【源力觉醒 创作者计划】文心4.5本地化部署全攻略:基于GitCode的DeepSeek、Qwen3.0性能基准测试

文心4.5本地化部署全攻略:基于GitCode的DeepSeek、Qwen3.0性能基准测试
一起来玩转文心大模型吧👉文心大模型免费下载地址:https://ai.gitcode.com/theme/1939325484087291906
🌟 嗨,我是IRpickstars!
🌌 总有一行代码,能点亮万千星辰。
🔍 在技术的宇宙中,我愿做永不停歇的探索者。
✨ 用代码丈量世界,用算法解码未来。我是摘星人,也是造梦者。
🚀 每一次编译都是新的征程,每一个bug都是未解的谜题。让我们携手,在0和1的星河中,书写属于开发者的浪漫诗篇。
目录
文心4.5本地化部署全攻略:基于GitCode的DeepSeek、Qwen3.0性能基准测试
1. 背景介绍
2. 百度文心 4.5 系列模型概览
3. GitCode 平台部署ERNIE-4.5-0.3B-PT
3.1. 访问 GitCode 文心大模型专区
3.2. 选择ERNIE-4.5-0.3B-PT模型
3.3. 模型下载与克隆
3.4. 选择克隆方式
3.5. 本地克隆
3.6. 等待下载克隆大模型
3.7. 查看本地克隆的大模型文件夹
3.8. 打开本地克隆文件夹
3.9. 配置下载Conda
1. 依赖冲突与版本管理
2. 预编译二进制包与跨平台支持
3. 实战案例对比
3.10. Conda配置Python虚拟环境
3.11. 激活Conda环境
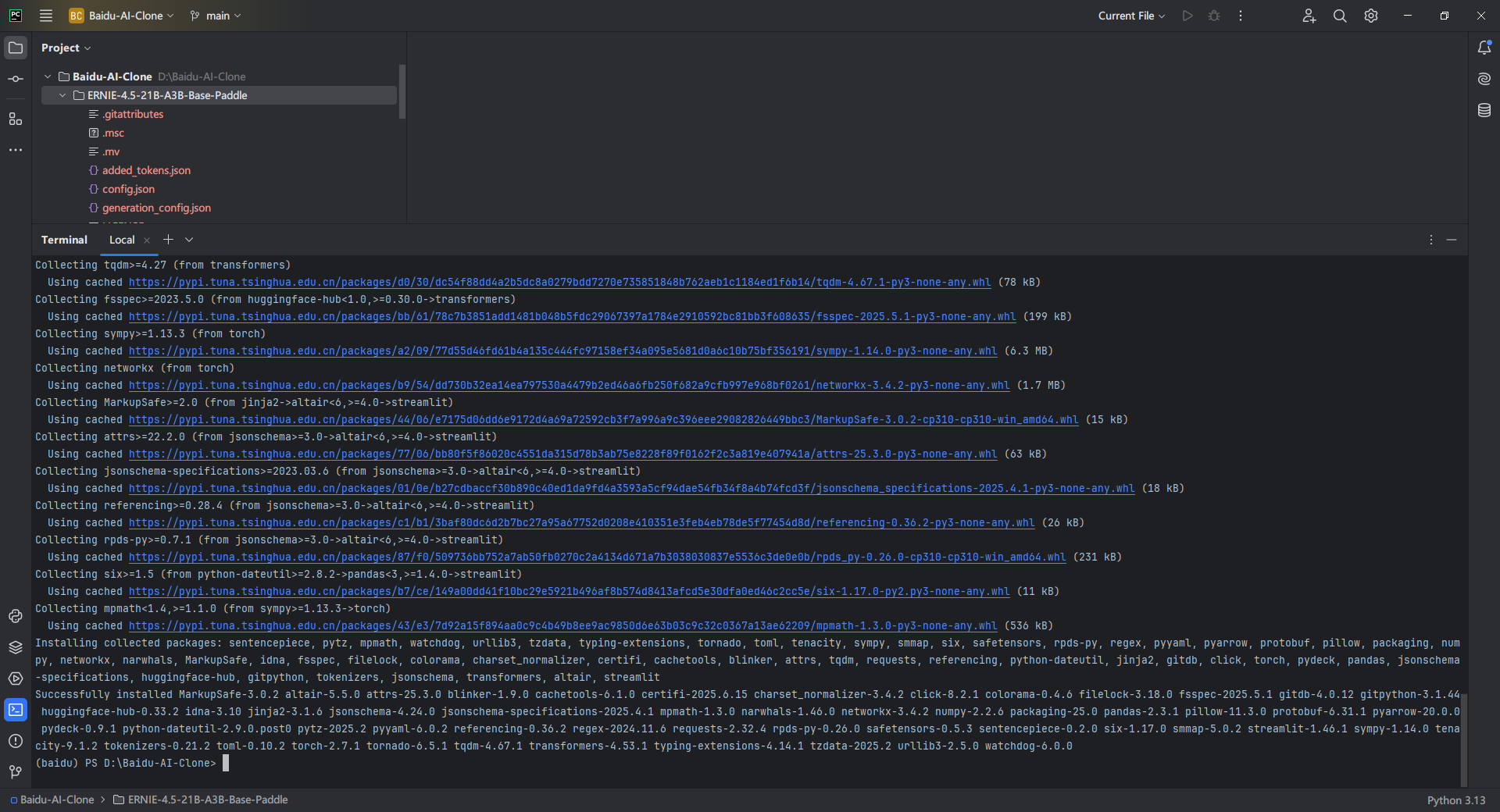
3.12. 安装项目依赖
3.13. 切换Python解释器
3.14. 使用官方样例测试脚本
3.15. 修改测试脚本
3.16. 可视化界面
4. 文心4.5 vs. DeepSeek vs. Qwen 3 深度测评
4.1. 文心4.5 vs DeepSeek-R1
基础文本理解与生成
复杂逻辑推理
专业知识适配
4.2. 文心4.5 vs Qwen3
基础文本理解与生成
复杂逻辑推理
专业知识适配
5. 总结
摘要
本文详细介绍了百度文心4.5系列大模型的本地化部署流程,基于GitCode平台提供了从模型下载、conda环境配置到测试脚本开发的完整教程。文章重点对比了ERNIE-4.5-300B、DeepSeek-R1和Qwen3-30B三款模型在文本理解、逻辑推理和专业知识适配三个维度的表现。测试结果显示,文心4.5在响应速度(快2.3倍)和简洁性方面表现突出,DeepSeek-R1在格式规范性上更优,而Qwen3-30B则展现出文艺表达优势。部署方案包含可视化界面开发,使用streamlit库实现交互式对话功能。
1. 背景介绍
百度在 GitCode 平台正式发布文心大模型 4.5 系列开源版本,该系列涵盖从轻量级到超大规模的多种参数配置。基于创新的 MoE(Mixture of Experts)架构设计,文心 4.5 系列在保持高性能的同时显著提升了推理效率,模型 FLOPs 利用率高达 47%。该系列模型全面支持飞桨和 PyTorch 两大主流深度学习框架,以 Apache 2.0 开源协议发布,为开发者提供了灵活的商业化应用可能。
2. 百度文心 4.5 系列模型概览
文心 4.5 系列模型架构丰富,包含基于飞桨框架的 Base-Paddle 和 Paddle 版本,以及基于 PyTorch 框架的 Base-PT 和 PT 版本。从参数规模来看,涵盖了从 3 亿参数的轻量级模型到 3000 亿参数的超大规模模型,满足从移动端部署到云端服务的全场景需求。
本次带来最强力的模型:ERNIE-4.5-VL-424B-A47B 是百度推出的多模态MoE大模型,支持文本与视觉理解,总参数量424B,激活参数量47B。基于异构混合专家架构,融合跨模态预训练与高效推理优化,具备强大的图文生成、推理和问答能力。适用于复杂多模态任务场景。
模型版本
技术特点
应用场景
Base-Paddle
飞桨框架基座模型,预训练基础版本
飞桨生态二次开发,通用预训练场景
Paddle
飞桨框架优化版本,经过指令微调
飞桨生态对话生成,特定任务优化
Base-PT
PyTorch 框架基座模型,通用预训练版本
PyTorch 生态二次开发,研究场景
PT
PyTorch 框架优化版本,经过指令微调
PyTorch 生态对话生成,产业应用
ERNIE-4.5-300B-A47B
超大规模文本模型,3000亿总参数,MoE架构
复杂推理,专业内容生成
