【网络与爬虫 10】AutoScraper智能爬虫:零代码实现网页数据自动提取
【网络与爬虫 10】AutoScraper智能爬虫:零代码实现网页数据自动提取
关键词:AutoScraper、智能爬虫、自动数据提取、零代码爬虫、网页抓取、Python爬虫、规则生成、模式匹配、网络数据采集、无监督学习
摘要:本文深入介绍AutoScraper这一革命性的智能网页数据提取工具,它能通过简单的示例学习如何从网页中提取相似数据,无需编写复杂的选择器和解析规则。文章从实际问题出发,详细讲解AutoScraper的工作原理、安装配置、基础用法和高级应用场景。通过多个实例展示如何用最少的代码实现电商产品信息、新闻文章、搜索结果等数据的批量提取,以及如何处理动态加载内容和保存复用规则。无论您是爬虫新手还是经验丰富的开发者,本文都将帮助您掌握这一强大工具,显著提升数据采集效率。
文章目录
- 【网络与爬虫 10】AutoScraper智能爬虫:零代码实现网页数据自动提取
-
- 引言:传统爬虫的痛点与挑战
- AutoScraper:智能化网页数据提取的革命
- 安装与环境配置
- 基础使用:三步实现数据提取
-
- 步骤1:导入AutoScraper并创建实例
- 步骤2:提供URL和要提取的数据样例
- 步骤3:让AutoScraper学习如何提取数据
- 进阶应用:提取多种类型的数据
-
- 提取多种数据并分组
- 保存和加载规则
- 实战案例:电商产品信息提取
- 高级技巧:处理复杂场景
-
- 处理动态加载内容
- 优化提取规则
- 处理分页数据
- 实用案例:新闻文章提取器
- AutoScraper的工作原理
- 与其他爬虫工具的比较
- 最佳实践与注意事项
-
- 1. 选择好的样例数据
- 2. 处理动态内容
- 3. 规则维护
- 4. 性能优化
- 5. 合规性考虑
- 结语:AutoScraper的未来与展望
- 参考资料
- 参考资料
引言:传统爬虫的痛点与挑战
你是否曾经遇到过这样的情况:需要从一个网站抓取数据,但是面对复杂的HTML结构,你不得不花费大量时间编写和调试CSS选择器或XPath表达式?更糟糕的是,当网站稍微更新了一下页面结构,你精心编写的爬虫代码就彻底失效了?
传统的网页爬虫开发通常面临以下挑战:
- 选择器编写复杂:需要深入分析HTML结构,编写精确的CSS选择器或XPath表达式
- 脆弱性高:网站结构稍有变化,爬虫就可能失效
- 开发效率低:从分析页面到编码测试,往往需要花费大量时间
- 维护成本高:需要不断更新和调整选择器以适应网站变化
- 学习曲线陡峭:新手需要学习HTML、CSS选择器、XPath等多种技术
这些问题让许多人望而却步,尤其是那些编程经验有限或只是偶尔需要抓取数据的用户。那么,有没有一种更智能、更简单的方法来解决这些问题呢?
