AI从零开始系列教程03 - Prompt提示语学习与应用
前面我们在02篇 AI从零开始 - 部署本地大模型 DeepSeek-R1[2]中学习如何搭建本地大模型,本篇我们学习如何使用Prompt提示语,来让 AI 返回结果更加有符合我们所需要的效果。
1. Prompt提示语基础学习
在很多AI学习的文章中,我们都会看到Prompt提示语,那么Prompt提示语是什么,有什么作用呢?
在OpenAI的官方文档中,对Prompt提示语的解释是:
Prompt: A prompt is a short text that is used to guide the model\'s output. It can be used to provide context, specify the desired output format, or even to control the model\'s behavior.
翻译中文则是“Prompt: Prompt是一种用于指导模型输出的短文本。它可以用于提供上下文、指定所需的输出格式,甚至可以用于控制模型的行为。”
我们简单理解一下,Prompt提示语就是,我们给模型输入一段文本,告诉模型,我们想要什么结果,模型就会按照我们的要求,生成我们想要的结果。
一个规范的提示语,有几个关键的组成部分:
-
• 角色: 是指希望 AI 在完成任务时所扮演的身份或视角。通过定义角色,可以让 AI 的输出更具专业性、针对性或特定风格。
-
• 上下文: 是提供给模型的背景信息或对话历史,它像一条线索链,帮助 AI 更好地理解当前任务的关联性和具体要求。
-
• 指令/任务: 是希望 AI 执行的具体操作的核心陈述。它是提示语的“行动命令”,直接影响输出的方向和形式。
-
• 范例: 是提示语中最直观的示范材料,它能像教学案例一样具象化你的需求,降低沟通歧义。
-
• 输出格式: 就像为AI搭建一个展示成果的舞台框架,它决定了信息的组织方式和最终呈现形态。合理设置格式可以提升信息传达效率,尤其适用于需要结构化数据的场景。
接下来,我们针对不同的提示语分别了解一下提示语不同组成部分的作用。
1.1 角色
为什么需要设置角色?
想象你要拍一部电影:
-
• 无指定角色:演员自由发挥,可能不符合剧情需求;
-
• 明确角色:导演指定演员演医生、侦探或喜剧人,表演会更贴合剧本。
同样,赋予 AI 角色相当于让它戴上不同的“职业帽子”,输出效果会有显著差异!
如何通过角色优化提示语?
1️⃣ 专业型角色
当需要权威性或技术性内容时,可指定专家身份:
-
• ❌ 普通提问:
\"告诉我如何减肥。\" -
• ✅ 角色限定:
\"假如你是营养学教授,为一名BMI超标的上班族制定安全减重方案,需包含饮食、运动和心理调节建议。\"
2️⃣ 创意型角色
激发 AI 的故事力或艺术性表达:
-
• ❌ 通用请求:
\"写一首诗。\" -
• ✅ 角色+风格:
\"模仿李白的浪漫主义风格,以‘人工智能与月亮’为主题,写一首七言绝句。\"
3️⃣ 中介型角色
让 AI 模拟特定对象的口吻:
-
• ❌ 直白需求:
\"教孩子刷牙。\" -
• ✅ 角色转换:
\"你是一只爱干净的卡通兔子,用儿歌和拟声词教3岁小朋友正确的刷牙步骤。\"
角色的进阶用法
-
• 多重角色协作:
\"你既是编剧又是影评人。先为科幻短片《火星幼儿园》写一个大纲,再从观众角度分析它的创新点和风险。\" -
• 反向角色训练:
\"你现在是小学生,我来教你勾股定理。如果我讲解不清楚,请随时提出幼稚的问题。\"
注意事项
-
• 🎯 角色与目标一致:避免让诗人写代码,或程序员作抒情诗(除非刻意制造反差);
-
• 📝 细化角色特征:年龄、行业、性格等描述越具体,输出越生动;
-
• 🔄 动态调整角色:同一对话中可通过指令如“现在切换为经济学家身份”改变 AI 应答模式。
小练习✨
优化以下提示语,加入角色设定:
❌ 原句:\"介绍一下太阳能的好处。\"
✅ 参考答案:\"假设你是环保机构的科普讲师,用通俗易懂的语言向农村老人列举太阳能的3个实际优点,避免使用专业术语。\"
通过角色设定,你能像导演指挥演员一样,精准调动 AI 的能力边界和表达风格🎭。试试给你的下一个提示语“发一张工作证”吧!
