GoLang学习笔记
Go语言定义变量
常见定义方法
- 使用
var:语法为var 变量名类型= 表达式,例如var name string = \"zhangsan\"。 - 类型推导(函数内部):语法为
变量名:= 表达式,例如n := 10;注意短变量只能用于声明局部变量,不能用于全局变量声明
fmt 包及打印方法
- 使用前提:需要引入 fmt 包,即
import \"fmt\"。 - Print 与 Println 的区别
- 多值输入时,Println 会在值中间加空格,Print 不会,例如
fmt.Println(\"go\", \"python\", \"php\", \"javascript\")输出为go python php javascript,fmt.Print(\"go\", \"python\", \"php\", \"javascript\")输出为gopythonphpjavascript。 - 换行方面,Println 会自动换行,Print 不会,例如连续使用
fmt.Println(\"hello\")和fmt.Println(\"world\"),输出结果为分行的hello和world;而连续使用fmt.Print(\"hello\")和fmt.Print(\"world\"),输出结果为helloworld。
- 多值输入时,Println 会在值中间加空格,Print 不会,例如
- Println 与 Printf 的区别:Printf 是格式化输出,需使用占位符,如
%d表示数字的十进制表示,且占位符与后面的变量一一对应,使用更灵活;例如fmt.Printf(\"a=%d,b=%d,c=%d\", a, b, c)可输出a=10,b=20,c=30,而fmt.Println(\"a=\", a, \",b=\", b, \",c=\", c)输出为a= 10 ,b= 20 ,c= 30。 - 更多占位符参考:可访问
http://docscn.studygolang.com/pkg/fmt/
注释
快捷注释方式:Windows 系统使用ctrl+/,Mac 系统使用command+/
- 注释形式
- 多行注释:
/* 这是一个注释 */ - 单行注释:
// 这是一个注释。
- 多行注释:
Go 变量、常量及命名规则
变量声明方式
- 使用
var声明:语法为var 变量名称 type,如var name string、var age int等;也可在声明时赋值,如var username=\"张三\"、var age int =20。 - 一次定义多个变量:
var identifier1, identifier2 type,如var username, sex string;也可在声明时赋值,如var a, b, c, d = 1, 2, 3, false。 - 批量声明变量并可指定类型或赋值:如
var (a string; b int; c bool),也可在批量声明时直接赋值,如var (a string = \"张三\"; b int = 20; c bool = true)。 - 变量初始化:声明时会自动初始化为类型默认值,如整型和浮点型默认值为 0,字符串为空字符串等;也可手动指定初始值,标准格式为
var 变量名类型= 表达式,还可一次初始化多个变量,如var name, age = \"zhangsan\", 20。 - 类型推导:省略变量类型,编译器根据等号右边值推导类型,如
var name = \"Q1mi\"。 - 短变量声明法:函数内部用
:=声明并初始化局部变量,不能用于全局变量,如n := 10,也可一次声明多个,如m1, m2, m3 := 10, 20, 30 - 匿名变量:用
_表示,用于忽略多重赋值中的某个值,不占用命名空间,无重复声明问题,如_, username := getInfo()。 - 注意事项:函数外语句须以关键字开头;
:=不能在函数外使用;_多用于占位忽略值
常量
- 定义:恒定不变的值,声明类似变量但用
const,定义时必须赋值,如const pi = 3.1415;可同时声明多个,如const (pi = 3.1415; e = 2.7182);同时声明多个时省略值则与上一行相同,如const (n1 = 100; n2; n3)中 n2、n3 均为 100。 - 结合 iota 使用:iota 是常量计数器,仅在常量表达式中使用,const 出现时重置为 0,每新增一行常量声明计数一次。如
const a = iota中 a=0;可跳过某些值、中间插队、多个定义在一行等,如const (n1 = iota; n2 = 100; n3 = iota)中 n1=0、n2=100、n3=2
命名规则
- 由数字、字母、下划线组成,开头不能是数字。
- 不能是保留字和关键字。
- 区分大小写,不建议用大小写区分两个变量。
- 见名思意,变量用名词,方法用动词。
- 一般用驼峰式,特有名词根据私有性全大写或小写。
代码风格
- 每行结束不用写分号。
- 运算符左右建议各加一个空格。
- 推荐驼峰式命名。
- 左括号须紧接着语句不换行。
- 可用
go fmt格式化文档统一风格
Go 语言基本数据类型
一、数据类型总体介绍
Go 语言数据类型分为基本数据类型和复合数据类型。
- 基本数据类型:整型、浮点型、布尔型、字符串。
- 复合数据类型:数组、切片、结构体、函数、map、通道 (channel)、接口等。
二、整型
-
分类
- 有符号整型:按长度分为 int8、int16、int32、int64,分别对应不同范围(如 int8 范围为 - 128 到 127),占用空间依次为 1、2、4、8 个字节。
- 无符号整型:对应有符号整型,为 uint8、uint16、uint32、uint64,范围从 0 开始(如 uint8 为 0 到 255),占用空间同对应有符号类型。
-
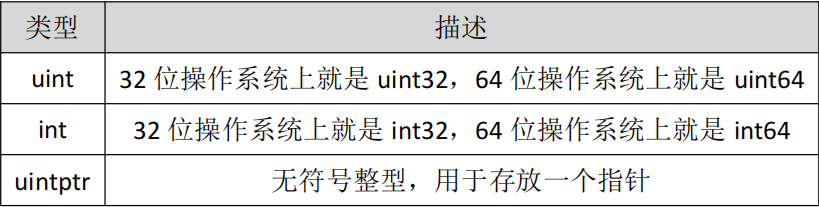
特殊整型
- uint:32 位系统上为 uint32,64 位系统上为 uint64;int:32 位系统上为 int32,64 位系统上为 int64;uintptr:无符号整型,用于存放指针。
- 注意:使用 int 和 uint 时需考虑平台差异,涉及二进制传输等场景避免使用。
-
相关操作
- 查看变量占用字节数:使用
unsafe.Sizeof(n1)(需引入 unsafe 包)。 - 类型转换:不同长度整型可显式转换,如
num2 := int32(num1)(num1 为 int8)。 - 数字字面量语法:Go1.13 后支持二进制(0b 前缀)、八进制(0o 前缀)、十六进制(0x 前缀)定义,可使用_分隔数字(如
v := 123_456)。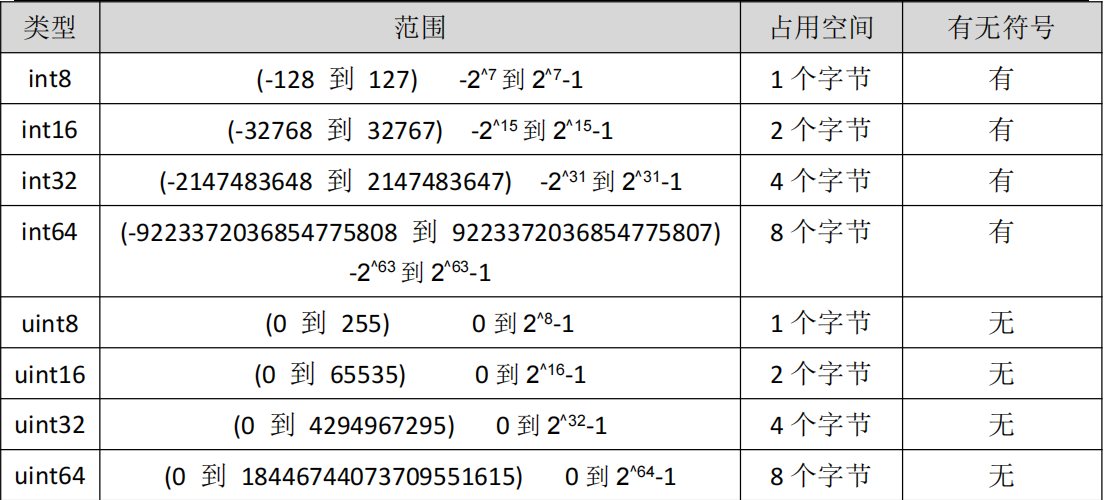
- 查看变量占用字节数:使用
注意: 在使用 int 和 uint 类型时,不能假定它是 32 位或 64 位的整型,而是考虑 int 和 uint 可能在不同平台上的差异。 注意事项:实际项目中整数类型、切片、 map 的元素数量等都可以用 int 来表示。在涉及 到二进制传输、为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使 用 int 和 uint。
三、浮点型
- 类型:float32(最大范围约 3.4e38)和 float64(最大范围约 1.8e308),默认类型为 float64。
- 打印:使用
fmt.Printf配合%f(默认保留 6 位小数)或%.2f(保留 2 位小数)等占位符。 - 精度问题:存在二进制浮点数精度丢失问题(如
8.2 - 3.8结果为 4.399999999999999),可使用第三方包(如github.com/shopspring/decimal)解决。 - 科学计数法:如
5.1234e2(5.1234×10²)、5.1234E-2(5.1234÷10²)。
四、布尔值
- 类型为 bool,值只有 true 和 false,默认值为 false。
- 注意:不允许将整型强制转换为布尔型,布尔型无法参与数值运算或与其他类型转换。
五、字符串
-
基本特性:以原生数据类型出现,内部使用 UTF-8 编码,值用双引号包裹,可包含非 ASCII 字符(如
s2 := \"你好\")。 -
转义符:包括
\\r(回车)、\\n(换行)、\\t(制表符)、\\\'(单引号)、\\\"(双引号)、\\\\(反斜杠)等。 -
多行字符串:使用反引号(`)定义,换行原样保留,转义符无效。
-
常用操作
- 长度:
len(str)。 - 拼接:
+或fmt.Sprintf。 - 分割:
strings.Split。 - 包含判断:
strings.Contains。 - 前缀 / 后缀判断:
strings.HasPrefix/strings.HasSuffix。 - 子串位置:
strings.Index(从前往后)、strings.LastIndex(从后往前)。 - 拼接切片:
strings.Join。
- 长度:
六、byte 和 rune 类型
- byte:即 uint8,代表 ASCII 码字符。
- rune:即 int32,代表 UTF-8 字符,用于处理中文、日文等复合字符。
- 区别与应用:一个字母占 1 个字节(byte),一个汉字占 3 个字节;遍历字符串时,
for i := 0; i < len(s); i++按 byte 遍历(可能乱码),for _, r := range s按 rune 遍历(正确处理中文)。
七、修改字符串
需先转换为[]rune(处理中文)或[]byte(处理 ASCII),修改后再转回 string,转换会重新分配内存。例如:
s1 := \"big\"byteS1 := []byte(s1)byteS1[0] = \'p\'fmt.Println(string(byteS1)) // 输出\"pig\"GoLang 基本数据类型转换
一、数据类型转换概述
Go 语言中只有强制类型转换,没有隐式类型转换。
二、数值类型之间的相互转换
- 包含类型:整型和浮点型。
- 转换规则:不同数值类型进行运算时,需转换为相同类型才能运行,例如
var a int8 = 20,var b int16 = 40,需将a转换为int16类型才能进行加法运算。 - 注意事项:建议从低位类型转换为高位类型,高位类型转换为低位类型可能会出现溢出,导致结果错误,如
var a int16 = 129,转换为int8类型后结果为-127。 - 应用场景:在使用某些函数时,需将参数转换为函数要求的类型,如使用
math包的Sqrt()函数计算直角三角形斜边长时,需将int类型的变量转换为float64类型。
三、其他类型转换成 String 类型
- 使用
fmt.Sprintf:需注意不同类型对应的格式,int为%d,float为%f,bool为%t,byte为%c。 - 使用