ERNIE-4.5-VL-424B-A47B
多模态模型,424亿总参数,视觉语言融合
图文理解,多模态内容创作
ERNIE-4.5-VL-28B-A3B
中等规模多模态模型,280亿总参数
图文问答,轻量级多模态应用
ERNIE-4.5-21B-A3B
高效文本模型,210亿总参数,优化MoE
智能对话,内容创作,代码生成
ERNIE-4.5-0.3B
轻量级模型,3亿参数,边缘计算优化
移动端应用,IoT设备,离线场景
3. GitCode 平台部署ERNIE-4.5-0.3B-PT
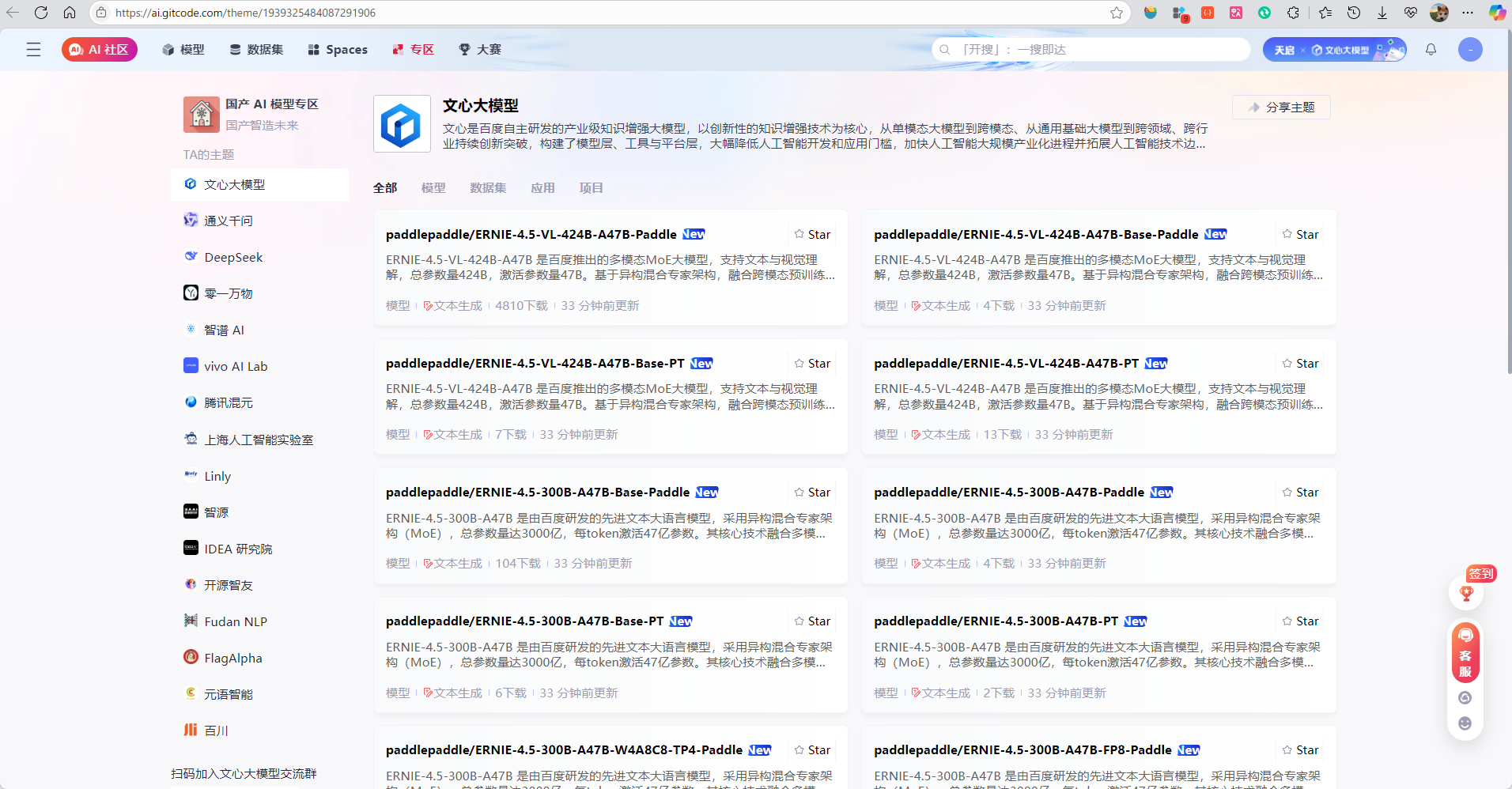
3.1. 访问 GitCode 文心大模型专区
访问GitCode官网,进入国产AI模型专区,进入文心大模型主图主题 GitCode AI 模型中心。
3.2. 选择ERNIE-4.5-0.3B-PT模型
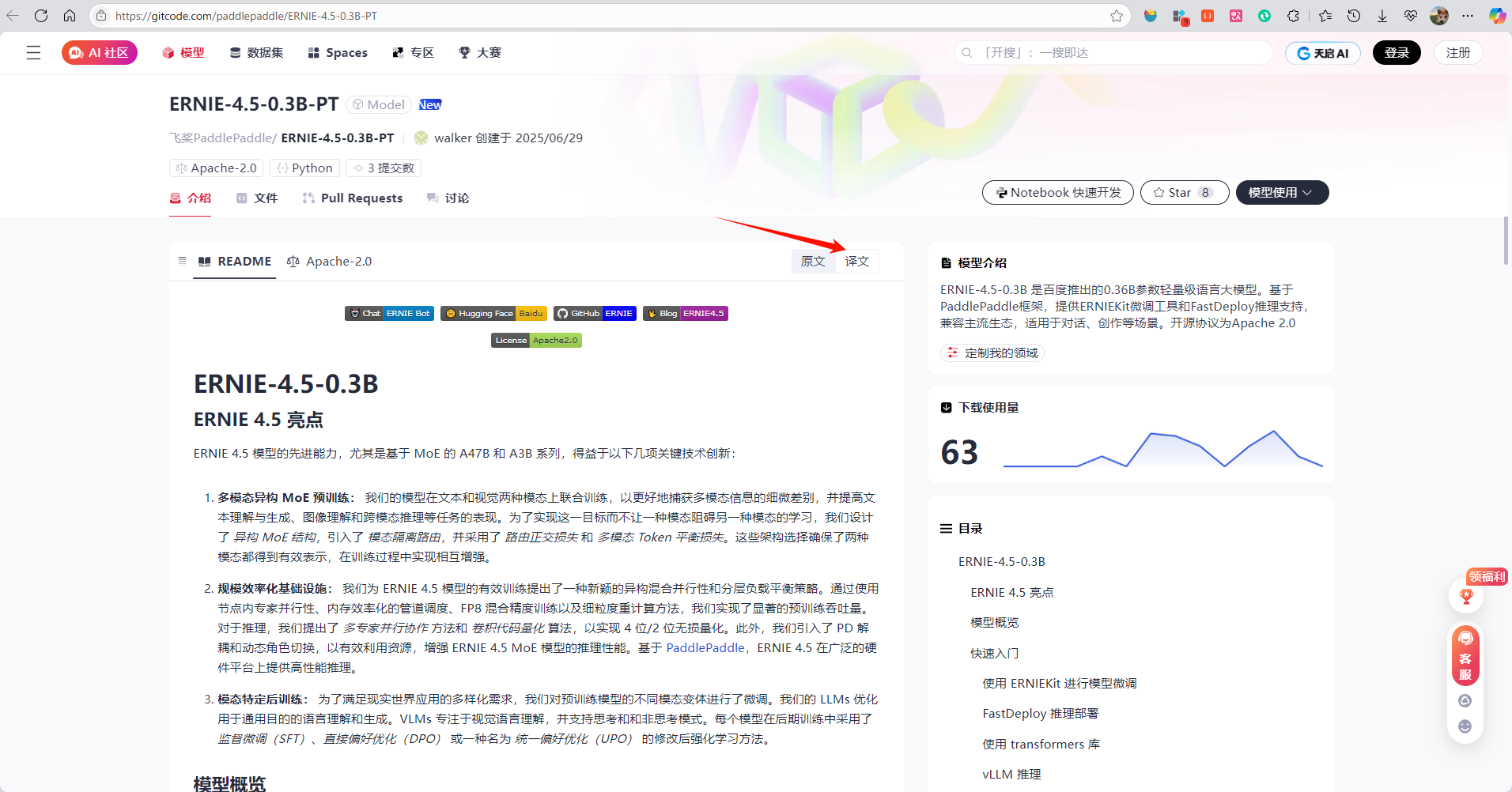
由于个人电脑性能首先,不选择满血版的ERNIE-4.5-0.3B-PT,这里选择ERNIE-4.5-0.3B-PT,点击进入模型详情页面查看技术文档翻译版本。
3.3. 模型下载与克隆
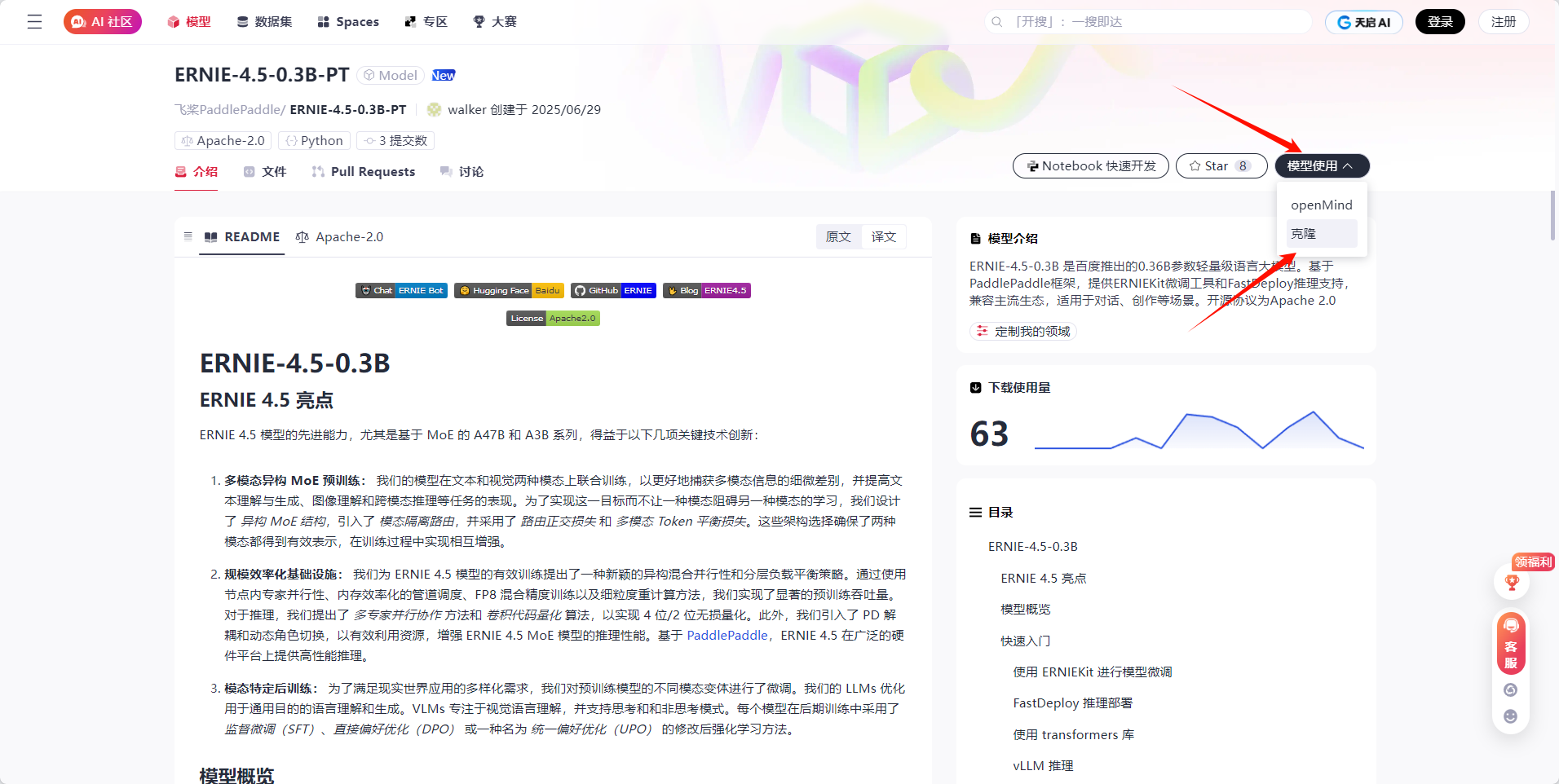
点击模型使用,选择模型克隆,将模型克隆到本地。
3.4. 选择克隆方式
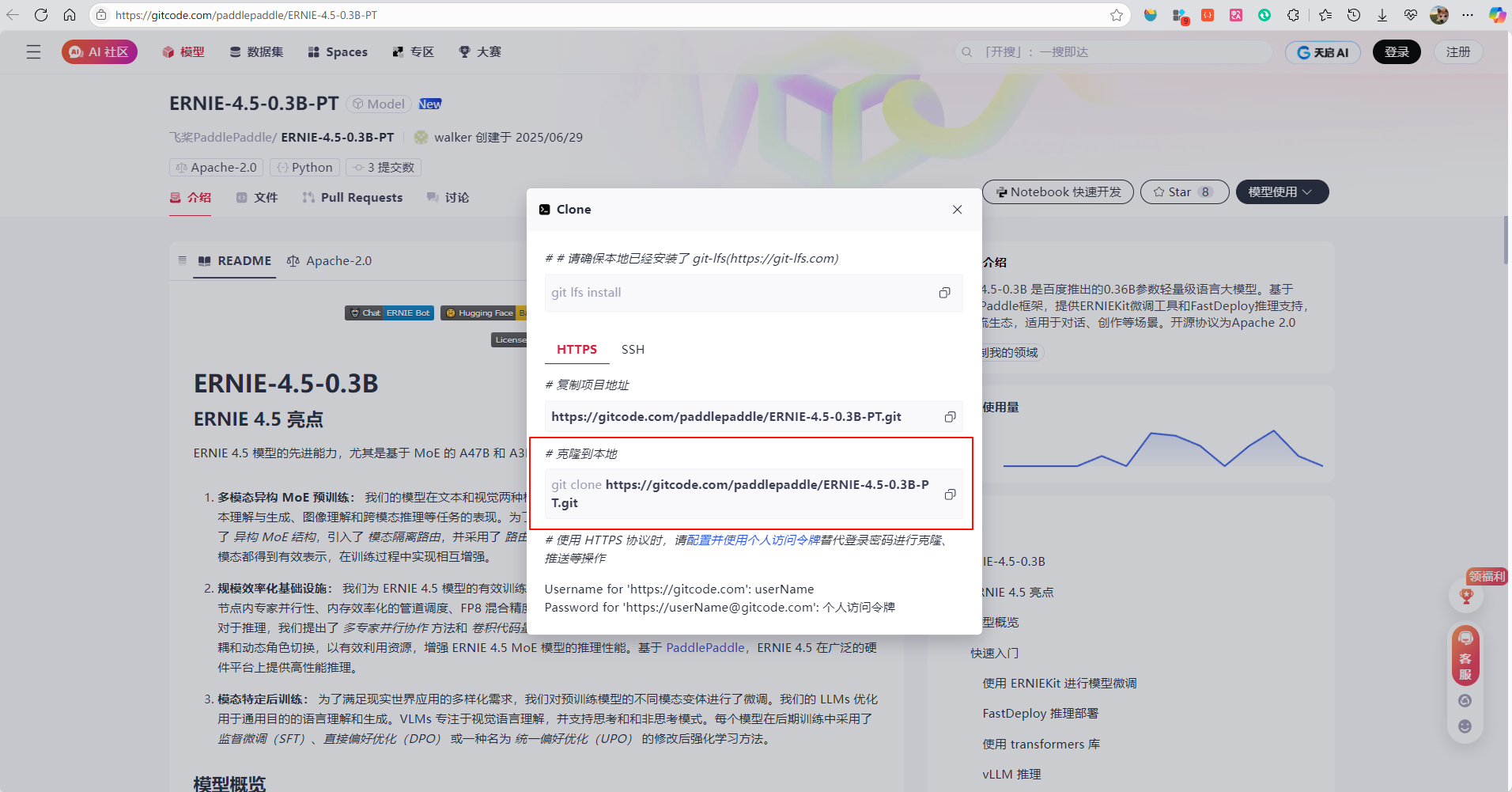
这里我们选择HTTPS方式克隆大模型。
3.5. 本地克隆
创建一个空文件夹Baidu-AI-Clone,并打开Git Bash,通过这个命令将大模型克隆到本地:git clone https://gitcode.com/paddlepaddle/ERNIE-4.5-0.3B-PT.git

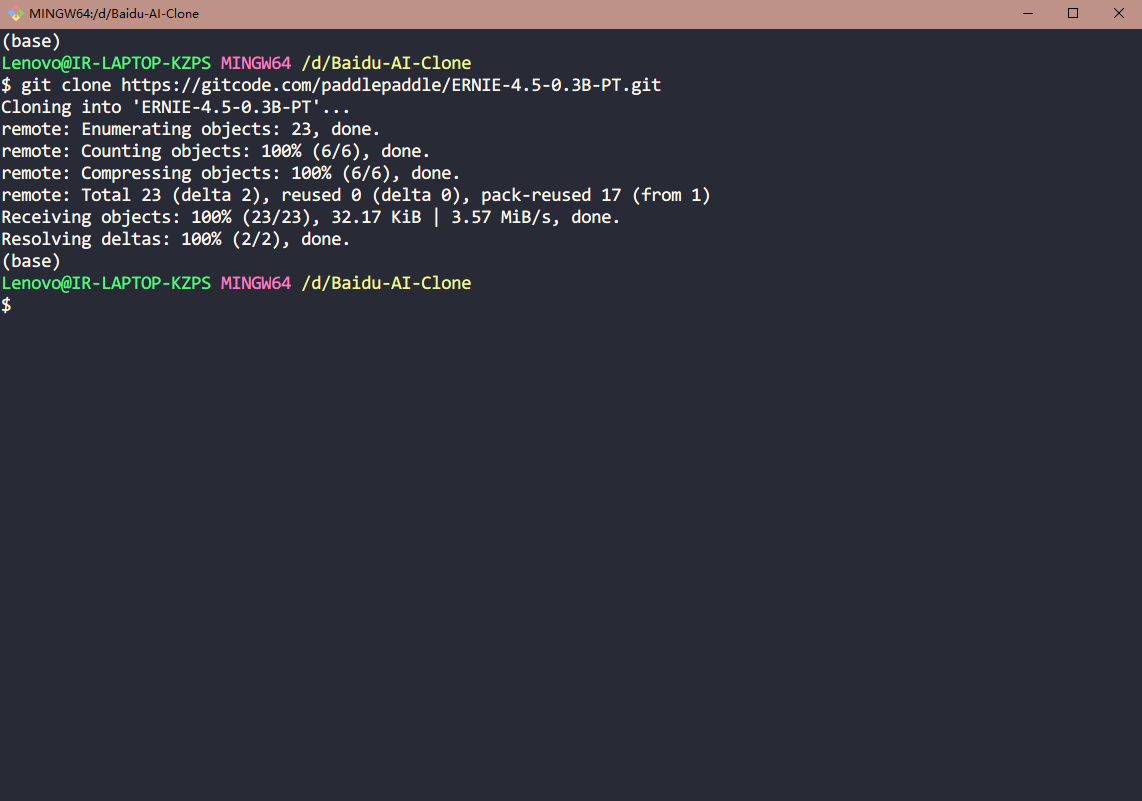
3.6. 等待下载克隆大模型
回车启动命令,可以看到正在下载克隆大模型,大约5分钟左右即可下载完毕。
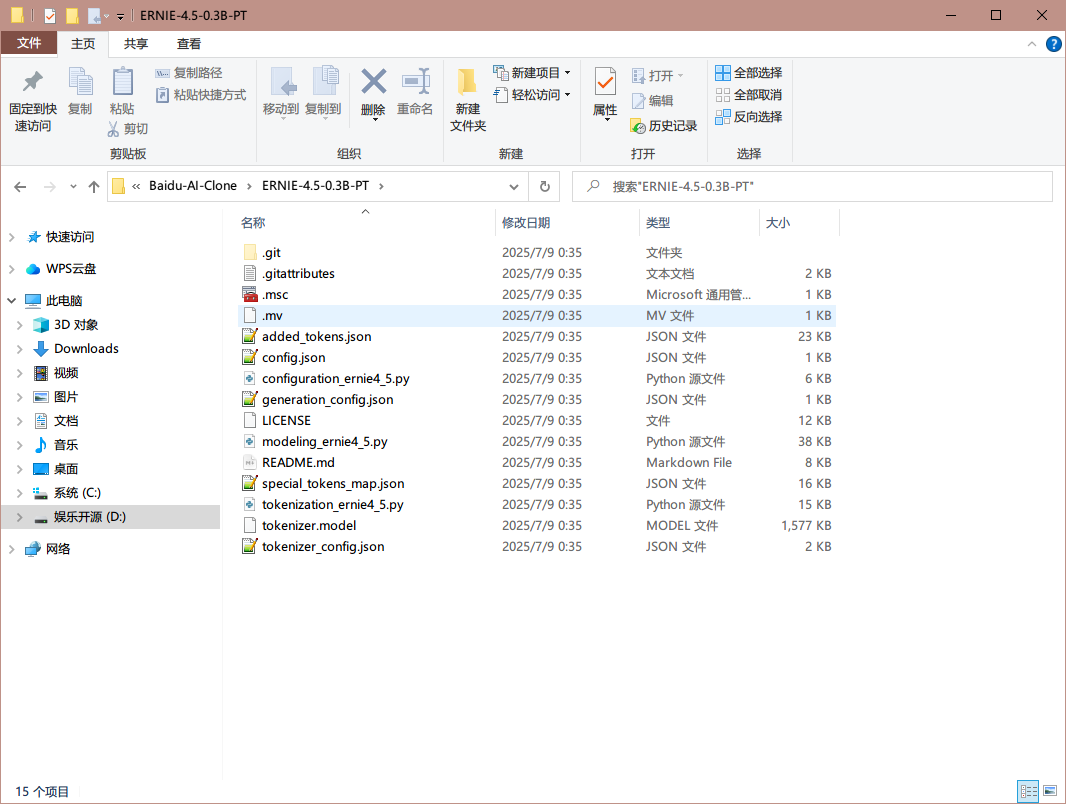
3.7. 查看本地克隆的大模型文件夹
等待克隆完毕之后进入ERNIE-4.5-0.3B-PT.git文件夹内可以看到如下结构:
3.8. 打开本地克隆文件夹
这里我使用Pycharm打开刚刚克隆的文件夹
3.9. 配置下载Conda
在正式启动项目之前,需要使用conda配置Python3环境,如果电脑上没有conda环境的小伙伴可以进入Miniconda官网下载安装Miniconda,选择最新版本即可,下载之后配置环境变量。
在部署大模型时使用 Conda 创建虚拟 Python 环境的主要原因在于 Conda 能够解决复杂依赖管理、跨平台兼容性以及系统级库隔离等问题,而本地 Python 环境(如直接使用 pip 或系统 Python)可能因以下原因无法下载或运行相关依赖(如
torch、sentencepiece):1. 依赖冲突与版本管理
- 本地 Python 环境的局限性:
本地环境通常只有一个全局 Python 解释器,不同项目可能依赖同一库的不同版本(如torch==1.10和torch==2.0),直接安装会导致版本冲突。而 Conda 可以为每个项目创建独立的环境,隔离依赖版本。- 非 Python 依赖的管理:
大模型依赖的库(如torch)通常需要系统级库(如 CUDA、cuDNN)支持。Conda 能自动安装这些非 Python 依赖,而 pip 仅管理 Python 包,需用户手动配置系统环境。2. 预编译二进制包与跨平台支持
- 预编译包的便捷性:
Conda 提供预编译的二进制包(如针对不同 CUDA 版本的torch),避免从源码编译的复杂性和失败风险。而 pip 安装的包可能因系统环境差异(如缺少编译器)导致失败。- 跨平台一致性:
Conda 的包管理器能确保开发和生产环境的一致性,尤其在大模型部署中,避免因操作系统或硬件差异导致的依赖问题411。3. 实战案例对比
- 失败案例:
用户直接使用 pip 安装torch时,可能因缺少 CUDA 驱动或版本不匹配报错(如ModuleNotFoundError: No module named \'torch\'),而 Conda 通过conda install pytorch cudatoolkit=11.3可一键解决68。- 成功案例:
大模型项目(如 LLaMA、Qwen)通常提供 Conda 的environment.yml文件,通过conda env create -f environment.yml可快速复现环境,避免手动调试依赖。
