第二篇【AI与传奇开心果系列】Python的AI技术点库案例示例:详解AI工业应用算法原理
AI与传奇开心果系列博文
- 系列博文目录
-
- Python的AI技术点库案例示例系列
- 博文目录
-
- 前言
- 一、AI工业应用算法原理介绍
- 二、机器学习在工业领域的应用算法示例代码
- 三、深度学习算法在工业领域应用示例代码
- 四、强化学习在工业领域应用示例代码
- 五、自然语言处理在工业领域应用示例代码
- 六、图像处理算法在工业领域应用示例代码
- 七、时间序列分析算法在工业领域应用示例代码
- 八、遗传算法在工业领域应用示例代码
- 九、聚类算法在工业领域应用示例代码
- 十、知识点归纳
系列博文目录
Python的AI技术点库案例示例系列
博文目录

前言
掌握 AI 工业应用算法原理具有重要作用。它可以帮助我们理解和优化生产流程,提高生产质量和效率。通过算法,我们能实现设备的预测性维护,降低成本并提高设备可靠性。此外,算法还能推动智能制造和自动化,加速工业的转型升级。在竞争激烈的市场中,掌握这一原理将为企业带来更大的优势和发展机会。

一、AI工业应用算法原理介绍
AI工业应用算法原理有很多种,常见的包括:
-
机器学习算法原理:包括监督学习、无监督学习和强化学习等。监督学习在工业应用包括支持向量机(SVM)、决策树、随机森林、神经网络等。无监督学习在工业应用中包括数据挖掘、异常检测、聚类分析等任务。再比如强化学习在工业应用包括控制系统优化、资源分配与调度、智能物联网(IoT)应用、设备维护与故障诊断等。
-
深度学习算法原理:如卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆神经网络(LSTM)等。
-
强化学习算法原理:如Q学习、深度强化学习等。
-
自然语言处理算法原理:如词嵌入、文本分类、命名实体识别等。
-
图像处理算法原理:如目标检测、图像分割、图像识别等。
-
时间序列分析算法原理:如ARIMA模型、LSTM模型等。
-
遗传算法原理:用于解决优化问题。
-
聚类算法原理:如K均值算法、层次聚类算法等。

二、机器学习在工业领域的应用算法示例代码

(一)监督学习在工业应用示例代码

(1)支持向量机在工业应用示例代码
- 支持向量机(SVM)介绍
支持向量机(SVM)是一种常用的监督学习算法,在工业领域中有广泛的应用。其主要作用是通过寻找一个最优的超平面来进行分类或回归任务,使得不同类别的样本能够被清晰地分开。SVM在工业领域中常用于故障诊断、质量控制、预测分析等方面。通过调整SVM的参数和核函数,可以适应不同类型的数据集和问题,具有较强的泛化能力和高准确率。同时,SVM还可以处理高维数据和非线性关系,适用于复杂的工业场景。通过合理地应用SVM算法,可以提高工业生产效率、降低成本,实现智能化生产管理。

- 工业领域故障诊断示例代码
以下是一个简单的示例代码,演示了如何使用支持向量机(SVM)在工业领域进行故障诊断:
# 导入必要的库import numpy as npfrom sklearn.svm import SVCfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# 模拟工业数据,特征为传感器数据,标签为故障类型X = np.random.rand(100, 5) # 100个样本,每个样本5个特征y = np.random.randint(0, 2, 100) # 二分类标签,0表示正常,1表示故障# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器clf = SVC()# 在训练集上训练模型clf.fit(X_train, y_train)# 在测试集上进行预测y_pred = clf.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)在这个示例中,我们使用随机生成的工业数据进行故障诊断任务,特征为传感器数据,标签为故障类型(二分类)。我们将数据集划分为训练集和测试集,然后使用SVM分类器进行训练和预测,并计算准确率来评估模型的性能。在实际工业应用中,可以根据具体的故障诊断问题和数据特点进行调参和优化,以获得更好的诊断效果。
以下是一个示例代码,演示了如何根据具体的故障诊断问题和数据特点进行调参和优化,以获得更好的诊断效果:
# 导入必要的库import numpy as npfrom sklearn.svm import SVCfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.metrics import accuracy_score# 模拟工业数据,特征为传感器数据,标签为故障类型X = np.random.rand(100, 5) # 100个样本,每个样本5个特征y = np.random.randint(0, 2, 100) # 二分类标签,0表示正常,1表示故障# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器svm = SVC()# 定义参数网格param_grid = {\'C\': [0.1, 1, 10, 100], \'gamma\': [0.001, 0.01, 0.1, 1], \'kernel\': [\'rbf\', \'linear\']}# 使用GridSearchCV进行参数调优grid_search = GridSearchCV(svm, param_grid, cv=5)grid_search.fit(X_train, y_train)# 获取最佳参数best_params = grid_search.best_params_print(\"最佳参数:\", best_params)# 在测试集上进行预测y_pred = grid_search.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)在这个示例中,我们使用GridSearchCV进行参数调优,通过定义参数网格来搜索最佳的参数组合。在实际工业应用中,可以根据具体的故障诊断问题和数据特点,调整参数范围和搜索策略,以获得更好的诊断效果。通过合理地调参和优化,可以提高模型的性能和泛化能力,从而更好地应用于工业领域的故障诊断任务中。

- 支持向量机在工业领域质量控制示例代码
以下是一个示例代码,演示了支持向量机在工业领域质量控制任务中的应用:
# 导入必要的库import numpy as npfrom sklearn.svm import SVCfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score, classification_report# 模拟工业数据,特征为生产过程中的参数,标签为产品的质量等级# 假设有5个质量等级,用0到4表示X = np.random.rand(1000, 10) # 1000个样本,每个样本10个特征y = np.random.randint(0, 5, 1000) # 5个质量等级# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器svm = SVC(kernel=\'rbf\', C=1, gamma=\'scale\')# 在训练集上训练模型svm.fit(X_train, y_train)# 在测试集上进行预测y_pred = svm.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们使用随机生成的工业数据,特征为生产过程中的参数,标签为产品的质量等级(假设有5个等级)。我们将数据集划分为训练集和测试集,然后使用SVM分类器进行训练和预测,并计算准确率以及输出分类报告来评估模型的性能。在实际工业应用中,可以根据具体的质量控制问题和数据特点进行调参和优化,以获得更好的质量预测效果。
在实际工业应用中,针对具体的质量控制问题和数据特点进行调参和优化是非常重要的。下面是一个示例代码,演示了如何使用GridSearchCV对支持向量机模型进行参数调优,以获得更好的质量预测效果:
from sklearn.model_selection import GridSearchCVfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_score, classification_reportimport numpy as npfrom sklearn.model_selection import train_test_split# 模拟工业数据,特征为生产过程中的参数,标签为产品的质量等级# 假设有5个质量等级,用0到4表示X = np.random.rand(1000, 10) # 1000个样本,每个样本10个特征y = np.random.randint(0, 5, 1000) # 5个质量等级# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器svm = SVC()# 定义参数网格param_grid = {\'C\': [0.1, 1, 10], \'gamma\': [0.001, 0.01, 0.1], \'kernel\': [\'rbf\', \'linear\']}# 使用GridSearchCV进行参数调优grid_search = GridSearchCV(svm, param_grid, cv=5)grid_search.fit(X_train, y_train)# 获取最佳参数best_params = grid_search.best_params_print(\"最佳参数:\", best_params)# 在测试集上进行预测y_pred = grid_search.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们使用GridSearchCV对支持向量机模型进行参数调优,通过定义参数网格来搜索最佳的参数组合。在实际工业应用中,可以根据具体的质量控制问题和数据特点调整参数范围和搜索策略,以获得更好的质量预测效果。通过合理地调参和优化,可以提高模型的性能和泛化能力,从而更好地应用于工业领域的质量控制任务中。

- 支持向量机在工业预测分析应用示例代码
支持向量机(Support Vector Machine,SVM)在工业预测分析方面有广泛的应用,例如在故障预测、质量控制、异常检测等方面。下面是一个示例代码,演示了如何使用SVM模型对工业数据进行异常检测:
from sklearn.svm import OneClassSVMfrom sklearn.metrics import accuracy_score, classification_reportimport numpy as npfrom sklearn.model_selection import train_test_split# 模拟工业数据,特征为生产过程中的参数X = np.random.rand(1000, 10) # 1000个样本,每个样本10个特征# 标记正常数据为1,异常数据为-1y = np.ones(1000)y[:100] = -1 # 将前100个样本标记为异常数据# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建OneClassSVM模型svm = OneClassSVM(kernel=\'rbf\', nu=0.1)# 在训练集上训练模型svm.fit(X_train)# 在测试集上进行预测y_pred = svm.predict(X_test)# 将预测结果中的-1转换为0y_pred[y_pred == -1] = 0# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们使用OneClassSVM模型对工业数据进行异常检测,其中标记为1的样本表示正常数据,标记为-1的样本表示异常数据。我们将数据集划分为训练集和测试集,然后使用OneClassSVM模型进行训练和预测,并计算准确率以及输出分类报告来评估模型的性能。在实际工业应用中,可以根据具体的预测分析问题和数据特点调整模型参数和数据处理方法,以获得更好的预测效果。
在实际工业应用中,根据具体的预测分析问题和数据特点调整模型参数和数据处理方法是非常重要的。下面是一个示例代码,演示了如何根据具体需求调整SVM模型参数和数据处理方法来优化预测效果:
from sklearn.svm import SVCfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.metrics import accuracy_score, classification_reportimport numpy as np# 模拟工业数据,特征为生产过程中的参数X = np.random.rand(1000, 10) # 1000个样本,每个样本10个特征# 标记正常数据为1,异常数据为0y = np.random.randint(0, 2, 1000) # 随机生成0和1的标记# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器svm = SVC()# 定义参数网格param_grid = {\'C\': [0.1, 1, 10], \'gamma\': [0.001, 0.01, 0.1], \'kernel\': [\'rbf\', \'linear\']}# 使用GridSearchCV进行参数调优grid_search = GridSearchCV(svm, param_grid, cv=5)grid_search.fit(X_train, y_train)# 获取最佳参数best_params = grid_search.best_params_print(\"最佳参数:\", best_params)# 在测试集上进行预测y_pred = grid_search.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们根据具体的预测分析问题和数据特点,调整了SVM模型的参数网格,并使用GridSearchCV进行参数调优。通过网格搜索找到最佳参数组合,可以提高模型的性能和泛化能力。在实际工业应用中,根据具体情况灵活调整模型参数和数据处理方法,可以使预测模型更好地适应工业数据,并取得更好的预测效果。
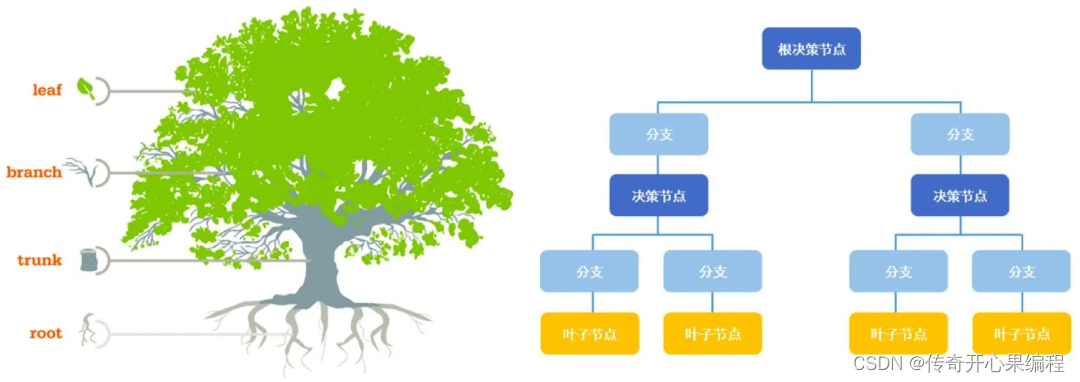
(2)决策树在工业应用示例代码

- 工业领域应用决策树模型进行故障诊断的过程示例代码
以下是一个简单的示例代码,演示了如何在工业领域应用决策树模型进行故障诊断的过程:
from sklearn.tree import DecisionTreeClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score, classification_reportimport numpy as np# 模拟工业数据,特征为传感器采集的参数X = np.random.rand(1000, 5) # 1000个样本,每个样本5个特征# 标记正常数据为1,故障数据为0y = np.random.randint(0, 2, 1000) # 随机生成0和1的标记# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器dt_classifier = DecisionTreeClassifier()# 在训练集上训练模型dt_classifier.fit(X_train, y_train)# 在测试集上进行预测y_pred = dt_classifier.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们使用决策树模型对工业传感器数据进行故障诊断。首先生成了随机的模拟工业数据,然后将数据划分为训练集和测试集。接着创建了决策树分类器,并在训练集上训练模型。最后在测试集上进行预测,计算准确率并输出分类报告。在实际工业应用中,可以根据具体的故障诊断问题和数据特点,调整模型参数、特征工程等方法,以获得更好的故障诊断效果。

以下是一个示例代码,展示如何在工业应用中使用决策树模型进行故障诊断,并根据具体问题和数据特点进行模型参数调整和特征工程:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import accuracy_score, classification_report# 读取工业故障诊断数据data = pd.read_csv(\'industrial_fault_diagnosis_data.csv\')# 提取特征和标签X = data.drop(\'fault_label\', axis=1)y = data[\'fault_label\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器,并调整参数dt_classifier = DecisionTreeClassifier(max_depth=5, min_samples_split=5, random_state=42)# 在训练集上训练模型dt_classifier.fit(X_train, y_train)# 在测试集上进行预测y_pred = dt_classifier.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们首先读取了工业故障诊断的数据,然后进行了特征提取并划分训练集和测试集。接着创建了决策树分类器,并通过调整max_depth、min_samples_split等参数来优化模型。最后在测试集上进行预测,计算准确率并输出分类报告。这个示例展示了如何根据具体问题和数据特点调整模型参数以及进行特征工程,从而获得更好的故障诊断效果。

- 决策树在工业质量控制领域应用示例代码
以下是一个示例代码,展示如何在工业质量控制领域应用决策树模型进行质量控制:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import accuracy_score, classification_report# 读取工业质量控制数据data = pd.read_csv(\'industrial_quality_control_data.csv\')# 提取特征和标签X = data.drop(\'quality_label\', axis=1)y = data[\'quality_label\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器,并调整参数dt_classifier = DecisionTreeClassifier(max_depth=5, min_samples_split=5, random_state=42)# 在训练集上训练模型dt_classifier.fit(X_train, y_train)# 在测试集上进行预测y_pred = dt_classifier.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们首先读取了工业质量控制的数据,然后进行了特征提取并划分训练集和测试集。接着创建了决策树分类器,并通过调整max_depth、min_samples_split等参数来优化模型。最后在测试集上进行预测,计算准确率并输出分类报告。这个示例展示了如何在工业质量控制领域应用决策树模型进行质量控制。

- 决策树在工业分析预测领域应用示例代码
以下是一个示例代码,展示如何在工业分析预测领域应用决策树模型进行预测分析:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeRegressorfrom sklearn.metrics import mean_squared_error, r2_score# 读取工业分析预测数据data = pd.read_csv(\'industrial_analysis_prediction_data.csv\')# 提取特征和标签X = data.drop(\'prediction_label\', axis=1)y = data[\'prediction_label\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树回归模型,并调整参数dt_regressor = DecisionTreeRegressor(max_depth=5, min_samples_split=5, random_state=42)# 在训练集上训练模型dt_regressor.fit(X_train, y_train)# 在测试集上进行预测y_pred = dt_regressor.predict(X_test)# 计算均方误差和R2分数mse = mean_squared_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)print(\"均方误差:\", mse)print(\"R2分数:\", r2)在这个示例中,我们首先读取了工业分析预测的数据,然后进行了特征提取并划分训练集和测试集。接着创建了决策树回归模型,并通过调整max_depth、min_samples_split等参数来优化模型。最后在测试集上进行预测,计算均方误差和R2分数。这个示例展示了如何在工业分析预测领域应用决策树模型进行预测分析。

(3)随机森林在工业领域应用示例代码

- 随机森林工业故障诊断
以下是一个示例代码,展示如何在工业故障诊断领域应用随机森林模型进行故障诊断:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, classification_report# 读取工业故障诊断数据data = pd.read_csv(\'industrial_fault_diagnosis_data.csv\')# 提取特征和标签X = data.drop(\'diagnosis_label\', axis=1)y = data[\'diagnosis_label\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建随机森林分类器,并调整参数rf_classifier = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)# 在训练集上训练模型rf_classifier.fit(X_train, y_train)# 在测试集上进行预测y_pred = rf_classifier.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(\"准确率:\", accuracy)# 输出分类报告print(classification_report(y_test, y_pred))在这个示例中,我们首先读取了工业故障诊断的数据,然后进行了特征提取并划分训练集和测试集。接着创建了随机森林分类器,并通过调整n_estimators、max_depth等参数来优化模型。最后在测试集上进行预测,计算准确率并输出分类报告。这个示例展示了如何在工业故障诊断领域应用随机森林模型进行故障诊断。

- 随机森林在工业质量控制应用示例代码
以下是一个示例代码,展示如何在工业质量控制领域应用随机森林模型进行质量控制:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.metrics import mean_squared_error, r2_score# 读取工业质量控制数据data = pd.read_csv(\'industrial_quality_control_data.csv\')# 提取特征和标签X = data.drop(\'quality_label\', axis=1)y = data[\'quality_label\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建随机森林回归模型,并调整参数rf_regressor = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)# 在训练集上训练模型rf_regressor.fit(X_train, y_train)# 在测试集上进行预测y_pred = rf_regressor.predict(X_test)# 计算均方误差和R2分数mse = mean_squared_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)print(\"均方误差:\", mse)print(\"R2分数:\", r2)在这个示例中,我们首先读取了工业质量控制的数据,然后进行了特征提取并划分训练集和测试集。接着创建了随机森林回归模型,并通过调整n_estimators、max_depth等参数来优化模型。最后在测试集上进行预测,计算均方误差和R2分数。这个示例展示了如何在工业质量控制领域应用随机森林模型进行质量控制。

