Datawhale AI夏令营-机器学习-用户新增预测项目学习笔记
用户新增预测项目学习笔记
项目概述
本项目通过机器学习模型预测用户是否为新增用户(is_new_did),使用F1分数作为评估指标。项目结合了复杂特征工程和LightGBM建模,处理了高基数类别特征、时间序列特征和用户行为模式分析。完整代码在最后面!
核心步骤与技术
1. 数据预处理
-
JSON解析:安全解析udmap字段提取botId和pluginId
-
时间特征工程:
-
提取小时、星期几、日期信息
-
创建时间段特征(0-6点、6-12点等)
-
避免使用分类类型,直接转为数值标签
-
-
重叠用户处理:
-
识别测试集中与训练集重叠的DID
-
直接使用训练集标签填充重叠用户
-
2. 特征工程
用户级聚合特征
user_agg = full_df.groupby(\'did\').agg( event_count=(\'eid\', \'count\'), unique_eid=(\'eid\', \'nunique\'), first_event_hour=(\'hour\', \'min\'), last_event_hour=(\'hour\', \'max\'), hour_std=(\'hour\', \'std\'))时序特征
-
用户事件累积计数
-
最近3次事件平均时间间隔
df[\'user_event_count\'] = df.groupby(\'did\')[\'eid\'].transform(\'cumcount\') + 1df[\'time_diff\'] = df.groupby(\'did\')[\'common_ts\'].diff()RFM特征
-
Recency:最近一次行为时间
-
Frequency:行为总次数
-
Monetary:不同事件类型数量
-
添加RFM分位数特征
组合特征
df[\'device_os\'] = df[\'device_brand\'] + \'_\' + df[\'os_type\']df[\'time_week_combo\'] = df[\'time_segment\'] + \'_\' + df[\'dayofweek\']目标编码
def target_encoding_cv(train_df, test_df, cat_cols, target_col, n_folds=5): # 交叉验证避免数据泄露 for fold, (train_idx, val_idx) in enumerate(kf.split(...)): # 仅使用训练部分计算目标均值 target_mean = train_fold.groupby(col)[target_col].mean().to_dict() # 应用编码到验证集 val_fold[col].map(target_mean)TF-IDF特征
vectorizer = TfidfVectorizer(max_features=100)tfidf_matrix = vectorizer.fit_transform(agg_text[col])# 为每个关键词创建新特征for i, feature_name in enumerate(feature_names): tfidf_features[f\'tfidf_{col}_{i}\'] = tfidf_matrix[:, i].toarray().ravel()3. 特征编码与对齐
-
LabelEncoder:处理分类特征
-
哈希编码:处理剩余的object类型特征
df[col] = df[col].astype(\'str\').apply(lambda x: hash(x) % 10000)-
特征对齐:
-
识别训练/测试集特有特征
-
数值特征填充0,非数值特征填充第一个有效值
-
确保特征顺序一致
-
4. 模型训练与优化
LightGBM参数配置
params = { \'objective\': \'binary\', \'metric\': \'binary_logloss\', \'max_depth\': 10, \'num_leaves\': 127, \'learning_rate\': 0.05, \'feature_fraction\': 0.8, \'class_weight\': \'balanced\'}阈值优化
def find_optimal_threshold(y_true, y_pred_proba): best_f1 = 0 for threshold in np.linspace(0.01, 0.99, 100): y_pred = (y_pred_proba >= threshold).astype(int) f1 = f1_score(y_true, y_pred) if f1 > best_f1: best_f1 = f1 best_threshold = threshold return best_threshold, best_f1交叉验证策略
-
分层5折交叉验证(StratifiedKFold)
-
每折独立搜索最优阈值
-
使用平均阈值作为最终分类阈值
5. 结果分析与提交
-
预测结果分析:
-
重叠用户占比
-
不同群体新增用户比例
-
-
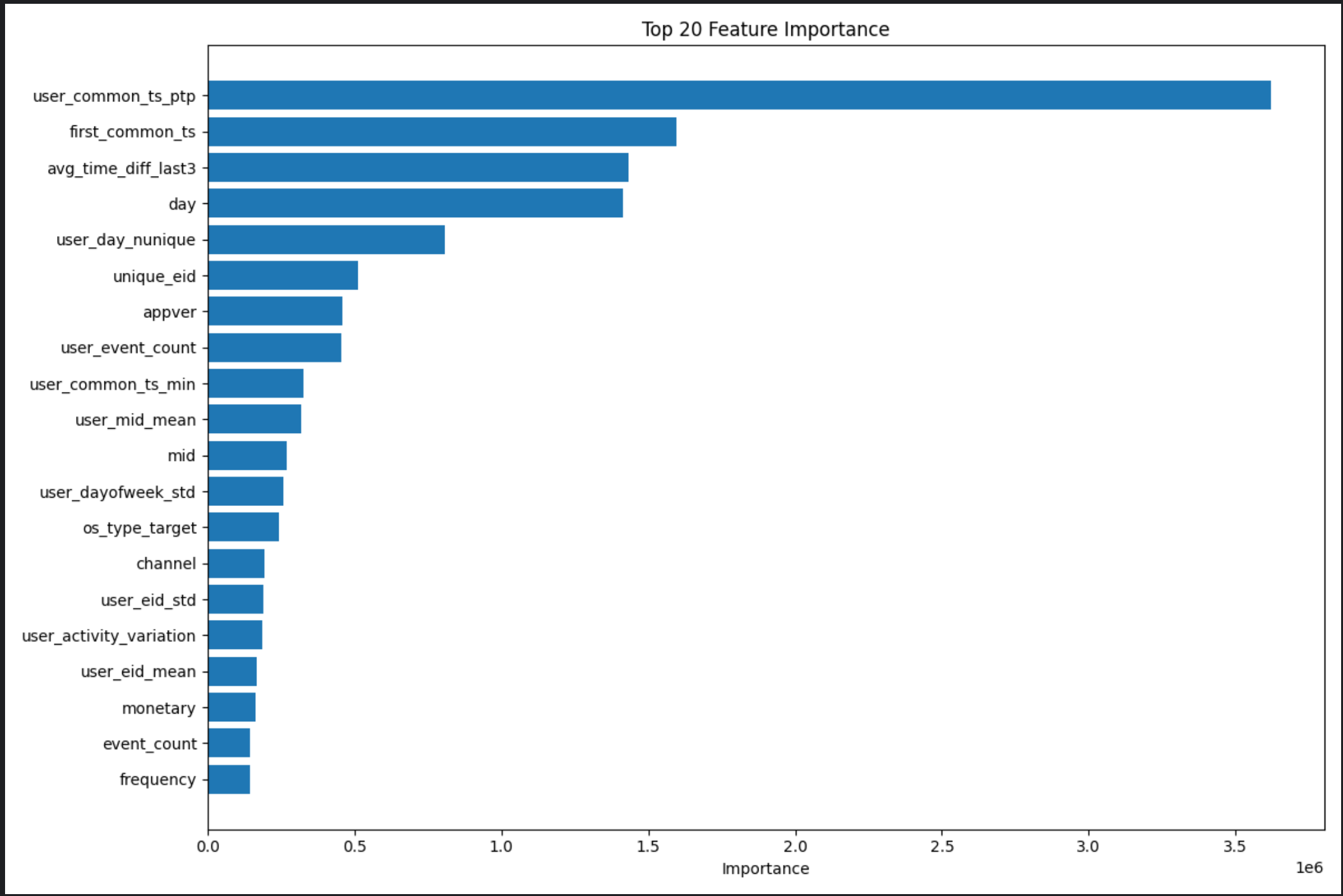
特征重要性分析:
-
基于增益(gain)评估特征重要性
-
可视化Top20重要特征
-
关键技术点
处理高基数类别特征
-
目标编码(Target Encoding)
-
TF-IDF向量化
-
哈希编码(Hashing)
时间序列处理
-
时间分桶(Time Bucketing)
-
滑动窗口统计
-
行为间隔分析
类别不平衡处理
-
class_weight=\'balanced\'参数
-
F1分数优化而非准确率
-
阈值动态调整
数据泄露预防
-
交叉验证目标编码
-
特征工程在用户级别进行
-
