分词搜索必须上Elasticsearch?试试MySQL分词查询,轻松满足大多数搜索场景的需求

🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志
🎐 个人CSND主页——Micro麦可乐的博客
🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战
🌺《RabbitMQ》专栏19年编写主要介绍使用JAVA开发RabbitMQ的系列教程,从基础知识到项目实战
🌸《设计模式》专栏以实际的生活场景为案例进行讲解,让大家对设计模式有一个更清晰的理解
🌛《开源项目》本专栏主要介绍目前热门的开源项目,带大家快速了解并轻松上手使用
🍎 《前端技术》专栏以实战为主介绍日常开发中前端应用的一些功能以及技巧,均附有完整的代码示例
✨《开发技巧》本专栏包含了各种系统的设计原理以及注意事项,并分享一些日常开发的功能小技巧
💕《Jenkins实战》专栏主要介绍Jenkins+Docker的实战教程,让你快速掌握项目CI/CD,是2024年最新的实战教程
🌞《Spring Boot》专栏主要介绍我们日常工作项目中经常应用到的功能以及技巧,代码样例完整
👍《Spring Security》专栏中我们将逐步深入Spring Security的各个技术细节,带你从入门到精通,全面掌握这一安全技术
如果文章能够给大家带来一定的帮助!欢迎关注、评论互动~
分词搜索必须上Elasticsearch?试试MySQL分词查询,轻松满足大多数搜索场景的需求
- 1. 前言
- 2. MySQL 全文索引原理
- 3. 配置全文索引与分词查询
-
-
- 3.1 建表与索引
- 3.2 基本查询语法
- 3.3 关键操作符
-
- 4. 中文分词 ngram 与插件方案
-
-
- 4.1 ngram 分词
- 4.2 第三方分词插件
-
- 5. 进阶优化与监控
- 6. 结语
1. 前言
