输出,但还是可以明显感知到,文心大模型返回结果的耗时也是要比千问更胜一筹的。总体来看,文心在响应速度上也占据了一定优势。
4.2 基于gradio库的文心大模型前端交互页面
为了方便调用ERNIE-4.5-VL-28B-A3B大模型,我使用python的gradio库写一个的大模型前端交互页面,支持图片和文本的输入,源码如下:
import gradio as grimport requestsimport jsonimport osfrom PIL import Imageimport ioimport timeimport uuiddef process_multimodal_input(image, text_input, history): \"\"\"处理多模态输入并调用API\"\"\" if image is None and not text_input.strip(): return history, \"请上传图片或输入文本\" # 准备API请求 url = \"http://127.0.0.1:8180/v1/chat/completions\" headers = { \"Content-Type\": \"application/json\" } # 构建消息内容 content = [] # 如果有图片,添加图片内容 if image is not None: # 保存上传的图片到临时文件 temp_dir = \"temp_images\" os.makedirs(temp_dir, exist_ok=True) temp_path = os.path.abspath(f\"{temp_dir}/temp_image_{uuid.uuid4()}.jpg\") image.save(temp_path) # 使用本地文件路径 image_url = f\"file://{temp_path}\" # 添加图片到内容 content.append({\"type\": \"image_url\", \"image_url\": {\"url\": image_url}}) # 添加文本到内容 if text_input.strip(): content.append({\"type\": \"text\", \"text\": text_input}) else: # 如果用户没有输入文本但上传了图片,添加默认提示 if image is not None: content.append({\"type\": \"text\", \"text\": \"描述一下这张图片\"}) # 更新历史记录中的用户消息 user_message = {\"role\": \"user\", \"content\": content} # 构建完整的请求体,包含历史消息 messages = [] # 添加历史消息(仅文本部分) for msg in history: if msg[0]: # 用户消息 messages.append({\"role\": \"user\", \"content\": [{\"type\": \"text\", \"text\": msg[0]}]}) if msg[1]: # 助手消息 messages.append({\"role\": \"assistant\", \"content\": msg[1]}) # 添加当前消息 messages.append(user_message) payload = { \"messages\": messages } # 更新UI显示 history.append((text_input if text_input.strip() else \"图片查询\", None)) yield history, \"\" try: response = requests.post(url, headers=headers, data=json.dumps(payload)) response_data = response.json() # 从响应中提取内容 if \"choices\" in response_data and len(response_data[\"choices\"]) > 0: result = response_data[\"choices\"][0][\"message\"][\"content\"] # 更新历史记录中的助手回复 history[-1] = (history[-1][0], result) yield history, \"\" else: error_msg = \"无法获取响应,API返回格式异常。