【kafka专栏】生产者数据批量发送流程源码解析
文章目录
一、生产者数据发送整体流程
kafka生产者客户端核心的数据发送流程主要为三个部分:
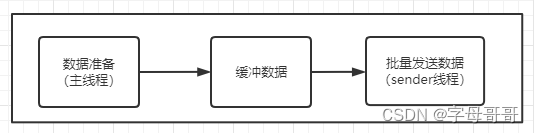
- 主线程调用KafkaProducer发送数据,数据不是直接发送给kafka broker服务端,而是先缓冲起来。
- 有一个单独的线程(sender)专门负责将缓冲数据发往kafka broker服务端。
- 缓冲的目的是:为避免高并发请求造成的服务端压力,所以数据不是一条一条发给服务端,而是缓冲后批量发送。
- 单独线程负责数据发送的目的是:避免造成主线程发送数据时阻塞,造成核心业务响应延时。
我们来查一下KafkaProducer,java源码,其核心构造方法为:
KafkaProducer(Map<String, Object> configs,Serializer<K> keySerializer,Serializer<V> valueSerializer,ProducerMetadata metadata,KafkaClient kafkaClient,ProducerInterceptors<K, V> interceptors,Time time) { //1.记录累加器 this.accumulator = new RecordAccumulator(……) //2. 数据发送线程 this.sender = newSender(logContext, kafkaClient, this.metadata); String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId; this.ioThread = new KafkaThread(ioThreadName, this.sender, true); this.ioThread.start();}我们只抽取了这个构造函数中的核心代码
- 记录累加器RecordAccumulator,也就是生产者KafkaProducer生产的数据不是直接发送给kafka broker。而是批量累加先放入RecordAccumulator,然后分批次发送给kafka broker。
- 数据发送有一个单独的线程来完成,这个线程为sender,一个KafkaProducer对象对应一个Sender线程。
从上面的源码可以部分验证我们对生产者数据整体流程的概括,后文会继续进行解析说明。
二、ProducerRecord与ProducerBatch与RecordAccumulator
上文我们提到了数据累加器,也就是数据缓冲区。下面我们就来深入学习一下数据缓冲区的构造,了解数据缓冲区的构造对于理解kafka整个架构都会有很大的帮助。下文是RecordAccumulator类定义的一个成员变量batches。
public final class RecordAccumulator { …… private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches; ……}从这个定义中我们可以看到
- 针对TopicPartition(代表一个主题的一个分区),RecordAccumulator维护了一个Deque双端队列。
- 这个双端队列里面可以存放的数据类型是ProducerBatch,ProducerBatch代表的是生产者生产的一批数据。
下面我们再看看RecordAccumulator类的append方法的片段 ,该方法用于向缓冲区中追加数据。
public RecordAppendResult append(TopicPartition tp, long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long maxTimeToBlock, boolean abortOnNewBatch, long nowMs) throws InterruptedException { …… try { //创建或获取已有的缓冲区(双端队列) Deque<ProducerBatch> dq = getOrCreateDeque(tp); //synchronized同步队列,避免用户编程异步操作导致数据发送数据顺序错乱的问题 synchronized (dq) {if (closed) throw new KafkaException("Producer closed while send in progress"); //tryAppend方法将一条消息数据的时间戳、key、value、 //header等信息追加到缓冲区中(Deque ) RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs); if (appendResult != null) return appendResult; }最后我们再看一下一个生产者生产的一条消息数据包含哪些方面的信息?
