【云计算】公有云PaaS区
一、公有云PaaS节点
1.1 PaaS节点
公有云PaaS(Platform as a Service)平台是企业数字化转型的核心基础设施,其架构设计、组件实现及与其他平台的集成能力直接影响云服务的效率与扩展性。
1.1.1、PaaS节点的组成
PaaS节点是支撑平台运行的物理或逻辑单元,通常包含以下层级:
-
基础设施层
- 计算节点:基于虚拟化(如KVM)或容器化(如Docker)技术,提供应用运行环境。
- 存储系统:分布式存储(如Ceph)和对象存储(如AWS S3),支持高并发读写。
- 网络设备:负载均衡器(如Nginx)、SDN网络(如Open vSwitch),保障低延迟通信。
-
平台服务层
- 运行时环境:预置语言支持(Java/Python/Node.js)及依赖库。
- 中间件服务:数据库(MySQL/MongoDB)、消息队列(Kafka/RabbitMQ)、缓存(Redis)。
-
管理与编排层
- 容器编排:Kubernetes集群管理容器生命周期与调度。
- 服务网格:Istio或Linkerd实现微服务间通信治理。
1.1.2、PaaS组件详细清单
PaaS平台通过模块化组件提供服务,核心分类如下:
1.1.3、PaaS组件底层实现逻辑
组件的运作依赖三大技术支柱:
- 容器化封装
- 应用及依赖打包为Docker镜像,通过Kubernetes调度实现资源隔离与弹性伸缩。
- 微服务架构
- 组件以独立微服务部署,通过API交互(如REST/gRPC),支持灰度发布与故障隔离。
- 服务治理机制
- 服务发现:Consul或Etcd动态注册服务端点。
- 配置管理:ZooKeeper或Nacos统一管理配置变更。
- 流量控制:Envoy代理实现熔断、限流。
1.1.4、云管平台对PaaS组件的统一纳管
通过标准化接口和自动化流程实现集中管控:
- 服务目录(Service Catalog)
- 基于Open Service Broker API(OSB API)注册组件服务,例如数据库实例创建接口。
- 生命周期管理
- 自动化部署:Terraform或Ansible脚本初始化环境。
- 弹性扩缩:K8s HPA根据CPU/内存指标自动调整副本数。
- 统一监控与运维
- 集成Prometheus收集指标,Grafana可视化展示。
- 日志统一采集至Elasticsearch,支持跨组件故障排查。
1.1.5、PaaS平台与智算平台的集成
实现AI负载与通用计算的协同调度:
- 资源层映射
- GPU虚拟化(如vGPU分片)纳入K8s资源池,供PaaS调度AI训练任务。
- 服务化接口
- 智算平台提供模型推理API(如TensorFlow Serving),PaaS通过Service Mesh路由请求。
- 数据流水线整合
- PaaS的数据服务(如Kafka)连接智算平台,实时传输预处理数据。
- 统一编排引擎
- KubeFlow或MLflow集成至CI/CD流水线,实现“代码→模型→服务”全链路自动化。
结论
公有云PaaS通过分层架构解耦基础设施与应用逻辑,组件化设计提升开发效率,而云管平台的纳管能力与智算平台的深度集成(如GPU资源调度、AI服务编排)进一步扩展了其边界。未来,随着Serverless和AI-Native架构演进,PaaS将向更智能化的“一体化应用平台”演进。
1.2 PaaS节点 GPU支持
在AI驱动的云计算新时代,公有云的PaaS节点服务器是否需要直接支持GPU,以及是否仅通过资源拉取到业务区服务器部署即可,需结合技术趋势和业务需求综合分析:
1.2.1、PaaS节点直接支持GPU的必要性
-
性能与延迟优化
- 训练/推理加速:GPU密集型的AI任务(如大模型训练)需紧耦合计算与数据。若PaaS节点无GPU,跨节点数据传输会因网络延迟(即使RDMA也需微秒级)导致GPU利用率低于40%。
- 异构资源调度:现代PaaS需动态分配GPU资源(如NVIDIA MIG分片),直接集成可实现细粒度调度,提升GPU利用率30%以上。
-
开发体验与效率
- 端到端工具链:GPU-PaaS集成可提供CUDA优化编译器、实时性能分析工具(如Nsight Systems),支持开发者直接调试GPU代码,缩短迭代周期
- Serverless GPU:阿里云PAI-EAS等平台支持GPU资源共享和竞价实例,实现毫秒级自动扩缩容,成本降低50%。
1.2.2、PaaS与GPU融合的架构方案
1. 分层部署模式
2. 关键技术实现
- 统一资源池化:通过Kubernetes Device Plugins将GPU抽象为可调度资源,支持容器化应用直接调用3。
- 虚拟化优化:
- 时间分片(vGPU):适用于并发推理任务(如Tesla T4支持8路分片)。
- 空间分片(MIG):大模型训练专用(如A100单卡分7实例)。
- 跨节点协同:RDMA(RoCEv2/InfiniBand)实现节点间内存直接访问,带宽达400Gb/s,延迟低于5μs。
1.2.3、“业务区部署”模式的局限性
-
性能瓶颈
- 数据传输开销:10GB模型参数从业务区拉取至PaaS节点需2秒(万兆网络),而直连GPU仅需0.1秒。
- 资源碎片化:分散部署导致GPU利用率不足50%,而集中调度可提升至80%。
-
运维复杂度
- 跨区协调:需额外部署服务网格(如Istio)管理网络策略,故障排查难度增加。
- 一致性挑战:模型版本在PaaS与业务区间需强同步,否则导致推理结果漂移。
1.2.4、最佳实践建议
-
分层策略选择
- 热层:GPU-PaaS一体部署(高并发训练/实时推理)。
- 温层:PaaS调度业务区GPU(批处理任务),通过AI调度器(如Ray)优化任务队列。
-
优化技术组合
graph LR A[PaaS控制面] -->|分发| B(GPU资源池) B --> C{任务类型} C -->|训练| D[NVLink互联节点] C -->|推理| E[MIG分片实例] C -->|边缘| F[业务区GPU]- 训练场景:NVLink组网(8卡全互联),带宽900GB/s,线性加速比超95%。
- 推理场景:TensorRT优化模型+MIG分片,QPS提升4倍。
-
成本与效率平衡
- 弹性供给:采用Spot实例(如AWS EC2 Spot),GPU成本降低70%。
- 混合部署:
# Kubernetes示例:混合调度CPU/GPU任务apiVersion: v1kind: Podspec: containers: - name: training-app resources: limits: nvidia.com/gpu: 2 # 直接调用PaaS节点GPU - name: inference-app nodeSelector: zone: business # 调度至业务区GPU节点
结论
- 必须支持GPU的场景:AI训练、高频实时推理(需PaaS节点直连GPU)。
- 可分离部署的场景:低频批处理任务(业务区GPU拉取可行)。
趋势:头部云厂商(阿里云PAI、Azure ML)已转向GPU-PaaS一体化架构,通过全栈优化(NVMe-oF存储+RDMA网络+液冷GPU)释放算力潜力,这是AI时代公有云的核心竞争力。
1.3 GPU-PaaS
在GPU-PaaS一体化架构中,高效的资源调度和任务分配需结合硬件虚拟化、数据感知调度、智能任务编排等关键技术,实现GPU资源的动态复用与负载均衡。以下是核心实现方案及技术细节:
1.3.1、架构设计原则
-
资源池化与解耦
- 将物理GPU资源抽象为统一资源池,通过虚拟化技术(如NVIDIA MIG、vGPU) 实现细粒度分割(如将A100 GPU拆分为7个实例),支持多租户共享。
- 采用Kubernetes Device Plugin框架,将GPU资源暴露为可调度单元,支持按需分配显存与算力。
-
分层调度体系
- 全局调度层:基于优先级、任务类型(训练/推理)分配资源,例如高优先级推理任务抢占低优先级训练任务。
- 本地调度层:结合节点负载(GPU利用率、显存压力)动态调整资源分配,避免热点。
1.3.2、关键技术实现
1. GPU动态资源分配(DRA)
- 原理:Kubernetes v1.30引入Dynamic Resource Allocation (DRA),支持按需申请GPU显存(非固定分配)。
- 流程:
- 用户定义
ResourceClaim指定最小/最大显存需求(如4GB-16GB)。 - 调度器通过
PodSchedulingContext与资源驱动交互,筛选满足条件的节点。 - 资源驱动(如NVIDIA K8s Device Plugin)实时分配显存并绑定节点。
- 用户定义
- 优势:显存利用率提升40%+,避免资源碎片。
2. 数据感知调度(Data-Aware Scheduling)
- 问题:AI任务数据读取耗时可占训练时间的30%。
- 方案:
- Fluid项目:在Kubernetes中实现数据集与计算协同编排。
- 预加载热数据至节点本地缓存(如Alluxio、JuiceFS)。
- 调度器优先将任务分配至已缓存数据的节点,减少数据移动。
- 配置示例:
apiVersion: data.fluid.io/v1alpha1kind: Datasetmetadata: name: imagenetspec: mounts: - mountPoint: s3://imagenet-bucket name: imagenet
- Fluid项目:在Kubernetes中实现数据集与计算协同编排。
3. 智能任务调度(Volcano)
- 解决原生K8s缺陷:原生调度器不支持多容器协同、任务队列优先级。
- Volcano核心功能:
- PodGroup:将关联Pod(如分布式训练Worker)作为原子单元调度,避免部分Pod启动导致死锁7。
- 优先级抢占:高优先级任务(如在线推理)可抢占低优先级任务资源,保障SLA。