\" history[-1] = (history[-1][0], error_msg) yield history, \"\" except Exception as e: error_msg = f\"发生错误: {str(e)}\" history[-1] = (history[-1][0], error_msg) yield history, \"\"def clear_chat(): \"\"\"清除聊天历史\"\"\" return [], \"\"# 创建Gradio界面with gr.Blocks(title=\"文心大模型4.5\") as demo: with gr.Column(): with gr.Row(): gr.Markdown(\"# 文心大模型4.5 - 多模态大模型智能助手,支持文本交互和图像识别\") # 聊天消息区域 chatbot = gr.Chatbot(height=500) # 图片上传(隐藏) image_input = gr.Image( type=\"pil\", label=\"\", visible=False ) # 文本输入区域独占一行 text_input = gr.Textbox( placeholder=\"输入消息或上传图片...\", label=\"\", lines=4, max_lines=10 ) # 按钮组 - 独立成行 with gr.Row(): # 添加scale参数确保按钮不被拉伸 # 上传图片按钮 upload_btn = gr.UploadButton( \"🖼️\", file_types=[\"image\"] ) # 发送按钮 send_btn = gr.Button(\"发送\") with gr.Row(): gr.Markdown(\"© 2025 文心大模型4.5 | 基于Gradio构建的现代大模型交互界面\") # 处理图片上传 def handle_image_upload(image): return image upload_btn.upload( fn=handle_image_upload, inputs=[upload_btn], outputs=[image_input] ) # 设置发送按钮事件 send_btn.click( fn=process_multimodal_input, inputs=[image_input, text_input, chatbot], outputs=[chatbot, text_input] ).then( fn=lambda: None, inputs=[], outputs=[image_input] ) # 设置文本框回车发送 text_input.submit( fn=process_multimodal_input, inputs=[image_input, text_input, chatbot], outputs=[chatbot, text_input] ).then( fn=lambda: None, inputs=[], outputs=[image_input] )# 启动应用if __name__ == \"__main__\": demo.queue() demo.launch(server_name=\"0.0.0.0\")4.3 图片验证码识别
接下来,我们再做一个实验,以下面这张验证码图片为例,继续验证文心大模型的图像识别理解能力。

接下来,我们通过该页面上传图片,让ERNIE-4.5-VL-28B-A3B模型进行识别。
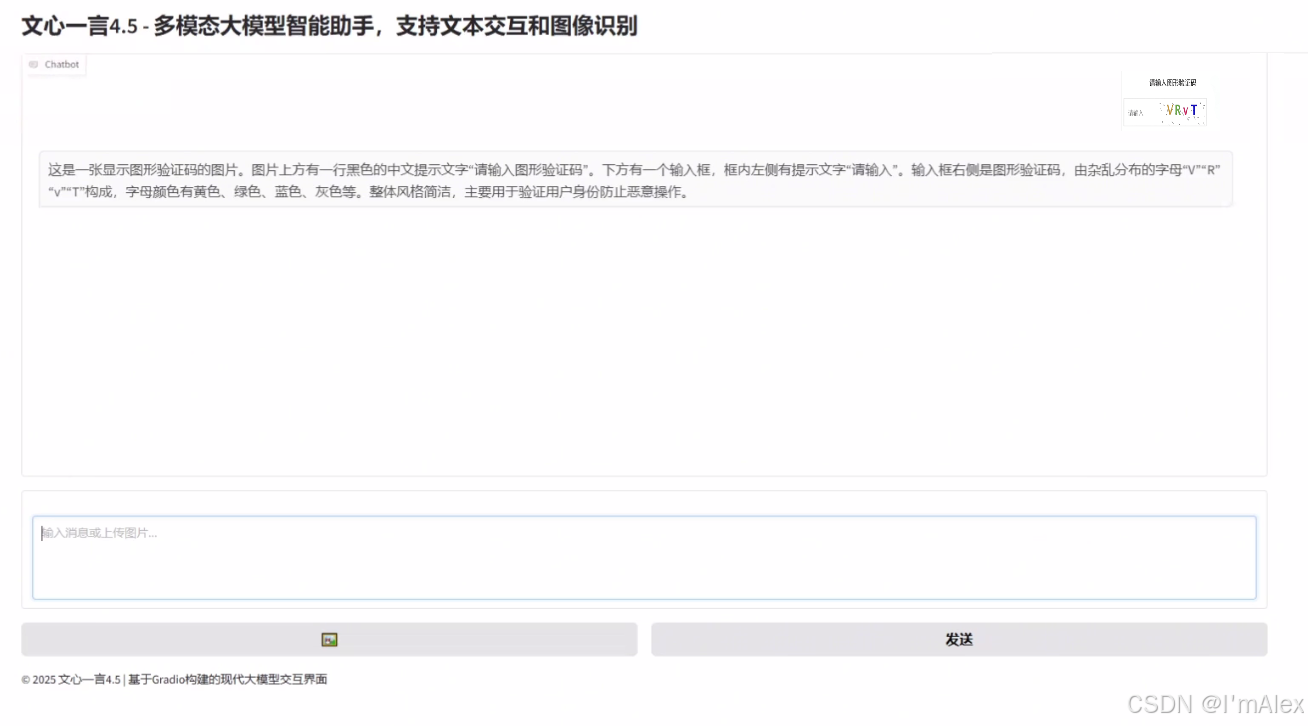
如上图所示,通过识别结果,我们可以看到,文心大模型顺利的把验证码识别了出来,甚至连大小写都精准的做了区分。这个效果强的可怕,远超市面上一众OCR模型,怕是除了百度自家的PaddleOCR,没有比它更强的了!!!
