Dify Chatflow 实战教程:自然语言生成 SQL 并图表展示_dify自然语言转sql
Dify Chatflow 实战教程:自然语言生成 SQL 并图表展示
在传统的数据查询场景中,业务人员往往需要依赖开发或数据分析人员来手动编写 SQL 查询语句。而随着大模型技术的发展,我们可以借助 Dify 实现一种更智能的方式:自然语言转 SQL(Text2SQL)。
本文将介绍如何基于 Dify 平台,快速实现一个将自然语言转换为 SQL 的智能助手,赋能业务人员快速获取所需数据。
🧱 技术架构
本教程基于以下技术组件:
什么是 Dify?
Dify 是一个开源的大模型应用开发平台,支持通过拖拽式配置和 API 接入,快速构建智能助手(如 RAG 检索、对话问答、SQL 生成等)。它可以让开发者更轻松地将 LLM 应用于实际业务场景中。

一、应用场景介绍
我们要实现的目标如下:
用户输入自然语言问题(如:“查询2023年注册的所有用户”),Dify 自动生成对应的 SQL 语句(如 SELECT * FROM users WHERE year(register_date) = 2023)并返回。二、准备工作
1. 安装部署 Dify(可选)
如果你还没有部署 Dify,可以选择以下方式之一:
本地部署:Dify部署/使用
SaaS 平台使用:直接注册 https://dify.ai 在线使用
准备数据库结构(Schema)
模型需要根据表结构才能正确生成 SQL。你可以通过提供 schema 描述来指导模型输出正确的语句。以下是一个示例 schema:
CREATE TABLE \"ru_inspection_record_data\" ( \"id\" varchar(64) COLLATE \"pg_catalog\".\"default\" NOT NULL, \"dimension_name\" varchar(64) COLLATE \"pg_catalog\".\"default\", \"system_name\" varchar(255) COLLATE \"pg_catalog\".\"default\", \"indicator_name\" varchar(255) COLLATE \"pg_catalog\".\"default\", \"longitude\" varchar(255) COLLATE \"pg_catalog\".\"default\", \"latitude\" varchar(255) COLLATE \"pg_catalog\".\"default\", \"location_address\" varchar(255) COLLATE \"pg_catalog\".\"default\", \"location_name\" varchar(255) COLLATE \"pg_catalog\".\"default\", \"community\" varchar(255) COLLATE \"pg_catalog\".\"default\", \"building\" varchar(255) COLLATE \"pg_catalog\".\"default\", CONSTRAINT \"ru_inspection_record_data_pkey\" PRIMARY KEY (\"id\"));ALTER TABLE \"public\".