知识图谱-Neo4j-开始构建知识图谱-01_neo4j构建知识图谱
Neo4j初探
Neo4j介绍
1. Neo4j 是什么?
- 定义:Neo4j 是一款高性能的 原生图数据库(Native Graph Database),专门为存储和查询图结构数据设计。
- 核心思想:以 节点(Node)、关系(Relationship) 和 属性(Property) 为基本单元,直接映射现实世界的关联关系。
- 查询语言:使用声明式查询语言 Cypher,语法简洁直观,专注于描述“连接模式”。
2. 核心概念
(1) 图数据模型
- 节点(Nodes):表示实体(如用户、商品、地点),可附加标签(Label)和属性。
CREATE (:Person {name: \"Alice\", age: 30}) - 关系(Relationships):连接两个节点,具有方向(→ 或 ←)和类型(Type),可附加属性。
MATCH (a:Person), (b:Person)CREATE (a)-[:FRIENDS_WITH {since: 2020}]->(b) - 属性(Properties):键值对,存储节点或关系的详细信息(如
name,age)。
(2) Cypher 查询语言
- 直观语法:通过模式匹配直接描述图结构。
MATCH (p:Person)-[:LIVES_IN]->(c:City {name: \"北京\"}) RETURN p.name, p.age - 高效遍历:支持复杂关系路径查询(如最短路径、模式匹配)。
3. 核心优势
(1) 原生图存储
- 物理存储优化:数据以图结构直接存储,避免传统数据库的“表连接”开销。
- 高效遍历:通过指针直接访问相邻节点,时间复杂度接近 O(1)。
(2) 高性能
- 复杂查询优化:擅长处理多跳查询(如“朋友的朋友”)、路径分析等场景。
- 实时分析:支持大规模图数据的实时查询和分析。
(3) 灵活性与扩展性
- 动态模式:无需预定义固定表结构,可随时扩展节点、关系和属性。
- 支持 ACID 事务:确保数据一致性,适用于金融、供应链等关键场景。
(4) 可视化工具
- Neo4j Browser:内置交互式界面,直观展示图结构和查询结果。
- Bloom:企业级可视化工具,支持动态探索大规模图数据。
4. 适用场景
5. 对比传统数据库
6. 版本与生态
- 社区版:免费开源,适合个人和小型项目。
- 企业版:付费,支持集群、备份、监控等高级功能。
- 工具与插件:
- APOC:扩展库,提供数据导入/导出、算法等实用功能。
- Neo4j Graph Data Science:内置图算法(如 PageRank、社区发现)。
- Neo4j Connectors:与 Kafka、Spark 等大数据工具集成。
7. 入门步骤
- 安装:下载 Neo4j Desktop(支持Windows/Mac/Linux)。
- 创建数据库:一键启动本地实例。
- 学习 Cypher:通过内置教程或官方文档实践。
- 导入数据:使用
LOAD CSV或neo4j-admin工具。 - 可视化探索:在 Neo4j Browser 中运行查询并查看图结果。
8. 缺点与注意事项
- 学习曲线:需掌握 Cypher 语法和图思维。
- 存储成本:图数据库存储开销可能高于关系型数据库。
- 适用边界:非关联型数据(如日志、时序数据)建议选择其他数据库。
Neo4j 安装
Docker Compose 安装
https://neo4j.com/docs/operations-manual/current/docker/docker-compose-standalone/
services: neo4j: image: neo4j:latest volumes: - /$HOME/neo4j/logs:/logs - /$HOME/neo4j/config:/config - /$HOME/neo4j/data:/data - /$HOME/neo4j/plugins:/plugins environment: - NEO4J_AUTH=neo4j/your_password ports: - \"7474:7474\" - \"7687:7687\" restart: always启动
