链表实战指南:手动实现单链表与双链表的接口及OJ挑战(含完整源码)

文章目录
- 一、链表的概念
- 二、链表的分类
- 三、手动实现单链表
-
- 1.链表的初始化
- 2.链表的打印
- 3.申请新的节点大小空间
- 4.链表的尾插
- 5.链表的头插
- 6.链表的尾删
- 7.链表的头删
- 8.链表的查找
-
- 9.在指定位置之前插入数据
- 10.在指定位置之后插入数据
- 11.删除指定节点
- 12.删除指定节点之后的数据
- 13.销毁链表
- 四、单链表的思考
- 五.经典链表OJ题
-
- [1. 移除链表元素](https://leetcode.cn/problems/remove-linked-list-elements/description/)
- [2. 反转链表](https://leetcode.cn/problems/reverse-linked-list/)
- [3. 链表的中间节点](https://leetcode.cn/problems/middle-of-the-linked-list/)
- [4. 合并两个有序链表](https://leetcode.cn/problems/merge-two-sorted-lists/)
- [5. 相交链表](https://leetcode.cn/problems/intersection-of-two-linked-lists/description/)
- [6. 环形链表](https://leetcode.cn/problems/linked-list-cycle/)
- [7. 环形链表II](https://leetcode.cn/problems/c32eOV/description/)
- [8. 随机链表的复制](https://leetcode.cn/problems/copy-list-with-random-pointer/)
- 六、单链表与双链表最全源码
-
- 单链表源码
- 双链表源码
- 总结
一、链表的概念
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
上述是书本的定义,链表也是属于线性表,所以在逻辑结构上是线性的,而由于链表的数据与数据之间是通过地址(指针)连接的,所以地址不一定连续,具体要看操作系统分配的地址是否连续。
下图是链表的形象表示:火车是通过一节一节车厢连接在一起,删除和增加某节车厢不影响其他车厢,即每个车厢都是独立存在,每节车厢是通过钩子连接起来这与链表中每个节点相互独立,却又通过该节点指向下一个节点的指针连接起来有异曲同工之处。
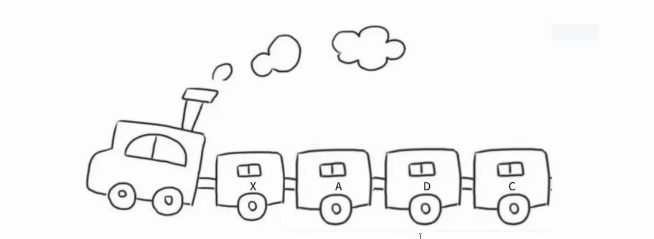
链表是由一个一个节点组成,节点由要存储的数据+下一个节点地址的指针,如图在第一个节点中保存的数据是1,还有下一个节点的地址:0x0012FFB0,也就是第二个节点的地址。依次往后看,直到第四个节点保存的数据是4,由于它的后面没有节点了,所以它保存的下一个节点的地址是NULL。

二、链表的分类
链表的结构非常多,以下情况组合起来共有8种(2x2x2)链表结构:
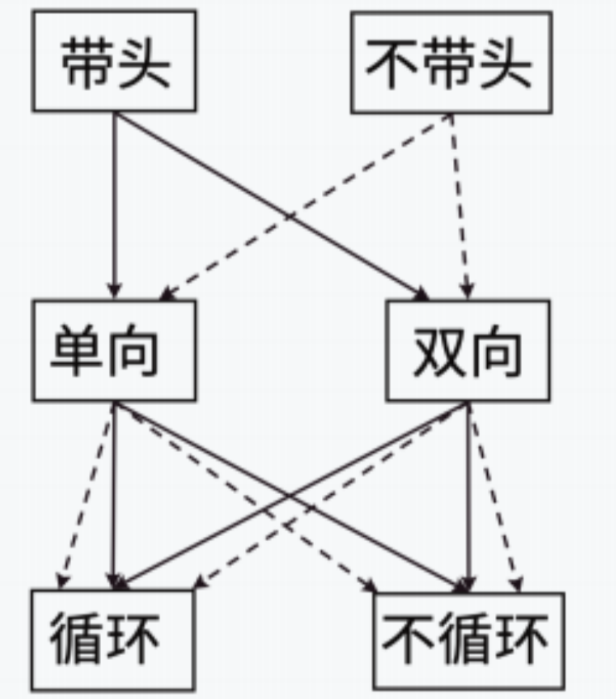
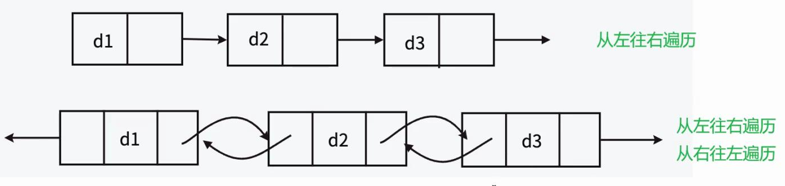
1.单向或者双向
在双向链表中,存放了两个指针:next指向下一个节点(后继节点),prev指向前一个节点(前驱节点)
2.带头或者不带头
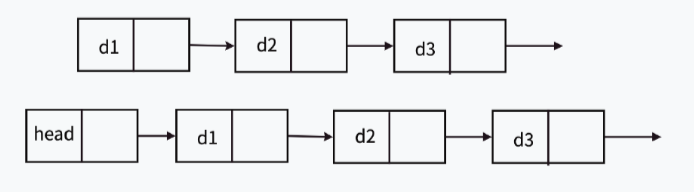
注意:在上课或者参考书上为了方便理解单链表会把链表的首节点称为头结点,但是这样的称呼是错误的,因为链表中存在一类链表叫做带头链表(不是指链表里的第一个有效的节点),这里的头结点即哨兵位(不保存任何有效数据,仅用来占位置,作用是不需要判断链表的头是否为空),如带头链表中只有头结点,那么我们就称该节点为空链表
3.循环或者不循环
在循环链表中尾节点的指向不为空,它指向了链表中第一个有效的节点
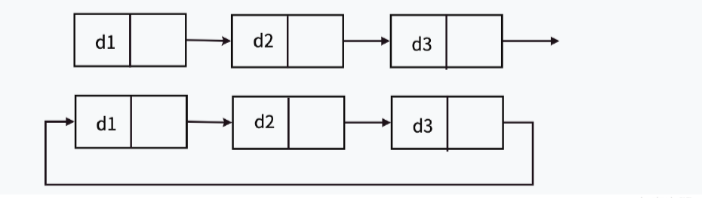
因此在前面我们实现的单链表的全称为:不带头单向不循环链表。链表有上面8种结构,但我们实际中用的最多的是单链表和双向带头循环链表!
