《破局!AI工具“充电线地狱“终结者蓝耘MCP来了,一套API玩转Cherry、Cursor等5大神器》
如何注册蓝耘智算平台
1. 点击注册链接:蓝耘智算平台
2. 进入下面图片界面,输入手机号并获取验证码,输入邮箱,设置密码,点击注册
前言:告别工具混乱时代
还在为AI工具各自为政而头疼?
作为一个代码程序员,最头疼的就是工具之间的不兼容。你知道那种感觉吗?就像家里一堆充电线,iPhone要Lightning,安卓要Type-C,老设备还得Micro-USB,出门旅行包里装的都是线。每次换个设备就得重新找对应的线,简直是噩梦。
AI工具也是一样的道理。我用ChatGPT的时候得记住它的API格式,换到Claude又是另一套接口,想集成到自己的项目里更是要写一堆适配代码。每个AI服务商都有自己的一套标准,开发者苦不堪言。
直到有一天,MCP协议的出现彻底改变了这个局面。就像USB-C统一了充电接口一样,**MCP(Model Context Protocol,模型上下文协议)**是由 Anthropic 公司(Claude 大模型的创造者)于 2024 年 11 月推出的一种开放标准协议,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信方式。

而蓝耘MCP平台,就是这个AI工具生态的\"统一标准\"。今天我就来教你怎么用一套配置,让所有AI工具都听你的话。
在蓝耘平台上玩转MCP Agent工作流
MCP Agent工作流设计实战
让我们从一个具体的场景开始 - 智能客服系统。想象一下,你的公司需要一个能够自动回答用户问题、查询订单状态、生成报告并发送邮件的智能客服。传统做法需要写一堆胶水代码,但有了MCP协议,一切变得简单了。
工作流构建过程:
首先,在蓝耘平台创建MCP服务器非常直观。蓝耘是专业的GPU算力云服务提供商,基于行业领先的灵活的基础设施及大规模的GPU算力资源,为客户提供开放、高性能、高性价比的算力云服务。你只需要在控制台点击\"创建MCP服务器\",填写基本信息,系统就会自动为你分配资源。

接下来是Agent配置,这是整个工作流的核心。我通常会创建三个主要的Agent:
- 数据库查询Agent - 负责从订单系统、用户数据库中检索信息
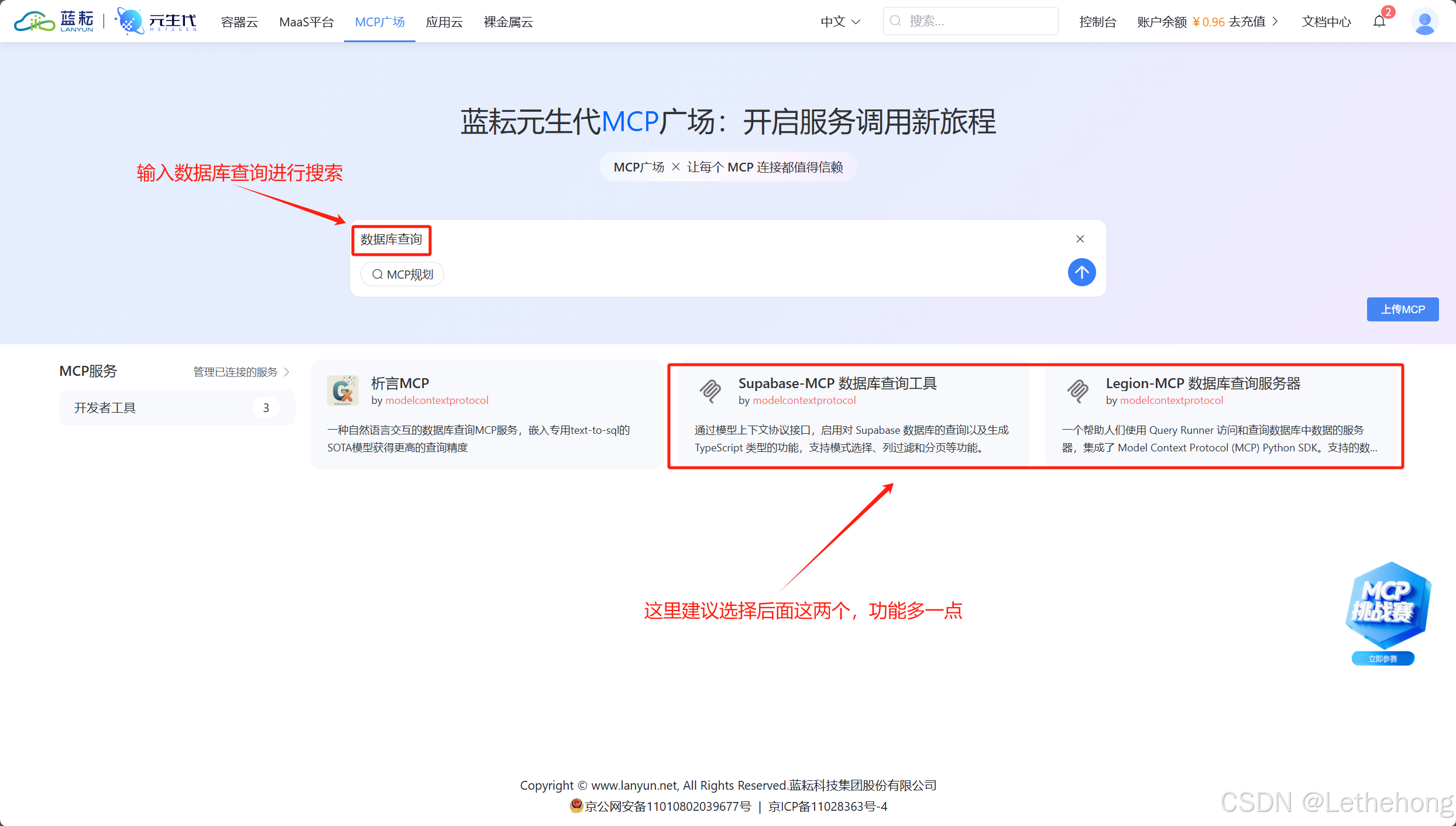
- 文档生成Agent - 根据查询结果生成格式化的报告或回复
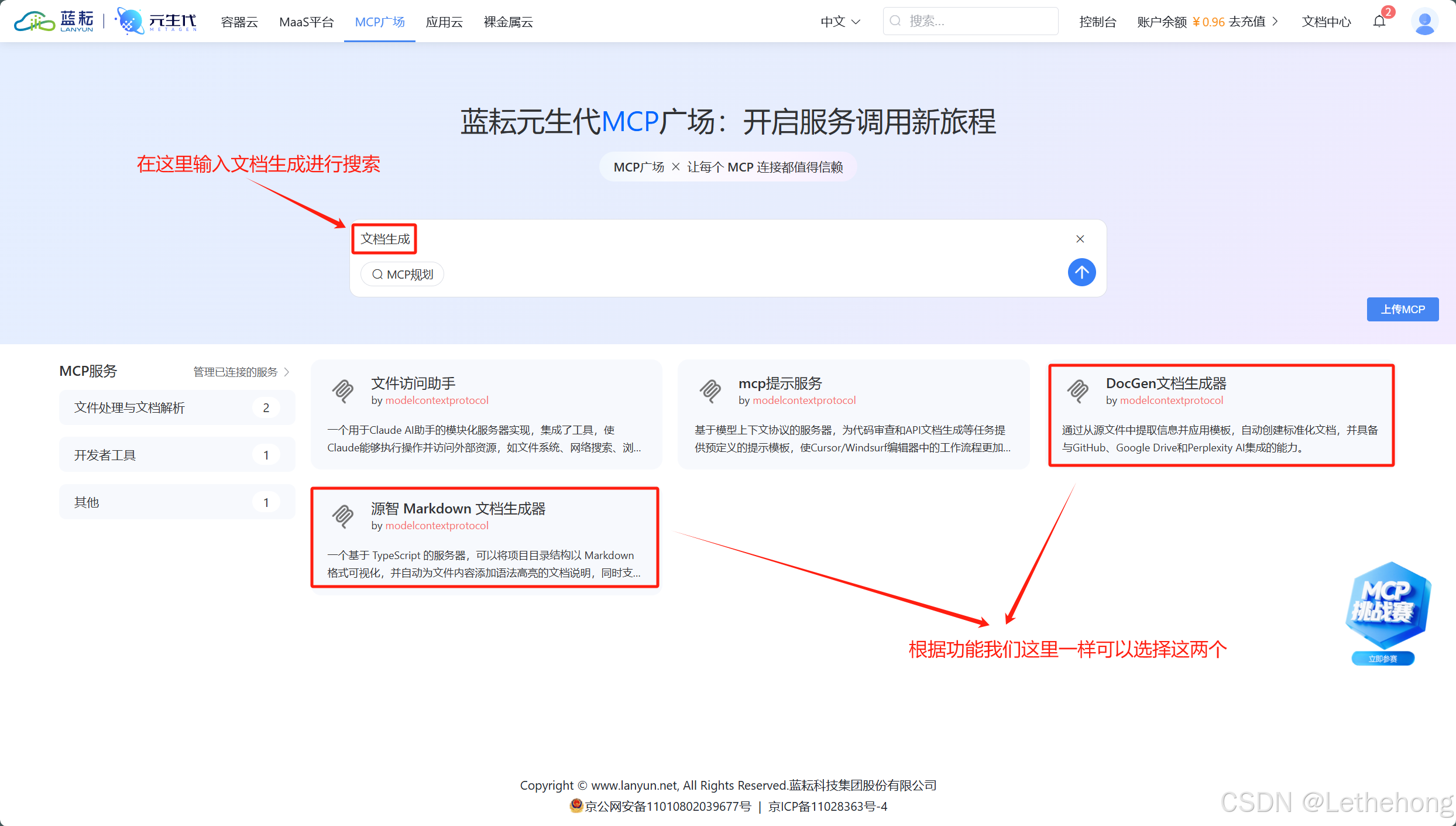
- 邮件发送Agent - 将生成的内容通过邮件发送给用户
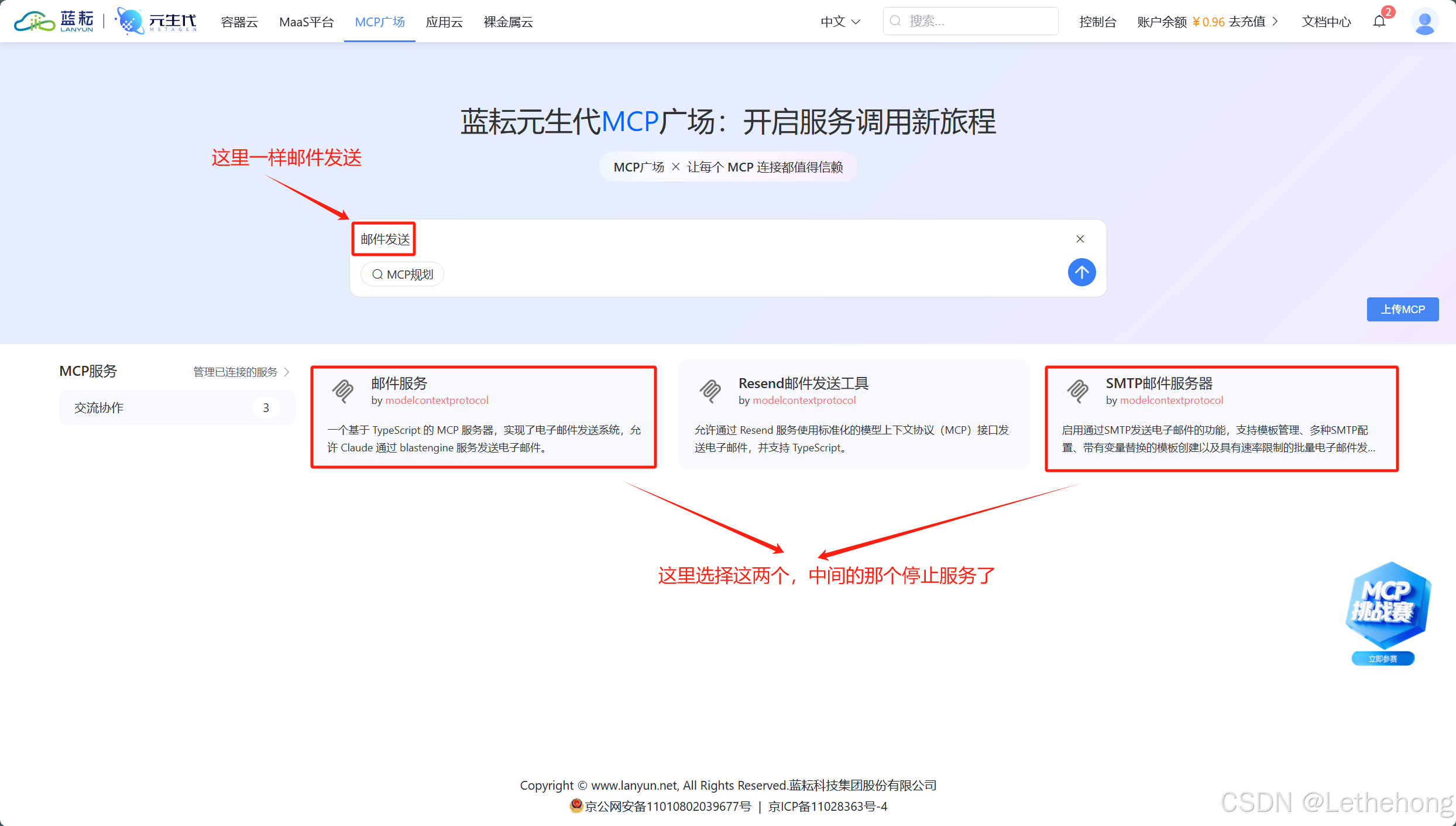
最关键的是设计数据流向和决策逻辑。MCP(Model Context Protocol)是解决AI自动化痛点的开放协议,标准化LLM与外部工具交互,提升AI助手的执行能力和稳定性,减少幻觉,支持多步骤工作流。
多工具协同实战:
在实际演示中,整个流程是这样的:
1. 用户询问订单状态
2. 数据库查询Agent接收到请求,自动查询相关订单信息
3. 文档生成Agent根据查询结果,生成包含订单详情、物流信息的格式化回复
4. 邮件发送Agent将回复内容发送给用户,同时抄送相关客服人员
我刚开始用的时候,最担心的是这些Agent之间会不会\"打架\",结果发现MCP协议的设计非常巧妙,每个Agent都有明确的输入输出格式,就像标准化的积木一样,可以任意组合。
创新应用场景展示
智能知识管理系统
试用下来最让我惊喜的是它在知识管理方面的能力。我用蓝耘MCP平台搭建了一个企业知识库系统,结合文档解析、知识图谱构建和问答系统。基于MCP协议的AI Agent应用开发,通过标准化协议,将工具提供方与应用研发者解耦,这让不同部门的文档可以无缝整合。
这里给大家提供一个pdf的示例文档
%PDF-1.41 0 obj<< /Title (示例文档)/Creator (Craft)/Author (腾讯云)/CreationDate (D:20250701120000)>>endobj2 0 obj<< /Type /Page/Parent 3 0 R/Contents 4 0 R>>endobj3 0 obj<< /Type /Pages/Kids [2 0 R]/Count 1>>endobj4 0 obj<< /Length 44 >>streamBT/F1 12 Tf100 700 Td(这是一个PDF解析示例文档) TjETendstreamendobj5 0 obj<</Type /Page/Parent 3 0 R/Contents 6 0 R>>endobj6 0 obj<< /Length 200 >>streamBT/F1 12 Tf100 650 Td(表格示例) Tj100 600 Td(产品名称 数量 价格) Tj100 580 Td(笔记本电脑 5台 ¥25,000) Tj100 560 Td(智能手机 10部 ¥15,000) TjETendstreamendobjxref0 70000000000 65535 f 0000000015 00000 n 0000000075 00000 n 0000000125 00000 n 0000000185 00000 n 0000000250 00000 n 0000000350 00000 n trailer<< /Size 7/Root 3 0 R>>startxref450%%EOF自动化内容创作流水线
另一个让我印象深刻的应用是自动化内容创作。从市场需求分析,到内容大纲生成,再到最终发布,整个流程都可以通过MCP Agent来自动化处理。比如我们公司的周报,现在完全可以让AI自动收集各部门数据,生成图表,写成报告,然后自动发送给相关人员。
数据驱动的业务洞察
最实用的场景还是数据分析。蓝耘平台可以同时连接多个数据源 - 销售系统、客户管理系统、财务系统,然后通过AI进行整合分析,生成业务洞察报告。以前需要数据分析师花几天时间做的事情,现在几分钟就能搞定。
