无需代码!MCP + Neo4j 如何颠覆知识图谱构建?_neo4j mcp
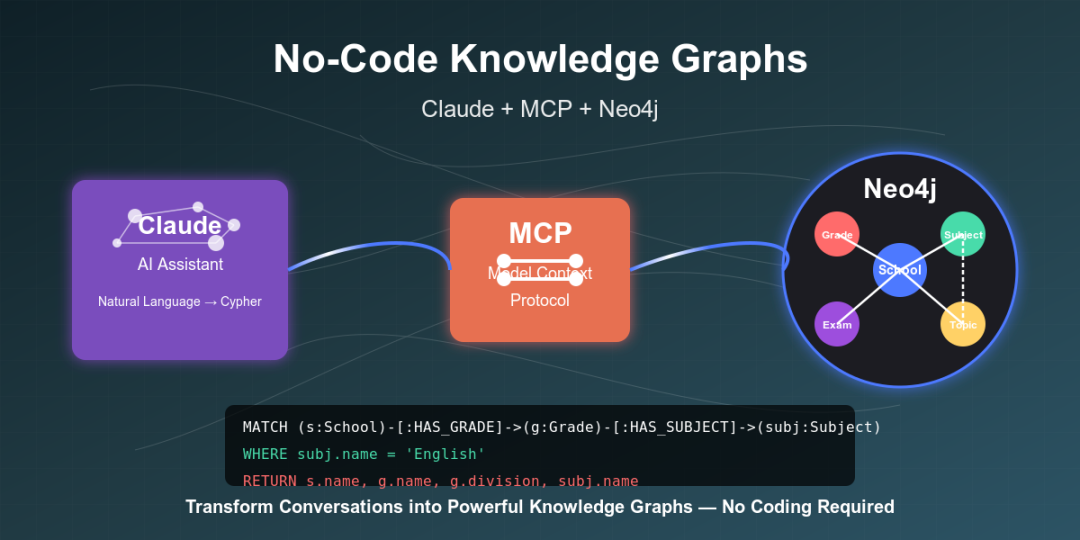
在当今数据驱动的世界里,知识图谱已成为一种强大的工具,能够捕获和查询不同实体之间复杂的关系。
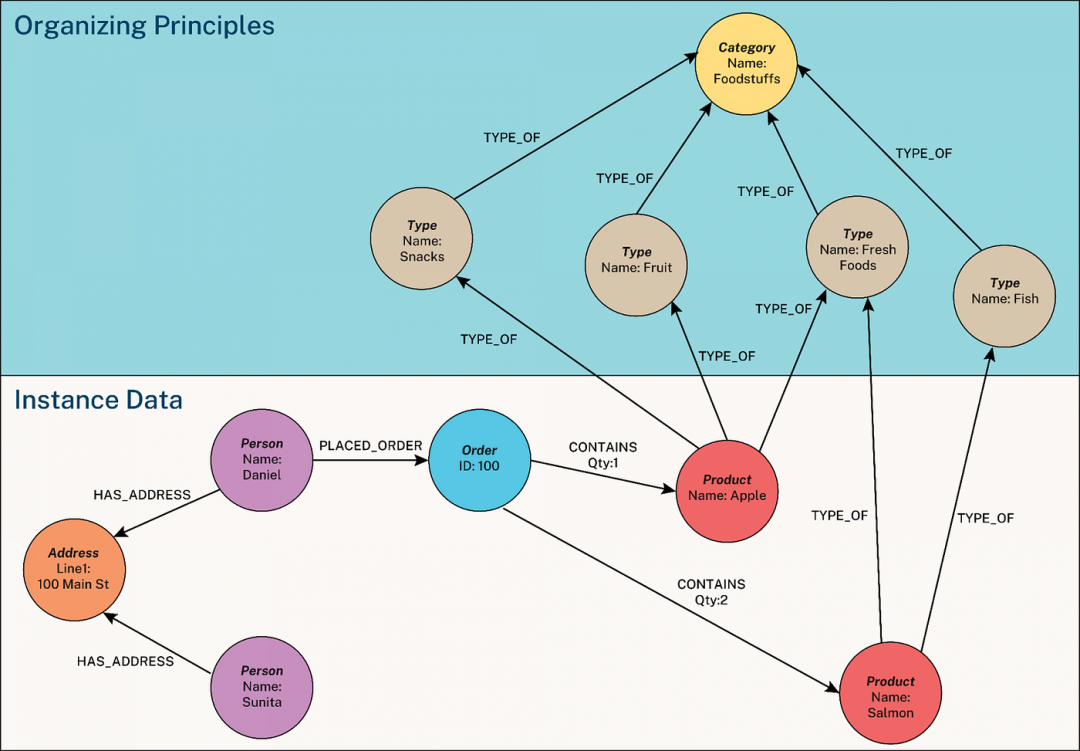 一张示例知识图谱,以圆形代表节点,箭头代表关系。图中突出显示了实例数据和组织原则。
一张示例知识图谱,以圆形代表节点,箭头代表关系。图中突出显示了实例数据和组织原则。
传统上构建知识图谱需要大量的编码知识,但现在情况正在发生变化。本文将介绍一种简化的构建方法,将 Anthropic 的 Claude AI 助手与 Neo4j 图数据库结合起来。借助模型上下文协议 (Model Context Protocol, MCP),这一过程完全无需编写任何代码。
本文将详细介绍我的实践经验,展示如何仅通过与 AI 助手的对话,就为一所学校(特别是建模其考试安排和课程信息)构建一个全面的教育系统知识图谱。
什么是模型上下文协议 (Model Context Protocol, MCP)?
模型上下文协议 (MCP) 是一项新兴标准,它允许 AI 模型与外部工具和数据源进行交互。借助 MCP,像 Claude 这样的 AI 助手能够在数据库等系统上直接执行命令,这极大地扩展了它们处理特定任务的能力,使其不再局限于自身的训练数据。
简单来说,MCP 让 Claude 能够直接访问并与你的 Neo4j 数据库交互。
前提条件
要按照此方法进行操作,你需要:
- \\1. Docker Desktop:用于在容器中运行 Neo4j。
- \\2. Neo4j 数据库:可以是 Docker 容器版或云实例。
- \\3. UV 包管理器:一个快速的 Python 包管理器,用于安装本方法所需的软件依赖。
MacOS/Linux:
curl -LsSf https://astral.sh/uv/install.sh | shWindows:
powershell -ExecutionPolicy ByPass -c \"irm https://astral.sh/uv/install.ps1 | iex\"4. Claude for Desktop
5. MCP 插件配置:用于连接 Claude 到 Neo4j;使用 Neo4j 提供的 mcp-neo4j-cypher 工具 (https://github.com/neo4j-contrib/mcp-neo4j/tree/main/servers/mcp-neo4j-cypher)。
设置 MCP 配置
成功实现此方法的关键在于正确设置 MCP 配置。我使用的配置如下:
\"neo4j\": { \"command\": \"/Users//.local/bin/uvx\", # **请替换此路径** \"args\": [ \"mcp-neo4j-cypher\", \"--db-url\", \"bolt://localhost\", \"--username\", \"neo4j\", \"--password\", \"password\" ]}此配置通过 Bolt 协议将 Claude 连接到本地运行的 Neo4j 实例。请务必将配置中的 /Users//.local/bin/uvx 替换为你系统中 uvx 可执行文件的完整路径,并根据你的实际数据库设置调整 --db-url、--username 和 --password 参数。
在此获取云配置和 MCP 插件的详细信息(https://github.com/neo4j-contrib/mcp-neo4j/tree/main/servers/mcp-neo4j-cypher)。
验证设置
启动 Claude for Desktop 后,你将看到以下由 Neo4j 提供的新功能工具:
- \\1. get-neo4j-schema:用于检索 Neo4j 数据库的模式 (schema)。
- \\2. read-neo4j-cypher:用于从图数据库中查询信息。
- \\3. write-neo4j-cypher:用于更新数据库中的图数据。