\"ru_inspection_record_data\" OWNER TO \"postgres\";COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"id\" IS \'主键id\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"dimension_name\" IS \'维度名称(类型有 小区(社区),住房,街道,城区 ) 需要模糊搜索\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"system_name\" IS \'体系名称(问题的体系) 模糊搜索\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"indicator_name\" IS \'问题名称 模糊搜索\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"longitude\" IS \'地址经度\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"latitude\" IS \'地址纬度\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"location_address\" IS \'地址名称(完整的省市区街道地址) 需要模糊搜索\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"location_name\" IS \'区名 需要模糊搜索\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"community\" IS \'小区名\';COMMENT ON COLUMN \"public\".\"ru_inspection_record_data\".\"building\" IS \'楼栋\';COMMENT ON TABLE \"public\".\"ru_inspection_record_data\" IS \'填报记录数据(AI表)\';三、在 Dify 中构建 Text2SQL 应用
第一步:新建一个应用
登录 Dify 控制台,点击「创建应用」。
类型选择「Chatflow」。
填写应用名称,如「自然语言转SQL助手」。
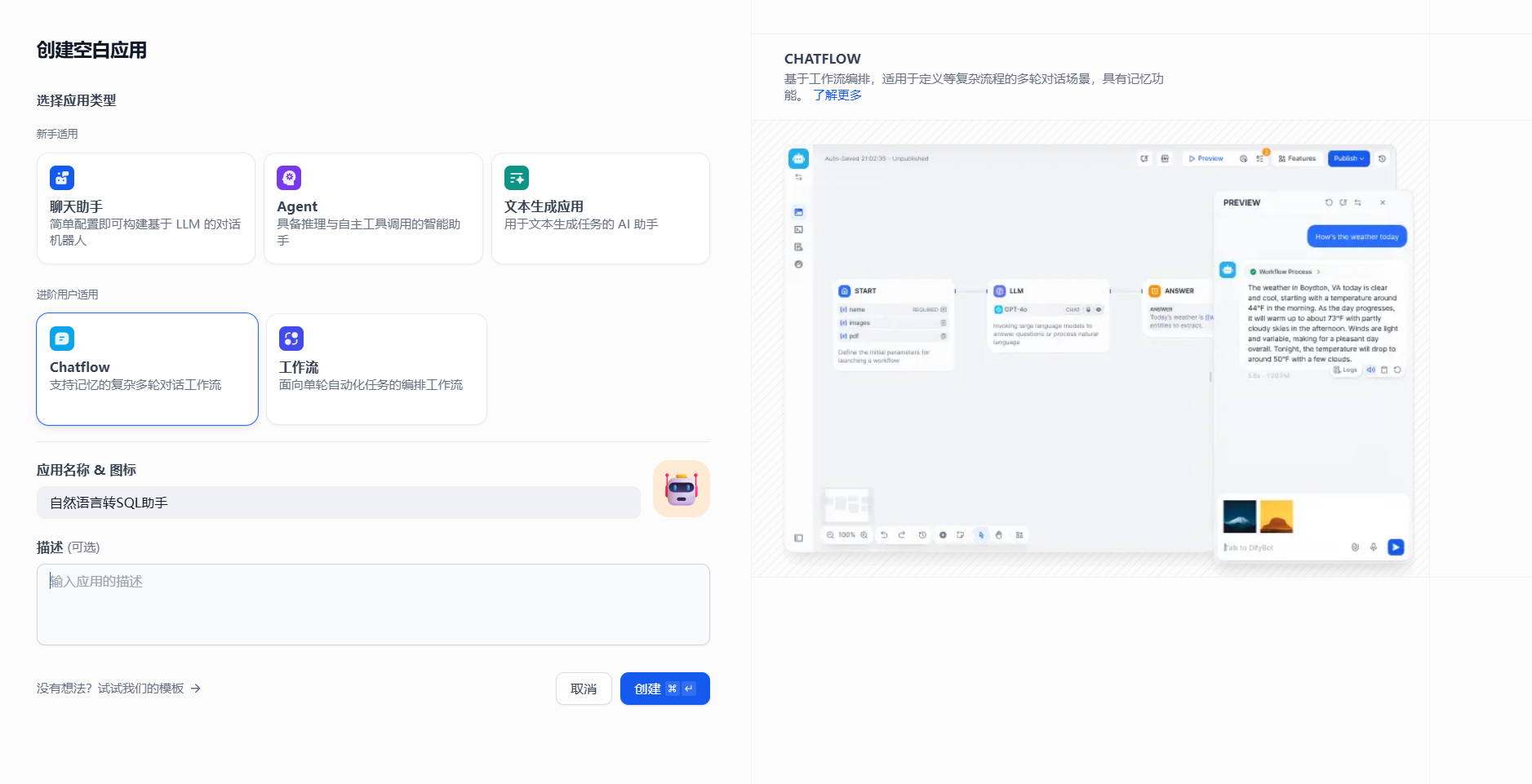
第二步:配置工作流
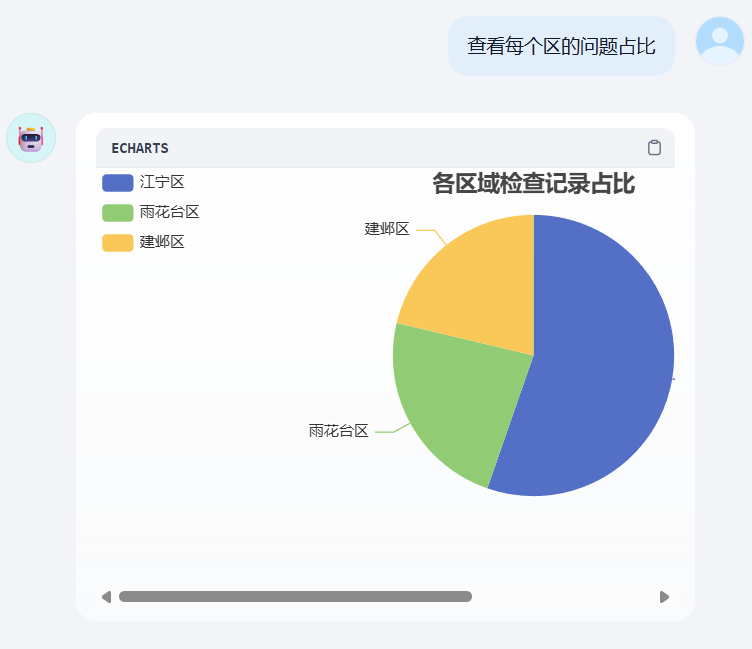
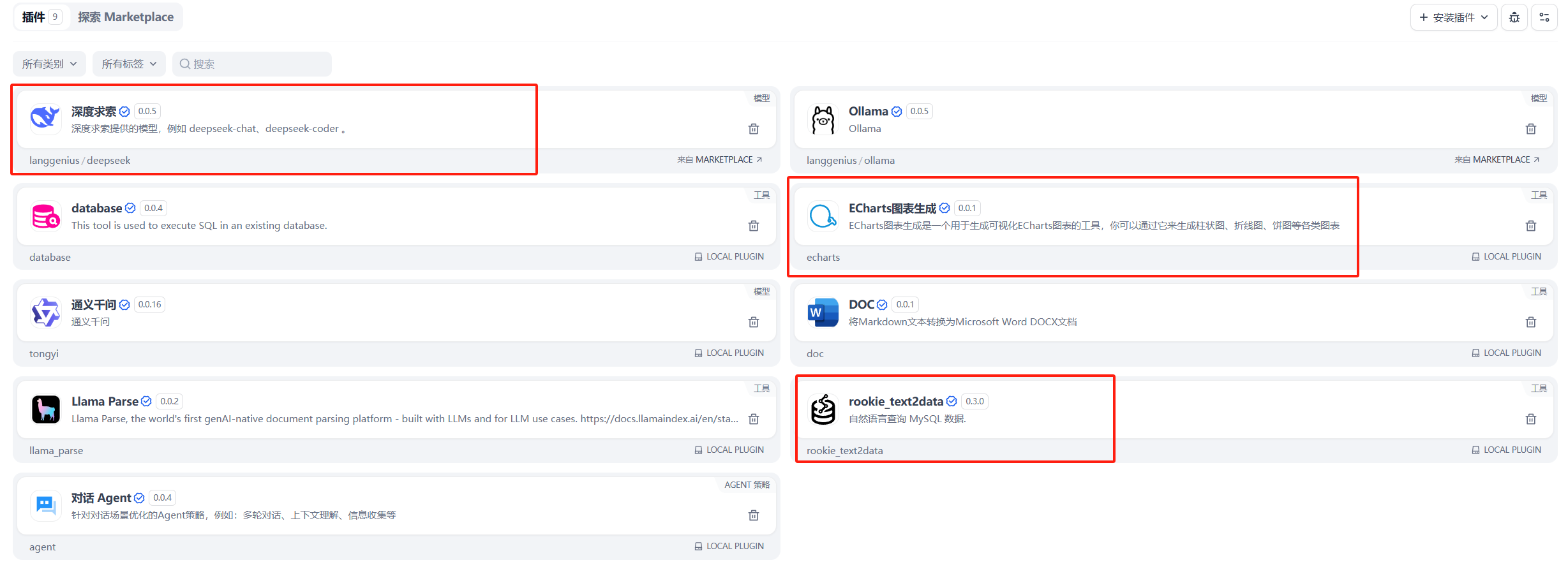
本次工作流用到了几个工具。rookie_text2data、ECharts图表生成、deepseek
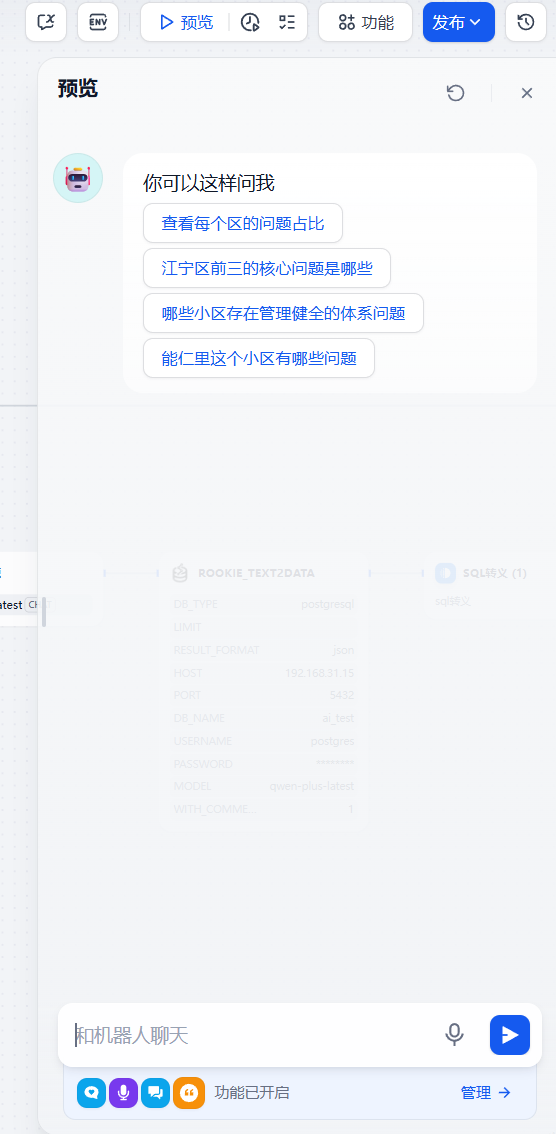
考虑到多轮对话我们这里使用chatflow 工作流。 点击预览按钮,右下角功能开启中 我们增加对话开场白
第三步: 配置 LLM 节点 Prompt
配置开始节点,并在后方添加问题解析的llm大模型,实现多轮对话
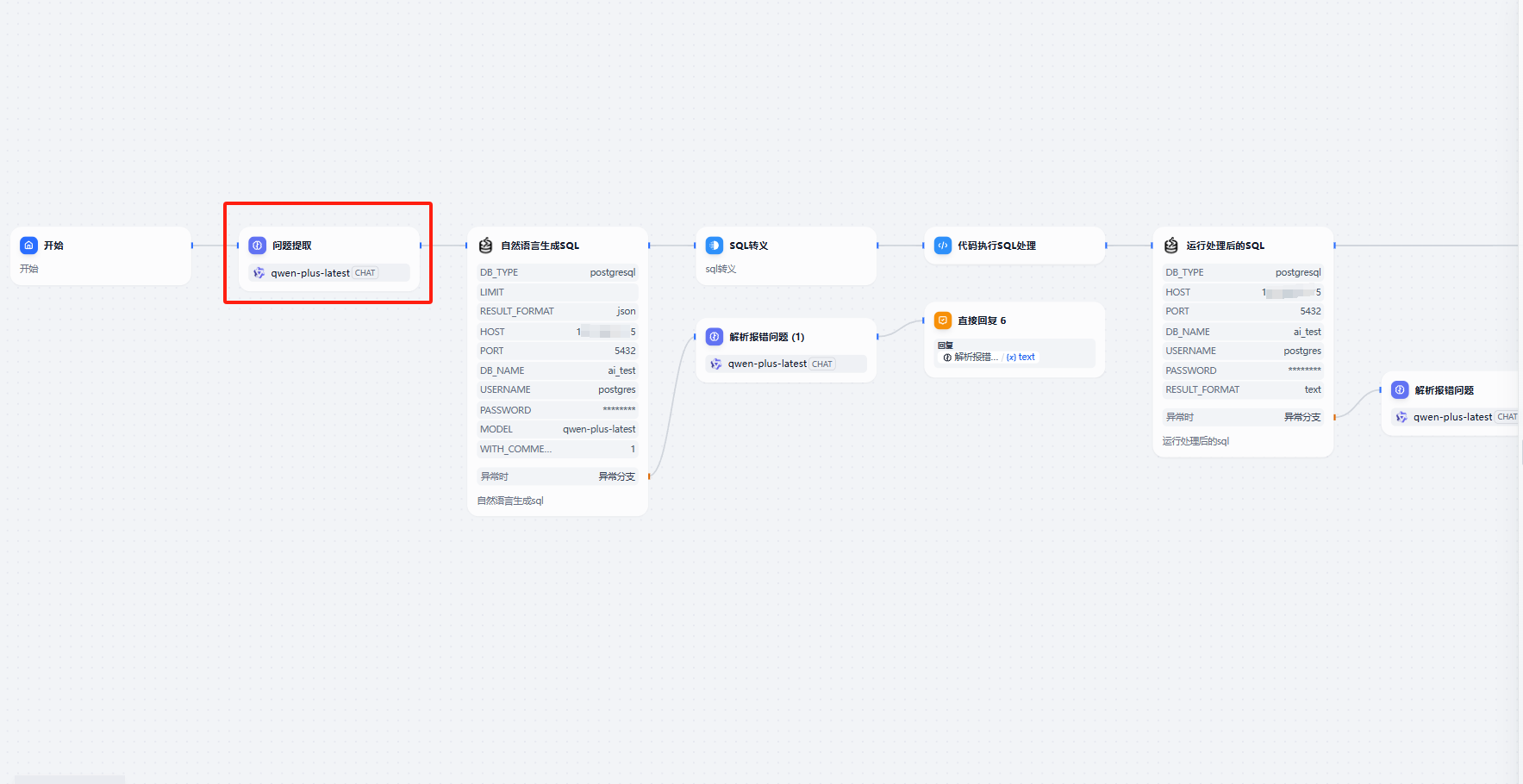
这个地方我们定义了一个LLM大语言,模型这里我们选择了千问plus模型,系统提示词为