docker compose up -d

访问
localhost:7876

知识图谱例子
- 2025-02-27 22:25
官方例子
这是一个Movie的例子。
这里分为两个方面看:
- 创建电影实体
CREATE (TheMatrix:Movie {title:\'The Matrix\', released:1999, tagline:\'Welcome to the Real World\'}) - 创建Person 实体
- 创建
Person - ACTED_IN -> MOVIE关系 和PERSON-DIRECTED->MOVIE关系
CREATE (TheMatrix:Movie {title:\'The Matrix\', released:1999, tagline:\'Welcome to the Real World\'})CREATE (Keanu:Person {name:\'Keanu Reeves\', born:1964})CREATE (Carrie:Person {name:\'Carrie-Anne Moss\', born:1967})CREATE (Laurence:Person {name:\'Laurence Fishburne\', born:1961})CREATE (Hugo:Person {name:\'Hugo Weaving\', born:1960})CREATE (LillyW:Person {name:\'Lilly Wachowski\', born:1967})CREATE (LanaW:Person {name:\'Lana Wachowski\', born:1965})CREATE (JoelS:Person {name:\'Joel Silver\', born:1952})CREATE(Keanu)-[:ACTED_IN {roles:[\'Neo\']}]->(TheMatrix),(Carrie)-[:ACTED_IN {roles:[\'Trinity\']}]->(TheMatrix),(Laurence)-[:ACTED_IN {roles:[\'Morpheus\']}]->(TheMatrix),(Hugo)-[:ACTED_IN {roles:[\'Agent Smith\']}]->(TheMatrix),(LillyW)-[:DIRECTED]->(TheMatrix),(LanaW)-[:DIRECTED]->(TheMatrix),(JoelS)-[:PRODUCED]->(TheMatrix)执行Movie Graph例子,生成图谱
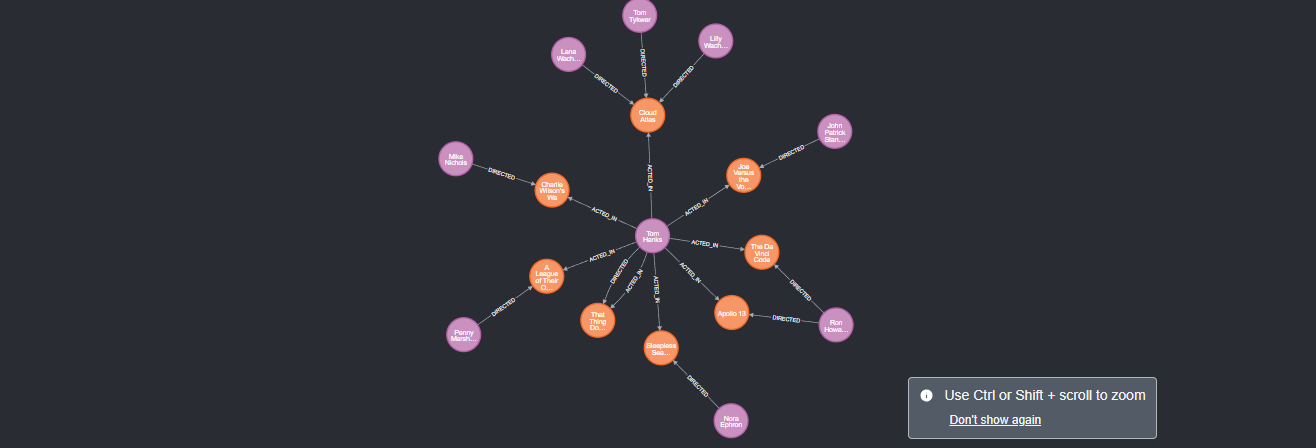
搜索图谱例子:查询
找到名叫“Tom Hanks”的演员
match (tom {name:\"Tom Hanks\"}) return tom 找到标题为“Cloud Atlas”的电影
match (a {title:\"Cloud Atlas\"}) RETURN a找到 10 个人
match(people:Person) RETURN people limit 10 查找 1990 年代上映的电影
match (nineties:Movie) where nineties.released >= 1990 AND nineties.released< 2000 return nineties列出所有 Tom Hanks 的电影…
match (tomHanks:Person {name:\"Tom Hanks\"}) -[:ACTED_IN]-> (movies) RETURN tomHanks,movies 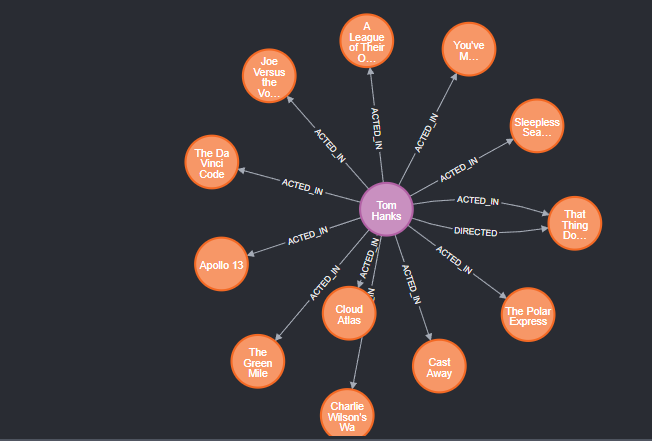
谁执导了《云图》?
