LLaMA-Factory部署以及微调大模型_llamafactory微调大模型
一、安装LLaMa-Factory
1.python环境安装
安装成功后,输入python能出现截图表示安装成功
2.CUDA和PyTorch安装
2.1 PyTorch安装
查看PyTorch与CUDA对应的版本,然后进行安装。PyTorch的管网地址:PyTorch
把网页往下拖能看到PyTorch和CUDA对应的版本。
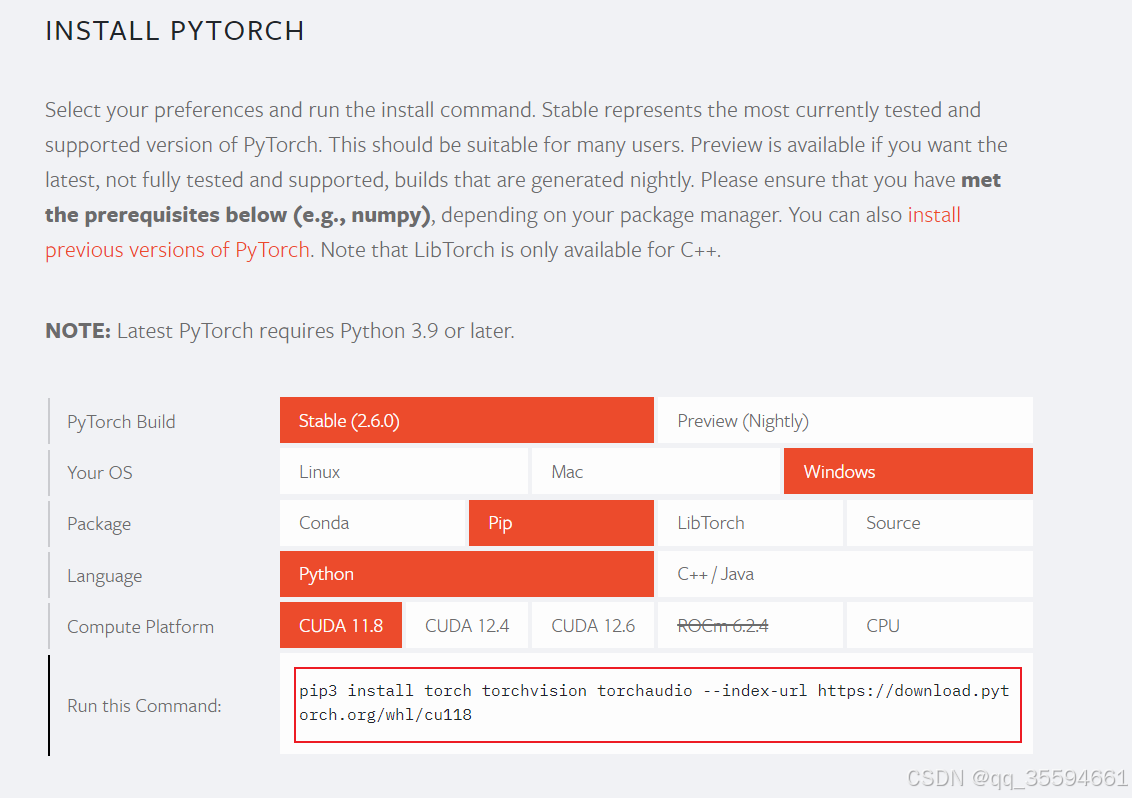
我这里将要选择的CUDA版本是11.8。我自己试过CUDA12.6的版本,不知道为什么没有跑通,后面就直接把CUDA的版本选成11.8了。
在终端中输入截图中的指令:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
就会安装PyTorch,不翻墙的情况下安装比较慢,建议有条件的可以翻墙安装。因为我已经安装成功了,再来编写的该文章,结果如截图所示。

到此PyTorch安装结束。
2.2 CUDA安装