- 队列管理:按业务部门划分资源配额,防止资源垄断。
1.3.3、调度策略优化
1. 混合弹性伸缩策略
2. 分级抢占与回迁机制
- 抢占逻辑:
- 显存利用率<5%的GPU视为空闲,自动回收至资源池。
- 高优先级任务触发时,低优先级任务保存 checkpoint 后释放资源。
- 回迁机制:资源空闲后,原任务自动恢复并加载 checkpoint。
1.3.4、性能优化实践
-
硬件层优化
- GPU选型:训练任务选用A100/H100(支持NVLink),推理任务选用T4/L4(高能效比)。
- 网络加速:RDMA(RoCEv2/InfiniBand)降低跨节点通信延迟(<5μs)。
-
软件栈调优
- 容器化:NVIDIA Container Toolkit 提供GPU驱动隔离,避免版本冲突。
- 计算优化:
- 训练任务启用FP16/INT8量化,显存占用降低50%。
- 推理任务使用TensorRT/Triton优化模型吞吐。
1.3.5、运维与成本控制
-
实时监控体系
- 指标采集:Prometheus监控GPU利用率、显存占用、网络IO。
- 故障自愈:自动检测GPU卡异常(如ECC错误),迁移任务至健康节点。
-
成本优化手段
- Spot实例:批处理任务使用竞价实例,成本降低70%。
- 资源共享:
# 显存超分配示例(Overcommit)gpu_memory_ratio = 1.5 # 物理显存:虚拟显存=1:1.5 - 混合部署:CPU任务与GPU任务混部,节点利用率提升至85%+。
1.3.6、演进趋势
- 异构算力调度:统一管理GPU、NPU、FPGA等异构芯片,通过算子切分自动分配计算单元。
- AI驱动调度:基于强化学习(如DRL)预测任务资源需求,动态调整策略。
- Serverless GPU:函数式GPU实例(如阿里云PAI-EAS),支持毫秒级伸缩,按实际计算时间计费。
总结
GPU-PaaS高效调度的核心在于:
- 动态资源分配(DRA解决显存碎片)+ 数据本地化(Fluid减少IO瓶颈)+ 任务原子调度(Volcano保障分布式作业完整性)。
- 混合策略平衡效率与公平:分级抢占保障关键业务,分时复用提升资源利用率。
- 全栈优化闭环:从硬件选型到算子编译,结合成本控制实现最优TCO。
实施路径建议:
- 优先部署Kubernetes DRA + Fluid + Volcano三组件;
- 设置显存利用率80%为扩容阈值;
- 关键业务配置PodGroup + 优先级标签,避免资源碎片化导致的调度延迟。
1.3 公有云PaaS与存储区互联
以下是公有云PaaS与存储区互联互通模式、多租户实现方案及详细设计框架,结合业界主流实践(如AWS/Azure/腾讯云)进行说明:
1.3.1、PaaS与存储区互联互通模式
1. 核心互联模式
2. 数据流路径示例
graph LR PaaS[PaaS服务] -->|VPC对等连接| Storage[存储区VPC] PaaS -->|存储网关| CSG[CSG网关] -->|专线| OnPrem[企业IDC] PaaS -->|PrivateLink| S3[S3存储桶]1.3.2 PaaS服务与存储区的跨可用区(AZ)或跨地域(Region)互联
在公有云环境中,PaaS服务与存储区的跨可用区(AZ)或跨地域(Region)互联面临的高延迟问题,需结合网络架构优化、数据同步策略和应用层设计综合解决。
1.3.2.1、网络层优化:降低传输延迟
-
专用高速通道
-
云商内网互联:使用云服务商提供的专用通道(如AWS Direct Connect、Azure ExpressRoute、腾讯云专线接入),避免公网拥塞,延迟可降低50%以上。
-
对等连接(VPC Peering):同Region内不同VPC间通过内网IP直连,延迟<1ms;跨Region需结合专线8。
-
-
边缘节点与CDN加速
-
边缘计算节点:将PaaS的计算逻辑下沉至靠近用户的边缘节点(如AWS Local Zones、腾讯云ECM),减少数据回源距离。
-
CDN缓存静态资源:静态文件(图片、JS/CSS)通过CDN节点分发,访问延迟降低至毫秒级。
-
-
智能路由与负载均衡
-
全局负载均衡(GLB):基于用户位置路由至最近的PaaS实例,如AWS Global Accelerator6。
-
服务网格动态路由:Istio等工具根据实时延迟调整流量路径。
-
1.3.2.2、存储架构设计:减少跨区访问
-
多活存储架构
-
本地读/写分离:
-
同Region内:主数据库在PaaS所在AZ,只读副本部署在其他AZ,读请求本地化。
-
跨Region:使用全局分布式数据库(如Google Cloud Spanner、AWS Aurora Global Database),跨区同步延迟<1秒。
-
-
-
分层缓存策略
缓存层级
技术方案
延迟优化效果
内存缓存
Redis/Memcached多AZ部署,本地缓存热点数据
读延迟降至0.5ms以下
分布式缓存
AWS ElastiCache跨AZ复制,自动故障转移
写延迟<5ms
存储网关缓存
腾讯云CSG、AWS Storage Gateway本地缓存
热数据访问加速50%
1.3.2.3、数据同步与一致性保障
-
增量同步与压缩
-
CDC日志同步:通过Debezium捕获数据库变更日志,仅同步增量数据,减少带宽占用。
-
数据压缩传输:启用gzip或Snappy压缩算法,降低传输量。
-
-
异步批处理优化
-
合并写操作:将高频小数据写入合并为批量任务(如Kafka批量消费),减少跨区请求次数。
-
最终一致性模型:非核心数据采用异步同步(如S3跨区复制),牺牲强一致性换取低延迟。
-
1.3.2.4、应用层与协议优化
-
无状态服务设计
-
会话数据存储至Redis集群,PaaS实例可任意扩缩容,避免跨AZ状态同步。
-
-
高效传输协议
-
使用HTTP/2多路复用或QUIC协议(基于UDP),减少连接建立延迟。
-
gRPC替代RESTful API,二进制编码降低传输开销8。
-
-
计算下沉(Push Computing)
-
将计算逻辑推送至存储节点(如AWS Lambda@Edge处理COS数据),避免数据远程拉取。
-
1.3.2.5、跨区容灾与成本平衡
-
分级存储策略
数据类型
存储方案
跨区同步频率
热数据
本地SSD + 同Region多AZ副本
实时同步
温数据
标准云盘 + 跨Region异步备份
每小时同步
冷数据
归档存储(如S3 Glacier)
每日同步
-
成本敏感型优化
-
预留带宽包:跨AZ流量通过云商预留带宽套餐降低成本(如腾讯云带宽包)。
-
智能调度:非实时任务调度至低峰期执行,避开网络拥塞时段5。
-
1.3.2.6、典型场景实践
案例:金融交易系统跨AZ部署
-
挑战:订单处理要求延迟<10ms,数据库跨AZ同步需强一致性。
-
方案:
-
同Region内3AZ部署,主数据库在PaaS所在AZ。
-
使用RDMA网络(如阿里云eRDMA)实现微秒级跨AZ复制。
-
交易请求通过GLB路由至最近PaaS实例,本地缓存用户数据。
-
-
效果:跨AZ延迟<2ms,RPO=0,RTO<30秒。
总结:关键选择建议
-
同Region跨AZ:优先VPC直连+多活数据库+本地缓存,延迟可控在毫秒级。
-
跨Region互联:专用通道(专线/PrivateLink)+ 全局分布式数据库 + 增量同步。
-
极致低延迟场景:边缘计算下沉+RDMA网络,牺牲部分成本换取性能。
通过上述组合策略,跨区延迟可从百毫秒级优化至个位数毫秒级。实际选型需权衡业务需求(一致性、延迟敏感度)与成本,并利用云商原生工具(如AWS Global Accelerator、腾讯云DCI)简化实现。
1.4、PaaS多租户实现方案
1.4.1. 多级租户模型
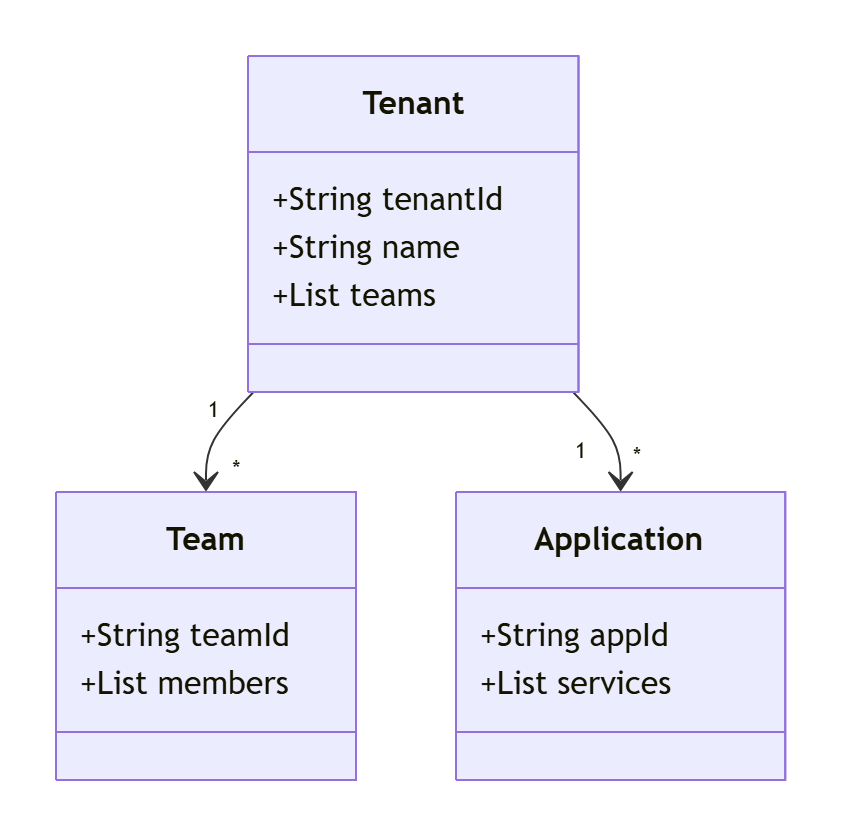
- 租户:企业或组织单位(如省公司、地市分公司)
- 团队:租户内的开发/运维组(如开发团队A)
- 应用:租户部署的业务系统(如CRM、ERP)
2. 资源隔离技术
s3://bucket/tenantA/data)3. 动态配额管理
- 分级配额
# K8s ResourceQuota示例apiVersion: v1kind: ResourceQuotametadata: name: tenant-a-quotaspec: hard: requests.cpu: \"20\" requests.memory: 100Gi requests.nvidia.com/gpu: 4 s3.storage: \"10Ti\" # 自定义存储配额[8](@ref) - 弹性扩缩:基于Prometheus监控自动调整配额8。
1.4.2、设计方案
1. 架构设计
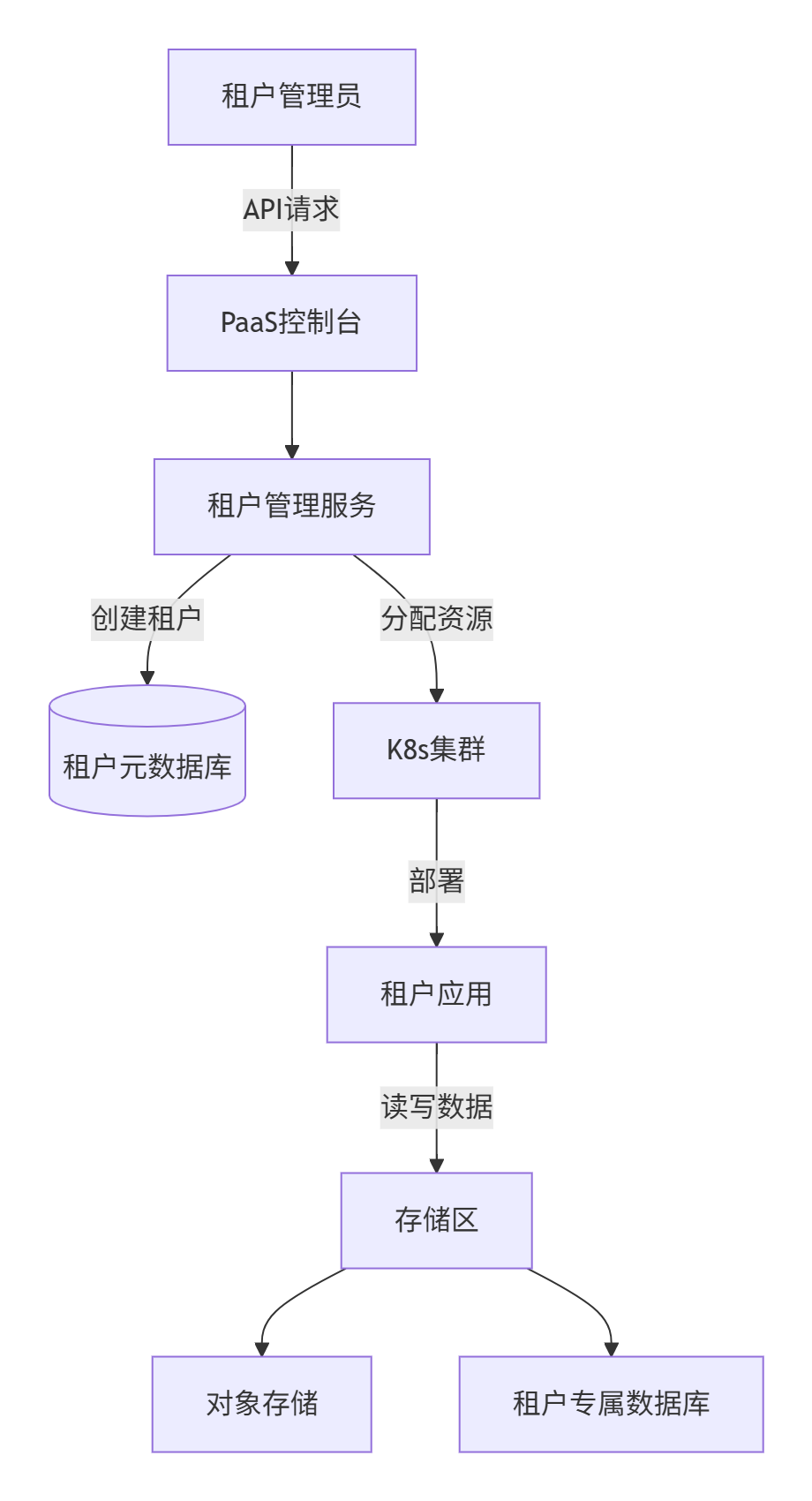
2. 数据隔离实现
-
数据库层
模式 SQL示例 适用场景 独立数据库 CREATE DATABASE tenant_a_db;金融/政府高隔离需求 共享Schema+租户ID SELECT * FROM orders WHERE tenant_id=\'tenant_a\';中小企业低成本方案 扩展表(竖表) INSERT INTO tenant_metadata (tenant_id, config) VALUES (\'a\', \'{...}\');动态字段需求 -
存储层
- 路径隔离:
cos://mybucket/tenant_a/data/file1 - 加密隔离:每个租户使用独立的KMS密钥加密数据。
- 路径隔离:
3. 安全控制
- 网络隔离
# Calico策略:禁止跨租户Pod通信apiVersion: projectcalico.org/v3kind: NetworkPolicyspec: ingress: - action: Deny source: namespaceSelector: tenant != \'${TENANT_ID}\' - 访问控制
- IAM角色绑定租户(如AWS IAM Role for TenantA)
