基于SambaNova的DeepSeek-R1、Qdrant二进制量化以及LangGraph,实现了32倍内存缩减的一个构建快速RAG系统方案
基于SambaNova的DeepSeek-R1、Qdrant二进制量化以及LangGraph,实现了32倍内存缩减的一个构建快速RAG系统方案
猫头虎分享最近阅读的一个适合处理大量文件和数据的场景构建快速RAG系统方案,通过Qdrant的二进制量化技术,减少向量数据的内存占用, 结合SambaNova DeepSeek-R1的推理能力,快速响应并提供高质量答案。
摘要
本文结合 SambaNova Systems 的 DeepSeek-R1 强大推理能力、Qdrant 的二进制量化(Binary Quantization,BQ)技术,以及 LangGraph 的流程编排能力,打造一个高性能、低内存占用的多文档检索增强生成(RAG)系统。通过对向量数据进行 1 bit 极限压缩,并配合「先快速筛选、后精确重评分」策略,实现高维嵌入检索的高速响应与高质量答案。
使用SambaNova Systems的高性能DeepSeek-R1、Qdrant 的 二进制量化以及 LangGraph 的编排功能。

文章目录
- 作者简介
-
- 猫头虎是谁?
- 作者名片 ✍️
- 加入我们AI共创团队 🌐
- 加入猫头虎的AI共创变现圈,一起探索编程世界的无限可能! 🚀
- 正文
-
- 目录
- 系统概览
- 为什么要做二进制量化?
- 二进制量化原理详解
- Qdrant 配置示例
- LangGraph + SambaNova DeepSeek-R1 快速 RAG 实现
-
- 1. 环境与依赖安装
- 2. 数据加载与预处理
- 3. 向量化与入库
- 4. 构建 LangGraph 流程
- 性能评估与内存优化效果
- 适用场景与注意事项
- 总结与后续展望
- 文末粉丝专属福利
- 联系我与版权声明 📩
作者简介
猫头虎是谁?
大家好,我是 猫头虎,AI全栈工程师,某科技公司CEO,猫头虎技术团队创始人,也被大家称为虎哥。我目前是COC北京城市开发者社区主理人、COC西安城市开发者社区主理人,以及云原生开发者社区主理人,在多个技术领域如云原生、前端、后端、运维和AI都有超多内容更新。
感谢全网三十多万粉丝的持续支持,我希望通过我的分享,帮助大家更好地掌握和使用各种技术产品,提升开发效率与体验。
作者名片 ✍️
- 博主:猫头虎
- 全网全平台搜索关键词 猫头虎 即可与我建联
- 作者微信号:Libin9iOak
- 作者公众号:猫头虎技术团队
- 更新日期:2025年06月09日
- 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能!
加入我们AI共创团队 🌐
- 猫头虎AI共创社群矩阵列表:
- 点我进入AI共创变现社群入口专区:
https://bbs.csdn.net/topics/617720781 - 点我进入CSDNWF万粉博主变现入口专区:
https://bbs.csdn.net/topics/617717169
- 点我进入AI共创变现社群入口专区:
加入猫头虎的AI共创变现圈,一起探索编程世界的无限可能! 🚀
正文
目录
- 系统概览
- 为什么要做二进制量化?
