SpringBoot 集成 Kafka_springboot kafka
(一)Kafka介绍
Kafka 也是是我们在开发过程中经常会使用的一种消息队列
Kafka的核心概念包括Producer、Consumer、Broker、Topic、Partition和Offset。
Producer:生产者,负责将数据发送到Kafka集群。
Consumer:消费者,从Kafka集群中读取数据。
Broker:Kafka服务器实例,Kafka集群通常由多个Broker组成。
Topic:主题,数据按主题进行分类。
Partition:分区,每个主题可以有多个分区,用于实现并行处理和提高吞吐量。
Offset:偏移量,每个消息在其分区中的唯一标识。
(二)使用场景
Kafka适用于以下场景:
日志收集:集中收集系统日志和应用日志,通过Kafka传输到大数据处理系统。
消息队列:作为高吞吐量、低延迟的消息队列系统。
数据流处理:实时处理数据流,用于实时分析、监控和处理。
事件源架构:将所有的变更事件存储在Kafka中,实现事件溯源和回放。
流数据管道:构建数据管道,连接数据源和数据存储系统。
(三)Spring Boot 集成 Kafka
前置条件:先启动zooker 服务器、再启动kafka 服务端
org.springframework.kafka spring-kafka生产者端 propertise配置
###################################################################### Kafka生产者配置文件# 包含:必须配置、强烈建议配置和可选配置# 用途:配置Kafka生产者的行为,包括消息发送方式、性能优化、可靠性保证等# 注意:某些配置项的值需要根据实际生产环境进行调整################################################################################【必须配置】############ Kafka服务器地址,多个地址用逗号分隔(必须)# 例如:localhost:9092,localhost:9093,localhost:9094spring.kafka.producer.bootstrap-servers=localhost:9092# 消息键和值的序列化器(必须)# 用于将Java对象转换为Kafka中的二进制数据spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializerspring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer###########【强烈建议配置】############ 可靠性配置# acks=all 所有副本都确认才算写入成功,最高可靠性# retries 发送失败时的重试次数# enable.idempotence=true 启用幂等性,防止消息重复spring.kafka.producer.acks=allspring.kafka.producer.retries=3spring.kafka.producer.properties.enable.idempotence=true# 性能配置# batch-size 批量发送的大小(字节)# buffer-memory 生产者缓冲区大小(字节)# compression-type 消息压缩类型(none, gzip, snappy, lz4, zstd)spring.kafka.producer.batch-size=16384spring.kafka.producer.buffer-memory=33554432spring.kafka.producer.compression-type=snappy# 请求配置# request.timeout.ms 等待服务器响应的最大时间# max.request.size 单个请求的最大大小spring.kafka.producer.properties.request.timeout.ms=30000spring.kafka.producer.properties.max.request.size=1048576# 批量发送配置# linger.ms 延迟发送时间,等待更多消息一起发送# 增加此值可以提高吞吐量,但会增加延迟spring.kafka.producer.properties.linger.ms=10# 发送缓冲区配置# send.buffer.bytes TCP发送缓冲区大小# receive.buffer.bytes TCP接收缓冲区大小spring.kafka.producer.properties.send.buffer.bytes=131072spring.kafka.producer.properties.receive.buffer.bytes=32768###########【可选配置】############ 事务配置# 如果启用事务,必须配置事务ID前缀# 不同的生产者必须使用不同的事务ID#spring.kafka.producer.transaction-id-prefix=tx-# 生产者限制配置# max.block.ms 发送阻塞的最大时间# max.in.flight.requests.per.connection 单个连接最大未确认请求数# spring.kafka.producer.properties.max.block.ms=60000# spring.kafka.producer.properties.max.in.flight.requests.per.connection=5影响 生产者进行发送 的两个重要配置
linger.ms和batch-size
linger.ms 的作用linger.ms 控制了生产者在发送一个批次之前等待更多消息加入该批次的时间。如果设置为 0,生产者将不会等待,而是会立即发送任何可用的消息批次,无论该批次是否达到了 batch-size 的大小限制。batch-size 的作用batch-size 定义了生产者发送的每个批次中消息的总字节大小。当生产者收集到足够多的消息(其总字节大小达到或超过 batch-size)时,它会发送这个批次,或者当达到 linger.ms 的时间限制时(如果 linger.ms 大于 0)。linger.ms=0 时的效果当 linger.ms 设置为 0 时,生产者不会等待更多消息加入当前批次,而是会立即发送任何已经收集到的消息。这意味着,如果生产者只收集到少量消息(其总字节大小远小于 batch-size),这些消息也会被发送出去。然而,如果生产者能够迅速收集到足够多的消息以达到或超过 batch-size,那么这些消息仍然会被组合成一个较大的批次发送。消费者端 propertise配置
# Kafka消费者配置文件# 包含:必须配置、强烈建议配置和可选配置# 用途:配置Kafka消费者的行为,包括消费方式、批量处理、会话管理等# 注意:某些配置项的值需要根据实际生产环境进行调整################################################################################【必须配置】############ Kafka服务器地址,多个地址用逗号分隔(必须)# 例如:localhost:9092,localhost:9093,localhost:9094spring.kafka.consumer.bootstrap-servers=localhost:9092# 消费者组ID,同一组的消费者协同消费消息(必须)# 相同组ID的消费者消费不同分区的消息,实现负载均衡spring.kafka.consumer.group-id=defaultConsumerGroup# 消息键和值的反序列化器(必须)# 用于将Kafka中的二进制数据转换为Java对象spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializerspring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer###########【强烈建议配置】############ 