找到CUDA的历史版本。链接地址:CUDA Toolkit Archive | NVIDIA Developer
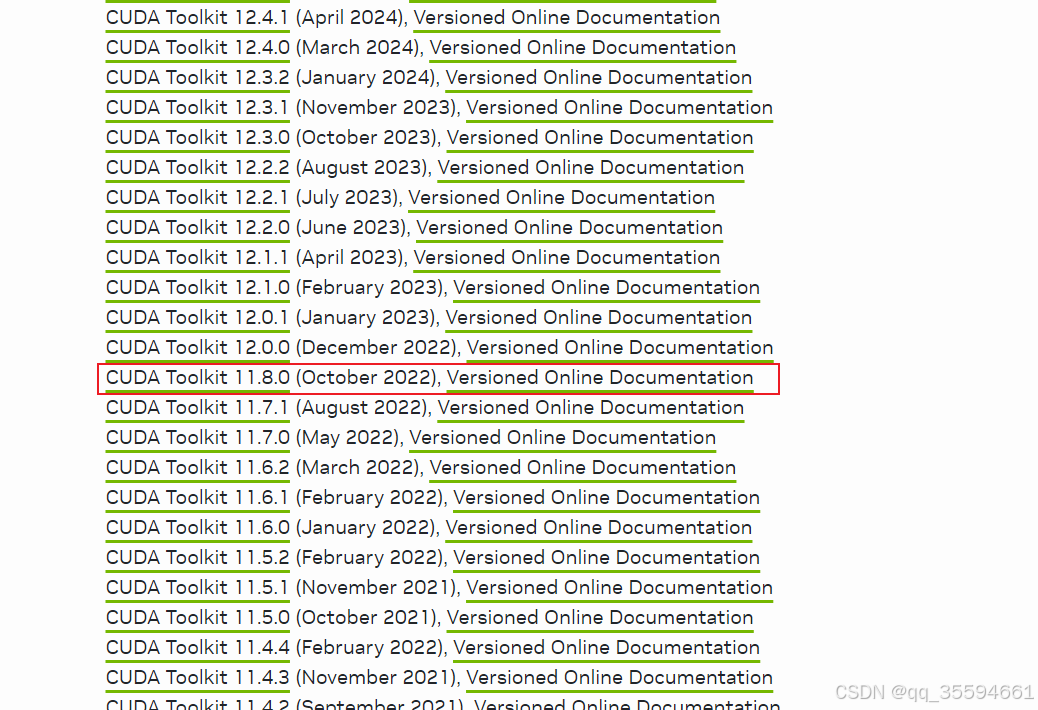
找到我们目标的安装包,下载安装。安装成功后在终端中输入:nvcc --version

如截图所示,cuda安装成功。
2.3 校验
校验下cuda和pytorch是否匹配成功
终端中输入:python
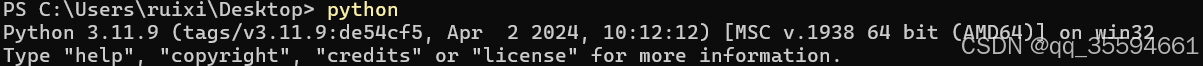
继续输入:import torch
![]()
继续输入:torch.cuda.current_device()
![]()
继续输入:torch.cuda.get_device_name(0)
![]()
继续输入:torch.__version__
![]()
如果出现什么异常错误,可能是环境没有处理好,还需自行检查。笔者前面遇到过下载cuda版本12.6以及对应的Tytorch,就遇到没有成功的状况,遂改用cuda版本为11.8