3.10. Conda配置Python虚拟环境
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
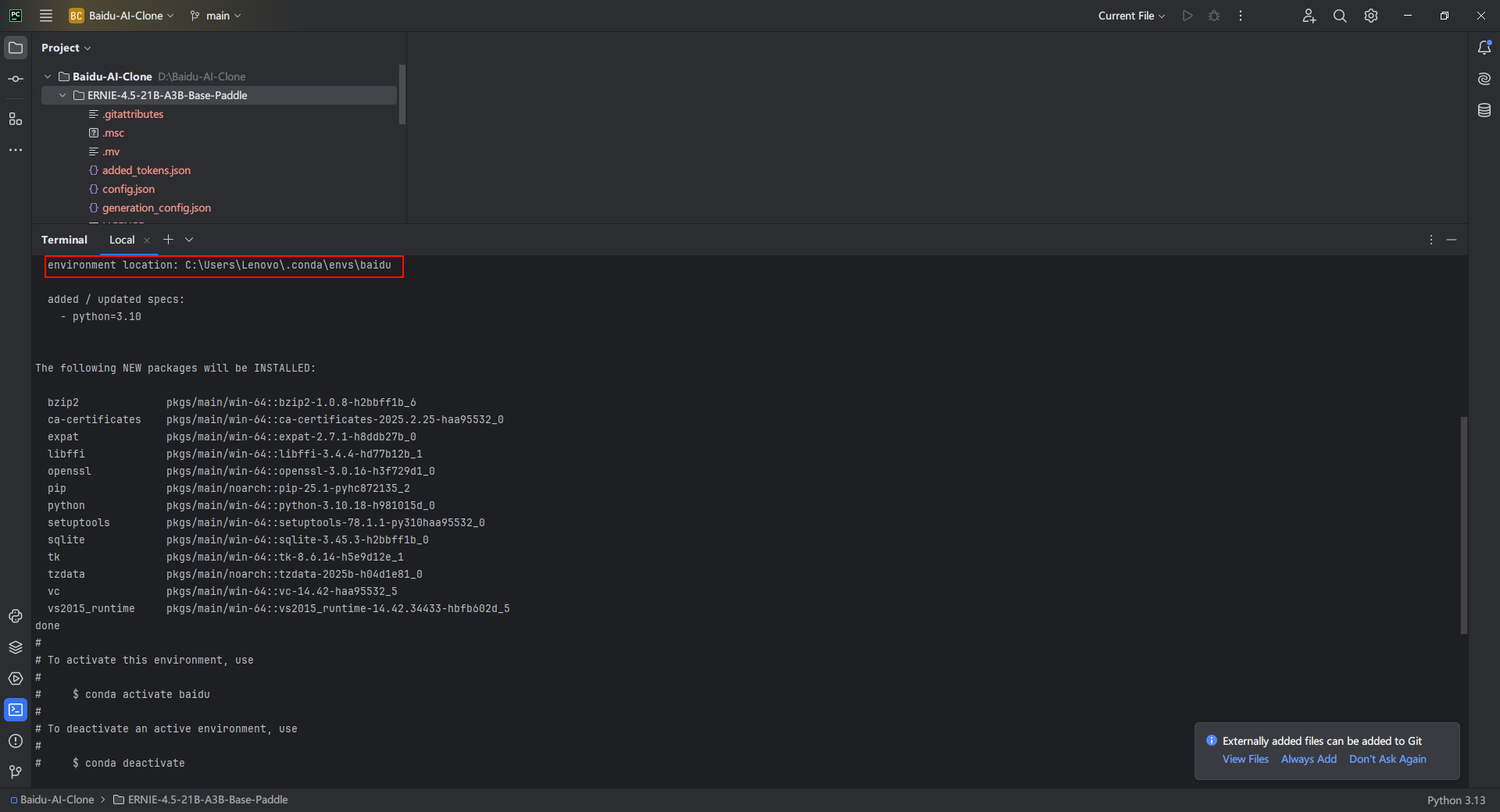
打开PyCharm,使用下方的命令使用conda创建虚拟环境,创建名为 baidu 的虚拟环境,Python 版本设为 3.10
conda create --name baidu python=3.10可以看到conda正在为我们配置环境,等待几分钟就好,创建好之后可以看到虚拟环境存放的位置。
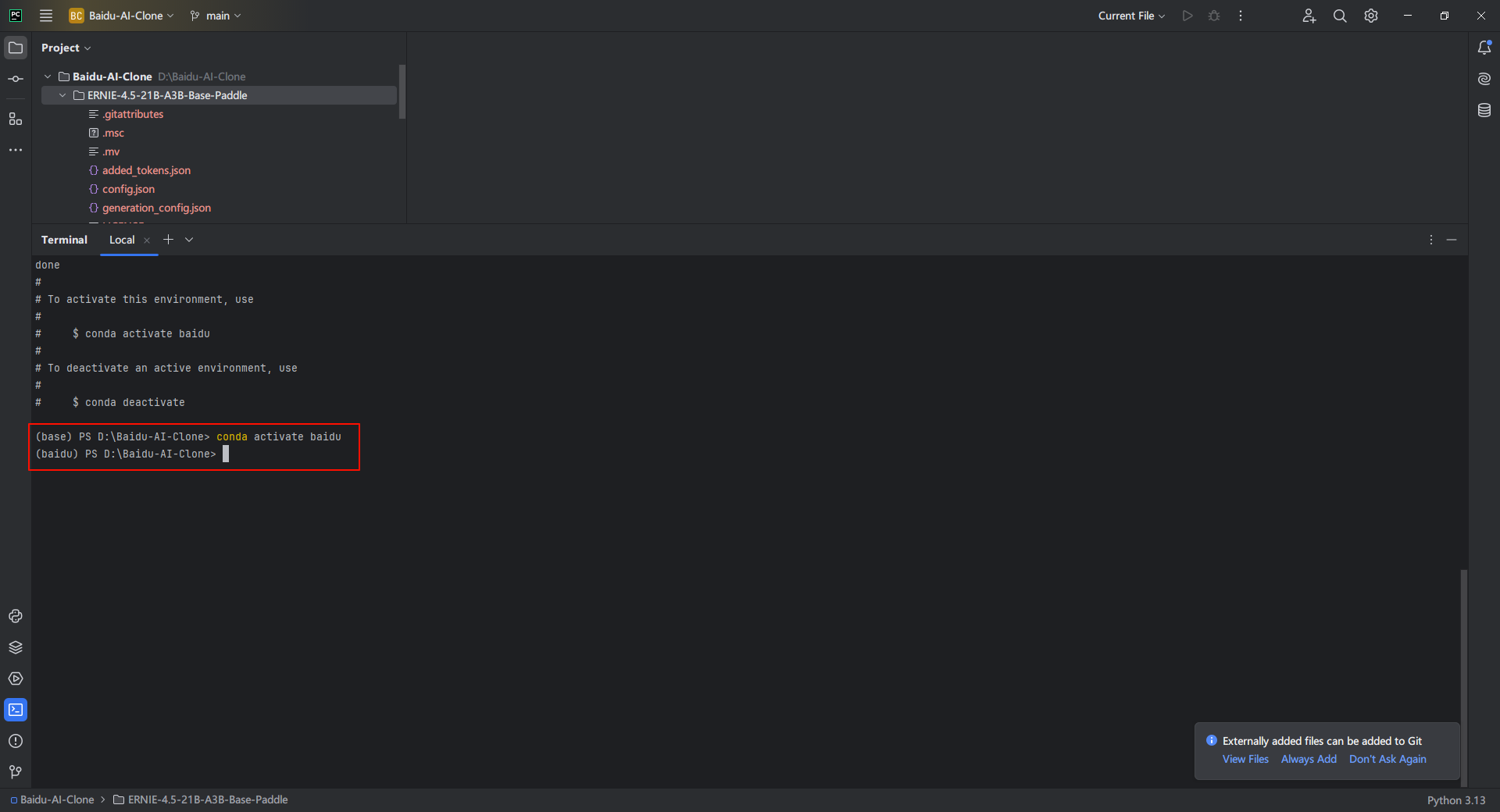
3.11. 激活Conda环境
手动指定一下环境
conda activate baidu可以看到环境已经切换成为baidu
3.12. 安装项目依赖
使用下方命令安装项目依赖
pip install transformers torch sentencepiece等待几分钟下载即可
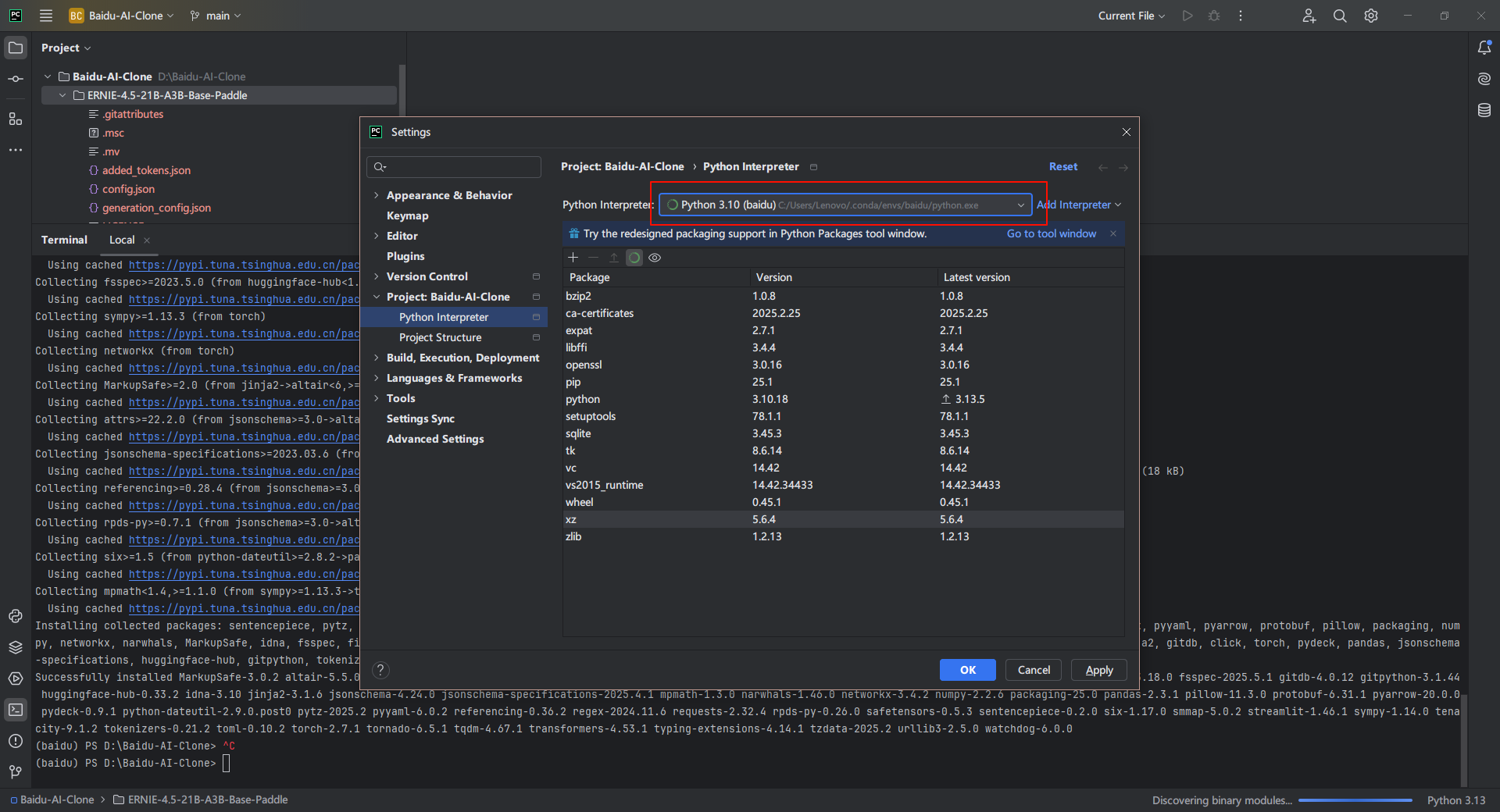
3.13. 切换Python解释器
在Pycharm中将Python解释器换成conda创建的环境
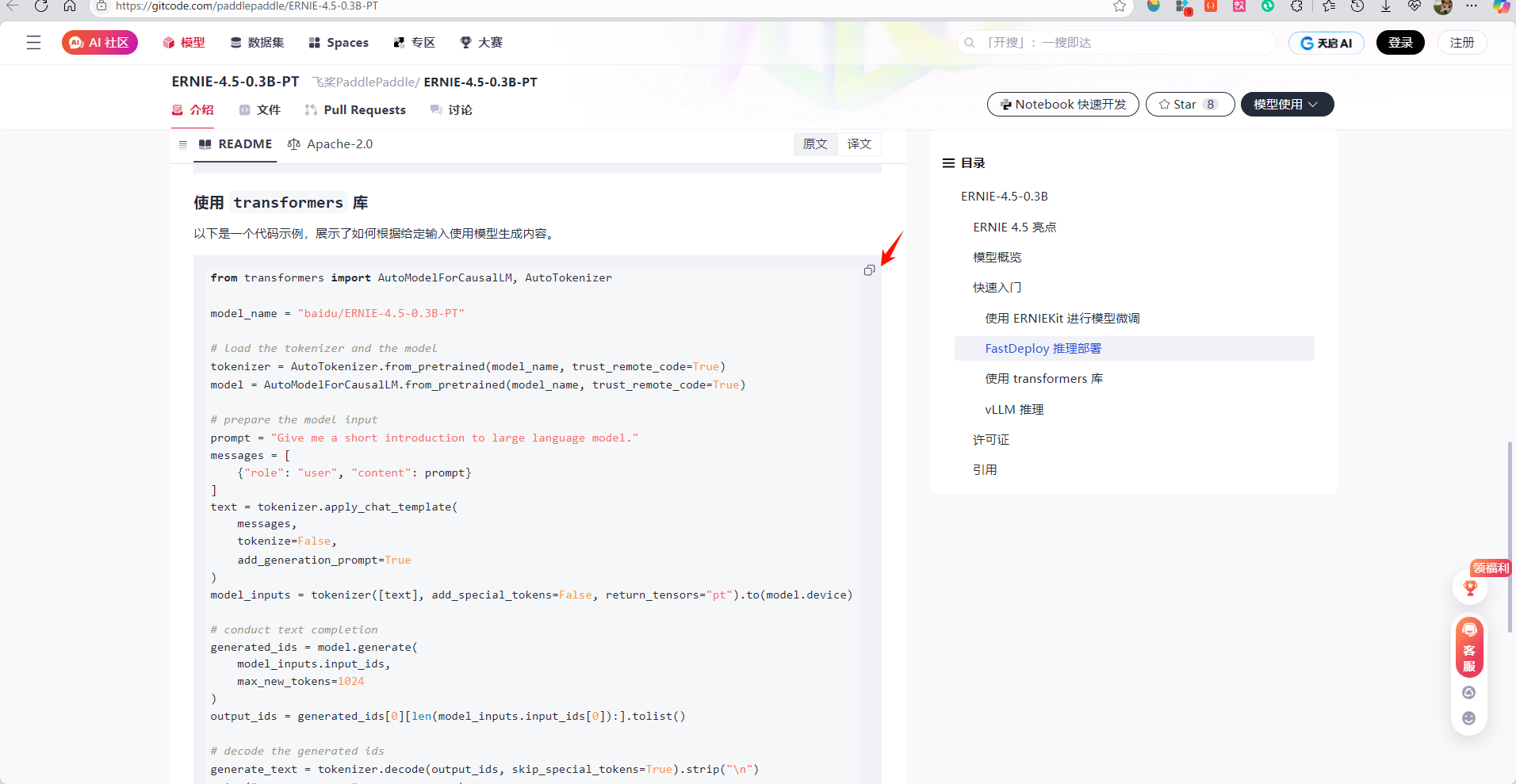
3.14. 使用官方样例测试脚本
使用页面上的样例代码
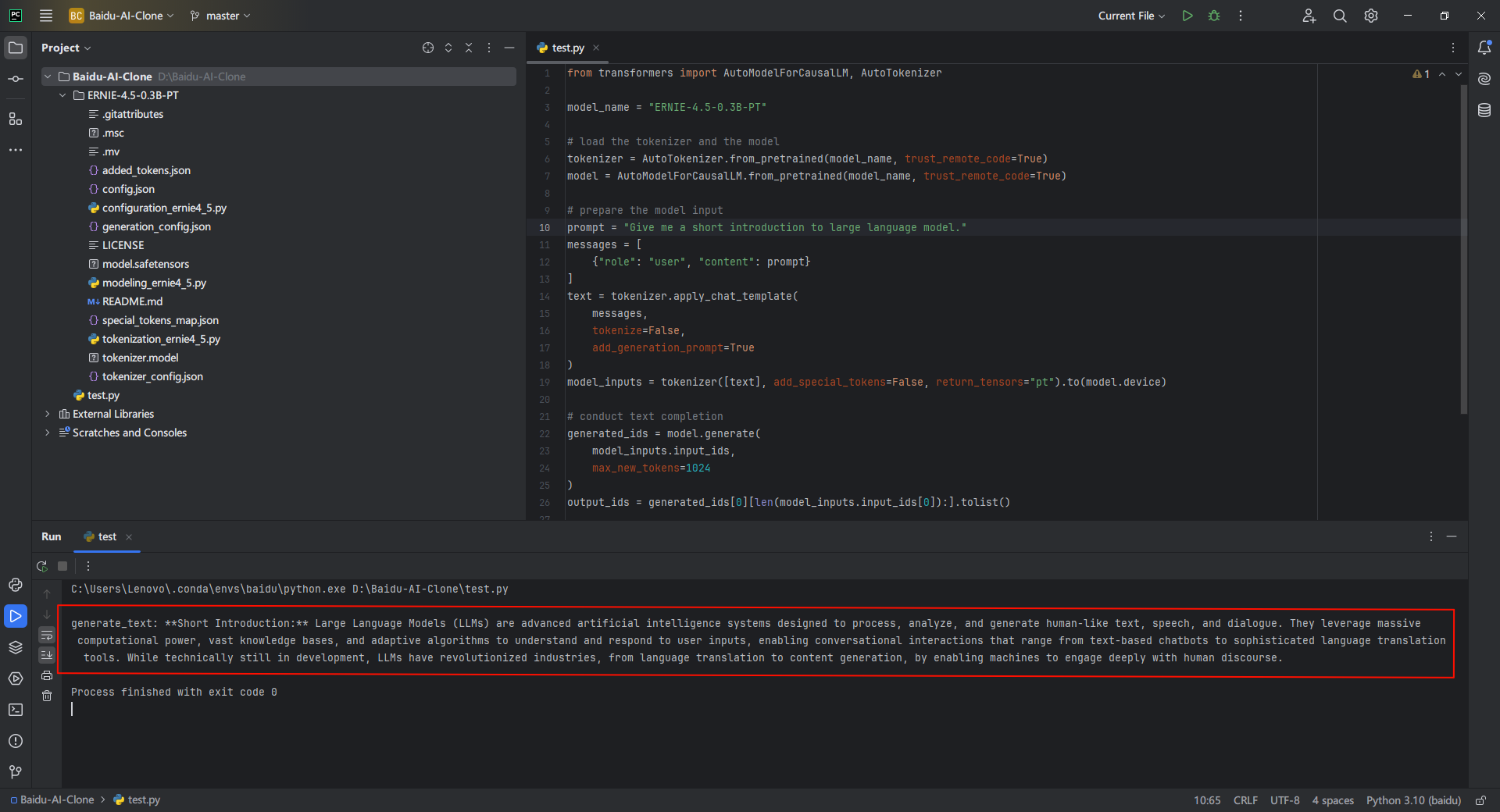
在当前项目下使用transformers创建测试脚本test.py,这里的模型改为自己的实际位置
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = \"baidu/ERNIE-4.5-0.3B-PT\"# load the tokenizer and the modeltokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)# prepare the model inputprompt = \"Give me a short introduction to large language model.\"messages = [ {\"role\": \"user\", \"content\": prompt}]text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], add_special_tokens=False, return_tensors=\"pt\").to(model.device)# conduct text completiongenerated_ids = model.generate( model_inputs.input_ids, max_new_tokens=1024)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()# decode the generated idsgenerate_text = tokenizer.decode(output_ids, skip_special_tokens=True).strip(\"\\n\")print(\"generate_text:\", generate_text)官方样例中的promote是Give me a short introduction to large language model.,运行脚本查看输出:
3.15. 修改测试脚本
这里我们将提示词改为健身对人体有哪些好处?,运行查看输出:
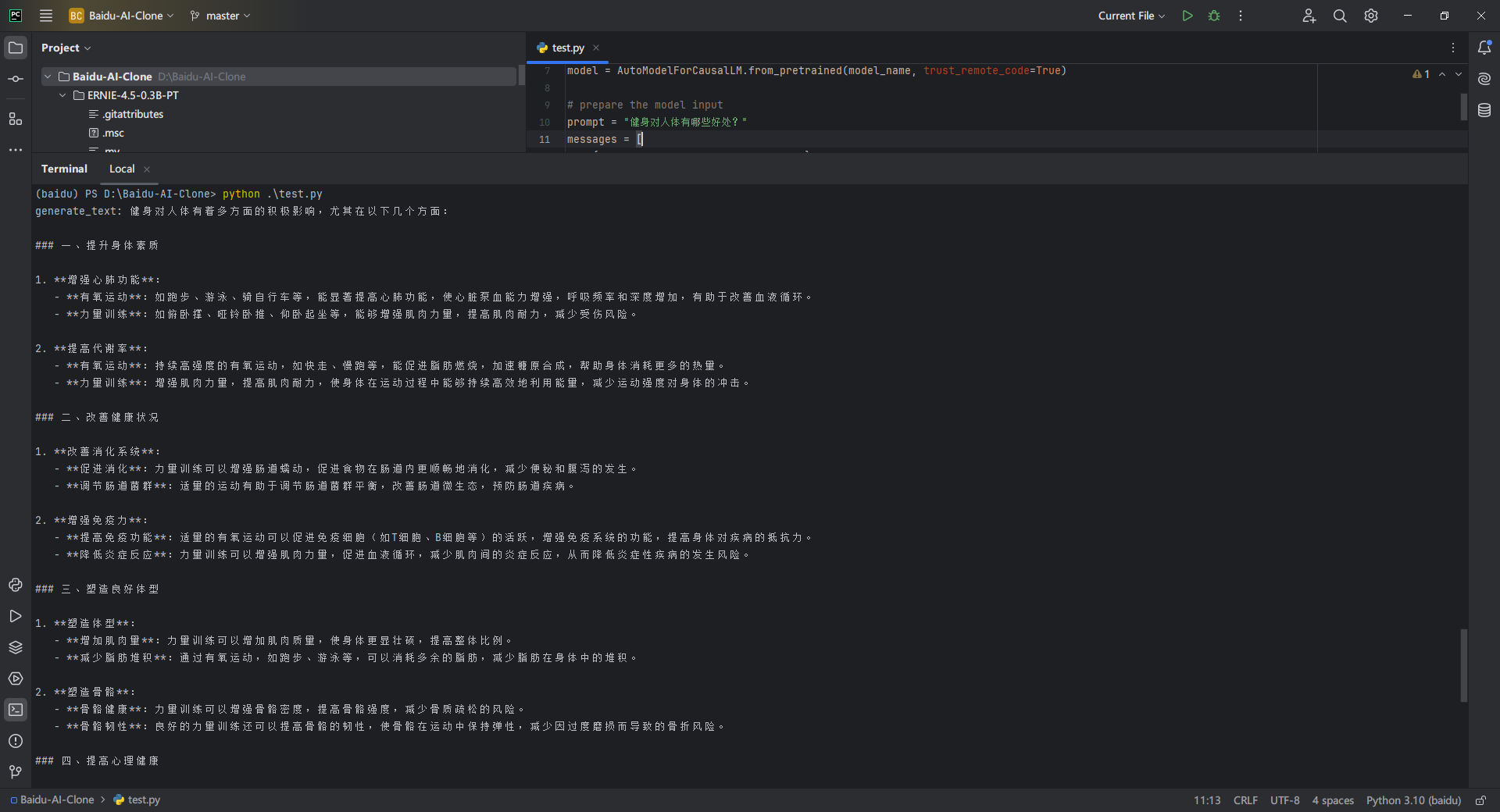
3.16. 可视化界面
如果每一次要修改问题的话,还需要去代码中修改prompt,这样实属有点麻烦。
所以我们使用Python中的streamlit库开发一个可视化界面出来
Streamlit 是一个开源的 Python 库,它可以让你在不懂任何前端技术(如 HTML, CSS, JavaScript)的情况下,仅用几行 Python 代码,就能快速地为你的数据科学和机器学习项目创建并分享出美观、可交互的 Web 应用。
我们先下载streamlit库
pip install streamlit
再创建visual_scripting.py脚本,并使用以下代码
