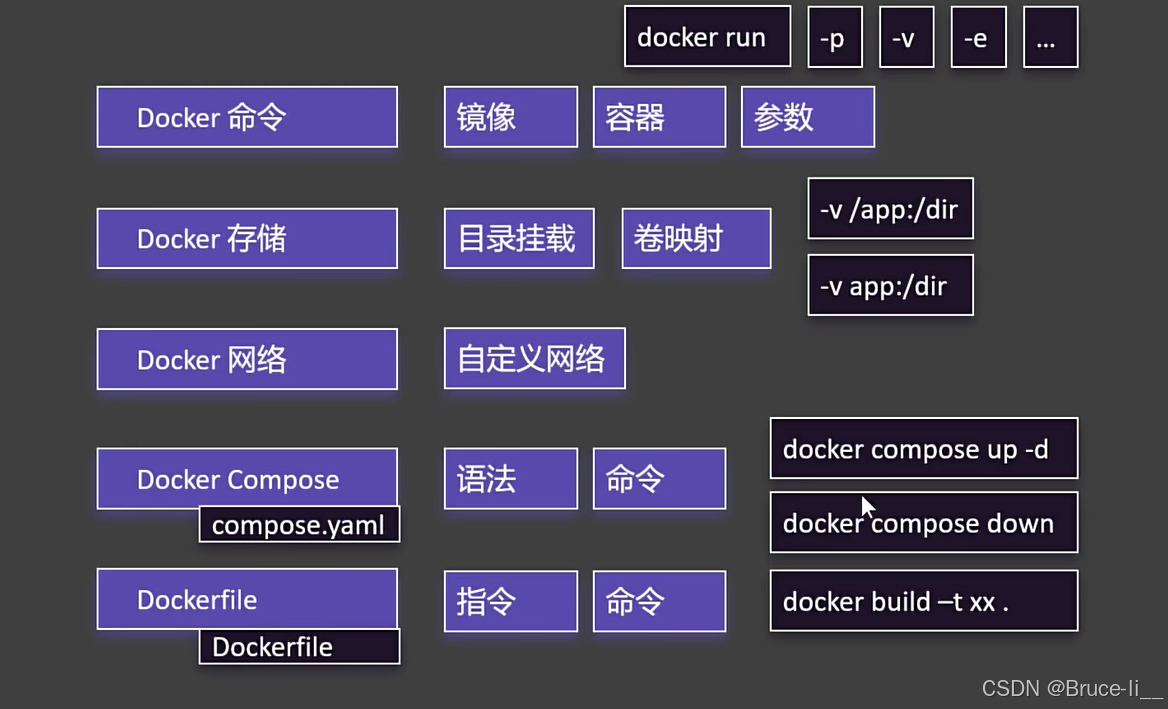
2025保姆级Docker教程------一篇学会使用docker
文章目录
- 一.为啥使用docker
-
- 1.1 环境一致性,解决\"在我机器上能跑\"问题
- 1.2快速部署,秒级启动
- 1.3 资源隔离与高效利用
- 1.4微服务架构的理想载体
- 1.5持续集成/交付(CI/CD)核心组件
- 1.6 跨平台兼容性
- 1.7 标准化运维管理
- 1.8 快速回滚与版本控制
- 1.9 丰富的生态系统
- 1.10 安全隔离
- 二.Docker架构
- 三.安装
-
- 3.1Liunx安装Docker
- 3.2常用命令
- 四.Demo
- 五.存储
-
- 5.1目录挂载
- 5.2卷映射
- 5.3目录挂载vs卷映射区别
-
- 5.3.1技术细节差异
- 5.3.2使用场景建议
- 5.3.3高级功能对比
- 5.3.4实际示例对比
- 六.网络
-
- 6.1自定义网络
-
- 6.1.1docker0
- 6.1.2自定义网络
- 6.1.3常用自定义网络命令
- 6.1.4自定义网络的实际应用场景
- 6.1.5自定义网络的高级特性
- 6.1.6最佳实践建议
- 6.2Redis主从集群
-
- 6.2.1redis集群
- 七.docker运行mysql8
- 八.Docker Compose
-
- 8.1命令式安装wordpress
- 8.2Docker Compose语法
- 8.3Docker Compose常用命令
-
- 8.3.1启动与停止
- 8.3.2 查看状态
- 8.3.3 管理服务
- 8.3.4 构建与更新
- 8.3.5 环境与变量
- 8.3.6 项目与扩展
- 九.Dockerfile
-
- 9.1 核心职责不同
- 9.2 为什么不能只用 Docker Compose?
- 9.3为什么不能只用 Dockerfile?
- 9.4 实际工作流中的分工
- 9.5何时可以只用 Docker Compose?
- 9.6制作镜像
- 9.7镜像分层机制
-
- 9.7.1 镜像分层的原理
- 9.7.2 分层如何工作?
- 9.7.3 分层机制的优势
- 9.7.4分层机制的注意事项
- 9.7.5实际操作示例
- 9.7.6总结
- 十.一键启动所有中间件
- 十一.进阶k8s
一.为啥使用docker
1.1 环境一致性,解决\"在我机器上能跑\"问题
问题:开发、测试、生产环境差异导致的各种报错Docker方案:将应用+依赖打包成镜像,确保全环境一致1.2快速部署,秒级启动
传统方式:装OS→配环境→部署应用(小时级)Docker方式:直接运行镜像(秒级)1.3 资源隔离与高效利用
对比虚拟机:特性 虚拟机Docker启动速度分钟级秒级资源占用GB级MB级性能损耗15-20%<5%1.4微服务架构的理想载体
典型场景:
graph LR A[用户服务] --> B[订单服务] B --> C[支付服务] C --> D[数据库]实现方式:每个服务独立容器,通过网络通信
docker run -d --name user-service user:1.0docker run -d --name order-service order:1.01.5持续集成/交付(CI/CD)核心组件
自动化流程:
graph LR A[代码提交] --> B[自动构建镜像] B --> C[测试环境部署] C --> D[生产环境滚动更新]1.6 跨平台兼容性
支持场景: 本地开发(Mac/Windows/Linux) 云服务器(AWS/阿里云/腾讯云) 边缘设备(树莓派等ARM设备)1.7 标准化运维管理
常用操作:
# 批量查看容器状态docker ps -a# 统一日志收集docker logs -f myapp# 资源监控docker stats1.8 快速回滚与版本控制
镜像版本管理:
# 部署v1版本docker run -d myapp:v1# 发现问题回滚到v0.9docker stop myapp && docker run -d myapp:v0.91.9 丰富的生态系统
工具链: Docker Compose(多容器编排) Docker Swarm/K8s(集群管理) Harbor(私有镜像仓库)1.10 安全隔离
防护机制:
内核级命名空间隔离资源限制(CPU/内存)只读文件系统docker run --read-only --memory=512m myapp典型应用场景
什么时候不该用Docker
需要极高性能的场景(直接使用物理机)强依赖GUI的应用(如桌面软件)对安全隔离要求极高的金融核心系统二.Docker架构

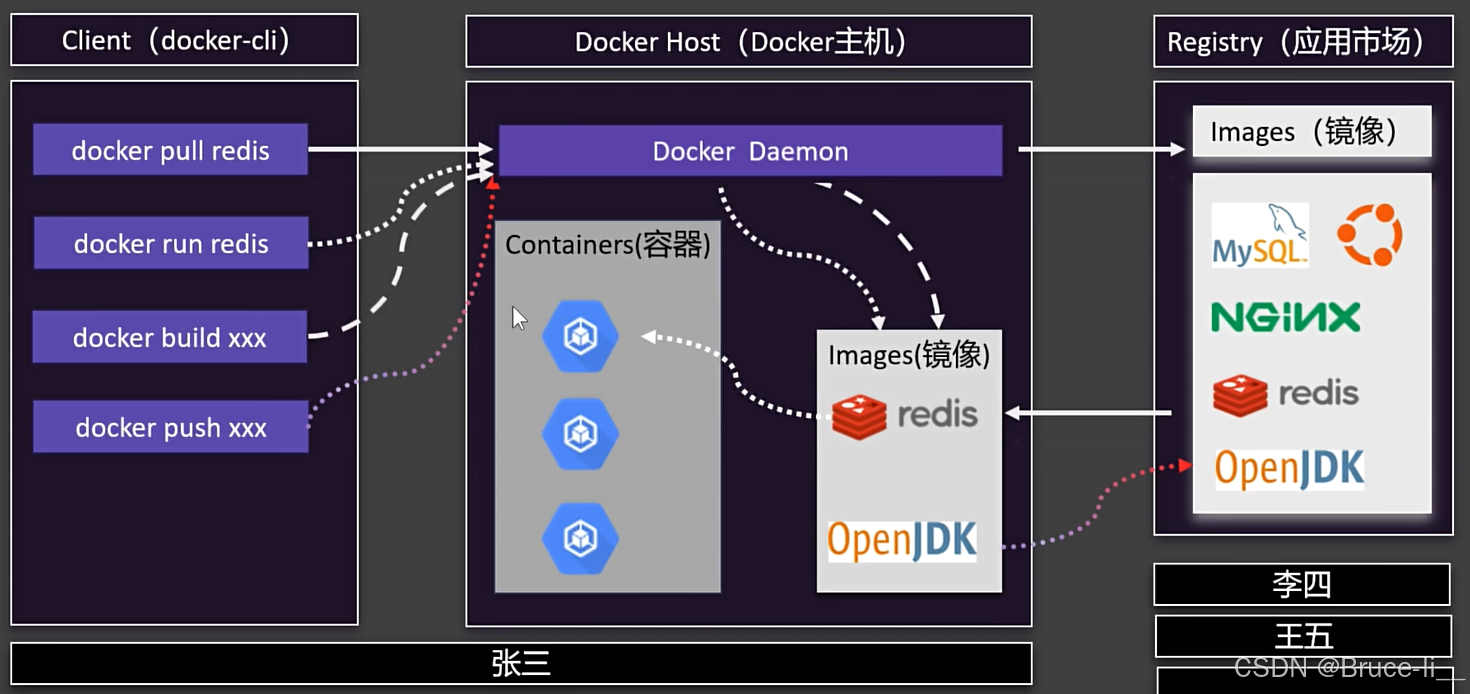 理解容器
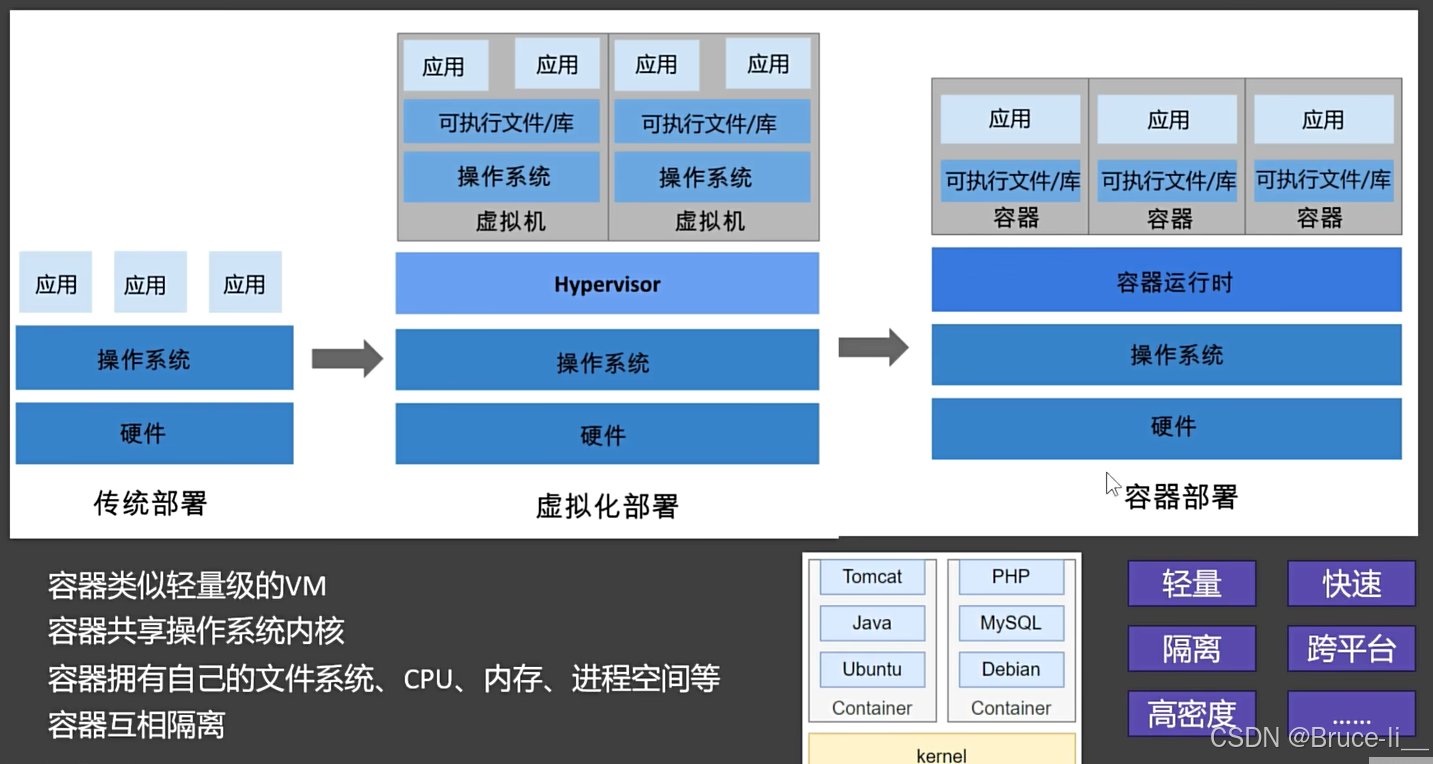
理解容器
三.安装
3.1Liunx安装Docker