测试集处理仅使用训练数据统计量
性能优化技巧
-
增量处理:避免全量数据一次性处理
-
类型转换:确保所有特征为数值类型
-
特征选择:基于重要性筛选Top特征
-
批处理:大规模特征分块处理
-
并行处理:利用LightGBM的n_jobs参数
常见问题解决方案
数据类型问题
-
错误:
Cannot setitem on a Categorical with a new category -
解决:避免使用分类类型,直接转为数值标签
df[\'time_segment\'] = pd.to_numeric(df[\'time_segment\'], errors=\'coerce\').fillna(-1)特征不一致问题
-
错误:训练/测试集特征不一致
-
解决:特征对齐策略
# 找出特有特征only_in_train = [col for col in train_cols if col not in test_cols]# 对齐处理for col in only_in_train: if train_df[col].dtype.kind in \'iufc\': test_df[col] = 0 # 数值型填充0 else: test_df[col] = train_df[col].iloc[0] # 非数值型填充第一个值内存问题
-
技巧:分块处理TF-IDF特征
-
技巧:使用稀疏矩阵存储高维特征
-
技巧:及时删除中间变量
项目总结
本项目展示了完整的机器学习工作流程:
-
通过创新的特征工程挖掘用户行为模式
-
使用多种技术处理高基数类别特征
-
采用交叉验证策略避免数据泄露
-
通过阈值优化最大化F1分数
-
进行细致的错误分析和结果解释
关键收获:
-
特征工程的质量决定模型上限
-
类型一致性是模型训练的基础
-
交叉验证是避免过拟合的关键
-
阈值优化对不平衡数据集至关重要
-
细致的错误分析指导模型改进方向
完整代码及运行结果图
import pandas as pdimport numpy as npimport jsonimport lightgbm as lgbfrom sklearn.model_selection import StratifiedKFoldfrom sklearn.metrics import f1_scorefrom sklearn.preprocessing import LabelEncoderfrom sklearn.feature_extraction.text import TfidfVectorizerimport matplotlib.pyplot as pltimport warningsimport timewarnings.filterwarnings(\'ignore\')# 1. 数据加载与预处理def load_data(): train_df = pd.read_csv(r\'D:\\语言\\python工程\\pythonProject1\\train.csv\') test_df = pd.read_csv(r\'D:\\语言\\python工程\\pythonProject1\\test.csv\') submit = test_df[[\'did\']].copy() return train_df, test_df, submittrain_df, test_df, submit = load_data()# 2. 关键优化:解析udmap字段(提取JSON中的有效特征)def parse_udmap(df): # 处理udmap字段 - 提取botId和pluginId df[\'udmap\'] = df[\'udmap\'].fillna(\'{}\').astype(str) df[\'udmap\'] = df[\'udmap\'].str.replace(\"\'\", \'\"\') # 使用更安全的JSON解析 def safe_json_parse(x): try: return json.loads(x) except: return {} udmap_parsed = df[\'udmap\'].apply(safe_json_parse) # 提取botId和pluginId df[\'botId\'] = udmap_parsed.apply(lambda x: x.get(\'botId\', \'unknown\')) df[\'pluginId\'] = udmap_parsed.apply(lambda x: x.get(\'pluginId\', \'unknown\')) # 创建组合特征 df[\'bot_plugin\'] = df[\'botId\'].astype(str) + \'_\' + df[\'pluginId\'].astype(str) return df.drop(columns=[\'udmap\'])train_df = parse_udmap(train_df)test_df = parse_udmap(test_df)# 3. 增强时间特征工程 - 修复分类类型问题def enhance_time_features(df): # 将时间戳转换为datetime对象 df[\'ts\'] = pd.to_datetime(df[\'common_ts\'], unit=\'ms\') # 提取基本时间特征 df[\'hour\'] = df[\'ts\'].dt.hour df[\'dayofweek\'] = df[\'ts\'].dt.dayofweek df[\'day\'] = df[\'ts\'].dt.day df[\'is_weekend\'] = df[\'dayofweek\'].isin([5, 6]).astype(int) # 创建时间段特征 - 避免使用分类类型 bins = [-1, 6, 12, 18, 23] labels = [0, 1, 2, 3] # 