AI-Compass GraphRAG技术生态:集成微软GraphRAG、蚂蚁KAG等主流框架,融合知识图谱与大语言模型实现智能检索生成
AI-Compass GraphRAG技术生态:集成微软GraphRAG、蚂蚁KAG等主流框架,融合知识图谱与大语言模型实现智能检索生成
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力
GraphRAG模块构建了涵盖主流框架的图检索增强生成技术生态,将知识图谱与大语言模型深度融合,实现结构化知识的智能检索与生成。该模块整合了微软GraphRAG模块化图RAG系统、蚂蚁KAG专业领域知识增强框架、港大LightRAG简单快速检索生成、CircleMind Fast-GraphRAG智能适应系统等核心技术,以及阿里OmniSearch多模态检索、StructRAG混合信息结构化等前沿研究成果。技术栈包含了nano-graphrag轻量级实现、tiny-graphrag简化版本、GraphRAG-Local-UI本地可视化界面、itext2kg增量知识图谱构造器等专业组件,覆盖了从原型开发到生产部署的全流程需求。模块深度集成了深度文档理解、实体关系抽取、多跳推理查询、子图检索优化等核心技术,支持动态VQA数据集、自适应规划智能体、推理时混合信息结构化、多模态知识图谱构建等高级功能。此外,还提供了OpenSPG语义增强可编程知识图谱、KAG技术报告与实践分享、LightRAG效率与准确性提升、GraphRAG本地LLM集成等理论与实践指导,以及医疗诊断、金融分析、法律咨询、科学研究等专业领域应用案例,帮助开发者构建基于图结构知识的下一代智能问答系统,实现更加准确、全面、可解释的知识服务。
目录
- 0.Fast-graphrag
- 0.GraphRAG-微软
- 0.KAG蚂蚁
- 0.LightRAG
- 0.nano-graphrag
- 1.GraphRAG-Local-UI
- 1.OmniSearch 阿里多模态rag
- 1.StructRAG 阿里
- 2.tiny-graphrag
================================================================================
3.GraphRAG
- 2.itext2kg:使用大型语言模型的增量知识图谱构造器
0.Fast-graphrag
简介
Fast GraphRAG 是一个流线型且可提示的快速图检索增强生成 (GraphRAG) 框架,旨在提供可解释、高精度、代理驱动的检索工作流。它致力于简化高级 RAG(检索增强生成)的实施,无需从头构建复杂的代理工作流。
核心功能
- 智能适应性检索: 能够根据具体用例、数据和查询智能地调整和优化信息检索。
- 高精度RAG: 提供高性能的检索增强生成能力,以获得更准确的答案。
- 代理驱动工作流: 支持通过代理(Agent)驱动的检索过程,提高工作效率和自动化水平。
- 简化集成: 设计用于无缝集成到现有检索管道中,降低使用门槛。