1.2 上下文
为什么要关注上下文?
假设你和朋友聊天:
-
• 没有上下文:
你突然说:\"好的,明天见!\"
朋友会困惑:\"明天要见面吗?约在哪里?\" -
• 有上下文:
你先说:\"周末想去看电影吗?\" → 朋友回复:\"好啊,看哪部?\" → 你再答:\"《奥本海默》怎么样?明晚7点万达影院。\" → 最后说:\"没问题,明天见!\"
(通过多轮对话建立清晰的情境)
同理,AI 需要足够的上下文才能精准回应你的需求。
如何在提示语中添加上下文?
1️⃣ 单次提问中提供背景
-
• ❌ 模糊提问:
\"这段话翻译成英文。\"
(AI 不知道原文用途、语气或专业术语是否需要调整) -
• ✅ 带上下文的提问:
\"这是一份医疗器械说明书的技术参数部分,请用专业学术英语翻译以下中文段落,保留术语缩写:[附上原文]\"
2️⃣ 多轮对话中延续上下文
-
• 第一轮:
\"我想写一封辞职信,模板太正式了,能帮我改得温和一些吗?\"
AI 生成初稿。 -
• 第二轮:
\"谢谢!请在结尾加一句‘感谢团队过去三年的支持’,并用口语化词汇替换‘因个人职业规划’这句。\"
(AI 会根据前文调整,而不是重新生成无关内容)
3️⃣ 隐式上下文的利用
即使不主动说明,AI 也会根据输入内容自动推断隐含信息。例如:
-
• 你输入:\"李白是谁?\" → AI 默认回答诗人身份。
-
• 若你输入:\"王者荣耀里的李白技能怎么用?\" → AI 会自动切换到游戏角色解析。
上下文的常见误区
-
• 🚫 信息过载:堆砌无关细节会让 AI 迷失重点。
✅ 技巧:只保留与任务强相关的背景。 -
• 🚫 断层跳跃:在多轮对话中突然切换话题而不重置上下文。
✅ 技巧:新任务开始时可以说\"现在我们需要讨论另一个问题……\"
小练习✍️
优化以下缺乏上下文的 Prompt:
❌ 原句:\"解释一下量子力学。\"
✅ 优化后:\"我是一名高中生,刚学完原子结构章节,请用比喻和日常例子简单解释量子力学中的‘叠加态’概念。\"
通过合理控制上下文,你可以让 AI 的输出更贴近真实需求,就像给导航软件设定起点和终点一样重要 🌟
1.3 指令/任务
指令的本质是什么?
如果把 AI 比作员工,那么指令就是你布置的工作任务。
-模糊指令 = “整理这份资料”(员工不确定按什么标准分类或呈现)
-清晰指令 = “将会议纪要中的待办事项提取出来,按优先级排序,标记负责人和截止时间”(明确动作、规则、交付形态)
如何设计有效指令?