三、手动实现单链表
1.链表的初始化
节点里存储两个变量,这里数据存储使用typedef将全部int改名成SLTDataType,方便以后修改,由于保存的下一个节点的地址也是节点类型,所以使用SListNode*类型,最后也把struct SListNode改名成SLTNode,方便书写。
//定义节点的结构typedef int SLTDataType;typedef struct SListNode{SLTDataType data;struct SListNode* next;}SLTNode;2.链表的打印
在实现链表的打印功能前需要手动构造一个链表,如下
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));node1->data = 1;SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));node2->data = 2;SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));node3->data = 3; SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));node4->data = 4;node1->next = node2;node2->next = node3;node3->next = node4;node4->next = NULL;以下是链表的打印,具体实现如下:
1.定义链表结构体指针指向phead
2.定义pcur等于phead即等于node1
3.若pcur不为NULL,则打印当前节点的data(存储的数据) ,并让pcur继续往下走
4.pcur走到为空,跳出while循环,打印NULL
5.最后打印结果为:1->2->3->4->NULL
注意:在这里直接使用phead来遍历也是一样的,重新创建pcur指针是为了避免由于指针指向的改变,导致无法重新找到链表的首节点
void SLTPrint(SLTNode* phead){//pcur存放的是当前节点的地址SLTNode* pcur = phead;while (pcur){printf(\"%d->\", pcur->data);pcur = pcur->next;}printf(\"NULL\\n\");}3.申请新的节点大小空间
注意:这里要判断申请空间是否成功,如果失败退出,申请成功对data和next进行初始化
SLTNode* SLTBuyNode(SLTDataType x){SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror(\"malloc fail!\\n\");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;}4.链表的尾插
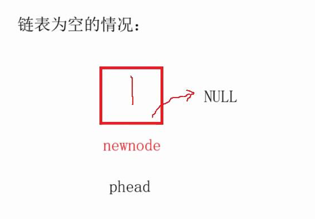
向操作系统动态申请一个节点大小的空间 然后断言若传来的是NULL,那么不能解引用,所以需要断言pphead不能为空,但是*pphead可以为空,因为它代表的是空链表,所以可以存在。这里尾插分两种情况
链表为空:即pphead为空,则让pphead等于newnode(为首节点)即1
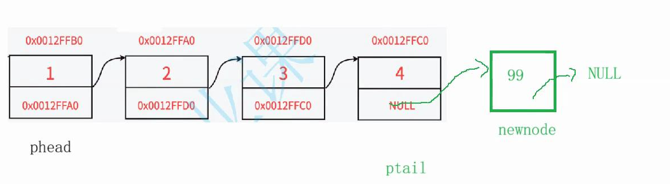
链表不为空:即pphead不为空,具体步骤如下
1.定义一个尾节点ptail,初始时等于首节点pphead
2.遍历链表,结束条件为不能等于尾节点,注意这里结束条件是ptail->next
3.若为尾节点,则让尾节点4的next指针指向新节点99
链表为空如下:
链表非空如下:
这里我们发现形参phead的改变没有影响到实参plist的改变(在传值的时候,形参的改变不影响实参 传地址:形参的改变影响实参 ),所以plist应该传地址而不是值,应为&plist,而plist是指针,所以phead要传二级指针来接受一级指针的地址,所以为**pphead。在if语句中药对pphead解引用(*pphead=plist)为一级指针,后面也是同样的意思。
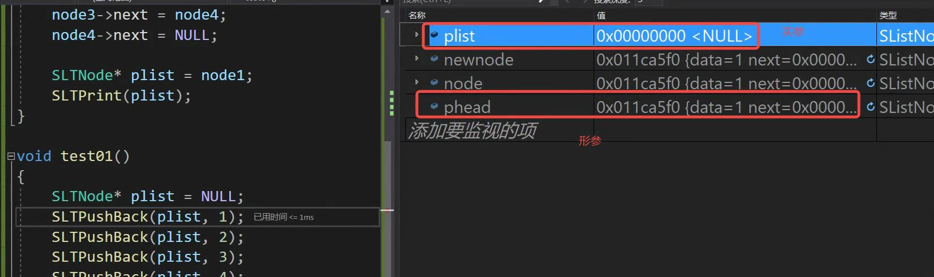
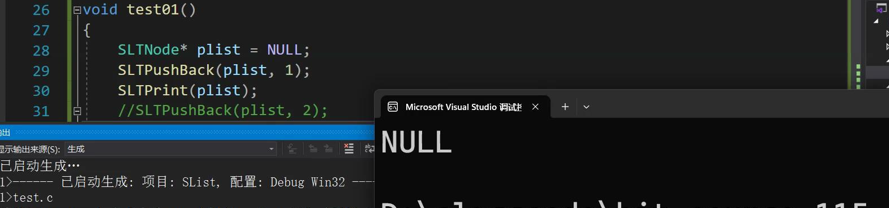
这里解释下一级指针和二级指针的概念
第一个节点 (解引用) *plist**phead(解引用两次),左边例如plist是实参,右边是形参
指向第一个节点的指针 plist*phead(解引用一次后变成一级指针)
指向第一个节点的指针的地址 (取地址) &plistpphead(二级指针)
//尾差void SLTPushBack(SLTNode**pphead, SLTDataType x){//如果传来的是NULL,那么不能解引用,所以需要断言pphead不能为空,但是*pphead可以为空,因为它代表的是空链表,所以可以存在assert(pphead);//*pphead就是指向第一个节点的指针//空链表和非空链表两种情况SLTNode* newnode = SLTBuyNode(x);if (*pphead == NULL){*pphead = newnode;}else{ SLTNode* ptail = *pphead;//如果ptail为空,那么在循环里面不可以对空指针解引用,所以会报错while (ptail->next){ptail = ptail->next;}//ptail指向的就是尾节点ptail->next = newnode;}}5.链表的头插
1.调用创建新节点的方法
2.让新节点9的next指针指向原来的头结点1(*pphead)
3.让新节点(newnode)为新的头结点
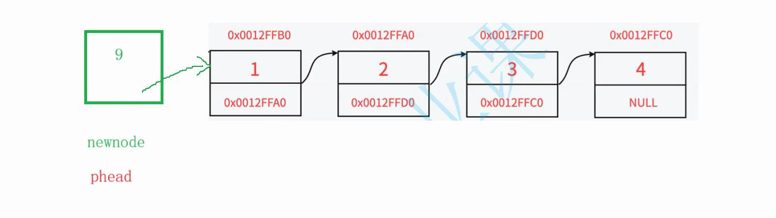
//头插void SLTPushFront(SLTNode** pphead, SLTDataType x){ //空链表和非空链表都可以运行assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;}6.链表的尾删
代码思路如下:
1.断言
2.判断链表中有一个节点还是多个节点
3.若只有一个节点(pphead->next==NULL),则直接释放,并把*pphead置为NULL
4.若有多个节点则定义prev和ptail指针指向头结点,然后遍历链表直至到尾节点,然后跳出循环,释放尾节点ptail并置为空,为了不让尾节点前一个节点的next指针为野指针,所以让prev为前一个节点并让其next指向空
注意这里断言时:pphead(一级指针的地址)不能为空,否则不能对二级指针解引用,其次不能让链表为空,总不能删空吧,这不可能的,所以和头插尾插不同的是添加了个(pphead)不能为空