# 移除旧版本dockersudo yum remove docker \\ docker-client \\ docker-client-latest \\ docker-common \\ docker-latest \\ docker-latest-logrotate \\ docker-logrotate \\ docker-engine# 配置docker yum源。sudo yum install -y yum-utilssudo yum-config-manager \\--add-repo \\http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 安装 最新 dockersudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin# 启动& 开机启动docker; enable + start 二合一systemctl enable docker --now# 配置加速sudo mkdir -p /etc/dockersudo tee /etc/docker/daemon.json <<-\'EOF\'{ \"registry-mirrors\": [ \"https://docker.1ms.run\" ]}EOFsudo systemctl daemon-reloadsudo systemctl restart docker3.2常用命令
#查看运行中的容器docker ps#查看所有容器docker ps -a#搜索镜像docker search nginx#下载镜像docker pull nginx#下载指定版本镜像docker pull nginx:1.26.0#查看所有镜像docker images#删除指定id的镜像docker rmi e784f4560448#运行一个新容器docker run nginx#停止容器docker stop keen_blackwell#启动容器docker start 592#重启容器docker restart 592#查看容器资源占用情况docker stats 592#查看容器日志docker logs 592#删除指定容器docker rm 592#强制删除指定容器docker rm -f 592# 后台启动容器docker run -d --name mynginx nginx# 后台启动并暴露端口docker run -d --name mynginx -p 80:80 nginx# 进入容器内部docker exec -it mynginx /bin/bash# 提交容器变化打成一个新的镜像docker commit -m \"update index.html\" mynginx mynginx:v1.0# 保存镜像为指定文件docker save -o mynginx.tar mynginx:v1.0# 删除多个镜像docker rmi bde7d154a67f 94543a6c1aef e784f4560448# 加载镜像docker load -i mynginx.tar # 登录 docker hubdocker login# 重新给镜像打标签docker tag mynginx:v1.0 leifengyang/mynginx:v1.0# 推送镜像docker push leifengyang/mynginx:v1.0四.Demo
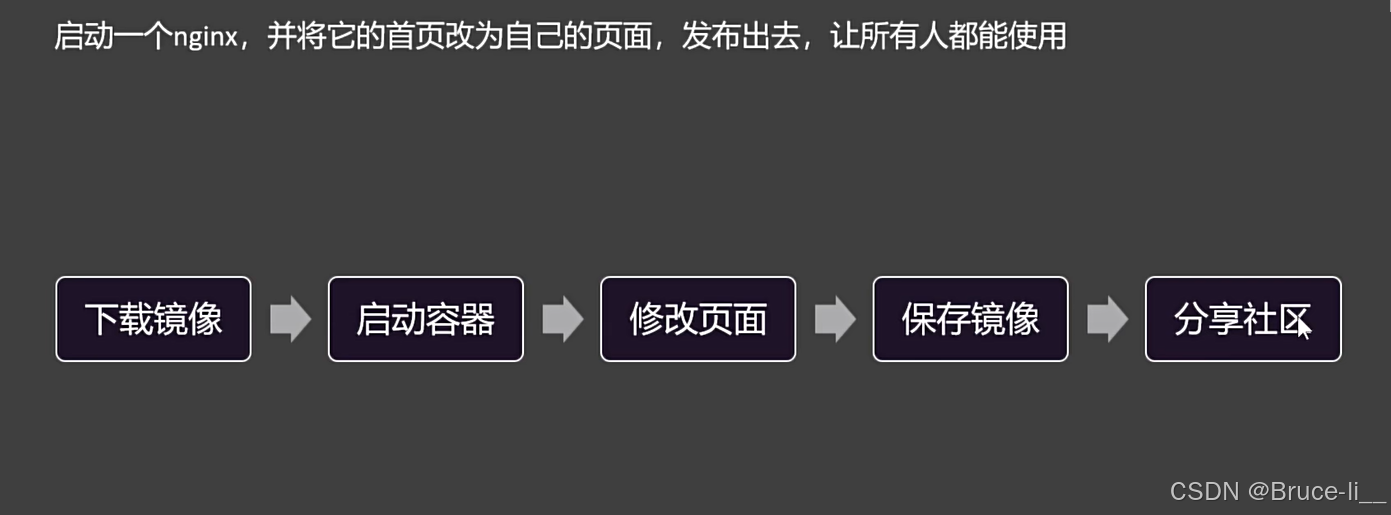
4.1下载镜像
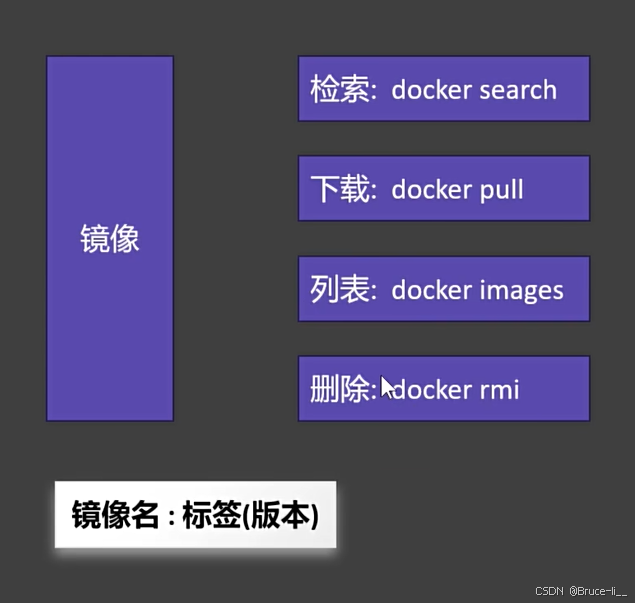
拉取最新版本
docker pull nginx拉取指定 版本
docker pull nginx:版本号查看所有镜像
docker images
4.2启动容器
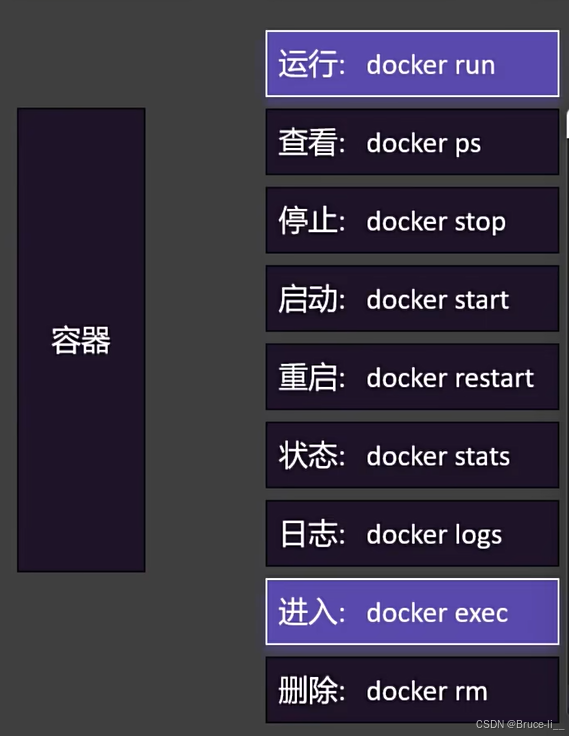
4.2.1 run的细节
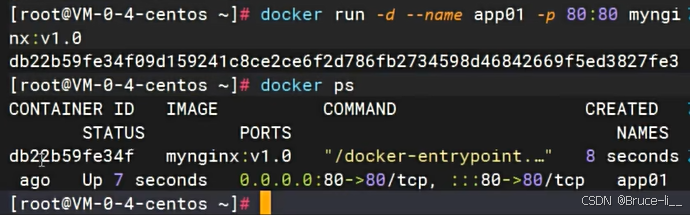
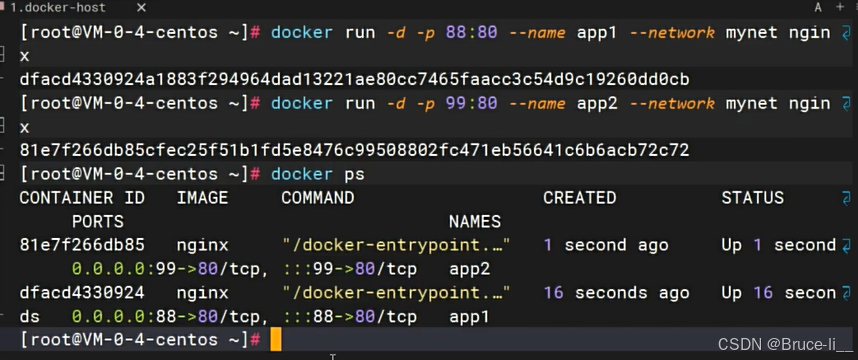
docker run -d --name mynginx -p 80:80 nginx#-d后台启动#--name 是自己取别名#-p端口映射-[HOST_PORT(宿主机(物理机或虚拟机)的端口)]:[CONTAINER_PORT(容器内部服务的端口)]

80能够重复,因为每个容器之间都是隔离的,互不影响,但外部访问容器的端口88是不能重复的
4.3修改页面
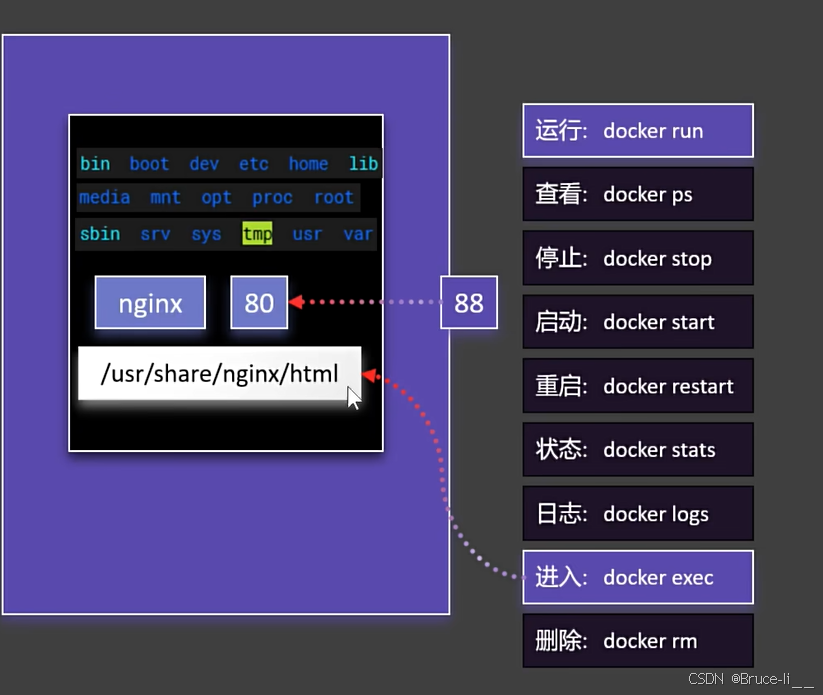
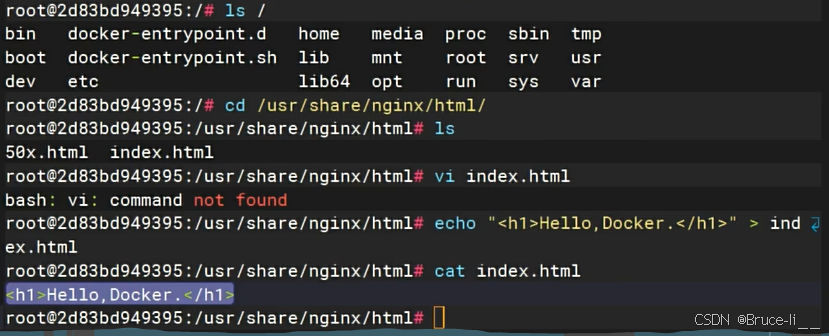
4.3.1进入容器内修改页面
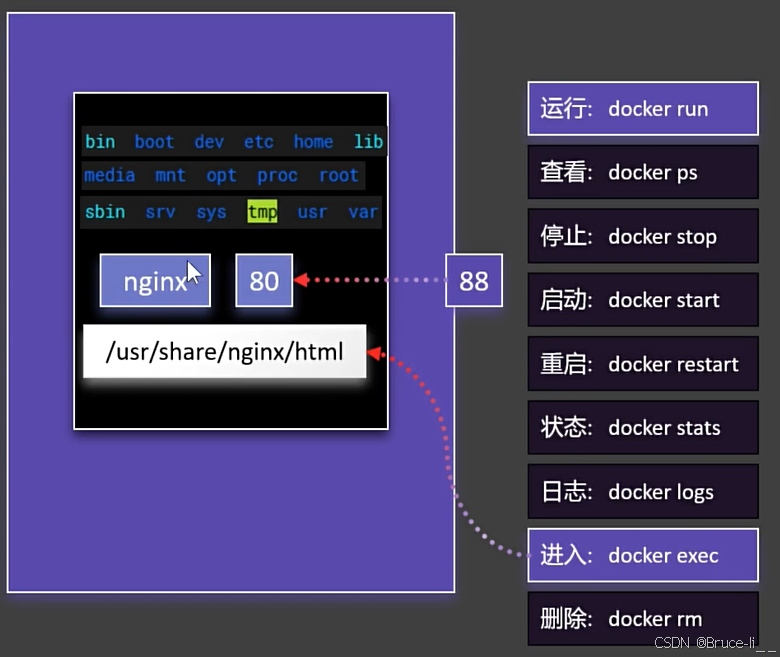
docker exec -it mynginx /bin/bash# -it:交互模式(进入终端)# mynginx 使用的镜像# /bin/bash:启动命令

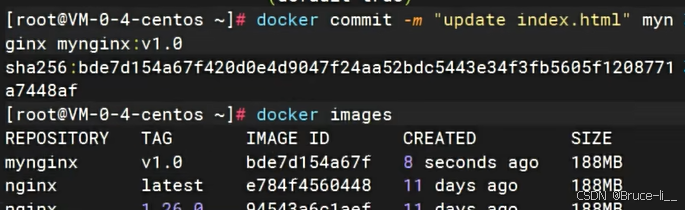
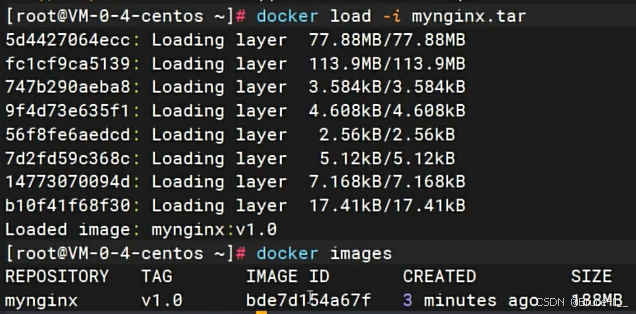
4.4保存镜像


4.5分享社区

4.5.1登录 Docker Hub
