华为云Flexus+DeepSeek征文|云智融合·构建AI开发创新引擎·Web Search工作流搭建2.0版本的DeepSeek:简易浏览器


前引:“当前,数字经济蓬勃发展,云计算已成为承载万物智能的坚实底座,而人工智能则以前所未有的速度渗透并重塑着千行百业。在这场深刻的技术变革浪潮中,华为云始终走在前沿,以其领先的技术实力和前瞻性的战略布局,致力于为全球企业提供强大、可靠的云服务。特别是其在AI领域的持续深耕,催生了如DeepSeek和Dify等一系列创新平台。本文将深入探讨华为云如何凭借Dify高效的LLM应用开发框架和插件组合出独特的AI搜索【搭建一个简易浏览器】,共同构建AI开发新范式,加速智能化转型,解锁未来产业的无限可能 !怎么样,感兴趣了吗?!
目录
【一】云计算与人工智能在各行业中的核心地位
(1)云计算:
(2)人工智能:
【二】华为云定位
(1)基础定位:
(2)核心定位:
(3)行业生态定位:
【三】本文核心
【四】华为云的整体框架
【五】华为云的服务体系
【六】华为云Flexus核心技术
【七】华为云Dify平台解析
(1)应用开发平台的特性
(2)核心优势
(3)华为云AI平台对比市场AI的优势
【八】DeepSeek R1/V3商用服务开通
(1)注意事项:
(2)开通教程:
(3)开通体验:
【九】云服务器单机框架优势
【十】云服务器单机部署
(1)部署教程:
(2)部署体验:
【十一】如何监测单机部署性能
(1)核心参数:
(2)监测方法:
(3)Linux命令安装插件:
(4)监测步骤:
【十二】CCE高可用框架优势
【十三】CCE高可用部署
(1)准备工作:
桶的创建:
秘钥创建:
委托创建:
委托授权:
(2)部署教程:
(3)部署体验:
【十四】如何监测CCE集群性能:Linux+集群
(1)监测指标:
(2)监测方法:
(3)云监控:
(4)云服务引擎:
【十五】Dify与DeepSeek实践应用
【十六】完成Dify登录
【十七】Dify添加华为云Qwen3模型
【十八】安装插件:博查
【十九】Web Search使用说明
【二十】搭建工作流:Web Search捕捉全网图片、网址链接
【二十一】捕获测试
搜索全网连接:盘古开天辟地
搜索免费播放器:播放仙逆
【二十二】如何删除资源停止计费
【二十三】测评建议
【二十四】后续优化方向
【二十五】心得与未来挑战
【一】云计算与人工智能在各行业中的核心地位
(1)云计算:
按需获取与弹性伸缩:企业不再需要投入巨额资金自建和维护数据中心。它们可以像使用水电一样,通过互联网按需获取计算、存储、网络等IT资源,并根据业务量的波峰波谷快速调整资源规模。这极大地降低了IT门槛和运营成本,特别是对于初创企业和中小企业
·
促进敏捷与创新:云计算的弹性使得企业能够快速搭建测试环境、部署新应用、尝试新业务模式,试错成本显著降低。这种“敏捷性”是数字时代企业保持竞争力的关键
·
海量数据存储与计算:物联网、社交媒体、移动应用产生了前所未有的海量数据。只有云计算提供的分布式架构和强大的算力,才能经济、高效地存储和处理这些大数据
·
数据孤岛的打破:通过云平台,企业可以将分散在不同系统、不同部门的数据进行集中管理和分析,打通数据孤岛,从而获得更全面的业务洞察,支持更精准的决策
(2)人工智能:
自动化与智能化:在制造业,AI驱动的机器人和视觉检测系统可以7x24小时不间断地执行高精度、重复性的任务,大幅提升生产效率和产品良率。在办公场景,RPA(机器人流程自动化)和智能助手能自动处理报表、邮件等日常工作,将人力从繁琐事务中解放出来
·
预测性维护:在能源、交通、制造等地方,AI可以通过分析设备运行数据,精准预测潜在故障,将传统的“事后维修”变为“事前维护”,有效减少停机时间和经济损失
·
数据驱动决策:在金融行业,AI风控模型可以瞬时分析海量交易数据,识别欺诈行为;在零售业,AI可以分析消费者行为,实现精准营销和动态定价。AI将人类经验与海量数据分析相结合,使决策更加科学、快速和精准
·
复杂系统优化:在物流领域,AI可以规划最优的配送路线和仓储布局,应对复杂的实时路况和订单变化。在城市管理中,“城市大脑”利用AI优化交通信号灯、调配公共资源,提升城市运行效率
【二】华为云定位
(1)基础定位:
华为云首先提供的是云计算的核心能力:全球化的计算(云服务器、裸金属、容器)、存储(对象存储、块存储)、网络(高速虚拟网络、CDN)、数据库、大数据、AI开发平台等高性能、高可靠的IaaS和PaaS基础服务。这是支撑一切上层应用和解决方案的基石!

(2)核心定位:
赋能应用: 通过灵活弹性、开箱即用的云服务和丰富的开发者工具链,最大化降低应用开发、部署、运维的成本与复杂度,加速企业数字化转型和业务创新
使能数据: 提供强大的数据湖、数据仓库、数据分析工具和治理能力,帮助企业将其海量数据资产转化为业务洞察力和决策依据
普惠AI: 将华为多年积累的AI技术(如昇腾芯片、昇思MindSpore框架、视觉/语音/NLP等地方强大模型)以云服务形式输出,从强大的训练推理平台到开箱即用的行业AI解决方案(如盘古大模型),显著降低企业应用AI的门槛,是重要的差异化竞争优势~



(3)行业生态定位:
深耕行业Know-How: 华为云不是孤立的通用技术平台,而是深入理解各行业(政务、金融、制造、能源、医疗、教育等)痛点与需求,提供融合行业经验的云服务组合、参考架构和解决方案
·
拥抱开放生态: 坚持开源开放,广泛兼容合作(如对Kubernetes等主流开源生态的深度支持),联合伙伴共同服务客户,构建繁荣的数字产业生态!
【三】本文核心
本文将深入探讨华为云旗下两大创新型平台:DeepSeek 与 Dify。探讨它们如何通过重构 AI 开发范式与应用生态,赋能企业智能化转型。借助 ModelArts Studio 提供的全流程大模型服务能力与开放底座,二者分别聚焦模型训练部署(DeepSeek)与低代码应用开发(Dify),形成模型即服务 + 工具链即开即用的双轮驱动体系,最终实现从数据处理、算法优化到场景落地的全链路革新,推动 AI 开发从专家专属走向普惠共创!跟着小编一起来看看吧!
【四】华为云的整体框架
华为云以 端-管-云-智全栈协同架构 为核心,构建了智能时代的数字基础设施,如下框架:
端侧触达:
整合手机、IoT设备、边缘计算节点(如Atlas边缘硬件),实现数据源头采集与实时响应网络中枢:
依托全球30+Region数据中心和华为自研5G技术,提供低时延、高可靠的云网一体服务云平台:
IaaS层:昇腾AI芯片+鲲鹏算力底座,提供弹性云服务器、裸金属容器等基础设施
PaaS层:ModelArts Studio、GaussDB数据库等使能平台
SaaS生态:联合伙伴开发3000+行业应用
智能引擎:
通过AI大模型(盘古)、大数据湖等组件驱动智能决策,形成闭环演进体系架构特点:自主可控的根技术栈(芯片+OS+数据库),支持公有云/混合云/边缘云全域部署,满足企业级安全合规需求!
【五】华为云的服务体系
华为云以 3大核心引擎+2大生态支撑 构建服务体系:
服务领域 关键能力 代表产品 AI开发 模型训练/调优/部署全流程 ModelArts Studio(大模型即服务平台)、盘古大模型 大数据 数据湖仓一体、实时分析、隐私计算 DataArts、可信计算环境 云原生 容器引擎+微服务治理+DevSecOps CCE Turbo、ServiceStage
服务本质:通过普惠AI(如DeepSeek可视化调参)开放生态(黑土地战略)实现技术民主化
【六】华为云Flexus核心技术
作为华为云AI基础设施的核心技术,Flexus 以分布式智能调度重构算力效率,例如:
超融合计算架构:
支持万卡级昇腾集群协同训练,采用华为自研 AI Fabric 无阻塞网络,通信效率提升60%动态自适应调度:
基于任务拓扑智能分配资源,实时规避热点瓶颈(如GPU带宽争用)端云协同推理:
模型自动分割技术,实现边缘端(≤10ms时延)与云端协同推理
场景 Flexus技术实现 实际效益 大模型训练 参数自动并行策略 + 梯度压缩算法 千亿级模型训练时间缩短40% 工业质检 边缘端轻量化模型 + 云端增量更新 产线漏检率↓至0.01% 智能参数调优 集成进 ModelArts Studio(如DeepSeek模块) 算法工程师调试效率提升5倍
技术定位:为华为云普惠AI战略提供底层算力保障,支撑推理精度提升20%,能耗节省35%
【七】华为云Dify平台解析
华为云的 Dify 平台是一套智能化的 AI 开发平台,旨在简化从模型训练、部署到优化的全过程,为开发者和企业提供一站式、高效的 AI 应用开发服务。该平台整合了华为云在计算、AI 算法和生态系统方面的优势!
(1)应用开发平台的特性
一站式服务 :平台提供了完整的 AI 开发生命周期工具,涵盖模型训练、推理、优化和管理等功能,让开发者可以高效地完成整个 AI 项目
大规模模型支持 :专门针对大规模机器学习和深度学习模型进行了优化,能够处理复杂的 AI 任务。如资料图所示,平台(ModelArts Studio)已集成 DeepSeek 等先进的大模型
智能化调优 :集成了自动化的参数调优工具,能够自动优化模型,减少了开发过程中的人工干预,显著提高了模型训练的效率和精度
·
无缝整合与跨平台 :支持多种操作系统和硬件环境,并能与华为云的数据存储、计算等其他云服务无缝结合,构建完整的解决方案
(2)核心优势
强大的自研算力 :平台的核心优势之一是其强大的计算能力。这主要得益于华为自研的昇腾(Ascend)AI芯片,为处理大数据和复杂模型训练提供了卓越的性能支持
完善的生态系统 :Dify 平台不仅仅是一个开发工具,它还深度整合了华为云的AI生态,如 AI Gallery(AI市场)等,为开发者提供了丰富的预训练模型、解决方案和更广泛的商业化途径
高效率与高可靠性 :依托华为云稳定可靠的基础设施,Dify 平台能够保证 AI 模型在开发和生产环境中的高效、稳定运行
(3)华为云AI平台对比市场AI的优势
与市场上的其他 AI 平台相比,华为云 AI 平台展现出以下主要优势:

自主与可控性:在核心硬件(昇腾芯片)和上层软件(如 ModelArts Studio 开发环境)方面都具备高度的自主可控能力,这为需要定制化和高安全性的企业用户提供了独特的价值
·
软硬协同的性能优化:由于软件平台与底层硬件(昇腾芯片)深度集成和协同优化,华为云 AI 平台在执行大规模模型训练等任务时,通常能实现优于通用平台的计算性能和能效比
·
丰富的开发工具与资源:平台为开发者提供了包括开源库、预训练模型、开发套件在内的丰富资源,有助于降低 AI 应用开发的门槛,加速从原型到产品的构建过程
【八】DeepSeek R1/V3商用服务开通
(1)注意事项:
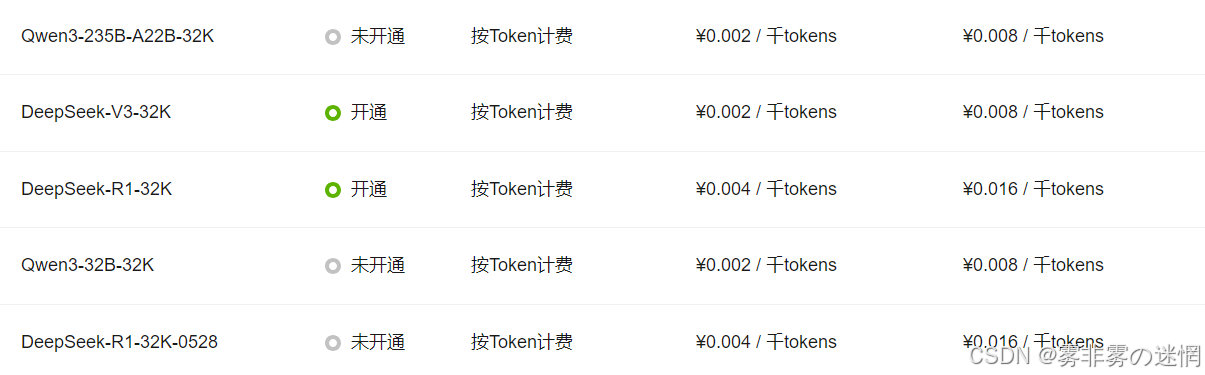
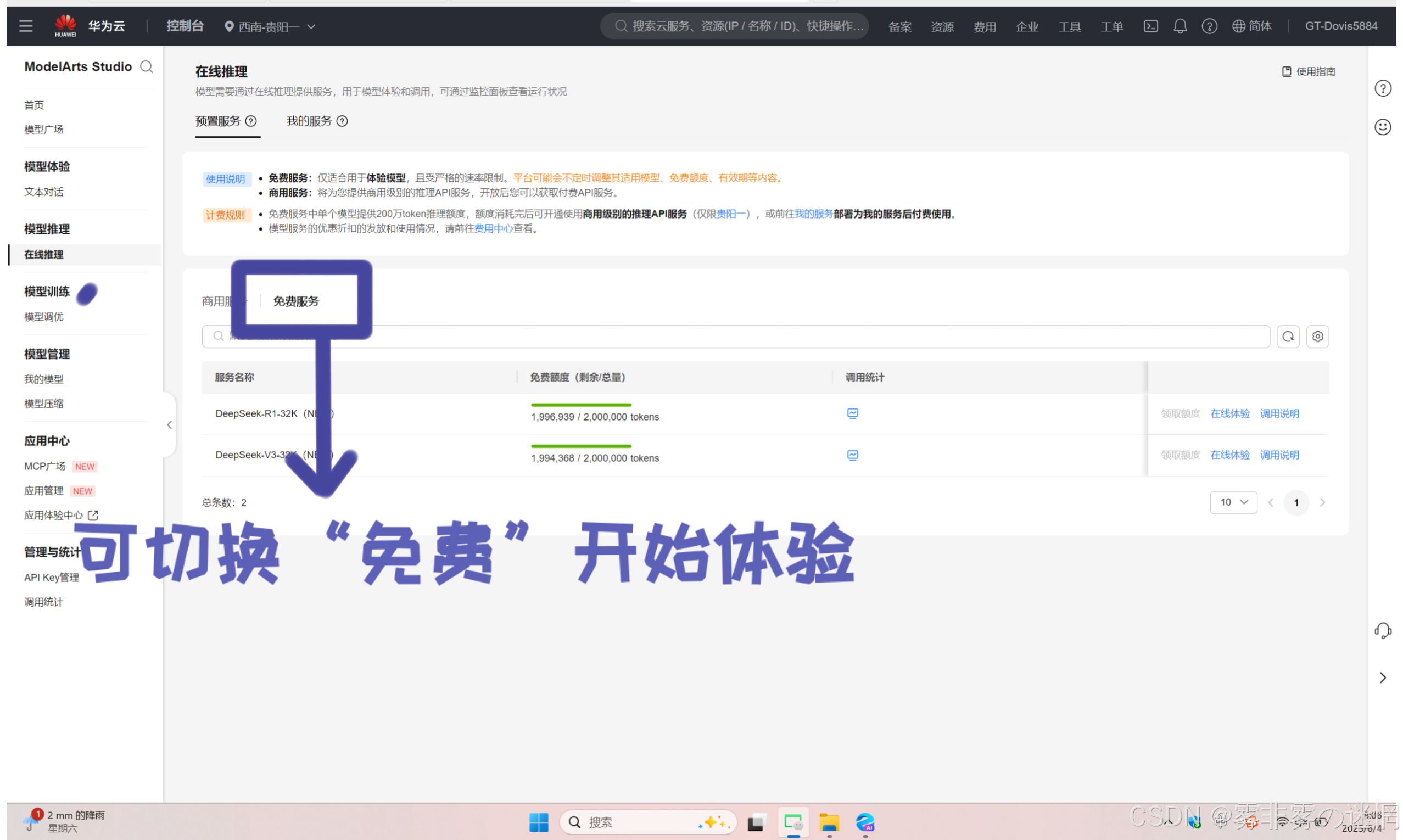
商用模型开通之后,使用是会收费的,因此可以提前体验一下免费版,感受一下AI的效率!
(2)开通教程:
(1)新人需要先完成华为云账号的登录、认证
(2)登录完成之后,点击ModelArts Studio控制台
(3)点击左边功能栏的“在线推理”,开通服务之后,点击体验就可以进行对话了
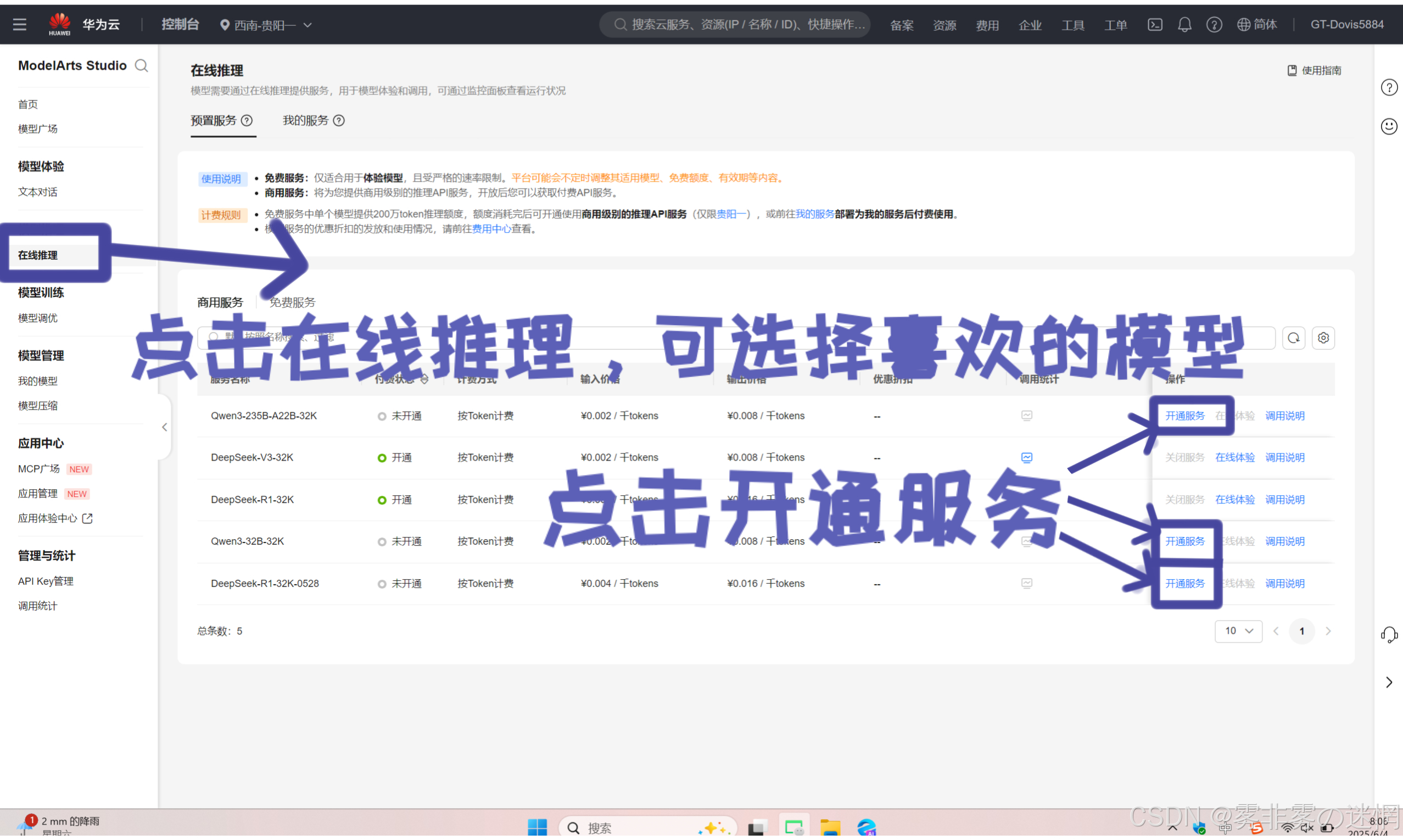
(4)当然也支持先体验免费版,感受效率再开通商用版
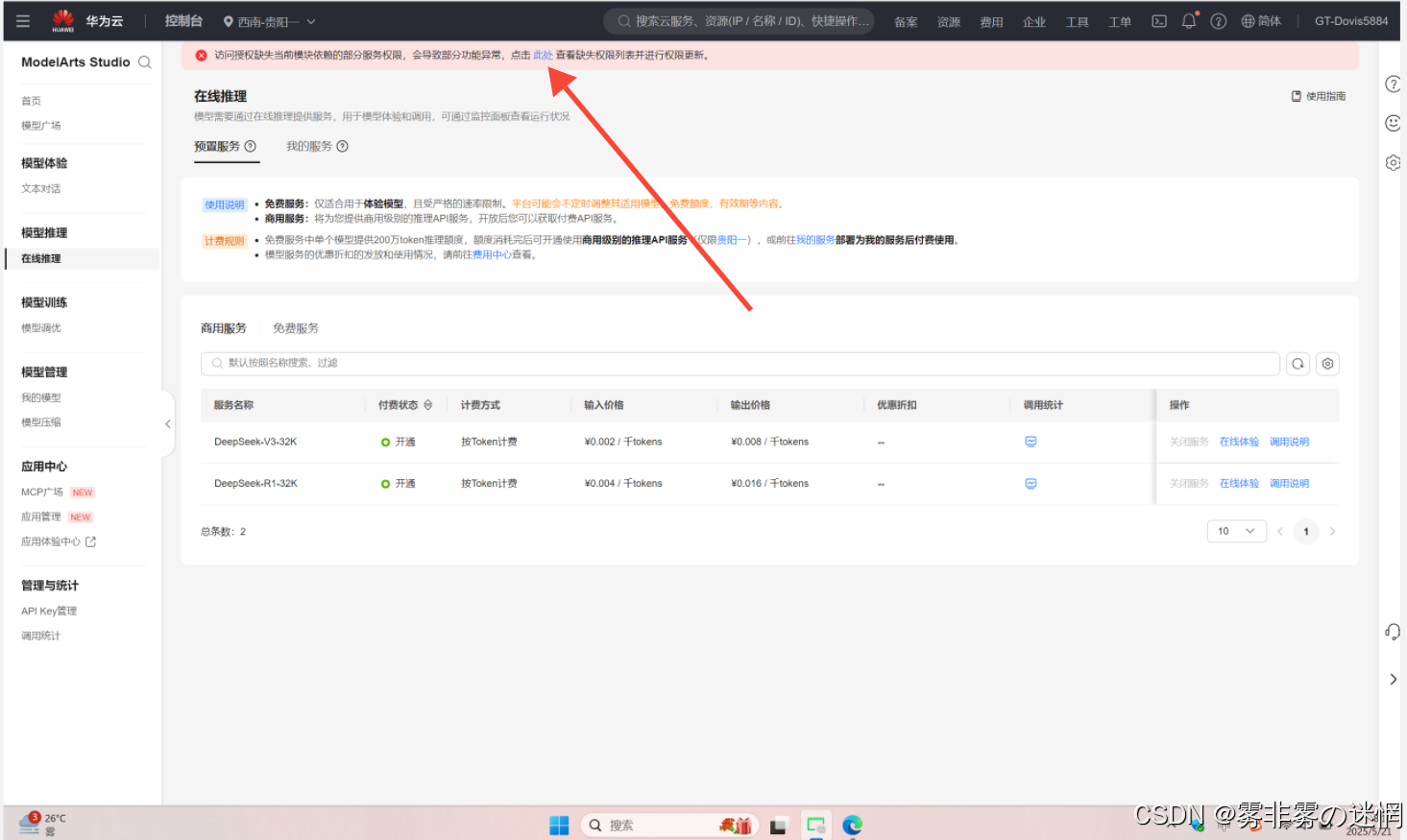
(5)另外需要在ModelArts Studio控制台开启权限,主要是为了后面的部署和AI搭建
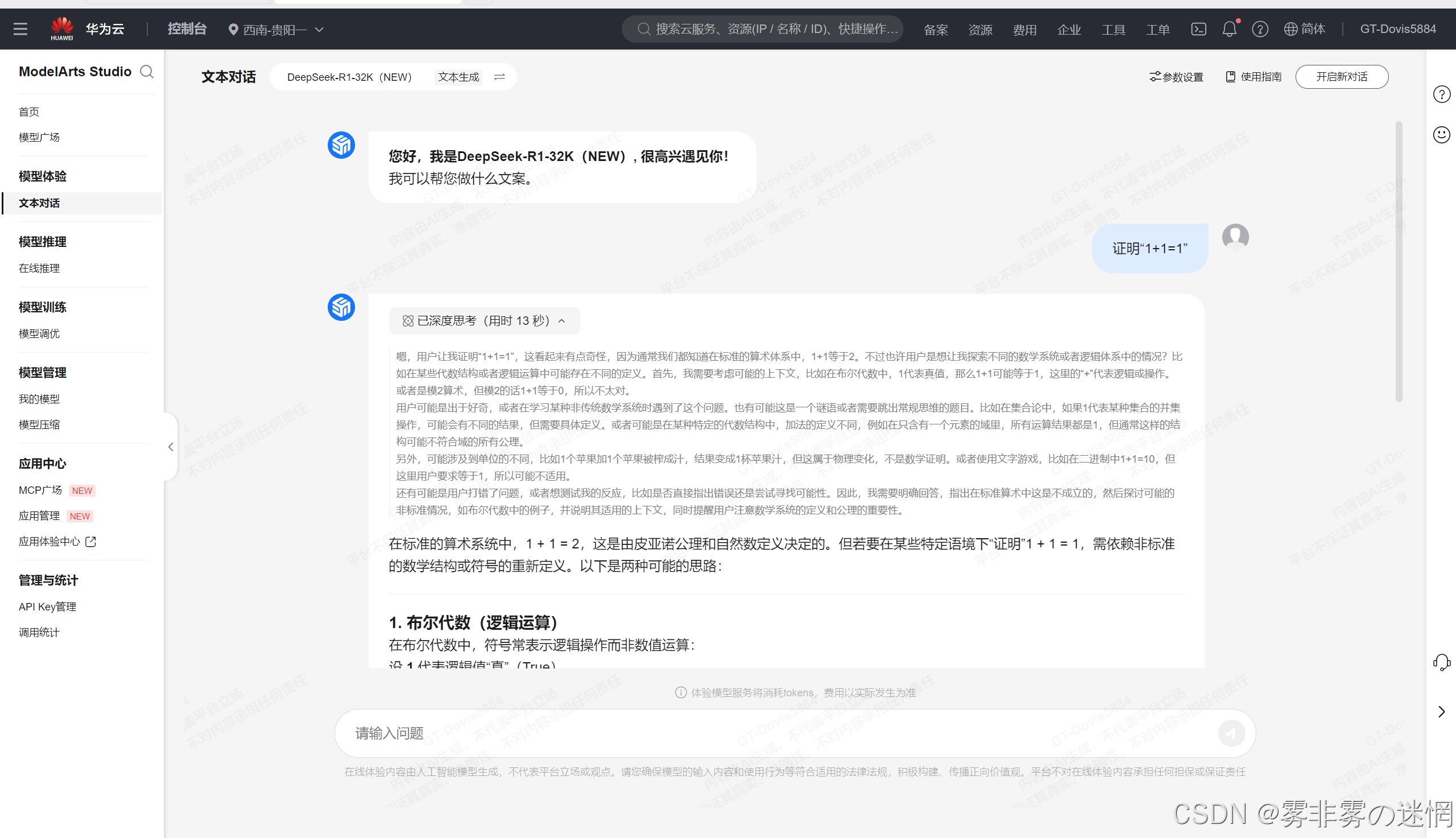
(3)开通体验:
从登录华为云账号,到进入ModelArts Studio平台选择相应的DeepSeek版本,再到完成信息确认,整个过程几乎是一气呵成,指引清晰,短短几个步骤就完成了服务的开通和环境的自动化配置,让我能立刻投入使用,几乎没有浪费任何时间在繁琐的设置上,开通很简单!
而开通的便捷仅仅是一个开始,真正让我印象深刻的是它强大的AI效率。在处理海量数据和进行复杂推理时,DeepSeek R1/V3的表现非常出色,不仅响应速度快,生成结果的质量也相当高。无论是模型训练还是即时调用,都能感受到它带来的显著性能提升,极大地加速了我们的项目研发进程。总而言之,这次体验让我深刻感受到,华为云不仅提供了顶尖的AI能力,更将开发者体验放在了重要位置,让高效的AI真正触手可及!
【九】云服务器单机框架优势
单机部署是指将应用及其所需的所有服务(如Dify服务、数据库、缓存等)都部署在一台云服务器(ECS)上。这种框架的核心优势在于其 简洁性 和 成本效益
弹性云服务器ECS介绍
部署简单快速:
一键式操作:正如架构图所示,该模式支持“一键部署”。整个过程高度自动化,无需复杂的网络配置和多节点协调,能够让应用在最短时间内上线运行
环境统一:所有组件都在同一台服务器上,避免了分布式环境下网络延迟、节点间通信等复杂问题,便于开发者快速进行功能验证和测试
成本效益极高:
资源占用少:仅需一台云服务器和关联的存储资源,无需为负载均衡、冗余节点等高可用组件支付额外费用
初期投入低:对于个人开发者、初创项目或非核心的内部应用,单机部署是性价比最高的选择,能以最小的成本启动项目
运维管理直观:
架构清晰:单节点的架构非常简单,排查问题时,只需登录一台服务器即可检查所有服务的状态和日志
维护方便:应用的更新、备份和恢复等操作相对直接,管理复杂度低
适用场景:主要适用于开发测试环境、个人项目、功能演示(PoC)、以及对可用性要求不高的轻量级生产应用
【十】云服务器单机部署
(1)部署教程:
(1)点击云服务部署的单机部署
(2)可以不用管配置,使用默认模板,直接下一步
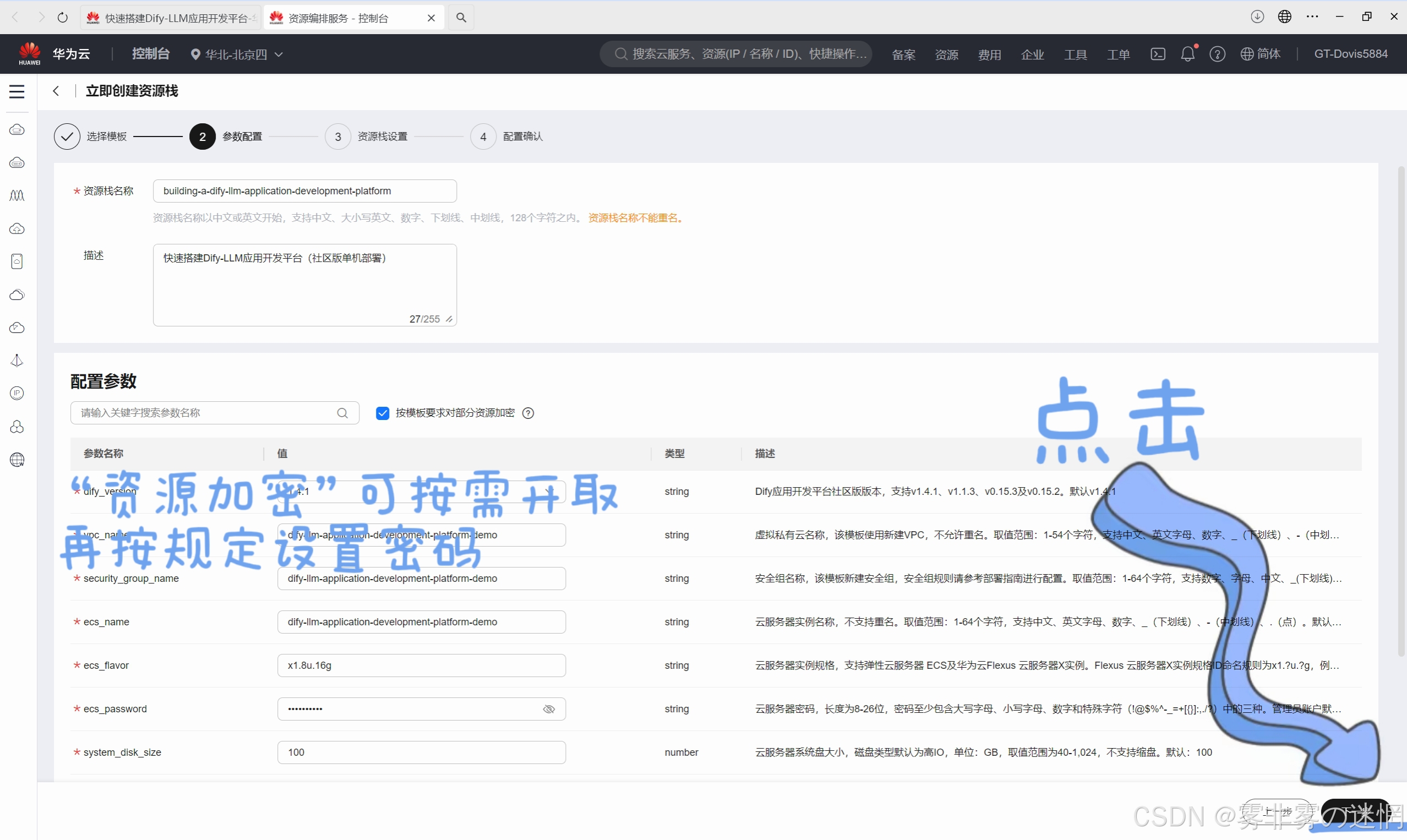
(3)版本、加密自由选择即可,注意密码的设置规则,完后点下一步
(4)打卡回滚设置有助于提高效率,可以不用设置委托,直接下一步
(5)确认配置之后点击创建执行计划
(6)待显示创建成功之后,点击开始部署
(7)这个过程大概需要10分钟,待部署成功
(8)点击“输出”就可以获得IP了,这是后面登录Dify要用的公网IP
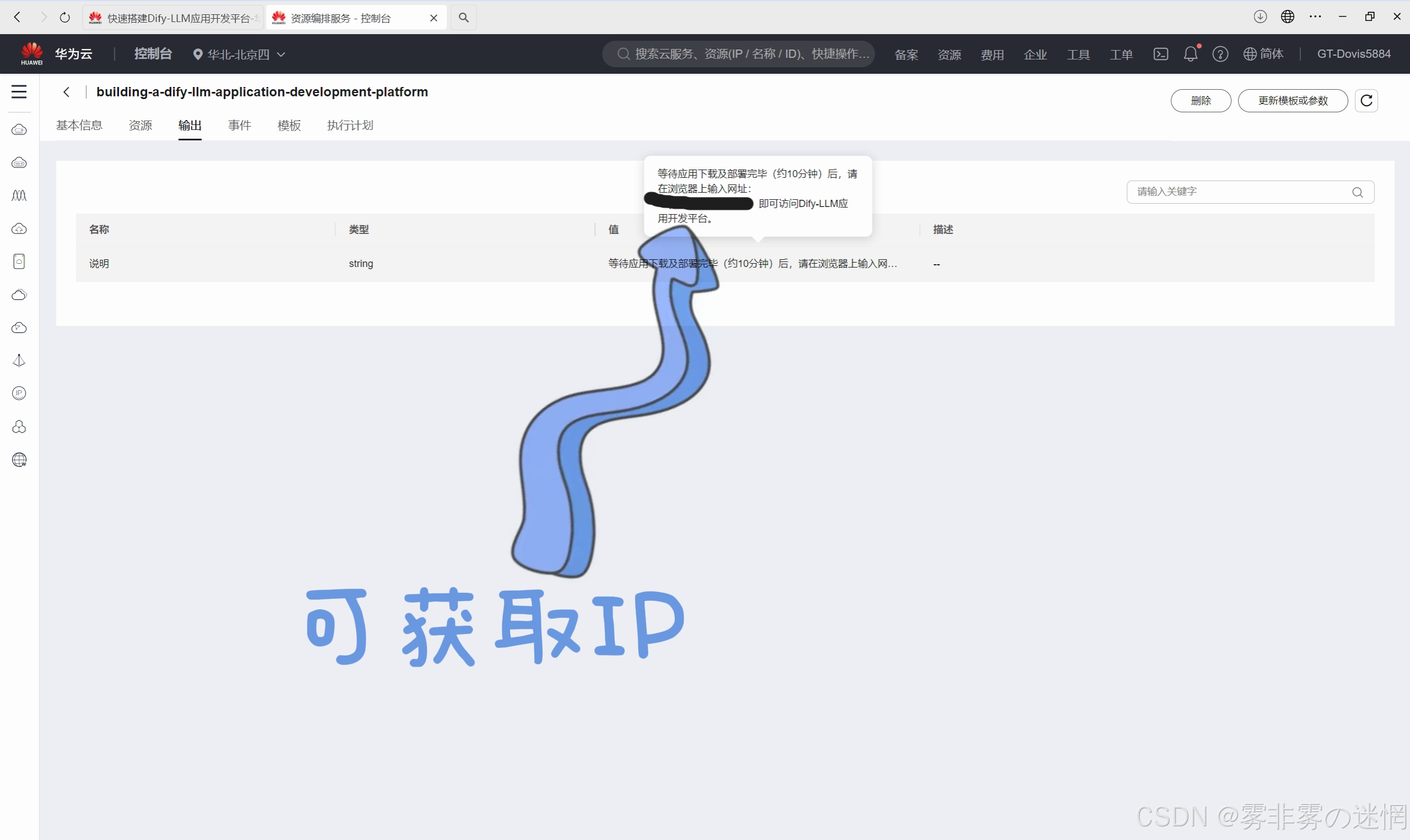
(2)部署体验:
这次在华为云上进行单机部署的体验,可以用高效、直观来形容。我的目标是快速搭建一个用于开发和功能验证的环境,而单机部署方案正好满足了我的需求。整个过程非常顺畅,从选择云服务器(ECS)规格,到配置虚拟私有云(VPC)和弹性IP(EIP),再到一键部署Dify应用以及关联的RDS数据库与Redis缓存,平台都提供了清晰的指引和高度自动化的脚本!