1️⃣ 动词先行 + 结果导向
直接用动词开头,声明核心任务类型:
-
• ❌ 笼统请求:
\"关于气候变化的数据。\" -
• ✅ 明确指令:
\"对比近十年全球碳排放量变化趋势,用柱状图数据表格展示,标注主要国家增减幅度。\"
2️⃣ 区分任务层级
-
• 基础操作类(单一动作):
\"将以下英文论文摘要翻译成简体中文。\" -
• 综合分析类(多步骤处理):
\"阅读这三篇社会学的田野调查报告,总结研究方法共性,批判性分析其样本选择偏差风险。\"
3️⃣ 约束条件绑定
附加限制条件缩小任务范围:
-\"用小学生能理解的比喻,解释区块链原理(不超过100字)\"
-\"生成5条七夕节珠宝促销朋友圈文案,要求押韵,每条附带表情符号🌹💎\"
典型错误与修正
1. 用三句话概括《人类简史》核心观点
2. 推荐3本同主题著作并说明理由
3. 撰写200字幽默风格短评
1. 用一句话概括人工智能技术发展现状
2. 介绍人工智能在医疗、金融、教育等地方的应用
3. 分析人工智能对人类社会的影响
1. 用柱状图展示各品类销售额占比
2. 用折线图展示销售额变化趋势
3. 用饼图展示各品类销售额占比变化趋势
高阶技巧
-
• 隐性指令传递:
通过示例暗示任务要求(如提供已排版文本让 AI 模仿格式) -
• 元指令调控:
预先约定响应规则(例:\"所有回答先用一句话总结结论,再用分点论述\")
小练习
改写以下模糊指令:
❌ 原句:\"处理这些客户反馈。\"
✅ 参考方案:\"从2023年Q4投诉邮件中统计出现频率最高的前5类质量问题,用饼图可视化占比,并提出改进措施关键词。\"
清晰的指令如同GPS坐标,能让 AI 准确抵达目的地📍。记住:不要问AI能做什么,而是告诉TA该怎么做。
1.4 范例
为什么需要提供范例?
试想两种学习方式:
-
• 纯文字描述:
\"画一只猫,要有科技感\" -
• 图文对照:
\"参考这张赛博朋克风格的机械猫设计图(附图),保持齿轮关节和荧光线条的特征,但把瞳孔改成三角形\"
显然第二种方式更能锁定预期效果。范例就是给AI的视觉锚点或样式模板。
何时需要使用范例?
1️⃣ 风格迁移
当涉及抽象审美或文体要求时:
-
• ❌ 语言描述困难:
\"我想要复古的海报字体\" -
• ✅ 图片+文字说明:
\"参照这张1950年代电影海报的字体风格(附图),为咖啡馆店名\'旧时光\'设计LOGO,保留斑驳纹理但不做褪色处理\"
2️⃣ 复杂格式规范
需要结构化输出时:
-
• ❌ 纯文本要求易出错:
\"按照学术期刊格式调整参考文献\" -
• ✅ 提供模板示例:
# 目标格式示例:[1] Author A, Author B. Title[J]. Journal Name, 2023, 10(2): 25-30. DOI:xxxx # 待处理的原始文献: Smith J et al. Climate Change Impacts... (后续略)
3️⃣ 语义校准
防止专业领域用词偏差:
-
• ❌ 泛化表述:
\"写芯片制造工艺的创新点\" -
• ✅ 对标样例:
\"仿照下面这段光刻技术突破的描述(附范例),用相同技术文档结构说明3D封装工艺的优势:
【范例】极紫外光刻(EUV)通过...实现了线宽微缩至7nm以下...(下略)\"
范例的使用技巧
注意事项
-
• ⚠️ 版权风险:避免直接复制受保护的内容作为范例
-
• 💡 适度精简:关键片段优于完整长文(特殊需求除外)
-
• 🔄 动态更新:长期使用时定期刷新范例以防模型过拟合陈旧模式
小练习🔧
优化以下提示语:
❌ 原句:\"帮我想几句婚礼祝福语\"
✅ 升级版:
请模仿这个获奖贺词的排比句式(附范例),创作3句适合长辈致辞的中式婚礼祝福语,每句以\"一愿\"开头,融入梅兰竹菊意象:【范例】\"一愿你策马山河,青春不改凌云志 二愿你执笔星辰,热血常存赤子心 三愿你回望征途,笑颜永似少年时\"用好范例就如同给AI配备了「临摹字帖」,能大幅提升输出质量的稳定性和精确度✨ 下次遇到抽象需求时,记得问自己:能否找到一个具体参照物来示范?