docker login4.5.2 给本地镜像打标签(假设镜像名为 my-python-app)
docker tag my-python-app your-username/python-app:v14.5.3推送镜像
docker push your-username/python-app:v1五.存储
5.1目录挂载
目录挂载(Volume Mounting)是指将宿主机上的目录或文件系统挂载到容器内部,使得容器可以访问宿主机的文件系统。
主要特点:
数据持久化:容器删除后数据不会丢失双向同步:宿主机和容器可以互相访问修改文件性能较好:比容器内文件系统性能更好
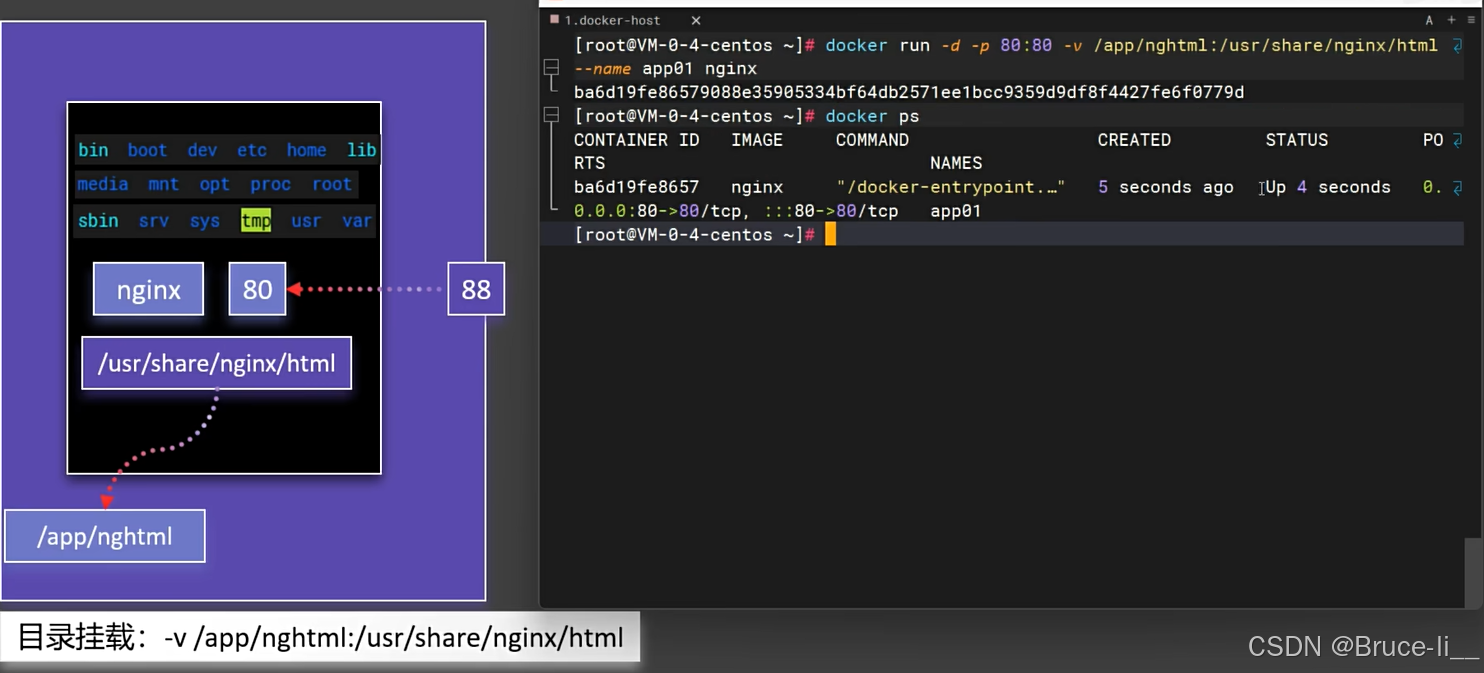
5.2卷映射
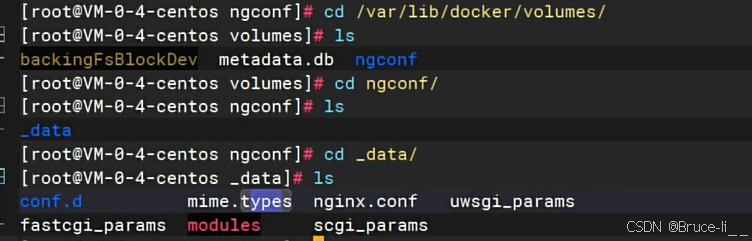
Docker 卷映射(Volume Mount)是将主机文件系统中的目录或文件映射到容器内部的一种机制,用于实现数据的持久化和主机与容器之间的数据共享
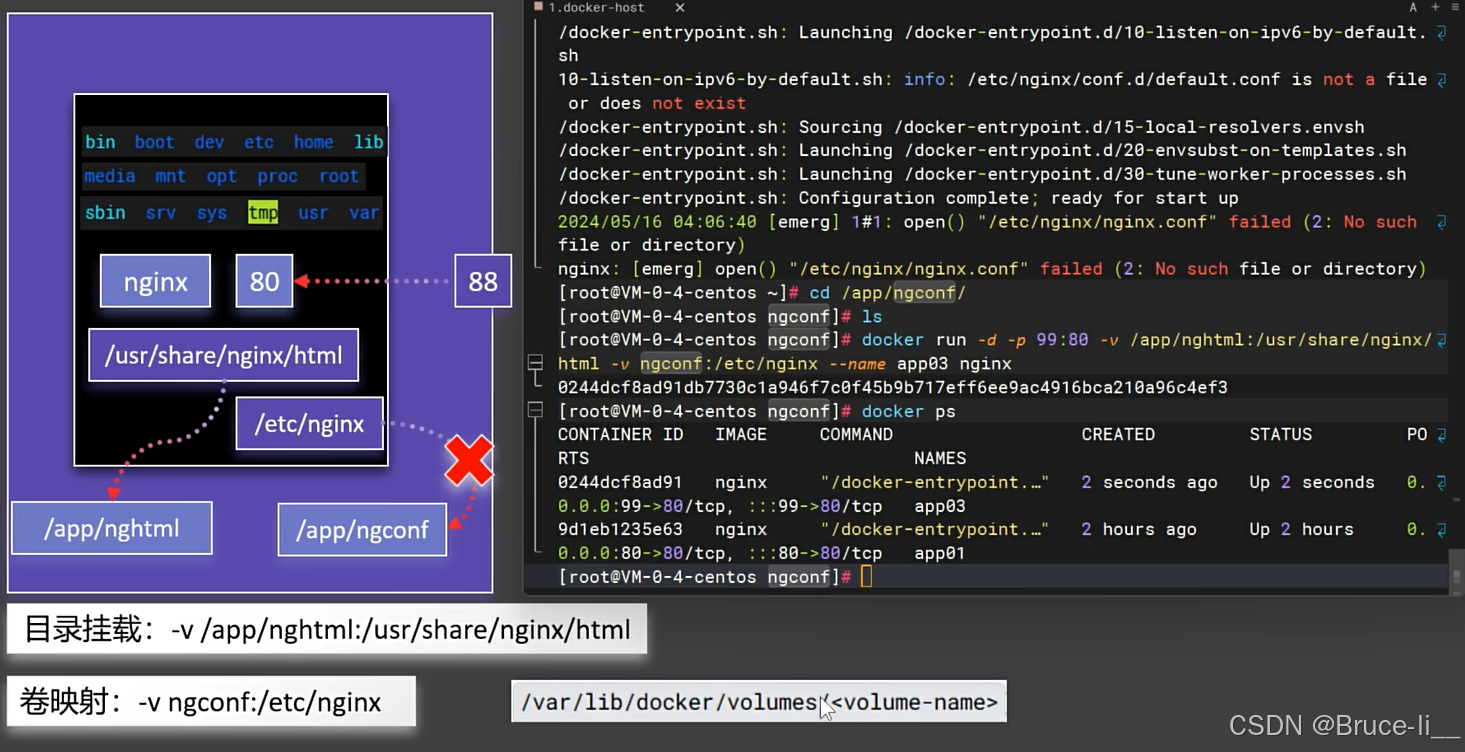

5.3目录挂载vs卷映射区别
5.3.1技术细节差异
1.管理方式
目录挂载:完全由用户控制,需要指定主机绝对路径
docker run -v /host/path:/container/path nginx卷映射:由 Docker 管理,只需指定卷名
docker run -v my_volume:/container/path nginx2.数据生命周期
目录挂载:数据与主机目录共存亡卷映射:数据独立于容器,docker volume prune 才会清除未使用卷3.初始化行为
目录挂载:会清空容器目标目录
# 会覆盖容器内的 /app 内容docker run -v /empty/host/dir:/app nginx卷映射:会将容器目录内容复制到卷
# 首次运行会将容器内 /var/lib/mysql 内容复制到卷docker run -v db_data:/var/lib/mysql mysql5.3.2使用场景建议
适合目录挂载的场景
1.开发环境:实时同步代码变更
docker run -v $(pwd)/src:/app/src node2.配置文件:挂载特定配置文件
docker run -v /host/nginx.conf:/etc/nginx/nginx.conf:ro nginx3.主机监控:访问主机系统信息
docker run -v /proc:/host/proc:ro monitoring-agent适合卷映射的场景
1.数据库存储:确保数据安全持久
docker run -v db_data:/var/lib/postgresql postgres2.生产应用:需要高性能持久化
docker run -v app_data:/data backend3.集群环境:配合网络存储驱动
docker volume create --driver nfs --opt device=nas:/share nfs_voldocker run -v nfs_vol:/data app5.3.3高级功能对比
1.权限控制
目录挂载:需手动处理 SELinux/AppArmor
docker run -v /host:/container:z # 共享SELinux标签卷映射:自动设置合理权限
2.扩展性
目录挂载:仅限于本地文件系统
卷映射:支持多种驱动(NFS, AWS EBS, 等)
docker volume create --driver cloudstor aws_volume3.备份方案
目录挂载:依赖传统备份工具
卷映射:内置备份命令
# 备份卷数据docker run --rm -v db_data:/data -v $(pwd):/backup alpine \\ tar cvf /backup/db_backup.tar /data5.3.4实际示例对比
目录挂载示例(开发环境)
# 挂载Node.js项目目录docker run -it -v $(pwd):/app -p 3000:3000 \\ -w /app node:16 npm run dev卷映射示例(生产数据库)
# 创建持久化卷docker volume create pg_data# 运行PostgreSQL容器docker run -d -v pg_data:/var/lib/postgresql/data \\ -e POSTGRES_PASSWORD=secret \\ -p 5432:5432 postgres:13决策建议
总结来说:开发用目录挂载方便,生产用卷映射可靠。理解这些区别可以帮助您根据具体需求选择最适合的数据持久化方案。
六.网络
6.1自定义网络
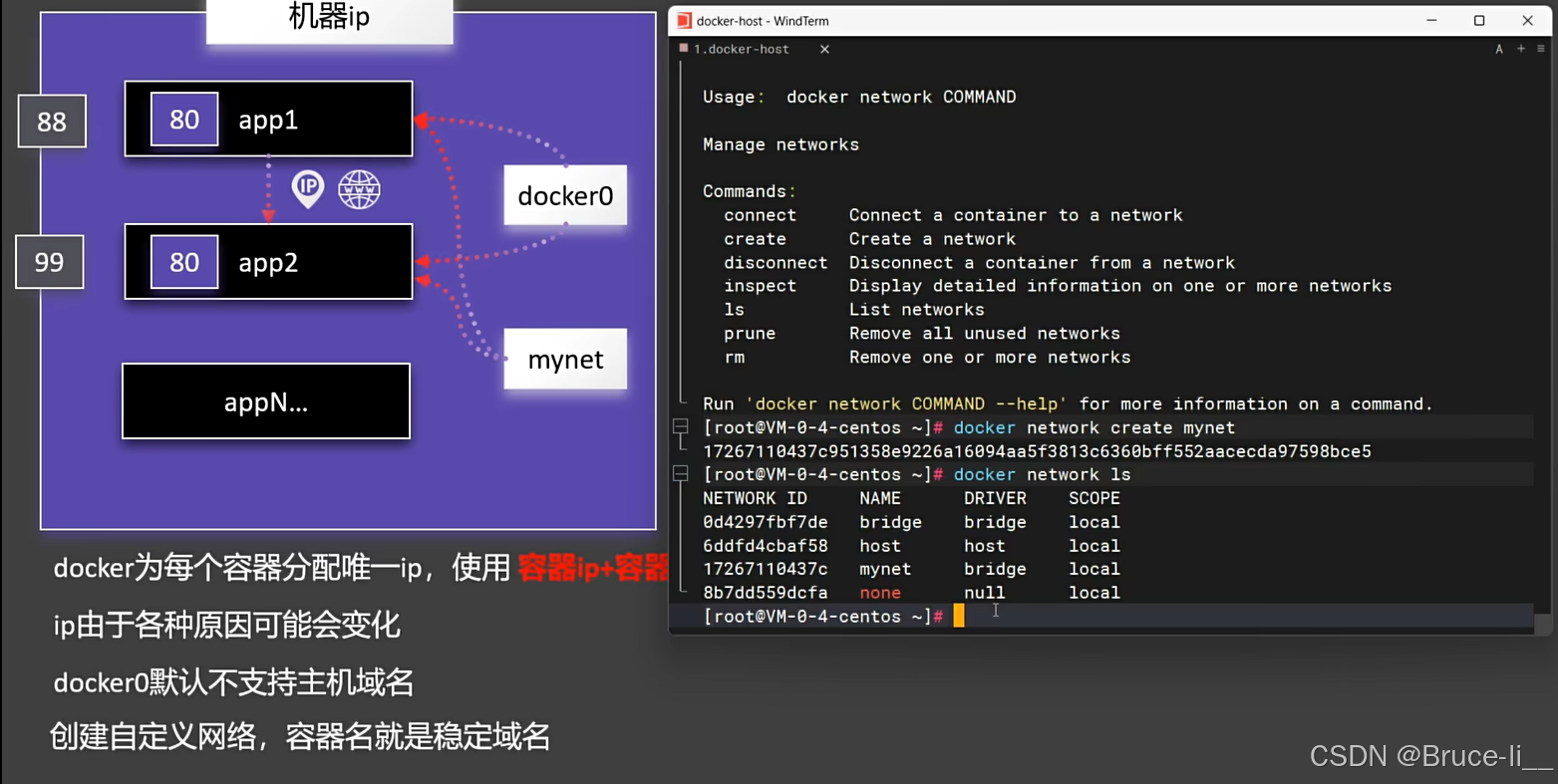
6.1.1docker0
docker0 是 Docker 在 Linux 主机上默认创建的虚拟网络接口,它是 Docker 默认桥接网络的核心组件
基本概念