最让我省心的是,我不必在各个组件的复杂网络配置上耗费太多精力。架构虽然简单,但五脏俱全,所有服务都集中在一台主机上,无论是调试、查看日志还是进行数据管理,都非常直接方便。这种部署方式极大地降低了初期的技术门槛和成本,让我们能将全部精力聚焦在应用本身的功能开发上。对于项目初期的快速迭代和原型验证来说,这无疑是性价比最高的选择!
【十一】如何监测单机部署性能
(1)核心参数:
CPU使用率:查看CPU是否空闲或过于繁忙
内存使用率:监控内存是否充足
磁盘使用率:监控磁盘空间是否即将耗尽
磁盘读写速率(IOPS):分析磁盘性能瓶颈
网络入/出带宽:查看公网或内网流量情况
GPU使用率/显存使用率
(2)监测方法:
华为云云服务监控 :这是最简单、最实用的测量工具,采用图形化趋势分析
在监控之前我们需要安装插件,否则只能看基础监测,不是很全面!
(3)Linux命令安装插件:
(1)需要已经部署成功的云服务器
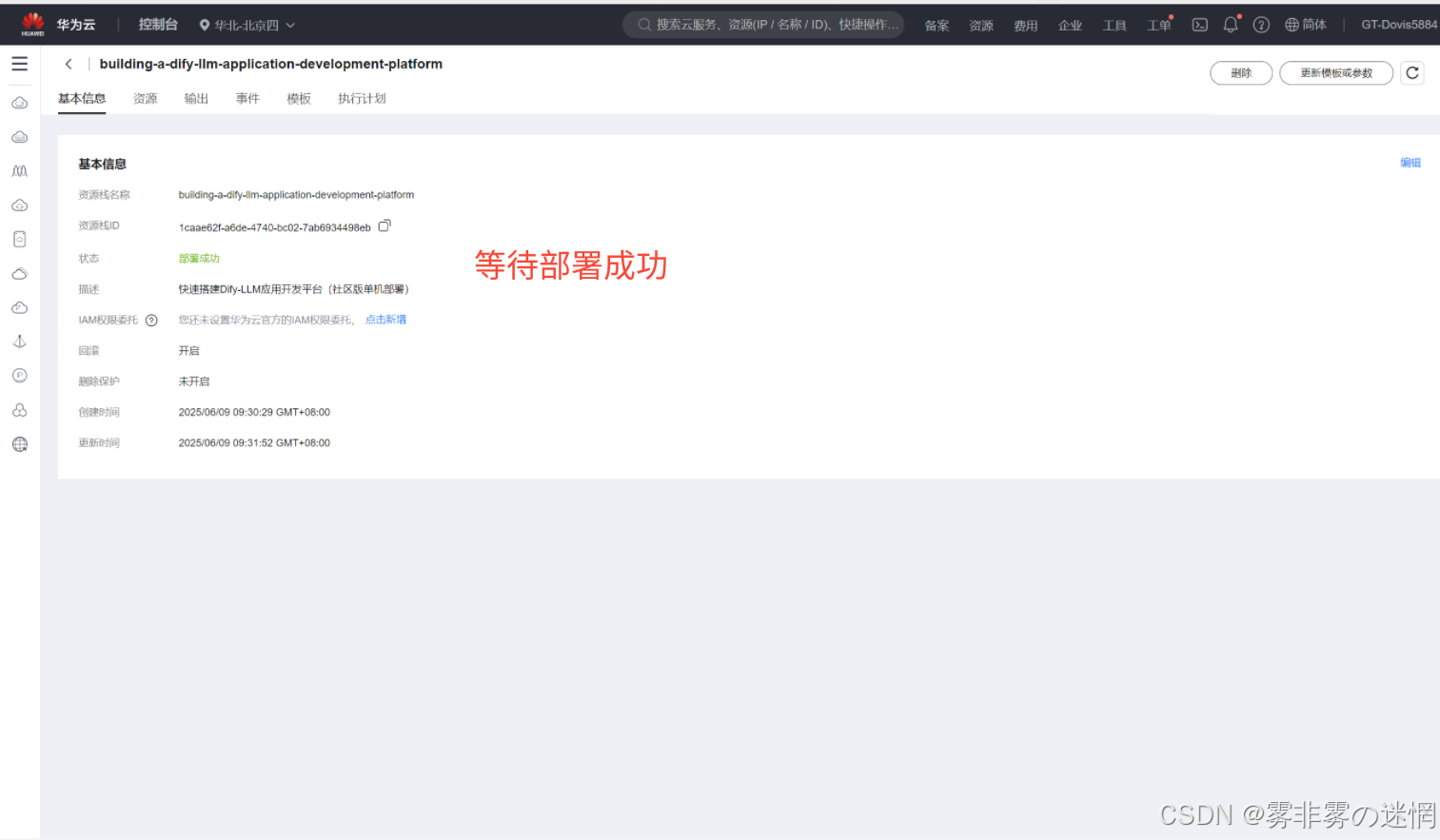
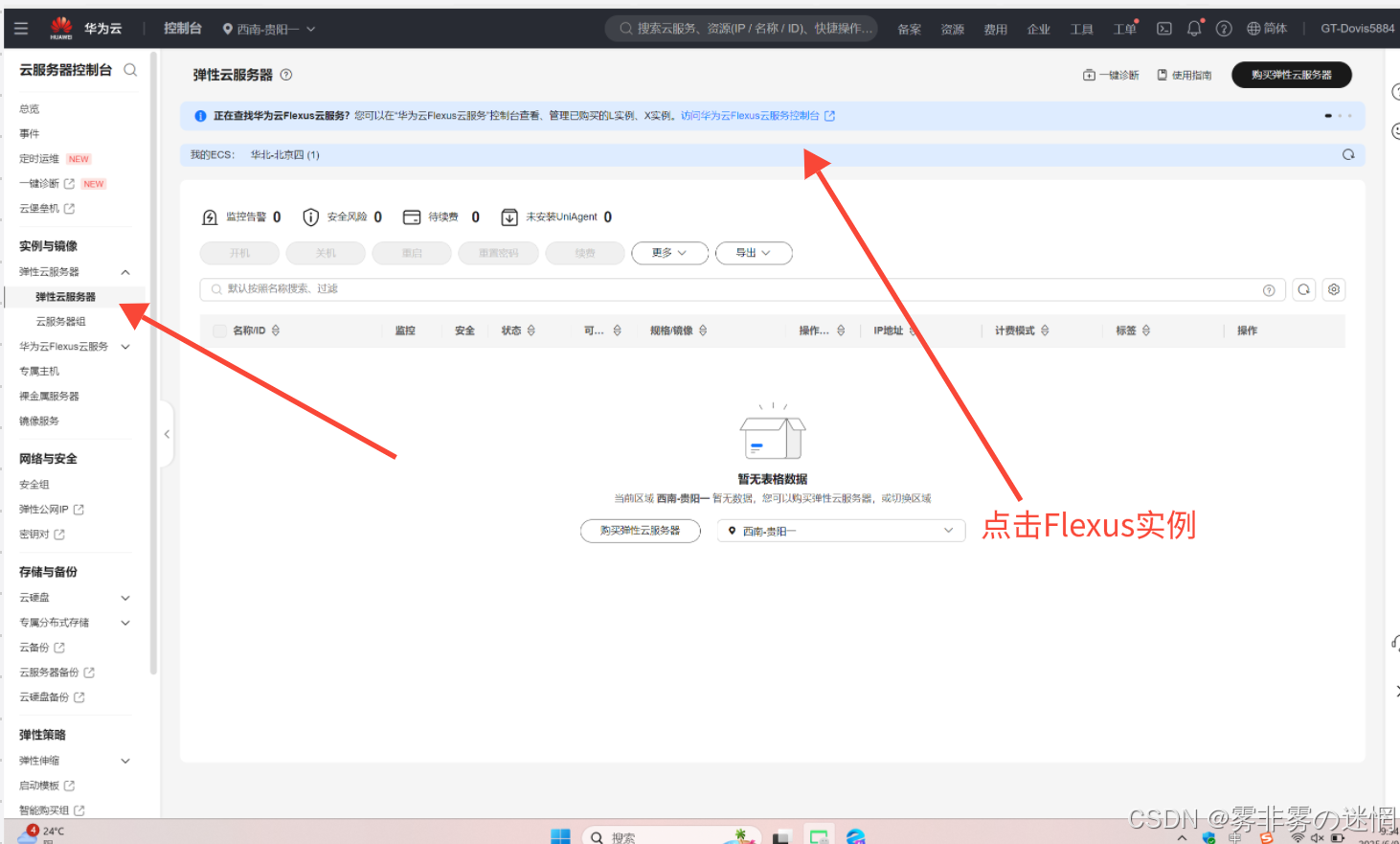
(2)然后去云服务控制台,点击弹性云服务器,点击上面的Flexus实例或者直接搜索也行
(3)点击Flexus X实例
(4)点击远程登录
(5)点击立刻登录
(6)先输入root,然后回车,再输入部署设置的密码(注意:密码的输入不会显示)再回车
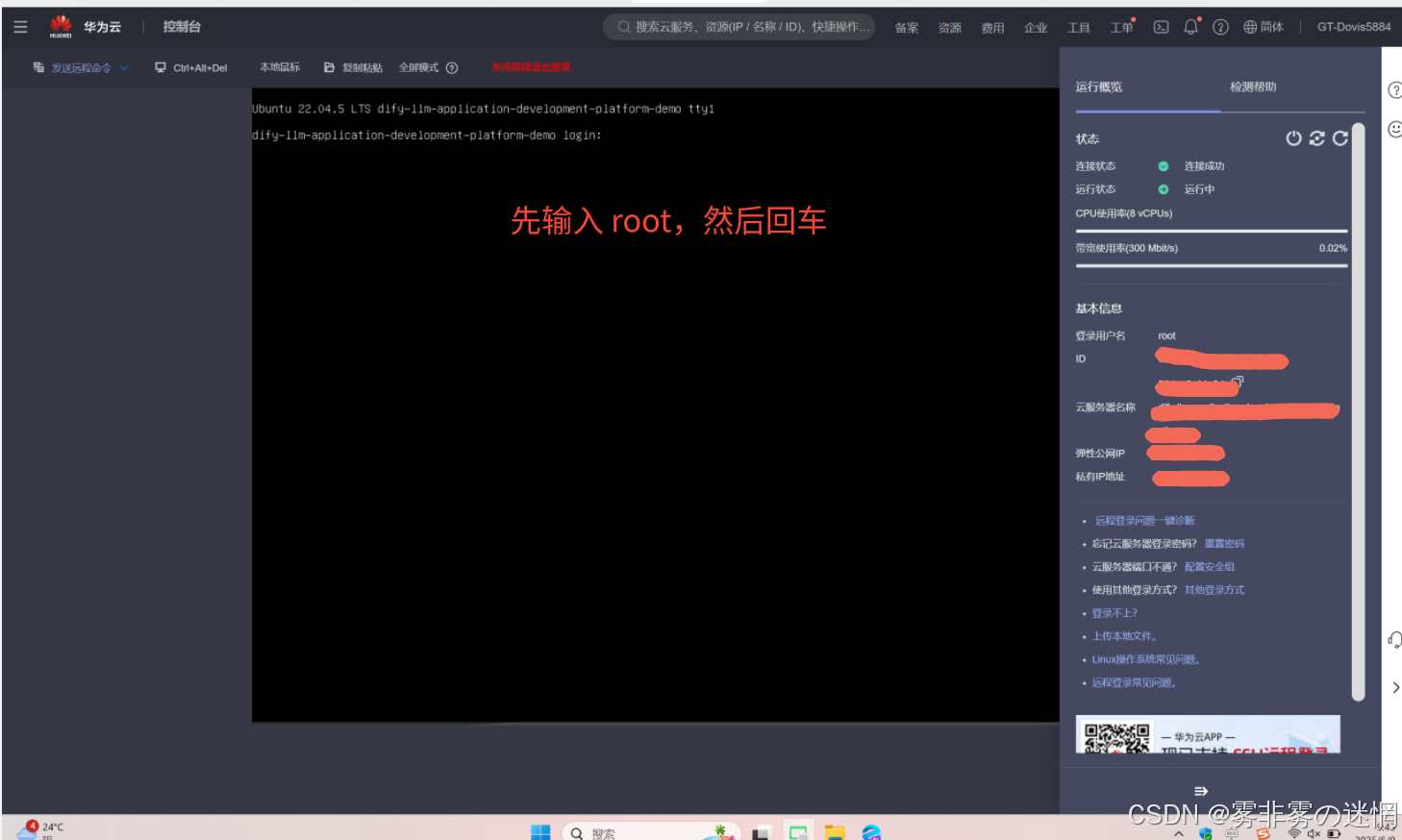
(7)这样的界面下,我们需要回到云监控服务复制 Linux 的执行命名
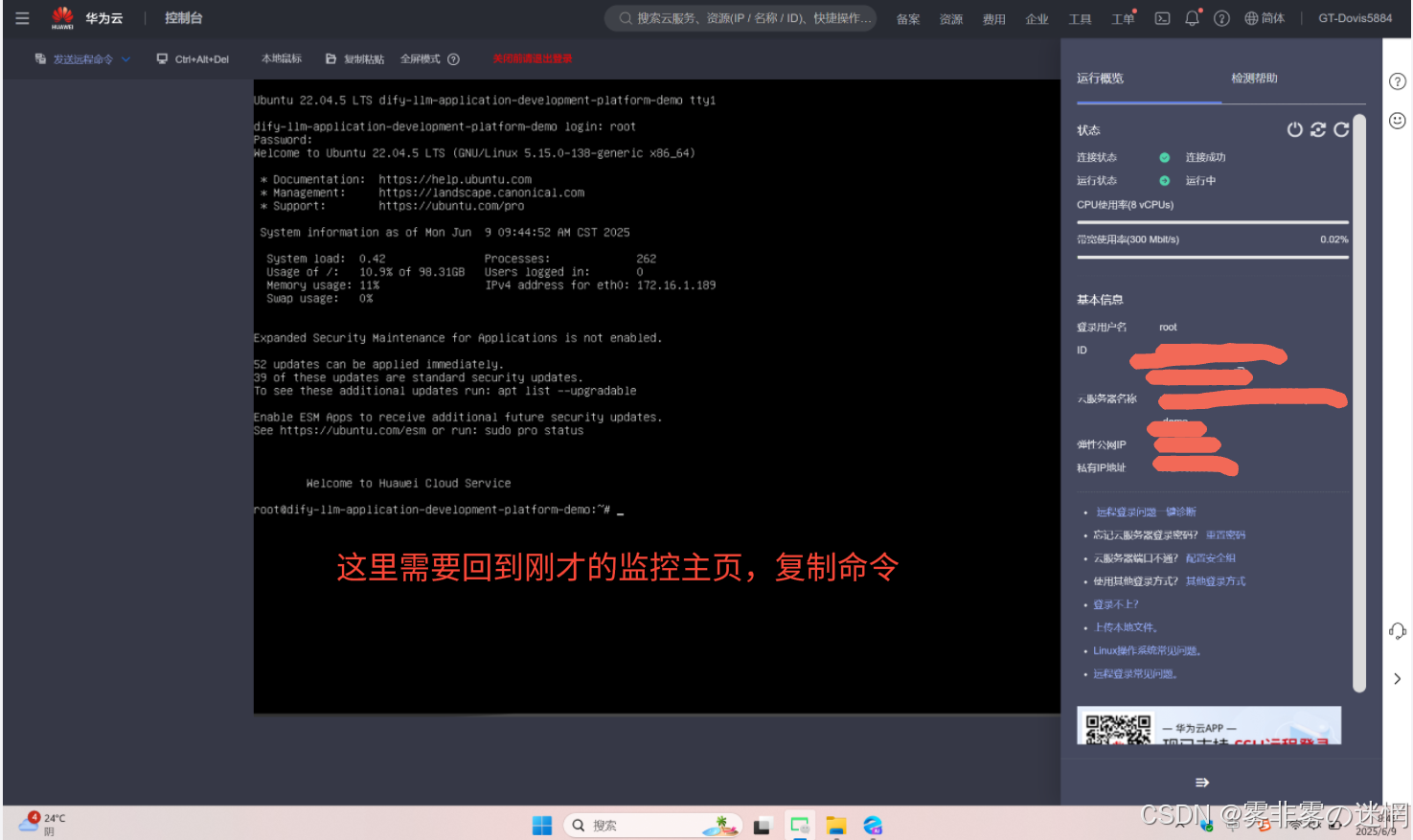
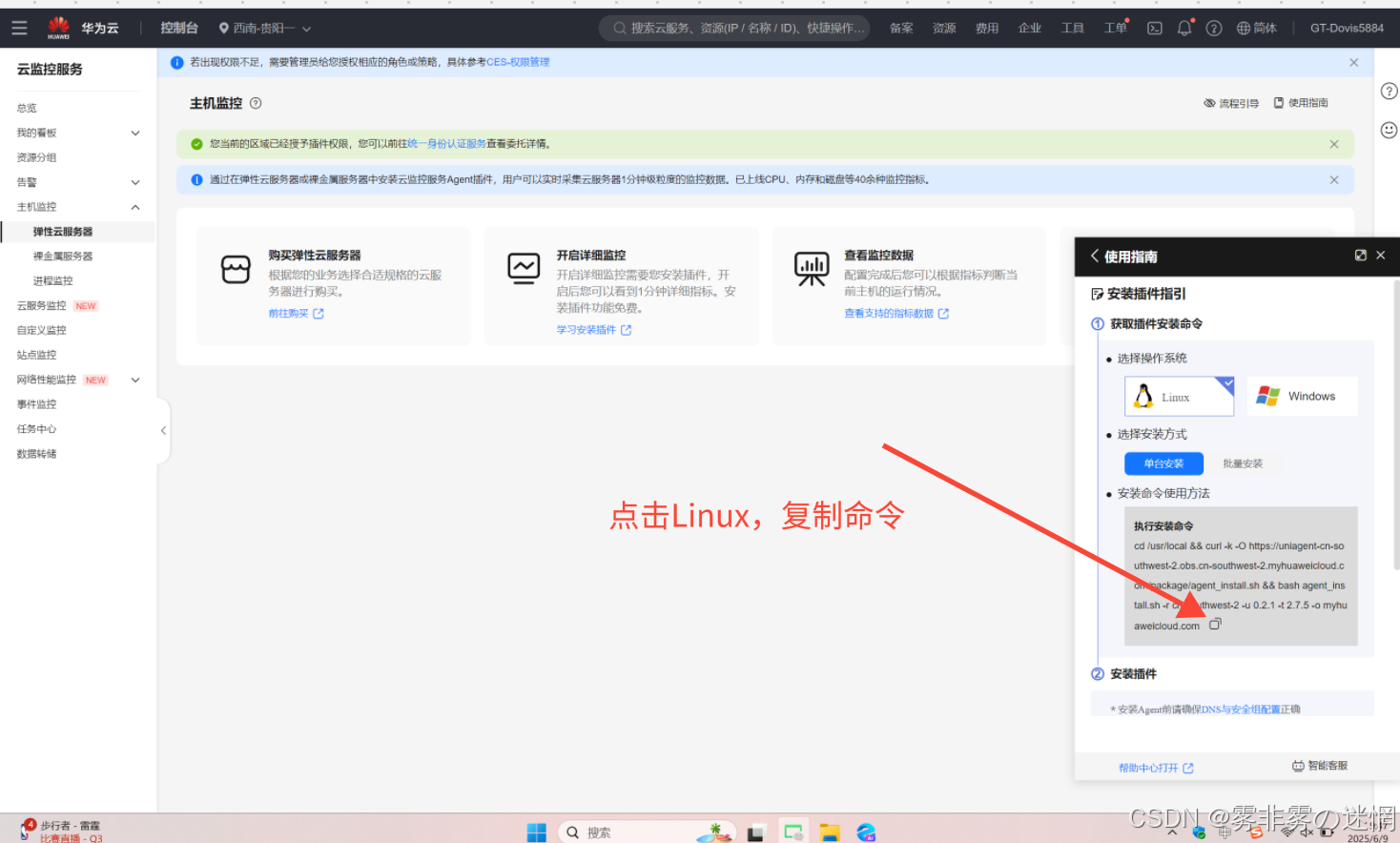
(8)点击弹性云云服务器,点击“开始详细监控”,点击 Linux,复制下面的执行命名
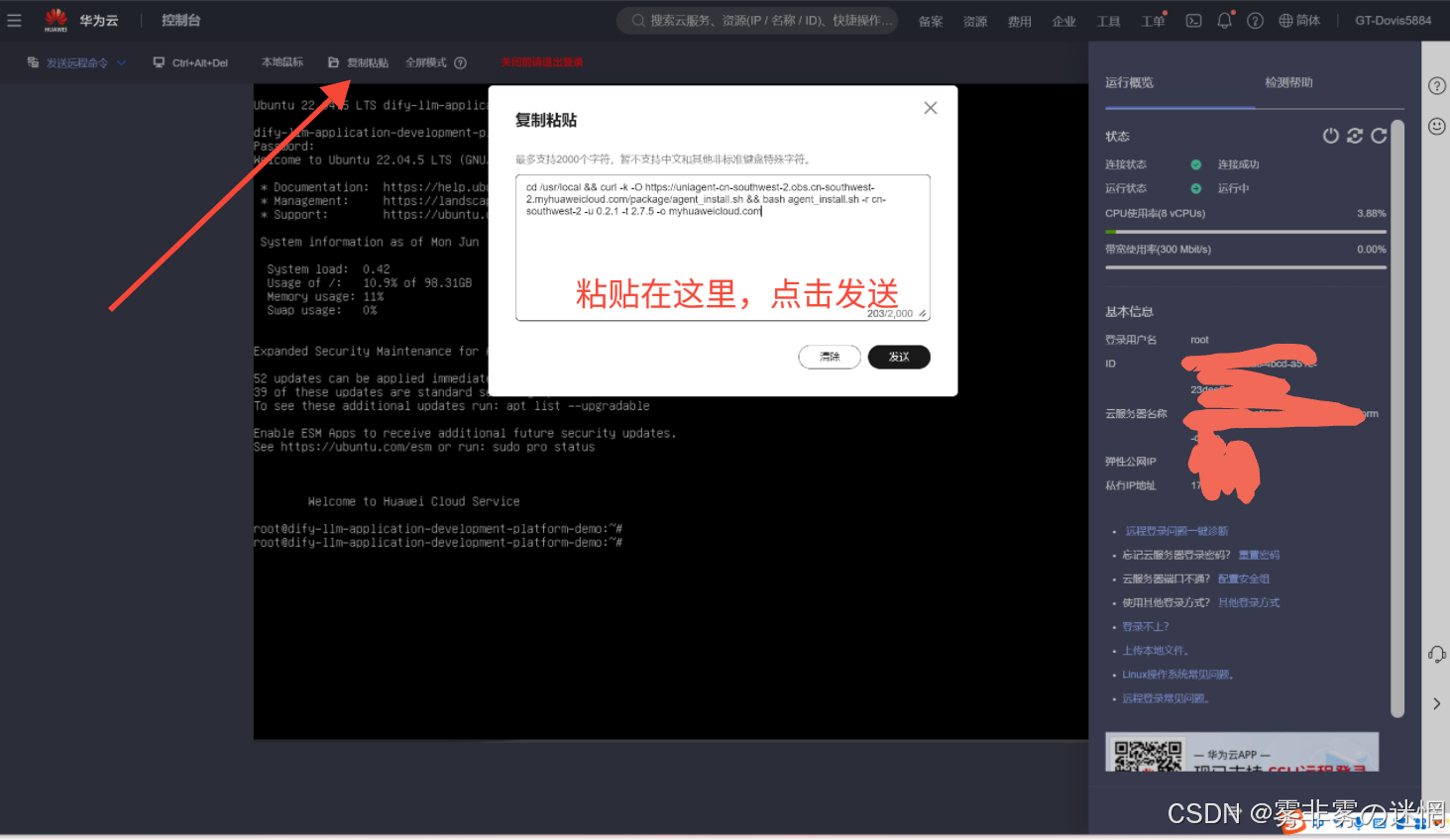
(9)然后回到登录界面,点击左上角的复制粘贴,粘贴命名然后发送
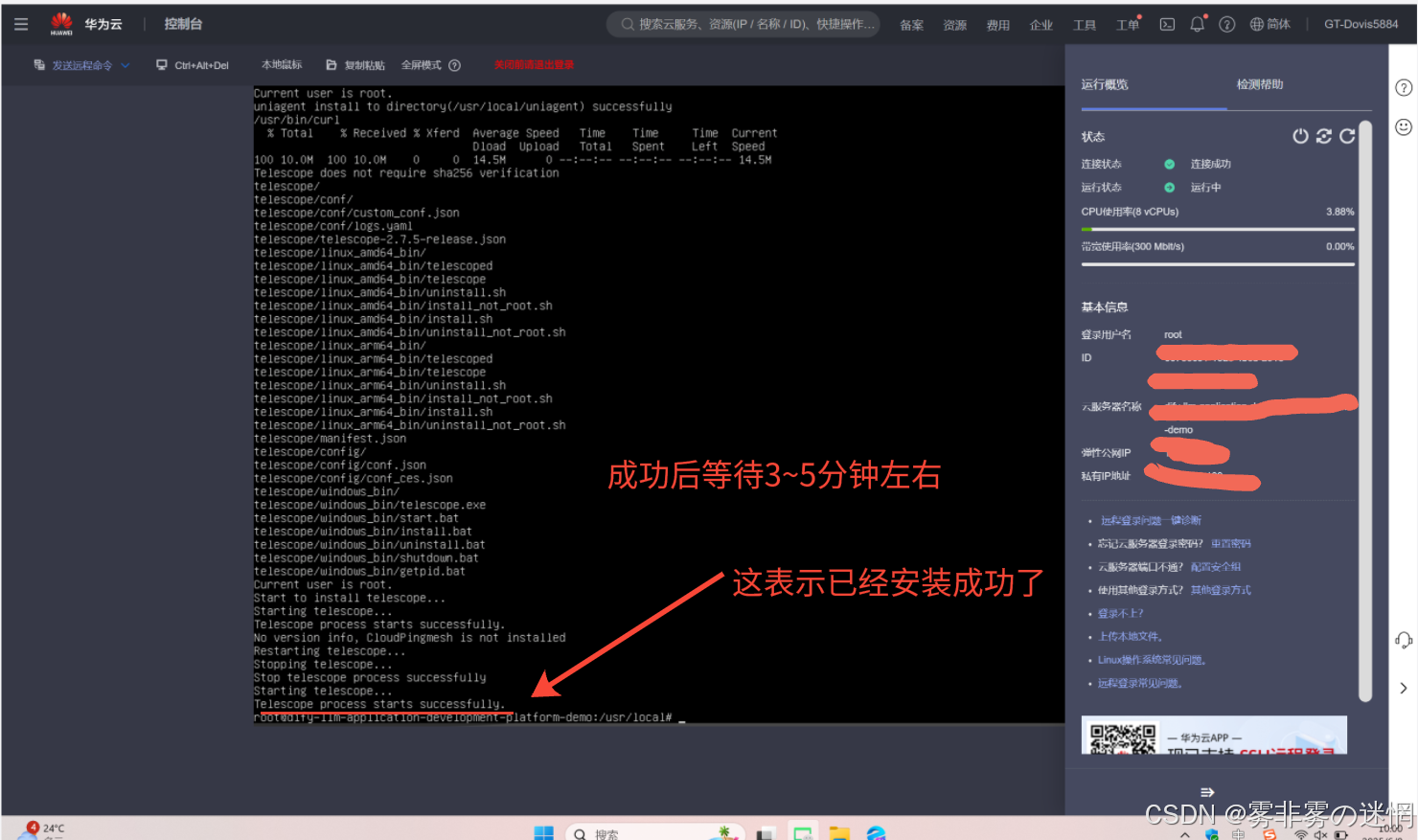
(10)这样就表示成功了,然后等待3~5分钟,就可以开始我们的“操作步骤”查看部署性能了
(4)监测步骤:
【监测步骤需要在完成“插件安装”之后进行,否则检测的不全面,效果不好!】
(1)登录华为云控制台
(2)搜索“Flexus云服务”,点击Flexus X实例,点击这个已经部署的实例
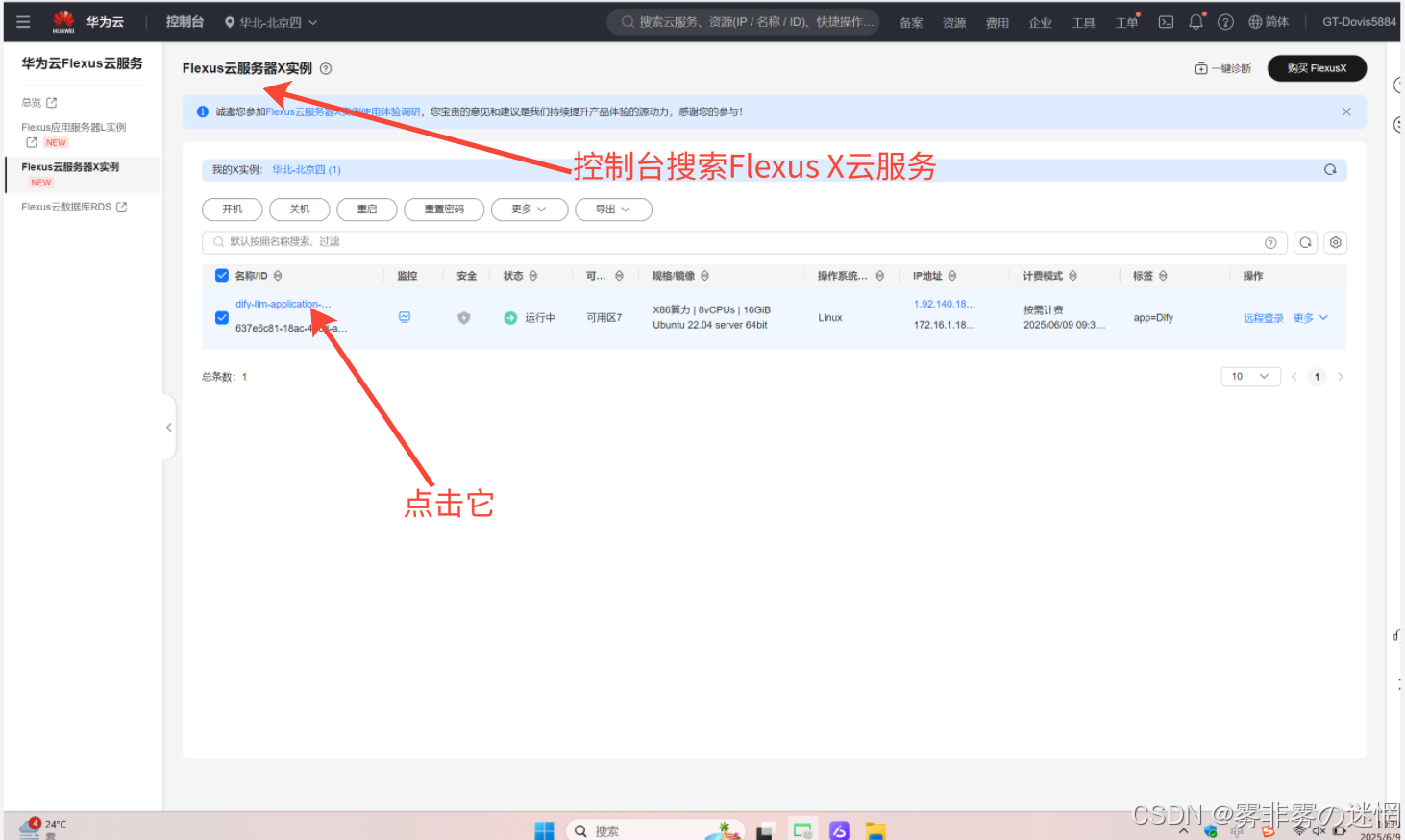
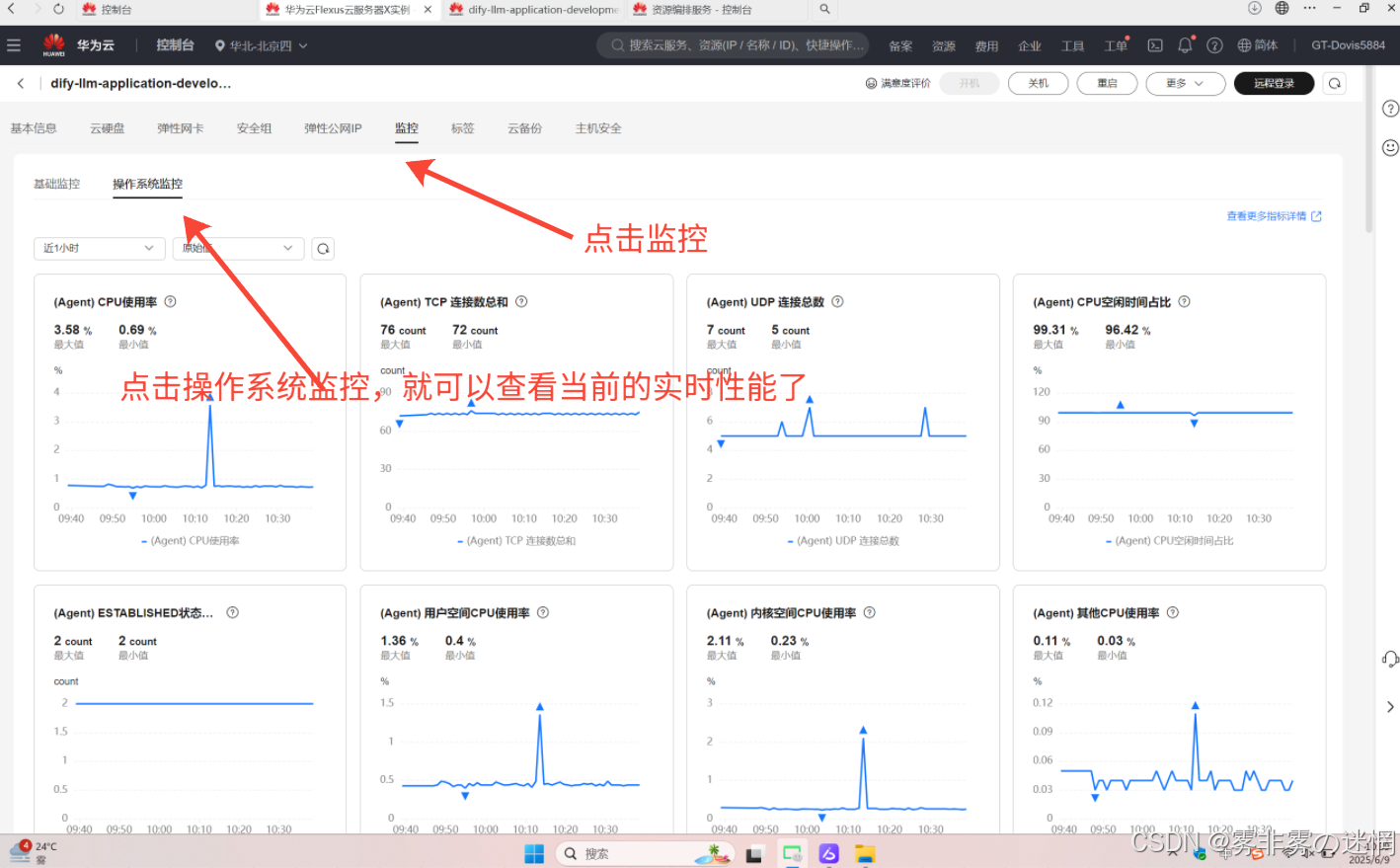