链表中只有一个节点:
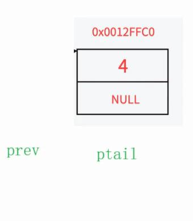
链表中多个节点:
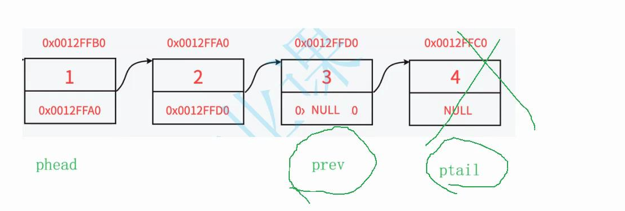
//尾删void SLTPopBack(SLTNode** pphead ){//这里和头插尾差不一样,因为尾删的话,链表不能为空,总不能删空吧,这不可能的,所以和头插尾插不同的是添加了个*pphead不能为空assert(pphead && *pphead);//链表只有一个节点if ((*pphead)->next == NULL)//这里给*pphead加了个括号,因为有符号的优先级,->的优先级高于*号{free(*pphead);*pphead = NULL;}else{//链表有多个节点SLTNode* prev = *pphead;SLTNode* ptail = *pphead;while (ptail->next){prev = ptail;ptail = ptail->next;}free(ptail);ptail = NULL;prev->next = NULL;}}7.链表的头删
1.定义next变量指向头结点的下一个节点
2.释放头结点
2.让next节点变为新的头结点
注意:这里不能直接删除pphead,若删除找不到后面的节点2,所以需要定义next保存下一个节点2
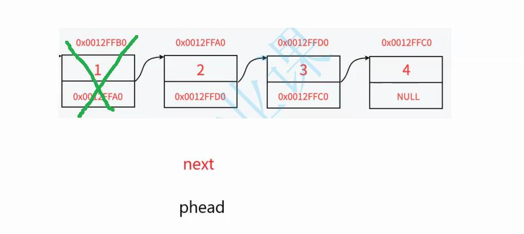
//头删void SLTPopFront(SLTNode** pphead){//这里和尾删是一样的,解释在上面assert(pphead && *pphead);//在这里不能直接删除第一个节点,这样就不能根据原本第一个节点的next指针找到原本第二个节点//在头删方法中,只有一个节点和多个节点如下方法都可以实现SLTNode* next = (*pphead)->next;//这里也是->的优先级大于*号free(*pphead);*pphead = next;}8.链表的查找
代码思路如下:
1.定义一个变量pcur指向头结点
2.循环遍历,若(if里的语句)pcur存储的data等于要查找的x,则返回该节点
3.否则继续往后遍历链表
4.若循环遍历结束,没有数据等于x,则该数据在链表中不存在
//查找SLTNode* SLTFind(SLTNode* phead, SLTDataType x){SLTNode* pcur = phead;while (pcur){if (pcur->data == x){return pcur;}else{pcur = pcur->next;}}return NULL;}9.在指定位置之前插入数据
代码思路如下:
1.前置条件的断言,如pphead和pos不能为空
2.若指定位置pos为头结点,那么就等于是头插,直接调用头插函数即可(特殊位置)
3.若pos不是头结点,定义prev指向头结点,遍历循环,循环条件为prev的next不等于pos
4.prev->next为pos跳出循环,将新节点的next指向pos,prev的next指向新节点
//在指定位置之前插入数据void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x){ assert(pphead && pos);//当pos为首节点的时候,会出现对空指针解引用的操作导致下面代码报错//若pos直接等于*pphead的时候则为头插,那么直接调用头插函数if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* newnode = SLTBuyNode(x);SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}newnode->next = pos;prev->next = newnode;}}10.在指定位置之后插入数据
注意:1. 这里(newnode->next = pos->next; pos->next = newnode)顺序不能反过来,否则自己指向自己了
2.这里只需pos和插入数据两个变量,与在指定位置之前插入数据不一样,不需要遍历找下一个节点,因为pos的next指针存储的就是下一个节点,而在指定位置之前插入数据,pos没有保存前一个节点,需要用pphead遍历链表来寻找
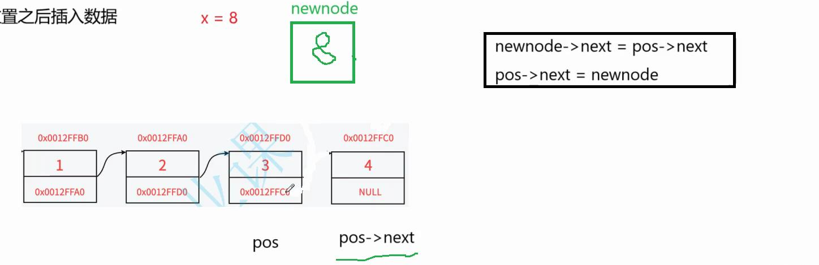
//在指定位置之后插⼊数据void SLTInsertAfter(SLTNode* pos, SLTDataType x){assert(pos);SLTNode* newnode = SLTBuyNode(x);//pos newnode -> (pos->next)newnode->next = pos->next;pos->next = newnode;}11.删除指定节点
代码思路:
1.断言pphead不为空且pos不为空,否则怎么删除pos节点
2.这里要判断特殊条件,若pos是头结点则直接调用已写好的头删方法
3.否则循环遍历链表,若prev的next指向pos,则退出循环
4.让prev的next指向pos的下一个节点后再释放pos,并把pos置为空
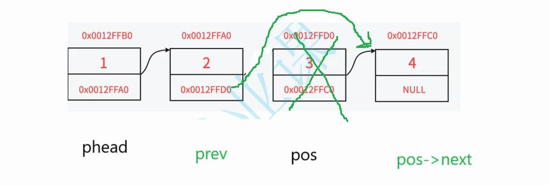
//删除pos结点void SLTErase(SLTNode** pphead, SLTNode* pos){assert(pphead && pos);//要删除的节点就是头结点if (pos == *pphead){SLTPopFront(pphead);}else {SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev pos pos->nextprev->next = pos->next;free(pos);pos = NULL;}}12.删除指定节点之后的数据
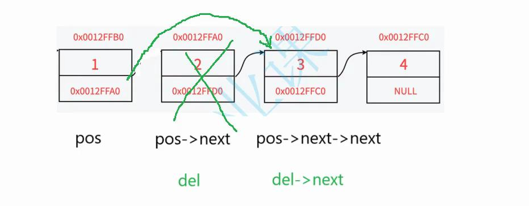
在下图我们要删除2节点(pos->next)
1.需要将1节点(pos)的next(pos->next)指向3(pos->next->next)
2.释放2节点(pos->next)
在上面操作中我们发现最后的pos->next指向3节点,也就是说最后释放的不是2而是3节点,所以我们需要定义del变量来存放pos->next
1.del赋值为pos->next,也就是2节点
2.让1节点(pos)的下一个节点为3(del->next)
3.释放节点2(del)并置为空
注意:这里断言不能让pos指向空,也不能为尾节点,因为尾节点之后没有数据,无法删除