strconv包int转string:使用strconv.Itoa函数。float转string:使用strconv.FormatFloat函数,需指定格式化类型、保留的小数位数等参数。bool转string:使用strconv.FormatBool函数。int64转string:使用strconv.FormatInt函数,需指定进制。
四、String 类型转换成数值类型
- 转换成
int类型:使用strconv.ParseInt函数,需指定字符串、进制和位数。 - 转换成
float类型:使用strconv.ParseFloat函数,需指定字符串和位数。 - 转换成
bool类型:使用strconv.ParseBool函数,不过实际意义不大。 - 转换成字符:可通过遍历字符串实现
五、特殊说明
在 Go 语言中,数值类型和bool类型不能相互转换
GoLang 中的运算符
一、内置运算符类型
Golang 内置的运算符包括算术运算符、关系运算符、逻辑运算符、位运算符、赋值运算符。
二、算术运算符
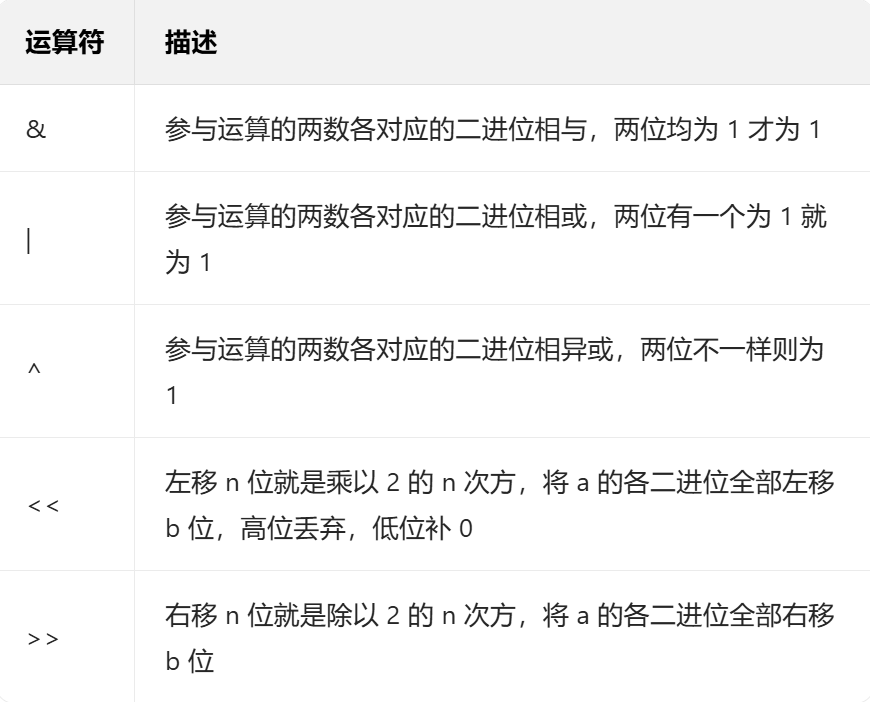
- 常用运算符:包括加(+)、减(-)、乘(*)、除(/)、求余(%,公式为被除数 - (被除数 / 除数)* 除数)。
- 特殊说明:++(自增)和 --(自减)在 Go 语言中是单独的语句,并非运算符;且只能独立使用,没有前 ++ 和前 -- 的用法,例如
a = i++和++i都是错误的,正确写法是i++。 - 除法特点:若运算数都是整数,结果会去掉小数部分,保留整数部分,如
10/3结果为 3;若有浮点数参与,结果为浮点数,如10.0/3结果约为 3.3333333333333335

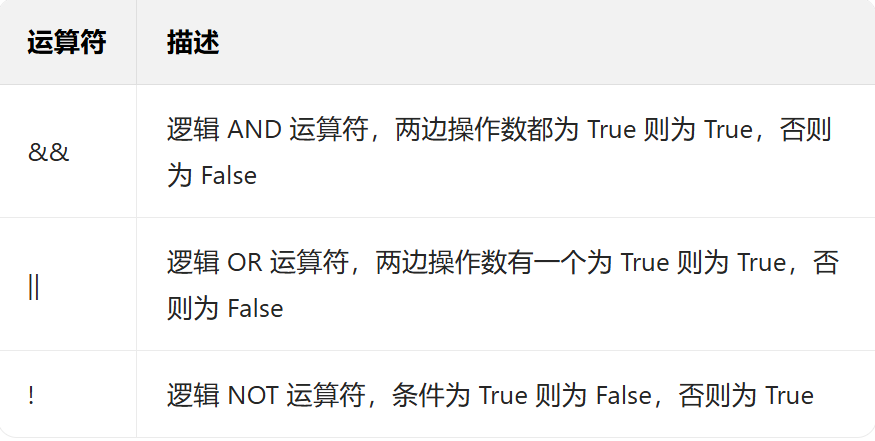
短路特性:对于&&,若左边操作数为 False,右边操作数不会执行;对于||,若左边操作数为 True,右边操作数不会执行

Go 语言中的流程控制
一、流程控制概述
Go 语言中常用的流程控制有 if 和 for,switch 和 goto 主要用于简化代码、降低重复代码,属于扩展类流程控制
二、if else(分支结构)
- 基本写法:格式为
if 表达式1 {分支1} else if 表达式2 {分支2} else {分支3},当表达式 1 为 true 时执行分支 1,否则判断表达式 2,满足则执行分支 2,都不满足则执行分支 3。 - 注意事项:与 if 匹配的左括号
{必须与 if 和表达式在同一行,与 else 匹配的{必须与 else 在同一行,else 也必须与上一个 if 或 else if 右边的大括号在同一行。 - 特殊写法:可在 if 表达式前添加执行语句,再根据变量值判断,如
if score := 56; score >= 90 {…},其中变量作用域仅限于该 if 语句内。
三、for(循环结构)
- 基本格式:
for 初始语句;条件表达式;结束语句{循环体语句},条件表达式为 true 时循环,为 false 时退出。 - 变体形式
- 省略初始语句(需保留分号):如
i := 0; for ; i < 10; i++ {…}。 - 省略初始语句和结束语句:类似 while 循环,如
i := 0; for i < 10 {…; i++}。 - 无限循环:
for {循环体语句},可通过 break、goto 等强制退出。
- 省略初始语句(需保留分号):如
四、for range(键值循环)
可遍历数组、切片、字符串、map 及通道,返回值规律如下:
- 数组、切片、字符串返回索引和值。
- map 返回键和值。
- 通道只返回通道内的值。
例如遍历字符串:str := \"abc 上海\"; for index, val := range str {…}。
五、switch case
- 基本用法:方便对大量值进行条件判断,每个 switch 只能有一个 default 分支。
- 特点:case 语句可不写 break,不会出现穿透现象;一个分支可包含多个值,用逗号分隔;也可在 switch 后不跟变量,直接在 case 中用表达式判断。
- fallthrough:可执行满足条件的 case 的下一个 case,默认穿透一层,如
case s == \"a\": fmt.Println(\"a\"); fallthrough; case s == \"b\": fmt.Println(\"b\")会输出 a 和 b。
六、break(跳出循环)
- 作用场景:用于循环中跳出循环;在 switch 中执行一条 case 后跳出;多重循环中可通过标号 label 指定要跳出的循环。
- 示例:如
lable2: for i := 0; i < 2; i++ {for j := 0; j < 10; j++ {if j == 2 {break lable2}}}。
七、continue(继续下次循环)
用于 for 循环内结束当前循环,开始下一次迭代;添加标签时,开始标签对应的循环。
八、goto(跳转到指定标签)
通过标签无条件跳转,可简化跳出循环等操作,如if n > 20 {goto label1}; ...; label1: ...。
Golang 中的数组
一、数组介绍
数组是一系列同一类型数据的集合,每个数据称为数组元素,包含的元素个数为数组长度。在 Golang 中,数组是长度固定的数据类型,长度是类型的一部分,例如[5]int和[10]int是不同类型;数组元素占用连续内存地址,索引访问速度快。与数组对应的是 Slice(切片),切片更灵活,但理解数组是理解切片的基础。
二、数组定义
定义格式为var 数组变量名[元素数量]T,其中元素数量必须是常量,且一旦定义长度不可变。例如var a [5]int定义了一个长度为 5、元素类型为 int 的数组,[5]int和[4]int是不同类型,不能相互赋值。数组通过下标访问,下标从 0 开始,最后一个元素下标为len-1,访问越界会触发 panic。
三、数组的初始化
- 方法一:使用初始化列表设置元素值,如
var numArray = [3]int{1, 2}初始化后为[1 2 0],未指定的元素为对应类型零值。 - 方法二:让编译器根据初始值个数推断长度,用
...代替长度,如var cityArray = [...]string{\"北京\", \"上海\", \"深圳\"},其类型为[3]string。 - 方法三:指定索引值初始化,如
a := [...]int{1: 1, 3: 5},结果为[0 1 0 5],类型为[4]int。
四、数组的遍历
- for 循环遍历:通过下标访问,如
for i := 0; i < len(a); i++ { fmt.Println(a[i]) }。 - for range 遍历:返回索引和值,如
for index, value := range a { fmt.Println(index, value) }。
五、数组是值类型
数组赋值和传参会复制整个数组,修改副本不会影响原数组。数组支持==、!=操作符,因内存总是被初始化。[n]*T表示指针数组,*[n]T表示数组指针。
六、多维数组
以二维数组为例,定义格式为var 数组变量名[元素数量][元素数量]T,如a := [3][2]string{{\"北京\", \"上海\"}, {\"广州\", \"深圳\"}, {\"成都\", \"重庆\"}}。遍历可使用嵌套 for range,如外层遍历获取每行,内层遍历获取每行元素。注意多维数组只有第一层可使用...推导长度,内层不可。
Golang中的切片
1. 切片的定义与本质
- 定义:切片可以看作是对数组的一个 “视图”,它本身并不是数组,不存储数据,而是描述了一个拥有相同类型元素的连续片段。切片的声明格式为
var 切片变量名 []类型,例如var s []int,这表示声明了一个名为s的整型切片。 - 本质:切片是一个结构体,包含三个字段:指向底层数组的指针(
array)、切片的长度(len)、切片的容量(cap)。长度是指切片中元素的个数,容量是指从切片的起始位置到底层数组末尾的元素个数。
2. 切片的初始化
- 使用字面量初始化:可以直接使用
[]类型{元素列表}的形式初始化切片,例如nums := []int{1, 2, 3},这种方式创建的切片长度和容量都等于元素的个数。 - 使用
make函数初始化:make函数用于创建切片,格式为make([]类型, 长度, 容量),其中容量参数是可选的。比如nums := make([]int, 5),表示创建一个长度为 5、容量也为 5 的整型切片,元素默认初始化为对应类型的零值(这里是 0);nums := make([]int, 5, 10),则创建了一个长度为 5、容量为 10 的整型切片。
关于 nil 的认识
- 未赋值的切片为
nil(如var a []int),其长度和容量均为 0。 - 注意:长度和容量为 0 的切片不一定是
nil(如var b = []int{}、make([]int,0))。
3. 切片的操作
- 获取长度和容量:使用内置函数
len()获取切片的长度,使用cap()获取切片的容量。例如length := len(s),capacity := cap(s)。 - 访问元素:切片的元素通过索引访问,索引从 0 开始,如
nums[0]表示访问切片nums的第一个元素。注意不能越界访问,即索引要小于切片的长度。 - 切片操作:可以对切片进行切片操作,格式为
切片[起始索引:结束索引],例如nums[1:3]表示从nums切片中获取索引为 1(包含)到索引为 3(不包含)的子切片。如果省略起始索引,默认从 0 开始;如果省略结束索引,默认到切片末尾。 - 追加元素:使用内置函数
append()向切片追加元素,例如nums = append(nums, 4),表示向nums切片追加一个元素 4。如果追加元素后长度超过了容量,append函数会自动重新分配更大的底层数组,并将原数组的元素复制过去。 - 复制切片:使用内置函数
copy()进行切片的复制,格式为copy(目标切片, 源切片),例如copy(newNums, nums),将nums切片的元素复制到newNums切片中。需要注意的是,copy函数只会复制源切片中长度较小的那部分元素。
4. 切片作为函数参数
切片作为函数参数传递时,传递的是切片的结构体,因此在函数内部对切片元素的修改会反映到函数外部,因为它们共享底层数组。例如:
func modifySlice(s []int) { s[0] = 100}func main() { nums := []int{1, 2, 3} modifySlice(nums) // 输出 [100 2 3] println(nums) }5. 切片与数组的区别
- 长度固定性:数组的长度是固定的,定义后不能改变;切片的长度是可变的,可以根据需要动态增长或缩小。
- 数据存储:数组直接存储元素,切片不直接存储元素,而是指向底层数组的一部分。
- 类型定义:数组的类型包含长度信息,例如
[5]int和[3]int是不同类型;切片的类型只包含元素类型,如[]int。
6. 切片的应用场景