- 二进制量化原理详解
- Qdrant 配置示例
- LangGraph + SambaNova DeepSeek-R1 快速 RAG 实现
- 性能评估与内存优化效果
- 适用场景与注意事项
- 总结与后续展望
系统概览
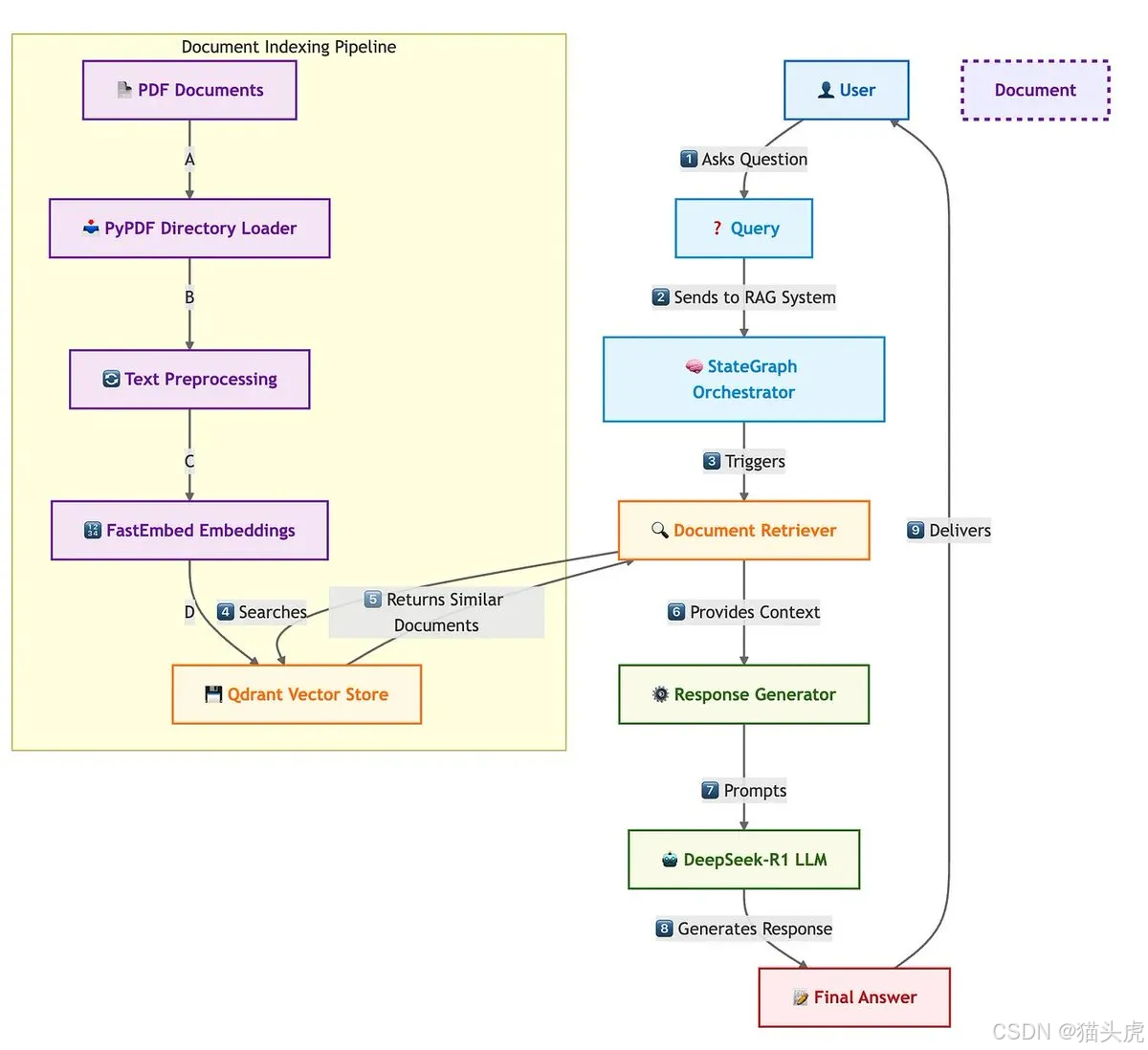
本方案主要包含三大核心组件:
- DeepSeek-R1(SambaNova):高性能推理引擎,负责最终答案生成。
- Qdrant(二进制量化):用于海量向量的存储与检索,通过 1 bit 压缩大幅节省 RAM。
- LangGraph:流程编排,串联「检索—生成」两步,实现端到端 RAG。
整体流程如下:
- 用户提问
- LangGraph 调度:先使用 Qdrant BQ 索引进行快速候选检索
- 提取候选文档后,加载原始浮点向量做精确重评分
- 将检索到的上下文与用户问题拼接,调用 DeepSeek-R1 生成答案
为什么要做二进制量化?