消息提交方式配置# enable-auto-commit=false 关闭自动提交,防止消息丢失# ack-mode=MANUAL 手动确认模式,确保消息被正确处理后才提交spring.kafka.consumer.enable-auto-commit=falsespring.kafka.listener.ack-mode=MANUAL# 批量消费配置# type=batch 启用批量消费模式,提高消费效率# max-poll-records 每次批量消费的最大消息数spring.kafka.listener.type=batchspring.kafka.consumer.max-poll-records=500# 会话超时配置# session.timeout.ms 消费者组会话超时时间,如果超过此时间没有心跳则认为消费者死亡# max.poll.interval.ms 两次poll之间的最大间隔,超过则认为消费者处理能力不足spring.kafka.consumer.properties.session.timeout.ms=45000spring.kafka.consumer.properties.max.poll.interval.ms=300000# 偏移量配置# earliest: 从最早的消息开始消费# latest: 从最新的消息开始消费,保证消费者只处理最新的消息# none: 如果无偏移量则抛出异常spring.kafka.consumer.auto-offset-reset=latest# 消费者拉取配置# fetch.min.bytes 每次最小拉取大小,避免频繁拉取# fetch.max.wait.ms 当数据量不足fetch.min.bytes时,最多等待时间spring.kafka.consumer.fetch.min.bytes=1spring.kafka.consumer.fetch.max.wait.ms=500# 心跳配置# heartbeat.interval.ms 心跳间隔时间,必须小于session.timeout.msspring.kafka.consumer.properties.heartbeat.interval.ms=3000###########【可选配置】############ 并发消费配置# 设置消费者线程数,提高消费能力spring.kafka.listener.concurrency=3# 消费者限制配置# max.partition.fetch.bytes 每个分区返回的最大数据量# fetch.max.bytes 一次请求中返回的最大数据量spring.kafka.consumer.max-partition-fetch-bytes=1048576spring.kafka.consumer.fetch.max.bytes=52428800简单实践
# 简单生产者@RestControllerpublic class KafkaProducer { @Autowired private KafkaTemplate kafkaTemplate; // 发送消息 @GetMapping(\"/kafka/normal/{message}\") public void sendMessage1(@PathVariable(\"message\") String normalMessage) { kafkaTemplate.send(\"topic1\", normalMessage); }}-------------------------------------------------------------------------------# 简单消费者@Componentpublic class KafkaConsumer { // 消费监听 @KafkaListener(topics = {\"topic1\"}) public void onMessage1(ConsumerRecord record){ // 消费的哪个topic、partition的消息,打印出消息内容 System.out.println(\"简单消费:\"+record.topic()+\"-\"+record.partition()+\"-\"+record.value()); }}上面示例创建了一个生产者,发送消息到topic1,消费者监听topic1消费消息。
监听器用@KafkaListener注解,topics表示监听的topic,支持同时监听多个,用英文逗号分隔。
启动项目,postman调接口触发生产者发送消息,
生产者
基本发送方式
ListenableFuture<SendResult> send(String topic, V value);
ListenableFuture<SendResult> send(String topic, K key, V value);参数:
topic:要发送消息的主题。
key:消息的键(可选)。如果指定了键,Kafka会根据分区器(Partitioner)的策略来决定消息应该发送到哪个分区。value:消息的值。
使用场景:这是最常用的发送方法。
当只需要发送消息到指定主题时,可以使用第一个方法
当需要控制消息的分区时,可以使用第二个方法并指定键。
指定分区发送
ListenableFuture<SendResult> send(String topic, int partition, K key, V value);
参数:
topic:要发送消息的主题。
partition:指定的分区号。
key:消息的键(虽然可以指定,但在这种情况下,分区已经由参数直接指定,因此键的分区作用被忽略)。
value:消息的值。使用场景:当需要确保消息发送到特定分区时,可以使用这个方法。
带有回调的发送
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理:(推荐使用以下这种方式)
@GetMapping(\"/kafka/callbackOne/{message}\")public void sendMessage2(@PathVariable(\"message\") String callbackMessage) { kafkaTemplate.send(\"topic1\", callbackMessage).addCallback(success -> { // 消息发送到的topic主题 String topic = success.getRecordMetadata().topic(); // 消息发送到的partition分区 int partition = success.getRecordMetadata().partition(); // 消息在分区内的offset偏移量 long offset = success.getRecordMetadata().offset(); System.out.println(\"发送消息成功:\" + topic + \"-\" + partition + \"-\" + offset); }, failure -> { System.out.println(\"发送消息失败:\" + failure.getMessage()); });}监听器 (用于生产者这边,异步监听生产者消息是否发送成功)
Kafka提供了ProducerListener 监听器来异步监听生产者消息是否发送成功,我们可以自定义一个kafkaTemplate添加ProducerListener,
当消息发送失败我们可以拿到消息进行重试或者把失败消息记录到数据库定时重试。