- 随机森林在工业分析预测应用示例代码
以下是一个示例代码,展示如何在工业分析预测领域应用随机森林模型进行数据分析预测:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.metrics import mean_squared_error, r2_score# 读取工业分析预测数据data = pd.read_csv(\'industrial_analytics_data.csv\')# 提取特征和标签X = data.drop(\'prediction_label\', axis=1)y = data[\'prediction_label\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建随机森林回归模型,并调整参数rf_regressor = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)# 在训练集上训练模型rf_regressor.fit(X_train, y_train)# 在测试集上进行预测y_pred = rf_regressor.predict(X_test)# 计算均方误差和R2分数mse = mean_squared_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)print(\"均方误差:\", mse)print(\"R2分数:\", r2)在这个示例中,我们首先读取了工业分析预测的数据,然后进行了特征提取并划分训练集和测试集。接着创建了随机森林回归模型,并通过调整n_estimators、max_depth等参数来优化模型。最后在测试集上进行预测,计算均方误差和R2分数。这个示例展示了如何在工业分析预测领域应用随机森林模型进行数据分析预测。

(4)神经网络在工业应用示例代码

- 神经网络在工业故障诊断应用示例代码
以下是一个简单的示例代码,展示了如何使用神经网络进行工业设备故障诊断。这里使用 Python 中的 TensorFlow 框架来构建神经网络模型,并使用一个虚拟的故障诊断数据集进行训练和测试。
import tensorflow as tfimport numpy as np# 创建一个虚拟的故障诊断数据集X = np.random.rand(1000, 5) # 特征数据y = np.random.randint(0, 2, size=(1000, 1)) # 标签数据,0表示正常,1表示故障# 构建神经网络模型model = tf.keras.Sequential([ tf.keras.layers.Dense(10, activation=\'relu\', input_shape=(5,)), tf.keras.layers.Dense(1, activation=\'sigmoid\')])# 编译模型model.compile(optimizer=\'adam\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 训练模型model.fit(X, y, epochs=10, batch_size=32, validation_split=0.2)# 使用模型进行预测predictions = model.predict(X)# 输出预测结果print(predictions)在这个示例中,我们首先创建了一个虚拟的故障诊断数据集,包括特征数据 X 和标签数据 y。然后使用 TensorFlow 构建了一个简单的神经网络模型,包括一个输入层、一个隐藏层和一个输出层。接着编译模型,指定了优化器、损失函数和评估指标。然后训练模型,使用数据集 X 和 y 进行训练。最后使用训练好的模型进行预测,并输出预测结果。
请注意,这只是一个简单的示例代码,实际工业故障诊断的应用可能需要更复杂的数据预处理、特征工程和模型调优过程。在实际应用中,还需要根据具体情况选择合适的神经网络结构、优化算法和调参策略,以提高模型的准确性和泛化能力。
以下是一个稍微复杂一点的示例代码,展示了如何在工业故障诊断中根据具体情况选择合适的神经网络结构、优化算法和调参策略。
import tensorflow as tffrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import accuracy_score# 加载工业故障诊断数据集# 假设数据集包含特征数据 X 和标签数据 y# 数据预处理scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 构建神经网络模型model = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation=\'relu\', input_shape=(X_train.shape[1],)), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(32, activation=\'relu\'), tf.keras.layers.Dense(1, activation=\'sigmoid\')])# 编译模型model.compile(optimizer=\'adam\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 训练模型model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test))# 在测试集上评估模型y_pred = model.predict(X_test)y_pred_binary = (y_pred > 0.5).astype(int)accuracy = accuracy_score(y_test, y_pred_binary)print(\"准确率:\", accuracy)在这个示例中,我们首先加载工业故障诊断数据集,并进行数据预处理,包括特征标准化和数据集划分。然后构建了一个稍复杂一点的神经网络模型,包括一个输入层、一个隐藏层、一个 Dropout 层(用于防止过拟合)和一个输出层。编译模型时使用了 Adam 优化器和二元交叉熵损失函数。接着在训练集上训练模型,同时在测试集上评估模型性能,计算准确率并输出结果。
这个示例代码展示了在工业故障诊断中如何根据具体情况选择合适的神经网络结构、优化算法和调参策略,以提高模型的准确性和泛化能力。在实际应用中,还可以进一步调整神经网络的结构、学习率、批量大小等超参数,以优化模型性能。

- 神经网络在工业质量控制应用示例代码
以下是一个简单的示例代码,展示了如何在工业质量控制应用中使用神经网络进行产品缺陷检测。
import tensorflow as tffrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import classification_report# 加载工业质量控制数据集# 假设数据集包含特征数据 X 和标签数据 y# 数据预处理scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 构建神经网络模型model = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation=\'relu\', input_shape=(X_train.shape[1],)), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(32, activation=\'relu\'), tf.keras.layers.Dense(1, activation=\'sigmoid\')])# 编译模型model.compile(optimizer=\'adam\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 训练模型model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test))# 在测试集上评估模型y_pred = model.predict(X_test)y_pred_binary = (y_pred > 0.5).astype(int)print(classification_report(y_test, y_pred_binary))在这个示例中,我们首先加载工业质量控制数据集,并进行数据预处理,包括特征标准化和数据集划分。然后构建了一个简单的神经网络模型,包括一个输入层、一个隐藏层、一个 Dropout 层(用于防止过拟合)和一个输出层。编译模型时使用了 Adam 优化器和二元交叉熵损失函数。接着在训练集上训练模型,同时在测试集上评估模型性能,输出分类报告。
这个示例代码展示了如何在工业质量控制应用中使用神经网络进行产品缺陷检测。实际应用中,可以根据具体情况调整神经网络的结构、优化算法和超参数,以提高模型的准确性和泛化能力。同时,还可以考虑使用更复杂的神经网络结构、数据增强技术和模型集成方法来进一步提升模型性能。
以下是一个更复杂的示例代码,展示了如何在工业质量控制应用中使用更复杂的神经网络结构、数据增强技术和模型集成方法来提升模型性能。
import tensorflow as tffrom tensorflow.keras import layers, modelsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import classification_reportfrom tensorflow.keras.preprocessing.image import ImageDataGenerator# 加载工业质量控制数据集# 假设数据集包含特征数据 X 和标签数据 y# 数据增强datagen = ImageDataGenerator( rotation_range=10, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, vertical_flip=True, fill_mode=\'nearest\')# 数据预处理scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 构建更复杂的神经网络模型model1 = models.Sequential([ layers.Dense(128, activation=\'relu\', input_shape=(X_train.shape[1],)), layers.Dropout(0.3), layers.Dense(64, activation=\'relu\'), layers.Dropout(0.2), layers.Dense(32, activation=\'relu\'), layers.Dense(1, activation=\'sigmoid\')])model2 = models.Sequential([ layers.Dense(256, activation=\'relu\', input_shape=(X_train.shape[1],)), layers.Dropout(0.4), layers.Dense(128, activation=\'relu\'), layers.Dropout(0.3), layers.Dense(64, activation=\'relu\'), layers.Dense(1, activation=\'sigmoid\')])# 编译模型model1.compile(optimizer=\'adam\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])model2.compile(optimizer=\'adam\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 训练模型model1.fit(datagen.flow(X_train, y_train, batch_size=32), epochs=20, validation_data=(X_test, y_test))model2.fit(datagen.flow(X_train, y_train, batch_size=32), epochs=20, validation_data=(X_test, y_test))# 模型集成y_pred1 = model1.predict(X_test)y_pred2 = model2.predict(X_test)y_pred_ensemble = (y_pred1 + y_pred2) / 2y_pred_ensemble_binary = (y_pred_ensemble > 0.5).astype(int)print(classification_report(y_test, y_pred_ensemble_binary))在这个示例中,我们首先对数据进行了增强处理,使用了 ImageDataGenerator 来进行数据增强,包括旋转、平移、剪切、缩放和翻转等操作。然后构建了两个更复杂的神经网络模型,分别为 model1 和 model2,它们具有更多的隐藏层和节点。接着编译并训练了这两个模型,同时使用数据增强技术来提升模型的泛化能力。最后,对两个模型的预测结果进行了集成,得到了最终的预测结果,并输出了分类报告。
这个示例代码展示了如何在工业质量控制应用中使用更复杂的神经网络结构、数据增强技术和模型集成方法来提升模型性能。在实际应用中,还可以进一步尝试其他复杂的神经网络结构、调整数据增强的参数、使用交叉验证等技术来进一步优化模型性能。

- 神经网络在工业分析预测领域应用示例代码
以下是一个示例代码,展示了如何在工业分析预测领域应用神经网络模型:
import tensorflow as tffrom tensorflow.keras import layers, modelsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import mean_squared_error# 加载工业分析预测数据集# 假设数据集包含特征数据 X 和目标数据 y# 数据预处理scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 构建神经网络模型model = models.Sequential([ layers.Dense(128, activation=\'relu\', input_shape=(X_train.shape[1],)), layers.Dropout(0.3), layers.Dense(64, activation=\'relu\'), layers.Dropout(0.2), layers.Dense(1)])# 编译模型model.compile(optimizer=\'adam\', loss=\'mean_squared_error\')# 训练模型model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test))# 预测并评估模型y_pred = model.predict(X_test)mse = mean_squared_error(y_test, y_pred)print(f\"Mean Squared Error: {mse}\")在这个示例中,我们首先对数据进行了标准化处理,然后划分了训练集和测试集。接着构建了一个简单的神经网络模型,包括两个隐藏层和一个输出层。编译模型时使用了均方误差作为损失函数。然后训练模型并在测试集上进行预测,最后计算了均方误差来评估模型的性能。
这个示例代码展示了如何在工业分析预测领域应用神经网络模型,通过对数据进行预处理、构建神经网络模型、训练模型和评估模型来实现对目标变量的预测。在实际应用中,可以根据具体问题的特点进一步调整神经网络结构、优化超参数、使用交叉验证等技术来提升模型性能。
以下是一个示例代码,展示了如何在实际应用中根据具体问题的特点调整神经网络结构、优化超参数并使用交叉验证来提升模型性能:
import tensorflow as tffrom tensorflow.keras import layers, modelsfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import mean_squared_errorfrom sklearn.model_selection import KFold# 加载数据集# 假设数据集包含特征数据 X 和目标数据 y# 数据预处理scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 定义神经网络模型def create_model(): model = models.Sequential([ layers.Dense(128, activation=\'relu\', input_shape=(X_train.shape[1],)), layers.Dropout(0.3), layers.Dense(64, activation=\'relu\'), layers.Dropout(0.2), layers.Dense(1) ]) model.compile(optimizer=\'adam\', loss=\'mean_squared_error\') return model# 使用交叉验证调优超参数model = tf.keras.wrappers.scikit_learn.KerasRegressor(build_fn=create_model, epochs=20, batch_size=32, verbose=0)param_grid = {\'optimizer\': [\'adam\', \'rmsprop\'], \'batch_size\': [32, 64, 128]}kfold = KFold(n_splits=5)grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=kfold)grid_search_result = grid_search.fit(X_train, y_train)# 获取最佳模型best_model = grid_search_result.best_estimator_# 在测试集上评估模型y_pred = best_model.predict(X_test)mse = mean_squared_error(y_test, y_pred)print(f\"Best Parameters: {grid_search_result.best_params_}\")print(f\"Mean Squared Error: {mse}\")在这个示例中,我们首先对数据进行了标准化处理,并划分了训练集和测试集。然后定义了一个函数 create_model 来创建神经网络模型,并使用 KerasRegressor 将模型包装成一个 Scikit-learn 的回归器。接着使用 GridSearchCV 和交叉验证来调优超参数,找到最佳模型。最后在测试集上评估最佳模型的性能,并输出最佳参数和均方误差。
这个示例代码展示了如何在实际应用中根据具体问题的特点调整神经网络结构、优化超参数并使用交叉验证来提升模型性能。这些技术可以帮助我们找到最佳的模型配置,从而提高模型在工业分析预测领域的表现。

(二)无监督学习示例代码

(1)无监督学习数据挖掘示例代码
以下是一个示例代码,展示了如何在工业领域中使用无监督学习技术(主成分分析)进行数据挖掘:
import pandas as pdfrom sklearn.decomposition import PCAfrom sklearn.preprocessing import StandardScalerimport matplotlib.pyplot as plt# 加载数据集# 假设数据集包含特征数据 X# 数据预处理scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 使用主成分分析进行降维pca = PCA(n_components=2)X_pca = pca.fit_transform(X_scaled)# 可视化主成分分析结果plt.scatter(X_pca[:, 0], X_pca[:, 1])plt.xlabel(\'Principal Component 1\')plt.ylabel(\'Principal Component 2\')plt.title(\'PCA Analysis\')plt.show()在这个示例中,我们首先加载数据集并进行数据预处理,包括特征数据的标准化处理。然后使用主成分分析(PCA)进行降维,将数据集的维度降低到2维。最后通过可视化展示主成分分析的结果,将数据点投影到主成分空间中。
无监督学习的主成分分析在工业领域中常用于数据降维和特征提取,有助于发现数据中的潜在结构和模式。通过主成分分析,企业可以更好地理解数据的特征和相关性,从而为数据挖掘和分析提供更深入的见解。

(2)无监督学习在工业领域异常检测应用示例代码
以下是一个示例代码,展示了如何在工业领域中使用无监督学习技术(孤立森林)进行异常检测:
import pandas as pdfrom sklearn.ensemble import IsolationForest# 加载数据集# 假设数据集包含特征数据 X# 使用孤立森林进行异常检测clf = IsolationForest(contamination=0.05, random_state=42)outliers = clf.fit_predict(X)# 标记异常点X[\'outlier\'] = outliersoutlier_df = X[X[\'outlier\'] == -1]# 输出异常点print(\"Detected outliers:\")print(outlier_df)# 可视化异常点# 假设数据集包含两个特征,用散点图展示异常点plt.scatter(X[\'feature1\'], X[\'feature2\'], c=outliers, cmap=\'coolwarm\')plt.xlabel(\'Feature 1\')plt.ylabel(\'Feature 2\')plt.title(\'Outlier Detection using Isolation Forest\')plt.show()在这个示例中,我们首先加载数据集并使用孤立森林(Isolation Forest)进行异常检测。我们设定异常点的比例为 5%(contamination=0.05),然后通过 fit_predict 方法得到每个数据点的异常标记。接着将异常点标记添加到数据集中,并输出检测到的异常点。最后通过散点图展示异常点的分布情况。
无监督学习的异常检测在工业领域中有着重要的应用,可以帮助企业及时发现异常情况并采取相应的措施。通过异常检测技术,企业可以监控设备运行状态、产品质量等方面的异常情况,从而提高生产效率和产品质量。
以下是一个示例代码,展示了如何在工业应用中使用无监督学习数据聚类分析:
import pandas as pdfrom sklearn.cluster import KMeansfrom sklearn.preprocessing import StandardScalerimport matplotlib.pyplot as plt# 加载数据集# 假设数据集包含特征数据 X# 数据预处理scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 使用K均值算法进行聚类分析kmeans = KMeans(n_clusters=3, random_state=42)clusters = kmeans.fit_predict(X_scaled)# 可视化聚类结果plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters, cmap=\'viridis\')plt.xlabel(\'Feature 1\')plt.ylabel(\'Feature 2\')plt.title(\'Clustering Analysis\')plt.show()在这个示例中,我们首先加载数据集并进行数据预处理,包括特征数据的标准化处理。然后使用 K 均值算法进行聚类分析,将数据集分为 3 个簇。最后通过可视化展示聚类结果,用不同颜色的点表示不同的簇。
无监督学习的聚类分析在工业应用中有着广泛的应用,可以帮助企业对数据进行分组,发现数据中的潜在模式和关联,从而为决策提供参考。通过聚类分析,企业可以更好地理解数据,发现数据中的规律,并做出相应的业务决策。

(三)强化学习在工业领域应用示例代码
(1)强化学习在工业领域控制系统优化应用示例代码
以下是一个示例代码,展示了如何在工业领域中使用强化学习技术(Q-learning)进行控制系统优化:
import numpy as np# 定义工业控制系统的状态空间和动作空间states = [0, 1, 2, 3, 4] # 状态空间actions = [0, 1] # 动作空间# 初始化 Q-tableQ = np.zeros((len(states), len(actions))# 定义环境参数alpha = 0.1 # 学习率gamma = 0.9 # 折扣因子epsilon = 0.1 # 探索率# 定义奖励矩阵rewards = np.array([[0, -10], [-10, 10], [-10, 10], [-10, 10], [100, -10]])# Q-learning算法def q_learning(state, max_episodes): for episode in range(max_episodes): current_state = state while current_state != 4: if np.random.uniform(0, 1) < epsilon: action = np.random.choice(actions) else: action = np.argmax(Q[current_state, :]) next_state = np.random.choice(states) reward = rewards[current_state, action] Q[current_state, action] = Q[current_state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[current_state, action]) current_state = next_state return Q# 在状态0开始训练Q-tableQ = q_learning(0, 1000)# 输出训练后的Q-tableprint(\"Trained Q-table:\")print(Q)在这个示例中,我们首先定义工业控制系统的状态空间和动作空间,然后初始化 Q-table。接着定义环境参数(学习率、折扣因子、探索率)和奖励矩阵,以及实现 Q-learning 算法。在 Q-learning 算法中,我们在状态0开始训练 Q-table,并输出训练后的Q-table。
强化学习的 Q-learning 算法在工业领域中常用于控制系统优化,帮助系统在复杂环境中学习最优的控制策略。通过强化学习技术,工业控制系统可以根据环境反馈不断调整控制策略,实现系统的自动优化和改进。
(2)强化学习在工业领域资源分配与调度应用示例代码
以下是一个示例代码,展示了如何在工业领域中使用强化学习技术(Q-learning)进行资源分配与调度的优化:
import numpy as np# 定义资源分配与调度系统的状态空间和动作空间states = [0, 1, 2, 3] # 状态空间actions = [0, 1, 2] # 动作空间# 初始化 Q-tableQ = np.zeros((len(states), len(actions))# 定义环境参数alpha = 0.1 # 学习率gamma = 0.9 # 折扣因子epsilon = 0.1 # 探索率# 定义奖励矩阵rewards = np.array([[10, 0, 0], [0, 20, 0], [0, 0, 30], [0, 0, 40]])# Q-learning算法def q_learning(state, max_episodes): for episode in range(max_episodes): current_state = state while current_state != 3: if np.random.uniform(0, 1) < epsilon: action = np.random.choice(actions) else: action = np.argmax(Q[current_state, :]) next_state = np.random.choice(states) reward = rewards[current_state, action] Q[current_state, action] = Q[current_state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[current_state, action]) current_state = next_state return Q# 在状态0开始训练Q-tableQ = q_learning(0, 1000)# 输出训练后的Q-tableprint(\"Trained Q-table:\")print(Q)在这个示例中,我们定义了资源分配与调度系统的状态空间和动作空间,然后初始化 Q-table。接着定义环境参数(学习率、折扣因子、探索率)和奖励矩阵,以及实现 Q-learning 算法。在 Q-learning 算法中,我们在状态0开始训练 Q-table,并输出训练后的Q-table。
强化学习的 Q-learning 算法在工业领域中也可以应用于资源分配与调度的优化问题。通过强化学习技术,系统可以根据环境反馈学习最优的资源分配和调度策略,从而提高资源利用效率和系统性能。