直接使用数值标签 # 使用cut函数创建时间段特征 df[\'time_segment\'] = pd.cut(df[\'hour\'], bins=bins, labels=labels) df[\'time_segment\'] = pd.to_numeric(df[\'time_segment\'], errors=\'coerce\').fillna(-1) # 创建时间桶特征 df[\'time_bucket\'] = pd.cut(df[\'hour\'], bins=[0, 6, 12, 18, 24], labels=[0, 1, 2, 3]) df[\'time_bucket\'] = pd.to_numeric(df[\'time_bucket\'], errors=\'coerce\').fillna(-1) # 删除临时列 df = df.drop(columns=[\'ts\']) return dftrain_df = enhance_time_features(train_df)test_df = enhance_time_features(test_df)# 4. 核心优化:利用重复did直接填充标签(测试集与训练集重叠用户)def fill_overlap_did_labels(train, test, submit): # 获取每个did在训练集中的最后标签 train_did_label = train.drop_duplicates(\'did\', keep=\'last\')[[\'did\', \'is_new_did\']] # 创建did到标签的映射 did_label_map = dict(zip(train_did_label[\'did\'], train_did_label[\'is_new_did\'])) # 标记测试集中哪些did在训练集中出现过 test[\'is_in_train\'] = test[\'did\'].isin(did_label_map) # 对于测试集中在训练集中出现过的did,直接使用训练集中的标签 submit[\'is_new_did\'] = test[\'did\'].map(did_label_map).fillna(-1) # 统计重叠情况 overlap_count = sum(test[\'is_in_train\']) overlap_ratio = overlap_count / len(test) print(f\"测试集与训练集重叠did数量:{overlap_count},占比:{overlap_ratio:.4f}\") return test, submittest_df, submit = fill_overlap_did_labels(train_df, test_df, submit)# 5. 按用户(did)聚合特征(将事件级数据转为用户级特征)def aggregate_user_features(train, test): # 合并训练集和测试集以便统一处理 full_df = pd.concat([ train.assign(data_type=\'train\'), test.assign(data_type=\'test\', is_new_did=np.nan) ], ignore_index=True) # 按did聚合特征 user_agg = full_df.groupby(\'did\').agg( event_count=(\'eid\', \'count\'), # 总事件数 unique_eid=(\'eid\', \'nunique\'), # 不同事件类型数 unique_mid=(\'mid\', \'nunique\'), # 不同模块数 first_event_hour=(\'hour\', \'min\'), # 首次事件时间(小时) last_event_hour=(\'hour\', \'max\'), # 最后事件时间(小时) hour_std=(\'hour\', \'std\'), # 事件时间标准差 unique_city=(\'common_city\', \'nunique\'), # 不同城市数 first_common_ts=(\'common_ts\', \'min\') # 首次事件时间戳 ).reset_index() # 将聚合特征合并回原始数据 train = train.merge(user_agg, on=\'did\', how=\'left\') test = test.merge(user_agg, on=\'did\', how=\'left\') return train, testtrain_df, test_df = aggregate_user_features(train_df, test_df)# 6. 新增:用户行为序列特征(滑动窗口统计)def add_sequential_features(df): # 确保按用户和时间排序 df.sort_values([\'did\', \'common_ts\'], inplace=True) # 用户事件累积计数 df[\'user_event_count\'] = df.groupby(\'did\')[\'eid\'].transform(\'cumcount\') + 1 # 用户最近3次事件的平均时间间隔 df[\'time_diff\'] = df.groupby(\'did\')[\'common_ts\'].diff() df[\'avg_time_diff_last3\'] = df.groupby(\'did\')[\'time_diff\'].transform( lambda x: x.rolling(3, min_periods=1).mean() ) return df.drop(columns=[\'time_diff\'])train_df = add_sequential_features(train_df)test_df = add_sequential_features(test_df)# 7. 