@Configurationpublic class KafkaConfig { private static final Logger logger = LoggerFactory.getLogger(KafkaConfig.class); /** * 配置生产者的KafkaTemplate * 用于发送消息到Kafka */ @Bean public KafkaTemplate kafkaTemplate(ProducerFactory producerFactory) { KafkaTemplate template = new KafkaTemplate(producerFactory); // 添加生产者监听器,用于监控消息发送状态 template.setProducerListener(new ProducerListener() { @Override public void onSuccess(ProducerRecord producerRecord, RecordMetadata recordMetadata) { logger.info(\"消息发送成功:topic = {}, partition = {}, offset = {}, value = {}\", producerRecord.topic(), recordMetadata.partition(), recordMetadata.offset(), producerRecord.value()); } @Override public void onError(ProducerRecord producerRecord, RecordMetadata recordMetadata, Exception exception) { logger.error(\"消息发送失败:topic = {}, value = {}, error = {}\", producerRecord.topic(), producerRecord.value(), exception.getMessage()); } }); return template; }}注意:当我们发送一条消息,既会走 ListenableFutureCallback 回调,也会走ProducerListener回调。
自定义分区器
我们知道,kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,这些策略对于数据在Kafka集群中的分布、负载均衡以及性能优化起着关键作用。以下是Kafka中几种常见的分区策略:
轮询策略(Round-Robin Strategy):
这是Kafka Java生产者API默认提供的分区策略。- 如果没有指定分区策略,则会默认使用轮询。
- 轮询策略按照顺序将消息发送到不同的分区,每个消息被发送到其对应分区,按照顺序轮询每个分区,以确保每个分区均匀地接收消息。
- 这种策略能够实现负载均衡,并且能够最大限度地利用集群资源。
按键分配策略(Key-Based Partitioning):
在Kafka中,如果消息指定了key,那么生产者会根据key的哈希值来决定消息应该发送到哪个分区。
这种策略通过hash(key) % numPartitions来计算分区号,其中numPartitions是主题的总分区数。
如果key相同,那么这些消息会被发送到同一个分区,这有助于保持消息的局部性和顺序性。
Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。
其路由机制为:若发送消息时指定了分区(即自定义分区策略),则直接将消息append到指定分区;
若发送消息时未指定 patition,但指定了 key(kafka允许为每条消息设置一个key),则对key值进行hash计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区;
patition 和 key 都未指定,则使用kafka默认的分区策略,轮询选出一个 patition;
我们来自定义一个分区策略,将消息发送到我们指定的partition,首先新建一个分区器类实现Partitioner接口,重写方法,其中partition方法的返回值就表示将消息发送到几号分区
public class CustomizePartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { // 自定义分区规则(这里假设全部发到0号分区) // ...... return 0; } @Override public void close() { } @Override public void configure(Map configs) { }}在application.propertise中配置自定义分区器,配置的值就是分区器类的全路径名
# 自定义分区器spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner开启事务
在Spring Kafka中,当您设置了transaction-id-prefix后,Spring会为您的KafkaTemplate配置一个事务性生产者。
事务性生产者会要求它的所有发送操作都必须在事务的上下文中进行,不然会报错错误如下:
No transaction is in process; possible solutions: run the template operation within the scope of a template.executeInTransaction() operation, start a transaction with @Transactional before invoking the template method, run in a transaction started by a listener container when consuming a record
前提
需要再配置文件中加transaction-id-prefix配置
理由:
唯一性:Kafka 使用事务 ID 来跟踪和协调跨多个分区和主题的消息发送。
防止存在多个生产者时,无法区分,所以需要通过这个参数来区分不同的生产者的事务。
比如生产者1号,我就给它配置 transaction-id-prefix=tx1_ 生产者2号,我就给它配置 transaction-id-prefix=tx2_
# 所以建议若要开启事务,则不管生产者是一个还是多个,都需要习惯去配置这个事务前缀(非固定命名,任意)# 事务ID前缀,确保唯一性spring.kafka.producer.transaction-id-prefix=tx1_# 还需改动两个参数值# 事务性生产者时,必须设置一个非零的重试次数spring.kafka.producer.retries=1 # 使用幂等性生产者,必须将acks设置为allspring.kafka.producer.acks=all事务的上下文的实现
// 方式1:使用 @Transactional注解@Transactional@GetMapping(\"/kafka/transaction\")public void sendMessage7(){ kafkaTemplate.send(\"topic1\",\"哇哈哈\"); //throw new RuntimeException(\"fail\");}// 方式2:使用 KafkaTemplate 的 executeInTransaction 方法来声明事务@GetMapping(\"/kafka/transaction\")public void sendMessage7(){ // 声明事务:出现报错的话, executeInTransaction 中包裹的 send消息是不会发出去 kafkaTemplate.executeInTransaction(operations -> { operations.send(\"topic1\",\"111 executeInTransaction\"); operations.send(\"topic1\",\"222 executeInTransaction\"); return null; //throw new RuntimeException(\"fail\"); });}消费者
指定topic、partition、offset消费
前面我们在监听消费topic1的时候,监听的是topic1上所有的消息。
如果我们想指定topic、指定partition、指定offset来消费呢?