//删除pos之后的结点void SLTEraseAfter(SLTNode* pos){assert(pos && pos->next);SLTNode* del = pos->next;//pos del del->nextpos->next = del->next;free(del);del = NULL;}13.销毁链表
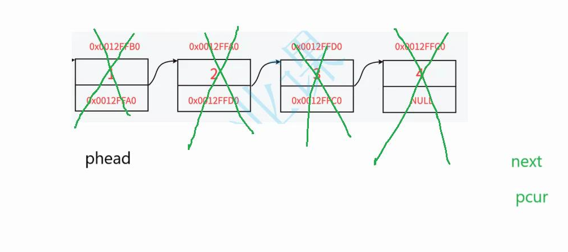
不能直接释放链表,应该一个一个释放链表里面的节点,这里不能直接释放节点,应该定义pcur保存该节点,并且还要保存下一个节点的地址,否则要销毁下一个节点的时候找不到该节点地址,变成野指针
代码思路如下:
1.定义pcur指向头结点
2.循环遍历链表,定义next并让他保存要销毁节点的下一个节点
2.释放要销毁的节点,并让链表继续往后遍历( pcur = next)
3.链表中所有节点都删除跳出循环,还需让*pphead置为空,否则它为野指针
//销毁链表void SListDestroy(SLTNode** pphead){SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;}四、单链表的思考
在上一篇博客里面讲解了顺序表的一些问题,链表相对于顺序表而言有以下几个优势:
1.链表头部插入删除时间复杂度为0(1)
2.链表无需增容
3.链表不存在空间浪费
五.经典链表OJ题
1. 移除链表元素
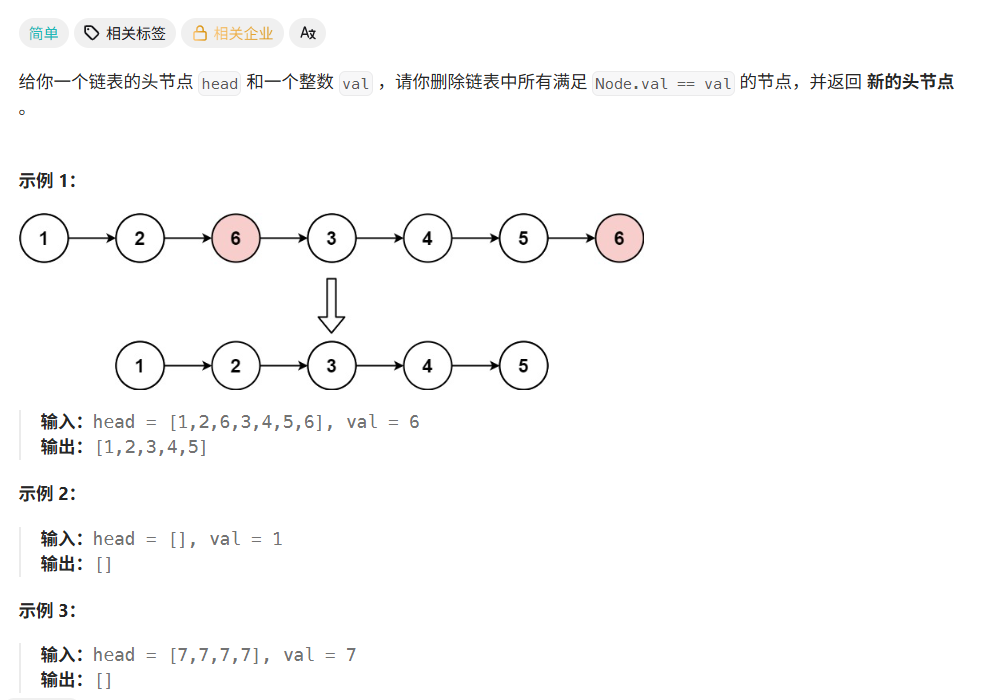
题目解释:
这道题题目很容易读懂,和上述我实现链表方法中的删除指定位置的节点意思类似,这里只需要给头结点就可以知道整个链表
思路 1: 遍历链表找到值为val的结点,执行删除指定pos位置结点的操作,时间复杂度为O(n^2)
思路2:创建新的链表,遍历原链表,将链表中值不为val的节点尾插到新链表中
1.遍历原链表,结束条件为pcur为空
2.若pcur存储的值不为val尾插到新链表中
这里尾插分两种情况:
新链表为空:pcur既是新链表的头结点也是尾节点
链表不为空:尾节点的next指向pcur,再让ptail从原来的尾节点走到pcur变成新的尾节点
3.让pcur往后走
4.走到空,遍历完链表跳出循环,然后一定要判断newtail不为空(若为空则不能解引用它的next,其中newtail为空时候原链表为空,如图1),让newtail的next指向空,因为newtail这个节点可能存储原链表的下一个节点(图2,图3),在图中5为尾节点,但是5保存了6的地址,所以让5的next置为空
图1: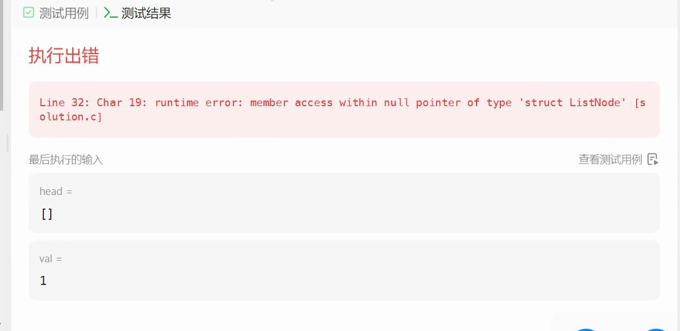
图2:
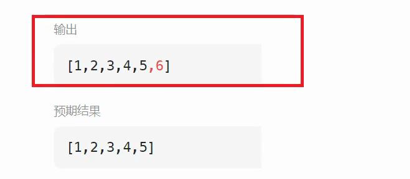
图3:
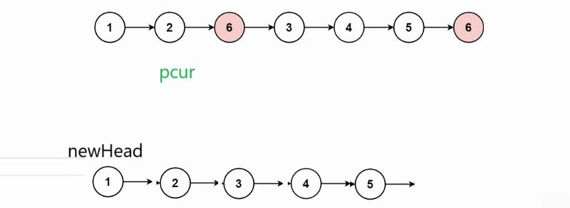
注意:这里不能使用双指针,因为双指针法只是修改节点里面的值却没有删除节点
代码实现:
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode; struct ListNode* removeElements(struct ListNode* head, int val) { //创建一个空链表 ListNode *newhead,*newtail; newhead=newtail=NULL; //遍历原链表 ListNode*pcur=head; while(pcur) { //找值不为val的结点尾插到新链表中 if(pcur->val!=val) { if(newhead==NULL){ //链表为空 newhead=newtail=pcur; } else{ //链表不为空 newtail->next=pcur; newtail=newtail->next; } } //遍历原链表 pcur=pcur->next; } if(newtail) { newtail->next=NULL; } return newhead;}2. 反转链表
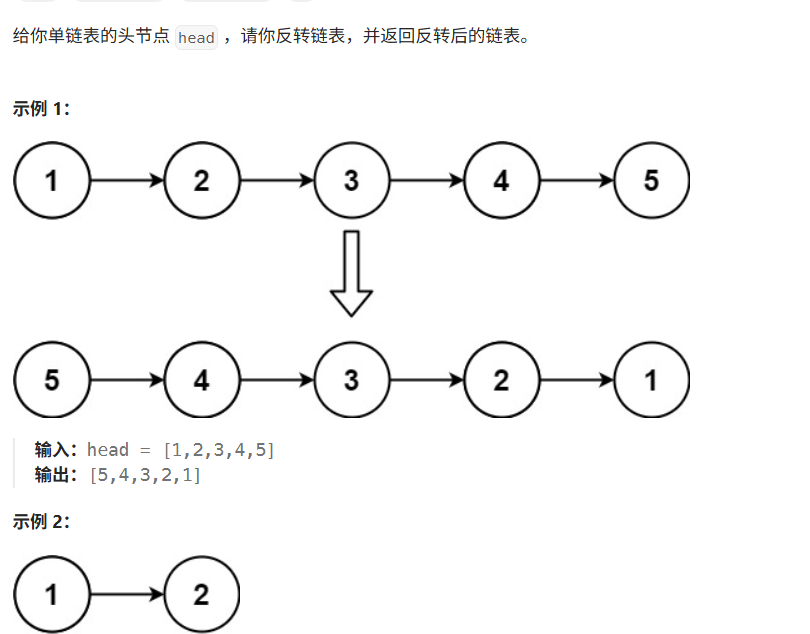
题目解释: 这里只需将反转链表后的头结点给返回即可·,题目意思很容易理解
思路1: 创建新链表,遍历旧链表中的节点拿过来头插
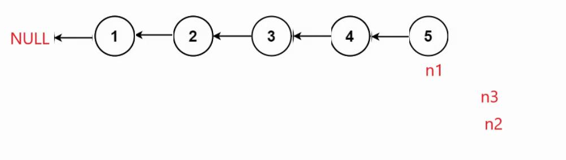
思路2: 创建3个指针,n1 初始指向空,n2指向头节点,n3指向头节点下一个节点,只要n2的节点不为空,就让n2的next指针不指向n3,改成指向n1。然后让n1走到n2的位置,n2走到n3的位置,n3走到下一个节点的位置。一直重复直到n2为空结束该过程,n1指向的节点即为头结点
注意: 这里有特殊情况,若链表为空直接返回头结点即可,因为n2为头结点,n2为空,那么n2->next是错误的,不能对空指针进行解引用
初始情况:
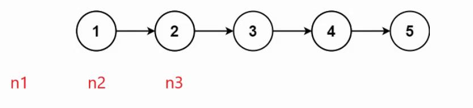
结束情况:
代码实现:
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */typedef struct ListNode ListNode;struct ListNode* reverseList(struct ListNode* head) { if(head==NULL){ return head; } ListNode*n1,*n2,*n3; n1=NULL,n2=head,n3=n2->next; while(n2) { n2->next=n1; n1=n2; n2=n3; if(n3) { n3=n3->next; } } return n1;}3. 链表的中间节点
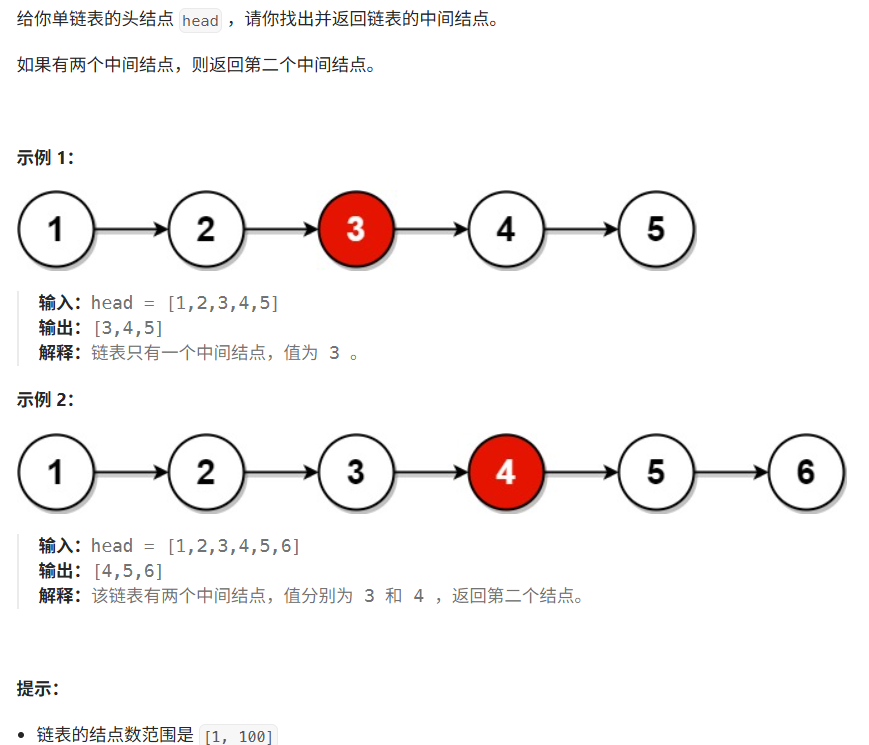
题目解释: 若链表里的节点是奇数个数,则直接返回该节点,如果节点是偶数个,那么返回第二个中间节点即可,这里题目描述很简单,但要注意节点是奇数个还是偶数个这两种情况
思路 1: 求链表结点总数,除2求中间位置,返回中间位置结点O(n)。在图1中,共有5个节点,5/2=2,定义pcur从0开始遍历,到3这个节点正好是下标为2,即3是中间节点
思路 2: 快慢指针,慢指针每次走一步,快指针每次走两步 即 2*慢指针=快指针 。
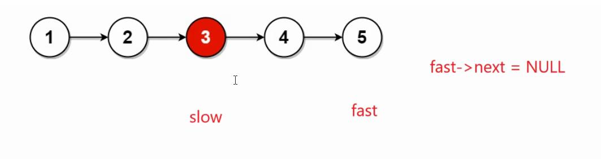
在奇数节点个数中,若fast->next=NULL,则不能往下走,slow指向的节点3的位置就是中间节点
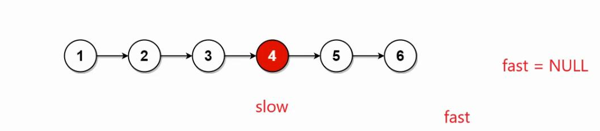
在偶数节点个数中,fast=NULL则不能往下走,slow指向的节点4为中间节点