这样,蓝耘平台就能自动完成多源数据分析和报告生成,极大提升业务效率。
一套API,五种玩法 - 让你的工具箱威力翻倍
Cherry Studio - 桌面AI助手的终极形态
说到桌面AI客户端,Cherry Studio绝对是我用过最顺手的。Cherry Studio是一个支持多模型服务的桌面客户端,为专业用户而打造,内置30多个行业的智能助手及多服务商,集成了超过300多个大语言模型。
配置步骤详解:
获取蓝耘API密钥的过程很简单,在蓝耘平台的MaaS平台找到\"API KEY管理\",点击\"创建新密钥\",系统会生成一个形如sk-xxxxxxxxxx的密钥,记得妥善保存。
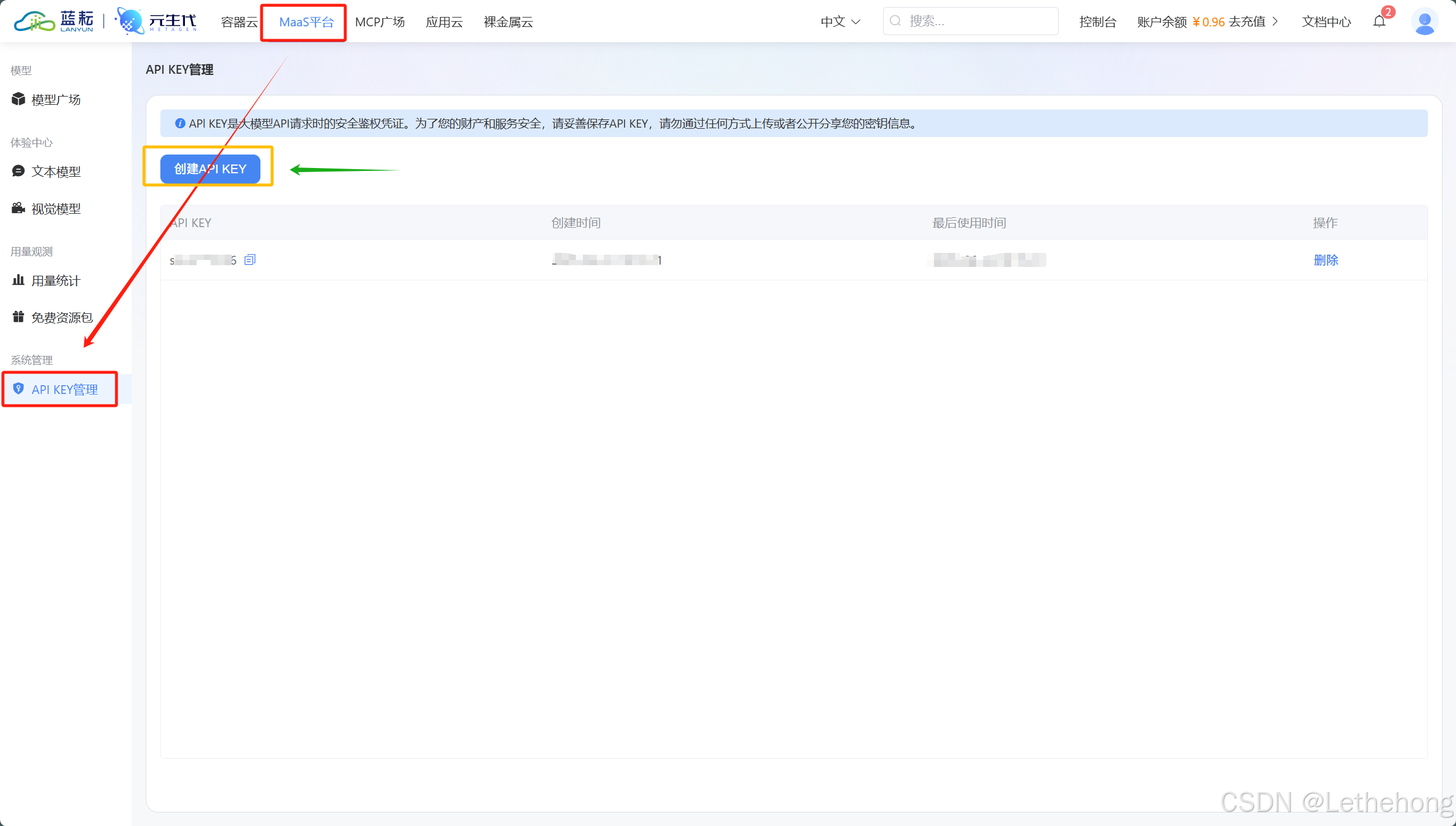
在Cherry Studio中添加蓝耘模型也很直观:
1. 打开Cherry Studio,进入设置页面
2. 找到\"自定义模型\"选项
3. 填入蓝耘的API端点:https://api.lanyun.net/v1
4. 输入刚才获取的API密钥
5. 设置模型参数:温度建议设为0.7,max_tokens根据需要调整
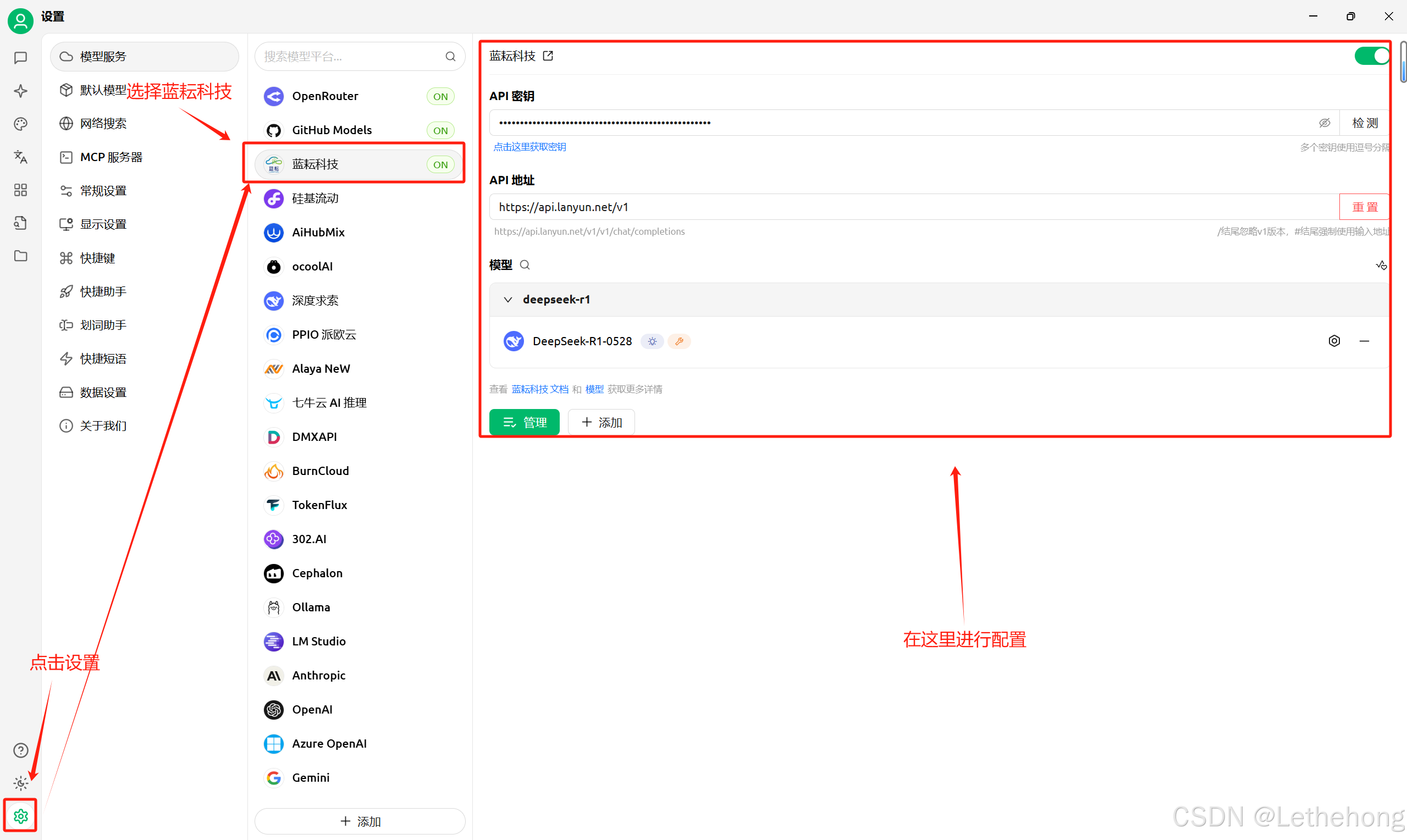
使用技巧分享:
我在Cherry Studio中设置了多个助手角色:代码审查助手、文档写作助手、数据分析助手。每个角色都有专门的系统提示词,这样切换不同任务时特别方便。
批量对话功能特别好用,可以同时向多个模型提问,然后对比它们的回答质量。我经常用这个功能来测试不同模型在特定任务上的表现。
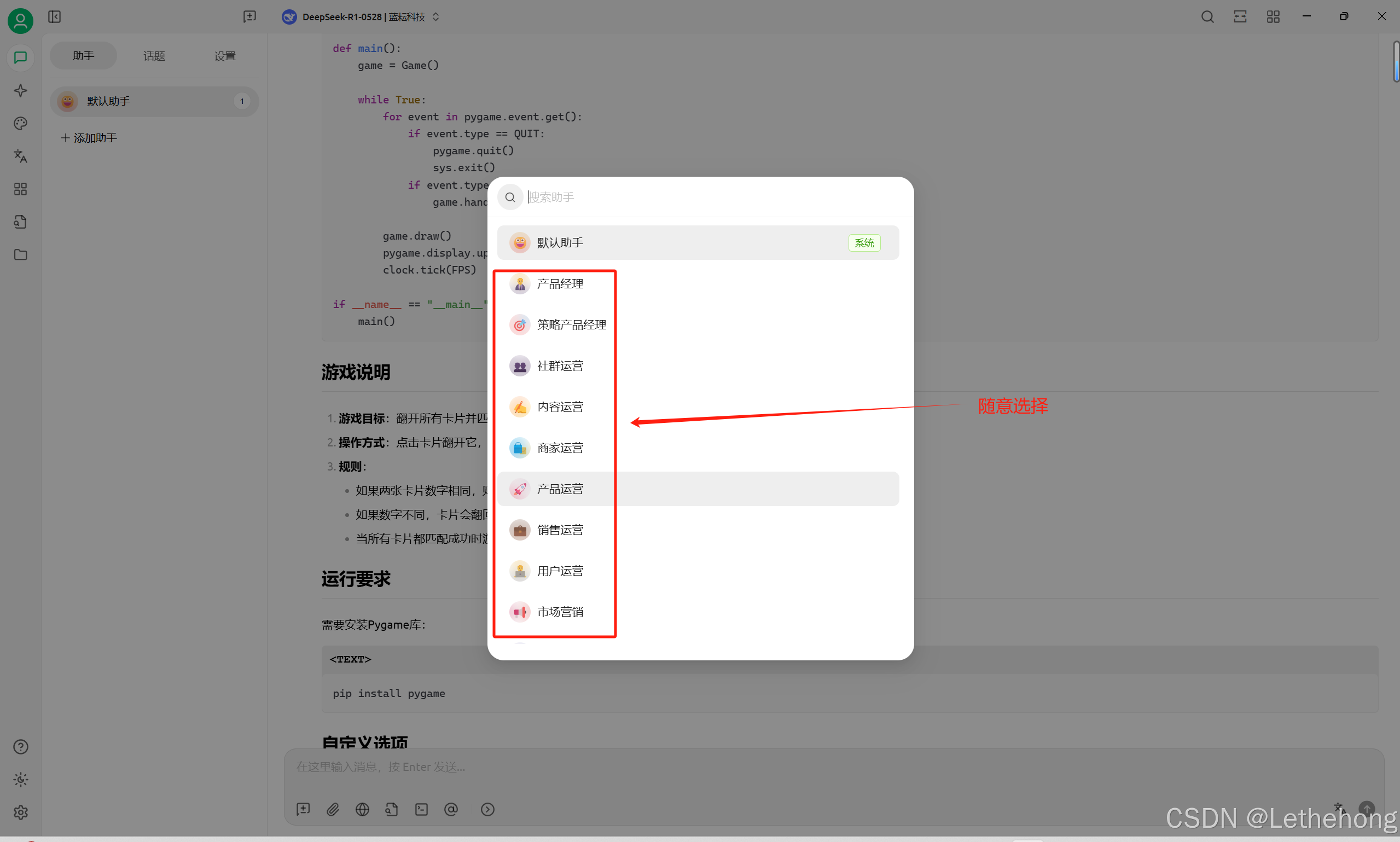
实际案例:代码审查助手
我用Cherry Studio和蓝耘API搭建了一个代码审查助手。把代码贴进去,它会自动检查潜在的Bug、性能问题、安全漏洞,还会给出修改建议。比传统的静态代码分析工具智能多了,能理解代码的业务逻辑。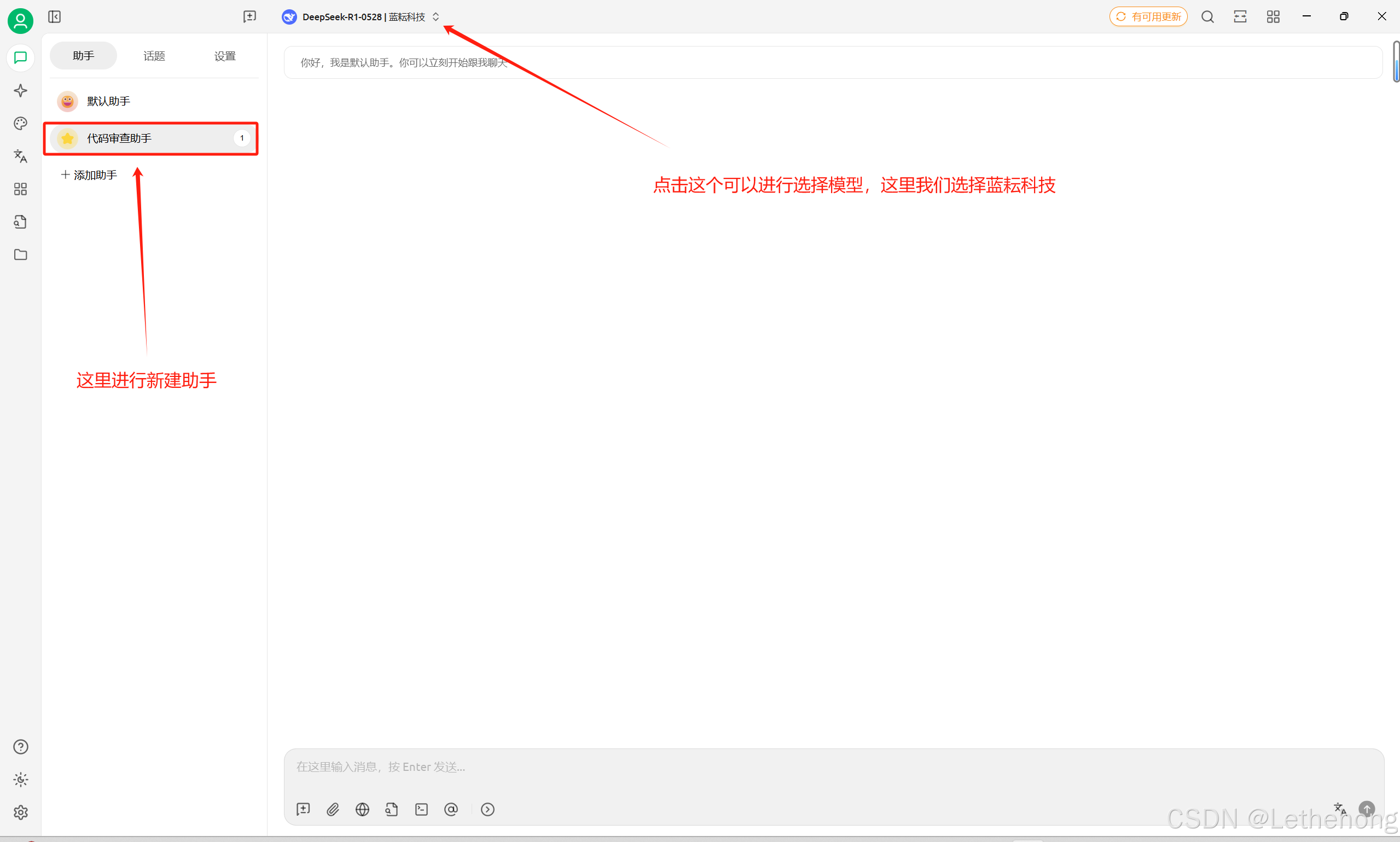
把代码贴进去就开始干活了,当然这个地方的模型不用在意,因为这里是用于示例,不用太讲究了,大家懂得都懂哈。这里的代码有点水了,就不给大家看debug了
Cursor - 让编程真的像聊天一样简单
Cursor是一款AI代码编辑器,最近在开发者圈子里特别火。集成蓝耘API后,编程效率真的提升了一个档次。
集成教程:
在Cursor的设置页面,有一个\"API Configuration\"选项。填入蓝耘的配置信息:
- API Provider: Custom
- Base URL: https://api.lanyun.net/v1
- API Key: 你的蓝耘密钥
- Model: 根据需要选择,我一般用deepseek-coder
有些同学可能遇到地区限制问题,这里分享个小技巧:可以设置代理服务器,或者使用蓝耘提供的海外节点接入。
编程实战经验:
用蓝耘API在Cursor中进行代码生成简直是神器。我只需要用自然语言描述需求,比如\"写一个处理用户注册的API接口,包括邮箱验证和密码加密\",Cursor就能生成完整的代码,包括错误处理和单元测试。
import express from \'express\';import bodyParser from \'body-parser\';import bcrypt from \'bcryptjs\';import nodemailer from \'nodemailer\';const app = express();app.use(bodyParser.json());const users: { [email: string]: { password: string, verified: boolean, code?: string } } = {};// 邮箱验证码发送app.post(\'/api/send-code\', async (req, res) => { const { email } = req.body; if (!email) return res.status(400).json({ message: \'邮箱不能为空\' }); // 生成验证码 const code = Math.floor(100000 + Math.random() * 900000).toString(); // 发送邮件 const transporter = nodemailer.createTransport({ service: \'qq\', // 这里以QQ邮箱为例 auth: { user: \'你的邮箱@qq.com\', pass: \'你的授权码\' } }); try { await transporter.sendMail({ from: \'你的邮箱@qq.com\', to: email, subject: \'注册验证码\', text: `您的验证码是:${code}` }); users[email] = { ...users[email], code, verified: false }; res.json({ message: \'验证码已发送\' }); } catch (err) { res.status(500).json({ message: \'发送失败\', error: err }); }});// 注册接口app.post(\'/api/register\', async (req, res) => { const { email, password, code } = req.body; if (!email || !password || !code) return res.status(400).json({ message: \'参数不完整\' }); const user = users[email]; if (!user || user.code !