Python 标准库详解:Json 模块的使用_python json
一、模块简介
json库是Python内置的一个标准库,用于在Python对象和JSON数据之间进行序列化和反序列化,json库在日常的开发中经常用到,它广泛应用于接口开发、配置管理、数据交换等场景。
由于日常开发中会经常用到这个库,今天闲来无事,打算来总结一下一些常用的json库的一些方法以及参数的含义。
本文会结合代码以及运行结果的方式来帮助你理解并真的会用他!
二、Json库的使用
首先,json库是python内置的一个库,我们直接调用即可
import json接下来,我们一起来看看json将Python对象进行序列化的两种方法
(后续标题会使用这种方法,可以简要了解一下*args和**kwargs,如下注)
注:在 Python 中,*args 和**kwargs 用于函数定义中接收可变数量的参数。*args表示接收任意数量的位置参数,函数内部将其打包为一个元组;而**kwargs 则用于接收任意数量的关键字参数,函数内部将其打包为一个字典。它们常用于不确定传入参数数量的场景,能够提高函数的灵活性与通用性。例如:def func(*args, **kwargs):就可以同时接收多个普通参数和命名参数。
2.1 序列化
2.1 json.dump(*args, **kwargs)方法
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)将 Python 对象 编码成 JSON 格式,并 写入到类文件对象
fp中。
其中各个参数的详解如下
objdict、list 等)fp.write() 方法,如打开的文件句柄skipkeysTrue,则字典中非字符串键会被跳过,否则会报 TypeErrorFalseensure_asciiTrue,所有非 ASCII 字符会转义为 \\uXXXX,否则输出原字符Truecheck_circularFalse,允许循环引用,否则报 ValueErrorTrueallow_nanTrue,允许 NaN, Infinity, -Infinity 并序列化为对应标识符,否则报 ValueErrorTrueclsJSONEncoder 子类,用于扩展序列化行为NoneindentNone 则输出紧凑版;若为非负整数,则美化输出Noneseparators(item_sep, key_sep) 元组,定义项与项、键与值间分隔符;默认 (\',\', \': \')NonedefaultNonesort_keysTrue,字典的键会被排序后输出False其中很常用的应该是obj,fp,ensure_ascii(想输出中文,一般会置为False),indent(调整输出缩进,可以使json格式更美观),sort_keys(用作排序)。
以下是一个简单的调用示例,将 Python 对象写入到 JSON 文件中。
import json# 创建一个字典对象data = { \'名字\': \'my\', \'年龄\': 20, \'tags\': [\'python\', \'博客\']}# 将字典写入到 data.json 文件中with open(\'out.json\', \'w\', encoding=\'utf-8\') as f: json.dump( data, f, ensure_ascii=False, # 保留中文 indent=2, # 缩进 2 格 sort_keys=True # 字段按字母排序 )运行过后会生成一个out.json文件,内容如下
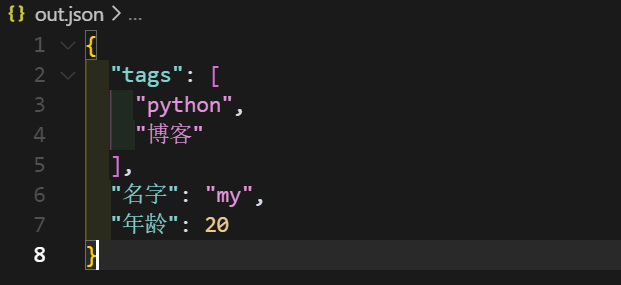
想要深刻的理解这些常用的参数,不妨我们试试修改他们,如果ensure_ascii置为True会是什么样子,非ASCii字符就会转为\\uXXXX,如下图所示
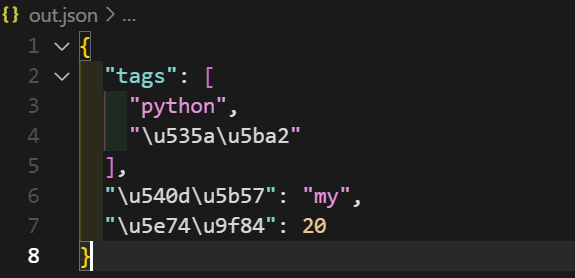
当我不适用缩进,也就是将indent置为0,会怎么样呢?
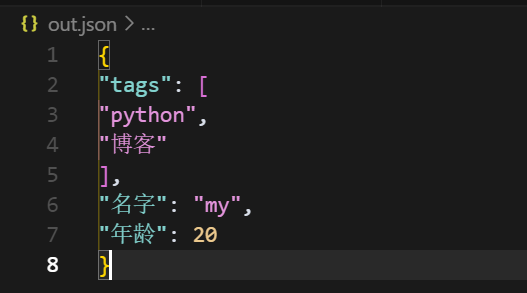
就会变成这样,是不是没有有缩进的看着舒服呢?当不按字段排序也就是sort_keys置为False时,会是什么样子呢?
