AI:新书预告—从机器学习避坑指南(分类/回归/聚类/可解释性)到大语言模型落地手记(RAG/Agent/MCP),一场耗时5+3年的技术沉淀—“代码可跑,经验可抄”—【一个处女座的程序猿】携两本AI
AI:新书预告—从机器学习避坑指南(分类/回归/聚类/可解释性)到大语言模型落地手记(RAG/Agent/MCP),一场耗时5+3年的技术沉淀—“代码可跑,经验可抄”—【一个处女座的程序猿】携两本AI实战书终于正式来了!
导读:大家好!今天2025年7月,我是「一个处女座的程序猿」博主,本人的两本新书《数据驱动:机器学习实战之道》和《语言之舞:大语言模型代码实战与部署应用》终于要在2025年的这个夏天,与大家见面了!
过去几年,有很多网友在博客评论区问博主的那些问题:“特征工程怎么避免过拟合?”“大模型怎么部署才不崩?”“有没有能直接用的代码模板?”——博主没有忘。这5年,博主把答案从博客搬进了书稿,从碎片整理成体系,现在终于能给出一份更完整的答卷了。
说实话,这两本书,是博主分别用心打磨了 5 年与 3 年的成果——从无数个不眠之夜、数百次论文、教材、代码仓库的研读与实践,到无数次实战项目的反复测试,尤其是第二本大模型的书籍,博主与倪静教授多次进行修改和迭代,终于要在这个夏天与大家见面。接下来,博主作为代表,将带大家一起扒一扒这两本书的来龙去脉。
5年磨一剑,3年铸一舞,两本AI实战新书重磅来袭!双书预售在即,愿与君共赴这场代码与智慧的共舞!
目录
相关文章
LLMs:LLM一天,人间一年—2024年度大模型技术三+四大趋势梳理(数据/算法/算力+RAG/Agent/Text2SQQL/混合部署)与2025年大模型技术趋势(强大推理/多模态)展望和探讨
一、写书背景
1.1、为什么写这两本书?——“淋过雨,所以想撑伞”
1.2、书里有什么不一样的干货?——“不说正确的废话,只给能跑的代码”
1.2.1、《数据驱动:机器学习实战之道》—— 让数据科学从实验室走向生产线
1.2.2、《语言之舞:大语言模型代码实战与部署应用》—— 手把手带你把LLM“接进”业务系统
1.3、博主是怎么“死磕”这两本书的?
1.4、关于作者:一位“卷王”式的技术博主
二、新书内容速览:理论+实战+前沿,直击AI学习痛点
2.1、第1本:《数据驱动:机器学习实战之道》——五年沉淀的工程化指南
2.1.1、写在前面:侧重机器学习实战,耗时5年,原稿70万字,出稿预估35万字
2.1.2、核心特色
2.1.3、内容架构
2.2、第2本:《语言之舞:大语言模型代码实战与部署应用》——三年追赶技术闪电
2.2.1、写在前面
2.2.2、核心特色
2.2.3、内容架构
三、新书上市 & 读者专属福利
3.1、成书背后:博主的“偏执”与诚意
3.2、购书指引 & 读者专属福利
四、结尾
4.1、感悟
4.2、后记
推荐历年还不错的总结系列文章
LLMs:LLM一天,人间一年—2024年度大模型技术三+四大趋势梳理(数据/算法/算力+RAG/Agent/Text2SQQL/混合部署)与2025年大模型技术趋势(强大推理/多模态)展望和探讨
LLMs:LLM一天,人间一年—2024年度大模型技术三+四大趋势梳理(数据/算法/算力+RAG/Agent/Text2SQQL/混合部署)与2025年大模型技术趋势(强大推理/多模态)展望和探讨_大模型推理成本趋势 图-CSDN博客
AGI:走向通用人工智能的【哲学】之现实世界的虚拟与真实——带你回看1998年的经典影片《The Truman Show》感悟“什么是真实”
AGI:走向通用人工智能的【哲学】之现实世界的虚拟与真实——带你回看1998年的经典影片《The Truman Show》感悟“什么是真实”_the truman show对真实的理解-CSDN博客
DayDayUp:2020,再见了,不平凡的一年,让我懂得了珍惜,让我明白了越努力越幸运
DayDayUp:2020,再见了,不平凡的一年,让我懂得了珍惜,让我明白了越努力越幸运_因为相信所以看见 春茗聚会通知-CSDN博客
DayDayUp:2021,再见了,无论是躺平还是内卷—愿大家改变不可接受的,接受不可改变的—心若有向往,何惧道阻且长
DayDayUp:2021,再见了,无论是躺平还是内卷—愿大家改变不可接受的,接受不可改变的—心若有向往,何惧道阻且长_keep loving keep living什么意思-CSDN博客
DayDayUp:7月25日,如何打造技术品牌影响力?顶级大咖独家传授—阿里云乘风者计划专家博主&CSDN TOP1“一个处女座程序猿”《我是如何通过写作成为百万粉丝博主的?》演讲全文回顾
DayDayUp:7月25日,如何打造技术品牌影响力?顶级大咖独家传授—阿里云乘风者计划专家博主&CSDN TOP1“一个处女座程序猿”《我是如何通过写作成为百万粉丝博主的?》演讲全文回顾-CSDN博客
成为顶级博主的秘诀是什么?《乘风者周刊》专访“处女座程序猿”牛亚运
成为顶级博主的秘诀是什么?《乘风者周刊》专访“处女座程序猿”牛亚运-阿里云开发者社区
一、写书背景
1.1、为什么写这两本书?——“淋过雨,所以想撑伞”
博主至今清楚记得2019年写第一篇机器学习实战笔记时,自己还在实验室熬夜调参。那时踩过的坑、绕过的弯路,后来都成了博客里“避坑指南”的素材。但后台留言让博主意识到:知识需要系统沉淀,经验需要可复现的载体。于是:
● 《数据驱动》写了5年:从70万字初稿删减到388页精要,聚焦 “工业级ML流水线”,涵盖数据清洗→特征工程→模型监控全链条,尤其强化了生产环境中最棘手的 “数据漂移预警”和“内存优化”实战方案;
● 《语言之舞》磨了3年:博主和倪静教授,从GPT-3追到Llama-4、Qwe系列,反复重写3章架构解析,只为把Transformer、RAG、Agent等前沿技术,拆解成可运行的代码块。书中还附赠 企业级LLM落地清单,直击中小团队算力瓶颈痛点。
有位读者曾问我:“你图什么?”
我图后来者少熬点夜——这是真心话。
从 2019年开始构思第一本书稿,到现在它的原稿已近 70 万字;第二本也有 68 万字原始积累。
回望过去,这些年博主在 AI 领域跑了很多项目,补过无数个坑,也在社区做了大量分享。每当读者问到“如何下手”、“为什么出错”,博主都希望有一本结合理论与实战的手册,可以帮助大家少走弯路。
1.2、书里有什么不一样的干货?——“不说正确的废话,只给能跑的代码”
1.2.1、《数据驱动:机器学习实战之道》—— 让数据科学从实验室走向生产线
● 独创“特征三化”框架:用归一化+编码化+向量化解决脏数据,配套金融/医疗场景案例;
● 模型调优避坑指南:L1/L2正则化效果可视化作图 + 过拟合修复代码模板(附内存压缩技巧);
● 部署监控实战:基于A/B测试的模型发布策略 + 生产环境漂移检测工具链。
● 出版社编辑笑称这是“处女座式排版”——388页塞进35个可复用代码模块,几乎每章都附上完整代码和数据链接,力求代码可跑,大家拿去运行就对了。
1.2.2、《语言之舞:大语言模型代码实战与部署应用》—— 手把手带你把LLM“接进”业务系统
● 主流模型全解析:LLaMA-3、GLM-4、Qwen-2架构对比 + 微调实战(含成本对比表)10;
● 企业级落地指南:从Docker分布式部署到提示工程框架库,降低80%试错成本;
● 前沿技术深度解耦:RAG增强检索、Agent任务编排、模型监控协议——附可修改的Python套件。
● 书中藏了个彩蛋:第5章案例代码页脚写着 “此处代码在凌晨3点调试通过,建议读者白天运行,以免怀疑人生”。
1.3、博主是怎么“死磕”这两本书的?
● 追论文追到怕:5年机器学习稿迭代100+版,3年大模型书啃完300+篇论文;
● 删稿比写稿痛:138万字原稿浓缩到73万出版稿,删掉冗余理论,保留90%实战案例;
● 你们的留言救了这本书:30%案例源自博客评论区高频问题——比如“模型上线即崩”的解决方案,就来自某位算法专家的踩坑经历。
1.4、关于作者:一位“卷王”式的技术博主
昵称:一个处女座的程序猿
>> 过往履历:人工智能硕学历,6项发明专利+9项软著主导者,国家级/省市级等算法竞赛累计十多项获奖(含5项一等奖),以及SCI国际期刊论文;
>> 社区影响:CSDN历史贡献总榜常年位居第一,CSDN十大博客之星三连冠,达摩院评测官,以及CSDN/阿里/掘金/51CTO/知乎/华为/Google等社区专家博主等十余项头衔,截止到2023年底,全网粉丝超100万(目前全网应该已超200万),文章阅读量破4000万(目前全网应该已超8000万);
>> 写作历程:
● 耗时多年:第一本《数据驱动:机器学习实战之道》(5年) + 第二本《语言之舞:大语言模型代码实战与部署应用》(3年);
● 字数爆炸:原稿合计138万字,精炼后仍超70万字;
● 熬夜无数:凌晨三点修改代码示例、通宵对比模型架构已成日常;
● 知识储备:查阅上百篇arxiv论文、跑通几十个开源模型、踩遍数百个技术坑;
>> 渡人初心:从“填坑笔记”起步,因一句“自己淋过雨,总想替人撑伞”被粉丝称为技术圈“救火队长”。
>> 幕后花絮:为了打磨这两部用心“作品”,真的是熬了无数次夜,查阅相关论文书籍太多了,本人很低调,但这的确是看了无数的论文与书籍带来的收获,同样地,也经历了数百次实战调优与代码重构。
一句话总结:“我不只是写书,更像是把5+3年技术生涯浓缩成了两本‘通关秘籍’。”










二、新书内容速览:理论+实战+前沿,直击AI学习痛点
2.1、第1本:《数据驱动:机器学习实战之道》——五年沉淀的工程化指南

2.1.1、写在前面:侧重机器学习实战,耗时5年,原稿70万字,出稿预估35万字
博主把它当作“我与读者一起构建数据科学管道”的全流程指南:从数据采集、清洗、可视化,到模型训练、发布及监控,每一步都有我亲测的 `.py` 示例,确保你跑得通、改得动。
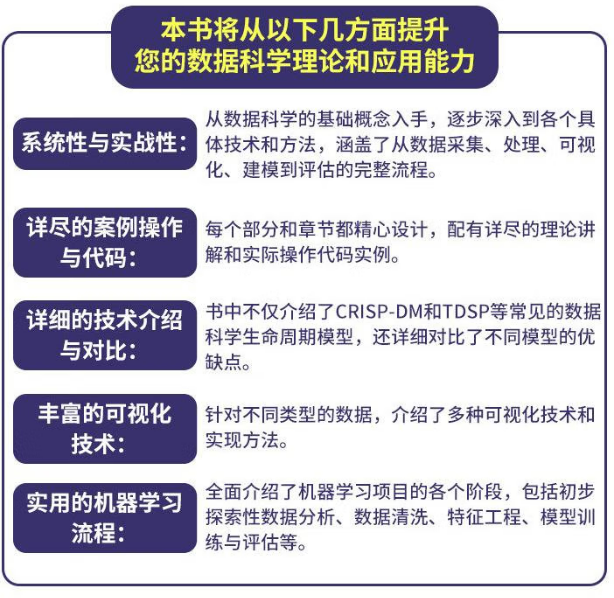
2.1.2、核心特色
>> 关键词:从零到精通 | 代码即答案 | 案例覆盖全
>> 核心定位:从数据到模型的全流程工业化落地,拒绝“纸上炼丹”!
● 0基础友好:从数据可视化到模型部署,每个步骤都有“傻瓜式”代码和注释。
● 知行合一:每章既有理论框架,也有完整可跑通的实战案例,直击行业需求。
● 全景视角:覆盖 CRISP‑DM、TDSP、EDA、特征三化、模型调优到 A/B 测试与生产监控,一条流水线跑到底。
● 易学易用:统一的代码风格+详尽注释,让“小白”也能快速上手。
● 前沿兼容:最新的训练方法、部署工具与优化策略,一次性学到最前沿。
>> 模块化实战设计:
● 数据层:独创“特征三化”(归一化/编码化/向量化)处理脏数据;原始数据→清洗→可视化(直方图、热力图、动态交互图);
● 模型层:从线性回归到 XGBoost 的超参调优与过拟合修复策略;过拟合解决方案对比(L1/L2正则化可视化+代码优化内存压缩术);
● 运维层:模型监控工具链实战,基于 REST API 的模型发布、A/B 测试和“数据漂移”预警;
● 案例工具箱:388页浓缩70万字原稿,配套30+可复用代码模板(覆盖金融/医疗场景)。
>> 特别彩蛋:
● 附赠代码包:扫码获取书中所有代码,复现案例无压力。
● 作者亲测:每章案例均在本地GPU和云服务器上跑通,确保“可复制”。
Github地址:https://github.com/monkeyongithub/ml-book-code
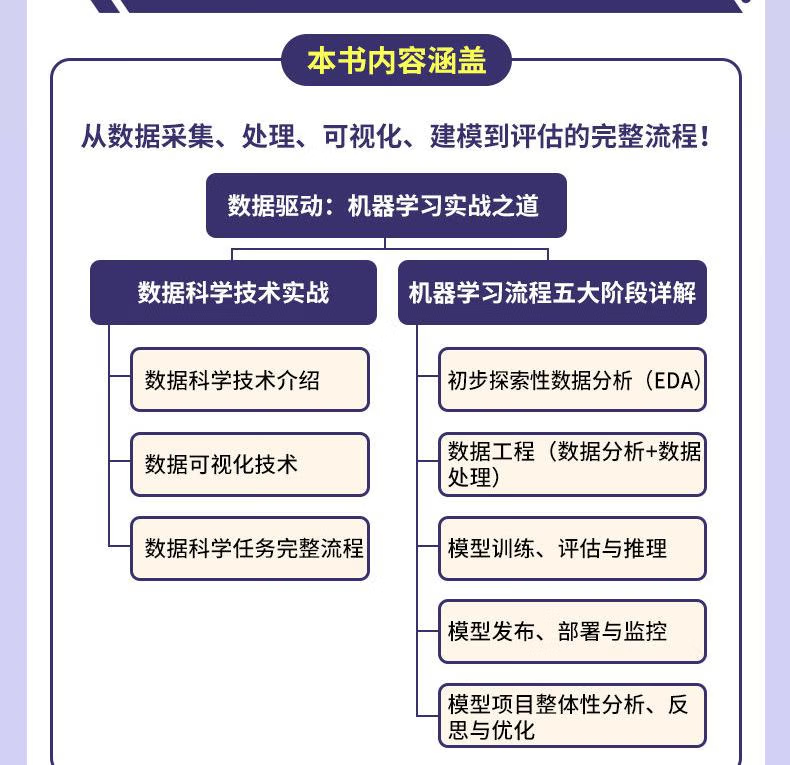
2.1.3、内容架构
《数据驱动》:机器学习的“全栈手册”
>> 第一部分:数据科学基础:数据科学技术实战,涉及数据科学生命周期、可视化技术、完整项目流程
● 数据生命周期管理(CRISP-DM vs TDSP)
● 数据可视化:从直方图到动态图表的10+种实战技巧
>> 第二部分:机器学习五大阶段:涉及EDA、数据工程、模型训练与推理、部署监控、项目优化
● EDA:用箱线图揪出数据中的“坏苹果”
● 数据工程:缺失值处理、特征三化(归一化/编码化/向量化)
● 模型训练:从线性回归到XGBoost的调参秘籍
● 模型部署:A/B测试、API接口设计、生产环境监控
● 项目优化:L1/L2正则化对比、数据增强策略、分布式优化
(注:内容架构,因为字数限制原因,未来会以出版社最终定稿为准,但核心章节不会有太大差异)

2.2、第2本:《语言之舞:大语言模型代码实战与部署应用》——三年追赶技术闪电

2.2.1、写在前面
这本书是博主和倪静教授对大语言模型(LLMs)领域的系统沉淀:从发展史到一线实践,从核心技术要素到高级应用,每一章都融入了我在实际项目中打磨的经验,以及倪静教授多年在教学上对大模型技术的理论研究和企业合作中的案例实践。我们把“大模型从学术到落地”的痛点一网打尽:从 Transformer 原理到 RAG、Agent,到 Docker & 分布式训练,全流程实战示例均由博主亲自调试。
2.2.2、核心特色
>> 关键词:LLM从理论到落地 | 跟大神学微调 | 前沿技术全解析
>> 核心定位:让LLM落地从“魔法”变“手艺”!
● 理论+实战:不仅讲原理,更用实战案例带你跑通整个流程。
● 体系化:从 SLM → NLM → PLM → LLM 四次浪潮,一条线带你看懂技术演进与架构迭代。
● 大模型全家桶:GPT、LLaMA、GLM、Qwen全系列实战,模型微调、推理、部署全覆盖,一本书跑遍主流模型。 以及RAG、Agent、MCP等高级技术实战演练。
● 部署不迷路:Docker部署、分布式训练、模型监控,手把手教你上线LLM。
● 工具全景:涵盖训练/推理框架、Docker 部署、分布式配置、提示库推荐。
>> 前沿技术覆盖:
● 全栈拆解:从Transformer架构到RAG、Agent增强技术,代码复现主流模型(LLaMA/Qwen/GLM/Deep Seek);
● 部署避坑指南:Docker分布式训练+模型监控体系,解决“上线即崩”痛点;
● 企业级适配:提示工程框架库、微调成本优化表,直击中小企业资源瓶颈。
● 特色章节:十大主流训练框架横向评测(含Hugging Face生态深度适配)。
>> 特别彩蛋:
● 作者私藏工具清单:LLM训练框架、提示词库、部署工具全汇总。
● 进阶版“避坑指南”:模型过拟合、资源耗尽、微调瓶颈的解决方案。
Github地址:https://github.com/monkeyongithub/llm-book-code

2.2.3、内容架构
《语言之舞》:LLM的“通关秘籍”
>> 第一部分:LLM的前世今生
● 大语言模型发展史:从SLM到LLM的四次技术浪潮
● 核心要素(数据、架构、评估与优化):Transformer架构的“灵魂画手”级解析
>> 第二部分:构建你的第一个LLM
● 构建流程(预训练→微调→推理):数据预处理:清洗、分词、向量化全流程
● 微调与推理实战:基于LLaMA-3和Qwen-2的代码模板,部署与监控(Docker、分布式、运维)
>> 第三部分:从实验室到生产
● 企业级项目落地:提示工程基础,RAG实现知识库问答、Agent自动化工作流
● 挑战与未来展望:常用框架与提示库,多模态LLM、模型压缩、伦理挑战
(注:内容架构,因为字数限制原因,未来会以出版社最终定稿为准,但核心章节不会有太大差异)

三、新书上市 & 读者专属福利
上市时间:2025年7月中下旬
渠道平台:京东 / 当当 / 淘宝,电子工业出版社 & 机械工业出版社官方旗舰店
在各大平台搜索书名、关键词,《数据驱动:机器学习实战之道》或《语言之舞:大语言模型代码实战与部署应用》,即可预定。
博主也会在正式最近几天,在微信公众号、微博、知乎、CSDN 等平台放出第一批购买链接和粉丝专属优惠。
3.1、成书背后:博主的“偏执”与诚意
● 时间成本:累计5+3年写作时长,5年机器学习稿迭代150+版,3年大模型书追更300+论文;
● 内容打磨:原稿138万字浓缩至73万出版稿,删减冗余理论,保留90%代码案例;
● 粉丝共创:书中30%案例源自博客评论区“高频求助问题”,真正对症下药。
● 彩蛋预警:书中藏有作者“秃头赶稿”的趣味注释——“此处代码在凌晨3点调试通过,建议读者白天运行,以免怀疑人生”;
