RK3588部署yolov11结合OpenCV进行实时推理(保姆级!建议收藏!)_rk3588 yolo
目录
前言
一、搭建环境
1、PT文件转换ONNX工具
2、ONNX转换RKNN环境配置工具
3、ONNX转换RKNN工具
4、安装 PyTorch 库、matplotlib库、tqdm、onnx库
二、PT转换ONNX步骤
编辑
三、ONNX转换RKNN步骤
1、环境配置
2、模型转换
四、模型端侧部署
1、安装lib库
2、编写运行rknn模型的代码
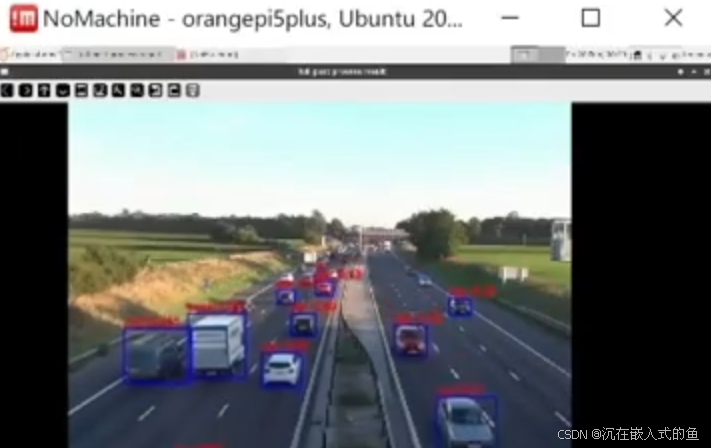
3、运行效果
前言
这篇文章主要讲述在RK3588上怎么部署yolov11模型且结合OpenCv进行实时推理
一、搭建环境
1、PT文件转换ONNX工具
github链接:https://github.com/airockchip/ultralytics_yolo11 --克隆main分支
2、ONNX转换RKNN环境配置工具
github链接:https://gitcode.com/gh_mirrors/rk/rknn-toolkit2/tree/v2.3.0?utm_source=csdn_github_accelerator&isLogin=1 --克隆V2.3.0标签
3、ONNX转换RKNN工具
github链接:https://gitcode.com/gh_mirrors/rk/rknn_model_zoo/tree/v2.3.0?utm_source=csdn_github_accelerator&isLogin=1 --克隆V2.3.0标签