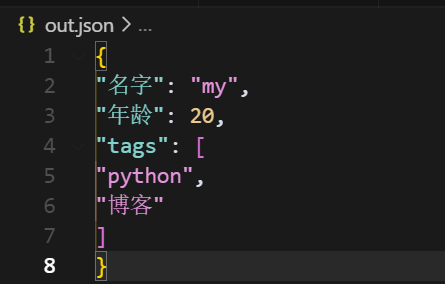
由这些可以知道,很好的利用这些参数,可以让可读性很强,观感更舒服。
总结:
- 将 Python 对象写入到 JSON 文件中
- 适合将数据保存为 JSON 格式的配置文件、缓存数据等
- indent以及sort_keys参数让文件内容更可读,常用于调试或用户可读场景
2.2 json.dumps(*args, **kwargs)方法
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False) → str将 Python 对象编码为 JSON 格式的 字符串
参数说明:和json.dump()几乎完全一致,区别是返回一个字符串,而不是写入文件。
以下是一个简单的调用示例,将 Python 对象转换成 JSON 字符串。
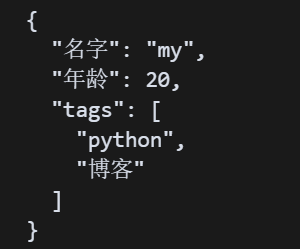
import json# 同样的 Python 对象data = { \'名字\': \'my\', \'年龄\': 20, \'tags\': [\'python\', \'博客\']}# 将 Python 对象转为 JSON 字符串json_str = json.dumps(data, ensure_ascii=False, indent=2)# 打印 JSON 字符串print(json_str)打印内容如下
总结:
- 将 Python 对象转换成 JSON 字符串
dumps()的结果是一个字符串,常用于传输数据(如发送给接口、保存数据库)- 和
dump()相比,区别是是否“写入文件”
2.2 反序列化
2.2.1 json.load(*args, **kwargs)方法
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None)从类文件对象
fp中读取 JSON 数据,并转换为 Python 对象
其中各个参数的详解如下
fpclsobject_hookparse_floatparse_intparse_constantNaN、Infinity 等object_pairs_hookobject_hook,保留键值顺序(如 OrderedDict)一般只需用到fp参数,其他参数可根据自己的需求来使用。
以下是一个简单的调用示例,从 JSON 文件中读取数据为 Python 对象。
import json# 假设已经存在out.json文件,并且文件内容是:# data = {# \'名字\': \'my\', # \'年龄\': 20, # \'tags\': [\'python\', \'博客\']# }# 从文件读取并转换为 Python 对象with open(\'out.json\', \'r\', encoding=\'utf-8\') as f: loaded_data = json.load(f)# 打印读取到的 Python 对象print(loaded_data)打印内容如下

总结
从 JSON 文件中读取数据为 Python 对象
常用于读取配置、存储的数据文件
注意文件路径、编码要匹配
2.2.2 json.loads(*args, **kwargs)方法
json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None) → obj将 JSON 格式的 字符串 反序列化为 Python 对象
参数说明:与load()相同,但第一个参数是字符串 。
以下是一个简单的调用示例,将 JSON 字符串解析成 Python 对象。
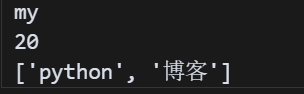
import json# 一个合法的 JSON 字符串json_str = \'{\"名字\": \"my\", \"年龄\": 20, \"tags\": [\"python\", \"博客\"]}\'# 转换为 Python 字典data = json.loads(json_str)# 访问其中的数据print(data[\'名字\']) # 输出:myprint(data[\'年龄\']) # 输出:20print(data[\'tags\']) # 输出:博客打印内容如下
总结
- 将 JSON 字符串解析成 Python 对象
- JSON 中的
true、false、null会自动映射为 Python 的True、False、None。
2.3 总结对比
json.dump().json)fp, indent, ensure_ascii, default, sort_keysjson.dumps()indent, ensure_ascii, default, sort_keysjson.load().json)fp, object_hook, parse_float, parse_intjson.loads()object_hook, parse_float, parse_int三、进阶用法:default 与 object_hook
3.1 default 参数 —— 定制化序列化(Python ➜ JSON)
当我们在使用json.dump()或json.dumps()将 Python 对象转换为 JSON 时,如果对象中包含 JSON 标准不支持的类型(如datetime、自定义类对象等),就会抛出错误。这时就可以通过default参数,告诉 JSON 如何处理这些类型。
json.dumps(obj, default=custom_function)参数说明:
- obj:要序列化的 Python 对象
- default:一个函数,接收一个不能序列化的对象,返回一个可被序列化的类型(如:字符串、数字、列表、字典)
以下是一个简单示例,序列化一个datetime对象。
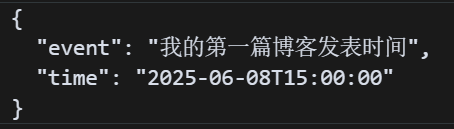
import jsonfrom datetime import datetime# 原始数据data = { \"event\": \"我的第一篇博客发表时间\", \"time\": datetime(2025, 6, 8, 15, 0)}# 自定义转换函数def datetime_serializer(obj): if isinstance(obj, datetime): return obj.isoformat() # 转为标准字符串 raise TypeError(f\"无法序列化类型: {type(obj)}\")# 使用 default 序列化json_str = json.dumps(data, default=datetime_serializer, ensure_ascii=False, indent=2)print(json_str)打印内容如下