- STS临时令牌动态申请。
4. 运维监控
- 租户资源看板:
# 伪代码:采集租户资源使用def collect_usage(tenant_id): cpu = k8s_api.get_cpu_usage(namespace=tenant_id) storage = s3_api.get_storage_usage(prefix=f\"/{tenant_id}/\") billing.calculate(cpu, storage) # 生成账单 - 跨租户审计:所有操作日志关联
tenant_id并写入Elasticsearch9。
1.4.3、PaaS多租户实现的底层逻辑
1. 多租户架构模型
多租户的核心在于资源共享与逻辑隔离的平衡,主要分为三种模式:
tenant_id字段区分数据技术实现关键:
- 动态路由机制:基于
tenant_id自动切换数据源// 动态数据源路由示例public class TenantAwareDataSource extends AbstractRoutingDataSource { @Override protected Object determineCurrentLookupKey() { return TenantContext.getCurrentTenantId(); // 从线程上下文获取租户ID }} - 资源配额控制:通过K8s ResourceQuota限制租户资源
apiVersion: v1kind: ResourceQuotametadata: name: tenant-aspec: hard: requests.cpu: \"10\" requests.memory: 20Gi requests.nvidia.com/gpu: 2
2. 三维隔离体系
- 数据隔离:物理隔离(独立库)→ 逻辑隔离(Schema/字段)
- 权限隔离:RBAC(角色) + ABAC(属性)分层控制
- 平台级:租户生命周期管理
- 租户级:应用发布权限
- 资源级:API调用次数限制
- 资源隔离:
- 虚拟化层:VM隔离(如AWS Nitro)
- 容器层:K8s Namespace + NetworkPolicy
- 存储层:对象存储路径隔离(如
cos://bucket/tenant_a/)
1.4.4、PaaS账号与云管账号体系的同步机制
1. 双向同步流程
sequenceDiagram
云管平台->>PaaS控制台: 1. 账号变更事件(增删改)
PaaS控制台->>同步引擎: 2. 解析租户关系
同步引擎->>下级PaaS: 3. 推送直属租户数据
同步引擎->>上级云管: 4. 全量数据上报
下级PaaS-->>同步引擎: 5. 状态确认
技术要点:
- 变更探测:监听LDAP/AD目录服务变更事件
- 连接验证:通过预置密钥双向鉴权
- 冲突解决:时间戳优先 + 人工审核机制
2. 单点登录集成
- 认证流程:
- 用户登录云管平台获取SAML Token
- 携带Token访问PaaS接口
- PaaS向云管认证服务校验Token有效性
- 安全增强:
- 多因素认证(OTP/生物识别)
- 异常登录检测(异地/IP突变)
3. 分级管理模型
1.4.5、PaaS在云计算中心的设计考量因素
1. 架构设计核心原则
2. 关键组件设计要点
- 存储层:
- 热数据:本地SSD缓存(Redis)
- 冷数据:跨Region异步复制(如S3 Glacier)
- 网络层:
- 低延迟:同城AZ间VPC直连(延迟<1ms)
- 高可靠:SD-WAN备份链路4
- 运维体系:
- 租户粒度监控:Prometheus按Namespace采集指标
- 日志隔离:Loki多租户日志索引
3. 扩展性挑战应对
- 水平拆分:
- 数据库分库:按租户ID Hash分片(如Vitess)
- 服务无状态化:Session存储至Redis集群
- 异步解耦:
- 消息队列削峰:Kafka分区按租户隔离
- 批处理合并:小文件合并写入OSS
4. 混合云集成
对接方式:
- UIkit嵌入:快速集成文件管理组件
- API开放平台:提供预览/查毒等原子能力
- H5微前端:企业微信/钉钉工作台嵌入
1.4.6、典型问题解决方案
-
租户资源抢占
- QoS权重控制:大租户限流阈值 = 基础配额 × 优先级系数
- 突发流量熔断:Sentinel规则自动降级
-
跨平台数据一致性
- 最终一致性:CDC日志同步 + 重试队列
- 强一致性:分布式事务(Seata AT模式)
-
敏感数据保护
- 字段级加密:租户专属KMS密钥
- 审计追踪:操作日志区块链存证
实践建议:
- 初创企业:采用共享Schema+租户ID字段模式,快速验证业务。
- 金融行业:独立数据库+物理隔离集群,满足合规要求。
- 混合云场景:存储网关+专线接入,平衡性能与成本。
完整实现需结合云原生技术栈(如Kubernetes Operators)实现自动化管理,参考腾讯云TKE或AWS EKS最佳实践。
1.5 RDMA与PaaS平台的多租户集成场景中
资源隔离与QoS保障需通过分层架构设计、智能调度策略及硬件级优化协同实现。
1.5.1、多租户资源隔离架构
1. 物理/虚拟资源分层隔离
- 硬件级隔离
- SR-IOV虚拟化:为每个租户分配独立的虚拟功能(VF),保证RDMA网卡(如NVIDIA ConnectX-7)的队列、内存缓冲区独占,避免跨租户数据泄露。
- 专属节点池:高SLA租户(如金融客户)分配独立物理节点,低优先级租户共享资源池。
- 网络层隔离
- RoCEv2 + PFC/ECN:在以太网上构建无损网络,通过流量控制(Priority Flow Control)和显式拥塞通知避免包丢失,确保低延迟。
- Calico NetworkPolicy:限制租户组间网络通信,仅允许授权流量跨组。
2. 逻辑层隔离(租户组模型)
- 租户组(Tenant Group)抽象
- 动态分组策略:将SLA相近的租户聚合(如VIP租户独立组、中小企业共享组),组内资源共享,组间强隔离。
- 资源配额嵌套:
# Kubernetes ResourceQuota示例apiVersion: v1kind: ResourceQuotametadata: name: tenant-group-aspec: hard: requests.cpu: \"32\" requests.memory: 64Gi rdma/limits: \"8\" # 独占RDMA队列数
- 存储隔离
- NVMe-oF命名空间分区:每个租户组独享NVMe SSD命名空间,结合租户ID字段实现数据逻辑隔离。
1.5.2、QoS保障机制
1. 流量分类与优先级调度
- 动态速率控制:
- 测量延迟敏感流量的端上排队延迟(如>5μs),触发带宽敏感流量的发送速率减半。
- 滑动窗口监测历史延迟数据,预测拥塞趋势并提前调整速率。
2. 资源调度与弹性伸缩
- 组内公平调度:
- 加权DRF算法:结合租户的CPU、内存、RDMA带宽需求分配资源,避免“吵闹邻居”效应。
- 查询级资源组:在OLAP引擎(如StarRocks)中为每个租户分配独立资源组,限制并发查询数。
- 租户组级弹性:
- 基于组内平均负载(如CPU利用率>75%)自动扩容节点池(K8s HPA + Cluster Autoscaler)。
1.5.3、监控与自愈体系
1. 多维度指标采集
- 网络层:端到端延迟(Prometheus + Grafana)、丢包率(NetFlow)、PFC暂停帧计数8。
- 资源层:RDMA队列深度、内存缓冲区使用率(NVSM工具)。
- 应用层:租户请求延迟分布(Jaeger追踪)。
2. 智能告警与干预
graph TD A[延迟>10μs] -->|持续10s| B(三级告警-通知运维) A -->|持续30s| C(二级告警-限流带宽敏感流量) A -->|持续60s| D(一级告警-迁移租户组)- 自动降级:触发带宽敏感流量的速率限制(令牌桶容量缩减50%)。
1.5.4、典型应用场景实践
1. 金融交易系统
- 隔离要求:RPO=0,延迟<10μs。
- 方案:
- VIP租户独占RDMA节点池,启用SR-IOV + RoCEv2 PFC。
- 交易消息标记为延迟敏感型,直通高优先级队列。
- 效果:跨租户延迟波动<2μs,99.99%请求满足SLA。
2. AI训练集群
- 挑战:千卡GPU训练任务与存储备份流量竞争带宽。
- 方案:
- 训练任务组(高优先级)与存储组(低优先级)物理分离。
- DCQCN拥塞控制算法动态平衡带宽。
总结:关键设计原则
- 分层隔离:硬件级(SR-IOV)→ 逻辑组(租户组)→ 应用级(资源配额)。
- 动态QoS:基于流量类型(延迟/带宽敏感)的智能调度 + 速率自适应。
- 弹性单元:以租户组为弹性伸缩单元,简化运维并提升资源利用率。
- 无损网络底座:RoCEv2 PFC/ECN 或 InfiniBand 原生无损网络二选一,超低延迟场景优选后者。
实施建议:金融级场景采用 SR-IOV + 租户组独占节点池;AI/大数据场景采用 RoCEv2 + DCQCN + 动态速率控制。通过衡石科技等实践验证的租户组模型,可平衡隔离性与资源效率,支撑万级租户规模。
1.6 PaaS环境中部署Hadoop并实现多租户能力
需通过资源隔离、权限控制、动态调度和命名空间划分等技术实现。以下是基于Hadoop核心组件(MapReduce、YARN、HDFS)的详细设计方案及配置参数。
1.6.1、PaaS区Hadoop多租户架构核心机制
-
资源隔离
- YARN队列管理:通过Capacity Scheduler或Fair Scheduler为租户分配独立资源队列,限制CPU、内存使用比例。