- 个性化Pagerank探索: 利用个性化PageRank算法在图谱中探索并找到最相关的信息片段。
技术原理
Fast GraphRAG 的核心技术原理基于图检索增强生成 (GraphRAG) 范式。它通过构建和利用知识图谱来组织和连接信息,从而实现更精确和上下文感知的检索。具体来说,该框架利用个性化PageRank算法在图结构数据中进行高效探索,根据查询找到与用户需求最相关的信息节点。结合代理驱动的工作流(Agentic Workflows),它能够实现更智能、更动态的检索过程,模拟人类推理和决策过程来优化信息获取。这使得RAG系统不仅能够检索到信息,还能理解信息之间的关系,从而生成高质量、可解释的输出。
应用场景
- 智能问答系统: 构建能够理解复杂查询并从海量知识库中提供精准答案的智能问答应用。
- 信息检索与推荐: 在大型数据集中快速定位相关信息,或根据用户兴趣进行个性化内容推荐。
- 知识管理: 帮助企业或组织更好地组织、管理和利用其内部知识资产。
- 研究与分析: 加速研究人员从大量文献或数据中提取关键信息,进行深入分析。
- 内容生成: 辅助大语言模型生成更准确、更具事实依据的内容,减少幻觉(hallucination)现象。
- circlemind-ai/fast-graphrag: RAG that intelligently adapts to your use case, data, and queries
0.GraphRAG-微软
简介
GraphRAG是微软研究院开发的一个模块化、基于图的检索增强生成(RAG)系统。它旨在通过结合知识图谱与大型语言模型(LLMs)的力量,从非结构化文本数据中提取有意义的结构化信息,并在此基础上进行问答和内容生成。相较于传统RAG方法,GraphRAG能够提供更结构化的信息检索和更全面的响应生成。
核心功能
- 结构化数据提取与转化: 利用LLMs将非结构化文本转化为结构化的图数据。
- 增强型检索: 基于构建的知识图谱进行信息检索,提高检索的精准性和关联性。
- 综合性问答: 能够对私有或此前未见的复杂数据集进行高效的问答。
- 信息整合与总结: 整合文本提取、网络分析、LLM提示和总结等多个环节,实现对文本数据集的深度理解。
- 系统模块化设计: 包含索引器(Indexer)、查询器(Query)和提示调优(Prompt Tuning)等核心子系统。
技术原理
GraphRAG的核心技术原理在于其创新的图-RAG范式。它首先通过自然语言处理(NLP)和大语言模型(LLM)对非结构化文本进行解析,识别实体、关系和事件,并将其转换为知识图谱(Knowledge Graph)结构。这一过程涉及信息提取(Information Extraction)和图构建(Graph Construction)。在检索阶段,系统利用图的拓扑结构和语义信息进行图遍历(Graph Traversal)和路径发现(Path Finding),以获取与查询相关的上下文信息,而非仅仅依赖文本相似度。随后,这些结构化和上下文化的信息被作为增强上下文(Augmented Context)输入到LLM中,通过提示工程(Prompt Engineering)引导LLM生成更精准、更具逻辑性和连贯性的回答。这种方法有效解决了传统RAG在处理复杂关系和多跳推理时的局限性,提升了回答的可解释性(Interpretability)和溯源性(Traceability)。