新增:RFM特征(Recency, Frequency, Monetary)def add_rfm_features(df): # 计算当前最大时间戳(作为参考点) max_ts = df[\'common_ts\'].max() # 计算RFM特征 rfm = df.groupby(\'did\').agg( recency=(\'common_ts\', lambda x: max_ts - x.max()), # 距离最近一次行为的时间 frequency=(\'eid\', \'count\'), # 行为总次数 monetary=(\'eid\', \'nunique\') # 不同事件类型数量 ).reset_index() # 添加RFM分位数特征 rfm[\'recency_rank\'] = pd.qcut(rfm[\'recency\'], 4, labels=False, duplicates=\'drop\') rfm[\'frequency_rank\'] = pd.qcut(rfm[\'frequency\'], 4, labels=False, duplicates=\'drop\') rfm[\'monetary_rank\'] = pd.qcut(rfm[\'monetary\'], 4, labels=False, duplicates=\'drop\') # 合并回原始数据 return df.merge(rfm, on=\'did\', how=\'left\')train_df = add_rfm_features(train_df)test_df = add_rfm_features(test_df)# 8. 新增:特征组合与交互def add_interaction_features(df): # 设备品牌 + 操作系统组合 df[\'device_os\'] = df[\'device_brand\'].astype(str) + \'_\' + df[\'os_type\'].astype(str) # 时间分段 + 星期几组合 df[\'time_week_combo\'] = df[\'time_segment\'].astype(str) + \'_\' + df[\'dayofweek\'].astype(str) # 插件ID + 时间段组合 df[\'plugin_time\'] = df[\'pluginId\'].astype(str) + \'_\' + df[\'time_bucket\'].astype(str) return dftrain_df = add_interaction_features(train_df)test_df = add_interaction_features(test_df)# 9. 目标编码特征构建def target_encoding_cv(train_df, test_df, cat_cols, target_col, n_folds=5): # 初始化目标编码列 for col in cat_cols: train_df[f\'{col}_target\'] = np.nan test_df[f\'{col}_target\'] = np.nan # 创建交叉验证分割器 kf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=42) # 交叉验证循环 for fold, (train_idx, val_idx) in enumerate(kf.split(train_df, train_df[target_col])): # 分割数据 train_fold = train_df.iloc[train_idx] val_fold = train_df.iloc[val_idx] # 处理每个分类特征 for col in cat_cols: # 计算训练部分的类别目标均值 target_mean = train_fold.groupby(col)[target_col].mean().to_dict() # 应用编码到验证集 val_col_target = val_fold[col].map(target_mean) # 处理缺失值(使用训练集的均值) global_mean = train_fold[target_col].mean() val_col_target = val_col_target.fillna(global_mean) # 更新验证集的目标编码列 val_fold.loc[:, f\'{col}_target\'] = val_col_target # 第一次折叠时处理测试集 if fold == 0: # 使用整个训练集计算目标均值 full_target_mean = train_df.groupby(col)[target_col].mean().to_dict() test_col_target = test_df[col].map(full_target_mean) # 处理缺失值(使用整个训练集的均值) global_mean_full = train_df[target_col].mean() test_col_target = test_col_target.fillna(global_mean_full) test_df.loc[:, f\'{col}_target\'] = test_col_target # 更新训练集中的编码列 train_df.loc[val_fold.index, f\'{col}_target\'] = val_col_target return train_df, test_df# 使用目标编码的特征列表cat_cols = [\'device_brand\', \'os_type\', \'botId\', \'pluginId\', \'time_segment\']train_df, test_df = target_encoding_cv(train_df, test_df, cat_cols, \'is_new_did\')# 10. TF-IDF特征生成(从设备品牌和操作系统提取文本特征)def create_tfidf_features(df, tfidf_cols, max_features=100): # 按用户聚合文本信息 agg_text = df.groupby(\'did\')[tfidf_cols].agg( lambda x: \' \'.join([str(val) for val in x if pd.notna(val)]) ) tfidf_features = pd.DataFrame(index=agg_text.index) for col in tfidf_cols: print(f\"处理字段: {col}\") try: # 创建TF-IDF向量器 vectorizer = TfidfVectorizer(max_features=max_features, token_pattern=r\'\\b\\w+\\b\') # 拟合和转换 tfidf_matrix = vectorizer.fit_transform(agg_text[col]) # 获取特征名称 feature_names = vectorizer.get_feature_names_out() # 创建特征列 for i, feature_name in enumerate(feature_names): tfidf_features[f\'tfidf_{col}_{i}\'] = tfidf_matrix[:, i].toarray().ravel() print(f\" 创建了 {len(feature_names)} 个特征\") except Exception as e: print(f\" 处理失败: {e}\") # 如果处理失败,创建默认特征列 for i in range(max_features): tfidf_features[f\'tfidf_{col}_{i}\'] = 0.0 return tfidf_features.reset_index()tfidf_cols = [\'device_brand\', \'os_type\', \'bot_plugin\']tfidf_train = create_tfidf_features(train_df, tfidf_cols)tfidf_test = create_tfidf_features(test_df, tfidf_cols)# 合并TF-IDF特征train_df = train_df.merge(tfidf_train, on=\'did\', how=\'left\')test_df = test_df.merge(tfidf_test, on=\'did\', how=\'left\')# 11. 用户级聚合特征增强def create_user_features(df): # 定义聚合函数 agg_funcs = { \'eid\': [\'count\', \'nunique\', \'mean\', \'std\'], # 事件相关 \'mid\': [\'nunique\', \'mean\'], # 模块相关 \'hour\': [\'mean\', \'std\', \'min\', \'max\'], # 时间相关 \'dayofweek\': [\'mean\', \'std\', \'min\', \'max\'], # 星期相关 \'day\': [\'nunique\', \'mean\', \'min\', \'max\'], # 日期相关 \'common_ts\': [\'mean\', \'min\', \'max\', np.ptp], # 时间戳相关 \'botId\': [\'nunique\'], # botId相关 \'pluginId\': [\'nunique\'], # pluginId相关 \'device_brand\': [\'nunique\'], # 设备品牌相关 \'ntt\': [\'nunique\'], # 网络类型相关 \'operator\': [\'nunique\'], # 运营商相关 \'common_city\': [\'nunique\'], # 城市相关 \'appver\': [\'nunique\'], # 应用版本相关 \'channel\': [\'nunique\'], # 应用渠道相关 \'is_weekend\': [\'mean\'] # 周末行为比例 } # 执行聚合 user_df = df.groupby(\'did\').agg(agg_funcs) # 重命名列 user_df.columns = [\'user_\' + \'_\'.join(col) for col in user_df.columns] # 派生特征 user_df[\'user_events_per_mid\'] = user_df[\'user_eid_count\'] / (user_df[\'user_mid_nunique\'] + 1e-5) user_df[\'user_activity_variation\'] = user_df[\'user_eid_nunique\'] / (user_df[\'user_eid_count\'] + 1e-5) user_df[\'user_weekend_ratio\'] = user_df[\'user_is_weekend_mean\'] return user_df.reset_index()# 创建用户级特征user_train = create_user_features(train_df)user_test = create_user_features(test_df)# 合并用户级特征train_df = train_df.merge(user_train, on=\'did\', how=\'left\')test_df = test_df.merge(user_test, on=\'did\', how=\'left\')# 12. 