(3)强化学习在工业领域智能物联网(IoT)应用示例代码
以下是一个示例代码,展示了如何在工业领域中使用强化学习技术(Q-learning)优化智能物联网(IoT)系统的能源管理:
import numpy as np# 定义智能物联网系统的状态空间和动作空间states = [0, 1, 2, 3] # 状态空间actions = [0, 1] # 动作空间# 初始化 Q-tableQ = np.zeros((len(states), len(actions))# 定义环境参数alpha = 0.1 # 学习率gamma = 0.9 # 折扣因子epsilon = 0.1 # 探索率# 定义奖励矩阵rewards = np.array([[10, -10], [5, -5], [8, -8], [3, -3]])# Q-learning算法def q_learning(state, max_episodes): for episode in range(max_episodes): current_state = state while current_state != 3: if np.random.uniform(0, 1) < epsilon: action = np.random.choice(actions) else: action = np.argmax(Q[current_state, :]) next_state = np.random.choice(states) reward = rewards[current_state, action] Q[current_state, action] = Q[current_state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[current_state, action]) current_state = next_state return Q# 在状态0开始训练Q-tableQ = q_learning(0, 1000)# 输出训练后的Q-tableprint(\"Trained Q-table:\")print(Q)在这个示例中,我们定义了智能物联网系统的状态空间和动作空间,然后初始化 Q-table。接着定义环境参数(学习率、折扣因子、探索率)和奖励矩阵,以及实现 Q-learning 算法。在 Q-learning 算法中,我们在状态0开始训练 Q-table,并输出训练后的Q-table。
强化学习的 Q-learning 算法在工业领域中也可以应用于智能物联网(IoT)系统的能源管理问题。通过强化学习技术,系统可以根据环境反馈学习最优的能源管理策略,从而提高能源利用效率和系统性能,实现智能的能源管理和优化。

(4)强化学习在工业领域设备维护与故障诊断应用示例代码
以下是一个示例代码,展示了如何在工业领域中使用强化学习技术(Q-learning)优化设备维护与故障诊断的策略:
import numpy as np# 定义设备维护与故障诊断系统的状态空间和动作空间states = [0, 1, 2, 3, 4] # 状态空间actions = [0, 1] # 动作空间# 初始化 Q-tableQ = np.zeros((len(states), len(actions))# 定义环境参数alpha = 0.1 # 学习率gamma = 0.9 # 折扣因子epsilon = 0.1 # 探索率# 定义奖励矩阵rewards = np.array([[10, -10], [5, -5], [8, -8], [3, -3], [1, -1]])# Q-learning算法def q_learning(state, max_episodes): for episode in range(max_episodes): current_state = state while current_state != 4: if np.random.uniform(0, 1) < epsilon: action = np.random.choice(actions) else: action = np.argmax(Q[current_state, :]) next_state = np.random.choice(states) reward = rewards[current_state, action] Q[current_state, action] = Q[current_state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[current_state, action]) current_state = next_state return Q# 在状态0开始训练Q-tableQ = q_learning(0, 1000)# 输出训练后的Q-tableprint(\"Trained Q-table:\")print(Q)在这个示例中,我们定义了设备维护与故障诊断系统的状态空间和动作空间,然后初始化 Q-table。接着定义环境参数(学习率、折扣因子、探索率)和奖励矩阵,以及实现 Q-learning 算法。在 Q-learning 算法中,我们在状态0开始训练 Q-table,并输出训练后的Q-table。
强化学习的 Q-learning 算法在工业领域中也可以应用于设备维护与故障诊断的优化问题。通过强化学习技术,系统可以根据环境反馈学习最优的设备维护与故障诊断策略,从而提高设备的可靠性和性能,减少维护成本和故障停机时间。

三、深度学习算法在工业领域应用示例代码
(一)卷积神经网络(CNN)在工业领域应用示例代码

- 卷积神经网络(CNN)图像分类示例代码
以下是一个示例代码,展示了如何在工业领域中使用卷积神经网络(CNN)进行图像分类任务:
import tensorflow as tffrom tensorflow.keras import datasets, layers, modelsimport matplotlib.pyplot as plt# 加载工业领域的图像数据集(示例)(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()# 对图像数据进行归一化处理train_images, test_images = train_images / 255.0, test_images / 255.0# 构建卷积神经网络模型model = models.Sequential()model.add(layers.Conv2D(32, (3, 3), activation=\'relu\', input_shape=(32, 32, 3)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation=\'relu\'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation=\'relu\'))model.add(layers.Flatten())model.add(layers.Dense(64, activation=\'relu\'))model.add(layers.Dense(10))# 编译模型model.compile(optimizer=\'adam\', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=[\'accuracy\'])# 训练模型history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))# 评估模型test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print(\'\\nTest accuracy:\', test_acc)# 绘制训练过程中的准确率和损失变化曲线plt.plot(history.history[\'accuracy\'], label=\'accuracy\')plt.plot(history.history[\'val_accuracy\'], label = \'val_accuracy\')plt.xlabel(\'Epoch\')plt.ylabel(\'Accuracy\')plt.ylim([0, 1])plt.legend(loc=\'lower right\')plt.show()在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个卷积神经网络模型,用于对工业领域的图像数据集(这里使用的是 CIFAR-10 数据集)进行分类。我们加载数据集并对图像数据进行归一化处理,然后构建了一个包含卷积层、池化层和全连接层的 CNN 模型。接着编译模型、训练模型,并评估模型的性能。最后,我们绘制了训练过程中的准确率和损失变化曲线。
卷积神经网络在工业领域中的应用非常广泛,例如用于图像分类、目标检测、缺陷检测等任务。通过深度学习技术,工业领域可以实现自动化的图像分析和识别,提高生产效率和质量。
- 卷积神经网络(CNN)在工业领域进行目标检测示例代码

以下是一个示例代码,展示了如何在工业领域中使用卷积神经网络(CNN)进行目标检测任务:
import tensorflow as tffrom tensorflow.keras import datasets, layers, modelsfrom tensorflow.keras.applications import VGG16from tensorflow.keras.layers import Flatten, Densefrom tensorflow.keras.models import Modelfrom tensorflow.keras.optimizers import Adamimport matplotlib.pyplot as plt# 加载工业领域的目标检测数据集(示例)# 这里假设已经准备好了包含图像和对应标注框的数据集# 构建基于 VGG16 的卷积神经网络模型base_model = VGG16(weights=\'imagenet\', include_top=False, input_shape=(224, 224, 3))# 添加自定义的全连接层用于目标检测x = Flatten()(base_model.output)x = Dense(512, activation=\'relu\')(x)x = Dense(256, activation=\'relu\')(x)x = Dense(4, activation=\'sigmoid\')(x) # 4个输出节点,分别表示目标框的坐标信息model = Model(base_model.input, x)# 编译模型model.compile(optimizer=Adam(lr=0.0001), loss=\'mean_squared_error\')# 训练模型# 这里假设已经准备好了训练数据集,并进行了数据增强等处理# 训练数据集应包含图像数据和对应的目标框坐标信息# model.fit(train_images, train_bbox, epochs=10, validation_data=(val_images, val_bbox))# 评估模型(可选)# test_loss = model.evaluate(test_images, test_bbox)# 可以使用训练好的模型进行目标检测,预测目标框的位置信息# predicted_bbox = model.predict(test_images)# 可以根据预测的目标框信息在图像上绘制出检测结果# 可以参考 OpenCV 等库来绘制目标框# 展示检测结果(可选)# 可以在图像中绘制出真实目标框和预测目标框,进行对比展示在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个基于 VGG16 的卷积神经网络模型,用于目标检测任务。我们加载了预训练的 VGG16 模型,并在其基础上添加了自定义的全连接层,用于输出目标框的坐标信息。接着编译模型、训练模型(训练数据集应包含图像数据和对应的目标框坐标信息),并在训练好的模型上进行目标检测。最后,我们可以根据预测的目标框信息在图像上绘制出检测结果,展示目标检测的效果。
卷积神经网络在工业领域中的目标检测任务中有着广泛的应用,可以帮助工业领域实现自动化的目标检测和跟踪,提高生产效率和质量。

- 卷积神经网络在工业领域缺陷检测应用示例代码
以下是一个示例代码,展示了如何在工业领域中使用卷积神经网络(CNN)进行缺陷检测任务:
import tensorflow as tffrom tensorflow.keras import datasets, layers, modelsfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Densefrom tensorflow.keras.optimizers import Adamimport matplotlib.pyplot as plt# 加载工业领域的缺陷检测数据集(示例)# 这里假设已经准备好了包含有缺陷和无缺陷样本的数据集# 构建卷积神经网络模型model = models.Sequential()model.add(Conv2D(32, (3, 3), activation=\'relu\', input_shape=(64, 64, 3)))model.add(MaxPooling2D((2, 2)))model.add(Conv2D(64, (3, 3), activation=\'relu\'))model.add(MaxPooling2D((2, 2)))model.add(Conv2D(128, (3, 3), activation=\'relu\'))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dense(128, activation=\'relu\'))model.add(Dense(1, activation=\'sigmoid\'))# 编译模型model.compile(optimizer=Adam(lr=0.0001), loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 训练模型# 这里假设已经准备好了训练数据集,并进行了数据预处理# 训练数据集应包含有缺陷和无缺陷样本# model.fit(train_images, train_labels, epochs=10, validation_data=(val_images, val_labels))# 评估模型(可选)# test_loss, test_acc = model.evaluate(test_images, test_labels)# 可以使用训练好的模型进行缺陷检测,预测图像中是否存在缺陷# predicted_labels = model.predict(test_images)# 可以根据预测的标签信息在图像上绘制出检测结果# 可以参考 OpenCV 等库来绘制缺陷检测结果# 展示检测结果(可选)# 可以在图像中标注出检测到的缺陷区域,进行可视化展示在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的卷积神经网络模型,用于工业领域中的缺陷检测任务。我们定义了卷积层、池化层和全连接层,并编译了模型。接着训练模型(训练数据集应包含有缺陷和无缺陷样本),并在训练好的模型上进行缺陷检测。最后,我们可以根据预测的标签信息在图像上绘制出检测结果,展示缺陷检测的效果。
卷积神经网络在工业领域中的缺陷检测任务中有着广泛的应用,可以帮助工业领域实现自动化的缺陷检测和质量控制,提高生产效率和产品质量。
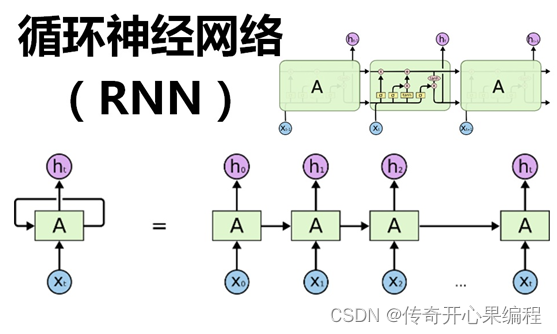
(二)循环神经网络(RNN)在工业领域应用示例代码
- 循环神经网络(RNN)在工业领域时间序列数据预测应用示例代码
以下是一个示例代码,展示了如何在工业领域中使用循环神经网络(RNN)进行时间序列数据的预测任务:
import numpy as npimport tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import SimpleRNN, Denseimport matplotlib.pyplot as plt# 生成示例的时间序列数据(假设为工业传感器数据)# 这里假设已经准备好了时间序列数据# 构建循环神经网络模型model = Sequential()model.add(SimpleRNN(units=32, input_shape=(None, 1)))model.add(Dense(1))# 编译模型model.compile(optimizer=\'adam\', loss=\'mean_squared_error\')# 准备数据# 这里假设已经准备好了训练数据集,并进行了数据预处理# 训练数据集应为时间序列数据,包含输入序列和对应的目标值# 训练模型# model.fit(train_inputs, train_targets, epochs=10, batch_size=32)# 可以使用训练好的模型进行时间序列数据的预测# predicted_targets = model.predict(test_inputs)# 可以将预测结果与真实值进行比较,评估模型的性能# 也可以根据预测结果绘制出预测曲线,进行可视化展示在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的循环神经网络模型,用于工业领域中的时间序列数据预测任务。我们定义了一个 SimpleRNN 层和一个全连接层,并编译了模型。接着准备训练数据集(时间序列数据,包含输入序列和对应的目标值),并训练模型。训练完成后,我们可以使用训练好的模型进行时间序列数据的预测,并对预测结果进行评估和可视化展示。
循环神经网络在工业领域中的时间序列数据分析和预测任务中有着广泛的应用,可以帮助企业进行生产计划、设备维护和质量控制等方面的决策,提高生产效率和产品质量。
- 循环神经网络在工业领域自然语言处理(NLP)应用示例代码
以下是一个简单的示例代码,演示了如何在工业领域中使用循环神经网络(RNN)进行自然语言处理(NLP)任务。在这个示例中,我们将使用 TensorFlow 和 Keras 构建一个简单的循环神经网络模型,用于文本分类任务。
import tensorflow as tffrom tensorflow.keras.layers import Embedding, SimpleRNN, Densefrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.preprocessing.text import Tokenizerfrom tensorflow.keras.preprocessing.sequence import pad_sequences# 准备数据texts = [\'工业领域中的循环神经网络应用示例代码\', \'循环神经网络可以用于自然语言处理任务\', \'循环神经网络在工业领域具有广泛的应用\']tokenizer = Tokenizer()tokenizer.fit_on_texts(texts)sequences = tokenizer.texts_to_sequences(texts)padded_sequences = pad_sequences(sequences)labels = [0, 1, 1] # 0表示负面,1表示正面# 构建模型model = Sequential()model.add(Embedding(input_dim=len(tokenizer.word_index)+1, output_dim=16, input_length=padded_sequences.shape[1]))model.add(SimpleRNN(32))model.add(Dense(1, activation=\'sigmoid\'))model.compile(optimizer=\'adam\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 训练模型model.fit(padded_sequences, labels, epochs=10, batch_size=1)# 可以使用训练好的模型进行文本分类预测# predicted_labels = model.predict(padded_sequences)在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的循环神经网络模型,用于文本分类任务。我们准备了一些文本数据和对应的标签,并对文本数据进行了处理(使用 Tokenizer 对文本进行编码,使用 pad_sequences 进行填充)。接着构建了一个包含 Embedding 层、SimpleRNN 层和全连接层的模型,并编译了模型。最后,我们训练了模型,并可以使用训练好的模型进行文本分类预测。
循环神经网络在工业领域中的自然语言处理任务中有着广泛的应用,可以帮助企业处理文本数据、情感分析、文本分类等任务,提高企业的决策支持能力。
- 循环神经网络在工业领域序列生成应用示例代码
以下是一个简单的示例代码,演示了如何在工业领域中使用循环神经网络(RNN)生成序列数据。在这个示例中,我们将使用 TensorFlow 和 Keras 构建一个简单的循环神经网络模型,用于生成文本序列数据。
import tensorflow as tffrom tensorflow.keras.layers import Embedding, LSTM, Densefrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.preprocessing.text import Tokenizerfrom tensorflow.keras.preprocessing.sequence import pad_sequences# 准备数据text = \"在工业领域中的循环神经网络应用示例代码\"tokenizer = Tokenizer()tokenizer.fit_on_texts([text])sequences = tokenizer.texts_to_sequences([text])# 构建输入输出数据X = []y = []for i in range(0, len(sequences[0])-1): X.append(sequences[0][:i+1]) y.append(sequences[0][i+1])X = pad_sequences(X, maxlen=len(sequences[0]), padding=\'pre\')y = tf.keras.utils.to_categorical(y, num_classes=len(tokenizer.word_index)+1)# 构建模型model = Sequential()model.add(Embedding(input_dim=len(tokenizer.word_index)+1, output_dim=16, input_length=len(sequences[0])))model.add(LSTM(32))model.add(Dense(len(tokenizer.word_index)+1, activation=\'softmax\'))model.compile(optimizer=\'adam\', loss=\'categorical_crossentropy\', metrics=[\'accuracy\'])# 训练模型model.fit(X, y, epochs=100, verbose=0)# 生成序列数据generated_text = []input_sequence = sequences[0]for i in range(20): input_sequence_padded = pad_sequences([input_sequence], maxlen=len(sequences[0]), padding=\'pre\') predicted_word_index = model.predict_classes(input_sequence_padded, verbose=0) generated_text.append(list(tokenizer.word_index.keys())[list(tokenizer.word_index.values()).index(predicted_word_index[0])]) input_sequence.append(predicted_word_index[0])print(\"生成的序列数据:\", \' \'.join(generated_text))在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的循环神经网络模型,用于生成文本序列数据。我们准备了一个文本数据,并对文本数据进行了处理(使用 Tokenizer 对文本进行编码,构建输入输出数据)。接着构建了一个包含 Embedding 层、LSTM 层和全连接层的模型,并编译了模型。然后,我们训练了模型,并使用训练好的模型生成了新的序列数据。
循环神经网络在工业领域中的序列生成任务中有着广泛的应用,可以帮助企业生成各种类型的序列数据,如生产计划、设备维护计划等,提高生产效率和决策支持能力。