性质:docker0 是一个虚拟的以太网桥接设备作用:作为 Docker 默认桥接网络(docker network bridge)的网关创建时机:Docker 守护进程(dockerd)启动时自动创建# 查看网络接口信息ifconfig docker0# 或ip addr show docker0# 查看桥接详细信息brctl show docker0与自定义网络的区别
实际应用中的注意事项
生产环境通常建议使用自定义网络而非默认的 docker0docker0 的性能通常不如用户自定义的桥接网络在需要高度网络隔离的场景,应考虑其他网络驱动(如 overlay, macvlan)6.1.2自定义网络
Docker 自定义网络是 Docker 网络系统的核心功能,它允许用户创建隔离的、可定制的网络环境,为容器提供更灵活、更安全的通信方式
- 容器隔离与安全
网络隔离:不同自定义网络中的容器默认不能互相通信
安全边界:限制容器间的暴露面,减少攻击风险 - 服务发现与DNS
自动DNS解析:容器可以通过名称相互发现(内置DNS服务)
别名支持:为容器设置网络别名实现灵活访问 - 连接控制
精细化的容器互联:精确控制哪些容器可以相互通信
多网络接入:单个容器可加入多个网络实现不同访问策略
与默认网络的对比

6.1.3常用自定义网络命令
1. 基本命令
# 创建自定义桥接网络docker network create my_network# 查看网络列表docker network ls# 运行容器并加入网络docker run -d --name web --network my_network nginx# 将已有容器连接到网络docker network connect my_network existing_container# 断开网络连接docker network disconnect my_network container_name2. 高级网络配置
# 创建带子网的自定义网络docker network create \\ --driver=bridge \\ --subnet=172.28.0.0/16 \\ --gateway=172.28.5.1 \\ my_custom_net# 指定IP地址运行容器docker run --network my_custom_net --ip 172.28.5.10 nginx6.1.4自定义网络的实际应用场景
1. 多服务应用架构
# 创建后端网络docker network create backend# 运行数据库服务docker run -d --name db --network backend postgres# 运行应用服务docker run -d --name app --network backend \\ -e DB_HOST=db my_app_image2. 微服务隔离
# 为每个微服务创建独立网络docker network create inventory_netdocker network create order_net# 各自服务连接到对应网络docker run -d --name inventory --network inventory_net inventory_svcdocker run -d --name orders --network order_net order_svc# API网关连接到所有网络docker network connect inventory_net api_gatewaydocker network connect order_net api_gateway3. 开发测试环境隔离
# 为每个开发人员创建独立网络docker network create dev_alicedocker network create dev_bob# 各自在独立网络中工作互不干扰6.1.5自定义网络的高级特性
1. 网络驱动选择
# 使用overlay驱动(集群模式)docker network create -d overlay my_overlay_net# 使用macvlan驱动(直接分配MAC地址)docker network create -d macvlan \\ --subnet=192.168.1.0/24 \\ --gateway=192.168.1.1 \\ -o parent=eth0 \\ my_macvlan2. 网络别名(Alias)
# 为容器设置网络别名docker run --name web --network my_net --network-alias www nginx# 其他容器可通过别名访问docker run --rm --network my_net curlimages/curl http://www3. 网络连接检查
# 检查网络详情docker network inspect my_network# 测试容器间连通性docker exec -it container1 ping container26.1.6最佳实践建议
1.生产环境:总是使用自定义网络而非默认桥接2.微服务架构:按功能划分不同网络3.敏感服务:将数据库等关键服务放在独立网络4.临时测试:使用 --network none 完全禁用网络5.网络清理:定期清理未使用的网络 docker network prune6.跨主机通信:在集群环境中使用 overlay 驱动自定义网络是 Docker 网络能力的核心体现,合理使用可以构建出既安全又灵活的容器网络架构,特别适合复杂的多容器应用场景