也很简单,@KafkaListener注解已全部为我们提供
/** * @Title 指定topic、partition、offset消费 * @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 \"0号和1号\" 分区,指向1号分区的offset初始值为8 属性解释:① id:消费者ID② groupId:消费组ID(这个配置项是用来指定消费者组ID的,它使得多个消费者实例可以协同工作,共同消费主题中的消息,并实现负载均衡、容错性和扩展性等功能)③ topics:监听的topic,可监听多个④ topicPartitions:可配置更加详细的监听信息,可指定topic、parition、offset监听**/@KafkaListener(id = \"consumer1\",groupId = \"felix-group\",topicPartitions = { @TopicPartition(topic = \"topic1\", partitions = { \"0\" }), @TopicPartition(topic = \"topic2\", partitions = \"0\", partitionOffsets = @PartitionOffset(partition = \"0\", initialOffset = \"8\"))})public void onMessage2(ConsumerRecord record) { System.out.println(\"topic:\"+record.topic()+\"|partition:\"+record.partition()+\"|offset:\"+record.offset()+\"|value:\"+record.value());}注意:topics和topicPartitions不能同时使用
批量消费
请注意:当Kafka监听器被配置为批量消费模式时,它接收的消息格式将是一个包含多个ConsumerRecord 对象的列表。在这种配置下,监听器不再直接支持处理单个ConsumerRecord 对象的方法签名。
设置application.prpertise开启批量消费即可
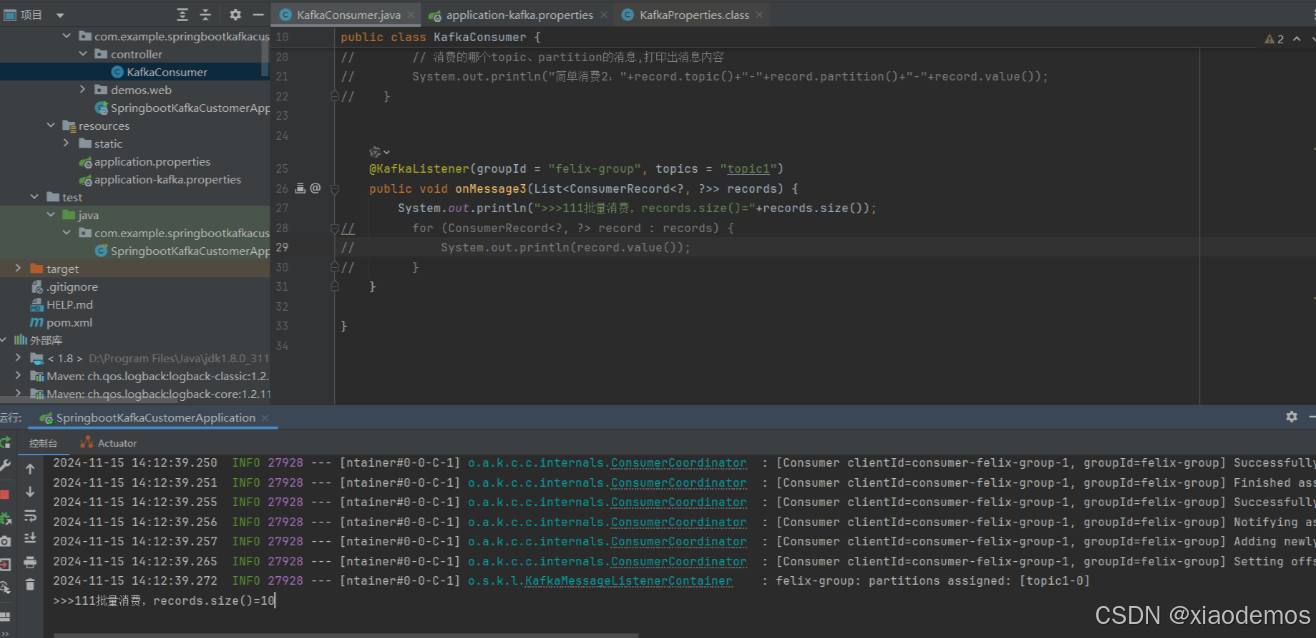
# 设置批量消费spring.kafka.listener.type=batch# 批量消费每次最多消费多少条消息spring.kafka.consumer.max-poll-records=50// 接收消息时用List来接收,监听代码如下@KafkaListener(id = \"consumer2\",groupId = \"felix-group\", topics = \"topic1\")public void onMessage3(List<ConsumerRecord> records) { System.out.println(\">>>批量消费一次,records.size()=\"+records.size()); for (ConsumerRecord record : records) { System.out.println(record.value()); }}提问:怎么测试才能有这个批量消费的体现呢?