5. 自媒体创作场景测评
通过上面2个多模态例子,可以看到,文心大模型4.5的多模态图像识别理解能力,还是非常强大的,说实话,已经超出了我最初的预期。图像识别能力超群,文心大模型作为产业级知识增强大模型,它的场景化能力表现如何呢?做过自媒体的同学,大家都知道,内容创作有3大难,怎么难呢,诶,分别是起号难、创意难、写作难。既然文心大模型4.5的视觉识别能力这么强,那接下来,我们就以自媒体创作这个典型场景对它进行深挖拷打,看看它能不能给我们的自媒体创作也带来新的超预期惊喜。
5.1 爆文分析
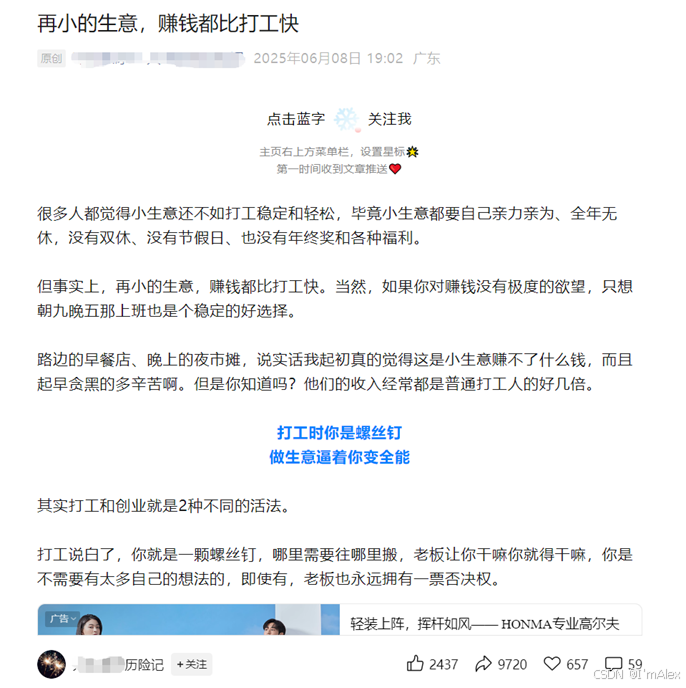
这是一篇阅读量十万W+甚至百万+的一篇微信公众号文章,可谓是超级爆文,我们复制文章内容,让文心大模型分析一下这篇文章的爆点在哪里。
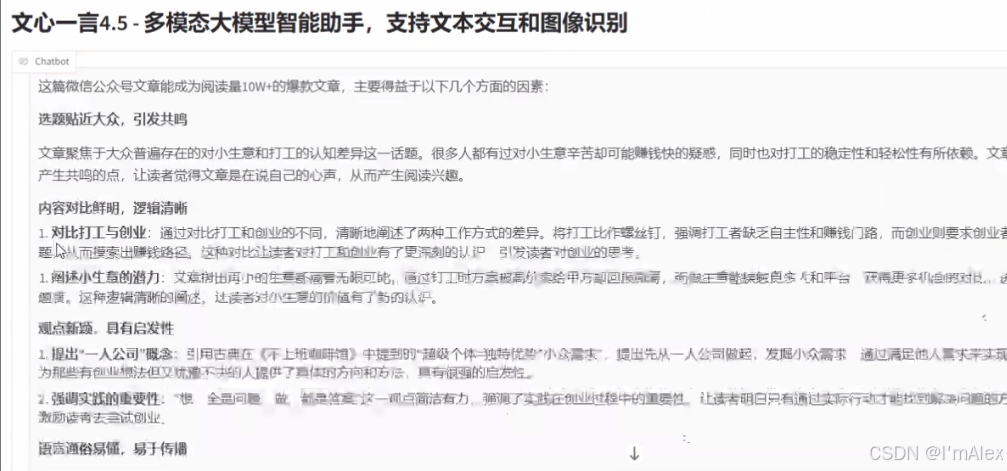
从结果可以看到,文心大模型给出了很有含金量的分析结果,包括选题、内容、观点、语言表达等多方面,分析结论非常非常清晰明确,看完之后是不是感觉并不难,我们也可以写出阅读量一篇10W+的文章了?有了文心大模型的爆文分析帮助,可以帮助我们快速获悉爆文账号的特点和文章写作手法,让我们也有了冲的机会,这就为我们解决了第一个起号难的问题。
5.2 创意生成
接下来,我们以职场自媒体为切入点,让文心大模型给我们梳理几个职场自媒体的灵感话题,用于扩充我们的自媒体创作素材库。
prompt:我是一个职场自媒体创作者,最近比较缺乏灵感,可以给我整理几个更容易成为爆文的话题吗?