3. 下载LLaMa-Factory的git仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git
下载完成后的截图:
在终端中进入刚下载好的LLaMa-Factory文件夹中
必须在该文件夹内输入指令:pip install -e \'.[torch,metrics]\'
安装一些必须的东西。安装结束后如截图所示。
验证安装是否成功。输入指令:llamafactory-cli version
如出现截图所示表示安装成功

二、下载模型
在魔塔社区中可以自行找个模型进行下载。笔者这里选这一个Qwen2.5-0.5B-Instruct模型进行下载。链接地址:魔搭社区
点击模型文件
选择下载模型
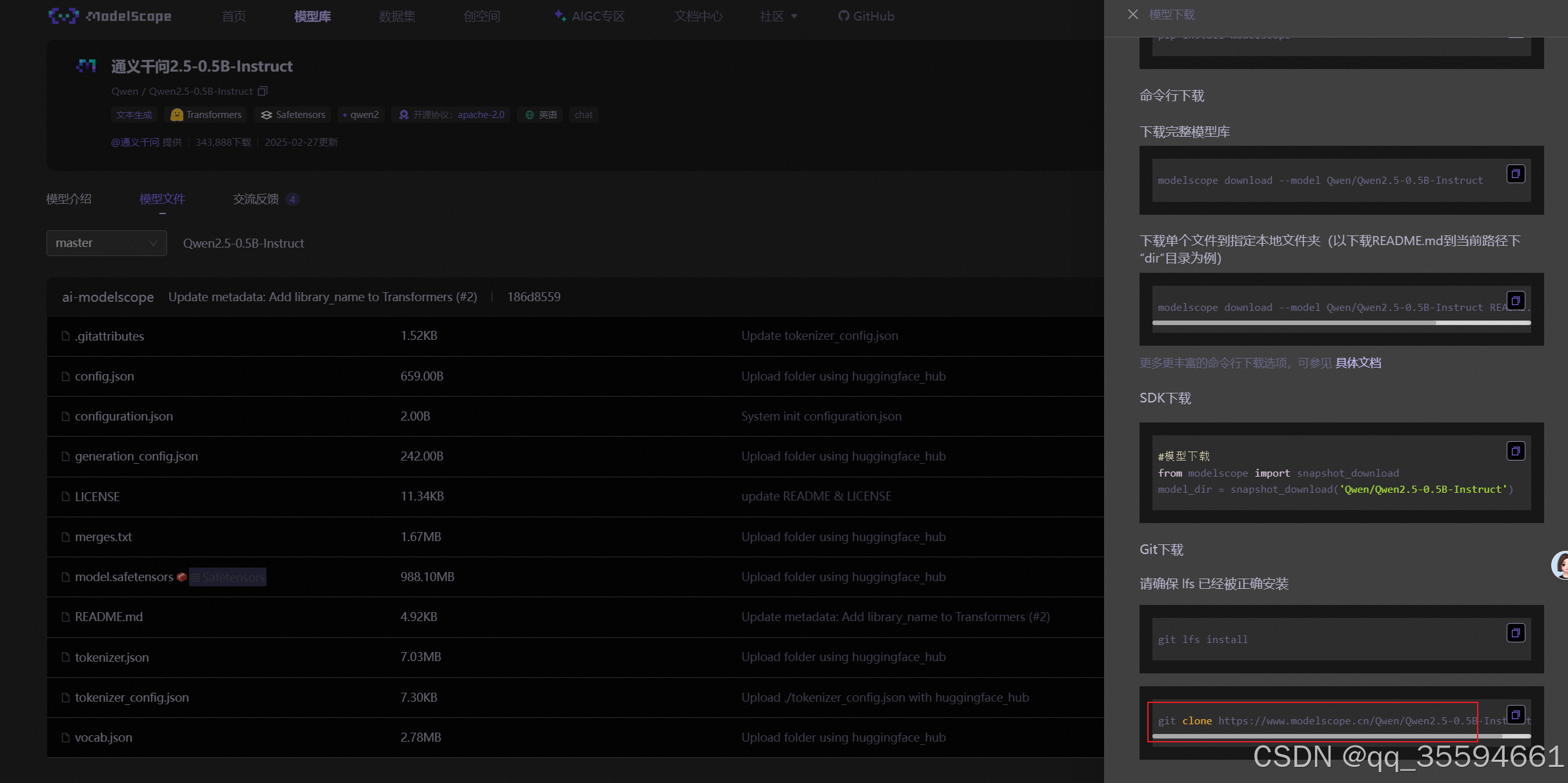
选择git下载。该模型的git下载url:git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
下载完成后
三、部署大模型
启动llama-factory的webui,输入指令:llamafactory-cli webui

