【论文阅读】Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models_latent的标准差
讨论了 Latent Diffusion Models (LDM) 中 重建能力和生成能力之间的矛盾(优化困境),并提出了一种新的 VAE 训练方式(VA-VAE) 来缓解这一问题,从而提升扩散模型的训练效率与生成质量。
总结:高维 latent 提高了重建质量,但却损害了扩散模型的训练效率和生成质量。论文提出一种 将 latent 表征对齐预训练视觉基础模型的正则方式(VF Loss),有效化解了这一冲突。
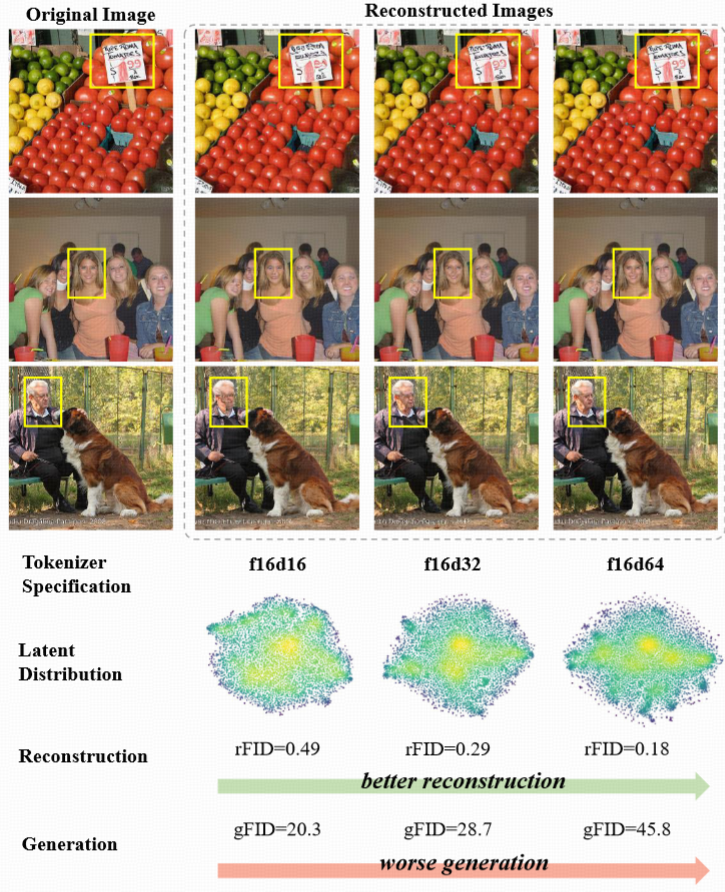
介绍
Latent Diffusion Model(LDM) LDM 由两部分组成:
- Tokenizer(通常是 VAE):将原始图像压缩成 latent 表征(比如从 256×256 RGB → 32×32×4 的 latent)
- Diffusion Model:在 latent 空间中做扩散过程,最后通过 decoder 还原为图像
好处:大大降低计算成本、支持高分辨率生成。
问题:重建 vs. 生成的矛盾(Optimization Dilemma) :若 提高 latent 的维度(比如从 4→8→16维)→
- 好处:重建更精细
- 坏处:扩散训练变慢,生成质量变差,收敛困难 这就形成了一个 两难困境:
原因分析:为作者发现了一个关键问题: 高维 latent 空间在训练初期不容易约束,容易形成“塌缩”或局部过密的分布,从而影响扩散模型的建模能力。
他们用可视化展示了 latent 空间的分布随维度上升而更加集中和扭曲 这会让 diffusion model 难以建模整个 latent 空间的分布