特征编码 - 确保所有特征为数值类型def encode_categorical_features(train, test): # 找出所有可能的分类特征 potential_cat_features = [ \'device_brand\', \'ntt\', \'operator\', \'common_country\', \'common_province\', \'common_city\', \'appver\', \'channel\', \'os_type\', \'botId\', \'pluginId\', \'time_segment\', \'bot_plugin\', \'device_os\', \'time_week_combo\', \'plugin_time\' ] # 只处理实际存在于数据中的特征 cat_features = [col for col in potential_cat_features if col in train.columns and col in test.columns] # 找出所有object类型的列 object_cols = list(set( train.select_dtypes(include=[\'object\']).columns.tolist() + test.select_dtypes(include=[\'object\']).columns.tolist() )) # 合并分类特征和object类型特征 all_cat_features = list(set(cat_features + object_cols)) # 使用LabelEncoder进行编码 label_encoders = {} for col in all_cat_features: if col in train.columns and col in test.columns: # 处理训练集和测试集中可能出现的不同类别 all_values = pd.concat([train[col].astype(str), test[col].astype(str)]) le = LabelEncoder() le.fit(all_values) # 转换训练集和测试集 train[col] = le.transform(train[col].astype(str)) test[col] = le.transform(test[col].astype(str)) label_encoders[col] = le # 确保所有特征为数值类型 for df in [train, test]: for col in df.columns: if df[col].dtype.name == \'object\': # 对于非分类特征,使用简单的哈希编码 df[col] = df[col].astype(\'str\').apply(lambda x: hash(x) % 10000) return train, test, all_cat_featurestrain_df, test_df, cat_features = encode_categorical_features(train_df, test_df)# 13. 特征对齐def align_features(train_df, test_df, target_col=\'is_new_did\'): # 获取训练集特征列(排除目标列) train_cols = [col for col in train_df.columns if col != target_col] # 获取测试集列 test_cols = test_df.columns # 找出只存在于一方的列 only_in_train = [col for col in train_cols if col not in test_cols] only_in_test = [col for col in test_cols if col not in train_cols] print(f\"只存在于训练集的列: {only_in_train}\") print(f\"只存在于测试集的列: {only_in_test}\") # 对齐特征 for col in only_in_train: # 对于数值列填充0,对于其他列填充合适的值 if train_df[col].dtype.kind in \'iufc\': # 数值类型 test_df[col] = 0 else: test_df[col] = train_df[col].iloc[0] if len(train_df) > 0 else 0 for col in only_in_test: # 对于数值列填充0,对于其他列填充合适的值 if test_df[col].dtype.kind in \'iufc\': # 数值类型 train_df[col] = 0 else: train_df[col] = test_df[col].iloc[0] if len(test_df) > 0 else 0 # 确保列顺序一致 test_df = test_df[train_cols] return train_df, test_dftrain_df, test_df = align_features(train_df, test_df)# 14. 