答案是肯定的——AutoScraper应运而生。
AutoScraper:智能化网页数据提取的革命
AutoScraper是一个基于Python的开源库,它采用了一种全新的思路来解决网页数据提取的问题:通过示例学习。
与传统爬虫不同,使用AutoScraper,你只需要:
- 提供要抓取的网页URL
- 提供几个你想要提取的数据样例
- AutoScraper会自动学习如何从页面中找到这些数据,并生成可以提取所有类似数据的规则
这种方法极大地简化了网页数据提取的过程,使得即使是编程新手也能快速实现高效的数据抓取。
安装与环境配置
在开始使用AutoScraper之前,我们需要先安装它。AutoScraper是一个纯Python库,安装非常简单:
pip install autoscraperAutoScraper依赖于以下几个库,它们会在安装过程中自动安装:
- requests:用于发送HTTP请求
- bs4 (Beautiful Soup):用于解析HTML
- lxml:高效的HTML解析器
安装完成后,我们就可以开始使用AutoScraper了。
基础使用:三步实现数据提取
让我们通过一个简单的例子来了解AutoScraper的基本用法。假设我们想要从亚马逊网站提取产品名称和价格。
步骤1:导入AutoScraper并创建实例
from autoscraper import AutoScraperscraper = AutoScraper()步骤2:提供URL和要提取的数据样例
url = \'https://www.amazon.com/s?k=iphone\'# 我们提供几个产品名称作为样例wanted_list = [\"Apple iPhone 13 Pro Max, 128GB, Sierra Blue\", \"Apple iPhone 12, 64GB, Blue\"]步骤3:让AutoScraper学习如何提取数据
result = scraper.build(url, wanted_list)print(result)就是这么简单!AutoScraper会访问提供的URL,分析页面结构,找出能够匹配我们提供的样例数据的模式,然后返回所有匹配这些模式的数据。
输出可能是这样的:
[\'Apple iPhone 13 Pro Max, 128GB, Sierra Blue\', \'Apple iPhone 12, 64GB, Blue\', \'Apple iPhone SE (2nd generation), 64GB, Black\', \'Apple iPhone 11, 64GB, Purple\', ...]AutoScraper不仅找到了我们提供的两个样例,还找到了页面上所有其他符合相同模式的产品名称。

进阶应用:提取多种类型的数据
在实际应用中,我们通常需要提取多种类型的数据,比如产品名称、价格、评分等。AutoScraper也能轻松处理这种情况。
提取多种数据并分组
url = \'https://www.amazon.com/s?k=iphone\'# 提供不同类型的数据样例wanted_dict = { \'product_title\': [\"Apple iPhone 13 Pro Max, 128GB, Sierra Blue\"], \'product_price\': [\"$999.00\", \"$699.00\"], \'product_rating\': [\"4.5 out of 5 stars\"]}# 构建分组规则scraper.build(url, wanted_dict)# 使用分组规则提取数据result = scraper.get_result_similar(url, grouped=True)print(result)输出结果将是一个字典,每种类型的数据单独分组:
{ \'product_title\': [\'Apple iPhone 13 Pro Max, 128GB, Sierra Blue\', \'Apple iPhone 12, 64GB, Blue\', ...], \'product_price\': [\'$999.00\', \'$699.00\', \'$499.00\', ...], \'product_rating\': [\'4.5 out of 5 stars\', \'4.7 out of 5 stars\', ...]}保存和加载规则
一旦我们创建了有效的提取规则,我们可以保存它们以便将来使用:
# 保存规则到文件scraper.save(\'amazon_iphone_rules\')# 加载规则new_scraper = AutoScraper()new_scraper.load(\'amazon_iphone_rules\')# 使用加载的规则提取新页面的数据new_url = \'https://www.amazon.com/s?k=iphone&page=2\'new_result = new_scraper.get_result_similar(new_url, grouped=True)这样,我们就可以在不同的页面上重复使用相同的提取规则,大大提高了效率。
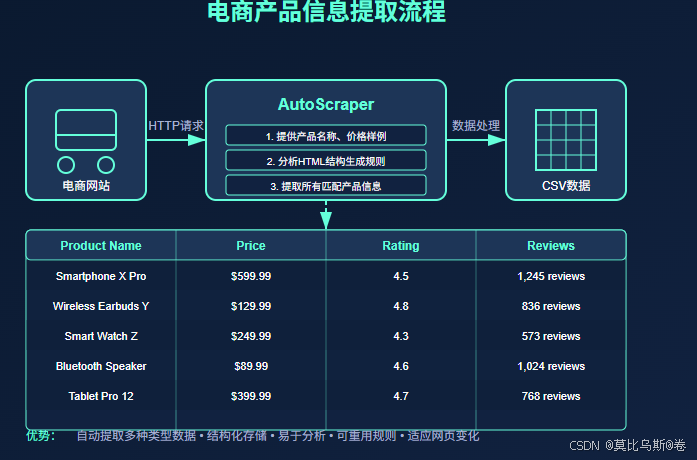