? -> directed -> movice
Match (one) -[:DIRECTED]-> (yuntu:Movie{title:\"Cloud Atlas\"}) RETURN one,yuntu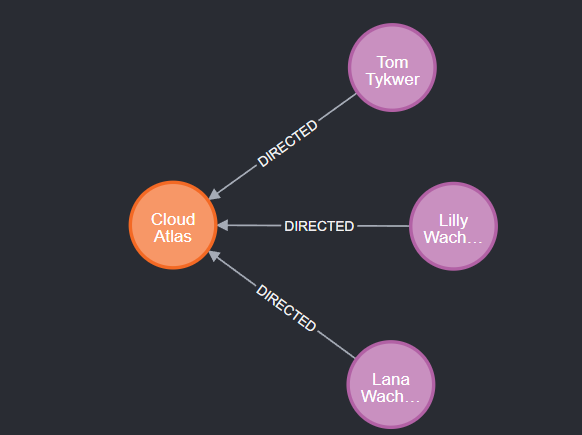
汤姆·汉克斯的合作演员
tom hanks - acted_in->(m) <- acted_in - ?
match (tom:Person {name:\"Tom Hanks\"}) -[:ACTED_IN]-> (m) <-[:ACTED_IN]- (actors) RETURN tom ,m, actors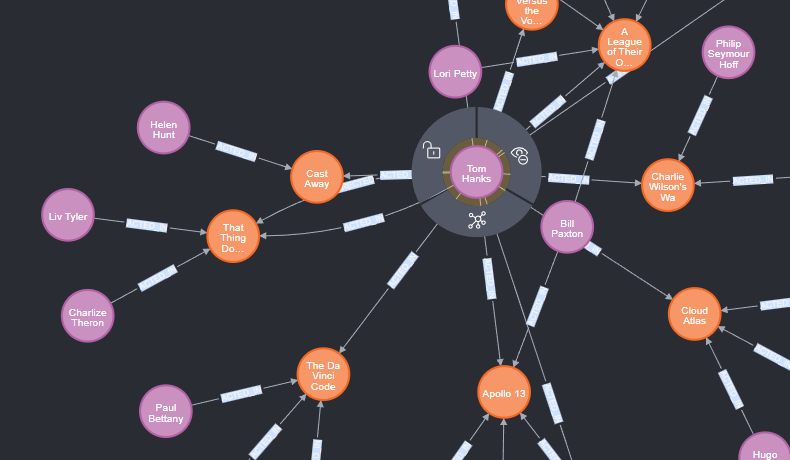
与“Cloud Atlas”有关系的人…
match (m)-[p]->(t:Movie{title:\"Cloud Atlas\"})return t,m 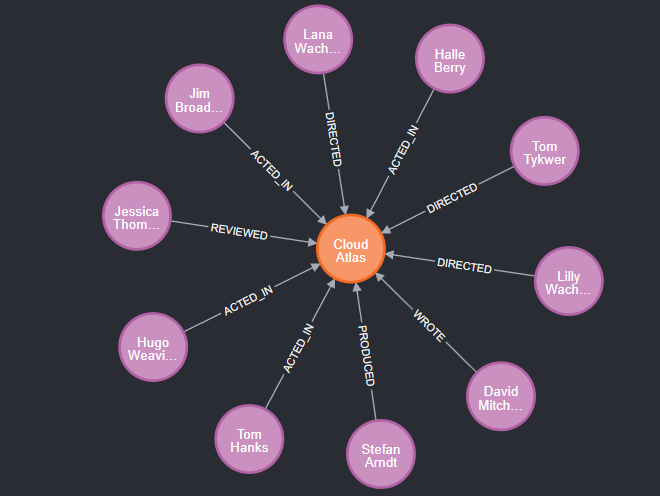
图谱例子:Solve 解决 路径查询
你听说过经典的“凯文·贝肯六度分隔”吗?这只是一个称为“贝肯路径”的最短路径查询。
- 内置最短路径()算法
电影和演员,与凯文·贝肯相距最多 4“跳”
这里指:kevin Bacon 关联的演员或电影,一次关联 就是 一跳。
我的理解:探针:每进一层,1跳。多层 多跳。 或者从 尾节点 找 上找 n次可找到目标
MATCH (bacon:Person {name:\"Kevin Bacon\"})-[*1..4]-(hollywood)RETURN DISTINCT hollywood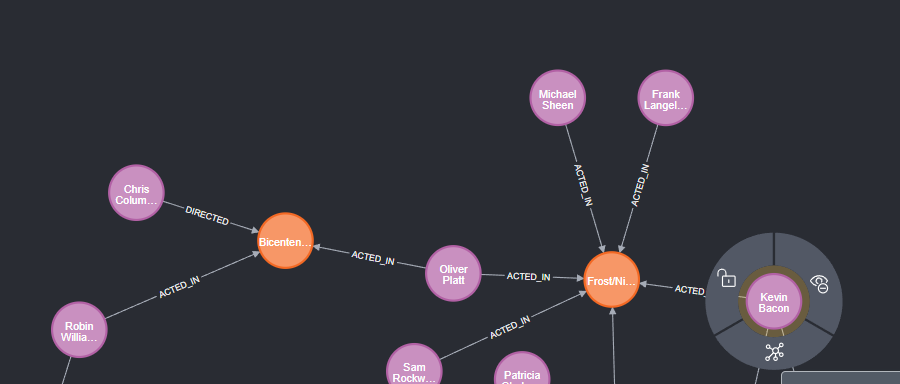
培根路径,任何关系到达梅格·瑞恩的最短路径
MATCH p=shortestPath((bacon:Person {name:\"Kevin Bacon\"})-[*]-(meg:Person {name:\"Meg Ryan\"}))RETURN p
请注意,您只需在首次创建关系时比较属性值即可
图谱例子:Recommend 推荐
让我们为汤姆·汉克斯推荐新的合演者。一种基本的推荐方法是找到与自身联系紧密的邻近区域以外的联系。
找到一个人,能介绍汤姆给他潜在的合作演员。
寻找汤姆·汉克斯尚未合作过的演员,但他的合作演员已经合作过的。
Find someone who can introduce Tom to his potential co-actor.
这个Neo4j查询语句用于推荐与Tom Hanks间接合作的演员(二级合作演员),并计算推荐强度。以下是逐层分析:
MATCH (tom:Person {name:\"Tom Hanks\"}) -[:ACTED_IN]-> (m) <-[:ACTED_IN]- (coActor),(coActor)-[:ACTED_IN]-> (m2)<-[:ACTED_IN]-(cocoAcotr)where NOT (tom)-[:ACTED_IN]->()<-[:ACTED_IN]-(cocoAcotr) AND tom cocoAcotr return tom.name, coActor, cocoAcotr ,count(*) as strengh order by strengh desc##-