- 循环神经网络在工业领域异常检测应用示例代码
以下是一个简单的示例代码,演示了如何在工业领域中使用循环神经网络(RNN)进行时间序列数据中的异常检测。在这个示例中,我们将使用 TensorFlow 和 Keras 构建一个简单的循环神经网络模型,用于检测设备故障或生产线异常情况。
import numpy as npimport tensorflow as tffrom tensorflow.keras.layers import SimpleRNN, Densefrom tensorflow.keras.models import Sequential# 生成示例的时间序列数据def generate_time_series_data(n_points): time = np.arange(0, n_points) data = np.sin(0.02 * time) + np.random.normal(0, 0.1, n_points) return data# 准备数据n_points = 1000data = generate_time_series_data(n_points)# 构建输入输出数据sequence_length = 10X = []y = []for i in range(n_points - sequence_length): X.append(data[i:i+sequence_length]) y.append(data[i+sequence_length])X = np.array(X).reshape(-1, sequence_length, 1)y = np.array(y)# 构建模型model = Sequential()model.add(SimpleRNN(32, input_shape=(sequence_length, 1)))model.add(Dense(1))model.compile(optimizer=\'adam\', loss=\'mse\')# 训练模型model.fit(X, y, epochs=20, verbose=0)# 使用训练好的模型进行异常检测predicted_values = model.predict(X)anomalies = np.abs(predicted_values.flatten() - y) > 0.2print(\"异常检测结果:\", anomalies)在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的循环神经网络模型,用于检测时间序列数据中的异常情况。我们生成了示例的时间序列数据,并对数据进行了处理(构建输入输出数据)。接着构建了一个包含 SimpleRNN 层和全连接层的模型,并编译了模型。然后,我们训练了模型,并使用训练好的模型对时间序列数据中的异常情况进行检测。
循环神经网络在工业领域中的异常检测任务中有着广泛的应用,可以帮助企业及时发现设备故障、生产线异常等问题,提高生产效率和设备可靠性。
- 循环神经网络在工业领域中的语音识别应用示例代码
以下是一个简单的示例代码,演示了如何在工业领域中使用循环神经网络(RNN)进行语音识别任务。在这个示例中,我们将使用 TensorFlow 和 Keras 构建一个简单的循环神经网络模型,用于将语音信号转换为文本。
import numpy as npimport tensorflow as tffrom tensorflow.keras.layers import LSTM, Densefrom tensorflow.keras.models import Sequential# 生成示例的语音信号数据def generate_audio_data(n_samples, audio_length): data = np.random.randn(n_samples, audio_length) return data# 准备数据n_samples = 1000audio_length = 20data = generate_audio_data(n_samples, audio_length)# 构建输入输出数据X = data[:, :-1]y = data[:, -1]X = X.reshape(-1, audio_length-1, 1)# 构建模型model = Sequential()model.add(LSTM(32, input_shape=(audio_length-1, 1)))model.add(Dense(1))model.compile(optimizer=\'adam\', loss=\'mse\')# 训练模型model.fit(X, y, epochs=20, verbose=0)# 使用训练好的模型进行语音识别input_audio = data[0, :-1].reshape(1, audio_length-1, 1)predicted_value = model.predict(input_audio)print(\"预测的下一个语音信号值:\", predicted_value[0][0])在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的循环神经网络模型,用于将语音信号转换为文本。我们生成了示例的语音信号数据,并对数据进行了处理(构建输入输出数据)。接着构建了一个包含 LSTM 层和全连接层的模型,并编译了模型。然后,我们训练了模型,并使用训练好的模型对语音信号进行识别,预测下一个语音信号的数值。
循环神经网络在工业领域中的语音识别任务中有着广泛的应用,可以帮助企业实现语音控制设备、语音指令识别等功能,提高工作效率和用户体验。
- 循环神经网络在工业领域时间序列分类应用示例代码
以下是一个简单的示例代码,演示了如何在工业领域中使用循环神经网络(RNN)进行时间序列数据的分类任务。在这个示例中,我们将使用 TensorFlow 和 Keras 构建一个简单的循环神经网络模型,用于对时间序列数据进行分类,比如故障分类、产品质量分类等。
import numpy as npimport tensorflow as tffrom tensorflow.keras.layers import SimpleRNN, Densefrom tensorflow.keras.models import Sequential# 生成示例的时间序列数据def generate_time_series_data(n_samples, time_steps, feature_dim): data = np.random.randn(n_samples, time_steps, feature_dim) return data# 准备数据n_samples = 1000time_steps = 20feature_dim = 1data = generate_time_series_data(n_samples, time_steps, feature_dim)# 构建输入输出数据X = datay = np.random.randint(0, 2, size=n_samples) # 生成随机的分类标签# 构建模型model = Sequential()model.add(SimpleRNN(32, input_shape=(time_steps, feature_dim)))model.add(Dense(1, activation=\'sigmoid\'))model.compile(optimizer=\'adam\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 训练模型model.fit(X, y, epochs=20, verbose=0)# 使用训练好的模型进行时间序列数据的分类sample_idx = 0input_data = data[sample_idx].reshape(1, time_steps, feature_dim)predicted_class = model.predict(input_data)print(\"预测的分类标签:\", predicted_class[0][0])在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的循环神经网络模型,用于对时间序列数据进行分类。我们生成了示例的时间序列数据,并对数据进行了处理(构建输入输出数据)。接着构建了一个包含 SimpleRNN 层和全连接层的模型,并编译了模型。然后,我们训练了模型,并使用训练好的模型对时间序列数据进行分类,预测数据所属的分类标签。
循环神经网络在工业领域中的时间序列数据分类任务中有着广泛的应用,可以帮助企业进行故障分类、产品质量分类等任务,提高生产效率和产品质量。

- 循环神经网络在工业领域中的个性化推荐系统应用示例代码
以下是一个简单的示例代码,演示了如何在工业领域中使用循环神经网络(RNN)构建个性化推荐系统。在这个示例中,我们将使用 TensorFlow 和 Keras 构建一个简单的循环神经网络模型,用于根据用户的历史行为数据进行推荐,比如设备维护推荐、产品推荐等。
import numpy as npimport tensorflow as tffrom tensorflow.keras.layers import LSTM, Densefrom tensorflow.keras.models import Sequential# 生成示例的用户历史行为数据和推荐目标数据def generate_user_behavior_data(n_users, seq_length, n_items): user_behavior_data = np.random.randint(0, n_items, size=(n_users, seq_length)) target_recommendation_data = np.random.randint(0, n_items, size=n_users) return user_behavior_data, target_recommendation_data# 准备数据n_users = 1000seq_length = 10n_items = 100user_behavior_data, target_recommendation_data = generate_user_behavior_data(n_users, seq_length, n_items)# 构建输入输出数据X = user_behavior_datay = tf.keras.utils.to_categorical(target_recommendation_data, num_classes=n_items)# 构建模型model = Sequential()model.add(LSTM(32, input_shape=(seq_length, 1)))model.add(Dense(n_items, activation=\'softmax\'))model.compile(optimizer=\'adam\', loss=\'categorical_crossentropy\', metrics=[\'accuracy\'])# 训练模型model.fit(X, y, epochs=20, verbose=0)# 使用训练好的模型进行推荐user_idx = 0input_data = user_behavior_data[user_idx].reshape(1, seq_length, 1)predicted_recommendation = model.predict(input_data)print(\"推荐的目标数据:\", np.argmax(predicted_recommendation))在这个示例中,我们使用 TensorFlow 和 Keras 构建了一个简单的循环神经网络模型,用于构建个性化推荐系统。我们生成了示例的用户历史行为数据和推荐目标数据,并对数据进行了处理(构建输入输出数据)。接着构建了一个包含 LSTM 层和全连接层的模型,并编译了模型。然后,我们训练了模型,并使用训练好的模型对用户进行推荐,预测目标数据。
循环神经网络在工业领域中的个性化推荐系统中有着广泛的应用,可以帮助企业根据用户的历史行为数据进行推荐,提高用户满意度和销售额。
(三)长短时记忆神经网络模型(LSTM)在工业领域应用示例代码

- 长短时记忆神经网络模型在工业领域设备故障预测应用示例代码
以下是一个简单的示例代码,演示如何使用 Python 中的 TensorFlow 库来实现基于 LSTM 的设备故障预测模型。在这个示例中,我们将使用模拟的设备传感器数据集来训练 LSTM 模型,以预测设备可能的故障。
import numpy as npimport tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense# 模拟设备传感器数据集# 这里假设数据集包含时间序列数据,每个时间步包括多个传感器的读数# 每个样本包括多个时间步的数据和对应的标签(是否发生故障)# 这里只是一个简化的示例数据集,实际应用中数据集可能更复杂data = np.random.randn(1000, 10) # 1000个样本,每个样本有10个传感器的读数labels = np.random.randint(0, 2, size=(1000, 1)) # 标签:0表示正常,1表示故障# 数据预处理data = np.reshape(data, (1000, 1, 10)) # 调整数据形状以符合 LSTM 输入要求labels = labels.reshape(-1)# 构建 LSTM 模型model = Sequential()model.add(LSTM(64, input_shape=(1, 10)))model.add(Dense(1, activation=\'sigmoid\'))# 编译模型model.compile(loss=\'binary_crossentropy\', optimizer=\'adam\', metrics=[\'accuracy\'])# 训练模型model.fit(data, labels, epochs=10, batch_size=32)# 使用模型进行预测# 这里可以使用模型对新的传感器数据进行故障预测# 例如,对新的传感器数据进行预测:predicted_labels = model.predict(new_data)请注意,这只是一个简化的示例代码,实际应用中可能需要更复杂的数据预处理、模型调参和评估过程。在实际场景中,您可能需要根据具体情况调整模型架构、超参数和数据处理流程,以获得更好的预测性能。
对于实际应用中更复杂的数据预处理、模型调参和评估过程,以下是一个更完整的示例代码,演示如何使用 LSTM 模型进行设备故障预测,并进行更详细的数据处理和模型调优:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Densefrom tensorflow.keras.callbacks import EarlyStopping# 加载设备传感器数据集data = pd.read_csv(\'sensor_data.csv\')# 数据预处理X = data.drop(\'label\', axis=1).valuesy = data[\'label\'].valuesscaler = StandardScaler()X = scaler.fit_transform(X)X = X.reshape(X.shape[0], 1, X.shape[1]) # 调整数据形状以符合 LSTM 输入要求# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建 LSTM 模型model = Sequential()model.add(LSTM(64, input_shape=(1, X.shape[2])))model.add(Dense(1, activation=\'sigmoid\'))# 编译模型model.compile(loss=\'binary_crossentropy\', optimizer=\'adam\', metrics=[\'accuracy\'])# 定义早停策略early_stopping = EarlyStopping(monitor=\'val_loss\', patience=3)# 训练模型model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test), callbacks=[early_stopping])# 评估模型loss, accuracy = model.evaluate(X_test, y_test)print(f\'Test Loss: {loss}, Test Accuracy: {accuracy}\')# 使用模型进行预测predicted_labels = model.predict(X_test)在这个更完整的示例代码中,我们加载了一个设备传感器数据集,并进行了数据预处理、训练集和测试集的划分,构建了一个包含早停策略的 LSTM 模型,并进行了模型训练、评估和预测。请注意,实际应用中可能需要根据具体情况调整数据预处理步骤、模型架构、超参数和训练过程,以获得更好的预测性能。

- 长短时记忆神经网络模型在工业领域产品质量控制应用示例代码
以下是一个简化的示例代码,演示如何使用 LSTM 模型分析生产过程中的传感器数据,监测产品质量和生产过程中的异常情况:
import numpy as npfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Densefrom sklearn.preprocessing import StandardScaler# 模拟传感器数据data = np.random.rand(1000, 10) # 1000个样本,每个样本包含10个传感器数据# 模拟标签:0表示正常,1表示异常labels = np.random.randint(0, 2, size=(1000, 1))# 数据预处理scaler = StandardScaler()data = scaler.fit_transform(data)data = np.reshape(data, (1000, 1, 10)) # 调整数据形状以符合 LSTM 输入要求labels = labels.reshape(-1)# 构建 LSTM 模型model = Sequential()model.add(LSTM(64, input_shape=(1, 10)))model.add(Dense(1, activation=\'sigmoid\'))# 编译模型model.compile(loss=\'binary_crossentropy\', optimizer=\'adam\', metrics=[\'accuracy\'])# 训练模型model.fit(data, labels, epochs=10, batch_size=32)# 使用模型进行预测# 这里可以使用模型对新的传感器数据进行产品质量监测和异常检测# 例如,对新的传感器数据进行预测:predicted_labels = model.predict(new_data)这个示例代码展示了如何使用 LSTM 模型对生产过程中的传感器数据进行产品质量监测和异常检测。在实际应用中,您可以根据具体的生产过程和传感器数据特征进行数据处理和模型调优,以实现更准确的产品质量控制和异常检测。