实战案例:电商产品信息提取
让我们通过一个更完整的实例来展示AutoScraper的强大功能。假设我们想要从一个电商网站提取产品信息,包括名称、价格、评分和评论数。
from autoscraper import AutoScraperimport pandas as pd# 创建AutoScraper实例scraper = AutoScraper()# 目标URLurl = \'https://www.example-ecommerce.com/products/electronics\'# 提供样例数据wanted_dict = { \'name\': [\"Smartphone X Pro\", \"Wireless Earbuds Y\"], \'price\': [\"$599.99\", \"$129.99\"], \'rating\': [\"4.5\", \"4.8\"], \'reviews\': [\"1,245 reviews\", \"836 reviews\"]}# 构建规则scraper.build(url, wanted_dict)# 提取数据result = scraper.get_result_similar(url, grouped=True)# 将结果转换为DataFramedf = pd.DataFrame({ \'Product Name\': result.get(\'name\', []), \'Price\': result.get(\'price\', []), \'Rating\': result.get(\'rating\', []), \'Reviews\': result.get(\'reviews\', [])})# 保存为CSVdf.to_csv(\'products.csv\', index=False)print(f\"提取了 {len(df)} 个产品的信息\")这个例子展示了如何使用AutoScraper提取多种类型的数据,并将结果保存为CSV文件,便于后续分析。
高级技巧:处理复杂场景
处理动态加载内容
许多现代网站使用JavaScript动态加载内容。对于这种情况,我们可以结合Selenium和AutoScraper:
from autoscraper import AutoScraperfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsimport time# 设置Chrome选项chrome_options = Options()chrome_options.add_argument(\"--headless\") # 无头模式driver = webdriver.Chrome(options=chrome_options)# 访问URL并等待内容加载url = \'https://www.example.com/dynamic-content\'driver.get(url)time.sleep(3) # 等待动态内容加载# 获取页面源代码page_content = driver.page_sourcedriver.quit()# 使用AutoScraper处理页面内容scraper = AutoScraper()wanted_list = [\"Example Data 1\", \"Example Data 2\"]scraper.build_from_html(page_content, wanted_list)# 提取数据result = scraper.get_result_from_html(page_content)print(result)优化提取规则
有时AutoScraper可能生成的规则不够精确,我们可以通过以下方法优化:
# 构建规则并获取所有可能的选择器url = \'https://www.example.com\'wanted_list = [\"Target Data 1\", \"Target Data 2\"]result, stack_list = scraper.build(url, wanted_list, get_stacks=True)# 查看生成的选择器栈for i, stack in enumerate(stack_list): print(f\"Stack {i}:\") for s in stack: print(f\" {s}\")# 选择最佳的选择器栈scraper.keep_stacks([0, 2]) # 只保留第1和第3个选择器栈# 使用优化后的规则提取数据optimized_result = scraper.get_result_similar(url)通过查看和筛选选择器栈,我们可以提高提取的精确度。
处理分页数据
对于需要处理多页数据的情况,我们可以结合循环和AutoScraper:
import time# 创建AutoScraper实例并构建规则scraper = AutoScraper()base_url = \'https://www.example.com/products?page=\'scraper.build(base_url + \'1\', wanted_dict)# 收集所有数据all_data = {key: [] for key in wanted_dict.keys()}# 循环遍历多个页面for page in range(1, 6): # 提取5页数据 page_url = base_url + str(page) print(f\"Processing page {page}...\") # 提取当前页数据 result = scraper.get_result_similar(page_url, grouped=True) # 合并数据 for key in wanted_dict.keys(): all_data[key].extend(result.get(key, [])) # 避免请求过于频繁 time.sleep(2)print(f\"Total items collected: {len(all_data[list(wanted_dict.keys())[0]])}\")实用案例:新闻文章提取器
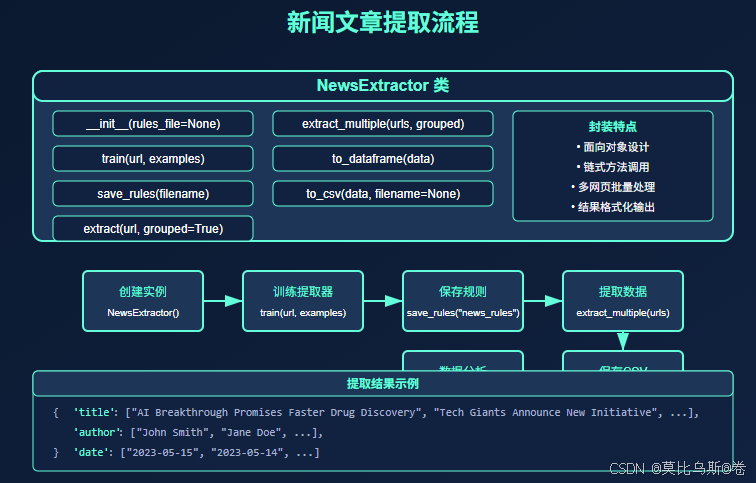
下面是一个完整的实例,展示如何使用AutoScraper创建一个新闻文章提取器:
from autoscraper import AutoScraperimport pandas as pdfrom datetime import datetimeclass NewsExtractor: def __init__(self, rules_file=None): self.scraper = AutoScraper() if rules_file: self.scraper.load(rules_file) def train(self, url, examples): \"\"\"训练提取器\"\"\" self.scraper.build(url, examples) return self def save_rules(self, filename): \"\"\"保存提取规则\"\"\" self.scraper.save(filename) return self def extract(self, url, grouped=True): \"\"\"从URL提取新闻数据\"\"\" return self.scraper.get_result_similar(url, grouped=grouped) def extract_multiple(self, urls, grouped=True): \"\"\"从多个URL提取新闻数据\"\"\" all_data = {} for url in urls: result = self.extract(url, grouped=grouped) if not all_data: all_data = {k: [] for k in result.keys()} if grouped else [] if grouped: for k, v in result.items(): all_data[k].extend(v) else: all_data.extend(result) return all_data def to_dataframe(self, data): \"\"\"将提取的数据转换为DataFrame\"\"\" if isinstance(data, list): return pd.DataFrame({\'content\': data}) else: return pd.DataFrame(data) def to_csv(self, data, filename=None): \"\"\"将数据保存为CSV\"\"\" if filename is None: filename = f\"news_data_{datetime.now().strftime(\'%Y%m%d_%H%M%S\')}.csv\" df = self.to_dataframe(data) df.to_csv(filename, index=False) print(f\"Data saved to {filename}\") return filename# 使用示例if __name__ == \"__main__\": # 创建新闻提取器 extractor = NewsExtractor() # 训练提取器 news_url = \"https://www.example-news.com/technology\" examples = { \'title\': [\"AI Breakthrough Promises Faster Drug Discovery\", \"Tech Giants Announce New Quantum Computing Initiative\"], \'author\': [\"John Smith\", \"Jane Doe\"], \'date\': [\"2023-05-15\", \"2023-05-14\"], \'summary\': [\"Researchers have developed a new AI system that can...