SpringAI——如何使用java来接入大模型
目录
使用Spring AI与Java快速接入大模型
一、Spring AI简介
二、环境准备
三、项目搭建
四、配置API密钥
五、创建配置类 (CommonConfiguration.java)
六、编写Controller接口
会话记忆功能
定义会话存储方式
InMemoryChatMemory 实现原理解析
配置会话记忆
什么是 “配置会话记忆 Advisor”?
添加会话ID
为什么要设置 conversationId?
使用场景 实现多轮对话的「记忆管理」
场景说明:
Repository:
Repository的实现类:
如何实现记忆管理?
✳ 实现目标
历史会话和记录查询接口
MessageVO返回前端
使用Spring AI与Java快速接入大模型
随着AI技术的飞速发展,越来越多的开发者希望将大模型的能力集成到自己的Java应用中。Spring AI提供了便捷的工具和框架,使得Java开发人员可以快速而优雅地接入各种主流大模型API,比如OpenAI、DeepSeek、阿里云通义千问等。
一、Spring AI简介
Spring AI是Spring生态中的新成员,专门为AI服务接入而设计,提供统一的API接口和自动配置能力,极大地简化了开发人员与不同大模型API集成的过程。
二、环境准备
首先,你需要确保以下环境:
-
JDK 17或更高版本
-
Maven或Gradle
-
一个大模型服务API账号

三、项目搭建
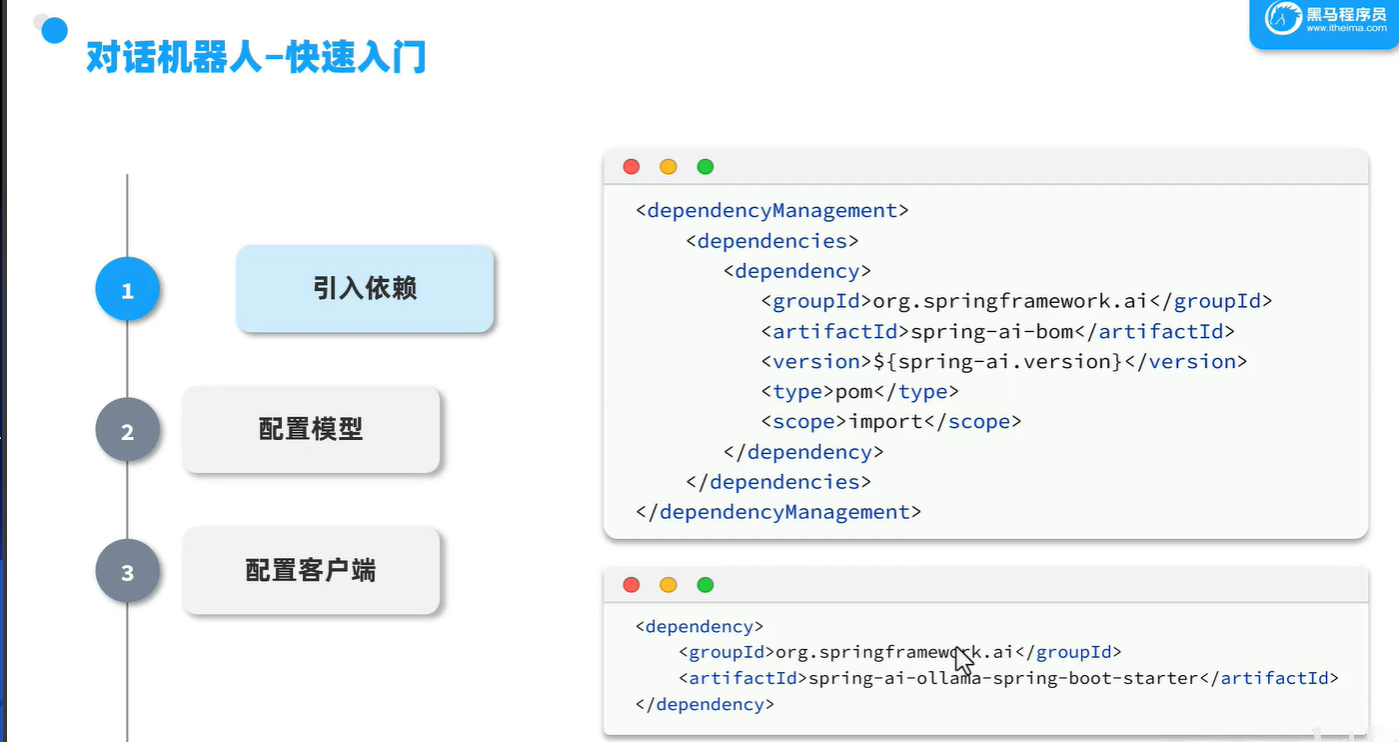
使用Spring Initializr创建一个Spring Boot项目,添加以下依赖:
-
Spring Web
-
Spring AI
例如,使用Maven配置依赖:
四、配置API密钥
在application.yml文件中配置你的大模型API,例如OpenAI:
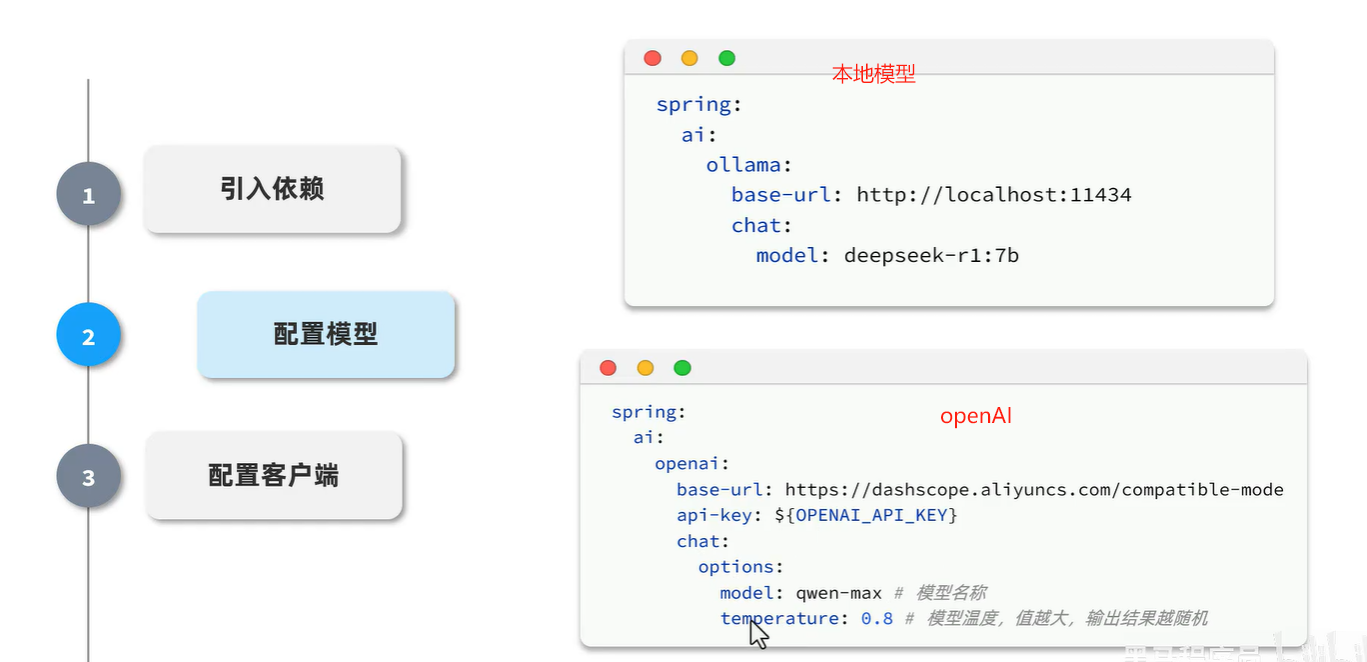
spring: ai: openai: base-url: https://ark.cn-beijing.volces.com/api api-key:你的API-key chat: options: model: deepseek-r1-250120 temperature: 0.7 embedding: options: model: text-embedding-v3 dimensions: 1024logging: level: org.springframework.ai.chat.client.advisor: debug com.gege.ai: DEBUG注意:
Spring AI在请求Chat API时,会默认在你指定的base-url后面自动追加/v1/chat/completions路径。这意味着你的base-url应该不包含v3之后的路径。如果包含多余路径,会造成拼接后的路径错误,导致404 Not Found异常。
错误的:
base-url: https://ark.cn-beijing.volces.com/api/v3五、创建配置类 (CommonConfiguration.java)
@Configurationpublic class CommonConfiguration { // 定义一个记忆存储的方式 底层是一个map把这个消息保存起来,可以考虑持久化存储 // ChatMemory是基于conversationId进行存储的,区分不同的会话 // 也就是说可以根据会话id查询到该会话的聊天记录 @Bean public ChatMemory chatMemory() { return new InMemoryChatMemory(); // 创建一个InMemoryChatMemory对象,用于保存聊天记录 } @Bean public ChatClient chatClient(OpenAiChatModel openAiChatModel) { return ChatClient.builder(openAiChatModel) .defaultSystem(\"你是一个可爱的助手,你的名字叫做格格,你的任务是帮助用户解决问题\") .defaultAdvisors( new SimpleLoggerAdvisor(), // 环绕增强 new MessageChatMemoryAdvisor(chatMemory()) // 将聊天记录保存到内存中 ) .build(); }}这里定义了两个关键Bean:
-
ChatMemory: 用于存储聊天记录,当前为内存存储。 -
ChatClient: 配置了系统提示和默认的增强器,自动处理对话历史。
六、编写Controller接口
创建一个REST接口,供前端调用:
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY;@RestController@RequestMapping(\"/ai\")@RequiredArgsConstructorpublic class ChatController { private final ChatClient chatClient; private final ChatHistoryRepository chatHistoryRepository; @RequestMapping(\"/chat\") public String chat( String prompt) { return chatClient.prompt() .user(prompt) .call() .content(); } // 使用流式传输,需要指定页面的内容类型,否则会乱码 @RequestMapping(value = \"/chatFlux\",produces = \"text/html;charset=UTF-8\") public Flux chatFlux(String message) { return chatClient.prompt() .user(message) .stream() .content(); }}
会话记忆功能
定义会话存储方式
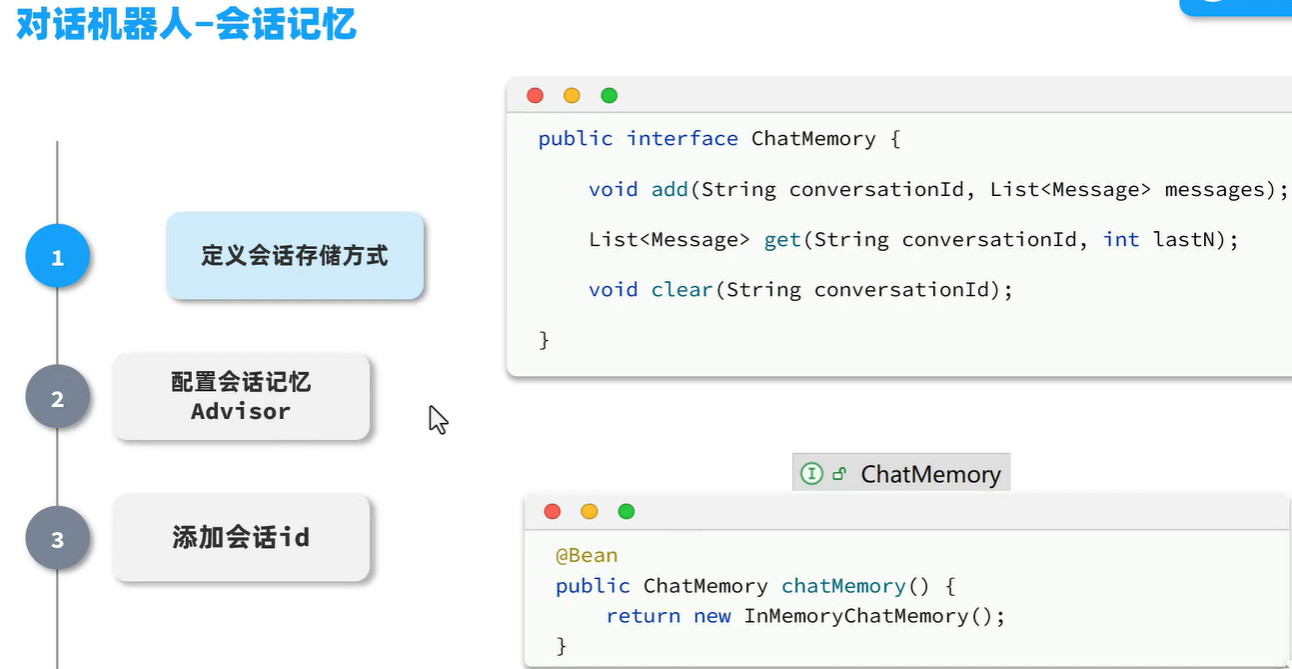
图中给出了以下接口定义:
public interface ChatMemory { void add(String conversationId, List messages); List get(String conversationId, int lastN); void clear(String conversationId);}接口的含义:
-
add:
存储指定会话ID的聊天消息列表到内存或持久存储中。 -
get:
根据会话ID和数量lastN,获取最近的N条聊天消息。 -
clear:
清空指定会话ID对应的消息列表。
InMemoryChatMemory 实现原理解析
上图中使用了InMemoryChatMemory类,这是一种最简单的基于内存实现的聊天记忆方案。其实现原理一般如下:
public class InMemoryChatMemory implements ChatMemory { // 内部存储结构:通过ConcurrentHashMap管理会话与消息列表映射 private final Map<String, List> memory = new ConcurrentHashMap(); @Override