好问题。
回答:先把消费者服务关闭,让生产者那边往同一个分区发多个消息,再把消费者打开,你就会发现“批量消费”效果出现了
“批量消费”效果如下:(生产者进行for循环了10次发送)
异常处理
通过 ConsumerAwareListenerErrorHandler 异常处理器 ,我们可以处理consumer在消费时发生的异常。
具体步骤:新建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法。
用@Bean注入,BeanName默认就是方法名。
然后我们将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面。
当监听抛出异常的时候,则会自动调用异常处理器。
import org.apache.kafka.clients.consumer.Consumer;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.listener.ConsumerAwareListenerErrorHandler;import org.springframework.kafka.listener.ListenerExecutionFailedException;import org.springframework.messaging.Message;@Configurationpublic class KafkaConfig { @Bean public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() { return new ConsumerAwareListenerErrorHandler() { @Override public Object handleError(Message message, ListenerExecutionFailedException exception, Consumer consumer) { System.out.println(\"消费异常:\" + message.getPayload()); return null; } }; }}单个消费加入异常类
@Componentpublic class KafkaConsumer { @KafkaListener(topics = {\"topic1\"}, errorHandler = \"consumerAwareErrorHandler\") public void onMessage4(ConsumerRecord record) throws Exception { throw new Exception(\"简单消费-模拟异常\"); }}批量消费加入异常类
@Component
public class KafkaConsumer {@KafkaListener(topics = \"topic1\", errorHandler = \"consumerAwareErrorHandler\")
public void onMessage5(List<ConsumerRecord> records) throws Exception {
System.out.println(\"批量消费一次...\");
throw new Exception(\"批量消费-模拟异常\");
}
}
消息过滤器
消息过滤器可以在消息抵达 consumer 之前被拦截,在实际应用中,我们可以根据自己的业务逻辑,筛选出需要的信息再交由KafkaListener处理,不需要的消息则过滤掉。
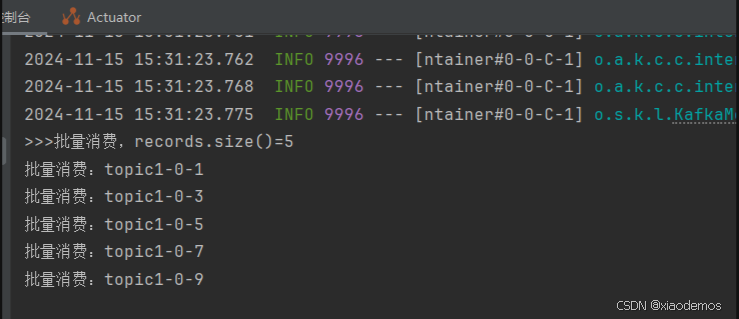
配置消息过滤只需要为 监听器工厂 配置一个RecordFilterStrategy(消息过滤策略),返回true的时候消息将会被抛弃,返回false时,消息能正常抵达监听容器。
其中有个设置如果是批量消费的情况下就要加上,如果不是批量的话就不用加
// 启用批量监听功能
// 配合application.properties中的批量消费设置使用
factory.setBatchListener(true);
/** * Kafka消息过滤器配置类 * 用于配置消息的过滤规则和批量处理相关的设置 */@Componentpublic class KafkaFilterConfig { /** * 注入Kafka消费者工厂 * 用于创建Kafka消费者实例 */ @Autowired ConsumerFactory consumerFactory; /** * 创建并配置Kafka监听器容器工厂 * 该工厂用于创建处理Kafka消息的监听器容器 * * @return 配置好的监听器容器工厂实例 */ @Bean public ConcurrentKafkaListenerContainerFactory filterContainerFactory() { // 创建监听器容器工厂,并指定String类型的key和value ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); // 设置消费者工厂 factory.setConsumerFactory(consumerFactory); // 设置是否自动确认被过滤的消息 // true表示被过滤的消息将被自动确认,不会重新消费 factory.setAckDiscarded(true); // 启用批量监听功能 // 配合application.properties中的批量消费设置使用 factory.setBatchListener(true); /** * 设置消息过滤策略 * 返回true表示消息将被过滤(丢弃) * 返回false表示消息将被保留并处理 */ factory.setRecordFilterStrategy(consumerRecord -> { try { // 获取消息的值并转换为字符串 String value = consumerRecord.value(); // 尝试将消息转换为整数 int intValue = Integer.parseInt(value); // 过滤规则:偶数返回true(被过滤),奇数返回false(被保留) // return true 表示消息将被过滤掉 // return false 表示消息将被保留并处理 return intValue % 2 == 0; } catch (NumberFormatException e) { // 如果消息无法转换为整数,则过滤掉该消息 // 可以在这里添加日志记录 // System.err.println(\"无法解析消息值为整数: \" + consumerRecord.value()); return true; } }); return factory; }}结果如下
消息转发
在实际开发中,我们可能有这样的需求,应用A从TopicA获取到消息,经过处理后转发到TopicB,再由应用B监听处理消息,即一个应用处理完成后将该消息转发至其他应用,完成消息的转发。
重点:由于使用了转发操作,相当于消费者服务这边也是生产者了,所以需要配置生产者相关的配置。
在SpringBoot集成Kafka实现消息的转发也很简单,只需要通过一个@SendTo注解,被注解方法的return值即转发的消息内容,如下:
//消息转发 从topic1转发到topic2@KafkaListener(topics = {\"topic1\"})@SendTo(\"topic2\")public String onMessage7(ConsumerRecord record) { return record.value()+\"-forward message\";}@KafkaListener(topics = {\"topic2\"})public void onMessage8(ConsumerRecord record) { System.out.println(\"收到topic2转发过来的消息:\" + record.value());}定时启动、停止
默认情况下,当消费者项目启动的时候,监听器就开始工作,监听消费发送到指定topic的消息,那如果我们不想让监听器立即工作,想让它在我们指定的时间点开始工作,或者在我们指定的时间点停止工作,该怎么处理呢——使用 KafkaListenerEndpointRegistry ,下面我们就来实现:
禁止监听器自启动;
创建两个定时任务,一个用来在指定时间点启动定时器,另一个在指定时间点停止定时器
新建一个定时任务类,用注解@EnableScheduling声明,KafkaListenerEndpointRegistry 在Spring中已经被注册为Bean,直接注入,设置禁止KafkaListener自启动