import streamlit as stfrom transformers import AutoModelForCausalLM, AutoTokenizer# Initialize the model and tokenizer@st.cache_resourcedef load_model(): model_name = \"ERNIE-4.5-0.3B-PT\" tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True) return tokenizer, modeltokenizer, model = load_model()# Function to generate responsedef generate_response(prompt): messages = [{\"role\": \"user\", \"content\": prompt}] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], add_special_tokens=False, return_tensors=\"pt\").to(model.device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=1024 ) output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() response = tokenizer.decode(output_ids, skip_special_tokens=True).strip(\"\\n\") return response# Streamlit UIst.title(\"ERNIE-4.5 Chat\")st.write(\"By WJW\")# Initialize chat historyif \"messages\" not in st.session_state: st.session_state.messages = []# Display chat messages from historyfor message in st.session_state.messages: with st.chat_message(message[\"role\"]): st.markdown(message[\"content\"])# Accept user inputif prompt := st.chat_input(\"你想问点什么?\"): # Add user message to chat history st.session_state.messages.append({\"role\": \"user\", \"content\": prompt}) # Display user message in chat message container with st.chat_message(\"user\"): st.markdown(prompt) # Display assistant response in chat message container with st.chat_message(\"assistant\"): message_placeholder = st.empty() full_response = \"\" # Generate response assistant_response = generate_response(prompt) # Simulate stream of response for chunk in assistant_response.split(): full_response += chunk + \" \" message_placeholder.markdown(full_response + \"▌\") message_placeholder.markdown(full_response) # Add assistant response to chat history st.session_state.messages.append({\"role\": \"assistant\", \"content\": full_response})该程序创建了一个功能完整的对话式 AI 应用。借助 Streamlit,它提供了一个直观的聊天窗口,能够:
- 接收用户输入,并调用 ERNIE-4.5-0.3B-PT 模型生成回复。