这里判断节点是偶数个(fast=NULL)或者奇数个(fast->next=NULL)的时候,fast和fast->next顺序不能相反,具体解释在代码中注释有
注意:这里不能使用双指针向中间遍历,phead可以向右遍历,因为存放next指针指向下一个节点,但是ptail不能往左走,因为没有存放前一个节点
图1:
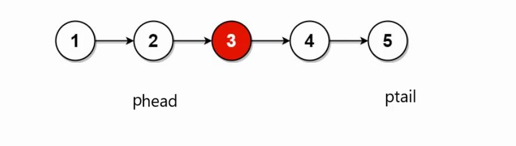
代码实现:
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode;struct ListNode* middleNode(struct ListNode* head) { ListNode*slow=head; ListNode*fast=head; while(fast&&fast->next){ //fast和fast->next位置不能换,如果先fast-> next,fast都已经为空了,不能对空解引用 //代码会报错,只要第一个为假,就不会判断fast->next为真为假 slow=slow->next; fast=fast->next->next; } return slow;}4. 合并两个有序链表
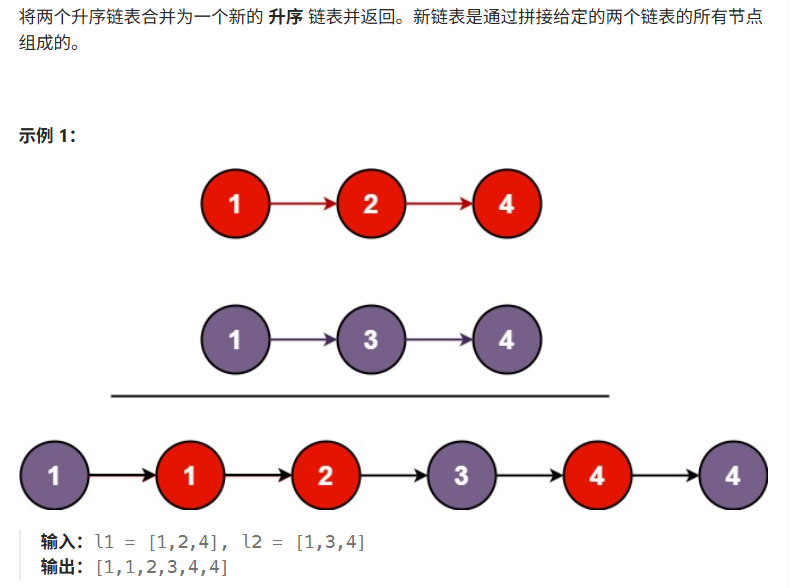
题目解释: 题目给我们两个排好的升序链表,将他们连在一起合并成一个新的升序链表
思路: 1. 定义l1指向第一个链表,l2指向第二个链表,定义一个新链表
2.循环遍历链表1和2,谁的值小放入新链表中,结束条件为:l1和l2其中一个走到为空就退出循环
3.l1小则将l1数据插入到新链表中,若新链表是为空,则插入进来的l1既事头结点也是尾节点,若链表不为空,则让为节点的下一个节点指向l1,newtail走到l1位置,同理l2也是如此
4. 跳出循环,只有两种情况,l1走到空,l2走到空,不可能有l1和l2均为空的情况,因为若l1和12存放的数据相等时,我们随机让l1或者l2走往后走,走到为空。
5.若l1不为空,则让newtail的next指向l1,同理l2也是如此
以上思路看起来是不是理所当然,但是当我们调试代码的时候报错了,下面的报错是不是很熟悉呀,我们根据他给的示例带入我们上述思路跑一下,l1为空无法进入循环,直接跳到思路5中,新链表为空,其尾节点为空,不能对空进行解引用,我们的代码却让新节点的newtail的next指向l2,所以报错。
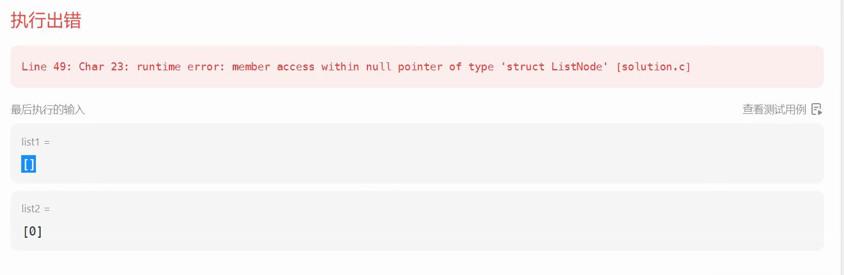
我们根据上面问题发现是没有对链表为空进行处理,所以我们在思路1后面直接进行判断,若l1为空,直接返回l2,同理l2也是如此。
在下面写代码时候我们发现思路中的步骤3判断链表是否为空,代码重复度过高,我们可以创建非空链表(malloc节点大小空间,别忘记最后要释放哦),则不需要进行判空号,直接尾插,如下图
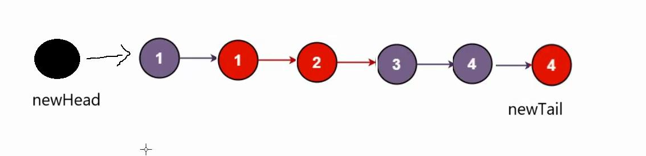
代码实现:
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode;struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) { ListNode*l1=list1; ListNode*l2=list2; if(list1==NULL) { return list2; } if(list2==NULL) { return list1; } //新链表 ListNode*newhead,*newtail; newhead=newtail=NULL; while(l1&&l2) { if(l1->val<l2->val) { //l1插入到新链表中 if(newhead==NULL) { //链表为空 newhead=newtail=l1; }else { newtail->next=l1; newtail=newtail->next; } l1=l1->next; } else{ //l2插入到新链表中 if(newhead==NULL) { newhead=newtail=l2; }else{ newtail->next=l2; newtail=newtail->next; } l2=l2->next; } } //跳出循环,只有两种情况,l1走到空,l2走到空 //有没有可能l1l2同时为空?不可能 if(l1){ newtail->next=l1; } if(l2) { newtail->next=l2; } return newhead;}5. 相交链表

题目解释: 如果两个链表相交则是相交链表,这里解释下啥是相交链表,若l1的某个节点和l2的某个节点相同,即是相交节点,有三种情况 l1和l2的头结点就相同,l1和l2中间有节点相同,l2和l3的尾节点相同。
注意大家可能疑惑有没有l1和l2链表相交成“x”字型,答案是否定的,若交叉点为n1,n1的next节点只能存放一个地址,而不是多个,若两个链表相交,则从交叉点开始后面的节点均相同
思路: 这里需要解决两个问题,1.如何判断链表是否相交 2.找相交的起始节点
试错: 一个个比较链表节点的next是否相等,这个方法仅限相交之前的节点个数相等(长度相同),所以该方法不行
问题1:看尾节点的地址是否相同
问题2:找长度差,也就是找大小链表(求出两个链表的长度差),大链表先走长度差次,然后再一起比较两个链表的next是否相同
代码实现:
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode;struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { //求出两个链表的长度 ListNode*pa=headA,*pb=headB; int sizeA=0,sizeB=0; while(pa) { ++sizeA; pa=pa->next; } while(pb) { ++sizeB; pb=pb->next; } int gap=abs(sizeA-sizeB);//abs:求绝对值的函数 //让长链表先走gap步 ListNode*shortlist=headA; ListNode*longlist=headB; if(sizeA>sizeB) { longlist=headA; shortlist=headB; } while(gap--) { longlist=longlist->next; } //shortlist longlist在同一起跑线 while(shortlist) { if(shortlist==longlist) { return shortlist; } shortlist=shortlist->next; longlist=longlist->next; } return NULL;}6. 环形链表