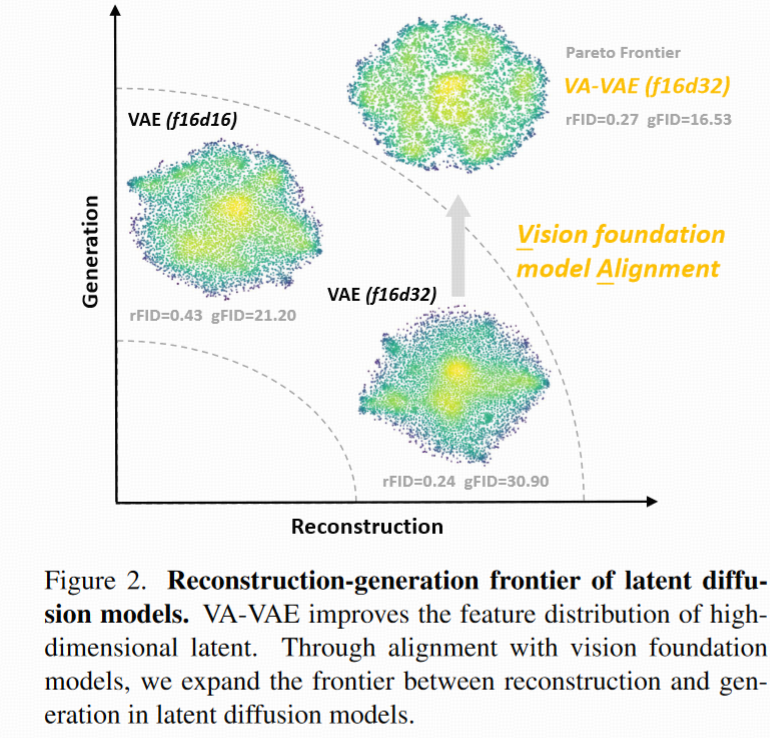
核心方法:VA-VAE + VF Loss
论文提出一种新的训练机制:
- VA-VAE:Vision-Aligned VAE。使用预训练的 视觉基础模型(如 DINOv2、CLIP、SAM 的特征) 来指导 VAE 的 latent 空间,让其更稳定、更有语义结构、更适合 diffusion 学习。
- VF Loss:对齐损失函数。核心思想:让 VAE 的 latent 表征与视觉基础模型提取的特征保持一致,包括:
- 元素级相似性(Element-wise similarity)→ 控制局部特征对齐
- 对组级结构相似性(Pairwise similarity)→ 保持结构性分布一致
- 加入 margin → 控制松弛程度,防止过拟合,保持信息容量
- 这样就能在 不牺牲重建能力的前提下,获得 更平滑、结构化的 latent 空间,进而提升 diffusion 的训练效率和生成质量。
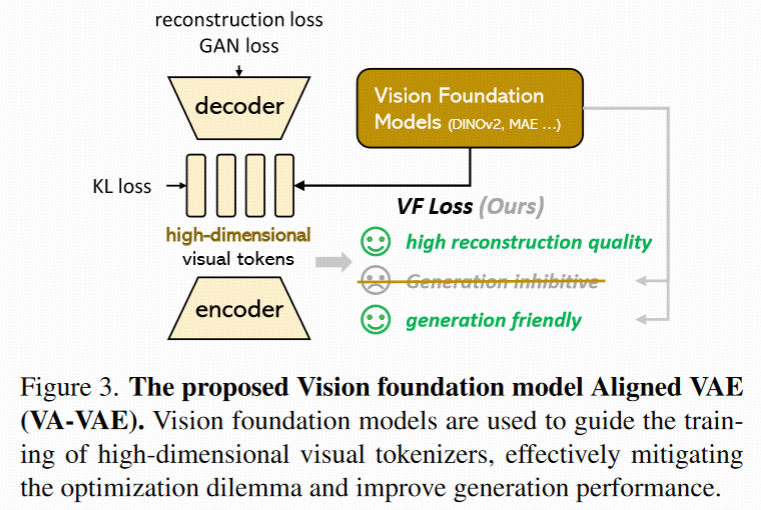
配套设计:LightningDiT
为了进一步发挥 VA-VAE 的潜力,作者还构建了一个改进版的扩散 Transformer: LightningDiT
- 包括 训练策略优化(如更合理的 noise schedule、loss 平衡等)
- 架构改进(更强的 attention 模块、更合理的 patchification)
这让整个系统在训练效率和生成质量上都大幅提升。
Align VAE with Vision Foundation Models
用视觉基础模型对齐 VAE(VA-VAE)
核心动机:高维 latent 空间虽然重建质量好,但 diffusion model 很难训练。