(3)点击“监控”,点击“操作系统监控”,这样就可以查看部署的服务器实时性能参数了
【十二】CCE高可用框架优势
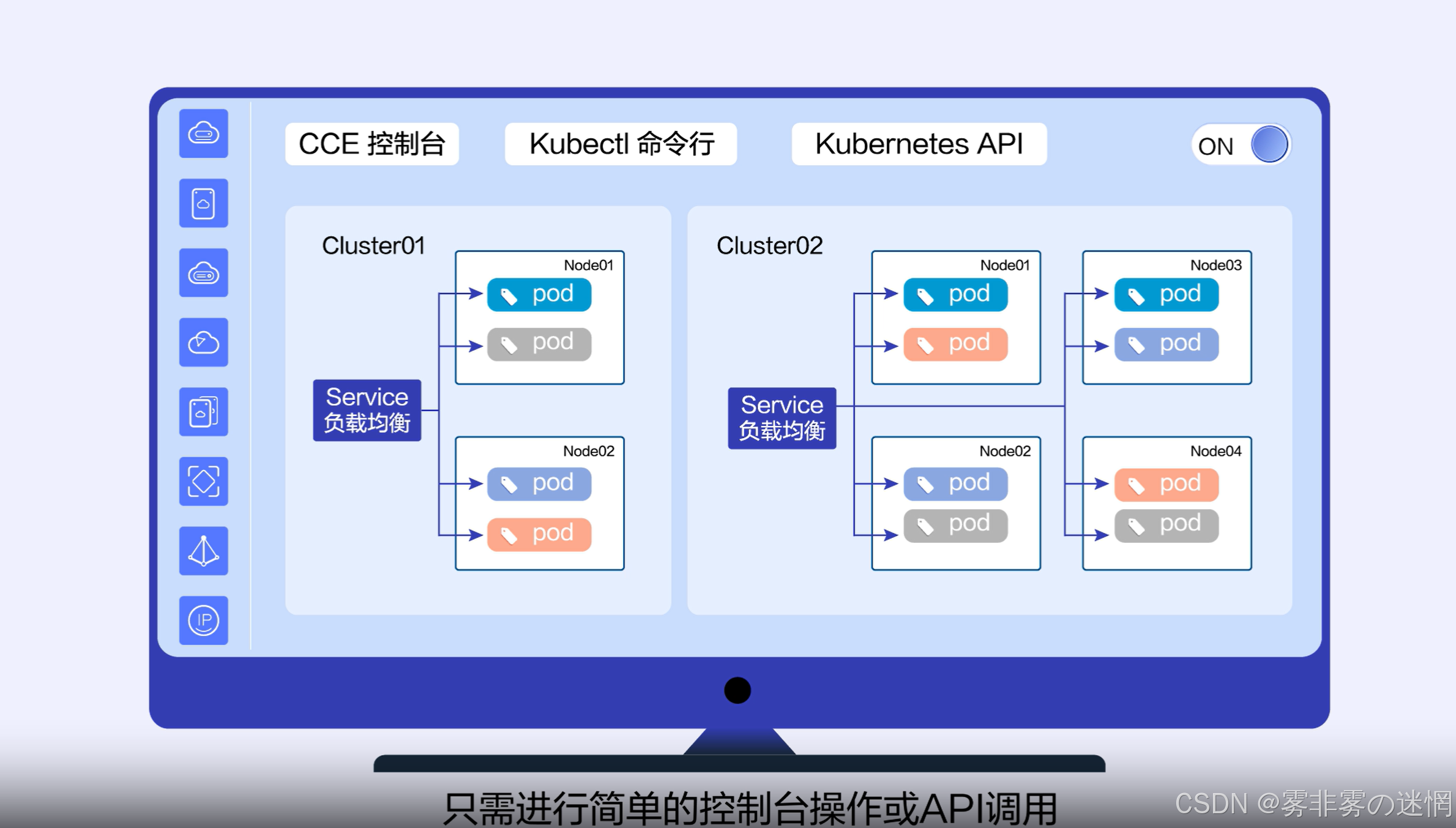
CCE(云容器引擎)是基于业界主流的 Kubernetes 技术构建的容器管理服务。CCE高可用部署利用了容器编排和云计算的优势,将应用容器化后部署在由多个云服务器节点组成的集群中。其核心优势在于 高可靠性、弹性伸缩 和 现代化架构支持
CCE集群介绍
卓越的高可用与可靠性:
消除单点故障:应用会以多个副本的形式运行在不同的服务器节点上,甚至可以跨越不同的物理可用区(AZ)。当单个节点或服务器发生故障时,CCE会自动将流量切换到健康的副本上,保证业务不中断
自愈能力:CCE集群会持续监控容器的健康状态。如果某个容器实例崩溃,系统会自动重新创建一个新的实例来替代,实现了故障的自动恢复
强大的弹性伸缩能力:
自动化扩缩容:可以根据CPU、内存使用率或自定义指标,自动增加或减少应用的容器实例数量。在业务高峰期,系统能平滑扩容以应对高并发访问;在业务低谷期,则自动缩减资源以节省成本
负载均衡:架构图中的负载均衡器(LB)会将外部访问流量智能地分发到后端的多个容器实例上,确保每个实例的负载都在合理范围内,提升了整体服务性能和响应速度
支持现代化微服务架构:
敏捷开发与部署:CCE天然支持微服务架构,如架构图中的 Dify 服务可以被拆分为多个独立的微服务(如 Embedding & Re-ranker 模块)。每个服务可以独立开发、部署和扩展,大大提升了研发效率和系统的灵活性
服务治理:提供了完善的服务发现、配置管理和流量治理能力,简化了复杂微服务应用的管理
DevOps与生态集成:
CI/CD友好:能够与持续集成/持续部署(CI/CD)工具链无缝集成,实现代码提交、构建、测试到部署的全流程自动化
云服务集成:可与华为云的RDS(数据库)、Redis(缓存)、CSS(搜索)等各类云服务高效协同,构建功能强大、架构完善的云原生应用
【十三】CCE高可用部署
(1)准备工作:
桶的创建:
(1)打开对象存储服务(也可以直接搜索“桶”),如果已有桶,则不用创建
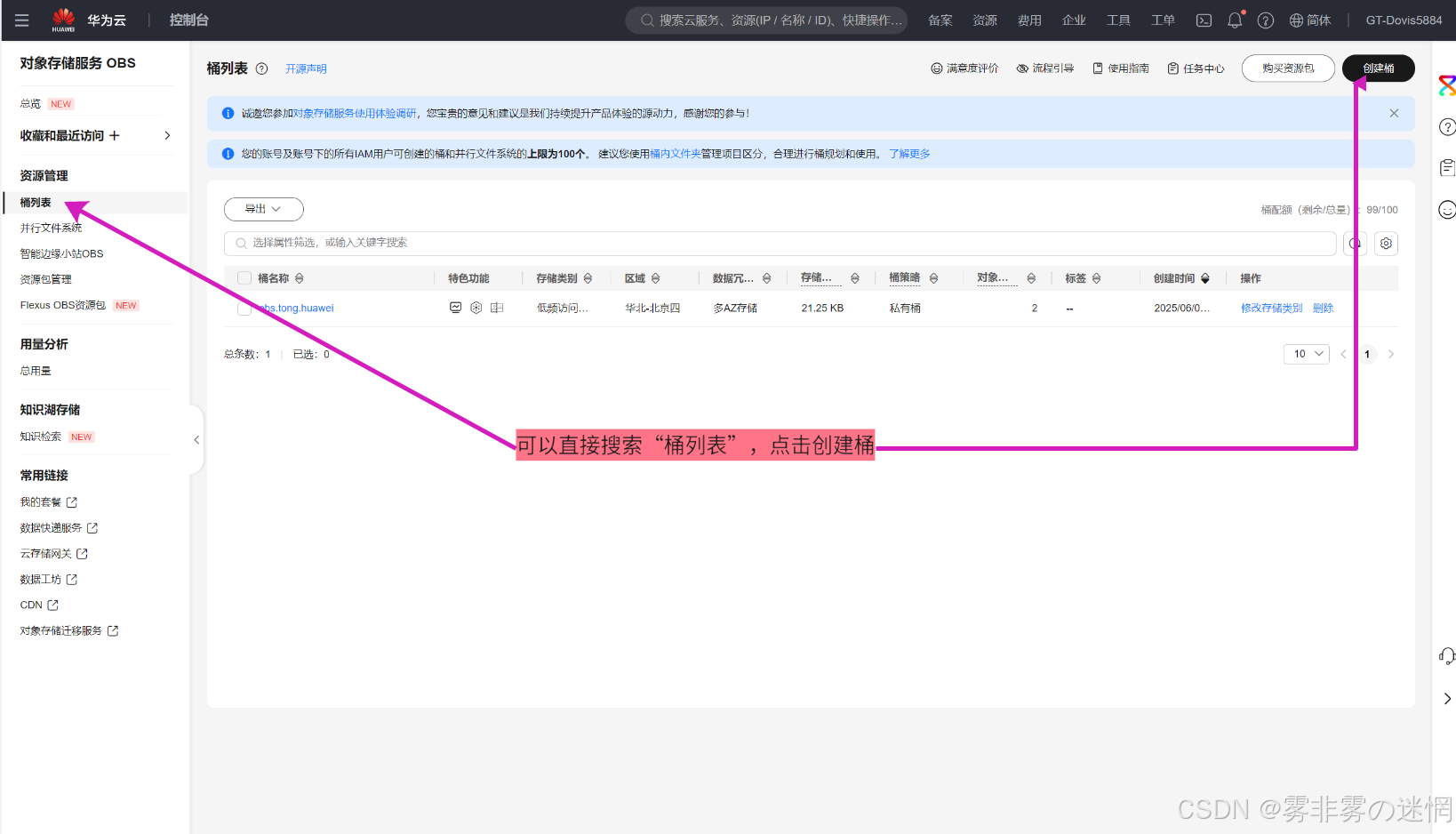
(2)配置建议:选择低频,可以较少费用开销,没问题之后点击创建
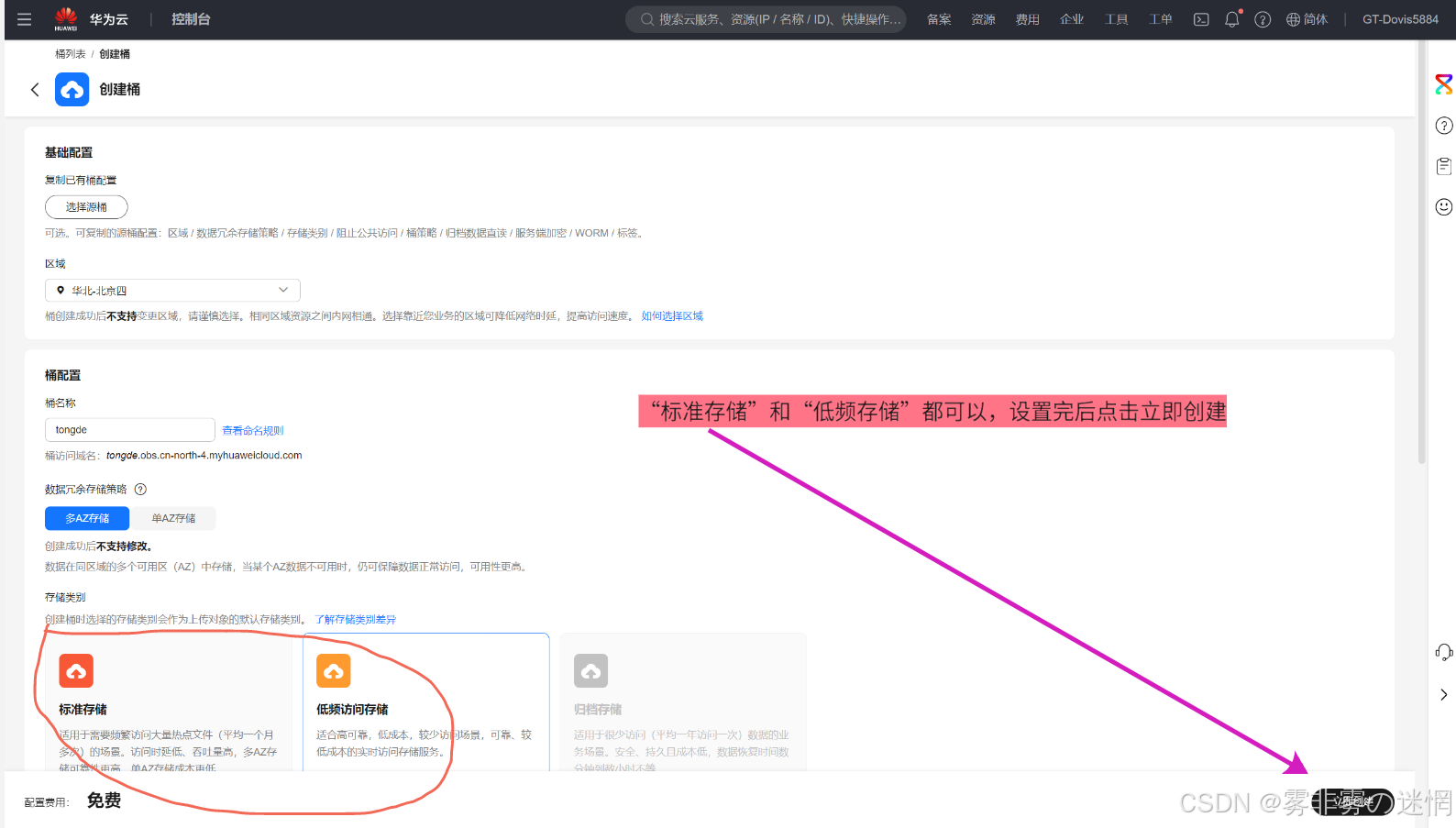
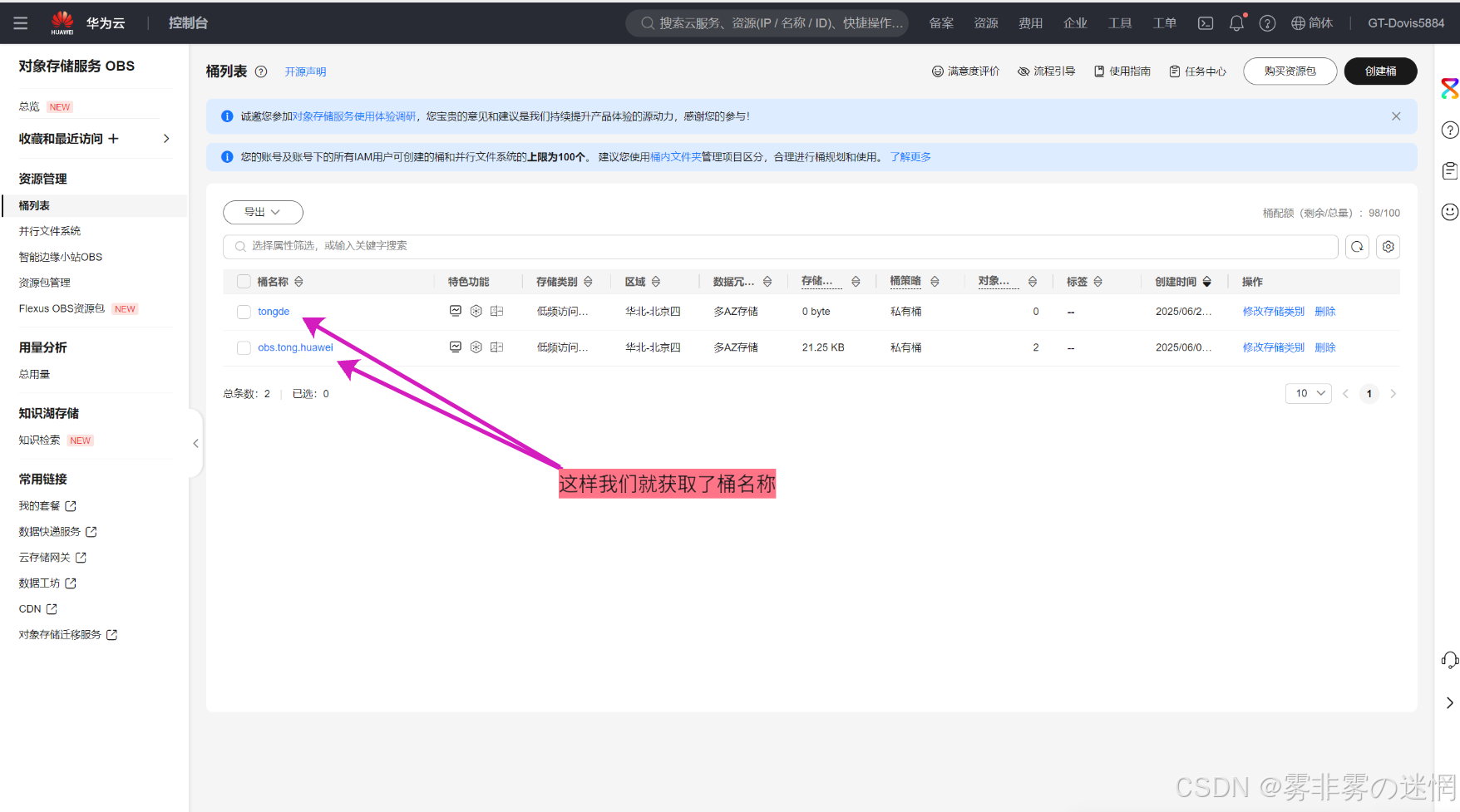
(3)我们后面需要用到桶的名称,点开这个桶,右上角就可以直接复制
秘钥创建:
(1)控制台搜索:“我的凭证”
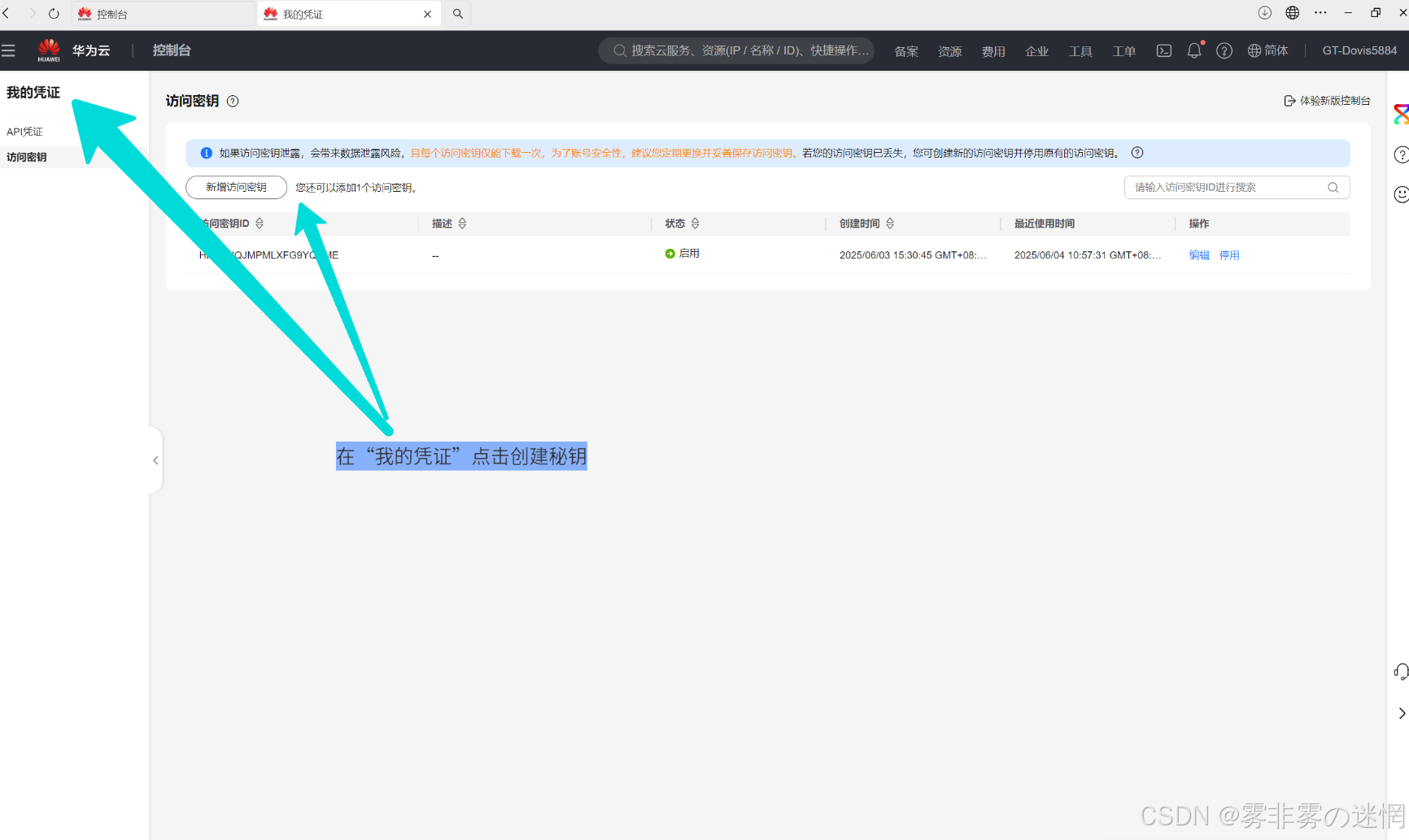