当面对数百万、乃至上亿条文档嵌入时,传统的 float32 向量(每维 4 Byte)带来的内存压力不可小觑。以常见的 1536 维 OpenAI 文本嵌入为例:
- 原始存储:1536 × 4B ≈ 6 KB/向量
- 1M 向量:6 GB RAM
量化(Quantization)技术通过压缩向量分量,牺牲少量精度换取存储与计算效率。
- 标量量化:8 bit 或 4 bit 表示每个分量,精度损失小,但压缩倍数有限。
- 二进制量化:每个分量仅用 1 bit,压缩比高达 32×。
二进制量化原理详解
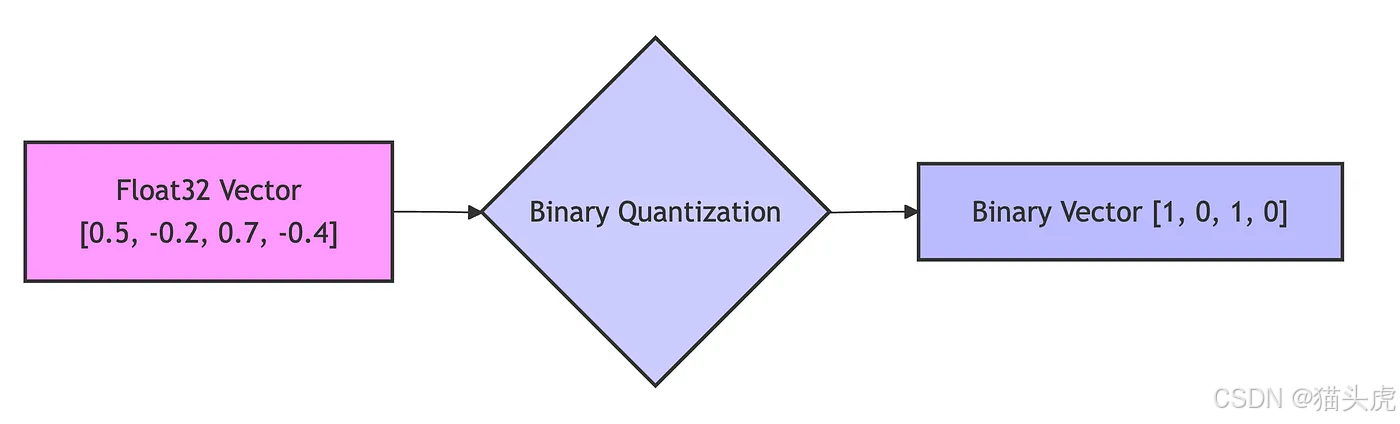
-
分量二值化
- 若原始值 > 0 → 1,否则 → 0。
- 将
float32(32 bit)降为 1 bit。
-
加速检索
- CPU 对位运算(AND、XOR)优化极佳,可在 RAM 中高速计算汉明距离(Hamming distance)。
- 先用二进制索引进行 快速筛选(oversampling),得到一批候选向量。
-
精确重评分
- 从磁盘加载对应的 原始浮点向量,对候选集做精确余弦/内积计算,确保检索质量。
核心价值:
- 速度:二进制检索在 RAM 内完成,毫秒级响应。
- 内存:向量数据压缩 32×,原地释放大量 RAM。
- 准确度:后端重评分弥补了量化带来的信息丢失。
Qdrant 配置示例
from qdrant_client import QdrantClient, modelsclient = QdrantClient( url=\"http://localhost:6333\", prefer_grpc=True,)# 名称可自定义collection_name = \"binary-quantization\"if not client.collection_exists(collection_name): client.create_collection( collection_name=collection_name, vectors_config=models.VectorParams( size=1536, # 嵌入维度 distance=models.Distance.DOT, # 点积距离 on_disk=True, # 原始向量存磁盘 ), optimizers_config=models.OptimizersConfigDiff( default_segment_number=5, ), hnsw_config=models.HnswConfigDiff( m=0, # HNSW 参数(示例) ), quantization_config=models.BinaryQuantization( binary=models.BinaryQuantizationConfig(always_ram=True), ), )else: print(\"Collection 已存在\")on_disk=True将 原始浮点向量 存储于磁盘,节省 RAMalways_ram=True将 二进制向量 与索引常驻 RAM,实现极速检索
LangGraph + SambaNova DeepSeek-R1 快速 RAG 实现
1. 环境与依赖安装
pip install langgraph langchain langchain-community \\ langchain-qdrant fastembed langchain-sambanova pypdf2. 数据加载与预处理
from langchain_community.document_loaders import PyPDFDirectoryLoaderloader = PyPDFDirectoryLoader( path=\"./data/\", glob=\"**/[!.]*.pdf\", extract_images=False, mode=\"page\", extraction_mode=\"plain\",)docs = loader.load()# 清理换行与制表符for d in docs: d.page_content = d.page_content.replace(\"\\n\", \" \").replace(\"\\t\", \" \")3. 向量化与入库
from langchain_community.embeddings import FastEmbedEmbeddingsfrom langchain_qdrant import QdrantVectorStoreembeddings = FastEmbedEmbeddings(model_name=\"thenlper/gte-large\")vector_store = QdrantVectorStore( client=client, collection_name=collection_name, embedding=embeddings,)vector_store.add_documents(docs)4. 构建 LangGraph 流程