注意下:必须是在LLMa-Factory仓库中输入该指令。
启动后的界面
切换页面到能部署模型的页面
点击chat
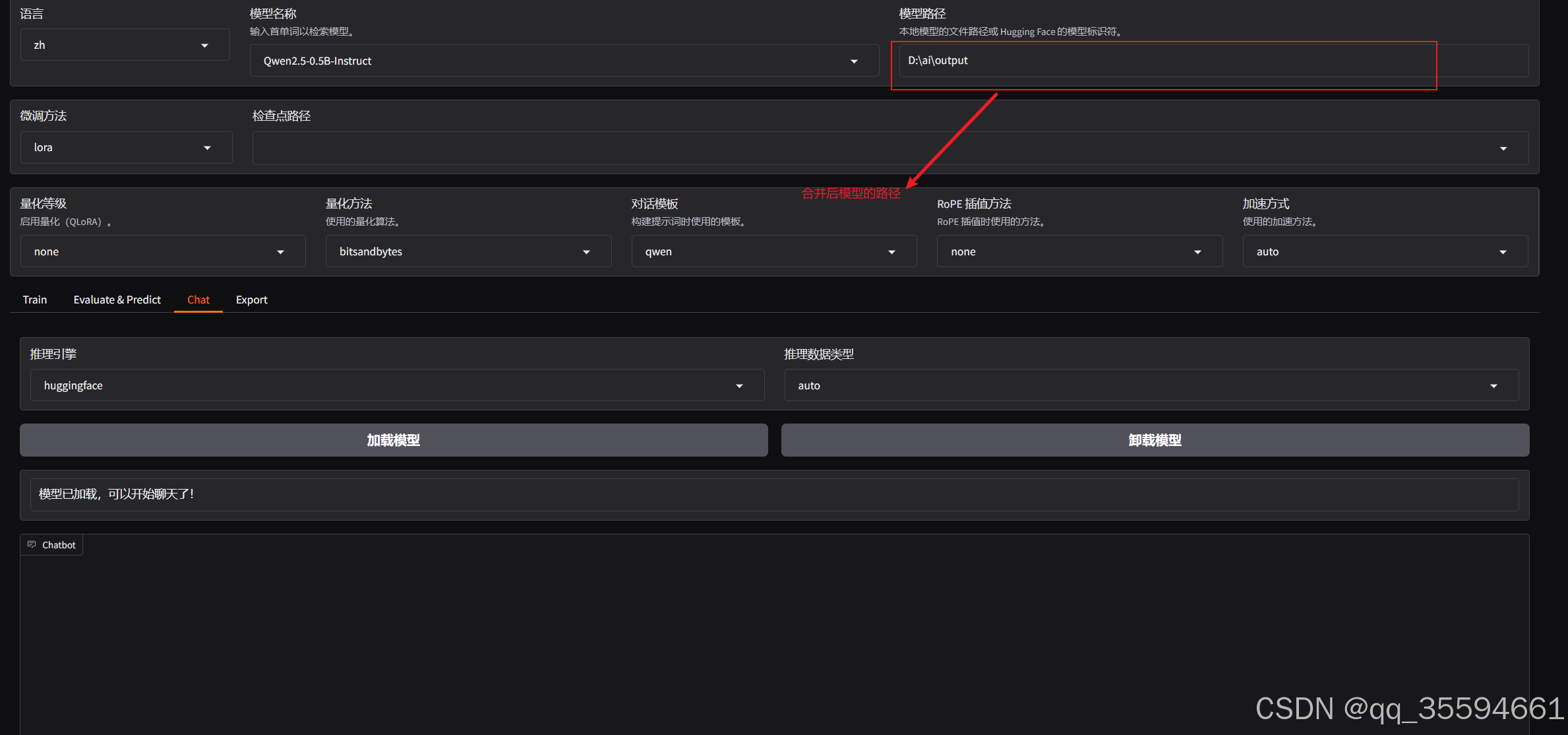
模型名称从下拉列表中选择Qwen2.5-0.5B-Instruct
模型路径填写,刚刚下载好的模型。注意:模型名称和模型路径中的模型要是对应的。
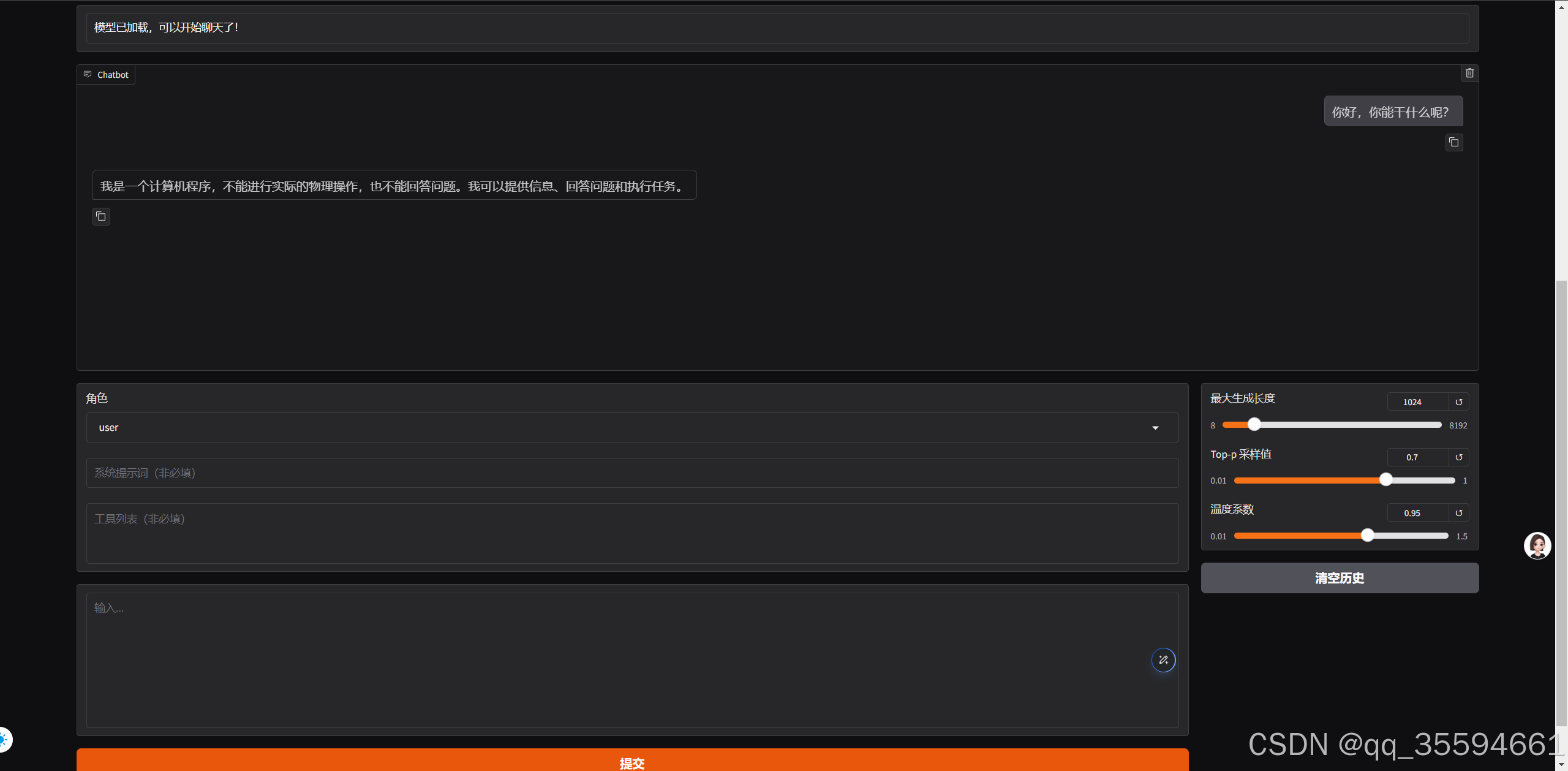
填写好,进行加载模型。
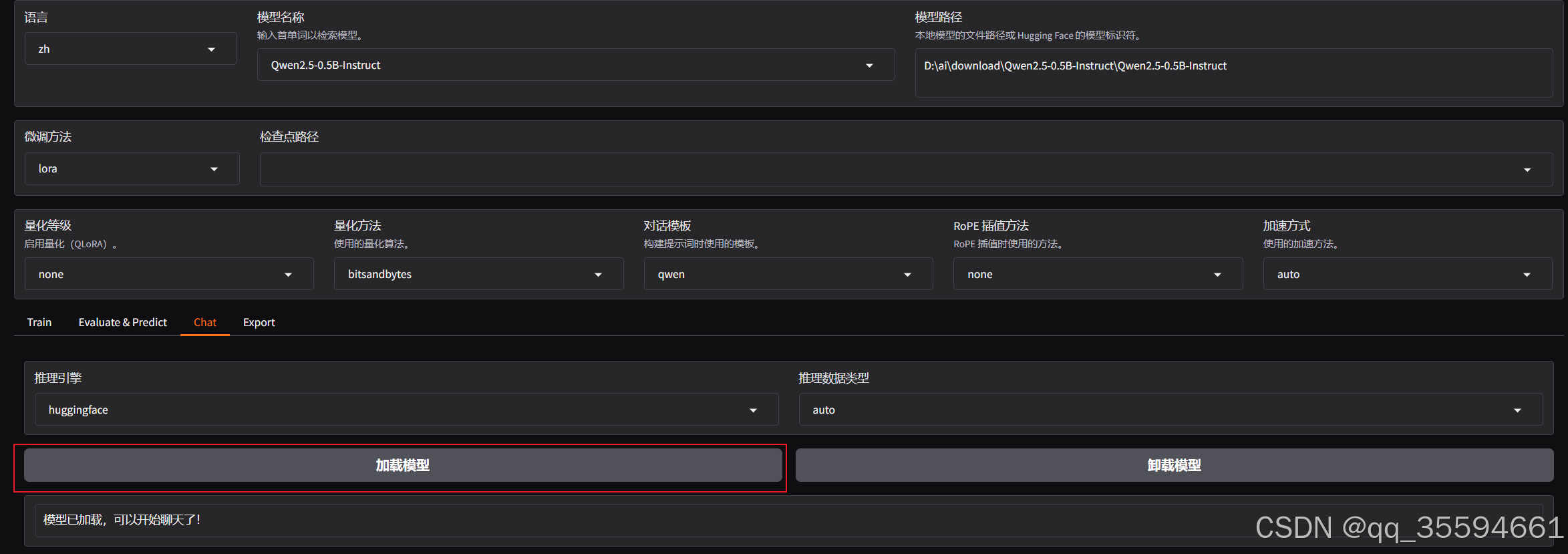
加载成功后,就可以进行聊天了。
四、模型微调
4.1 生成训练的数据集
代码:
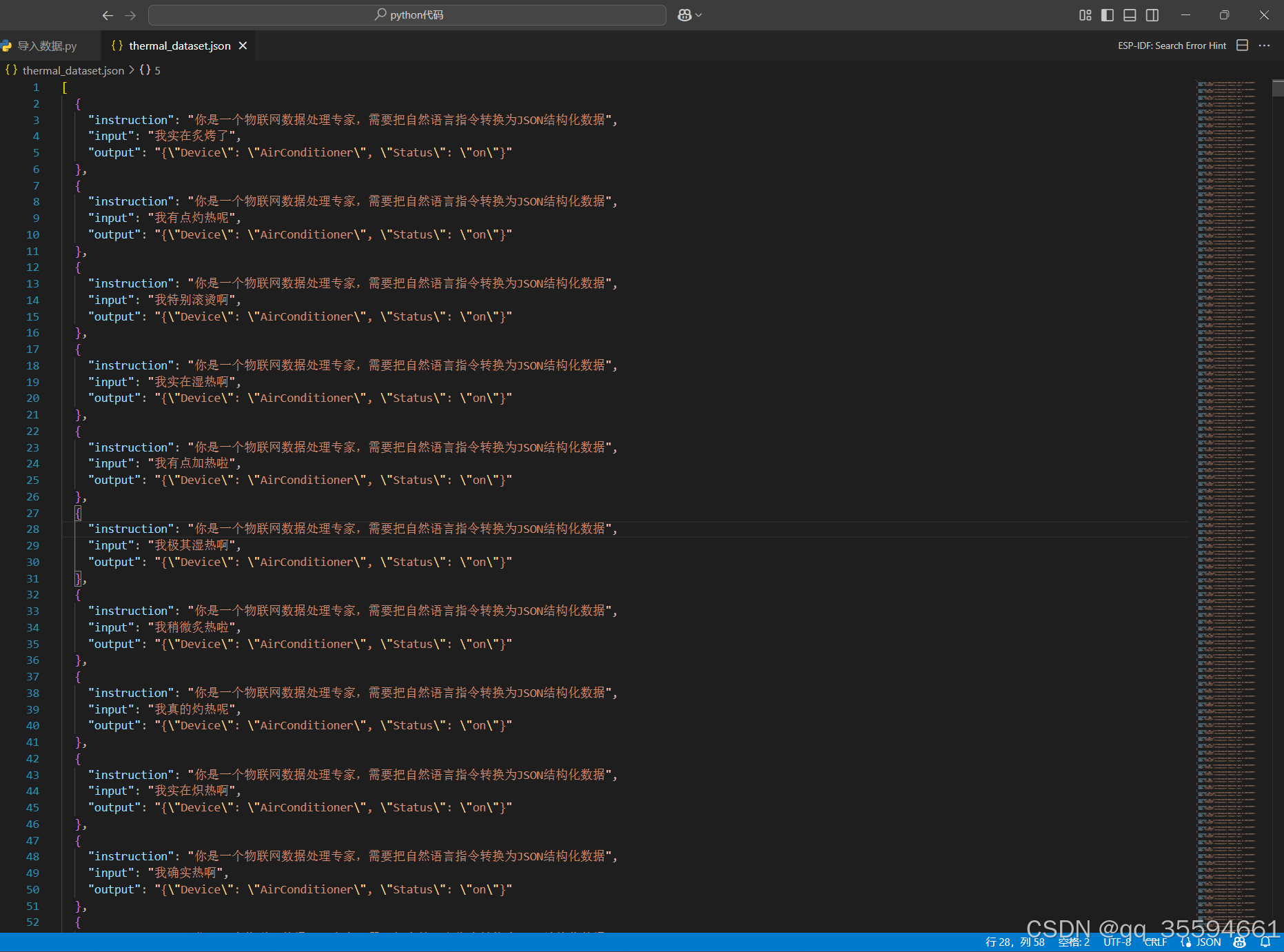
import jsonimport randomfrom faker import Fakerdef generate_thermal_dataset(output_path=\"thermal_dataset.json\"): \"\"\"生成智能家居温度调控指令数据集\"\"\" fake = Faker(\'zh_CN\') # 定义数据生成模板组件:ml-citation{ref=\"1\" data=\"citationList\"} base_phrases = [\"有点\", \"非常\", \"特别\", \"实在\", \"真的\", \"确实\", \"越来越\", \"稍微\", \"极其\"] heat_verbs = [\"热\",\"炎热\",\"火热\",\"酷热\",\"炽热\",\"闷热\",\"灼热\",\"滚烫\",\"炙热\",\"沸热\",\"炙烤\",\"加热\",\"升温\",\"燥热\",\"湿热\",\"高温\",\"暖热\"] quantifiers = [\"了\", \"啦\", \"啊\", \"呢\", \"\"] dataset = [] for _ in range(2000): # 构造自然语言输入:ml-citation{ref=\"4\" data=\"citationList\"} phrase = random.choice(base_phrases) verb = random.choice(heat_verbs) quantifier = random.choice(quantifiers) input_text = f\"我{phrase}{verb}{quantifier}\" # 生成带逻辑的JSON输出:ml-citation{ref=\"3,5\" data=\"citationList\"} output_json = { \"Device\": \"AirConditioner\", \"Status\": \"on\" } # 构建完整数据项:ml-citation{ref=\"1,6\" data=\"citationList\"} dataset.append({ \"instruction\": \"你是一个物联网数据处理专家,需要把自然语言指令转换为JSON结构化数据\", \"input\": input_text, \"output\": json.dumps(output_json, ensure_ascii=False), }) # 保存数据集:ml-citation{ref=\"2\" data=\"citationList\"} with