3.2、购书指引 & 读者专属福利
● 上市时间:2025年7月中下旬(京东/当当/淘宝,电子工业出版社、机械工业出版社等旗舰店);
● 早鸟福利:首周购书赠配套代码库+作者直播答疑门票;
● 粉丝通道:私信博主暗号“渡己渡人”,后续,将可获赠经博主整理(目前还未结束)的《LLM调优避坑清单》电子手册!
《数据驱动:机器学习实战之道》
T1、京东图书(机械工业出版社旗舰店):https://item.jd.com/10156712292354.html
T2、淘宝天猫图书(机械工业出版社旗舰店):https://e.tb.cn/h.h81kfSl4jXEbkY2?tk=ylZ14cP1BJQ
T3、当当平台(当当自营店):http://product.dangdang.com/11954503932.html
T4、京东图书(当当自营店):https://item.jd.com/10162534946860.html
注意:不同店铺价格不一样,可能相差较大,建议前去平台查找书名,然后查找价格最便宜的下单即可!
《语言之舞:大语言模型应用实战全书》
T1、京东图书(电子工业出版社官方旗舰店):https://item.jd.com/10165602994409.html
T2、京东图书(博文视点旗舰店):https://item.jd.com/10165603699289.html
T3、淘宝天猫图书(电子工业出版社旗舰店):https://e.tb.cn/h.h81Vu0tDZJcdieo?tk=cpCT4ckv65G
T4、当当平台(当当自营店):https://product.dangdang.com/29919200.html
注意:不同店铺价格不一样,可能相差较大,建议前去平台查找书名,然后查找价格最便宜的下单即可!
如果你是:
想转行AI的职场人
在读计算机/数据科学学生
对LLM部署和调参感兴趣的开发者
那么,这两本书就是你的“技术加速器”!
四、结尾
4.1、感悟
写书的过程,是博主对自己知识体系的一次次打磨,也是博主与读者共同成长的旅程。希望这两本书,能为你点亮“实践之路”,让你在 AI 的世界里更自信、更高效。
预热就到这里了,之后博主会陆续分享章节摘录、实战视频、代码仓库等干货,敬请关注!
4.2、后记
最后,说两句心里话:
写书是场苦修,但每次看到读者说“这段代码跑通了”“项目终于上线了”,我都觉得值了。技术会老,代码会变,但开发者之间“不藏私”的接力传承,永远是这个行业最浪漫的事。
我图的很简单——让你比我少熬几个夜,少踩几个坑。
因为自己淋过雨,所以总想替别人撑把伞。
新书不是终点,而是我们对话的新起点!
江湖路远,代码相见……
倒计时已启动,请锁定 2025年7月中下旬,和博主一起揭开这两本“技术通关秘籍”的面纱!
最后的彩蛋:博主的第三本新书,《大语言模型驱动的智能体(LLM Agent):从理论到实战》目前已累计58万字,预估今年年底,也会如约将与大家见面!敬请期待!
一个处女座的程序猿
2025年7月16日凌晨