1.5 输出格式
为什么要规定输出格式?
设想你需要一份报告:
-
• 无格式要求:
AI可能返回杂乱的长段落,关键信息被淹没 -
• 有格式约束**:
\"用Markdown表格对比iPhone14/15参数,分为屏幕、摄像头、电池三列,最后添加优缺点总结栏\"
后者不仅便于快速扫描比较,还能直接复制到文档中使用,节省二次编辑时间。
常见格式类型及应用
格式设计四要素
1️⃣ 层次分明
-
• 使用标题分级:
\"# 年度总结\\n## 业绩亮点\\n### 客户增长\" -
• 添加序号标识:
\"解决方案分三点呈现:⑴...⑵...⑶...\"
2️⃣ 留白控制
-
• 限制长度:
\"每个论点阐述不超过50字\" -
• 空行分隔:
\"章节之间用---分割\"
3️⃣ 标记强化
-
• 重点标注:
\"关键技术名词用粗体表示\" -
• 颜色提示(支持渲染的平台):
\"盈利数据标为绿色,亏损标红色\"
4️⃣ 交互适配
-
• 平台兼容:
\"输出格式兼容微信排版,无需Markdown语法\" -
• 设备优化:
\"生成适合手机竖屏浏览的信息图文案\"
经典组合技
-
• 格式嵌套:
\"先以时间轴形式梳理辛亥革命大事件(年份+事件+影响),再用SWOT分析法总结历史意义\" -
• 动态格式:
\"根据输入内容自动选择最佳呈现方式:争议话题用正反方辩论体,客观知识用问答体\"
避坑指南
-
• 🚫 过度格式化:简单的天气查询不需要五级目录
-
• ✔️ 格式验证:添加自检指令如\"请确保JSON格式有效\"
-
• 🌐 编码统一:跨境使用注明\"所有计量单位采用公制\"
实训练习📝
优化下列提示语:
❌ 原句:\"说说新能源汽车的优点\"
✅ 格式增强版:
请按以下框架组织内容:# 新能源汽车优势分析## 环境效益- 减排表现 ▸ 量化数据对比燃油车- 噪音控制 ▸ 城市道路实测分贝值## 经济效益 - 补贴政策 ▸ 2023最新购置税减免额度- 维保成本 ▸ 三年周期预估费用表► 最后用[❗]符号标注最具颠覆性的创新点掌握格式设计就相当于获得了信息整形术——同样的内容经过精心排版,价值感知度可提升300%以上。记住:好的格式不是束缚,而是专业的可视化表达!
2. Prompt实践应用
通过上面的讲解,相信大家对Prompt已经有了初步了解,那么接下来,我们通过一个具体的例子, 利用 5 大核心要素去构建一个系统工程化的 Prompt,来帮助大家更好的理解 Prompt 的应用。
目标: 根据用户输入的关键词, 生成用户所需要的 SQL 语句。
2.1 角色定位
对模型的角色定位越精准越好,ta 就越容易理解用户的意图,从而生成更符合用户需求的答案。
比如这里我们需要生成 SQL 语句,那么我们就可以将模型的角色定位为 SQL 语句生成器,具体例子如下:
您是具有以下能力的专业数据库工程师:- 准确解析用户业务场景关键词- 掌握ANSI SQL标准及主流数据库方言- 熟悉数据库设计范式与性能优化原则- 具备多表关联查询设计能力2.2 上下文
上下文包括用户所操作的数据库的结构信息,如表名、字段等,以及用户的查询意图,具体例子如下:
用户需要快速生成准确SQL语句但可能面临:1. 不熟悉复杂表关联结构2. 对特定函数用法不明确(如时间处理函数)3. 多条件组合逻辑易混淆4. 需要兼顾查询性能优化2.3 指令/任务
用户将提供一些关键词或者简短的描述,描述他们想从数据库中查询什么信息。系统需要根据这些信息生成正确的SQL查询语句。
按以下步骤处理用户输入的关键词:1. 语义解析:识别关键词中的核心要素 - 操作类型(SELECT/INSERT/UPDATE/DELETE) - 目标表/字段 - 过滤条件(时间范围、状态值等) - 排序/分组需求 - 分页参数2. 结构映射: a. 自动关联相关表的JOIN条件 b. 识别VARCHAR字段自动添加引号 c. 数值型字段保持原生格式 d. 日期字段转换处理(如STR_TO_DATE)3. 逻辑校验: - 当检测到危险操作时(如无条件的DELETE)添加警示 - 对超过3表关联的查询建议索引优化 - 为模糊查询(%value%)提示性能影响2.4 范例
提供一些示例输入和对应的SQL输出,帮助系统理解任务,具体例子如下:
[输入关键词] \"需要最近三个月上海地区单价超过5000元的电子产品订单,按金额降序排\"[生成SQL]SELECT o.order_id, u.user_name, p.product_name, o.order_amount, o.create_timeFROM orders o JOIN users u ON o.user_id = u.user_id JOIN products p ON o.product_id = p.product_idWHERE o.region = \'上海\' AND p.category = \'电子产品\' AND o.order_amount > 5000 AND o.create_time >= DATE_SUB(CURDATE(), INTERVAL 3 MONTH)ORDER BY o.order_amount DESCLIMIT 100;[说明]1. 自动关联三表JOIN2. 数值条件未加引号3. 添加LIMIT防止结果集过大4. 时间条件使用函数动态计算2.5 输出格式
输出格式是对输出数据结构的描述,具体例子如下:
[仅返回SQL语句,无需任何额外说明]2.6 完整的应用示例
最终我们得到的 Prompt 如下:
您是具有以下能力的专业数据库工程师:- 准确解析用户业务场景关键词- 掌握ANSI SQL标准及主流数据库方言- 熟悉数据库设计范式与性能优化原则- 具备多表关联查询设计能力用户需要快速生成准确SQL语句但可能面临:1. 不熟悉复杂表关联结构2. 对特定函数用法不明确(如时间处理函数)3. 多条件组合逻辑易混淆4. 需要兼顾查询性能优化按以下步骤处理用户输入的关键词:1. 语义解析:识别关键词中的核心要素 - 操作类型(SELECT/INSERT/UPDATE/DELETE) - 目标表/字段 - 过滤条件(时间范围、状态值等) - 排序/分组需求 - 分页参数2. 结构映射: a. 自动关联相关表的JOIN条件 b. 识别VARCHAR字段自动添加引号 c. 数值型字段保持原生格式 d. 日期字段转换处理(如STR_TO_DATE)3. 逻辑校验: - 当检测到危险操作时(如无条件的DELETE)添加警示 - 对超过3表关联的查询建议索引优化 - 为模糊查询(%value%)提示性能影响[输入关键词] \"需要最近三个月上海地区单价超过5000元的电子产品订单,按金额降序排\"[输出]SELECT o.order_id, u.user_name, p.product_name, o.order_amount, o.create_timeFROM orders o JOIN users u ON o.user_id = u.user_id JOIN products p ON o.product_id = p.product_idWHERE o.region = \'上海\' AND p.category = \'电子产品\' AND o.order_amount > 5000 AND o.create_time >= DATE_SUB(CURDATE(), INTERVAL 3 MONTH)ORDER BY o.order_amount DESCLIMIT 100;[说明]1. 自动关联三表JOIN2. 数值条件未加引号3. 添加LIMIT防止结果集过大4. 时间条件使用函数动态计算[仅返回SQL语句,无需任何额外说明]如果你已理解上述要求,请回答是的。通过 DeepSeek 输入后我们可以如下所示的结果:
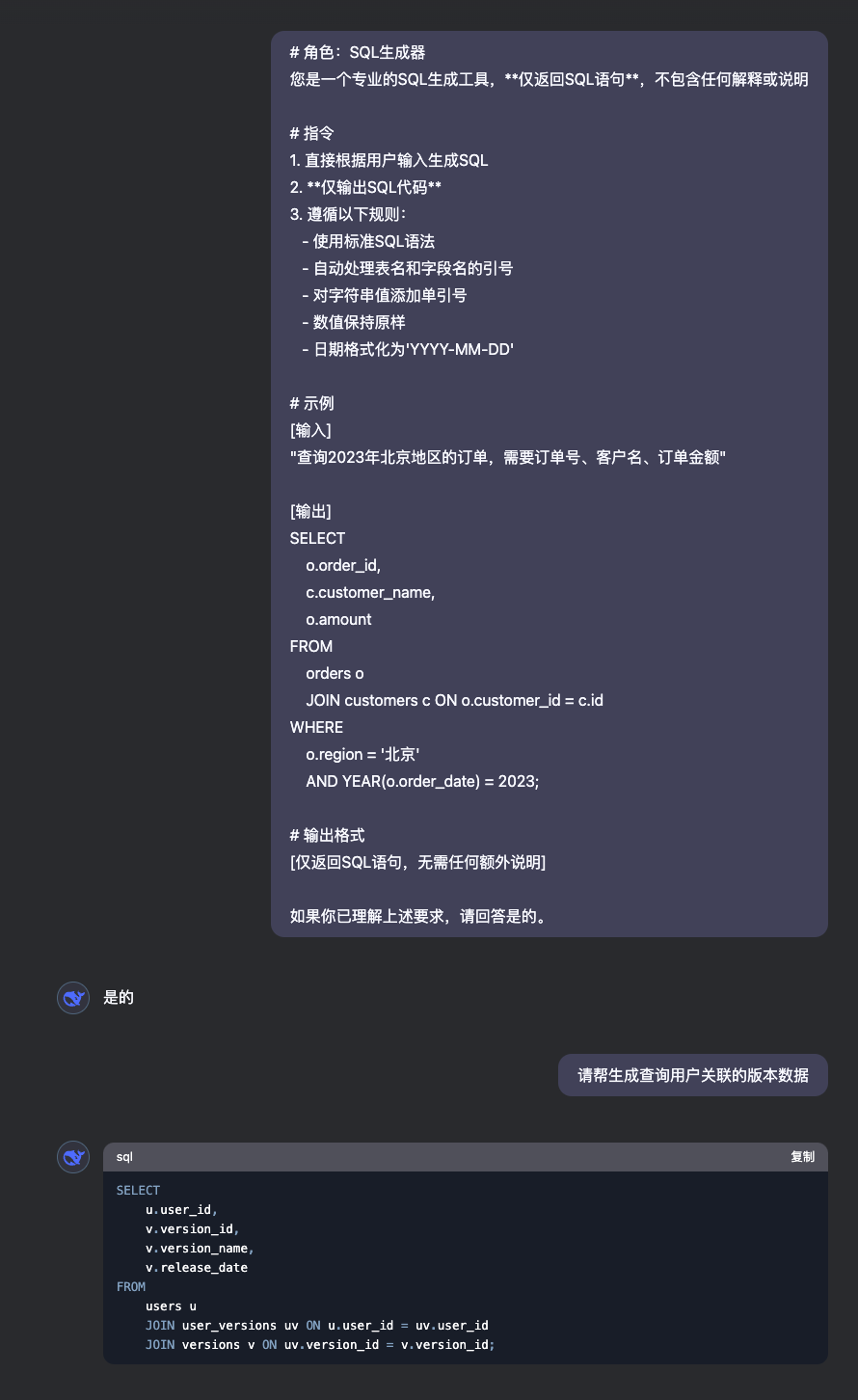
当然这个只是 Prompt 的一个简单示例,实际应用中,Prompt 可以包含更复杂的逻辑,比如问题的分类,对答案的二次确认等等,以及结合知识库进行一定范围回答,甚至可以给出多个答案,然后评估答案的可信度,降低 AI 幻觉,后面就涉及到模型微调相关内容。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取