相信小伙伴们在学习 Spring Cloud 微服务的过程中涉及到搜索相关的,你一定会想到使用Elasticsearch !没错 Elasticsearch 很强大,但是对于一些中小型的项目、网站,简单的一些分词搜索需求,如果使用 Elasticsearch 无论是硬件成本、开发开发成本都大大增加!
如果中小项目中一些简单的分词搜索,可以试试 MySQL 分词查询,本章节跟着博主深入探讨 MySQL 的分词查询技术,从基础使用到中文处理全面解析。

2. MySQL 全文索引原理
MySQL 自 5.6 起提供了全文索引(Full‑Text Index)功能,通过分词(Tokenization)机制将一段文本拆分成一个个“词元”(token),并建立倒排索引,从而实现高效的分词查询
1、分词(Tokenization)
将待索引文本(通常是 TEXT 或 VARCHAR)拆分为一个个词元。例如,英文文本会按空格与标点分词;中文文本默认按字符切割,但可配置 ngram 分词。
2、倒排索引(Inverted Index)
对每个词元,记录它所出现的所有行号(文档 ID),并统计词元出现频次。查询时,将搜索词同样分词后,快速在倒排索引中定位相关文档。
3、相关性计算
MySQL 根据词元在文档中出现的频次(Term Frequency)、在整个表中出现的文档数(Document Frequency)等,使用类似 TF‑IDF 的算法计算相关度,从高到低排序返回。
3. 配置全文索引与分词查询
下面我们以一个articles表,字段 articles_id 、title、content 为例子来进行操作,以下是建表语句和测试数据
CREATE TABLE `articles` ( `articles_id` int NOT NULL AUTO_INCREMENT COMMENT \'文章ID\', `title` varchar(255) DEFAULT NULL COMMENT \'文章标题\', `content` text COMMENT \'文章内容\', PRIMARY KEY (`articles_id`)) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO `articles` (`articles_id`, `title`, `content`) VALUES (1, \'分词MySQL查询\', \'跟麦可乐学编程:MySQL分词查询\');INSERT INTO `articles` (`articles_id`, `title`, `content`) VALUES (2, \'MySQL分词\', \'跟麦可乐学:MySQL分词\');3.1 建表与索引
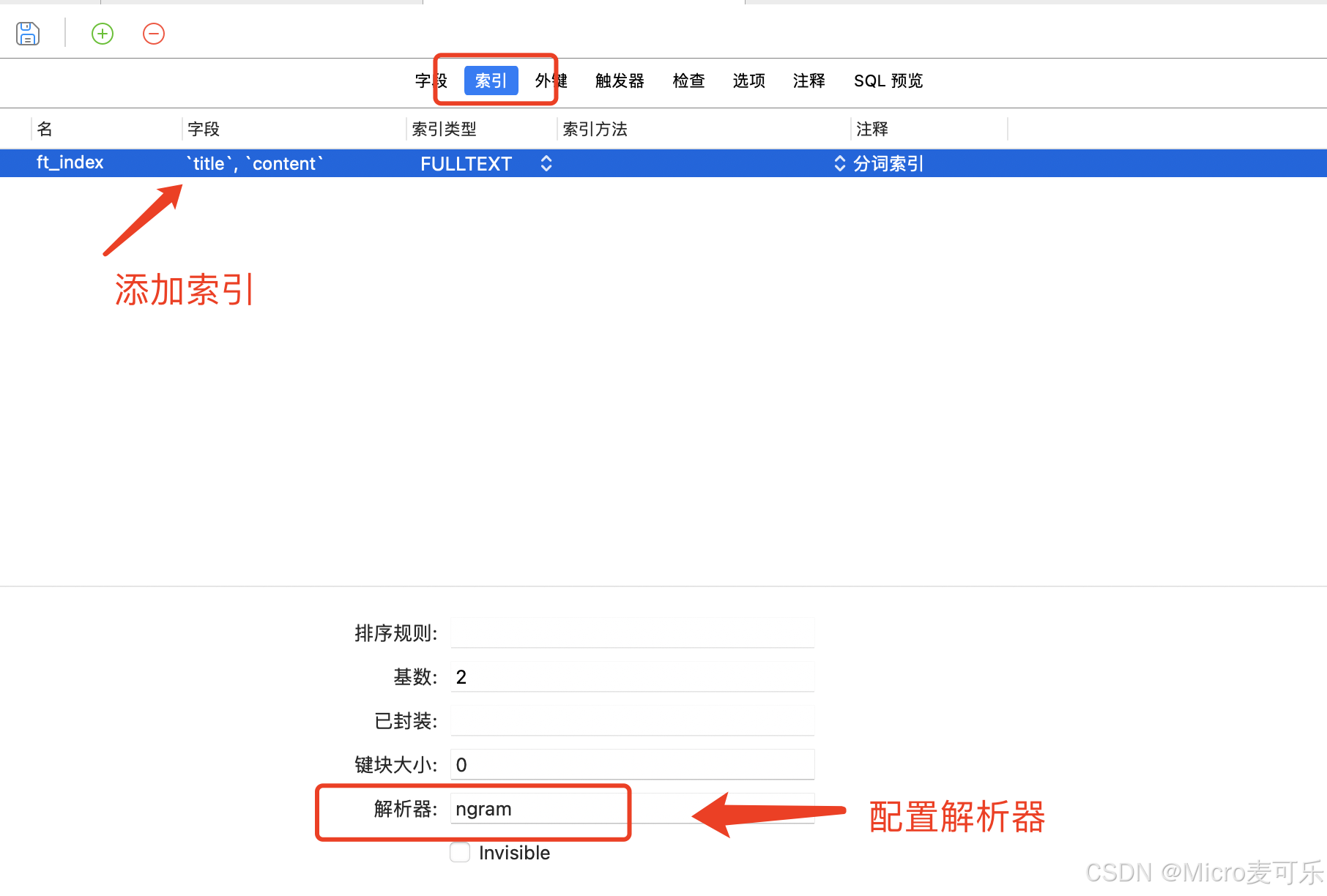
对Mysql熟悉的小伙伴,可以直接使用SQL进行设置
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title, content) WITH PARSER ngram; -- 中文需指定ngram解析器喜欢图形化操作的小伙伴可按下图设置
3.2 基本查询语法
自然语言模式(Natural Language Mode)
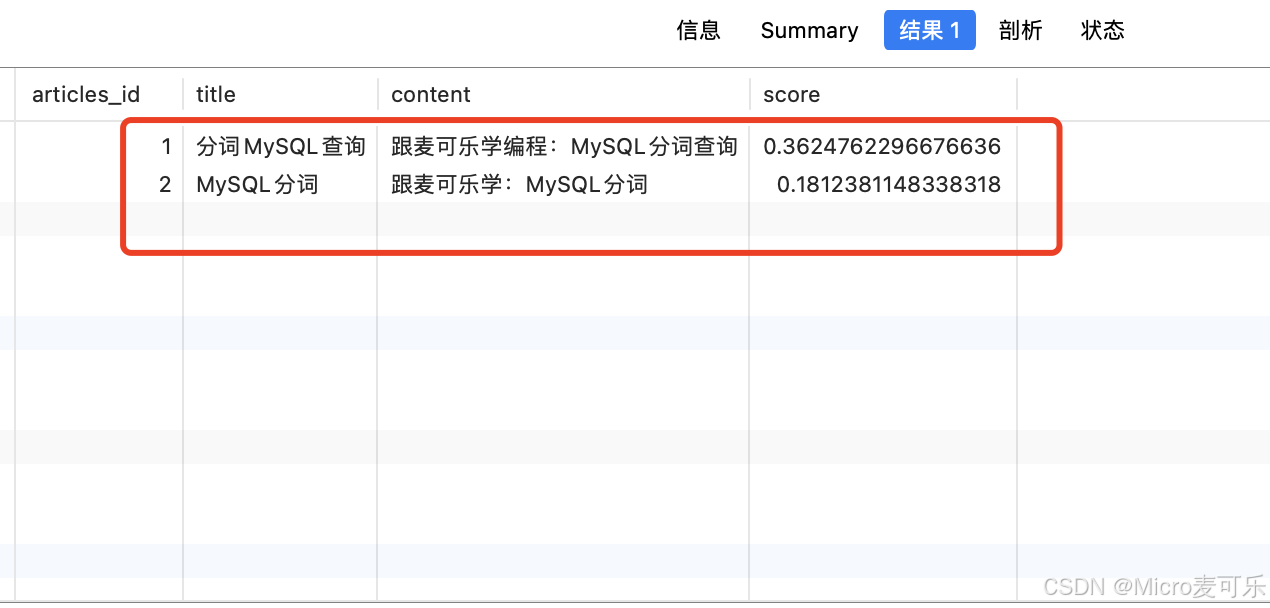
SELECT articles_id, title, content,MATCH(title, content) AGAINST(\'分词 查询\') AS scoreFROM articlesWHERE MATCH(title, content) AGAINST(\'分词 查询\');默认按自然语言解析查询词,忽略停用词、极短词和频繁出现词
查询输出效果
布尔模式(Boolean Mode)
SELECT articles_id, title, content FROM articlesWHERE MATCH(title,content) AGAINST(\'+分词 -查询\' IN BOOLEAN MODE);查询输出效果
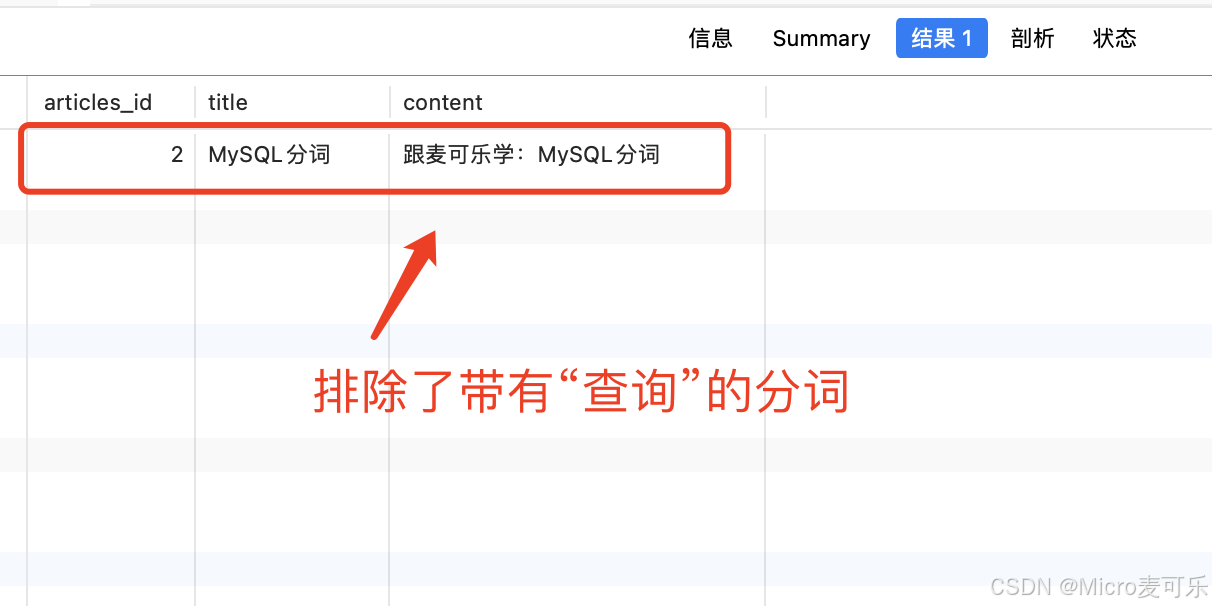
3.3 关键操作符
通过布尔模式查询上图的效果,下面介绍一下布尔模式支持逻辑运算符:
++apple +juice-apple -macbook~~fruit ~vegetable*data* (匹配database等)\"\"\"high performance\"小伙伴们通过上述操作符,就可以自由定制自己的分词查询规则
4. 中文分词 ngram 与插件方案
4.1 ngram 分词
MySQL 自带的 ngram 插件可实现中文近似分词:
-- 修改my.cnf(建议token长度2)[mysqld]ngram_token_size=2-- 建表时指定分词器 如:CREATE TABLE chinese_news ( id INT PRIMARY KEY, content TEXT, FULLTEXT INDEX (content) WITH PARSER ngram);配置了 ngram_token_size=2 中文分词原理,按两字切分,例如
原始文本:\"分词查询\"分词结果:[\"分词\",\"词查\",\"查询\"]4.2 第三方分词插件
Mecab、jieba 插件:将分词逻辑交给外部库,实现更精准的中文分词。
这里博主就不做过多介绍了,可以根据插件文档进行安装即可
5. 进阶优化与监控
-
查询性能监控
使用EXPLAIN查看FULLTEXT查询是否走全文索引。
利用慢查询日志筛选耗时的全文检索。 -
分片与分表
对于超大文本表,可按日期或业务维度分表分区,保证索引文件大小可控。 -
增量索引
InnoDB 支持后台算法自动增量更新全文索引,无需手动重建整个索引。 -
权重调优
MATCH() AGAINST()可对多列设置权重:MATCH(title) AGAINST(\'分词\') * 2 +MATCH(content) AGAINST(\'分词\') AS relevance
6. 结语
MySQL分词查询为全文搜索提供了高效的内置解决方案。通过合理配置分词参数、选择合适的分词器(如 ngram 或第三方插件),并运用自然语言模式与布尔模式,小伙伴们可以轻松满足大多数中小项目中的搜索场景的需求。对于更复杂的需求,建议结合专业搜索引擎如Elasticsearch构建搜索体系。
如果你在实践过程中有任何疑问或更好的扩展思路,欢迎在评论区留言,最后希望大家 一键三连 给博主一点点鼓励!