6.2Redis主从集群
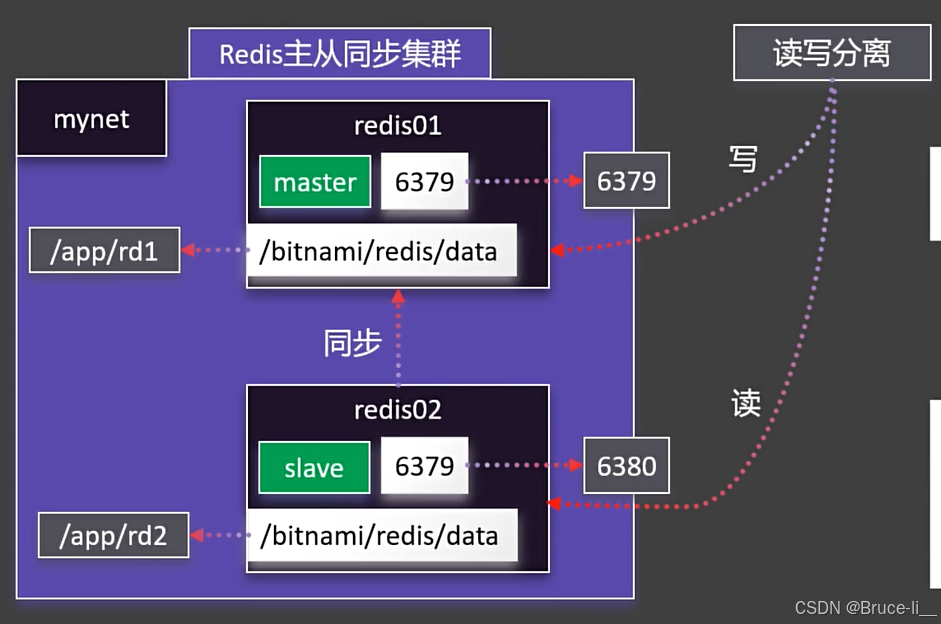

使用Bitnami Redis镜像
Bitnami提供了大量经过优化的生产级应用容器镜像,包括Redis、MySQL、PostgreSQL、MongoDB等流行服务。下面详细介绍Bitnami镜像的特点和使用方法
Bitnami提供的Redis Docker镜像是经过优化的生产级Redis镜像,下面介绍如何使用Bitnami/Redis镜像搭建Redis集群
主节点
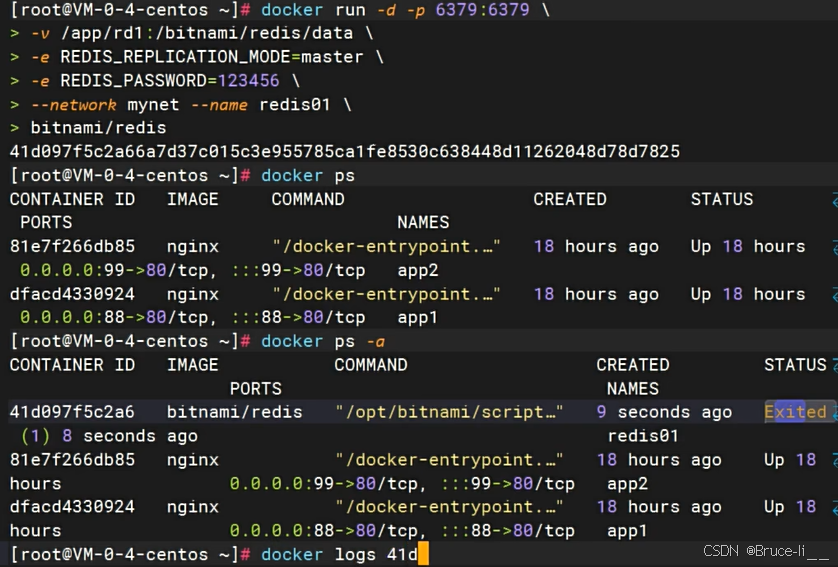
docker run -d -p 6379:6379 \\-v /app/rd1:/bitnami/redis/data \\-e REDIS_REPLICATION_MODE=master \\-e REDIS_PASSWORD=123456 \\--network mynet --name redis01 \\bitnami/redis查看redis01运行日志
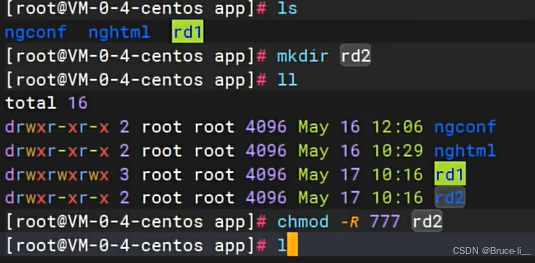
docker logs [CONTAINER ID]文件夹没有权限,提高读写权限
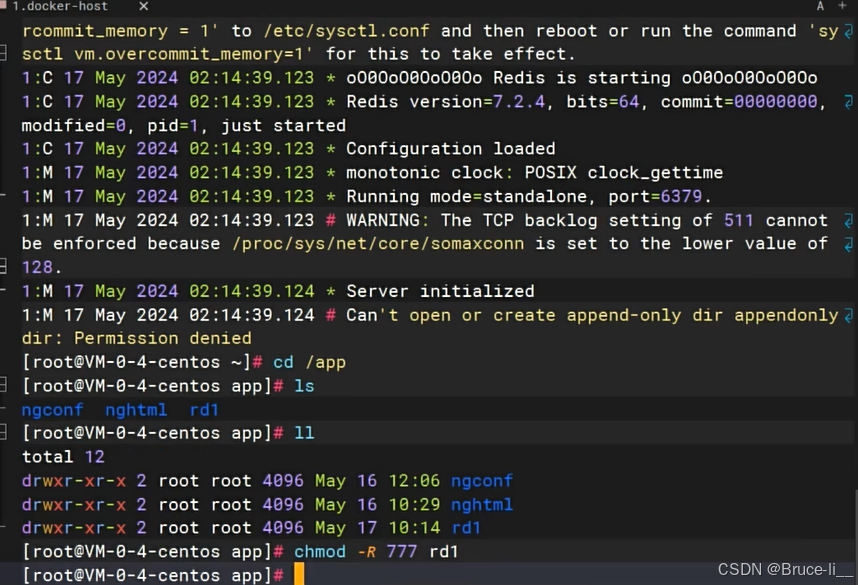 重启容器
重启容器

先提升权限,再创建容器
从节点
docker run -d -p 6380:6379 \\-v /app/rd2:/bitnami/redis/data \\-e REDIS_REPLICATION_MODE=slave \\-e REDIS_MASTER_HOST=redis01 \\-e REDIS_MASTER_PORT_NUMBER=6379 \\-e REDIS_MASTER_PASSWORD=123456 \\-e REDIS_PASSWORD=123456 \\--network mynet --name redis02 \\bitnami/redis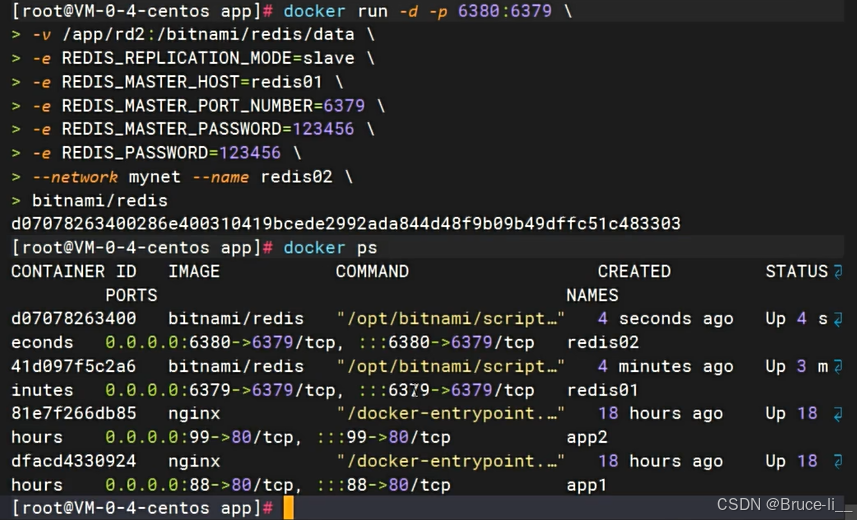
6.2.1redis集群
Redis 集群(Redis Cluster) 是 Redis 官方提供的分布式解决方案,用于解决单机 Redis 的性能和存储瓶颈,提供 高可用、高性能、可扩展 的分布式数据存储能力
1.Redis 集群的核心作用
✅ 数据分片(Sharding)
将数据分散存储在多个节点(默认 16384 个哈希槽),突破单机内存限制。例如:单机 Redis 只能存 32GB,而集群可以扩展到多个节点(如 100GB+)。✅ 高可用(High Availability)
采用 主从复制(Master-Slave) 架构,主节点宕机时,从节点自动接管(故障转移)。避免单点故障,提高系统稳定性。✅ 高性能(High Performance)
数据分布在多个节点,读写请求可以并行处理,提高吞吐量。适用于高并发场景(如电商秒杀、社交热点数据)。✅ 自动故障转移(Failover)
集群通过 Gossip 协议 和 Raft 选举 机制自动检测节点状态,无需人工干预2. 适用场景
🟢 适合使用 Redis 集群的场景
🔹 大规模缓存(如电商商品缓存、社交平台热点数据)
🔹 高并发读写(如秒杀、抢购、实时排行榜)
🔹 大数据存储(单机 Redis 内存不足时)
🔹 需要高可用(如金融交易、游戏服务器状态存储)
🔴 不适合 Redis 集群的场景
❌ 事务(Transaction)要求严格(Redis 集群仅支持同一节点上的事务)
❌ 强一致性需求(Redis 集群是 最终一致性,主从同步有延迟)
❌ 单 Key 超大 Value(如 1GB 的 Key,会影响数据迁移和负载均衡)
❌ 跨 Slot 的复杂操作(如 MGET 多个 Key 不在同一节点时会报错
3. Redis 集群 vs. 哨兵(Sentinel) vs. 单机 Redis
4.典型 Redis 集群架构示例
Node1 (Master) —— Node1-Slave | Slot 0-5000 Node2 (Master) —— Node2-Slave | Slot 5001-10000 Node3 (Master) —— Node3-Slave | Slot 10001-16383 客户端访问任意节点,如果 Key 不在当前节点,Redis 会返回 MOVED 重定向。
推荐使用 Smart Client(如 Jedis Cluster、Lettuce)自动处理重定向
总结
Redis 集群适用于大数据量、高并发、高可用的场景(如电商、社交、游戏)。不适用于强事务、超大 Key、跨 Slot 复杂查询的场景。如果只是需要 高可用 但数据量不大,可以用 Redis 哨兵(Sentinel)。如果你的业务需要 分布式存储 + 高可用 + 高性能,Redis 集群是一个很好的选择!