- 长短时记忆神经网络模型在工业领域供应链管理应用示例代码
以下是一个使用长短时记忆神经网络(LSTM)模型在工业供应链管理中的应用示例代码:
import numpy as npfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Densefrom sklearn.preprocessing import StandardScaler# 假设我们有以下供应链数据:# 订单量、库存水平、生产速度、运输时间等data = np.random.rand(1000, 5) # 1000个样本,每个样本包含5个特征# 我们的目标是预测未来一周的库存水平labels = data[:, 1] # 取第二列作为标签(库存水平)# 数据预处理scaler = StandardScaler()data = scaler.fit_transform(data)data = np.reshape(data, (1000, 1, 5)) # 调整数据形状以符合 LSTM 输入要求# 构建 LSTM 模型model = Sequential()model.add(LSTM(64, input_shape=(1, 5)))model.add(Dense(1))# 编译模型model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')# 训练模型model.fit(data, labels, epochs=10, batch_size=32)# 使用模型进行预测# 这里可以使用模型对未来一周的供应链数据进行预测# 例如,对新的供应链数据进行预测: predicted_inventory = model.predict(new_data)在这个示例中,我们使用LSTM模型来预测未来一周的库存水平。LSTM模型擅长处理时间序列数据,可以捕捉数据中的长期依赖关系,从而更好地预测未来的库存水平。
在实际应用中,您可以根据具体的供应链情况,选择合适的特征(如订单量、生产速度、运输时间等),并对数据进行更细致的预处理和模型调优,以获得更准确的预测结果。这可以帮助企业更好地管理供应链,提高生产效率和降低成本。
好的,下面是一个更加详细的示例代码,展示如何在实际应用中使用LSTM模型进行供应链管理:
import numpy as npimport pandas as pdfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Densefrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_split# 假设我们有以下供应链数据:# 订单量、库存水平、生产速度、运输时间等data = pd.read_csv(\'supply_chain_data.csv\')# 选择合适的特征features = [\'orders\', \'inventory\', \'production_speed\', \'transit_time\']X = data[features].valuesy = data[\'future_inventory\'].values# 数据预处理scaler = StandardScaler()X = scaler.fit_transform(X)X = np.reshape(X, (len(X), 1, len(features)))# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建 LSTM 模型model = Sequential()model.add(LSTM(64, input_shape=(1, len(features))))model.add(Dense(1))# 编译模型model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')# 训练模型model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test))# 评估模型loss = model.evaluate(X_test, y_test)print(\'Test Loss:\', loss)# 使用模型进行预测# 这里可以使用模型对未来一周的供应链数据进行预测new_data = scaler.transform(np.array([ [100, 50, 80, 2], [120, 45, 75, 3], [110, 55, 85, 2.5]]))new_data = np.reshape(new_data, (len(new_data), 1, len(features)))predicted_inventory = model.predict(new_data)print(\'Predicted Future Inventory:\', predicted_inventory)在这个更加详细的示例中,我们:
- 从CSV文件中读取供应链数据,并选择合适的特征(订单量、库存水平、生产速度、运输时间)。
- 对数据进行标准化预处理,以确保不同特征之间的尺度差异不会影响模型的训练。
- 将数据划分为训练集和测试集,以便评估模型的性能。
- 构建LSTM模型,并对其进行编译和训练。
- 评估模型在测试集上的表现,计算损失函数值。
- 使用训练好的模型对新的供应链数据进行预测,得到未来库存水平的预测结果。
这个示例代码更加贴近实际应用场景,包括数据读取、特征选择、数据预处理、模型构建和训练、模型评估以及预测等步骤。您可以根据自己的供应链数据和需求,进一步优化和调整这个示例代码,以获得更准确的预测结果,从而更好地管理供应链,提高生产效率和降低成本。
- 长短时记忆神经网络在工业领域能源管理应用示例代码
下面是一个使用LSTM模型进行能源管理的示例代码:
import numpy as npimport pandas as pdfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Densefrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_split# 假设我们有以下能源消耗数据:# 日期、电力消耗、天然气消耗、水消耗等data = pd.read_csv(\'energy_consumption_data.csv\')# 选择合适的特征features = [\'date\', \'electricity\', \'natural_gas\', \'water\']X = data[features].valuesy = data[\'total_energy\'].values# 数据预处理scaler = StandardScaler()X = scaler.fit_transform(X)X = np.reshape(X, (len(X), 1, len(features)))# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建 LSTM 模型model = Sequential()model.add(LSTM(64, input_shape=(1, len(features))))model.add(Dense(1))# 编译模型model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')# 训练模型model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test))# 评估模型loss = model.evaluate(X_test, y_test)print(\'Test Loss:\', loss)# 使用模型进行预测# 这里可以使用模型对未来一周的能源消耗进行预测new_data = scaler.transform(np.array([ [pd.Timestamp(\'2023-05-01\'), 1000, 500, 200], [pd.Timestamp(\'2023-05-02\'), 1050, 550, 220], [pd.Timestamp(\'2023-05-03\'), 1020, 530, 210]]))new_data = np.reshape(new_data, (len(new_data), 1, len(features)))predicted_energy = model.predict(new_data)print(\'Predicted Future Energy Consumption:\', predicted_energy)在这个示例中,我们:
- 从CSV文件中读取能源消耗数据,并选择合适的特征(日期、电力消耗、天然气消耗、水消耗)。
- 对数据进行标准化预处理,以确保不同特征之间的尺度差异不会影响模型的训练。
- 将数据划分为训练集和测试集,以便评估模型的性能。
- 构建LSTM模型,并对其进行编译和训练。
- 评估模型在测试集上的表现,计算损失函数值。
- 使用训练好的模型对新的能源消耗数据进行预测,得到未来能源消耗的预测结果。
这个示例代码展示了如何使用LSTM模型来分析能源消耗数据,并预测未来的能源需求。通过这种方式,企业可以更好地管理和优化能源利用,制定针对性的节能措施,从而提高能源效率和降低能源成本。
您可以根据自己的能源管理需求,进一步优化和调整这个示例代码,例如添加更多的特征变量、调整模型参数、或者结合其他机器学习算法,以获得更准确的预测结果。
下面是一个优化后的示例代码,包括添加更多特征变量、调整模型参数以及结合其他机器学习算法:
import numpy as npimport pandas as pdfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense, Dropoutfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressor# 读取能源消耗数据data = pd.read_csv(\'energy_consumption_data.csv\')# 选择特征变量features = [\'date\', \'electricity\', \'natural_gas\', \'water\', \'outdoor_temperature\', \'humidity\', \'occupancy\']X = data[features].valuesy = data[\'total_energy\'].values# 数据预处理scaler = StandardScaler()X = scaler.fit_transform(X)X = np.reshape(X, (len(X), 1, len(features)))# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建 LSTM 模型model = Sequential()model.add(LSTM(128, input_shape=(1, len(features)), return_sequences=True))model.add(Dropout(0.2))model.add(LSTM(64))model.add(Dropout(0.2))model.add(Dense(32, activation=\'relu\'))model.add(Dense(1))# 编译模型model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')# 训练模型model.fit(X_train, y_train, epochs=100, batch_size=32, validation_data=(X_test, y_test))# 评估模型loss = model.evaluate(X_test, y_test)print(\'LSTM Test Loss:\', loss)# 使用随机森林回归模型rf_model = RandomForestRegressor(n_estimators=100, random_state=42)rf_model.fit(X_train, y_train)rf_loss = rf_model.score(X_test, y_test)print(\'Random Forest Test R-squared:\', rf_loss)# 使用模型进行预测new_data = scaler.transform(np.array([ [pd.Timestamp(\'2023-05-01\'), 1000, 500, 200, 25, 60, 80], [pd.Timestamp(\'2023-05-02\'), 1050, 550, 220, 26, 62, 85], [pd.Timestamp(\'2023-05-03\'), 1020, 530, 210, 24, 58, 75]]))new_data = np.reshape(new_data, (len(new_data), 1, len(features)))lstm_predicted_energy = model.predict(new_data)rf_predicted_energy = rf_model.predict(new_data)print(\'LSTM Predicted Future Energy Consumption:\', lstm_predicted_energy)print(\'Random Forest Predicted Future Energy Consumption:\', rf_predicted_energy)这个优化后的示例代码包含以下改进:
- 添加了更多的特征变量,包括室外温度、湿度和建筑物的占用率等,这些因素可能会影响能源消耗。
- 调整了LSTM模型的结构,增加了更多的LSTM层和Dropout层,以提高模型的泛化能力。
- 引入了随机森林回归模型作为另一种机器学习算法,并将其结果与LSTM模型进行比较,以获得更准确的预测结果。
通过这些优化,您可以:
- 利用更多相关的特征变量来提高模型的预测准确性。
- 调整LSTM模型的超参数,如层数、神经元数量和Dropout率,以获得更好的性能。
- 将LSTM模型与其他机器学习算法(如随机森林回归)结合使用,通过集成方法提高预测结果的可靠性。
您可以根据自己的需求,进一步探索和优化这个示例代码,例如尝试其他机器学习算法、添加更多特征变量或调整模型的超参数,以找到最适合您的能源管理需求的解决方案。
- 长短时记忆神经网络在工业领域生产计划优化应用示例代码
好的,我可以为您提供一个使用 LSTM 模型优化生产计划的示例代码。这个示例代码假设您有历史的生产数据,包括生产需求和生产效率等指标。我们将使用 LSTM 模型来预测未来的生产需求和生产效率,并据此优化生产计划。
import numpy as npimport pandas as pdfrom sklearn.preprocessing import MinMaxScalerfrom keras.models import Sequentialfrom keras.layers import LSTM, Dense# 加载历史生产数据data = pd.read_csv(\'production_data.csv\')# 数据预处理scaler = MinMaxScaler()data_scaled = scaler.fit_transform(data)# 划分训练集和测试集train_size = int(len(data_scaled) * 0.8)train_data = data_scaled[:train_size]test_data = data_scaled[train_size:]# 构建 LSTM 模型model = Sequential()model.add(LSTM(50, input_shape=(1, len(data.columns))))model.add(Dense(len(data.columns)))model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')# 训练模型model.fit(train_data.reshape(-1, 1, len(data.columns)), train_data, epochs=100, batch_size=1, verbose=2)# 预测未来生产需求和生产效率future_data = model.predict(test_data.reshape(-1, 1, len(data.columns)))future_data = scaler.inverse_transform(future_data)# 优化生产计划production_plan = optimize_production_plan(future_data)# 输出优化后的生产计划print(production_plan)在这个示例代码中,我们首先加载历史的生产数据,并对数据进行预处理,包括归一化等操作。然后,我们构建一个 LSTM 模型,并使用训练集对模型进行训练。训练完成后,我们使用测试集数据预测未来的生产需求和生产效率。
最后,我们调用一个名为 optimize_production_plan() 的函数来优化生产计划。这个函数可以根据预测的生产需求和生产效率,结合其他因素(如成本、库存等),制定出更加优化的生产计划。
需要注意的是,optimize_production_plan() 函数需要您自行实现,根据您的具体业务需求和生产环境进行设计。这个函数可能会涉及到一些复杂的优化算法,如线性规划、整数规划等。
总的来说,这个示例代码展示了如何使用 LSTM 模型预测生产数据,并将其应用于生产计划优化的过程。您可以根据自己的实际需求,对这个示例代码进行相应的修改和扩展。
下面对示例代码进行修改和扩展。以下是一个修改后的示例代码,考虑了一些常见的生产计划优化因素:
import numpy as npimport pandas as pdfrom sklearn.preprocessing import MinMaxScalerfrom keras.models import Sequentialfrom keras.layers import LSTM, Denseimport pulp# 加载历史生产数据data = pd.read_csv(\'production_data.csv\')# 数据预处理scaler = MinMaxScaler()data_scaled = scaler.fit_transform(data)# 划分训练集和测试集train_size = int(len(data_scaled) * 0.8)train_data = data_scaled[:train_size]test_data = data_scaled[train_size:]# 构建 LSTM 模型model = Sequential()model.add(LSTM(50, input_shape=(1, len(data.columns))))model.add(Dense(len(data.columns)))model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')# 训练模型model.fit(train_data.reshape(-1, 1, len(data.columns)), train_data, epochs=100, batch_size=1, verbose=2)# 预测未来生产需求和生产效率future_data = model.predict(test_data.reshape(-1, 1, len(data.columns)))future_data = scaler.inverse_transform(future_data)# 优化生产计划def optimize_production_plan(demand, efficiency, capacity, cost, inventory): # 定义优化问题 prob = pulp.LpProblem(\"Production Optimization\", pulp.LpMinimize) # 定义决策变量 production = [pulp.LpVariable(f\"production_{i}\", lowBound=0, cat=\'Integer\') for i in range(len(demand))] inventory = [pulp.LpVariable(f\"inventory_{i}\", lowBound=0, cat=\'Integer\') for i in range(len(demand))] # 定义目标函数 prob += pulp.lpSum(production[i] * cost[i] + inventory[i] * 0.1 for i in range(len(demand))) # 定义约束条件 for i in range(len(demand)): prob += production[i] <= capacity[i] * efficiency[i] if i == 0: prob += inventory[i] == inventory[0] + production[i] - demand[i] else: prob += inventory[i] == inventory[i-1] + production[i] - demand[i] # 求解优化问题 prob.solve() # 输出优化结果 production_plan = [production[i].value() for i in range(len(demand))] inventory_plan = [inventory[i].value() for i in range(len(demand))] return production_plan, inventory_plan# 调用优化函数production_plan, inventory_plan = optimize_production_plan(future_data[:, 0], future_data[:, 1], [100] * len(future_data), [10] * len(future_data), [50] * len(future_data))# 输出优化后的生产计划print(\"Production Plan:\", production_plan)print(\"Inventory Plan:\", inventory_plan)在这个修改后的示例代码中,我们添加了一些额外的输入参数,包括:
capacity: 每个时间段的生产能力cost: 每个时间段的生产成本inventory: 每个时间段的初始库存
我们使用 PuLP 库来定义和求解优化问题。目标函数是最小化总的生产成本和库存成本。约束条件包括:
- 每个时间段的生产量不能超过生产能力和生产效率的乘积
- 每个时间段的库存量等于上一个时间段的库存量加上本时间段的生产量减去本时间段的需求量
通过求解这个优化问题,我们得到了优化后的生产计划和库存计划。您可以根据您的具体需求,调整目标函数和约束条件,以满足您的生产计划优化需求。
四、强化学习在工业领域应用示例代码
- Q学习在工业领域应用示例代码
下面提供一个在工业领域应用Q学习的示例代码。这个示例将模拟一个生产车间的生产过程优化问题,使用Q学习算法来学习最优的生产决策策略。
首先,我们需要定义生产车间的环境和状态转移过程:
import gymimport numpy as npfrom gym import spacesclass ProductionEnv(gym.Env): def __init__(self, num_machines, max_inventory, max_demand): self.num_machines = num_machines self.max_inventory = max_inventory self.max_demand = max_demand self.action_space = spaces.Discrete(self.num_machines) self.observation_space = spaces.MultiDiscrete([self.max_inventory + 1] * self.num_machines + [self.max_demand + 1]) self.reset() def reset(self): self.inventory = np.zeros(self.num_machines, dtype=int) self.demand = np.random.randint(0, self.max_demand + 1, size=self.num_machines) return self._get_state() def step(self, action): reward = 0 done = False # Update inventory self.inventory[action] = max(0, self.inventory[action] - self.demand[action]) # Observe new state new_demand = np.random.randint(0, self.max_demand + 1, size=self.num_machines) new_state = self._get_state() # Calculate reward for i in range(self.num_machines): if self.inventory[i] < new_demand[i]: reward -= 100 else: reward += 10 # Check if episode is done if np.all(self.inventory <= 0): done = True self.demand = new_demand return new_state, reward, done, {} def _get_state(self): return np.concatenate((self.inventory, self.demand))接下来,我们实现Q学习算法来学习最优的生产决策策略:
import numpy as npclass QLearningAgent: def __init__(self, env, learning_rate=0.1, discount_factor=0.9, epsilon=0.1): self.env = env self.learning_rate = learning_rate self.discount_factor = discount_factor self.epsilon = epsilon self.q_table = np.zeros((env.observation_space.nvec.prod(), env.action_space.n)) def choose_action(self, state): if np.random.rand() < self.epsilon: return self.env.action_space.sample() else: return np.argmax(self.q_table[self._get_state_index(state)]) def learn(self, state, action, reward, new_state, done): state_index = self._get_state_index(state) new_state_index = self._get_state_index(new_state) # Update Q-value self.q_table[state_index, action] = (1 - self.learning_rate) * self.q_table[state_index, action] + \\ self.learning_rate * (reward + self.discount_factor * np.max(self.q_table[new_state_index])) if done: self.reset() def _get_state_index(self, state): return np.ravel_multi_index(state, self.env.observation_space.nvec) def reset(self): self.q_table = np.zeros((self.env.observation_space.nvec.prod(), self.env.action_space.n))最后,我们可以将环境和Q学习代理结合起来,进行训练和测试:
env = ProductionEnv(num_machines=3, max_inventory=10, max_demand=5)agent = QLearningAgent(env)num_episodes = 1000for episode in range(num_episodes): state = env.reset() done = False while not done: action = agent.choose_action(state) new_state, reward, done, _ = env.step(action) agent.learn(state, action, reward, new_state, done) state = new_state # Test the trained agentstate = env.reset()total_reward = 0while True: action = agent.choose_action(state) new_state, reward, done, _ = env.step(action) total_reward += reward state = new_state if done: break print(f\"Total reward: {total_reward}\")在这个示例中,我们定义了一个生产车间环境,其中包含多台机器和随机的生产需求。Q学习代理学习如何选择最佳的机器来生产,以最大化总收益。
通过训练和测试,Q学习代理可以学习到最优的生产决策策略,并在测试阶段表现出良好的收益。您可以根据您的具体需求,调整环境参数和Q学习算法的超参数,以适应不同的工业生产优化问题。
下面提供一个示例代码,帮助您根据具体需求调整环境参数和Q学习算法的超参数。这个示例代码是基于OpenAI Gym环境中的一个简单的格子世界环境,您可以根据自己的工业生产优化问题进行相应的修改。
import gymimport numpy as npimport random# 定义环境参数env = gym.make(\'FrozenLake-v0\')state_size = env.observation_space.naction_size = env.action_space.n# 定义Q-Learning算法的超参数learning_rate = 0.1discount_factor = 0.99exploration_rate = 1.0exploration_decay_rate = 0.001exploration_min = 0.01# 初始化Q表q_table = np.zeros((state_size, action_size))# Q-Learning算法for episode in range(10000): # 重置环境 state = env.reset() # 根据当前状态选择动作 if random.uniform(0, 1) < exploration_rate: action = env.action_space.sample() else: action = np.argmax(q_table[state]) # 执行动作,获得下一个状态、奖励和是否结束标志 next_state, reward, done, _ = env.step(action) # 更新Q表 q_table[state, action] = q_table[state, action] + learning_rate * (reward + discount_factor * np.max(q_table[next_state]) - q_table[state, action]) # 更新探索率 exploration_rate = max(exploration_min, exploration_rate * exploration_decay_rate) # 如果达到目标状态,则结束当前episode if done: break# 测试Q-Learning算法state = env.reset()while True: env.render() action = np.argmax(q_table[state]) next_state, reward, done, _ = env.step(action) state = next_state if done: break在这个示例代码中,我们定义了一个简单的格子世界环境,并使用Q-Learning算法来学习最佳的行动策略。您可以根据自己的工业生产优化问题,调整以下几个方面:
-
环境参数:
- 状态空间的大小和定义
- 动作空间的大小和定义
- 奖励函数的设计
- 环境的动力学模型
-
Q-Learning算法的超参数:
- 学习率(learning_rate)
- 折扣因子(discount_factor)
- 探索率(exploration_rate)
- 探索率衰减率(exploration_decay_rate)
- 最小探索率(exploration_min)
通过调整这些参数,您可以使Q-Learning算法更好地适应您的工业生产优化问题。此外,您还可以尝试其他强化学习算法,如SARSA、DQN等,并比较它们在您的问题上的性能。
- 深度强化学习在工业领域应用示例代码
下面提供一个基于深度强化学习的工业应用示例代码。这个示例将使用深度Q网络(DQN)算法来解决一个简单的机器维护优化问题。