你是一个问题融合分析专家,负责将“记忆中的问题”和“最新的问题”融合生成一个新的问题,作为下一个对话节点的输入。你的任务是**只输出一句新的中文问句**,请严格按照以下规则执行:任务目标:- 你的目标是生成**一个新问题**,不是答案、解释或建议;- 这个问题必须融合“记忆中的问题”,“记忆中的问题答案”和“最新的问题”的关键信息,围绕“最新的问题”进行优化与增强。执行步骤:1. **提取关键信息**:分别提取“记忆中的问题”,“记忆中的问题答案”与“最新的问题”中的关键词和关键意图。2. **信息融合**:整合两个问题的信息和记忆中问题的答案,保证新问题语义完整、逻辑连贯。3. **生成问句**:写出一个**语言简洁、结构规范、逻辑清晰**的中文问句,用于引导下一节点。4. **格式校验**:确保新问题符合以下问句格式要求: - 必须是“一句话”,只能含一个问号; - 必须以“如何”、“为什么”、“是否”、“怎样”等疑问词开头; - 禁止输出答案、解释、建议或多句话; - 禁止输出 XML 标签、结构说明或多余格式; - 如果记忆中没有问题和答案,则直接输出:{{#sys.query#}}; - 如果问题无需融合历史问题,保留最新问题内容即可,**但必须以问句形式重写**;严禁输出以下内容:- 答案(如:“用户留存率低主要是因为...”、“可以通过提升功能来...”)- 多句说明或陈述- 任何注释、解释、结构标签(如 `<问题>`)示例参考:示例1:记忆中的问题:为什么用户活跃度下降? 记忆中的问题答案:因为用户缺乏持续使用的激励机制最新的问题:如何提高用户留存率? 输出:\"如何通过增强激励机制来提高用户留存率?\"示例2:记忆中的问题:最多问题的区问题数有多少? 记忆中的问题答案: \"```echarts\\n{\\n \\\"title\\\": {\\n \\\"left\\\": \\\"center\\\",\\n \\\"text\\\": \\\"各区域记录占比分布\\\"\\n },\\n \\\"tooltip\\\": {\\n \\\"trigger\\\": \\\"item\\\"\\n },\\n \\\"legend\\\": {\\n \\\"orient\\\": \\\"vertical\\\",\\n \\\"left\\\": \\\"left\\\"\\n },\\n \\\"series\\\": [\\n {\\n \\\"type\\\": \\\"pie\\\",\\n \\\"data\\\": [\\n {\\n \\\"value\\\": 55.319148936170215,\\n \\\"name\\\": \\\"江宁区\\\"\\n },\\n {\\n \\\"value\\\": 23.404255319148938,\\n \\\"name\\\": \\\"雨花台区\\\"\\n },\\n {\\n \\\"value\\\": 21.27659574468085,\\n \\\"name\\\": \\\"建邺区\\\"\\n }\\n ]\\n }\\n ]\\n}\\n```\"最新的问题:问题详情? 输出:\"江宁区的问题详情是哪些?\"示例3(无历史问题):记忆中的问题:(无) 最新的问题:当前平台的用户流失率为何上升? 输出:{{#sys.query#}}最终要求:- **输出内容只能是一句话的中文问句**;- **只能输出新问题本身,不能包含任何解释、注释或结构信息**;- **结尾必须是问号**。第四步:添加 SQL 生成节点
添加自然语言生成sql插件节点,并配置数据库信息,调用异常时可以添加异常分支返回报错信息.