应用场景
- 企业内部知识管理: 用于分析和查询大量的非结构化企业文档,如报告、合同、邮件等,实现高效的知识发现和问答。
- 科研数据分析: 辅助科学家从海量的科研论文、专利和实验数据中提取关键信息和潜在关联,加速研究进程。
- 智能客服与问答系统: 构建能够理解复杂用户意图并提供精准、结构化回答的智能客服机器人。
- 情报分析: 从公开或私有数据源中识别实体、事件和关系,进行复杂的网络分析,支持决策制定。
- 法律与合规领域: 分析法律文件、判例和法规,辅助律师进行案例研究和风险评估。
- microsoft/Graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system
- GraphRAG-文档手册
- Microsoft GraphRAG | 基于知识图谱的RAG套件,构建更完善的知识库_哔哩哔哩_bilibili
0.KAG蚂蚁
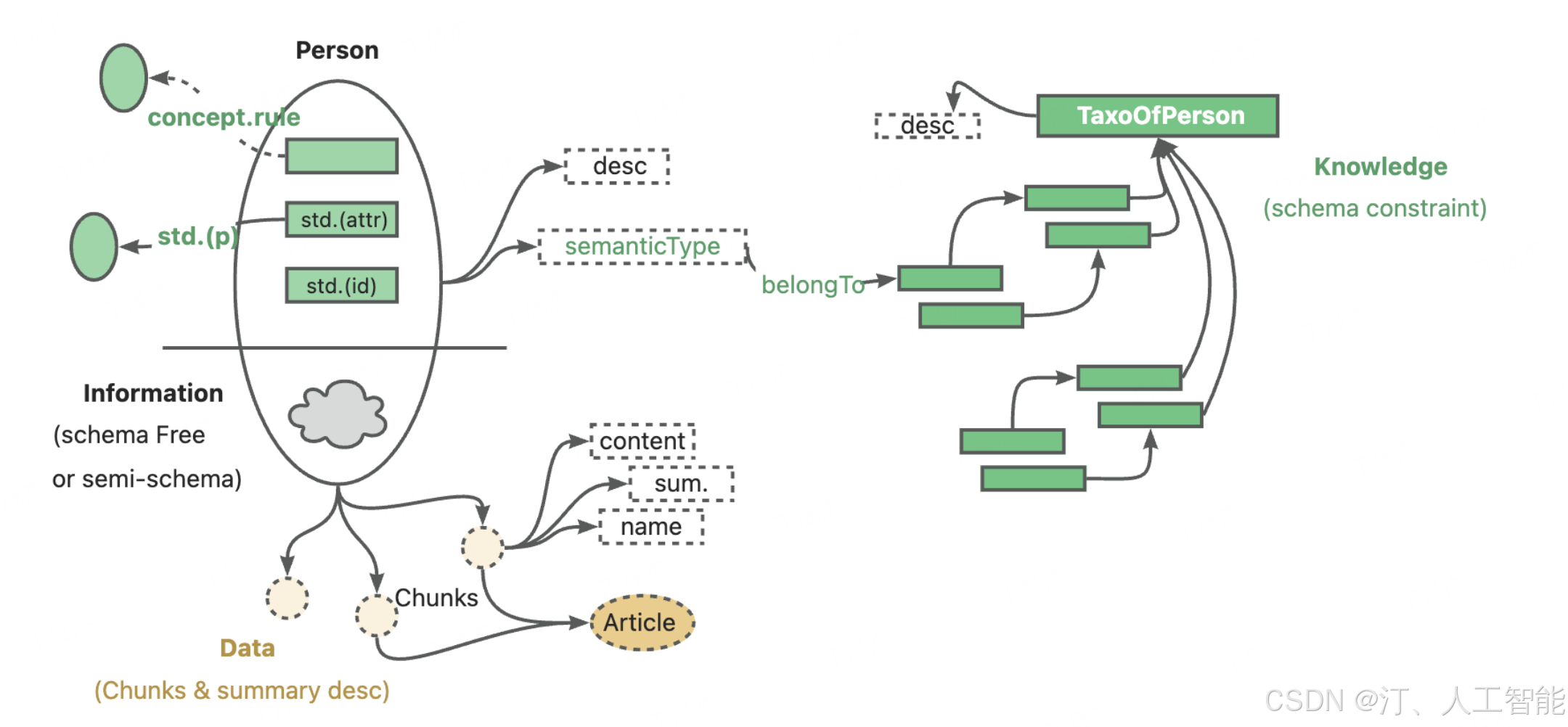
- KAG/README_cn.md at master · OpenSPG/KAG
- 语义增强可编程知识图谱
- OPENSPG用户手册
- 国内首个专业领域知识增强服务框架 KAG 技术报告,助力大模型落地垂直领域
- KAG 技术与实践分享|基于 KAG 框架自主完成领域图谱构建和知识问答
- 蚂蚁 KAG 框架核心功能研读
0.LightRAG
简介
LightRAG是香港大学和北京邮电大学研究团队推出的轻量级、高效检索增强生成(RAG)方法。它将图结构融入文本索引和检索,采用双层检索系统,结合增量更新算法,能高效处理不同层次查询,快速整合新信息,在生成速度和上下文相关性上表现出色,适合更多开发者和小型企业。
核心功能
- 图增强文本索引:建立相关实体复杂关系,提升上下文理解能力。
- 双层检索系统:同时处理低层具体细节和高层抽象概念查询。
- 增量更新算法:不重建数据索引,快速整合最新信息。
- 支持多类型存储:提供多种存储实现选项,如Neo4J、PostgreSQL等。
- 多模型集成:支持OpenAI、Hugging Face、Ollama等模型,以及与LlamaIndex集成。
- 对话历史支持:支持多轮对话,考虑对话历史进行查询。
- 用户提示定制:通过
user_prompt参数引导LLM处理检索结果。 - 插入功能多样:支持基本插入、批量插入,可关联文件路径实现溯源。
技术原理
- 基于图的文本索引:将原始文本分割成小块,利用大语言模型提取实体和关系,生成键值对,构建知识图谱。
- 双层检索:详细层面关注文档具体小部分,实现精确信息检索;抽象层面关注整体意义,理解不同部分广泛连接。
- 存储机制:使用四种类型存储,每种有多种实现选项,初始化时可通过参数设置。