public class ProducerRecord<K, V> { private final String topic; //消息属于哪个的主题 private final Integer partition; //消息属于哪个分区 private final Headers headers; //消息的headers,可以理解为附加信息 private final K key; //消息的key private final V value; //消息的数据值 private final Long timestamp; //消息时间戳}看完上面的源码,我们再看下面的这张图
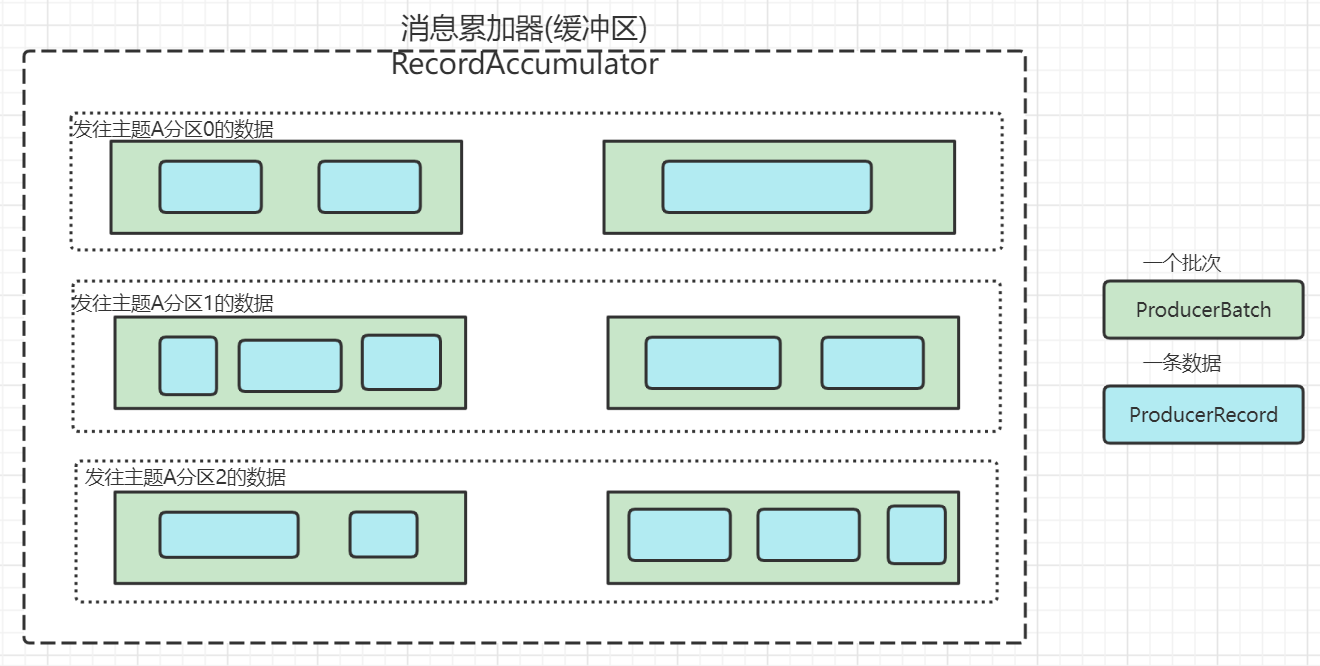
- 一个缓存区RecordAccumulator,包含若干Deque双端队列
- 针对一个主题的一个分区,在kafka生产者客户端维护一个Deque双端队列
- 每个队列Deque里面放入若干个批次ProducerBatch的数据
- 每一个批次ProducerBatch包含若干条数据记录ProducerRecord
- 具有相同的key的数据会被发往主题的同一个分区。
由此可以看出kafka生产者在数据发送给服务端之前,就已将数据分类、分批次的缓冲好,然后由单独线程将数据异步发送到kafka服务端,从而提升数据的发送效率。这就好像快递公司在快件配送之前,就将邮件按照区域、小区等信息分配好了。对于kafka的生产者而言,消息value是按照topic、partition、key进行分类的,按照timestamp的顺序进行投递。
三、定时发送与定量发送
从上文的介绍我们可以知道,kafka生产者的数据先放入缓冲区,然后由单独的线程sender负责发往kafka服务端。这就涉及到一个问题:什么条件可以触发一次缓冲数据的批量发送?
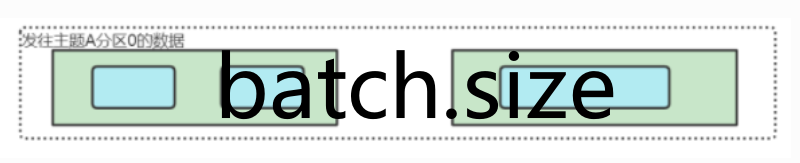
- 第一个重要的参数
batch.size,当准备发往某一个分区的缓冲数据量(如下图所示Deque双端队列)超过batch.size设置的值的时候,就会将该队列中的所有数据一次性发往kafka服务端。batch.size的默认值是16KB。
- 如果
batch.size设置的比较大,在某些非活跃时间段产生的数据量又比较小,一直达不到batch.size的阈值,是不是留在缓冲区里面的消息就一直不发往kafka服务端了?这就要提到另一个重要的参数是linger.ms,该参数的作用是如果缓冲区一直达不到发送标准,当时间超过linger.ms设置的值的时候,也会进行数据的发送。
所以kafka生产者采用的数据批量发送的方式是:定时或者定量,满足其中一个标准数据就会被发往服务端。
需要注意的是:
linger.ms的默认值是0,也就是有数据就发送。有的朋友可能会提出疑问:有数据就发,数据是一条一条放入缓冲区的,那不就是一条一条发送么?所以kafka的批量数据发送机制就失效了啊。其实不是的,我们要考虑发送线程sender是单线程,生产者有很多缓冲队列Deque,所以缓冲区里面的数据需要等待sender线程空闲后才能被发送。linger.ms的默认值是0的灵活性就在这,数据量的时候sender线程忙,缓冲区机制可以保证吞吐量;数据量小的时候sender线程闲处理速度快,可以保证消息的低延时。
最后为大家介绍的参数buffer.memory,他配置的是整个生产者缓冲区的大小,默认值32MB。
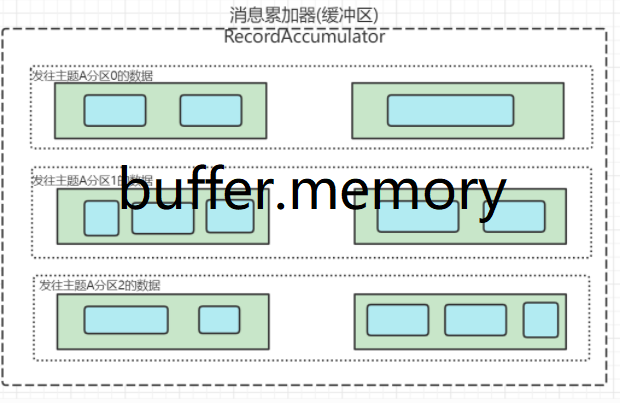
这个buffer.memory参数非常重要,特别是当你的kafka集群主题与分区非常多的时候,对应的生产者分区缓冲队列也就非常多。如果该值设置的比较小,消息数据产生的速率又比较快,就会导致缓冲区被填满,一旦填满就会发生线程阻塞,影响效率。
- buffer.memory :buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器。会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息。buffer.memory要大于batch.size,否则会报申请内存不足的错误,不要超过物理内存,根据实际情况调整
四、生产者数据发送流程环节
生产者数据发送的流程环节如下图所示,其中拦截器、序列化器、分区器是可以自定义的。
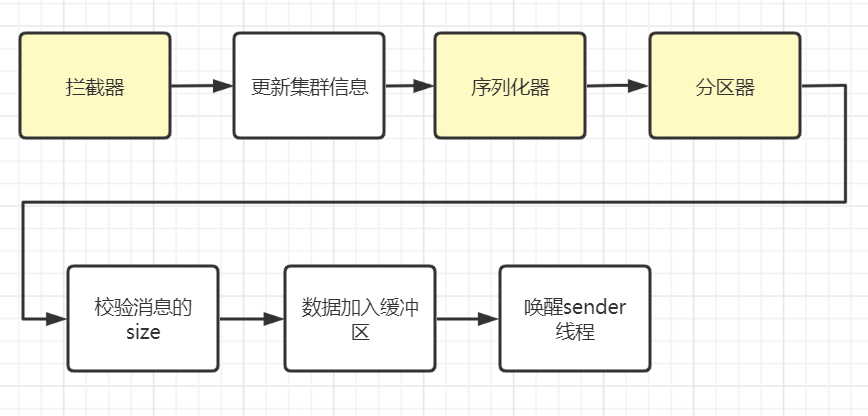
我们结合源码来理解上面的图示。
- 首先在KafkaProducer中使用拦截器,对发送的数据进行预处理。拦截器可以自定义后面的章节我们会介绍
- 然后调用doSend方法执行数据的异步发送。