(2)点击“访问秘钥”,创建一个新秘钥,秘钥之会显示一次,建议下载
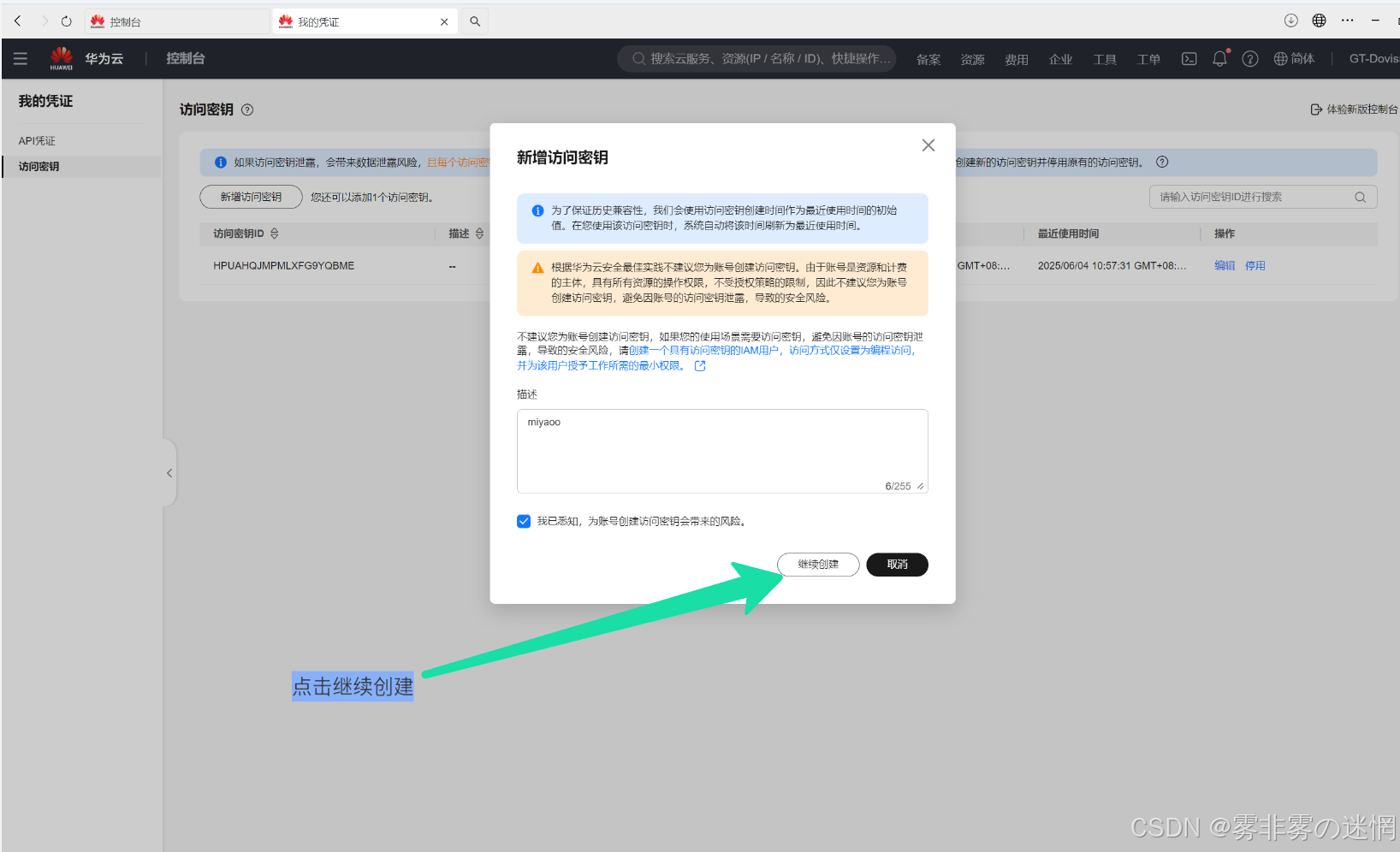
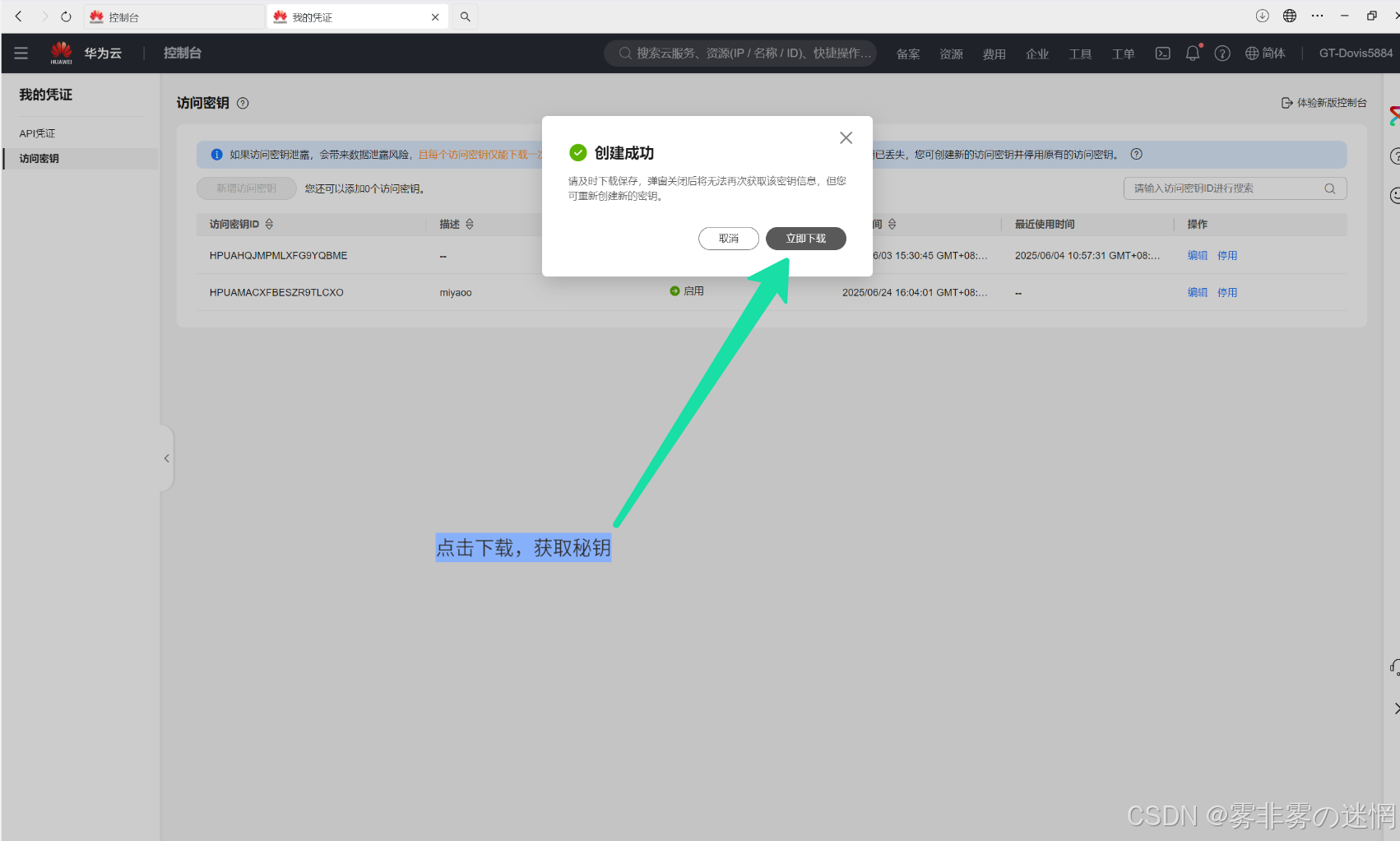
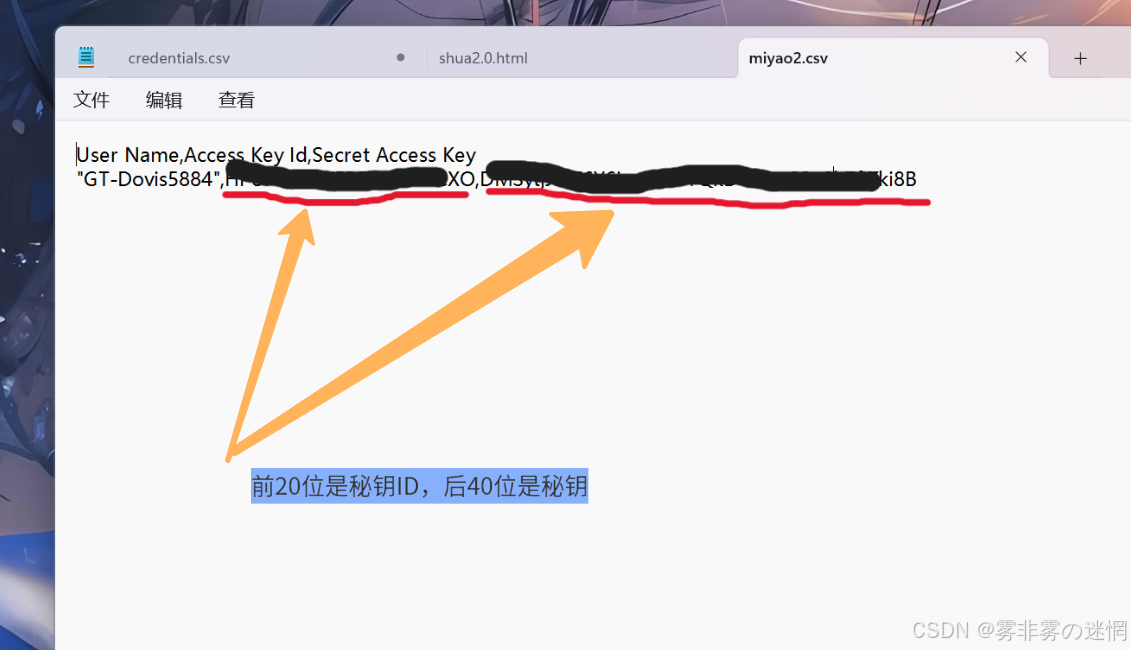
(3)小编下载在了桌面,后面可以在记事本打开,秘钥、秘钥ID如下参考
委托创建:
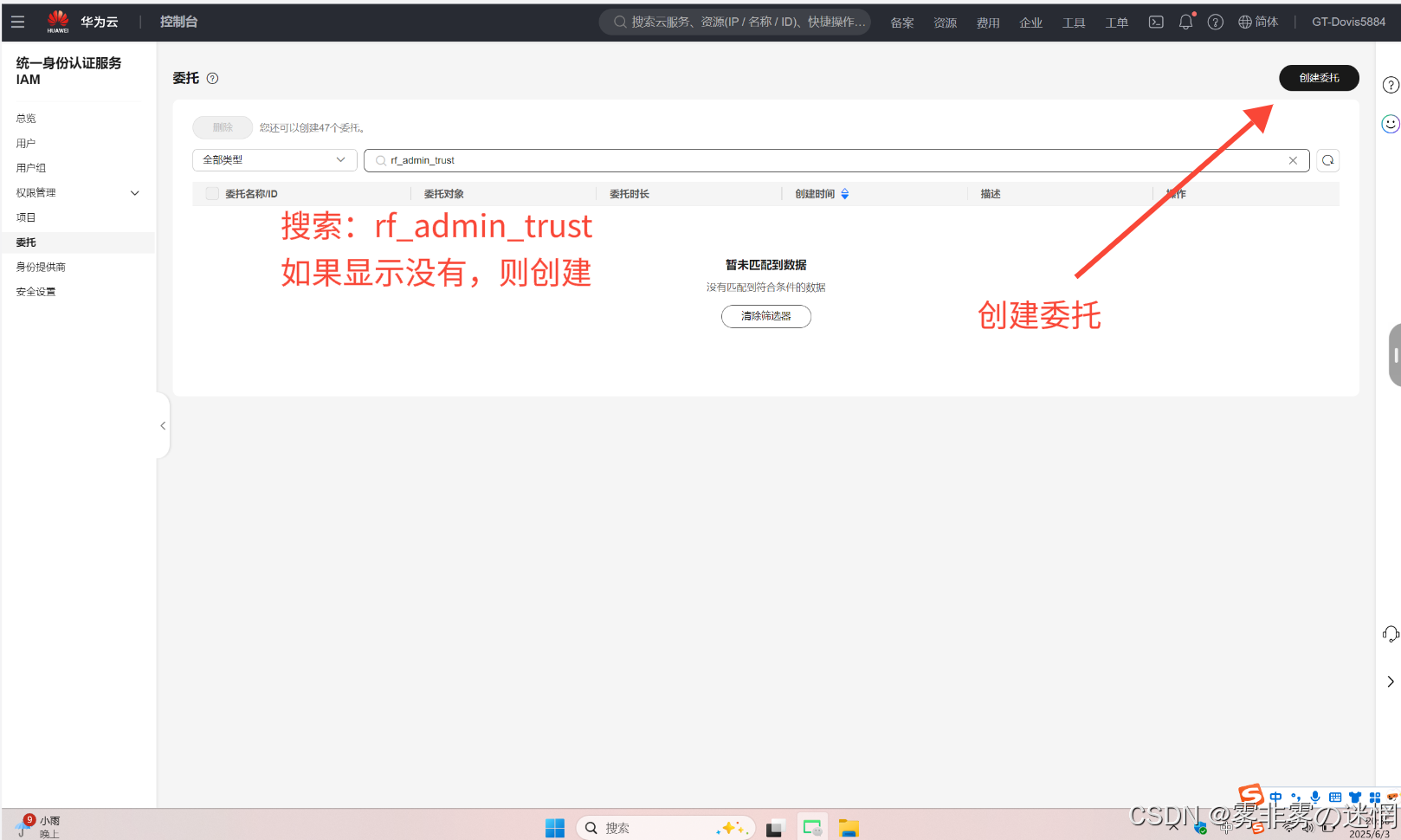
(1)可以直接在控制台搜索“委托”,搜索下面这个委托名
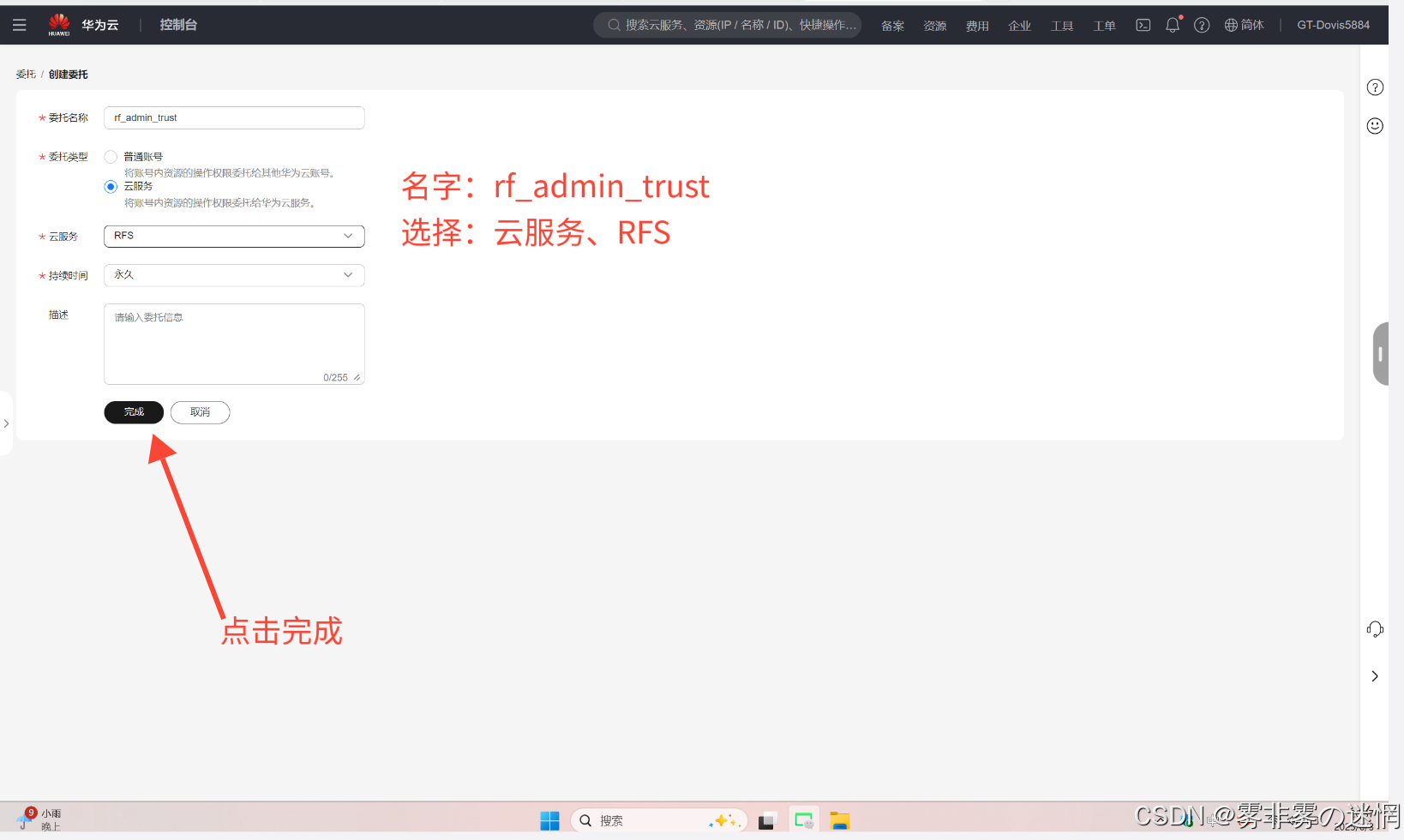
(2)名字设置为:rf_admin_trust,选择云服务,RFS编排
(3)这里需要立刻授权
(4)搜索下面这个权限,需要添加
(5)这里选择“所有资源”
(6)然后点击完成即可
委托授权:
打开云容器引擎CCE,这里是需要给委托授权的
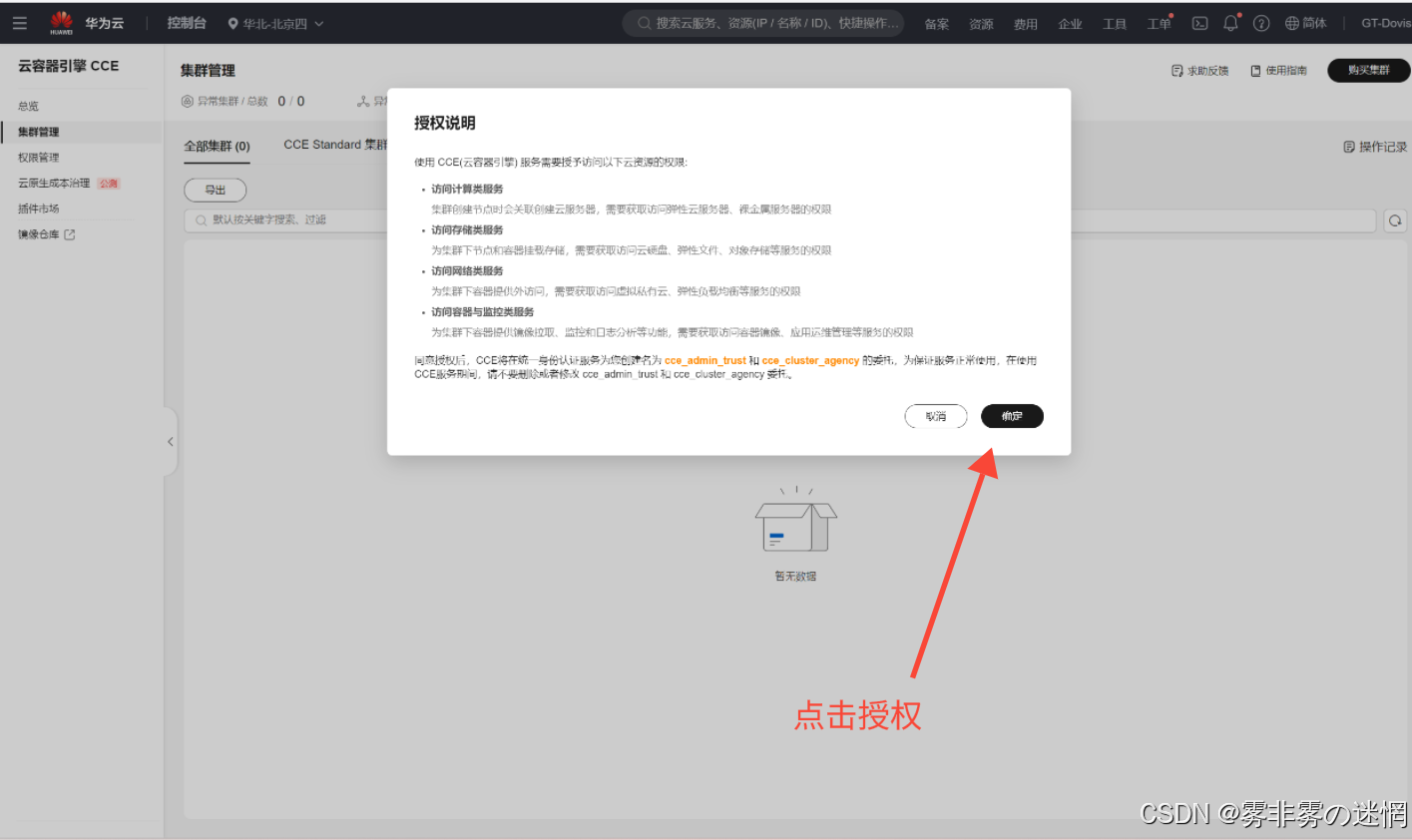
(2)部署教程:
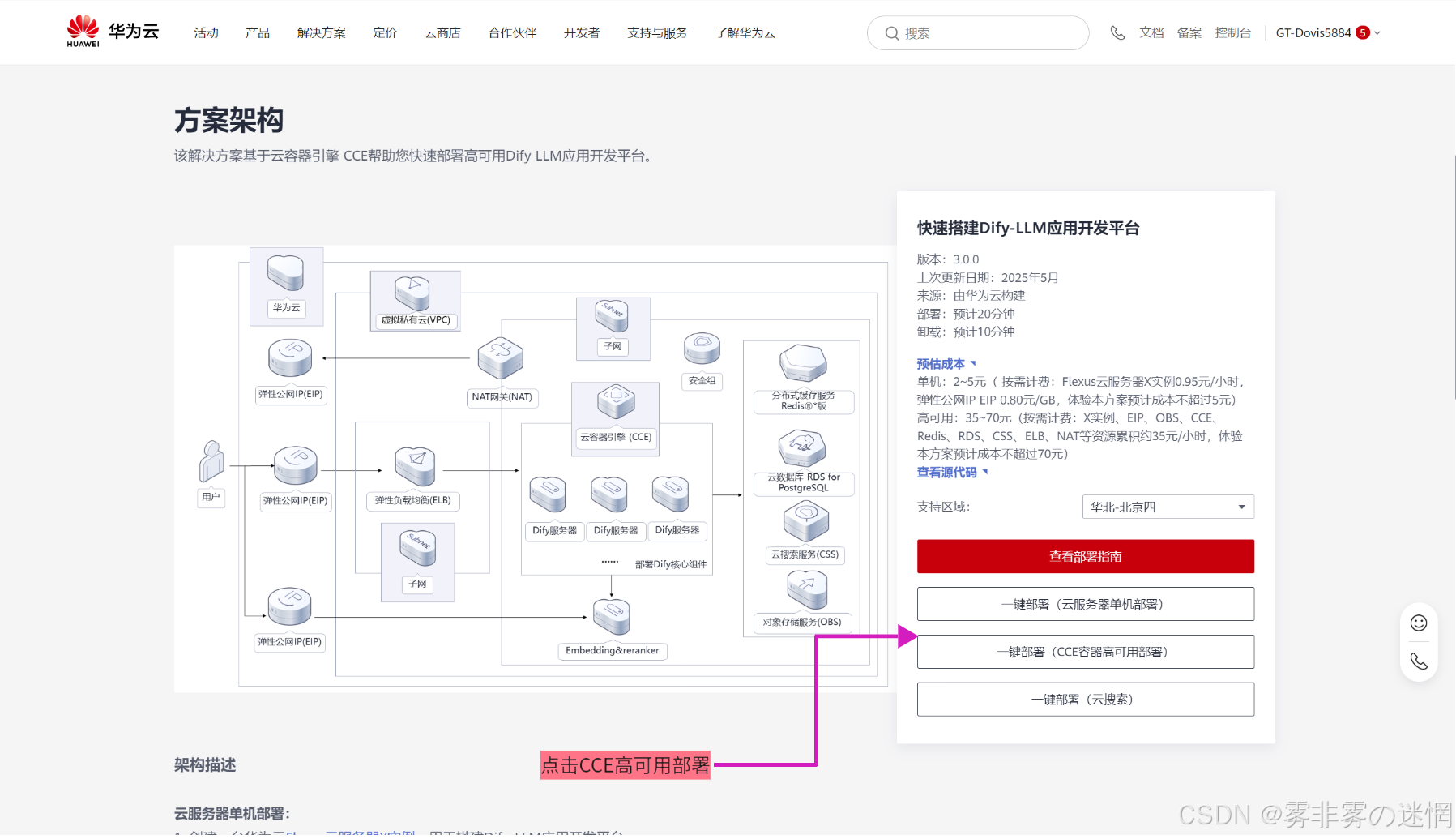
(1)点击高可用部署
(2)可直接用默认模板,点击下一步
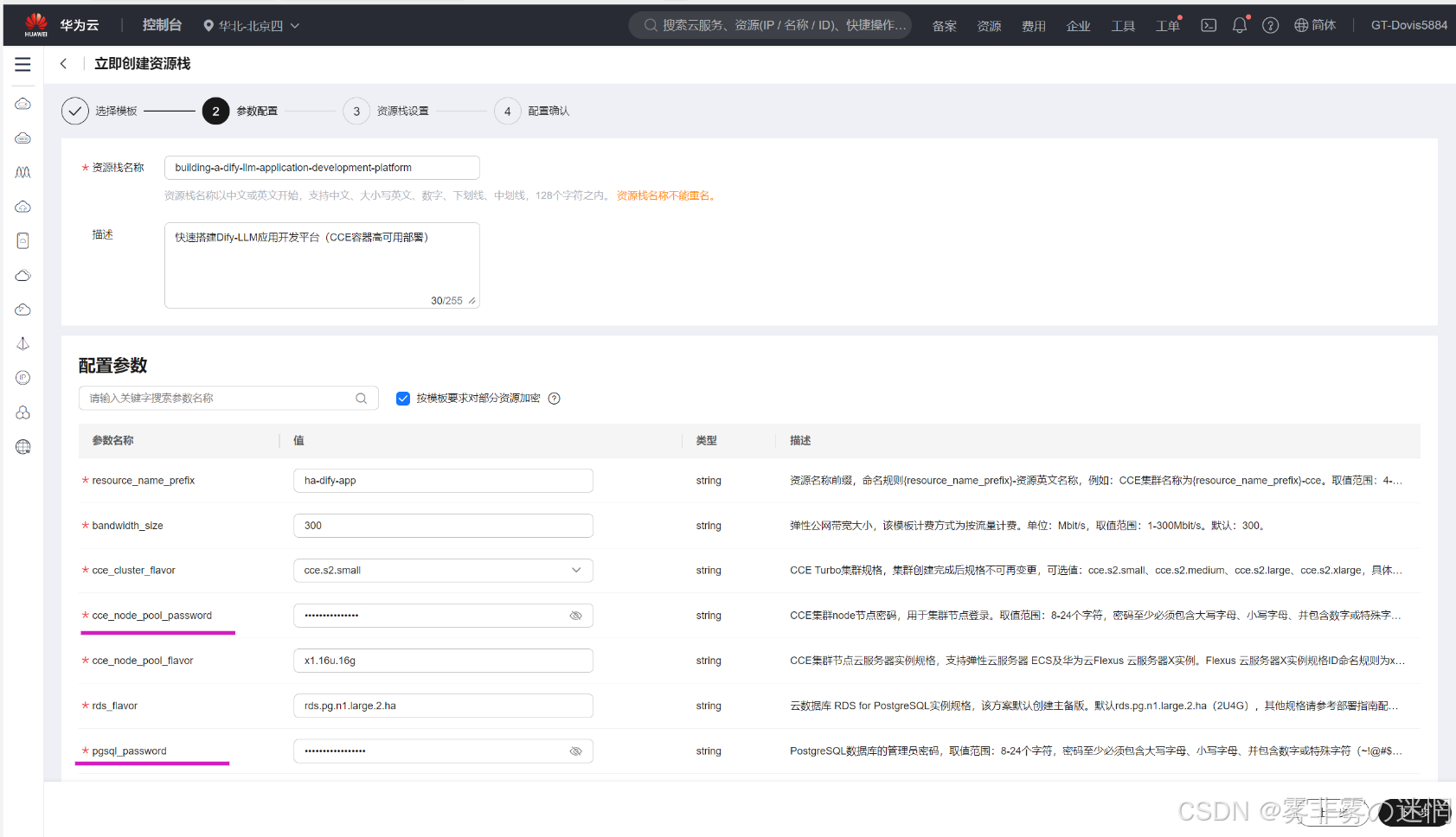
(3)这里大概需要设置密码,大家按照要求设置即可,需要注意下面三个配置
桶的名称、秘钥ID、秘钥的获取可参考“准备工作”里的教程,直接粘贴即可
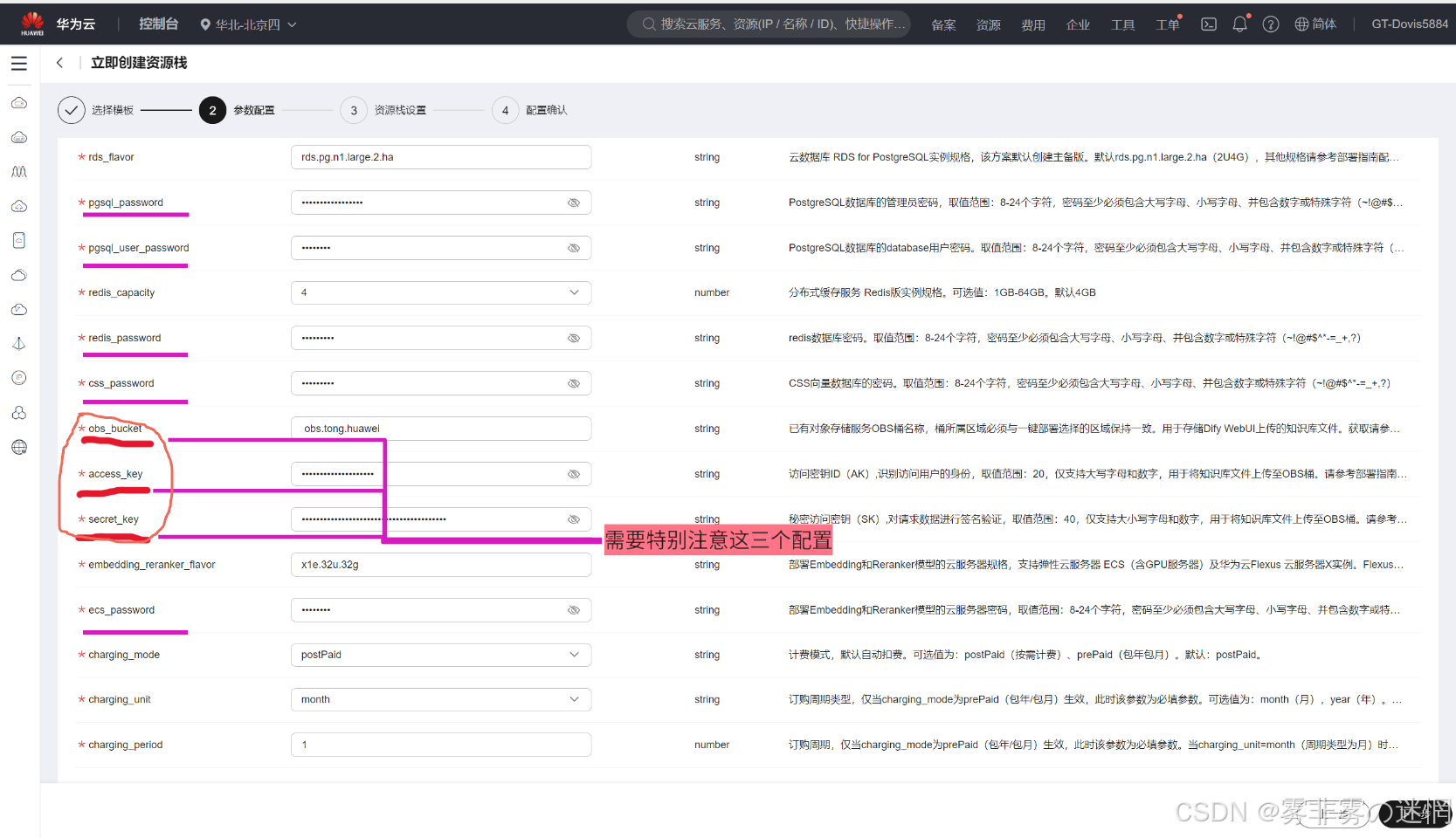
(4)这里需要选择rf_admin_trust委托,回滚可以打开提高效率,删除保护自定义选择
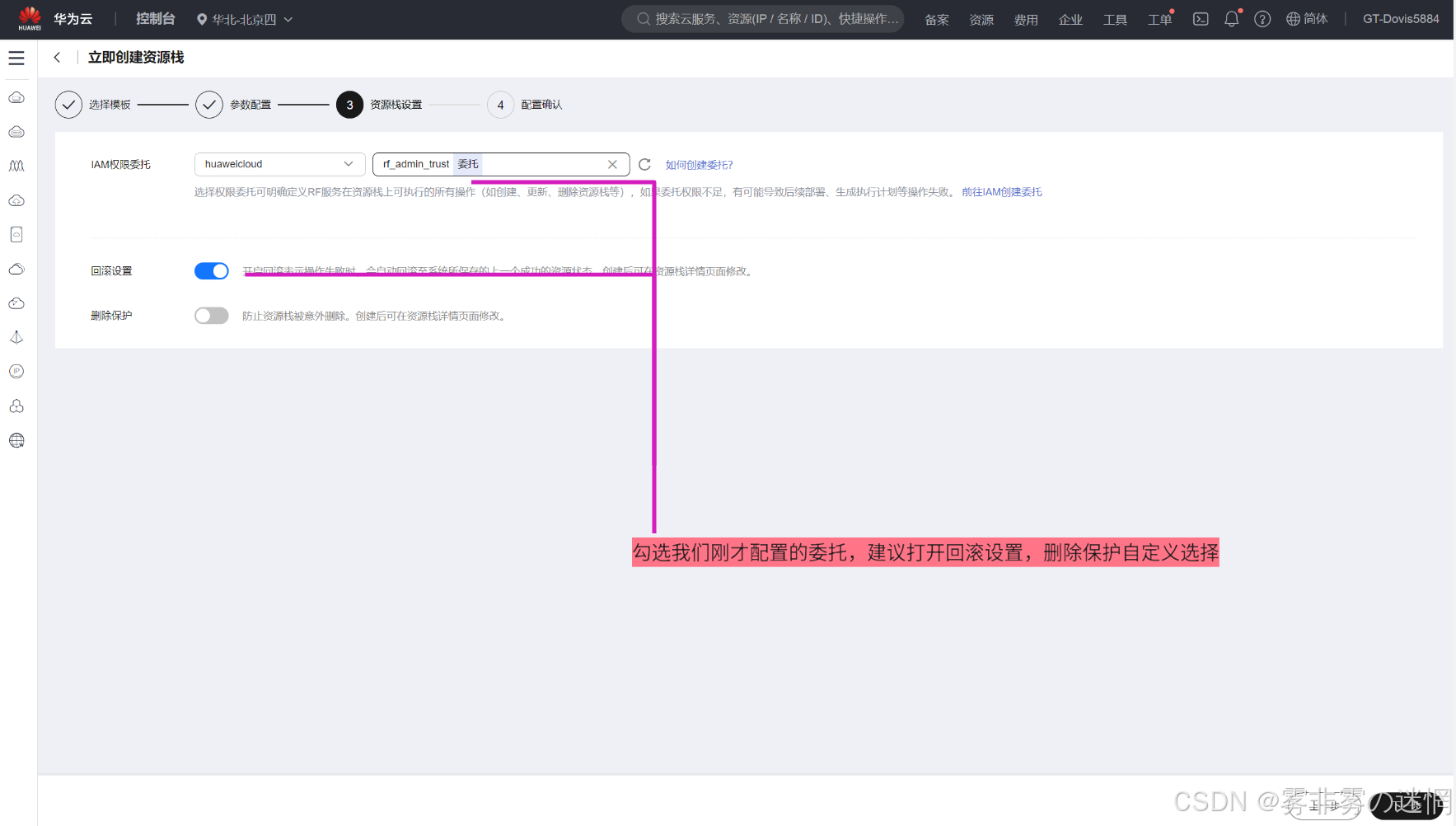
(5)确认配置之后可以点击创建执行计划
(6)选择确定
(7)待显示创建成功之后,点击开始部署
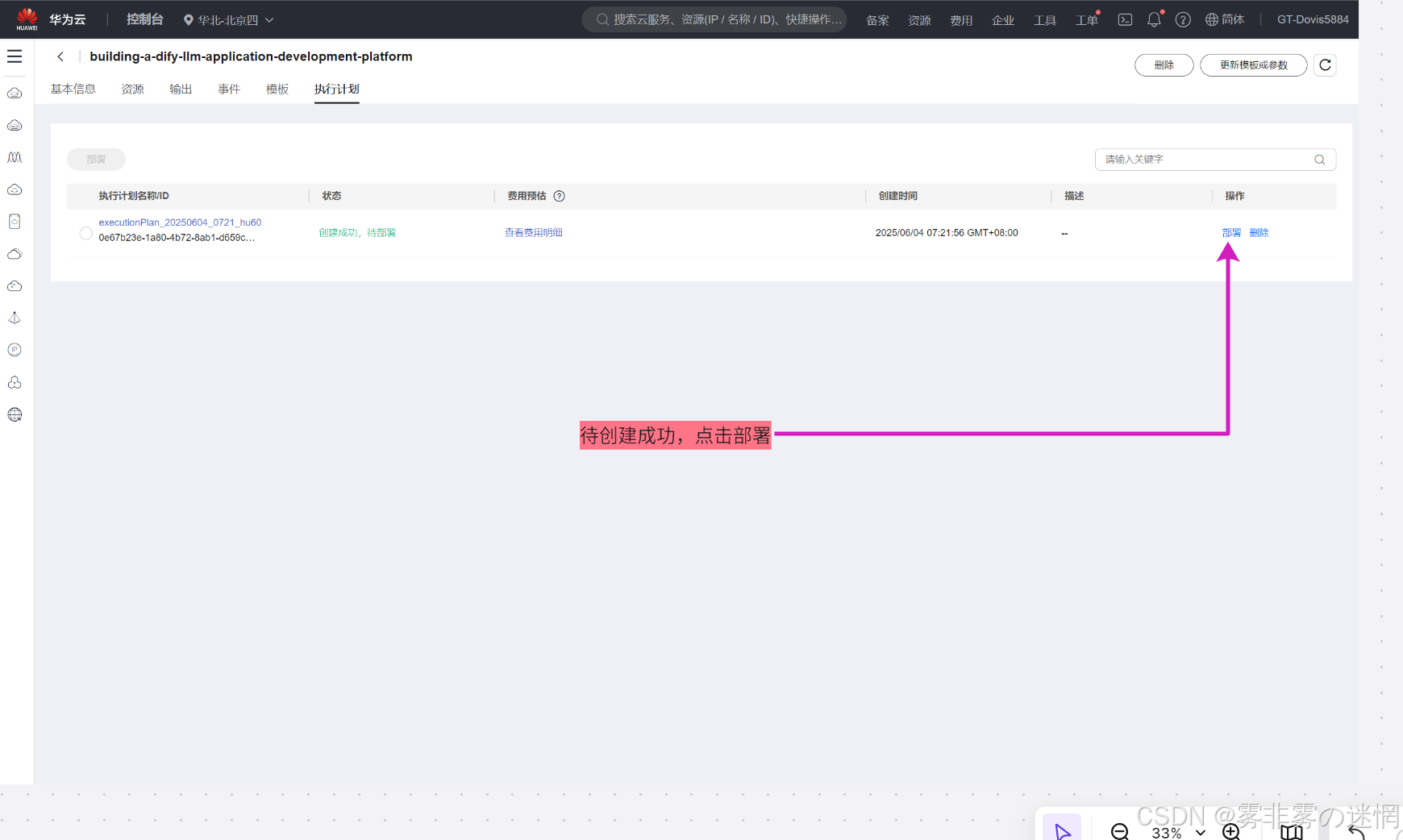
(8)部署的过程大概18分钟左右,大家耐心等待部署成功
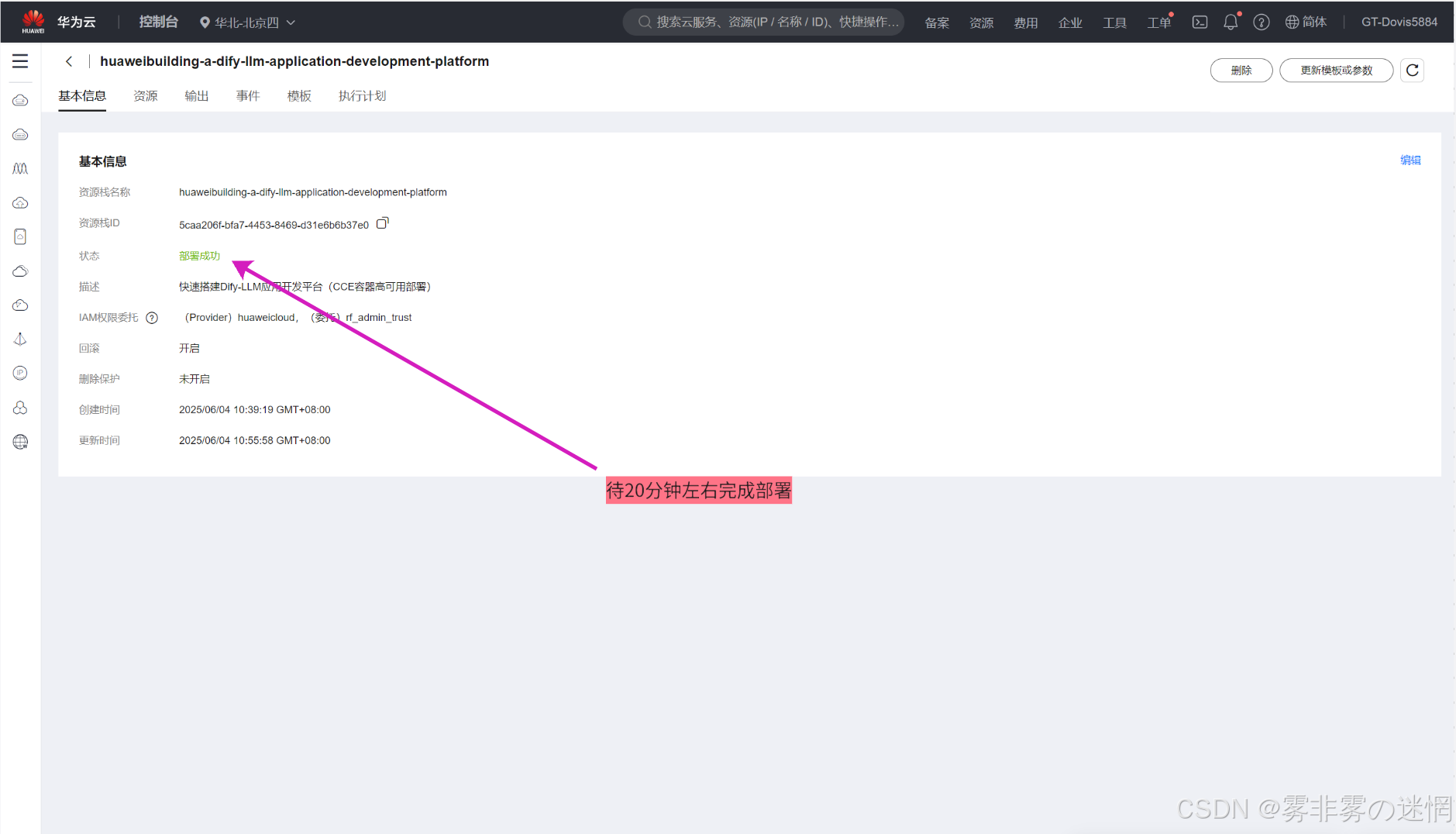
(9)在“输出”可以看见IP,这是我们后面Dify登录的时候需要用到
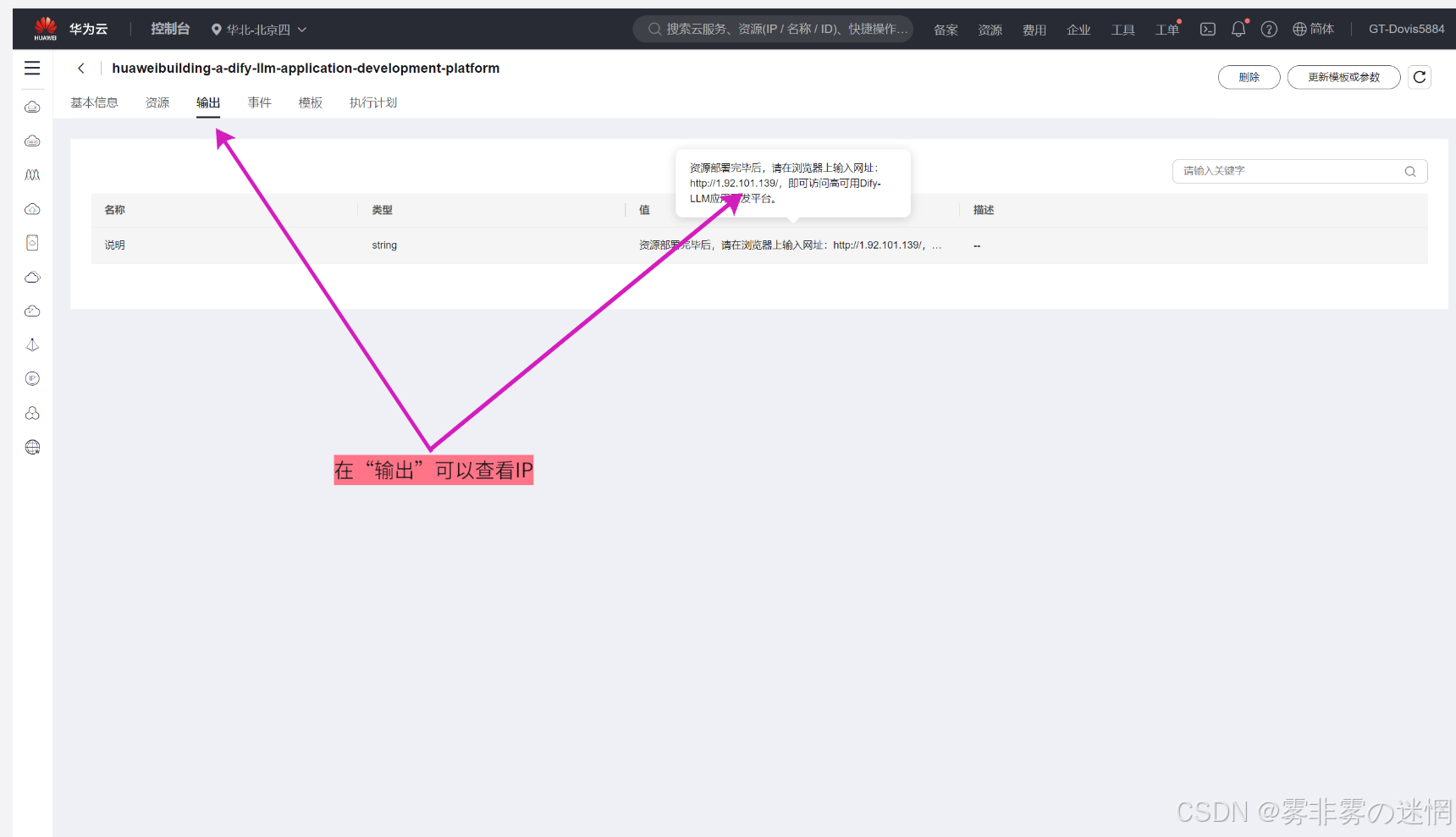
(3)部署体验:
当应用准备迈向生产环境时,我选择了华为云的CCE高可用部署方案,这次的体验核心感受是稳固、安心。与单机部署不同,CCE的部署显然是为了应对更严苛的生产级挑战。整个过程始于构建一个跨可用区的Kubernetes容器集群,这从根基上为应用的可靠性打下了坚实的基础!