- 模型注入:初始化时需注入LLM和Embedding模型的调用方法,支持多种模型API。
应用场景
-
信息检索:适用于回答具体和抽象问题,如文献检索、知识问答。
-
动态数据处理:用于新闻、实时分析等数据变化频繁的场景。
-
智能客服:支持多轮对话,结合对话历史提供准确回复。
-
小型企业应用:轻量化特性适合处理大规模知识库,降低计算成本。
-
知识图谱构建:建立相关实体复杂关系,提升系统上下文理解能力。
-
HKUDS/LightRAG: “LightRAG: Simple and Fast Retrieval-Augmented Generation”
-
论文:LightRAG: Simple and Fast Retrieval-Augmented Generation
-
LightRAG:提升检索增强生成的效率与准确性
0.nano-graphrag
简介
nano-graphrag 是 GraphRAG 模型的一个简化且易于访问的实现,旨在从文本文档中进行知识提取和问答。它提供了一个更易于用户使用和修改的替代方案,解决了官方 GraphRAG 实现代码量大、不易阅读研究的痛点,其代码量更小、运行更快。
核心功能
- 知识提取与问答: 能够从文本数据中提取知识并支持问答功能。
- 简化RAG操作: 提供简化的RAG(检索增强生成)插入和查询功能,允许只返回图谱中检索到的上下文。
- 去重处理: 使用内容的MD5哈希作为键,避免了块的重复存储。
- 可定制性: 支持用户自定义分块方法,并允许替换存储相关的组件。
- JSON格式输出: 可以通过
best_model_func将输出格式化为JSON对象。 - 高效社区处理: 不同于原始GraphRAG的Map-Reduce风格,nano-graphrag仅使用Top-K个重要且核心的社区(默认为512个社区)来填充上下文,从而优化了全局搜索。
技术原理
nano-graphrag 的核心在于对GraphRAG模型的轻量级重构与优化。它利用图结构来组织和连接文本信息,将知识点及其关系构建成图谱。在数据处理层面,通过对内容进行MD5哈希来确保数据块的唯一性,避免重复存储。在检索过程中,它支持**朴素RAG(Naive RAG)**模式,能够直接从构建的知识图谱中检索相关上下文。
与原始GraphRAG的一个主要区别在于全局搜索策略。原始实现采用Map-Reduce风格来填充上下文,而nano-graphrag则通过识别和选择Top-K个最重要和中心的社区(Community Detection),将这些精选社区的信息作为上下文,极大地提高了检索效率和相关性。这暗示其可能采用了某种图算法(如中心性度量、社区发现算法)来评估社区的重要性。此外,它集成了语言模型(如DeepSeek)和嵌入功能(如GLM)来处理文本数据并生成嵌入向量,从而实现高效的知识存储、检索与查询。
应用场景
- 轻量级知识库构建: 适用于需要快速搭建小型或中型知识库,进行高效知识管理和查询的场景。
- 文档智能问答系统: 可用于构建针对特定领域文档的智能问答系统,例如企业内部文档、技术手册等。