@Overridepublic Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) { //调用拦截器对record进行预处理 ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record); //真实进行消息的发送操作 return doSend(interceptedRecord, callback);}在doSend方法中,又进行了如下的一系列步骤,参考源码中的中文注释信息
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) { TopicPartition tp = null; try { //1、检测生产者是否已经关闭 throwIfProducerClosed(); //2、检查正要将数据发往的主题在kafka集群中的包含哪些分区 //获取集群中一些元数据信息 ClusterAndWaitTime clusterAndWaitTime; try { clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs); } catch (KafkaException e) { //为了避免阅读障碍,这里去掉了一些异常处理代码 } long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs); Cluster cluster = clusterAndWaitTime.cluster; //3、对消息的key进行序列化,序列化key的目的是进行网络传输 byte[] serializedKey; try { serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key()); } catch (ClassCastException cce) { //为了避免阅读障碍,这里去掉了一些异常处理代码 } //4、对消息的vlaue进行序列化 byte[] serializedValue; try { serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value()); } catch (ClassCastException cce) { //为了避免阅读障碍,这里去掉了一些异常处理代码 } //5、根据分区器决定此条数据发往哪个TopicPartition int partition = partition(record, serializedKey, serializedValue, cluster); tp = new TopicPartition(record.topic(), partition); setReadOnly(record.headers()); Header[] headers = record.headers().toArray(); //6、预估发送消息的大小,内容包括key、value以及头部信息 int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),compressionType, serializedKey, serializedValue, headers); //7、检查发送的消息大小没有超过设置标准 ensureValidRecordSize(serializedSize); long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp(); // 拦截器回调函数 Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp); if (transactionManager != null && transactionManager.isTransactional()) transactionManager.maybeAddPartitionToTransaction(tp); //8、将消息添加到消息累加器(缓冲区)中 RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs); //9、如果添加进的缓冲队列已经满了或者是首次创建的,那么唤醒sender线程进行数据发送 if (result.batchIsFull || result.newBatchCreated) { log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition); this.sender.wakeup(); } //10、返回异步对象 return result.future; } catch (ApiException e) {}当然上面所述的生产者数据发送流程中,我们的讲解内容省略了一些细节:比如消息发送失败之后的异常处理机制,重试机制等,会在后面文章中介绍。