- 动态数据集合:当需要处理长度不确定的数据集合时,切片非常适用,比如从文件中读取内容并存储、网络请求返回的数据处理等。
- 数据传递:在函数之间传递数据时,切片比数组更灵活,因为不需要担心长度限制,并且能在函数内部修改数据。
- 实现栈、队列等数据结构:通过切片的
append和切片操作,可以方便地实现栈、队列等数据结构。
Golang的sort包排序算法
在 Go 语言中,sort包提供了对切片(slice)和用户自定义集合进行排序的功能,支持多种排序算法(如快速排序、归并排序等),且内部会根据数据特点自动选择高效算法。以下是sort包的详细讲解:
一、核心功能与适用类型
sort包主要针对切片进行排序,支持的基本类型包括:
- 整数切片(
[]int) - 浮点型切片(
[]float64) - 字符串切片(
[]string)
同时,通过实现sort.Interface接口,可对自定义类型(如结构体切片)进行排序。
二、对基本类型切片排序
sort包为基本类型提供了便捷的排序函数,无需手动实现接口:
1. 整数切片([]int)
使用sort.Ints()函数,按升序排序:
package mainimport (\"fmt\"\"sort\")func main() {nums := []int{3, 1, 4, 2}sort.Ints(nums) // 升序排序fmt.Println(nums) // 输出:[1 2 3 4]// 检查是否已排序fmt.Println(sort.IntsAreSorted(nums)) // 输出:true}2. 浮点型切片([]float64)
使用sort.Float64s()函数,按升序排序:
func main() {floats := []float64{3.2, 1.5, 4.1, 2.8}sort.Float64s(floats)fmt.Println(floats) // 输出:[1.5 2.8 3.2 4.1]}3. 字符串切片([]string)
使用sort.Strings()函数,按字典序(ASCII 码顺序) 排序:
func main() {strs := []string{\"banana\", \"apple\", \"cherry\"}sort.Strings(strs)fmt.Println(strs) // 输出:[apple banana cherry]}三、自定义排序(实现sort.Interface接口)
对于自定义类型(如结构体切片),需通过实现sort.Interface接口的 3 个方法来定义排序规则:
Len() int:返回集合长度Less(i, j int) bool:定义排序规则(i是否应排在j前面)Swap(i, j int):交换索引i和j的元素
示例:对结构体切片排序
假设有一个Person结构体,需按年龄升序排序:
package mainimport (\"fmt\"\"sort\")// 定义结构体type Person struct {Name stringAge int}// 定义结构体切片类型type Persons []Person// 实现sort.Interface接口func (p Persons) Len() int { return len(p) }func (p Persons) Less(i, j int) bool { return p[i].Age < p[j].Age } // 按年龄升序func (p Persons) Swap(i, j int) { p[i], p[j] = p[j], p[i] }func main() {people := Persons{{\"Alice\", 25},{\"Bob\", 20},{\"Charlie\", 30},}sort.Sort(people) // 按年龄升序排序fmt.Println(people)// 输出:[{Bob 20} {Alice 25} {Charlie 30}]}四、降序排序
sort包默认是升序排序,若需降序,可使用sort.Reverse()函数包装排序对象:
func main() {nums := []int{3, 1, 4, 2}// 降序排序(基于IntSlice接口)sort.Sort(sort.Reverse(sort.IntSlice(nums)))fmt.Println(nums) // 输出:[4 3 2 1]}对于自定义类型,同样适用:
// 对Person按年龄降序排序sort.Sort(sort.Reverse(people))五、查找操作
sort包提供了Search系列函数,用于在已排序的切片中快速查找元素(基于二分查找):
1. 基本类型查找
sort.SearchInts(a []int, x int):在整数切片中查找x,返回第一个>=x的索引sort.SearchStrings(a []string, x string):在字符串切片中查找xsort.SearchFloat64s(a []float64, x float64):在浮点型切片中查找x
示例:
func main() {nums := []int{1, 2, 3, 4, 5}// 查找第一个>=3的索引idx := sort.SearchInts(nums, 3)fmt.Println(idx) // 输出:2(nums[2] = 3)}2. 自定义查找
sort.Search(n int, f func(int) bool):通用查找函数,对长度为n的有序集合,返回第一个使f(i) == true的索引i。
示例:在结构体切片中查找年龄 >=25 的第一个元素:
func main() {people := Persons{{\"Bob\", 20},{\"Alice\", 25},{\"Charlie\", 30},}// 已按年龄升序排序,查找第一个年龄>=25的索引idx := sort.Search(len(people), func(i int) bool {return people[i].Age >= 25})fmt.Println(idx) // 输出:1(people[1].Age=25)}六、注意事项
- 排序会修改原切片:
sort包的排序函数直接修改原切片,不会返回新切片。 - 切片必须有序才能使用查找功能:
Search系列函数依赖二分查找,需确保切片已排序,否则结果不可靠。 - 自定义排序的性能:
sort包内部算法高效(时间复杂度为 O (n log n)),自定义类型排序的性能取决于Less方法的实现效率。 - 避免对
nil切片排序:对nil切片排序会引发恐慌(panic),需确保切片已初始化。
Golang中的map
在 Go 语言中,map(映射)是一种无序的键值对(key-value)集合,用于快速存储和查找数据,类似于其他语言中的字典(如 Python 的dict)。map的底层实现基于哈希表,因此查找、插入、删除操作的平均时间复杂度为 O (1),非常高效。以下是对 Go 语言map的详细讲解:
一、map 的定义与本质
-
定义格式
map的声明格式为:var map变量名 map[键类型]值类型其中,键类型必须是支持
==和!=比较的类型(如int、string、bool、指针等),不能是切片、map、函数等不可比较类型;值类型可以是任意类型。示例:
var m1 map[string]int // 声明一个键为string、值为int的mapvar m2 map[int][]string // 键为int,值为字符串切片 -
本质
map是引用类型,其底层结构包含指向哈希表的指针。未初始化的map值为nil,此时不能进行读写操作(否则会触发panic)。
二、map 的初始化
map必须初始化后才能使用,常用初始化方式有两种:
-
使用
make()函数(推荐)
格式:make(map[键类型]值类型, 初始容量)
其中,初始容量是可选参数,用于指定map的初始存储空间(提前指定可减少扩容开销)。示例:
m1 := make(map[string]int) // 初始化一个空map,默认容量m2 := make(map[int]string, 10) // 初始容量为10,可存储10个键值对 -
使用字面量初始化
直接指定初始键值对:m3 := map[string]int{ \"apple\": 5, \"banana\": 3,} // 初始化包含两个键值对的map
三、map 的基本操作
1. 新增 / 修改键值对
语法:map变量[键] = 值
- 若键不存在,则新增键值对;
- 若键已存在,则更新对应的值。
示例:
m := make(map[string]int)m[\"math\"] = 90 // 新增:键\"math\"不存在,添加键值对m[\"english\"] = 85m[\"math\"] = 95 // 修改:键\"math\"已存在,更新值为952. 获取键值对
语法:值 := map变量[键]
- 若键存在,返回对应的值;
- 若键不存在,返回值类型的零值(如
int返回 0,string返回空串)。
判断键是否存在:
由于不存在的键会返回零值,无法直接区分 “键不存在” 和 “键存在但值为零值”,需使用双返回值语法:
value, ok := map变量[键]ok为bool类型,true表示键存在,false表示键不存在。
示例:
m := map[string]int{\"math\": 95}score, ok := m[\"math\"]if ok { fmt.Println(\"math score:\", score) // 输出:math score: 95}// 键不存在的情况score2, ok2 := m[\"chinese\"]if !ok2 { fmt.Println(\"chinese not exists\") // 输出:chinese not exists fmt.Println(score2) // 输出:0(int的零值)}3. 删除键值对
使用内置函数delete(),语法:
delete(map变量, 键)- 若键存在,删除该键值对;
- 若键不存在,
delete()无任何效果(不会报错)。
示例:
m := map[string]int{\"math\": 95, \"english\": 85}delete(m, \"english\") // 删除键\"english\"fmt.Println(m) // 输出:map[math:95]delete(m, \"chinese\") // 键不存在,无操作4. 获取 map 长度
使用内置函数len(),返回map中键值对的数量:
m := map[string]int{\"a\": 1, \"b\": 2}fmt.Println(len(m)) // 输出:2四、map 的遍历
使用for range循环遍历map,返回键和对应的值:
m := map[string]int{\"apple\": 5, \"banana\": 3, \"orange\": 2}// 遍历键和值for key, value := range m { fmt.Printf(\"key: %s, value: %d\\n\", key, value)}// 仅遍历键for key := range m { fmt.Println(\"key:\", key)}// 仅遍历值(不推荐,效率低,需先获取键再取值)for _, value := range m { fmt.Println(\"value:\", value)}注意:map是无序的,每次遍历的顺序可能不同(Go 1.12 + 后遍历顺序固定,但不保证与插入顺序一致)。若需按固定顺序遍历,需先将键存入切片排序后再遍历。
五、map 的特性与注意事项
-
引用类型
map是引用类型,赋值或传参时,拷贝的是指针,修改副本会影响原map:m1 := map[string]int{\"a\": 1}m2 := m1 // m2与m1指向同一个底层哈希表m2[\"a\"] = 100fmt.Println(m1) // 输出:map[a:100](原map被修改) -
不能对
nilmap 进行操作
未初始化的map为nil,读写nil map会触发panic:var m map[string]int // nil mapm[\"a\"] = 1 // 报错:panic: assignment to entry in nil map -
容量自动扩容
当map中的键值对数量超过容量时,会自动扩容(重新分配更大的哈希表并复制数据),但扩容不会改变原map的引用(因为map是引用类型,指针会指向新哈希表)。 -
键的类型限制
键必须是可比较类型(支持==和!=),以下类型不能作为键:- 切片(
[]T) map本身- 函数(
func)
若需使用复合类型作为键,可转为string(如通过json.Marshal序列化)或使用结构体(需保证结构体字段都是可比较类型)。
- 切片(
-
并发不安全
map在并发场景下(多个 goroutine 同时读写)是不安全的,会导致程序崩溃。需使用sync.Map(Go 1.9 + 新增)或加锁(如sync.Mutex)保证并发安全。
六、map 的应用场景
- 存储键值对数据:如配置信息、用户信息(用户名→用户详情)等。
- 去重:利用
map的键唯一性,快速实现切片去重:func removeDuplicates(nums []int) []int { m := make(map[int]bool) res := []int{} for _, num := range nums { if !m[num] { m[num] = true res = append(res, num) } } return res} - 计数:统计元素出现次数(如单词频率统计):
words := []string{\"apple\", \"banana\", \"apple\"}count := make(map[string]int)for _, word := range words { count[word]++}fmt.Println(count) // 输出:map[apple:2 banana:1]
七、map 与其他数据结构的对比
map总结
map是 Go 语言中用于存储键值对的高效数据结构,基于哈希表实现,支持快速的增删改查操作。使用时需注意:map必须初始化后才能使用;键必须是可比较类型;map是引用类型,赋值会共享底层数据;并发场景下需保证安全。掌握map的使用,能有效处理各种需要键值映射的场景,提升程序效率。
Golang的函数
在 Go 语言中,函数(Function)是执行特定任务的代码块,是代码复用和模块化的核心单位。Go 的函数设计简洁而强大,支持多种特性如多返回值、匿名函数、闭包等。以下是对 Go 语言函数的详细讲解:
一、函数的定义与基本结构
1. 函数定义格式
Go 语言函数的基本定义格式如下:
func 函数名(参数列表) (返回值列表) { // 函数体}func:关键字,用于声明函数。函数名:遵循标识符规则,建议使用驼峰式命名(如calculateSum)。参数列表:格式为参数名 类型,多个参数用逗号分隔(如a int, b string)。返回值列表:可以是类型列表(如int, string),也可以指定返回值名称(如sum int, err error)。函数体:实现函数功能的代码块。
2. 示例:基本函数
// 无参数、无返回值func sayHello() { fmt.Println(\"Hello, World!\")}// 有参数、有返回值func add(a int, b int) int { return a + b}// 多参数、多返回值(返回值指定名称)func divide(dividend, divisor float64) (result float64, err error) { if divisor == 0 { err = errors.New(\"除数不能为0\") return // 可省略返回值,直接返回已赋值的result和err } result = dividend / divisor return}二、函数的参数
1. 参数类型简写
当多个参数类型相同时,可简写为:
// 等价于 func add(a int, b int) intfunc add(a, b int) int { return a + b}2. 可变参数
函数可以接受可变数量的参数,格式为参数名 ...类型,可变参数必须是参数列表的最后一个:
// 计算任意数量整数的和func sum(nums ...int) int { total := 0 for _, num := range nums { total += num } return total}// 调用func main() { fmt.Println(sum(1, 2, 3)) // 输出:6 fmt.Println(sum(10, 20, 30, 40)) // 输出:100}- 可变参数在函数内部表现为切片(如
nums ...int在函数内是[]int类型)。 - 可将切片作为可变参数传递,需在切片后加
...(如sum([]int{1,2,3}...))。
3. 函数参数传递方式
Go 语言中函数参数传递为值传递:
- 传递基本类型(int、string 等)时,函数接收的是参数的副本,修改副本不影响原变量。
- 传递引用类型(切片、map、通道、指针等)时,函数接收的是引用的副本,但引用指向同一个底层数据,因此修改底层数据会影响原变量。
示例:
// 基本类型(值传递,不影响原变量)func modifyInt(a int) { a = 100}// 引用类型(切片,修改会影响原切片)func modifySlice(s []int) { s[0] = 100}func main() { x := 10 modifyInt(x) fmt.Println(x) // 输出:10(原变量未变) s := []int{1, 2, 3} modifySlice(s) fmt.Println(s) // 输出:[100 2 3](原切片被修改)}三、函数的返回值
1. 多返回值
Go 语言支持函数返回多个值,这在处理错误(如(result, error))时非常常用:
// 返回商和余数func divideAndRemainder(a, b int) (int, int) { quotient := a / b remainder := a % b return quotient, remainder}func main() { q, r := divideAndRemainder(10, 3) fmt.Printf(\"商:%d,余数:%d\\n\", q, r) // 输出:商:3,余数:1}2. 命名返回值
可以为返回值指定名称,在函数体中直接赋值,return 语句可省略返回值:
func calculate(a, b int) (sum, product int) { sum = a + b // 直接给命名返回值赋值 product = a * b return // 等价于 return sum, product}3. 忽略返回值
若不需要某个返回值,可用_(空白标识符)忽略:
q, _ := divideAndRemainder(10, 3) // 忽略余数四、函数的特殊形式
1. 匿名函数
没有名称的函数,可直接定义并调用,或赋值给变量:
func main() { // 直接调用匿名函数 func(msg string) { fmt.Println(msg) }(\"Hello, Anonymous!\") // 输出:Hello, Anonymous! // 赋值给变量 add := func(a, b int) int { return a + b } fmt.Println(add(2, 3)) // 输出:5}2. 闭包(Closure)
闭包是引用了外部变量的匿名函数,它可以 “捕获” 并访问外部作用域中的变量:
// 返回一个闭包函数,每次调用递增计数器func counter() func() int { count := 0 // 被闭包捕获的变量 return func() int { count++ return count }}func main() { c1 := counter() fmt.Println(c1()) // 输出:1 fmt.Println(c1()) // 输出:2 c2 := counter() fmt.Println(c2()) // 输出:1(c2有独立的count变量)}- 闭包会 “记住” 外部变量的状态,每次调用共享同一个变量。
- 闭包可用于实现工厂函数、状态保持等场景。
3. 递归函数
函数调用自身的函数,需注意设置终止条件避免无限递归:
// 计算n的阶乘func factorial(n int) int { if n == 0 { // 终止条件 return 1 } return n * factorial(n-1) // 递归调用}func main() { fmt.Println(factorial(5)) // 输出:120(5! = 5×4×3×2×1)}4. 高阶函数
接受函数作为参数或返回函数的函数:
// 接受函数作为参数func apply(n int, f func(int) int) int { return f(n)}// 返回函数func makeAdder(x int) func(int) int { return func(y int) int { return x + y }}func main() { // 调用apply,传入匿名函数作为参数 result := apply(5, func(n int) int { return n * 2 }) fmt.Println(result) // 输出:10 // 使用makeAdder返回的函数 add5 := makeAdder(5) fmt.Println(add5(3)) // 输出:8(5+3)}五、函数的作用域
函数内定义的变量为局部变量,仅在函数内有效;函数外定义的变量为全局变量,在整个包内可见:
var globalVar = 100 // 全局变量func test() { localVar := 200 // 局部变量 fmt.Println(globalVar, localVar) // 可访问全局变量和局部变量}func main() { test() fmt.Println(globalVar) // 可访问全局变量 // fmt.Println(localVar) // 错误:局部变量在函数外不可见}六、函数与包
- 函数名首字母大写:可被其他包访问(公有函数)。
- 函数名首字母小写:仅在当前包内可见(私有函数)。
示例:
// 包名为mymathpackage mymath// 公有函数:可被其他包调用func Add(a, b int) int { return a + b}// 私有函数:仅在mymath包内使用func subtract(a, b int) int { return a - b}七、defer 语句
defer用于延迟执行函数调用,通常用于释放资源(如关闭文件、释放锁等),无论函数是否正常返回,defer语句都会执行:
func readFile(filename string) error { file, err := os.Open(filename) if err != nil { return err } defer file.Close() // 延迟关闭文件,函数退出时执行 // 读取文件操作... return nil}- 多个
defer语句按后进先出(LIFO) 顺序执行。 defer语句中的表达式在定义时求值,而非执行时:func main() { i := 0 defer fmt.Println(i) // 定义时i=0,延迟输出0 i = 100}
八、函数的应用场景
- 代码复用:将重复逻辑封装为函数,减少冗余。
- 模块化设计:将程序拆分为多个函数,每个函数负责单一功能。
- 错误处理:利用多返回值返回错误信息(如
(result, error))。 - 回调函数:通过高阶函数实现回调(如排序中的比较函数)。
- 并发控制:结合 goroutine(Go 的轻量级线程)实现并发任务。
总结
Go 语言的函数是构建程序的基础,支持多返回值、可变参数、匿名函数、闭包等特性,设计灵活且高效。掌握函数的定义、参数传递、返回值处理及特殊形式(如闭包、高阶函数),能帮助编写简洁、模块化的代码。同时,defer语句为资源管理提供了便捷方式,是 Go 函数的重要特性之一。
Golang中的指针
在 Go 语言中,指针(Pointer)是一种特殊的数据类型,用于存储变量的内存地址。通过指针,我们可以直接接访问和修改变量在内存中的数据,这在某些场景下(如函数传参、复杂数据结构操作)非常有用。以下是对 Go 语言指针的详细讲解:
一、指针的基本概念
-
内存地址
计算机中,每个变量都存储在特定的内存单元中,内存地址是标识该单元的唯一编号(通常用十六进制表示,如0xc0000a0020)。 -
指针变量
指针变量是专门用于存储内存地址的变量,其类型为*T(T为指向的变量类型),表示 “指向T类型的指针”。示例:
var a int = 10 // 普通int变量var p *int = &a // p是指向int的指针,存储a的内存地址fmt.Println(p) // 输出a的地址(如0xc0000a0020)fmt.Println(*p) // 输出p指向的变量值(即a的值10)&:取地址运算符,用于获取变量的内存地址(如&a表示变量a的地址)。*:指针解引用运算符,用于通过指针访问其指向的变量值(如*p表示p指向的变量的值)。
二、指针的声明与初始化
-
声明指针
格式:var 指针变量名 *类型示例:
var p1 *int // 声明指向int的指针var p2 *string // 声明指向string的指针var p3 *[]int // 声明指向int切片的指针注意:未初始化的指针值为
nil(空指针),表示不指向任何内存地址。对nil指针解引用(*p)会触发panic。 -
初始化指针
指针必须指向一个已存在的变量(即存储该变量的地址)才能使用:a := 20p := &a // 初始化p,使其指向a(p存储a的地址)错误示例(对 nil 指针赋值):
var p *int*p = 100 // 报错:panic: runtime error: invalid memory address or nil pointer dereference
三、指针的基本操作
1. 通过指针修改变量值
通过指针解引用(*p)可以修改其指向的变量的值:
func main() { a := 10 p := &a *p = 20 // 通过指针修改a的值 fmt.Println(a) // 输出:20(a的值被修改)}2. 指针作为函数参数
当函数需要修改外部变量的值时,可将指针作为参数传递(避免值传递的副本开销,且能直接修改原变量):
// 通过指针修改外部变量func modify(p *int) { *p = 100 // 解引用指针,修改指向的变量}func main() { x := 10 modify(&x) // 传递x的地址 fmt.Println(x) // 输出:100(x被修改)}对比值传递(无法修改原变量):
// 值传递:修改的是副本,不影响原变量func modifyValue(x int) { x = 100}func main() { x := 10 modifyValue(x) fmt.Println(x) // 输出:10(x未变)}3. 指针的指针(二级指针)
指针本身也是变量,也有内存地址,因此可以定义 “指向指针的指针”(二级指针),类型为**T:
func main() { a := 10 p := &a // p是一级指针(*int),指向a pp := &p // pp是二级指针(**int),指向p fmt.Println(*p) // 输出:10(p指向a的值) fmt.Println(** pp) // 输出:10(通过二级指针访问a的值)}二级指针常用于函数中修改外部指针变量本身(如动态分配内存时):
// 通过二级指针修改外部指针func initPointer(pp **int) { *pp = new(int) // 为pp指向的指针分配内存 **pp = 200 // 给新分配的内存赋值}func main() { var p *int // 未初始化的一级指针(nil) initPointer(&p) // 传递p的地址(二级指针) fmt.Println(*p) // 输出:200(p已被正确初始化)}四、new函数:创建指针
new(T)函数用于分配一块T类型的内存空间,返回该内存的地址(即*T类型的指针),内存中的值为T类型的零值:
func main() { p := new(int) // 分配int类型内存,返回*int指针 fmt.Println(*p) // 输出:0(int的零值) *p = 100 // 给分配的内存赋值 fmt.Println(*p) // 输出:100}new函数与直接取地址的区别:
new(T)直接创建一个匿名的T类型变量,并返回其地址。&a是获取已声明变量a的地址。
五、指针与引用类型的区别
Go 中的引用类型(切片、map、通道等)本质上是对底层数据的封装,其内部包含指针,但使用时无需显式解引用,而指针需要显式操作:
*T)*解引用*p = 10[]T)s[0] = 10m[\"key\"] = 10六、指针的限制与注意事项
-
不能对常量或字面量取地址
指针必须指向可修改的变量,不能指向常量或字面量:p := &10 // 错误:cannot take the address of 10const c = 20p := &c // 错误:cannot take the address of c -
不支持指针运算
与 C 语言不同,Go 不允许对指针进行算术运算(如p++、p+1),避免内存操作的复杂性:a := 10p := &ap++ // 错误:invalid operation: p++ (non-numeric type *int) -
函数参数传递仍是值传递
指针作为函数参数时,传递的是指针的副本(地址的副本),但副本仍指向原变量,因此可通过解引用修改原变量:func changePtr(p *int) { p = new(int) // 修改指针副本,不影响外部指针 *p = 200}func main() { a := 10 p := &a changePtr(p) fmt.Println(*p) // 输出:10(外部指针p未变)} -
空指针(
nil)处理
对nil指针解引用会触发panic,使用前需判断:var p *intif p != nil { *p = 100 // 仅在p非nil时执行}
七、指针的应用场景
- 修改函数外部变量:当函数需要修改调用者的变量时,传递指针比值传递更高效(避免拷贝大对象)。
- 传递大型数据结构:对于结构体、数组等大型数据,传递指针可减少内存拷贝,提高性能。
type BigStruct struct { data [10000]int // 大型数组}// 传递指针,避免拷贝整个BigStructfunc process(b *BigStruct) { b.data[0] = 100} - 实现数据共享:在多个函数间共享同一个数据对象,通过指针操作保证数据一致性。
- 与接口结合:某些接口需要指针接收器才能修改结构体实例(见结构体方法部分)。
总结
Go 语言的指针提供了直接访问内存的能力,核心操作包括:
- 用
&取变量地址,用*解引用指针访问变量值。 - 指针作为函数参数可实现对外部变量的修改,减少大型数据的拷贝开销。
new(T)函数用于动态分配内存并返回指针。
与 C 语言相比,Go 的指针限制更多(如不支持算术运算),更安全易用。掌握指针的使用,能在性能优化和复杂数据操作中发挥重要作用。
Golang中的结构体
在 Go 语言中,结构体(Struct)是一种用户自定义的复合数据类型,用于将多个不同类型的字段(Field)组合在一起,形成一个有意义的实体。结构体是 Go 语言中组织复杂数据的核心方式,类似于其他语言中的 “类”(但不支持继承)。以下是对 Go 语言结构体的详细讲解:
一、结构体的定义与声明
1. 基本定义
结构体通过type和struct关键字定义,格式如下:
type 结构体名 struct { 字段名1 字段类型1 字段名2 字段类型2 // ...更多字段}- 结构体名:遵循标识符规则,建议使用大驼峰命名(如
Person、Student),便于跨包访问。 - 字段:由 “字段名” 和 “字段类型” 组成,字段名可省略(匿名字段),类型可以是任意基本类型、引用类型或其他结构体。
示例:
// 定义一个Person结构体type Person struct { Name string // 姓名 Age int // 年龄 Sex string // 性别}// 定义一个包含嵌套结构体的类型type Student struct { ID int Person // 匿名字段(嵌套结构体) Score float64}2. 字段的可见性