- 研究与原型开发: 由于其代码量小、易于修改,非常适合研究人员和开发者进行GraphRAG模型原理的理解、功能验证及快速原型开发。
- 资源受限环境下的RAG部署: 相比于复杂的官方实现,nano-graphrag更适合在计算资源或存储空间有限的环境中部署RAG应用。
- 定制化信息检索: 适用于需要根据特定需求定制分块、存储或检索逻辑的场景。
- gusye1234/nano-graphrag: A simple, easy-to-hack GraphRAG implementation
1.GraphRAG-Local-UI
简介
GraphRAG-Local-UI是一个旨在成为终极的本地图RAG(Retrieval-Augmented Generation,检索增强生成)和知识图谱(KG)本地大语言模型(LLM)应用的生态系统。它利用本地LLM,提供一个用户友好的界面,用于管理和交互GraphRAG系统,尤其专注于对大型文本数据进行索引和查询。目前该项目正处于向独立的索引/提示调优和查询/聊天应用过渡的阶段,所有功能都围绕一个强大的中心API构建。
核心功能
- 本地LLM集成: 支持配置和使用如Ollama等本地大语言模型。
- 索引与提示调优: 提供对文本数据进行索引和优化提示词的功能。
- 查询与聊天界面: 允许用户通过直观的UI进行内容查询和交互式聊天。
- 数据可视化: 包含可视化功能,便于理解知识图谱和RAG流程。
- API驱动架构: 所有核心功能通过一个健壮的中心API提供服务,支持多应用集成。
技术原理
该项目基于检索增强生成(RAG)方法,结合本地大语言模型(LLM)与知识图谱(KG)技术。其核心架构包括:
- GraphRAG系统: 作为主干,处理大型文本数据的索引和查询。
- 本地LLM支持: 允许用户利用本地部署的大模型进行生成式任务。
- API服务器: 基于FastAPI构建的强大后端服务器,处理所有核心操作。
- 向量存储: 可能利用向量数据库来存储和检索嵌入,以支持高效的语义搜索。
- Gradio界面: 用户交互界面可能通过Gradio框架构建,提供友好的前端体验。
应用场景
- 本地知识管理: 适用于希望在本地环境管理和查询大量私有或敏感文本数据的用户。
- 企业内部RAG系统: 构建基于企业文档和知识库的智能问答和内容生成系统。
- 研究与开发: 为研究人员和开发者提供一个实验和优化GraphRAG模型与本地LLM交互的平台。
- 教育与学习: 创建个性化的学习助手,通过知识图谱和LLM提供定制化的信息检索和解释。
- 离线AI应用: 对于网络受限或对数据隐私要求高的场景,提供离线的本地LLM解决方案。
- severian42/GraphRAG-Local-UI: GraphRAG using Local LLMs - Features robust API and multiple apps for Indexing/Prompt Tuning/Query/Chat/Visualizing/Etc. This is meant to be the ultimate GraphRAG/KG local LLM app.