原因:高维 latent 空间未经约束,分布混乱,结构松散,扩散器难以建模。
本文的关键思路是:用一个结构良好的视觉基础模型(如 DINOv2、CLIP)引导 latent 空间的分布结构,从而让 tokenizer 既保持重建能力,又有更好的生成质量。
VA-VAE 架构 整体流程如下:
原图像 I
├──► VAE 编码器 → latent 表征 Z ─► 投影为 Z′
└──► 冻结的视觉基础模型(如 DINOv2) → 特征向量 F
目标是让 Z′ 和 F 对齐(语义结构、特征分布都一致),通过两个损失函数实现:
- Marginal Cosine Similarity Loss(Lmcos)
- Marginal Distance Matrix Similarity Loss(Lmdms)
Lmcos
作用:点对点地对齐 Z 和 F 的语义特征。
- 先用一个线性变换将 latent Z 映射到和 foundation model F 相同维度,得到 Z′:

- 对每个空间位置 (i, j),计算:
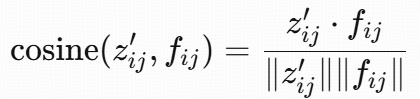
- 定义损失为(只惩罚相似度低于 margin 的位置):
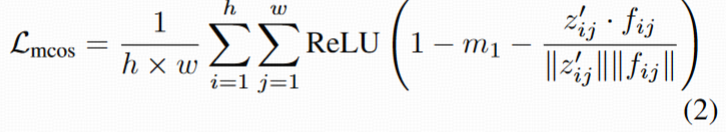
结果:鼓励 latent 表征在语义上靠近视觉基础模型提取的特征,但通过 margin 控制自由度。
Lmdms
作用:对齐整个 feature map 的相对结构分布
- 计算 latent 特征矩阵 Z 和 F 中任意两个位置之间的余弦相似度,并将两者的距离矩阵对齐:
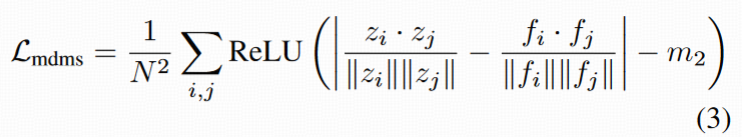
结果:让 latent 特征内部的相对结构保持一致(结构对齐),从而优化整体空间的可学习性。
