学习SpringAI这一篇就够了
文章目录
- 一、简介
-
- 1.1 Spring AI 简介
-
- 定义与目标
- 与 Spring 生态系统的关系
- 1.2 应用场景
-
- 自然语言处理
- 图像生成
- 智能客服
- 1.3 优势与特点
-
- 简化 AI 集成
- 多模型支持
- 与 Spring 框架的无缝结合
- 二、快速入门
-
- 一、环境要求与支持版本
- 二、项目创建方式
- 三、依赖管理与仓库配置
-
- (一)稳定版本(1.0.0-M6 及以后)
- (二)快照版本(Snapshot)
- 四、引入 Spring AI BOM
- 五、添加具体功能依赖
- 六、快速开始示例
- 三、SpringAI核心概念
-
- Models
- Prompts
- Embeddings
- Structured Output
- Bringing Your Data
- Tool Calling
-
- 工具调用流程详解
- Retrieval Augmented Generation
-
- 技术实现流程
-
- 1. **批处理式数据预处理(ETL管道)**
- 2. **用户查询实时处理**
- 技术优势
- 四、SpringAI核心组件
-
- ChatClient
-
- 一、ChatClient 概述
- 二、创建 ChatClient
- 三、流式 API 核心用法
- 四、提示模板与动态参数
- 五、默认配置与动态覆盖
- 六、Advisors配置
- Advisor
-
- 一、Advisors 核心概念与作用
- 二、核心组件与接口
- 三、执行流程与顺序控制
- 四、自定义顾问实现
- 五、内置顾问与常用场景
- 六、配置与最佳实践
- Prompt
-
- 一、Prompts 核心概念与作用
- 二、Prompt 核心结构与接口
- 三、Prompt 构建示例
- 四、多模态与高级特性
- 五、与其他组件的集成
- ChatMemory
-
- 一、ChatMemory 核心概念与作用
- 二、快速开始与默认配置
- 三、记忆类型与实现
- 四、存储实现与配置
- 五、与 ChatClient 集成(通过 Advisors)
- 六、与 ChatModel 直接集成
- 七、配置属性与最佳实践
- Tool Calling
-
- 一、Tool Calling 核心概念与作用
- 二、快速开始:工具定义与使用
- 三、工具定义方式
-
- (一)基于方法的工具(Method as Tools)
- (二)基于函数的工具(Functions as Tools)
- 四、工具核心组件与接口
- 五、工具执行流程
- 六、工具结果处理
- 七、工具上下文与异常处理
- 八、支持的模型与最佳实践
- 九、工具与其他组件集成
- RAG
-
- 一、RAG 核心概念与作用
- 二、核心 Advisor 实现
-
- (一)QuestionAnswerAdvisor
- (二)RetrievalAugmentationAdvisor
- 三、RAG 模块化架构
-
- (一)Pre-Retrieval(检索前处理)
- (二)Retrieval(检索)
- (三)Post-Retrieval(检索后处理)
- (四)Generation(生成)
- 四、关键配置与最佳实践
- 五、依赖与集成
- 六、典型应用场景
一、简介
1.1 Spring AI 简介
定义与目标
- SpringAI是一个基于Spring框架的开源项目,旨在简化人工智能(AI)技术在 Java 应用程序中的集成过程。
- 可以快速将大语言模型、自然语言处理、图像生成等 AI 功能融入到 Spring Boot 或其他 Spring 项目中。
- 核心目标在于降低 AI 技术的使用门槛,并提升 AI 应用开发效率
与 Spring 生态系统的关系
- 在架构层面,Spring AI 遵循 Spring 框架的依赖注入(DI)、控制反转(IoC)以及面向切面编程(AOP)等核心设计理念。
- 开发者可以像使用 Spring 其他组件一样,通过注解或 XML 配置的方式管理 AI 相关的 Bean,如模型客户端、提示工程处理器等,实现 AI 功能的灵活装配与扩展。
1.2 应用场景
自然语言处理
- 文本生成:利用 Spring AI 可轻松实现自动生成文章、故事、报告等内容。例如在新闻媒体行业,可基于模板和现有数据自动生成体育赛事、财经数据等方面的简短新闻报道。
- 情感分析:通过 Spring AI 可以对用户评论、社交媒体内容等文本进行情感分析,判断其情感倾向(积极、消极或中性)。电商平台可利用该功能分析用户对商品的评价,帮助商家了解消费者的满意度和需求,及时调整产品策略和服务质量。
图像生成
- 创意设计辅助:广告公司或设计团队可以使用 Spring AI 开发的应用,根据文字描述生成创意图像,为设计工作提供灵感和参考。
- 产品展示图生成:电商平台可以利用 Spring AI 自动生成产品的展示图片。
智能客服
- 自动问答:基于 Spring AI 开发的智能客服系统可以自动回答用户的常见问题,减轻客服人员的工作负担。
1.3 优势与特点
简化 AI 集成
- Spring AI 为不同类型的 AI 模型(如语言模型、图像模型等)提供了统一的编程接口,开发者可以使用相同的方式调用不同的模型。
- 无论是调用 OpenAI 的 GPT 模型还是本地部署的 LLaMA 模型,都可以通过 Spring AI 提供的 ChatClient 接口进行操作。
多模型支持
- Spring AI 支持多种主流的 AI 模型和服务提供商,具有良好的模型兼容性和扩展性。
与 Spring 框架的无缝结合
- Spring AI 遵循 Spring 框架的编程模型,使用注解、依赖注入等特性,开发者可以使用熟悉的方式开发 AI 应用。
- Spring AI 提供了 Spring Boot Starter 依赖,能够与 Spring Boot 无缝集成。通过自动配置和 Starter 机制,开发者可以快速搭建基于 Spring Boot 的 AI 应用。
二、快速入门
一、环境要求与支持版本
- Spring Boot 版本:当前支持 Spring Boot 3.4.x,未来将支持 3.5.x。
- JDK 版本:需使用与 Spring Boot 兼容的 JDK 版本(建议 JDK 17+)。
二、项目创建方式
- Spring Initializr:
- 访问 start.spring.io。
- 在依赖选择中添加 AI 相关模块(如 AI Models、Vector Stores)。
- 手动创建:通过 Maven 或 Gradle 构建项目,添加对应依赖。
三、依赖管理与仓库配置
(一)稳定版本(1.0.0-M6 及以后)
- Maven 配置:无需额外仓库,直接从 Maven Central 拉取。
- Gradle 配置:使用
mavenCentral()仓库。
(二)快照版本(Snapshot)
- Maven 仓库配置:
<repositories> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases><enabled>false</enabled></releases> </repository> <repository> <name>Central Portal Snapshots</name> <id>central-portal-snapshots</id> <url>https://central.sonatype.com/repository/maven-snapshots/</url> <snapshots><enabled>true</enabled></snapshots> </repository></repositories>- Gradle 仓库配置:
repositories { mavenCentral() maven { url \'https://repo.spring.io/milestone\' } maven { url \'https://repo.spring.io/snapshot\' } maven { name = \'Central Portal Snapshots\' url = \'https://central.sonatype.com/repository/maven-snapshots/\' }}- Maven 镜像配置注意事项:
- 若
settings.xml中存在通配符镜像(*),需排除 Spring 快照仓库:
- 若