在部署过程中,我深刻体会到了容器化和云原生架构的魅力。通过CCE,我将Dify的各个服务模块(如服务端、Embedding模块等)容器化,并以多副本的形式运行在不同的节点上。配合平台提供的负载均衡器(LB),流量被智能地分发,单点故障的风险被彻底消除。最让我放心的是CCE的自愈和弹性伸缩能力。当流量高峰来临时,系统可以自动扩容容器实例来应对压力;即使某个节点出现问题,集群也能自动恢复,整个过程对用户几乎无感知,这为业务的连续性提供了强大的保障
虽然CCE的配置比单机模式要复杂一些,但它带来的高可用性、弹性和运维自动化能力,对于一个需要7x24小时稳定运行的线上服务而言,是不可或缺的。这次部署让我对构建一个真正健壮、可扩展的生产系统有了更强的信心!
【十四】如何监测CCE集群性能:Linux+集群
(1)监测指标:
工作负载状态:您的应用是否都在正常运行
节点列表:列出集群中所有的云服务器节点,每个节点的状态、IP、CPU和内存的分配率
集群资源概览:整个集群总的CPU、内存的 请求量和 限制量
CPU使用率、内存、磁盘I/O、网络带宽等
(2)监测方法:
(1)直接使用华为云监控控制台是最直观、最集成、最快捷的方法(云监控)
(2)使用云服务引擎CCE监测CCE节点信息(云服务集群)
(3)云监控:
与“云服务单机部署”监测的方法一致!可直接参考,这里就不重复了!同样可以获得下面效果
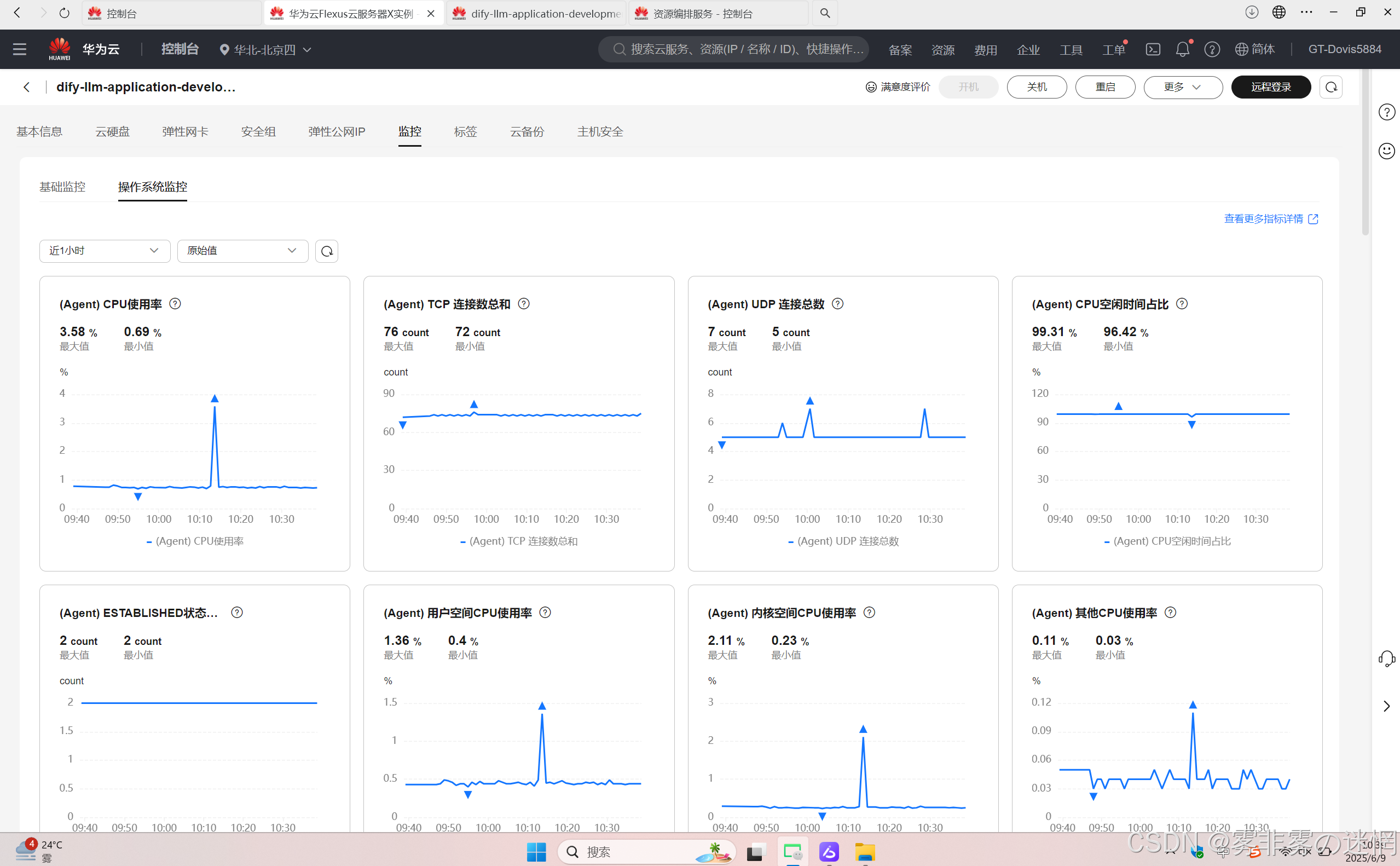
(4)云服务引擎:
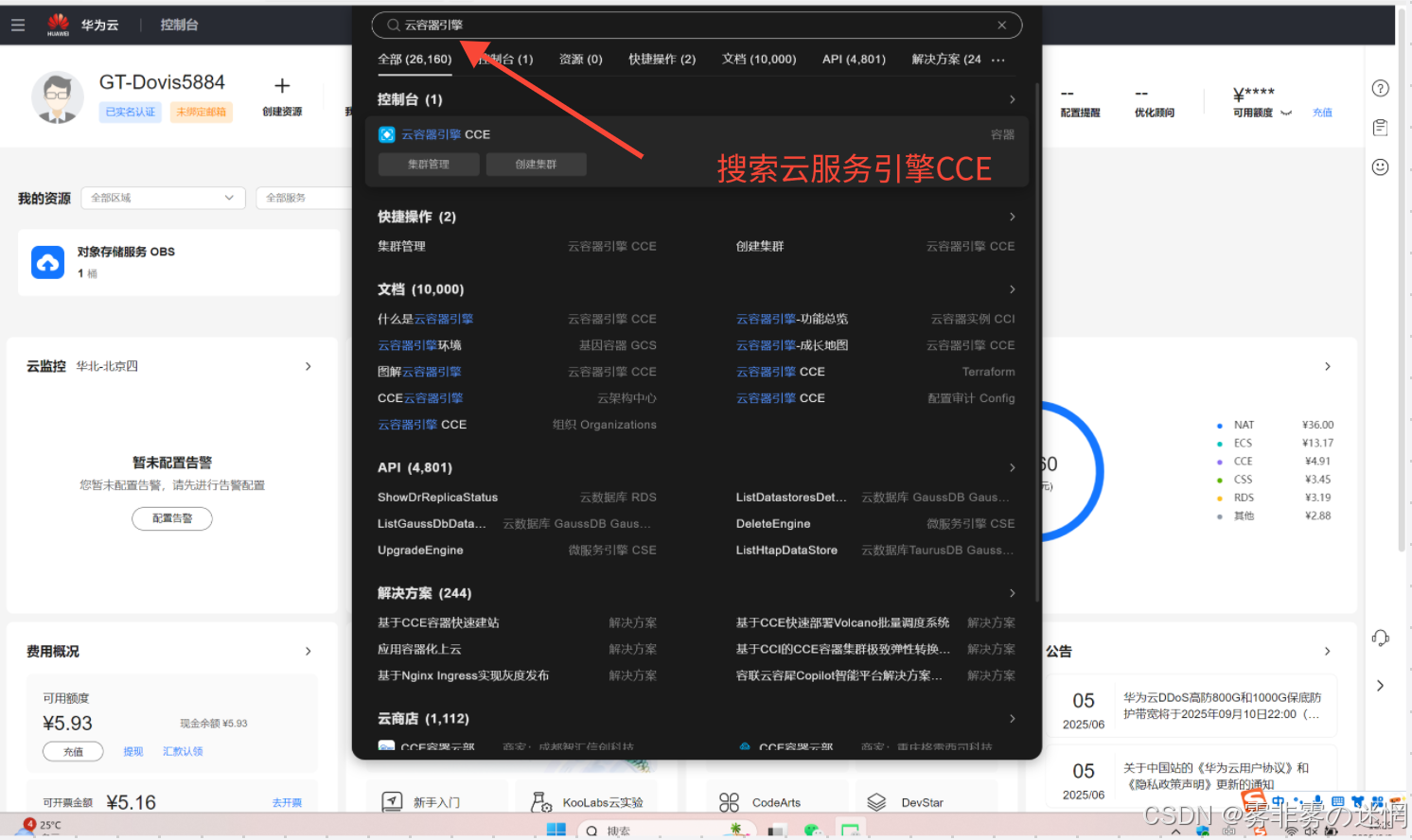
(1)进入云服务引擎CCE,找到集群管理
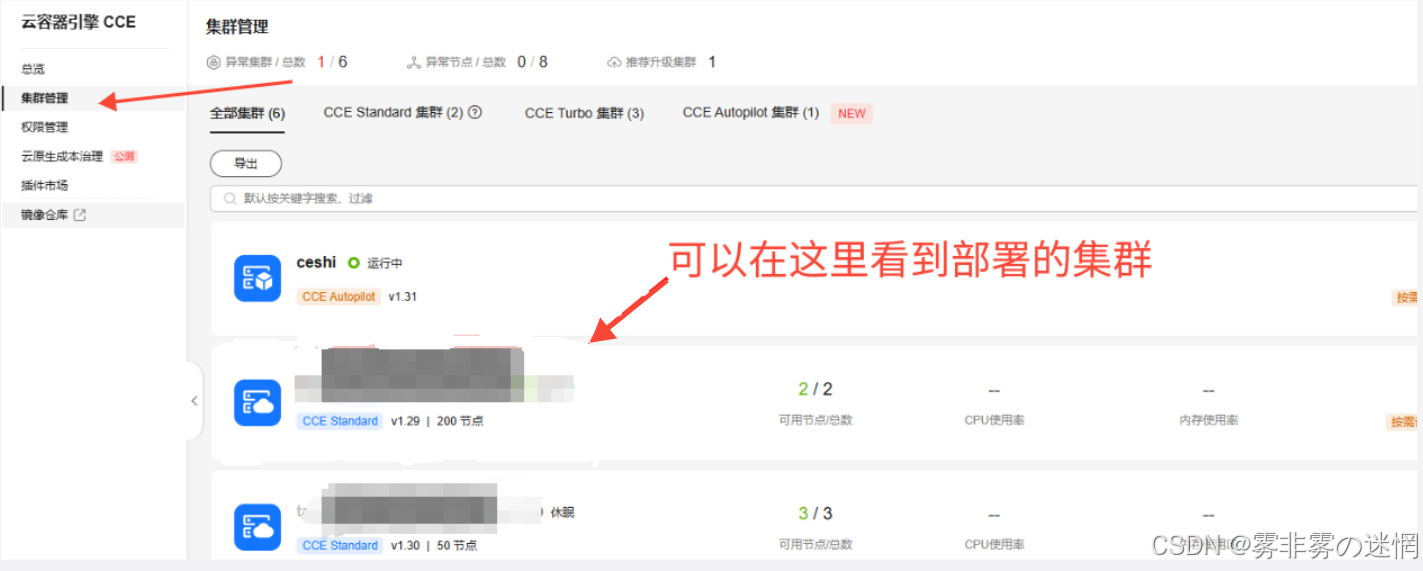
(2)点击集群管理,就可以看见已经部署的集群了,点击进去
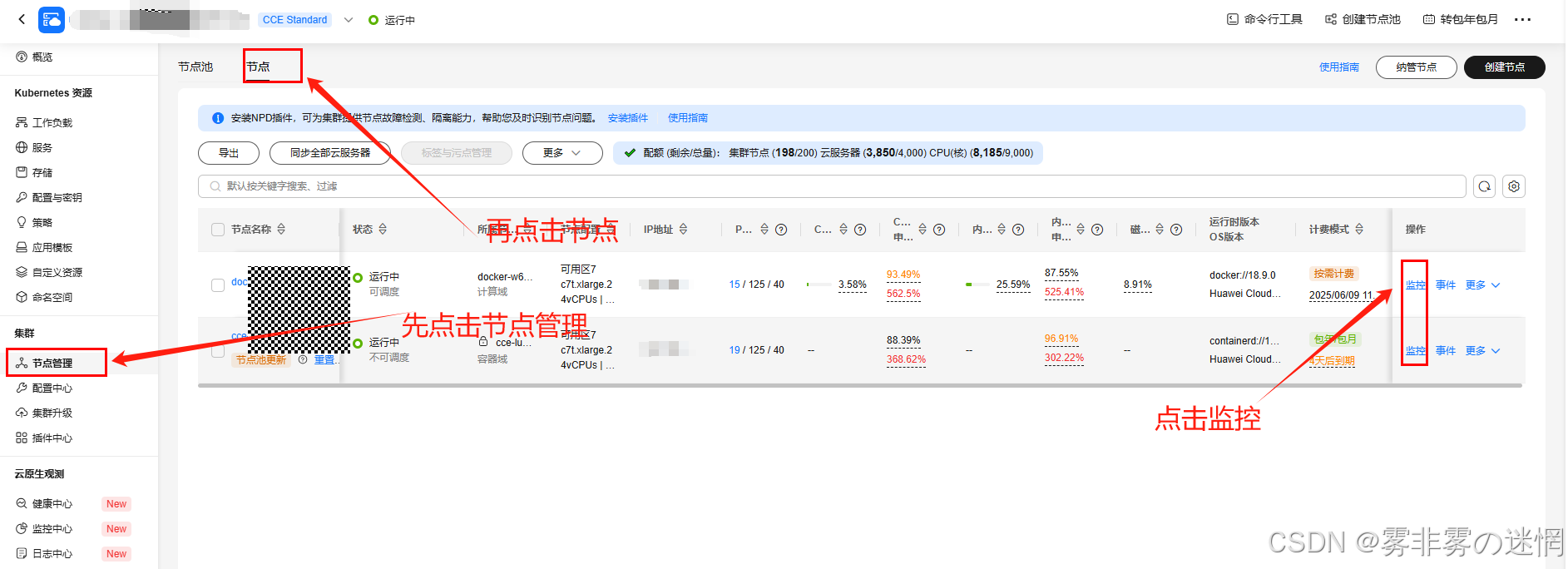
(3)左边工作栏找到“节点管理”,再点击“节点”->“监控”
(4)可以点击“查看更多数据”,就可以观察集群的性能图形化分析
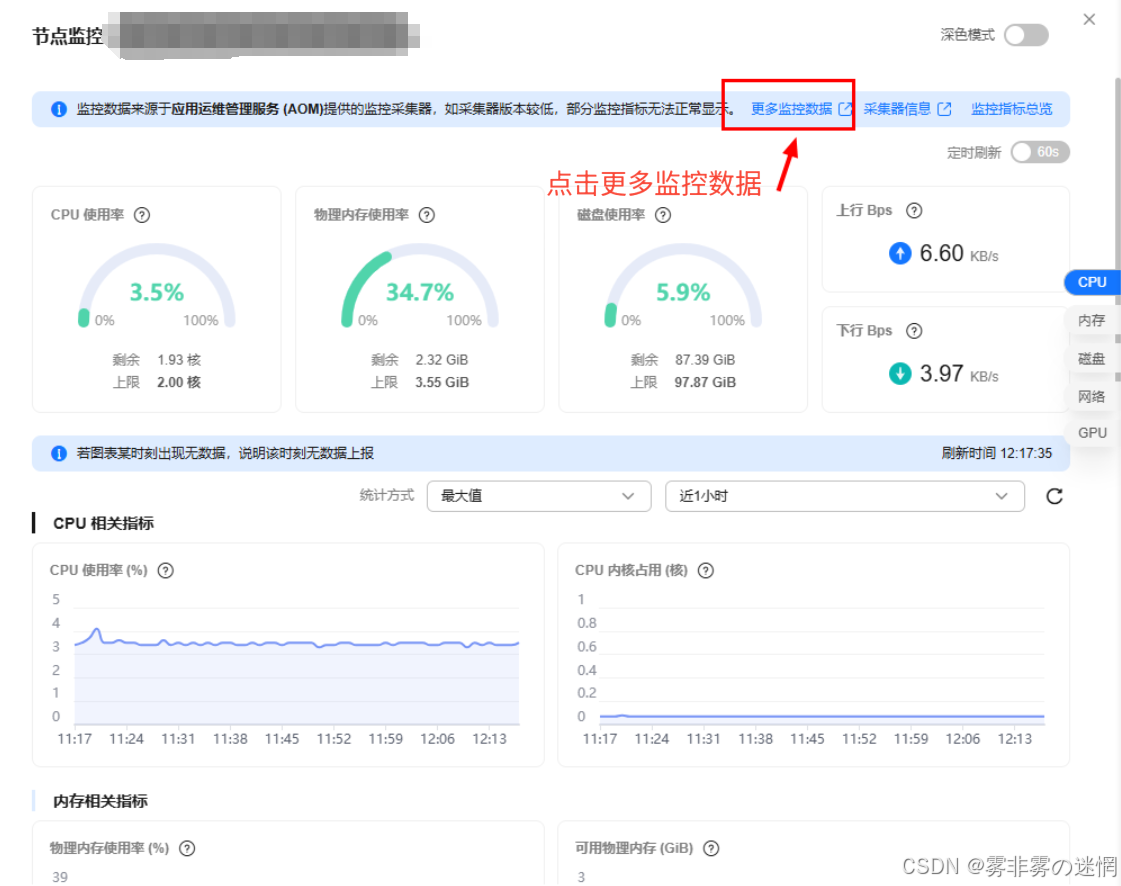
【十五】Dify与DeepSeek实践应用
简单来说,华为云 Dify 与 DeepSeek 的实践应用 就是:Dify 提供了一个稳定、高效、功能完备的 舞台,负责处理网络、数据、流程编排和用户交互等所有工程化问题。DeepSeek 作为 明星主演,在这个舞台上展现其顶级的 AI 理解和生成能力!
Dify:AI 应用的全能开发与运行平台解析:
坚实的基础设施:Dify 运行在华为云上,背后有弹性IP(EIP)、NAT网关、负载均衡(LB)等网络服务,以及云数据库RDS等存储服务作为支撑。这意味着您的 AI 应用天生就具备了连接公网、保障数据安全和处理高并发访问的能力
·