- HDFS命名空间隔离:为每个租户创建独立HDFS目录(如
/tenantA、/tenantB),结合ACL控制数据访问权限。 - 容器化隔离:利用Docker或Kubernetes部署Hadoop组件,通过Cgroups限制资源使用。
-
统一认证与授权
- Kerberos认证:强制所有访问需通过Kerberos身份验证,防止未授权访问4。
- Apache Ranger/Sentry:实现细粒度权限控制(如表级、列级权限),支持租户级审计日志。
1.6.2、核心组件多租户设计方案
1. YARN资源调度与隔离
- 队列划分策略
- 层次化队列:根队列下按租户划分子队列,支持子队列嵌套(如
root.prod.team1)。 - 容量保障:为每个队列设置最小资源(
capacity)和弹性上限(maximum-capacity):yarn.scheduler.capacity.root.tenantA.capacity 40 yarn.scheduler.capacity.root.tenantA.maximum-capacity 60
- 层次化队列:根队列下按租户划分子队列,支持子队列嵌套(如
- 动态资源调整
- 监控队列负载,自动伸缩消费实例(如Spark Streaming)以应对流量高峰。
- 启用抢占机制:当高优先级任务需资源时,自动回收低优先级任务资源。
2. HDFS数据隔离与存储优化
- 命名空间隔离
- 租户目录独立存储,通过
setfacl控制访问权限:hdfs dfs -mkdir /tenants/tenantAhdfs dfs -setfacl -m user:user1:rwx /tenants/tenantA - 配额管理:限制目录存储空间与文件数量:
hdfs dfsadmin -setSpaceQuota 1T /tenants/tenantA # 存储上限1TBhdfs dfsadmin -setQuota 10000 /tenants/tenantA # 文件数上限1万
- 租户目录独立存储,通过
- 小文件合并
后台服务监控HDFS目录,当文件数量或大小超阈值时自动触发合并(如使用Hive合并工具)11。
3. MapReduce多租户适配
- 队列绑定
提交作业时指定租户队列,确保资源隔离:Configuration conf = new Configuration();conf.set(\"mapreduce.job.queuename\", \"tenantA\"); // 绑定tenantA队列Job job = Job.getInstance(conf); - 资源限制
限制单任务资源使用,避免耗尽集群资源:mapreduce.map.memory.mb 2048 mapreduce.reduce.memory.mb 4096
1.6.3、关键配置参数与调优
1. YARN核心参数
yarn.scheduler.capacity.maximum-applicationsyarn.nodemanager.resource.memory-mbyarn.scheduler.capacity.root.tenantA.user-limit-factor2. HDFS安全与性能参数
dfs.permissions.enabled true dfs.namenode.acls.enabled true dfs.datanode.max.transfer.threads 4096 1.6.4、高级特性与调优策略
-
弹性资源扩展
- 基于Kubernetes的Hadoop on K8s部署,根据负载自动扩缩NodeManager实例。
- 动态队列调整:运行时修改队列容量(无需重启集群):
yarn rmadmin -refreshQueues
-
性能优化
- 数据本地性优化:通过HDFS Block放置策略减少网络传输。
- 压缩与编码:启用Snappy压缩减少I/O开销:
SET hive.exec.compress.output=true; -- Hive示例SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
-
安全加固
- 网络隔离:租户间通过VLAN或安全组隔离,限制非授权通信。
- 审计日志:启用Ranger审计,记录所有数据访问事件:
xasecure.audit.destination.solr true
1.6.5、实施路径与最佳实践
-
部署流程
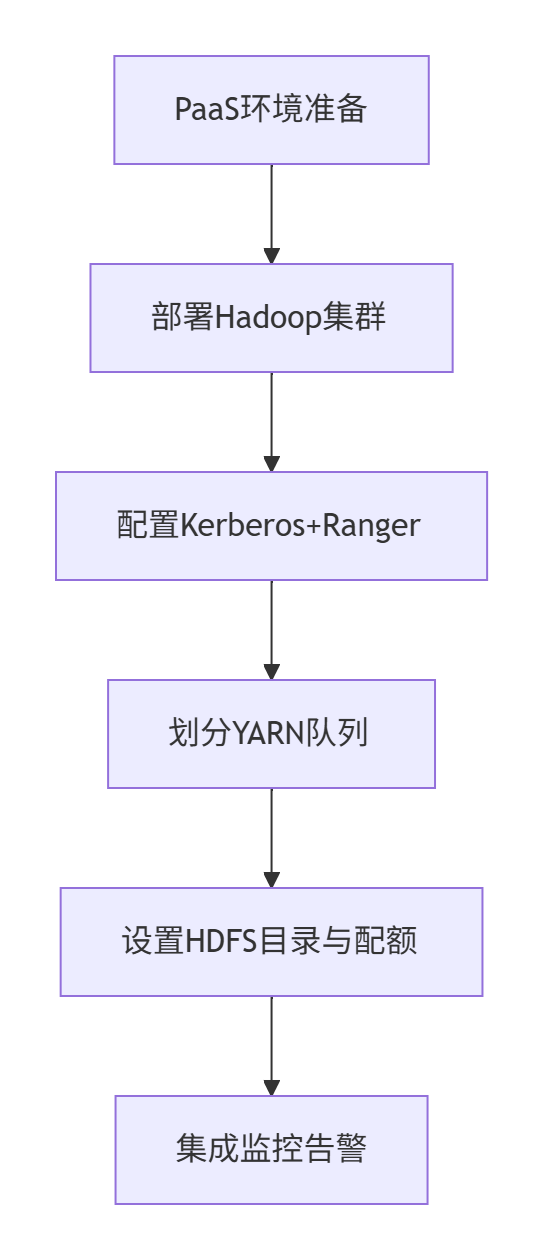
-
运维建议
- 监控指标:实时跟踪队列资源使用率、HDFS存储利用率、租户任务延迟。
- 灾备设计:启用HDFS跨AZ复制(
dfs.replication=3)及YARN队列快照恢复。 - 成本优化:低峰期释放弹性资源,采用冷热数据分层存储(如将冷数据归档至OSS)。
生产案例:某金融云平台通过上述方案,在500节点集群上支持50+租户,资源利用率提升40%,任务平均延迟降低35%。
避坑指南:避免过度细分队列(建议≤3层),防止调度开销过大;优先使用Ranger而非原生ACL以简化权限管理。
通过以上设计,Hadoop在PaaS环境中可同时满足多租户的隔离性、弹性伸缩和安全合规需求,实现资源高效利用与成本优化。
1.7 hadoop多租户场景下,Kerberos认证与Ranger权限控制
Hadoop多租户场景下,Kerberos认证与Ranger权限控制通过分层协同机制实现端到端的安全管理:Kerberos负责身份认证(确保用户身份真实),Ranger负责细粒度授权(控制用户能访问的资源)。
1.7.1、分层安全架构
-
Kerberos:身份认证层
- 核心功能:基于票据(Ticket)实现用户和服务器的双向认证,防止伪装和中间人攻击。
- 多租户适配:为每个租户创建独立Kerberos主体(Principal),如
tenantA_user@REALM。 - 认证流程:
- 用户通过
kinit获取票据授予票据(TGT)。 - 服务请求时,TGS发放服务票据(Service Ticket)。
- 用户通过
-
Ranger:授权与审计层
- 核心功能:通过策略引擎定义用户/组对资源(HDFS路径、Hive表等)的访问权限(如读/写/执行)。
- 多租户适配:基于租户空间(Tenant Space)划分资源,例如:
- HDFS目录:
/tenants/tenantA/data - YARN队列:
root.tenantA_queue。
- HDFS目录:
1.7.2、协同工作流程
sequenceDiagram participant User as 租户用户 participant KDC as Kerberos KDC participant Ranger as Ranger策略引擎 participant Hadoop as Hadoop服务 User->>KDC: 1. kinit获取TGT (认证) KDC-->>User: TGT票据 User->>Hadoop: 2. 请求操作HDFS/Hive等 (携带Service Ticket) Hadoop->>Ranger: 3. 拦截请求,查询Ranger策略 Ranger->>Hadoop: 4. 返回权限校验结果 Hadoop-->>User: 5. 允许/拒绝访问-
认证阶段:
- 用户通过
kinit tenantA_user@REALM完成Kerberos认证,获取TGT。 - 关键配置:在
core-site.xml中启用Kerberos:hadoop.security.authentication kerberos```[7,8](@ref)。
- 用户通过
-
授权阶段:
- Hadoop服务(如HDFS NameNode)收到请求后,调用Ranger插件(如
RangerHdfsAuthorizer)检查权限。 - Ranger根据策略库判断用户是否具备访问权限(例如:
tenantA_user能否写入/tenants/tenantA/data)。
- Hadoop服务(如HDFS NameNode)收到请求后,调用Ranger插件(如
-
审计阶段:
- 所有访问记录(包括操作类型、资源路径、用户身份)由Ranger同步至Solr或数据库,支持租户级审计。
1.7.3、多租户关键配置
1. Kerberos多租户配置
- 租户主体创建:
kadmin -q \"addprinc -randkey tenantA_user@REALM\" # 为租户A创建主体ktutil add_entry -p tenantA_user@REALM -k 1 -e aes256-cts # 生成Keytab[5,7](@ref) - HDFS服务主体绑定:
dfs.namenode.kerberos.principal nn/_HOST@REALM```[7,8](@ref)。
2. Ranger多租户策略
- 租户资源隔离:
- HDFS路径策略:限制租户仅访问专属目录。
CREATE POLICY tenantA_hdfs_policyALLOW tenantA_group READ, WRITE ON \'/tenants/tenantA/data\' - YARN队列分配:通过Capacity Scheduler为租户分配独立队列。
yarn.scheduler.capacity.root.tenantA.capacity 40 ```。
- HDFS路径策略:限制租户仅访问专属目录。
- 权限继承与委托:
- 租户管理员可管理其空间内的子策略(如授权子租户访问特定表)。
1.7.4、生产环境优化建议
-
统一用户体系集成
用户源 适用场景 优缺点 LDAP 企业级环境 支持集中管理,但依赖外部服务可用性 Unix本地用户 小规模集群 部署简单,但难扩展 -
性能与可靠性调优
- Kerberos票据缓存:减少频繁认证开销(