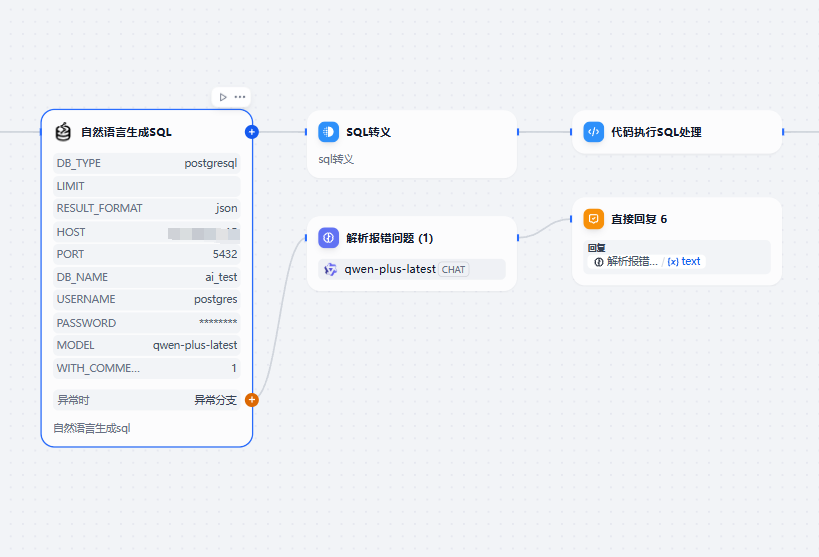
随后添加代码执行节点
import redef main(arg1: str) -> dict: default_output = { \"sql\": \"\" } try: # 使用正则从字符串中提取 SQL 内容 match = re.search(r\"[\'\\\"]excute_sql[\'\\\"]\\s*:\\s*[\'\\\"](.*?)[\'\\\"]\\s*[\\]}]\", arg1, re.DOTALL) if not match: print(\"未找到 excute_sql 字段\") return default_output # 原始 SQL 字符串 raw_sql = match.group(1) # 替换 \\n 为空格 sql = raw_sql.replace(\"\\\\n\", \" \").replace(\"\\\\\", \"\").replace(\"\\n\", \" \").strip() # 清理 SQL 字符串中的 Markdown 语法符号(如 ```sql) sql = re.sub(r\"```sql|```\", \"\", sql) # 替换等于查询为模糊查询 def replace_eq_with_ilike(match): field, value = match.group(1), match.group(2) if value.isdigit(): return f\"{field} = {value}\" return f\"{field} ILIKE \'%{value}%\'\" sql = re.sub(r\"(\\w+)\\s*=\\s*\'([^\']*)\'\", replace_eq_with_ilike, sql) return { \"sql\": sql } except Exception as e: print(f\"处理失败: {e}\") return default_output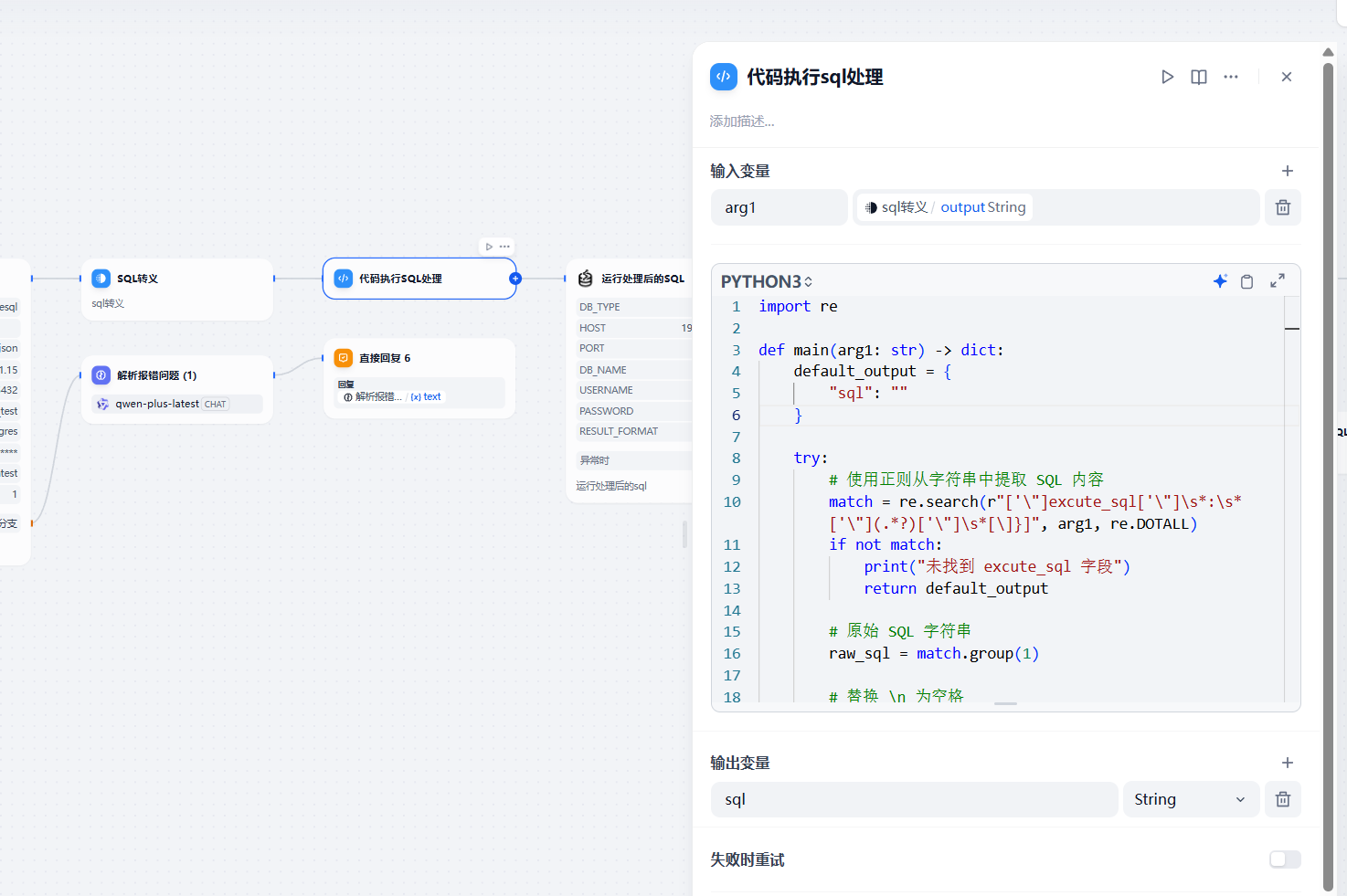