4、安装 PyTorch 库、matplotlib库、tqdm、onnx库
pip install torch torchvision torchaudiopip install matplotlibpip install tqdmpip install onnx二、PT转换ONNX步骤
先将训练好的yolov11PT文件放入PT文件转换ONNX工具的目录中
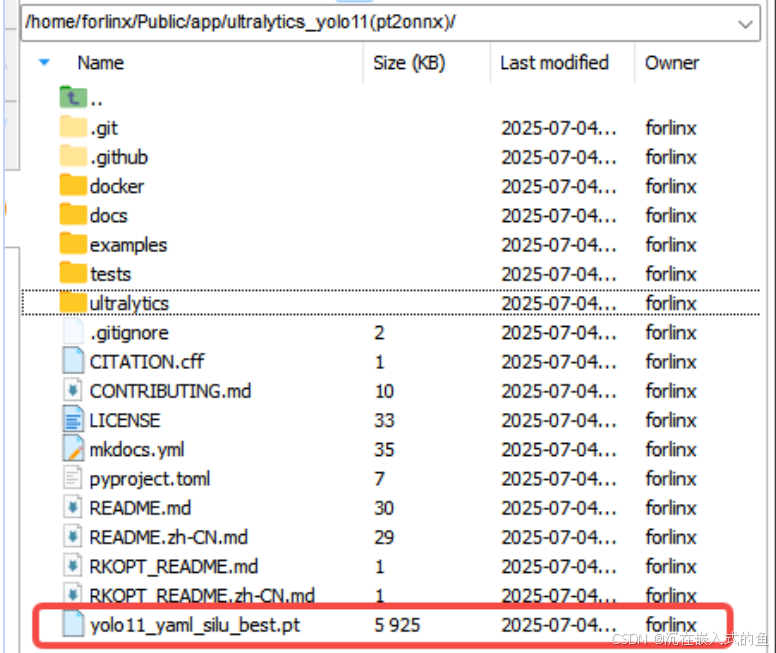
上传了pt文件后修改./ultralytics/cfg/default.yaml中的model文件路径,以下是我的路径和pt文件名,将其修改成你们对应的绝对路径和文件名字就好
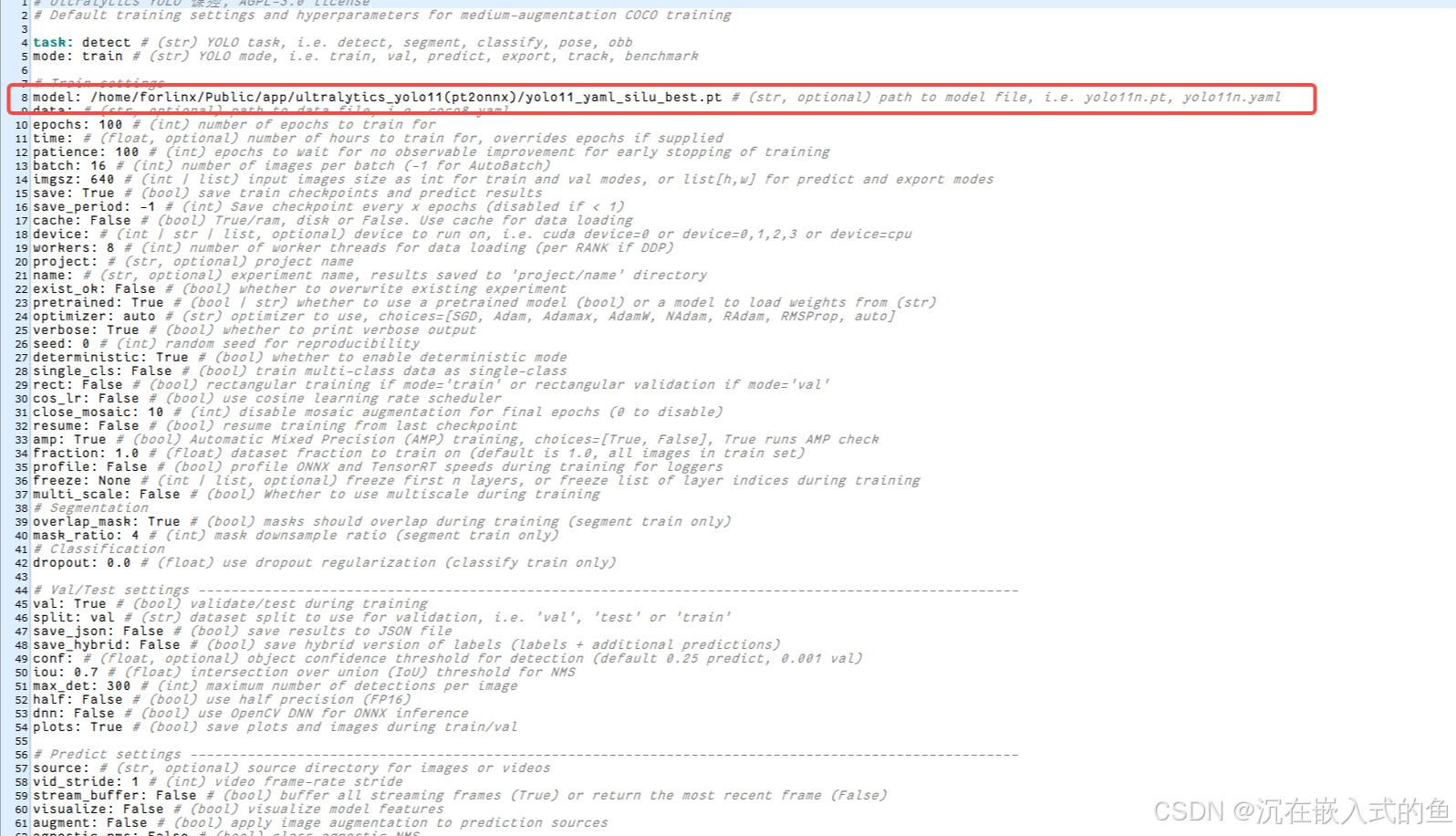
修改完default.yaml后,在终端输入:
export PYTHONPATH=./python ./ultralytics/engine/exporter.py运行完后显示这样的界面就是转换ONNX文件成功了

最后该模型down下来后复制到虚拟机中。
三、ONNX转换RKNN步骤
1、环境配置
先在虚拟机安装miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh安装完后手动激活,这里换成你们安装miniconda3的路径即可
source ~/miniconda3/bin/activate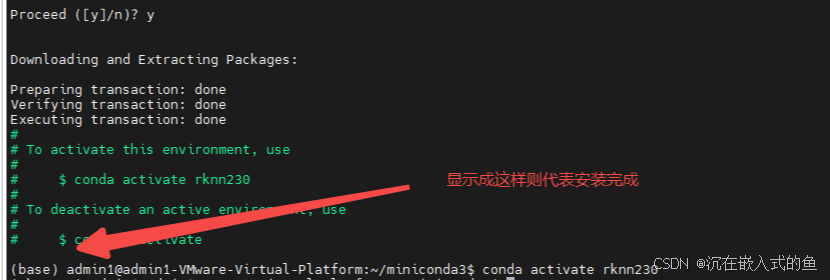
然后在终端运行以下命令创建环境
conda create -n rknn230 python=3.8再在终端敲以下命令激活环境
conda activate rknn230![]()
进入rknn-toolkit2/rknn-toolkit2/packages/x86_64目录,找到这两个文件

找到后终端输入
pip install -r requirements_cp38-2.3.2.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepip install rknn_toolkit2-2.3.2-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
到这里,rknn的环境配置就完成了
2、模型转换
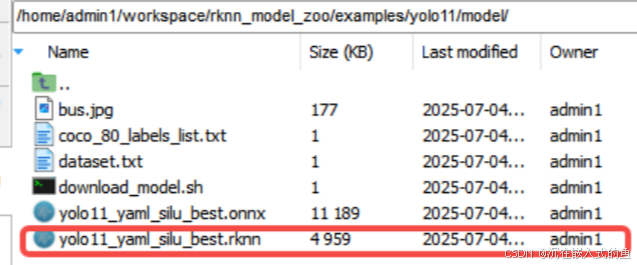
把转换好的onnx文件放在rknn_model_zoo/examples/yolo11/model目录下
进入rknn_model_zoo/examples/yolo11/python目录,修改coNvert.py和yolov11.py两个文件
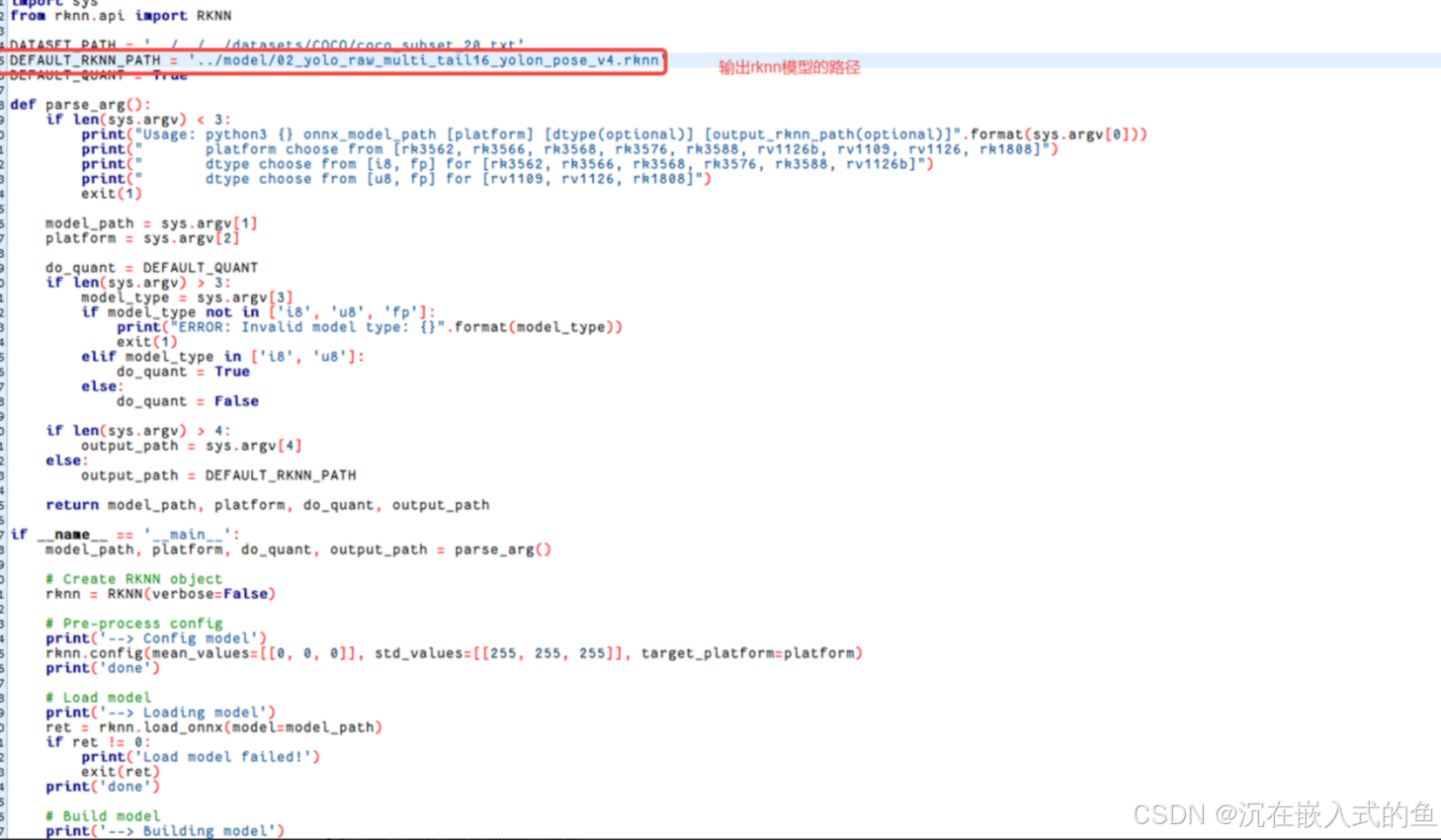
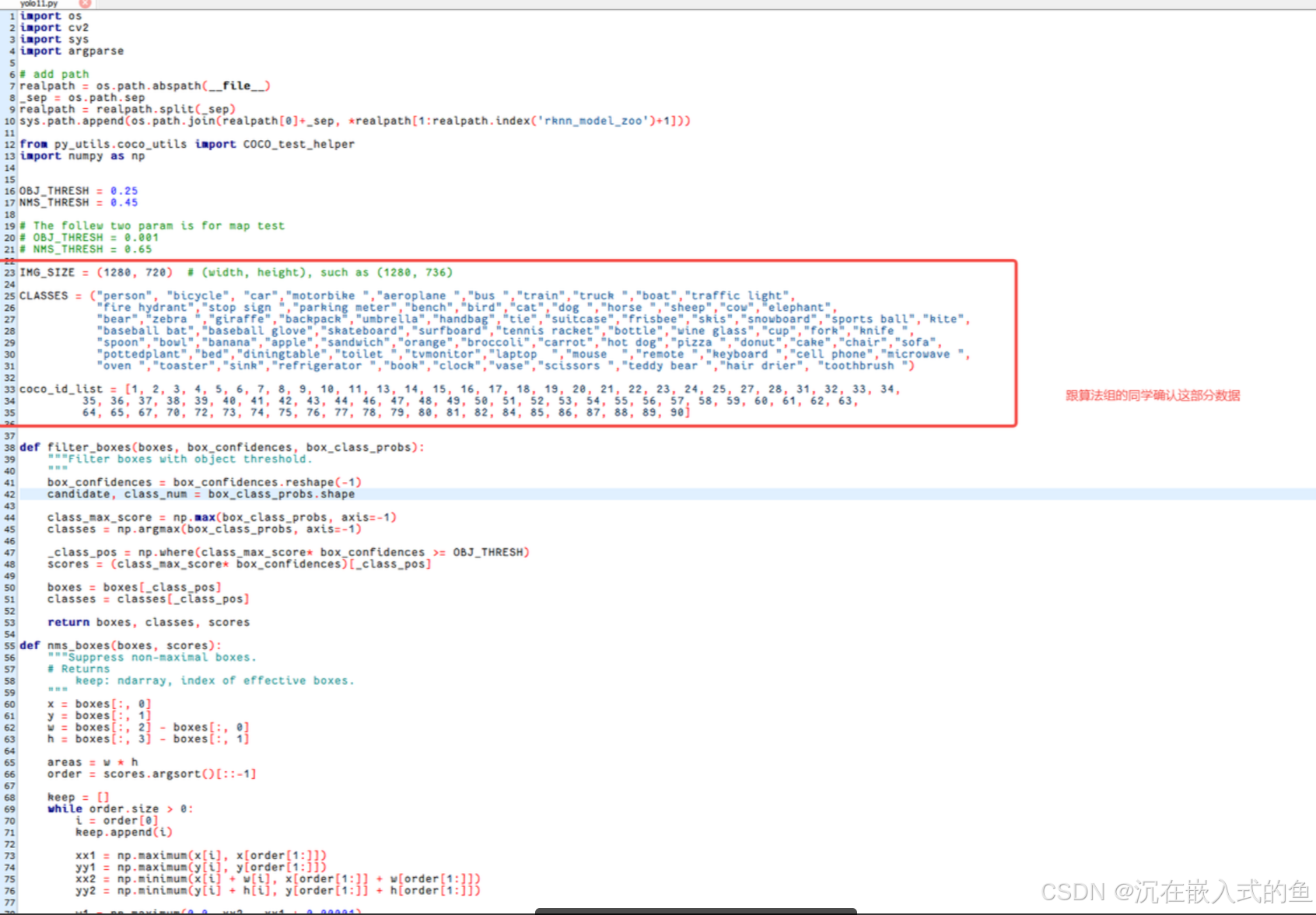
修改完成后,在终端输入以下命令,就可以转换出rknn文件了
python convert.py ../model/yolo11_yaml_silu_best.onnx rk3588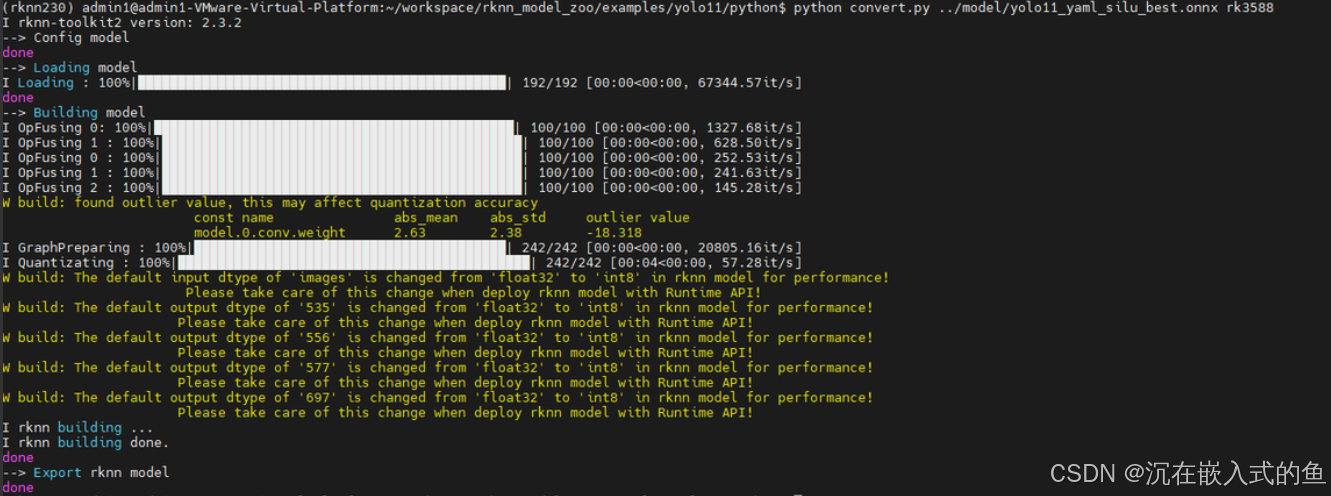