== code) return res.status(400).json({ message: \'验证码错误\' }); // 密码加密 const hashedPassword = await bcrypt.hash(password, 10); users[email] = { password: hashedPassword, verified: true }; res.json({ message: \'注册成功\' });});app.listen(3001, () => { console.log(\'Server running on http://localhost:3001\');});调试和重构的AI辅助流程也很棒。选中一段有问题的代码,按Ctrl+K,告诉AI\"这段代码有性能问题,帮我优化一下\",它会给出优化方案并解释原因。
踩坑经验分享:
刚开始我也遇到了API调用失败的问题,后来发现是因为网络环境的问题。建议大家配置好代理,或者联系蓝耘技术支持获取最适合的接入节点。
NextChat - 部署你的专属AI聊天室
NextChat是个开源项目,可以快速部署ChatGPT-like的聊天界面。根据SiliconFlow的文档,配置过程很简单。
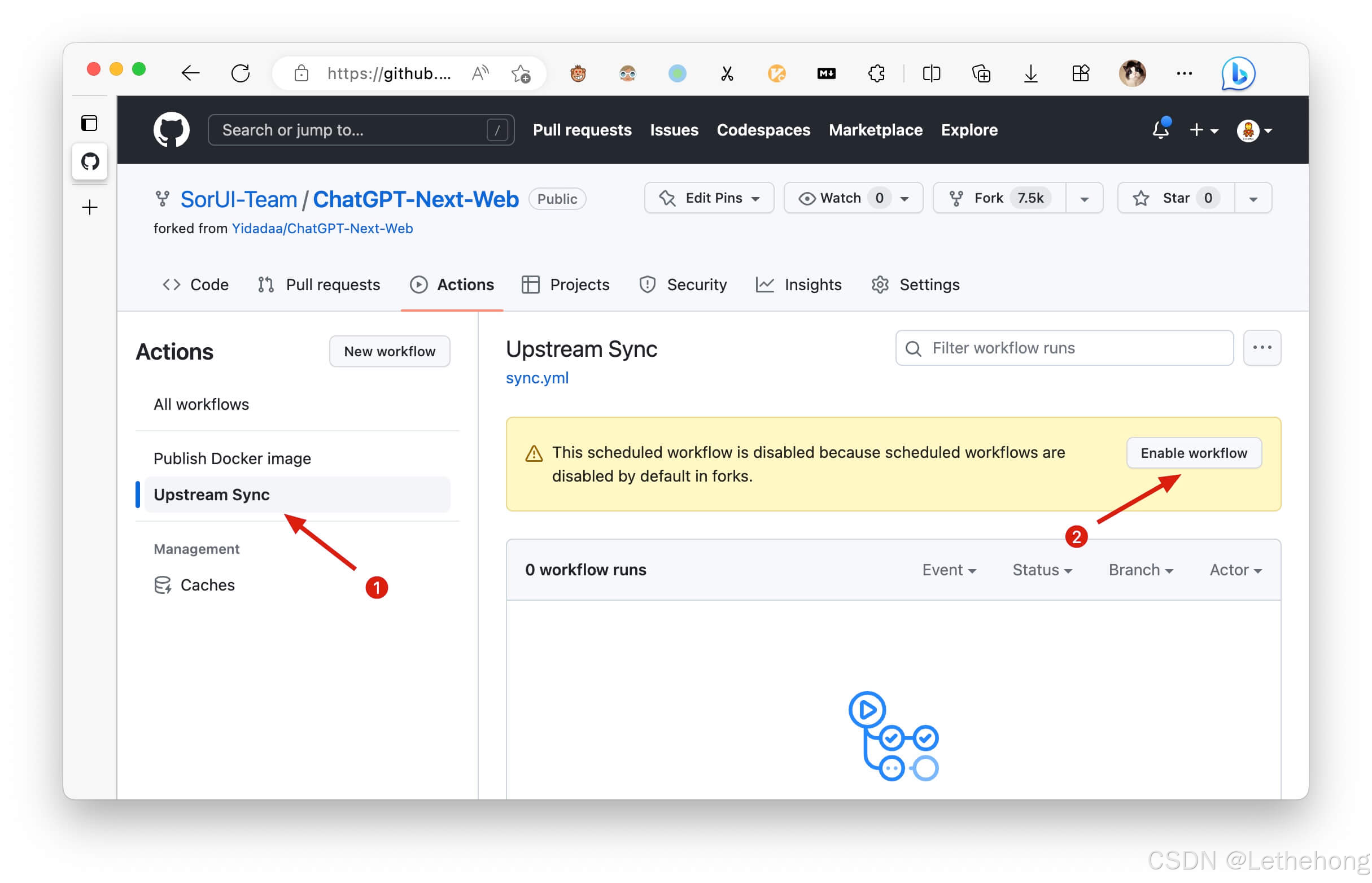
部署指南:
本地部署vs云端部署的选择主要看你的需求。如果是个人使用或小团队,本地部署就够了;如果需要高可用和负载均衡,建议选择云端部署。
环境变量配置是关键:
OPENAI_API_KEY=你的蓝耘API密钥OPENAI_API_BASE_URL=https://api.lanyun.net/v1DEFAULT_MODEL=gpt-3.5-turbo定制化配置技巧:
集成蓝耘的多种模型很简单,在配置文件中添加模型列表:
{ \"models\": [ \"gpt-3.5-turbo\", \"gpt-4\", \"deepseek-chat\", \"claude-3-haiku\" ]}创建不同场景的对话模板特别实用。我为公司创建了技术支持、销售咨询、产品反馈等不同的模板,每个模板都有专门的系统提示词。
团队使用场景:
为团队搭建内部AI助手的效果超出预期。我们把公司的文档、产品手册都集成进去,新员工入职时可以直接问AI各种问题,大大减少了培训成本。
DB-GPT - 数据库的AI化改造
DB-GPT是一个开源的AI原生数据应用开发框架,支持Text2SQL、RAG等功能。
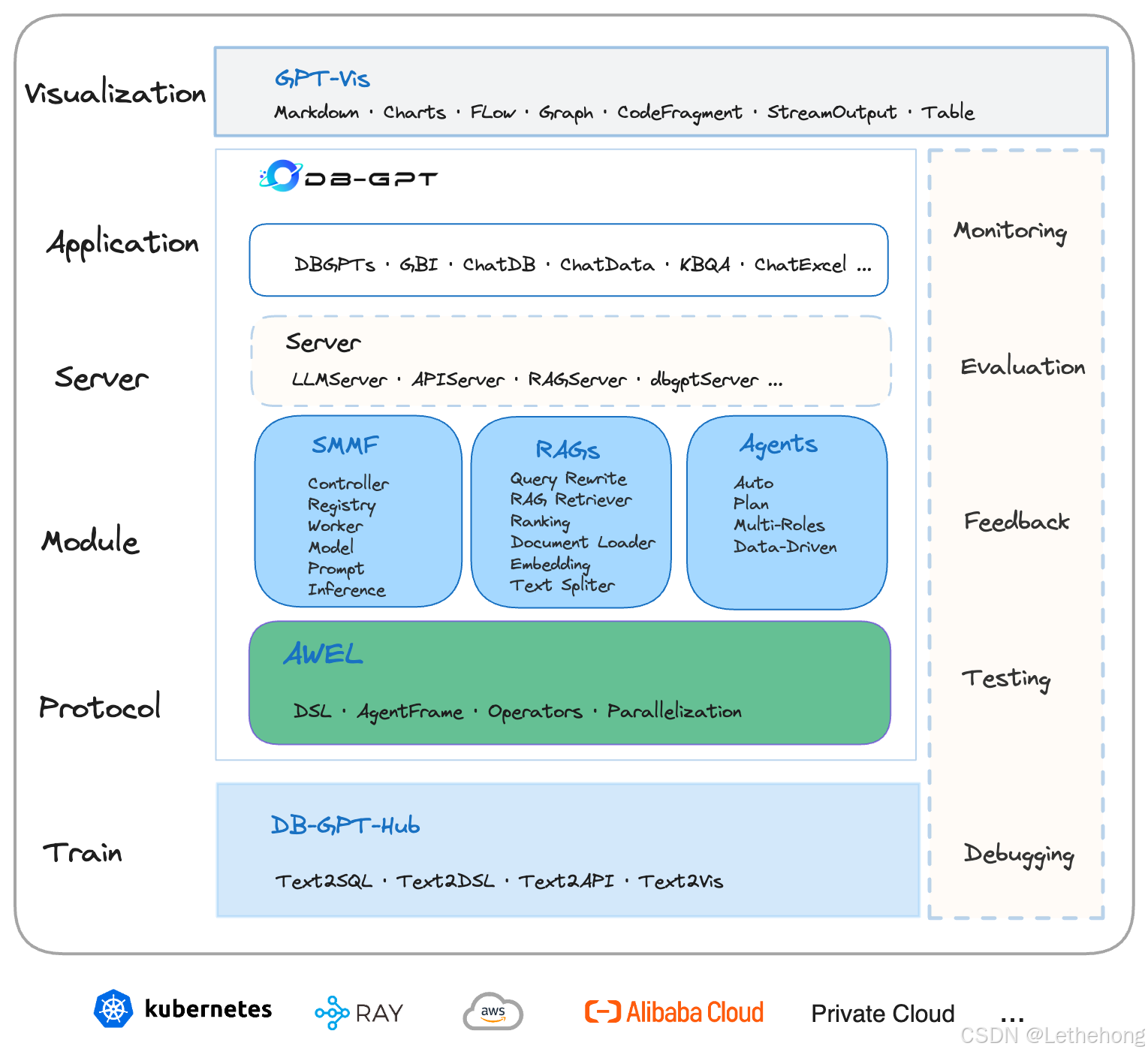
安装配置流程:
从源码安装到Docker部署,我推荐Docker方式,更稳定:
docker pull eosphorosai/db-gptdocker run -d -p 5000:5000 \\ -e LLM_MODEL=chatgpt_proxyllm \\ -e PROXY_API_KEY=你的蓝耘密钥 \\ -e PROXY_SERVER_URL=https://api.lanyun.net/v1/chat/completions \\ eosphorosai/db-gptText2SQL实战:
训练适合自己业务的SQL生成器需要一些技巧。我建议先用少量的业务数据做微调,然后逐步扩展。蓝耘平台的GPU资源在这里就发挥作用了,训练速度很快。
RAG知识库的构建也很重要。 我把公司的数据字典、表结构说明都加入到知识库中,这样AI生成的SQL更准确。
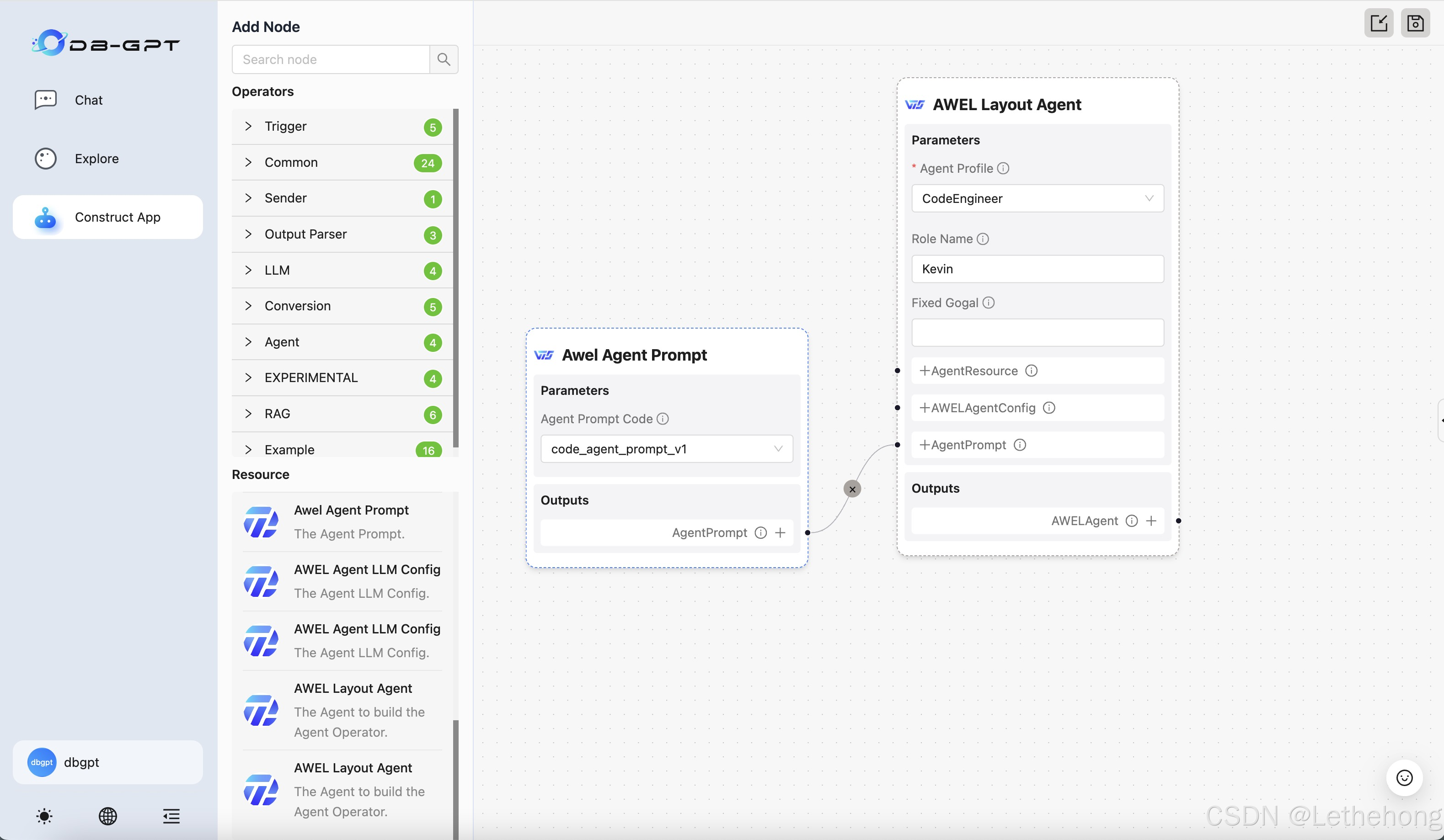
复杂查询案例:
多表关联查询是DB-GPT的强项。比如\"查询上个月销售额最高的前10个客户,以及他们的订单详情\",这种复杂的业务查询,AI都能准确理解并生成相应的SQL。
Obsidian Copilot - 个人知识库的AI升级
Obsidian Copilot是一款开源的AI助手插件,设计简洁,使用方便。
插件配置流程:
在Obsidian社区插件中搜索\"Copilot\",安装后在设置中配置:
- API Provider: OpenAI Compatible
- API Key: 你的蓝耘密钥
- Base URL: https://api.lanyun.net/v1
- Model: gpt-3.5-turbo
知识管理实践:
Vault QA功能简直是知识工作者的福音。我把所有的读书笔记、项目文档都放在Obsidian里,现在可以直接问AI\"上个月关于机器学习的笔记有哪些重点?\",AI会自动整理相关内容。
自定义提示词的设置也很重要。我设置了几个常用的提示词模板:
- 总结文档要点
- 生成思维导图
- 查找相关笔记
- 生成写作大纲
工作流整合:
结合其他Obsidian插件的效果更好。比如配合Dataview插件,可以自动统计和分析笔记数据;配合Calendar插件,可以生成时间线式的知识回顾。
从新手到高手,这些坑我已经替你踩过了
API调用优化策略
成本控制技巧:
合理设置token限制是省钱的关键。我一般把max_tokens设为1024,对于大部分任务够用了。如果是代码生成任务,可以适当调高到2048。
批处理是另一个省钱技巧。把多个相似的请求合并成一个batch,可以减少API调用次数。蓝耘平台支持批处理API,性价比很高。
性能优化实践:
缓存策略特别重要。我用Redis缓存了常见问题的回答,命中率能达到70%以上。对于相同的输入,直接返回缓存结果,既快又省钱。
并发控制也不能忽视。我设置了并发限制为10,避免瞬间发送太多请求导致限流。异步调用配合队列机制,可以显著提升响应速度。
错误处理方案:
常见的API错误主要有几种:
- 429 Too Many Requests:触发限流,需要实现退避重试
- 401 Unauthorized:API密钥问题,检查配置
- 500 Internal Server Error:服务端问题,稍后重试
我写了一个通用的错误处理函数,支持指数退避重试,大部分错误都能自动恢复。