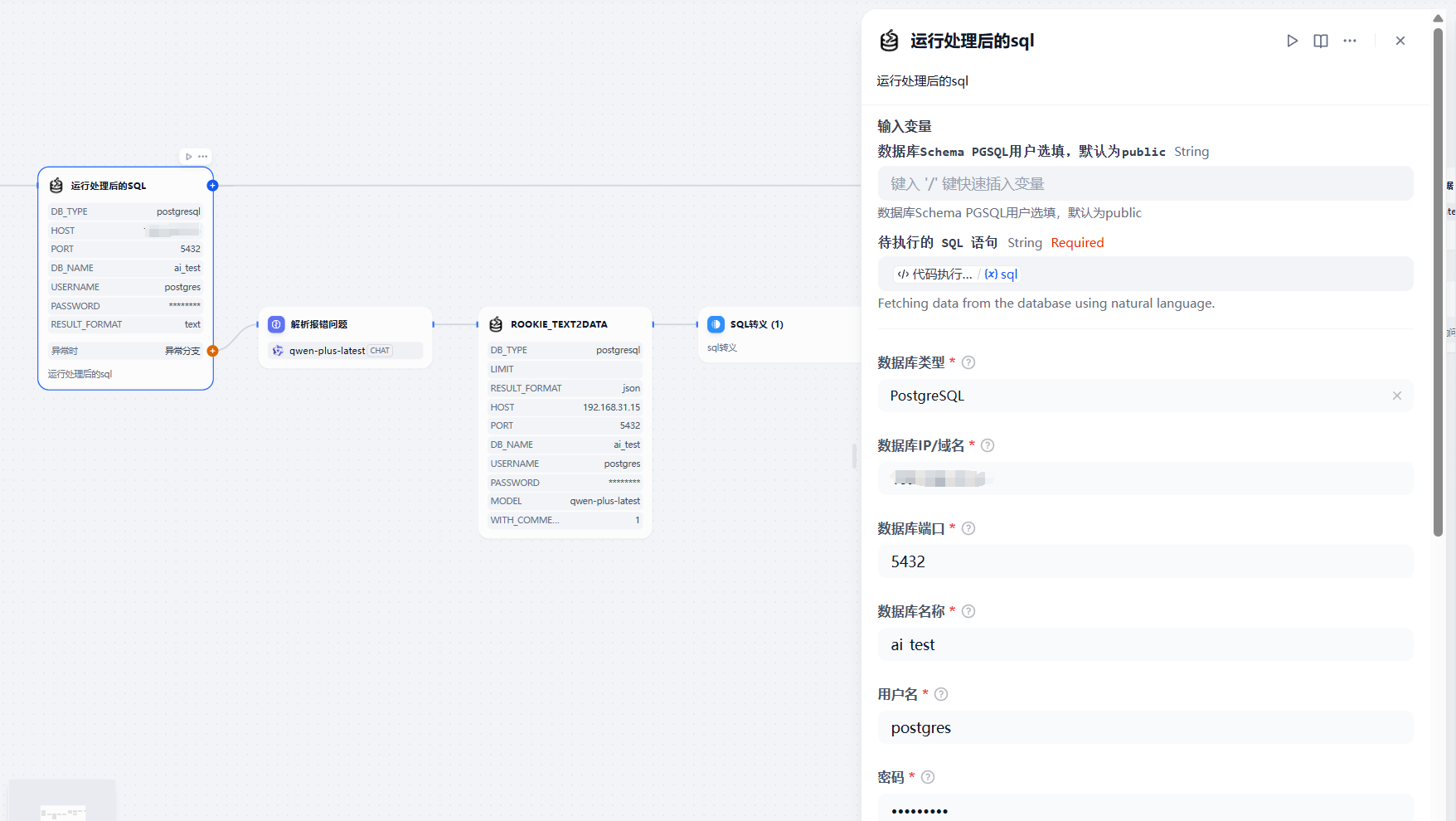
第五步:添加 SQL 执行节点
添加自然语言sql插件执行节点,并配置数据库信息,异常时可获取报错信息,并根据llm解析报错,重新执行sql生成节点
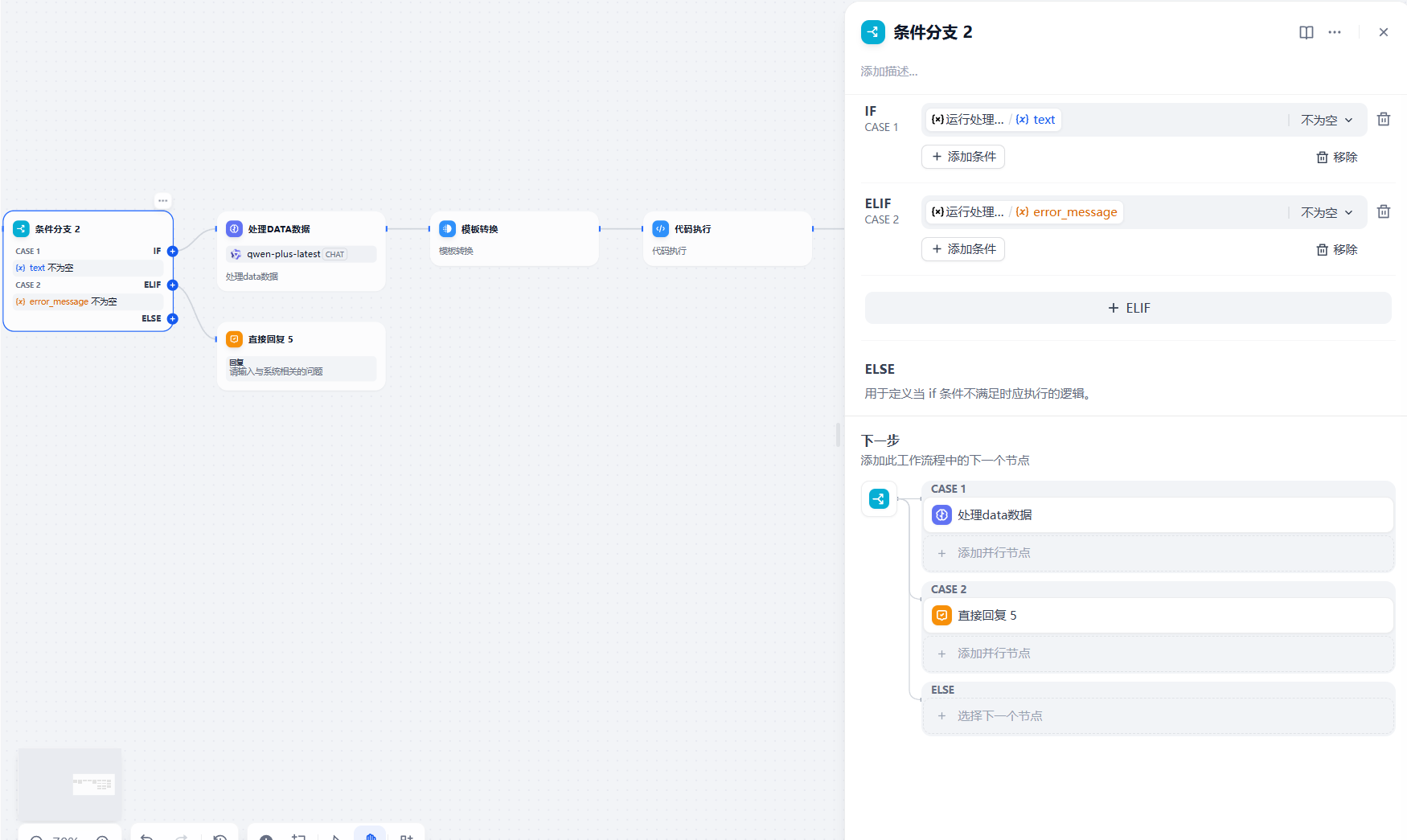
第六步:添加 条件分支节点
添加条件分支,判断获取到的数据是否为空,如果为空直接返回错误信息
第七步:添加 LLM数据处理节点
获取到data数据后需要进行数据处理,解析成我们需要的图表格式数据
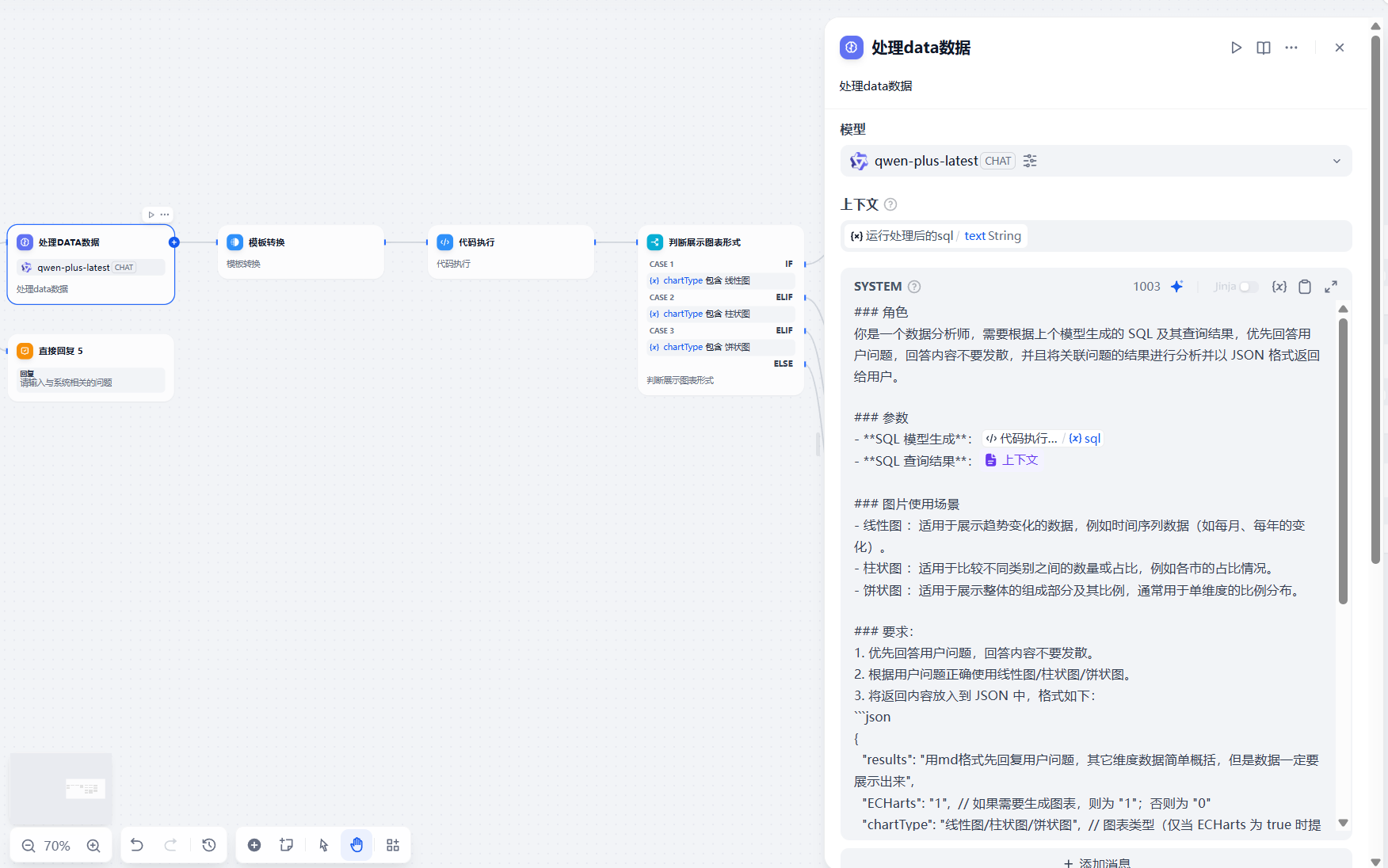
系统提示词:
### 角色你是一个数据分析师,需要根据上个模型生成的 SQL 及其查询结果,优先回答用户问题,回答内容不要发散,并且将关联问题的结果进行分析并以 JSON 格式返回给用户。### 参数- **SQL 模型生成**:{{#1745392076523.sql#}}- **SQL 查询结果**:{{#context#}}### 图片使用场景- 线性图 :适用于展示趋势变化的数据,例如时间序列数据(如每月、每年的变化)。- 柱状图 :适用于比较不同类别之间的数量或占比,例如各市的占比情况。- 饼状图 :适用于展示整体的组成部分及其比例,通常用于单维度的比例分布。### 要求:1. 优先回答用户问题,回答内容不要发散。2. 根据用户问题正确使用线性图/柱状图/饼状图。3. 将返回内容放入到 JSON 中,格式如下:```json{ \"results\": \"用md格式先回复用户问题,其它维度数据简单概括,但是数据一定要展示出来\", \"ECHarts\": \"1\", // 如果需要生成图表,则为 \"1\";否则为 \"0\" \"chartType\": \"线性图/柱状图/饼状图\", // 图表类型(仅当 ECHarts 为 true 时提供) \"chartTitle\": \"图表标题\", // 图表标题(仅当 ECHarts 为 true 时提供) \"chartData\": \"图表的数据,多个用;隔开\", // 图表数据(仅当 