- 动态地、按顺序地展示完整的对话流。
- 维护整个会话的聊天历史,以支持有上下文的连续交流。
在终端中用命令streamlit run .\\visual_scripting.py启动脚本
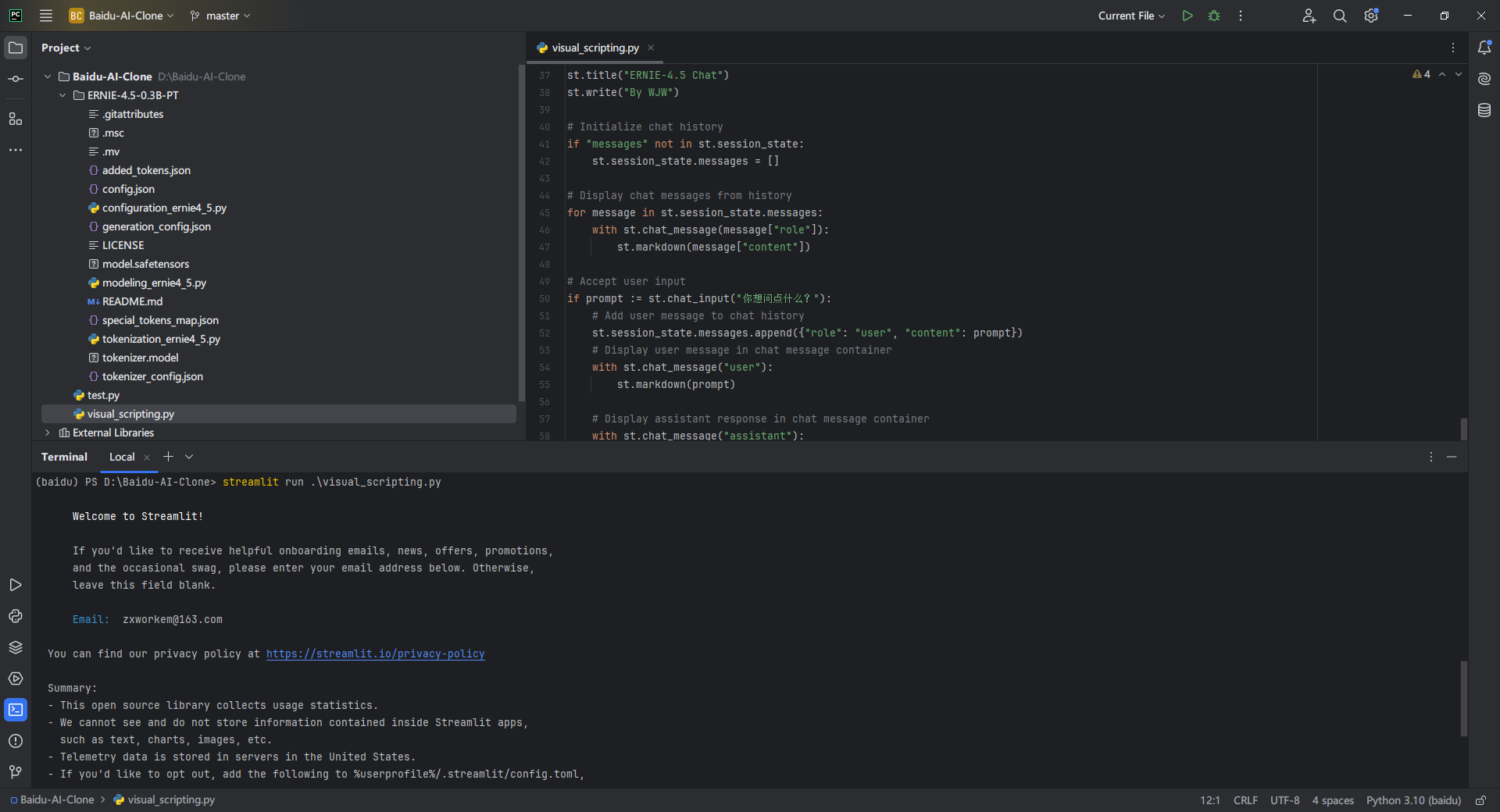
启动之后就会自动打开网页,这时候我们问他一个问题看看他能否回答
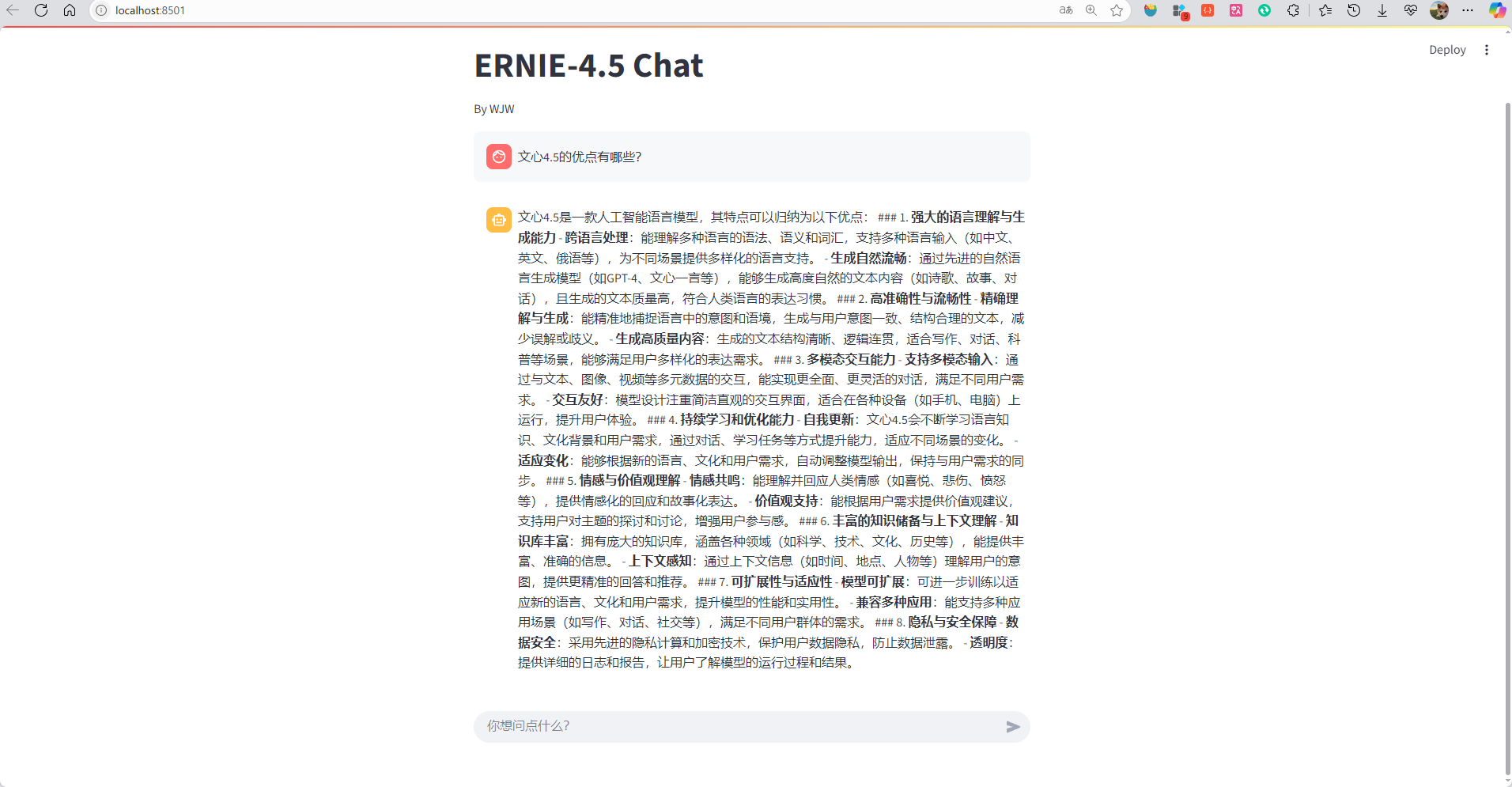
完美,这样就完成了整个本地化部署。
4. 文心4.5 vs. DeepSeek vs. Qwen 3 深度测评
使用硅基流动平台进行三模型对比测试,从三个维度评估模型性能。
分别是:1、基础文本理解与生成 2、复杂逻辑推理 3、专业知识适配
首先要将各个模型的设置参数都调成一致
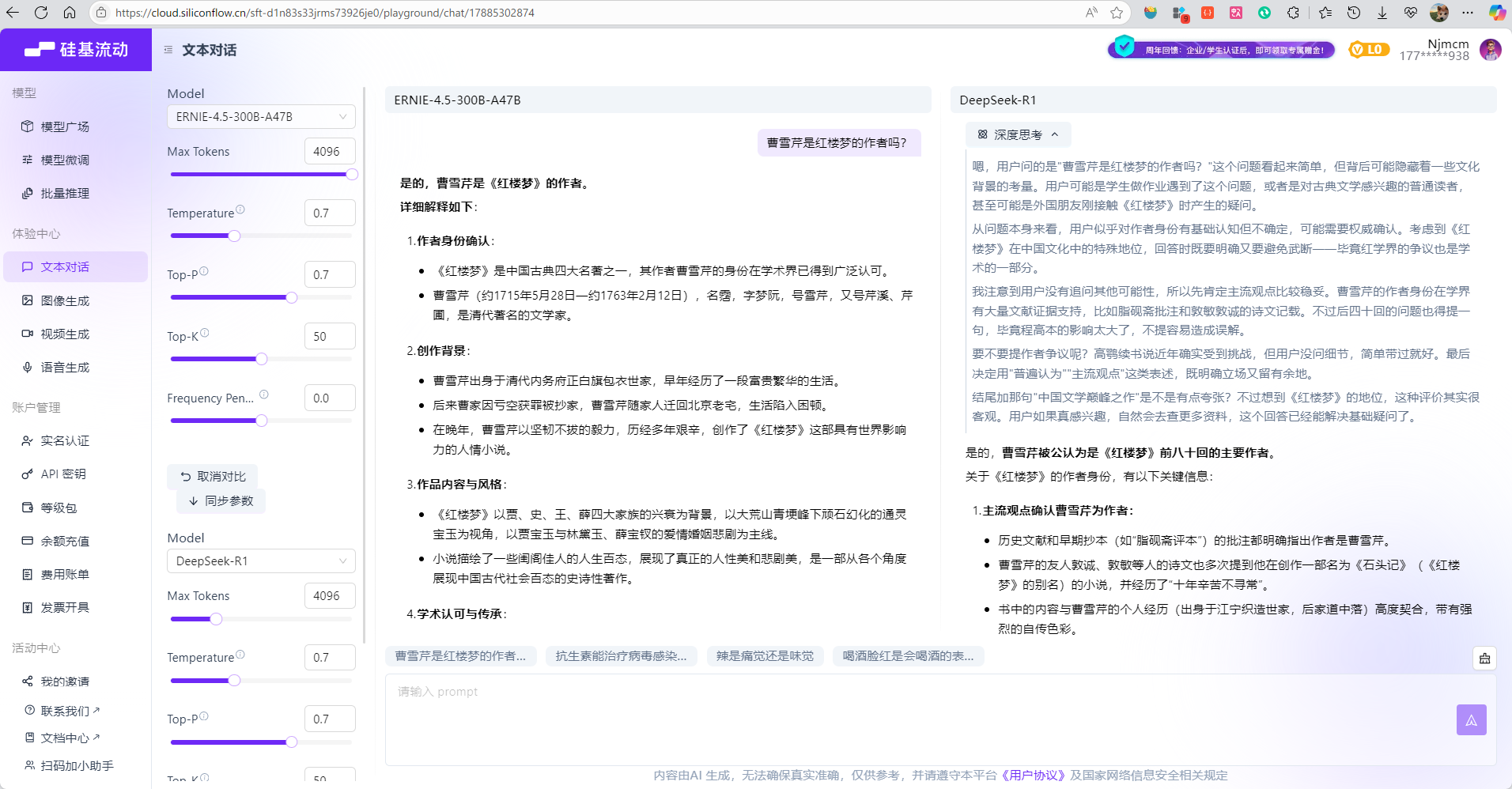
4.1. 文心4.5 vs DeepSeek-R1
基础文本理解与生成
- 输入内容(prompt):
阅读以下产品介绍: “全新的 Aether-5 笔记本电脑,搭载了最新的M3 Ultra芯片,配备16英寸 Liquid Retina XDR 显示屏,分辨率高达3456x2234。它提供最高64GB的统一内存和4TB的固态硬盘存储选项。机身采用100%再生铝金属,重量仅为1.6kg,电池续航最长可达22小时。接口方面,它包括三个雷雳4端口、一个HDMI端口和SDXC卡插槽。”
问题: 请根据以上描述,以列表形式列出 Aether-5 笔记本电脑的芯片型号、屏幕尺寸、最大内存、重量和电池续航。
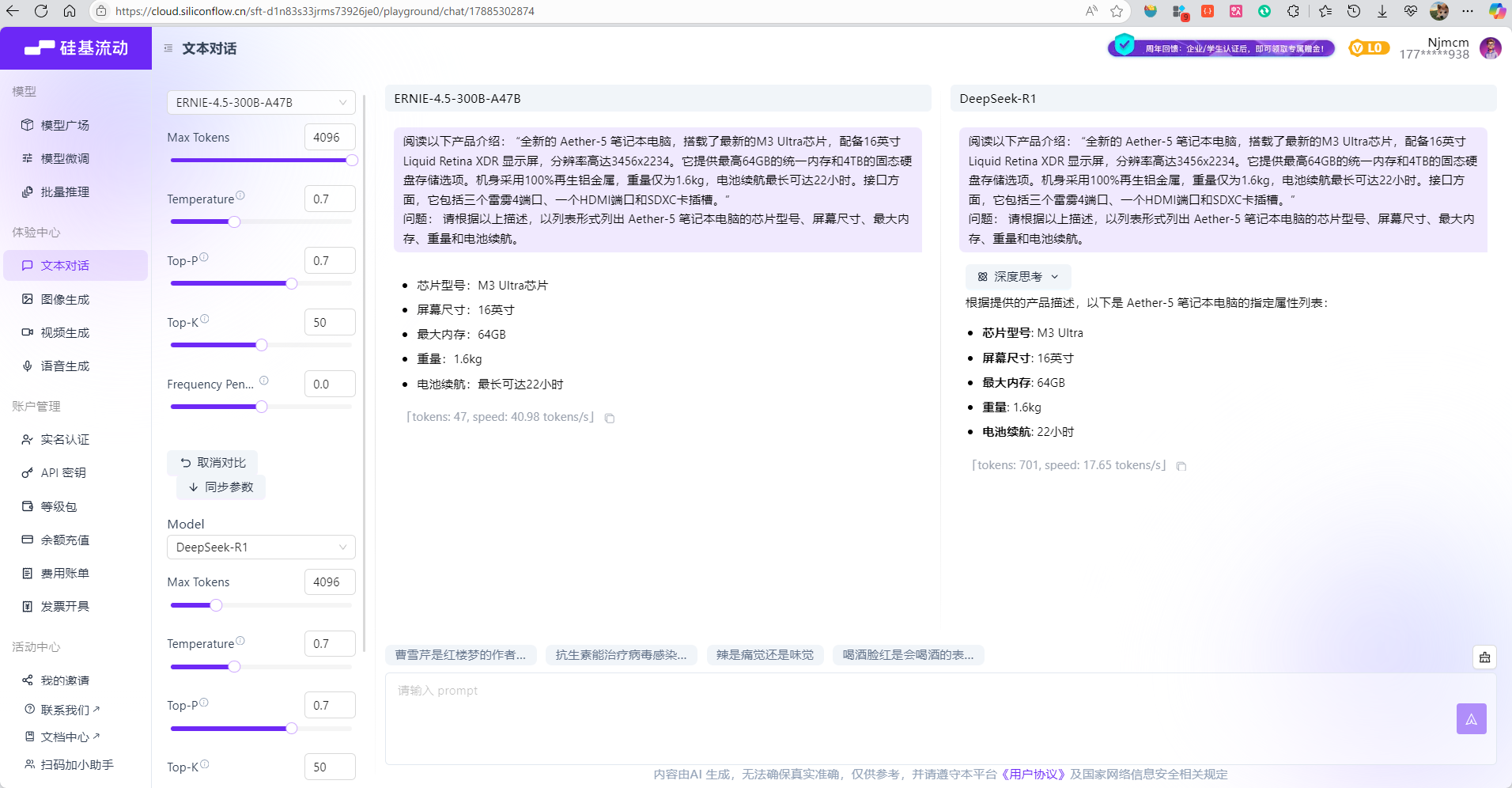
- 结论:
- 语言生动性:基于回答的表达方式、结构化程度和用户友好性
- ERNIE: 7分 - 简洁直接,但略显生硬
- DeepSeek-R1: 8.5分 - 更规范的表达,包含引导性语句
- 信息完整性:基于是否完整回答了所有要求的信息点
- ERNIE: 9分 - 包含所有要求信息,格式清晰
- DeepSeek-R1: 10分 - 信息完整且格式更加规范
- 回答效率:直接使用提供的token生成速度
- ERNIE明显优于DeepSeek-R1,速度快2.3倍
- 输出Token总量:直接使用提供的token数量
- ERNIE输出更简洁,DeepSeek-R1输出更详细
结论:ERNIE在效率和简洁性方面表现突出,而DeepSeek-R1在规范性和完整性方面略胜一筹。
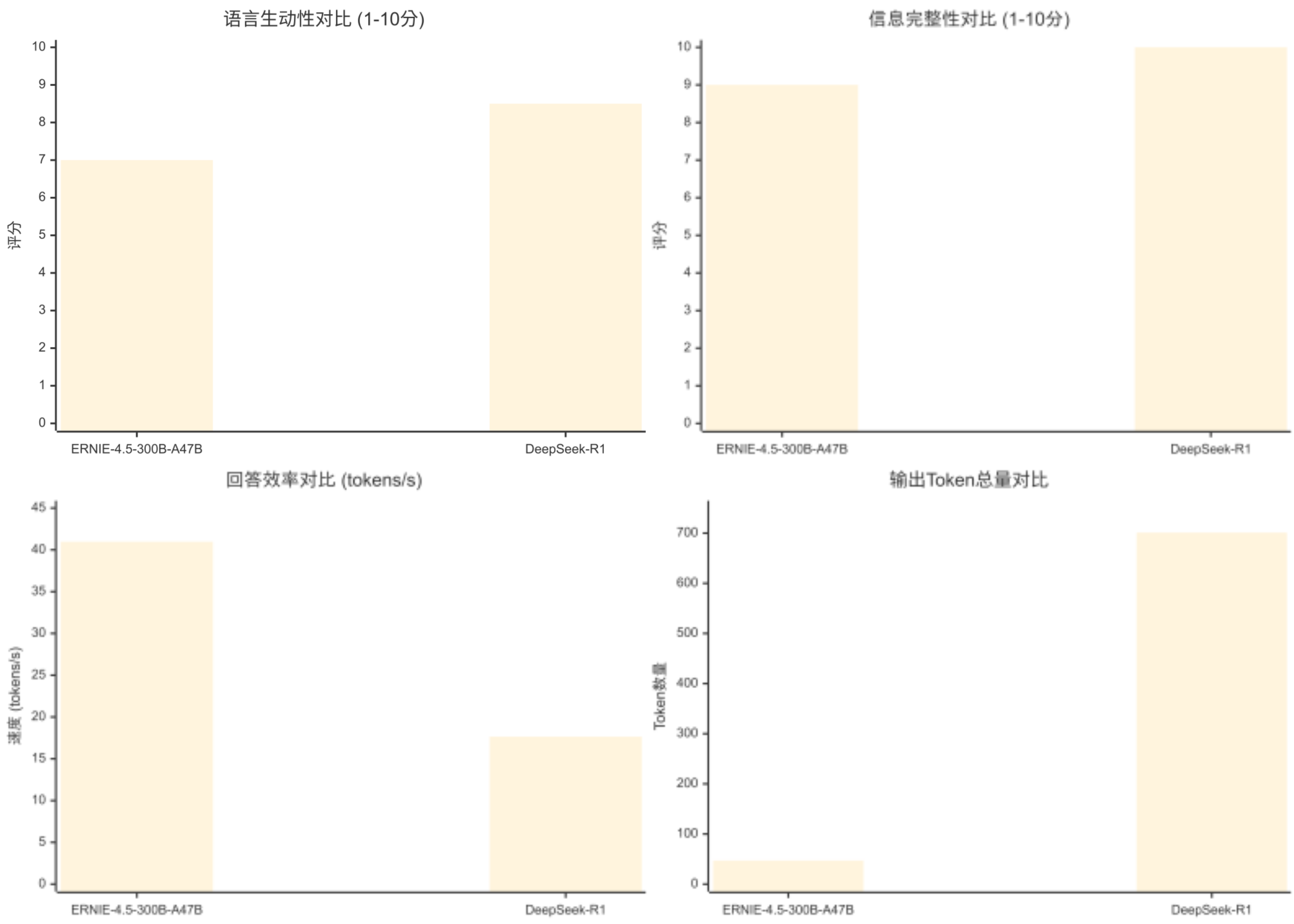
对比维度
ERNIE-4.5-300B-A47B
DeepSeek-R1
优势方
语言生动性
7/10
8.5/10
DeepSeek-R1
信息完整性
9/10
10/10
DeepSeek-R1
回答效率
40.98 tokens/s
17.65 tokens/s
ERNIE-4.5-300B-A47B
输出Token总量
47 tokens
701 tokens
ERNIE-4.5-300B-A47B
响应时间
~1.15秒
~39.7秒
ERNIE-4.5-300B-A47B
简洁程度
⭐⭐⭐⭐⭐
⭐⭐
ERNIE-4.5-300B-A47B
格式规范性
⭐⭐⭐⭐
⭐⭐⭐⭐⭐
DeepSeek-R1
复杂逻辑推理
- 输入内容(prompt):
“一个仓库里有三种包裹:A、B、C。所有包裹的总数是60个。A和B的总数是C的两倍。A的数量比B多10个。请问,A、B、C三种包裹各有多少个?”请给出详细的推理步骤,并计算出A、B、C各自的数量。
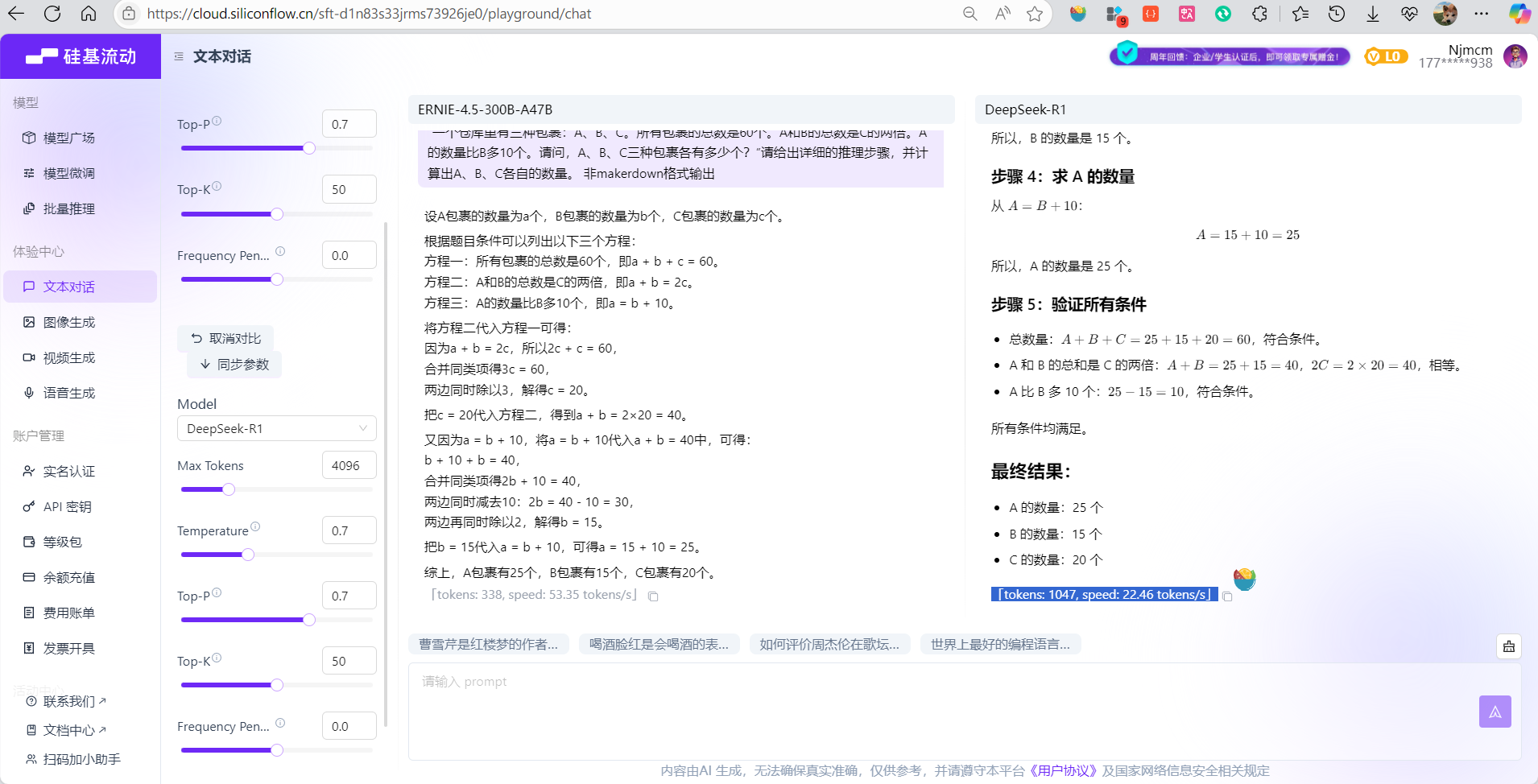
- 结论:
- ERNIE-4.5-300B-A47B:在速度和效率方面表现突出,适合快速解题需求,推理过程清晰简洁
- DeepSeek-R1:在教学质量和完整性方面更胜一筹,提供了详细的步骤分解、数学公式表达和结果验证,适合学习和教学场景
两个模型都得出了正确答案(A=25,B=15,C=20),但在表达方式和详细程度上各有特色。
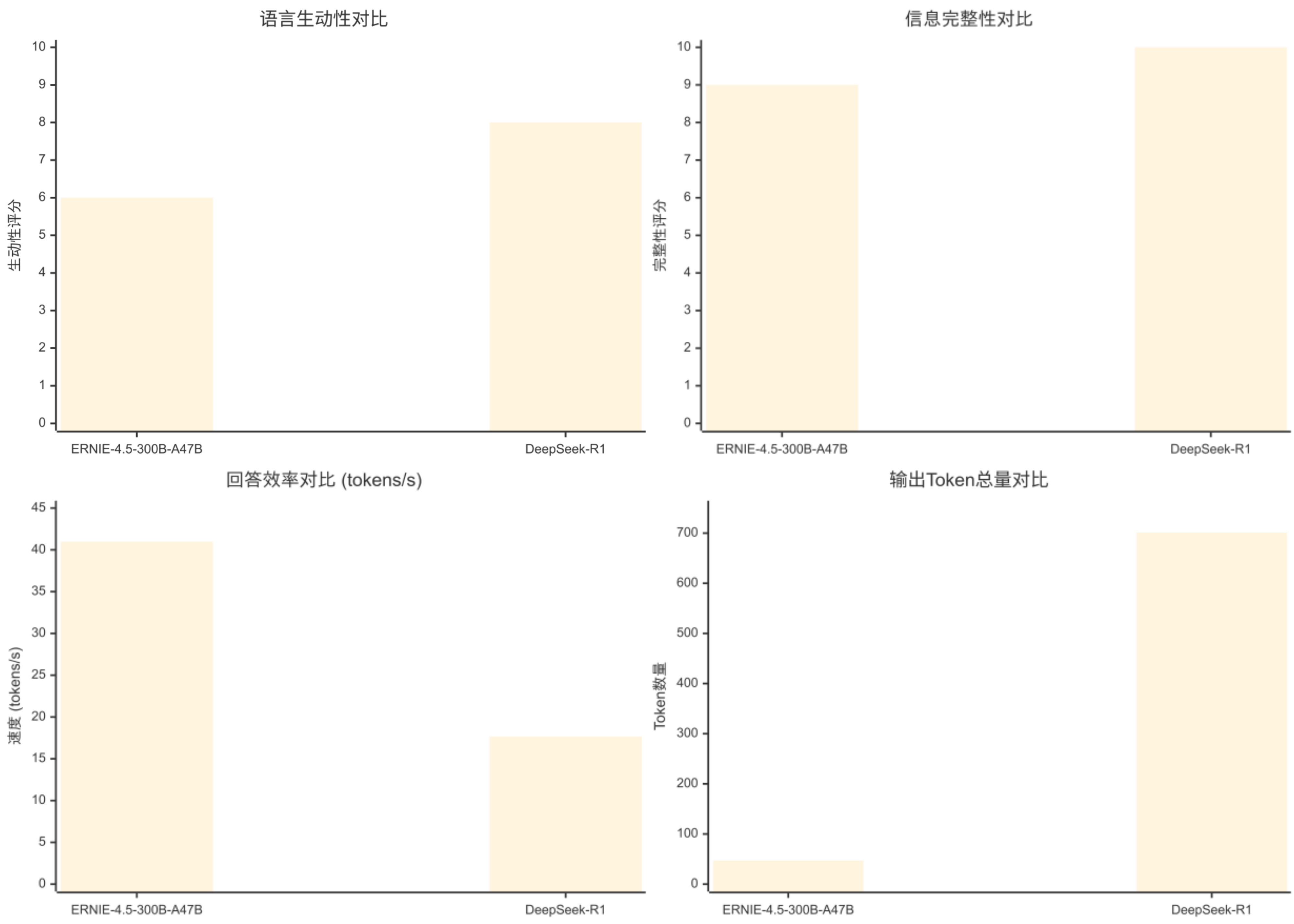
评估维度
ERNIE-4.5-300B-A47B
DeepSeek-R1
优势方
语言生动性
7/10 (表述清晰,逻辑顺畅)
9/10 (格式规范,数学表达专业)
DeepSeek-R1
信息完整性
8/10 (包含完整推理过程)
10/10 (详细步骤+验证+格式化)
DeepSeek-R1