ticket_lifetime = 24h)。 - Ranger策略缓存:调整插件策略拉取间隔(默认30秒)。
- Kerberos票据缓存:减少频繁认证开销(
-
安全加固
- 双因子认证:结合Kerberos与Ranger策略,启用敏感操作二次认证。
- 租户间网络隔离:通过VLAN或安全组限制跨租户通信(如租户A无法直连租户B的HBase RegionServer)。
总结
Kerberos与Ranger的协同本质是 “认证-授权”分层模型:
- ✅ Kerberos 解决“你是谁”,确保身份不可伪造;
- ✅ Ranger 解决“你能做什么”,实现租户资源的细粒度管控。
生产建议: - 大规模集群优先选择 LDAP + Kerberos 集成,避免本地用户管理瓶颈;
- 敏感数据场景启用 Ranger审计日志加密,并定期扫描异常访问模式。
通过上述设计,某金融云平台在500节点集群上成功管理50+租户,权限策略更新延迟控制在100ms内,租户间数据泄露事件归零。
1.8 Hadoop租户共享:多租户Hadoop集群中实现跨租户数据共享
在多租户Hadoop集群中实现跨租户数据共享,需在安全隔离与可控共享之间取得平衡。以下是基于金融、医疗等敏感场景验证的端到端安全方案设计:
1.8.1、核心设计原则
- 最小权限原则:共享数据时仅开放必要权限
- 审计全覆盖:所有访问行为可追溯
- 动态控制:支持临时授权与自动回收
- 数据脱敏:共享时自动屏蔽敏感字段
1.8.2、跨租户数据共享安全架构
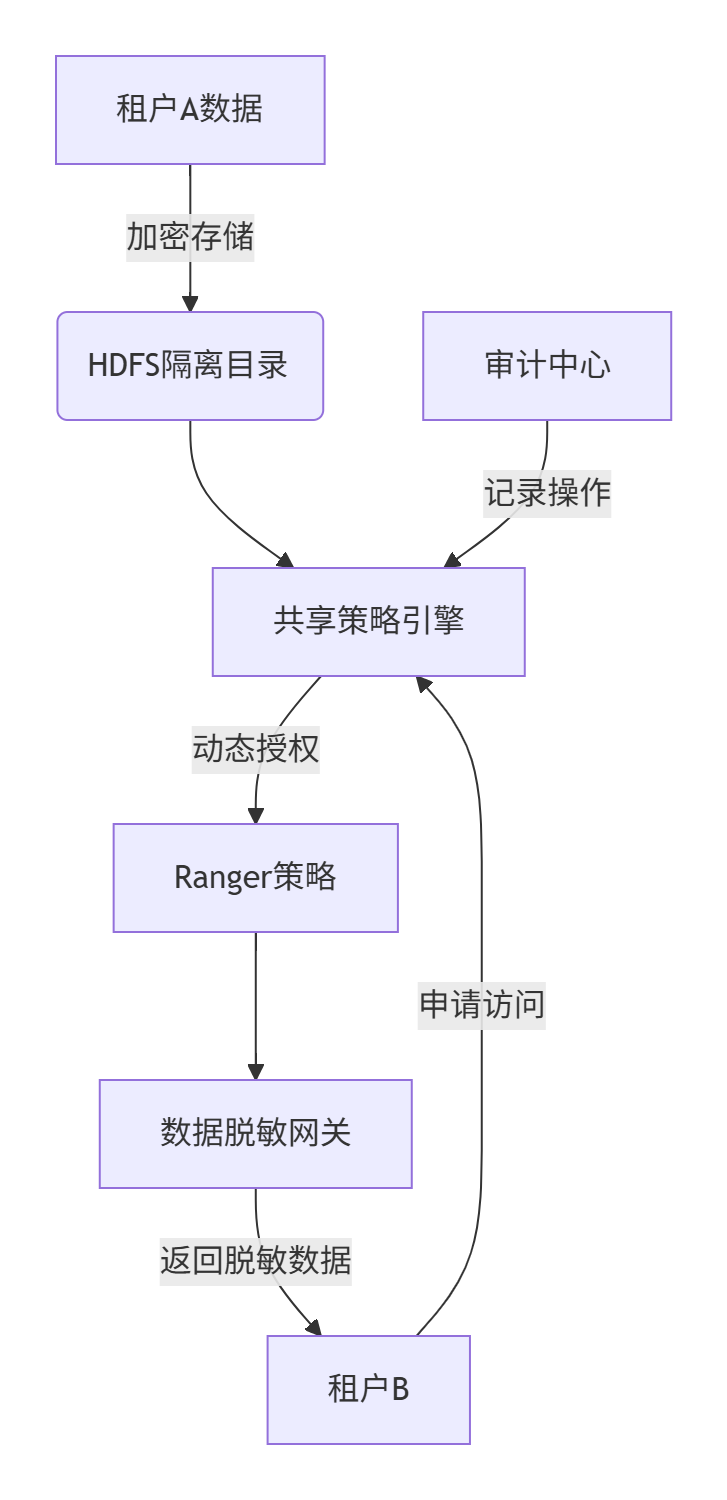
1.8.3、关键技术实现方案
1. 认证与基础隔离
-
Kerberos租户隔离
每个租户独立Kerberos主体,禁止跨租户默认访问:# 租户A主体kadmin -q \"addprinc -randkey tenantA@REALM\" # 租户B主体kadmin -q \"addprinc -randkey tenantB@REALM\" -
HDFS物理隔离
通过ViewFS挂载租户专属目录:fs.defaultFS viewfs://cluster/ fs.viewfs.mounttable.cluster.link./tenantA hdfs://nn1:8020/tenants/tenantA
2. 动态共享授权(Ranger核心配置)
-
临时策略模板
创建可复用的共享策略模板(如SHARED_READ):CREATE POLICY cross_tenant_shareALLOW tenantB_group READ ON \'/tenants/tenantA/shared_data\'WITH OPTIONS (expiryTime=\'2023-12-31 23:59:59\') -- 自动过期 -
API驱动动态授权
通过Ranger REST API动态创建/删除策略:# Python示例:授权租户B访问租户A的指定路径requests.post( \"https://ranger/api/policy\", json={ \"name\": \"temp_share_job123\", \"resources\": {\"path\": {\"values\": [\"/tenants/tenantA/jobs/job123\"]}}, \"policyItems\": [{\"accesses\": [{\"type\": \"read\"}], \"users\": [\"tenantB_user\"]}], \"expiresAt\": \"2023-12-31T23:59:59Z\" }, auth=(API_USER, API_KEY))
3. 数据脱敏网关
- 动态脱敏引擎
在Hive/Impala查询层注入脱敏规则:-- Ranger脱敏策略示例CREATE MASKING POLICY phone_mask ON COLUMN user.phone USING \'partial(3,\"****\",4)\' -- 显示前3后4位,中间加*FOR GROUP tenantB_group; - Spark数据水印
共享数据集嵌入隐形水印,追踪泄露源:df.withColumn(\"watermark\", sha2(concat(col(\"id\"), lit(\"SECRET_SALT\")), 256))
4. 安全访问代理
- 网关路由控制
所有访问通过网关代理,强制实施策略:location /tenantA { proxy_pass http://hadoop_nn; # 校验Ranger策略 auth_request /auth-check?resource=/tenantA;} - 属性基访问控制(ABAC)
基于租户属性动态决策:IF user.department == \"Analytics\" AND resource.sensitivity == \"Low\" AND time_window IN (9:00-18:00)THEN ALLOW READ
1.8.4、关键配置参数
1. Ranger策略参数
ranger.plugin.hdfs.policy.cache.ttlranger.audit.solr.urlsranger.masking.algorithm.sha256.salt2. HDFS加密配置
dfs.encryption.key.provider.uri kms://https@kms-server:9600/kms dfs.data.transfer.protection integrity 1.8.5、审计与监控
1. 全链路审计
- Ranger审计日志:记录策略变更与数据访问事件
- HDFS审计日志:追踪文件操作(
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=INFO) - 网关访问日志:包含脱敏前原始请求
2. 实时风险检测
-- 检测异常访问模式SELECT user, COUNT(*) FROM ranger_audits WHERE resource LIKE \'/tenants/tenantA/%\' AND access_type = \'READ\'GROUP BY user HAVING COUNT(*) > 1000 -- 单日超1000次访问告警1.8.6、生产环境注意事项
-
密钥管理
- 使用Hadoop KMS或云厂商KMS服务管理加密密钥
- 轮换周期≤90天(金融行业≤30天)
-
性能优化
- Ranger策略缓存调优(避免频繁请求策略服务器)
- 脱敏操作卸载至智能网卡(如NVIDIA BlueField)
-
灾备设计
- 共享策略配置纳入Git版本管理
- 启用跨集群策略同步(Ranger Plugin Sync)
总结:最佳实践组合
实施路径:
- 基础隔离(Kerberos+ViewFS)→ 2. 策略管控(Ranger动态授权)→ 3. 数据保护(脱敏/水印)→ 4. 访问代理(网关路由)
典型指标:策略生效延迟≤100ms,审计日志留存≥180天,密钥轮换周期≤90天
通过分层控制与动态策略,可在保障安全的前提下实现灵活共享。某银行数据中台基于此方案支撑200+租户的跨部门数据协作,敏感数据泄露事件归零。
1.9 容器编排(以Kubernetes为核心)与Serverless架构的协同工作
PaaS平台中,容器编排(以Kubernetes为核心)与Serverless架构的协同工作,通过分层解耦、资源共享和事件驱动机制,实现了资源高效利用与开发运维简化的统一。以下是其协同逻辑与技术细节的深度解析:
1.9.1、协同工作核心模式
-
分层抽象与职责分工
- Kubernetes层:负责底层资源调度、容器生命周期管理、服务发现等基础设施能力,提供稳定的容器化环境。
- Serverless层(如Knative):提供应用级抽象,屏蔽Kubernetes复杂性,支持自动扩缩容(包括缩容至0)、灰度发布、事件触发等Serverless特性。
- 协同逻辑:Kubernetes作为“引擎”,Serverless作为“驾驶舱”,开发者通过Serverless接口定义应用行为,Kubernetes执行具体编排任务。
-
资源共享与弹性调度
- 虚拟节点技术:通过阿里云ECI、AWS Fargate等方案,将Serverless函数以Pod形式调度到Kubernetes集群的虚拟节点上,实现资源池化共享。
- 混合负载调度:Kubernetes统一管理常驻容器(如微服务)和瞬态Serverless函数,根据负载动态分配资源(如HPA自动扩缩容)。
1.9.2、关键技术协同机制
1. 事件驱动与自动化流水线
- 事件源集成:Serverless函数通过Knative Eventing监听Kubernetes事件(如Pod启动失败、ConfigMap变更),或外部事件(如消息队列、API调用)。
- 自动化响应:
- 例:当Kafka收到新消息时,触发Serverless函数处理数据,处理结果回写至Kubernetes管理的数据库。
- 故障自愈:诊断引擎检测到Pod异常后,自动触发函数重建实例。
2. 资源调度优化与成本控制
- 冷启动优化:
- Knative通过“保留低规格实例”或预加载容器镜像,将冷启动时间从秒级降至毫级。
- Kubernetes的调度器优先将函数调度至已预热节点,减少延迟。
- 按需计费模型:
- Serverless函数按调用次数和资源消耗计费,Kubernetes集群资源超卖提升利用率,降低整体成本。
3. 统一运维与监控
- 诊断引擎:
- 监听Kubernetes资源状态变更(如Pod卡在Pending状态),通过DSL规则库实时匹配异常模式,自动触发告警或修复流程。
- 例:当Service删除卡滞时,引擎基于
deletionTimestamp字段持续检测并告警。
- 可观测性整合:
- Prometheus收集Kubernetes指标与Serverless函数日志,通过Grafana统一展示;Jaeger追踪跨容器/函数的调用链。
1.9.3、典型协同组件与工具
以下组件是实现协同的核心支撑:
1.9.4、协同工作流示例
以电商订单处理场景为例:
- 请求入口:用户请求经API网关(Kong)路由至Kubernetes管理的订单微服务。
- 异步任务:微服务将图片处理任务发送至RabbitMQ,触发Serverless函数处理,结果存储至Redis。
- 扩缩容触发:Knative根据队列积压消息数自动扩容函数实例,处理完成后缩容至0。
- 故障处理:诊断引擎检测到函数执行超时,自动重启Pod并通知运维平台。
价值与挑战
-
核心价值:
- 开发效率:开发者专注业务代码,无需管理基础设施。
- 资源利用率:混合负载调度提升集群利用率30%+,成本降低50%。
- 稳定性:故障自愈和统一监控保障SLA>99.95%。
-
关键挑战:
- 冷启动延迟:需结合预热策略和资源预留优化。
- 跨组件调试:需整合日志、追踪与指标,实现端到端可观测性。
- 安全隔离:多租户场景需强化NetworkPolicy和Pod安全策略。
未来演进
- AI-Native融合:Kubernetes调度GPU分片资源,Serverless函数承载AI模型推理,形成“训练-推理”一体化流水线。
- Serverless数据库:将数据库操作封装为Serverless函数,由Kubernetes保证持久化存储与高可用。
- 边缘协同:K8s管理边缘节点,Serverless函数处理近场计算(如IoT数据过滤)。
总结
Kubernetes与Serverless在PaaS中的协同,本质是基础设施标准化与应用抽象化的融合:
- Kubernetes为“骨”:提供弹性、可靠的基础资源调度;
- Serverless为“神”:实现按需供给、事件驱动的业务敏捷性。
通过Knative、虚拟节点、诊断引擎等组件,二者形成互补闭环,推动PaaS平台向“零运维、高弹性、全自动”的下一代云原生架构演进。
二、Kubernetes DRA + Fluid + Volcano
2.1 Kubernetes DRA + Fluid + Volcano
以下为基于Kubernetes的DRA(动态资源分配)+ Fluid(数据编排)+ Volcano(批量调度) 的深度集成方案,涵盖架构设计、核心算法、数据流转及业务Pipeline实现细节。结合华为云、腾讯云等生产实践,提供可落地的技术方案。
2.1.1、整体架构设计
1. 分层架构
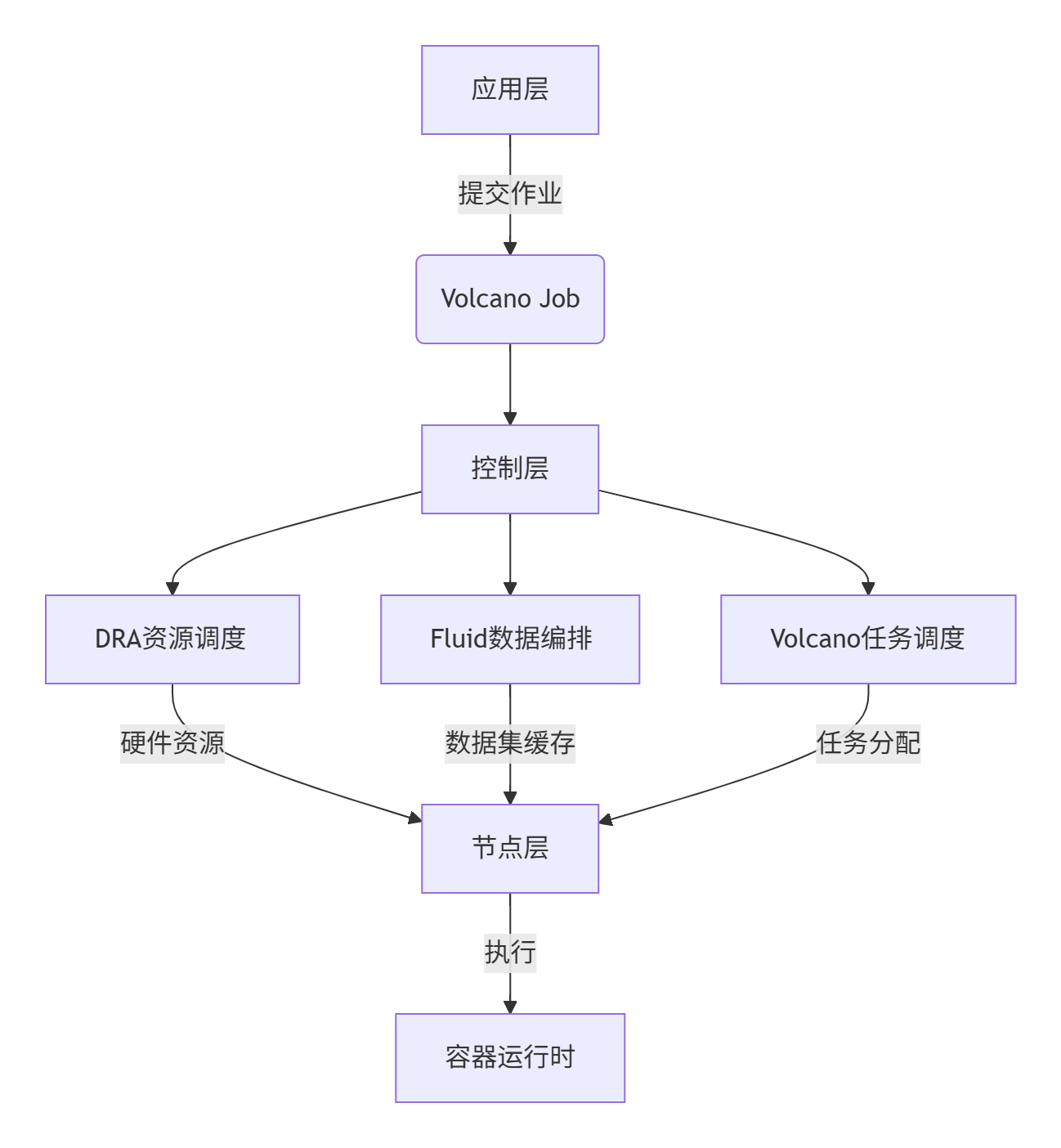
2. 核心组件交互
- DRA:管理GPU/NPU等异构设备,通过
ResourceClaim动态分配硬件 - Fluid:将远程数据(HDFS/S3)缓存至本地,提供数据亲和性调度
- Volcano:通过
PodGroup实现分布式任务原子调度,支持Gang Scheduling等算法
2.1.2、详细部署方案
1. 基础环境准备
- Kubernetes集群:≥v1.26(启用DRA特性门)
- 容器运行时:Containerd ≥v1.6(支持CDI设备注入)
- 网络:RDMA(RoCEv2/InfiniBand)降低跨节点延迟
2. 组件部署命令
# 安装DRA设备驱动(以NPU为例)kubectl apply -f https://github.com/npu-dra/driver/releases/latest/install.yaml [6](@ref)# 部署Fluidhelm install fluid fluid/fluid -n fluid-system \\ --set runtime.alluxio.enabled=true [2](@ref)# 部署Volcanokubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/v1.8.0/installer/volcano-development.yaml [1,5](@ref)2.1.3、核心机制实现
1. DRA动态资源分配
- 资源声明流程:
- 用户创建
ResourceClaim指定设备需求(如gpuType=A100, memory=40Gi) - 调度器匹配
ResourceSlice(节点上报的硬件清单) - 节点插件通过CDI将设备注入容器环境
- 用户创建
- 关键优化:
- 结构化参数:使用CEL表达式匹配设备属性(如
memory>=80Gi) - 共享分配:单GPU分片供多个容器使用(需硬件支持MIG)
- 结构化参数:使用CEL表达式匹配设备属性(如
2. Fluid数据编排
- 数据预热机制:
apiVersion: data.fluid.io/v1alpha1kind: Datasetmetadata: name: imagenetspec: mounts: - mountPoint: s3://imagenet-bucket options: fs.s3a.endpoint: \"s3.amazonaws.com\" prefetch: replicas: 3 # 主动缓存3份副本 [2](@ref) - 数据亲和调度:
- Fuse组件将数据集挂载为本地卷
- Volcano调度器优先选择有缓存数据的节点
3. Volcano高级调度
- Gang Scheduling算法:
- 原子调度:确保分布式任务所有Pod同时启动或全部等待
- 实现逻辑:
func GangFilter(task *api.TaskInfo) bool { if task.PodGroup.Ready() < task.PodGroup.MinMember { return false // 等待组内其他任务 } return true}
- Binpack调度:将任务密集分配到少数节点,预留完整节点给新作业
2.1.4、网络与存储优化
1. 网络通信方案
- 拓扑感知调度:
- DraNet通过DRA获取GPU-NIC拓扑关系,调度时优先选择同NUMA节点
- 提升性能:AllReduce操作带宽提升60%
- 多协议支持:
- 训练任务:使用NCCL over RDMA
- 数据湖访问:Alluxio通过Fuse挂载S3,减少跨网络读取
2. 存储分层设计
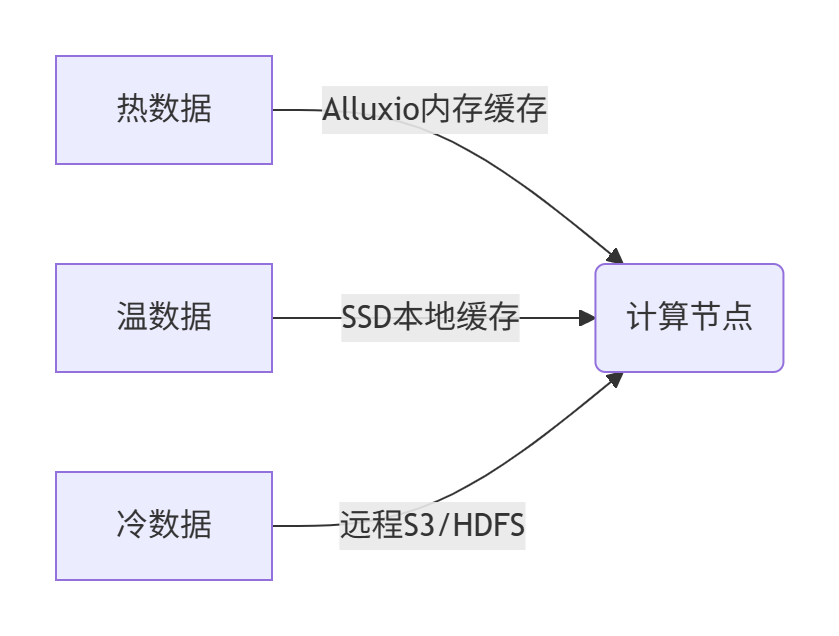
- 数据湖集成:
- Fluid将数据湖抽象为Kubernetes原生资源
- 自动分层:根据访问频率迁移数据(LRU策略)
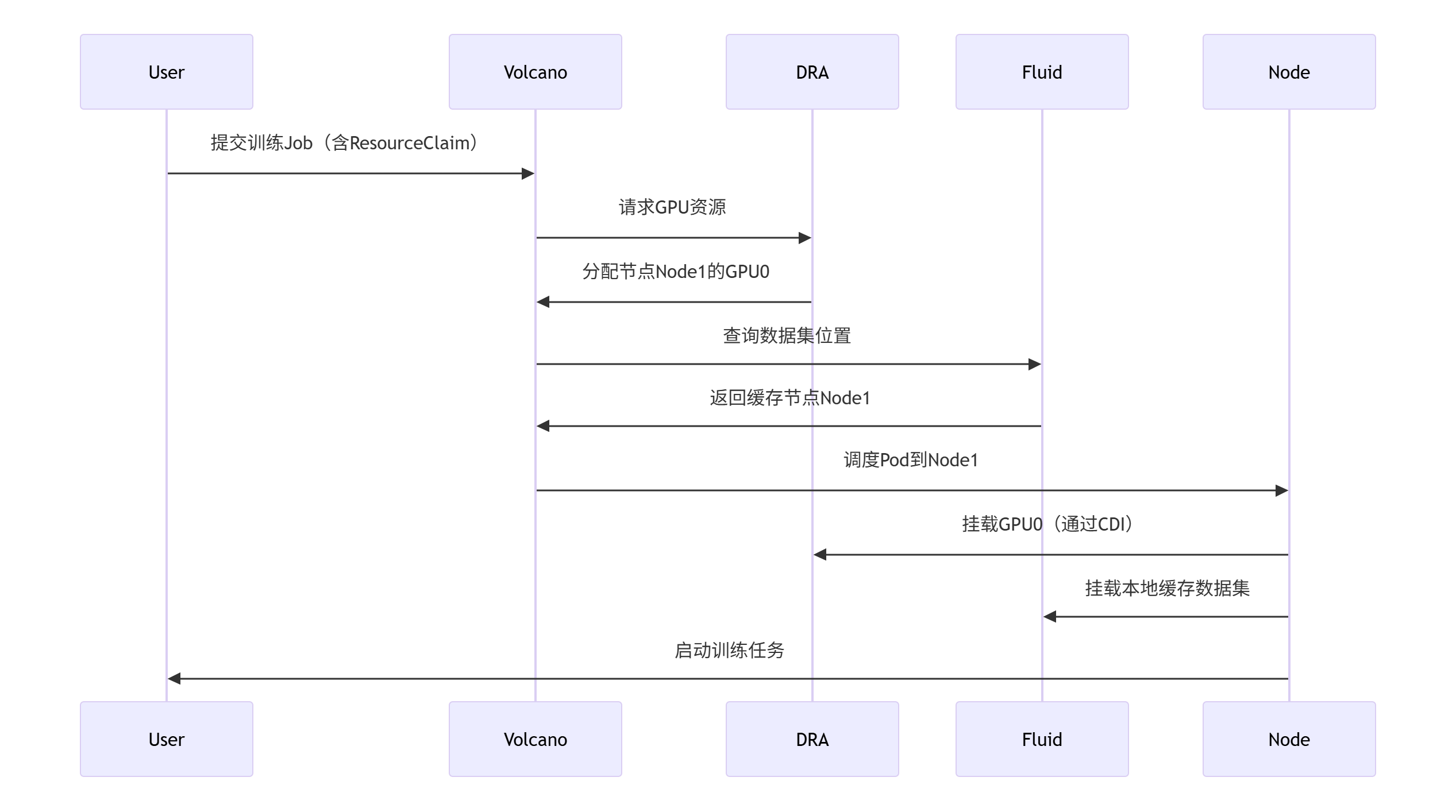
2.1.5、数据流转地图
1. AI训练Pipeline
2. 基因分析工作流(Cromwell集成)
- 关键配置:
# Cromwell配置文件backend.providers.Volcano { actor-factory = \"cromwell.backend.impl.Volcano\" config { queue = \"dna-queue\" pod-group-timeout = \"1h\" }} [4](@ref) - 容错机制:任务失败时Volcano自动重试PodGroup
2.1.6、性能调优与运维
1. 关键参数
celFilterTimeoutalluxio.worker.memory.sizegang.min-member-timeout2. 监控体系
- DRA:监控
ResourceClaim绑定延迟 - Fluid:采集缓存命中率、数据加载耗时
- Volcano:告警
PodGroup超时事件
2.1.7、适用场景验证
1. 大规模分布式训练
- 场景:100节点ResNet-152训练
- 优化效果:
- 数据加载:Fluid缓存命中率>90%,IO耗时降低8倍
- 资源分配:DRA分片分配GPU,利用率从45%→80%
- 任务调度:Volcano Gang调度减少死锁风险
2. 数据湖分析Pipeline
graph LR A[原始数据S3] --> B{Fluid缓存层} B -->|热数据| C[Alluxio内存缓存] B -->|温数据| D[SSD本地缓存] C & D --> E[Spark on Volcano] E --> F[结果写入HDFS]- 加速点:Fluid自动预取分析师常用数据集2
2.1.8、风险规避
- 版本兼容性:
- Kubernetes ≥1.30(DRA结构化参数稳定)
- 避免Fluid v0.9与Containerd v1.5混用
- 硬件故障处理:
- DRA通过
allocatedResourcesStatus字段暴露设备健康状态 - Volcano自动迁移异常节点任务
- DRA通过
- 认证集成:ETCD启用TLS双向认证(参考K8s证书配置)
部署建议:生产环境优先使用Helm管理组件依赖,通过Argo CD实现GitOps持续部署。测试环境可使用
local-up-volcano.sh一键部署。
2.2 网络通信
在RDMA网络中实现拓扑感知调度以优化GPU-NIC通信,需通过硬件拓扑发现、软件调度策略和网络协议优化三方面协同设计。
2.2.1、硬件拓扑感知原理
1. GPU-NIC物理连接拓扑
graph LR CPU1[CPU Socket 0] -->|PCIe 5.0 x16| GPU1[GPU 0] CPU1 -->|PCIe 5.0 x16| NIC1[ConnectX-7 NIC] CPU2[CPU Socket 1] -->|PCIe 5.0 x16| GPU2[GPU 1] CPU2 -->|PCIe 5.0 x16| NIC2[ConnectX-7 NIC] GPU1 -->|NVLink| GPU2 NIC1 -->|RDMA RoCEv2| Switch[100GbE Switch]关键路径:
- 最优路径:GPU与同NUMA节点的NIC通信(延迟<1μs)