@EnableScheduling@Componentpublic class CronTimer { /** * @KafkaListener注解所标注的方法并不会在IOC容器中被注册为Bean, * 而是会被注册在KafkaListenerEndpointRegistry中, * 而KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean **/ @Autowired private KafkaListenerEndpointRegistry registry; @Autowired private ConsumerFactory consumerFactory; // 监听器容器工厂(设置禁止KafkaListener自启动) @Bean public ConcurrentKafkaListenerContainerFactory delayContainerFactory() { ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory(); container.setConsumerFactory(consumerFactory); //禁止KafkaListener自启动 container.setAutoStartup(false); return container; } // 监听器 @KafkaListener(id=\"timingConsumer\",topics = \"sb_topic\",containerFactory = \"delayContainerFactory\") public void onMessage1(ConsumerRecord record){ System.out.println(\"消费成功:\"+record.topic()+\"-\"+record.partition()+\"-\"+record.value()); } // 定时启动监听器 @Scheduled(cron = \"0 42 11 * * ? \") public void startListener() { System.out.println(\"启动监听器...\"); // \"timingConsumer\"是@KafkaListener注解后面设置的监听器ID,标识这个监听器 if (!registry.getListenerContainer(\"timingConsumer\").isRunning()) { registry.getListenerContainer(\"timingConsumer\").start(); } //registry.getListenerContainer(\"timingConsumer\").resume(); } // 定时停止监听器 @Scheduled(cron = \"0 45 11 * * ? \") public void shutDownListener() { System.out.println(\"关闭监听器...\"); registry.getListenerContainer(\"timingConsumer\").pause(); }}手动确认消息
手动提交目前有两种模式
MANUAL :对性能要求高(推荐)
MANUAL_IMMEDIATE:对数据一致性要求高
# 关闭自动提交spring.kafka.consumer.enable-auto-commit=false# 手动ack模式spring.kafka.listener.ack-mode=MANUAL消费消息的时候,给方法添加 Acknowledgment 参数签收消息,同时执行 acknowledge 方法
@KafkaListener(topics = {\"sb_topic\"})public void onMessage9(ConsumerRecord record, Acknowledgment ack) { System.out.println(\"收到消息:\" + record.value()); //确认消息 ack.acknowledge();}propertise 与 java 显式设置 的差异 (有坑,请看!!!)
我在测试中,发现 有些 propertise 配置不生效,有些功能必须在 KafkaConfig 配置 中 java 显式设置,才能生效。
Java 配置 优先级高于 properties 中的配置
Kafka中生产者、消费者配置类
生产者
package com.example.springbootkafkacustomer.config;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.clients.producer.RecordMetadata;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.core.ProducerFactory;import org.springframework.kafka.support.ProducerListener;import org.springframework.kafka.support.converter.StringJsonMessageConverter;import org.springframework.kafka.transaction.KafkaTransactionManager;/** * Kafka生产者配置类 * 用于配置生产者的高级特性,包括: * 1. 默认主题 - 配置消息发送的默认目标主题 * 2. 消息转换 - 支持JSON格式的消息转换 * 3. 事务支持 - 确保消息发送的事务性 * 4. 发送监听 - 监控消息发送结果 * 5. 重试队列 - 处理发送失败的消息 * 6. 错误处理 - 统一处理发送异常 * 7. 告警机制 - 发送失败时的告警通知 * * 每个特性都可以通过功能开关单独控制,便于根据实际需求启用或禁用 * * 注意:部分功能 需要特定的前置配置才能生效 */@Configurationpublic class KafkaProducerConfig { private static final Logger logger = LoggerFactory.getLogger(KafkaProducerConfig.class); /** * 功能开关配置 */ private final boolean enableDefaultTopic = true; // 是否启用默认主题 private final boolean enableJsonConverter = true; // 是否启用JSON转换器 private final boolean enableTransaction = true; // 是否启用事务支持 private final boolean enableProducerListener = true; // 是否启用发送结果监听 private final boolean enableRetryQueue = true; // 是否启用重试队列 private final boolean enableAlert = true; // 是否启用告警机制 /** * 配置KafkaTemplate * 用于发送消息到Kafka,支持事务和结果监听 * */ @Bean public KafkaTemplate kafkaTemplate(ProducerFactory producerFactory) { KafkaTemplate template = new KafkaTemplate(producerFactory); // 1. 设置默认主题 // 替代的配置: // spring.kafka.template.default-topic=defaultTopic // 前置要求: // spring.kafka.producer.bootstrap-servers 必须配置生产者服务器 if (enableDefaultTopic) { template.setDefaultTopic(\"defaultTopic\"); } // 2. 设置消息转换器 // 无法通过properties配置实现 if (enableJsonConverter) { template.setMessageConverter(new StringJsonMessageConverter()); } // 3. 