<mirror> <id>my-mirror</id> <mirrorOf>*,!spring-snapshots,!central-portal-snapshots</mirrorOf> <url>https://my-company-repository.com/maven</url></mirror>四、引入 Spring AI BOM
- 作用:统一管理 Spring AI 依赖版本,避免版本冲突。
- Maven 配置:
<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.0.0-SNAPSHOT</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies></dependencyManagement>- Gradle 配置:
dependencies { implementation platform(\"org.springframework.ai:spring-ai-bom:1.0.0-SNAPSHOT\") // 添加具体模块依赖(如 OpenAI 集成) implementation \'org.springframework.ai:spring-ai-openai\'}五、添加具体功能依赖
根据需求选择以下模块依赖:
- 聊天模型(Chat Models):
spring-ai-openai:集成 OpenAI 聊天模型(如 GPT-3.5/4)。spring-ai-anthropic:集成 Anthropic 模型(如 Claude)。
- 嵌入模型(Embeddings Models):
spring-ai-embeddings-openai:OpenAI 文本嵌入模型。
- 图像生成模型(Image Generation Models):
spring-ai-image-generator-openai:OpenAI 图像生成(如 DALL・E)。
- 转录模型(Transcription Models):
spring-ai-transcription-openai:OpenAI 语音转文本(如 Whisper)。
- 向量数据库(Vector Databases):
spring-ai-vector-store-pinecone:集成 Pinecone 向量存储。spring-ai-vector-store-weaviate:集成 Weaviate 向量存储。
六、快速开始示例
- 引入 OpenAI 聊天模型依赖:
<dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency></dependencies>- 创建简单的聊天客户端:
import org.springframework.ai.chat.ChatClient;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class AIController { private final ChatClient chatClient; @Autowired public AIController(ChatClient chatClient) { this.chatClient = chatClient; } @GetMapping(\"/ai/chat\") public String chat(@RequestParam String message) { return chatClient.prompt() .user(message) .call() .content(); }}- 配置 OpenAI API 密钥:
- 在
application.properties中添加:
- 在
spring.ai.openai.api-key=your-openai-api-key三、SpringAI核心概念
Models
根据输入输出类型对常见的模型进行分类:
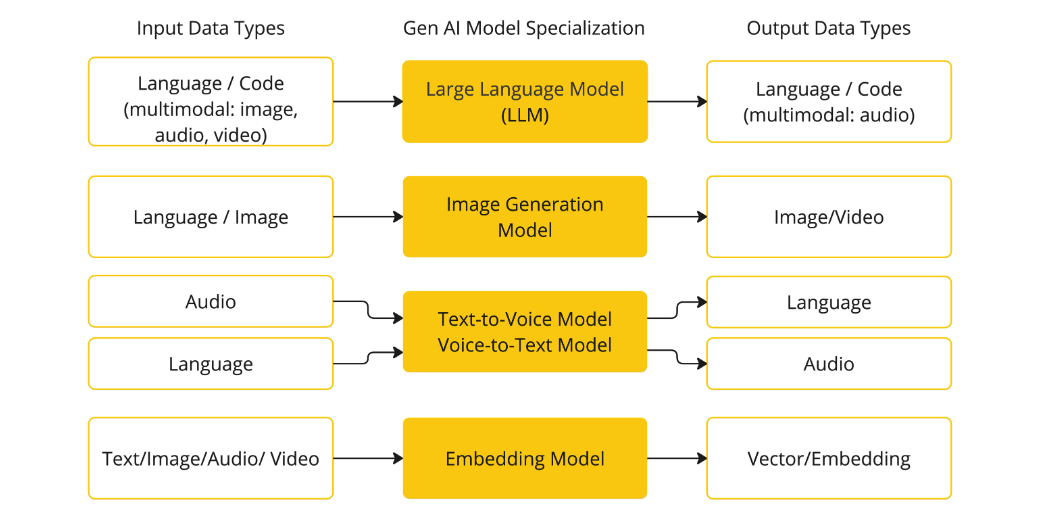
Prompts
提示词(Prompt)是引导AI模型生成特定输出的语言输入基础。
提示词并非简单的字符串——以ChatGPT的API为例,单个提示词可能包含多个具有不同角色的文本输入。
- 系统角色(System Role):定义模型行为准则,设定交互上下文
- 用户角色(User Role):通常指用户的实际输入内容
Spring AI采用基于文本的模板引擎来实现提示词的创建与管理,其底层使用开源库StringTemplate实现该功能。
例如一个基础提示词模板:
Tell me a {adjective} joke about {content}.在Spring AI框架中,提示词模板的定位类似于Spring MVC架构中的视图层(View)。开发者通过提供模型对象(通常是java.util.Map)来填充模板中的占位符,最终\"渲染\"生成的字符串将作为AI模型的输入内容。
Embeddings
嵌入是将文本、图像或视频转化为数值化表示的技术,其核心在于捕捉输入数据之间的关联性。
通过将文本、图像及视频转换为浮点数数组(即向量),嵌入技术能够有效编码原始数据的语义信息。该数组的长度称为向量的维度(dimensionality)。
通过计算两个文本对应向量之间的数值距离,应用程序可精确量化原始对象之间的相似度。例如:
- 语义搜索:比对查询文本与文档库的嵌入向量
- 内容推荐:识别相似特征的媒体资源
- 异常检测:发现偏离常规模式的数据点
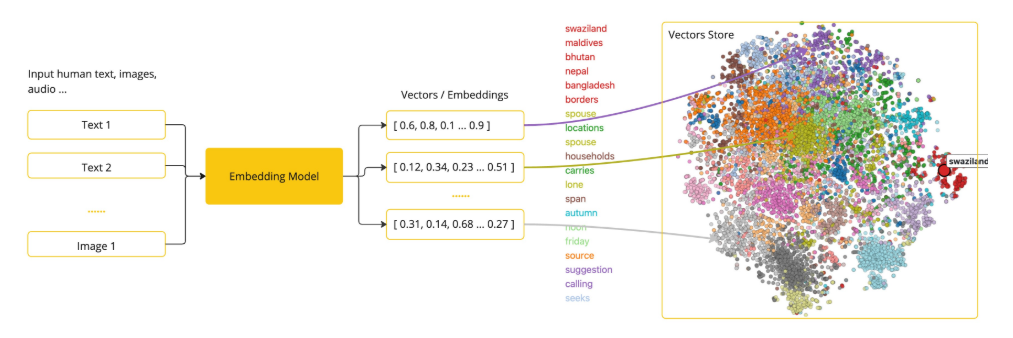
Structured Output
AI模型的输出本质上是字符串形态,即使请求返回JSON格式,其本质仍是包含JSON文本的java.lang.String,而非可直接操作的JSON数据结构。
SpringAI提供结构化输出适配器解决该痛点
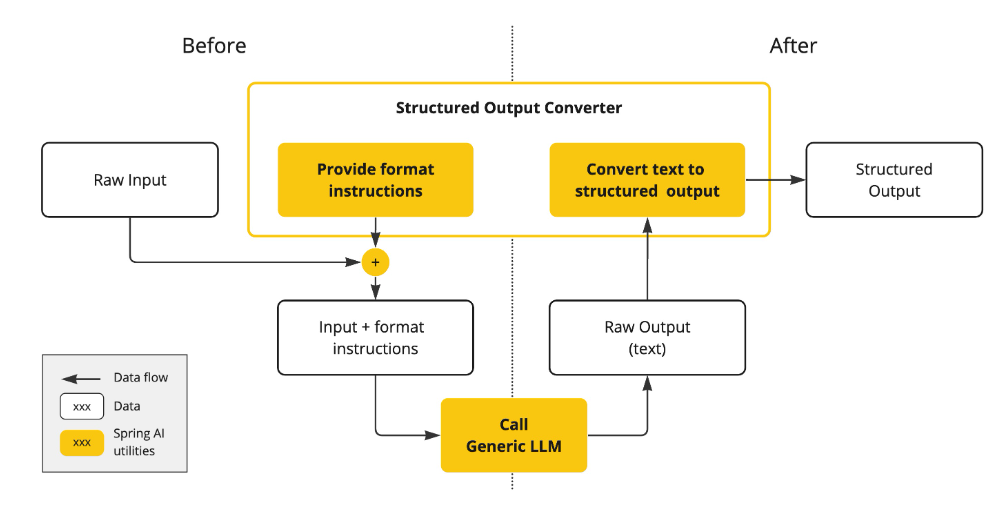
Bringing Your Data
GPT-3.5/4.0等模型的训练数据截止到2021年9月(约650GB数据集),对于之后的事件或专有领域知识存在固有局限。以下是突破这一限制的解决方案:
- 微调(Fine-Tuning):通过调整模型内部权重参数,使其适应特定领域数据
- 提示词填充:在上下文窗口中直接注入相关数据
- 检索增强生成(RAG):基于语义相似度的向量搜索,动态构建含上下文的提示词
Spring AI推荐优先采用RAG模式,通过VectorStoreTemplate简化实现
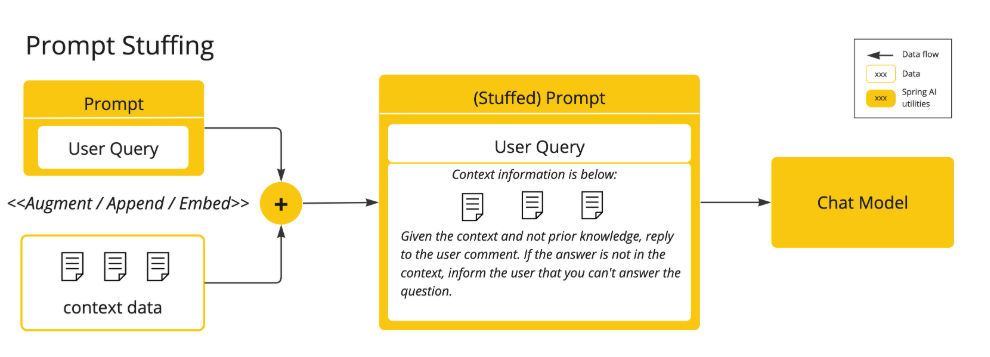
Tool Calling
大语言模型(LLMs)在训练完成后即处于固化状态,这导致其知识存在时效性局限,且无法直接访问或修改外部数据。
工具调用(Tool Calling)机制正是为了解决这些缺陷而设计。该机制允许开发者将自定义服务注册为工具,从而将大语言模型与外部系统的API连接起来。这些外部系统能够为LLM提供实时数据,并代其执行数据处理操作。
Spring AI 极大简化了工具调用的代码实现:
- 自动处理工具调用的交互流程
- 只需通过
@Tool注解声明工具方法,并在提示词配置中启用,即可让模型调用该工具 - 支持在单次提示词中定义和引用多个工具
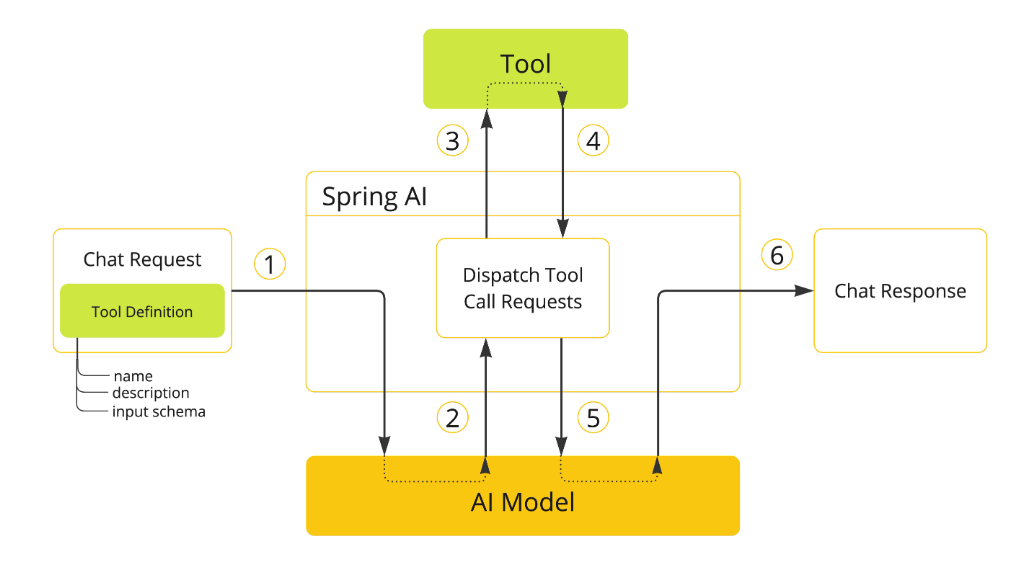
工具调用流程详解
- 工具注册
在聊天请求中需包含工具定义,每个工具定义包括:- 工具名称
- 功能描述
- 输入参数的结构化模式(Schema)
- 模型决策
当模型决定调用工具时,会返回包含以下内容的响应:- 目标工具名称
- 符合预定义模式的输入参数
- 应用端执行
- 应用根据工具名称定位并执行对应服务
- 处理工具调用的返回结果
- 结果反馈
- 应用将工具执行结果返回给模型
- 模型结合该结果生成最终响应
Retrieval Augmented Generation
检索增强生成(Retrieval Augmented Generation,RAG)是一种通过将相关数据动态注入提示词,以提升AI模型响应准确性的技术方案。其核心在于建立外部知识库与大语言模型的协同机制。
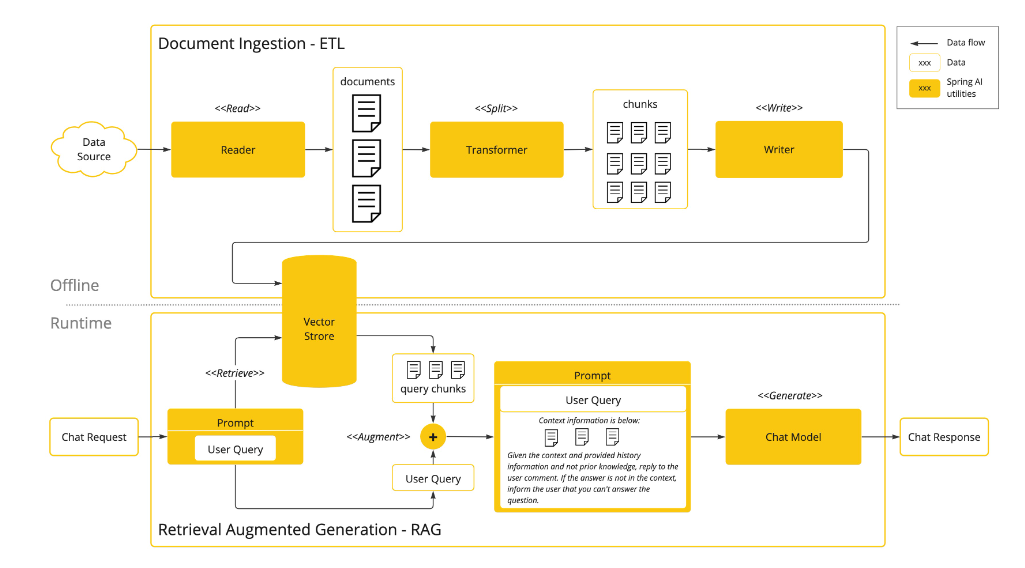
技术实现流程
1. 批处理式数据预处理(ETL管道)
- 数据提取(Extract):从非结构化文档(PDF/HTML/Markdown等)读取原始内容
- 数据转换(Transform):关键步骤包括:
- 语义分块:保持内容逻辑完整性
- 避免在段落/表格中间拆分
- 代码文件需确保方法完整性(不截断函数实现)
- 尺寸优化:每个分块大小需控制在模型令牌限制的20%-30%(如GPT-4的32K上下文窗口对应6K-10K令牌/块)