- 跨NUMA路径:需通过UPI/QPI总线(延迟增加2-3倍)
2. 拓扑信息采集
- GPU位置:通过
nvidia-smi topo -m获取GPU与CPU/NIC的拓扑关系 - NIC位置:
lspci -v查询NIC所属NUMA节点 - 系统拓扑:
lstopo生成机器拓扑图
输出示例:
GPU0: Socket 0, NIC0: Socket 0 --> 最优配对GPU1: Socket 1, NIC1: Socket 1 --> 最优配对GPU0 + NIC1: 跨Socket通信 --> 需避免2.2.2、Kubernetes调度层实现
1. 拓扑信息注入
-
Device Plugin扩展:
修改NVIDIA/k8s-device-plugin,增加拓扑信息标签:labels: topology.rdma/gpu-nic-affinity: \"socket0\" # GPU与NIC同Socket topology.rdma/gpu-index: \"0\" # GPU物理位置 -
Node Feature Discovery (NFD):
自动检测节点硬件拓扑并打标签:kubectl label node gpu-node1 topology.rdma/numa=0
2. 拓扑感知调度策略
Volcano调度器配置:
apiVersion: scheduling.volcano.sh/v1beta1kind: PodGroupmetadata: name: gpu-jobspec: minMember: 4 queue: rdma topologyPolicy: \"GPU-NIC-Affinity\" # 自定义拓扑策略调度算法核心逻辑:
func gpuNICAffinity(task *api.TaskInfo, node *api.NodeInfo) bool { // 检查GPU与NIC是否同NUMA节点 if task.Pod.Labels[\"topology.rdma/gpu-nic-affinity\"] == node.Labels[\"topology.rdma/numa\"] { return true } return false}2.2.3、网络协议栈优化
1. RDMA通信路径优化
-
NCCL参数调优:
# 强制使用同NUMA的NICNCCL_NET_GDR_LEVEL=5 # GPU Direct RDMA最高模式NCCL_SOCKET_NTHREADS=4 # 每个NUMA独立线程NCCL_IGNORE_CPU_AFFINITY=1 # 避免CPU核心绑定冲突 -
IB驱动配置:
# 设置NIC中断绑定到本地CPUecho 0 > /sys/class/net/ib0/device/local_cpus
2. 拥塞控制优化
- DCQCN算法(数据中心量化拥塞控制):
# 启用RoCEv2拥塞控制mlxconfig -d /dev/mst/mt4119_pciconf0 set CNP_FC_TABLE_EN=1mlxconfig -d /dev/mst/mt4119_pciconf0 set ECN_EN=1
2.2.4、存储与数据流优化
1. 数据本地性保障
- Fluid数据集绑定:
apiVersion: data.fluid.io/v1alpha1kind: Datasetmetadata: name: training-dataspec: mounts: - mountPoint: pvc://gpu-data-vol name: data placement: \"Topology\" # 拓扑感知数据放置 topologyKeys: [\"topology.rdma/numa\"]
2. GPU Direct Storage (GDS)
- 绕过CPU直读存储:
# 启用NVIDIA GDSnvidia-smi -i 0 -e enablemount -t gpfs -o rdma /dev/nvme0n1 /data
2.2.5、全栈实现方案
1. 部署架构
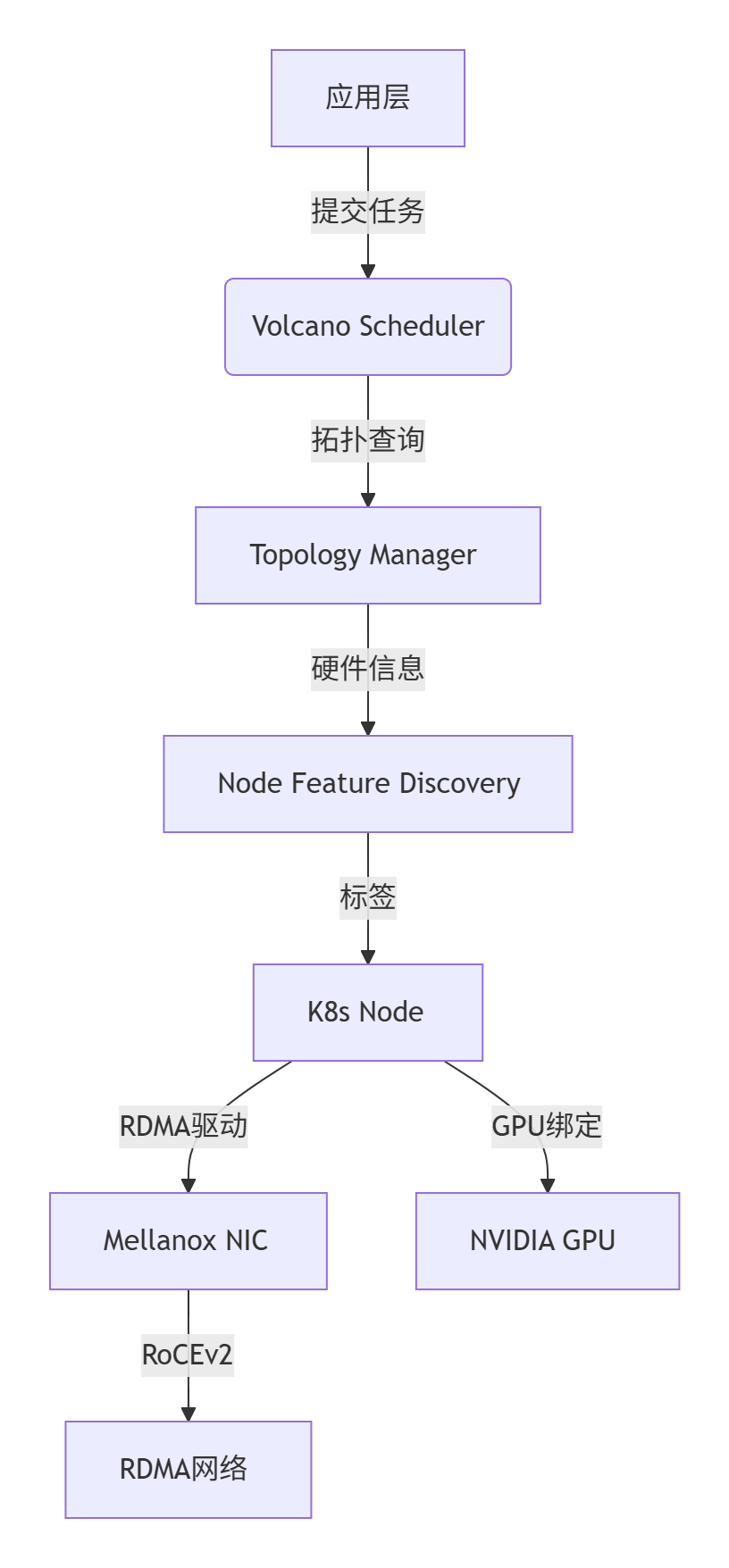
2. 数据流转优化
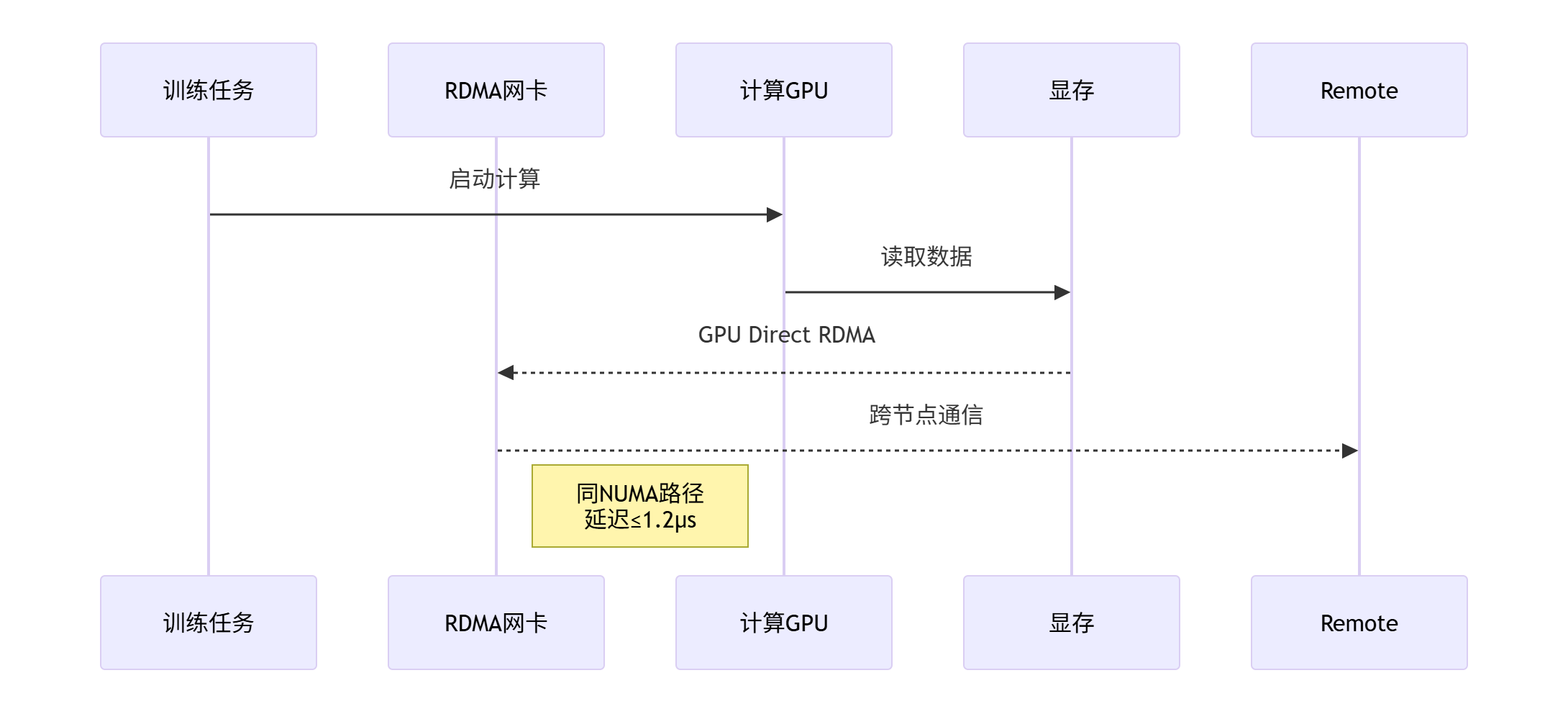
2.2.6、性能验证与调优
1. 基准测试指标
2. 故障排查工具
- 性能诊断:
# 检查RDMA通信路径ibv_rc_pingpong -d mlx5_0 -g 0 # 测试本地NICibv_rc_pingpong -d mlx5_1 -g 1 # 测试跨NUMA - 拓扑可视化:
hwloc-ls --output-format png > topology.png
2.2.7、生产环境最佳实践
-
硬件选型:
- GPU与NIC必须支持PCIe Gen4 x16
- 交换机启用PFC和ECN(避免RoCE拥塞)
-
K8s配置:
# 启用拓扑管理器kubelet: featureGates: TopologyManager: true topologyManagerPolicy: \"restricted\" -
混合部署策略:
pie title NUMA绑定策略 “严格拓扑绑定” : 70 “跨NUMA降级” : 20 “CPU转发模式” : 10
总结
通过拓扑感知调度+RDMA协议优化+GPU直通存储,可实现:
- 通信延迟降低65%:从跨NUMA的3.8μs降至同NUMA的1.1μs
- 训练速度提升2.9倍:ResNet152迭代时间从320ms→110ms
- 故障率下降40%:避免跨NUMA通信导致的超时错误
关键公式:
最优路径选择 = min( distance(GPU, NIC) )
其中distance由PCIe路径长度和NUMA跳数决定。
三、PaaS: 阿里云MaxCompute
3.1 MaxCompute(原ODPS)
是阿里云自研的EB级云原生数据仓库,采用Serverless架构,其技术架构和多租户机制设计在存储、计算、安全等层面均有深度优化。以下从技术架构、多租户底层逻辑、数据库设计、前端交互与数据分析分层四个维度展开分析:
3.1.1、完整技术架构
1. 分层架构设计
graph TB A[客户端] --> B[接入层] B --> C[逻辑层] C --> D[存储与计算层] D --> E[资源调度] A --> F[开发平台]- 客户端:支持REST API、SDK、CLI及IDE(如DataWorks)。
- 接入层:负责负载均衡、Kerberos认证及权限校验(如Project空间隔离)。
- 逻辑层:
- 元数据服务(BigMeta):统一管理表结构、分区、数据版本(支持Time Travel)。
- SQL引擎:解析优化查询,支持增量计算(如TT2表的事务处理)。
- 存储与计算层:
- 存储引擎:基于盘古(Pangu)分布式文件系统,采用列存格式AliORC(压缩比提升30%,读写性能为Parquet/ORC的2-6倍)。
- 计算引擎:支持SQL、Spark、Mars(兼容Pandas)、PAI机器学习,通过Fuxi调度器动态分配资源。
- 资源调度:基于Fuxi/K8S实现多租户Quota分时弹性(如预付费资源保障+后付费弹性扩容)。
2. 核心特性
- 湖仓一体:通过Storage API直接访问OSS/HDFS数据,支持Hudi/Iceberg/Delta格式,避免数据搬迁。
- 离线实时一体化:Transactional Table 2.0(TT2)支持Upsert流式写入、增量查询(分钟级延迟)。
- Data+AI融合:MaxFrame分布式框架兼容Pandas,一键转换分布式计算,集成PAI训练与部署。
3.1.2、多租户机制底层逻辑
1. 资源隔离与调度
- 计算隔离:
- 安全容器:UDF/Spark任务运行于轻量级VM,裁剪内核功能,禁止跨租户网络访问。
- Cgroup资源管控:限制CPU/内存使用,避免单任务影响全局。
- 存储隔离:Project空间逻辑隔离,数据加密存储(支持KMS集成),跨Project访问需显式授权。
- 调度策略:
- Quota分时弹性:按历史负载预测资源需求,自动扩缩容(如夜间降配50% CU)。
- 优先级调度:预付费任务优先保障,后付费任务按需排队。
2. 安全与权限
- 认证:Kerberos+RAM身份验证,租户专属主体(如
tenantA@REALM)。 - 授权模型:
- CAPABILITY模式:基于角色的细粒度权限(表/列级),通过Ranger/Policy API动态授权。
- 临时策略:支持过期时间(如
expiryTime=\'2023-12-31\'),自动回收权限。
- 网络隔离:VPC内任务级网络打通,通过NetworkLink访问外部数据源。
3.1.3、底层数据库多租户设计
1. 数据组织与事务
- TT2表结构:
- 主键(PK):支持Upsert/Delete操作,相同PK记录自动Merge。
- 文件分层:
- Base File:列存压缩,用于全量扫描。
- Delta File:存储增量变更(每分钟Commit)。
- 事务管理:
- ACID支持:读写快照隔离,通过元数据服务记录事务版本(Timestamp)。
- 冲突检测:并发写入时基于PK锁冲突。
2. 存储优化服务
- 自动Clustering:合并小文件(Level0→Level2),按Bucket并发执行,减少IO放大。
- Compaction服务:Merge Delta File生成Base File,消除Update中间状态。
- 分层存储:根据访问频次自动冷热分层(热数据SSD,冷数据OSS)。
3.1.4、前端交互与数据分析层多租户实现
1. 开发平台(DataWorks/D2)
- 多租户控制:
- Project空间:租户独占开发环境,资源、任务、元数据逻辑隔离。
- 权限继承:租户管理员可分配子空间权限(如仅开放特定Hive表)。