安全与隐私最佳实践
API密钥管理:
千万不要把API密钥硬编码在代码里!我用环境变量的方式管理:
export LANYUN_API_KEY=\"sk-xxxxxxxxxx\"密钥轮换也很重要,我设置了每30天自动轮换一次,降低安全风险。
权限控制方面,蓝耘平台支持创建不同权限级别的密钥,生产环境和测试环境分开管理。
数据脱敏处理:
对于敏感信息,我会先做脱敏处理再发送给AI。比如身份证号码用***替换中间几位,手机号码只保留前3位和后4位。
合规要求也要注意,特别是GDPR、个人信息保护法等,确保用户数据的处理符合法规要求。
私有化部署考虑:
企业级应用建议考虑私有化部署。蓝耘平台支持私有云部署,数据不出企业内网,安全性更高。
配置防火墙和VPN也是必要的,确保API调用的网络安全。
不同场景的工具组合推荐
个人开发者最佳组合:Cursor + Obsidian Copilot
这个组合特别适合个人开发者。Cursor负责代码开发,Obsidian Copilot管理技术文档和学习笔记。两者都接入蓝耘API,形成完整的开发-学习闭环。
我用这套组合开发了好几个小项目,效率提升了至少50%。代码有问题时问Cursor,想查技术资料时问Obsidian,无缝切换。
小团队协同方案:NextChat + DB-GPT
小团队推荐这个组合。NextChat作为统一的AI交互入口,团队成员都可以使用;DB-GPT处理数据分析需求,生成各种业务报表。
我们5个人的小团队用这套方案,客服效率提升了3倍,数据分析从原来的几小时缩短到几分钟。
企业级应用:完整MCP生态
企业级应用建议构建完整的MCP生态。蓝耘MCP平台作为核心,集成各种业务系统的MCP服务器,形成企业AI中台。
这样的好处是所有业务系统都可以统一接入AI能力,避免重复建设,降低维护成本。
这只是开始,未来更精彩
个人感悟分享
用了这么多工具下来,我发现MCP协议真的改变了游戏规则。以前做AI应用,最头疼的就是各种工具和API的集成问题,现在有了统一标准,开发效率提升了一个档次。
最让我印象深刻的是蓝耘平台的稳定性。我的几个项目已经稳定运行了3个月,几乎没有遇到过服务中断的情况。作为一个对稳定性要求很高的老程序员,这点特别让我满意。
技术趋势展望
MCP逐渐被接受,是因为MCP是开放标准。在AI项目开发中可以发现,集成AI模型复杂,现有框架如LangChain Tools、LlamaIndex和Vercel AI SDK存在问题。MCP协议的出现解决了这些痛点。
我预测,未来2-3年内,MCP会成为AI工具领域的事实标准。就像HTTP协议统一了Web应用一样,MCP将统一AI应用的开发模式。
蓝耘作为国内较早拥抱MCP标准的云服务商,未来肯定会有更大的发展空间。他们的GPU资源优势加上MCP生态布局,形成了很强的竞争壁垒。
行动建议
从哪个工具开始尝试?
如果你是开发者,我建议从Cursor开始,上手最快,收益最明显。如果你是知识工作者,Obsidian Copilot是个不错的选择。