准备模型数据def prepare_model_data(train, test, submit, target_col=\'is_new_did\'): # 排除非特征列 non_feature_cols = [\'did\', \'udmap\', \'common_ts\', \'ts\', \'is_in_train\', \'data_type\', target_col] # 动态选择所有可用特征 features = [col for col in train.columns if col not in non_feature_cols and col in test.columns] # 确保所有特征为数值类型 for col in features: if train[col].dtype.name == \'object\': # 对于任何剩余的object类型,使用哈希编码 train[col] = train[col].astype(\'str\').apply(lambda x: hash(x) % 10000) if col in test.columns and test[col].dtype.name == \'object\': test[col] = test[col].astype(\'str\').apply(lambda x: hash(x) % 10000) print(f\"最终使用的特征数量: {len(features)}\") print(f\"前10个特征: {features[:10]}\") # 打印特征数据类型分布 print(\"\\n特征数据类型分布:\") print(train[features].dtypes.value_counts()) # 准备训练和测试数据 X_train = train[features] y_train = train[target_col] # 确定需要预测的样本 need_predict_mask = (submit[target_col] == -1) X_test = test.loc[need_predict_mask, features] return X_train, y_train, X_test, features, need_predict_maskX_train, y_train, X_test, features, need_predict_mask = prepare_model_data( train_df, test_df, submit)# 15. 优化F1阈值搜索def find_optimal_threshold(y_true, y_pred_proba): best_threshold = 0.5 best_f1 = 0 thresholds = np.linspace(0.01, 0.99, 100) for threshold in thresholds: y_pred = (y_pred_proba >= threshold).astype(int) f1 = f1_score(y_true, y_pred) if f1 > best_f1: best_f1 = f1 best_threshold = threshold return best_threshold, best_f1# 16. 模型训练与交叉验证def train_model(X_train, y_train, X_test, features): # 设置随机种子 seed = int(time.time()) % 10000 # 模型参数 params = { \'objective\': \'binary\', \'metric\': \'binary_logloss\', # 使用logloss作为早期停止指标 \'boosting_type\': \'gbdt\', \'max_depth\': 10, \'num_leaves\': 127, \'learning_rate\': 0.05, \'feature_fraction\': 0.8, \'bagging_fraction\': 0.8, \'bagging_freq\': 3, \'min_child_samples\': 20, \'class_weight\': \'balanced\', # 处理类别不平衡 \'verbose\': -1, \'n_jobs\': 4, \'seed\': seed } # 交叉验证设置 n_folds = 5 kf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=42) # 初始化结果存储 test_preds = np.zeros(len(X_test)) oof_probas = np.zeros(len(X_train)) fold_thresholds = [] fold_f1_scores = [] print(\"\\n开始交叉验证训练...\") # 交叉验证循环 for fold, (tr_idx, val_idx) in enumerate(kf.split(X_train, y_train)): print(f\"\\n=== Fold {fold + 1}/{n_folds} ===\") # 分割数据 X_tr, X_val = X_train.iloc[tr_idx], X_train.iloc[val_idx] y_tr, y_val = y_train.iloc[tr_idx], y_train.iloc[val_idx] # 创建LightGBM数据集 train_set = lgb.Dataset(X_tr, label=y_tr) val_set = lgb.Dataset(X_val, label=y_val, reference=train_set) # 训练模型 model = lgb.train( params, train_set, num_boost_round=1000, valid_sets=[val_set], callbacks=[ lgb.early_stopping(stopping_rounds=50, verbose=True), lgb.log_evaluation(period=100) ] ) # 验证集预测 val_proba = model.predict(X_val) oof_probas[val_idx] = val_proba # 寻找最佳阈值 best_thresh, best_f1 = find_optimal_threshold(y_val, val_proba) fold_thresholds.append(best_thresh) fold_f1_scores.append(best_f1) print(f\"Fold {fold + 1} 最佳阈值: {best_thresh:.4f}, F1: {best_f1:.4f}\") # 测试集预测 test_preds += model.predict(X_test) / n_folds # 计算平均阈值 avg_thresh = np.mean(fold_thresholds) # 计算OOF F1分数 oof_preds = (oof_probas >= avg_thresh).astype(int) overall_f1 = f1_score(y_train, oof_preds) # 打印交叉验证结果 print(\"\\n===== 交叉验证结果 =====\") print(f\"平均最佳阈值: {avg_thresh:.4f}\") print(f\"各折F1分数: {[f\'{f:.4f}\' for f in fold_f1_scores]}\") print(f\"平均F1分数: {np.mean(fold_f1_scores):.4f}\") print(f\"OOF F1分数: {overall_f1:.4f}\") # 特征重要性分析(使用最后一个模型) feature_importance = pd.DataFrame({ \'Feature\': features, \'Importance\': model.feature_importance(importance_type=\'gain\') }).sort_values(\'Importance\', ascending=False) print(\"\\nTop 10重要特征:\") print(feature_importance.head(10)) # 可视化特征重要性 plt.figure(figsize=(12, 8)) top_features = feature_importance.head(20) plt.barh(top_features[\'Feature\'], top_features[\'Importance\']) plt.xlabel(\'Importance\') plt.title(\'Top 20 Feature Importance\') plt.gca().invert_yaxis() plt.tight_layout() plt.savefig(\'feature_importance.png\') print(\"特征重要性图已保存: feature_importance.png\") return test_preds, avg_thresh# 训练模型并获取预测结果test_probs, optimal_thresh = train_model(X_train, y_train, X_test, features)# 17. 生成最终提交文件def generate_submission(submit, test_probs, need_predict_mask, threshold): # 设置预测结果 submit.loc[need_predict_mask, \'is_new_did\'] = (test_probs >= threshold).astype(int) submit[\'is_new_did\'] = submit[\'is_new_did\'].astype(int) # 分析预测结果 total_samples = len(submit) overlap_samples = total_samples - need_predict_mask.sum() new_user_ratio = submit[\'is_new_did\'].mean() overlap_new_ratio = submit.loc[~need_predict_mask, \'is_new_did\'].mean() if overlap_samples > 0 else 0 predicted_new_ratio = submit.loc[need_predict_mask, \'is_new_did\'].mean() if need_predict_mask.sum() > 0 else 0 print(f\"\\n预测结果分析:\") print(f\"总样本数: {total_samples}\") print(f\"重叠用户占比: {overlap_samples / total_samples:.4f}\") print(f\"重叠用户中新增比例: {overlap_new_ratio:.4f}\") print(f\"预测用户中新增比例: {predicted_new_ratio:.4f}\") print(f\"整体新增比例: {new_user_ratio:.4f}\") # 保存提交文件 submit[[\'did\', \'is_new_did\']].to_csv(\'submit.csv\', index=False) print(\"\\n提交文件已生成: submit.csv\")# 生成提交文件generate_submission(submit, test_probs, need_predict_mask, optimal_thresh)