七.docker运行mysql8
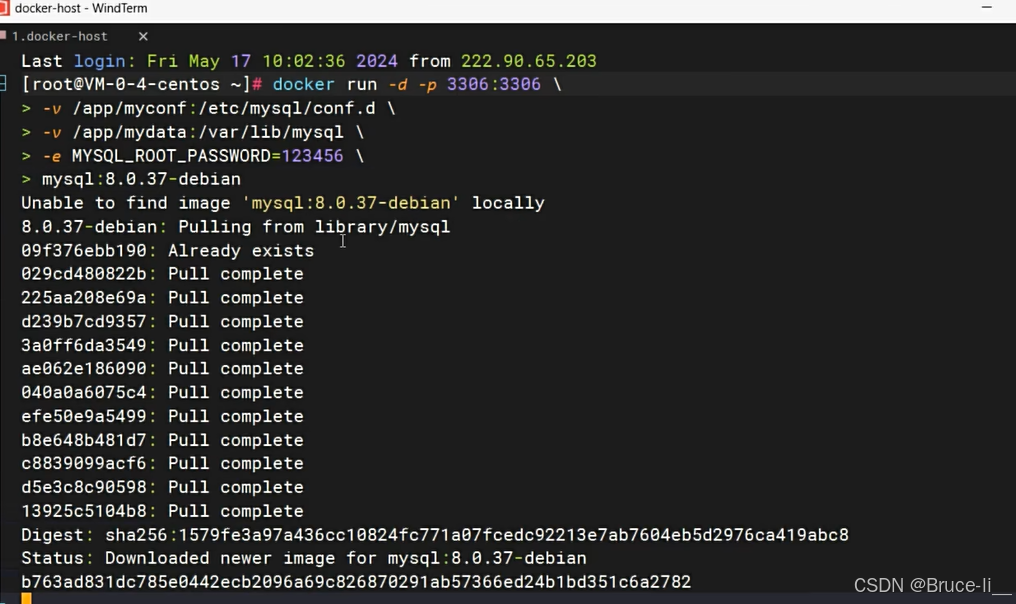
docker run -d -p 3306:3306 \\-v /app/myconf:/etc/mysql/conf.d \\-v /app/mydata:/var/lib/mysql \\-e MYSQL_ROOT_PASSWORD=123456 \\mysql:8.0.37-debian八.Docker Compose
Docker Compose 是一个用于定义和运行多容器 Docker 应用程序的工具,它通过一个简单的 YAML 文件(docker-compose.yml)来配置和管理多个容器,使得复杂应用的部署和管理变得更加方便
Docker Compose 的主要用途
1.简化多容器管理 传统方式运行多个容器需要手动执行多个 docker run 命令,而 Compose 允许你用一个 docker-compose up 启动所有服务。 适合微服务架构(如 Web + 数据库 + Redis + 消息队列等)。2.统一管理容器依赖关系 可以定义服务之间的依赖关系(如 Web 服务依赖数据库),Compose 会自动按顺序启动容器。3.方便配置环境变量、网络、存储卷 可以在 YAML 文件中定义: 网络(容器间通信) 存储卷(持久化数据) 环境变量(不同环境的配置)4.一键部署和销毁 docker-compose up 启动所有服务 docker-compose down 停止并清理所有容器、网络、存储卷典型使用场景
本地开发环境:快速启动 Web + 数据库 + Redis 等依赖服务。CI/CD 测试:在自动化测试中一键部署测试环境。微服务部署:管理多个相互依赖的服务。Docker Compose vs 纯 Docker
8.1命令式安装wordpress
#创建网络docker network create blog#启动mysqldocker run -d -p 3306:3306 \\-e MYSQL_ROOT_PASSWORD=123456 \\-e MYSQL_DATABASE=wordpress \\-v mysql-data:/var/lib/mysql \\-v /app/myconf:/etc/mysql/conf.d \\--restart always --name mysql \\--network blog \\mysql:8.0#启动wordpressdocker run -d -p 8080:80 \\-e WORDPRESS_DB_HOST=mysql \\-e WORDPRESS_DB_USER=root \\-e WORDPRESS_DB_PASSWORD=123456 \\-e WORDPRESS_DB_NAME=wordpress \\-v wordpress:/var/www/html \\--restart always --name wordpress-app \\--network blog \\wordpress:latest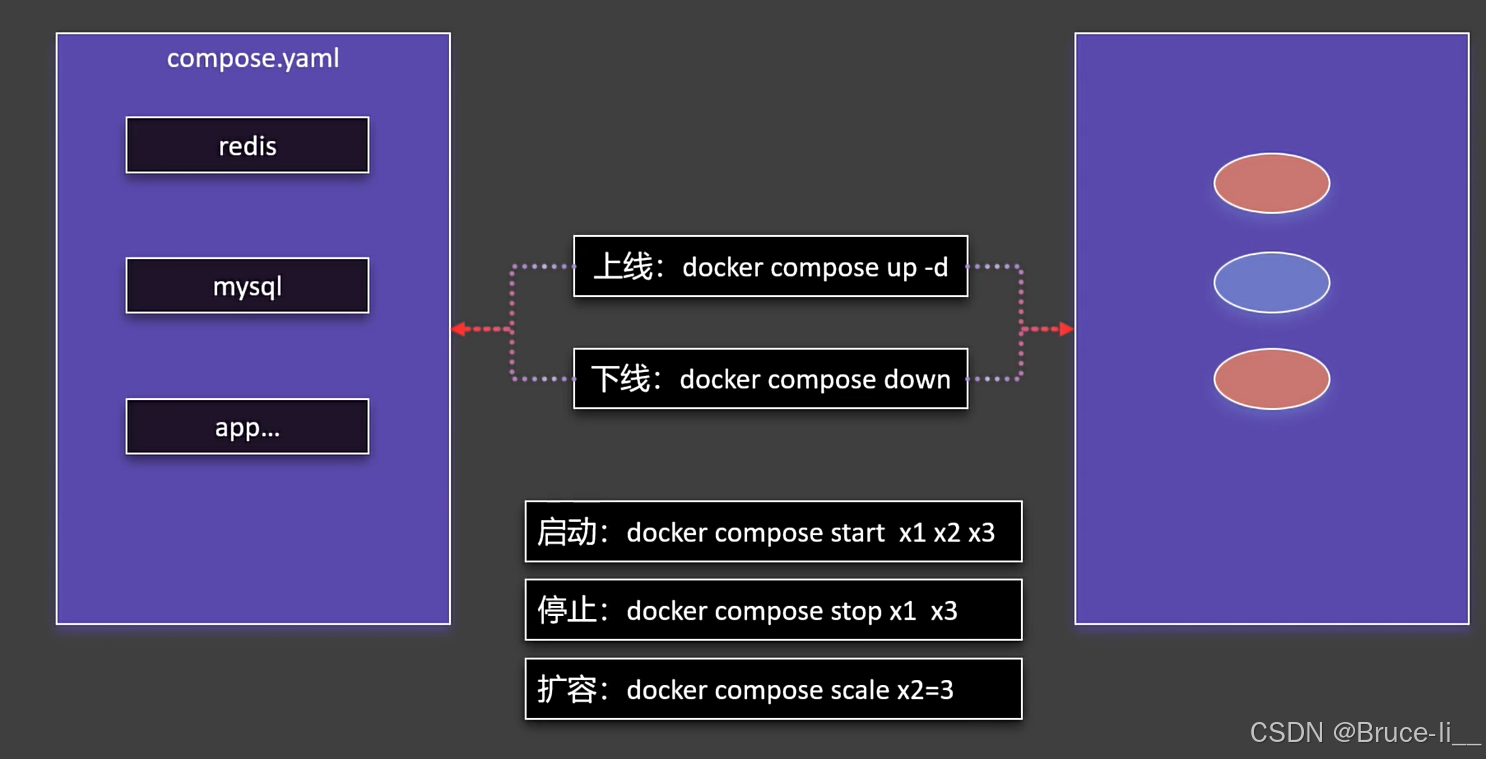
8.2Docker Compose语法

name: myblogservices: mysql: container_name: mysql image: mysql:8.0 ports: - \"3306:3306\" environment: - MYSQL_ROOT_PASSWORD=123456 - MYSQL_DATABASE=wordpress volumes: - mysql-data:/var/lib/mysql - /app/myconf:/etc/mysql/conf.d restart: always networks: - blog wordpress: image: wordpress ports: - \"8080:80\" environment: WORDPRESS_DB_HOST: mysql WORDPRESS_DB_USER: root WORDPRESS_DB_PASSWORD: 123456 WORDPRESS_DB_NAME: wordpress volumes: - wordpress:/var/www/html restart: always networks: - blog depends_on: - mysqlvolumes: mysql-data: wordpress:networks: blog:运行之前清空一下网络,数据卷,容器
8.3Docker Compose常用命令
8.3.1启动与停止
8.3.2 查看状态
8.3.3 管理服务
8.3.4 构建与更新
8.3.5 环境与变量
8.3.6 项目与扩展
九.Dockerfile
Dockerfile 是一个纯文本文件,包含一系列指令(Instructions),用于自动化构建 Docker 镜像。
它定义了镜像的组成内容,包括:
基础环境(如 Ubuntu、Python、Node.js)依赖安装(如 apt-get、pip、npm)文件复制(如代码、配置文件)运行时配置(如环境变量、启动命令)Dockerfile 关键指令详解
Dockerfile 和 Docker Compose 的区别
使用 Dockerfile 还是 Docker Compose 取决于你的具体需求,因为它们的职责不同,通常需要结合使用而非二选一。以下是关键区别和适用场景
9.1 核心职责不同
9.2 为什么不能只用 Docker Compose?
场景 1:你需要自定义镜像
问题:如果你的应用需要安装特定依赖(如 Python 包、系统库),或复制代码文件到镜像中,Compose 本身无法完成这些操作。解决方案:必须在 Dockerfile 中定义这些步骤,然后在 Compose 文件中引用该镜像。Dockerfile 负责构建一个包含 Python 和依赖的镜像:
FROM python:3.9COPY requirements.txt .RUN pip install -r requirements.txtCOPY . .CMD [\"python\", \"app.py\"]docker-compose.yml 负责运行该镜像并配置端口、卷等:
services: web: build: . # 使用当前目录的 Dockerfile 构建镜像 ports: - \"8000:8000\"场景 2:你需要可移植的基础镜像
如果直接使用 Compose 的 image: nginx,你只能运行官方 Nginx 镜像,无法自定义其配置或预装插件。此时仍需通过 Dockerfile 扩展镜像:
FROM nginx:latestCOPY my-nginx.conf /etc/nginx/conf.d/场景 3:镜像需要版本化
通过 Dockerfile 构建的镜像可以打标签(如 my-app:v1)并推送到仓库,供其他环境复用。Compose 仅负责运行现有镜像,不涉及构建逻辑。9.3为什么不能只用 Dockerfile?
场景 1:你需要协调多个容器
如果应用包含多个服务(如 Web + 数据库 + Redis),仅用 Dockerfile 需要手动启动每个容器并配置网络,而 Compose 可以一键管理所有服务:services: web: build: . ports: [\"8000:8000\"] db: image: postgres volumes: [\"db-data:/var/lib/postgresql/data\"]volumes: db-data:场景 2:需要快速定义运行时配置
Compose 可以便捷地声明环境变量、挂载卷、端口映射等,而这些在 Dockerfile 中需要通过 docker run 手动指定:
services: app: build: . environment: - DEBUG=1 volumes: - ./data:/app/data9.4 实际工作流中的分工
开发阶段: 用 Dockerfile 定义应用镜像。 用 docker-compose.yml 启动开发环境(可能包含热重载、调试工具)。生产部署: 用 Dockerfile 构建优化后的生产镜像。 用 Compose 或 Kubernetes 编排生产环境(可能替换为 docker stack deploy 或 Helm Chart)。9.5何时可以只用 Docker Compose?