如何建立自己的AI工具链?
建议按照这个顺序:
- 先选一个主力工具深度使用
- 根据实际需求逐步添加其他工具
- 最后考虑整合和自动化
- 不要贪多,工具在精不在多。
社区资源和学习路径
蓝耘有个不错的开发者社区,定期会有技术分享和案例交流。GitHub上也有很多MCP相关的开源项目,可以学习参考。
我建议加入一些AI开发者的微信群或Discord频道,大家交流经验,遇到问题也能快速得到帮助。
开放式思考
AI技术发展这么快,今天的最佳实践可能明天就过时了。但我觉得有几个趋势是确定的:
- 标准化协议会越来越重要
- 多模态AI会成为主流
- 私有化部署的需求会增加
- AI安全和隐私保护会被更加重视
作为开发者,我们需要保持学习的心态,关注技术发展趋势,同时也要在实践中不断总结经验。
MCP协议和蓝耘平台只是一个开始,真正的AI时代才刚刚开始。你准备好了吗?
附录
快速配置模板
Cherry Studio配置示例:
{ \"name\": \"蓝耘GPT\", \"provider\": \"openai\", \"apiKey\": \"sk-xxxxxxxxxx\", \"baseURL\": \"https://api.lanyun.net/v1\", \"model\": \"gpt-3.5-turbo\", \"temperature\": 0.7, \"maxTokens\": 1024}Cursor配置示例:
{ \"api.provider\": \"custom\", \"api.baseUrl\": \"https://api.lanyun.net/v1\", \"api.key\": \"sk-xxxxxxxxxx\", \"api.model\": \"deepseek-coder\"}常见问题FAQ
Q: API调用失败怎么办?
A: 首先检查密钥是否正确,然后确认网络连接。如果问题持续,联系蓝耘技术支持。
Q: 如何控制API调用成本?
A: 设置合理的token限制,使用缓存机制,避免重复调用。
Q: 多个工具可以共用一个API密钥吗?
A: 可以,但建议为不同应用创建不同的密钥,便于管理和安全控制。
资源链接汇总
蓝耘MCP平台:https://mcp.lanyun.net/#/home
Cherry Studio官网:https://www.cherry-ai.com/
Cursor官网:https://cursor.sh/
NextChat项目:https://github.com/Yidadaa/ChatGPT-Next-Web
DB-GPT项目:https://github.com/eosphoros-ai/DB-GPT
Obsidian Copilot:https://github.com/logancyang/obsidian-copilot
希望这篇文章能帮你在AI工具的海洋中找到自己的航向。记住,工具只是手段,关键是要解决实际问题。 祝你在AI的世界里玩得开心!