总结 VF Loss 的作用:
LightningDiT
优化版的 Diffusion Transformer
作者为配合 VA-VAE,构建了一个 训练快速、效果强的 DiT 架构,称为 LightningDiT。 模型优化分三类:
① 训练加速策略
- 使用 torch.compile 加速 PyTorch 执行图
- 用 bfloat16 降低显存
- 增大 batch size 优化 AdamW(将 β2 降为 0.95)
② 扩散过程优化
- 用 Rectified Flow 作为采样方法
- 使用 logit-normal 分布噪声
- 引入 velocity direction loss
这些都能提升生成质量,减少训练轮数。
③ Transformer 架构优化
- RMSNorm(比 LayerNorm 更稳)
- SwiGLU 激活函数(性能更强)
- RoPE(旋转位置编码)
实验效果
Experiments
实验目标:通过 VF Loss + LightningDiT 构建 latent diffusion 系统,打破“重建 vs 生成质量不能兼得”的困局,实现 reconstruction-generation frontier。
Implementation
Tokenizer: 用 VQGAN 架构,不量化,采用 KL loss(即连续 latent 空间)。
对比 3 种版本的 tokenizer:
- baseline(无 VF Loss)
- VF Loss + MAE
- VF Loss + DINOv2
参数设定:
- downsampling factor f=16
- latent dim d=16/32/64
- margin m1=0.5, m2=0.25,loss 权重 whyper=0.1