如果以下条件全部满足,可以暂时不用 Dockerfile:
仅使用官方镜像(如 nginx、postgres),且无需自定义。所有配置通过环境变量或运行时挂载文件完成。无需构建自己的应用代码镜像。总结:
最终建议:
总是用 Dockerfile 定义镜像内容(除非完全使用官方镜像)。用 Docker Compose 管理多容器协作和运行时配置。两者是互补关系,而非替代关系9.6制作镜像
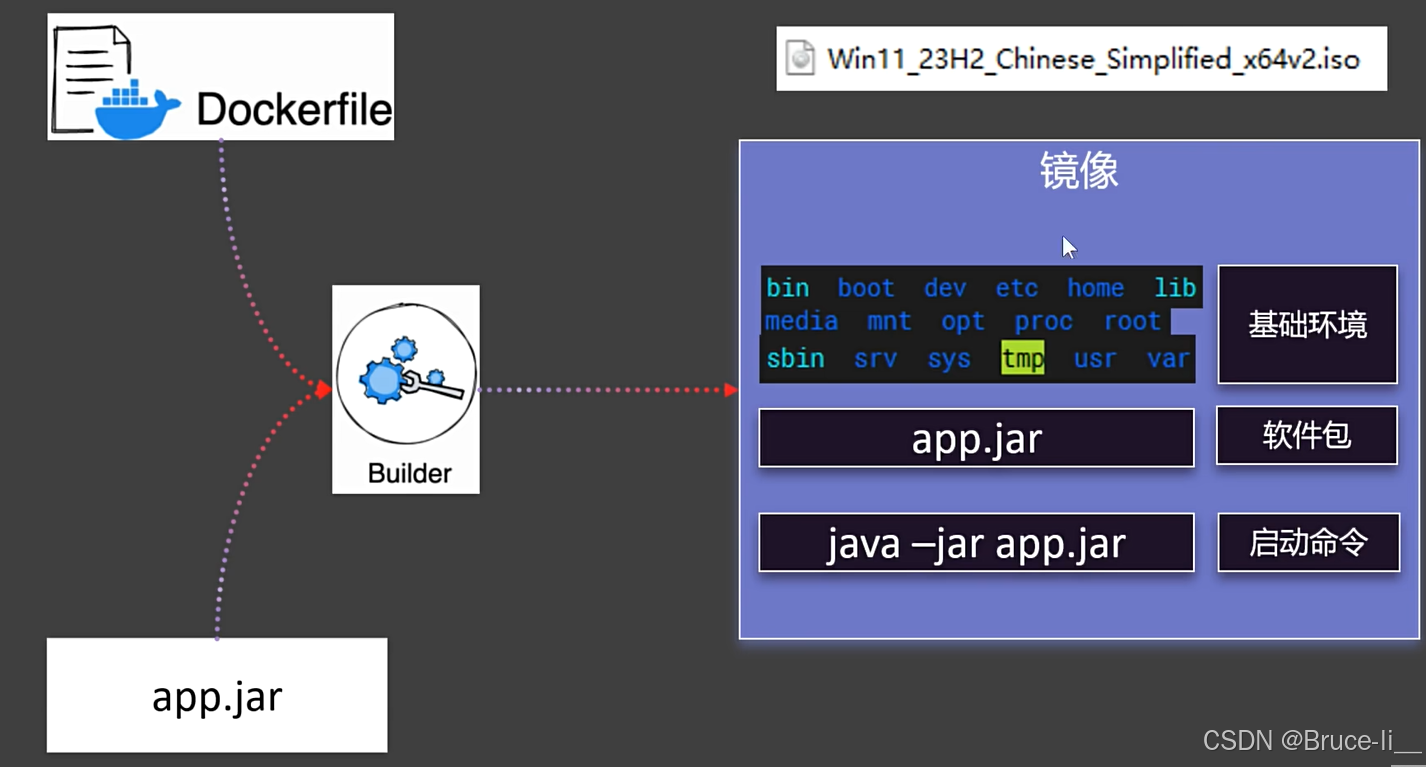
FROM openjdk:17LABEL author=testCOPY app.jar /app.jarEXPOSE 8080ENTRYPOINT [\"java\",\"-jar\",\"/app.jar\"]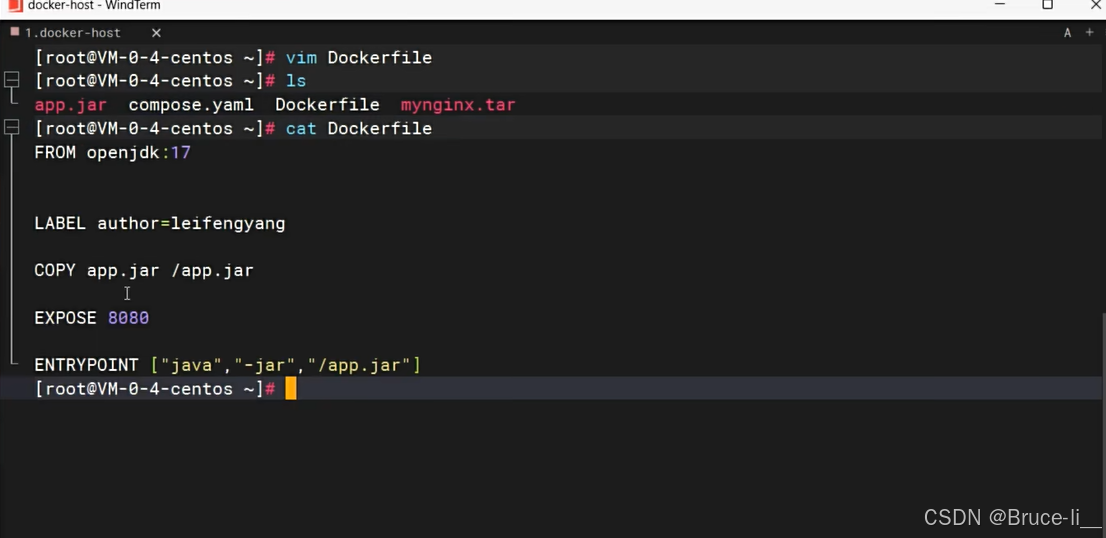


9.7镜像分层机制
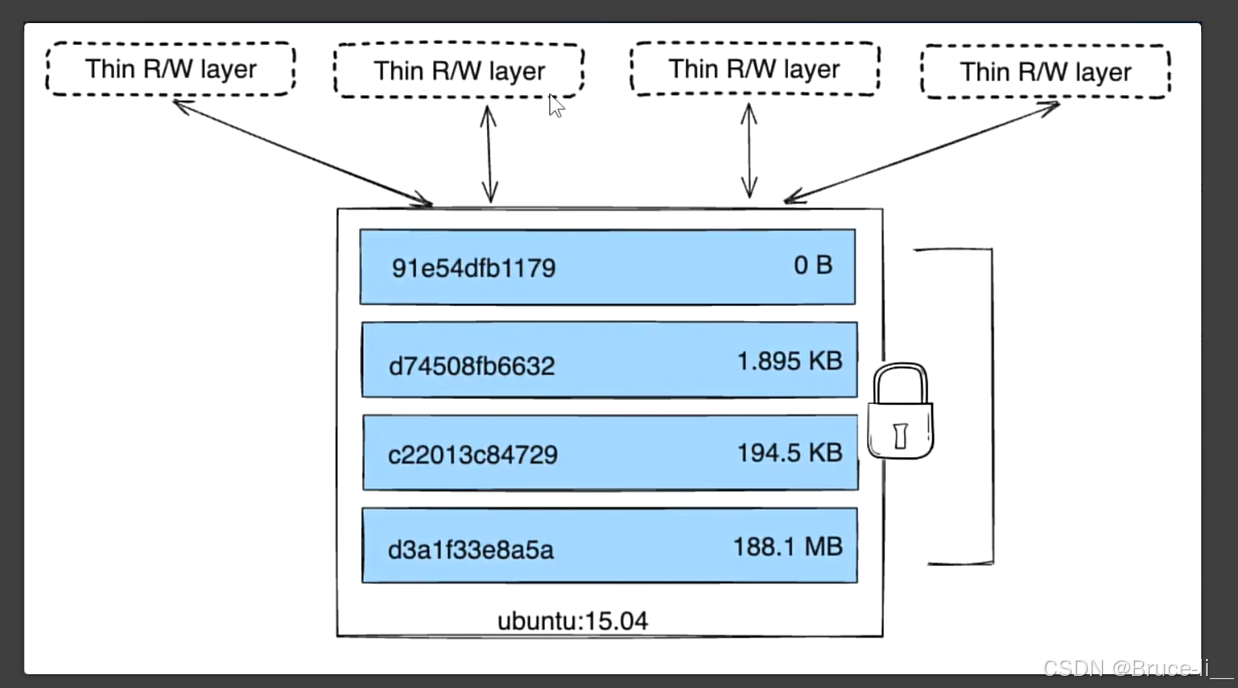
Docker 镜像的分层机制(Layer)是其核心设计之一,它通过**联合文件系统(UnionFS)**实现镜像的轻量化、高效构建和快速分发。以下是分层机制的详细解析
9.7.1 镜像分层的原理
(1)什么是分层?
每个 Docker 镜像由多个**只读层(Read-only Layers)**叠加组成,每一层代表镜像构建过程中的一个操作(如安装软件、复制文件等)。当容器启动时,Docker 会在所有只读层之上添加一个可写层(容器层),供容器运行时修改文件。(2)联合文件系统(UnionFS)
作用:将多个分层透明地合并为一个统一的文件系统视图。常见实现:overlay2(现代 Docker 默认)、aufs、devicemapper 等。示例:假设镜像有 3 层,联合文件系统会按顺序叠加它们,最终呈现为一个完整的文件系统:Layer 3 (添加文件C) → Layer 2 (修改文件B) → Layer 1 (基础镜像含文件A/B)用户看到的是合并后的结果:文件A(来自Layer1)、文件B(来自Layer2)、文件C(来自Layer3)。9.7.2 分层如何工作?
(1)镜像构建时的分层
每个 Dockerfile 指令生成一个新层:
FROM ubuntu:22.04 # 层1:基础镜像RUN apt update && apt install -y curl # 层2:安装curlCOPY app.py /app/ # 层3:复制文件CMD [\"python\", \"/app/app.py\"] # 层4:启动命令构建后镜像包含 4 个只读层(+1个可写容器层)。
分层复用(缓存机制):
如果重新构建镜像且 Dockerfile 未更改,Docker 会直接使用缓存中的现有层,大幅加速构建。
(2)容器运行时的分层
容器 = 镜像层 + 可写层:所有容器共享镜像的只读层,修改文件时通过**写时复制(Copy-on-Write, CoW)**机制: 读操作:直接访问镜像层文件。 写操作:将文件从镜像层复制到可写层,修改保存在可写层。9.7.3 分层机制的优势
原理
多个镜像共享相同的基础层:
例如,10个基于 ubuntu:22.04 的镜像,在本地存储或传输时只需保存/下载一次 ubuntu:22.04 的层。联合文件系统(UnionFS):所有镜像通过指针引用同一基础层,物理存储仅一份。示例
镜像A:ubuntu:22.04(层1) + RUN apt install curl(层2)镜像B:ubuntu:22.04(层1) + COPY app.py(层3)实际存储:层1(共享) + 层2 + 层3,而非两份完整的镜像。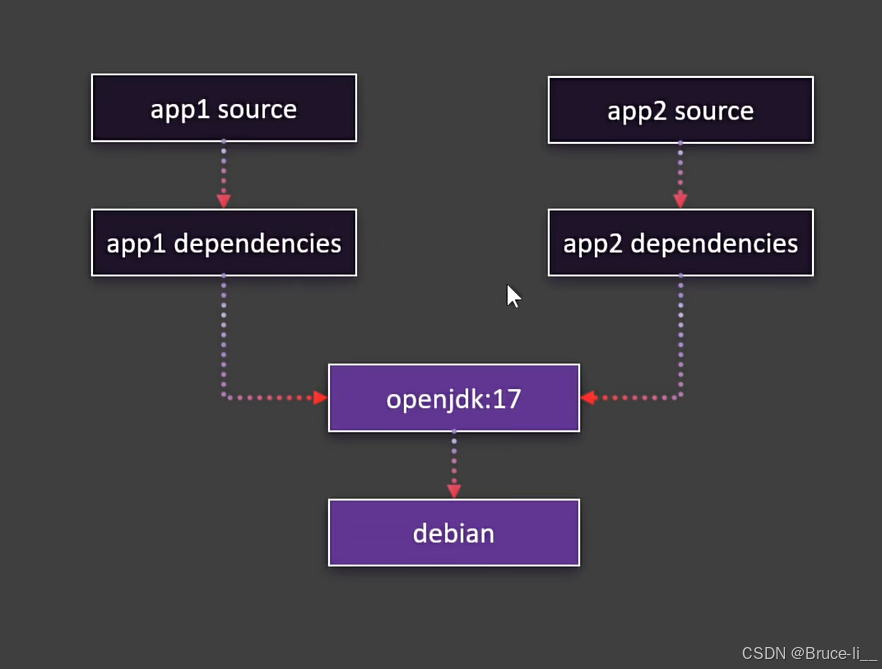
9.7.4分层机制的注意事项
(1)层数过多的问题
问题:每个 RUN、COPY 等指令都会生成新层,可能导致: 镜像体积增大(每层有少量元数据开销)。 构建效率下降(需管理更多层)。优化方法:合并指令(如用 && 连接多个命令):
# 不推荐:生成2层RUN apt updateRUN apt install -y curl# 推荐:合并为1层RUN apt update && apt install -y curl && rm -rf /var/lib/apt/lists/*(2)可写层的性能影响
容器频繁写操作(如日志、数据库)会增大可写层,可能影响性能。解决方案: 使用 volumes 挂载外部存储(如数据库数据目录)。 设置日志轮转(Log Rotation)避免日志爆增。9.7.5实际操作示例
(1)查看镜像分层
# 查看镜像的层结构docker inspect ubuntu:22.04# 输出中的 \"Layers\" 字段显示所有层的哈希值\"Layers\": [ \"sha256:2dc39ba059dcd42ade30aae30147b5692777ba9ff0779a62ad93a74de02e3e1f\", ...](2)构建时优化分层
# 优化前:6层FROM ubuntu:22.04RUN apt updateRUN apt install -y curlRUN apt install -y python3COPY . /appCMD [\"python3\", \"/app/main.py\"]# 优化后:3层FROM ubuntu:22.04RUN apt update && \\ apt install -y curl python3 && \\ rm -rf /var/lib/apt/lists/*COPY . /appCMD [\"python3\", \"/app/main.py\"]9.7.6总结
理解分层机制有助于编写高效的 Dockerfile 并优化容器性能!
