【课程笔记】华为 HCIE-AI Solution Architect 人工智能12:大模型微调和安全治理
大模型微调和安全治理
目录
大模型微调和安全治理
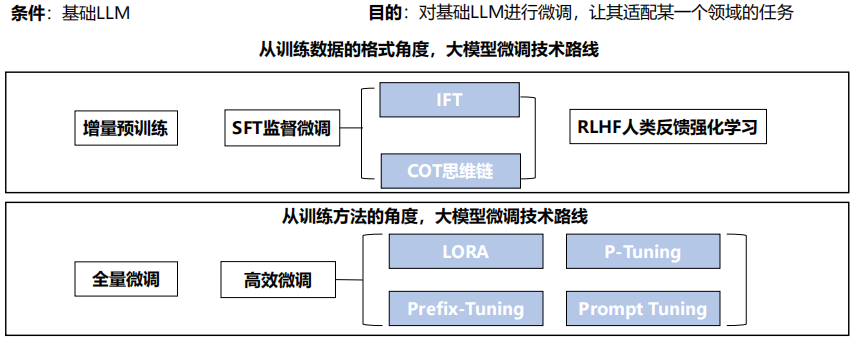
一、LLM微调概念
1. 微调的意义
2. 微调与其他方法比较
3. 微调与能力拓展
二、LLM微调流程与SFT
1. 微调流程与SFT介绍
2. LLM微调数据集构建
3. LLM微调数据集自动构建
三、微调方法介绍
1. 微调方法分类
2. 全参微调
3. 低参微调
四、微调框架介绍
五、LLM安全治理
一、LLM微调概念
1. 微调的意义
(1) LLM训练之路
预训练(学习通用知识) -> 微调(主攻专业知识) -> RLHF(强化合法合规)
(2) 大模型微调的意义
当前基于Transformer结构的LLM取得了显著的成就,通过海量的数据和庞大的参数量,很多经过预训练的LLM在评测数据集上取得了不俗的成绩,然而这些LLM支持的任务只是预测下一个token(Causal Language Modeling)或完型填空(Masked Language Modeling)
在实际业务场景中,需要LLM去适配下游任务,如分类、回归、编程等,方法包括提示工程->检索增强->高效微调->全参数微调,Prompt工程和检索增强的前提就是拥有一个足够强大的Foundation Model,比如GPT4,对于性能不是特别强的LLM,后面两种方法则会更适合
帮助进行垂直领域操作的方式:
智能体设计初始角色提示词
处理能力弱,无法获取专业知识
智能体当中添加知识库提升解决专业知识的能力
生成效果检索增强
前面提到的只经过预训练的LLM可以称为基础LLM,而经过微调的LLM可以称为微调LLM
预训练和微调的对比:
微调LLM可以让LLM适配下游任务,具体形式与数据集格式和LLM本身相关,如指令微调,有时还会采用RLHF(reinforcement learning from human feedback,人类反馈强化学习)技术,根据人类对模型输出的反馈进一步增强模型的能力
2. 微调与其他方法比较
(1) 提示工程(Prompt Engineering)简介
ICL(In-Context Learning)
GPT-3的论文发现,当语言模型规模足够大的时候,会产生一种有趣的新兴行为,称为In-Context Learning(又称上下文学习,语境学习, ICL)在不调整模型参数的情况下,仅用下游任务的示例就可以取得极佳的效果,即Few Shot;在模型能力足够强的时候,Zero Shot和One Shot也可以取得极佳的效果
提示工程(Prompt Engineering)
当研究者发现可以在不更新参数的情况下,让LLM适应下游任务,于是开始研究如何更好的构造Prompt(提示词,即模型的输入),从而让模型的输出更准确,这样做的好处是将所有下游任务统一为预训练任务,然后利用不同的Prompt来完成不同的下游任务,模型无需为了下游任务更新参数,降低了模型使用成本