核心的 AI 服务:架构图中的 Embedding&Re-ranker 是关键。这是 Dify 平台提供的核心 AI能力之一。当您需要处理非结构化数据(如文本、图片)时,Embedding 服务会将其转化为机器能够理解的数学向量。当用户进行搜索或提问时,Re-ranker 服务则负责对检索出的结果进行优化排序,确保返回最相关、最精准的答案
·
统一的管理界面:您当前所在的这个“工作室”界面,就是您作为开发者的“总控台”。您将在这里创建应用、管理工具(比如API、插件等),并构建和维护您的“知识库”(上传文档、数据等,作为 AI 的知识来源)!
DeepSeek 扮演的角色:提供强劲动力的超级大脑解析:
在 Dify 中创建应用:
您首先会在当前这个空白的“工作室”界面点击“创建应用”,选择一个应用类型,比如“聊天助手”、“知识库问答”或“文本生成”等选择并集成 DeepSeek 模型:
在创建应用的过程中,Dify 会允许您选择一个底层的大语言模型(LLM)作为驱动。在这里,您就可以选择集成 DeepSeek。这意味着您应用的所有智能(如理解、推理、生成能力)都将由 DeepSeek 来提供构建知识库:
如果您想让 AI 回答关于特定领域(比如您的公司产品、技术文档)的问题,您会使用 Dify 的“知识库”功能。您上传文档后,Dify 会调用 Embedding 服务(可能由 DeepSeek 或其他专业模型完成),将这些文档内容向量化,存入数据库用户交互与处理流程:
当一个最终用户向您的应用提问时,请求首先通过负载均衡(LB)进入 Dify 系统
Dify 将问题同样进行 Embedding 处理,然后去您的知识库中进行向量检索,找到最相关的几段原文
【十六】完成Dify登录
(1)复制单机部署/高可用部署在部署成功之后,“输出”里面显示的IP,在浏览器打开
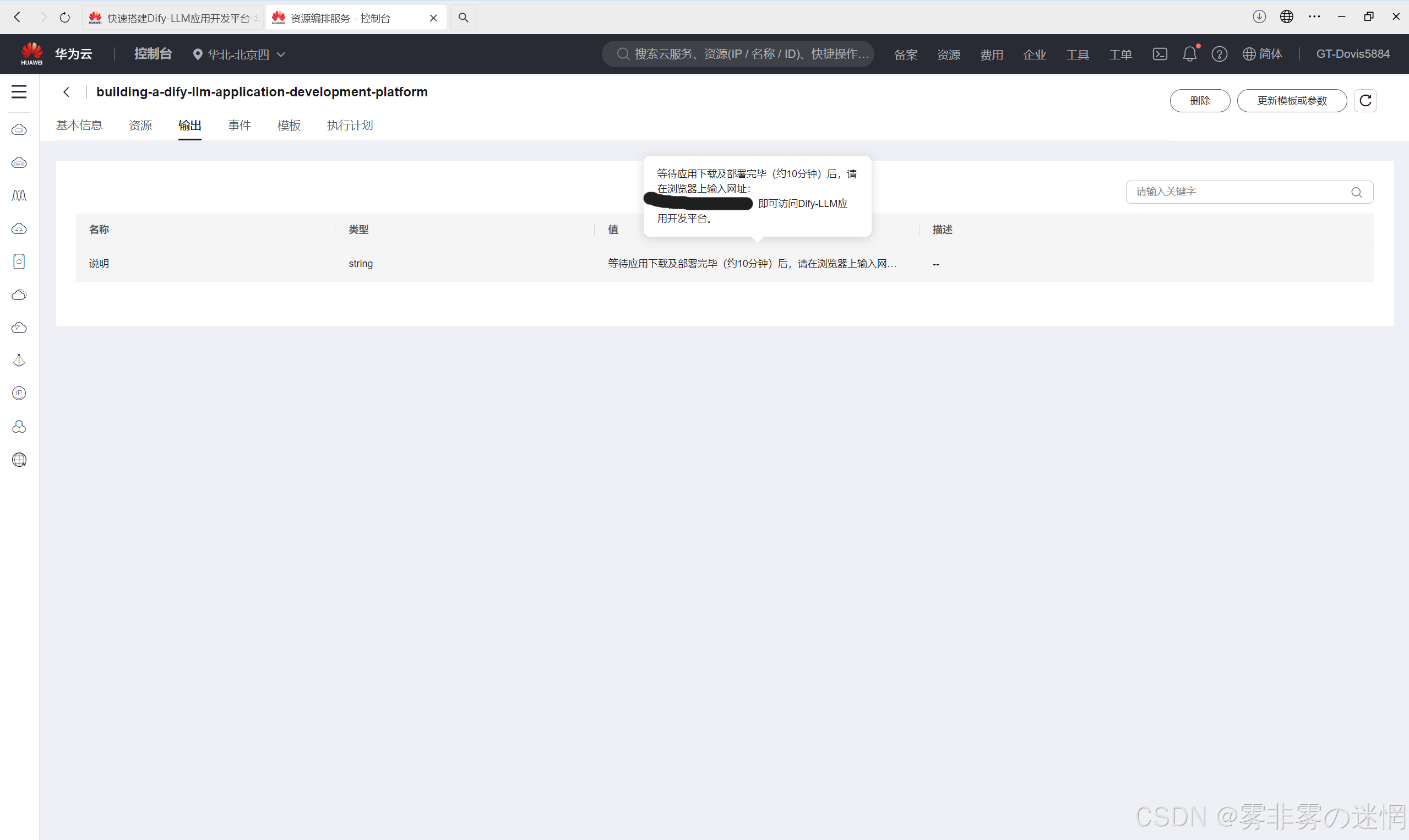
(2)重新输入邮箱密码
(3)完成登录之后,我们就可以开始搭建AI了
【十七】Dify添加华为云Qwen3模型
(1)点击主页的设置
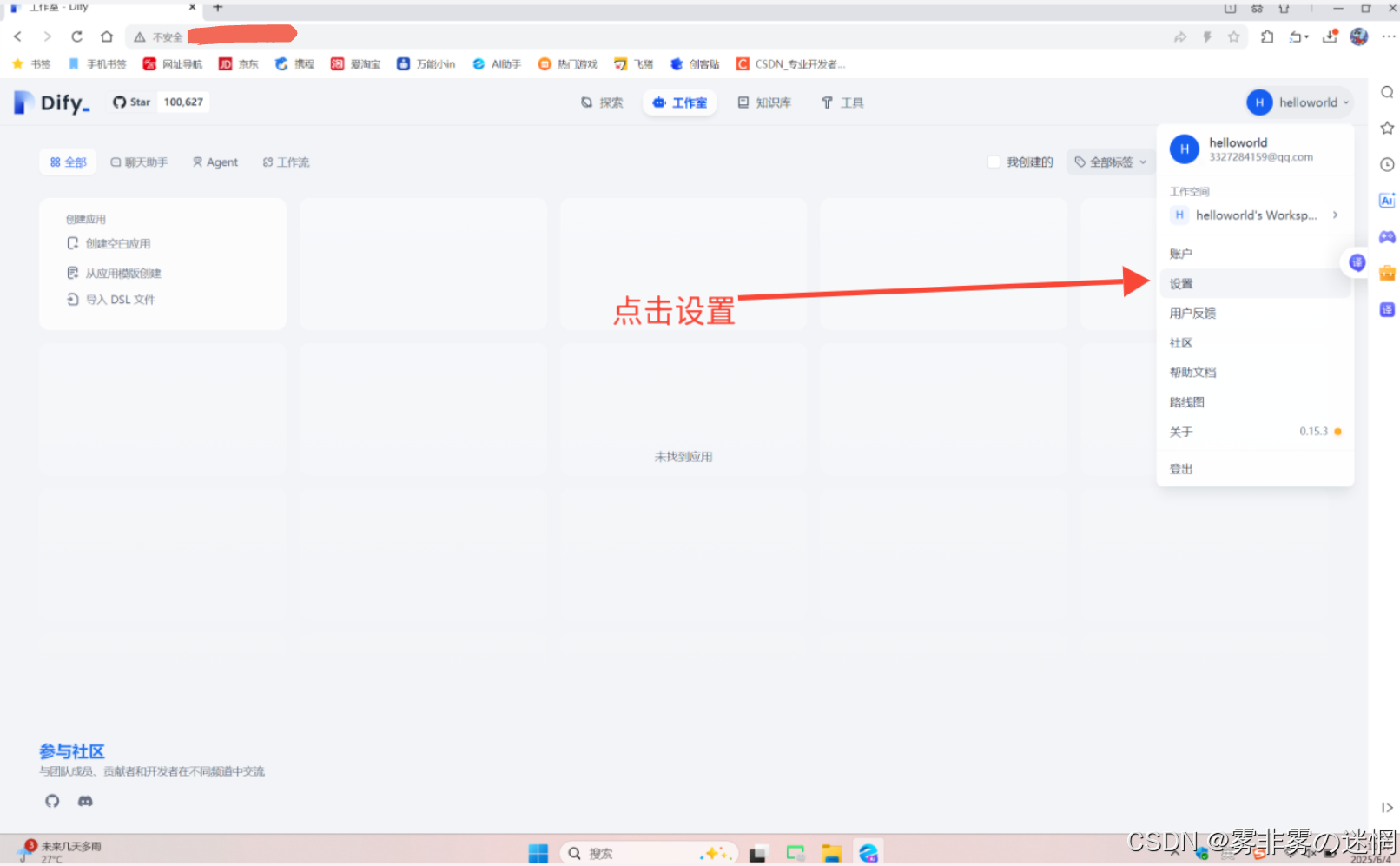
(2)点击模型供应商,找到下面这个AI模型,然后添加
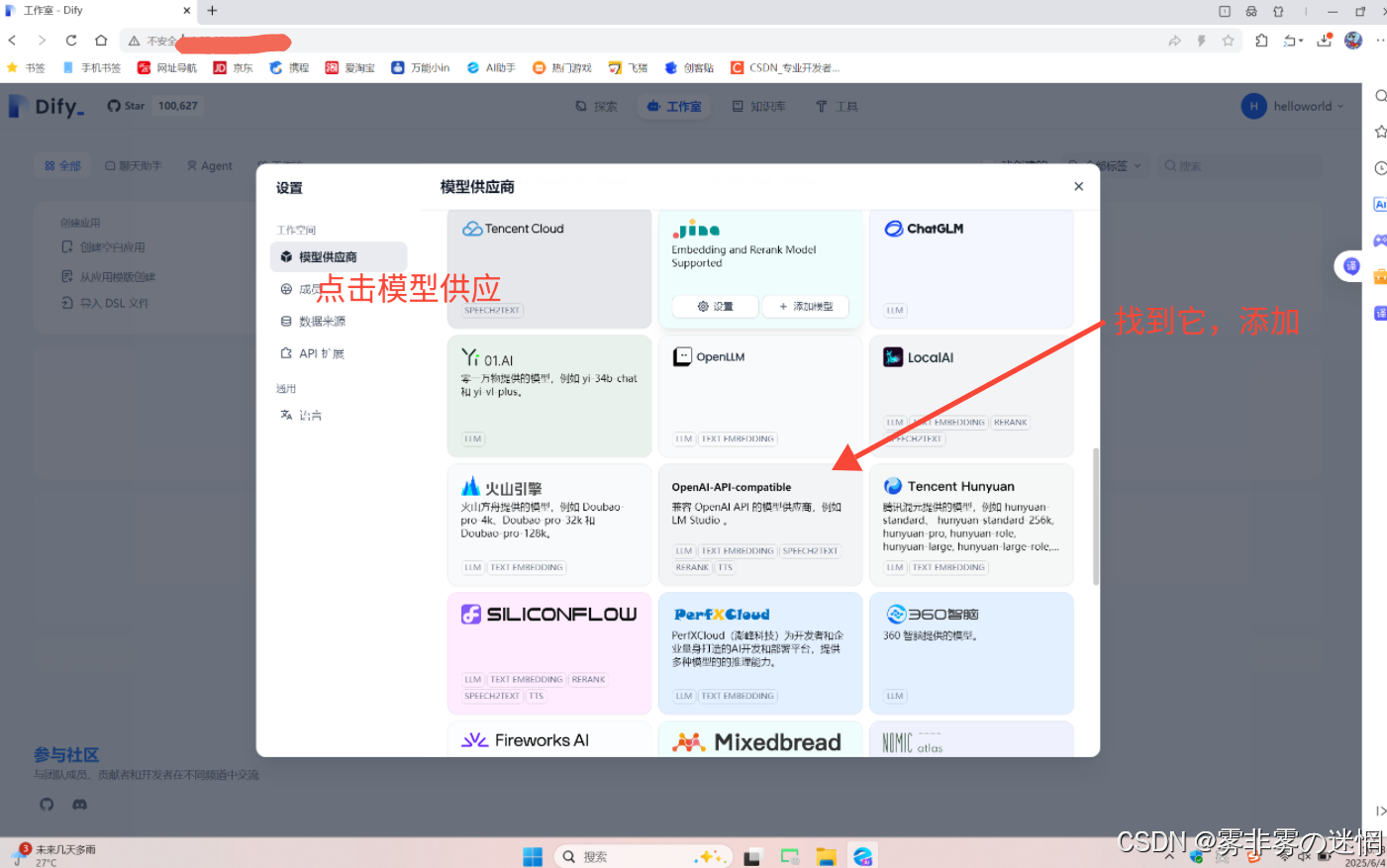
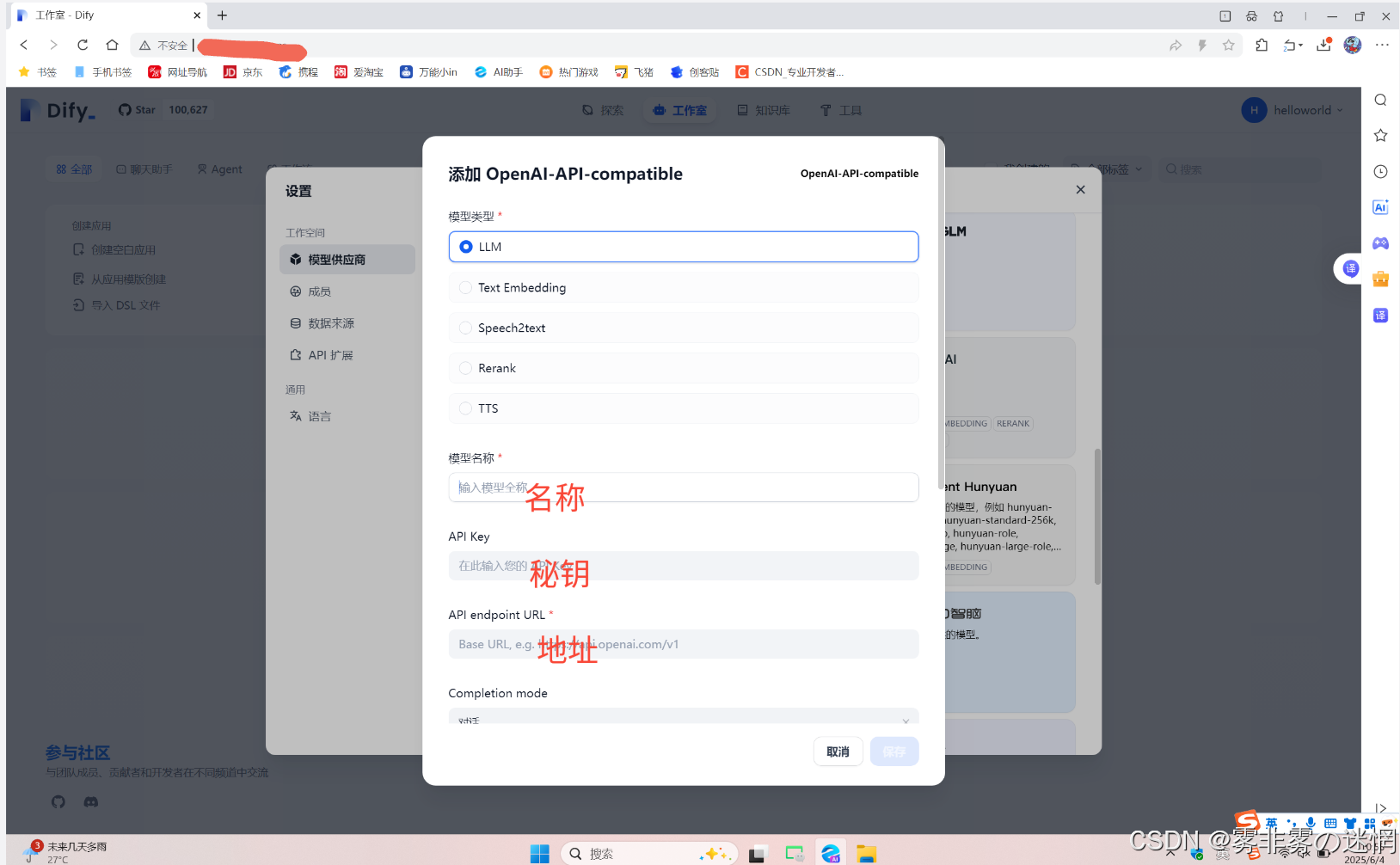
(3)选择LLM,下面我们将分开获取这三个配置
名称、地址:
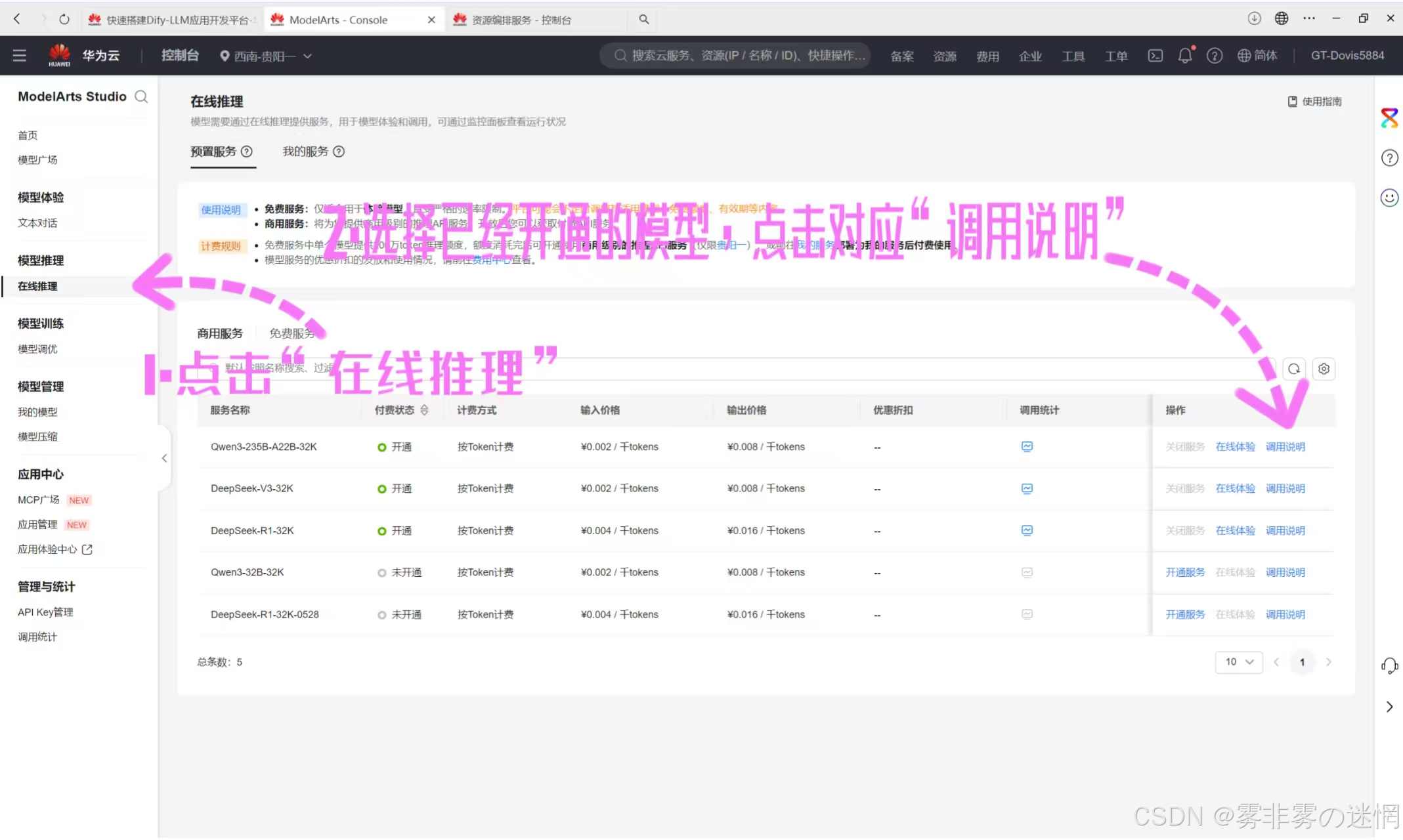
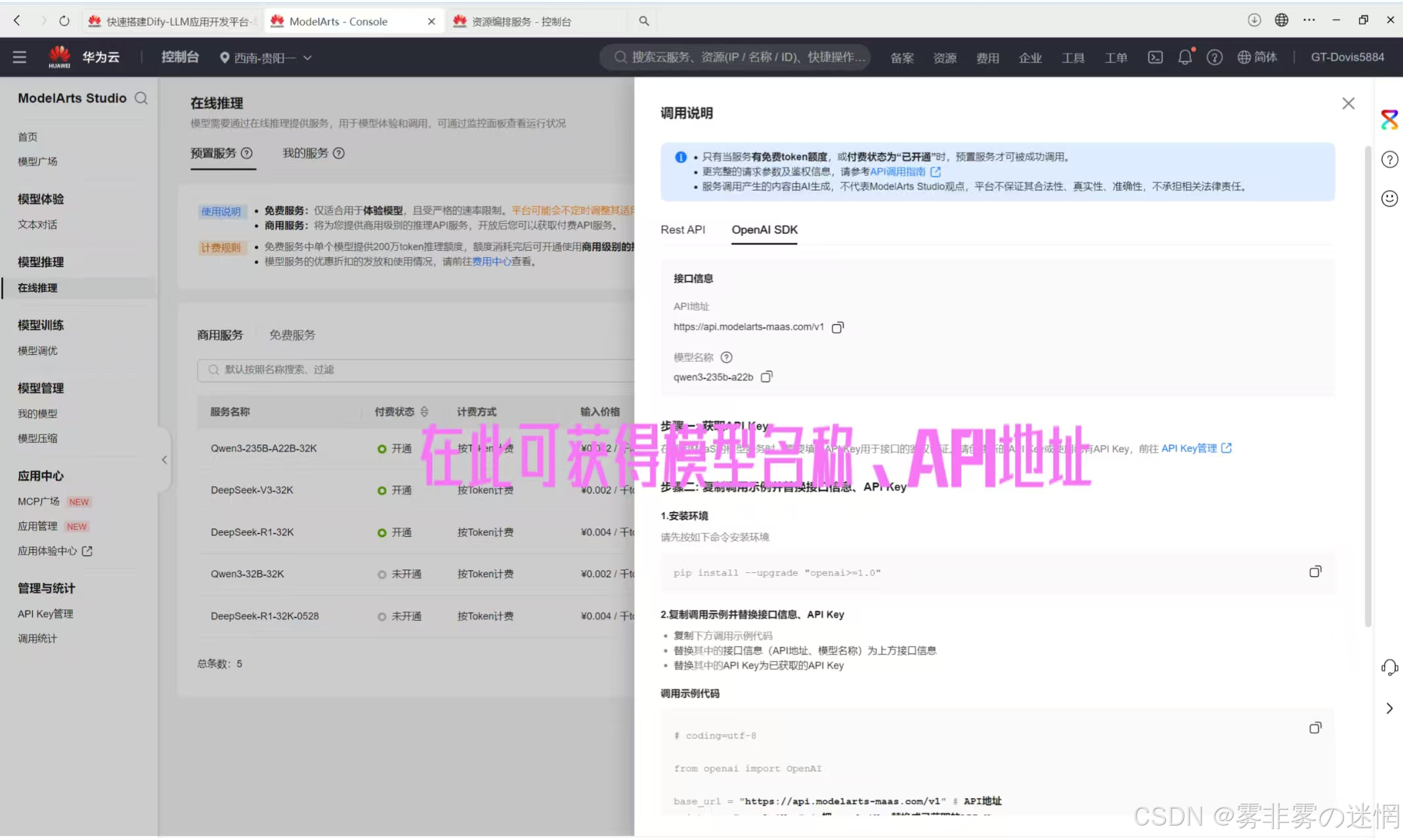
打开ModelArts Studio控制台,选择在线推理,需要使用已经开通的模型
再点击“调用说明”,然后点击“Open AI”,这里显示的就是名称、地址,粘贴到配置栏
秘钥:
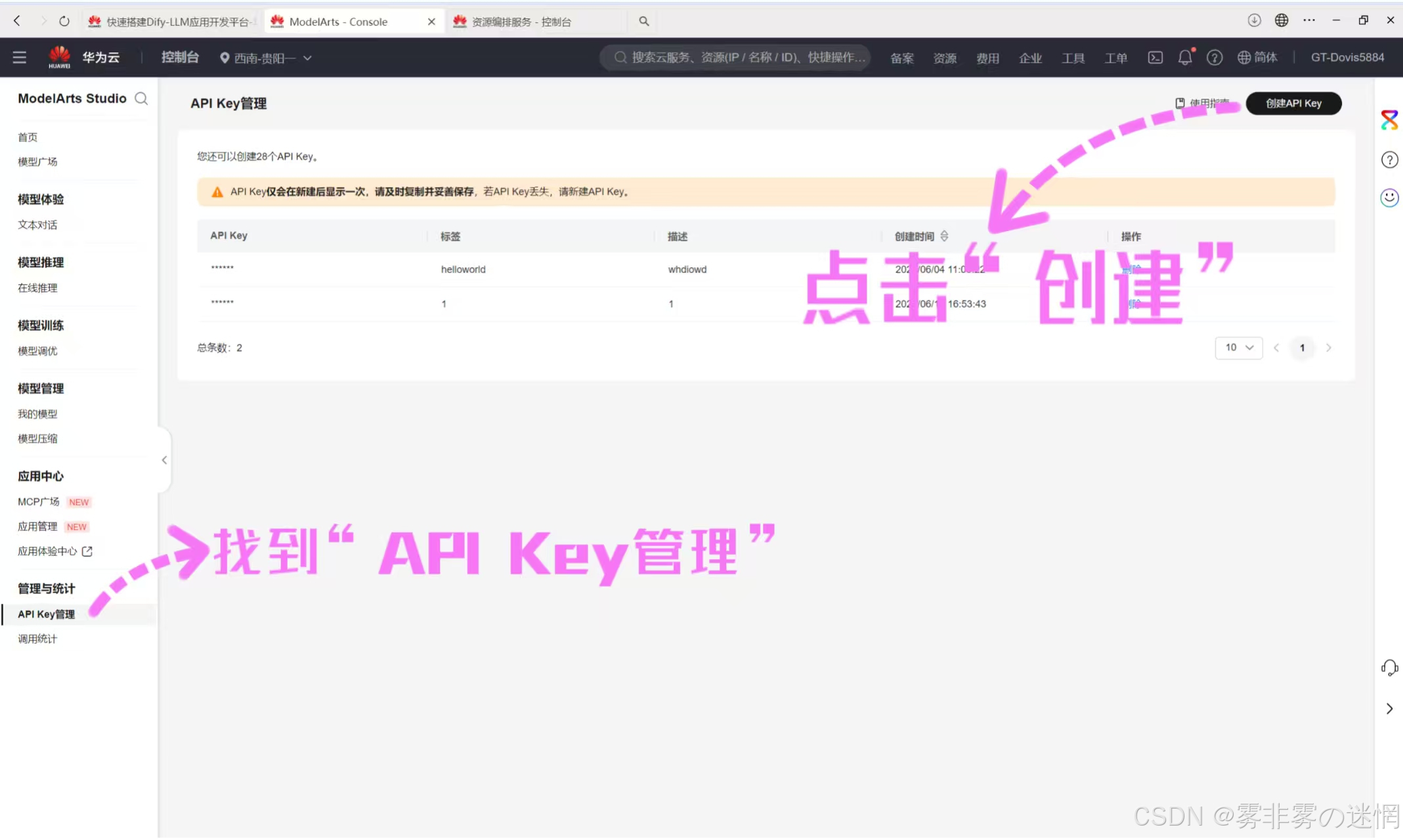
在ModelArts Studio控制台最下面点击API管理,点击创建