这些工具会出现在你的 Claude for Desktop 界面中,表明 MCP 已成功与 Neo4j 集成。
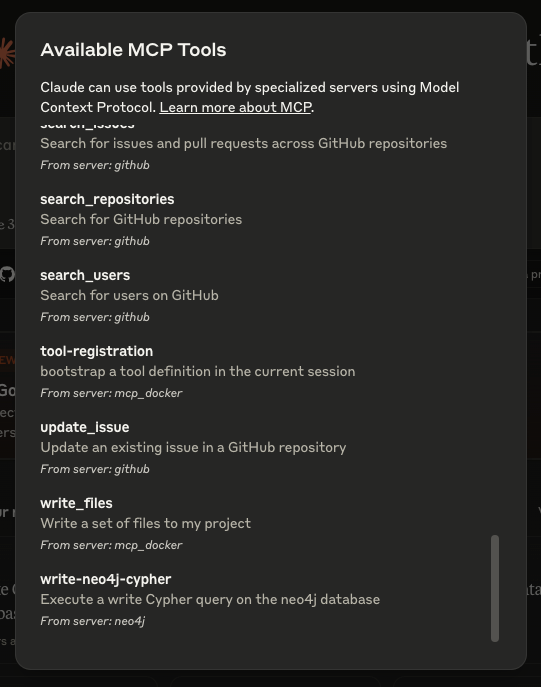 我的已安装 MCP 工具列表,其中包括 Neo4j 工具
我的已安装 MCP 工具列表,其中包括 Neo4j 工具
案例研究:构建教育系统知识图谱
为了展示此方法的强大之处,我决定构建一个教育系统——具体来说,是 Brainiacs 辅导中心 4B 班第二学期的考试安排和课程信息(https://brainiacstutoring.co.za/product-category/grade4/)。
第一步:创建基本模式 (schema)
第一步是建立图数据库的基本结构。通过与 Claude 对话,我说明了需要建模的实体和关系:
- • 学校 (School):Brainiacs 辅导中心
- • 年级 (Grade):四年级,B班
- • 科目 (Subjects):数学、英语、科学等
- • 考试 (Exams):安排了具体日期的考试
- • 主题/内容 (Topics):每个科目的具体课程章节
我没有编写查询语句,只是简单地向 Claude 解释了我的需求,然后它就生成并执行了相应的 Neo4j Cypher 命令来构建这个结构。
 指示 Claude 生成模式并分析文档
指示 Claude 生成模式并分析文档
第二步:添加实体和关系
建立模式后,我需要从我的学校文档中提取实际数据来填充数据库。Claude 分析了我分享的考试安排和课程文档,然后自动创建了:
- • 带有正确名称的学校节点 (School node)
- • 带有班级和学期信息的年级节点 (Grade node)
- • 各科目的科目节点 (Subject nodes)
- • 带有日期、时间和星期几的考试节点 (Exam nodes)
- • 代表课程章节的主题/内容节点 (Topic nodes)
- • 有意义地连接所有这些实体的关系 (Relationships)
所有这些都是通过自然对话完成的。我完全无需亲手编写任何 Cypher 查询语句!