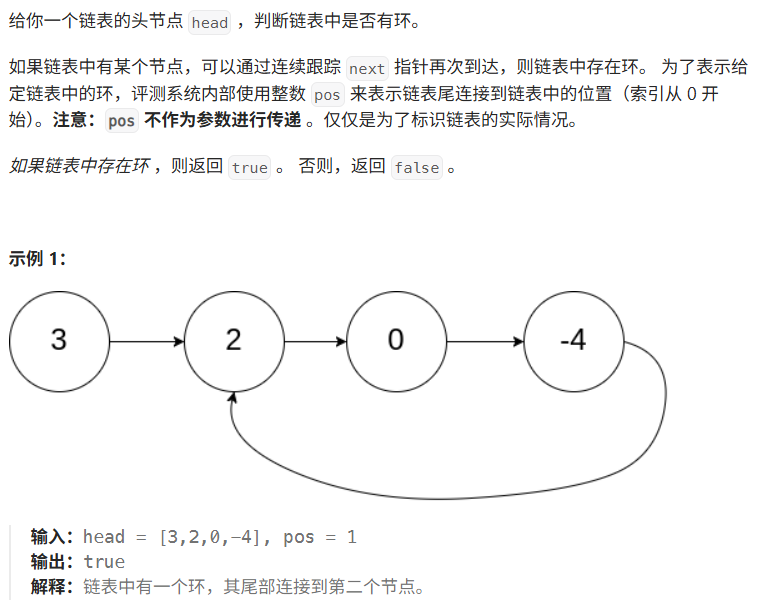
题目解释: 链表带环如上图一样,它具有尾节点的next指向不为空的性质,若链表带环则返回true否则返回false
思路: 快慢指针( 慢指针每次走一步,快指针每次走两步):在环内追逐,若链表带环,快慢指针会相遇
**证明:**这里大家如果感兴趣可以自己证明或者在网上搜下为啥在环形链表中使用快慢指针,最终两指针会相遇!
代码实现:
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ typedef struct ListNode ListNode;bool hasCycle(struct ListNode *head) { ListNode*slow=head,*fast=head; while(fast&&fast->next) { slow=slow->next; fast =fast->next->next; if(slow==fast) { //相遇 return true; } } return false;}7. 环形链表II
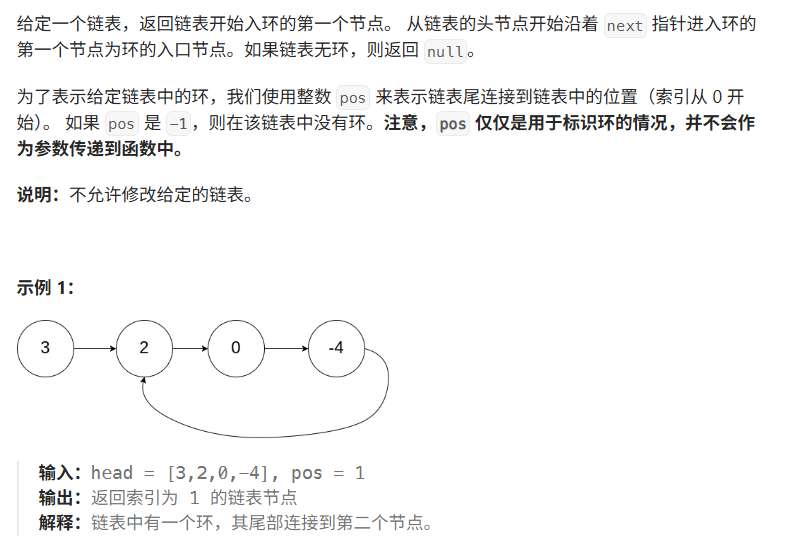
题目解释: 这与上题类似,不过多解释
思路: 这里还是快慢指针,但是要注意的是这里有个结论:相遇点到入环起始结点的距离等于链表头结点到入环起始结点的距离
这里大家也可以自己证明下该结论如何成立的
代码实现:
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */typedef struct ListNode ListNode;struct ListNode *detectCycle(struct ListNode *head) { ListNode*slow=head,*fast=head; while(fast&&fast->next) { slow=slow->next; fast=fast->next->next; if(fast==slow) { //相遇点 ListNode*pcur=head; while(slow!=pcur ) { slow=slow->next; pcur=pcur->next; } return pcur; } } return NULL;}8. 随机链表的复制

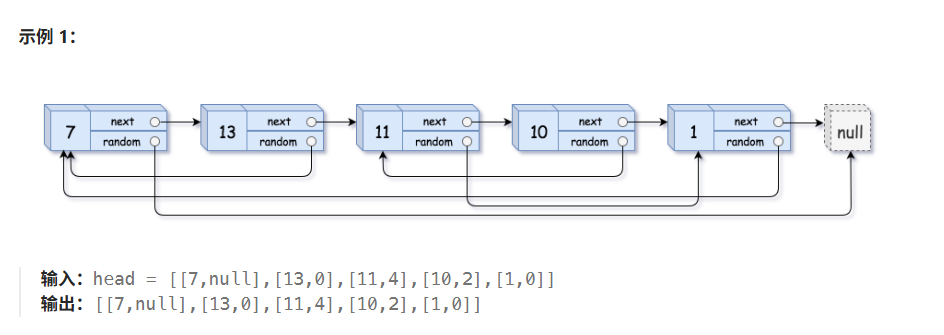
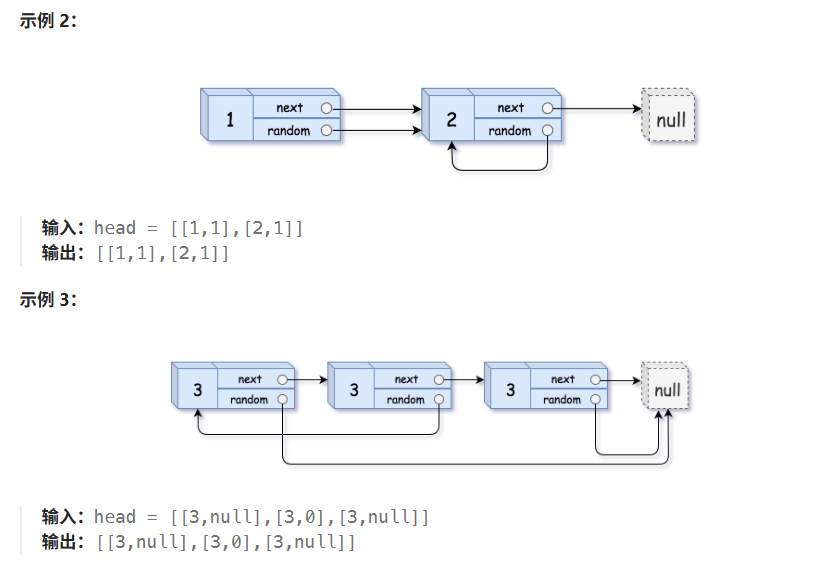
题目解释: 这道题提到我们要对这个链表进行深拷贝,这里我们要拷贝原链表中所有的数据,拷贝到一个全新的链表,即复制的链表中的指针不能指向原链表,藕断丝连。(该链表与普通节点不同的是额外添加了指针,该指针可以指向链表中的任何节点或空节点)
深拷贝:定义pcur指针指向当前节点,再来一个指针pcur2指向另外一个节点,但是该节点存储的值和前面一个节点存储的值相同,但是节点的地址互不相同(如图 1),简单理解就是把链表从一个地方拿到别的地方,链表里面存放到值完全一样,就是链表的位置即地址不一样而已
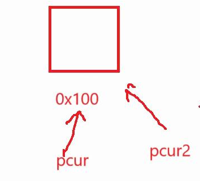
浅拷贝:定义pcur指针指向当前节点,再来一个指针pcur2也指向该节点,它们使用的是同一块地址即浅拷贝(如图2)
图 1:
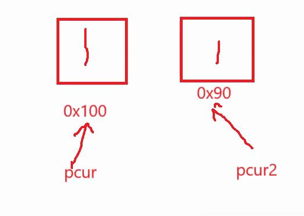
图 2:
代码思路: 这里大家可能想到把链表中除了random指针其他全部复制过来,然后再遍历原链表设置新链表的random指针,这个想法是正确的,但是我们发现置random指针很麻烦,无法处理
思路2:
- 拷贝节点:在原链表上申请新的节点pcur,让它遍历原链表并不断创建和它当前位置节点一模一样的节点,然后让创建的这个节点尾插到该位置的后面(这里暂时只需改变next指向即可),依次重复该操作直至pcur走到空为止,链表拷贝完成
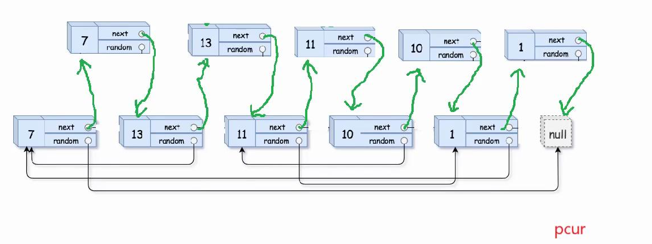 2.置random指针:在复制链表中定义copy指针和pcur一起遍历新旧链表,让copy->random=pcur->random->next
2.置random指针:在复制链表中定义copy指针和pcur一起遍历新旧链表,让copy->random=pcur->random->next
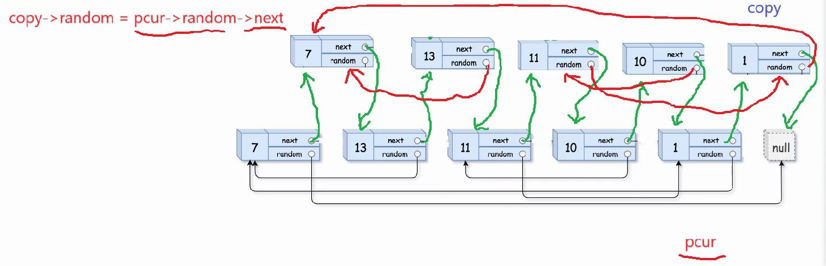
3.断开新旧链表:pcur和copy同时遍历新旧链表,让copy->next不再指向pcur,而是指向pcur->next,依次重复执行直至copy走到空,那么新旧链表已断开
注意:若链表为空需要特殊处理,直接返回即可
代码实现:
/** * Definition for a Node. * struct Node { * int val; * struct Node *next; * struct Node *random; * }; */typedef struct Node Node;//创建新节点Node*buyNode(int x){ Node*node=(Node*)malloc(sizeof(Node)); node->val=x; node->next=node->random=NULL; return node;}void AddNode(Node*head){ Node*pcur=head; while(pcur){ Node*next=pcur->next; //创建新节点,插入到pcur结点之后 Node*newnode=buyNode(pcur->val); newnode->next=pcur->next; pcur->next=newnode; pcur=next; }}void setRandom(Node*head){ Node*pcur=head; while(pcur) { Node*copy=pcur->next; if(pcur->random) { copy->random=pcur->random->next; } pcur=copy->next; }}struct Node* copyRandomList(struct Node* head) { if(head==NULL) { return head; } //1. 拷贝结点 AddNode(head); //2. 置random指针 setRandom(head); //3 断开链表 Node*pcur=head; Node*newHead,*newTail; newHead=newTail=pcur->next; while(newTail->next) { pcur=newTail->next; newTail->next=pcur->next; newTail=newTail->next; } return newHead;}代码如下(示例):
data = pd.read_csv( \'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv\')print(data.head())该处使用的url网络请求的数据。
六、单链表与双链表最全源码
单链表源码
SList.h源码
#pragma once#include#include#include//定义节点的结构typedef int SLTDataType;typedef struct SListNode{SLTDataType data;struct SListNode* next;}SLTNode;void SLTPrint(SLTNode* phead);//尾差void SLTPushBack(SLTNode**pphead, SLTDataType x);//头插void SLTPushFront(SLTNode** pphead, SLTDataType x);//尾删void SLTPopBack(SLTNode** pphead);//头删void SLTPopFront(SLTNode** pphead);//查找SLTNode* SLTFind(SLTNode* pphead, SLTDataType x);//在指定位置之前插入数据void SLTInsert(SLTNode** pphead,SLTNode*pos ,SLTDataType x);//在指定位置之后插入数据void SLTInsertAfter(SLTNode* pos, SLTDataType x);//删除pos节点void SLTErase(SLTNode** pphead, SLTNode* pos);//删除pos之后的节点void SLTEraseAfter(SLTNode* pos);//顺序表的销毁void SListDestroy(SLTNode**pphead);SList.c源码
#include\"SList.h\"void SLTPrint(SLTNode* phead){//pcur存放的是当前节点的地址SLTNode* pcur = phead;while (pcur){printf(\"%d->\", pcur->data);pcur = pcur->next;}printf(\"NULL\\n\");}SLTNode* SLTBuyNode(SLTDataType x){SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror(\"malloc fail!\\n\");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;}//尾差void SLTPushBack(SLTNode**pphead, SLTDataType x){//如果传来的是NULL,那么不能解引用,所以需要断言pphead不能为空,但是*pphead可以为空,因为它代表的是空链表,所以可以存在assert(pphead);//*pphead就是指向第一个节点的指针//空链表和非空链表两种情况SLTNode* newnode = SLTBuyNode(x);if (*pphead == NULL){*pphead = newnode;}else{SLTNode* ptail = *pphead;//如果ptail为空,那么在循环里面不可以对空指针解引用,所以会报错while (ptail->next){ptail = ptail->next;}//ptail指向的就是尾节点ptail->next = newnode;}}//头插void SLTPushFront(SLTNode** pphead, SLTDataType x){//空链表和非空链表都可以运行assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;}//尾删void SLTPopBack(SLTNode** pphead ){//这里和头插尾差不一样,因为尾删的话,链表不能为空,总不能删空吧,这不可能的,所以和头插尾插不同的是添加了个*pphead不能为空assert(pphead && *pphead);//链表只有一个节点if ((*pphead)->next == NULL)//这里给*pphead加了个括号,因为有符号的优先级,->的优先级高于*号{free(*pphead);*pphead = NULL;}else{//链表有多个节点SLTNode* prev = *pphead;SLTNode* ptail = *pphead;while (ptail->next){prev = ptail;ptail = ptail->next;}free(ptail);ptail = NULL;prev->next = NULL;}}//头删void SLTPopFront(SLTNode** pphead){//这里和尾删是一样的,解释在上面assert(pphead && *pphead);//在这里不能直接删除第一个节点,这样就不能根据原本第一个节点的next指针找到原本第二个节点//在头删方法中,只有一个节点和多个节点如下方法都可以实现SLTNode* next = (*pphead)->next;//这里也是->的优先级大于*号free(*pphead);*pphead = next;}//查找SLTNode* SLTFind(SLTNode* phead, SLTDataType x){SLTNode* pcur = phead;while (pcur){if (pcur->data == x){return pcur;}else{pcur = pcur->next;}}return NULL;}//在指定位置之前插入数据void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x){ assert(pphead && pos);//当pos为首节点的时候,会出现对空指针解引用的操作导致下面代码报错//若pos直接等于*pphead的时候则为头插,那么直接调用头插函数if (pos == *pphead){SLTPushFront(pphead, x);}else{assert(pphead && *pphead);assert(pos);SLTNode* newnode = SLTBuyNode(x);SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}newnode->next = pos;prev->next = newnode;}}//在指定位置之后插入数据void SLTInsertAfter(SLTNode* pos, SLTDataType x)//为啥没有头结点???{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;}//删除pos节点void SLTErase(SLTNode** pphead, SLTNode* pos){assert(pphead && *pphead);assert(pos);//pos是头结点,那么可以直接调用头删代码if (pos == *pphead){SLTPopFront(pphead);//测试过只能是pphead不能是*pphead}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}}//删除pos之后的节点void SLTEraseAfter(SLTNode* pos){assert(pos&&pos->next);//这里注意pos的next也不能为空,不然怎么删除SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;//注意不能这样写:pos->next=pos->next->next//free(pos)//pos->next=NULL;因为这样写就是把pos后的节点的下一个节点也释放掉了}//顺序表的销毁void SListDestroy(SLTNode**pphead){assert(pphead && *pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}//pcur为空*pphead = NULL;}test.c
#include\"SList.h\"void test(){//手动构造一个链表SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));node1->data = 1;node2->data = 2;node3->data = 3;node4->data = 4;node1->next = node2;node2->next = node3;node3->next = node4;node4->next = NULL;SLTNode* plist = node1;SLTPrint(plist);}void test01(){SLTNode* plist = NULL;SLTPushBack(&plist, 1);SLTPushBack(&plist, 2);SLTPushBack(&plist, 3);SLTPushBack(&plist, 4);SLTPrint(plist);//SLTPushFront(&plist, 1);//SLTPushFront(&plist, 2);//SLTPushFront(&plist, 3);//SLTPushFront(&plist, 4);//SLTPrint(plist);//SLTPopBack(&plist);//SLTPrint(plist);//SLTPopBack(&plist);//SLTPrint(plist);//SLTPopBack(&plist);//SLTPrint(plist);//SLTPopBack(&plist);//SLTPrint(plist);////SLTPopFront(&plist);//SLTPrint(plist);//SLTPopFront(&plist);//SLTPrint(plist);//SLTPopFront(&plist);//SLTPrint(plist);//SLTPopFront(&plist);//SLTPrint(plist);//SLTPopFront(&plist);//SLTPrint(plist);SLTNode* find = SLTFind(plist, 4);//if (find == NULL)//{//printf(\"未找到!\\n\");//}//else//{//printf(\"找到了!\\n\");//}//SLTInsert(&plist, find, 88);//1 88 2 3 4//SLTInsertAfter(find, 88);//1 2 88 3 4//SLTErase(&plist, find);//SLTEraseAfter(find);//1 3 4SListDestroy(&plist);SLTPrint(plist);}struct ListNode {int val;//datastruct ListNode* next;};typedef struct ListNode ListNode;struct ListNode* removeElements(struct ListNode* head, int val) {ListNode* newHead, * newTail;newHead = newTail = NULL;ListNode* pcur = head;while (pcur){//找值不为val的结点尾插到新链表中if (pcur->val != val){//尾插if (newHead == NULL){//链表为空newHead = newTail = pcur;}else {//链表不为空newTail->next = pcur;newTail = newTail->next;}}pcur = pcur->next;}return newHead;}void test02(){ListNode* node1 = (ListNode*)malloc(sizeof(ListNode));ListNode* node2 = (ListNode*)malloc(sizeof(ListNode));ListNode* node3 = (ListNode*)malloc(sizeof(ListNode));ListNode* node4 = (ListNode*)malloc(sizeof(ListNode));ListNode* node5 = (ListNode*)malloc(sizeof(ListNode));ListNode* node6 = (ListNode*)malloc(sizeof(ListNode));ListNode* node7 = (ListNode*)malloc(sizeof(ListNode));node1->val = 1;node2->val = 2;node3->val = 6;node4->val = 3;node5->val = 4;node6->val = 5;node7->val = 6;node1->next = node2;node2->next = node3;node3->next = node4;node4->next = node5;node5->next = node6;node6->next = node7;node7->next = NULL;ListNode* plist = node1;removeElements(plist, 6);}int main(){//test();//test01();test02();return 0;}双链表源码