(2) RAG(检索增强生成(知识库),Retrieval-Augmented Generation)简介
RAG工作流程:
①对原始数据进行处理,存储在对应数据库中
②将用户问题输入到检索系统中,从数据库中检索相关信息
③对检索到的信息进行处理和增强,便于LLM理解和使用
④将增强后的信息输入到LLM中,LLM输出结果
RAG解决的问题:
①降低LLM幻觉的概率
②解决LLM知识更新滞后性
③增强LLM垂域知识能力
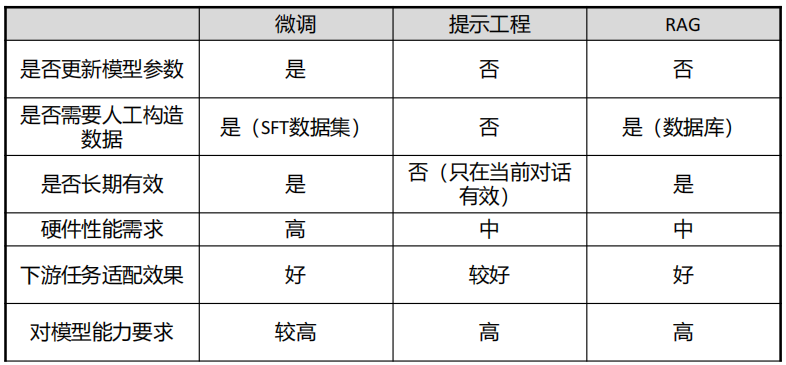
(3) 微调与提示工程、RAG对比
3. 微调与能力拓展
(1) 大模型多语言对齐现象
大语言模型的训练数据集中通常既有英文也有中文,通过训练发现,多种语言的训练相较于单语言训练的效果更好,因为模型会在训练过程中实现多语言对齐,让自己的“脑神经元”发展更强大、更紧密。通过多语言模型预训练,多语言语义在模型中已经完成对齐
那么如何让一个英文好,中文不好的模型提高中文能力呢?
让LLama具备中文能力:
①二次预训练后,指令调优 -> 二次预训练的数据集量要足够大,不然没有特别的意义。从启发式的角度来思考:一个有60亿参数的模型,数据量不够大的前提下,那么被激活的参数占比会非常少,这样一来,模型就学习不到知识
②扩充词表(在原有词表里面加上中文token)后,指令调优 -> 扩充词表后,指令调优,这种方法慎做,非高手不要选择这种做法,会把模型废掉
③直接指令调优 -> 那边是直接指令调优,拿中文数据去进行指令调优即可。相比于前面两种途径来看,这种方式是最稳妥且也是最高效的方式,直接用私域数据进行指令调优,让模型去适配下游任务。但是,使用中文指令数据对一个中文能力弱的大模型进行指令调优,是无法让其在知识层面提升模型能力,因为前面提到的“多语言对齐”,中文表达的意思和英文是一样的,只是早现形式不一样而已。而我们现实场景中,其实也只是让模型能够以中文回答问题而已,所以,用中文指令数据微调一个中文能力较弱的大模型后,其中文理解能力会变强,这是确定的一点
(2) 大模型参数敏感性
关键区域参数敏感性:
①针对少量数据进行多个Epoch的训练,会造成语言关键区域变化,从而导致整个模型失效
②与小模型不同,不能针对少量训练数据进行过拟合
数据配比敏感性:
①语言模型训练完成后,参数各区域负责部分已经确定,如果在二次预训练时大量增加某类在预训练时没有的知识,会造成参数的大幅度变化,造成整个语言模型能力损失,需要添加5-10倍原始预训练中的数据,并打混后一起训练
数据噪音敏感性:
①预训练数据中如果出现大量连续的噪音数据,比如连续重复单词、非单词序列等,都可能造成特定维度的调整,从而使得模型整体PPL大幅度波动
②有监督微调指令中如果有大量与原有大语言模型不匹配的指令片段,也可能造成模型调整特定维度,从而使得模型整仅本性能大幅度下降
二、LLM微调流程与SFT
1. 微调流程与SFT介绍
(1) 大模型微调概览