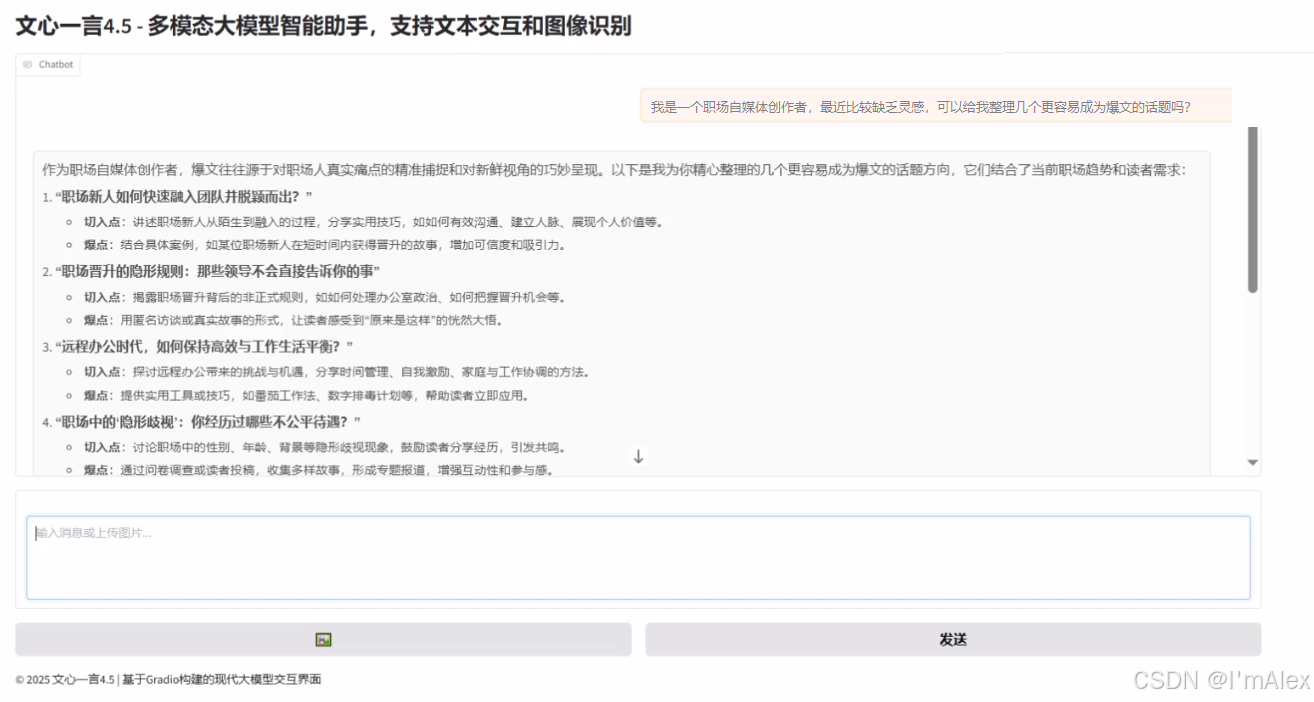
如上图所示,文心大模型化身为一位资深的职场自媒体创作者,精准捕捉到了职场人的真实痛点,然后结合了当前职场趋势和读者需求,精心整理的几个更容易成为爆文的话题方向。这就为我们解决了第二个创意难的问题。
5.3 内容创作
好,素材和灵感都有了,我们继续让文心大模型完成初稿的编写,看看他的写作水平如何。
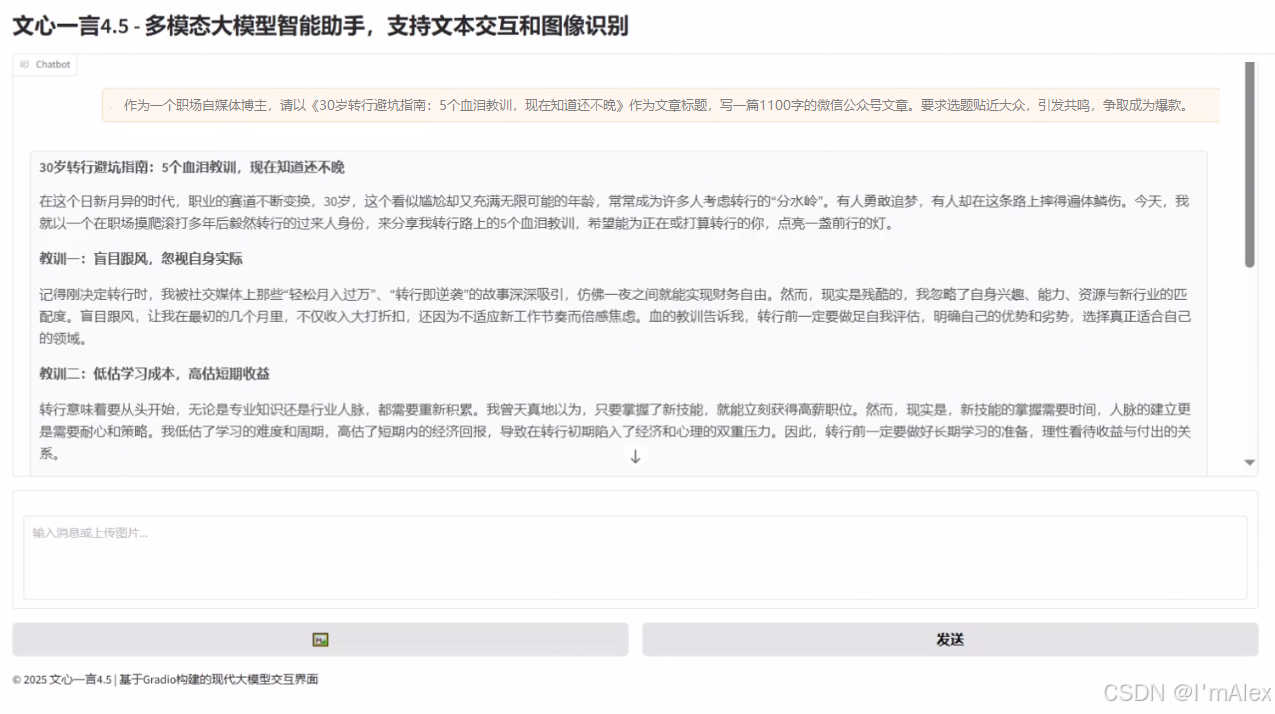
prompt:作为一个职场自媒体博主,请以《30岁转行避坑指南:5个血泪教训,现在知道还不晚》作为文章标题,写一篇1100字的微信公众号文章。要求选题贴近大众,引发共鸣,争取成为爆款。
如上图所示,文心大模型根据我们的要求,为我们创作了一篇优秀并富有吸引力的微信公众号文章初稿,我们只需要对其进行稍加润色,就是一篇有超高几率成为爆文的文章了。到这里,文心大模型就帮我们解决了第三个创作难的问题。顺利为我们的自媒体创作进行了闭环。
6. 总结
通过对文心大模型4.5开源模型的深度测评,我们可以很清晰的感知到,百度这次开源的模型还是非常有水平的。主要有下面几个点:
- 模型参数从0.3B到474B(参数丰富,可选择多),跨度大,可以根据自己的需求选择使用不同参数规模的模型,兼顾性能和效率。
- 基于GitCode托管的模型,我们可以实现模型的高速下载,基于百度自研的飞桨框架,我们可以实现一条命令快速部署。
- 文心大模型多模态理解识别能力强,可以非常准确的识别人物和验证码图片,未来我们甚至可以直接使用文心大模型4.5替代复杂的视觉类识别算法。
- 作为产业级知识增强大模型,文心大模型的场景化能力还是非常强的,可以帮助我们高效的完成自媒体创作领域的辅助工作,让我们的创作效率直线提升。