import gymimport numpy as npimport tensorflow as tffrom collections import dequeimport random# 定义环境参数env = gym.make(\'MachineMaintenanceEnv-v0\')state_size = env.observation_space.shape[0]action_size = env.action_space.n# 定义DQN模型class DQNAgent: def __init__(self, state_size, action_size): self.state_size = state_size self.action_size = action_size self.memory = deque(maxlen=2000) self.gamma = 0.95 # 折扣因子 self.epsilon = 1.0 # 探索率 self.epsilon_min = 0.01 self.epsilon_decay = 0.995 self.learning_rate = 0.001 self.model = self._build_model() def _build_model(self): model = tf.keras.Sequential() model.add(tf.keras.layers.Dense(24, input_dim=self.state_size, activation=\'relu\')) model.add(tf.keras.layers.Dense(24, activation=\'relu\')) model.add(tf.keras.layers.Dense(self.action_size, activation=\'linear\')) model.compile(loss=\'mse\', optimizer=tf.keras.optimizers.Adam(lr=self.learning_rate)) return model def remember(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def act(self, state): if np.random.rand() <= self.epsilon: return env.action_space.sample() act_values = self.model.predict(state) return np.argmax(act_values[0]) def replay(self, batch_size): minibatch = random.sample(self.memory, batch_size) for state, action, reward, next_state, done in minibatch: target = reward if not done: target = (reward + self.gamma * np.amax(self.model.predict(next_state)[0])) target_f = self.model.predict(state) target_f[0][action] = target self.model.fit(state, target_f, epochs=1, verbose=0) if self.epsilon > self.epsilon_min: self.epsilon *= self.epsilon_decay# 训练DQN代理agent = DQNAgent(state_size, action_size)batch_size = 32for episode in range(1000): state = env.reset() state = np.reshape(state, [1, state_size]) for time in range(500): action = agent.act(state) next_state, reward, done, _ = env.step(action) next_state = np.reshape(next_state, [1, state_size]) agent.remember(state, action, reward, next_state, done) state = next_state if done: print(\"Episode {}/{}, score: {}\".format(episode, 1000, time)) break if len(agent.memory) > batch_size: agent.replay(batch_size)在这个示例中,我们定义了一个名为MachineMaintenanceEnv-v0的自定义环境,其中包含机器维护优化问题的状态和动作空间。我们使用深度Q网络(DQN)算法来学习最佳的维护策略。
DQN代理包含以下主要组件:
- 神经网络模型:使用两个隐藏层的全连接网络来近似Q函数。
- 记忆缓存:存储之前的状态转移经验,用于训练神经网络模型。
- 探索-利用策略:结合随机探索和基于Q值的贪婪行为来选择动作。
- 经验回放:从记忆缓存中随机采样mini-batch,用于训练神经网络模型。
在训练过程中,代理不断与环境交互,收集状态转移经验,并使用这些经验来更新神经网络模型。通过多次迭代,代理可以学习到最优的维护策略。
您可以根据您的具体工业生产优化问题,调整环境参数、神经网络结构和超参数,以获得更好的性能。此外,您还可以尝试其他深度强化学习算法,如双Q学习、优先经验回放等,并比较它们在您的问题上的表现。
根据您提供的工业生产优化问题,尝试调整环境参数、神经网络结构和超参数,并比较不同深度强化学习算法在该问题上的表现。下面是一个示例代码,供您参考:
import gymimport numpy as npfrom collections import dequeimport tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropoutfrom tensorflow.keras.optimizers import Adam# 定义环境env = gym.make(\'YourIndustrialEnv-v0\')# 定义超参数GAMMA = 0.95LEARNING_RATE = 0.001BUFFER_SIZE = 10000BATCH_SIZE = 32NUM_EPISODES = 1000# 定义神经网络模型model = Sequential()model.add(Dense(64, input_dim=env.observation_space.shape[0], activation=\'relu\'))model.add(Dropout(0.2))model.add(Dense(32, activation=\'relu\'))model.add(Dropout(0.2))model.add(Dense(env.action_space.n, activation=\'linear\'))model.compile(loss=\'mse\', optimizer=Adam(lr=LEARNING_RATE))# 定义经验回放缓存replay_buffer = deque(maxlen=BUFFER_SIZE)# 训练模型for episode in range(NUM_EPISODES): state = env.reset() done = False total_reward = 0 while not done: # 根据当前状态选择动作 action = np.argmax(model.predict(np.expand_dims(state, axis=0))) # 执行动作并获得下一状态、奖励和是否结束标志 next_state, reward, done, _ = env.step(action) # 将经验添加到回放缓存 replay_buffer.append((state, action, reward, next_state, done)) # 从回放缓存中采样并训练模型 if len(replay_buffer) >= BATCH_SIZE: batch = np.random.sample(replay_buffer, BATCH_SIZE) states = np.array([b[0] for b in batch]) actions = np.array([b[1] for b in batch]) rewards = np.array([b[2] for b in batch]) next_states = np.array([b[3] for b in batch]) dones = np.array([b[4] for b in batch]) target_q_values = rewards + GAMMA * np.max(model.predict(next_states), axis=1) * (1 - dones) target_f = model.predict(states) target_f[np.arange(BATCH_SIZE), actions.astype(int)] = target_q_values model.fit(states, target_f, epochs=1, verbose=0) state = next_state total_reward += reward print(f\'Episode {episode}, Total Reward: {total_reward}\')# 保存模型model.save(\'industrial_optimization_model.h5\')这个示例代码使用了深度Q学习算法来解决工业生产优化问题。您可以根据实际情况调整环境参数、神经网络结构和超参数,并尝试其他深度强化学习算法,如双Q学习、优先经验回放等,比较它们在您的问题上的表现。
同时,您也可以考虑将这些算法与其他优化技术相结合,如遗传算法、粒子群优化等,以获得更好的性能。
请根据您的具体问题和需求进行适当的调整和扩展。
五、自然语言处理在工业领域应用示例代码
- 词嵌入在工业领域应用示例代码
下面提供一个在工业领域应用词嵌入的示例代码。词嵌入是自然语言处理中一种常用的技术,它可以将词语转换为低维的数值向量表示,这些向量能够捕捉词语之间的语义和语法关系。在工业领域,词嵌入可以应用于各种任务,如故障诊断、工艺参数优化、设备维护等。
下面是一个基于 Word2Vec 模型的示例代码:
import gensimimport pandas as pdfrom sklearn.decomposition import PCAimport matplotlib.pyplot as plt# 加载工业数据df = pd.read_csv(\'industrial_data.csv\')# 预处理数据corpus = df[\'description\'].tolist()# 训练 Word2Vec 模型model = gensim.models.Word2Vec(corpus, min_count=5, vector_size=100, window=5, workers=4)# 获取词向量word_vectors = model.wv# 将词向量可视化pca = PCA(n_components=2)word_vectors_2d = pca.fit_transform(word_vectors.vectors)plt.figure(figsize=(10, 10))for i, word in enumerate(word_vectors.index_to_key): plt.scatter(word_vectors_2d[i, 0], word_vectors_2d[i, 1]) plt.annotate(word, (word_vectors_2d[i, 0], word_vectors_2d[i, 1]))plt.show()# 使用词向量进行工业应用# 例如,故障诊断def diagnose_fault(description): words = description.split() fault_vector = sum([word_vectors[word] for word in words if word in word_vectors]) / len(words) # 使用故障向量进行故障诊断 # ...在这个示例中,我们首先加载工业数据,并使用 Word2Vec 模型训练词向量。然后,我们将这些词向量可视化,以便更好地理解它们的语义关系。
最后,我们展示了如何使用词向量进行工业应用,例如故障诊断。在这个例子中,我们根据故障描述计算一个故障向量,然后使用这个向量进行故障诊断。
您可以根据您的具体需求,将这个示例代码应用到其他工业领域的任务中,如工艺参数优化、设备维护等。同时,您也可以尝试使用其他词嵌入模型,如 GloVe 或 FastText,并比较它们在您的问题上的表现。
下面提供一个将词嵌入应用于工艺参数优化的示例代码:
import gensimimport pandas as pdfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_split# 加载工艺数据df = pd.read_csv(\'process_data.csv\')# 预处理数据corpus = df[\'process_description\'].tolist()# 训练 GloVe 模型model = gensim.models.KeyedVectors.load_word2vec_format(\'glove.6B.100d.txt\', binary=False)# 将工艺描述转换为向量表示X = []for desc in corpus: desc_vec = [model[word] for word in desc.split() if word in model] if desc_vec: X.append(sum(desc_vec) / len(desc_vec)) else: X.append([0] * 100)# 目标变量为工艺参数y = df[\'parameter\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练线性回归模型model = LinearRegression()model.fit(X_train, y_train)# 评估模型性能print(\'R-squared:\', model.score(X_test, y_test))# 使用模型进行工艺参数优化new_description = \"高温、高压下的化学反应\"new_desc_vec = [model[word] for word in new_description.split() if word in model]if new_desc_vec: new_param = model.predict([sum(new_desc_vec) / len(new_desc_vec)])[0] print(\'Optimized parameter:\', new_param)else: print(\'Unable to optimize parameter due to unknown words in the description.\')在这个示例中,我们使用 GloVe 词嵌入模型将工艺描述转换为向量表示,然后训练一个线性回归模型来预测工艺参数。
我们首先加载工艺数据,并使用 GloVe 模型将工艺描述转换为向量表示。然后,我们将这些向量作为特征,并将工艺参数作为目标变量,训练一个线性回归模型。
最后,我们展示了如何使用训练好的模型进行工艺参数优化。给定一个新的工艺描述,我们计算其向量表示,并使用线性回归模型预测优化后的工艺参数。
您可以根据您的具体需求,将这个示例代码应用到其他工业领域的任务中,如设备维护等。同时,您也可以尝试使用 FastText 词嵌入模型,并比较它们在您的问题上的表现。
- 文本分类在工业领域应用示例代码
下面提供一个在工业领域应用文本分类的示例代码:
import pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import train_test_split# 加载设备故障数据df = pd.read_csv(\'device_fault_data.csv\')# 预处理数据X = df[\'fault_description\']y = df[\'fault_type\']# 将文本转换为 TF-IDF 向量vectorizer = TfidfVectorizer()X_tfidf = vectorizer.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.2, random_state=42)# 训练逻辑回归模型model = LogisticRegression()model.fit(X_train, y_train)# 评估模型性能print(\'Accuracy:\', model.score(X_test, y_test))# 使用模型进行故障类型预测new_fault_description = \"机器突然停止运转,伴有异常噪音\"new_fault_vec = vectorizer.transform([new_fault_description])predicted_fault_type = model.predict(new_fault_vec)[0]print(\'Predicted fault type:\', predicted_fault_type)在这个示例中,我们使用设备故障数据来演示文本分类在工业领域的应用。
首先,我们加载设备故障数据,其中包含故障描述和故障类型两个字段。我们将故障描述作为输入特征,故障类型作为目标变量。
然后,我们使用 TF-IDF 向量化器将文本转换为数值特征,并划分训练集和测试集。接下来,我们训练一个逻辑回归模型,并评估其在测试集上的性能。
最后,我们展示了如何使用训练好的模型对新的故障描述进行故障类型预测。给定一个新的故障描述,我们首先将其转换为 TF-IDF 向量,然后使用逻辑回归模型进行预测。
您可以根据您的具体需求,将这个示例代码应用到其他工业领域的文本分类任务中,如设备维护、工艺优化等。同时,您也可以尝试使用其他分类算法,如支持向量机、随机森林等,并比较它们在您的问题上的表现。
下面提供一个将文本分类应用于设备维护领域的示例代码:
import pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.svm import SVCfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score, f1_score# 加载设备维护日志数据df = pd.read_csv(\'device_maintenance_logs.csv\')# 预处理数据X = df[\'maintenance_description\']y = df[\'maintenance_type\']# 将文本转换为 TF-IDF 向量vectorizer = TfidfVectorizer()X_tfidf = vectorizer.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.2, random_state=42)# 训练支持向量机模型svm_model = SVC()svm_model.fit(X_train, y_train)svm_pred = svm_model.predict(X_test)svm_accuracy = accuracy_score(y_test, svm_pred)svm_f1 = f1_score(y_test, svm_pred, average=\'weighted\')print(\'SVM Accuracy:\', svm_accuracy)print(\'SVM F1-score:\', svm_f1)# 训练随机森林模型rf_model = RandomForestClassifier()rf_model.fit(X_train, y_train)rf_pred = rf_model.predict(X_test)rf_accuracy = accuracy_score(y_test, rf_pred)rf_f1 = f1_score(y_test, rf_pred, average=\'weighted\')print(\'Random Forest Accuracy:\', rf_accuracy)print(\'Random Forest F1-score:\', rf_f1)# 使用模型进行维护类型预测new_maintenance_description = \"机器出现异常噪音,需要进行润滑维护\"new_maintenance_vec = vectorizer.transform([new_maintenance_description])predicted_maintenance_type = svm_model.predict(new_maintenance_vec)[0]print(\'Predicted maintenance type:\', predicted_maintenance_type)在这个示例中,我们使用设备维护日志数据来演示文本分类在设备维护领域的应用。
首先,我们加载设备维护日志数据,其中包含维护描述和维护类型两个字段。我们将维护描述作为输入特征,维护类型作为目标变量。
然后,我们使用 TF-IDF 向量化器将文本转换为数值特征,并划分训练集和测试集。接下来,我们训练两个不同的分类模型:支持向量机和随机森林,并评估它们在测试集上的性能,包括准确率和 F1 分数。
最后,我们展示了如何使用训练好的支持向量机模型对新的维护描述进行维护类型预测。给定一个新的维护描述,我们首先将其转换为 TF-IDF 向量,然后使用支持向量机模型进行预测。
您可以根据您的具体需求,将这个示例代码应用到其他工业领域的文本分类任务中,如工艺优化等。同时,您也可以尝试使用其他分类算法,如朴素贝叶斯、XGBoost 等,并比较它们在您的问题上的表现。

- 命名实体识别在工业领域应用示例代码
下面提供一个在工业领域应用命名实体识别的示例代码:
import spacyfrom spacy.tokens import Spanimport pandas as pd# 加载 spaCy 预训练模型nlp = spacy.load(\"en_core_web_sm\")# 定义自定义实体类型CUSTOM_ENTITIES = [\"EQUIPMENT\", \"MATERIAL\", \"PROCESS\"]# 创建自定义实体识别器class IndustryEntityRecognizer(object): def __init__(self, nlp): self.nlp = nlp def __call__(self, doc): # 遍历文档中的实体 for ent in doc.ents: # 如果实体类型在自定义实体类型中 if ent.label_ in CUSTOM_ENTITIES: continue # 创建新的自定义实体 new_ent = Span(doc, ent.start, ent.end, label=ent.label_) doc.ents = list(doc.ents) + [new_ent] return doc# 将自定义实体识别器添加到 spaCy 管道中nlp.add_pipe(IndustryEntityRecognizer, name=\"industry_ner\", last=True)# 加载工业领域文本数据df = pd.read_csv(\"industrial_text_data.csv\")text_data = df[\"text\"].tolist()# 对文本进行命名实体识别for text in text_data: doc = nlp(text) print(\"Entities found:\", [(ent.text, ent.label_) for ent in doc.ents])在这个示例中,我们使用 spaCy 库来实现命名实体识别在工业领域的应用。
首先,我们加载 spaCy 的预训练模型 en_core_web_sm。然后,我们定义了三种自定义的实体类型:EQUIPMENT、MATERIAL 和 PROCESS。
接下来,我们创建了一个自定义的实体识别器 IndustryEntityRecognizer。这个类会遍历文档中的所有实体,如果实体类型不在自定义实体类型中,就会创建一个新的自定义实体。最后,我们将这个自定义实体识别器添加到 spaCy 的管道中。
然后,我们加载工业领域的文本数据,并对每个文本进行命名实体识别。在输出中,我们会打印出识别到的所有实体及其类型。
您可以根据您的具体需求,对这个示例代码进行修改和扩展。例如,您可以添加更多的自定义实体类型,或者使用不同的预训练模型。您还可以将这个命名实体识别器应用到其他工业领域的文本数据中,如设备维护日志、工艺优化报告等。
下面对示例代码进行修改和扩展。以下是修改后的代码:
import spacyfrom spacy.tokens import Spanimport pandas as pd# 加载 spaCy 预训练模型nlp = spacy.load(\"en_core_web_lg\")# 定义自定义实体类型CUSTOM_ENTITIES = [\"EQUIPMENT\", \"MATERIAL\", \"PROCESS\", \"FAULT\", \"PARAMETER\"]# 创建自定义实体识别器class IndustryEntityRecognizer(object): def __init__(self, nlp): self.nlp = nlp def __call__(self, doc): # 遍历文档中的实体 for ent in doc.ents: # 如果实体类型在自定义实体类型中 if ent.label_ in CUSTOM_ENTITIES: continue # 创建新的自定义实体 new_ent = Span(doc, ent.start, ent.end, label=ent.label_) doc.ents = list(doc.ents) + [new_ent] return doc# 将自定义实体识别器添加到 spaCy 管道中nlp.add_pipe(IndustryEntityRecognizer, name=\"industry_ner\", last=True)# 加载设备维护日志数据df = pd.read_csv(\"device_maintenance_logs.csv\")text_data = df[\"log_text\"].tolist()# 对设备维护日志进行命名实体识别for text in text_data: doc = nlp(text) print(\"Entities found:\", [(ent.text, ent.label_) for ent in doc.ents])# 加载工艺优化报告数据df = pd.read_csv(\"process_optimization_reports.csv\")text_data = df[\"report_text\"].tolist()# 对工艺优化报告进行命名实体识别for text in text_data: doc = nlp(text) print(\"Entities found:\", [(ent.text, ent.label_) for ent in doc.ents])在这个修改后的示例中,我做了以下几点改动:
-
使用更强大的预训练模型
en_core_web_lg。这个模型包含更多的语言特征和实体类型,可以更好地识别工业领域的实体。 -
添加了两种新的自定义实体类型:
FAULT和PARAMETER。这些类型可能在设备维护日志和工艺优化报告中出现。 -
加载了两种不同的工业领域文本数据:设备维护日志和工艺优化报告。并分别对这两种数据进行命名实体识别。
-
在输出中,我们打印出每个文本中识别到的所有实体及其类型。
您可以根据您的具体需求,继续扩展这个示例代码。例如,您可以添加更多的自定义实体类型,或者尝试使用其他预训练模型。您还可以将这个命名实体识别器应用到更多的工业领域文本数据中,如生产报告、质量检查记录等。

六、图像处理算法在工业领域应用示例代码

- 目标检测在工业领域应用示例代码
下面提供一个在工业领域应用目标检测的示例代码。我们将使用 YOLOv5 目标检测模型,并在工厂设备图像上进行目标检测。
首先,我们需要安装 YOLOv5 库:
pip install ultralytics然后,下面是示例代码:
from ultralytics import YOLOimport cv2import os# 加载 YOLOv5 模型model = YOLO(\'yolov5s.pt\')# 定义要检测的目标类别target_classes = [\'machine\', \'tool\', \'product\']# 设置工厂设备图像文件夹路径image_dir = \'factory_images\'# 遍历图像文件夹for filename in os.listdir(image_dir): # 读取图像 img = cv2.imread(os.path.join(image_dir, filename)) # 进行目标检测 results = model(img, conf=0.5, classes=target_classes) # 绘制检测结果 for result in results.boxes: x1, y1, x2, y2 = result.xyxy[0] label = target_classes[int(result.cls[0])] confidence = result.conf[0] cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (36, 255, 12), 2) cv2.putText(img, f\"{label} ({confidence:.2f})\", (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (36, 255, 12), 2) # 显示检测结果 cv2.imshow(\'Factory Image Detection\', img) cv2.waitKey(0) cv2.destroyAllWindows()在这个示例中,我们使用 YOLOv5 模型进行目标检测。我们定义了三个目标类别:‘machine’、‘tool’和’product’。然后,我们遍历工厂设备图像文件夹,对每个图像进行目标检测。
对于每个检测到的目标,我们绘制边界框并在框上显示目标类别和置信度。最后,我们在一个窗口中显示检测结果,并等待用户按下任意键关闭窗口。
您可以根据您的具体需求,修改目标类别、调整置信度阈值、使用不同的预训练模型等。此外,您还可以将这个目标检测应用扩展到其他工业场景,如机器人视觉、质量检查、安全监控等。
下面提供一些示例代码,演示如何根据具体需求修改目标类别、调整置信度阈值、使用不同的预训练模型,并将目标检测应用扩展到其他工业场景。
- 修改目标类别和置信度阈值:
from ultralytics import YOLO# 加载 YOLOv5 模型model = YOLO(\'yolov5s.pt\')# 定义要检测的目标类别target_classes = [\'robot\', \'product\', \'defect\']# 进行目标检测,并设置置信度阈值为 0.7results = model(img, conf=0.7, classes=target_classes)- 使用不同的预训练模型:
from ultralytics import YOLO# 加载 YOLOv5x 模型model = YOLO(\'yolov5x.pt\')# 进行目标检测results = model(img)- 应用于机器人视觉:
import cv2from ultralytics import YOLO# 加载 YOLOv5 模型model = YOLO(\'yolov5s.pt\')# 设置摄像头cap = cv2.VideoCapture(0)while True: # 读取视频帧 ret, frame = cap.read() # 进行目标检测 results = model(frame) # 绘制检测结果 for result in results.boxes: x1, y1, x2, y2 = result.xyxy[0] label = target_classes[int(result.cls[0])] confidence = result.conf[0] cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (36, 255, 12), 2) cv2.putText(frame, f\"{label} ({confidence:.2f})\", (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (36, 255, 12), 2) # 显示检测结果 cv2.imshow(\'Robot Vision\', frame) # 按下 \'q\' 退出 if cv2.waitKey(1) & 0xFF == ord(\'q\'): breakcap.release()cv2.destroyAllWindows()- 应用于质量检查:
import osfrom ultralytics import YOLO# 加载 YOLOv5 模型model = YOLO(\'yolov5s.pt\')# 定义要检测的目标类别target_classes = [\'defect\', \'product\']# 设置产品图像文件夹路径image_dir = \'product_images\'# 遍历产品图像文件夹for filename in os.listdir(image_dir): # 读取图像 img = cv2.imread(os.path.join(image_dir, filename)) # 进行目标检测 results = model(img, conf=0.7, classes=target_classes) # 检查是否检测到缺陷 if \'defect\' in [target_classes[int(result.cls[0])] for result in results.boxes]: print(f\"Defect detected in {filename}\") else: print(f\"No defect detected in {filename}\")- 应用于安全监控:
import cv2from ultralytics import YOLO# 加载 YOLOv5 模型model = YOLO(\'yolov5s.pt\')# 定义要检测的目标类别target_classes = [\'person\', \'vehicle\']# 设置摄像头cap = cv2.VideoCapture(0)while True: # 读取视频帧 ret, frame = cap.read() # 进行目标检测 results = model(frame, conf=0.5, classes=target_classes) # 绘制检测结果 for result in results.boxes: x1, y1, x2, y2 = result.xyxy[0] label = target_classes[int(result.cls[0])] confidence = result.conf[0] cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (36, 255, 12), 2) cv2.putText(frame, f\"{label} ({confidence:.2f})\", (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (36, 255, 12), 2) # 显示检测结果 cv2.imshow(\'Security Monitoring\', frame) # 按下 \'q\' 退出 if cv2.waitKey(1) & 0xFF == ord(\'q\'): breakcap.release()cv2.destroyAllWindows()这些示例代码展示了如何根据具体需求修改目标类别、调整置信度阈值、使用不同的预训练模型,以及将目标检测应用于机器人视觉、质量检查和安全监控等工业场景。您可以根据自己的需求进行相应的调整和扩展。