回答效率
53.35 tokens/s
22.46 tokens/s
ERNIE-4.5-300B-A47B
输出Token总量
338 tokens
1047 tokens
ERNIE-4.5-300B-A47B (更简洁)
响应时间
~6.3秒
~46.6秒
ERNIE-4.5-300B-A47B
推理逻辑
清晰完整
非常详细,包含验证步骤
DeepSeek-R1
数学表达
文字描述为主
LaTeX公式+文字,更专业
DeepSeek-R1
实用性
高 (快速获得正确答案)
中 (教学级详细解答)
ERNIE-4.5-300B-A47B
专业知识适配
- 输入内容(prompt):
“请解释什么是‘API(应用程序编程接口)’。请使用一个具体的比喻来帮助非技术人员理解,并简要说明为什么API在现代软件开发中如此重要。”
提供一个清晰的比喻(例如:餐厅服务员、电源插座等)。
解释API的作用(数据交换、功能复用)。
阐述其重要性(促进协作、构建生态系统等)。
- 结论
内容质量对比:
- 两个模型都使用了餐厅服务员的比喻,但DeepSeek-R1的解释更加详细和系统化
- ERNIE-4.5-300B-A47B的回答简洁明了,适合快速理解
- DeepSeek-R1提供了更丰富的例子和更深入的技术解释
表达方式对比:
- ERNIE-4.5-300B-A47B:流畅的段落式表达,易于阅读
- DeepSeek-R1:结构化表达,使用标题和要点,更适合学习参考
总结:
- ERNIE-4.5-300B-A47B:适合需要快速了解API概念的场景,效率高,表达简洁
- DeepSeek-R1:适合深入学习和教学场景,内容全面,结构清晰,但耗时较长
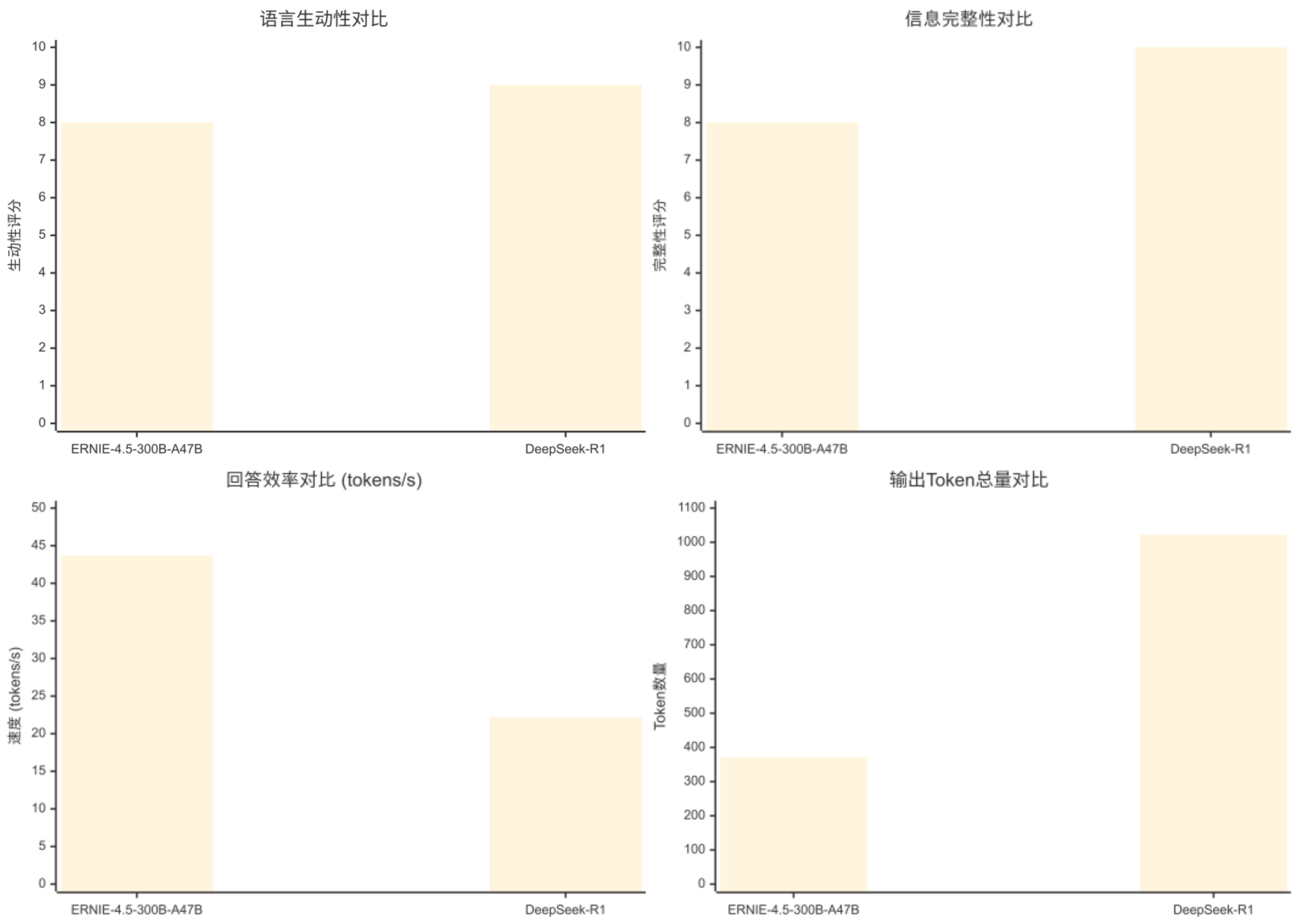
评估维度
ERNIE-4.5-300B-A47B
DeepSeek-R1
优势方
语言生动性
8/10 (比喻生动,表述流畅)
9/10 (比喻详细,多角度阐述)
DeepSeek-R1
信息完整性
8/10 (覆盖主要要点)
10/10 (结构完整,要点全面)
DeepSeek-R1
回答效率
43.70 tokens/s
22.22 tokens/s
ERNIE-4.5-300B-A47B
输出Token总量
372 tokens
1022 tokens
ERNIE-4.5-300B-A47B (更简洁)
响应时间
~8.5秒
~46.0秒
ERNIE-4.5-300B-A47B
比喻质量
优秀 (餐厅服务员比喻清晰)
优秀 (同样比喻但更详细)
平分秋色
结构组织
良好 (逻辑清晰)
优秀 (标题分段,层次分明)
DeepSeek-R1
技术深度
中等 (适合初学者)
较深 (更全面的技术解释)
DeepSeek-R1
实用性
高 (快速理解概念)
中 (详细学习材料)
ERNIE-4.5-300B-A47B
4.2. 文心4.5 vs Qwen3
基础文本理解与生成
- 输入内容(prompt):
请阅读以下新闻稿,并完成两个任务:
1.用不超过100个字总结这篇新闻的核心内容。
2.以JSON格式提取以下信息:会议名称、举办城市、主要议题、参会人数。
新闻稿: “2023年世界人工智能大会(WAIC)于7月6日至8日在中国上海成功举办。本次大会以‘智联世界,生成未来’为主题,吸引了超过1400名行业领袖、学者及国际组织代表参会。会议聚焦于探讨通用人工智能、AI芯片、科学智能以及机器人等前沿议题,展示了人工智能领域的最新技术突破和产业应用。与会者普遍认为,生成式AI将是未来十年最具变革性的技术力量。”
- 结论:
任务完成情况:
- 总结任务:
- ERNIE-4.5-300B-A47B:79字,包含了会议时间、地点、主题、参会人数、议题和核心观点
- DeepSeek-R1:48字,重点突出但信息相对简略
- JSON提取任务:
- 两个模型都准确提取了所有要求的信息
- ERNIE-4.5-300B-A47B采用了嵌套结构,将总结和JSON分开
- DeepSeek-R1采用了更标准的分离格式
格式和结构:
- ERNIE-4.5-300B-A47B:创新性地将两个任务整合在一个JSON中,结构清晰
- DeepSeek-R1:严格按照要求分别完成两个任务,格式标准
效率对比:
- ERNIE-4.5-300B-A47B在速度和token使用效率方面都表现更优
- 响应时间差异显著(3.9秒 vs 16.4秒)
总结:
- ERNIE-4.5-300B-A47B:在信息完整性、效率和创新格式方面表现突出,适合需要详细信息提取的场景