List.h
#pragma once#include#include#include#includetypedef int LTDatatype;//定义双向链表(结点)结构typedef struct ListNode {LTDatatype data;struct ListNode* next;struct ListNode* prev;}LTNode;//初始化LTNode* LTInit();//void LTDesTroy(LTNode** pphead);//接口一致性,传一级,在函数调用结束后需要手动将实参置为NULLvoid LTDesTroy(LTNode* phead);//void LTInit(LTNode** pphead);void LTPrint(LTNode* phead);bool LTEmpty(LTNode* phead);//尾插//phead节点不会发生改变,参数就为一级//phead节点发生改变,参数就为二级void LTPushBack(LTNode* phead, LTDatatype x);void LTPushFront(LTNode* phead, LTDatatype x);//尾删void LTPopBack(LTNode* phead);void LTPopFront(LTNode* phead);//在pos位置之后插⼊数据----pos位置之前插入代码基本是一样的(双向的)--课下可以实现以下在pos之前插入void LTInsert(LTNode* pos, LTDatatype x);void LTErase(LTNode* pos);LTNode* LTFind(LTNode* phead, LTDatatype x);List.c
#include\"List.h\"LTNode* buyNode(LTDatatype x){LTNode* node = (LTNode*)malloc(sizeof(LTNode));node->data = x;node->next = node->prev = node;return node;}LTNode* LTInit(){//创建头结点//LTNode* phead = (LTNode*)malloc(sizeof(LTNode));//phead->data = -1;//phead->next = phead->prev = phead;LTNode* phead = buyNode(-1);return phead;}//void LTInit(LTNode** pphead)//{//assert(pphead);//*pphead = (LTNode*)malloc(sizeof(LTNode));//(*pphead)->data = -1;//(*pphead)->next = (*pphead)->prev = *pphead;//}//void LTDesTroy(LTNode** pphead)//{//LTNode* pcur = (*pphead)->next;//while (pcur != *pphead)//{//LTNode* next = pcur->next;//free(pcur);//pcur = next;//}//free(*pphead);//*pphead = NULL;//}void LTDesTroy(LTNode* phead){LTNode* pcur = phead->next;while (pcur != phead){LTNode* next = pcur->next;free(pcur);pcur = next;}free(phead);phead = NULL;}void LTPushBack(LTNode* phead, LTDatatype x){assert(phead);LTNode* newnode = buyNode(x);//phead phead->prev newnodenewnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;}void LTPushFront(LTNode* phead, LTDatatype x){assert(phead);LTNode* newnode = buyNode(x);//phead newnode phead->nextnewnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;}void LTPrint(LTNode* phead){LTNode* pcur = phead->next;while (pcur != phead){printf(\"%d -> \", pcur->data);pcur = pcur->next;}printf(\"\\n\");}bool LTEmpty(LTNode* phead){assert(phead);return phead->next == phead;}//尾删void LTPopBack(LTNode* phead){assert(!LTEmpty(phead));LTNode* del = phead->prev;//phead del->prev deldel->prev->next = phead;phead->prev = del->prev;free(del);del = NULL;}void LTPopFront(LTNode* phead){assert(!LTEmpty(phead));LTNode* del = phead->next;//phead del del->nextdel->next->prev = phead;phead->next = del->next;free(del);del = NULL;}LTNode* LTFind(LTNode* phead, LTDatatype x){LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;}//在pos位置之后插⼊数据void LTInsert(LTNode* pos, LTDatatype x){assert(pos);LTNode* newnode = buyNode(x);//pos newnode pos->nextnewnode->next = pos->next;newnode->prev = pos;pos->next->prev = newnode;pos->next = newnode;}void LTErase(LTNode* pos){assert(pos);//pos->prev pos pos->nextpos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);pos = NULL;}test.c
#include\"List.h\"void test(){//LTNode* plist = NULL;//LTInit(&plist);LTNode* plist = LTInit();LTPushBack(plist, 1);LTPushBack(plist, 2);LTPushBack(plist, 3);LTPushBack(plist, 4);//LTPushFront(plist, 1);//LTPushFront(plist, 2);//LTPushFront(plist, 3);//LTPushFront(plist, 4);LTPrint(plist);//4 3 2 1////LTPopBack(plist);//LTPrint(plist);//LTPopBack(plist);//LTPrint(plist);//LTPopBack(plist);//LTPrint(plist);//LTPopBack(plist);//LTPrint(plist);////LTPopFront(plist);//LTPrint(plist);//LTPopFront(plist);//LTPrint(plist);//LTPopFront(plist);//LTPrint(plist);//LTPopFront(plist);//LTPrint(plist);//LTPopFront(plist);//LTPrint(plist);//LTNode* find = LTFind(plist, 3);//if (find == NULL)//{//printf(\"ûҵ\\n\");//}//else {//printf(\"ҵˣ\\n\");//}//LTInsert(find, 99);//LTErase(find);//LTPrint(plist);LTDesTroy(plist);plist = NULL;}int main(){test();return 0;}总结
链表作为数据结构中的重要线性结构,其灵活的存储方式和高效的插入删除操作使其在众多场景中不可或缺。本文从链表的基本概念入手,详细解析了链表的分类方式,通过手动实现单链表的各项核心操作,深入剖析了指针操作的细节与边界条件的处理,尤其对二级指针的使用场景和原理进行了重点说明。
在此基础上,通过对比顺序表,凸显了链表在头部操作、空间利用等方面的优势,并结合 8 道经典 OJ 题,展示了链表在实际问题中的应用技巧,如快慢指针、新链表构建、环形链表特性利用等。最后提供的单链表和双链表完整源码,为实践练习提供了直接参考。
掌握链表不仅是理解更复杂数据结构(如哈希表、树、图)的基础,其指针操作逻辑也能显著提升对内存管理和程序设计的理解。希望本文能帮助读者扎实掌握链表知识,为后续数据结构学习和算法提升奠定坚实基础。