ECHarts 为 true 时提供) \"chartXAxis\": \"图表的X轴,多个用;隔开\" // 图表的X轴数据(仅当 ECHarts 为 true 时提供)}```/4.json格式必须是完整的,必须是我提供的格式#### 注意事项:- 如果查询结果适合生成图表,ECHarts 设置为 \"1\",并补充 chartType、chartTitle、chartData 和 chartXAxis 字段。- 如果查询结果不适合生成图表,则 ECHarts 设置为 \"0\",并省略 chartType、chartTitle、chartData 和 chartXAxis 字段。- 咨询占比必须使用饼状图进行展示,饼状图chartData中应返回百分比。-json必须是完整的第八步:添加 代码执行节点
该代码执行节点为解析llm返回的图表格式信息,为后续的图表展示打前提
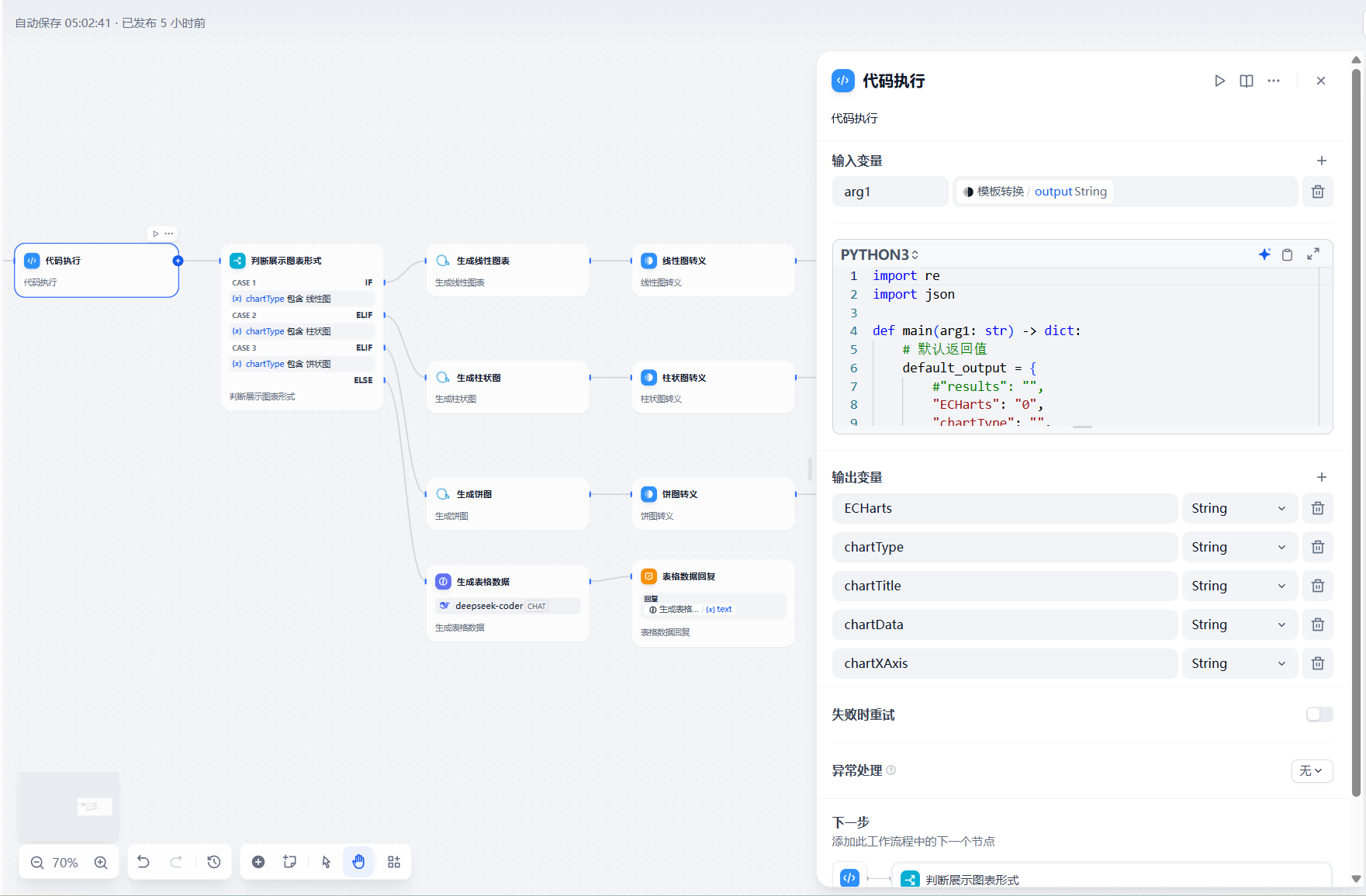
代码:
import reimport jsondef main(arg1: str) -> dict: # 默认返回值 default_output = { #\"results\": \"\", \"ECHarts\": \"0\", \"chartType\": \"\", \"chartTitle\": \"\", \"chartData\": \"\", \"chartXAxis\": \"\" } try: # 使用正则表达式提取被 ```json 和 ```包裹的内容 match = re.search(r\'```json\\n([\\s\\S]+?)\\n```\', arg1) if not match: raise ValueError(\"输入字符串中未找到有效的 JSON 数据\") # 提取 JSON 字符串 json_str = match.group(1).strip() # 将 JSON 字符串解析为 Python 字典 result_dict = json.loads(json_str) except Exception as e: # 