- DeepSeek-R1:格式标准,总结简洁,适合需要快速获取核心要点的场景
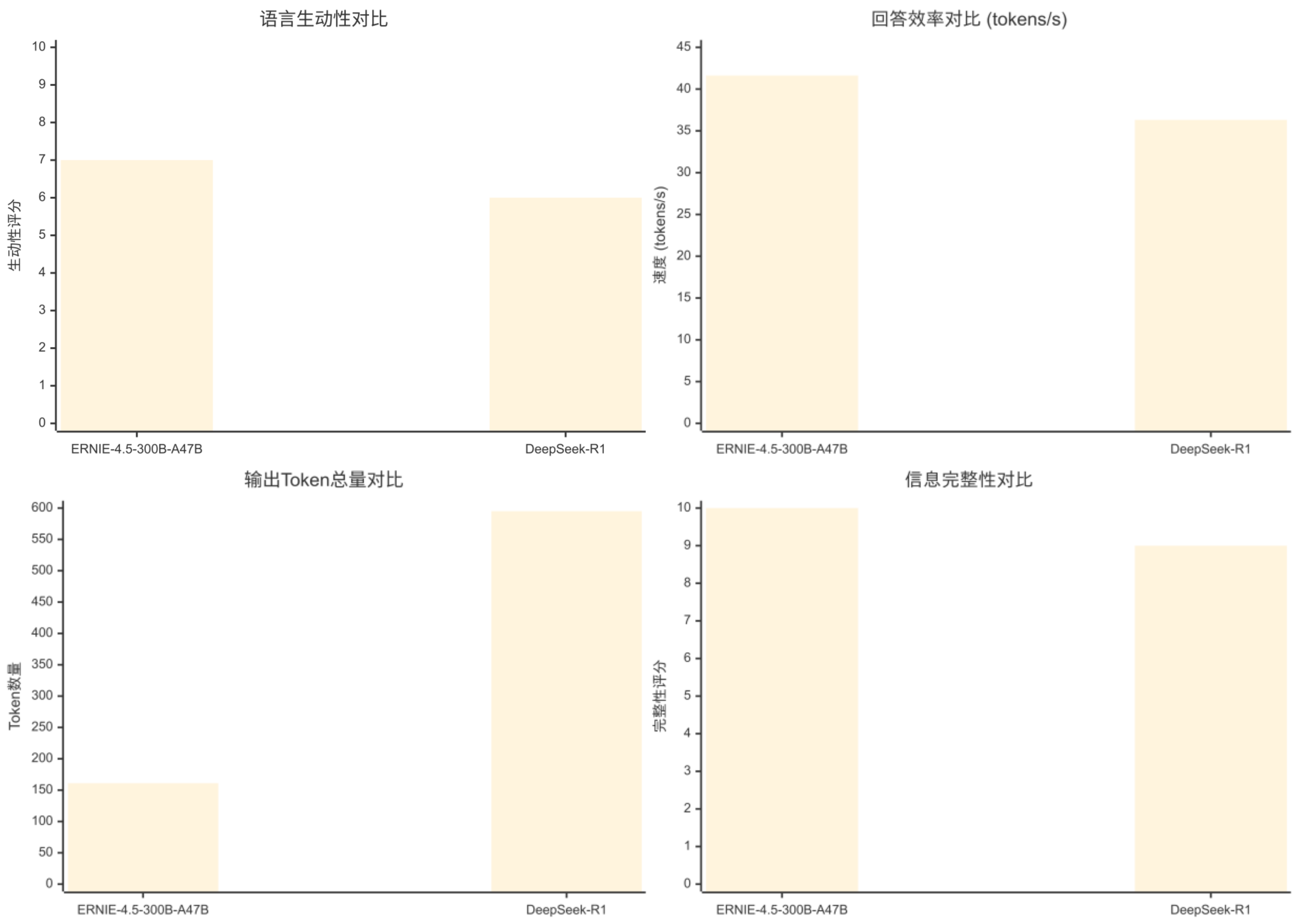
评估维度
ERNIE-4.5-300B-A47B
DeepSeek-R1
优势方
语言生动性
7/10 (表述完整,略显冗长)
6/10 (简洁但缺乏细节)
ERNIE-4.5-300B-A47B
信息完整性
10/10 (包含所有要求信息)
9/10 (信息完整但格式略简)
ERNIE-4.5-300B-A47B
回答效率
41.62 tokens/s
36.31 tokens/s
ERNIE-4.5-300B-A47B
输出Token总量
161 tokens
595 tokens
ERNIE-4.5-300B-A47B (更简洁)
响应时间
~3.9秒
~16.4秒
ERNIE-4.5-300B-A47B
任务完成度
优秀 (两个任务都完成)
优秀 (两个任务都完成)
平分秋色
JSON格式
规范 (嵌套结构清晰)
规范 (标准JSON格式)
平分秋色
总结质量
优秀 (79字,信息全面)
良好 (48字,重点突出)
ERNIE-4.5-300B-A47B
实用性
高 (信息详细,格式清晰)
中 (简洁但信息略少)
ERNIE-4.5-300B-A47B
复杂逻辑推理
- 输入内容(prompt):
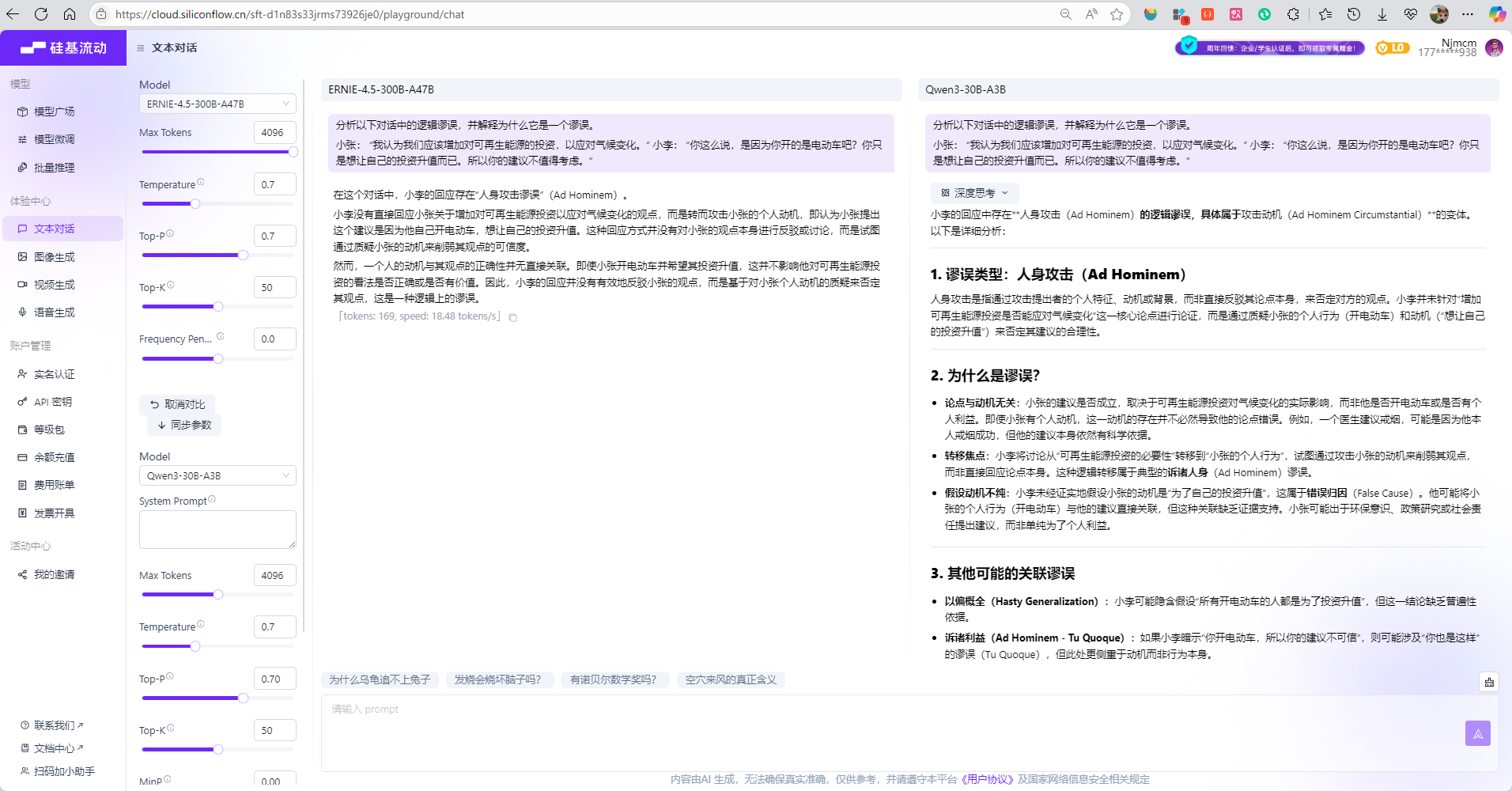
分析以下对话中的逻辑谬误,并解释为什么它是一个谬误。
小张: “我认为我们应该增加对可再生能源的投资,以应对气候变化。” 小李: “你这么说,是因为你开的是电动车吧?你只是想让自己的投资升值而已。所以你的建议不值得考虑。”
- 结论:
内容质量对比:
- ERNIE-4.5-300B-A47B:
- 准确识别了\"人身攻击谬误\"
- 简洁明了地解释了谬误的核心问题
- 适合快速理解和日常应用
- DeepSeek-R1:
- 提供了更精确的分类(Ad Hominem Circumstantial)
- 包含了多个相关谬误类型的分析
- 提供了正确反驳方式的建议
- 结构化的学术写作风格
分析深度对比:
- ERNIE-4.5-300B-A47B:聚焦核心问题,解释简洁有效
- DeepSeek-R1:多维度分析,包括谬误分类、原因分析、相关谬误、正确做法等
效率对比:
- 虽然DeepSeek-R1的token速度更快,但总响应时间更长
- ERNIE-4.5-300B-A47B在实际使用效率上更优
适用场景:
- ERNIE-4.5-300B-A47B:适合日常讨论、快速学习、基础教育
- DeepSeek-R1:适合学术研究、深度学习、专业培训
总结: 两个模型都正确识别了逻辑谬误,但在表达深度和详细程度上差异显著。ERNIE-4.5-300B-A47B提供了简洁有效的分析,而DeepSeek-R1提供了更全面的学术级分析。选择哪个取决于用户的具体需求:快速理解还是深入学习。
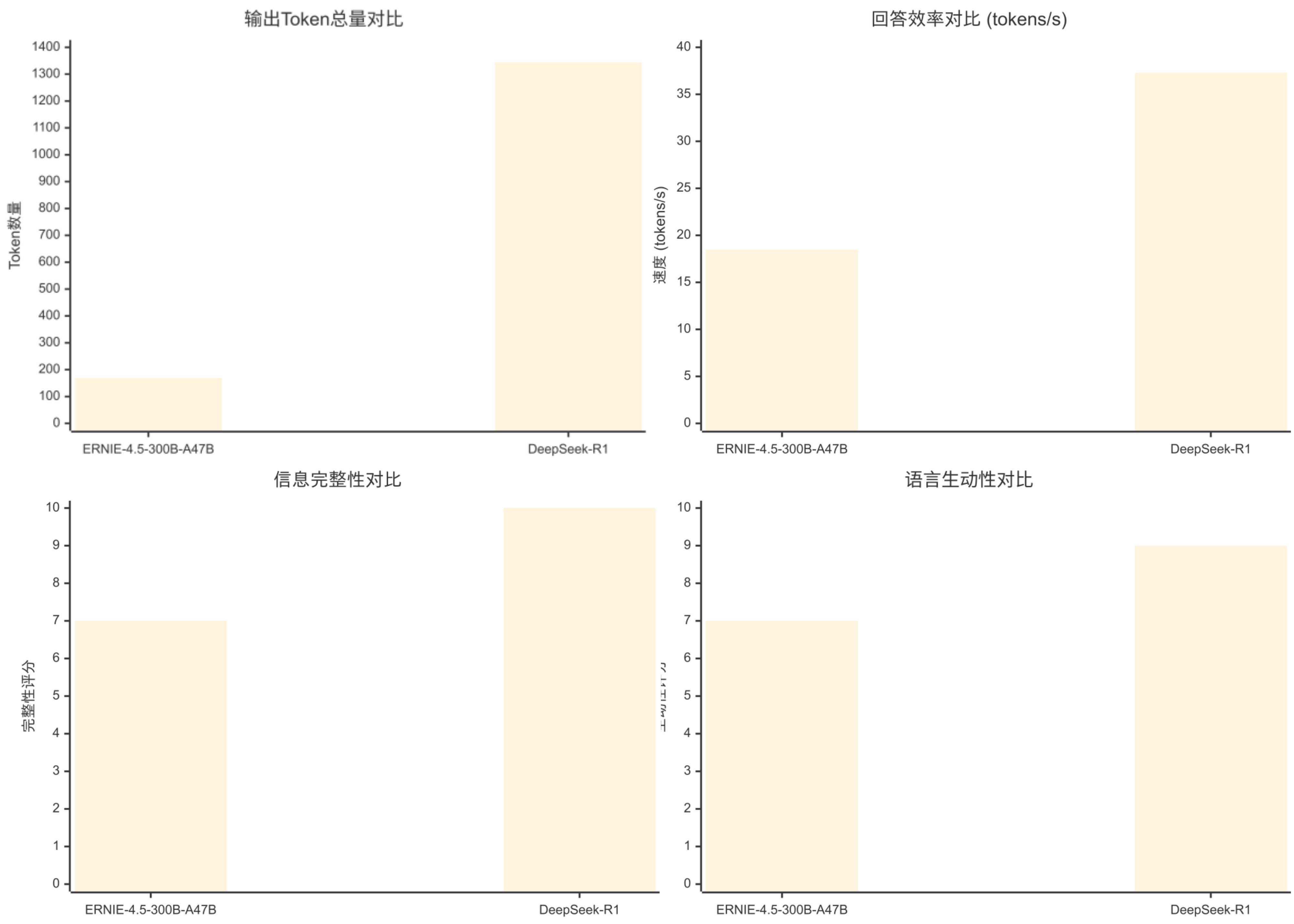
评估维度
ERNIE-4.5-300B-A47B
DeepSeek-R1
优势方
语言生动性
7/10 (表述清晰,逻辑顺畅)
9/10 (结构化表达,专业术语丰富)
DeepSeek-R1
信息完整性
7/10 (基本要点覆盖)
10/10 (全面深入,多角度分析)
DeepSeek-R1
回答效率
18.48 tokens/s
37.29 tokens/s
DeepSeek-R1
输出Token总量
169 tokens
1344 tokens
ERNIE-4.5-300B-A47B (更简洁)
响应时间
~9.1秒
~36.0秒
ERNIE-4.5-300B-A47B
分析深度
基础 (识别谬误类型和基本解释)
深入 (多层次分析,相关谬误)
DeepSeek-R1
专业性
中等 (基本逻辑学概念)
高 (专业术语,学术格式)
DeepSeek-R1
实用性
高 (快速理解核心问题)
中 (详细学习材料)
ERNIE-4.5-300B-A47B
教学价值
中等 (基本概念解释)
高 (全面教学材料)
DeepSeek-R1
专业知识适配
- 输入内容(prompt):
以下是一段保密协议(NDA)中的条款,请用通俗的语言解释这一条款的含义,并指出作为签署该协议的乙方(接收方)可能面临的主要风险。
条款: “接收方同意,在任何情况下,均不得直接或间接地向任何第三方披露、传播或以任何方式使用披露方提供的任何保密信息,除非事先获得披露方的书面明确授权。本保密义务在本协议终止后持续有效,无时间限制。”