设置事务支持 // 替代的配置: // spring.kafka.producer.transaction-id-prefix=tx- // spring.kafka.producer.enable.idempotence=true // spring.kafka.producer.acks=all // 前置要求: // 1. producerFactory必须支持事务 // 2. spring.kafka.producer.bootstrap-servers 必须配置 // 3. 必须配置唯一的transaction-id-prefix if (enableTransaction) { template.setTransactionIdPrefix(\"tx-\"); } // 4. 设置发送结果监听器 // 无法通过properties配置实现 // 前置要求: // 1. spring.kafka.producer.acks=all 建议配置 // 2. spring.kafka.producer.retries>0 建议配置 // 3. spring.kafka.producer.properties.max.in.flight.requests.per.connection=1 建议配置 if (enableProducerListener) { template.setProducerListener(new ProducerListener() { @Override public void onSuccess(ProducerRecord record, RecordMetadata metadata) { logger.info(\"消息发送成功:topic={}, partition={}, offset={}, key={}, value={}\", metadata.topic(), metadata.partition(), metadata.offset(), record.key(), record.value()); } @Override public void onError(ProducerRecord record, RecordMetadata recordMetadata, Exception exception) { logger.error(\"消息发送失败:topic={}, key={}, value={}, error={}\", record.topic(), record.key(), record.value(), exception.getMessage()); handleSendError(record, exception); } }); } return template; } /** * 处理发送失败的消息 * 无法通过properties配置实现 * 前置要求: * 1. spring.kafka.producer.retries 建议配置重试次数 * 2. spring.kafka.producer.retry.backoff.ms 建议配置重试间隔 * 3. 如果要将失败消息保存到数据库,需要配置数据源 * 4. 如果要将失败消息保存到Redis,需要配置Redis连接 */ private void handleSendError(ProducerRecord record, Exception exception) { try { // 记录错误日志 logger.error(\"处理发送失败的消息:topic={}, key={}, value={}, error={}\", record.topic(), record.key(), record.value(), exception.getMessage()); // 保存到重试队列 if (enableRetryQueue) { saveToRetryQueue(record); } // 发送告警通知 if (enableAlert) { sendAlert(record, exception); } } catch (Exception e) { logger.error(\"处理发送失败消息时发生异常\", e); } } /** * 将消息保存到重试队列 * 无法通过properties配置实现 * 前置要求: * 1. 如果使用数据库存储: * - 需要配置数据源 * - 需要创建对应的数据表 * 2. 如果使用Redis存储: * - 需要配置Redis连接 * - 需要定义数据结构 * 3. 如果使用Kafka重试主题: * - 需要创建重试主题 * - 需要配置重试主题的分区数和副本数 */ private void saveToRetryQueue(ProducerRecord record) { if (!enableRetryQueue) { return; } logger.info(\"将消息保存到重试队列:{}\", record.value()); // TODO: 实现重试队列逻辑 } /** * 发送告警通知 * 无法通过properties配置实现 * 前置要求: * 1. 邮件告警: * - spring.mail.* 相关配置 * - 配置邮件服务器信息 * 2. 短信告警: * - 配置短信服务商的相关参数 * 3. 钉钉/企业微信告警: * - 配置webhook地址 * - 配置加密密钥 */ private void sendAlert(ProducerRecord record, Exception exception) { logger.warn(\"发送告警通知:消息={}, 异常={}\", record.value(), exception.getMessage()); // TODO: 实现告警通知逻辑 }} 消费者
package com.example.springbootkafkacustomer.config;import org.apache.kafka.clients.consumer.Consumer;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;import org.springframework.kafka.core.ConsumerFactory;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.listener.ConsumerAwareListenerErrorHandler;import org.springframework.kafka.listener.ContainerProperties;import org.springframework.kafka.listener.DefaultErrorHandler;import org.springframework.kafka.listener.ListenerExecutionFailedException;import org.springframework.messaging.Message;import org.springframework.util.backoff.FixedBackOff;/** * Kafka消费者配置类 * 用于配置消费者的高级特性,包括: * 1. 手动确认机制 - 控制消息的确认方式,确保消息被正确处理 * 2. 批量消费 - 支持批量接收和处理消息,提高处理效率 * 3. 消息过滤 - 在消费前过滤不需要处理的消息 * 4. 重试机制 - 消费失败时的重试策略 * 5. 异常处理 - 统一处理消费过程中的异常 * 6. 死信队列 - 处理无法正常消费的消息 * 7. 消息转发 - 支持消息处理后转发到其他主题 * 8. 