查询目标
找到满足以下条件的演员:- 二级合作演员:与Tom Hanks的直接合作演员(一级合作演员)合作过,但自己从未与Tom Hanks直接合作过。
- 推荐强度:基于这些二级合作演员与一级合作演员的共同参演次数,次数越多强度越高。
-
模式分解
路径1:Tom → 电影 ← 一级合作演员(tom:Person {name:\"Tom Hanks\"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors)- 逻辑:找到Tom Hanks参演的所有电影(
m),以及与他共同参演这些电影的一级合作演员(coActors)。
路径2:一级合作演员 → 其他电影 ← 二级合作演员
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cocoActors)- 逻辑:找到一级合作演员参演的其他电影(
m2),以及这些电影中的其他二级合作演员(cocoActors)。
3. 过滤条件
WHERE NOT (tom)-[:ACTED_IN]->()<-[:ACTED_IN]-(cocoActors) AND tom cocoActors- 排除直接合作:确保二级合作演员(
cocoActors)从未与Tom Hanks共同参演过同一部电影。 - 排除自己:确保结果不包含Tom Hanks本人。
4. 结果统计与排序
RETURN cocoActors AS Recommended, count(*) AS Strength ORDER BY Strength DESC- 统计逻辑:对每个二级合作演员,统计其通过不同路径(不同的一级合作演员和电影)被推荐的次数。
- 排序:按推荐强度(路径数量)降序排列,次数越多表示关联越强。
- 逻辑:找到Tom Hanks参演的所有电影(
基本用法
创建一个索引(只读)
// Create an index// Replace:// \'IndexName\' with name of index (optional)// \'LabelName\' with label to index// \'propertyName\' with property to be indexedCREATE INDEX [IndexName] FOR (n:LabelName)ON (n.propertyName)创建 唯一 的属性约束(只读)
// Create unique property constraint// Replace:// \'ConstraintName\' with name of constraint (optional)// \'LabelName\' with node label// \'propertyKey\' with property that should be uniqueCREATE CONSTRAINT [ConstraintName]FOR (n:<LabelName>)REQUIRE n.<propertyKey> IS UNIQUE获取一些数据
MATCH (n1)-[r]->(n2) RETURN r, n1, n2 LIMIT 25
Hello World!
