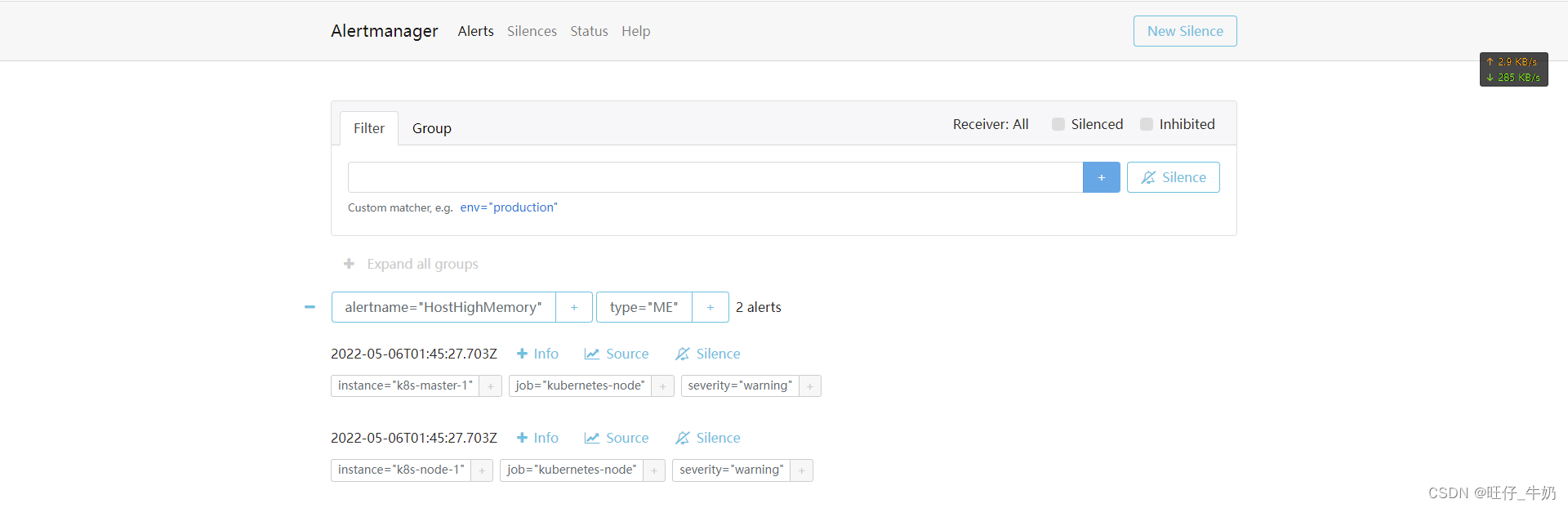
k8s之Alertmanager-v0.24实现微信|邮箱告警
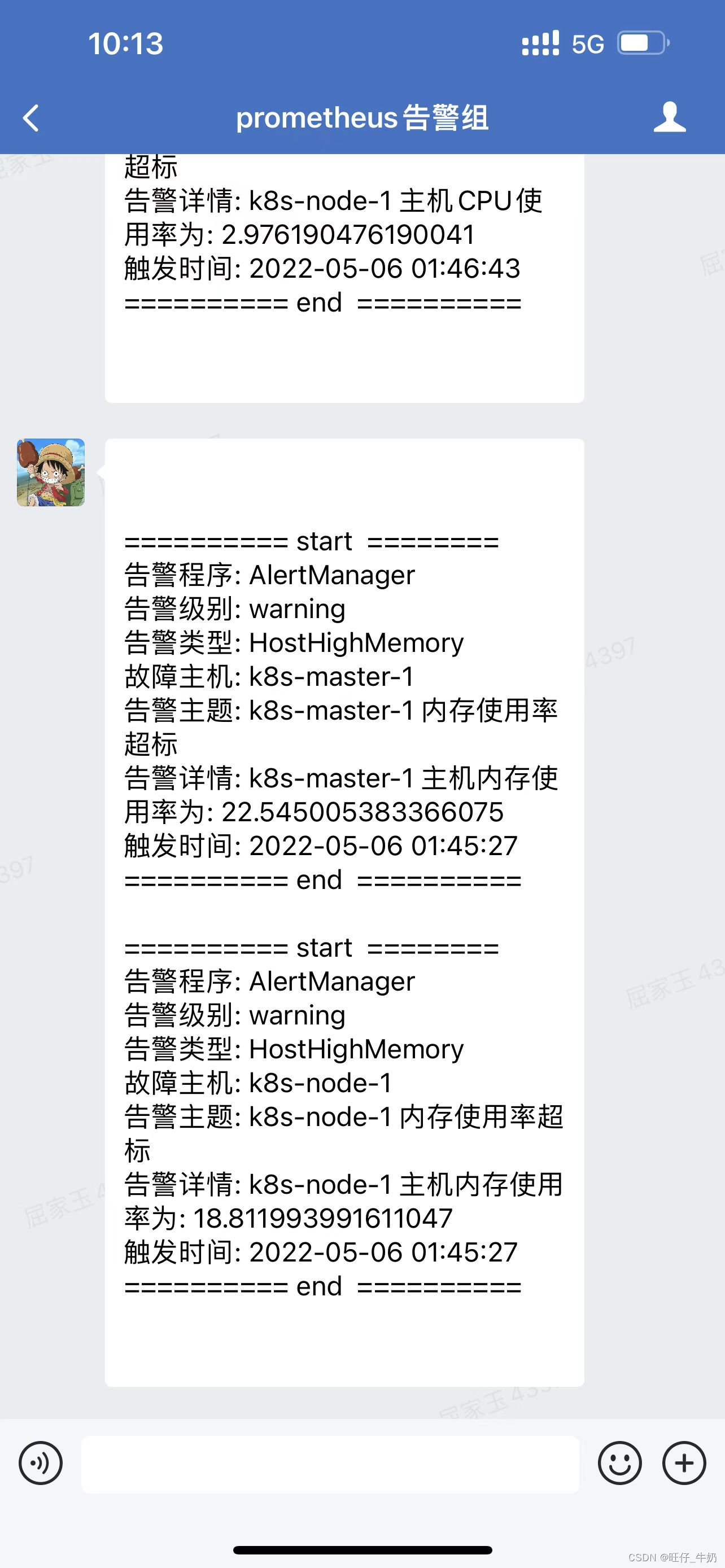
告警效果

Prometheus-server-config
Prometheus-server规则参考链接(提供了不同exporter下各类常规指标告警规则):https://awesome-prometheus-alerts.grep.to/rules
注:由于监控etcd时需要使用相关证书,需要将etcd相关证书制作成secret,并挂载给prometheus-server使用
kubectl -n kube-prometheus create secret generic etcd-certs --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pem --from-file=/etc/etcd/ssl/etcd-ca.pem[root@k8s-master-1 prometheus-server]# cat prometheus-config.yaml apiVersion: v1kind: ConfigMapmetadata: name: prometheus-config namespace: kube-prometheusdata: prometheus.rules: |- groups: - name: CPU # CPU类告警,可用来划分不同的组,不同的组用来放不同的规则 rules: - alert: HostHighCpuLoad # 监控名称最后会在Prometheus的Alert的告警规则中生成一个alertname=HostHighCpuLoad的标签,如果在alertmanager中已altername来划分告警组的话,最后都会到一组去 expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 1 for: 1s labels: # 在alert rule中添加新的label,可以被后续的altermanager所使用到 type: CPU severity: warning annotations: summary: "{{ $labels.instance }} CPU使用率超标" description: "{{ $labels.instance }} 主机CPU使用率为: {{ $value }}" - alert: HostHighCpuLoad # 严重警告,alertmanager中可以配置抑制 expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 5 for: 1s labels:type: CPU severity: critical annotations: summary: "{{ $labels.instance }} CPU使用率超标" description: "{{ $labels.instance }} 主机CPU使用率为: {{ $value }}" - name: ME # Memory类告警 rules: - alert: HostHighMemory expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100) > 10 for: 1s labels: type: ME severity: warning annotations: summary: "{{ $labels.instance }} 内存使用率超标" description: "{{ $labels.instance }} 主机内存使用率为: {{ $value }}" prometheus.yml: |- global: scrape_interval: 15sscrape_timeout: 10s evaluation_interval: 1m alerting: alertmanagers: - scheme: http static_configs: - targets: - "alertmanager.kube-prometheus.svc:9093" rule_files: - /etc/prometheus/prometheus.rules scrape_configs: - job_name: 'kubenernetes-prometheus-server' static_configs: - targets: ['localhost:9090'] relabel_configs: - source_labels: [instance] # 将instance=localhost:9090 -> instance=prometheus-server:9090 regex: '(.*)' replacement: 'prometheus-server:9090' target_label: instance action: replace - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] # 将__address__=192.168.0.10:10250 -> 192.168.0.10:9100,node_exporter默认是9100,且我已事先与宿主机共享网络空间了 regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: '__meta__kubernetes_node_label_(.+)' # 保留__meta__kubernetes_node_label_标签后面的值作为新标签 - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [ __meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name, ] action: keep regex: default;kubernetes;https - job_name: "kubernetes-cadvisor" scheme: https metrics_path: /metrics/cadvisor tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) # 保留匹配到的具有__meta_kubernetes_node_label的标签 - target_label: __address__ # 获取到的地址:__address__="192.168.0.11:10250" replacement: kubernetes.default.svc:443 # 把获取到的地址替换成新的地址kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ # 获取 __metrics_ 对应的值 replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor # 把metrics替换成新的值,新的url就是: https://kubernetes.default.svc/api/v1/nodes/k8s-master-1/proxy/metrics/cadvisor metric_relabel_configs: # grafana 315 所需 - action: replace source_labels: [id] regex: '^/machine\.slice/machine-rkt\\x2d([^\\]+)\\.+/([^/]+)\.service$' target_label: rkt_container_name replacement: '${2}-${1}' - action: replace source_labels: [id] regex: '^/system\.slice/(.+)\.service$' target_label: systemd_service_name replacement: '${1}' - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scraped] # 仅抓取到的具有"prometheus.io/scrape: true"的annotation的端点 action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] # 应用中自定义暴露的指标,也许你暴露的 API 接口不是 /metrics 这个路径,那么你可以在这个POD 对应的 service 中做一个 "prometheus.io/path = /mymetrics"声明 action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) # ; 对应 source_labels里面的 replacement: $1:$2 # 暴露自定义的应用的端口,就是把地址和你在 service 中定义的 "prom etheus.io/port=" 声明做一个拼接然后赋值给 __ address__,这样 prometheus 就能获取自定义应用的端口,然后通过这个端口再结合 __metrics_ 来获 取 指标,如果 __metrics_ 值不是默认的 /metrics 那么就要使用上面的标签替换来获取真正暴露的具体路径 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_service_namemetric_relabel_configs: # grafana 13332 所需,kube-state-metrics - target_label: cluster replacement: kubernetes-service-endpoints - job_name: 'kubernetes-proxy' static_configs: - targets: ['192.168.0.10:10249','192.168.0.11:10249'] # 默认可以通过HTTP方式访问:curl http://192.168.0.10:10249/metrics - job_name: 'kubernetes-scheduler' static_configs: - targets: ['192.168.0.10:10251'] # 10251 暴露指标 - job_name: 'kubernetes-controller-manager' static_configs: - targets: ['192.168.0.10:10252'] - job_name: 'kubernetes-etcd' scheme: https tls_config: # 这些证书通过在kube-prometheus内创建secret方式挂载给prometheus-server使用 ca_file: /var/run/secrets/kubernetes.io/etcd/etcd-ca.pem cert_file: /var/run/secrets/kubernetes.io/etcd/etcd.pem key_file: /var/run/secrets/kubernetes.io/etcd/etcd-key.pem static_configs: - targets: ['192.168.0.10:2379'] # 默认本机可以通过localhost:2379/metrics 获取指标,但是如果以192.168.0.10:2379/mymetrics方式访问的话就需要提供证书了Prometheus-Server-deployment
[root@k8s-master-1 prometheus-server]# cat prometheus-deployment.yaml apiVersion: v1kind: Servicemetadata: name: prometheus namespace: kube-prometheus labels: name: prometheus-serverspec: ports: - name: prometheus protocol: TCP port: 9090 targetPort: 9090 nodePort: 40000# 将其在宿主机暴露端口固定成40000 selector: name: prometheus-server type: NodePort---apiVersion: apps/v1kind: Deploymentmetadata: name: prometheus-server namespace: kube-prometheus labels: name: prometheus-serverspec: replicas: 1 selector: matchLabels: name: prometheus-server template: metadata: labels: name: prometheus-server annotations:# prometheus.io/scrape: 'true' # The default configuration will scrape all pods and, if set to false, this annotation will exclude the pod from the scraping process.# prometheus.io/path: '/metrics' # If the metrics path is not /metrics, define it with this annotation.# prometheus.io/port: '9090' # Scrape the pod on the indicated port instead of the pod’s declared ports (default is a port-free target if none are declared) spec: nodeName: k8s-master-1 # 设置在k8s-master-1上运行 tolerations: # 设置能容忍在master节点运行 - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule" serviceAccountName: prometheus containers: - name: prometheus image: prom/prometheus:v2.35.0 imagePullPolicy: IfNotPresent command: - prometheus - --config.file=/etc/prometheus/prometheus.yml - --storage.tsdb.path=/prometheus# 旧数据存储目录 - --storage.tsdb.retention=720h # 何时删除旧数据,默认为15天。 - --web.enable-lifecycle # 开启热加载 ports: - containerPort: 9090 protocol: TCP volumeMounts: - name: prometheus-storage-volume mountPath: /prometheus/ - name: prometheus-config mountPath: /etc/prometheus/prometheus.yml subPath: prometheus.yml - name: prometheus-config mountPath: /etc/prometheus/prometheus.rules subPath: prometheus.rules - name: prometheus-cert-volume mountPath: /var/run/secrets/kubernetes.io/etcd readinessProbe: httpGet: path: /-/ready port: 9090 failureThreshold: 3 successThreshold: 1 periodSeconds: 5 initialDelaySeconds: 5 timeoutSeconds: 5 livenessProbe: httpGet: path: /-/healthy port: 9090 failureThreshold: 3 successThreshold: 1 periodSeconds: 5 initialDelaySeconds: 15 timeoutSeconds: 5 volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-storage-volume hostPath: path: /prometheus - name: prometheus-cert-volume secret: secretName: etcd-certs 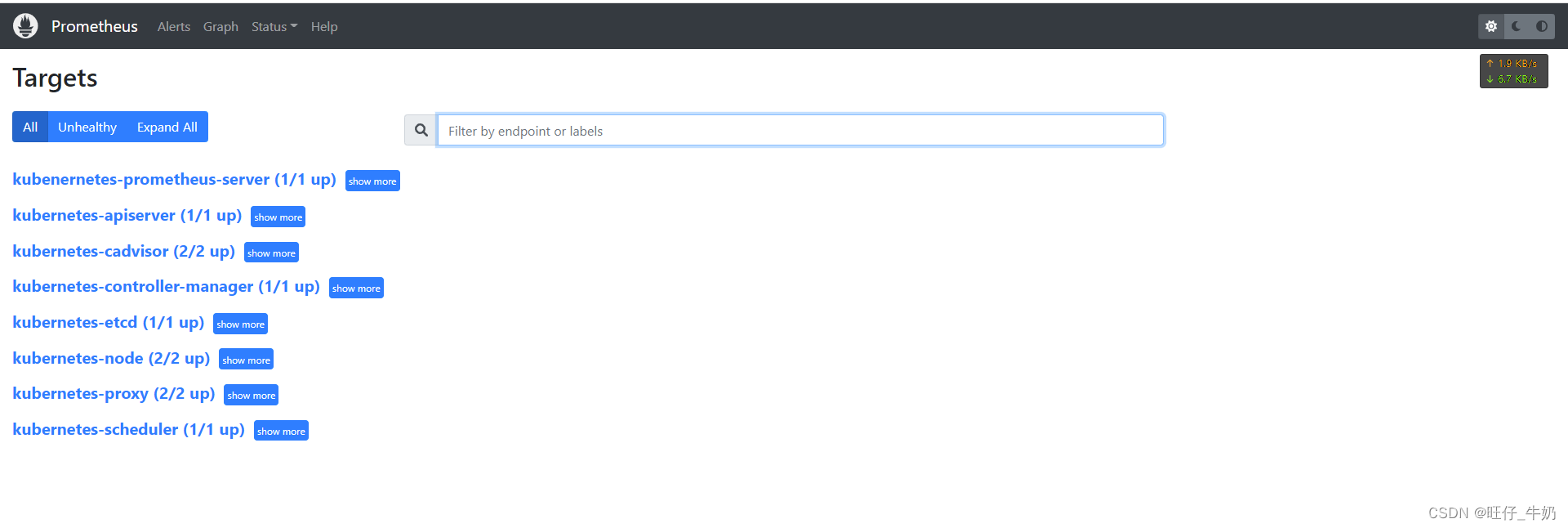
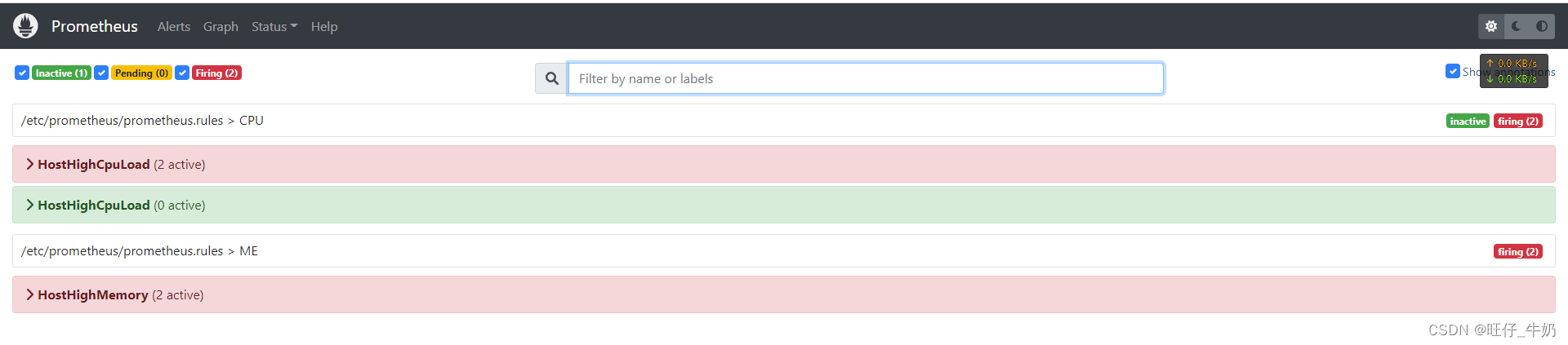
AlertManager-Deployment
[root@k8s-master-1 alertmanager]# cat alertmanager-deployment.yaml apiVersion: v1kind: Servicemetadata: name: alertmanager namespace: kube-prometheusspec: ports: - nodePort: 41000 port: 9093 protocol: TCP targetPort: 9093 selector: name: alertmanager type: NodePort---apiVersion: v1kind: ConfigMapmetadata: name: alertmanager-config namespace: kube-prometheusdata: alertmanager.yml: |- global: resolve_timeout: 1m # 每分钟检测一次是否恢复 # Email 配置 smtp_smarthost: 'smtp.163.com:25' smtp_from: '' smtp_auth_username: '' smtp_auth_password: '' smtp_require_tls: false # 不使用加密认证 # wechat 配置 wechat_api_url: '' # api接口 wechat_api_corp_id: '' # 企业微信账号唯一 ID, 可以在我的企业中查看 wechat_api_secret: '' # 第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看 templates: - '/etc/template/*.yml' route: # 用于配置告警分发策略 group_by: ['alertname','type','serverity'] # 采用哪个标签来作为分组依据,默认每个rule都会带alertname这个标签 group_wait: 10s # 组告警等待时间。也就是告警产生后等待 10s ,如果有同组告警一起发出 group_interval: 10s # 上下两组发送告警的间隔时间 repeat_interval: 10m# 重复发送告警的时间,减少相同邮件的发送频率 ,默认是 1h receiver: wechat # 定义谁来收告警,单子路由如果没有匹配到,则由默认的reciver来发 routes: - match: # 支持match和match_re type: CPU receiver: 'email' - match_re: type: ^(ME|TEST)$ receiver: 'wechat' receivers: - name: 'wechat' wechat_configs: - send_resolved: true # to_party: '1|2' # 发送给企业微信某个部门 # to_user: 'user_name2|username2|@all' # 发送给企业微信中某个用户 to_user: '@all' agent_id: '' # 企业微信中创建的应用的ID corp_id: '' # 企业微信账号唯一 ID, 可以在我的企业中查看 api_secret: ''message: '{{ template "wechat.default.message" . }}' # 指定使用模板 - name: 'email' email_configs: - send_resolved: true to: '2281823407@qq.com' html: '{{ template "email.default.html" . }}' # 指定使用模板 inhibit_rules: # 当遇到serverity: 'critical'告警时将会将serverity: 'warning'的告警抑制,并一并发送告警给recevier - source_match: serverity: 'critical'target_match: serverity: 'warning' equal: ['HostHighCpuLoad'] # Apply inhibition if the alertname is the same. template-email.yml: |- # 不同模板可以定义不一样的内容 {{ define "email.default.html" }} {{ range .Alerts }} <pre> ========== start ========== 告警程序: AlertManager 告警级别: {{ .Labels.severity }} 告警类型: {{ .Labels.alertname }} 故障主机: {{ .Labels.instance }} 告警主题: {{ .Annotations.summary }} 告警详情: {{ .Annotations.description }} 触发时间: {{ (.StartsAt.Add 28801e9).Format "2006-01-02 15:04:05" }} ========== end ========== </pre> {{ end }} {{ end }} template-wechat.yml: |- {{ define "wechat.default.message" }} {{ range .Alerts }} ========== start ======== 告警程序: AlertManager 告警级别: {{ .Labels.severity }} 告警类型: {{ .Labels.alertname }} 故障主机: {{ .Labels.instance }} 告警主题: {{ .Annotations.summary }} 告警详情: {{ .Annotations.description }} 触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} ========== end ========== {{ end }} {{ end }}---apiVersion: apps/v1kind: Deploymentmetadata: name: alertmanager namespace: kube-prometheusspec: replicas: 1 selector: matchLabels: name: alertmanager template: metadata: name: alertmanager labels: name: alertmanager spec: nodeName: k8s-master-1 # 设置在k8s-master-1上运行 tolerations: # 设置能容忍在master节点运行 - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule" containers: - name: alertmanager image: prom/alertmanager:v0.24.0 args: - "--config.file=/etc/alertmanager.yml" - "--storage.path=/alertmanager" ports: - name: alertmanager containerPort: 9093 volumeMounts: - name: alertmanager-storage mountPath: /etc/alertmanager - name: alertmanager-config mountPath: /etc/alertmanager.yml subPath: alertmanager.yml - name: alertmanager-config mountPath: /etc/template/template-email.yml subPath: template-email.yml - name: alertmanager-config mountPath: /etc/template/template-wechat.yml subPath: template-wechat.yml volumes: - name: alertmanager-config configMap: name: alertmanager-config - name: alertmanager-storage hostPath: path: /alertmanager