- 字段名首字母大写:可被其他包访问(公有字段)。
- 字段名首字母小写:仅在当前包内可见(私有字段)。
示例:
type User struct { Username string // 公有字段(跨包可见) password string // 私有字段(仅当前包可见)}二、结构体变量的创建与初始化
结构体变量的创建和初始化有多种方式,核心是为字段赋值。
1. 基本初始化
func main() { // 方式1:声明后逐个赋值 var p1 Person p1.Name = \"Alice\" p1.Age = 25 p1.Sex = \"female\" // 方式2:使用结构体字面量初始化(按字段顺序) p2 := Person{\"Bob\", 30, \"male\"} // 方式3:使用字段名初始化(推荐,顺序无关) p3 := Person{ Name: \"Charlie\", Age: 28, Sex: \"male\", }}2. 指针结构体
通过&取结构体地址,或使用new函数创建结构体指针:
func main() { // 方式1:取结构体地址 p4 := &Person{Name: \"David\", Age: 35} // 通过指针访问字段(Go语法糖,等价于(*p4).Name) p4.Age = 36 // 方式2:new函数创建(返回指针) p5 := new(Person) p5.Name = \"Eve\" (*p5).Age = 22 // 也可显式解引用,但通常省略}3. 匿名结构体
无需提前定义结构体类型,直接创建临时结构体变量(适用于一次性场景):
func main() { // 匿名结构体 car := struct { Brand string Price float64 }{ Brand: \"Tesla\", Price: 29.9, } fmt.Println(car.Brand) // 输出:Tesla}三、结构体的嵌套与匿名字段
结构体可以嵌套其他结构体作为字段,若嵌套时省略字段名,则称为 “匿名字段”(或 “嵌入字段”),可简化字段访问。
1. 嵌套结构体
type Address struct { City string Street string}type Employee struct { Name string Addr Address // 嵌套结构体(有名字段) Salary int}func main() { e := Employee{ Name: \"Frank\", Addr: Address{City: \"Beijing\", Street: \"Chaoyang Road\"}, Salary: 50000, } fmt.Println(e.Addr.City) // 访问嵌套字段:需通过字段名Addr}2. 匿名字段(嵌入字段)
type Employee struct { Name string Address // 匿名字段(直接嵌入结构体类型) Salary int}func main() { e := Employee{ Name: \"Frank\", Address: Address{City: \"Beijing\", Street: \"Chaoyang Road\"}, Salary: 50000, } // 访问匿名字段的字段:可直接省略匿名字段名 fmt.Println(e.City) // 等价于 e.Address.City fmt.Println(e.Address.Street) // 也可显式访问}注意:若匿名字段与结构体自身字段同名,访问时需显式指定匿名字段名以避免冲突:
type A struct { x int }type B struct { x int; A } // B自身有x字段,与A的x冲突func main() { b := B{x: 10, A: A{x: 20}} fmt.Println(b.x) // 输出:10(访问B自身的x) fmt.Println(b.A.x) // 输出:20(访问匿名字段A的x)}四、结构体方法
方法是与结构体关联的函数,用于定义结构体的行为。通过方法,结构体可以模拟 “类” 的成员函数。
1. 方法的定义
格式:
func (接收者) 方法名(参数列表) (返回值列表) { // 方法体}- 接收者:表示方法属于哪个结构体,分为 “值接收者” 和 “指针接收者”。
示例:
// 为Person结构体定义方法type Person struct { Name string Age int}// 值接收者:接收者是结构体的副本func (p Person) SayHello() { fmt.Printf(\"Hello, I\'m %s, %d years old\\n\", p.Name, p.Age)}// 指针接收者:接收者是结构体的指针func (p *Person) Grow() { p.Age++ // 指针接收者可修改结构体本身}func main() { p := Person{Name: \"Alice\", Age: 25} p.SayHello() // 输出:Hello, I\'m Alice, 25 years old p.Grow() // 调用指针接收者方法,年龄+1 p.SayHello() // 输出:Hello, I\'m Alice, 26 years old}2. 值接收者 vs 指针接收者
注意:结构体变量调用方法时,Go 会自动转换接收者类型(值→指针或指针→值),无需显式转换:
p := Person{Name: \"Bob\"}p.Grow() // 等价于 (&p).Grow()(值自动转指针)pp := &Person{Name: \"Charlie\"}pp.SayHello() // 等价于 (*pp).SayHello()(指针自动转值)五、结构体的比较
结构体能否比较取决于其字段类型:
- 若结构体所有字段都是可比较类型(如
int、string、指针等),则结构体可比较(支持==、!=)。 - 若包含不可比较类型(如切片、
map、函数等),则结构体不可比较。
示例:
type Point struct { X, Y int }func main() { p1 := Point{1, 2} p2 := Point{1, 2} p3 := Point{3, 4} fmt.Println(p1 == p2) // 输出:true(所有字段相等) fmt.Println(p1 == p3) // 输出:false}不可比较的结构体(含切片字段):
type Data struct { Values []int // 切片不可比较}func main() { d1 := Data{Values: []int{1,2}} d2 := Data{Values: []int{1,2}} // fmt.Println(d1 == d2) // 错误:invalid operation: d1 == d2 (struct containing []int cannot be compared)}六、结构体的序列化与反序列化
结构体常与 JSON 等格式相互转换(序列化 / 反序列化),通过字段标签(Tag)指定 JSON 字段名等信息。
示例:
import ( \"encoding/json\" \"fmt\")type User struct { Username string `json:\"username\"` // 序列化后字段名为username Age int `json:\"age\"` // 序列化后字段名为age password string `json:\"-\"` // 忽略该字段,不参与序列化}func main() { u := User{Username: \"alice\", Age: 25, password: \"123456\"} // 序列化:结构体→JSON字符串 data, _ := json.Marshal(u) fmt.Println(string(data)) // 输出:{\"username\":\"alice\",\"age\":25}(password被忽略) // 反序列化:JSON字符串→结构体 jsonStr := `{\"username\":\"bob\",\"age\":30}` var u2 User json.Unmarshal([]byte(jsonStr), &u2) fmt.Println(u2.Username) // 输出:bob}- 字段标签(
json:\"xxx\")用于指定序列化后的字段名,或添加特殊规则(如json:\"-\"表示忽略字段)。 - 反序列化时,JSON 字段名需与结构体字段名(或标签指定的名称)匹配,且结构体字段必须是公有的(首字母大写)。
七、结构体的应用场景
-
封装数据:将相关数据字段组合成有意义的实体(如用户信息、订单信息等)。
type Order struct { ID string UserID int Amount float64 Status string CreateAt string} -
模拟 “类” 的行为:通过结构体 + 方法实现面向对象的核心功能(封装、行为定义)。
type Circle struct { Radius float64}// 方法:计算面积func (c Circle) Area() float64 { return 3.14 * c.Radius * c.Radius} -
数据传输:在函数间或网络中传递复杂数据(如 API 请求 / 响应体)。
-
实现接口:结构体通过实现接口的所有方法,成为接口的实现类型(Go 的多态方式)。
总结
结构体是 Go 语言中组织复杂数据的核心机制,具有以下特点:
- 由多个字段组成,支持嵌套和匿名字段,字段有可见性控制。
- 通过方法定义行为,支持值接收者和指针接收者,模拟类的成员函数。
- 可比较性取决于字段类型,支持 JSON 序列化 / 反序列化(通过标签配置)。
掌握结构体的使用,能有效封装数据和行为,编写模块化、可读性强的代码,是 Go 语言开发的基础技能。
Golang的包和go mod
在 Go 语言中,包(Package) 是代码组织的基本单位,用于实现代码复用和模块化;go mod 是 Go 1.11 引入的模块管理工具,用于解决依赖管理问题(替代传统的GOPATH模式)。两者结合构成了 Go 项目的核心管理机制。以下是详细讲解:
一、Go 包(Package)详解
1. 包的基本概念
包是多个 Go 源文件的集合,所有文件共享同一个包名,用于封装相关功能的代码(函数、结构体、变量等)。其核心作用是:
- 代码复用:将通用逻辑封装为包,供其他代码导入使用。
- 命名空间隔离:不同包中可存在同名标识符(如函数、结构体),通过包名区分。
- 访问控制:通过标识符大小写控制可见性(公有 / 私有)。
2. 包的定义与声明
每个 Go 源文件的第一行必须通过package关键字声明所属包:
// 文件路径:mymath/add.gopackage mymath // 声明该文件属于mymath包func Add(a, b int) int { return a + b}- 包名规范:通常与所在目录名一致(非强制,但建议遵循,便于维护);使用小写字母,简短且有意义(如
net、encoding/json)。 - 单包多文件:一个包可包含多个
.go文件,所有文件共享包级变量和函数(无需导入即可相互访问)。
3. 包的可见性(访问控制)
包内标识符(函数、结构体、变量、常量等)的可见性由首字母大小写决定:
- 首字母大写:公有(Public),可被其他包导入并访问(如
Add、Person)。 - 首字母小写:私有(Private),仅在当前包内可见(如
add、person)。
示例:
// 包:mypkgpackage mypkgvar PublicVar int = 10 // 公有变量,其他包可访问var privateVar int = 20 // 私有变量,仅本包可见type PublicStruct struct { // 公有结构体 PublicField int // 公有字段 privateField string // 私有字段(其他包无法访问)}func PublicFunc() { ... } // 公有函数func privateFunc() { ... } // 私有函数4. 包的导入(Import)
使用import关键字导入其他包,才能使用其公有标识符。导入路径是包的唯一标识。
(1)导入路径规则
- 标准库包:直接使用包名(如
fmt、os、net/http),由 Go 官方维护。 - 第三方包:导入路径为模块路径 + 包所在目录(如
github.com/sirupsen/logrus)。 - 本地自定义包:导入路径为模块路径 + 包相对模块根目录的路径(如模块
myproject下的utils/str包,导入路径为myproject/utils/str)。
(2)导入语法
// 基本导入import \"fmt\"import \"mypackage/mymath\"// 分组导入(推荐,更简洁)import ( \"fmt\" \"mypackage/mymath\" \"github.com/sirupsen/logrus\" // 第三方包)(3)特殊导入方式
-
别名导入:为包指定别名,解决同名包冲突或简化调用。
import m \"mypackage/mymath\" // 别名mfunc main() { m.Add(1, 2) // 通过别名调用} -
空白导入(
_):仅执行包的初始化逻辑(如注册驱动),不使用包内标识符。import _ \"github.com/go-sql-driver/mysql\" // 初始化MySQL驱动 -
点导入(
.):将包内公有标识符导入当前包的作用域,可直接调用(不推荐,易冲突)。import . \"fmt\"func main() { Println(\"Hello\") // 无需加包名fmt}
5. 包的初始化(init函数)
每个包可以定义多个init函数(无参数、无返回值),在包被导入时自动执行,用于初始化包资源(如连接数据库、注册路由等)。
特性:
- 执行时机:在包级变量初始化后,
main函数(若为可执行程序)前执行。 - 执行顺序:同一包内多个
init函数按源码出现顺序执行;不同包的init按导入依赖关系执行(被依赖的包先初始化)。 - 不可调用:
init函数由 Go runtime 自动调用,不能手动调用。
示例:
// 包:dbpackage dbimport \"fmt\"var DBName string // 包级变量// 包级变量初始化func init() { DBName = \"mydb\"}// 第一个init函数func init() { fmt.Println(\"db init 1: connect to\", DBName)}// 第二个init函数func init() { fmt.Println(\"db init 2: check connection\")}6. 主包(main包)
- 若包名为
main,则该包是可执行程序的入口,必须包含main函数(程序启动入口)。 main包不能被其他包导入(导入会报错)。
示例:
package main // 主包import \"fmt\"func main() { // 程序入口函数 fmt.Println(\"Hello, main package\")}二、go mod(模块管理)详解
go mod是 Go 的模块管理工具,用于管理项目依赖(第三方库版本)、定义模块边界,解决了传统GOPATH模式下依赖混乱、版本冲突等问题。
1. 模块(Module)的概念
一个模块是一个包含go.mod文件的项目根目录,它是一组相关包的集合。go.mod文件记录了模块的元信息(如模块路径)和依赖信息(依赖包及其版本)。
- 模块路径:模块的唯一标识,通常是项目的仓库地址(如
github.com/username/project),用于其他项目导入该模块的包。
2. go.mod文件结构
go.mod是模块的核心配置文件,自动生成和维护,基本结构如下:
module github.com/username/myproject // 模块路径(必填)go 1.21 // 声明Go版本(可选,指定项目使用的Go版本)require ( // 依赖声明:指定依赖包及其版本 github.com/sirupsen/logrus v1.9.3 golang.org/x/text v0.13.0)replace github.com/sirupsen/logrus => ./local/logrus // 替换依赖(可选,本地开发用)exclude github.com/sirupsen/logrus v1.9.2 // 排除依赖版本(可选)核心指令:
module:定义模块路径(如myproject)。go:指定项目使用的 Go 版本(影响语言特性支持)。require:声明依赖包及其版本(格式:包路径 版本号)。replace:临时替换依赖包(如将远程包替换为本地目录,方便开发)。exclude:排除特定版本的依赖(不常用)。
3. go mod常用命令
go mod init go.mod文件(如go mod init github.com/my/project)。go mod downloadgo.mod中声明的所有依赖到本地缓存(默认路径:$GOPATH/pkg/mod)。go mod tidygo mod get go get github.com/sirupsen/logrus@v1.9.3指定版本)。go mod editgo.mod文件(如go mod edit -require=github.com/xxx@v1.0.0)。go mod vendorvendor文件夹(用于离线构建,优先使用 vendor 依赖)。go mod graphgo mod verify4. 依赖版本表示
go mod使用语义化版本(Semantic Versioning)管理依赖,格式为vMAJOR.MINOR.PATCH(如v1.2.3):
MAJOR:主版本号(不兼容的 API 变更)。MINOR:次版本号(向后兼容的功能新增)。PATCH:修订号(向后兼容的问题修复)。
特殊版本:
v0.x.y:开发阶段,API 不稳定。v1.0.0:第一个稳定版本。- commit 哈希:可直接指定依赖的 git commit 哈希(如
github.com/xxx@a1b2c3d)。
5. 模块开发流程示例
(1)创建模块
bash
# 创建项目目录mkdir myproject && cd myproject# 初始化模块(模块路径通常为仓库地址)go mod init github.com/myusername/myproject执行后生成go.mod文件:
module github.com/myusername/myprojectgo 1.21 # 自动识别当前Go版本(2)编写代码并添加依赖
创建main.go:
package mainimport ( \"fmt\" \"github.com/sirupsen/logrus\" // 第三方日志库)func main() { logrus.Info(\"Hello, go mod!\") fmt.Println(\"Done\")}(3)整理依赖
bash
go mod tidy # 自动检测并添加缺失的依赖此时go.mod会自动添加require github.com/sirupsen/logrus v1.9.3(版本可能因最新版变化)。
(4)更新依赖
bash
# 更新到最新版本go get github.com/sirupsen/logrus# 更新到指定版本go get github.com/sirupsen/logrus@v1.9.0(5)本地开发依赖替换
若依赖的包正在本地开发,未推送到远程,可使用replace临时替换:
bash
go mod edit -replace github.com/sirupsen/logrus=../local/logrusgo.mod会添加:
replace github.com/sirupsen/logrus => ../local/logrus开发完成后,可通过go mod edit -dropreplace删除替换。
三、包与模块的关系
- 包是代码组织的基本单位(多个文件→一个包)。
- 模块是包的集合(多个包→一个模块),通过
go.mod管理依赖。 - 导入路径 = 模块路径 + 包在模块内的相对路径。
例如:
- 模块路径:
github.com/myproject。 - 模块内有一个包
utils/str(目录:myproject/utils/str)。 - 其他项目导入该包的路径为:
github.com/myproject/utils/str。
四、常见问题与最佳实践
- 避免循环导入:包 A 导入包 B,包 B 又导入包 A,会导致编译错误。解决:提取公共逻辑到新包,或通过接口解耦。
- 模块路径与仓库一致:模块路径建议与代码仓库地址一致(如
github.com/username/project),便于他人通过go get导入。 - 慎用
replace:replace仅用于本地开发,提交代码时需移除(或通过条件编译处理),避免影响他人使用。 - 合理拆分包:按功能拆分包(如
db、utils、api),每个包专注单一职责,避免过大或过小。 - 优先使用
go mod tidy:通过tidy自动管理依赖,减少手动编辑go.mod的错误。
总结
- 包(Package) 是 Go 代码组织的核心,通过
package声明,通过import导入,通过标识符大小写控制可见性,init函数用于初始化。 go mod是模块管理工具,通过go.mod文件管理依赖版本和模块信息,核心命令包括init、tidy、get等,解决了依赖管理问题。
掌握包和go mod的使用,是编写可维护、可扩展 Go 项目的基础。