四、模型端侧部署
1、安装lib库
板载的librknnrt太低,而加载的模型版本很新,会导致无法适配。
到下载的rknn-toolkit2工程目录:
/home/forlinx/rknn-toolkit2-master/rknpu2/runtime/Linux/librknn_api/aarch64/到这个目录下找到最新的librknnrt.so文件后,复制到自己的目录下

2、编写运行rknn模型的代码
import cv2import numpy as npfrom rknnlite.api import RKNNLitemodel_path = ./rknnModel/yolo11_yaml_silu_best.rknnclass MicePoseDetector: def __init__(self, model_path): self.rknn = RKNNLite() # 加载RKNN模型 ret = self.rknn.load_rknn(model_path) assert ret == 0, \"Load RKNN model failed\" # 初始化运行时(使用NPU核心0和1) ret = self.rknn.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1) assert ret == 0, \"Init runtime failed\" # 配置参数 self.input_size = 640 self.anchors = { 8: [[10,13], [16,30], [33,23]], 16: [[30,61], [62,45], [59,119]], 32: [[116,90], [156,198], [373,326]] } def preprocess(self, img): \"\"\"高性能预处理\"\"\" img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = cv2.resize(img, (self.input_size, self.input_size)) return np.expand_dims(img, 0).astype(np.uint8) # 量化模型需uint8输入 def decode_pose(self, output): \"\"\"解码姿态关键点(示例:17个关键点)\"\"\" # output形状: [1, 51, 8400] (x,y,score)*17 keypoints = output.reshape(17, 3, -1).transpose(2, 0, 1) return keypoints[:, :, :2] # 仅返回x,y坐标 def detect(self, img): \"\"\"执行推理\"\"\" # 预处理 img_data = self.preprocess(img) # 推理(异步模式提升性能) outputs = self.rknn.inference( inputs=[img_data], data_format=\'nhwc\' ) # 后处理 boxes = outputs[0].reshape(-1, 6) # [x1,y1,x2,y2,conf,cls] keypoints = self.decode_pose(outputs[3]) return boxes, keypoints def release(self): self.rknn.release()if __name__ == \'__main__\': detector = MicePoseDetector(\"yolov11_mice_pose.rknn\") cap = cv2.VideoCapture(0) # 或cv2.CAP_GSTREAMER for MIPI while True: ret, frame = cap.read() if not ret: break # 推理(约15-25ms) boxes, keypoints = detector.detect(frame) # 可视化 for box in boxes: x1, y1, x2, y2 = map(int, box[:4]) cv2.rectangle(frame, (x1,y1), (x2,y2), (0,255,0), 2) for kps in keypoints: for x, y in kps: cv2.circle(frame, (int(x), int(y)), 3, (0,0,255), -1) cv2.imshow(\"Mice Pose\", frame) if cv2.waitKey(1) & 0xFF == ord(\'q\'): break detector.release() cap.release()3、运行效果