CREATE (database:Database {name:\"Neo4j\"})-[r:SAYS]->(message:Message {name:\"Hello World!\"}) RETURN database, message, r
找到某人介绍汤姆·汉克斯给汤姆·克鲁斯认识
# 演员关系match (tomH:Person{name:\"Tom Hanks\"}) -[:ACTED_IN]-> (m) <-[:ACTED_IN]-(someOne),(someOne)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(tomC:Person{name:\"Tom Cruise\"})return tomH,m,tomC,someOne# 所有关系match (tomH:Person{name:\"Tom Hanks\"}) -[*]-> (m) <-[*]-(someOne),(someOne)-[*]->(m2)<-[*]-(tomC:Person{name:\"Tom Cruise\"})return tomH,m,tomC,someOne
Clean up 清理
当你完成实验后,您可以删除电影数据集。
Note: 注意:
节点存在关系时无法删除
删除节点和关系
WARNING: This will remove all Person and Movie nodes!
警告:这将删除所有人物和电影节点!
删除所有电影和人物节点及其关系
MATCH (n) DETACH DELETE n证明电影图已消失
MATCH (n) RETURN n从关系型数据库到图,使用经典数据集:Northwind Graph 北温图
从关系型数据库到图,使用经典数据集
北风图展示了如何从关系型数据库迁移到 Neo4j。这种转换是迭代和有意的,强调从关系表到图节点和关系的概念转变。
本指南将向您展示如何:
Northwind 在几个类别中销售食品产品,由供应商提供。让我们先加载产品目录表。
Product Catalog 产品目录
加载:从外部 CSV 文件创建数据
Product Catalog 产品目录
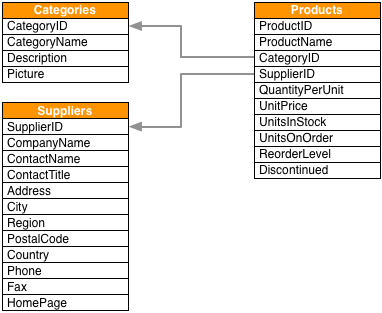
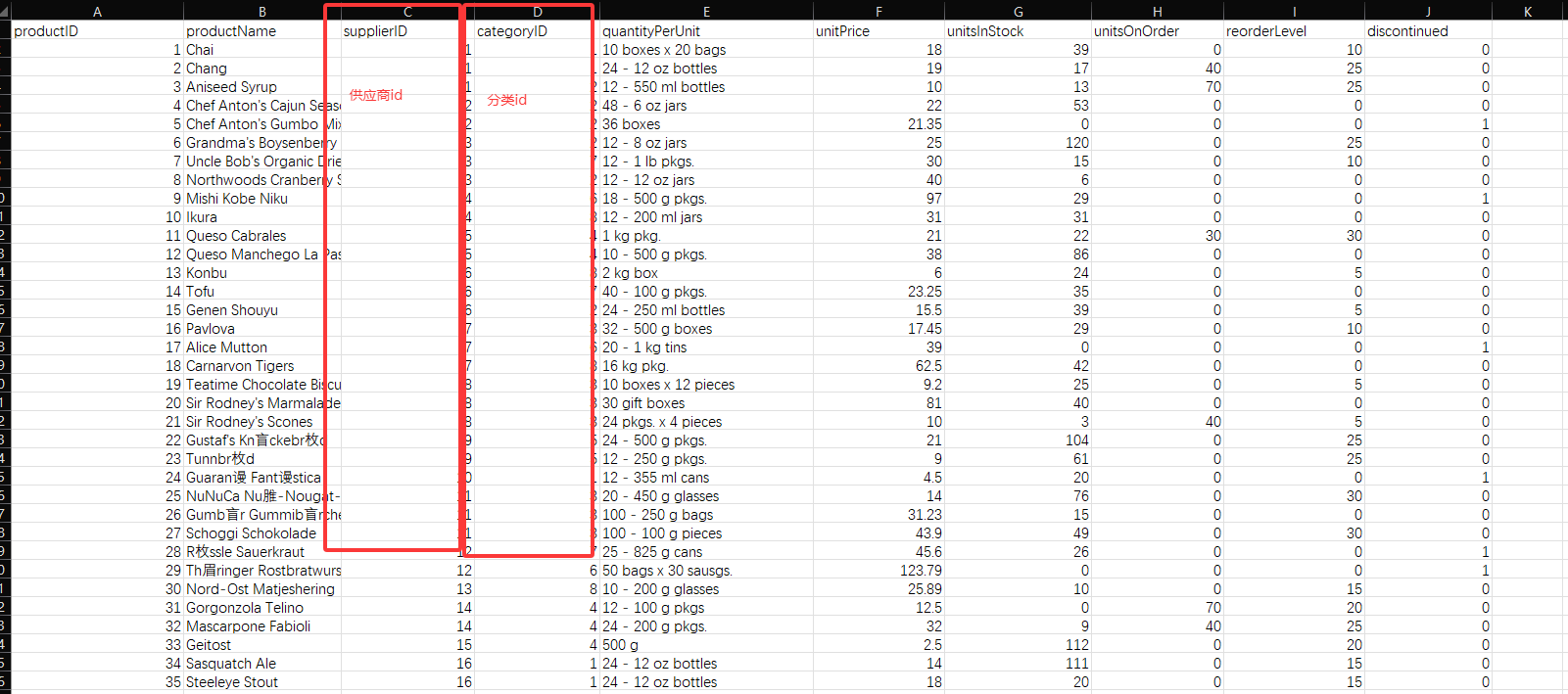


# 加载productLOAD CSV WITH HEADERS FROM \"https://data.neo4j.com/northwind/products.csv\" AS rowCREATE (n:Product)SET n = row,n.unitPrice = toFloat(row.unitPrice),n.unitsInStock = toInteger(row.unitsInStock), n.unitsOnOrder = toInteger(row.unitsOnOrder),n.reorderLevel = toInteger(row.reorderLevel), n.discontinued = (row.discontinued \"0\")# 加载categoryLOAD CSV WITH HEADERS FROM \"https://data.neo4j.com/northwind/categories.csv\" AS rowCREATE (n:Category)SET n = row# 加载SupplierLOAD CSV WITH HEADERS FROM \"https://data.neo4j.com/northwind/suppliers.csv\" AS rowCREATE (n:Supplier)SET n = row索引:根据标签索引节点
CREATE INDEX FOR (p:Product) ON (p.productID)CREATE INDEX FOR (p:Product) ON (p.productName)CREATE INDEX FOR (c:Category) ON (c.categoryID)CREATE INDEX FOR (s:Supplier) ON (s.supplierID)相关:将外键引用转换为数据关系
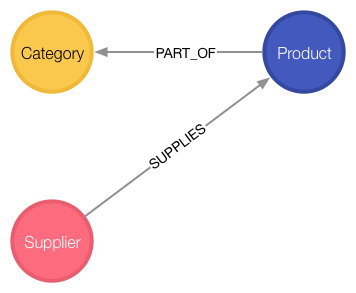
创建数据关系
MATCH (p:Product),(c:Category)WHERE p.categoryID = c.categoryIDCREATE (p)-[:PART_OF]->(c)MATCH (p:Product),(s:Supplier)WHERE p.supplierID = s.supplierIDCREATE (s)-[:SUPPLIES]->(p)使用模式查询
推广:将连接记录转换为关系
列出每个供应商提供的产品类别。
MATCH (s:Supplier)-->(:Product)-->(c:Category)RETURN s.companyName as Company, collect(distinct c.categoryName) as Categories查找产品供应商
MATCH (s:Supplier)-->(:Product)-->(c:Category)RETURN s.companyName as Company, collect(distinct c.categoryName) as Categories
Customer Orders 客户订单

