Java处理PDF就靠它!Apache PDFBox:开源免费的PDF全能王

01 引言
在日常开发中,我们可能会遇到PDF的处理,如PDF的内容提取、分割、合并等操作。你们都是用什么工具操作的呢?
今天介绍一款Apache出品的工具PDFBox,作为Apache基金会开源项目,它以轻量级、高扩展性著称,完美解决PDF的解析、生成与操作难题。
官网地址:https://pdfbox.apache.org/
02 核心功能一览

Apache PDFBox库是用于处理PDF文档的开源 Java 工具。此项目允许创建新的 PDF 文档、作现有文档以及从文档中提取内容的能力。Apache PDFBox 还包括几个命令行实用程序。Apache PDFBox 在 Apache 许可证 v2.0 下发布。
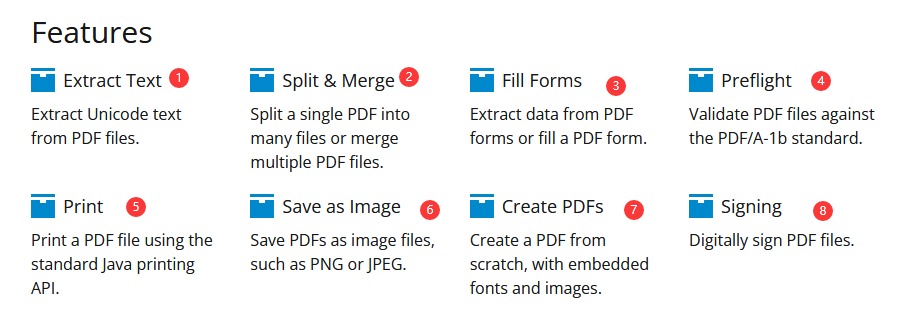
主要有8个功能:
- 从
PDF文件提取中文本 PDF的合并和分割- 从
PDF表单中提取数据,或填充PDF表单 - 验证
PDF否符合PDF/A-1b标准 - 使用标准的
Java打印API打印PDF文件 - 将
PDF文件另存为图像格式 - 从零开始创建
PDF文件,包括嵌入字体和图像 - 对
PDF文件进行数字签名
03 功能展示
Apache PDFBox 主要提供了8个功能,通过演示几个常用的功能,了解一下Apache PDFBox的魅力。
展示的版本为当期那最新版本3.0.5:
<dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfbox</artifactId> <version>3.0.5</version></dependency>3.1 文本提取
文本提取的关键类:org.apache.pdfbox.text.PDFTextStripper
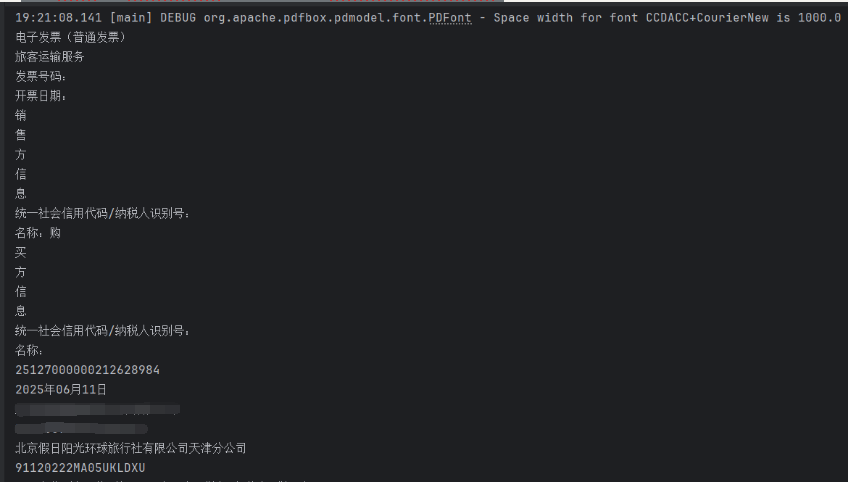
@Testvoid test01() throws IOException { try (PDDocument pdDocument = Loader.loadPDF(ResourceUtils.getFile(\"classpath:pdf/wyc-fp.pdf\"))){ PDFTextStripper textStripper = new PDFTextStripper(); String text = textStripper.getText(pdDocument); System.out.println(text); }}因为PDDocument使用完毕之后需要关闭资源,类似JDK中的流。这里使用try-with-resources自动关闭资源。案例提取了一张网约车发票的信息。
结果展示
3.2 PDF合并
PDF合并的关键类是:org.apache.pdfbox.multipdf.PDFMergerUtility
@Testvoid test02() throws IOException { PDFMergerUtility pdfMerger = new PDFMergerUtility(); pdfMerger.addSource(ResourceUtils.getFile(\"classpath:pdf/wyc-fp.pdf\")); pdfMerger.addSource(ResourceUtils.getFile(\"classpath:pdf/wyc-fp2.pdf\")); // 设置合并后的pdf名称 pdfMerger.setDestinationFileName(\"merge-fp.pdf\");// pdfMerger.setDestinationStream(new FileOutputStream(file)); pdfMerger.mergeDocuments(MemoryUsageSetting.setupMainMemoryOnly().streamCache); System.out.println(\"PDF文件合并完成\");}通过addSource()方法,添加要合并的PDF资源。然后设置合并后的PDF名称,也可以通过setDestinationStream()指定合并的PDF保存的位置。
执行结果
默认保存在项目的根路径下面:

3.3 提取图像
提取PDF中图像的关键类:org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject
@Testvoid test03() throws Exception { try (PDDocument pdDocument = Loader.loadPDF(ResourceUtils.getFile(\"classpath:pdf/wyc-fp.pdf\"));) { // 获取第一页:因为只有一页 PDPage page = pdDocument.getPage(0); PDResources resources = page.getResources(); Iterable<COSName> xObjectNames = resources.getXObjectNames(); for (COSName xObjectName : xObjectNames) { // 判断是否包含图片对象 if (resources.isImageXObject(xObjectName)) { PDImageXObject imageObject = (PDImageXObject) resources.getXObject(xObjectName); BufferedImage bImage = imageObject.getImage(); // 将图像保存为 PNG 格式 try (ByteArrayOutputStream baos = new ByteArrayOutputStream()) { // 将图片写入输出流里面 ImageIO.write(bImage, \"png\", baos); byte[] imageBytes = baos.toByteArray(); String imageFilePath = \"image_\" + System.currentTimeMillis() + \".png\"; try (FileOutputStream fos = new FileOutputStream(imageFilePath)) { fos.write(imageBytes); System.out.println(\"Page Image path: \" + imageFilePath); } } } } }}通过resources.getXObject(xObjectName)获取图像资源,通过ImageIO.write()写到输出流里面
执行结果
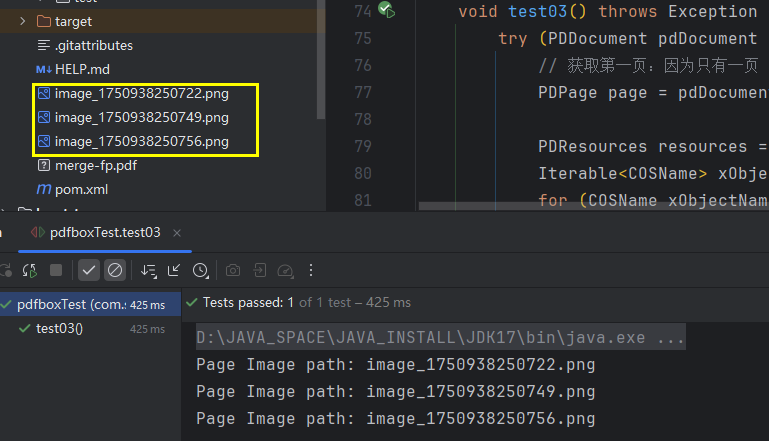
可以看出打印和输出的图片名称和图片。提取出了那些图片呢?

这里为了方便截图,将三张图展示在了一起。
3.4 增加签章
增加签章的关键类:org.apache.pdfbox.pdmodel.PDPageContentStream
@Testvoid test04() throws Exception { PDDocument pdDocument = Loader.loadPDF(ResourceUtils.getFile(\"classpath:pdf/wyc-fp.pdf\")); PDImageXObject pdImage = PDImageXObject.createFromFile(\"src/main/resources/pdf/apache-logo.jpg\", pdDocument); // 设置logo的宽度和高度 float imageWidth = 100; float imageHeight = 100; if (pdDocument != null) { PDPage page = pdDocument.getPage(pdDocument.getNumberOfPages() - 1); float pageWidth = page.getMediaBox().getWidth();; // 计算logo位置:页面右下角 float x = pageWidth - imageWidth - 20; // 右边距20 float y = 20; // 下边距20 // 为最后一页创建一个新的内容流以添加logo try (PDPageContentStream contentStream = new PDPageContentStream(pdDocument, page, PDPageContentStream.AppendMode.APPEND, true, true)) { // 绘制logo图片 contentStream.drawImage(pdImage, x, y, imageWidth, imageHeight); } pdDocument.save(\"logo_\" + System.currentTimeMillis() + \".pdf\"); // 保存修改后的PDF }}这里的签章用的是Apache的logo。将签章放在右下角。
执行结果

04 避坑指南
4.1 内存泄露的风险
用完必须关闭文档对象。推荐Try-with-resources:
try (PDDocument pdDocument = Loader.loadPDF(file)){ // *** }4.2 版本差异
2.0.x与3.0存在API部分不兼容,如:
// 2.0.x 加载文件PDDocument.load(file) // 3.0 加载文件Loader.loadPDF(file) 4.3 JDK版本要求差异
2.0.x与3.0对JDK版本最低要求不一样
# 2.0.x 最低要求:JDK1.6# 3.0 最低要求:JDK1.805 小结
Apache PDFBox以其简洁的API设计和强大的底层能力,成为Java开发者处理PDF的首选利器。无论是自动化报表生成还是文档分析系统,它都能提供可靠支持。结合本文的代码示例与避坑指南,可快速构建稳健的PDF处理流程。
本文只是简单的介绍了其部分功能,里面还有很多深藏的功能,等待你去挖掘!