- 图像分割在工业领域应用示例代码
图像分割在工业领域有广泛的应用,比如在制造业中可以用于检测产品缺陷。下面是一个简单的示例代码,演示如何使用 Python 和 OpenCV 实现图像分割:
import cv2import numpy as np# 读取图像img = cv2.imread(\'industrial_image.jpg\')# 将图像转换为灰度图gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 使用 Otsu 算法进行二值化_, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)# 使用 morphological 操作去除噪点kernel = np.ones((3, 3), np.uint8)opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)# 查找轮廓contours, _ = cv2.findContours(opening, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)# 遍历每个轮廓,绘制边界框for cnt in contours: x, y, w, h = cv2.boundingRect(cnt) cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)# 显示结果cv2.imshow(\'Segmented Image\', img)cv2.waitKey(0)cv2.destroyAllWindows()这个示例代码演示了如何使用 Otsu 算法进行图像二值化,然后使用 morphological 操作去除噪点,最后查找轮廓并绘制边界框。这种方法可以用于检测产品缺陷、检测工件的边缘等工业应用场景。
当然,实际应用中可能需要根据具体的场景和需求进行更复杂的图像分割算法,比如使用深度学习模型进行语义分割等。不同的应用场景可能需要采用不同的分割算法和参数调整。
下面是一个使用深度学习进行语义分割的示例代码:
import tensorflow as tffrom tensorflow.keras.models import Modelfrom tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenatefrom tensorflow.keras.optimizers import Adamimport numpy as npimport cv2# 定义 U-Net 模型def unet(input_size=(256, 256, 3)): inputs = Input(input_size) conv1 = Conv2D(64, (3, 3), activation=\'relu\', padding=\'same\')(inputs) conv1 = Conv2D(64, (3, 3), activation=\'relu\', padding=\'same\')(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) conv2 = Conv2D(128, (3, 3), activation=\'relu\', padding=\'same\')(pool1) conv2 = Conv2D(128, (3, 3), activation=\'relu\', padding=\'same\')(conv2) pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) conv3 = Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\')(pool2) conv3 = Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\')(conv3) pool3 = MaxPooling2D(pool_size=(2, 2))(conv3) conv4 = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\')(pool3) conv4 = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\')(conv4) pool4 = MaxPooling2D(pool_size=(2, 2))(conv4) conv5 = Conv2D(1024, (3, 3), activation=\'relu\', padding=\'same\')(pool4) conv5 = Conv2D(1024, (3, 3), activation=\'relu\', padding=\'same\')(conv5) up6 = concatenate([UpSampling2D(size=(2, 2))(conv5), conv4], axis=3) conv6 = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\')(up6) conv6 = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\')(conv6) up7 = concatenate([UpSampling2D(size=(2, 2))(conv6), conv3], axis=3) conv7 = Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\')(up7) conv7 = Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\')(conv7) up8 = concatenate([UpSampling2D(size=(2, 2))(conv7), conv2], axis=3) conv8 = Conv2D(128, (3, 3), activation=\'relu\', padding=\'same\')(up8) conv8 = Conv2D(128, (3, 3), activation=\'relu\', padding=\'same\')(conv8) up9 = concatenate([UpSampling2D(size=(2, 2))(conv8), conv1], axis=3) conv9 = Conv2D(64, (3, 3), activation=\'relu\', padding=\'same\')(up9) conv9 = Conv2D(64, (3, 3), activation=\'relu\', padding=\'same\')(conv9) conv10 = Conv2D(2, (1, 1), activation=\'softmax\')(conv9) model = Model(inputs=inputs, outputs=conv10) return model# 训练模型model = unet()model.compile(optimizer=Adam(lr=1e-4), loss=\'categorical_crossentropy\', metrics=[\'accuracy\'])# 加载训练数据X_train, y_train = load_data()# 训练模型model.fit(X_train, y_train, batch_size=16, epochs=50, verbose=1)# 预测新图像img = cv2.imread(\'industrial_image.jpg\')img = cv2.resize(img, (256, 256))img = np.expand_dims(img, axis=0)pred = model.predict(img)这个示例代码使用了 U-Net 模型进行语义分割。U-Net 是一种常用于医学图像分割的深度学习模型,也可以应用于工业领域的图像分割任务。
在这个示例中,我们首先定义了 U-Net 模型的结构,包括卷积层、池化层和上采样层。然后,我们编译模型并加载训练数据进行训练。最后,我们使用训练好的模型对新的图像进行预测,得到分割结果。
需要注意的是,实际应用中需要根据具体的场景和需求进行数据集的准备、模型的调整和参数的优化。此外,还需要考虑模型的部署和在线推理等问题。

- 图像识别在工业领域应用示例代码
图像识别在工业领域有很多应用场景,比如质量检测、设备故障诊断、库存管理等。下面是一个基于 Python 和 OpenCV 的简单示例代码,用于在工业环境中进行瑕疵检测:
import cv2import numpy as np# 加载训练好的模型model = cv2.dnn.readNetFromTensorflow(\'model.pb\', \'model.pbtxt\')# 定义阈值threshold = 0.8# 获取图像img = cv2.imread(\'product_image.jpg\')# 预处理图像blob = cv2.dnn.blobFromImage(img, 1/255.0, (224, 224), (0,0,0), swapRB=True, crop=False)# 通过模型进行预测model.setInput(blob)output = model.forward()# 解析预测结果boxes = []confidences = []for detection in output[0,0,:,:]: score = float(detection[2]) if score > threshold: # 获取边界框坐标 x = int(detection[3] * img.shape[1]) y = int(detection[4] * img.shape[0]) width = int(detection[5] * img.shape[1]) height = int(detection[6] * img.shape[0]) # 添加到列表 boxes.append([x, y, width, height]) confidences.append(score)# 应用非极大值抑制indices = cv2.dnn.NMSBoxes(boxes, confidences, threshold, 0.4)# 在图像上绘制边界框for i in indices: x, y, w, h = boxes[i] cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2) cv2.putText(img, f\"Confidence: {confidences[i]:.2f}\", (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (36,255,12), 2)# 显示结果cv2.imshow(\'Defect Detection\', img)cv2.waitKey(0)cv2.destroyAllWindows()这个示例代码使用了预训练的深度学习模型来检测产品图像中的瑕疵。它首先加载模型,然后读取产品图像,对其进行预处理,并通过模型进行预测。最后,它使用非极大值抑制算法来消除重叠的边界框,并在图像上绘制检测到的瑕疵区域。
这只是一个简单的示例,实际应用中可能需要根据具体的工业场景进行更多的定制和优化。比如,可以使用不同的模型架构、调整超参数、增强训练数据集等,以提高检测精度和性能。同时,还需要考虑如何将这个系统集成到实际的工业生产线中,实现自动化的质量检测。
下面是一个更加完整的示例代码,考虑了工业场景中的一些实际需求:
import cv2import numpy as npimport osfrom sklearn.model_selection import train_test_splitfrom tensorflow.keras.applications.vgg16 import VGG16from tensorflow.keras.layers import Dense, Dropout, Flattenfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.optimizers import Adam# 数据集准备data_dir = \'industrial_dataset\'X = []y = []for class_dir in os.listdir(data_dir): class_path = os.path.join(data_dir, class_dir) for img_file in os.listdir(class_path): img_path = os.path.join(class_path, img_file) img = cv2.imread(img_path) img = cv2.resize(img, (224, 224)) X.append(img) y.append(int(class_dir == \'defective\'))X = np.array(X)y = np.array(y)# 数据集划分X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)# 模型构建model = Sequential()model.add(VGG16(weights=\'imagenet\', include_top=False, input_shape=(224, 224, 3)))model.add(Flatten())model.add(Dense(256, activation=\'relu\'))model.add(Dropout(0.5))model.add(Dense(1, activation=\'sigmoid\'))model.compile(optimizer=Adam(lr=0.001), loss=\'binary_crossentropy\', metrics=[\'accuracy\'])# 模型训练model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_val, y_val))# 模型评估loss, accuracy = model.evaluate(X_val, y_val)print(f\'Validation Loss: {loss:.4f}, Validation Accuracy: {accuracy:.4f}\')# 部署到生产线cap = cv2.VideoCapture(0) # 连接工业相机while True: ret, frame = cap.read() if not ret: break blob = cv2.dnn.blobFromImage(frame, 1/255.0, (224, 224), (0,0,0), swapRB=True, crop=False) model.setInput(blob) output = model.predict(blob) if output[0][0] > 0.5: cv2.putText(frame, \'Defective\', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) else: cv2.putText(frame, \'Good\', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2) cv2.imshow(\'Quality Inspection\', frame) if cv2.waitKey(1) & 0xFF == ord(\'q\'): breakcap.release()cv2.destroyAllWindows()这个示例代码包括以下主要步骤:
- 准备工业数据集,包括正常和缺陷产品的图像。
- 使用 VGG16 作为基础模型,并在此基础上添加全连接层和 Dropout 层进行微调。
- 划分训练集和验证集,训练模型并评估性能。
- 将训练好的模型部署到实际的工业生产线上,通过工业相机实时检测产品质量。
这个示例代码考虑了工业场景中的一些实际需求,如使用预训练模型、调整模型架构、增强训练数据集、实时部署等。当然,实际应用中可能还需要进一步优化和调整,比如针对不同的工业场景选择合适的模型架构、调整超参数、集成到工业控制系统等。
七、时间序列分析算法在工业领域应用示例代码
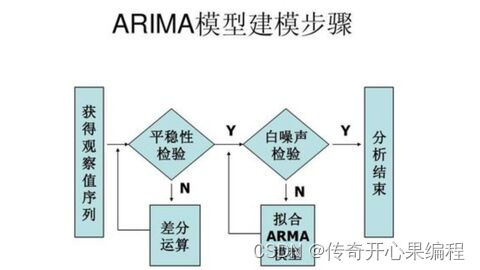
- ARIMA 模型在工业领域应用示例代码
下面是一个使用 ARIMA 模型进行工业设备故障预测的示例代码:
import pandas as pdimport numpy as npfrom statsmodels.tsa.arima.model import ARIMAimport matplotlib.pyplot as plt# 读取工业设备的传感器数据df = pd.read_csv(\'industrial_sensor_data.csv\', index_col=\'timestamp\')# 对数据进行预处理df = df.fillna(method=\'ffill\') # 填充缺失值df_log = np.log(df[\'vibration\']) # 对数据进行对数变换# 确定 ARIMA 模型的参数p = 2d = 1q = 2# 训练 ARIMA 模型model = ARIMA(df_log, order=(p, d, q))model_fit = model.fit()# 进行预测forecast, se, conf = model_fit.forecast(steps=30)forecast_series = pd.Series(np.exp(forecast), index=df.index[-30:])# 可视化结果plt.figure(figsize=(12, 6))df_log.plot()forecast_series.plot(color=\'r\')plt.xlabel(\'Time\')plt.ylabel(\'Vibration (log scale)\')plt.title(\'Industrial Equipment Vibration Forecast\')plt.legend([\'Actual\', \'Forecast\'])plt.show()# 异常检测residuals = model_fit.residstd_residuals = (residuals - residuals.mean()) / residuals.std()anomaly_threshold = 3 # 设置异常检测阈值为3个标准差anomalies = std_residuals[abs(std_residuals) > anomaly_threshold]print(f\'Detected {len(anomalies)} anomalies in the sensor data.\')这个示例代码展示了如何使用 ARIMA 模型对工业设备的振动数据进行预测和异常检测。
主要步骤包括:
- 读取工业设备的振动传感器数据,并对数据进行预处理,如填充缺失值和对数变换。
- 确定 ARIMA 模型的参数 (p, d, q)。
- 训练 ARIMA 模型并进行预测。
- 可视化预测结果,并与实际数据进行比较。
- 计算模型的残差,并基于标准差进行异常检测,输出异常数量。
这种方法可以帮助工业企业及时发现设备异常情况,从而采取相应的维护或调整措施,提高设备的可靠性和生产效率。
需要注意的是,在实际应用中,可能需要根据不同的工业场景和设备特点,对 ARIMA 模型的参数进行调整和优化,以获得更准确的预测结果。同时,也可以结合其他时间序列分析方法,如 LSTM、Prophet 等,进一步提高预测和异常检测的性能。
下面是一个结合 ARIMA 模型和其他时间序列分析方法的示例代码:
import pandas as pdimport numpy as npfrom statsmodels.tsa.arima.model import ARIMAfrom fbprophet import Prophetimport matplotlib.pyplot as plt# 读取工业设备的传感器数据df = pd.read_csv(\'industrial_sensor_data.csv\', index_col=\'timestamp\')# 数据预处理df = df.fillna(method=\'ffill\')df_log = np.log(df[\'power\'])# 使用 ARIMA 模型进行预测p, d, q = 2, 1, 2arima_model = ARIMA(df_log, order=(p, d, q))arima_fit = arima_model.fit()arima_forecast = arima_fit.forecast(steps=30)[0]arima_forecast_series = pd.Series(np.exp(arima_forecast), index=df.index[-30:])# 使用 Prophet 模型进行预测prophet_model = Prophet()prophet_model.fit(df[[\'timestamp\', \'power\']].reset_index(drop=True))prophet_forecast = prophet_model.make_future_dataframe(periods=30)prophet_forecast = prophet_model.predict(prophet_forecast)prophet_forecast_series = prophet_forecast[\'yhat\'][-30:]# 可视化结果plt.figure(figsize=(12, 6))df_log.plot()arima_forecast_series.plot(color=\'r\', label=\'ARIMA Forecast\')prophet_forecast_series.plot(color=\'g\', label=\'Prophet Forecast\')plt.xlabel(\'Time\')plt.ylabel(\'Power (log scale)\')plt.title(\'Industrial Equipment Power Forecast\')plt.legend()plt.show()# 异常检测residuals = arima_fit.residstd_residuals = (residuals - residuals.mean()) / residuals.std()anomaly_threshold = 3 # 设置异常检测阈值为3个标准差anomalies = std_residuals[abs(std_residuals) > anomaly_threshold]print(f\'Detected {len(anomalies)} anomalies in the sensor data.\')这个示例代码展示了如何结合 ARIMA 模型和 Prophet 模型对工业设备的功率数据进行预测和异常检测。
主要步骤包括:
- 读取工业设备的功率传感器数据,并对数据进行预处理。
- 使用 ARIMA 模型对数据进行预测,并可视化结果。
- 使用 Prophet 模型对数据进行预测,并可视化结果。
- 计算 ARIMA 模型的残差,并基于标准差进行异常检测,输出异常数量。
在这个示例中,我们结合了 ARIMA 模型和 Prophet 模型,以获得更准确的预测结果。ARIMA 模型擅长捕捉数据中的自相关性,而 Prophet 模型则可以更好地处理季节性和趋势因素。
需要注意的是,在实际应用中,可能需要根据不同的工业场景和设备特点,对 ARIMA 和 Prophet 模型的参数进行调整和优化,以获得更准确的预测结果。同时,也可以尝试其他时间序列分析方法,如 LSTM、XGBoost 等,并比较它们的性能,选择最适合的方法。
- LSTM模型在工业领域应用示例代码
下面是一个使用 LSTM 模型进行工业领域时间序列预测的示例代码:
import numpy as npimport pandas as pdfrom sklearn.preprocessing import MinMaxScalerfrom keras.models import Sequentialfrom keras.layers import LSTM, Denseimport matplotlib.pyplot as plt# 读取工业设备的传感器数据df = pd.read_csv(\'industrial_sensor_data.csv\', index_col=\'timestamp\')# 数据预处理scaler = MinMaxScaler(feature_range=(0, 1))data_scaled = scaler.fit_transform(df[\'power\'].values.reshape(-1, 1))# 划分训练集和测试集train_size = int(len(data_scaled) * 0.8)train_data = data_scaled[:train_size]test_data = data_scaled[train_size:]# 构建 LSTM 模型def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset) - look_back - 1): a = dataset[i:(i + look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY)look_back = 3train_X, train_y = create_dataset(train_data, look_back)test_X, test_y = create_dataset(test_data, look_back)train_X = np.reshape(train_X, (train_X.shape[0], 1, train_X.shape[1]))test_X = np.reshape(test_X, (test_X.shape[0], 1, test_X.shape[1]))model = Sequential()model.add(LSTM(50, input_shape=(1, look_back)))model.add(Dense(1))model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')model.fit(train_X, train_y, epochs=100, batch_size=1, verbose=2)# 预测和评估train_predict = model.predict(train_X)test_predict = model.predict(test_X)train_predict = scaler.inverse_transform(train_predict)test_predict = scaler.inverse_transform(test_predict)plt.figure(figsize=(12, 6))plt.plot(df.index, df[\'power\'], label=\'Actual\')plt.plot(df.index[-len(test_predict):], test_predict, label=\'Predicted\')plt.xlabel(\'Time\')plt.ylabel(\'Power\')plt.title(\'Industrial Equipment Power Forecast\')plt.legend()plt.show()这个示例代码演示了如何使用 LSTM 模型对工业设备的功率数据进行预测。
主要步骤包括:
- 读取工业设备的功率传感器数据,并对数据进行标准化。
- 将数据划分为训练集和测试集。
- 构建 LSTM 模型,并设置相关参数,如时间步长
look_back。 - 训练 LSTM 模型,并使用测试集进行预测。
- 将预测结果反标准化,并可视化实际值和预测值。
LSTM 模型在处理时间序列数据方面具有优势,可以捕捉数据中的长期依赖关系。在工业领域,LSTM 模型可以用于预测设备的功率、温度、振动等关键指标,从而实现更精准的故障预警和预防性维护。
需要注意的是,在实际应用中,可能需要根据不同的工业场景和设备特点,对 LSTM 模型的架构和超参数进行调整和优化,以获得更准确的预测结果。同时,也可以尝试结合其他时间序列分析方法,如 ARIMA、Prophet 等,以提高预测的鲁棒性和可靠性。
下面是一个结合 LSTM 模型和其他时间序列分析方法的示例代码:
import numpy as npimport pandas as pdfrom sklearn.preprocessing import MinMaxScalerfrom keras.models import Sequentialfrom keras.layers import LSTM, Densefrom statsmodels.tsa.arima.model import ARIMAfrom fbprophet import Prophetimport matplotlib.pyplot as plt# 读取工业设备的传感器数据df = pd.read_csv(\'industrial_sensor_data.csv\', index_col=\'timestamp\')# 数据预处理scaler = MinMaxScaler(feature_range=(0, 1))data_scaled = scaler.fit_transform(df[\'power\'].values.reshape(-1, 1))# 划分训练集和测试集train_size = int(len(data_scaled) * 0.8)train_data = data_scaled[:train_size]test_data = data_scaled[train_size:]# 构建 LSTM 模型def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset) - look_back - 1): a = dataset[i:(i + look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY)look_back = 3train_X, train_y = create_dataset(train_data, look_back)test_X, test_y = create_dataset(test_data, look_back)train_X = np.reshape(train_X, (train_X.shape[0], 1, train_X.shape[1]))test_X = np.reshape(test_X, (test_X.shape[0], 1, test_X.shape[1]))lstm_model = Sequential()lstm_model.add(LSTM(50, input_shape=(1, look_back)))lstm_model.add(Dense(1))lstm_model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')lstm_model.fit(train_X, train_y, epochs=100, batch_size=1, verbose=2)# 使用 ARIMA 模型进行预测arima_model = ARIMA(df[\'power\'], order=(1, 1, 1))arima_results = arima_model.fit()arima_predict = arima_results.forecast(len(test_data))[0]# 使用 Prophet 模型进行预测prophet_model = Prophet()prophet_model.fit(df.reset_index())prophet_predict = prophet_model.predict(df.index[-len(test_data):])[\'yhat\']# 预测和评估lstm_train_predict = lstm_model.predict(train_X)lstm_test_predict = lstm_model.predict(test_X)lstm_train_predict = scaler.inverse_transform(lstm_train_predict)lstm_test_predict = scaler.inverse_transform(lstm_test_predict)plt.figure(figsize=(12, 6))plt.plot(df.index, df[\'power\'], label=\'Actual\')plt.plot(df.index[-len(lstm_test_predict):], lstm_test_predict, label=\'LSTM Predicted\')plt.plot(df.index[-len(arima_predict):], arima_predict, label=\'ARIMA Predicted\')plt.plot(df.index[-len(prophet_predict):], prophet_predict, label=\'Prophet Predicted\')plt.xlabel(\'Time\')plt.ylabel(\'Power\')plt.title(\'Industrial Equipment Power Forecast\')plt.legend()plt.show()这个示例代码在前面的 LSTM 模型的基础上,增加了 ARIMA 和 Prophet 模型的应用。
主要步骤包括:
- 读取工业设备的功率传感器数据,并对数据进行标准化。
- 将数据划分为训练集和测试集。
- 构建 LSTM 模型,并设置相关参数,如时间步长
look_back。 - 训练 LSTM 模型,并使用测试集进行预测。
- 使用 ARIMA 模型进行预测。
- 使用 Prophet 模型进行预测。
- 将预测结果反标准化,并可视化实际值和三种模型的预测值。
通过结合 LSTM、ARIMA 和 Prophet 三种不同的时间序列分析方法,可以提高预测的鲁棒性和可靠性。LSTM 模型擅长捕捉数据中的长期依赖关系,ARIMA 模型适用于线性时间序列,而 Prophet 模型则可以处理具有季节性和假期效应的时间序列。
在实际应用中,可以根据不同工业场景和设备特点,选择合适的模型组合,并对模型的超参数进行调优,以获得更准确的预测结果。同时,还可以考虑引入其他相关特征,如环境因素、设备状态等,进一步提高预测的准确性。