## 加载和索引记录LOAD CSV WITH HEADERS FROM \"https://data.neo4j.com/northwind/customers.csv\" AS rowCREATE (n:Customer)SET n = row## 订单LOAD CSV WITH HEADERS FROM \"https://data.neo4j.com/northwind/orders.csv\" AS rowCREATE (n:Order)SET n = row## CREATE INDEX FOR (n:Customer) ON (n.customerID)## CREATE INDEX FOR (o:Order) ON (o.orderID)## 创建数据关系MATCH (c:Customer),(o:Order)WHERE c.customerID = o.customerIDCREATE (c)-[:PURCHASED]->(o)Customer Order Graph 客户订单图
注意,订单详情始终是订单的一部分,并且它们将订单与产品关联起来——它们是一个连接表。连接表总是数据关系的标志,表示两个其他记录之间的共享信息。
这里,我们将直接将每个 OrderDetail 记录提升为图中的一个关系。
# 加载和索引记录LOAD CSV WITH HEADERS FROM \"https://data.neo4j.com/northwind/order-details.csv\" AS rowMATCH (p:Product), (o:Order)WHERE p.productID = row.productID AND o.orderID = row.orderIDCREATE (o)-[details:ORDERS]->(p)SET details = row,details.quantity = toInteger(row.quantity)# queryMATCH (cust:Customer)-[:PURCHASED]->(:Order)-[o:ORDERS]->(p:Product), (p)-[:PART_OF]->(c:Category {categoryName:\"Produce\"})RETURN DISTINCT cust.contactName as CustomerName, SUM(o.quantity) AS TotalProductsPurchased# 客户Pedro Afonso的订购订单的产品MATCH (cust:Customer{contactName:\"Pedro Afonso\"})-[:PURCHASED]->(o:Order)-[:ORDERS]->(p:Product)RETURN cust,o,p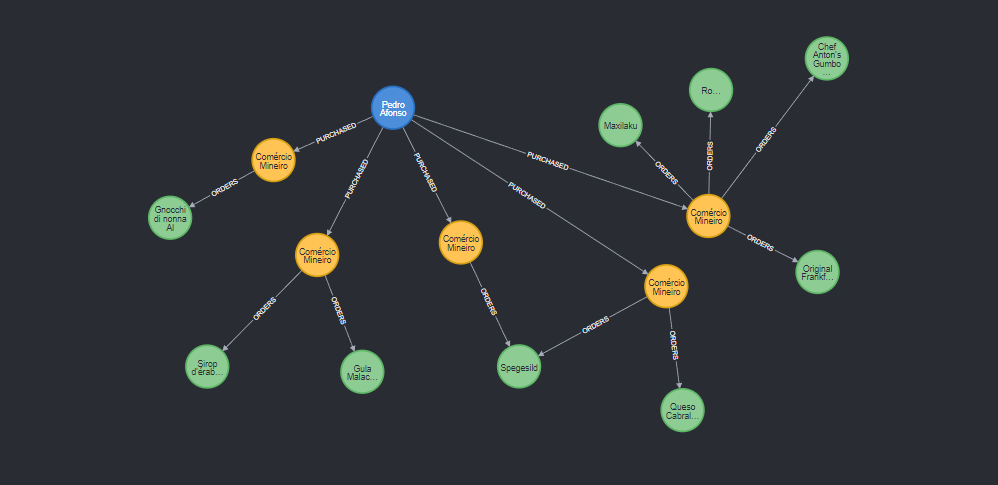
数据概览 语法
# 计算所有节点MATCH (n) RETURN count(n)// 计算所有关系 这是--两个 - MATCH ()-->() RETURN count(*)// 显示约束和索引:schema计算所有节点
MATCH (n) RETURN count(n)
计算所有关系