public void add(String conversationId, List messages) { memory.computeIfAbsent(conversationId, key -> new ArrayList()) .addAll(messages); } @Override public List get(String conversationId, int lastN) { List messages = memory.getOrDefault(conversationId, Collections.emptyList()); int size = messages.size(); return messages.subList(Math.max(0, size - lastN), size); } @Override public void clear(String conversationId) { memory.remove(conversationId); }}-
使用
ConcurrentHashMap进行线程安全的内存存储,适合并发环境。
ConcurrentHashMap是支持高并发访问的哈希映射表,允许多个线程同时读写,而不会发生线程安全问题。
-
每个会话
conversationId对应一个List,消息按时间顺序存储。 -
获取消息时,返回最新的N条消息,方便后续调用大模型进行上下文处理。
它是 ChatMemory 接口的一个实现类,用于在内存中保存每个会话的聊天消息。
你可以理解为这是一个“简易版的聊天历史数据库”,但它存在于内存中,不会持久化到磁盘或数据库
配置会话记忆
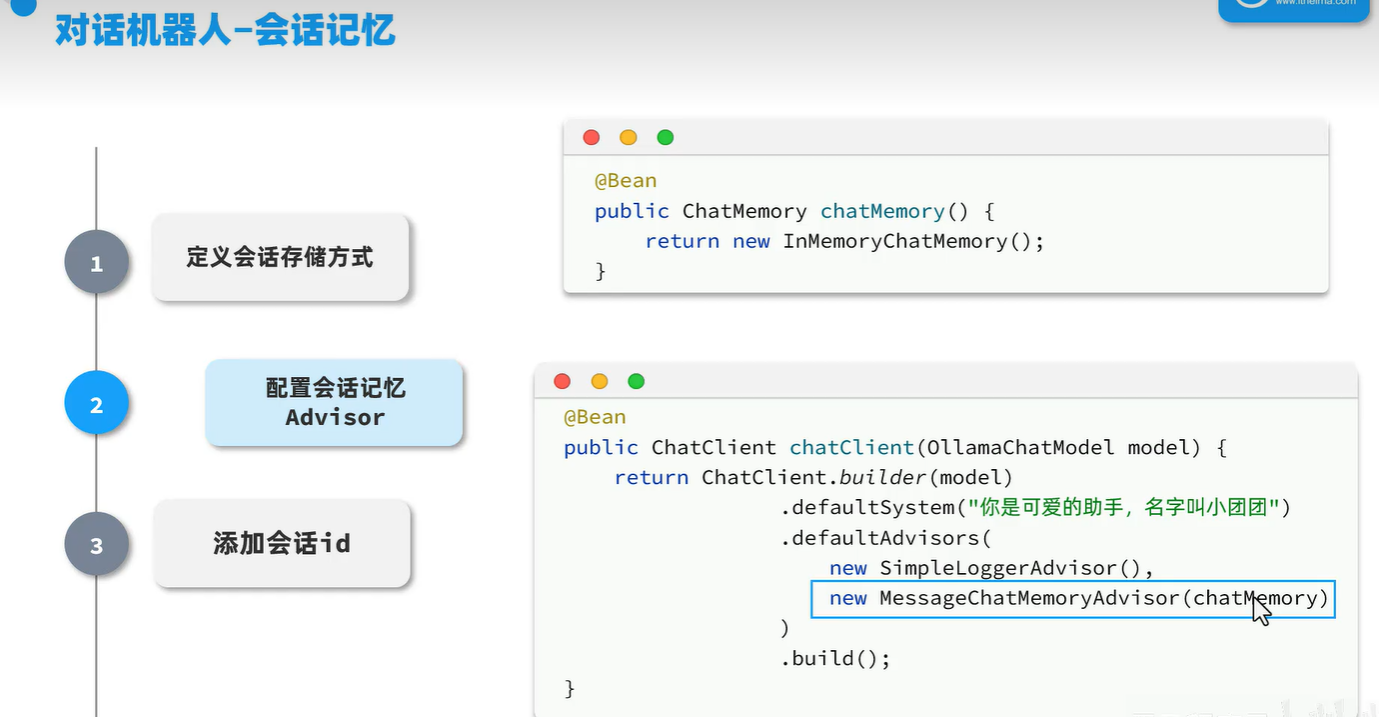
什么是 “配置会话记忆 Advisor”?
在 Spring AI 中,Advisor 是一种增强机制(类似于 AOP),你可以把它理解为:
对 ChatClient 的一次调用进行“前处理”和“后处理”,我们通过它实现对话上下文(历史聊天)的自动管理。
@Beanpublic ChatClient chatClient(OllamaChatModel model) { return ChatClient.builder(model) .defaultSystem(\"你是可爱的助手,名字叫小团团\") // 系统提示词 .defaultAdvisors( new SimpleLoggerAdvisor(), // 日志输出 new MessageChatMemoryAdvisor(chatMemory()) // ⭐ 记忆增强器 ) .build();}这一段中:
-
MessageChatMemoryAdvisor(chatMemory)会注册一个增强器。 -
它会拦截每次调用
.call()或.stream()的前后行为:-
前:取出
chatId对应的历史消息 → 添加到 prompt 中 -
后:把当前响应消息写入对应的会话历史中
-
添加会话ID
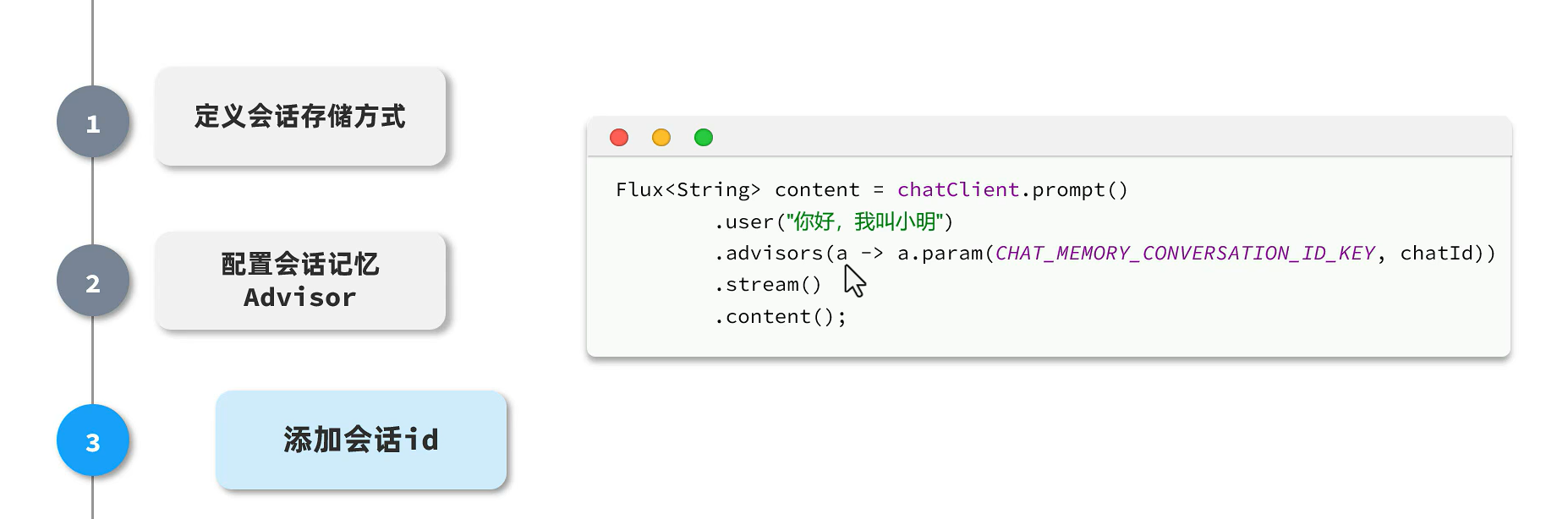
会话 ID(conversationId) 是如何添加进去的?”——它正是由 Advisor 机制 + 手动设置参数 配合完成的
1. 给当前对话上下文设置参数
你传入了一个名为 CHAT_MEMORY_CONVERSATION_ID_KEY 的参数,这个就是 Spring AI 内置识别的「会话 ID 键名」。
相当于告诉 Advisor:本轮对话属于 chatId 这个会话。
这个 key 实际上是:
public static final String CHAT_MEMORY_CONVERSATION_ID_KEY = \"conversationId\";为什么要设置 conversationId?
conversationId 就是一个“会话编号”,它的作用是标记和区分不同用户或同一用户的不同对话场景,使每次请求都能关联到自己的上下文(聊天历史),从而实现「多轮对话记忆」。
使用场景 实现多轮对话的「记忆管理」
场景说明:
在一个对话系统中(如客服、智能助理、问答机器人),我们往往要:
Repository:
而且如果存在不同的业务比如说chat,助理等等业务在同一个网站,此时我们需要根据不同的业务保存该业务下面的会话ID,此时我们如果需要完成记忆存储的话就需要实现将不同的业务下的会话ID保存在内存中的方法以及获取该业务下面所有的会话ID这种方法
public interface ChatHistoryRepository { /** * 保存会话记录 * @param type 业务类型 * @param chatId 会话ID */ void save(String type, String chatId); /** * 获取会话ID列表 * @param type 业务类型 * @return */ List getChatIds(String type);}Repository的实现类:
// TODO 先使用内存保存会话记录,等以后可以改造为数据库保存@Componentpublic class InMemoryChatHistoryRepository implements ChatHistoryRepository{ private final Map<String,List> chatHistory = new HashMap(); @Override public void save(String type, String chatId) { // 首先需要判断是否已经存在,如果存在,则更新,如果不存在,则新增 /*if(!chatHistory.containsKey(type)){ chatHistory.put(type,new ArrayList()); } List chatIds = chatHistory.get(type); // 取到对应的chatIds */ List chatIds = chatHistory.computeIfAbsent(type, k -> new ArrayList()); if(chatIds.contains(chatId)){ // 如果已经存在,则不处理 return; } chatIds.add(chatId); } @Override public List getChatIds(String type) {// return chatHistory.get(type) == null ? List.of() : chatHistory.get(type); return chatHistory.getOrDefault(type,List.of()); }}① computeIfAbsent
List chatIds = chatHistory.computeIfAbsent(type, k -> new ArrayList());含义:
如果
chatHistory中 不存在 keytype,就为它创建一个新的ArrayList并返回;
否则直接返回已有的List。
-
你想往某个
type下添加一个chatId -
如果这个类型还没有记录,就自动创建一个新的列表
② getOrDefault
return chatHistory.getOrDefault(type, List.of());含义:
如果
chatHistory中存在 keytype,返回其对应的值;
否则返回一个默认的空 List(不可变)。
如何实现记忆管理?