Diffusion 模型: LightningDiT
- patch size=1(保持 VAE 编码器为唯一压缩组件)
- 训练 80/160 epochs,在 ImageNet 256×256 上测试。
提升
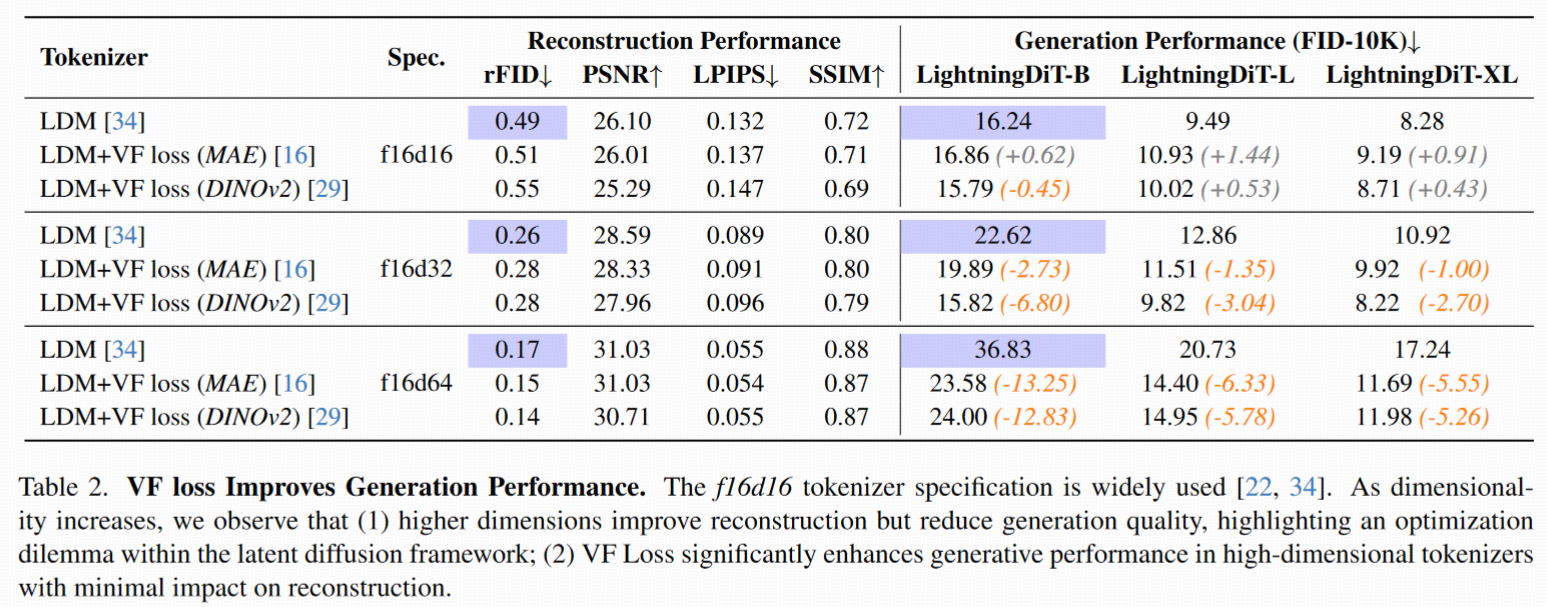
核心发现: 在高维 latent(如 f16d32/f16d64)上,VF Loss 显著改善生成性能。
现象验证:
- baseline: latent dim ↑ ⇒ 重建更好(rFID ↓),生成更差(FID ↑)
- 加入 VF Loss 后:可以在高维 latent 上兼顾重建与生成,打破二者之间的 trade-off
效果数据: f16d64 上的 VF Loss 提升生成 FID,并将收敛速度提升到原来的 2.76 倍
结论: VF Loss 更适合 高维 latent 空间,低维时(如 f16d16)不明显,因为低维空间本身就容易收敛到良好分布。
可扩展性验证
对比不同大小的 LightningDiT(0.1B ~ 1.6B),发现:
- 不使用 VF Loss: 即使模型变大(到 1.6B),高维 latent 的生成性能仍低于低维。
- 使用 VF Loss: 随着模型增大,f16d32+VF Loss(橙线)最终 超越 f16d16(绿线),说明其具备更强的可扩展性。
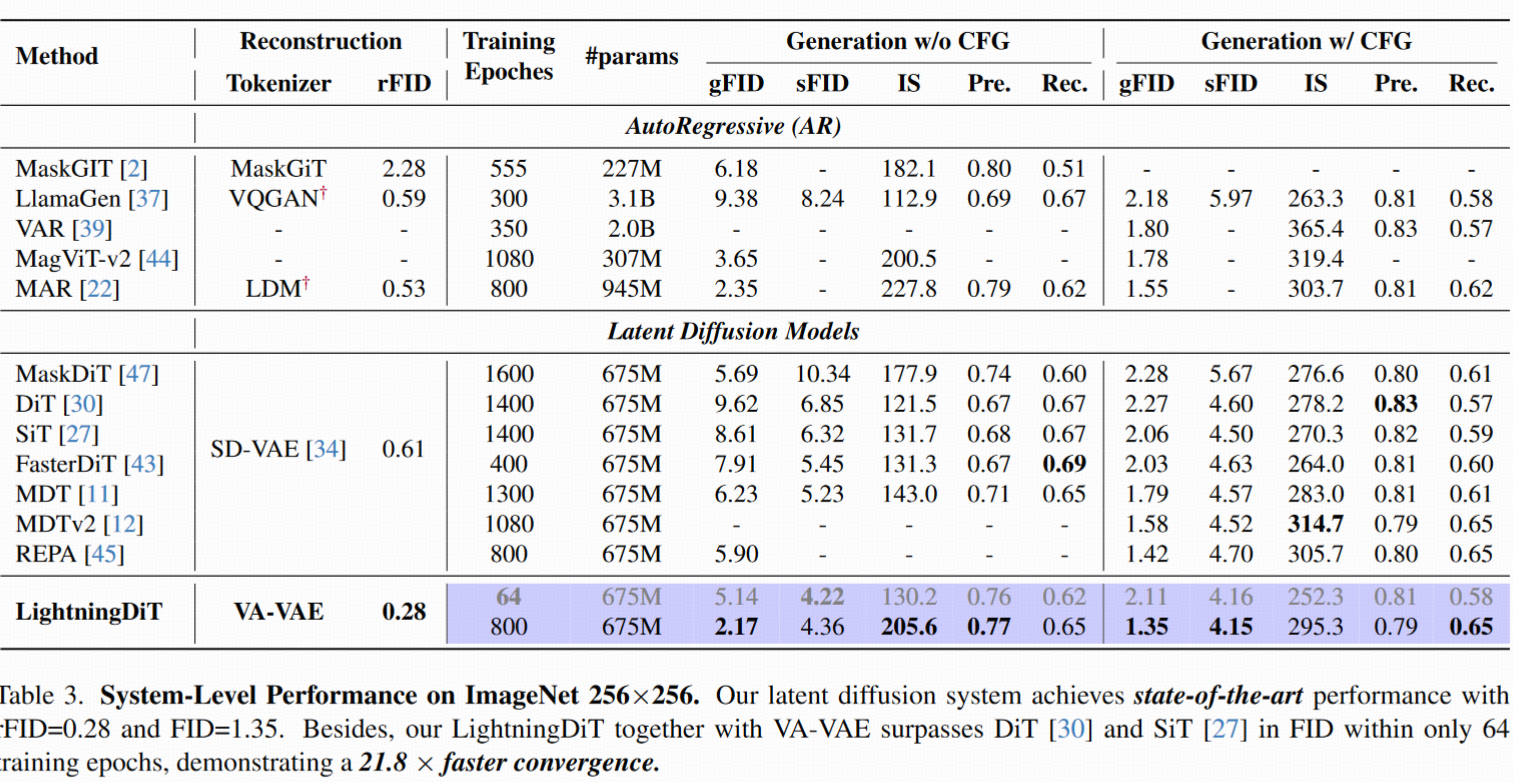
极限收敛能力(21.8× 加速)
更长训练: 用 progressive strategy 训练 VA-VAE 到 125 epoch,LightningDiT-XL 训练到 800 epoch
采样优化: 用 Euler 采样器 + cfg interval + timestep shift