MATCH ()–>() RETURN count(*)
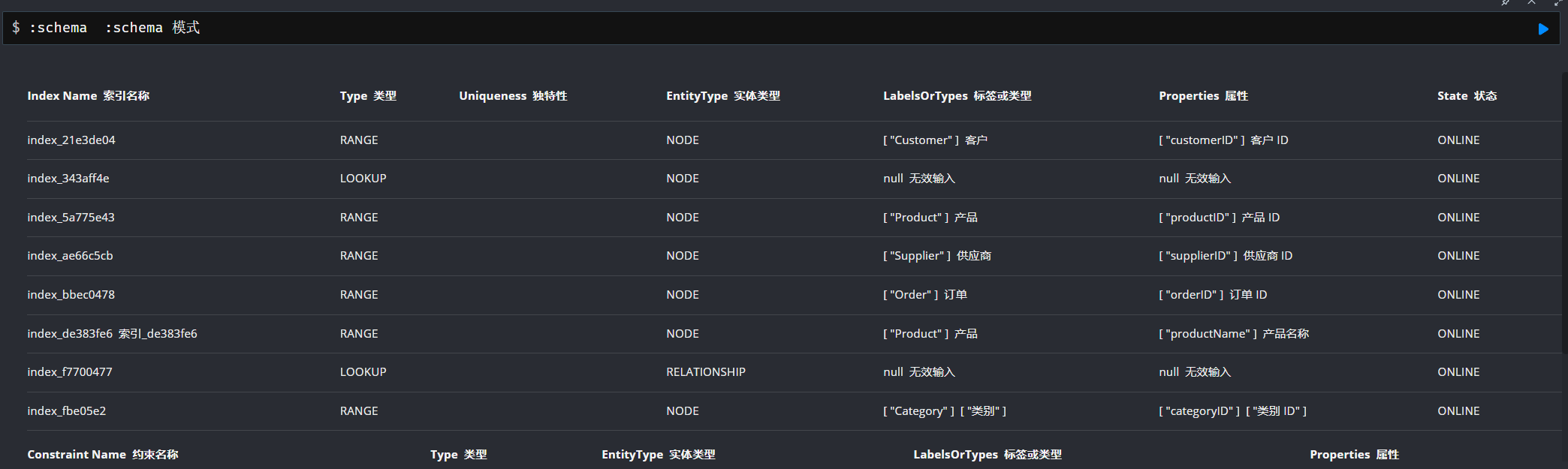
显示约束和索引
:schema
列出节点标签
CALL db.labels()
Table 表格Text 文本Code 代码╒══════════╕│label │╞══════════╡│\"Database\"│├──────────┤│\"Message\" │├──────────┤│\"Product\" │├──────────┤│\"Category\"│├──────────┤│\"Supplier\"│├──────────┤│\"Customer\"│├──────────┤│\"Order\" │└──────────┘列出关系类型
CALL db.relationshipTypes()
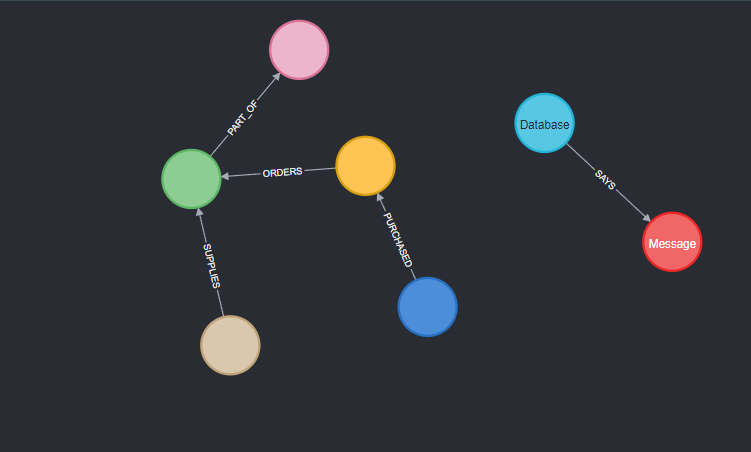
╒════════════════╕│relationshipType│╞════════════════╡│\"SAYS\" │├────────────────┤│\"PART_OF\" │├────────────────┤│\"SUPPLIES\" │├────────────────┤│\"PURCHASED\" │├────────────────┤│\"ORDERS\" │└────────────────┘DB中 实体中存在的相关的是什么,以及如何调用
db.schema.visualization()
存在哪些节点
// 存在哪些节点类型 // 抽取一些节点,报告每个节点的属性和关系计数
// What kind of nodes exist// Sample some nodes, reporting on property and relationship counts per node.MATCH (n) WHERE rand() <= 0.1RETURNDISTINCT labels(n),count(*) AS SampleSize,avg(size(keys(n))) as Avg_PropertyCount,min(size(keys(n))) as Min_PropertyCount,max(size(keys(n))) as Max_PropertyCount,avg(count{ (n)-[]-() } ) as Avg_RelationshipCount,min(count{ (n)-[]-() } ) as Min_RelationshipCount,max(count{ (n)-[]-() } ) as Max_RelationshipCount
列表函数(只读)
// List functionsSHOW FUNCTIONS列表程序(只读)
// List proceduresSHOW PROCEDURES