如果不进行该定制化序列化,该datetime就是JSON标准所不支持的类型,而提供了default的参数,会告诉JSON如何处理这些数据(也就是所定义的datetime_seriallizer函数)则会报错,而定制化序列化很好的解决了这个问题。下面我们来一个进阶例子。
以下是一个示例,序列化自定义类对象。
class Student: def __init__(self, name, score): self.name = name self.score = scorestudent = Student(\"小z\", 100)def student_serializer(obj): if isinstance(obj, Student): return {\"name\": obj.name, \"score\": obj.score} raise TypeError(\"无法序列化的对象\")json_str = json.dumps(student, default=student_serializer, ensure_ascii=False)print(json_str)打印内容如下

总结:
default参数用于解决 无法被 JSON 默认序列化的对象(如自定义类、datetime等),它接收一个函数,将特殊对象转换为可被 JSON 接受的标准格式(如字典或字符串)。常用于json.dumps()和json.dump()中。
3.2 object_hook 参数:定制化反序列化(JSON ➜ Python 对象)
当我们在使用json.load()或json.loads()将 JSON 字符串转为 Python 对象时,默认只返回 dict 类型。但我们可以通过object_hook参数,自定义将 JSON 字典转换为 Python 中的类实例,实现“还原成对象”。
json.loads(json_str, object_hook=custom_decoder)参数说明:
- 待解析的 JSON 字符串
- 一个函数,它会接收反序列化后的每一个 JSON 对象(即字典dict),并返回转换后的 Python 对象
(它会在 JSON 嵌套结构中从最内层到外层递归调用)
以下是一个进阶示例,将 JSON 反序列化为自定义类
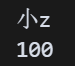
class Student: def __init__(self, name, score): self.name = name self.score = score# JSON 字符串json_str = \'{\"name\": \"小z\", \"score\": 100}\'# 自定义解码函数def dict_to_student(d): return Student(d[\'name\'], d[\'score\'])# 使用 object_hook 解码student = json.loads(json_str, object_hook=dict_to_student)print(student.name) # 小zprint(student.score) # 100打印内容如下
经过我们前面的学习,我们知道json.loads()会将json格式的数据反序列化为python对象,而我们所加的这个参数object_hook=dict_to_student,就等价于一个映射函数,将经典的python对象映射为我们所自定义的类对象。方便我们可以直接调用自定义类的功能。
下面我们来一个进阶例子,将带类型字段的 JSON 动态还原多个对象类型。
class Student: def __init__(self, name, score): self.name = name self.score = scoreclass Teacher: def __init__(self, name, subject): self.name = name self.subject = subjectjson_str = \'\'\'[ {\"type\": \"student\", \"name\": \"小z\", \"score\": 100}, {\"type\": \"teacher\", \"name\": \"小l\", \"subject\": \"数学\"}]\'\'\'def smart_decoder(d): if d.get(\"type\") == \"student\": return Student(d[\"name\"], d[\"score\"]) elif d.get(\"type\") == \"teacher\": return Teacher(d[\"name\"], d[\"subject\"]) return d # 默认返回 dictdata = json.loads(json_str, object_hook=smart_decoder)for obj in data: print(type(obj), vars(obj)) # 输出对象类型和属性字典打印内容如下

这里只是在前者的例子上多加了一个自定义类,在映射函数中多加了一个判断逻辑。
3.3 总结对比
defaultdumps() / dump()object_hookloads() / load()比较常见的场景和建议
- 序列化 datetime、自定义类
default 参数object_hook 参数type 字段与 object_hook 实现object_hook 会自动递归调用四、注意事项
Python JSON dictobject list,tuplearray strstring int,floatnumber True/Falsetrue/false Nonenull - dumps() 与 loads() 用于字符串处理,dump() 与 load() 用于文件处理
- 不支持直接序列化自定义类、函数、集合等 —— 需借助 default 参数手动转换
五、结语
相信今天所讲的这些在你的json生涯中已经绰绰有余了,json模块完结撒花!!!
这是我写博客的第二篇,也是第二天,想着每天抽出来一点闲暇时间来写一些东西,顺便也丰富一下自己的逻辑表达能力,以及知识储备能力,后续会陆续推出其他各种模块包的经典用法,等有闲时间了,当下时间有点紧,其他方面的东西在当下不适合写,等今年过了,明年开始尝试写一些项目实战还有原理性的东西!