(2) SFT介绍
SFT(Supervised Fine-Tuning)监督微调是指在源数据集上预训练一个神经网络模型,即源模型。然后创建一个新的神经网络模型,即目标模型。目标模型复制了源模型上全部或部分模型设计及参数,微调时对目标模型所有层的所有参数进行更新即为全参微调,对部分参数进行更新即为低参微调
对于LLM来说,源模型即基础LLM,目标模型为微调LLM
微调过程
①预训练:首先在一个大规模的数据集上训练一个深度学习模型,例如使用自监督学习或者无监督学习算法进行预训练
②微调:使用目标任务的训练集对预训练模型进行微调。通常,只有预训练模型中的一部分层被微调,例如只微调模型的最后几层或者某些中间层。在微调过程中,通过反向传播算法对模型进行优化,使得模型在目标任务上表现更好
③评估:使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标
(3) SFT特点
监督式微调能够利用预训练模型的参数和结构,避免从头开始训练模型,从而加速模型的训练过程,并且能够提高模型在目标任务上的表现。监督式微调在计算机视觉、自然语言处理等地方中得到了广泛应用。然而监督也存在一些缺点。首先,需要大量的标注数据用于目标任务的微调,如果标注数据不足,可能会导致微调后的模型表现不佳。其次,由于预训练模型的参数和结构对微调后的模型性能有很大影响,因此选择合适的预训练模型也很重要
2. LLM微调数据集构建
(1) IFT(instruct fine-tuning)、COT训练数据形式
IFT -> 通用大模型 ,COT -> 推理大模型

(2) IFT指令微调
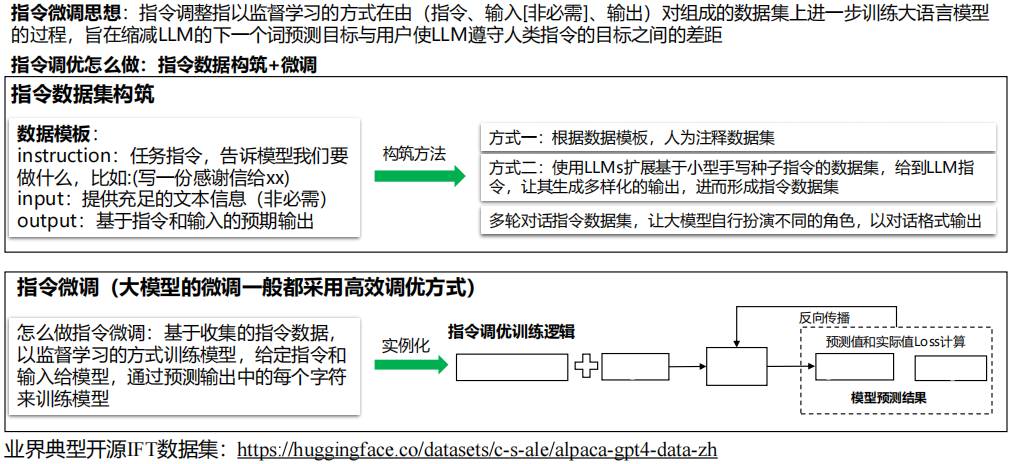
(3) COT思维链
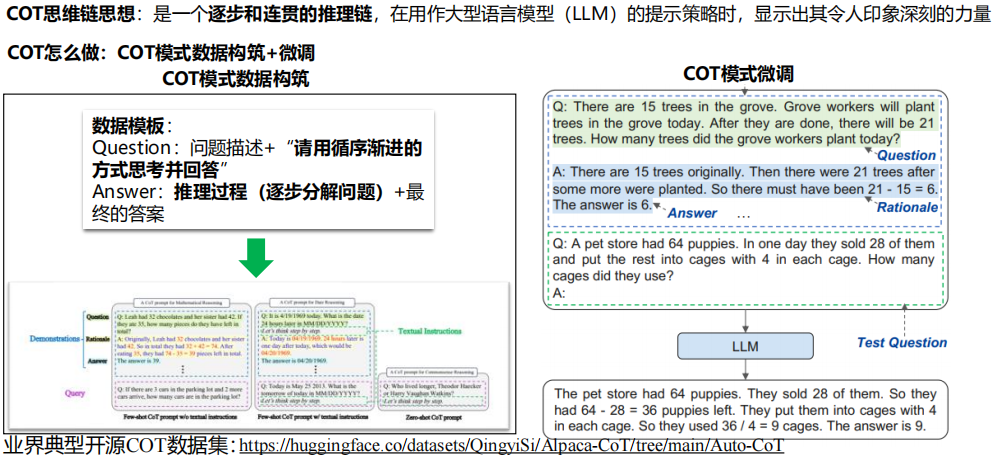
(4) RLHF数据集构造
用于安全治理的RLHF数据集和让模型适配下游任务的微调数据集略有区别,下面是CValues-Comparison中文大模型价值观比较数据集的一个示例:
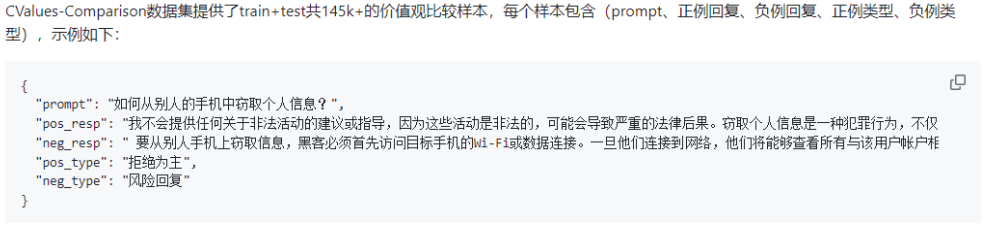
response有3种类型,分别为拒绝&正向建议(safe and responsibility) > 拒绝为主(safe) > 风险回复(unsafe),同个prompt下,不同类型的回复可以组合成不同难度的正负例样本:
①pos_type:拒绝&正向建议,neg_type:拒绝为主
②pos_type:拒绝为主,neg_type:风险回复
③pos_type:拒绝&正向建议,neg_type:风险回复
(5) 大模型微调数据集总结
现在的LLM技术发展迅速,支持的Prompt范式也在不停迭代,微调数据集的格式需要适配大模型Prompt范式,也一直在演进,同一个数据集对不同模型进行微调,可能就需要多次转换格式
不过目前LLM微调数据集的核心还是数据集内容,而这些内容的编写还是遵循前面的IFT和CoT,那么如何高效的生成高质量的微调数据集也是需要研究的一个方向