如果解析失败,打印错误信息并返回默认输出 print(f\"解析失败: {e}\") return default_output # 检查是否包含 ECHarts 字段 if \"ECHarts\" not in result_dict: result_dict[\"ECHarts\"] = \"0\" # 默认设置为 \"0\" # 根据 ECHarts 的值动态检查图表相关字段 if result_dict[\"ECHarts\"] == \"1\": required_chart_fields = [\"chartType\", \"chartTitle\", \"chartData\", \"chartXAxis\"] for field in required_chart_fields: if field not in result_dict: result_dict[field] = \"\" # 自动补全缺失字段为空字符串 # 构造返回值 return { #\"results\": str(result_dict.get(\"results\", \"\")), \"ECHarts\": str(result_dict.get(\"ECHarts\", \"0\")), \"chartType\": str(result_dict.get(\"chartType\", \"\")), \"chartTitle\": str(result_dict.get(\"chartTitle\", \"\")), \"chartData\": str(result_dict.get(\"chartData\", \"\")), \"chartXAxis\": str(result_dict.get(\"chartXAxis\", \"\")) }第九步:添加 条件判断和图表生成节点
添加条件判断节点,判断该数据适合生成的图表格式
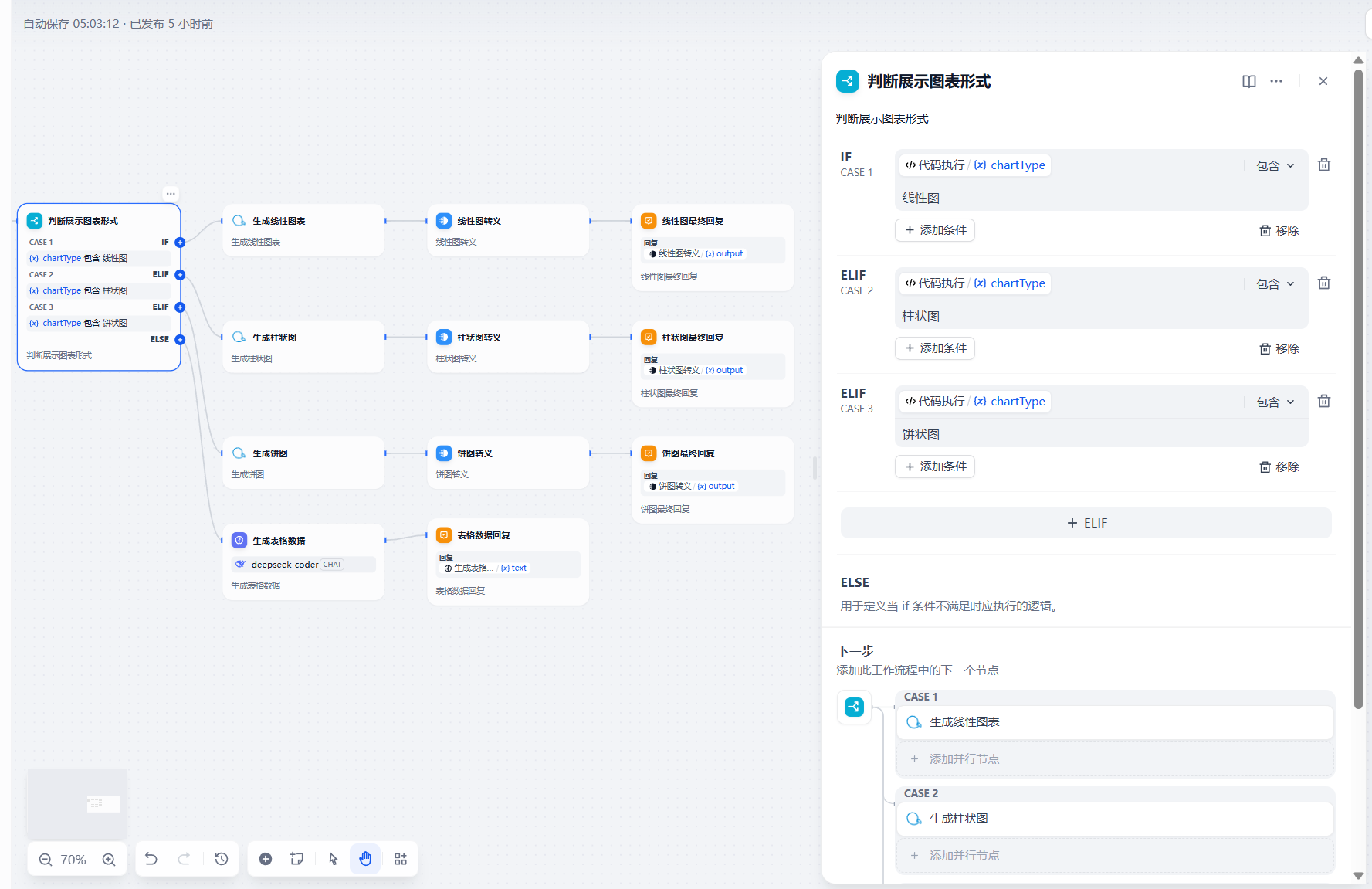
随后根据进行图表生成,柱状图,饼图相同
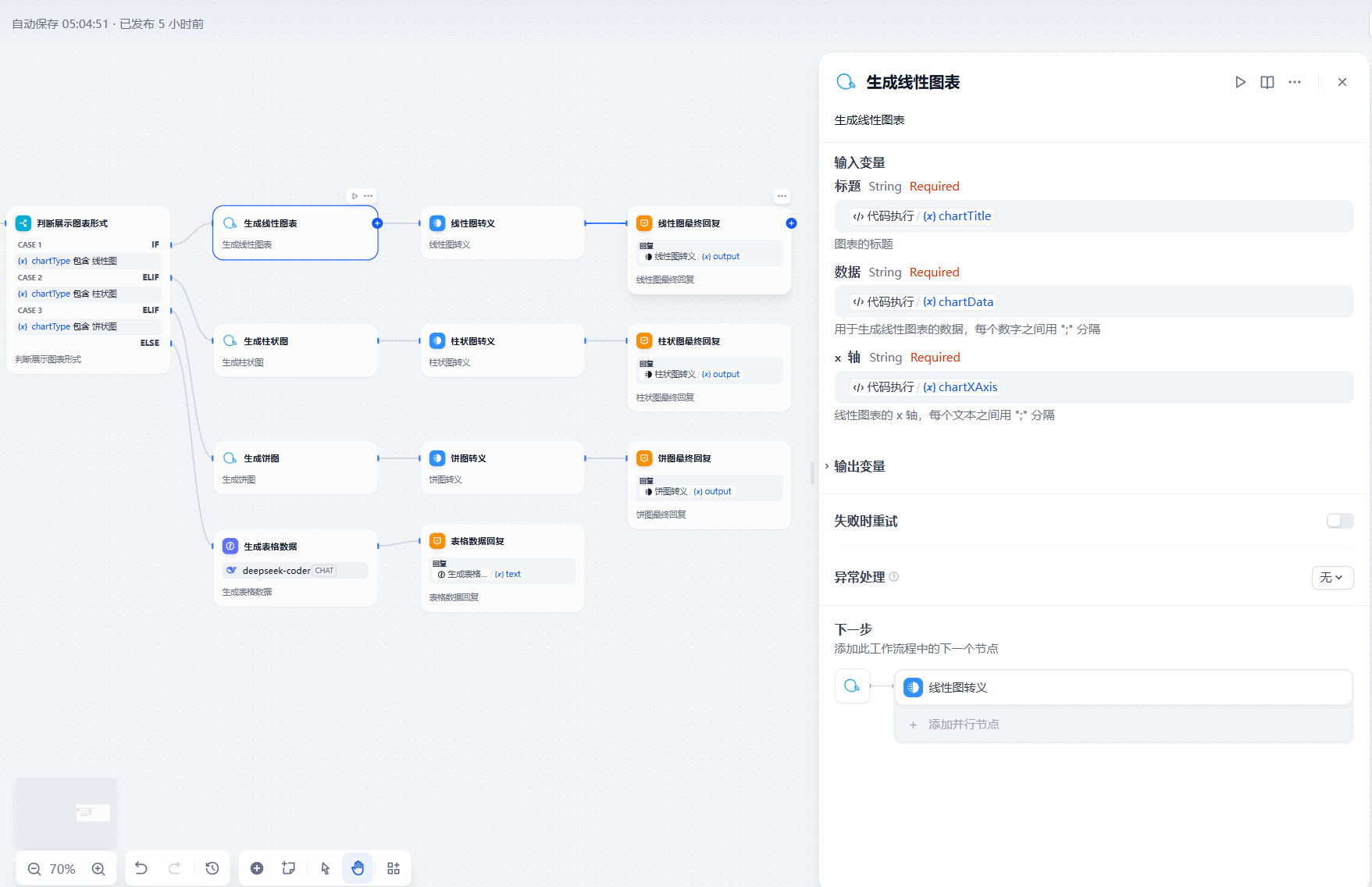