1.OmniSearch 阿里多模态rag
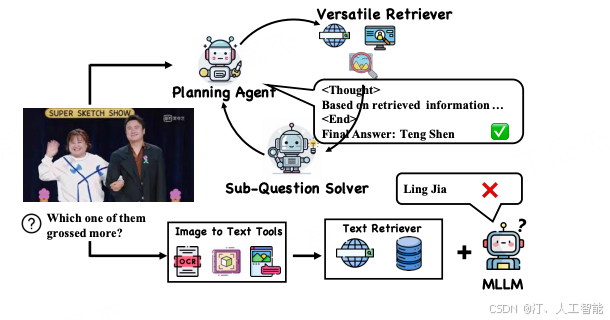
简介
围绕多模态检索增强生成(mRAG)展开。首先指出现有启发式 mRAG 存在非自适应和过载检索查询问题,且当前 VQA 数据集无法充分反映。为此构建了 Dyn - VQA 数据集,包含三种动态问题类型。同时提出了首个自适应规划代理 OmniSearch,能实时规划检索动作,大量实验证明其有效性。
核心功能
- Dyn - VQA 数据集:评估 mRAG 方法处理动态知识检索任务的表现,涵盖多种领域和动态问题类型。
- OmniSearch:将复杂多模态问题分解为子问题链,根据问题解决状态和检索内容动态调整检索策略,为 MLLMs 提供相关准确知识。
技术原理
- Dyn - VQA 数据集构建:通过文本问题写作、多模态改写、中英文翻译与校对三步构建,确保问题质量和多样性。
- OmniSearch 框架:由规划 agent、检索器、子问题求解器组成。规划 agent 根据问题和反馈生成子问题、选择检索工具;检索器执行检索操作;子问题求解器解答子问题并反馈。
应用场景
-
实时信息查询:如体育赛事结果、股票价格等实时变化信息的查询。
-
多模态知识问答:结合图像和文本信息进行推理的问答场景。
-
复杂问题推理:需要多步推理的问题,如人物职业推理等。
-
Alibaba-NLP/OmniSearch: Repo for Benchmarking Multimodal Retrieval Augmented Generation with Dynamic VQA Dataset and Self-adaptive Planning Agent
-
OmniSearch论文
-
阿里多模态RAG新框架,快速提升图文检索准确率
1.StructRAG 阿里
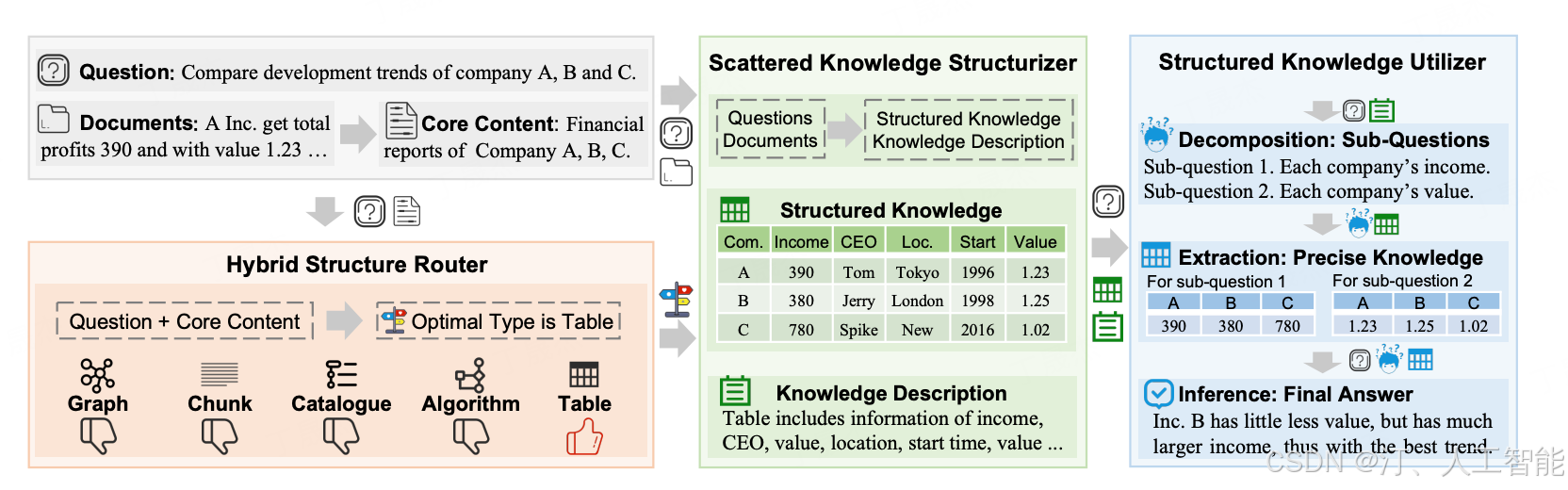
简介
StructRAG 是中国科学院和阿里巴巴集团研究人员提出的新 RAG 框架。现有 RAG 方法处理知识密集型推理任务时,因信息分散难以准确识别关键信息和全局推理。StructRAG 借鉴人类处理复杂问题时将信息结构化的认知理论,采用混合信息结构化机制,根据任务需求构建和利用结构化知识,提升 LLMs 在知识密集型推理任务上的性能。
核心功能
- 混合结构路由器:根据输入问题和文档核心内容,选择最合适的知识结构类型,如表格、图形等,使用基于 DPO 的方法训练。
- 分散知识结构化器:将原始文档转化为选定格式的结构化知识及知识描述,汇总成整体知识结构和总体描述。
- 结构化知识利用器:将复杂问题分解为简单子问题,从结构化知识中提取精确知识,整合后生成最终答案。
技术原理
- 采用混合信息结构化机制,通过三个模块依次完成任务。混合结构路由器基于问题和文档核心内容确定最佳结构类型;分散知识结构化器利用 LLM 能力将原始文档转化为对应结构化知识;结构化知识利用器对问题分解和知识提取以进行准确推理。