- 语义分块:保持内容逻辑完整性
- 数据加载(Load):将处理后的数据存入向量数据库(如Pinecone/Weaviate)
2. 用户查询实时处理
语义检索:
# 伪代码示例:向量相似度搜索 query_embedding = embed(\"Spring AI的事务管理机制\") similar_chunks = vector_db.search(query_embedding, top_k=3)提示词构建:将用户问题与检索到的相似文档片段组合:
请基于以下上下文回答问题: [检索到的文档片段1...] [检索到的文档片段2...] 问题:如何配置Spring AI的事务管理?- 模型推理:增强后的提示词发送至AI模型生成最终响应
技术优势
四、SpringAI核心组件
ChatClient
一、ChatClient 概述
- 核心功能:提供与 AI 模型通信的流式 API,支持同步和流式编程模型。
- 输入构建:通过流式 API 构建包含用户消息和系统消息的提示(Prompt),消息可包含运行时替换的占位符。
- 输出处理:支持返回文本内容、结构化实体、带元数据的响应(如 token 使用量),以及流式响应。
二、创建 ChatClient
- 自动配置方式
- Spring Boot 自动配置会创建
ChatClient.Builderbean,可直接注入并构建实例:
- Spring Boot 自动配置会创建
@RestControllerclass MyController { private final ChatClient chatClient; public MyController(ChatClient.Builder chatClientBuilder) { this.chatClient = chatClientBuilder.build(); } @GetMapping(\"/ai\") String generation(String userInput) { return this.chatClient.prompt().user(userInput).call().content(); }}- 手动创建方式
- 禁用自动配置后(
spring.ai.chat.client.enabled=false),可手动创建多个实例:
// 同一模型类型,不同配置ChatModel model = ...; // 自动配置的模型ChatClient client1 = ChatClient.create(model);ChatClient client2 = ChatClient.builder(model) .defaultSystemPrompt(\"You are a helper.\") .build();// 不同模型类型@Configurationclass ChatConfig { @Bean ChatClient openAiClient(OpenAiChatModel model) { return ChatClient.create(model); } @Bean ChatClient anthropicClient(AnthropicChatModel model) { return ChatClient.create(model); }}三、流式 API 核心用法
- 构建提示的三种方式
prompt():空参,手动构建用户、系统消息。prompt(Prompt prompt):传入已构建的 Prompt 实例。prompt(String content):快速设置用户消息内容。
- 同步调用(call)返回值
content():返回字符串内容。chatResponse():返回包含元数据(如 token 数)的ChatResponse。entity(Class type):将响应映射为实体类(如record ActorFilms(String actor, List movies))。
- 流式调用(stream)返回值
content():返回Flux流式文本。chatResponse():返回Flux流式响应(含元数据)。
四、提示模板与动态参数
- 模板语法:默认使用
{}包裹变量,基于StTemplateRenderer引擎,可自定义分隔符:
String response = ChatClient.create(model).prompt() .user(u -> u.text(\"Tell me 5 movies by {director}\") .param(\"director\", \"Christopher Nolan\")) .call().content();- 自定义模板引擎:实现
TemplateRenderer接口,或配置现有引擎(如修改分隔符为)。
五、默认配置与动态覆盖
- 默认系统消息
- 在配置类中设置全局默认系统消息,避免每次调用重复设置:
@Configurationclass Config { @Bean ChatClient chatClient(ChatClient.Builder builder) { return builder.defaultSystem(\"You speak like a pirate.\") .build(); }}- 带参数的动态默认值
- 系统消息中使用占位符,运行时通过
system(sp -> sp.param(\"key\", value))动态赋值:
- 系统消息中使用占位符,运行时通过
// 配置类中设置带参数的默认系统消息builder.defaultSystem(\"You speak as {character}.\");// 运行时覆盖参数chatClient.prompt().system(sp -> sp.param(\"character\", \"Shakespeare\")) .user(\"Tell a story\").call().content();- 其他默认配置
defaultOptions(ChatOptions):设置模型默认参数(如温度、模型类型)。defaultFunctions(Function...):注册默认工具调用函数。defaultAdvisors(Advisor...):添加默认顾问(如记忆、检索增强)。
六、Advisors配置
- 核心作用:拦截、修改提示或上下文,支持检索增强生成(RAG)、对话记忆等。
- 常用顾问
MessageChatMemoryAdvisor:维护对话历史,超过最大窗口(默认 20 条)时淘汰旧消息。QuestionAnswerAdvisor:结合向量存储检索上下文,增强回答准确性。SimpleLoggerAdvisor:日志记录请求和响应,用于调试(需设置日志级别为 DEBUG)。
- 配置示例:按顺序执行多个顾问,先添加对话历史,再检索相关文档:
chatClient.prompt() .advisors( MessageChatMemoryAdvisor.builder(chatMemory).build(), QuestionAnswerAdvisor.builder(vectorStore).build() ) .user(\"What is RAG?\") .call().content();Advisor
一、Advisors 核心概念与作用
- 定义:Advisors 是 Spring AI 中用于拦截、修改和增强 AI 交互的组件,可封装通用的生成式 AI 模式,实现数据转换和跨模型复用。
- 核心价值:
- 封装对话历史管理、检索增强(RAG)等重复模式。
- 支持请求和响应的预处理与后处理,提升 LLM 交互灵活性。
- 集成可观测性,记录执行指标和追踪信息。
- 使用场景:
- 对话记忆管理(维护历史消息)。
- 检索增强生成(结合向量存储补充上下文)。
- 内容安全过滤(防止有害输出)。
- 日志记录与调试。
二、核心组件与接口
- 基础接口
Advisor:所有顾问的基接口,继承Ordered,需实现getName()和getOrder()。CallAroundAdvisor:同步顾问接口,处理非流式请求,核心方法aroundCall(AdvisedRequest, CallAroundAdvisorChain)。StreamAroundAdvisor:流式顾问接口,处理响应式请求,核心方法aroundStream(AdvisedRequest, StreamAroundAdvisorChain)。
- 请求与响应载体
AdvisedRequest:包含可修改的 Prompt 数据(用户文本、参数)和共享上下文adviseContext。AdvisedResponse:包含 LLM 响应ChatResponse和上下文,用于顾问链间数据传递。