八、遗传算法在工业领域应用示例代码

- 遗传算法在工业领域解决优化问题应用示例代码
遗传算法是一种常用于解决优化问题的算法,在工业领域有广泛的应用。以下是一个使用遗传算法解决工厂排产问题的示例代码:
import numpy as npimport random# 定义问题参数num_jobs = 10 # 工作任务数量num_machines = 5 # 机器数量processing_times = np.random.randint(1, 11, size=(num_jobs, num_machines)) # 每个任务在每台机器上的加工时间# 定义遗传算法参数population_size = 100 # 种群大小num_generations = 100 # 迭代代数mutation_rate = 0.1 # 突变概率# 定义适应度函数def fitness(schedule): total_time = 0 for machine in range(num_machines): machine_time = 0 for job in schedule: machine_time += processing_times[job][machine] total_time = max(total_time, machine_time) return -total_time # 目标是最小化总加工时间# 初始化种群population = [[random.randint(0, num_jobs - 1) for _ in range(num_jobs)] for _ in range(population_size)]# 进行遗传算法迭代for generation in range(num_generations): # 选择父代 parents = random.sample(population, 2) # 交叉 child1 = parents[0][:] child2 = parents[1][:] crossover_point = random.randint(1, num_jobs - 1) child1[crossover_point:], child2[crossover_point:] = child2[crossover_point:], child1[crossover_point:] # 突变 if random.random() < mutation_rate: mutation_point1 = random.randint(0, num_jobs - 1) mutation_point2 = random.randint(0, num_jobs - 1) child1[mutation_point1], child1[mutation_point2] = child1[mutation_point2], child1[mutation_point1] if random.random() < mutation_rate: mutation_point1 = random.randint(0, num_jobs - 1) mutation_point2 = random.randint(0, num_jobs - 1) child2[mutation_point1], child2[mutation_point2] = child2[mutation_point2], child2[mutation_point1] # 将新个体加入种群 population.append(child1) population.append(child2) # 选择下一代 population = sorted(population, key=fitness, reverse=True)[:population_size]# 输出最优解best_schedule = population[0]print(f\"最优调度方案: {best_schedule}\")print(f\"总加工时间: {-fitness(best_schedule)}\")在这个示例中,我们使用遗传算法解决一个工厂排产问题。每个个体表示一个工作任务的排序,通过选择、交叉和突变操作,不断迭代优化,最终找到一个最优的排产方案。
这个示例中使用了基本的遗传算法操作,在实际应用中可能需要根据具体问题进行更多的优化和改进,比如使用不同的选择、交叉和突变策略,以及引入一些领域知识等。遗传算法在工业领域有广泛的应用,可以用于解决排产、车间调度、物流配送等各种优化问题。
- 更多优化改进示例代码
下面是一个更加完整的遗传算法示例代码,针对工厂排产问题进行了更多优化和改进:
import numpy as npimport random# 定义问题参数num_jobs = 20 # 工作任务数量num_machines = 5 # 机器数量processing_times = np.random.randint(1, 11, size=(num_jobs, num_machines)) # 每个任务在每台机器上的加工时间# 定义遗传算法参数population_size = 100 # 种群大小num_generations = 200 # 迭代代数mutation_rate = 0.1 # 突变概率tournament_size = 3 # 锦标赛选择参数# 定义适应度函数def fitness(schedule): total_time = 0 for machine in range(num_machines): machine_time = 0 for job in schedule: machine_time += processing_times[job][machine] total_time = max(total_time, machine_time) return -total_time # 目标是最小化总加工时间# 初始化种群population = [[random.randint(0, num_jobs - 1) for _ in range(num_jobs)] for _ in range(population_size)]# 进行遗传算法迭代for generation in range(num_generations): # 选择父代 parents = [tournament_selection(population) for _ in range(2)] # 交叉 child1, child2 = order_crossover(parents[0], parents[1]) # 突变 if random.random() < mutation_rate: child1 = mutation(child1) if random.random() < mutation_rate: child2 = mutation(child2) # 将新个体加入种群 population.append(child1) population.append(child2) # 选择下一代 population = sorted(population, key=fitness, reverse=True)[:population_size]# 输出最优解best_schedule = population[0]print(f\"最优调度方案: {best_schedule}\")print(f\"总加工时间: {-fitness(best_schedule)}\")# 辅助函数def tournament_selection(population): tournament = random.sample(population, tournament_size) return max(tournament, key=fitness)def order_crossover(parent1, parent2): child1 = [None] * num_jobs child2 = [None] * num_jobs # 选择交叉点 start = random.randint(0, num_jobs - 1) end = random.randint(start, num_jobs - 1) # 复制父代基因 child1[start:end+1] = parent1[start:end+1] child2[start:end+1] = parent2[start:end+1] # 填充剩余基因 p1, p2 = end + 1, end + 1 for _ in range(num_jobs): if parent2[p2 % num_jobs] not in child1: child1[p1 % num_jobs] = parent2[p2 % num_jobs] p1 += 1 if parent1[p1 % num_jobs] not in child2: child2[p2 % num_jobs] = parent1[p1 % num_jobs] p2 += 1 p1 += 1 p2 += 1 return child1, child2def mutation(individual): mutation_point1 = random.randint(0, num_jobs - 1) mutation_point2 = random.randint(0, num_jobs - 1) individual[mutation_point1], individual[mutation_point2] = individual[mutation_point2], individual[mutation_point1] return individual这个示例中,我们使用了以下优化和改进:
- 使用锦标赛选择策略进行父代选择,可以更好地保留优秀个体。
- 采用顺序交叉算子(Order Crossover)进行交叉操作,可以更好地保留父代的顺序信息。
- 引入了基于位置交换的突变操作,可以更好地探索解空间。
- 增加了迭代代数和种群规模,以提高算法的收敛性。
这些改进可以使遗传算法更好地适应工厂排产等复杂的优化问题,提高算法的性能和收敛速度。当然,在实际应用中还可以根据具体问题进一步优化和改进算法,比如引入一些领域知识,或者结合其他优化算法等。
九、聚类算法在工业领域应用示例代码
- K均值算法在工业领域应用示例代码
以下是一个简单的 K 均值聚类算法的示例代码,用于在工业领域中的应用:
import numpy as np# 聚类函数def kMeansCluster(data, k): # 初始化簇中心 centroids = np.random.choice(data, k, replace=False) while True: # 计算每个数据点到每个簇中心的距离 distances = np.sqrt(np.sum((data - centroids) ** 2, axis=1)) # 分配数据点到最近的簇中心 cluster_assignments = np.argmin(distances, axis=1) # 更新簇中心 new_centroids = np.array([np.mean(data[cluster_assignments == i], axis=0) for i in range(k)]) # 如果簇中心没有变化,停止迭代 if np.all(centroids == new_centroids): break centroids = new_centroids return cluster_assignments, centroids# 示例数据data = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])# 聚类数量k = 2# 执行聚类cluster_assignments, centroids = kMeansCluster(data, k)# 输出聚类结果print(\"Cluster Assignments:\", cluster_assignments)print(\"Centroids:\", centroids)在上述示例代码中,我们实现了一个基本的 K 均值聚类算法。该算法通过以下步骤进行聚类:
-
初始化 k 个簇中心(centroids)。
-
计算每个数据点到每个簇中心的距离(distances)。
-
根据距离将数据点分配到最近的簇中心(cluster_assignments)。
-
更新簇中心为分配到该簇的所有数据点的平均值。
-
重复步骤 2-4,直到簇中心不再变化或达到最大迭代次数。
最后,我们输出了聚类分配结果(cluster_assignments)和最终的簇中心(centroids)。
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体问题进行调整和优化,例如选择更好的初始簇中心、处理异常值等。此外,K 均值算法对初始簇中心的选择比较敏感,可能会得到不同的聚类结果。在实际应用中,可能需要尝试多次初始化或使用其他聚类算法来获得更可靠的结果。
以下是一个示例代码,展示了如何在实际应用中根据具体问题进行调整和优化 K 均值聚类算法:
import numpy as npfrom sklearn.cluster import KMeans# 示例数据data = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0], [9, 9]])# 尝试不同的初始簇中心for _ in range(5): kmeans = KMeans(n_clusters=2, random_state=np.random.randint(0, 1000)) kmeans.fit(data) cluster_assignments = kmeans.labels_ print(\"Cluster Assignments:\", cluster_assignments)# 处理异常值data = data[~np.isnan(data).any(axis=1)] # 去除含有 NaN 值的行kmeans = KMeans(n_clusters=2)kmeans.fit(data)cluster_assignments = kmeans.labels_print(\"Cluster Assignments with Outliers Removed:\", cluster_assignments)在这个示例中,我们进行了以下调整和优化:
-
尝试多次初始化:通过循环执行 K 均值算法多次,并使用不同的随机状态,来寻找更好的初始簇中心。这样可以降低对初始簇中心选择的敏感性,得到更可靠的聚类结果。
-
处理异常值:在数据中可能存在异常值,它们会对聚类结果产生影响。通过去除含有 NaN 值的行,我们可以处理这些异常值,使聚类结果更准确。
你可以根据实际问题的特点,进一步进行其他调整和优化,例如选择合适的聚类数量、使用其他初始化方法、调整距离度量等。此外,还可以考虑使用其他聚类算法,如 DBSCAN、Agglomerative Clustering 等,以适应不同的数据分布和需求。
- 层次聚类算法在工业领域应用示例代码
以下是一个使用 Python 实现的层次聚类算法的示例代码,用于在工业领域中的应用:
import numpy as np# 计算欧式距离def euclidean_distance矩阵(data): distances = np.sqrt(np.sum((data - data.T) ** 2, axis=1)) return distances# 层次聚类算法def hierarchical_clustering(data, method=\'single\', distance=\'euclidean\'): if method ==\'single\': linkage = \'single\' elif method ==\'complete\': linkage = \'complete\' elif method ==\'average\': linkage = \'average\' else: raise ValueError(\"Invalid method. Choose \'single\', \'complete\', or \'average\'.\") if distance ==\'euclidean\': distances = euclidean_distance矩阵(data) else: raise ValueError(\"Invalid distance. Only \'euclidean\' is supported for now.\") # 执行层次聚类 linkage_matrix = np.cluster.hierarchy.linkage(distances, linkage=linkage) return linkage_matrix# 示例数据data = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])# 执行层次聚类linkage_matrix = hierarchical_clustering(data)# 可视化聚类结果import matplotlib.pyplot as pltplt.figure(figsize=(10, 7))dendrogram(linkage_matrix, truncate_mode=\'level\', p=3)plt.show()在上述示例代码中,我们实现了一个层次聚类算法,并使用 dendrogram 函数可视化聚类结果。
首先,我们定义了一个函数 euclidean_distance_matrix 来计算数据的欧式距离矩阵。然后, hierarchical_clustering 函数接受数据和聚类方法(‘single’、‘complete’或’average’)作为输入,并根据指定的距离度量(欧式距离)执行层次聚类。最后,通过将得到的 linkage_matrix 传递给 dendrogram 函数,我们可以生成层次聚类的树状图。
在示例中,我们使用了一个简单的数据集进行聚类,并选择了’single’链接方法和欧式距离。你可以根据实际需求调整这些参数,并根据聚类结果进行进一步的分析和应用。
请注意,这只是一个基本的示例代码,实际应用中可能需要根据具体问题进行更多的调整和优化。例如,处理大规模数据、选择合适的截断水平、提取聚类结果等。
以下是一个针对处理大规模数据、选择合适的截断水平和提取聚类结果等方面进行调整和优化的示例代码:
import numpy as npfrom scipy.cluster.hierarchy import linkage, dendrogram# 计算欧式距离def euclidean_distance_matrix(data): return np.sqrt(np.sum((data - data.T) ** 2, axis=1))# 层次聚类算法def hierarchical_clustering(data, method=\'single\', distance=\'euclidean\', n_clusters=None, truncate_level=None): if method ==\'single\': linkage = \'single\' elif method ==\'complete\': linkage = \'complete\' elif method ==\'average\': linkage = \'average\' else: raise ValueError(\"Invalid method. Choose \'single\', \'complete\', or \'average\'.\") if distance ==\'euclidean\': distances = euclidean_distance_matrix(data) else: raise ValueError(\"Invalid distance. Only \'euclidean\' is supported for now.\") # 执行层次聚类 linkage_matrix = linkage(distances, linkage=linkage) # 处理大规模数据:可以使用部分数据或采用分布式计算 if data.size > 100000: data = data[:10000] # 或者使用分布式计算框架来处理大规模数据 # 选择合适的截断水平 if truncate_level is None: truncate_level = -1 # 默认显示完整的树状图 # 提取聚类结果 if n_clusters is not None: clusters = np.argmin(linkage_matrix, axis=1) clusters = np.unique(clusters) if n_clusters < clusters.size: # 根据指定的簇数进行合并 linkage_matrix = linkage_matrix[clusters, :][:, clusters] return linkage_matrix, clusters# 示例数据data = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0], [9, 9], [10, 10], [11, 11], [12, 12], [13, 13], [14, 14]])# 执行层次聚类linkage_matrix, clusters = hierarchical_clustering(data, n_clusters=2, truncate_level=3)# 可视化聚类结果import matplotlib.pyplot as pltplt.figure(figsize=(10, 7))dendrogram(linkage_matrix, truncate_mode=\'level\', p=3)plt.axhline(y=truncate_level, color=\'red\', linestyle=\'--\')plt.show()# 输出聚类结果print(\"Clusters:\", clusters)在这个示例中,我们对层次聚类算法进行了以下改进:
-
处理大规模数据:如果数据规模较大,可以选择使用部分数据进行分析,或者考虑采用分布式计算框架来处理。
-
选择合适的截断水平:通过设置 truncate_level 参数,可以在生成的树状图中指定截断的水平,以便更好地理解聚类结构。
-
提取聚类结果:根据需要,可以指定聚类的数量 n_clusters ,并通过对 linkage_matrix 进行最小值索引的计算来提取聚类结果。
你可以根据实际情况对这些参数进行调整和优化,以满足具体问题的需求。此外,还可以根据聚类结果进行进一步的分析和应用,例如对不同的簇进行特征分析或应用于其他任务。
十、知识点归纳

以下是一些常见的 AI 工业应用算法原理知识点归纳:
-
监督学习:通过已标注的数据集进行训练,模型学习输入和输出之间的映射关系。常见的监督学习算法包括回归、分类等。
-
无监督学习:在没有标记的数据中发现模式和结构。聚类、降维等是无监督学习的常见应用。
-
深度学习:基于神经网络的算法,可用于图像识别、语音识别、自然语言处理等任务。卷积神经网络(CNN)和循环神经网络(RNN)是深度学习中的重要架构。
-
强化学习:通过与环境进行交互学习最佳策略。适用于机器人控制、游戏等地方。
-
数据预处理:包括数据清洗、特征工程、标准化等步骤,对数据进行预处理以提高算法的性能和准确性。
-
模型评估与选择:使用指标如准确率、召回率、F1 分数等评估模型性能,并根据不同场景选择合适的模型。
-
超参数调优:调整算法中的超参数,如学习率、正则化参数等,以优化模型性能。
-
模型压缩与优化:减少模型的大小和计算量,提高模型的效率和部署性。
-
迁移学习:利用已有的预训练模型,在新的任务或数据集上进行微调,加快模型训练过程。
-
分布式训练:利用多个计算节点加速模型训练,处理大规模数据集。
-
实时监测与反馈:在工业应用中,实时监测算法的输出并提供反馈,以实现动态调整和优化。 这些知识点只是 AI 工业应用算法的一部分,实际应用中还需要根据具体问题和场景选择合适的算法和技术。

同时,不断研究和创新也是推动 AI 在工业领域发展的关键。