- 训练混合结构路由器时,使用合成 - 模拟 - 判断方法构建偏好对,通过 DPO 算法训练,使路由器能准确选择结构类型。
应用场景
适用于各种知识密集型推理任务,如财务报告分析、多文档信息比较、总结归纳、长链推理、规划任务等,可有效解决任务中信息分散和噪音问题,提升推理准确性。
- Li-Z-Q/StructRAG: StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization
- StructRAG:通过推理时混合信息结构化提升 LLMs 的知识密集型推理
- StructRAG论文
2.tiny-graphrag
简介
Tiny GraphRAG 是一个轻量级、约1000行的GraphRAG(图谱检索增强生成)算法的Python实现。它旨在提供一个易于理解、可修改且不依赖任何框架的解决方案。该项目的一大特色是仅使用本地运行的语言模型,不依赖于OpenAI或任何商业大模型服务商,支持完全本地化部署和运行。
核心功能
- 本地化信息抽取与知识图谱构建: 利用本地运行的语言模型从文本数据中提取实体和关系,并构建结构化的知识图谱。
- 图谱驱动的检索增强: 基于构建的知识图谱进行信息检索,为语言模型提供更精准和丰富的上下文信息。
- 本地化大模型生成: 结合检索到的图谱信息,使用本地部署的大模型进行高质量的文本生成。
- 知识图谱可视化: 提供知识图谱的构建与查询结果的可视化功能。
技术原理
Tiny GraphRAG的核心技术原理在于将知识图谱与检索增强生成(RAG)范式相结合,并特别强调本地化部署。
- 文本预处理与分块: 输入的文本数据被进行预处理和逻辑分块。
- 实体与关系抽取: 利用预训练的本地语言模型对文本分块进行自然语言理解,从中识别关键实体及其相互之间的关系。
- 知识图谱构建: 将抽取的实体和关系转化为图结构数据,存储在图数据库中,形成知识图谱(Knowledge Graph)。这通常涉及节点(实体)和边(关系)的定义。
- 图谱检索: 当用户提出查询时,系统会基于查询内容在知识图谱中进行路径查找或子图匹配,检索出与查询最相关的图谱信息(结构化上下文)。
- 本地大模型融合生成: 将检索到的知识图谱信息作为增强上下文,输入到本地运行的语言模型中。语言模型结合这些结构化信息,生成更准确、更具上下文相关性的回答。整个过程不涉及外部API调用,保证数据隐私和运行效率。
应用场景
- 本地知识库问答系统: 构建私有的、不依赖云服务的企业内部或个人知识库问答系统,适用于对数据隐私要求高的场景。
- 离线智能助手: 在没有互联网连接或网络环境不稳定的情况下,提供智能问答、信息检索和内容生成服务。
- 轻量级RAG系统原型开发: 为研究人员和开发者提供一个简洁、易于理解和修改的GraphRAG实现,用于快速验证概念和功能。
- 资源受限环境下的AI应用: 在计算资源相对有限的环境中运行检索增强生成任务,实现高效的信息处理。
- limafang/tiny-graphrag
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟