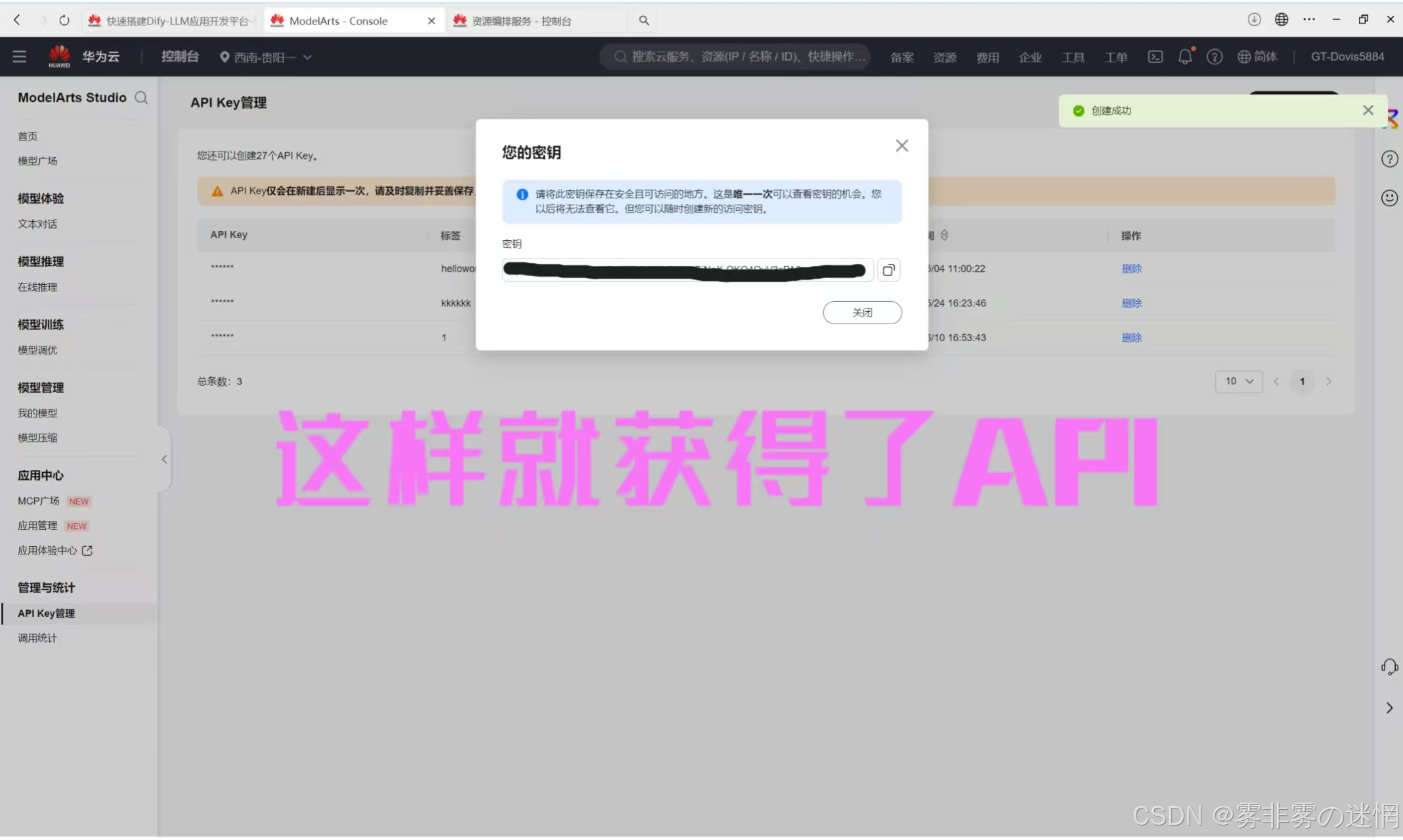
注意秘钥创建之后只能显示一次,注意一次性复制成功,再粘贴在刚才的配置栏
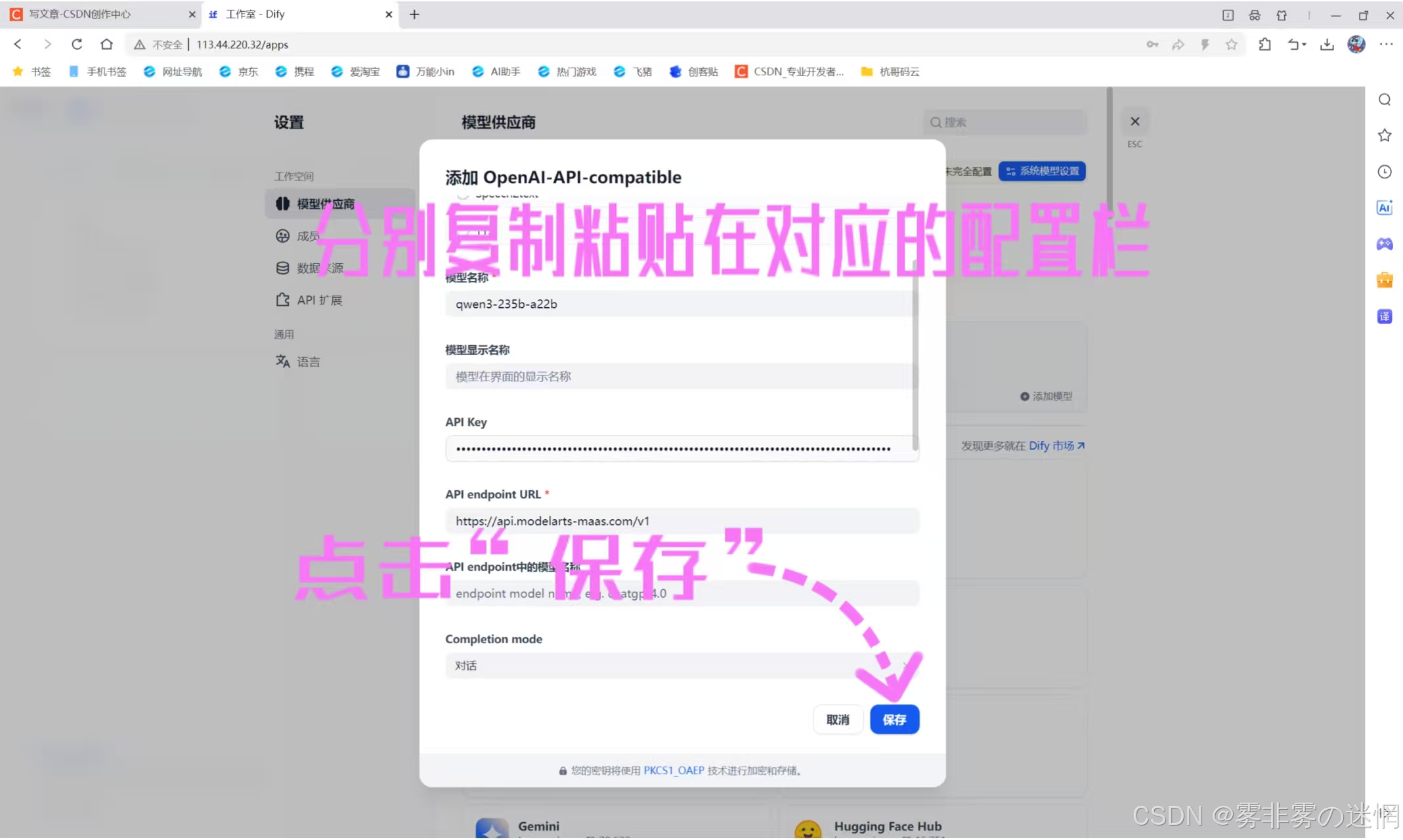
(4)其它的配置我们可以不用管,然后点击“保存”,如果是下面这样就代表添加成功了
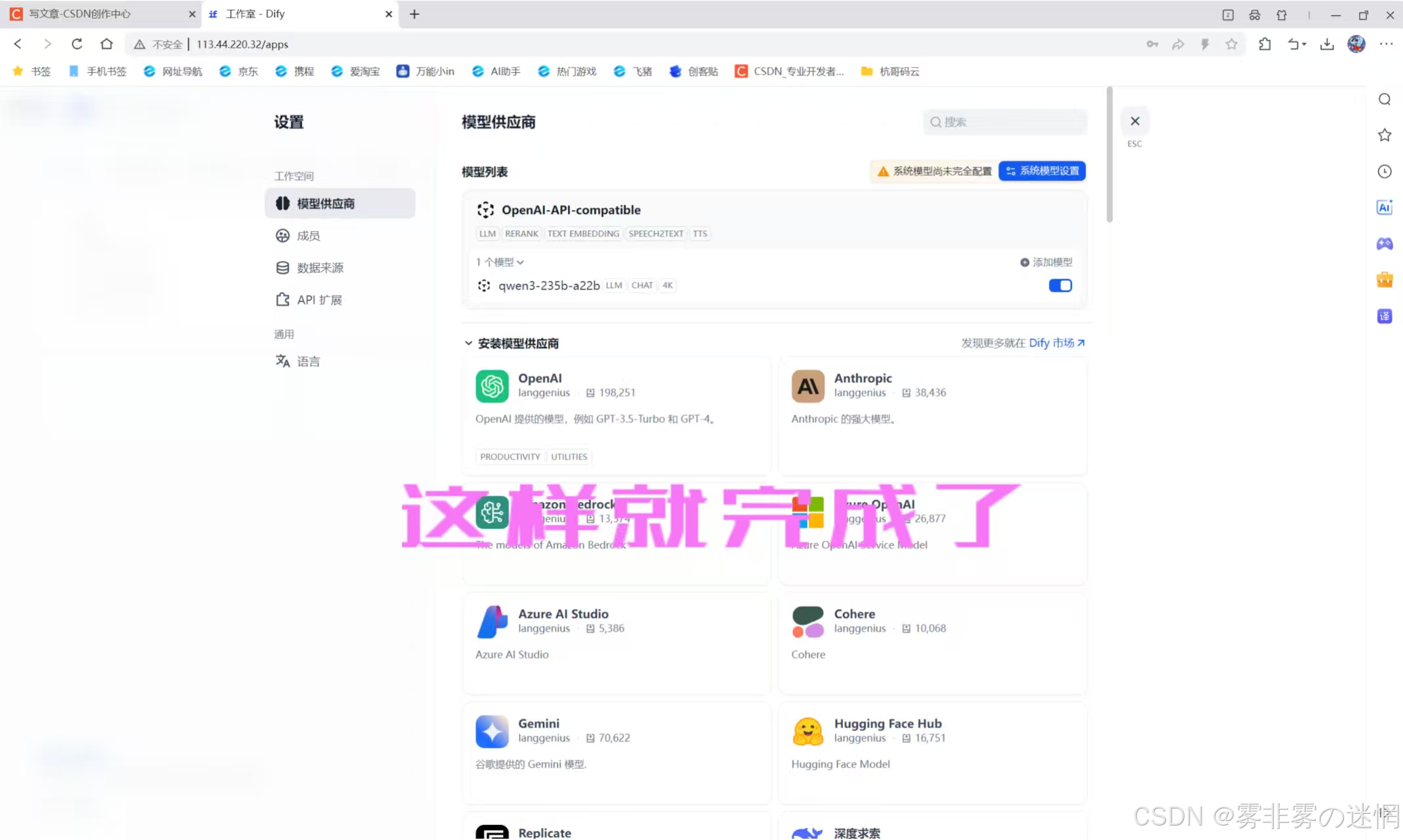
【十八】安装插件:博查
(1)点击插件
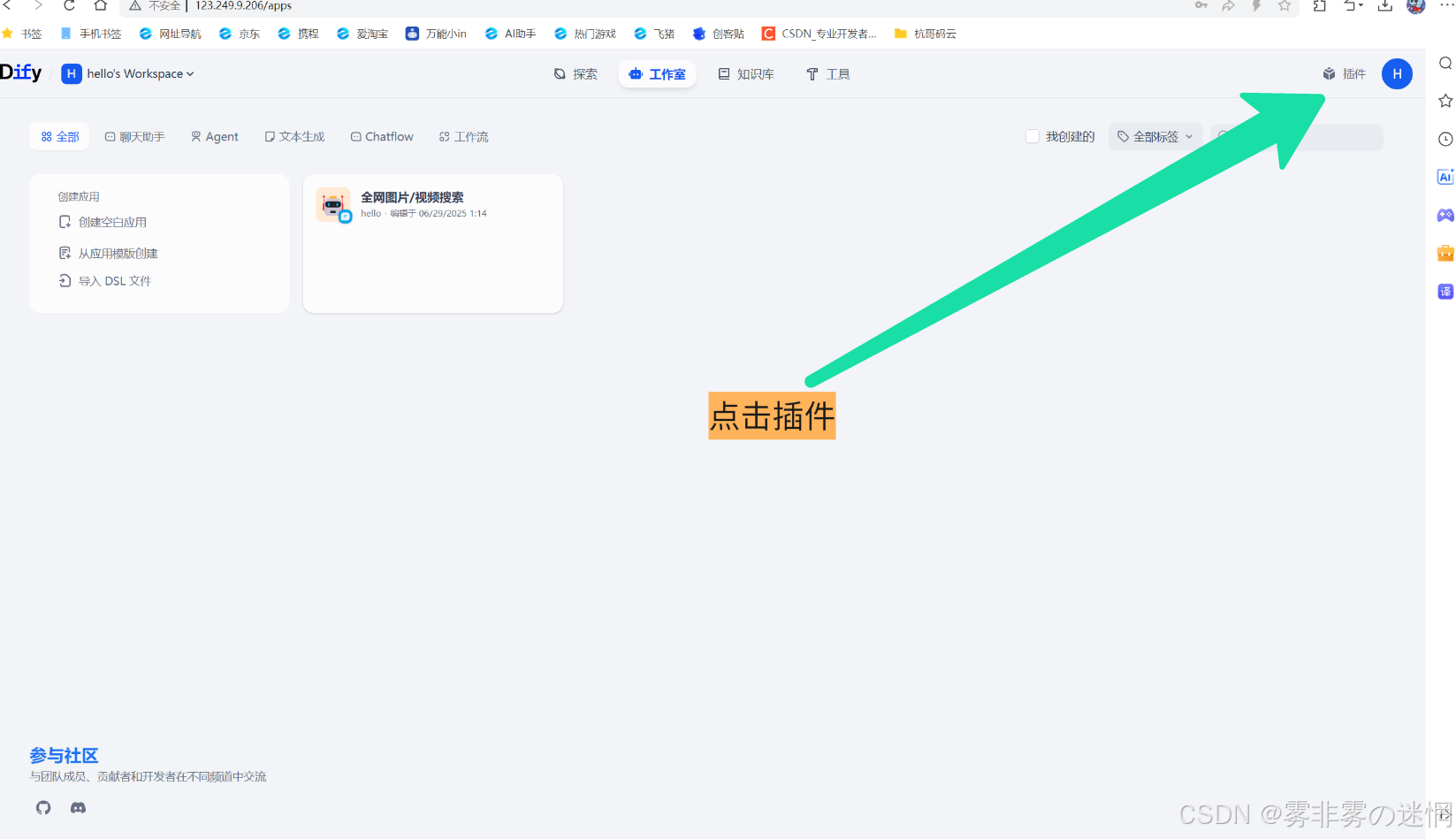
(2)前往插件广场安装插件
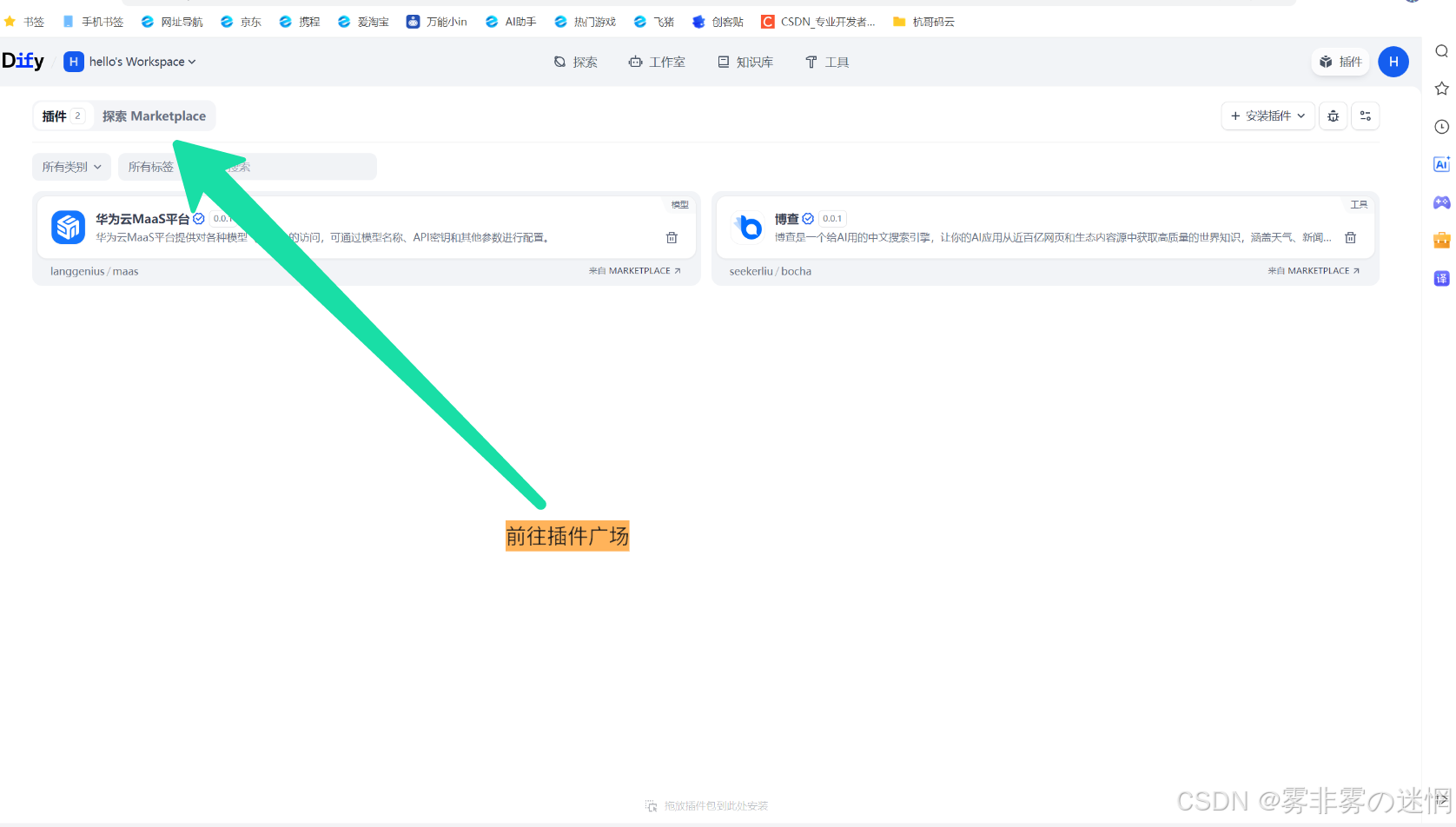
(3)点击博查,安装
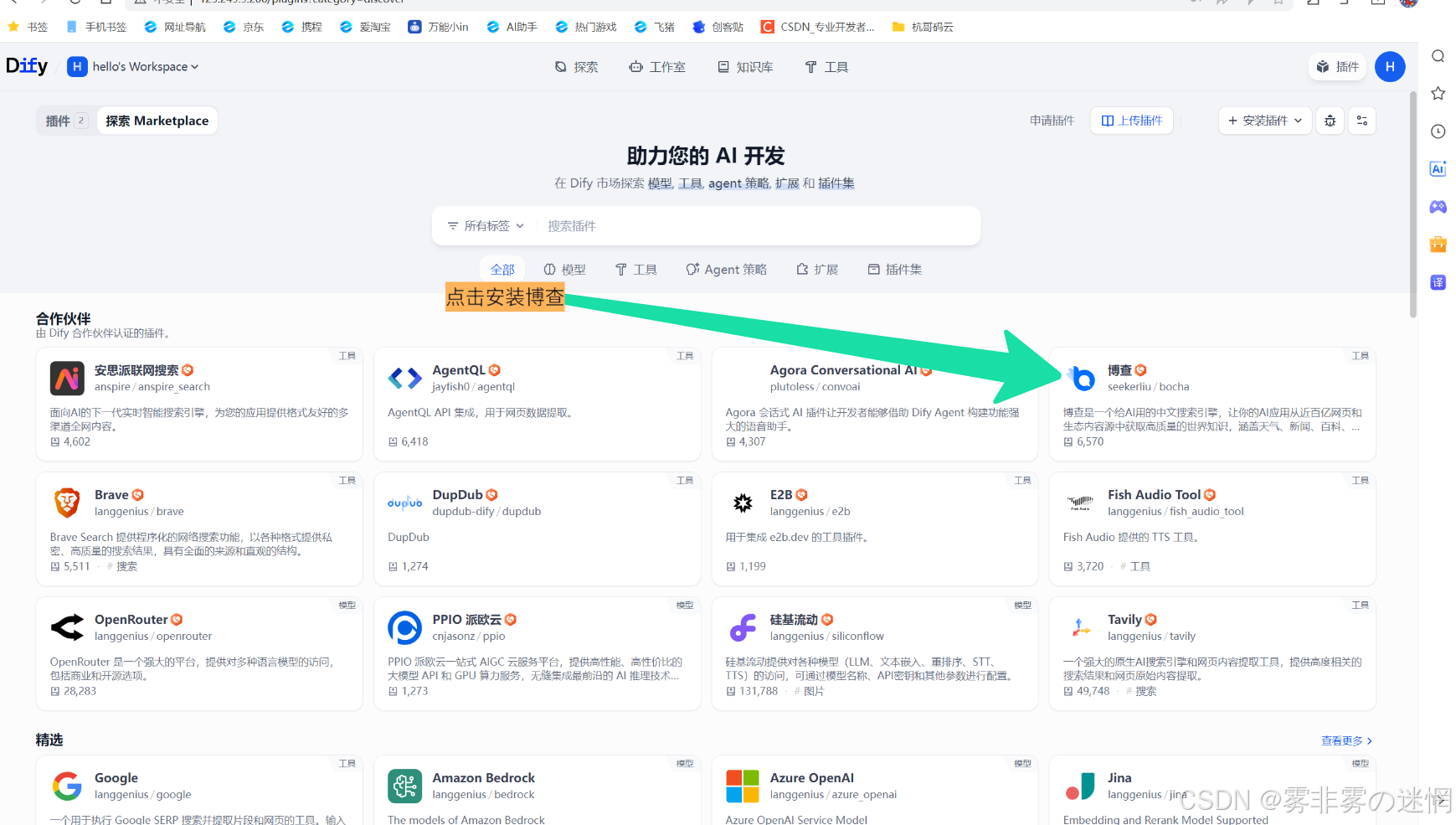
(4)切换安装地址为部署的服务器公网IP
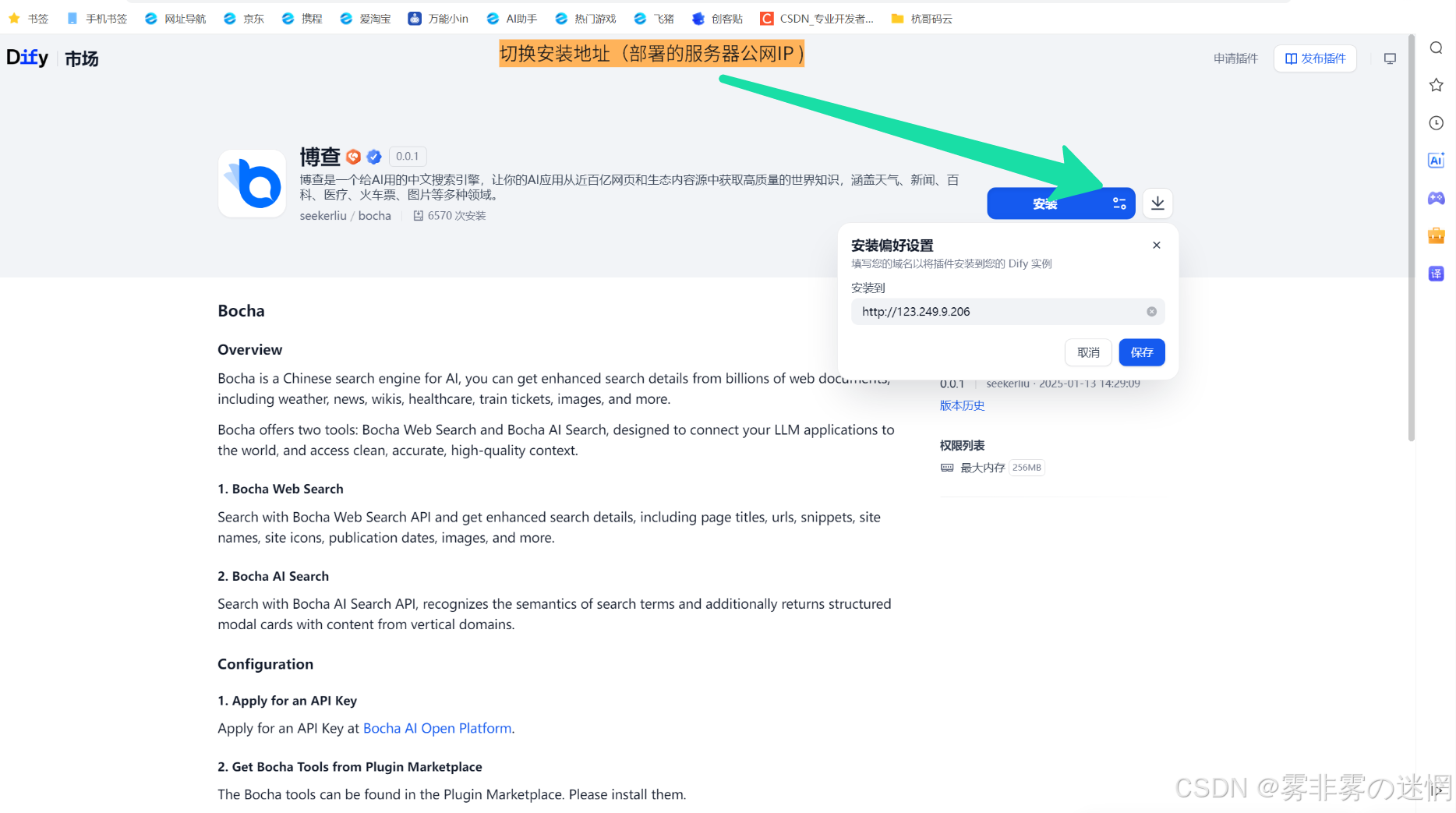
(5)点击授权(我这里是提前授权好了的)
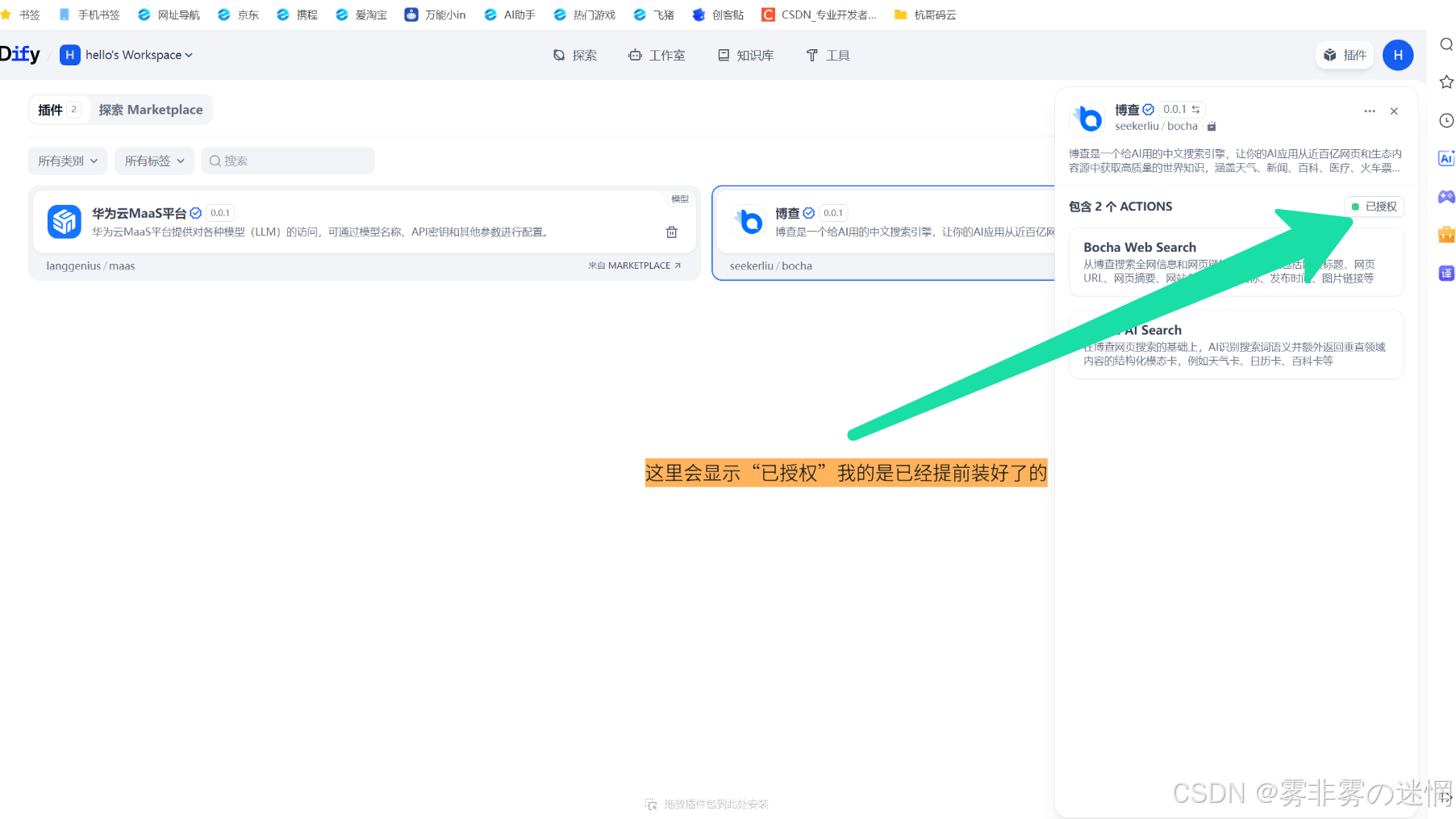
(6)前往博查官网,点击使用搜索API
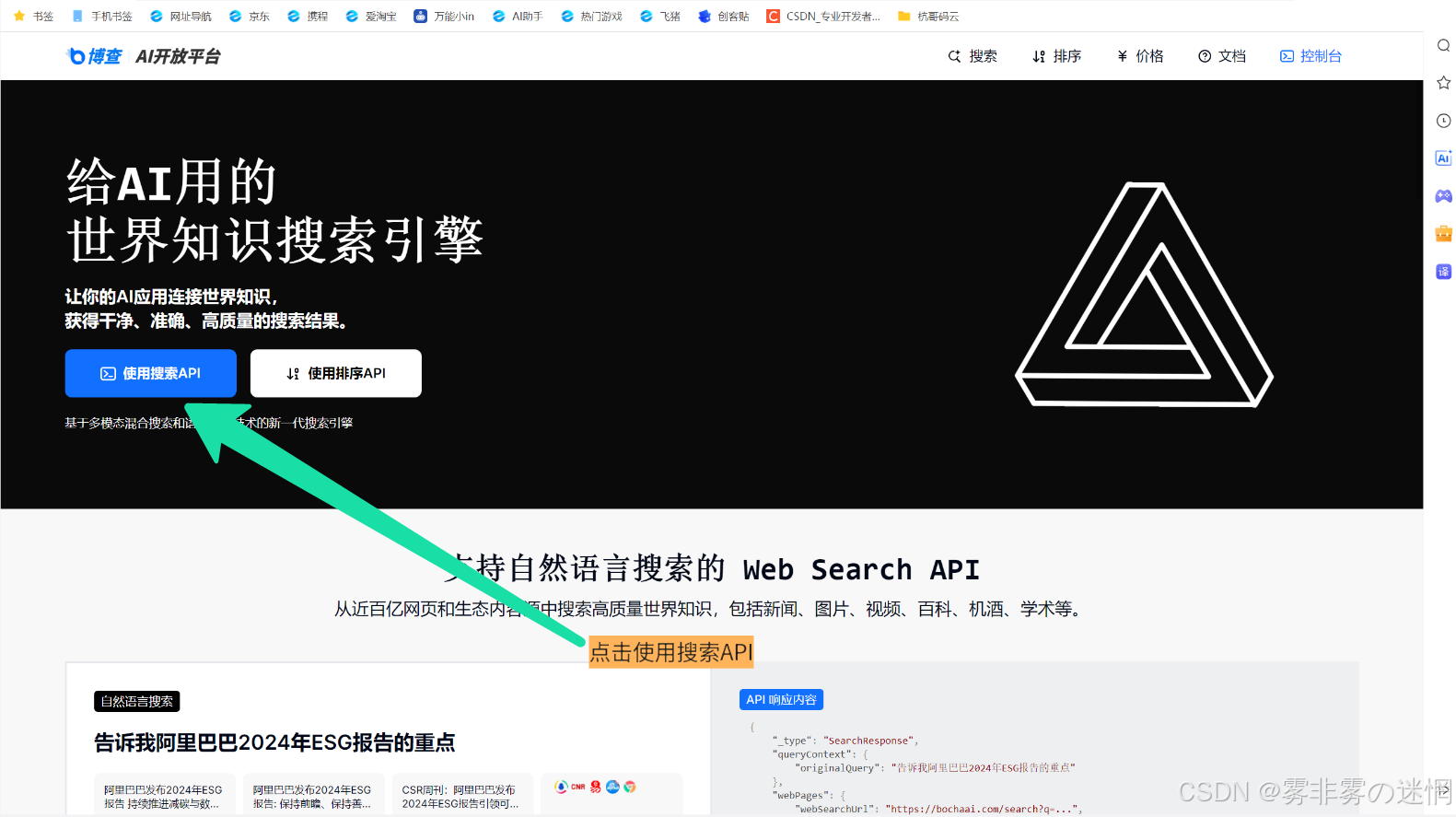
(7)点击API管理,创建API
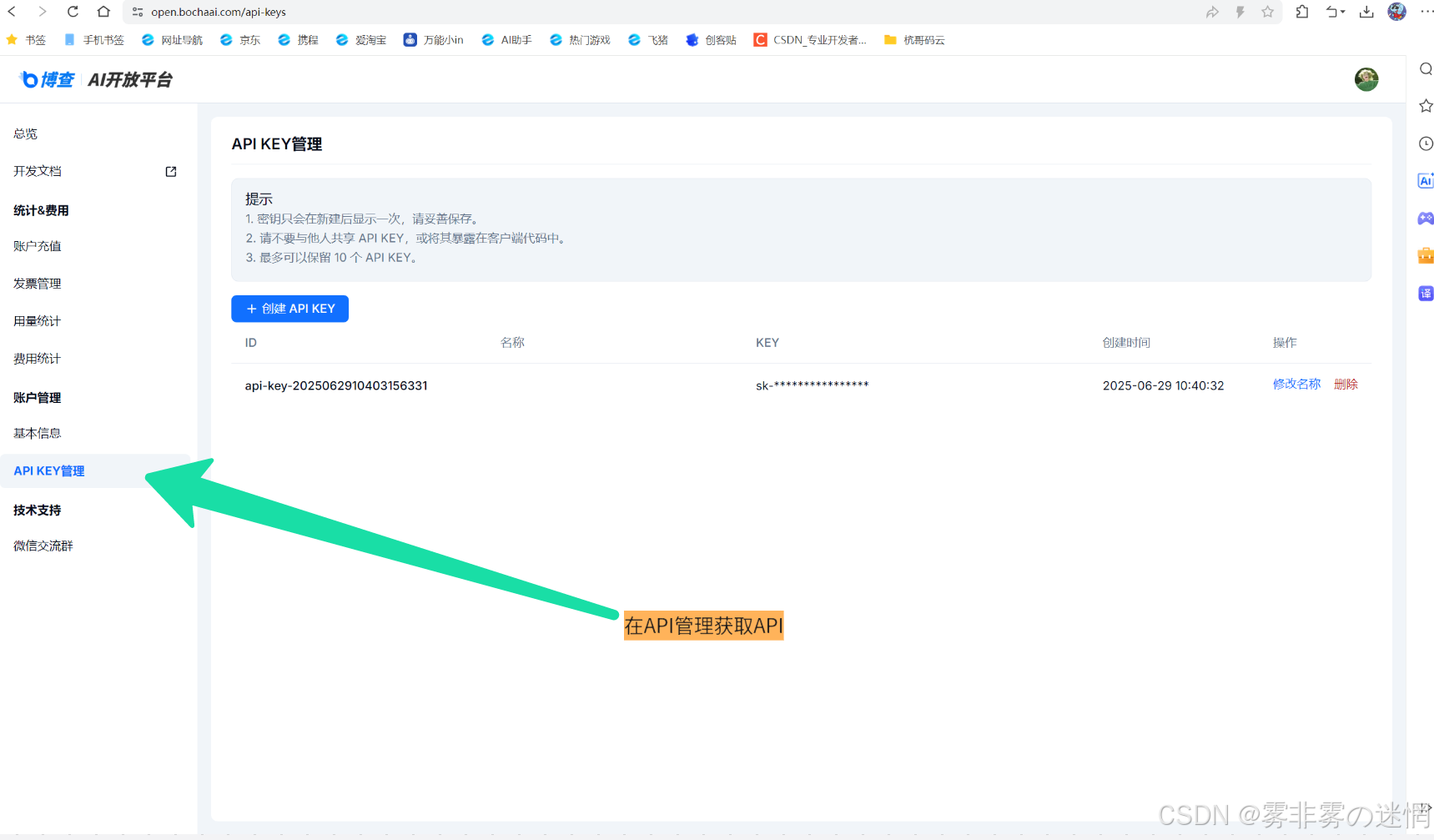
(8)这样就可以正常使用了
【十九】Web Search使用说明
从全网搜索任何网页信息和网页链接,结果准确、摘要完整,更适合AI使用!
(1)网页包括name、url、snippet、summary、siteName、siteIcon等信息
(2)图片包括 contentUrl、hostPageUrl、width、height等信息
(3)视频搜索目前在WebSearch中暂未开放
按照安装教程来不会出现配置问题的!如果出现“403”报错,可能是余额不足导致!充值即可
【二十】搭建工作流:Web Search捕捉全网图片、网址链接
这是最基础的Web Search搭建,自己可尝试将Qwen3接入工作流尝试更高级的浏览器哦!
(1)点击创建工作流
(2)选择ChatFlow,设置完昵称选择创建
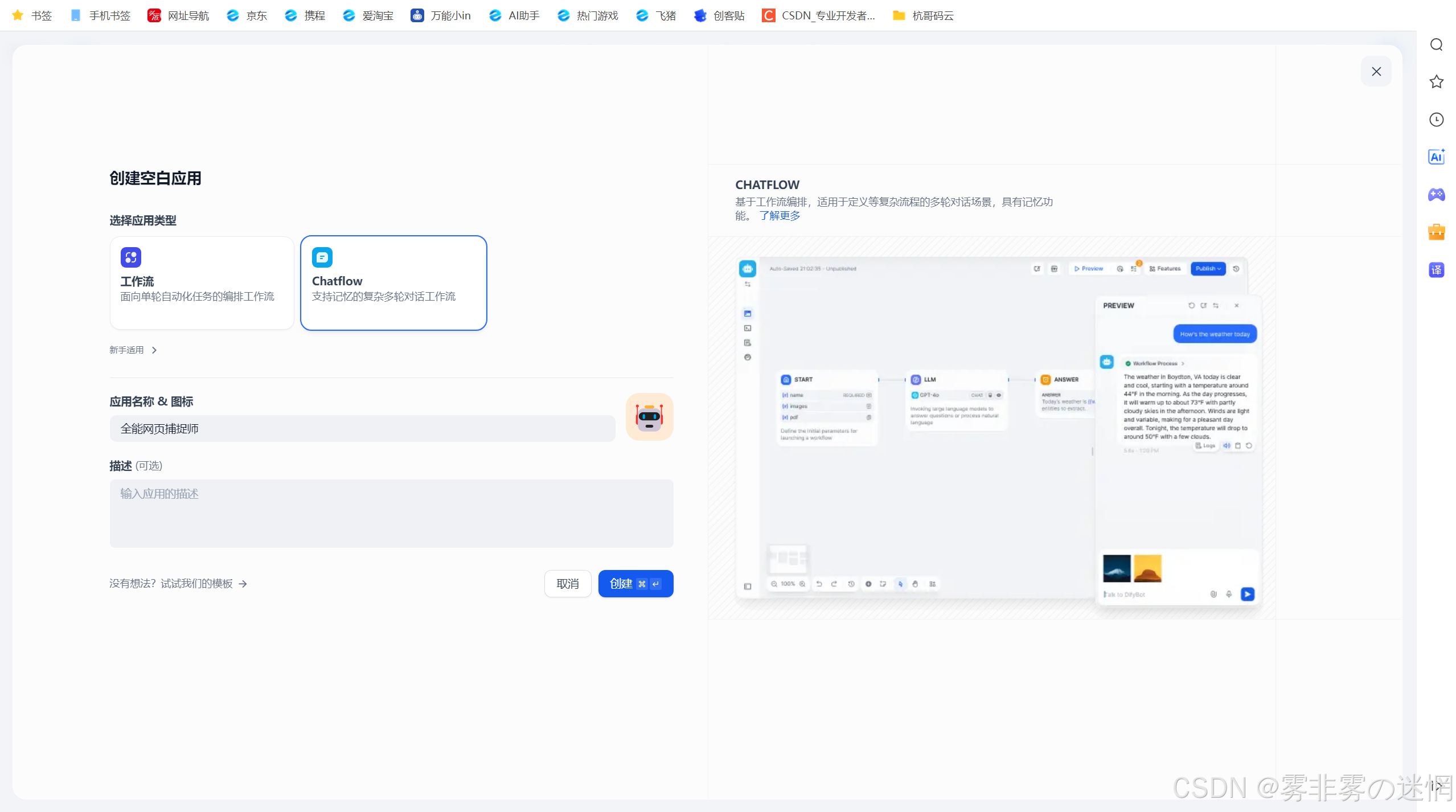
(3)选择博查Web节点
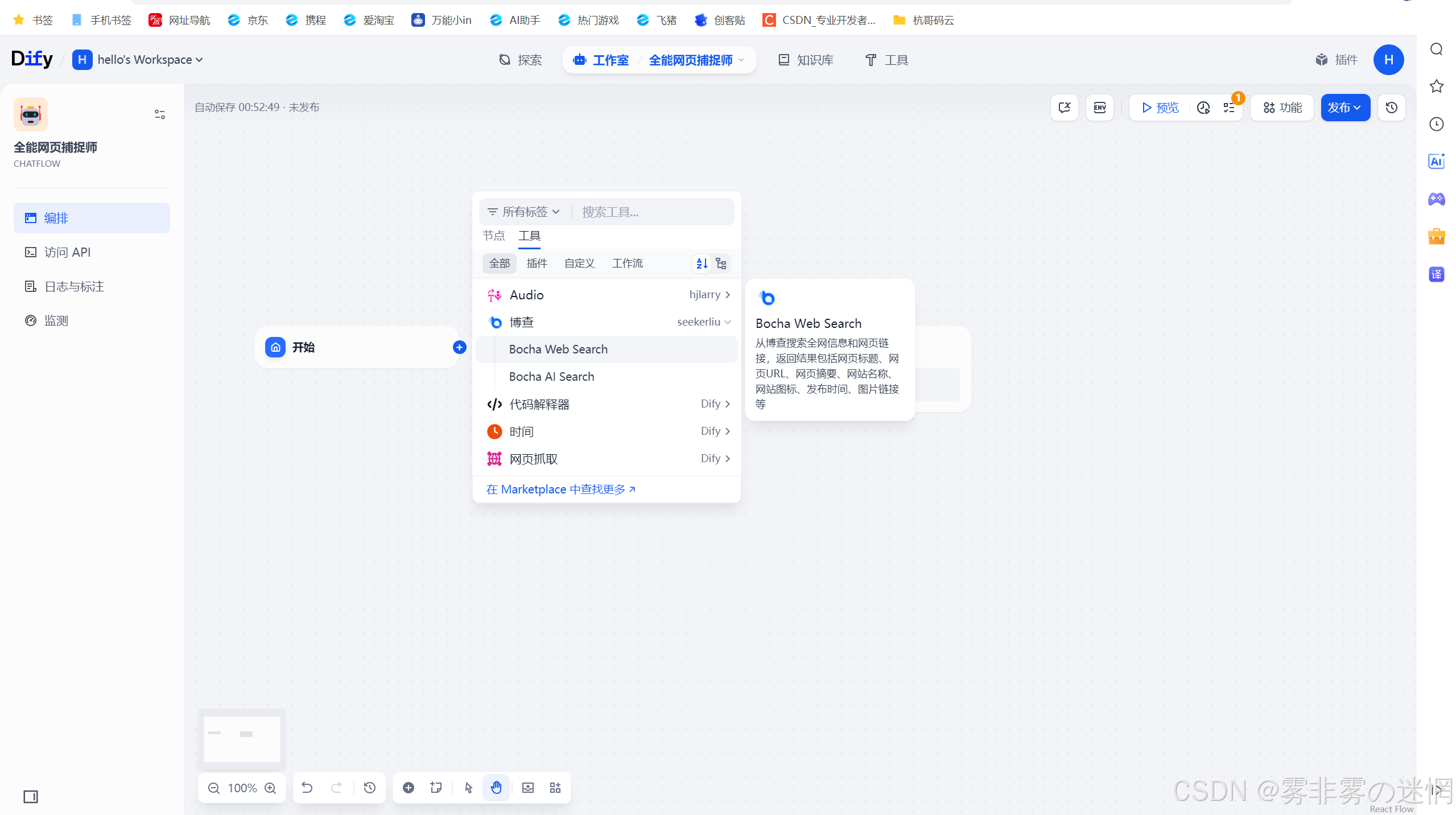
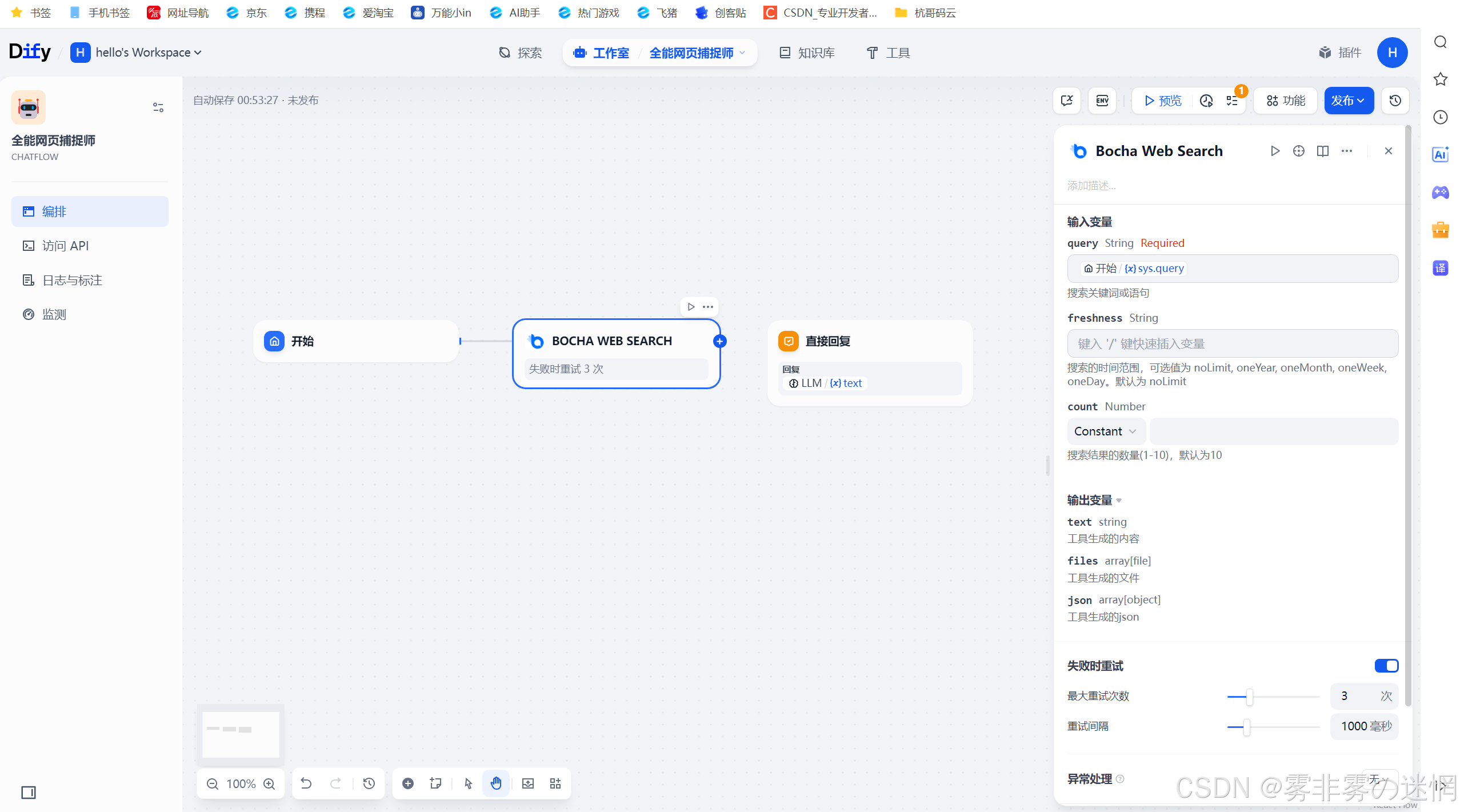
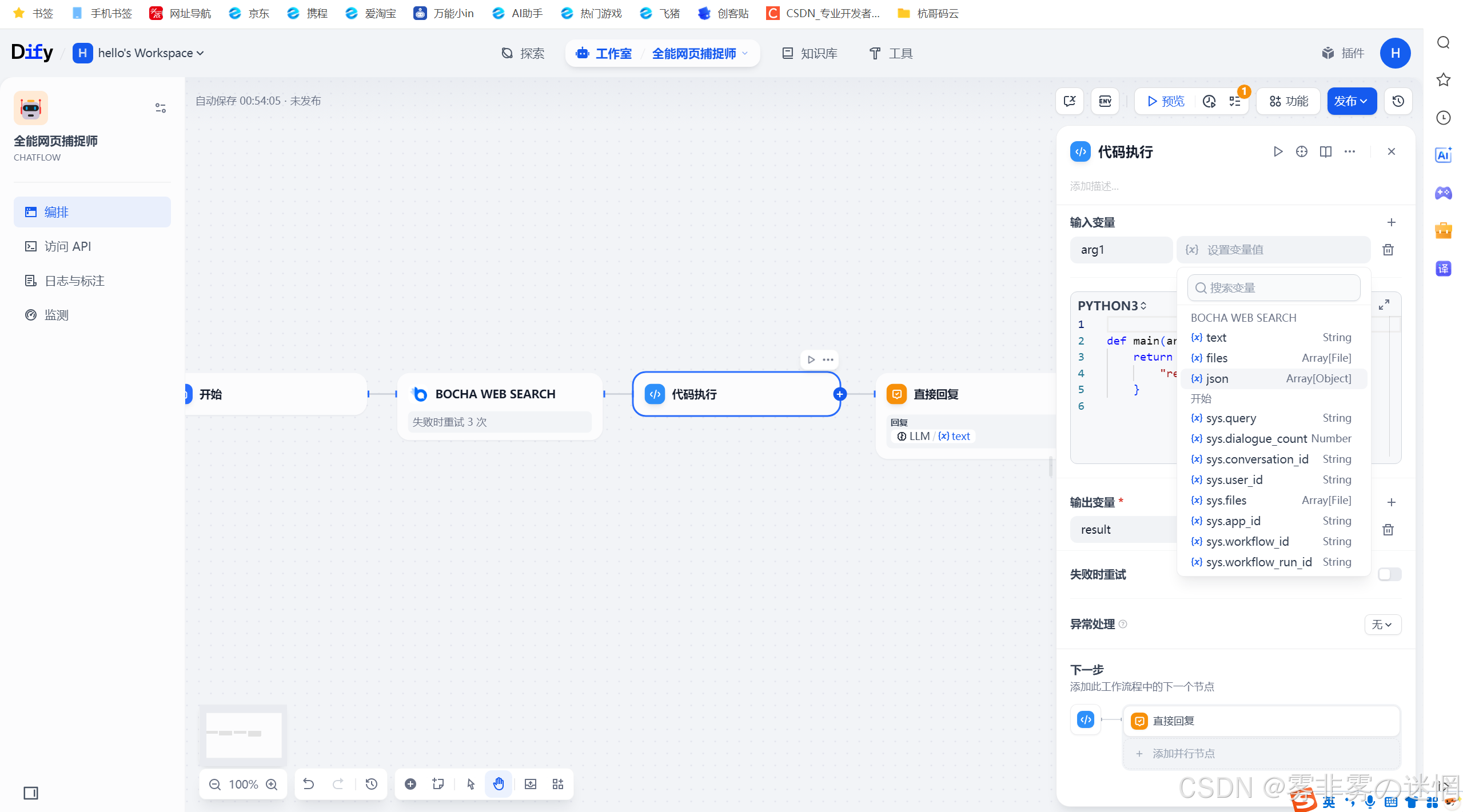
(4)输入变量设置为query:接收输入的字符串
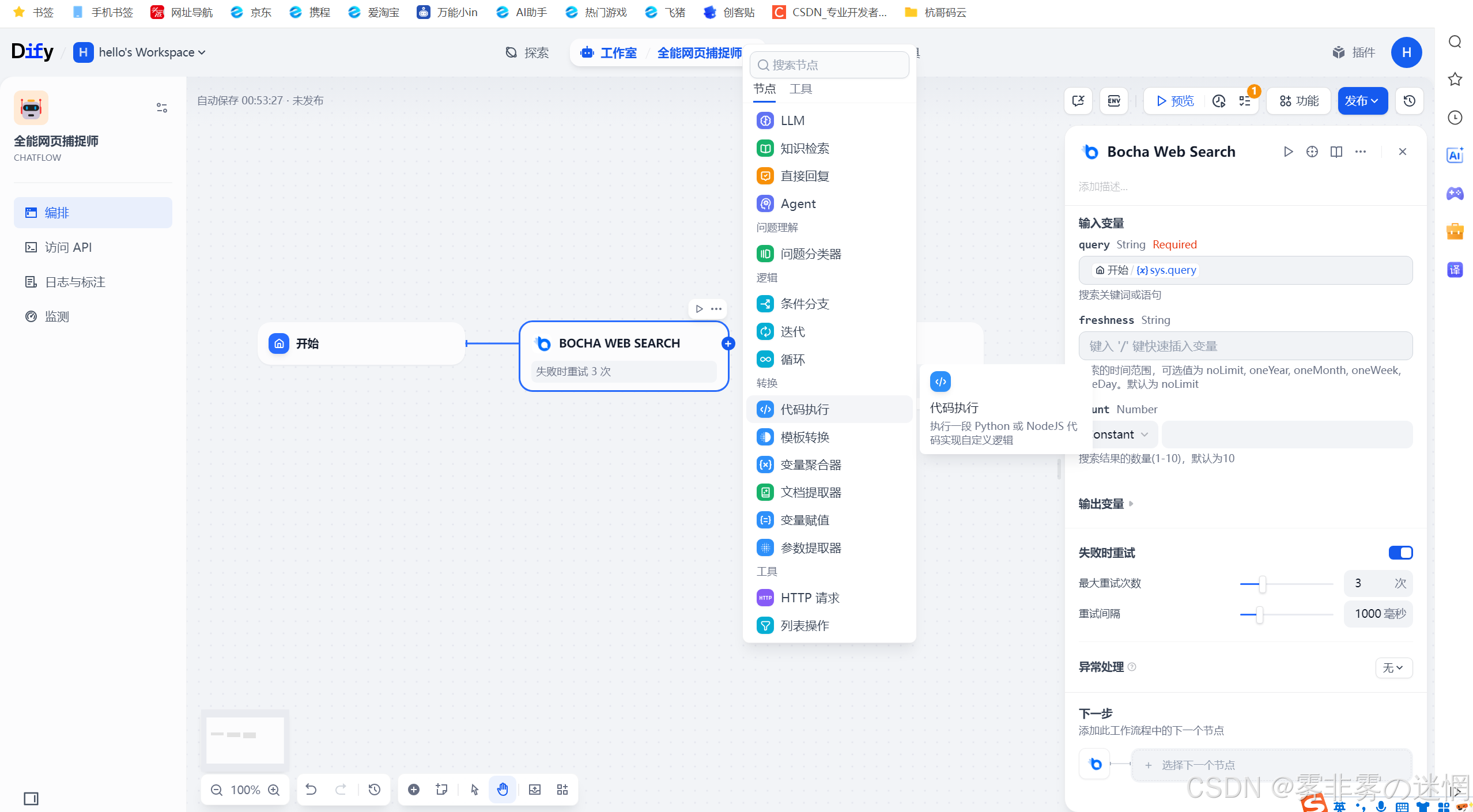
(5)再连接一个代码解析器
原因:博查输出的是JSON内容,我们只需要用Python解析里面有用的数据就行,而 JSON内容如果直接输出可能是一串乱码,这里是一个转化的效果!