\", \"Leading technology companies announced today...\"] } extractor.train(news_url, examples) # 保存规则 extractor.save_rules(\"tech_news_rules\") # 提取数据 result = extractor.extract(news_url) # 保存为CSV extractor.to_csv(result, \"tech_news.csv\") # 提取多个页面的数据 urls = [ \"https://www.example-news.com/technology\", \"https://www.example-news.com/technology/page/2\" ] multiple_results = extractor.extract_multiple(urls) extractor.to_csv(multiple_results, \"tech_news_multiple_pages.csv\")这个新闻提取器类封装了AutoScraper的功能,提供了更加友好的API,可以轻松地从新闻网站提取标题、作者、日期和摘要等信息。
AutoScraper的工作原理
了解AutoScraper的工作原理有助于我们更好地使用它。AutoScraper主要通过以下步骤工作:
-
获取HTML内容:首先,AutoScraper使用requests库获取目标URL的HTML内容。
-
解析HTML:使用Beautiful Soup和lxml解析HTML结构,构建DOM树。
-
定位样例数据:在DOM树中查找用户提供的样例数据。
-
生成选择器栈:对于每个找到的样例数据,AutoScraper会生成多个可能的选择器路径(称为\"选择器栈\")。
-
评估选择器:AutoScraper会评估每个选择器栈,找出能够最准确地匹配所有样例数据的选择器。
-
应用规则提取数据:使用选定的选择器栈从页面中提取所有匹配的数据。
AutoScraper的核心优势在于它能够自动生成和评估多种可能的选择器,并选择最适合的一种,无需用户手动编写复杂的选择器表达式。
与其他爬虫工具的比较
为了更全面地了解AutoScraper的优势和局限性,我们将它与其他常用的爬虫工具进行比较:
从比较中可以看出,AutoScraper在易用性和维护成本方面具有明显优势,特别适合小型项目和快速数据提取任务。但对于需要高度定制化的大规模爬虫项目,Scrapy可能是更好的选择。
最佳实践与注意事项
在使用AutoScraper时,以下最佳实践可以帮助你获得更好的结果:
1. 选择好的样例数据
- 提供多个不同的样例,增加模式识别的准确性
- 样例应该是页面上实际存在的文本,完全匹配
- 选择具有代表性的样例,覆盖不同的格式和长度
2. 处理动态内容
- 对于JavaScript渲染的内容,结合Selenium使用
- 确保页面完全加载后再提取数据
- 考虑使用等待策略,而不是固定的sleep时间
3. 规则维护
- 定期检查和更新规则,适应网站变化
- 保存多个版本的规则,以便在规则失效时回退
- 为不同类型的页面创建不同的规则集
4. 性能优化
- 避免过于频繁的请求,添加适当的延迟
- 对于大型网站,考虑使用代理轮换
- 利用多线程或异步处理提高爬取效率
5. 合规性考虑
- 遵守网站的robots.txt规则
- 避免过度爬取,可能导致IP被封
- 考虑网站的使用条款,确保合法使用数据
结语:AutoScraper的未来与展望
AutoScraper代表了网页数据提取工具的一个重要发展方向:通过智能化和自动化,降低技术门槛,提高开发效率。它特别适合那些需要快速提取网页数据但不想深入学习复杂爬虫技术的用户。
随着人工智能技术的进步,我们可以预见未来的网页数据提取工具将变得更加智能和自适应,能够处理更复杂的页面结构和动态内容。AutoScraper已经是这一趋势的先行者。
通过本文的学习,你应该已经掌握了AutoScraper的基本用法和高级技巧,能够应用它来解决各种网页数据提取问题。无论是个人项目还是企业应用,AutoScraper都能帮助你以最小的代码量实现高效的数据采集。
参考资料
- AutoScraper GitHub仓库
- AutoScraper官方文档
- Python Requests库文档
- Beautiful Soup文档
- Selenium Python文档
- 网页抓取法律与道德指南
toScraper都能帮助你以最小的代码量实现高效的数据采集。
参考资料
- AutoScraper GitHub仓库
- AutoScraper官方文档
- Python Requests库文档
- Beautiful Soup文档
- Selenium Python文档
- 网页抓取法律与道德指南
- 数据科学中的网页抓取技术