最终结果:
- FID = 1.35(当前 ImageNet 256×256 任务 SOTA)
- 无 cfg 生成下 FID = 2.17,仍优于许多 cfg 模型
- 64 epoch 达成 FID = 2.11 ⇒ 收敛速度提升 21.8×
Ablations
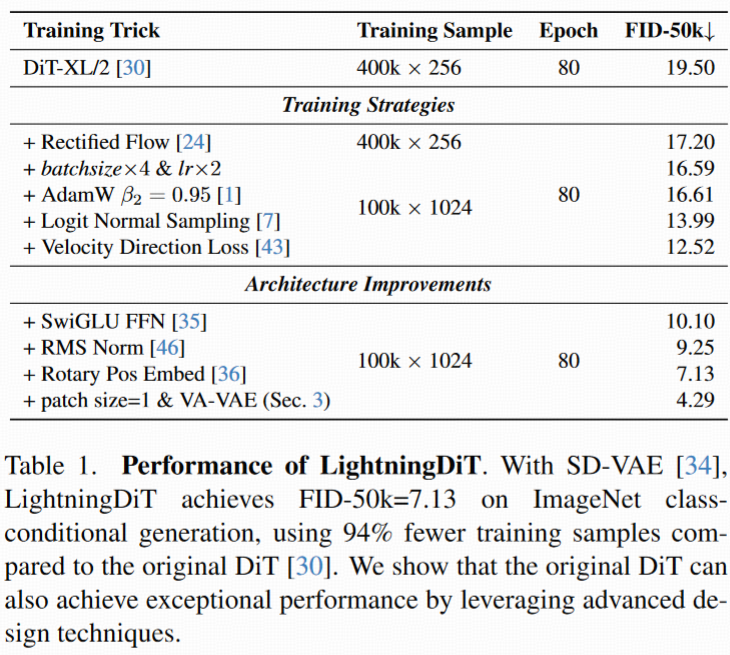
Tokenizer 设计:patch size 越小越好
比较了 patch size = 1 的 VA-VAE 与 patch size = 2 的 SDVAE:
VA-VAE 的 FID 从 7.13 降至 4.29
原因:patch size=1 有更精细的结构,配合 DINOv2 提升语义分布质量。
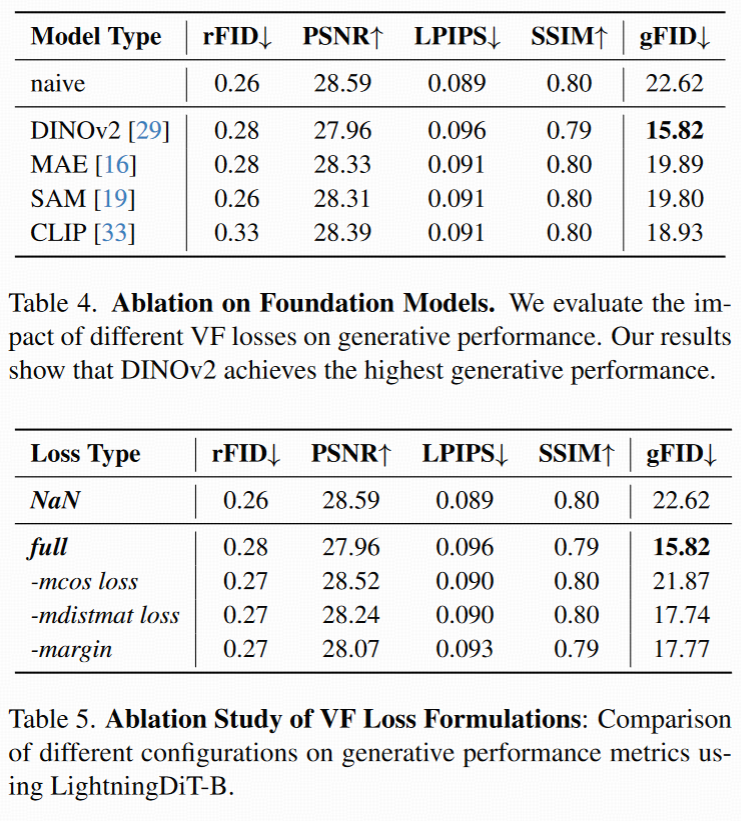
不同 foundation model 对比
对比了三种引导模型:
- MAE / DINOv2(自监督)
- CLIP(图文对比)
- SAM(Segment Anything)
结果:DINOv2 效果最佳,说明: 语义结构好的视觉表征对对齐 latent 空间更有效。
Loss 设计消融
三个 ablation 实验:
- 移除 mcos
- 移除 mdms
- 移除 margin
结果:三者移除都会明显退化生成效果
表明:
- mcos 控制语义对齐
- mdms 控制结构对齐
- margin 控制自由度,防止过拟合
机制分析:latent 分布更加均匀
- 对比 discrete VAE 中的 codebook utilization 问题
- Continuous latent 也存在类似的问题:高维空间分布容易密集不均
- 用 t-SNE + KDE 可视化 latent 分布