open(output_path, \"w\", encoding=\"utf-8\") as f: json.dump(dataset, f, indent=2, ensure_ascii=False) print(f\"数据集已生成:{output_path}\")if __name__ == \"__main__\": generate_thermal_dataset()该代码会生成2000条训练数据。
运行代码的结果:

4.2 配置训练参数
找到llama-factory中的训练参数集的配置文件
data文件夹中的dataset_info文件。打开文件并配置。
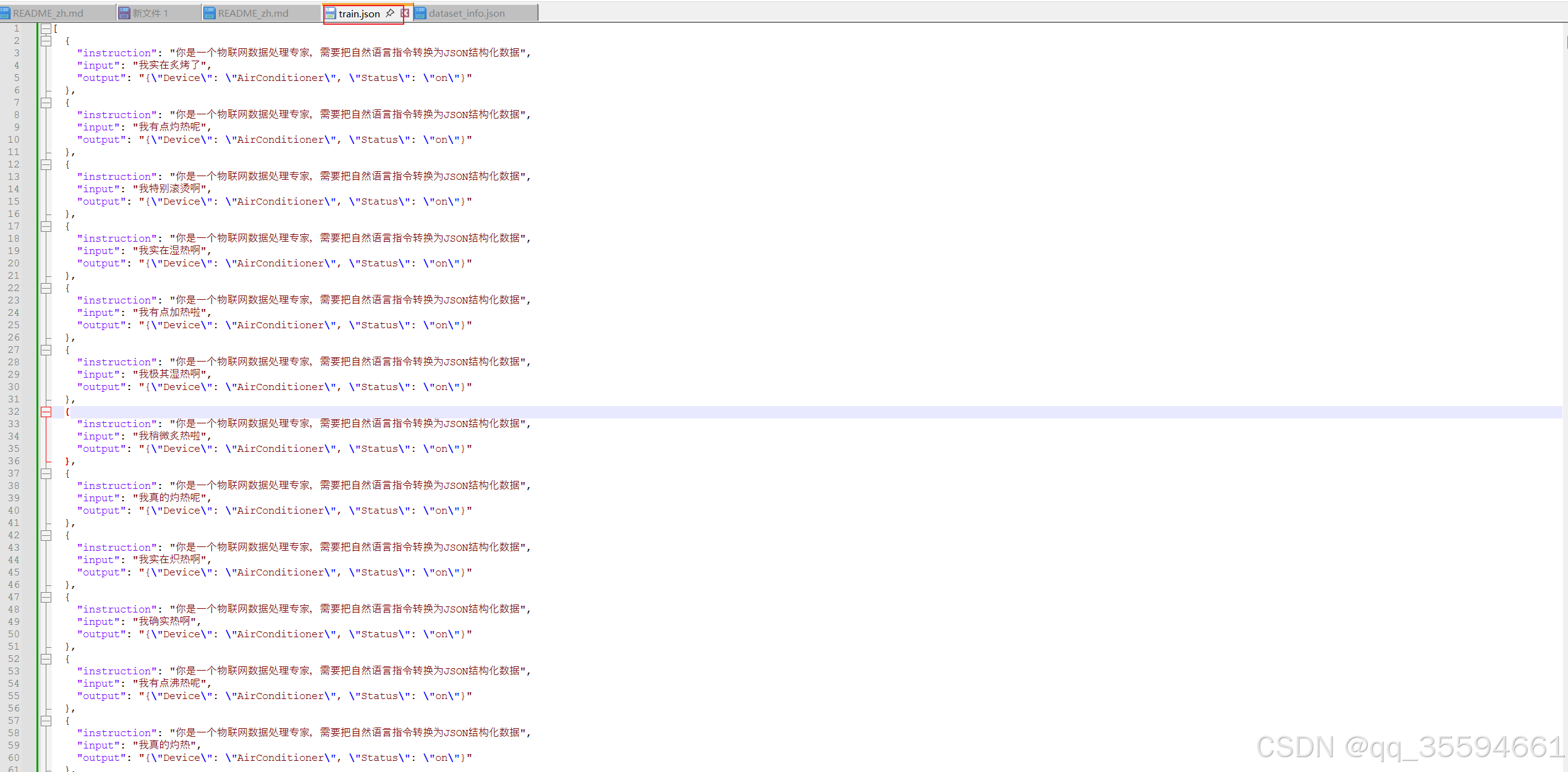
我们在json字符串中再加入一组

配置完成后,我们在data文件夹中再新建一个train.json文件,用于保存生成出来的训练数据集。
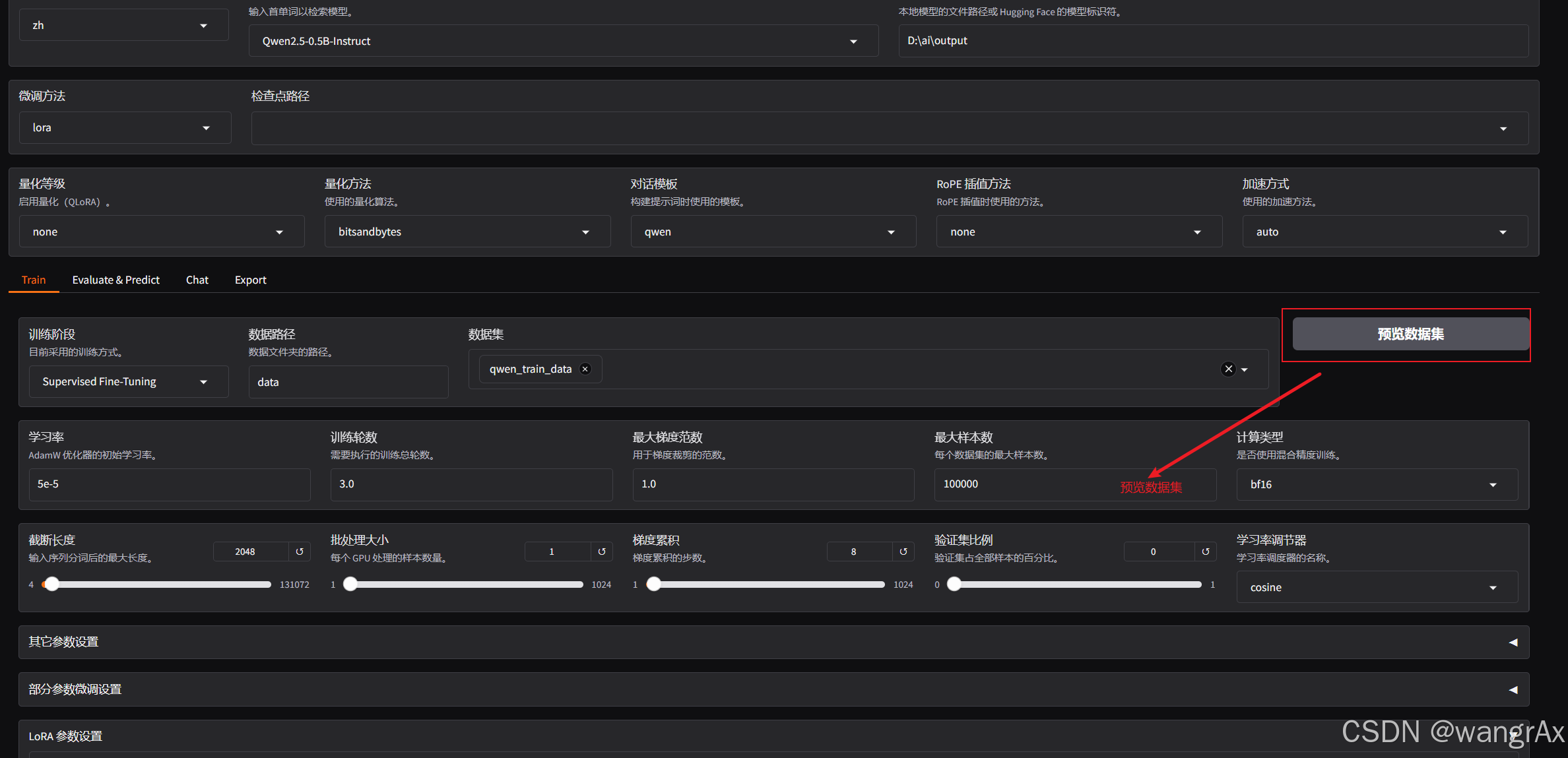
在webui中配置上刚刚添加好的数据训练集