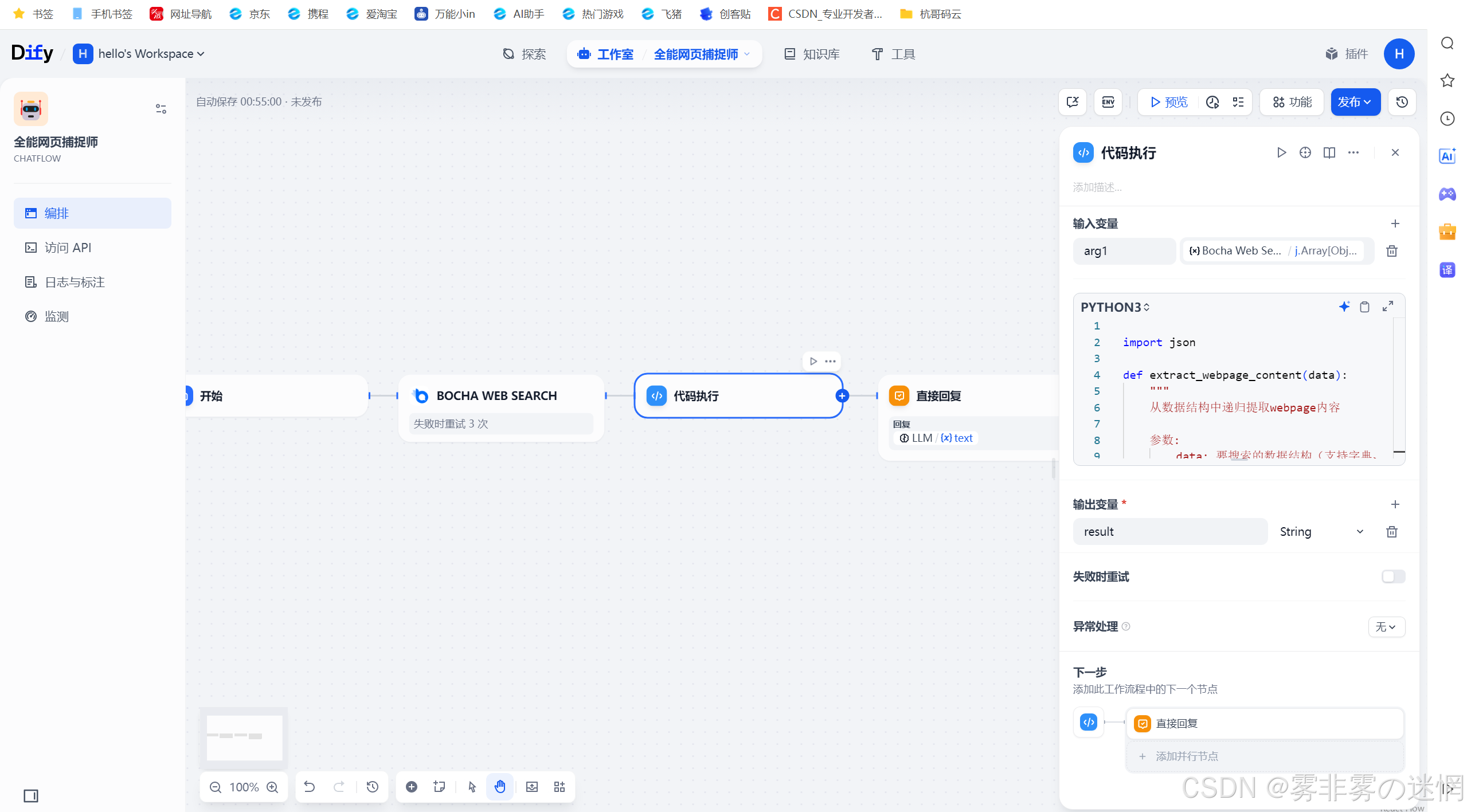
(6)代码设置如下参考,可以直接复制使用
输入选择:JSON
输出选择:string
代码展示:
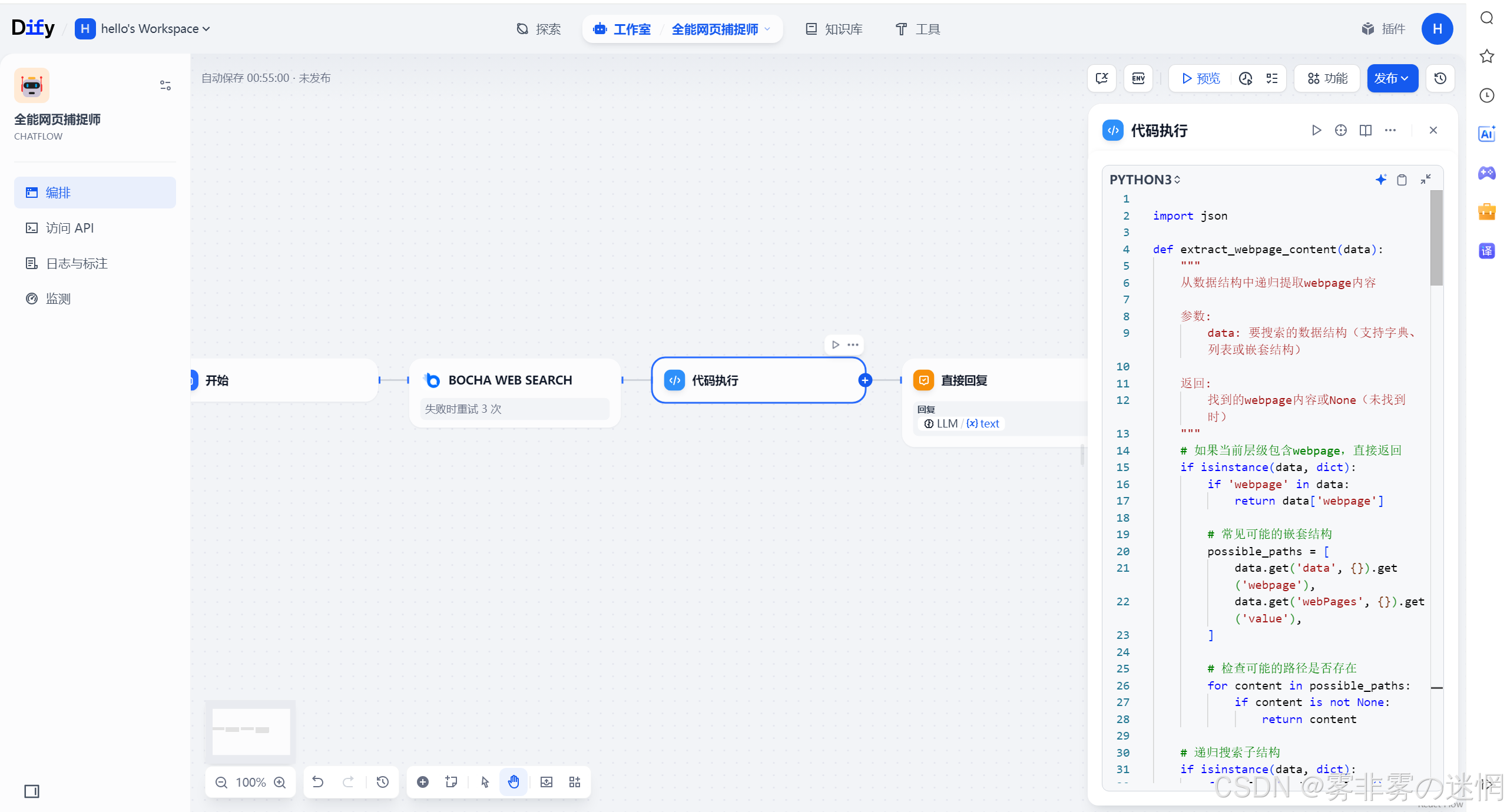
import jsondef extract_webpage_content(data): \"\"\" 从数据结构中递归提取webpage内容 参数: data: 要搜索的数据结构(支持字典、列表或嵌套结构) 返回: 找到的webpage内容或None(未找到时) \"\"\" # 如果当前层级包含webpage,直接返回 if isinstance(data, dict): if \'webpage\' in data: return data[\'webpage\'] # 常见可能的嵌套结构 possible_paths = [ data.get(\'data\', {}).get(\'webpage\'), data.get(\'webPages\', {}).get(\'value\'), ] # 检查可能的路径是否存在 for content in possible_paths: if content is not None: return content # 递归搜索子结构 if isinstance(data, dict): for value in data.values(): result = extract_webpage_content(value) if result is not None: return result elif isinstance(data, list): for item in data: result = extract_webpage_content(item) if result is not None: return result return Nonedef format_structured_content(content, indent_level=0): \"\"\" 将内容格式化为结构化的文本 参数: content: 要格式化的内容 indent_level: 当前的缩进级别 返回: 格式化后的文本字符串 \"\"\" indent = \" \" * indent_level result = \"\" # 处理字典类型 if isinstance(content, dict): for key, value in content.items(): # 跳过技术性字段 if key in [\"sitelcon\", \"id\", \"datePublished\"]: continue # 处理嵌套结构 if isinstance(value, (dict, list)): result += f\"{indent}【{key}】\\n\" result += format_structured_content(value, indent_level + 1) else: # 处理特殊键 if key == \"name\": result += f\"{indent}【{value}】\\n\" elif key == \"content\": result += f\"{indent}{value}\\n\" else: # 格式化键值对 formatted_value = str(value).replace(\"\\n\", \"\\n\" + indent + \" \") result += f\"{indent}- {key}: {formatted_value}\\n\" # 处理列表类型 elif isinstance(content, list): for i, item in enumerate(content): if isinstance(item, (dict, list)): result += f\"{indent}【条目 {i+1}】\\n\" result += format_structured_content(item, indent_level + 1) else: result += f\"{indent}- {item}\\n\" # 处理字符串类型 elif isinstance(content, str): # 尝试解析字符串中的JSON结构 try: parsed = json.loads(content) result += format_structured_content(parsed, indent_level) except: # 如果不是JSON,直接返回 result += f\"{indent}{content}\\n\" # 其他类型 else: result += f\"{indent}{str(content)}\\n\" return resultdef main(arg1) -> dict: \"\"\" 主函数:提取JSON中的webpage内容并转换为结构化文本 参数: arg1: 来自博查(Bocha)输出的JSON数据 返回: dict: 包含提取结果的字典,键为\"result\" \"\"\" try: # 处理输入数据类型:字符串解析为对象,否则直接使用 if isinstance(arg1, str): data = json.loads(arg1) else: data = arg1 # 提取webpage内容 content = extract_webpage_content(data) if content is None: return {\"result\": \"未找到可识别的webpage字段\"} # 将内容格式化为结构化的文本 formatted_result = format_structured_content(content) return {\"result\": formatted_result} except Exception as e: # 错误处理 return { \"result\": ( f\"提取webpage内容时出错: \" f\"{type(e).__name__}: {str(e)}\" ) }
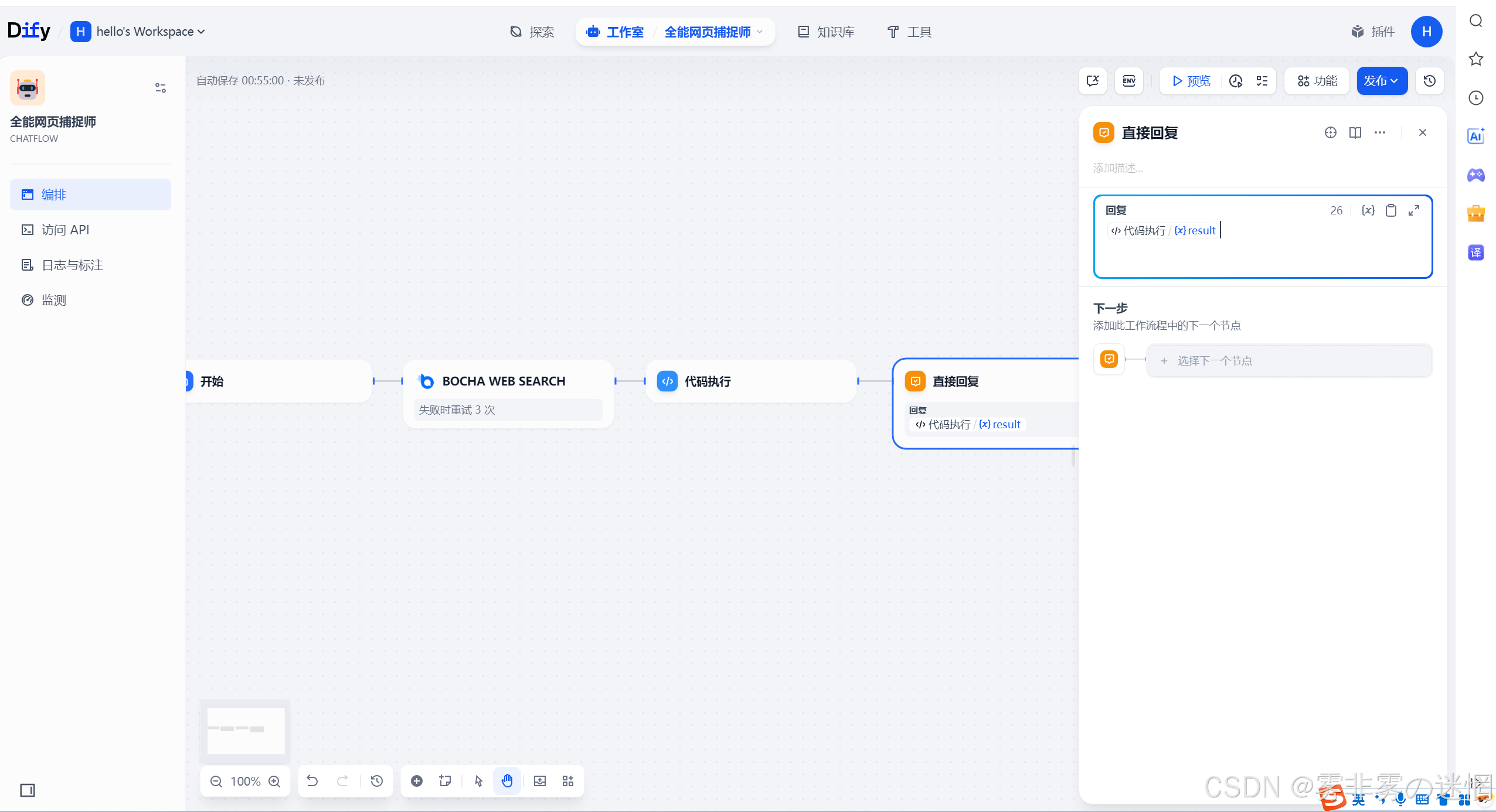
(7)我们已经用代码解析器转换JSON格式了,然后选择直接回复:回复最终结果即可
(8)发布更新使用
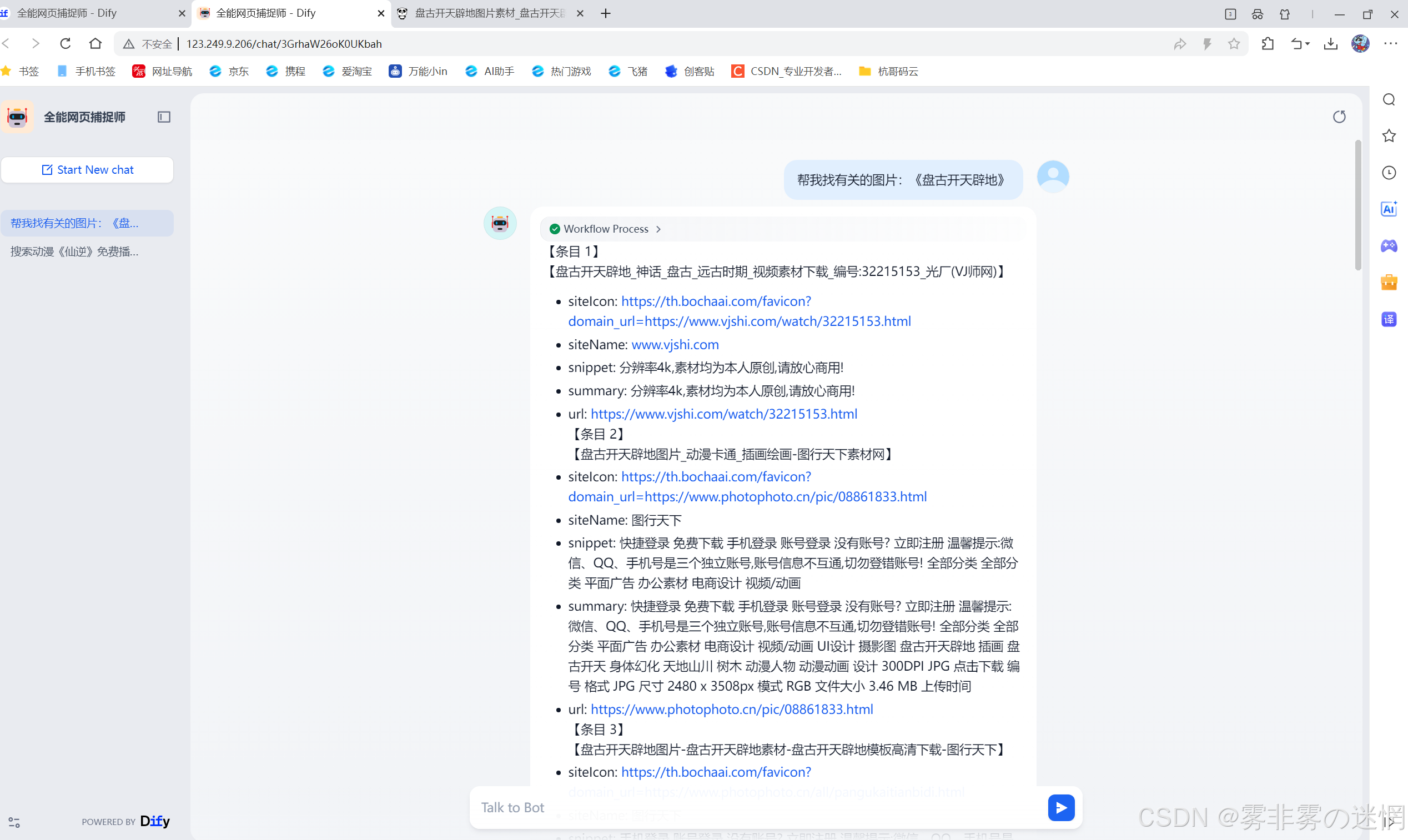
【二十一】捕获测试
搜索全网连接:盘古开天辟地
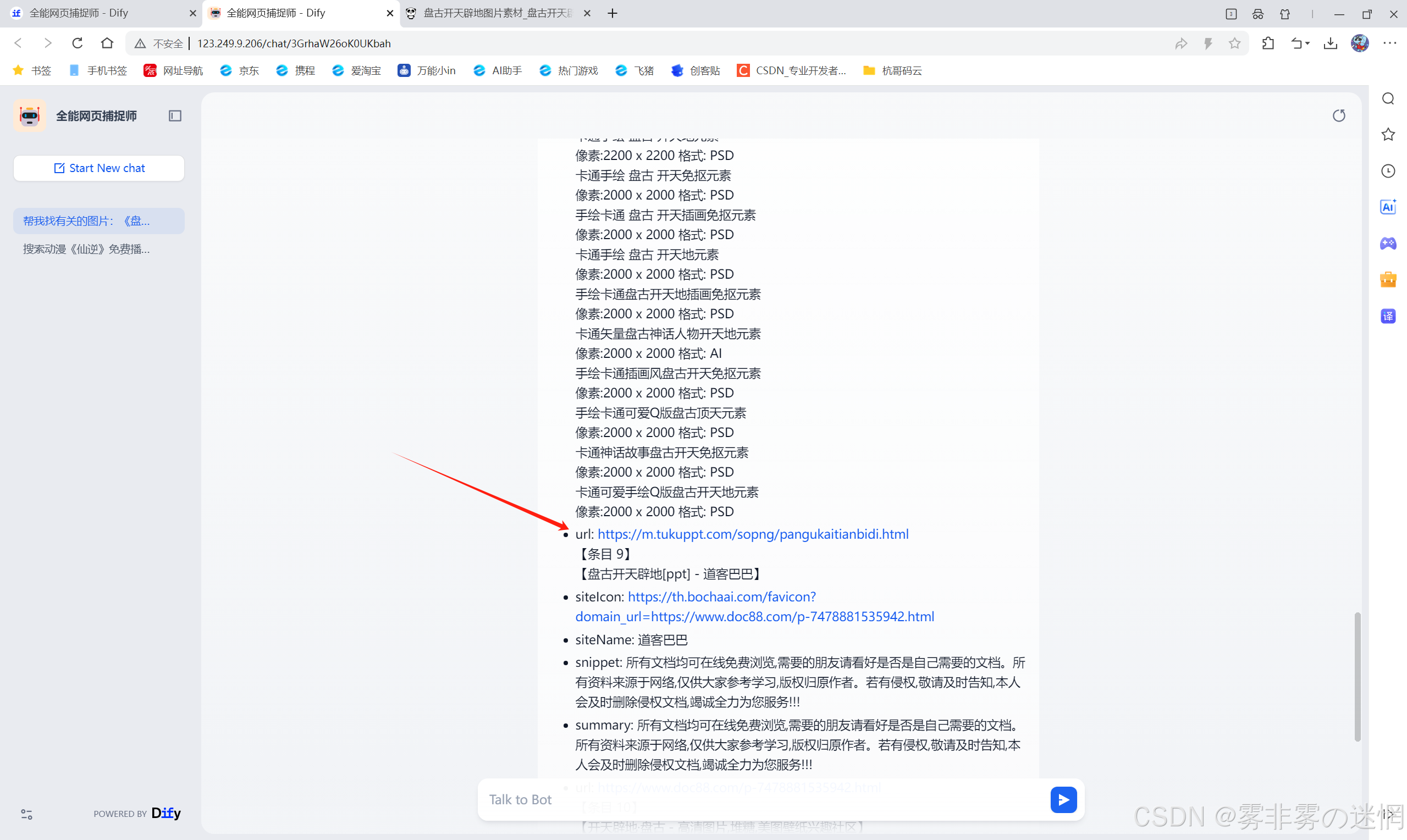
搜索免费播放器:播放仙逆
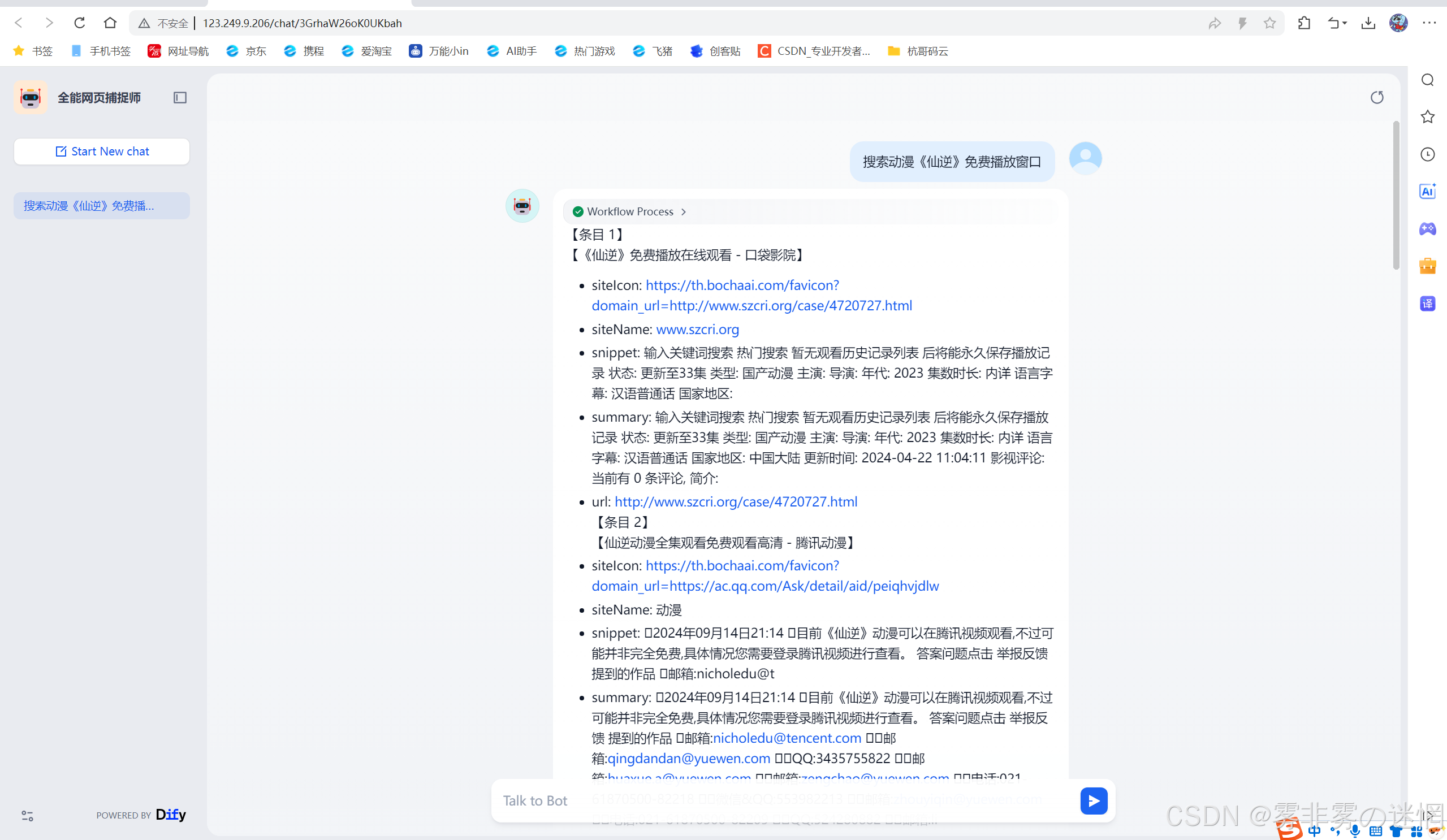
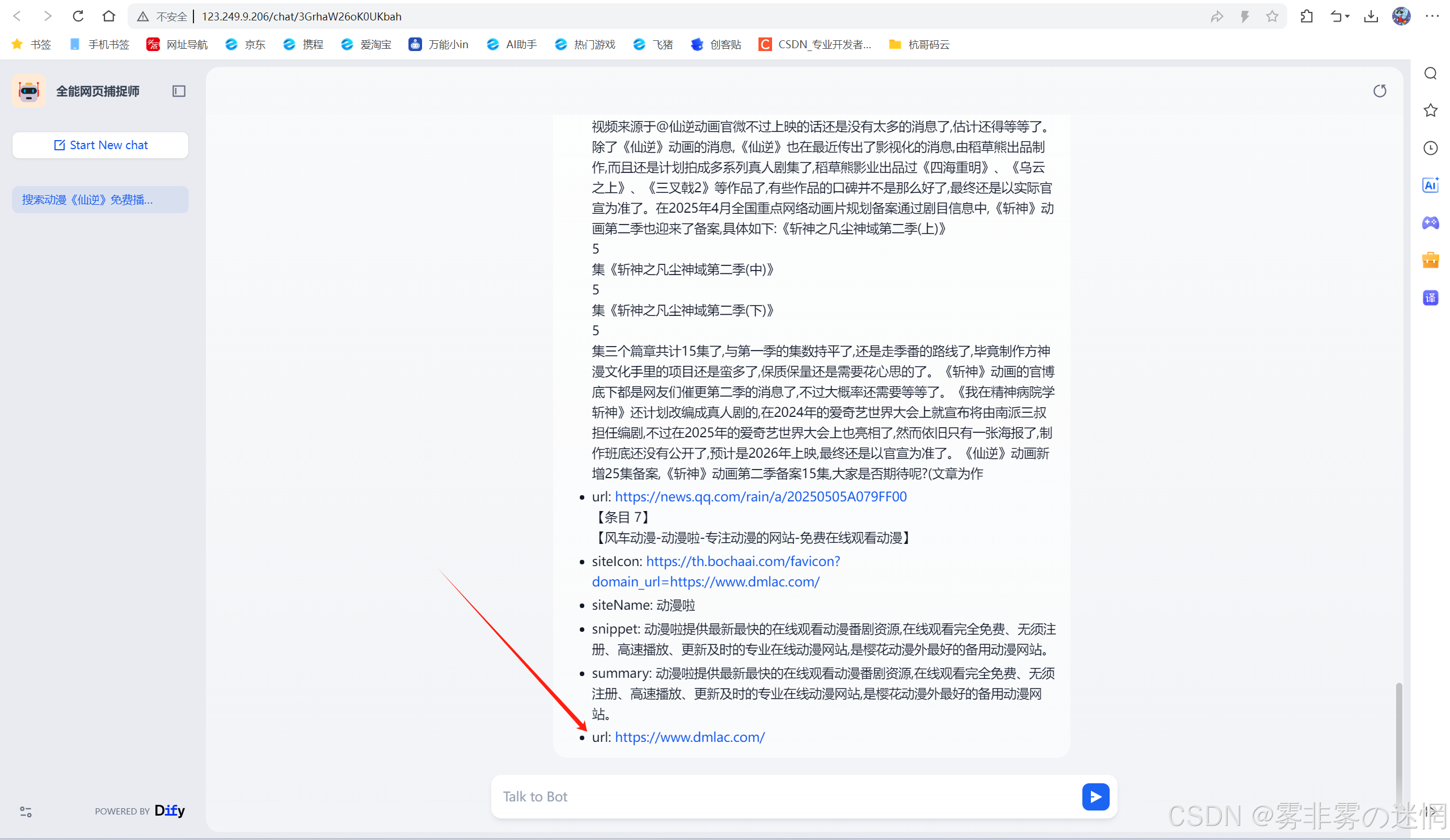
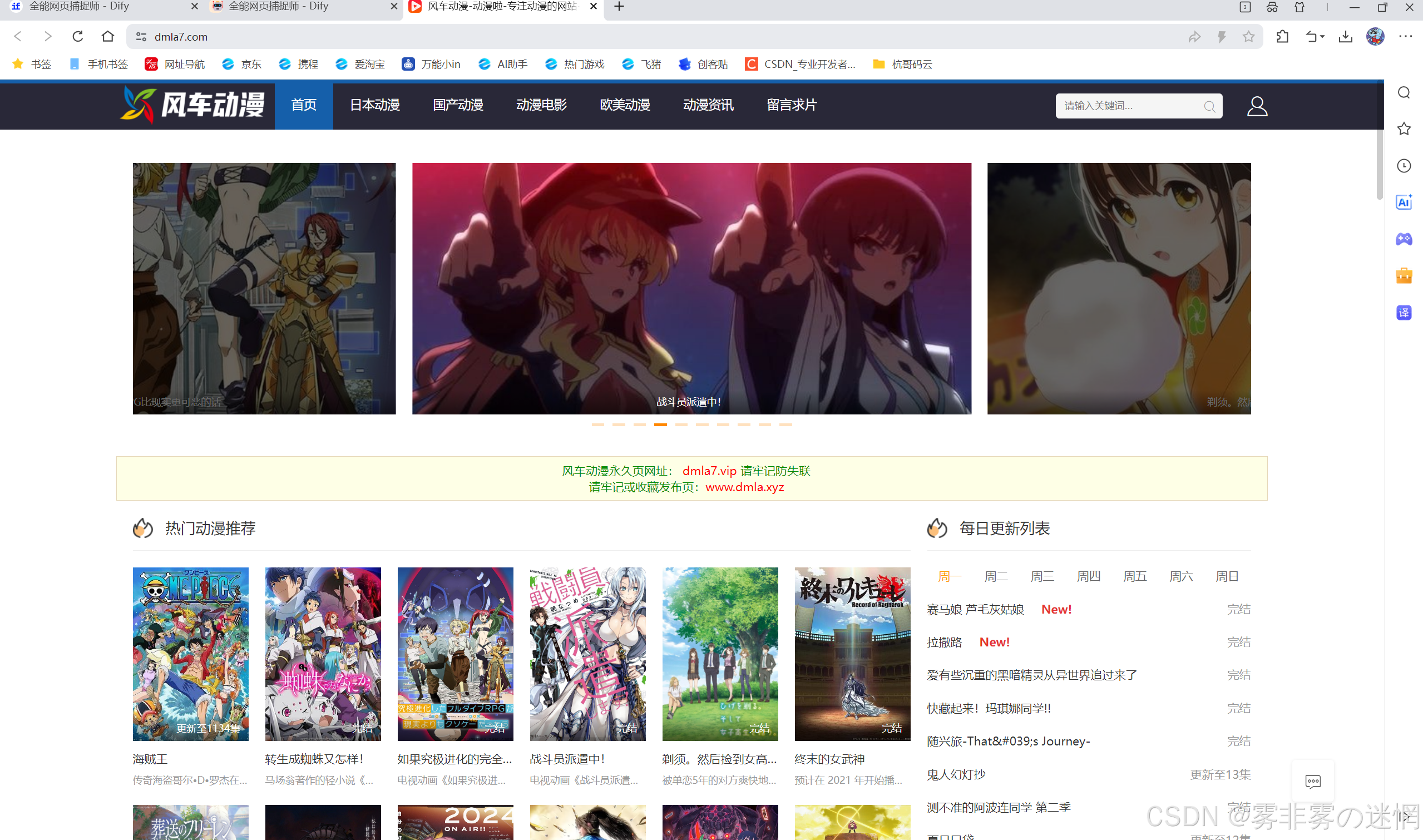
【二十二】如何删除资源停止计费
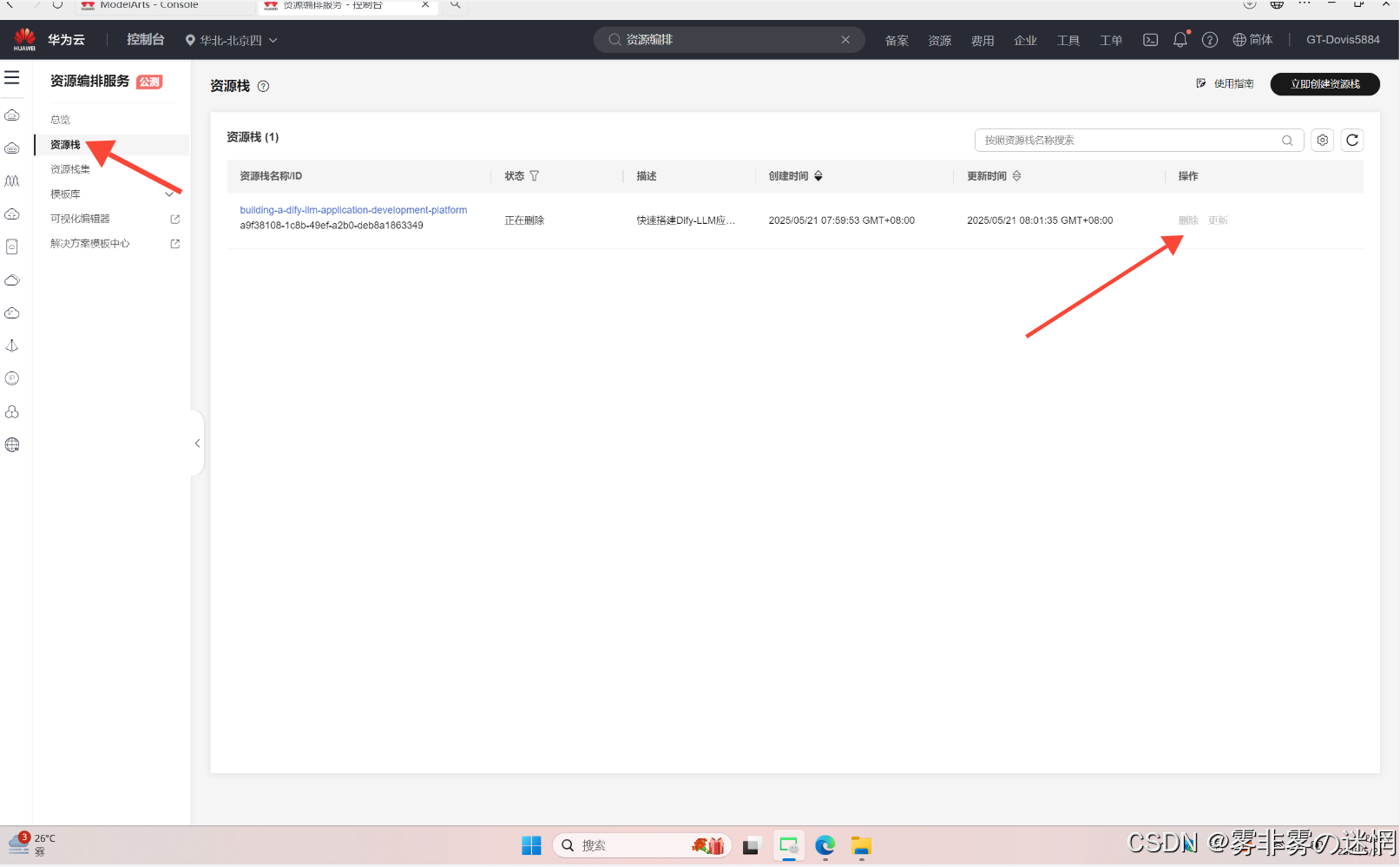
(1)在控制台搜索栏搜索“资源编排”打开
(2)然后点击“资源栈”,在这里面可以看到已经部署成功的资源
(3)如果要停止计费,点击“删除”即可
【二十三】测评建议
云服务器单机版部署建议:
适用场景:适合个人开发者、测试环境或小规模应用,不宜用于生产环境
资源配置:建议选择带GPU的ECS实例(如P系列实例),以提升AI推理效率
安全加固:单机版需手动设置安全组规则,限制入站端口(如仅开放Dify的80/443端口)
备份策略:利用华为云云硬盘备份功能,定期快照防止数据丢失
成本优化:使用竞价实例降低测试成本,但注意实例可能被回收
CCE高可用版部署建议:
架构设计:采用多可用区部署,将工作节点分散在不同可用区(AZ),结合ELB自动分流
弹性伸缩:配置HPA(Horizontal Pod Autoscaling),根据CPU/内存使用率自动扩展Dify服务Pod
持续集成:通过华为云DevCloud构建CI/CD流水线,实现Dify应用的蓝绿发布
监控告警:启用APM(应用性能管理)监控Dify服务的响应延迟和错误率,设置阈值告警
灾备方案:定期将Dify的PostgreSQL数据库同步到异地Region的RDS实例
【二十四】后续优化方向
指标 单机版改进措施 高可用版改进措施 响应速度 为ECS绑定增强型SSD云盘 启用GPU直通模式加速模型推理 安全防护 安装主机安全卫士防暴力破解 配置Web应用防火墙(WAF)过滤恶意请求 可观测性 云监控基础版CPU/内存监控 使用APM绘制Dify服务拓扑图
【二十五】心得与未来挑战
云服务器单机版心得:
部署效率:基于华为云市场Dify镜像,10分钟内即可启动服务,远超手工部署效率
性能瓶颈:单节点同时处理AI推理请求和数据库操作时,CPU易满载(实测QPS≤5),需通过Redis缓存会话数据优化
CCE高可用版心得:
稳定性验证:模拟单个节点故障时,ELB在15秒内将流量切至健康节点,服务中断接近零(实测99.95% SLA)
资源利用率:通过容器化部署,Dify的Model服务与Worker服务可按需分配资源(如GPU实例专供推理)
技术适配:需要调整Dify的docker-compose.yaml适配Kubernetes StatefulSet(特别注意PVC存储声明)
成本洞察:高可用版月成本约单机版的8倍(CCE版测评费用约70元),但支撑了200+ QPS并发,企业级场景ROI显著
致胜心法:单机版求快,高可用版求稳。生产环境务必遵循 \"ELB+多AZ+持久化存储\"三位一体原则 —— 这是华为云容错设计的黄金组合!本文到此结束,对你有用的话可否支持一下小编!