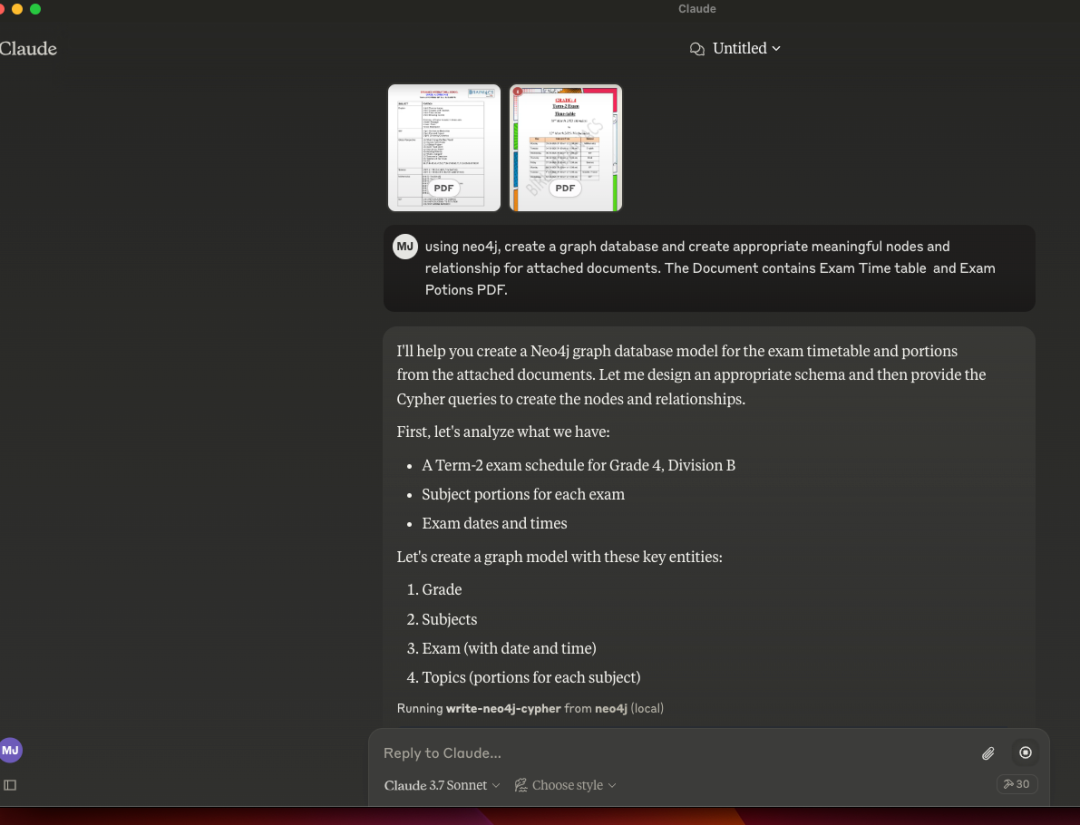 通过分析文档自动创建图模型
通过分析文档自动创建图模型
要使用某个工具,你需要授权给它,可以选择授权一次或针对整个对话授权。在本例中,由于我正在更新数据库,所以需要注意,Claude 对我配置的数据库拥有完整的写入权限。
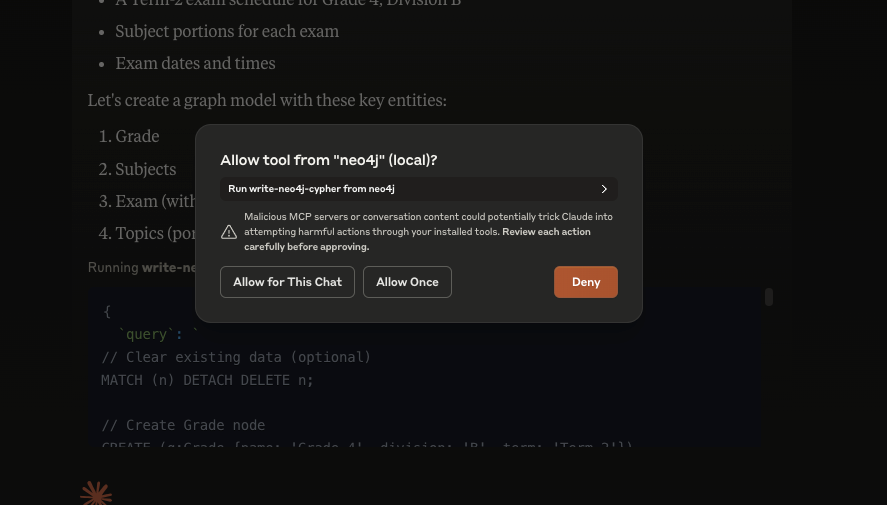 在被要求时授权
在被要求时授权
接着,Claude 从文档中提取信息,并使用 Cypher 语句在数据库中创建节点,包括:
- • 年级 (Grade)
- • 科目 (Subject(s))
- • 考试 (Exam)
- • 主题/内容 (Topics)
它会迭代处理每个主题/内容并单独创建。(注意:如果指示它从列表中创建,效率会更高。)
Claude 还会创建插入的节点之间的关系,这样我们就能从原始 PDF 文档中得到一个完整的图结构。
第三步:查询知识图谱
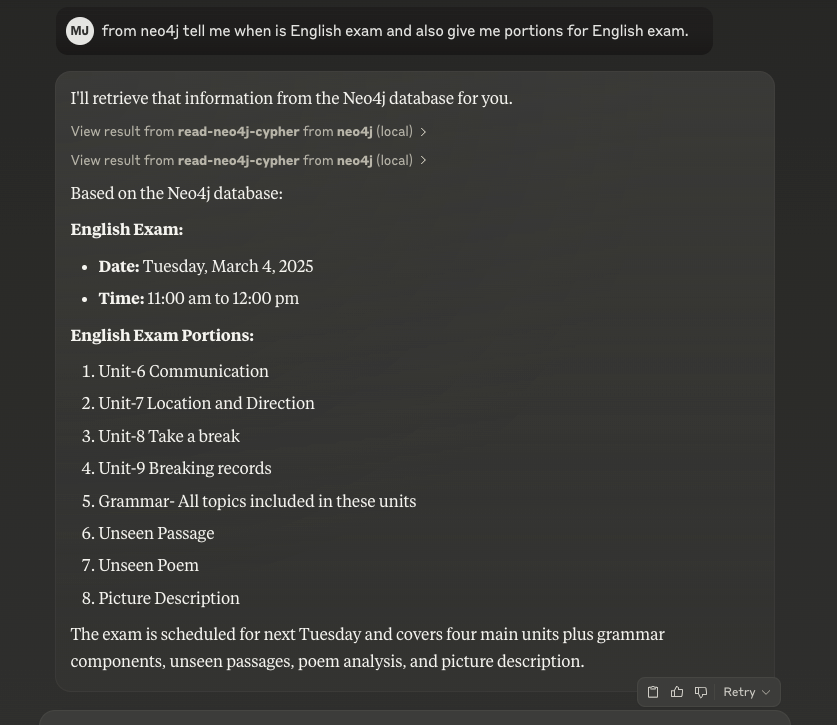
数据库填充完成后,我可以通过用普通英语向 Claude 提问来查询。例如,当我问“英语考试是什么时候?考哪些内容?”,Claude 就自动生成并运行了相应的 Cypher 查询,返回了以下信息:
英语考试:
- • 日期: 2025年3月4日,星期二
- • 时间: 上午11点至中午12点
英语考试内容:
- \\1. 第6单元 — 交流
- \\2. 第7单元 — 地点和方向
- \\3. 第8单元 — 休息一下
- \\4. 第9单元 — 打破纪录
- \\5. 语法 — 包含在这些单元里的所有主题
- \\6. 未见过的文章 (Unseen Passage)
- \\7. 未见过的诗歌 (Unseen Poem)
- \\8. 图片描述 (Picture Description)
在幕后,Claude 执行了类似以下的 Cypher 查询:
// 查询英语考试的时间安排MATCH (subject:Subject {name: \'English\'})-[:HAS_EXAM]->(exam:Exam)RETURN exam.date AS Date, exam.day AS Day, exam.startTime AS StartTime, exam.endTime AS EndTime// 查询英语考试的主题/内容MATCH (subject:Subject {name: \'English\'})-[:INCLUDES_TOPIC]->(topic:Topic)RETURN topic.name AS Portion这些复杂的 Cypher 查询语句,正是 Claude 根据我的自然语言提问自动生成并执行的,我完全无需关心查询细节。
 Claude 的输出结果
Claude 的输出结果
以下是一些原始文档,Claude 从中提取信息并转换成了图谱元素。
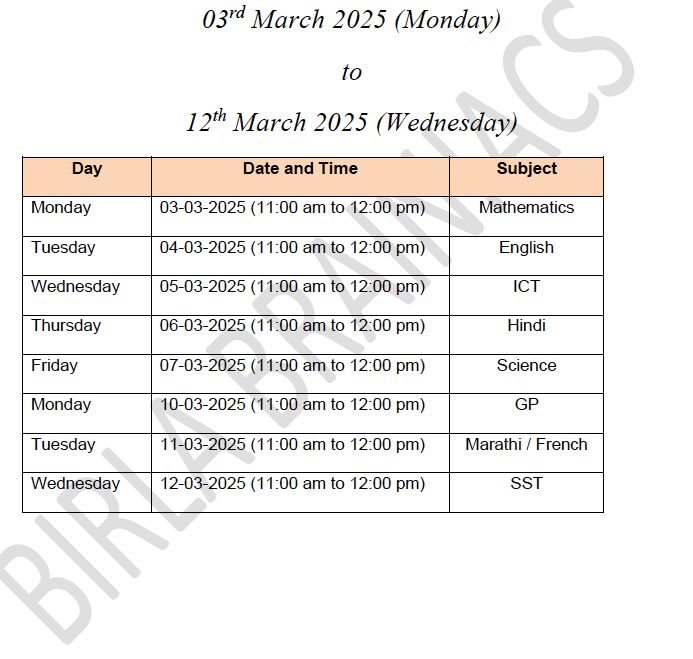 原始考试安排 PDF
原始考试安排 PDF
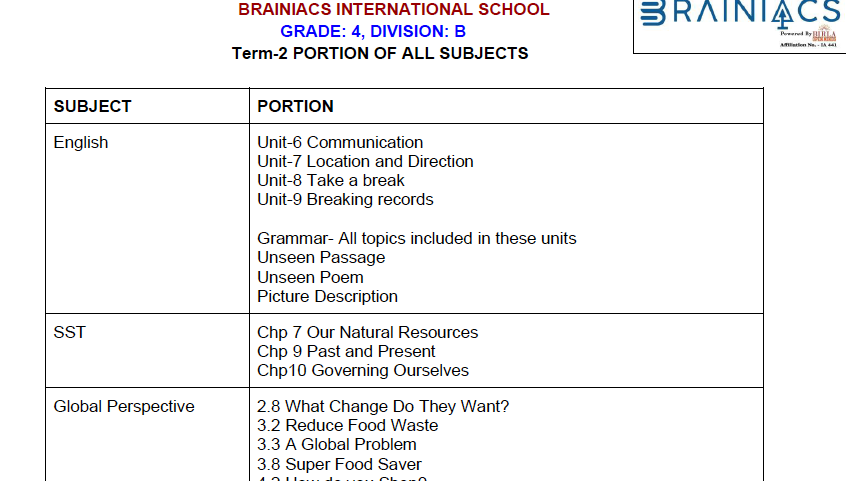 考试内容 PDF
考试内容 PDF
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

知识图谱可视化
此方法的一个强大之处在于 Claude 能够创建图结构的可视化效果。通过我们的对话,Claude 生成并执行了代码来可视化:
- \\1. 显示节点类型和关系的结构模式图。
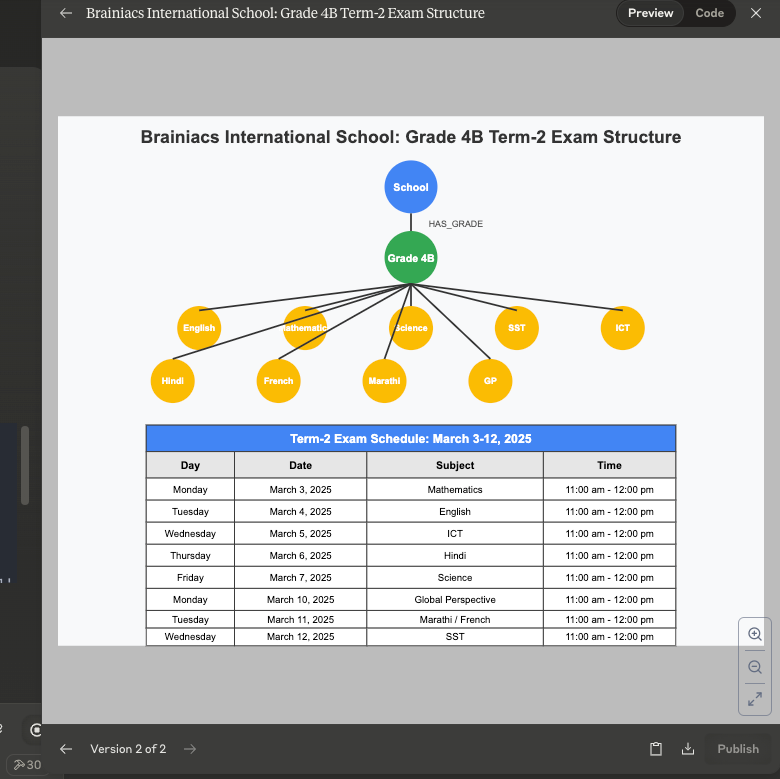 显示节点类型和关系的结构模式图