十.一键启动所有中间件
#Disable memory paging and swapping performancesudo swapoff -a# Edit the sysctl config filesudo vi /etc/sysctl.conf# Add a line to define the desired value# or change the value if the key exists,# and then save your changes.vm.max_map_count=262144# Reload the kernel parameters using sysctlsudo sysctl -p# Verify that the change was applied by checking the valuecat /proc/sys/vm/max_map_count
注意:将下面文件中 kafka 的 119.45.147.122 改为你自己的服务器IP。所有容器都做了时间同步,这样容器的时间和linux主机的时间就一致了准备一个 compose.yaml文件,内容如下:
name: devsoftservices: redis: image: bitnami/redis:latest restart: always container_name: redis environment: - REDIS_PASSWORD=123456 ports: - \'6379:6379\' volumes: - redis-data:/bitnami/redis/data - redis-conf:/opt/bitnami/redis/mounted-etc - /etc/localtime:/etc/localtime:ro mysql: image: mysql:8.0.31 restart: always container_name: mysql environment: - MYSQL_ROOT_PASSWORD=123456 ports: - \'3306:3306\' - \'33060:33060\' volumes: - mysql-conf:/etc/mysql/conf.d - mysql-data:/var/lib/mysql - /etc/localtime:/etc/localtime:ro rabbit: image: rabbitmq:3-management restart: always container_name: rabbitmq ports: - \"5672:5672\" - \"15672:15672\" environment: - RABBITMQ_DEFAULT_USER=rabbit - RABBITMQ_DEFAULT_PASS=rabbit - RABBITMQ_DEFAULT_VHOST=dev volumes: - rabbit-data:/var/lib/rabbitmq - rabbit-app:/etc/rabbitmq - /etc/localtime:/etc/localtime:ro opensearch-node1: image: opensearchproject/opensearch:2.13.0 container_name: opensearch-node1 environment: - cluster.name=opensearch-cluster # Name the cluster - node.name=opensearch-node1 # Name the node that will run in this container - discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster - cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligibile to serve as cluster manager - bootstrap.memory_lock=true # Disable JVM heap memory swapping - \"OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m\" # Set min and max JVM heap sizes to at least 50% of system RAM - \"DISABLE_INSTALL_DEMO_CONFIG=true\" # Prevents execution of bundled demo script which installs demo certificates and security configurations to OpenSearch - \"DISABLE_SECURITY_PLUGIN=true\" # Disables Security plugin ulimits: memlock: soft: -1 # Set memlock to unlimited (no soft or hard limit) hard: -1 nofile: soft: 65536 # Maximum number of open files for the opensearch user - set to at least 65536 hard: 65536 volumes: - opensearch-data1:/usr/share/opensearch/data # Creates volume called opensearch-data1 and mounts it to the container - /etc/localtime:/etc/localtime:ro ports: - 9200:9200 # REST API - 9600:9600 # Performance Analyzer opensearch-node2: image: opensearchproject/opensearch:2.13.0 container_name: opensearch-node2 environment: - cluster.name=opensearch-cluster # Name the cluster - node.name=opensearch-node2 # Name the node that will run in this container - discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster - cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligibile to serve as cluster manager - bootstrap.memory_lock=true # Disable JVM heap memory swapping - \"OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m\" # Set min and max JVM heap sizes to at least 50% of system RAM - \"DISABLE_INSTALL_DEMO_CONFIG=true\" # Prevents execution of bundled demo script which installs demo certificates and security configurations to OpenSearch - \"DISABLE_SECURITY_PLUGIN=true\" # Disables Security plugin ulimits: memlock: soft: -1 # Set memlock to unlimited (no soft or hard limit) hard: -1 nofile: soft: 65536 # Maximum number of open files for the opensearch user - set to at least 65536 hard: 65536 volumes: - /etc/localtime:/etc/localtime:ro - opensearch-data2:/usr/share/opensearch/data # Creates volume called opensearch-data2 and mounts it to the container opensearch-dashboards: image: opensearchproject/opensearch-dashboards:2.13.0 container_name: opensearch-dashboards ports: - 5601:5601 # Map host port 5601 to container port 5601 expose: - \"5601\" # Expose port 5601 for web access to OpenSearch Dashboards environment: - \'OPENSEARCH_HOSTS=[\"http://opensearch-node1:9200\",\"http://opensearch-node2:9200\"]\' - \"DISABLE_SECURITY_DASHBOARDS_PLUGIN=true\" # disables security dashboards plugin in OpenSearch Dashboards volumes: - /etc/localtime:/etc/localtime:ro zookeeper: image: bitnami/zookeeper:3.9 container_name: zookeeper restart: always ports: - \"2181:2181\" volumes: - \"zookeeper_data:/bitnami\" - /etc/localtime:/etc/localtime:ro environment: - ALLOW_ANONYMOUS_LOGIN=yes kafka: image: \'bitnami/kafka:3.4\' container_name: kafka restart: always hostname: kafka ports: - \'9092:9092\' - \'9094:9094\' environment: - KAFKA_CFG_NODE_ID=0 - KAFKA_CFG_PROCESS_ROLES=controller,broker - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://0.0.0.0:9094 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://119.45.147.122:9094 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093 - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER - ALLOW_PLAINTEXT_LISTENER=yes - \"KAFKA_HEAP_OPTS=-Xmx512m -Xms512m\" volumes: - kafka-conf:/bitnami/kafka/config - kafka-data:/bitnami/kafka/data - /etc/localtime:/etc/localtime:ro kafka-ui: container_name: kafka-ui image: provectuslabs/kafka-ui:latest restart: always ports: - 8080:8080 environment: DYNAMIC_CONFIG_ENABLED: true KAFKA_CLUSTERS_0_NAME: kafka-dev KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092 volumes: - kafkaui-app:/etc/kafkaui - /etc/localtime:/etc/localtime:ro nacos: image: nacos/nacos-server:v2.3.1 container_name: nacos ports: - 8848:8848 - 9848:9848 environment: - PREFER_HOST_MODE=hostname - MODE=standalone - JVM_XMX=512m - JVM_XMS=512m - SPRING_DATASOURCE_PLATFORM=mysql - MYSQL_SERVICE_HOST=nacos-mysql - MYSQL_SERVICE_DB_NAME=nacos_devtest - MYSQL_SERVICE_PORT=3306 - MYSQL_SERVICE_USER=nacos - MYSQL_SERVICE_PASSWORD=nacos - MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true - NACOS_AUTH_IDENTITY_KEY=2222 - NACOS_AUTH_IDENTITY_VALUE=2xxx - NACOS_AUTH_TOKEN=SecretKey012345678901234567890123456789012345678901234567890123456789 - NACOS_AUTH_ENABLE=true volumes: - /app/nacos/standalone-logs/:/home/nacos/logs - /etc/localtime:/etc/localtime:ro depends_on: nacos-mysql: condition: service_healthy nacos-mysql: container_name: nacos-mysql build: context: . dockerfile_inline: | FROM mysql:8.0.31 ADD https://raw.githubusercontent.com/alibaba/nacos/2.3.2/distribution/conf/mysql-schema.sql /docker-entrypoint-initdb.d/nacos-mysql.sql RUN chown -R mysql:mysql /docker-entrypoint-initdb.d/nacos-mysql.sql EXPOSE 3306 CMD [\"mysqld\", \"--character-set-server=utf8mb4\", \"--collation-server=utf8mb4_unicode_ci\"] image: nacos/mysql:8.0.30 environment: - MYSQL_ROOT_PASSWORD=root - MYSQL_DATABASE=nacos_devtest - MYSQL_USER=nacos - MYSQL_PASSWORD=nacos - LANG=C.UTF-8 volumes: - nacos-mysqldata:/var/lib/mysql - /etc/localtime:/etc/localtime:ro ports: - \"13306:3306\" healthcheck: test: [ \"CMD\", \"mysqladmin\" ,\"ping\", \"-h\", \"localhost\" ] interval: 5s timeout: 10s retries: 10 prometheus: image: prom/prometheus:v2.52.0 container_name: prometheus restart: always ports: - 9090:9090 volumes: - prometheus-data:/prometheus - prometheus-conf:/etc/prometheus - /etc/localtime:/etc/localtime:ro grafana: image: grafana/grafana:10.4.2 container_name: grafana restart: always ports: - 3000:3000 volumes: - grafana-data:/var/lib/grafana - /etc/localtime:/etc/localtime:rovolumes: redis-data: redis-conf: mysql-conf: mysql-data: rabbit-data: rabbit-app: opensearch-data1: opensearch-data2: nacos-mysqldata: zookeeper_data: kafka-conf: kafka-data: kafkaui-app: prometheus-data: prometheus-conf: grafana-data:# 在 compose.yaml 文件所在的目录下执行docker compose up -d# 等待启动所有容器如果重启了服务器,可能有些容器会启动失败。再执行一遍 docker compose up -d即可。所有程序都可运行成功,并且不会丢失数据。请放心使用。
十一.进阶k8s

k8s和docker compose
Kubernetes (k8s) 与 Docker Compose 比较
Kubernetes (k8s) 和 Docker Compose 都是容器编排工具,但设计用于不同的场景和规模。
主要区别
使用场景
Docker Compose 更适合:
本地开发和测试环境快速启动一组关联的容器小型项目或个人项目CI/CD 管道中的测试阶段Kubernetes 更适合:
生产环境部署需要高可用性的服务需要自动扩展的应用复杂的微服务架构跨多个服务器/节点的部署示例对比
Docker Compose 示例 (docker-compose.yml)
version: \'3\'services: web: image: nginx:alpine ports: - \"8080:80\" depends_on: - db db: image: postgres:13 environment: POSTGRES_PASSWORD: example volumes: - db_data:/var/lib/postgresql/datavolumes: db_data:Kubernetes 等效示例 (deployment.yaml)
apiVersion: apps/v1kind: Deploymentmetadata: name: webspec: replicas: 3 selector: matchLabels: app: web template: metadata: labels: app: web spec: containers: - name: nginx image: nginx:alpine ports: - containerPort: 80---apiVersion: v1kind: Servicemetadata: name: web-servicespec: selector: app: web ports: - protocol: TCP port: 80 targetPort: 80 type: LoadBalancer---apiVersion: apps/v1kind: Deploymentmetadata: name: dbspec: selector: matchLabels: app: db template: metadata: labels: app: db spec: containers: - name: postgres image: postgres:13 env: - name: POSTGRES_PASSWORD value: \"example\" volumeMounts: - mountPath: /var/lib/postgresql/data name: db-data volumes: - name: db-data persistentVolumeClaim: claimName: postgres-pvc如何选择
1.从 Compose 开始:如果你是初学者或开发小型应用,从 Docker Compose 开始2.过渡到 k8s:当需要扩展到生产环境时,考虑 Kubernetes3.开发/生产分离:可以在开发时使用 Compose,生产使用 k8s4.Kompose 工具:可以使用 kompose 工具将 docker-compose.yml 转换为 k8s 配置两者结合使用
许多开发者会在本地开发时使用 Docker Compose,然后将应用部署到 Kubernetes 集群。一些工具如 kind (Kubernetes in Docker) 允许你在本地运行 Kubernetes 集群进行测试