- 顾问链
CallAroundAdvisorChain:同步顾问链,通过nextAroundCall()按顺序调用下一个顾问。StreamAroundAdvisorChain:流式顾问链,通过nextAroundStream()处理响应式流。
三、执行流程与顺序控制
- 执行流程
- 框架将用户 Prompt 转换为
AdvisedRequest,并初始化空上下文。 - 顾问链按顺序处理请求,可修改 Prompt 或阻塞请求(不调用下一个顾问)。
- 最后一个顾问将请求发送给 LLM,响应沿顾问链反向处理,最终转换为
AdvisedResponse。
- 框架将用户 Prompt 转换为
- 顺序控制
- 通过
getOrder()确定执行顺序:值越小优先级越高(Ordered.HIGHEST_PRECEDENCE为最小)。 - 同步场景下,顾问链类似栈结构:先执行的顾问后处理响应,后执行的顾问先处理响应。
- 示例:设置
getOrder() = 0使顾问优先执行,getOrder() = Integer.MAX_VALUE最后执行。
- 通过
四、自定义顾问实现
- 同步 / 流式顾问示例
public class SimpleLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor { @Override public String getName() { return \"SimpleLoggerAdvisor\"; } @Override public int getOrder() { return 0; } // 优先执行 @Override public AdvisedResponse aroundCall(AdvisedRequest req, CallAroundAdvisorChain chain) { logger.debug(\"请求前: {}\", req); AdvisedResponse res = chain.nextAroundCall(req); logger.debug(\"响应后: {}\", res); return res; } @Override public Flux<AdvisedResponse> aroundStream(AdvisedRequest req, StreamAroundAdvisorChain chain) { logger.debug(\"流式请求前: {}\", req); Flux<AdvisedResponse> flux = chain.nextAroundStream(req); return flux.doOnNext(res -> logger.debug(\"流式响应后: {}\", res)); }}- 核心方法说明
aroundCall/aroundStream:拦截请求,调用chain.nextAroundCall/Stream()继续链执行,可修改AdvisedRequest或直接返回响应。updateContext:通过advisedRequest.updateContext(map -> {...})修改共享上下文(生成新不可变 map)。
五、内置顾问与常用场景
- 对话记忆顾问(Chat Memory Advisors)
MessageChatMemoryAdvisor:从记忆存储中获取历史消息,以消息集合形式添加到 Prompt。PromptChatMemoryAdvisor:将历史消息合并到系统消息中。VectorStoreChatMemoryAdvisor:从向量存储检索相关记忆,添加到系统消息。
- 检索增强顾问(RAG)
QuestionAnswerAdvisor:结合向量存储,检索相关文档并追加到 Prompt,实现检索增强生成。
- 内容安全顾问
SafeGuardAdvisor:过滤有害内容,防止模型生成不当响应。
- 日志顾问
SimpleLoggerAdvisor:记录请求和响应数据,用于调试(需设置日志级别为 DEBUG)。
六、配置与最佳实践
- 注册方式
- 在
ChatClient.Builder中通过defaultAdvisors()注册全局顾问:
- 在
ChatClient client = ChatClient.builder(model) .defaultAdvisors( new MessageChatMemoryAdvisor(chatMemory), new QuestionAnswerAdvisor(vectorStore) ) .build();- 运行时通过 `advisors(Advisor...)` 动态覆盖:client.prompt() .advisors(new SimpleLoggerAdvisor()) .user(\"问题\") .call().content();- 最佳实践
- 单一职责:每个顾问专注于一个功能(如仅记录日志或仅处理记忆)。
- 上下文共享:通过
adviseContext在顾问间传递状态(如对话 ID、检索结果)。 - 兼容两种模式:同时实现
CallAroundAdvisor和StreamAroundAdvisor以支持同步 / 流式场景。 - 顺序测试:通过
getOrder()严格控制执行顺序,避免逻辑冲突。
Prompt
一、Prompts 核心概念与作用
- 定义:Prompt 是引导 AI 模型生成特定输出的输入,其设计和措辞直接影响模型响应。类比 Spring MVC 中的 “View” 或带占位符的 SQL 语句,支持动态内容替换。
- 核心组件:
Prompt:封装多个Message和ChatOptions,作为与 AI 模型交互的基本输入单元。Message:包含文本内容、元数据和角色(如用户、系统、助手),构成 Prompt 的基本元素。PromptTemplate:模板引擎,支持动态生成 Prompt,替换占位符内容。
- 演进历程:从简单字符串发展为结构化消息集合,OpenAI 引入按角色分类的消息(如 USER、SYSTEM),提升交互精度。
二、Prompt 核心结构与接口
- Prompt 类
public class Prompt implements ModelRequest<List<Message>> { private final List<Message> messages; private ChatOptions chatOptions;}messages:消息列表,每个消息有明确角色(如用户、系统)。chatOptions:模型请求参数(如温度、最大 token 数)。
- Message 接口与实现
public interface Message extends Content { MessageType getMessageType();}public enum MessageType { USER, ASSISTANT, SYSTEM, TOOL }- 主要实现类:
UserMessage:用户输入消息(getMessageType() = USER)。SystemMessage:系统指令消息(getMessageType() = SYSTEM)。AssistantMessage:助手响应消息(getMessageType() = ASSISTANT,可包含工具调用)。ToolResponseMessage:工具返回结果(getMessageType() = TOOL)。
- 多模态支持:
MediaContent接口支持附加媒体内容(如图像、音频)。
- 消息角色与作用
- System:设定 AI 行为和响应风格(如 “你是一个乐于助人的助手”)。
- User:用户问题或指令(如 “告诉我三个著名海盗”)。
- Assistant:AI 历史响应,维持对话上下文。
- Tool:工具调用结果或函数返回值(如计算结果、数据查询)。
三、Prompt 构建示例
- 基础构建:手动创建消息并组装为 Prompt
// 创建用户消息Message userMsg = new UserMessage(\"Tell me about famous pirates\");// 创建系统消息(带模板变量)SystemPromptTemplate sysTemplate = new SystemPromptTemplate( \"You are a helper named {name}, respond in {voice} style\");Message sysMsg = sysTemplate.createMessage(Map.of(\"name\", \"PirateBot\", \"voice\", \"pirate\"));// 组装 PromptPrompt prompt = new Prompt(List.of(sysMsg, userMsg));// 调用模型ChatResponse response = chatModel.call(prompt);- 模板引擎构建:通过
PromptTemplate动态生成
// 定义模板PromptTemplate template = new PromptTemplate( \"Generate a {adjective} joke about {topic}\");// 渲染为 PromptPrompt prompt = template.create(Map.of(\"adjective\", \"funny\", \"topic\", \"cats\"));// 调用模型String result = chatModel.call(prompt).getResult();- 资源文件加载:从类路径加载模板文件
@Value(\"classpath:/prompts/system-template.st\")private Resource systemResource;SystemPromptTemplate template = new SystemPromptTemplate(systemResource);Message sysMsg = template.createMessage(Map.of(\"key\", \"value\"));四、多模态与高级特性
- 多模态支持:通过
MediaContent接口添加媒体内容(如图像 URL、音频文件):
// 创建带媒体的消息Media image = Media.builder() .name(\"logo\") .mimeType(MimeType.IMAGE_PNG) .data(ByteArrayResource) // 或 URL .build();Message mediaMsg = new UserMessage(\"Describe this image\", List.of(image));- 工具调用集成:在
AssistantMessage中包含工具调用指令:
ToolCall toolCall = ToolCall.builder() .id(\"calc-1\") .name(\"calculate\") .arguments(\"{\\\"formula\\\": \\\"2+2\\\"}\") .build();Message toolMsg = new AssistantMessage(null, List.of(toolCall));五、与其他组件的集成
- 与 ChatClient 结合:通过
ChatClient的流式 API 构建 Prompt:
String response = chatClient.prompt() .system(\"You are a translator\") .user(\"Translate \'hello\' to French\") .call().content();- 与 Advisors 结合:通过顾问动态修改 Prompt(如添加对话历史):
ChatClient client = ChatClient.builder(model) .defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory)) .build();// 顾问会自动将历史消息添加到 Prompt 中String response = client.prompt().user(\"What did we talk about earlier?\").call().content();ChatMemory
一、ChatMemory 核心概念与作用
- 背景:LLM(大语言模型)无状态,无法保留历史交互信息,ChatMemory 用于存储和检索跨交互的上下文,维持对话连续性。
- 核心区别:
- Chat Memory:模型用于维持对话上下文的相关信息(非完整历史)。
- Chat History:用户与模型交互的完整消息记录(需用其他方式存储,如 Spring Data)。
- 抽象设计:
ChatMemory:管理对话上下文的核心接口,决定保留哪些消息。ChatMemoryRepository:负责消息的底层存储(如内存、数据库)。
二、快速开始与默认配置
- 自动配置:Spring AI 自动配置
ChatMemorybean,默认使用:- 存储:
InMemoryChatMemoryRepository(内存存储)。 - 实现:
MessageWindowChatMemory(窗口大小 20 条消息)。
- 存储:
- 直接使用:
@AutowiredChatMemory chatMemory;- 手动创建示例:
// 创建窗口大小为 10 的内存存储对话记忆ChatMemory memory = MessageWindowChatMemory.builder() .maxMessages(10) .build();三、记忆类型与实现
- MessageWindowChatMemory(核心实现):
- 特点:维护固定大小的消息窗口,超出时移除旧消息,但保留系统消息。
- 配置:
// 设置最大消息数为 10MessageWindowChatMemory memory = MessageWindowChatMemory.builder() .maxMessages(10) .build();四、存储实现与配置
- InMemoryChatMemoryRepository(默认):
- 存储方式:使用
ConcurrentHashMap在内存中存储消息。 - 手动创建:
- 存储方式:使用
ChatMemoryRepository repository = new InMemoryChatMemoryRepository();- JdbcChatMemoryRepository(关系型数据库):
- 依赖:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId></dependency>- 支持数据库:PostgreSQL、MySQL/MariaDB、SQL Server、HSQLDB。
- 配置示例:
@AutowiredJdbcChatMemoryRepository repository;ChatMemory memory = MessageWindowChatMemory.builder() .chatMemoryRepository(repository) .maxMessages(10) .build();- Schema 初始化:通过
spring.ai.chat.memory.repository.jdbc.initialize-schema控制(默认仅嵌入式数据库初始化)。
- CassandraChatMemoryRepository(分布式存储):
- 依赖:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-chat-memory-repository-cassandra</artifactId></dependency>- 特点:支持时间序列模式、TTL(生存时间),适合大规模持久化存储。
- Neo4jChatMemoryRepository(图数据库):
- 依赖:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-chat-memory-repository-neo4j</artifactId></dependency>- 特点:将消息存储为图节点和关系,利用 Neo4j 的图查询能力。
五、与 ChatClient 集成(通过 Advisors)
核心 Advisors:
- MessageChatMemoryAdvisor:
* 行为:从记忆中获取历史消息,以消息集合形式添加到 Prompt。
* 配置:
ChatMemory memory = MessageWindowChatMemory.builder().build();ChatClient client = ChatClient.builder(model) .defaultAdvisors(MessageChatMemoryAdvisor.builder(memory).build()) .build();- PromptChatMemoryAdvisor:
- 行为:将历史消息作为纯文本追加到系统提示中。
- 自定义模板:
PromptTemplate template = PromptTemplate.builder() .template(\"Instructions: {instructions}\\nMemory: {memory}\") .build();PromptChatMemoryAdvisor advisor = PromptChatMemoryAdvisor.builder(memory) .promptTemplate(template) .build();- VectorStoreChatMemoryAdvisor:
- 行为:从向量存储中检索历史消息,追加到系统提示。
- 自定义模板:需包含
{instructions}和{long_term_memory}占位符。
- 运行时指定对话 ID:
String conversationId = \"007\";String response = chatClient.prompt() .user(\"Do I have license to code?\") .advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId)) .call().content();六、与 ChatModel 直接集成
- 手动管理记忆流程:
// 1. 创建记忆实例ChatMemory memory = MessageWindowChatMemory.builder().build();String conversationId = \"007\";// 2. 第一次交互UserMessage msg1 = new UserMessage(\"My name is James Bond\");memory.add(conversationId, msg1);ChatResponse res1 = chatModel.call(new Prompt(memory.get(conversationId)));memory.add(conversationId, res1.getResult().getOutput());// 3. 第二次交互UserMessage msg2 = new UserMessage(\"What is my name?\");memory.add(conversationId, msg2);ChatResponse res2 = chatModel.call(new Prompt(memory.get(conversationId)));// res2 应包含 \"James Bond\"七、配置属性与最佳实践
- Jdbc 配置属性:
spring.ai.chat.memory.repository.jdbc.initialize-schema:控制 Schema 初始化(embedded/always/never)。spring.ai.chat.memory.repository.jdbc.schema:自定义 Schema 脚本路径。
- Cassandra 配置属性:
spring.ai.chat.memory.cassandra.time-to-live:消息生存时间(TTL)。
- 最佳实践:
- 内存存储:适合测试或小型应用,无需持久化。
- JDBC/Neo4j:适合需要持久化和复杂查询的场景。
- Cassandra:适合大规模、分布式部署,需高可用性和可扩展性。
- 窗口大小:根据模型上下文窗口调整
maxMessages(如 GPT-3 通常 4K tokens,约 20-30 条短消息)。
Tool Calling
一、Tool Calling 核心概念与作用
- 定义:允许 AI 模型调用外部工具(如 API、数据库查询),扩展模型能力,实现信息检索和操作执行。
- 两大应用场景:
- 信息检索:获取实时数据(如天气、新闻),支持 RAG 场景。
- 操作执行:自动化任务(如发送邮件、创建数据库记录)。
- 安全机制:模型仅能请求工具调用,实际执行由应用负责,模型无法直接访问 API。
二、快速开始:工具定义与使用
- 信息检索工具(获取当前时间)
class DateTimeTools { @Tool(description = \"获取用户时区的当前日期和时间\") String getCurrentDateTime() { return LocalDateTime.now().atZone(LocaleContextHolder.getTimeZone().toZoneId()).toString(); }}// 使用 ChatClient 调用String response = ChatClient.create(chatModel) .prompt(\"明天是星期几?\") .tools(new DateTimeTools()) .call().content();// 输出:\"Tomorrow is 2025-06-27.\"- 操作执行工具(设置闹钟)
class DateTimeTools { @Tool(description = \"设置指定时间的闹钟,时间格式为 ISO-8601\") void setAlarm(@ToolParam(description = \"ISO-8601 格式时间\") String time) { LocalDateTime alarmTime = LocalDateTime.parse(time, DateTimeFormatter.ISO_DATE_TIME); System.out.println(\"闹钟设置为: \" + alarmTime); }}// 使用 ChatClient 调用String response = ChatClient.create(chatModel) .prompt(\"10分钟后设置一个闹钟\") .tools(new DateTimeTools()) .call().content();// 控制台输出闹钟时间三、工具定义方式
(一)基于方法的工具(Method as Tools)
- 声明式定义(@Tool 注解)
- 注解参数:
name:工具名称(默认方法名)。description:工具描述(关键,影响模型调用决策)。returnDirect:是否直接返回结果给客户端(默认 false,返回给模型)。
- 参数注解:
@ToolParam(description = \"参数说明\", required = false):设置参数描述和必填性。
- 注解参数:
class Tools { @Tool(description = \"计算两数之和\") int add(@ToolParam(\"第一个加数\") int a, @ToolParam(\"第二个加数\") int b) { return a + b; }}- 编程式定义(MethodToolCallback)
Method method = ReflectionUtils.findMethod(Tools.class, \"add\", int.class, int.class);ToolCallback toolCallback = MethodToolCallback.builder() .toolDefinition(ToolDefinition.builder(method) .description(\"计算两数之和\") .build()) .toolMethod(method) .toolObject(new Tools()) .build();(二)基于函数的工具(Functions as Tools)
- 编程式定义(FunctionToolCallback)
// 函数接口interface WeatherService extends Function<WeatherRequest, WeatherResponse> { @Override WeatherResponse apply(WeatherRequest request);}record WeatherRequest(String location, Unit unit) {}record WeatherResponse(double temp, Unit unit) {}// 创建工具ToolCallback toolCallback = FunctionToolCallback.builder( \"currentWeather\", new WeatherService() { @Override public WeatherResponse apply(WeatherRequest request) { return new WeatherResponse(25.5, request.unit()); } }) .description(\"获取指定地点的天气\") .inputType(WeatherRequest.class) .build();- 动态定义(@Bean 注解)
@Configurationclass ToolConfig { public static final String WEATHER_TOOL = \"currentWeather\"; @Bean(WEATHER_TOOL) @Description(\"获取指定地点的天气\") Function<WeatherRequest, WeatherResponse> currentWeather() { return request -> new WeatherResponse(30.0, request.unit()); }}// 使用工具名称调用ChatClient.create(chatModel) .prompt(\"哥本哈根天气如何?\") .tools(WeatherTools.WEATHER_TOOL) .call().content();四、工具核心组件与接口
- ToolCallback 接口:工具的核心接口,定义执行逻辑。
public interface ToolCallback { ToolDefinition getToolDefinition(); // 工具定义(名称、描述、输入 schema) ToolMetadata getToolMetadata(); // 工具元数据(如是否直接返回结果) String call(String toolInput); // 执行工具}- ToolDefinition 接口:工具元数据,供模型理解调用方式。
public interface ToolDefinition { String name(); // 工具名称 String description(); // 工具描述 String inputSchema(); // 输入参数的 JSON Schema}- ToolCallingManager:工具执行管理器,处理工具调用流程。
// 自定义工具执行管理器@BeanToolCallingManager toolCallingManager() { return ToolCallingManager.builder() .exceptionProcessor(exception -> \"工具调用失败: \" + exception.getMessage()) .build();}五、工具执行流程
- 框架控制执行(默认)
- 模型返回工具调用请求(含工具名和参数)。
ChatModel调用ToolCallingManager执行工具。- 工具结果返回给模型,模型生成最终响应。
- 用户控制执行:手动处理工具调用循环。
ChatOptions options = ToolCallingChatOptions.builder() .toolCallbacks(tools) .internalToolExecutionEnabled(false) // 禁用自动执行 .build();ChatResponse response = chatModel.call(new Prompt(\"6*8是多少?\", options));ToolCallingManager manager = ToolCallingManager.builder().build();while (response.hasToolCalls()) { ToolExecutionResult result = manager.executeToolCalls(prompt, response); prompt = new Prompt(result.conversationHistory(), options); response = chatModel.call(prompt);}六、工具结果处理
- 直接返回结果(returnDirect = true)
@Tool(description = \"获取用户信息\", returnDirect = true)UserInfo getUser(@ToolParam(\"用户ID\") Long id) { return userRepository.findById(id);}// 结果直接返回给客户端,不经过模型- 自定义结果转换
// 自定义转换器class CustomConverter implements ToolCallResultConverter { @Override public String convert(Object result, Type returnType) { if (result instanceof UserInfo) { return \"用户: \" + ((UserInfo) result).getName(); } return String.valueOf(result); }}// 使用自定义转换器@Tool(description = \"获取用户信息\", resultConverter = CustomConverter.class)UserInfo getUser(Long id) { ... }七、工具上下文与异常处理
- 工具上下文(ToolContext):传递额外参数(如租户 ID)。
ChatClient.create(chatModel) .prompt(\"查询客户42的信息\") .tools(new CustomerTools()) .toolContext(Map.of(\"tenantId\", \"acme\")) // 传递租户ID .call().content(); // 工具中使用上下文@Tool(description = \"查询客户信息\")Customer getCustomer(Long id, ToolContext context) { String tenantId = context.get(\"tenantId\"); return customerRepo.findByTenantAndId(tenantId, id);}- 异常处理:自定义工具执行异常处理器。
@BeanToolExecutionExceptionProcessor exceptionProcessor() { return e -> { if (e.getCause() instanceof SQLException) { return \"数据库错误: \" + e.getMessage(); } return \"工具调用失败: \" + e.getMessage(); };}八、支持的模型与最佳实践
- 支持模型:OpenAI、Anthropic Claude 3、Azure OpenAI、Mistral AI、Ollama 等。
- 最佳实践:
- 描述清晰:工具描述需明确用途和参数要求,避免模型误用。
- 参数必填性:合理设置
@ToolParam(required = false),防止模型虚构参数。 - 安全考虑:工具不应暴露敏感操作,结果直接返回时需验证权限。
- 性能优化:批量处理工具调用,减少模型交互次数。
九、工具与其他组件集成
- 与对话记忆(ChatMemory)集成:
ChatMemory memory = MessageWindowChatMemory.builder().build();ChatClient client = ChatClient.builder(chatModel) .defaultAdvisors(MessageChatMemoryAdvisor.builder(memory).build()) .defaultTools(new DateTimeTools()) .build(); // 对话中自动包含历史工具调用记录String response = client.prompt(\"之前设置的闹钟时间是?\").call().content();- 与检索增强(RAG)集成:工具可调用向量存储检索上下文。
@Tool(description = \"检索相关文档\")List<Document> searchDocs(@ToolParam(\"查询关键词\") String query) { return vectorStore.search(query, 5);}RAG
一、RAG 核心概念与作用
- 定义:RAG 是一种结合检索与生成的技术,解决大语言模型(LLM)在长文本处理、事实准确性和上下文感知方面的局限。
- 核心逻辑:通过检索外部知识库(如向量数据库)获取相关文档,将其作为上下文附加到用户查询中,辅助 LLM 生成更准确、有依据的回答。
- Spring AI 支持:提供模块化架构和开箱即用的 Advisor,允许自定义 RAG 流程或使用现成实现。
二、核心 Advisor 实现
(一)QuestionAnswerAdvisor
- 功能:基于向量存储检索相关文档,并将结果附加到用户查询中,形成上下文。
- 使用方式:
// 基础用法ChatResponse response = ChatClient.builder(chatModel) .build().prompt() .advisors(new QuestionAnswerAdvisor(vectorStore)) .user(userText) .call() .chatResponse();// 配置检索参数(阈值、返回数量)var qaAdvisor = new QuestionAnswerAdvisor(vectorStore, SearchRequest.builder() .similarityThreshold(0.8d) // 相似度阈值 .topK(6) // 返回前6条结果 .build());// 动态过滤(运行时设置过滤条件)String content = chatClient.prompt() .user(\"请回答问题\") .advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, \"type == \'Spring\'\")) .call().content();- 过滤表达式:使用类似 SQL 的过滤语法,支持跨向量存储的便携式过滤(如
type == \'Spring\')。
(二)RetrievalAugmentationAdvisor
- 模块化 RAG 实现:基于模块化架构,支持构建复杂 RAG 流程。
- 基础用法(Naive RAG):
// 基础配置Advisor advisor = RetrievalAugmentationAdvisor.builder() .documentRetriever(VectorStoreDocumentRetriever.builder() .similarityThreshold(0.50) .vectorStore(vectorStore) .build()) .build();// 允许空上下文(无相关文档时仍生成回答)Advisor advisor = RetrievalAugmentationAdvisor.builder() .documentRetriever(...) .queryAugmenter(ContextualQueryAugmenter.builder() .allowEmptyContext(true) .build()) .build();- 高级用法(带查询转换):
Advisor advisor = RetrievalAugmentationAdvisor.builder() .queryTransformers(RewriteQueryTransformer.builder() .chatClientBuilder(chatClientBuilder.build().mutate()) .build()) .documentRetriever(...) .build();三、RAG 模块化架构
Spring AI 将 RAG 拆分为四个阶段模块,每个模块可独立定制:
(一)Pre-Retrieval(检索前处理)
- 查询转换(Query Transformation):优化用户查询,提升检索效果。
- CompressionQueryTransformer:压缩对话历史和查询为独立查询(适用于长对话场景)。
Query query = Query.builder() .text(\"第二大城市是?\") .history(new UserMessage(\"丹麦首都\"), new AssistantMessage(\"哥本哈根\")) .build();QueryTransformer transformer = CompressionQueryTransformer.builder() .chatClientBuilder(chatClientBuilder) .build();Query transformed = transformer.transform(query);- **RewriteQueryTransformer**:重写查询以提高检索相关性(适用于模糊或冗长查询)。- **TranslationQueryTransformer**:翻译查询至嵌入模型支持的语言。- 查询扩展(Query Expansion):生成多个语义变体查询,增加命中概率。
MultiQueryExpander expander = MultiQueryExpander.builder() .chatClientBuilder(chatClientBuilder) .numberOfQueries(3) // 生成3个变体 .includeOriginal(false) // 不包含原始查询 .build();List<Query> expanded = expander.expand(new Query(\"如何运行Spring Boot应用?\"));(二)Retrieval(检索)
- 文档检索(Document Search):从向量存储获取相关文档。
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder() .vectorStore(vectorStore) .similarityThreshold(0.73) .topK(5) .filterExpression(new FilterExpressionBuilder() .eq(\"genre\", \"fairytale\") .build()) .build();List<Document> docs = retriever.retrieve(new Query(\"故事主角是谁?\"));- **动态过滤**:支持通过 `Supplier` 或查询上下文动态设置过滤条件。- 文档合并(Document Join):合并多源检索结果,去重排序。
DocumentJoiner joiner = new ConcatenationDocumentJoiner();List<Document> merged = joiner.join(documentsForQuery);(三)Post-Retrieval(检索后处理)
- 文档排序(Document Ranking):按相关性重排文档顺序(不删除文档)。
- 文档筛选(Document Selection):移除不相关或冗余文档(解决上下文长度限制)。
- 文档压缩(Document Compression):压缩文档内容,减少噪声(不改变文档列表顺序)。
(四)Generation(生成)
- 查询增强(Query Augmentation):将检索到的文档内容附加到查询中,形成完整上下文。****
QueryAugmenter augmenter = ContextualQueryAugmenter.builder() .allowEmptyContext(true) // 允许空上下文时生成回答 .build();- 提示模板定制:通过
promptTemplate()和emptyContextPromptTemplate()自定义生成阶段的提示格式。
四、关键配置与最佳实践
- 查询转换温度设置:配置
ChatClient.Builder为低温(如 0.0),确保查询转换结果更确定(默认温度过高可能影响检索效果)。 - 空上下文处理:通过
allowEmptyContext(true)允许无相关文档时仍生成回答,避免模型拒答。 - 过滤表达式优先级:查询级过滤表达式(
Query.context)优先级高于检索器级过滤。 - 多阶段组合:结合查询转换、扩展、筛选等模块,构建复杂 RAG 流程(如翻译→扩展→检索→压缩→生成)。
五、依赖与集成
- 必备依赖:添加
spring-ai-advisors-vector-store依赖以使用 RAG Advisors。 - 向量存储集成:支持主流向量存储(如 Pinecone、Weaviate、Elasticsearch 等),通过
VectorStore接口对接。
六、典型应用场景
- 企业知识库问答:基于内部文档库,快速响应员工问题。
- 客服系统:结合产品文档,生成准确的客户支持回答。
- 学术研究辅助:检索相关文献,辅助论文写作。
- 代码问答:基于代码库文档,回答开发问题。