from langchain_sambanova import ChatSambaNovaCloudfrom langgraph.graph import START, StateGraphfrom langchain_core.documents import Documentfrom typing_extensions import TypedDict# 定义状态结构class State(TypedDict): question: str context: list[Document] answer: str# 初始化 LLMimport osfrom google.colab import userdataos.environ[\'SAMBANOVA_API_KEY\'] = userdata.get(\"SAMBANOVA_API_KEY\")llm = ChatSambaNovaCloud( model=\"DeepSeek-R1\", max_tokens=1024, temperature=0.1, top_p=0.01,)# 检索节点def search(state: State): docs = vector_store.max_marginal_relevance_search(state[\"question\"]) return {\"context\": docs}# 生成节点SYSTEM_TEMPLATE = \"\"\"…\"\"\"HUMAN_TEMPLATE = \"\"\"…\"\"\"def generate(state: State): ctx = \"\\n\\n\".join( f\"{d.page_content}\\nMetadata: Source-{d.metadata[\'source\']} Page-{d.metadata[\'page_label\']}\" for d in state[\"context\"] ) messages = [ {\"role\": \"system\", \"content\": SYSTEM_TEMPLATE}, {\"role\": \"user\", \"content\": HUMAN_TEMPLATE.format(context_str=ctx, query=state[\"question\"])}, ] resp = llm.invoke(messages) return {\"answer\": resp.content}# 组装图graph_builder = StateGraph(State).add_sequence([search, generate])graph_builder.add_edge(START, \"search\")graph = graph_builder.compile()# 执行示例response = graph.invoke({\"question\": \"如何快速进入工作状态?\"})print(response[\"answer\"])性能评估与内存优化效果
- 内存占用:从 6 GB 降至 187.5 MB,释放 5.8 GB RAM
- 查询速度:纯 BQ 检索耗时约 30 ms,整体 RAG 端到端耗时 ≈200 ms
适用场景与注意事项
-
高维嵌入
- 推荐维度 ≥ 1024,否则二值化后信息严重丢失。
-
海量向量
- 文档量级 ≥100K 时,内存优势更为显著。
-
查询模式
- 适合对吞吐与延迟敏感的在线问答、客服机器人等场景。
-
精度-性能平衡
- 可调节 oversampling 候选集大小,兼顾速度与准确度。
总结与后续展望
通过 Qdrant 二进制量化、SambaNova DeepSeek-R1 与 LangGraph 的强强联合,本方案在保证检索精度的前提下,实现了 32× 内存压缩与 毫秒级 检索响应。
更多资源
教程原文:https://medium.aiplanet.com/fast-multi-document-rag-using-qdrant-binary-quantization-and-sambanova-deepseek-r1-using-langgraph-a9c7d1532290
SambaNova Cloud:https://cloud.sambanova.ai
Qdrant Cloud:https://cloud.qdrant.io
作者主页(Tarun R Jain):
- YouTube:AI with Tarun
- LinkedIn:jaintarun75
- GitHub:lucifertrj
文末粉丝专属福利
👉 更多信息:有任何疑问或者需要进一步探讨的内容,欢迎点击文末名片获取更多信息。我是猫头虎,期待与您的交流! 🦉💬
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥88/月¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
粉丝福利 GO ! GO ! Go !cursor随便用!GPT4.5和GPT4.1 粉丝特享 88园子/🈷️万粉变现入口:https://gitcode.com/qq_44866828/CSDNWF
AI编程工具特惠入口:https://yeka.ai/i/CHATVIP
GPT4.5/GPT4.1 粉丝特享 88园子/🈷️
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥88/月¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
联系我与版权声明 📩
- 联系方式:
- 猫头虎微信号: Libin9iOak
- 万粉变现经纪人微信号:CSDNWF
- 公众号: 猫头虎技术团队
- 版权声明:
本文为原创文章,版权归作者所有。未经许可,禁止转载。更多内容请访问猫头虎的博客首页。
点击✨⬇️下方名片⬇️✨,加入猫头虎AI共创社群,交流AI新时代变现的无限可能。一起探索科技的未来,共同成长。🚀
🔗 猫头虎抱团AI共创社群 | 🔗 100天精通八种AI编程语言基础教程 | 🔗 GitHub 代码仓库 | 🔗 Java进阶之路:必知必会的核心知识点与版本对比🔗 ✨ 猫头虎精品博客