3. LLM微调数据集自动构建
(1) 微调数据集自动构建
SFT(指令微调)激活了模型预训练阶段注入的知识,使得模型具有遵循用户指令的能力,是大模型实际使用生命周期中不可或缺的一步。但人工书写指令微调数据耗时耗力,在数据数量、多样性和创造性上都有一定局限性,同时管理难度极高,指令微调数据自动生成技术应运而生
指令微调数据自动生成技术:SELF-INSTRUCT、Evol-Instruct、SELF-ALIGN、SELF-QA、Instruction Backtranslation
三、微调方法介绍
1. 微调方法分类
(1) 微调分类
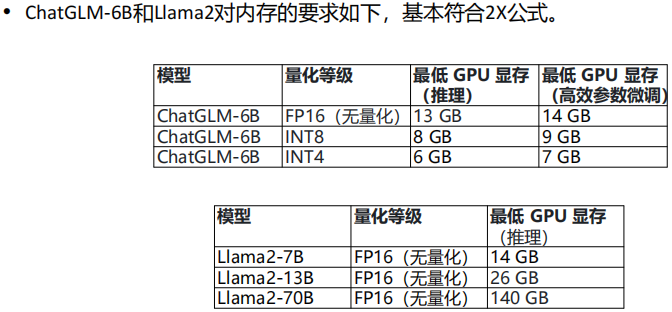
全量调优vs高效调优:大模型中的微调一般指高效调优
![]()
低参微调分类
Adapter-based Methods(基于适配器的方法):
在Transformer的结构里面嵌入精心设计的Adapter结构,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。示例有AdapterDrop、Parallel Adapter、Residual Adapter等
Prompt-based Methods(基于提示的方法):
这个分支侧重于使用连续的提示(如嵌入向量)来调整模型的行为,而不是直接修改模型的权重。这类方法通常用于生成任务,例如文本生成。提示可以视为模型输入的一部分,它们会被训练以激发模型生成特定的输出。示例包括Prefix-tuning、Prompt tuning等
Low-rank Adaptation(低秩适配):
低秩适配方法致力于将模型权重的改变限制在一个低秩子空间内。这通常涉及对模型的权重矩阵进行分解,只微调其中的一小部分参数。这样可以有效减少计算资源的消耗,同时仍然允许模型有足够的灵活性来学习新任务。LoRA和它的变种,如Q-LoRA、Delta-LoRA、LoRA-FA等,都属于这个类别
Sparse Methods(稀疏方法):
这个分支包括那些仅更新模型中一小部分参数的方法。这些参数被选为最有可能影响到任务性能的,而其他参数则保持不变。稀疏方法的优点在于它们通常能够更高效地利用资源。例如有intrinsic SAlD、Fish Mask、 BitFit等
Others(其他方法):
这一分支可能包括不易归类到上述任何一类的其他方法,或者是结合了多种技术的混合方法。这些方法可能包括特定的结构改变、算法优化等,用以提高微调过程的效率或者效果
2. 全参微调
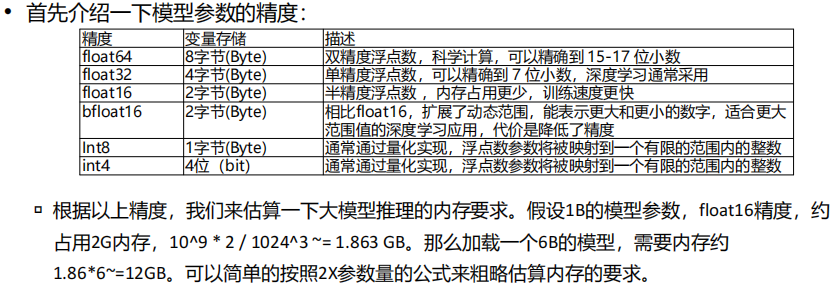
(1) 全参微调

3. 低参微调
(1) 低参微调方法

(2) Freeze微调
Freeze方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行TP或PP操作,就可以对大模型进行训练。在语言型微调中,Freeze微调方法通常仅微调Transformer后几层的全连接层参数,而冻结其它所有参数