- VF Loss 提升了 latent 分布的 均匀性(标准差更小,Gini 系数更低) ,更均匀的 latent 分布 ⇒ 更强的生成质量(gFID 更好)

通俗理解
解决什么问题
扩散模型经常先用一个 VAE 把图片压缩成 latent 表示(比如小图),再在这个 latent 空间里做图像生成(比如用 DiT 这样的 transformer 做扩散)。但这时候出现了一个“两难问题”:
-
如果想让 VAE 重建图片很清晰(重建质量好),你就需要让 latent 维度变大,信息更丰富;
-
但 latent 维度一大,扩散模型就很难训练、收敛慢、生成质量变差。
核心想法:用已有的“视觉大模型”来“指导”VAE压缩图片时怎么做。比如像 CLIP、DINOv2、MAE 这些模型,它们已经训练得很好、对图像结构非常了解,那就让 VAE 学着它们的方式来压缩图片。
方法
VF Loss(视觉基础模型对齐损失)
具体流程如下:
-
拿一张图片,送进:
-
一个训练中的 VAE 编码器 → 得到 latent 表示
Z -
一个冻结的视觉大模型(比如 DINOv2)→ 得到语义特征
F
-
-
对齐这两种特征(Z 和 F),通过两个方法:
① 点对点对齐(Marginal Cosine Similarity Loss)
-
比较 latent
Z和视觉模型F每个位置的向量是不是很接近(角度类似) -
如果太不接近,就用 loss 惩罚它
② 整体结构对齐(Marginal Distance Matrix Similarity Loss)
-
比较 Z 和 F 各位置之间的相对“距离结构”是不是一致
-
比如说:图中某两块区域在语义上很接近,Z 表示里也要如此
两个 loss 都加入了“margin”,意思是:只关注那些差得比较多的地方,别全局硬压一致,否则可能影响表达能力。
-