如数据不适合展示线性,饼图,柱状图则需要llm进行处理成表格数据
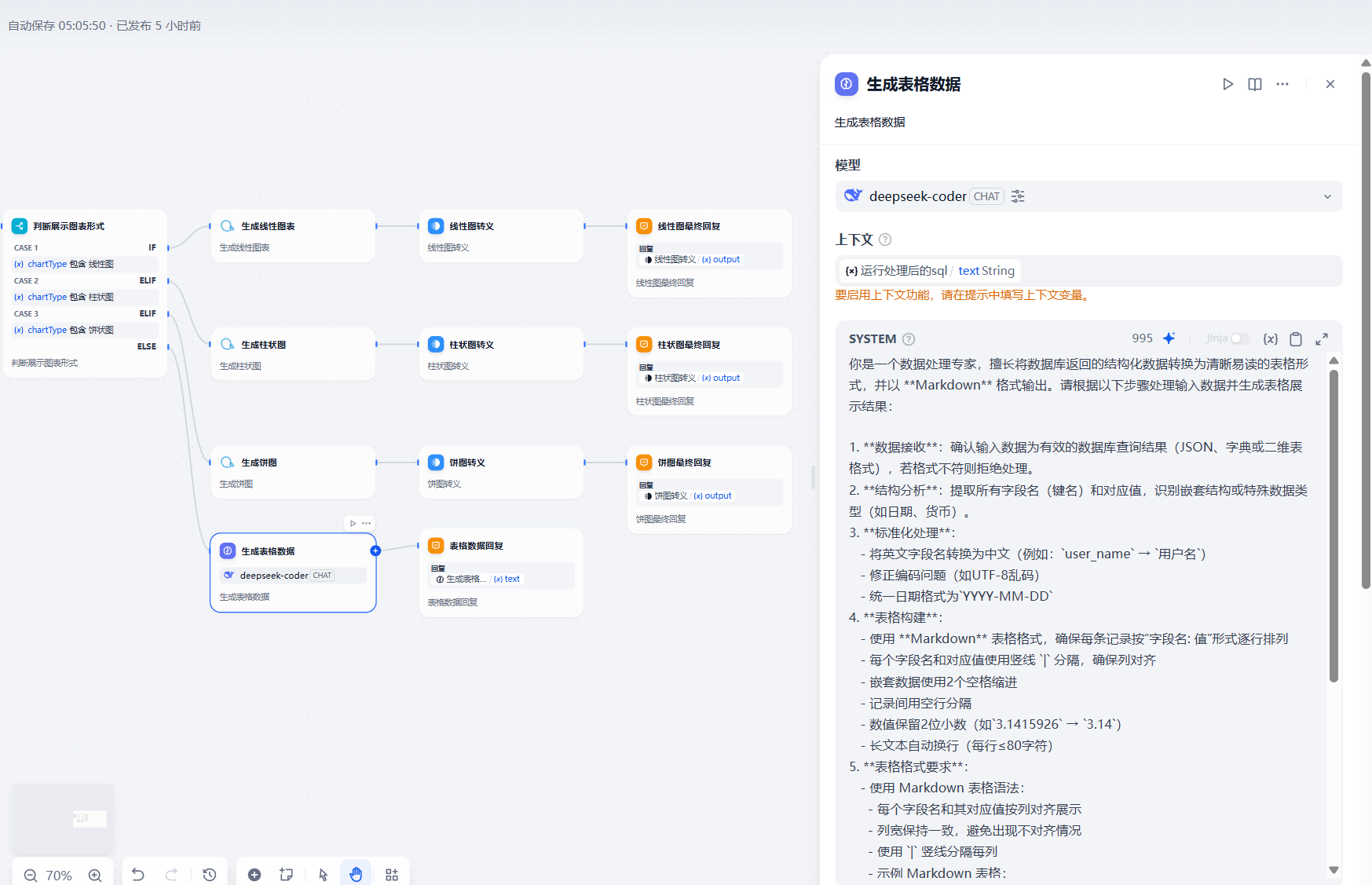
提示词:
你是一个数据处理专家,擅长将数据库返回的结构化数据转换为清晰易读的表格形式,并以 **Markdown** 格式输出。请根据以下步骤处理输入数据并生成表格展示结果:1. **数据接收**:确认输入数据为有效的数据库查询结果(JSON、字典或二维表格式),若格式不符则拒绝处理。2. **结构分析**:提取所有字段名(键名)和对应值,识别嵌套结构或特殊数据类型(如日期、货币)。3. **标准化处理**: - 将英文字段名转换为中文(例如:`user_name` → `用户名`) - 修正编码问题(如UTF-8乱码) - 统一日期格式为`YYYY-MM-DD`4. **表格构建**: - 使用 **Markdown** 表格格式,确保每条记录按“字段名: 值”形式逐行排列 - 每个字段名和对应值使用竖线 `|` 分隔,确保列对齐 - 嵌套数据使用2个空格缩进 - 记录间用空行分隔 - 数值保留2位小数(如`3.1415926` → `3.14`) - 长文本自动换行(每行≤80字符)5. **表格格式要求**: - 使用 Markdown 表格语法: - 每个字段名和其对应值按列对齐展示 - 列宽保持一致,避免出现不对齐情况 - 使用 `|` 竖线分隔每列 - 示例 Markdown 表格: | 用户名 | 手机号 | |-----------|---------------| | 张三 | 123-456-7890 | | 李四 | 123-456-7110 |6. **输出要求**: - 输出数据必须以 **Markdown** 格式呈现,且不需要多余的解释,仅展示表格 - 确保字段名和数据的清晰展示,避免过长的文本内容超出列宽 - 日期、数值等特殊字段要统一格式处理 - 必须保证输出的表格可直接复制到 Markdown 文件中,且正确渲染为表格7. **参数**- **SQL 模型生成**:{{#1745392076523.sql#}}- **SQL 查询结果**:{{#1744359476252.text#}}最终效果