告警机制 - 异常情况的告警通知 * * 每个特性都可以通过功能开关单独控制,便于根据实际需求启用或禁用 * * 注意:部分功能 需要特定的前置配置才能生效 */@Configurationpublic class KafkaConsumerConfig { private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerConfig.class); /** * 功能开关配置 */ private final boolean enableManualAck = true; // 是否启用手动确认 private final boolean enableBatchListener = true; // 是否启用批量监听 private final boolean enableMessageFilter = true; // 是否启用消息过滤 private final boolean enableErrorHandler = true; // 是否启用错误处理 private final boolean enableRetry = true; // 是否启用重试机制 private final boolean enableForward = true; // 是否启用消息转发 private final boolean enableDeadLetter = true; // 是否启用死信队列 private final boolean enableAlert = true; // 是否启用告警机制 /** * 配置消费者监听器工厂 * 用于创建消费者监听器容器,处理消息的消费逻辑 * */ @Bean public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory( ConsumerFactory consumerFactory, KafkaTemplate kafkaTemplate) { ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); // 基础配置 factory.setConsumerFactory(consumerFactory); // 1. 手动确认配置 // 替代的配置: // spring.kafka.consumer.enable-auto-commit=false // spring.kafka.listener.ack-mode=MANUAL // 前置要求: // spring.kafka.consumer.group-id 必须配置消费者组ID if (enableManualAck) { factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL); } // 2. 批量监听配置 // 替代的配置: // spring.kafka.listener.type=batch // spring.kafka.consumer.max-poll-records=500 // 前置要求: // spring.kafka.consumer.fetch.min.bytes 建议配置最小抓取大小 // spring.kafka.consumer.fetch.max.wait.ms 建议配置最大等待时间 if (enableBatchListener) { factory.setBatchListener(true); } // 3. 消息过滤器配置 // 无法通过properties配置实现 // 前置要求: // spring.kafka.consumer.group-id 必须配置消费者组ID // spring.kafka.consumer.enable-auto-commit=false 建议关闭自动提交 if (enableMessageFilter) { factory.setRecordFilterStrategy(consumerRecord -> { try { String value = consumerRecord.value(); if (value == null || value.trim().isEmpty()) { logger.info(\"过滤掉空消息\"); return true; } return false; } catch (Exception e) { logger.error(\"消息过滤发生异常\", e); return true; } }); } // 4. 错误处理配置 // 替代的配置: // spring.kafka.consumer.properties.retry.backoff.ms=1000 // spring.kafka.consumer.properties.retries=3 // 前置要求: // spring.kafka.consumer.group-id 必须配置消费者组ID // spring.kafka.listener.ack-mode=MANUAL 建议使用手动提交 if (enableErrorHandler && enableRetry) { DefaultErrorHandler errorHandler = new DefaultErrorHandler( new FixedBackOff(1000L, 3)); // 1秒间隔,重试3次 factory.setCommonErrorHandler(errorHandler); } // 5. 消息转发配置 // 无法通过properties配置实现 // 前置要求: // spring.kafka.producer.bootstrap-servers 必须配置生产者服务器 // spring.kafka.producer.key-serializer 必须配置生产者序列化器 // spring.kafka.producer.value-serializer 必须配置生产者序列化器 if (enableForward) { factory.setReplyTemplate(kafkaTemplate); } return factory; } /** * 异常处理器配置 * 无法通过properties配置实现 * 前置要求: * 1. spring.kafka.consumer.group-id 必须配置消费者组ID * 2. spring.kafka.listener.ack-mode=MANUAL 建议使用手动提交 * 3. 如果需要发送告警邮件,需要配置邮件服务器 * 4. 如果需要发送告警短信,需要配置短信服务 */ @Bean @ConditionalOnProperty(name = \"kafka.error-handler.enabled\", havingValue = \"true\", matchIfMissing = true) public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() { return (Message message, ListenerExecutionFailedException exception, Consumer consumer) -> { // 记录错误信息 logger.error(\"消费异常:消费者组={}, topic={}, 分区={}, 偏移量={}, 消息内容={}, 异常={}\", consumer.groupMetadata().groupId(), message.getHeaders().get(\"kafka_receivedTopic\"), message.getHeaders().get(\"kafka_receivedPartitionId\"), message.getHeaders().get(\"kafka_offset\"), message.getPayload(), exception.getMessage()); // 消费告警通知 if (enableAlert) { sendAlert(message, exception); } // 将失败的消息写入死信队列 if (enableDeadLetter) { sendToDeadLetter(message); } return null; }; } /** * 告警通知配置 * 无法通过properties配置实现 * 前置要求: * 1. 如果使用邮件告警: * - spring.mail.* 相关配置 * - 配置邮件服务器信息 * 2. 如果使用短信告警: * - 配置短信服务商的相关参数 * 3. 如果使用钉钉/企业微信告警: * - 配置webhook地址 * - 配置加密密钥 */ private void sendAlert(Message message, Exception exception) { logger.warn(\"发送告警通知:消息={}, 异常={}\", message.getPayload(), exception.getMessage()); } /** * 死信队列配置 * 无法通过properties配置实现 * 前置要求: * 1. 如果使用Kafka死信主题: * - 需要创建死信主题 * - 配置死信主题的分区数和副本数 * 2. 如果使用数据库存储: * - 需要配置数据源 * - 需要创建对应的数据表 * 3. 如果使用Redis存储: * - 需要配置Redis连接 * - 需要定义数据结构 */ private void sendToDeadLetter(Message message) { if (!enableDeadLetter) { return; } logger.info(\"发送到死信队列:消息={}\", message.getPayload()); }}