基于 Spring AI,我们可以借助
ChatMemory + Advisor + ChatHistoryRepository实现完整的记忆管理能力。
✳ 实现目标
-
每轮对话都可带上会话ID(
conversationId) -
自动记录该
chatId -
自动查询旧对话列表(展示历史记录)
-
绑定业务类型(如:客服、AI问答)
@RequestMapping(\"/chat\") public Flux chat( String prompt,String chatId) { // 保存会话 chatHistoryRepository.save(\"chat\",chatId);// chat是一种类型 return chatClient.prompt() .user(prompt) .advisors(a->a.param(CHAT_MEMORY_CONVERSATION_ID_KEY,chatId)) .stream() .content(); }.advisors(a -> a.param(\"conversationId\", chatId)) 就是 告诉 Spring AI:当前这条对话属于哪个会话(chatId)
相当于你告诉 Spring AI:“这次对话属于 chatId=xxx 的上下文,请你去读它之前的消息,也记得把这次对话记录进去。”
只要你设置了 .advisors(a -> a.param(\"conversationId\", chatId)),Spring AI 就会:
-
自动读取之前属于这个 chatId 的 UserMessage + AssistantMessage
-
自动把当前用户输入和模型生成的 AssistantMessage 保存到这个 chatId 下的上下文中
-
下一次再问,就能“记得住之前说了什么”
用户发送请求 => /chat?prompt=你好&chatId=user1231️⃣ 保存会话 chatId 到 ChatHistoryRepository chatHistoryRepository.save(\"chat\", \"user123\")2️⃣ 构造 prompt 请求 + 设置 advisors ChatClient.prompt().user(\"你好\").advisors(...)3️⃣ MessageChatMemoryAdvisor 做了两件事: - doBefore:从 chatMemory 取出 user123 的历史消息,注入 prompt - doAfter:将生成的新回复追加到 user123 的上下文记录中4️⃣ ChatClient.stream().content() 启动流式大模型响应5️⃣ 返回 Flux 流结果给前端,逐字展示
历史会话和记录查询接口
import static java.lang.Integer.MAX_VALUE;@RequestMapping(\"/ai/history\")@RequiredArgsConstructor@RestControllerpublic class ChatHistoryController { private final ChatHistoryRepository chatHistoryRepository; private final ChatMemory chatMemory; // 查询到该业务类型下的所有的会话ID @GetMapping(\"/{type}\") public List getChatIds(@PathVariable String type) { return chatHistoryRepository.getChatIds(type); } // 根据会话ID 查询到对应的信息 @GetMapping(\"/{type}/{chatId}\") public List getChatHistory(@PathVariable String type, @PathVariable String chatId) { List messages = chatMemory.get(chatId, MAX_VALUE); if (messages == null){ return List.of(); } return messages.stream().map(MessageVO::new).toList(); }}
getChatIds(String type)ChatHistoryRepositorygetChatHistory(String type, String chatId)ChatMemory(记忆上下文)
MessageVO返回前端
为什么需要返回role?
因为前段需要根据role区分是谁回答的进行不同的渲染
@NoArgsConstructor@Datapublic class MessageVO { private String role; private String content; public MessageVO(Message message) { switch (message.getMessageType()) { case USER: this.role = \"user\"; break; case ASSISTANT: this.role = \"assistant\"; break; default: role=\",\"; break; } this.content = message.getText(); }}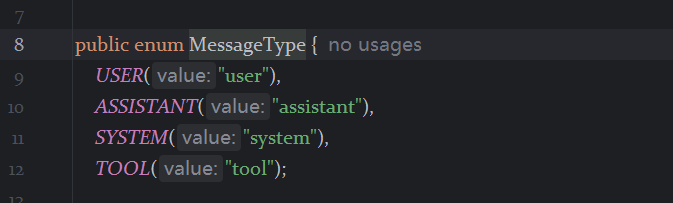
MessageType有四种,在当前场景下面我们只需要获取到其中两种即可。
实现多轮对话记忆管理的核心是: 使用
conversationId作为对话唯一标识 + 自动记忆上下文(ChatMemory + Advisor)+ 分类记录(ChatHistoryRepository)。