Golang的接口
在 Go 语言中,接口(Interface)是实现抽象和多态的核心机制,它定义了一组方法签名(仅声明方法名、参数和返回值,不包含实现),用于描述 “做什么” 而非 “怎么做”。Go 的接口设计简洁而灵活,采用 “隐式实现” 方式,无需显式声明,极大地降低了代码耦合度。以下是对 Go 接口的详细讲解:
一、接口的基本概念与定义
1. 核心概念
接口是一种抽象类型,它不关心数据的具体类型,只关注数据能执行的操作(即方法)。例如,“可写” 接口只要求实现Write方法,而不关心是文件、网络连接还是内存缓冲区。
2. 定义格式
使用type和interface关键字定义接口,格式如下:
type 接口名 interface { 方法名1(参数列表1) 返回值列表1 方法名2(参数列表2) 返回值列表2 // ... 更多方法}- 接口名:遵循驼峰命名法,通常以
er结尾(表示 “能做某事的类型”,如Reader、Writer)。 - 方法签名:仅包含方法名、参数类型、返回值类型,无函数体。
示例:定义一个 “几何图形” 接口,要求实现面积和周长计算:
type Shape interface { Area() float64 // 计算面积 Perimeter() float64 // 计算周长}二、接口的实现(隐式实现)
Go 接口的实现是隐式的:无需显式声明 “某类型实现了某接口”,只要该类型的方法集完全包含接口的所有方法签名,就自动实现了该接口。这种 “非侵入式” 设计是 Go 接口的核心特点,避免了代码冗余。
示例:实现Shape接口
// 圆形type Circle struct { Radius float64}// 实现Shape接口的Area方法func (c Circle) Area() float64 { return 3.14 * c.Radius * c.Radius}// 实现Shape接口的Perimeter方法func (c Circle) Perimeter() float64 { return 2 * 3.14 * c.Radius}// 矩形type Rectangle struct { Width, Height float64}// 实现Shape接口的Area方法func (r Rectangle) Area() float64 { return r.Width * r.Height}// 实现Shape接口的Perimeter方法func (r Rectangle) Perimeter() float64 { return 2 * (r.Width + r.Height)}此时,Circle和Rectangle都隐式实现了Shape接口,可直接赋值给Shape类型变量。
三、接口的使用(多态)
接口变量可以接收所有实现了该接口的类型的值,调用接口方法时会自动执行具体类型的实现(多态特性)。
示例:
// 接收Shape接口的函数:统一处理所有几何图形func PrintShapeInfo(s Shape) { fmt.Printf(\"面积: %.2f, 周长: %.2f\\n\", s.Area(), s.Perimeter())}func main() { c := Circle{Radius: 5} r := Rectangle{Width: 3, Height: 4} // 接口变量接收不同类型 var s Shape s = c // 合法:Circle实现了Shape PrintShapeInfo(s) // 输出:面积: 78.50, 周长: 31.40 s = r // 合法:Rectangle实现了Shape PrintShapeInfo(s) // 输出:面积: 12.00, 周长: 14.00}四、接口的方法集
一个类型的 “方法集” 是该类型所有方法的集合。接口实现的本质是:类型的方法集必须包含接口的所有方法。
根据接收者类型(值接收者 / 指针接收者),方法集的范围不同:
示例:方法集与接口实现的关系
type MyInterface interface { MethodA() // 需实现的方法 MethodB()}type MyType struct{}// 值接收者方法:T和*T都包含func (m MyType) MethodA() {}// 指针接收者方法:仅*T包含func (m *MyType) MethodB() {}func main() { var i MyInterface t := MyType{} // i = t // 错误:t的方法集只有MethodA,缺少MethodB(指针接收者) pt := &MyType{} i = pt // 正确:pt的方法集包含MethodA和MethodB}五、空接口(interface{})
没有定义任何方法的接口称为空接口(interface{}),它可以接收任意类型的值(因为任何类型都隐式实现了空接口)。
空接口的典型应用场景:
- 通用函数参数:函数需要接收任意类型的参数。
- 通用容器:存储任意类型的数据(如
map[string]interface{})。
示例:空接口的使用
// 1. 通用函数参数func Print(v interface{}) { fmt.Println(v) // 可接收int、string、切片等任意类型}// 2. 通用容器func main() { // 打印任意类型 Print(100) // 输出:100(int) Print(\"hello\") // 输出:hello(string) Print([]int{1,2}) // 输出:[1 2](切片) // 存储任意类型的map data := map[string]interface{}{ \"name\": \"Alice\", \"age\": 25, \"hobbies\": []string{\"reading\", \"running\"}, } fmt.Println(data[\"name\"]) // 输出:Alice}六、类型断言(Type Assertion)
接口变量存储了动态类型(具体类型)和动态值(具体值)。类型断言用于从接口中提取底层具体类型的值,格式:
value, ok := 接口变量.(具体类型)- 若接口变量的动态类型是
具体类型,则value为对应值,ok为true。 - 若类型不匹配,
ok为false,value为该类型的零值(不会触发panic)。
示例:安全的类型断言
func main() { var i interface{} = \"hello\" // 提取string类型 s, ok := i.(string) if ok { fmt.Println(\"字符串长度:\", len(s)) // 输出:字符串长度:5 } // 尝试提取int类型(不匹配) num, ok := i.(int) if !ok { fmt.Println(\"不是int类型,num的零值为:\", num) // 输出:不是int类型,num的零值为:0 }}类型切换(Type Switch)
当需要判断接口的多种可能类型时,使用type switch更简洁:
func checkType(i interface{}) { switch v := i.(type) { // v是对应类型的值 case int: fmt.Println(\"int类型,值为:\", v) case string: fmt.Println(\"string类型,值为:\", v) case []int: fmt.Println(\"[]int类型,长度为:\", len(v)) default: fmt.Println(\"未知类型\") }}func main() { checkType(100) // 输出:int类型,值为:100 checkType(\"hello\") // 输出:string类型,值为:hello checkType([]int{1,2}) // 输出:[]int类型,长度为:2}七、接口组合
接口可以嵌套其他接口,形成新的接口(类似 “继承”,但更灵活),这种方式称为接口组合。
示例:组合Reader和Writer接口:
// 基础接口:读type Reader interface { Read(p []byte) (n int, err error)}// 基础接口:写type Writer interface { Write(p []byte) (n int, err error)}// 组合接口:同时支持读和写type ReadWriter interface { Reader // 嵌套Reader接口 Writer // 嵌套Writer接口}// 实现ReadWriter需同时实现Read和Writetype File struct{}func (f *File) Read(p []byte) (n int, err error) { /* 实现读逻辑 */ }func (f *File) Write(p []byte) (n int, err error) { /* 实现写逻辑 */ }标准库中的io.ReadWriter就是这样实现的,体现了 “小接口组合” 的设计哲学。
八、接口的 nil 判断
接口变量的 “nil” 有两层含义,需特别注意:
- 接口的动态类型为 nil(未绑定任何具体类型)。
- 接口的动态值为 nil(绑定的具体类型是指针,且指针值为 nil)。
只有当 “动态类型和动态值都为 nil” 时,接口变量才是真正的 nil。
示例:
type MyInterface interface { Do()}type MyType struct{}func (m *MyType) Do() {} // 指针接收者方法func main() { var t *MyType = nil // 指针类型,值为nil var i MyInterface = t // 接口动态类型是*MyType,动态值是nil fmt.Println(t == nil) // 输出:true(t是nil指针) fmt.Println(i == nil) // 输出:false(接口动态类型非nil)}九、接口的应用场景
- 多态设计:通过接口统一不同类型的行为,如
Shape接口统一处理圆形、矩形等。 - 依赖注入:定义接口抽象依赖,运行时传入具体实现(如测试时用模拟对象替换真实数据库)。
- 通用组件:用空接口实现通用工具(如日志函数、配置解析器)。
- 模块解耦:定义模块间的交互契约(如
database/sql包的Driver接口,数据库驱动只需实现该接口即可接入)。 - 适配器模式:将不同类型适配到统一接口,如将第三方库的函数包装为接口方法。
总结
Go 接口是实现抽象和多态的核心机制,具有以下特点:
- 隐式实现:无需显式声明,类型方法集包含接口方法即自动实现。
- 非侵入式:不要求类型修改代码以适配接口,降低耦合。
- 灵活性:支持空接口(通用类型)、接口组合(功能扩展)、类型断言(类型还原)。
掌握接口的使用,能极大提升代码的灵活性和可维护性,是 Go 语言 “少即是多” 设计哲学的典型体现。