显示节点类型和关系的结构模式图
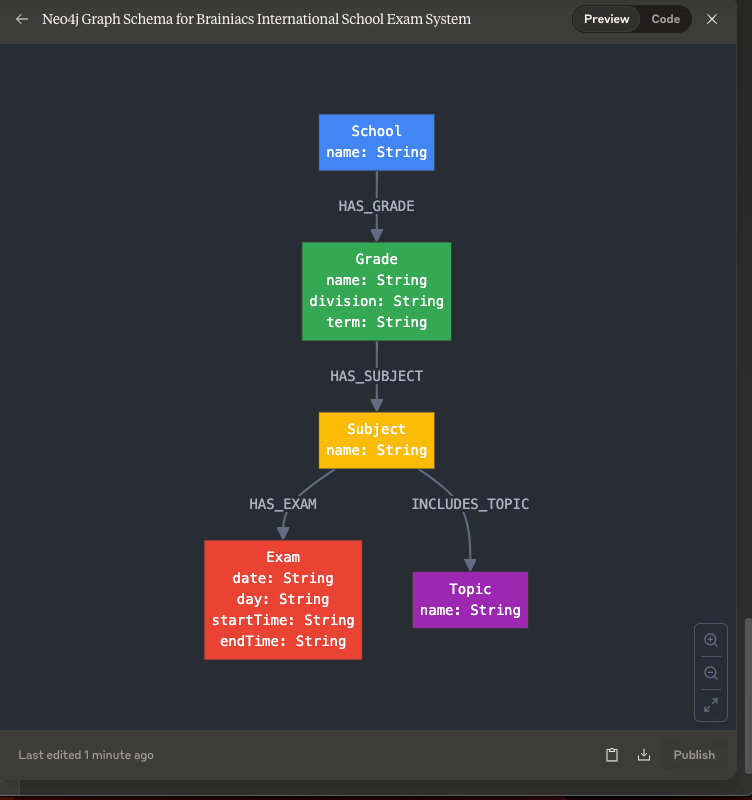 显示节点类型和关系的结构模式图
显示节点类型和关系的结构模式图
\\2. 年级-科目-考试关系的图表示。
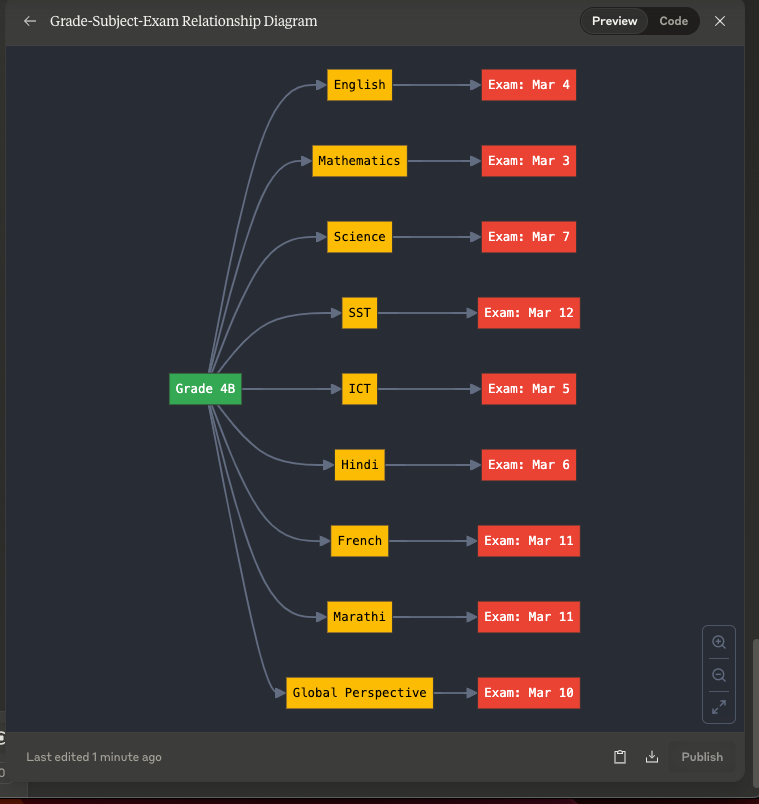 年级-科目-考试关系的图表示
年级-科目-考试关系的图表示
\\3. 显示各科目主题/内容数量的柱状图。
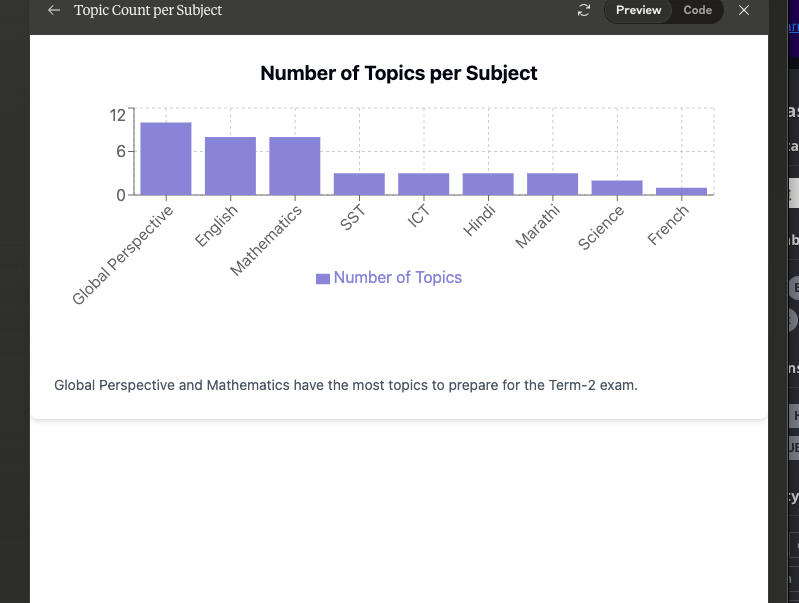 显示各科目主题/内容数量的柱状图
显示各科目主题/内容数量的柱状图
全程无需代码的 MCP 方法的核心优势
完成这个项目后,我发现将 Claude 与 MCP 结合用于 Neo4j 具有以下几个显著优势:
- \\1. 易用性:图数据库操作对非开发人员更加友好,无需编程基础即可上手。
- \\2. 速度:构建复杂数据库的速度显著加快。
- \\3. 自然语言接口:可以使用日常语言查询数据库。
- \\4. 自动化文档:Claude 自动为数据库结构生成文档。
- \\5. 内置可视化:无需额外工具即可获得有用的可视化效果。
- \\6. 敏捷迭代:通过对话即可轻松修改和扩展数据库。
局限性与注意事项
尽管此方法功能强大,但也存在一些值得注意的局限性:
- \\1. 复杂查询:复杂的查询模式可能仍需要手动优化才能获得最佳性能。
- \\2. 安全性:需要注意 MCP 配置中数据库凭据的安全问题。
- \\3. 性能:对于大型数据库,专门的工具可能提供更好的性能。
- \\4. 验证:始终需要验证大型语言模型 (LLM) 的操作,包括数据提取、数据创建、查询结果和生成的代码。作为你所在领域和用例的专家,最终结果的准确性和可靠性仍需你来把控并负责。
总结
Claude、MCP 和 Neo4j 的结合代表着图数据库技术走向民主化的重要一步。通过消除编码障碍,此方法为更广泛的受众开启了强大的知识图谱构建能力。
无论你是构建课程关系的教育工作者,还是绘制复杂网络的科研人员,抑或是可视化组织结构的业务分析师,这种对话驱动的方法都让图数据库比以往任何时候都更易于使用。
我期待看到这种方法的未来发展,以及通过 AI 辅助的对话驱动开发,能够进一步简化哪些复杂数据库任务。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