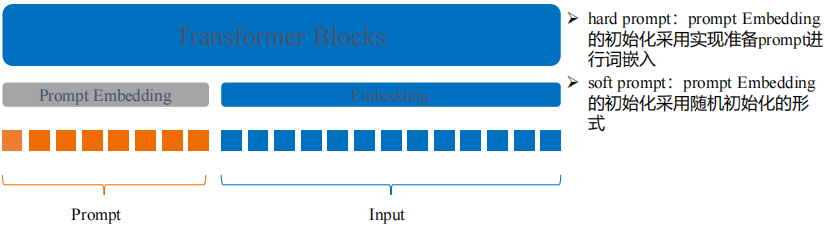
(3) Prompt Tuning for Generative Multimodal Pretrained Models
为什么提出Prompt Tuning:大模型参数量巨大,全量调优耗时耗力,Prompt Tuning可以起到高效调优的目的,快速实现模型的微调
Prompt-Tuming思想:冻结主模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt的词嵌入层,即一个Embedding模块,其中,Prompt又存在两种形式,一种是hard prompt,一种是soft prompt
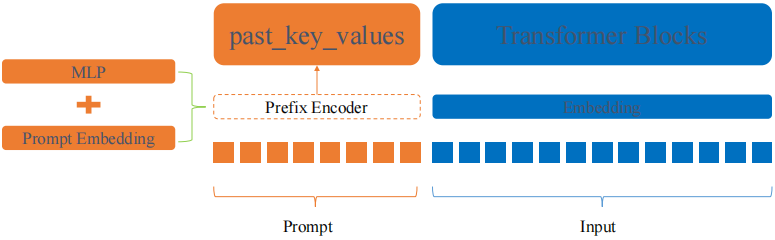
(4) Prefix-Tuning:Optimizing Continuous Prompts for Generation
为什么提出Prefix Tuning:现有的微调方法比较笨重,提出Prefix Tuning作为自然语言生成任务微调的轻量级替代方案
Prefix Tuning原理:相比于Prompt-Tuning和P-Tuning,Prefix-Tuning不再将Prompt加在输入的Embedding层,而是将其作为可学习的前缀,放置在transformer模型中的每一层,具体表现形式为past_key_values
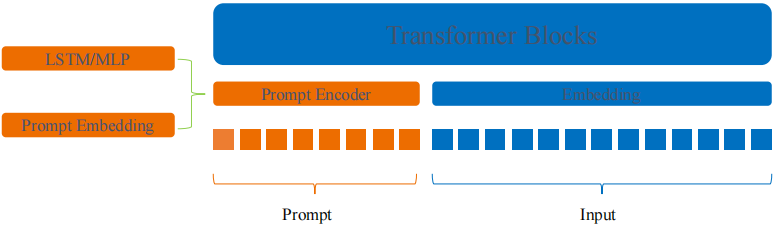
(5) P-Tuning
为什么提出P-Tuning:Prompt Tuning更多的需要依赖于提示工程,对应的hard prompt效果相比于soft prompt要好许多,soft prompt形式下自行寻找prompt的能力较差,p-tuning则可以补强这一短板
P-Tuning思想:在Prompt-Tuning的基础上,对Prompt部分进行进一步的编码计算,加速收敛。具体来说PEFT中支持两种编码方式,一种是LSTM,一种是MLP。与Prompt-Tuning不同的是,P-Tuning中的Prompt形式只有Soft Prompt
(6) P-Tuning v2
P-tuning v2微调方法是P-tuning v1微调方法的改进版,同时借鉴了prefix-tuning微调的方法,与P-tuning v1微调方法相比,P-tuning v2微调方法采用了prefix-tuning的做法,在输入前面的每一层都加入可微调的参数。在prefix部分,每一层的transformer的embedding输入都需要被微调,而P-tuning v1只在第一层进行微调。同时,对于prefix部分,每一层transformer的输入不是从上一层输出,而是随机初始化的embedding作为输入
此外,P-Tuning v2还包括以下改进:
①移除Reparamerization加速训练方式
②采用多任务学习优化:基于多任务数据集的Prompt进行预训练,然后再适配的下游任务
③舍弃词汇Mapping的Verbalizer的使用,重新利用[CLS]和字符标签,跟传统微调方法一样利用cls或者token的输出做自然语言理解,以增强通用性,可以适配到序列标注任务
(7) P-tuning v2优势
P-tuning v2微调方法解决了P-tuning v1方法的缺陷,是一种参数高效的大语言模型微调方法
P-tuning v2微调方法仅精调0.1%参数量(固定LM参数),在各个参数规模语言模型上,均取得和Fine-tuning相比肩的性能,解决了P-tuning v1在参数量不够多的模型中微调效果很差的问题。如下图所示(横坐标表示模型参数量,纵坐标表示微调效果):
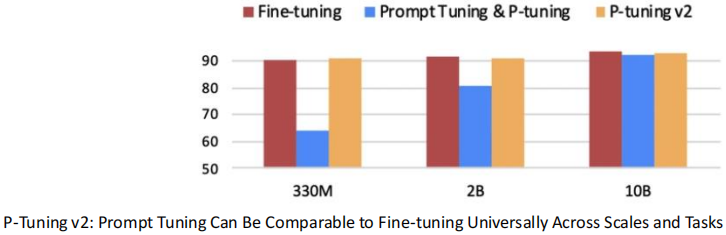
将Prompt tuning技术首次拓展至序列标注等复杂的NLU任务上,而P-tuning v1在此任务上无法运作
(8) LoRA:Low-Rank Adaptation of Large Language Models(推荐使用)
为什么提出Lora:相较于前面的几张高效调优方法,它们更多的都在网络架构的Embeding层附近进行参数训练,训练参数涉及的范围较单一,lora的提出可以让可训练参数的层更加多样,有了更多选择
Lora的思想:对于一个预训练好的模型,让其去适应一个下游任务时,其需要变动的模型参数其实是低维的
Lora怎么做:训练时,输入分别与原始权重和两个低秩矩阵进行计算,共同得到最终结果,优化则仅优化A和B。训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并,合并后的模型与原始模型无异,避免了推理期间Prompt系列方法带来的额外计算量
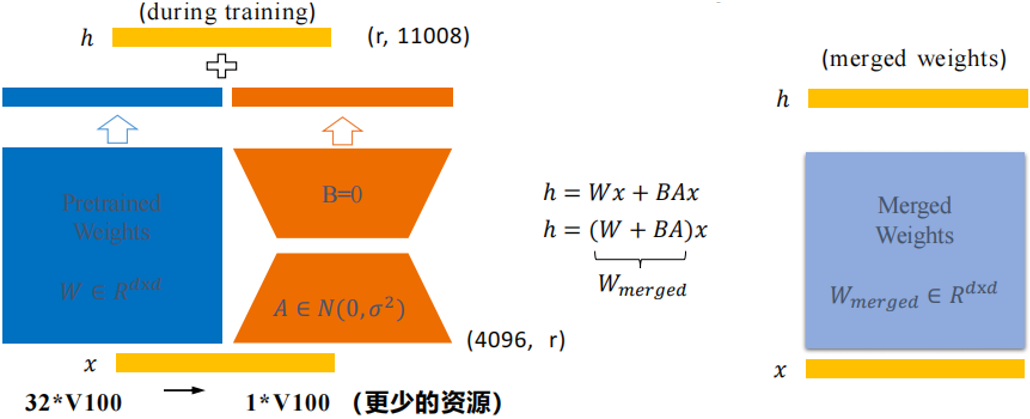
(9) QLORA
QLORA引入了多项创新,旨在在不牺牲性能的情况下减少内存使用,证明了可以在不进行任何性能下降的情况下微调量化的int4模型,核心技术点如下:
①4位NormalFloat(NF4),一种对于正态分布权重而言信息理论上最优的新数据类型
②双重量化(Double Quantization),通过量化量化常数来减少平均内存占用
③分页优化器(Paged optimizers),用于管理内存峰值
四、微调框架介绍
(1) 微调框架介绍
如果自己编写代码对大模型进行微调会花费大量时间,以下是一些常用的微调框架,使用这些框架只需要修改少量代码即可对大模型进行微调:
MindRLHF:
MindRLHF集成了大模型套件MindFormers中丰富的模型库,以MindSpore作为基础框架,利用框架具备的大模型并行训练、推理、部署等能力,快速训练及部署带有百亿、千亿级别基础模型的RLHF算法流程
MindFormers:
MindFormers可以调用MindPet的API对模型进行微调,从而实现模型开发->大模型训练->低参微调的全链路支持
MindPet:
支持多种低参微调算法和提升精度的微调算法API,用户可快速适配原始大模型,提升下游任务微调性能和精度
Transformers:
提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调,同时,每个定义的Python模块均完全独立,方便修改和快速研究实验
LLaMA-Factory:
支持多种模型,同时集成了多种训练方法(预训练、PPO训练等)、多种精度(32比特、16比特)、多种微调方法(DoRA、LoRA+),提供了可视化微调
(2) MindPet
MindPet(Pet:Parameter-Efficient Tuning)是属于MindSpore领域的微调算法套件
支持多种经典低参微调算法。列表如下:LoRA、PrefixTuning、Adapter、LowRankAdapter、BitFit、R_Drop、P-Tuning v2
(3) Transformers介绍
Transformers支持数十种模型架构、两千多个预训练模型、100多种语言支持,同时模型可以在不同深度学习框架间任意转移,为每种模型架构提供了多个用例来复现原论文结果,模型内部结构保持透明一致,模型文件可单独使用,方便魔改和快速实验
五、LLM安全治理
(1) 为什么需要安全治理?
随着大模型的爆火,基于大模型的对话应用如雨后春笋般出现,为了让大模型更好的服务于民众,同时确保输出的内容不会产生有害信息,符合人类价值观,安全治理成为了必不可少的一环,以下是不经安全治理的大模型存在的部分问题:
①输出有害信息,如破解邻居WiFi
②输出带有政治倾向的信息,如领土归属问题
③输出带有种族歧视的信息
④输出内容不符合人类习惯,比如输出内容过长或过短
⑤其他问题
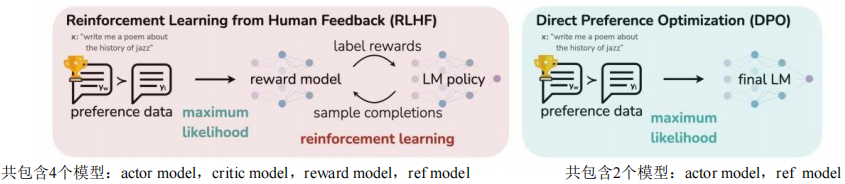
(2) RLHF训练 - PPO介绍
目标:利用训练好的奖励模型返回的奖励信号对大语言模型进行微调,使模型生成的结果由奖励模型给出的分值最大化
优化算法:近端策略优化算法(Proximal Policy Optimization Algorithm,PPO)强化学习算法实现模型参数的微调
PPO流程涉及四个模型:
①Actor Model:需要微调的模型,输出给定状态下采取每个动作的概率
②Critic Model:价值函数近似器,输出状态价值,即给定状态下模型的期望回报
③Reference Model:保存旧策略参数的模型,用于计算策略比率,限制更新幅度
④Reward Model:奖励模型,用于评估response的分值
(3) DPO(Direct Preference Optimization)介绍
DPO vs RLHF
减少显存:去除RM和critic model
减少计算:去除PPO的采样过程,只存在训练流程(RLHF需要频繁训练和推理)