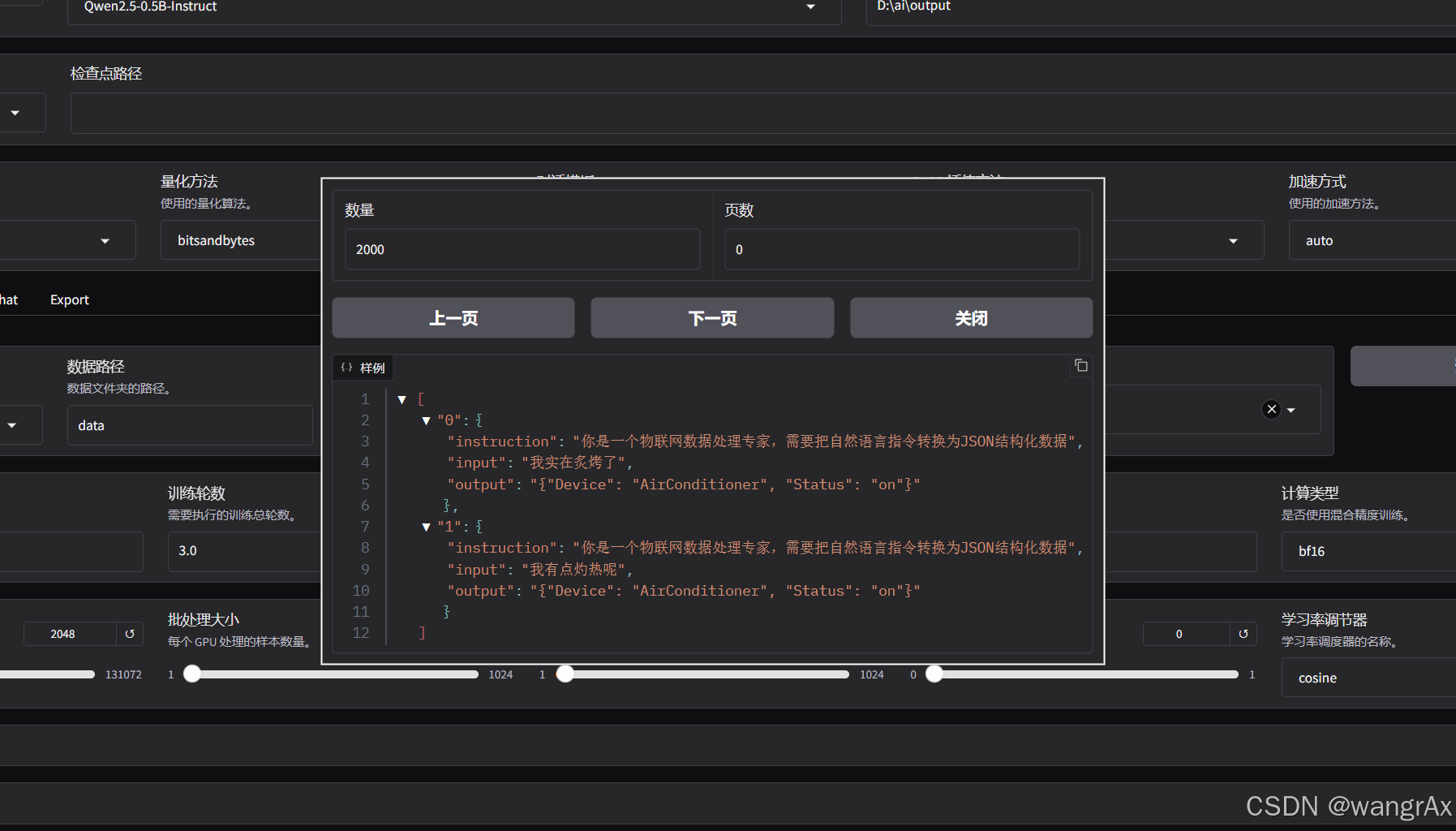
预览数据集
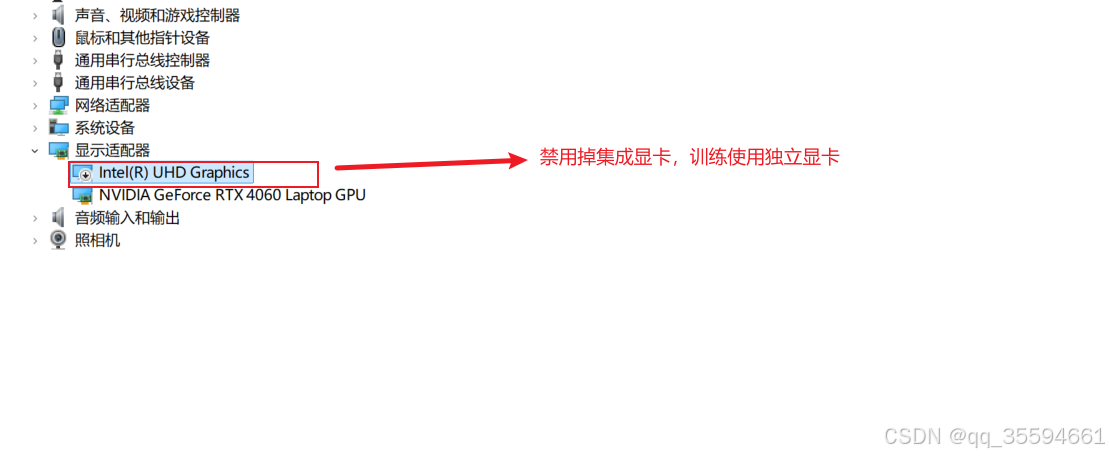
确定数据集后。进入设备管理器,禁用集成显卡,使用独立显卡进行训练
webui中点击,开始训练
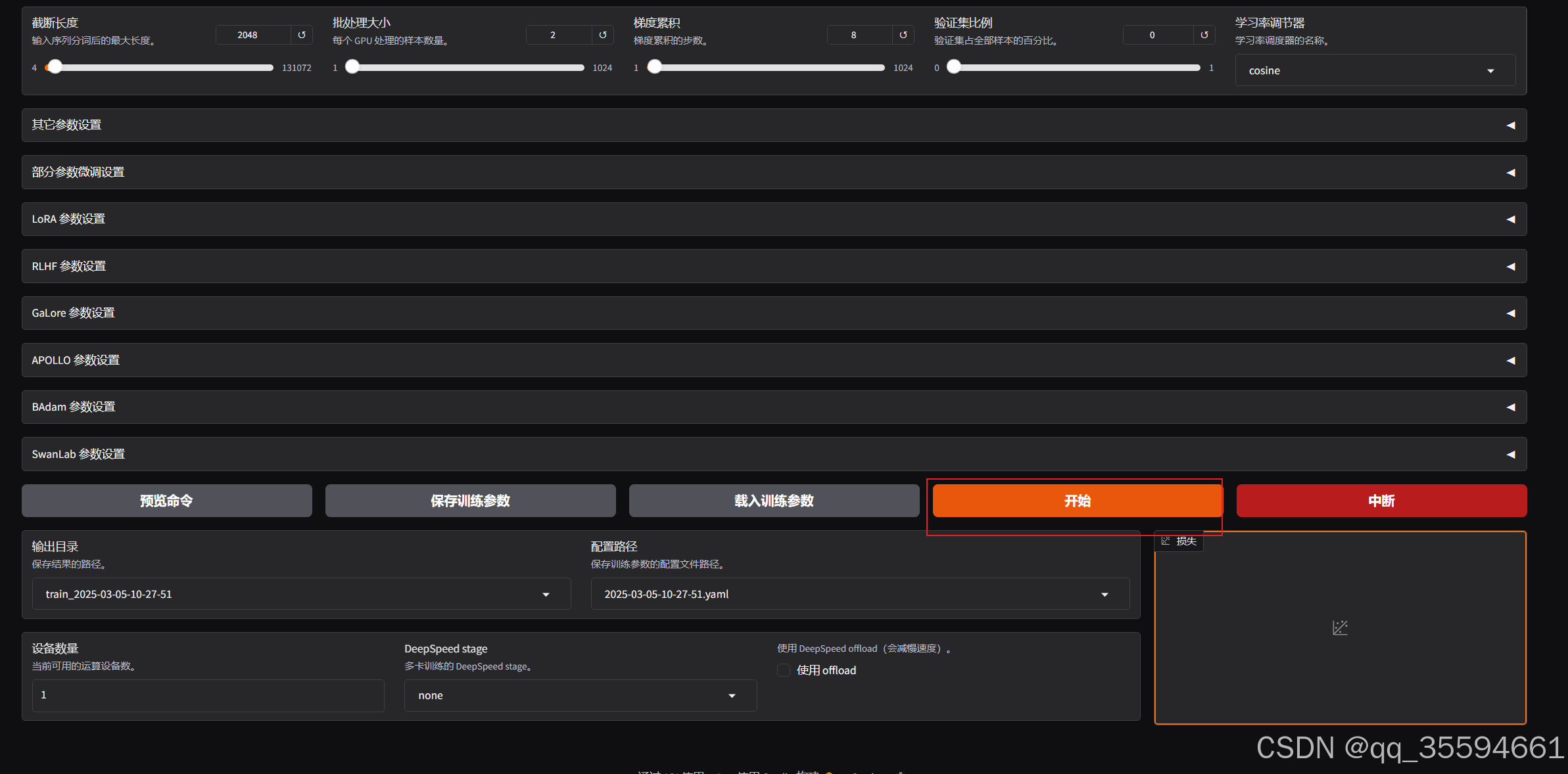
可以看到已经开始训练
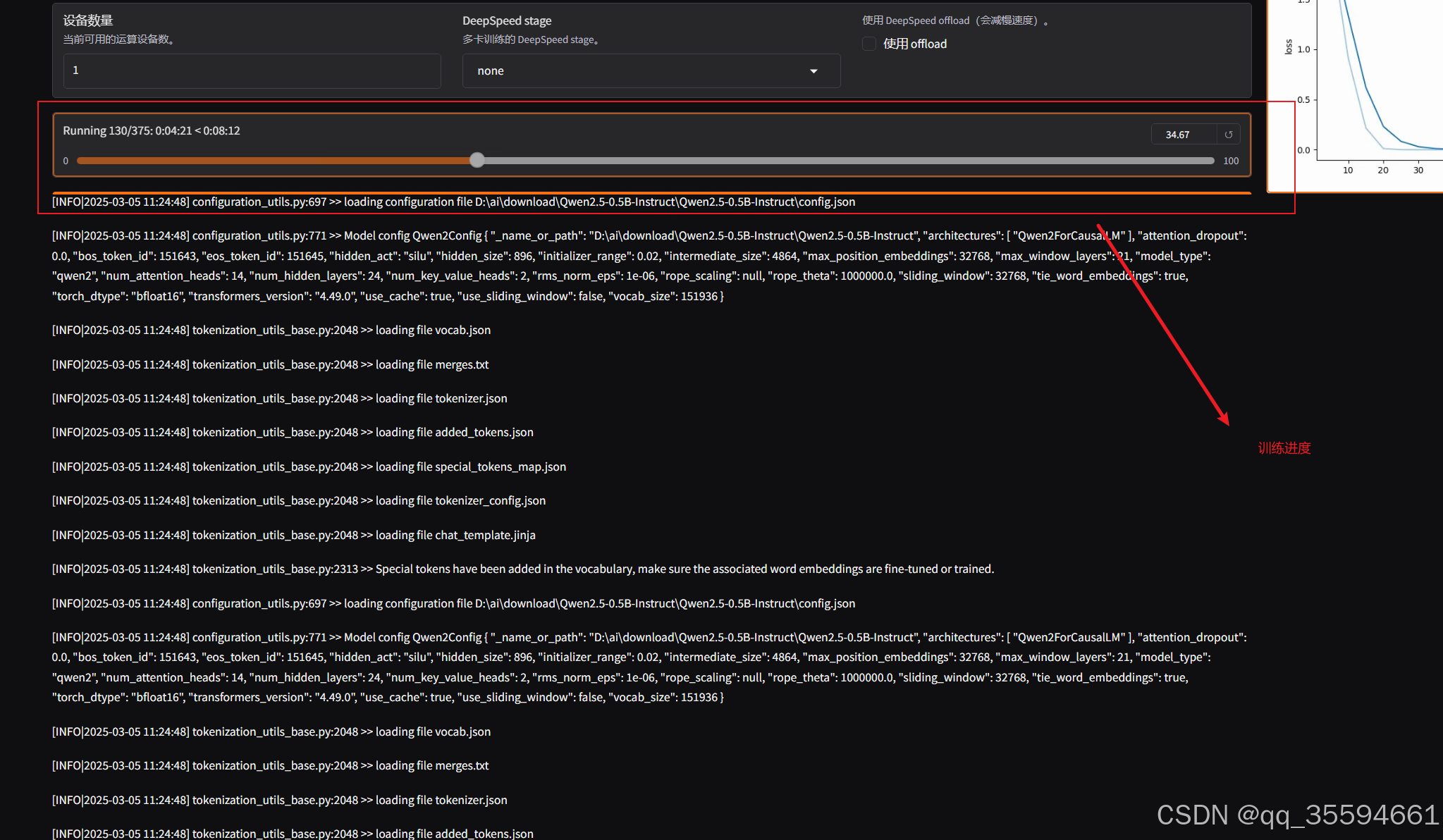
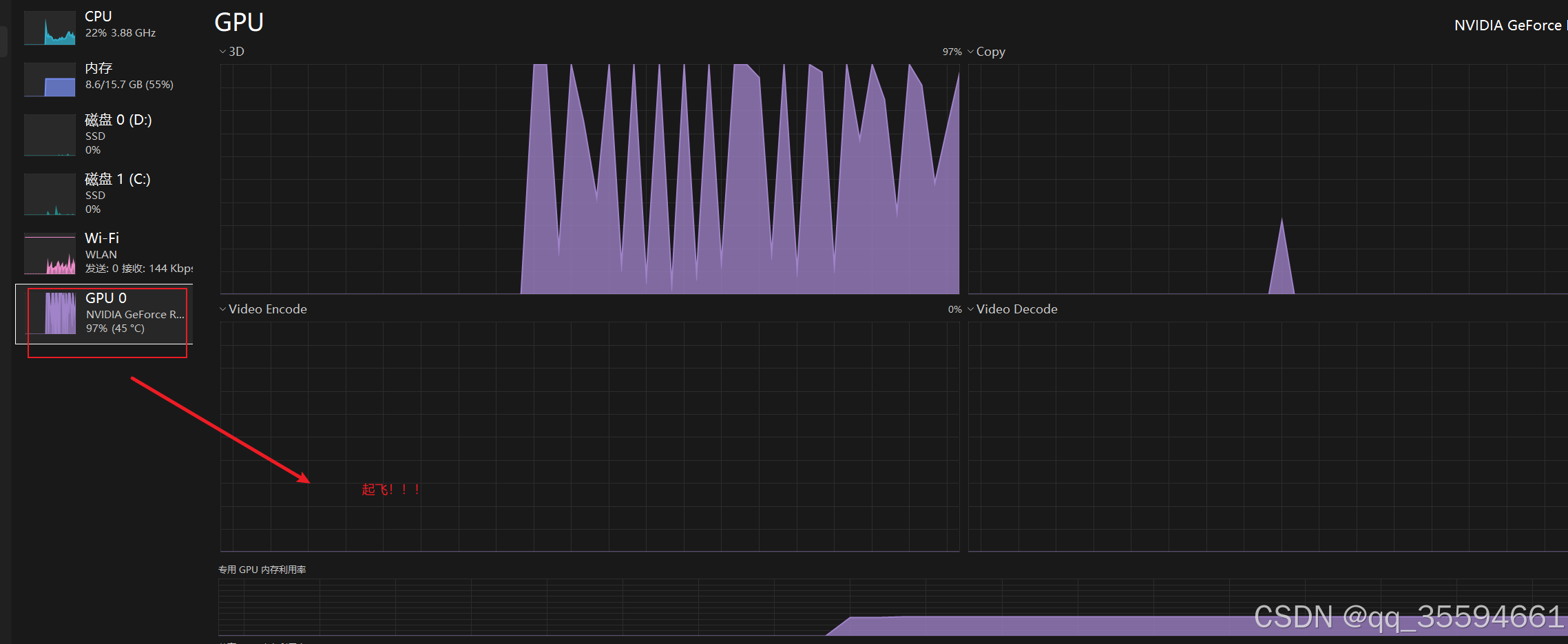
训练完成
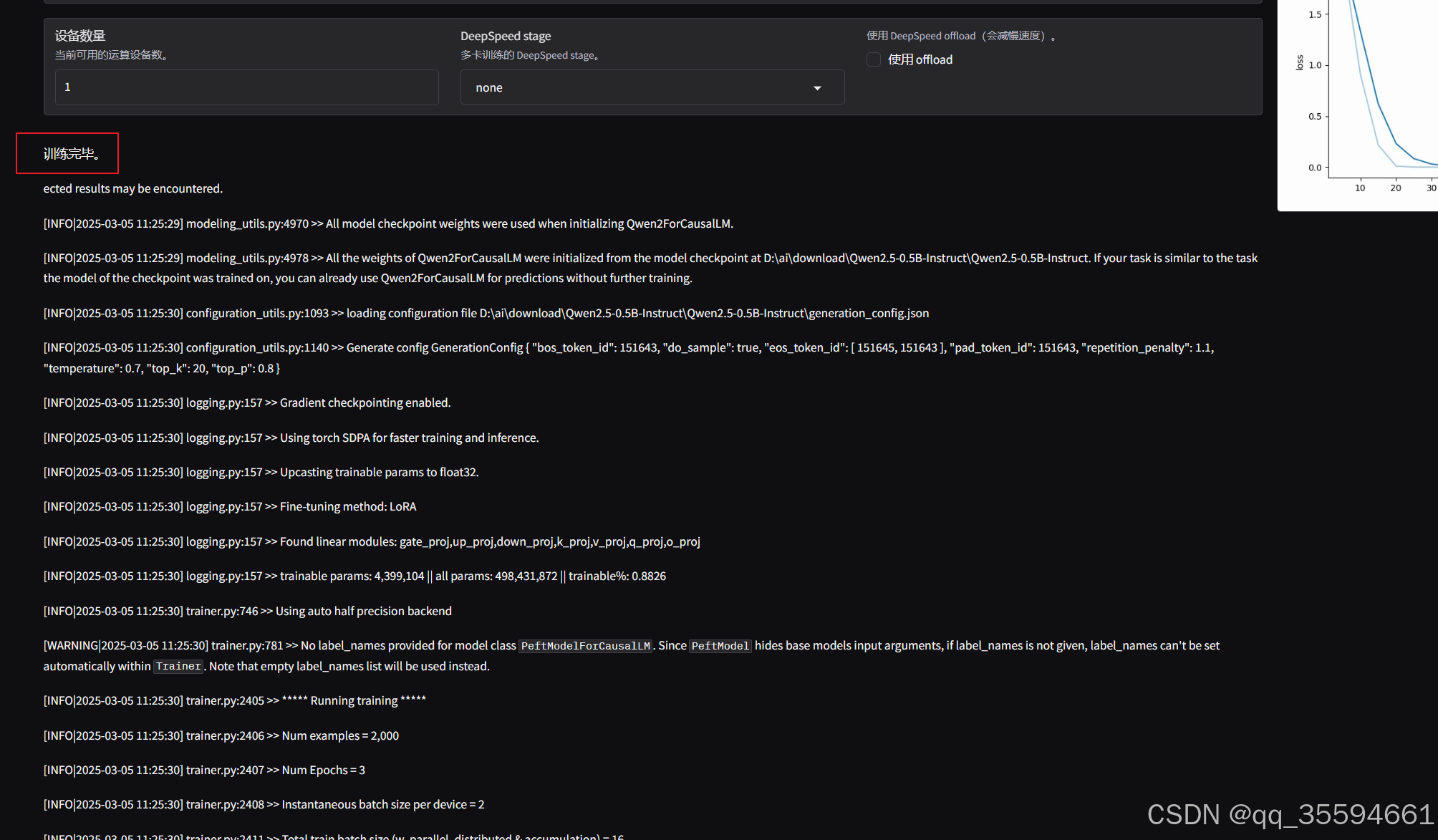
看到log上面出现训练完毕,表示训练结束了。
4.3 合并导出
选择export
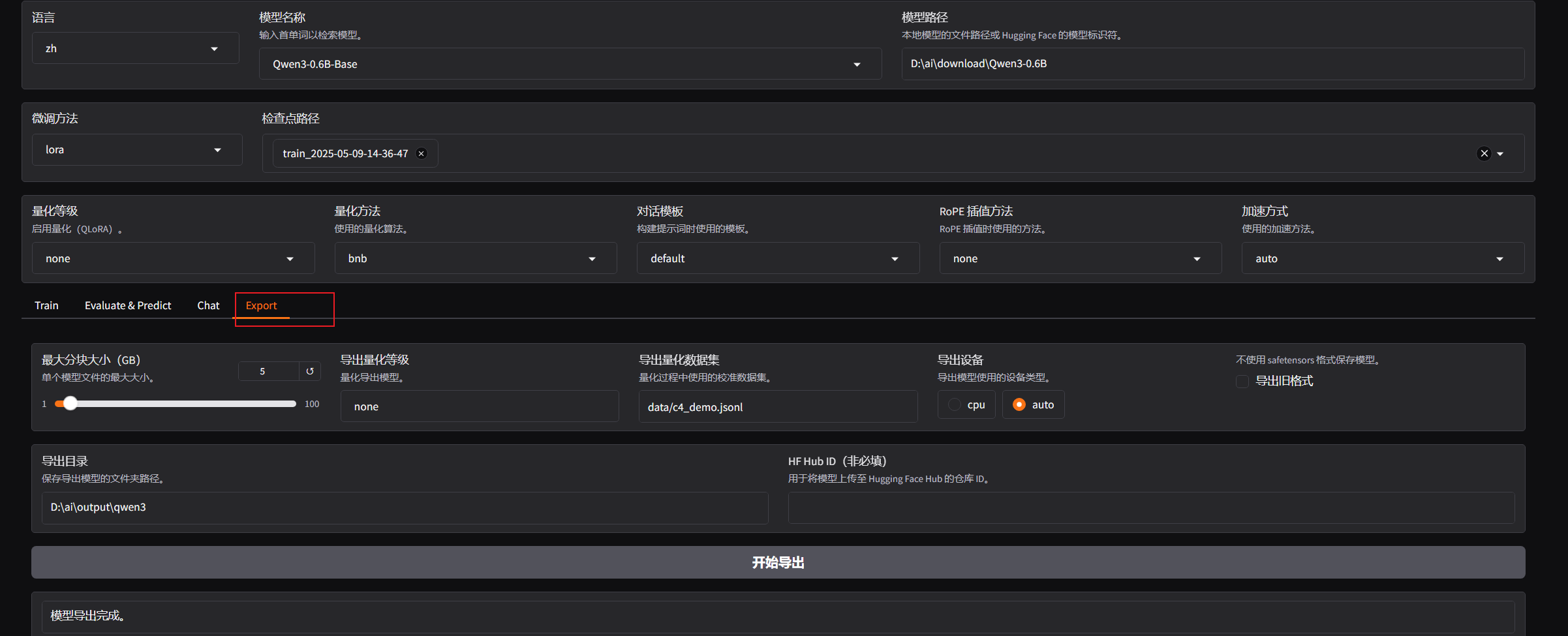
然后把这三个地方配置正确
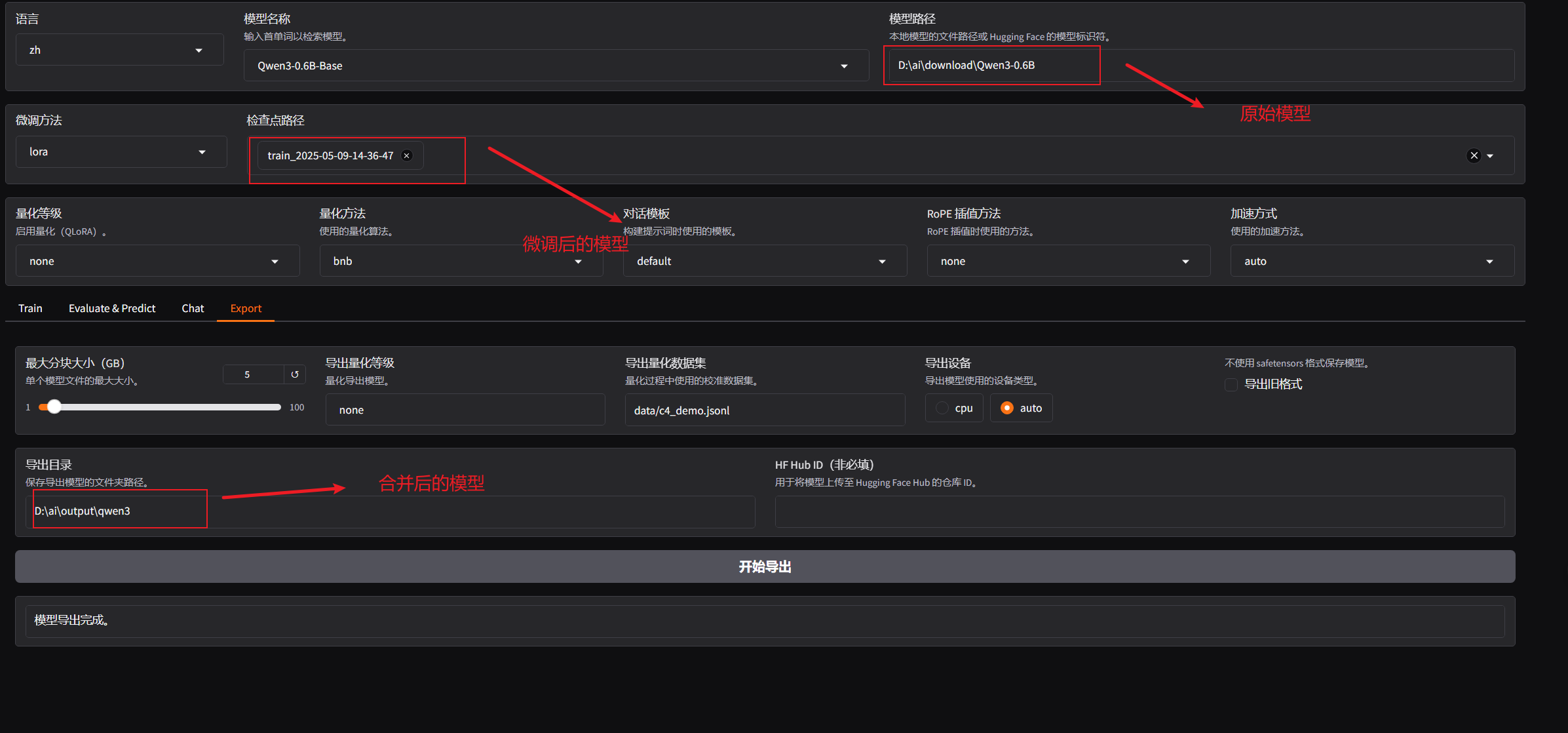
点击开始导出就能合并导出微调好的模型了
4.4 加载合并后的模型