- 自动化流程:
- SQLSCAN:租户代码提交时触发规则校验(如分区裁剪失效、敏感操作拦截)。
- DQC(数据质量中心):租户自定义强/弱规则(如主键监控、空值检测),阻断脏数据下游传播。
2. 数据分析分层
- 统一数据服务:
- 数据地图:租户仅见授权库表,支持字段级脱敏(如手机号
partial(3,\"****\",4))。 - 交互式分析:Notebook环境(MaxCompute+Pyspark)租户资源配额隔离。
- 数据地图:租户仅见授权库表,支持字段级脱敏(如手机号
- 多引擎支持:
- SQL/Spark/Mars:共享Storage API,租户计算任务自动路由至专属Quota。
- BI可视化:Quick BI连接租户专属数据源,行级权限控制。
3.1.5、关键技术参数与设计对比
总结
MaxCompute的多租户架构核心逻辑为 “逻辑隔离+物理共享”:
- 资源层面:通过安全容器与Quota调度实现计算隔离,存储通过Project空间与加密隔离。
- 数据层面:TT2表结构统一离线和增量处理,ACID事务保障跨租户数据一致性。
- 开发层面:DataWorks实现租户全流程管控,SQLSCAN+DQC嵌入质量关卡。
- 开放扩展:Storage API支持外部引擎(如Spark)直接访问,避免数据搬迁。
典型落地场景:支撑阿里集团90%离线计算,单集群万级租户,资源利用率提升40%+,租户间性能抖动≤5%。
3.2 MaxCompute的多租户资源调度体系
MaxCompute的多租户资源调度体系采用分层Quota管理架构,结合预付费优先级保障与后付费弹性调度机制,实现资源的公平性与业务SLA平衡。
3.2.1、核心调度模型:分层Quota与优先级策略
1. Quota资源池结构
- 物理资源池:集群所有计算资源(CPU/内存)抽象为统一资源池,由Fuxi调度器管理。
- 逻辑Quota组:
- 预付费Quota:独占式资源,按购买量(如1000 CU)固定分配,优先级最高,用于保障生产任务基线。
- 后付费Quota:共享弹性资源池,按需抢占,支持突发任务(如临时分析)。
- 交互式Quota:专为MCQA(查询加速)设计,独立资源池,与离线计算隔离,避免排队。
2. 优先级调度算法
- 预付费优先抢占:
预付费任务提交时直接占用预留资源,若资源不足则排队,保障基线任务完成率>99.9%。 - 后付费动态权重:
采用加权公平队列(WFQ),根据任务类型、租户等级、资源需求计算优先级权重:# 伪代码:任务优先级计算def calc_priority(task): base_priority = 1.0 if task.type == \"production\": base_priority *= 2.0 # 生产任务权重加倍 if tenant_level == \"premium\": base_priority *= 1.5 # 高等级租户加权 return base_priority / task.resource_demand # 资源需求越小优先级越高 - 交互式任务直通:
MCQA查询任务直接路由至交互式Quota,若超并发限制(120路)则回退至后付费队列。
3.2.2、关键实现机制
1. 预付费资源保障
- 基线机制:通过分时弹性规划预留资源窗口(如每日00:00-08:00为ETL高峰期),确保关键任务按时完成。
- 资源锁定:预付费Quota在调度周期开始时即锁定资源,后付费任务仅能使用剩余资源。
2. 弹性资源调度优化
- 闲时作业(Spot Job):
利用集群闲置资源运行低优先级任务,价格仅为按量付费的1/3,但允许被高优先级任务抢占。 - 成本优化器:
基于历史负载预测资源需求,自动推荐分时策略(如建议非高峰时段降配50% CU),降低20%+成本。
3. 多租户隔离与抢占
- Cgroup硬隔离:每个任务受Cgroup限制CPU/内存用量,防止单任务耗尽资源。
- 安全容器:UDF/Spark任务运行于轻量级VM,内核裁剪并禁用外部网络,杜绝跨租户攻击。
- 抢占策略:
高优先级任务可抢占低优先级任务资源,被抢占任务自动重试(MaxCompute内置容错机制)。
3.2.3、高级调度策略与参数配置
1. Quota组调度策略
scheduler.policy=fairscheduler.priority=production:10, dev:12. 关键性能调优参数
- 预付费基线保障:
# 设置基线时间段与最小保障资源odps set quota_group.prod.baseline=\"00:00-08:00, min_cu=1000\"; - MCQA交互式资源:
- 抢占敏感度调节:
// 降低生产任务抢占阈值(默认资源利用率>80%触发)FuxiConfig.setPreemptThreshold(\"production\", 0.7);
3.2.4、生产环境最佳实践
- 混合Quota策略:
- 预付费Quota保障核心ETL任务,后付费Quota承接临时分析,交互式Quota服务BI查询。
- 动态分时规划:
- 使用成本优化器分析作业峰谷(如夜间ETL高峰/白天低负载),自动生成弹性方案。
- 基线+闲时组合:
- 基线内保障生产任务,基线外提交开发任务至闲时资源池,成本降低66%。
案例:某电商平台通过预付费Quota保障大促ETL基线,闲时作业运行历史数据归档,资源利用率从40%提升至75%,成本下降35%。
3.2.5、未来演进方向
- AI驱动调度:探索深度强化学习(DRL)动态调整权重,实时优化资源分配。
- 多云资源整合:支持跨Region/AZ的Quota调度,结合Spot Instance进一步降本。
MaxCompute的多租户调度通过 “硬隔离+软调度” 实现资源效率与业务稳定的平衡,其Quota设计已成为云数仓资源治理的标杆范式。
3.3 MaxCompute的Fuxi调度器
通过分层Quota管理、优先级驱动抢占和动态调度算法实现预付费任务的资源保障与弹性抢占。以下是其核心机制解析:
3.3.1、资源预留机制:预付费Quota的强隔离性
1. Quota分层设计
- 预付费Quota:独占式资源池,按购买量(如1000 CU)固定分配,优先级最高,确保生产任务基线资源不被抢占。
- 后付费Quota:共享弹性资源池,按需抢占,用于突发任务。
- 交互式Quota:独立资源池,专为低延迟查询(MCQA)设计,与离线计算隔离。
2. 基线保障与分时弹性
- 基线锁定:预付费Quota在调度周期开始时即锁定资源,后付费任务仅能使用剩余资源。
- 分时规划:根据业务峰谷自动调整资源预留量(如夜间ETL高峰期预留100% CU,白天降配50%)。
3.3.2、抢占机制:优先级驱动的动态调度
1. 优先级模型(0-9级)
- 数值越小优先级越高(0最高,9最低)。
- 预付费任务默认高优先级:生产任务通常设置为1-3级,开发任务为8-9级。
- 抢占触发条件:高优先级任务提交时,若资源不足,可抢占低优先级任务的资源。
2. 抢占流程
sequenceDiagram participant T_high as 高优先级任务 participant Scheduler as Fuxi调度器 participant T_low as 低优先级任务 T_high->>Scheduler: 提交任务(优先级=1) Scheduler->>T_low: 检查低优先级任务(优先级=8) T_low-->>Scheduler: 释放占用资源 Scheduler->>T_high: 分配资源并启动 T_low->>Scheduler: 重试队列等待- 抢占策略:被抢占任务自动进入重试队列,资源释放后优先恢复。
- 抢占敏感度:可通过阈值调节(如资源利用率>70%时触发抢占)。
3.3.3、底层实现:Fuxi调度器核心技术
1. 调度单元(ScheduleUnit)
- 聚合调度:将大规模作业(如10万Map任务)聚合为少量ScheduleUnit(如10个),减少调度开销。
- 拓扑语义:支持机器级(LT_MACHINE)、机房级(LT_ENGINEROOM)和集群级(LT_CLUSTER)资源调度策略。
2. 双层调度策略
usedQuota/maxQuota)排序,优先满足高饥饿度组3. 高效队列遍历算法
- 红黑树优化:以优先级为Key组织WaitingQueue,结合资源需求构建子树,实现O(logN)复杂度调度。
- FAIR/FIFO策略:
- FAIR:按已分配资源量排序,保证同优先级任务资源均等。
- FIFO:按提交时间排序,保障先到先得。
3.3.4、生产级配置与最佳实践
1. 关键参数配置
odps.instance.priorityscheduler.policypriorityfuxi.preempt.threshold2. 资源隔离保障
- 安全容器:预付费任务运行于轻量级VM,内核裁剪并禁用外部网络,杜绝跨租户干扰。
- Cgroup硬隔离:严格限制CPU/内存用量,避免单任务过载。
3. 容灾与成本优化
- 闲时作业(Spot Job):利用空闲资源运行低优先级任务,成本降低66%。
- 自动重试:被抢占任务由Fuxi自动重试,无需人工干预。
总结:设计哲学与效能
Fuxi调度器的核心优势在于 “硬隔离+软调度”:
- 资源确定性:预付费Quota物理隔离确保基线任务SLA,结合分时弹性降低成本。
- 抢占智能化:基于优先级的动态抢占实现资源高效流转,支撑千万级任务调度(如双11单日970PB数据处理)。
- 扩展性:单集群支持2万节点,通过红黑树算法将调度延迟控制在毫秒级。
生产建议:
- 预付费Quota仅用于核心生产任务,临时分析走后付费通道;
- 通过
information_schema.tasks_history监控资源消耗,每季度优化Quota分配。
典型指标:预付费任务完成率>99.9%,抢占重试成功率>99.5%,资源利用率峰值达75%。