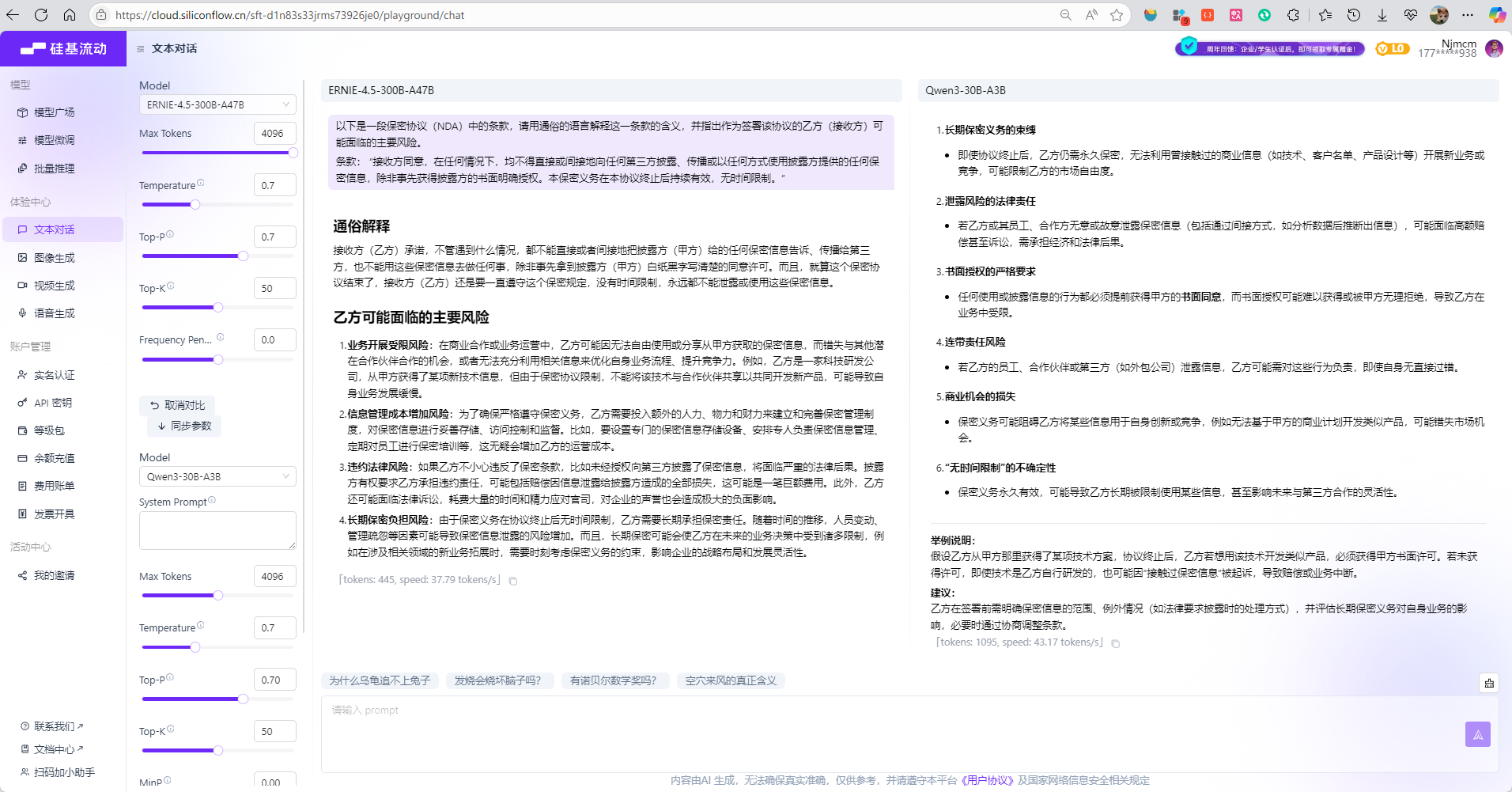
- 结论:
内容质量对比:
- ERNIE-4.5-300B-A47B:
- 通俗解释简洁明了,使用\"白纸黑字\"等生活化表达
- 风险分析全面,涵盖业务、成本、法律、长期负担四个维度
- 每个风险点都有具体的例子说明
- DeepSeek-R1:
- 结构化表达,使用标准格式和分隔线
- 风险分析更细致,包含6个具体风险点
- 额外提供了举例说明和实用建议
- 包含了\"连带责任\"等更专业的法律概念
专业性对比:
- 两个模型都准确理解了NDA条款的法律含义
- DeepSeek-R1在法律专业术语和风险识别方面更加细致
- ERNIE-4.5-300B-A47B更注重通俗化解释
实用价值对比:
- ERNIE-4.5-300B-A47B:适合普通用户快速理解NDA风险
- DeepSeek-R1:适合需要详细风险评估和决策参考的商业场景
效率对比:
- DeepSeek-R1在token生成速度上略胜一筹
- 但ERNIE-4.5-300B-A47B在总响应时间上更优
- 内容密度方面,ERNIE-4.5-300B-A47B更加简洁高效
总结: 两个模型都提供了高质量的法律条款解释和风险分析。ERNIE-4.5-300B-A47B在简洁性和响应速度方面表现更好,适合快速咨询;DeepSeek-R1在完整性和专业深度方面更胜一筹,适合需要详细分析的商业决策场景。
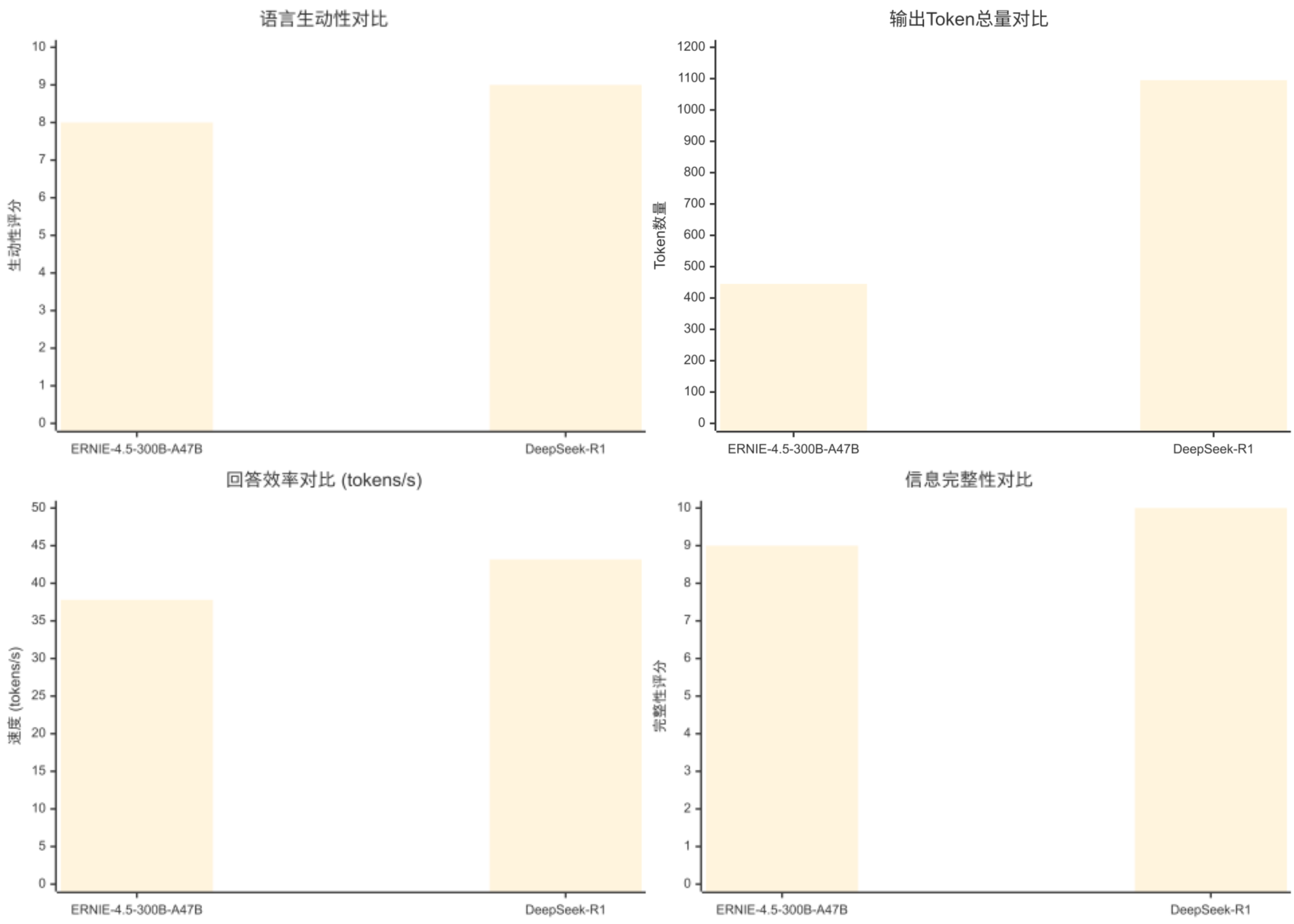
评估维度
ERNIE-4.5-300B-A47B
DeepSeek-R1
优势方
语言生动性
8/10 (通俗易懂,例子生动)
9/10 (结构清晰,举例具体)
DeepSeek-R1
信息完整性
9/10 (风险分析全面)
10/10 (包含建议和举例说明)
DeepSeek-R1
回答效率
37.79 tokens/s
43.17 tokens/s
DeepSeek-R1
输出Token总量
445 tokens
1095 tokens
ERNIE-4.5-300B-A47B (更简洁)
响应时间
~11.8秒
~25.4秒
ERNIE-4.5-300B-A47B
法律解释准确性
优秀 (准确理解条款含义)
优秀 (准确理解条款含义)
平分秋色
风险分析深度
深入 (4个主要风险类别)
深入 (6个具体风险点)
DeepSeek-R1
实用性
高 (详细解释,易于理解)
高 (包含建议和具体举例)
DeepSeek-R1
结构组织
良好 (清晰分段)
优秀 (标准化格式,层次分明)
DeepSeek-R1
5. 总结
本文聚焦百度最新发布的文心4.5系列开源大模型,深入解析其丰富的参数配置、前沿架构设计、开源许可机制以及实际部署与Web UI构建方法。通过横向对比测试结果显示,ERNIE-4.5-300B-A47B在表达生动性与信息全面性等关键指标上表现卓越,特别适用于专业学术研究和报告编写场景;Qwen3-30B-A3B紧随其后,凭借其文艺精致的表达风格,在知识普及和文案创意方面具有明显优势;DeepSeek-R1虽然综合表现相对较弱,但其朴实直接的表达方式和逻辑推理能力,使其在基础概念解释方面颇具实用价值。各模型特色鲜明,实际应用中应根据具体业务场景进行针对性选择。
🔥架构体系丰富:采用先进MoE架构与多模态异构设计,全面支持飞桨、PyTorch等主流框架,参数规模从数亿到数百亿不等,满足通用开发、复杂任务处理及移动端应用等多样化需求
🚀性能表现卓越:FLOPs利用效率高达47%,在文本处理与多模态任务领域创下多项基准测试新纪录,实现了高性能与部署便捷性的完美平衡
🌟开源生态友好:基于Apache 2.0协议完全开源,全面兼容飞桨框架端到端操作流程,为学术探索与工业级应用的二次开发提供便利条件
🌟 嗨,我是IRpickstars!如果你觉得这篇技术分享对你有启发:
🛠️ 点击【点赞】让更多开发者看到这篇干货
🔔 【关注】解锁更多架构设计&性能优化秘籍
💡 【评论】留下你的技术见解或实战困惑作为常年奋战在一线的技术博主,我特别期待与你进行深度技术对话。每一个问题都是新的思考维度,每一次讨论都能碰撞出创新的火花。
🌟 点击这里👉 IRpickstars的主页 ,获取最新技术解析与实战干货!
⚡️ 我的更新节奏:
- 每周三晚8点:深度技术长文
- 每周日早10点:高效开发技巧
- 突发技术热点:48小时内专题解析

